GlusterFS企业分布式存储
GlusterFS
- 分布式文件系统
- 代表-nfs
- 常见分布式存储
- Gluster存储基础梳理
- GlusterFS 适合大文件还是小文件存储?
- 应用场景
- 术语
- Trusted Storage Pool
- Brick
- Volumes
- Glusterfs整体工作流程-数据访问流程
- GlusterFS客户端访问流程
- GlusterFS常用命令
- 部署 GlusterFS 群集
- 准备环境(所有node节点上操作)
- 关闭防火墙
- 磁盘分区,并挂载
- 修改主机名,配置/etc/hosts文件
- 安装、启动GlusterFS(所有node节点上操作)
- 添加节点到存储信任池中(在 node1 节点上操作)
- 创建卷
- 创建分布式卷(dis-volume)
- 创建条带卷(stripe-volume)
- 创建复制卷(rep-volume)
- 创建分布式条带卷(dis-stripe)
- 创建分布式复制卷(dis-rep)
- 部署 Gluster 客户端
- 安装客户端软件
- 创建挂载目录
- 配置 /etc/hosts 文件
- 挂载 Gluster 文件系统
- 对五种卷进行文件测试
- 卷中写入文件,客户端操作
- 服务端查看文件分布
- 破坏性测试
- 对分布式卷进行扩容缩容实验
- 扩容
- 缩容
- yum安装glusterfs对三种基本卷进行测试
- 创建分布式卷(dis-volume)
- 创建条带卷(stripe-volume)
- 创建复制卷(rep-volume)
分布式文件系统
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源并不直接与本地节点相连,而是分布于计算网络中的一个或者多个节点的计算机上。目前意义上的分布式文件系统大多都是由多个节点计算机构成,结构上是典型的客户机/服务器模式。流行的模式是当客户机需要存储数据时,服务器指引其将数据分散的存储到多个存储节点上,以提供更快的速度,更大的容量及更好的冗余特性;
产生
计算机通过文件系统管理、存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,已经不能满足目前的需求。
分布式文件系统可以有效解决数据的存储和管理难题,将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据;
代表-nfs
NFS(Network File System)即网络文件系统,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样;
优点
1)节约使用的磁盘空间客户端经常使用的数据可以集中存放在一台机器上,并使用NFS发布,那么网络内部所有计算机可以通过网络访问,不必单独存储;
2)节约硬件资源NFS还可以共享软驱,CDROM和ZIP等的存储设备,减少整个网络上的可移动设备的数量;
3)用户主目录设定对于特殊用户,如管理员等,为了管理的需要,可能会经常登录到网络中所有的计算机,若每个客户端,均保存这个用户的主目录很繁琐,而且不能保证数据的一致性.实际上,经过NFS服务的设定,然后在客户端指定这个用户的主目录位置,并自动挂载,就可以在任何计算机上使用用户主目录的文件;
缺点
1) 存储空间不足,需要更大容量的存储;
2) 直接用NFS挂载存储,有一定风险,存在单点故障;
3) 某些场景不能满足要求,大量的访问磁盘IO是瓶颈;
4) 扩容,缩容影响服务器较多;
5) 目录层级不要太深,合理组织目录,数量不要太多,增大glusterfs目录缓存,另外还可以设计把元数据和数据分离,将元数据放到内存数据库,并在ssd持久保存;
6) 小文件性能较差,它主要为大文件设计,对小文件优化很少, 虽然在客户端采用了元数据缓存md-cache提高小文件性能,但是md-cache大小有限,海量小文件缓存命中率会严重下降,优化效果会减小,需要增大元数据缓存或者将小文件合并为一个大文件,成为block
常见分布式存储
FastDFS:
一个开源的轻量级分布式文件系统,是纯C语言开发的。它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。FastDFS 针对大量小文件存储有优势。
GlusterFS:
主要应用在集群系统中,具有很好的可扩展性。软件的结构设计良好,易于扩展和配置,通过各个模块的灵活搭配以得到针对性的解决方案。GlusterFS适合大文件,小文件性能相对较差。
MooseFS:
比较接近GoogleFS的c++实现,通过fuse支持了标准的posix,支持FUSE,相对比较轻量级,对master服务器有单点依赖,用perl编写,算是通用的文件系统,可惜社区不是太活跃,性能相对其他几个来说较差,国内用的人比较多。
Ceph:
C++编写,性能很高,支持Fuse,并且没有单点故障依赖;Ceph 是一种全新的存储方法,对应于 Swift 对象存储。在对象存储中,应用程序不会写入文件系统,而是使用存储中的直接 API 访问写入存储。因此,应用程序能够绕过操作系统的功能和限制。在openstack社区比较火,做虚机块存储用的很多!
GoogleFS:性能十分好,可扩展性强,可靠性强。用于大型的、分布式的、对大数据进行访问的应用。运用在廉价的硬件上。
Gluster存储基础梳理
GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。Glusterfs是一个横向扩展的分布式文件系统,就是把多台异构的存储服务器的存储空间整合起来给用户提供统一的命名空间。用户访问存储资源的方式有很多,可以通过NFS,SMB,HTTP协议等访问,还可以通过gluster本身提供的客户端访问。
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能;
GlusterFS 适合大文件还是小文件存储?
弹性哈希算法和Stripe 数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储的性能。对于小文件,无元数据服务设计解决了元数据的问题。但GlusterFS 并没有在I/O 方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。
因此,GlusterFS 适合存储大文件,小文件性能较差,还存在很大优化空间。
应用场景
GlusterFS 在企业中应用场景理论和实践上分析,GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。海量小文件LOSF问题是工业界和学术界公认的难题,GlusterFS作为通用的分布式文件系统,并没有对小文件作额外的优化措施,性能不好也是可以理解的;
- Media: 文档、图片、音频、视频
- Shared storage: 云存储、虚拟化存储、HPC(高性能计算)
- Big data: 日志文件、RFID(射频识别)数据
术语
Brick: GlusterFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识,如’SERVER:EXPORT’。Client:挂载了GlusterFS卷的设备;
GFID: GlusterFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,其用于模拟inode;
Namespace: 每个Gluster卷都导出单个ns作为POSIX的挂载点; Node: 一个拥有若干brick的设备;
RDMA: 远程直接内存访问,支持不通过双方的OS进行直接内存访问; RRDNS: round robin
DNS是一种通过DNS轮转返回不同的设备以进行负载均衡的方法;
Self-heal: 用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致; Split-brain: 脑裂
Volfile: Glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname;
Volume: 一组bricks的逻辑集合;
Trusted Storage Pool
• 一堆存储节点的集合
• 通过一个节点“邀请”其他节点创建,这里叫probe
• 成员可以动态加入,动态删除
添加命令如下:
gluster peer probe node2
删除命令如下:
gluster peer detach node3
Brick
Brick是一个节点和一个导出目录的集合,e.g. node1:/brick1
• Brick是底层的RAID或磁盘经XFS或ext4文件系统格式化而来,所以继承了文件系统的限制
• 每个节点上的brick数是不限的
• 理想的状况是,一个集群的所有Brick大小都一样。
Volumes
Volume是brick的逻辑组合
• 创建时命名来识别
• Volume是一个可挂载的目录
• 每个节点上的brick数是不变的,e.g.mount –t glusterfs www.std.com:test /mnt/gls
• 一个节点上的不同brick可以属于不同的卷
• 支持如下种类:
a) 分布式卷
b) 条带卷
c) 复制卷
d) 分布式复制卷
e) 条带复制卷
f) 分布式条带复制卷
1)分布式卷• 文件分布存在不同的brick里
• 目录在每个brick里都可见
• 单个brick失效会带来数据丢失
• 无需额外元数据服务器
2)复制卷
• 同步复制所有的目录和文件
• 节点故障时保持数据高可用
• 事务性操作,保持一致性
• 有changelog
• 副本数任意定
3)分布式复制卷
• 最常见的一种模式
• 读操作可以做到负载均衡
4)条带卷
• 文件切分成一个个的chunk,存放于不同的brick上
• 只建议在非常大的文件时使用(比硬盘大小还大)
• Brick故障会导致数据丢失,建议和复制卷同时使用
• 区块(chunks)是带有空洞的文件——这有助于保持偏移量的一致性
Glusterfs整体工作流程-数据访问流程

a)首先是在客户端, 用户通过glusterfs的mount point 来读写数据, 对于用户来说,集群系统的存在对用户是完全透明的,用户感觉不到是操作本地系统还是远端的集群系统。
b)用户的这个操作被递交给 本地linux系统的VFS来处理。
c)VFS 将数据递交给FUSE 内核文件系统:在启动 glusterfs 客户端以前,需要想系统注册一个实际的文件系统FUSE,如上图所示,该文件系统与ext3在同一个层次上面, ext3 是对实际的磁盘进行处理, 而fuse 文件系统则是将数据通过/dev/fuse 这个设备文件递交给了glusterfs client端。所以, 我们可以将 fuse文件系统理解为一个代理。
d)数据被fuse 递交给Glusterfs client 后, client 对数据进行一些指定的处理(所谓的指定,是按照client 配置文件据来进行的一系列处理, 我们在启动glusterfs client 时需要指定这个文件。
e)在glusterfs client的处理末端,通过网络将数据递交给 Glusterfs Server,并且将数据写入到服务器所控制的存储设备上。
这样, 整个数据流的处理就完成了。
GlusterFS客户端访问流程
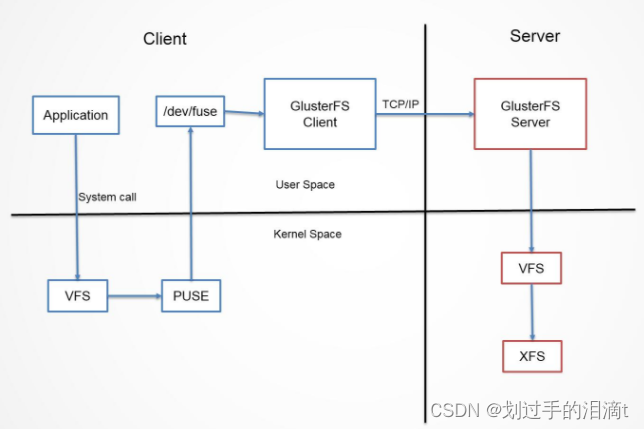
当客户端访问GlusterFS存储时,首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地还是在远程服务器上。读写操作将会被交给VFS(Virtual File System)来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client的计算,并最终经过网络将请求或数据发送到GlusterFS Server上;
GlusterFS常用命令
# 1 启停和开机启动
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service#2 为存储池添加/移除服务器节点
gluster peer probe <SERVER>
gluster peer detach <SERVER>
#注意,移除节点时,需要提前将该节点上的Brick移除。# 3查看所有节点的基本状态(不包括本节点):
gluster peer status# 4 挂载glusterfs
mount -t glusterfs <SERVER>:/<VOLNAME><MOUNTDIR>#5 创建/启动/停止/删除卷
gluster volume create <NEW-VOLNAME>[stripe <COUNT> \| replica <COUNT>] \[transport [tcp | rdma | tcp,rdma]] \<NEW-BRICK1> <NEW-BRICK2> \<NEW-BRICK3> <NEW-BRICK4>...
#force 参数可能用于强制执行一些可能有风险的操作,比如删除卷、移除存储节点等。使用 force 参数可能会绕过一些安全检查或确认步骤,因此需要谨慎使用,以避免意外造成数据丢失或系统不稳定。
gluster volume start <VOLNAME>
gluster volume stop <VOLNAME>
gluster volume delete <VOLNAME>
#注意,删除卷的前提是先停止卷。# 6 查看卷信息
gluster volume list #列出集群中的所有卷:
gluster volume info [all] #查看集群中的卷信息:
gluster volume status [all] #查看集群中的卷状态:
gluster volume status <VOLNAME> [detail| clients | mem | inode | fd] # 7 配置卷
gluster volume set <VOLNAME> <OPTION> <PARAMETER># 8 扩展卷
gluster volume add-brick <VOLNAME> <NEW-BRICK>
#如果是复制卷,则每次添加的Brick数必须是replica的整数倍。# 9 收缩卷
## 9.1 先将数据迁移到其它可用的Brick,迁移结束后才将该Brick移除:
gluster volume remove-brick <VOLNAME> <BRICK> start
#在执行了start之后,可以使用status命令查看移除进度:
gluster volume remove-brick <VOLNAME> <BRICK> status## 9.2不进行数据迁移,直接删除该Brick:
gluster volume remove-brick <VOLNAME> <BRICK> commit
#注意,如果是复制卷或者条带卷,则每次移除的Brick数必须是replica或者stripe的整数倍。
# 关于收缩卷,线上几乎不会收缩,基本上都是扩容,而且裁剪只能收缩没有数据的,否则可能数据丢失。所以,有些卷是不支持收缩的。# 10 迁移卷
#使用start命令开始进行迁移
#迁移过程中,可以使用pause命令暂停迁移:
# 可以使用abort命令终止迁移:
# 可以使用status命令查看迁移进度:
#在数据迁移结束后,执行commit命令来进行Brick替换:
gluster volume replace-brick <VOLNAME> <BRICK> <NEW-BRICK> start
gluster volume replace-brick <VOLNAME> <BRICK> <NEW-BRICK> pause
gluster volume replace-brick <VOLNAME> <BRICK> <NEW-BRICK> abort
gluster volume replace-brick <VOLNAME> <BRICK> <NEW-BRICK> status
gluster volume replace-brick <VOLNAME> <BRICK> <NEW-BRICK> commit# 11 重新均衡卷
#不迁移数据:
gluster volume rebalance <VOLNAME> lay-outstart
gluster volume rebalance <VOLNAME> start
gluster volume rebalance <VOLNAME> startforce
gluster volume rebalance <VOLNAME> status
gluster volume rebalance <VOLNAME> stop# 12 磁盘配额
#开启/关闭系统配额:
gluster volume quota <VOLNAME> enable | disable
#设置目录配额:
gluster volume quota <VOLNAME> limit-usage <DIR> <VALUE>
#查看配额:
gluster volume quota <VOLNAME> list [<DIR>]# 13 地域复制(geo-replication):
gluster volume geo-replication <MASTER> <SLAVE> start | status | stop# 14 IO信息查看:
gluster volume profile <VOLNAME> start | info | stop# 15 Top监控:
#Top命令允许你查看Brick的性能,例如:read,write, file open calls, file read calls, file write calls, directory opencalls, and directory real calls。所有的查看都可以设置top数,默认100。gluster volume top <VOLNAME> open[brick <BRICK>] [list-cnt <COUNT>]
#其中,open可以替换为read, write, opendir, readdir等。gluster volume top <VOLNAME> read-perf [bs <BLOCK-SIZE> count <COUNT>] [brick <BRICK>] [list-cnt <COUNT>]
#其中,read-perf可以替换为write-perf等。
部署 GlusterFS 群集
| 服务器 | 磁盘 | 挂载点 | 系统 |
|---|---|---|---|
| Node1节点:192.168.99.118 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 | centos7.4 |
| Node2节点:192.168.99.119 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 | centos7.4 |
| Node3节点:192.168.99.121 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 | centos7.4 |
| Node4节点:192.168.99.177 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 | centos7.4 |
| 客户端节点:192.168.99.179 | centos7.4 |
准备环境(所有node节点上操作)
四台机器分别添加四块硬盘,系统为centos7.4,7.9会有glibc依赖库问题。
关闭防火墙
systemctl stop firewalld
setenforce 0
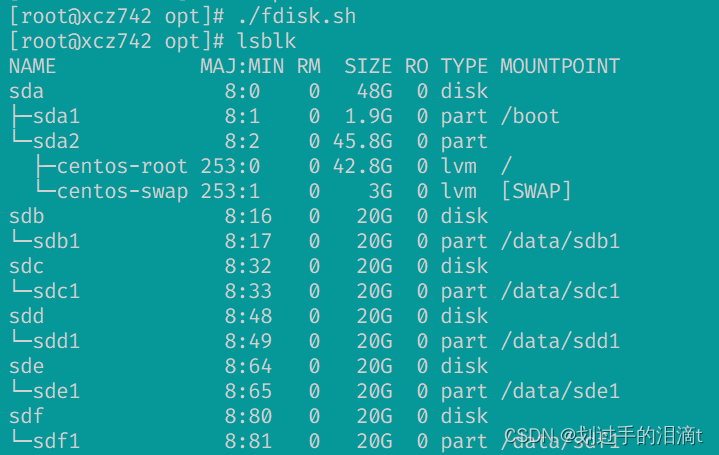
磁盘分区,并挂载
#编写脚本
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/nullmkfs.xfs /dev/${VAR}"1" &> /dev/nullmkdir -p /data/${VAR}"1" &> /dev/nullecho "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
#给权限
chmod +x /opt/fdisk.sh
cd /opt/
#执行脚本
./fdisk.sh
# 查看挂载情况
df -h

修改主机名,配置/etc/hosts文件
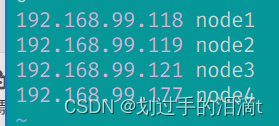
hostnamectl set-hostname node1echo "192.168.99.118 node1" >> /etc/hosts
echo "192.168.99.119 node2" >> /etc/hosts
echo "192.168.99.121 node3" >> /etc/hosts
echo "192.168.99.177 node4" >> /etc/hosts
安装、启动GlusterFS(所有node节点上操作)
- glusterfs:这是 GlusterFS 的客户端软件包。它允许将远程 GlusterFS 卷挂载到本地文件系统上,以便应用程序可以像访问本地文件一样访问远程文件系统中的数据。它实现了 FUSE(Filesystem in Userspace)技术,以在用户态管理文件系统操作。
- glusterfs-server:这是 GlusterFS 的服务器软件包。它包含了 GlusterFS 存储服务器的核心组件,用于存储和管理数据。这些服务器一起组成一个分布式存储解决方案,可以将数据分布在多个节点上,提供高可用性和可扩展性。
- glusterfs-fuse:这是 GlusterFS FUSE 客户端的依赖软件包。当使用 glusterfs 客户端将 GlusterFS 卷挂载到本地文件系统上时,通常需要安装这个软件包来支持 FUSE 技术。
- glusterfs-rdma:这是可选的 GlusterFS 组件,用于启用 RDMA(Remote Direct Memory Access)支持,以提高数据传输的性能和效率。RDMA 是一种高性能的网络传输技术,适用于需要低延迟和高吞吐量的应用场景。这个软件包通常是可选的,根据特定需求决定是否安装。
#修改yum源之前先安装pciutils
yum -y install pciutils unzip
# 将gfsrepo.zip上传到/opt目录下解压缩
cd /opt
unzip gfsrepo.zip#将glfsrepo 软件上传到/opt目录下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1yum clean all && yum makecacheyum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
# 官方目前为9x版本,而6x之后已不再支持条带卷,
# 故本次试验使用3x版本,由于安装gluster-server时依赖的glibc包需要2.17-196版本,故使用centos7.4版本,且进入后不要yum update,否则会导致glibc版本更新
#如采用官方 YUM 源安装,可以直接指向互联网仓库
# 安装server
# yum install -y centos-release-gluster
# yum install -y glusterfs-serversystemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
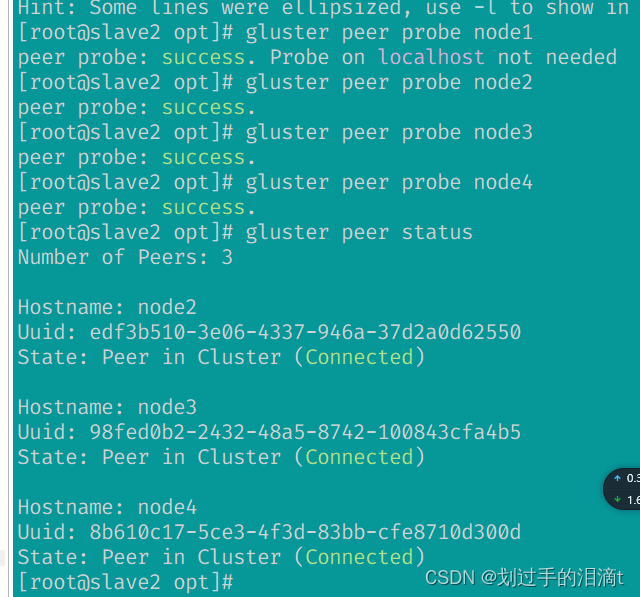
添加节点到存储信任池中(在 node1 节点上操作)
#只要在一台Node节点上添加其它节点即可
# GlusterFS 将会尝试建立节点之间的对等关系,从而形成一个分布式存储集群,可以共享数据和提供冗余性。
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4#在每个Node节点上查看群集状态
gluster peer status
创建卷
根据规划创建如下卷:
| 卷名 | 类型 | brick |
|---|---|---|
| dis-volume | 分布式卷 | node1-4(/data/sdb1) |
| stripe-volume | 条带卷 | node1-2(/data/sdc1) |
| rep-volume | 复制卷 | node3-4(/data/sdc1) |
| dis-stripe | 分布式条带卷 | node1-4(/data/sdd1) |
| dis-rep | 分布式复制卷 | node1-4(/data/sde1) |
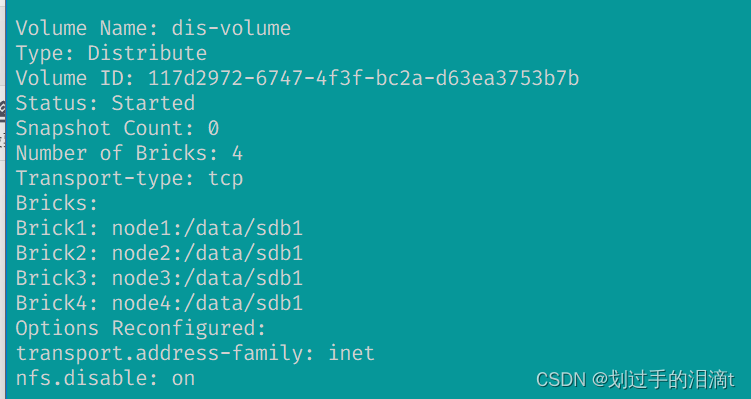
创建分布式卷(dis-volume)
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume \
node1:/data/sdb1 node2:/data/sdb1 node3:/data/sdb1 node4:/data/sdb1 force
#在 GlusterFS 中,force选项用于强制操作,即使存在一些潜在的问题或警告。GlusterFS 在创建卷时会检查相关的条件和限制,如果发现问题或者不符合要求,就会拒绝创建卷并返回相应的错误信息。#查看卷列表
gluster volume list
#启动新建分布式卷
gluster volume start dis-volume
#查看创建分布式卷信息
gluster volume info dis-volume
创建条带卷(stripe-volume)
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume
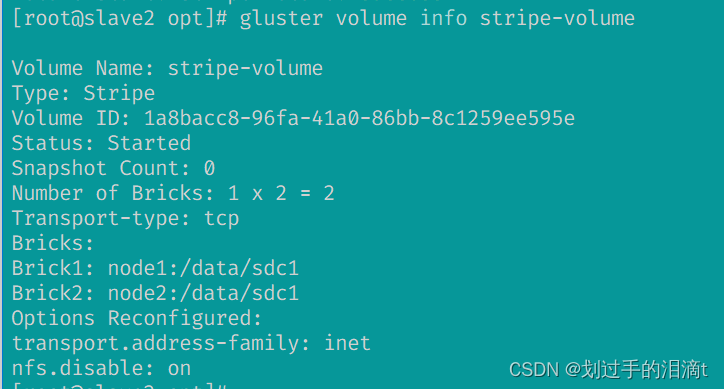
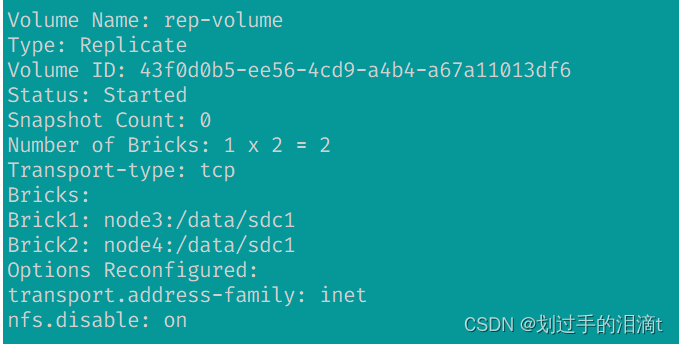
创建复制卷(rep-volume)
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdc1 node4:/data/sdc1 force
gluster volume start rep-volume
gluster volume info rep-volume
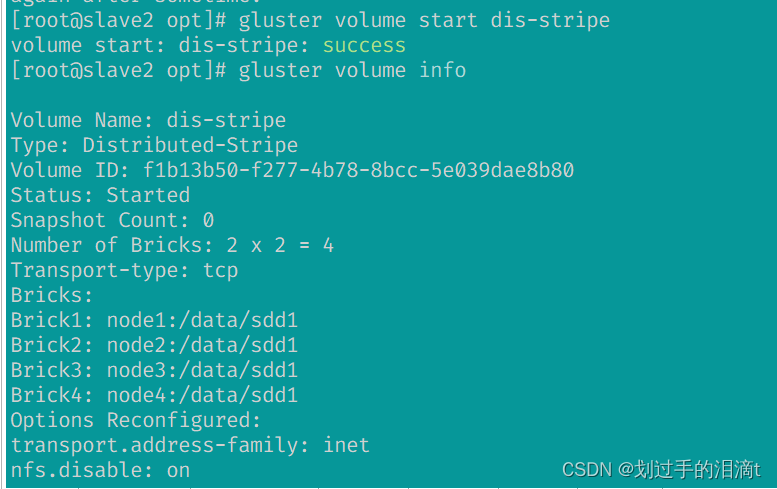
创建分布式条带卷(dis-stripe)
#指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 forcegluster volume start dis-stripe
gluster volume info dis-stripe
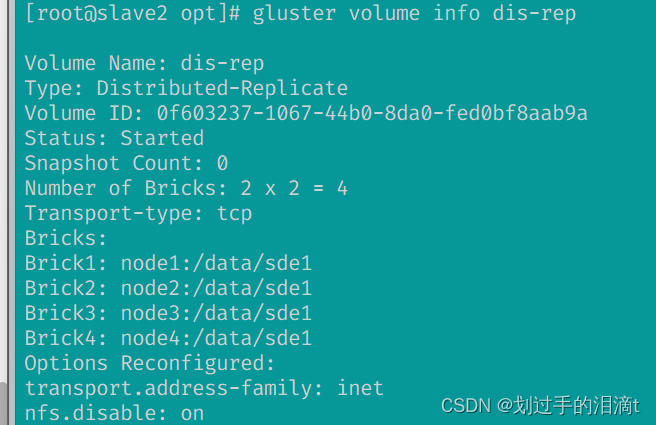
创建分布式复制卷(dis-rep)
#指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
gluster volume start dis-rep
gluster volume info dis-rep
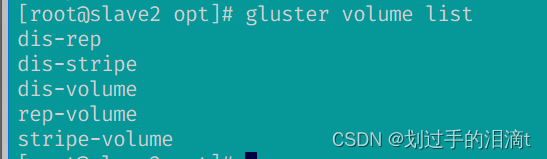
#查看当前所有卷的列表
gluster volume list
部署 Gluster 客户端
安装客户端软件
#将gfsrepo 软件上传到/opt目下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
yum clean all && yum makecache
yum -y install glusterfs glusterfs-fuse
创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test

配置 /etc/hosts 文件
挂载 Gluster 文件系统
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_rep
df -Th

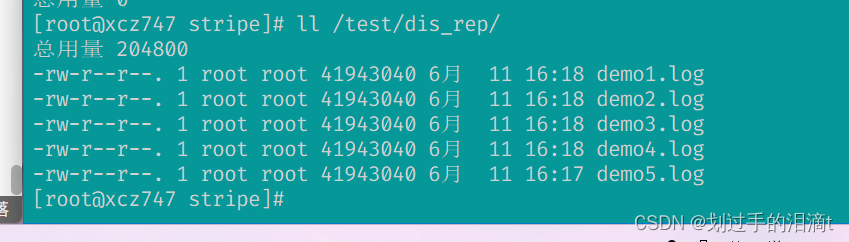
对五种卷进行文件测试
卷中写入文件,客户端操作
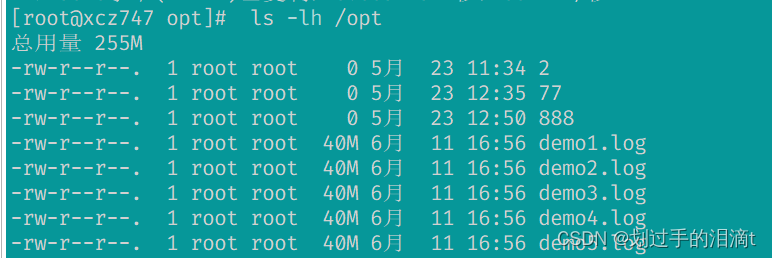
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40
ls -lh /opt
cp -i /opt/demo* /test/dis/
cp -i /opt/demo* /test/stripe/
cp -i /opt/demo* /test/rep/
cp -i /opt/demo* /test/dis_stripe/
cp -i /opt/demo* /test/dis_rep/
服务端查看文件分布
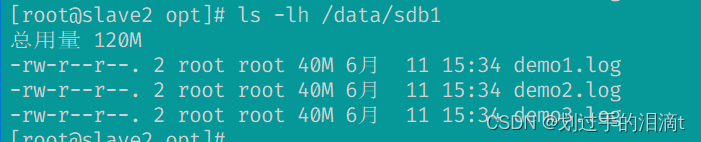
#查看分布式文件分布
#node1
ls -lh /data/sdb1
#node2
ll -h /data/sdb1
#node4
ll -h /data/sdb1


#查看条带卷文件分布
#node1ls -lh /data/sdc1 #数据被分片50% 没副本 没冗余#node2ls -lh /data/sdc1
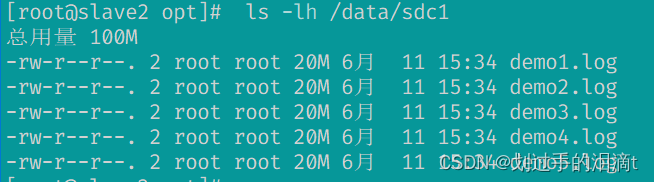
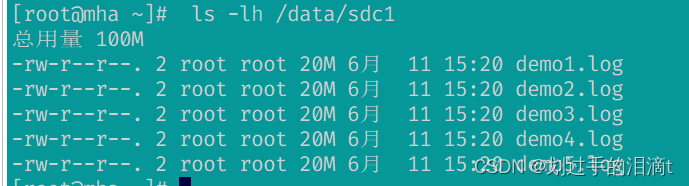
#查看复制卷分布
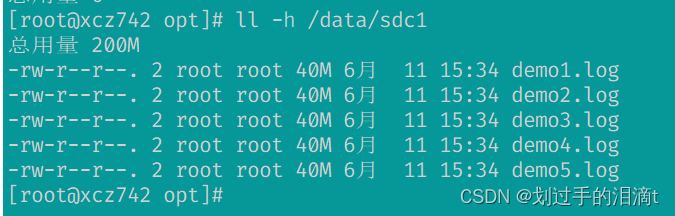
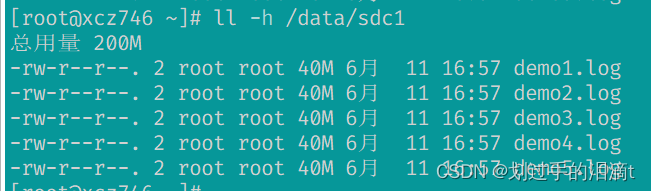
#node3ll -h /data/sdc1#数据没有被分片 有副本 有冗余
#node4
ll -h /data/sdc1
#数据没有被分片 有副本 有冗余
#查看分布式条带卷分布
#node1、2、3、4
ll -h /data/sdd1
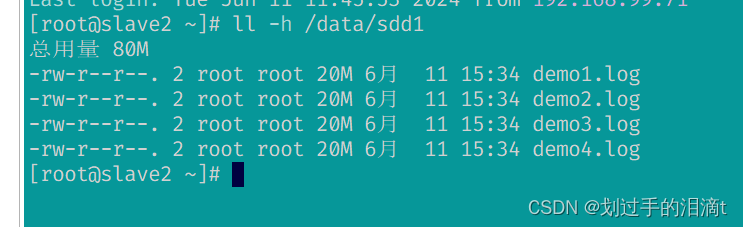
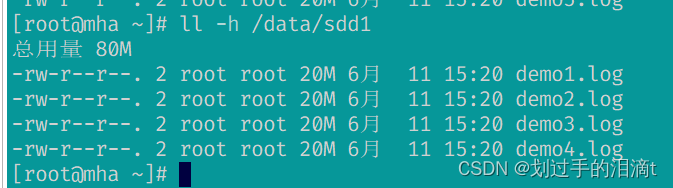


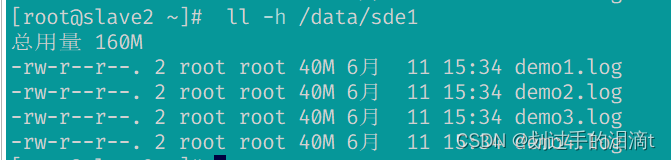
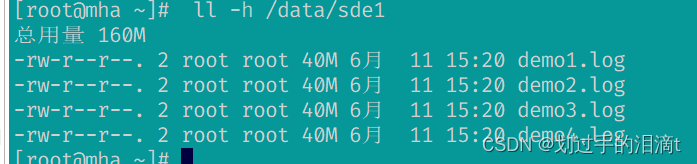
#查看分布式复制卷分布
#数据没有被分片 有副本 有冗余
ll -h /data/sde1


破坏性测试
#挂起 node2 节点或者关闭glusterd服务来模拟故障
#systemctl stop glusterd.service
#或者关闭虚拟机
shutdown -h now
#在客户端上查看文件是否正常
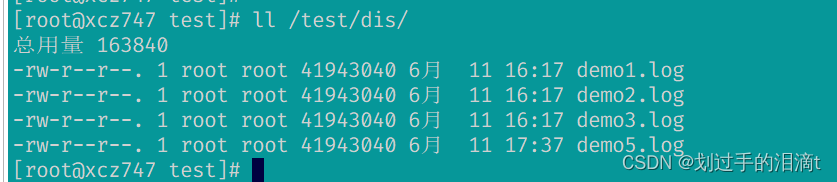
#分布式卷数据查看
ll /test/dis/
#条带卷
cd /test/stripe/ #无法访问,条带卷不具备冗余性
#分布式条带卷ll /test/dis_stripe/ #无法访问,分布条带卷不具备冗余性

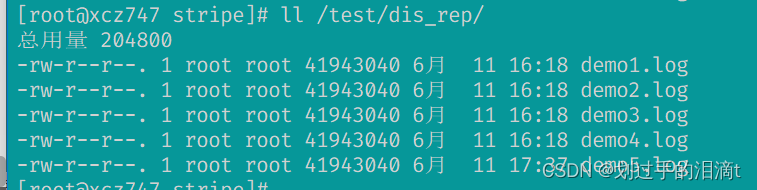
#分布式复制卷
ll /test/dis_rep/ #可以访问,分布式复制卷具备冗余性
#挂起 node2 和 node4 节点,在客户端上查看文件是否正常
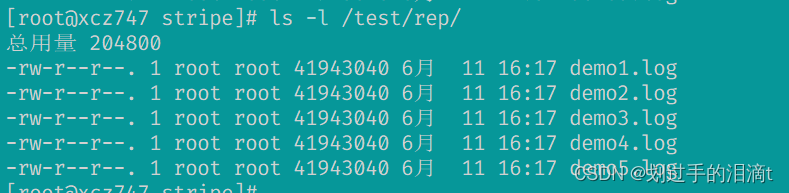
#测试复制卷是否正常
ls -l /test/rep/ #在客户机上测试正常 数据有
#测试分布式条卷是否正常ll /test/dis_stripe/ #在客户机上测试没有数据

#测试分布式复制卷是否正常ll /test/dis_rep/ #在客户机上测试正常 有数据
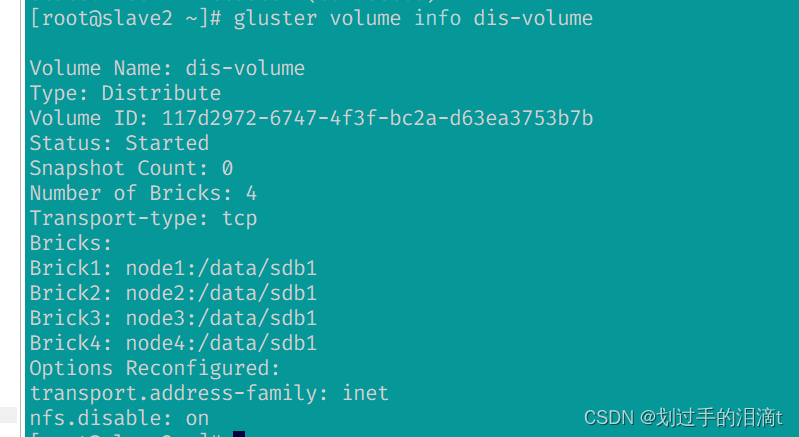
对分布式卷进行扩容缩容实验
gluster volume info dis-volume
挂载新硬盘sdf1
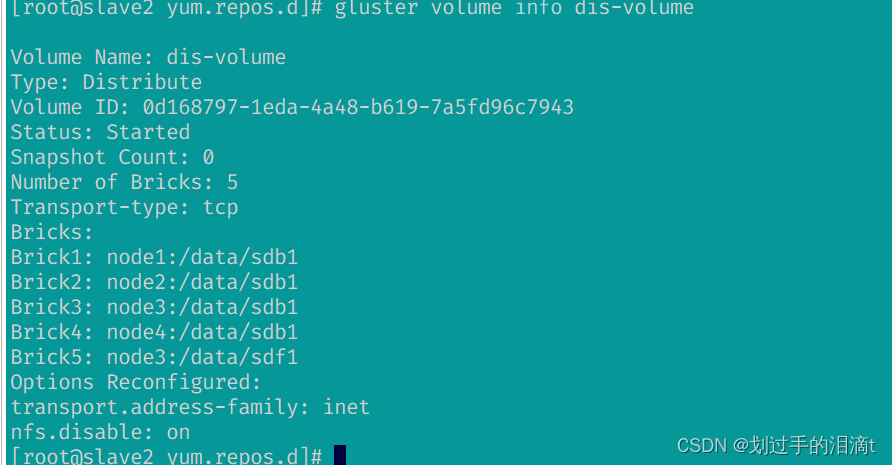
扩容
#增加一个brickgluster volume add-brick dis-volume node3:/data/sdf1 forcegluster volume rebalance dis-volume start force
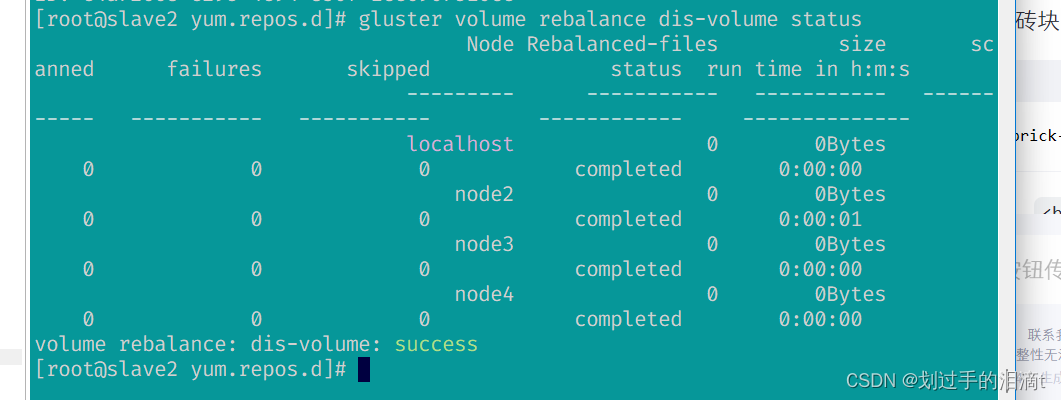
缩容
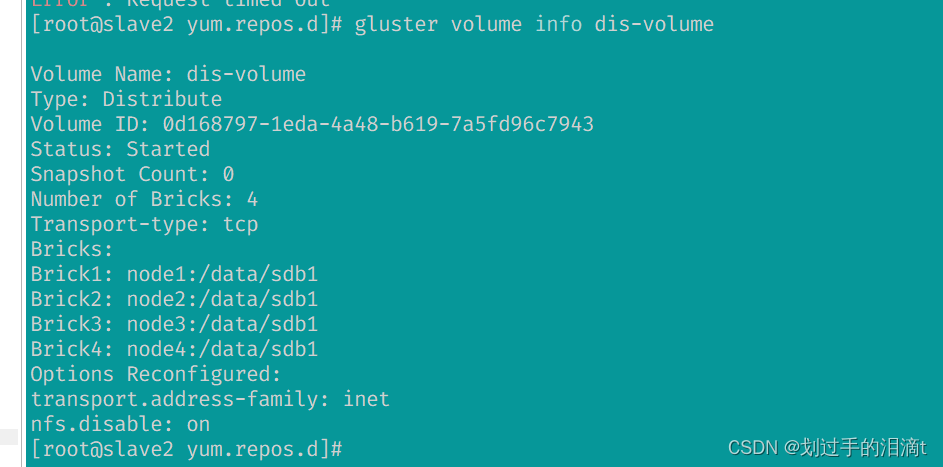
gluster volume rebalance dis-volume start force
gluster volume remove-brick dis-volume node3:/data/sdf1 force
y
yum安装glusterfs对三种基本卷进行测试
| 服务器 | 磁盘 | 挂载点 | 系统 |
|---|---|---|---|
| Node1节点:192.168.99.118 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 | centos7.4 |
| Node2节点:192.168.99.119 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 | centos7.4 |
chmod +x /opt/fdisk.sh
cd /opt/
#执行脚本
./fdisk.sh
# 查看挂载情况
df -h

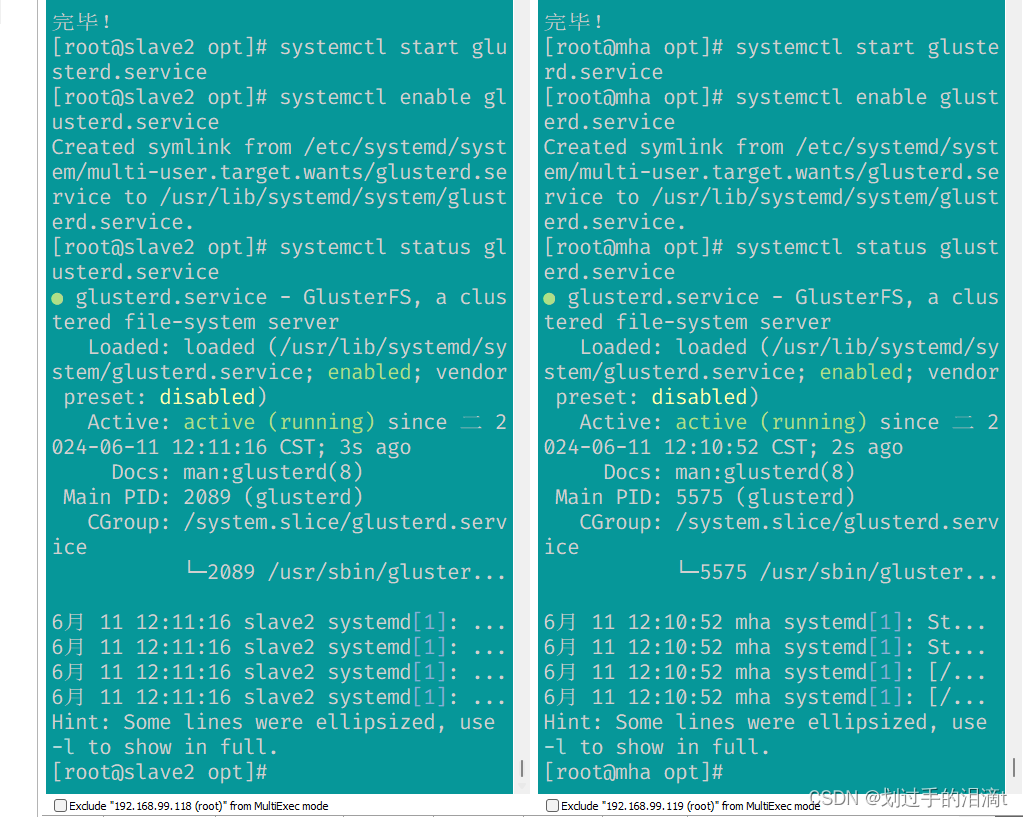
yum install -y centos-release-glusteryum install -y glusterfs-server
gluster peer probe node1
gluster peer probe node2
根据规划创建如下卷:
| 卷名 | 类型 | brick |
|---|---|---|
| dis-volume | 分布式卷 | node1-4(/data/sdb1) |
| stripe-volume | 条带卷 | node1-2(/data/sdc1) |
| rep-volume | 复制卷 | node3-4(/data/sdc1) |
创建分布式卷(dis-volume)
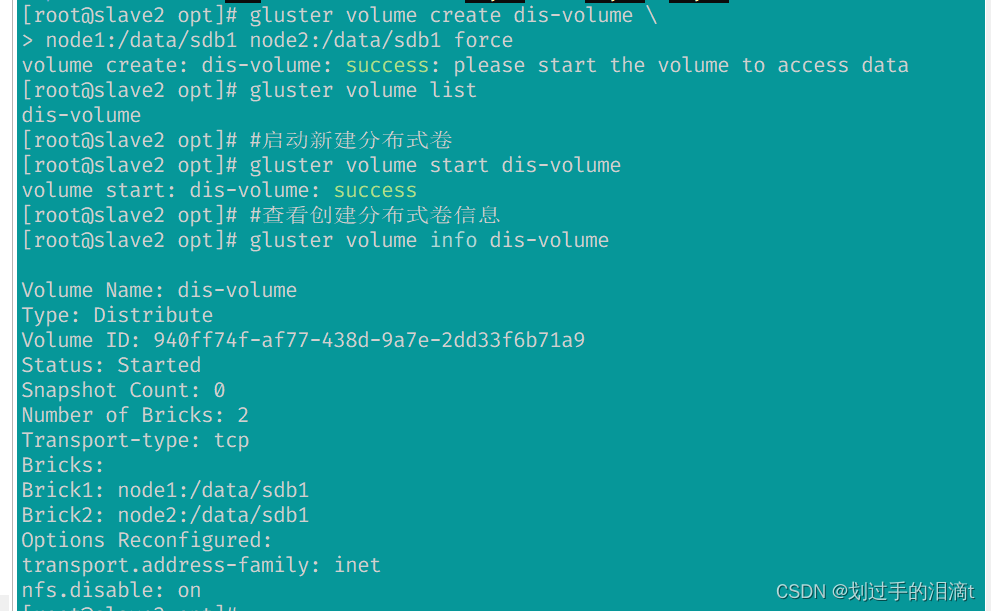
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume \
node1:/data/sdb1 node2:/data/sdb1 force
#在 GlusterFS 中,force选项用于强制操作,即使存在一些潜在的问题或警告。GlusterFS 在创建卷时会检查相关的条件和限制,如果发现问题或者不符合要求,就会拒绝创建卷并返回相应的错误信息。#查看卷列表
gluster volume list
#启动新建分布式卷
gluster volume start dis-volume
#查看创建分布式卷信息
gluster volume info dis-volume
创建条带卷(stripe-volume)
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume
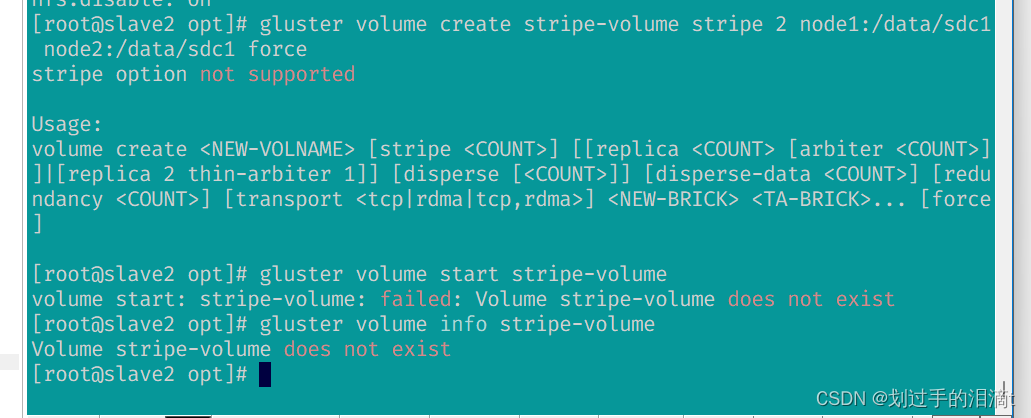
失败
创建复制卷(rep-volume)
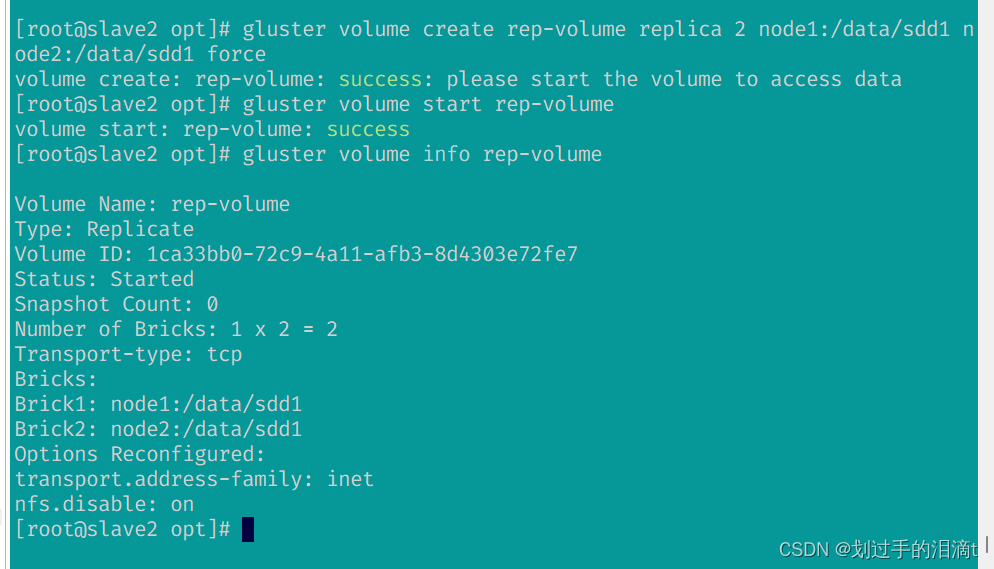
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
gluster volume create rep-volume replica 2 node1:/data/sdd1 node2:/data/sdd1 force
gluster volume start rep-volume
gluster volume info rep-volume
相关文章:
GlusterFS企业分布式存储
GlusterFS 分布式文件系统代表-nfs常见分布式存储Gluster存储基础梳理GlusterFS 适合大文件还是小文件存储? 应用场景术语Trusted Storage PoolBrickVolumes Glusterfs整体工作流程-数据访问流程GlusterFS客户端访问流程 GlusterFS常用命令部署 GlusterFS 群集准备环…...
)
SSH生成SSH密钥(公钥和私钥)
在设置SSH服务时,生成SSH密钥(公钥和私钥)是一个常见的任务。这些密钥用于安全地进行身份验证,无需输入密码。以下是如何生成SSH密钥的步骤: 1. 生成SSH密钥对 首先,您需要在客户端机器上生成一个SSH密钥…...

阶段性总结:如何快速上手一个新的平台或者技术
作为研发一枚,为了实现客户的各种需求,为了避免重复造轮子,通常需要快速调查到哪个轮子(比如各种平台,或者开发包等)好用,然后快速熟悉和上手。在接触到一个新的平台或者技术的时候,…...

kettle从入门到精通 第七十一课 ETL之kettle 再谈http post,轻松掌握body中传递json参数
场景: kettle中http post步骤如何发送http请求且传递body参数? 解决方案: http post步骤中直接设置Request entity field字段即可。 1、手边没有现成的post接口,索性用python搭建一个简单的接口,关键代码如下&#…...

第十二章:会话控制
会话控制 文章目录 会话控制一、介绍二、cookie2.1 cookie 是什么2.2 cookie 的特点2.3 cookie 的运行流程2.4 浏览器操作 cookie2.5 cookie 的代码操作(1)设置 cookie(2)读取 cookie(3)删除 cookie 三、se…...

【LeetCode滑动窗口算法】长度最小的子数组 难度:中等
我们先看一下题目描述: 解法一:暴力枚举 时间复杂度:o(n^3) class Solution { public:int minSubArrayLen(int target, vector<int>& nums){int i 0, j 0;vector<int> v;for (;i < nums.size();i){int sum nums[i];fo…...
MySQL 用户权限管理:授权、撤销、密码更新和用户删除(图文解析)
目录 前言1. 授予权限2. 撤销权限3. 查询权限4. Demo 前言 公司内部的数据库权限一般针对不同人员有不同的权限分配,而不都统一给一个root权限 1. 授予权限 授予用户权限的基本命令是GRANT 可以授予的权限种类很多,涵盖从数据库和表级别到列和存储过…...

Day39
Day39 JSP JSP底层 全称为Java Server Pages,JSP实际上就是一个servelet JSP:HTML页面Java代码,本质:servlet。 public class login_jsp{//JSP的9大内置对象private JSPWriter out;//当前JSP输出流对象private HttpServletRequest request;…...

Nginx之HTTP模块详解
Nginx是模块化的代码架构,其代码由核心代码与功能模块代码构成。Nginx的主要功能模块是HTTP功能模块,HTTP功能模块在HTTP核心功能的基础上为Nginx对HTTP请求的处理流程提供了扩展功能,这些扩展功能可以让用户很方便地应对访问控制、数据处理、…...

JCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断
JJCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断 目录 JJCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断分类效果格拉姆矩阵图GAF-PCNNGASF-CNNGADF-CNN 基本介绍程序设计参考资料 分类效果 格拉姆…...

最新Prompt预设词分享,DALL-E3文生图+文档分析
使用指南 直接复制使用 可以前往已经添加好Prompt预设的AI系统测试使用(可自定义添加使用) 支持GPTs SparkAi SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。支持GPT-4o…...

基于SpringBoot+Vue会所产后护理系统设计和实现
基于SpringBootVue会所产后护理系统设计和实现 🍅 作者主页 网顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各种定制系统 &#…...

Linux中的EINTR和EAGAIN错误码
Linux中的EINTR和EAGAIN错误码 在Linux系统中,进行系统调用时经常会遇到各种错误码。其中,EINTR(Interrupted system call)和EAGAIN(Resource temporarily unavailable)是两个较为常见的错误码,…...

用户需求分析揭秘:最佳实践与策略
大多数产品团队都有自己处理客户需求的一套流程。但是那些潜在的客户和他们的需求呢?如果在产品管理上已经有一定的资历,很可能对此见惯不怪了。 通常,这些需求是销售人员跑来告诉你的,大概就是说:“超棒的潜在客户一…...
批量创建文件夹 就是这么简单 一招创建1000+文件夹
批量创建文件夹 就是这么简单 一招创建1000文件夹 在工作中,或者生活中,我们经常要用到批量创建文件夹,并且根据不同的工作需求,要求是不一样的,比如有些人需要创建上千个不一样名称的文件夹,如果靠手动创…...

LogicFlow 学习笔记——8. LogicFlow 基础 事件 Event
事件 Event 当我们使用鼠标或其他方式与画布交互时,会触发对应的事件。通过监听这些事件,可以获取其在触发时所产生的数据,根据这些数据来实现需要的功能。详细可监听事件见事件API。 监听事件 lf实例上提供on方法支持监听事件。 lf.on(&…...
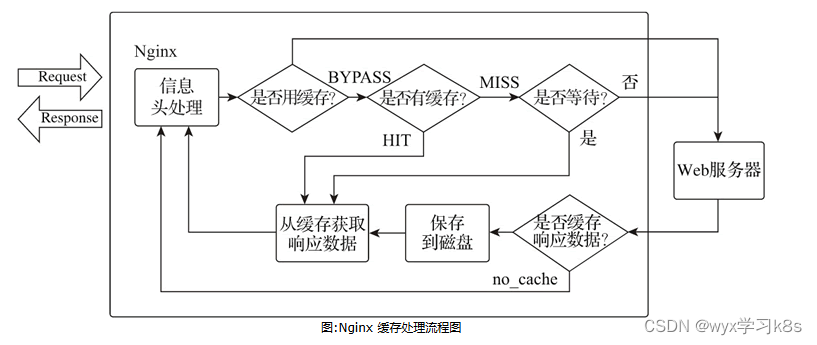
Nginx缓存之代理缓存配置
Nginx 的缓存功能是集成在代理模块中的,当启用缓存功能时,Nginx 将请求返回的响应数据持久化在服务器磁盘中,响应数据缓存的相关元数据、有效期及缓存内容等信息将被存储在定义的共享内存中。当收到客户端请求时,Nginx 会在共享内…...

【Android】使用SeekBar控制数据的滚动
项目需求 有一个文本数据比较长,需要在文本右侧加一个SeekBar,然后根据SeekBar的上下滚动来控制文本的滚动。 项目实现 我们使用TextView来显示文本,但是文本比较长的话,需要在TextView外面套一个ScrollView,但是我…...

新能源汽车的能源动脉:中国星坤汽车电缆在新能源汽车电气化中的应用!
随着新能源汽车行业的蓬勃发展,汽车电缆组件作为汽车电气系统的核心组成部分,其重要性日益凸显。中国星坤汽车电缆组件以其卓越的性能和创新技术,为汽车的电能传输、信号传递和控制提供了坚实的保障。本文将深入解析星坤汽车电缆组件的特性、…...

AVL许可证查询系统
在数字化时代,软件已经成为企业运营的核心组成部分。然而,随着软件应用的不断增加,许可证管理也变得越来越复杂。AVL许可证查询系统作为企业软件资产管理的重要工具,能够帮助企业实现对软件许可证的全面掌控。本文将深入探讨AVL许…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...
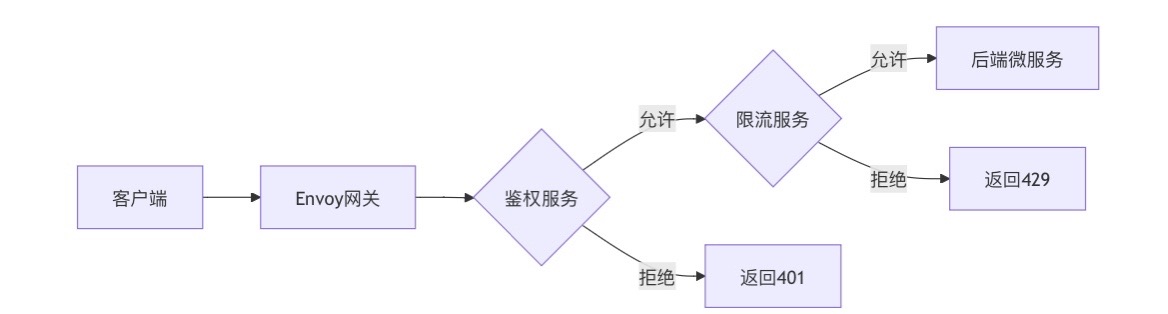
云原生安全实战:API网关Envoy的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关 作为微服务架构的统一入口,负责路由转发、安全控制、流量管理等核心功能。 2. Envoy 由Lyft开源的高性能云原生…...
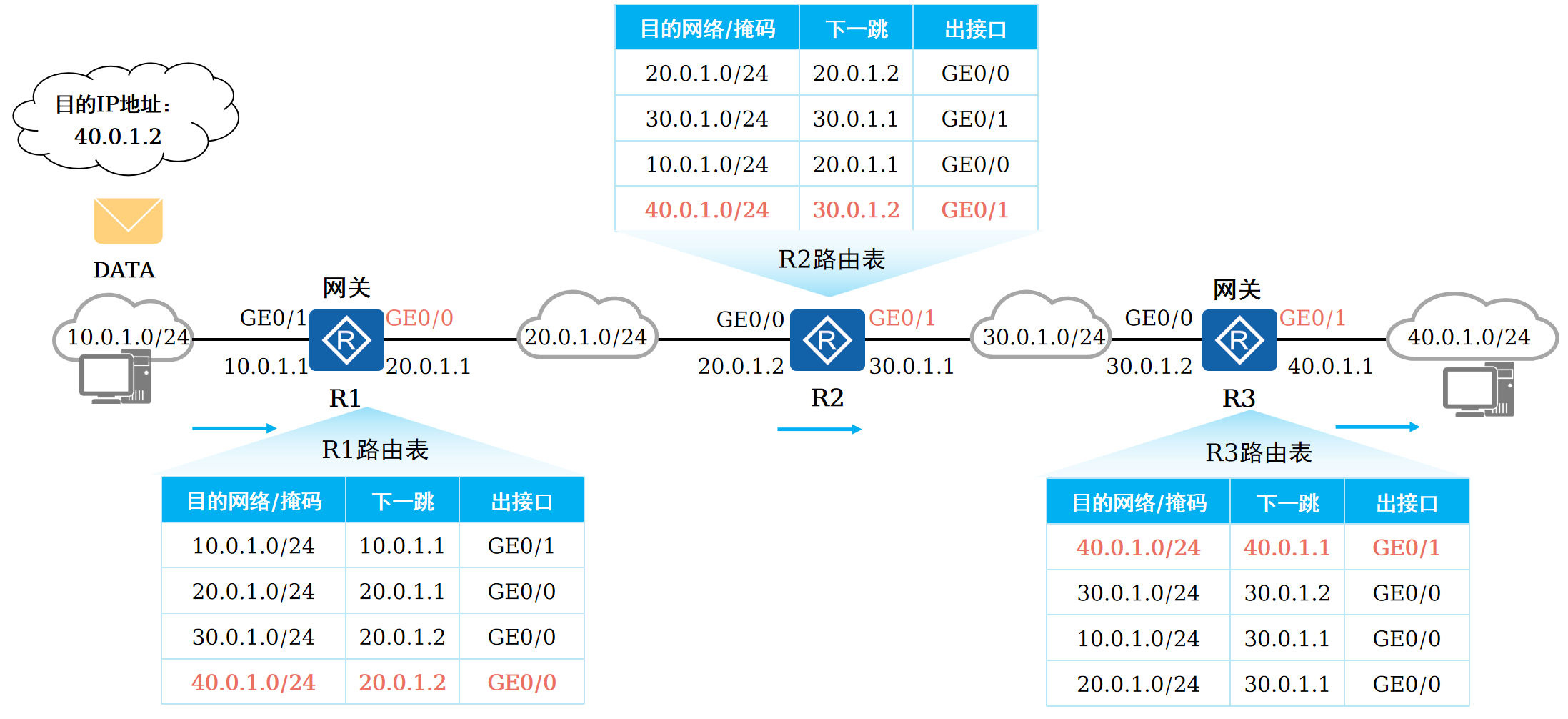
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...
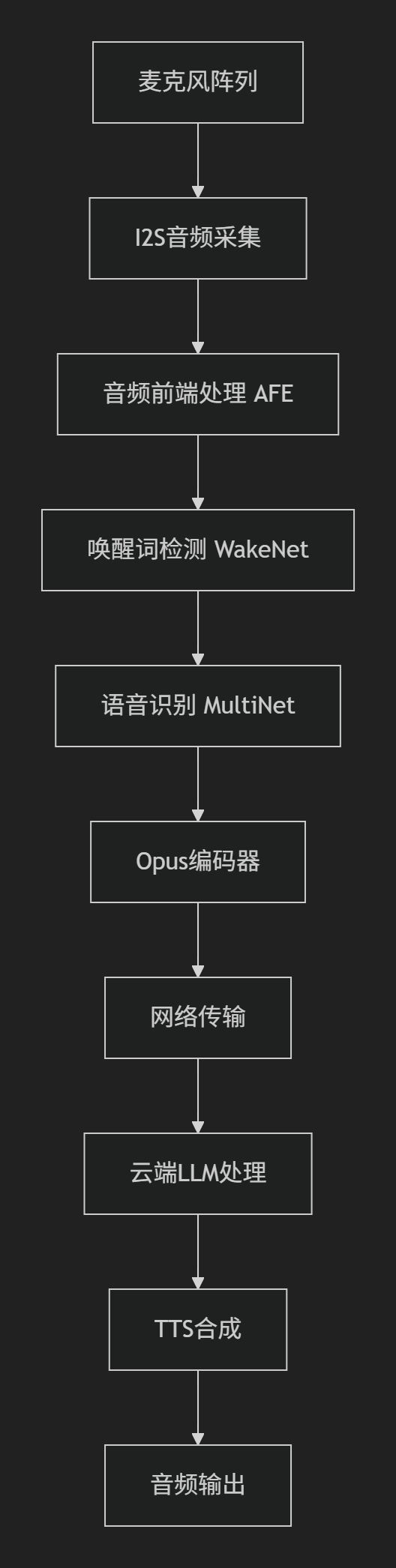
SDU棋界精灵——硬件程序ESP32实现opus编码
一、 音频处理框架 该项目基于Espressif的音频处理框架构建,核心组件包括 ESP-ADF 和 ESP-SR,以下是完整的音频处理框架实现细节: 1.核心组件 (1) 音频前端处理 (AFE - Audio Front-End) main/components/audio_pipeline/afe_processor.c功能: 声学回声…...

Docker 镜像上传到 AWS ECR:从构建到推送的全流程
一、在 EC2 实例中安装 Docker(适用于 Amazon Linux 2) 步骤 1:连接到 EC2 实例 ssh -i your-key.pem ec2-useryour-ec2-public-ip步骤 2:安装 Docker sudo yum update -y sudo amazon-linux-extras enable docker sudo yum in…...