【Python机器学习实战】 | 基于决策树的药物研究分类预测

🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,
点赞加收藏支持我,点击关注,一起进步!
引言
决策树模型是一种基于树结构进行决策的监督学习算法,它在机器学习和数据挖掘中被广泛应用。以下是关于决策树模型的详细介绍:
1. 模型原理
决策树模型基于树形结构来进行决策,树的每个内部节点表示一个属性上的决策规则,每个叶节点表示一个类别标签(或者在回归问题中是一个数值)。模型通过学习从数据特征到目标值的映射关系来进行预测。
2. 特点和优势
易于理解和解释:生成的决策树可以直观地展示决策过程,便于解释给定特征条件下的预测结果。
能处理数值型和类别型数据:决策树模型可以处理各种类型的数据,不需要额外的数据预处理(如标准化)。
可以处理多输出问题:决策树可以直接扩展到多输出问题,并且不需要额外的复杂性。
非参数化模型:与线性模型等参数化模型不同,决策树通常被认为是非参数化的,因为模型的复杂度不受数据分布的影响。
3. 模型构建过程
决策树的构建包括以下步骤:
特征选择:根据不同的标准(如信息增益、基尼不纯度等),选择最佳的特征来分裂数据集。
树的构建:从根节点开始,递归地选择最佳特征进行分裂,直到叶节点达到预定的停止条件(如节点数、深度、信息增益阈值等)。
4. 应用领域
决策树模型在以下方面有广泛应用:
分类问题:如客户信用评估、疾病诊断等。
回归问题:如房价预测、股票价格预测等。
特征选择:决策树可以用于特征选择,帮助识别最重要的特征。
5. 参数调优
决策树模型的参数包括树的深度、分裂标准(如信息增益、基尼不纯度)、叶节点最小样本数等,调优这些参数可以优化模型的性能和泛化能力。
6. 可能的局限性
过拟合:容易在训练数据上过拟合,可以通过剪枝、设置最小叶节点数等方法缓解。
对数据噪声敏感:决策树对数据中的噪声和异常值比较敏感,可能会导致过度拟合。
正文
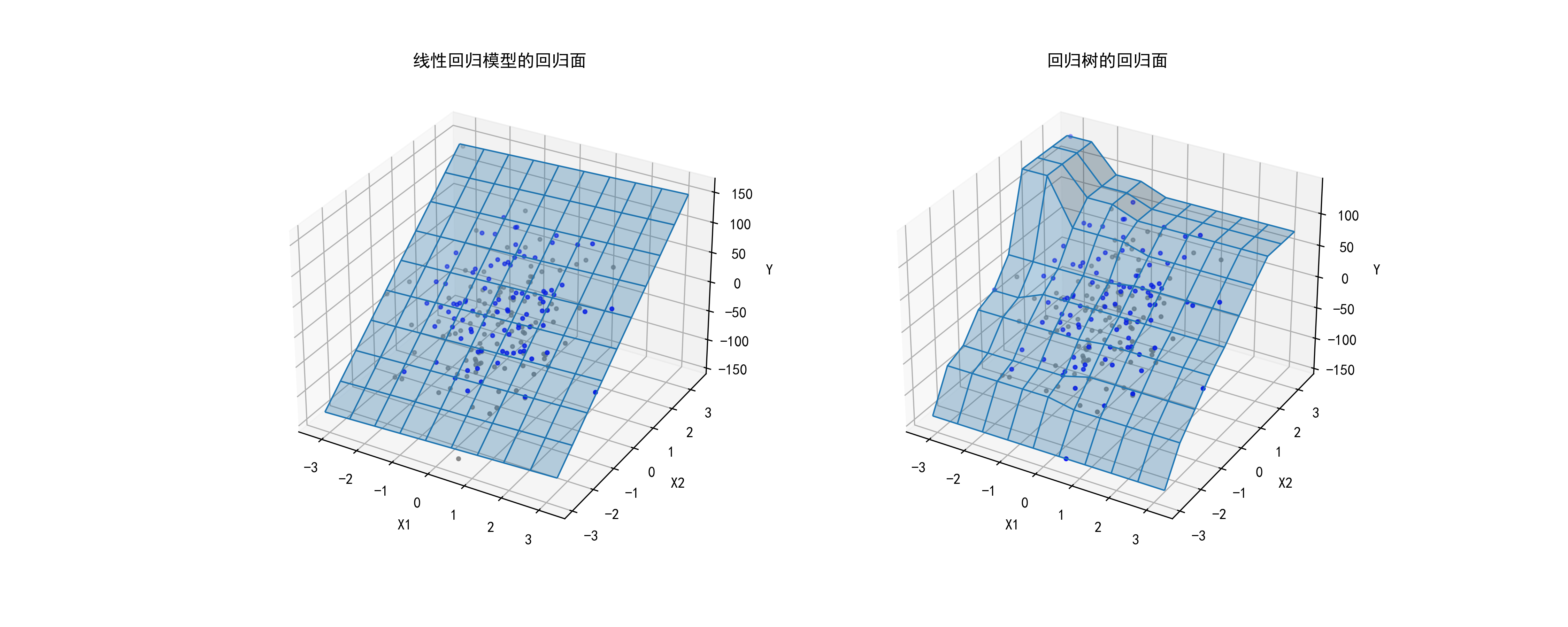
01-回归树的回归面展示
这段代码主要是用来比较线性回归模型和决策树回归模型在生成的回归面上的表现,并且将结果可视化。
数据生成和模型训练部分:
make_regression: 生成一个具有线性关系的合成数据集X和对应的目标变量Y。modelLR.fit(X, Y): 使用线性回归模型 (LinearRegression) 对数据进行拟合。modelDTC = tree.DecisionTreeRegressor(max_depth=5, random_state=123): 创建决策树回归模型 (DecisionTreeRegressor),设定最大深度为5,并使用随机状态123以确保结果的可复现性。modelDTC.fit(X, Y): 对数据进行决策树回归模型的拟合。数据可视化部分:
plt.rcParams['font.sans-serif']=['SimHei']和plt.rcParams['axes.unicode_minus']=False: 设置 matplotlib 以支持中文显示。- 创建一个 15x6 的图形 (
fig),包含两个子图 (ax0和ax1),每个子图都是 3D 投影 (projection='3d')。ax0绘制线性回归模型的回归面:
- 使用
scatter绘制原始数据点,其中颜色根据模型预测值和真实值的关系而定。- 使用
plot_wireframe和plot_surface绘制线性回归模型的回归面。ax1绘制决策树回归模型的回归面:
- 同样使用
scatter绘制原始数据点,并根据决策树模型的预测结果着色。- 使用
plot_wireframe和plot_surface绘制决策树回归模型的回归面。- 设置每个子图的标题和坐标轴标签。
- 使用
fig.subplots_adjust(wspace=0)调整子图之间的水平间距。- 最后通过
plt.savefig("../4.png", dpi=300)将生成的图形保存为 PNG 文件。这段代码的主要作用是通过比较可视化线性回归模型和决策树回归模型的回归面,展示它们在预测合成数据集时的差异和特点。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
import sklearn.linear_model as LM
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.datasets import make_regression
from sklearn import tree
from sklearn.preprocessing import LabelEncoderX,Y=make_regression(n_samples=200,n_features=2,n_informative=2,noise=10,random_state=666)
modelLR=LM.LinearRegression()
modelLR.fit(X,Y)
modelDTC = tree.DecisionTreeRegressor(max_depth=5,random_state=123)
modelDTC.fit(X,Y)
data=pd.DataFrame(X)x,y = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),10), np.linspace(X[:,1].min(),X[:,1].max(),10))
Xtmp=np.column_stack((x.flatten(),y.flatten())) #Xtmp=np.hstack((x.reshape(100,1),y.reshape(100,1)))fig = plt.figure(figsize=(15,6))
ax0 = fig.add_subplot(121, projection='3d')
data['col']='grey'
data.loc[modelLR.predict(X)<=Y,'col']='blue'
ax0.scatter(X[:,0],X[:,1],Y,marker='o',s=6,c=data['col'])
ax0.plot_wireframe(x, y, modelLR.predict(Xtmp).reshape(10,10),linewidth=1)
ax0.plot_surface(x, y, modelLR.predict(Xtmp).reshape(10,10), alpha=0.3)
ax0.set_xlabel('X1')
ax0.set_ylabel('X2')
ax0.set_zlabel('Y')
ax0.set_title('线性回归模型的回归面')ax1 = fig.add_subplot(122, projection='3d')
data['col']='grey'
data.loc[modelDTC.predict(X)<=Y,'col']='blue'
ax1.scatter(X[:,0],X[:,1],Y,marker='o',s=6,c=data['col'])
ax1.plot_wireframe(x, y, modelDTC.predict(Xtmp).reshape(10,10),linewidth=1)
ax1.plot_surface(x, y, modelDTC.predict(Xtmp).reshape(10,10), alpha=0.3)
ax1.set_xlabel('X1')
ax1.set_ylabel('X2')
ax1.set_zlabel('Y')
ax1.set_title('回归树的回归面')
#fig.subplots_adjust(hspace=0.5)
fig.subplots_adjust(wspace=0)
plt.savefig("../4.png", dpi=300)运行结果如下图所示
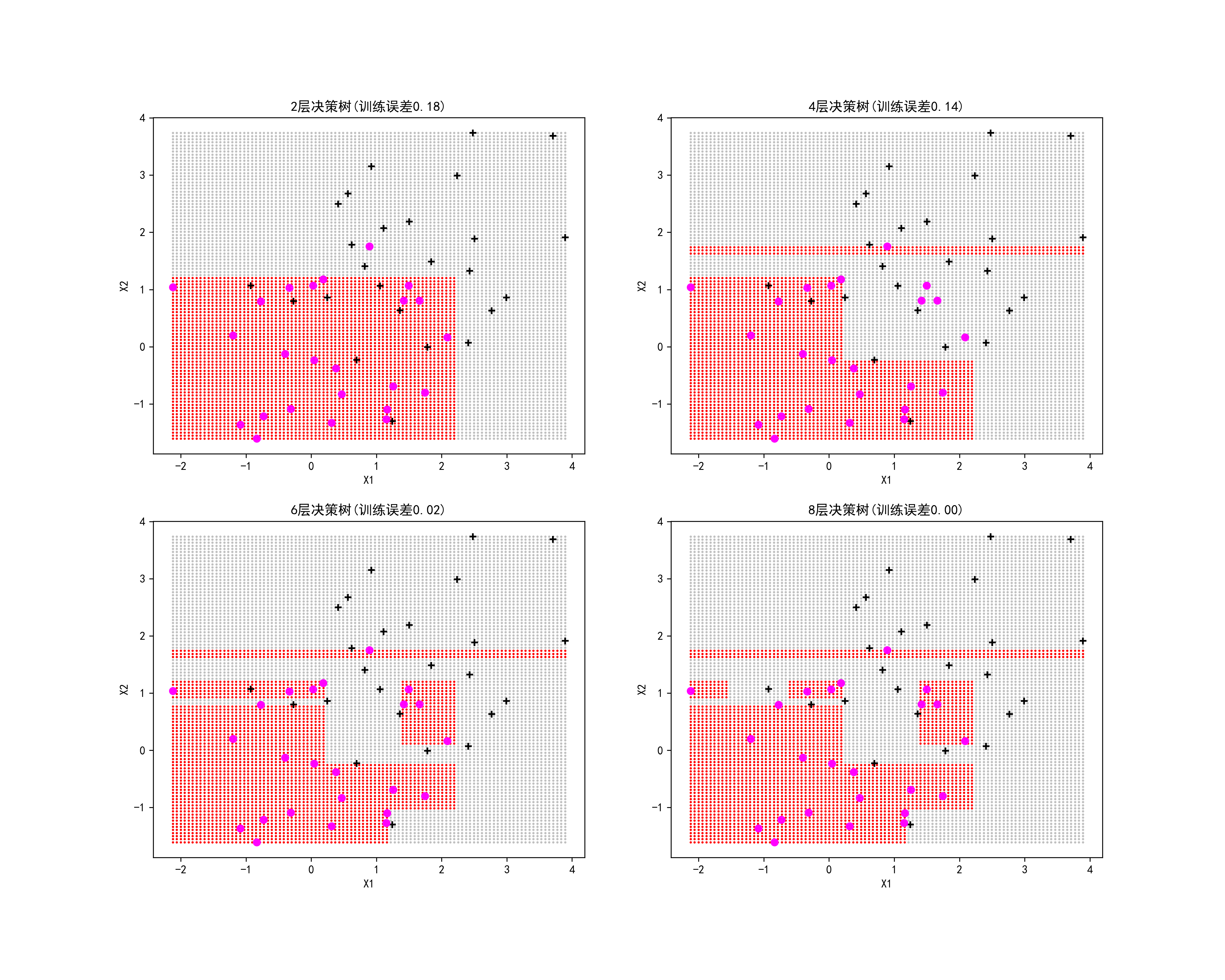
02-不同树深度的决策树进行分类预测
这段代码的主要目的是生成并可视化不同深度的决策树在分类任务上的表现。
数据生成部分:
np.random.seed(123): 设置随机种子以确保结果的可重现性。N=50和n=int(0.5*N): 定义样本数量和每个类别的样本数量。X=np.random.normal(0,1,size=100).reshape(N,2): 生成服从正态分布的数据集X,共50个样本,每个样本有2个特征。Y=[0]*n+[1]*n: 生成类别标签,前半部分为0,后半部分为1。X[0:n]=X[0:n]+1.5: 将前半部分类别的样本特征值增加1.5,使得数据集具有明显的类别分离特征。X1,X2 = np.meshgrid(...): 生成用于绘制决策边界的网格数据。模型训练和可视化部分:
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(15,12)): 创建一个包含4个子图的图形。- 循环遍历不同的决策树深度
(2, 4, 6, 8):
modelDTC = tree.DecisionTreeClassifier(max_depth=K,random_state=123): 创建决策树分类器模型,设定最大深度为K。modelDTC.fit(X,Y): 使用生成的数据集X和标签Y进行模型训练。Yhat=modelDTC.predict(data): 对网格数据data进行预测,获取分类结果。- 绘制子图中的散点图:
axes[H,L].scatter(data[Yhat==k,0],data[Yhat==k,1],color=c,marker='o',s=1): 根据预测结果将分类结果可视化,其中k表示分类标签,c表示颜色。axes[H,L].scatter(X[:n,0],X[:n,1],color='black',marker='+'): 绘制训练集中类别0的样本。axes[H,L].scatter(X[(n+1):N,0],X[(n+1):N,1],color='magenta',marker='o'): 绘制训练集中类别1的样本。- 设置子图的标题和坐标轴标签。
"%d层决策树(训练误差%.2f)"%((K,1-modelDTC.score(X,Y))): 设置子图的标题,包含决策树深度和训练误差。保存图形:
plt.savefig("../4.png", dpi=300): 将生成的图形保存为 PNG 文件。这段代码主要用于比较不同深度的决策树分类器在生成的合成数据上的分类效果,并通过散点图可视化不同深度决策树的决策边界和分类效果,以便于直观地理解和比较不同深度决策树的表现。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
import sklearn.linear_model as LM
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.datasets import make_regression
from sklearn import tree
from sklearn.preprocessing import LabelEncodernp.random.seed(123)
N=50
n=int(0.5*N)
X=np.random.normal(0,1,size=100).reshape(N,2)
Y=[0]*n+[1]*n
X[0:n]=X[0:n]+1.5
X1,X2 = np.meshgrid(np.linspace(X[:,0].min(),X[:,0].max(),100), np.linspace(X[:,1].min(),X[:,1].max(),100))
data=np.hstack((X1.reshape(10000,1),X2.reshape(10000,1)))fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(15,12))
for K,H,L in [(2,0,0),(4,0,1),(6,1,0),(8,1,1)]:modelDTC = tree.DecisionTreeClassifier(max_depth=K,random_state=123)modelDTC.fit(X,Y)Yhat=modelDTC.predict(data) for k,c in [(0,'silver'),(1,'red')]:axes[H,L].scatter(data[Yhat==k,0],data[Yhat==k,1],color=c,marker='o',s=1)axes[H,L].scatter(X[:n,0],X[:n,1],color='black',marker='+')axes[H,L].scatter(X[(n+1):N,0],X[(n+1):N,1],color='magenta',marker='o')axes[H,L].set_xlabel("X1")axes[H,L].set_ylabel("X2")axes[H,L].set_title("%d层决策树(训练误差%.2f)"%((K,1-modelDTC.score(X,Y))))
plt.savefig("../4.png", dpi=300)运行结果如下图所示
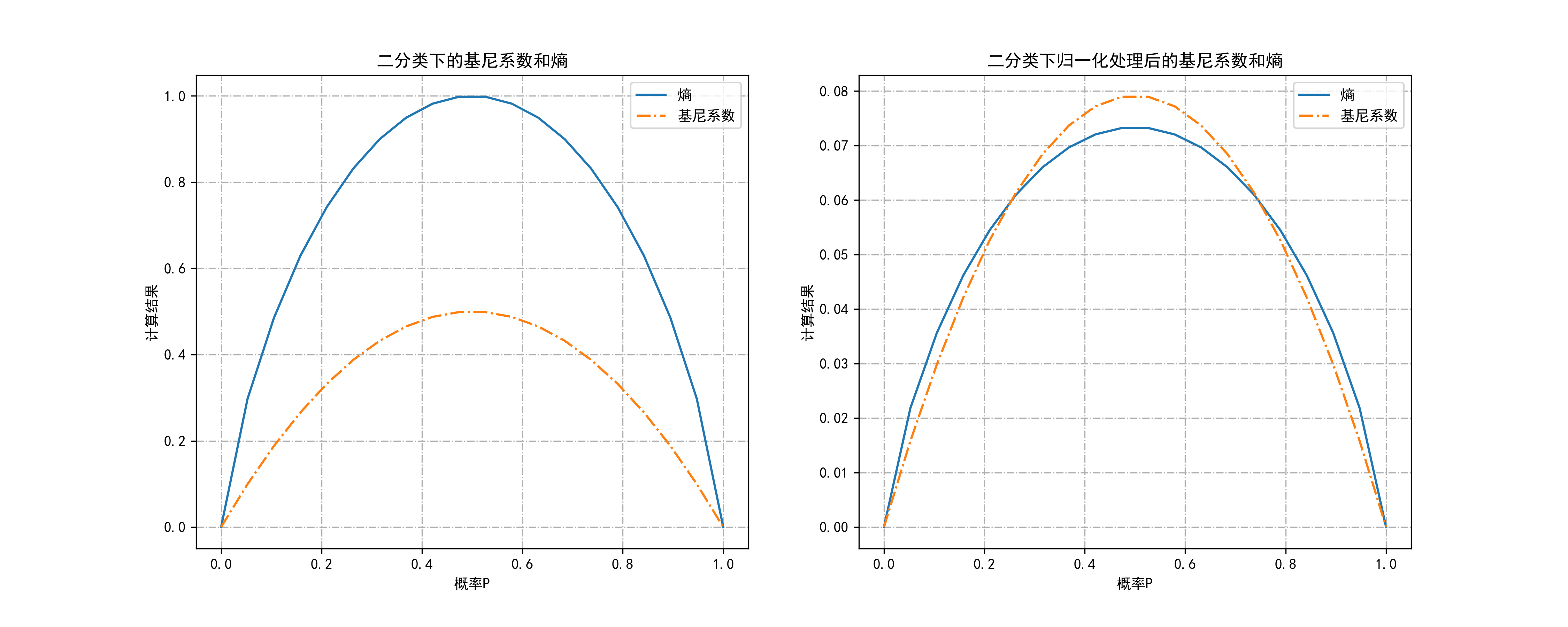
03-对比两个异质性度量指标
这段代码的主要目的是比较二分类任务中基尼系数和熵的变化,并进行归一化处理后的比较,最终生成可视化图形保存为图片。
导入库和设置:
- 导入必要的库,包括NumPy、Pandas、Matplotlib等。
- 设置警告忽略和中文显示设置。
创建图形和子图:
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(15,6)): 创建一个包含两个子图的图形,每个子图排列在一行两列的布局中,总图形大小为15x6英寸。计算基尼系数和熵:
P=np.linspace(0,1,20): 生成20个在0到1之间均匀分布的概率值。- 使用循环遍历每个概率值
p:
- 计算熵
Ent:当p为0或1时熵为0,否则根据熵的公式计算。- 计算基尼系数
Gini:根据基尼系数的公式计算。绘制图形:
- 在第一个子图
axes[0]中绘制两条曲线:
axes[0].plot(P,Ent,label='熵'): 绘制熵随概率变化的曲线。axes[0].plot(P,Gini,label='基尼系数',linestyle='-.'): 绘制基尼系数随概率变化的曲线。- 设置标题
'二分类下的基尼系数和熵',以及坐标轴标签和图例,使得图形信息清晰表达。axes[0].grid(True, linestyle='-.'): 添加网格线,增强可视化效果。归一化处理并绘制第二个子图:
- 在第二个子图
axes[1]中,绘制归一化处理后的结果:
axes[1].plot(P,Ent/sum(Ent),label='熵'): 绘制归一化后的熵曲线。axes[1].plot(P,Gini/sum(Gini),label='基尼系数',linestyle='-.'): 绘制归一化后的基尼系数曲线。- 设置标题
'二分类下归一化处理后的基尼系数和熵',以及坐标轴标签和图例。axes[1].grid(True, linestyle='-.'): 添加网格线。保存图形:
plt.savefig("../4.png", dpi=300): 将生成的图形保存为 PNG 文件,指定分辨率为300 DPI。这段代码的目的是通过绘制基尼系数和熵随着概率变化的曲线,展示它们在二分类问题中的变化规律,并通过归一化处理后的曲线进行对比,帮助理解和比较这两种常用的分类不纯度衡量指标。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
import sklearn.linear_model as LM
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.datasets import make_regression
from sklearn import tree
from sklearn.preprocessing import LabelEncoderfig,axes=plt.subplots(nrows=1,ncols=2,figsize=(15,6))
P=np.linspace(0,1,20)
Ent=[]
Gini=[]
for p in P:if (p==0) or (p==1):ent=0else:ent = -p * np.log2(p)-(1-p)*np.log2(1-p)Ent.append(ent)gini=1-(p**2+(1-p)**2)Gini.append(gini)
axes[0].plot(P,Ent,label='熵')
axes[0].plot(P,Gini,label='基尼系数',linestyle='-.')
axes[0].set_title('二分类下的基尼系数和熵')
axes[0].set_xlabel('概率P')
axes[0].set_ylabel('计算结果')
axes[0].grid(True, linestyle='-.')
axes[0].legend()axes[1].plot(P,Ent/sum(Ent),label='熵')
axes[1].plot(P,Gini/sum(Gini),label='基尼系数',linestyle='-.')
axes[1].set_title('二分类下归一化处理后的基尼系数和熵')
axes[1].set_xlabel('概率P')
axes[1].set_ylabel('计算结果')
axes[1].grid(True, linestyle='-.')
axes[1].legend()
plt.savefig("../4.png", dpi=300)运行结果如下图所示
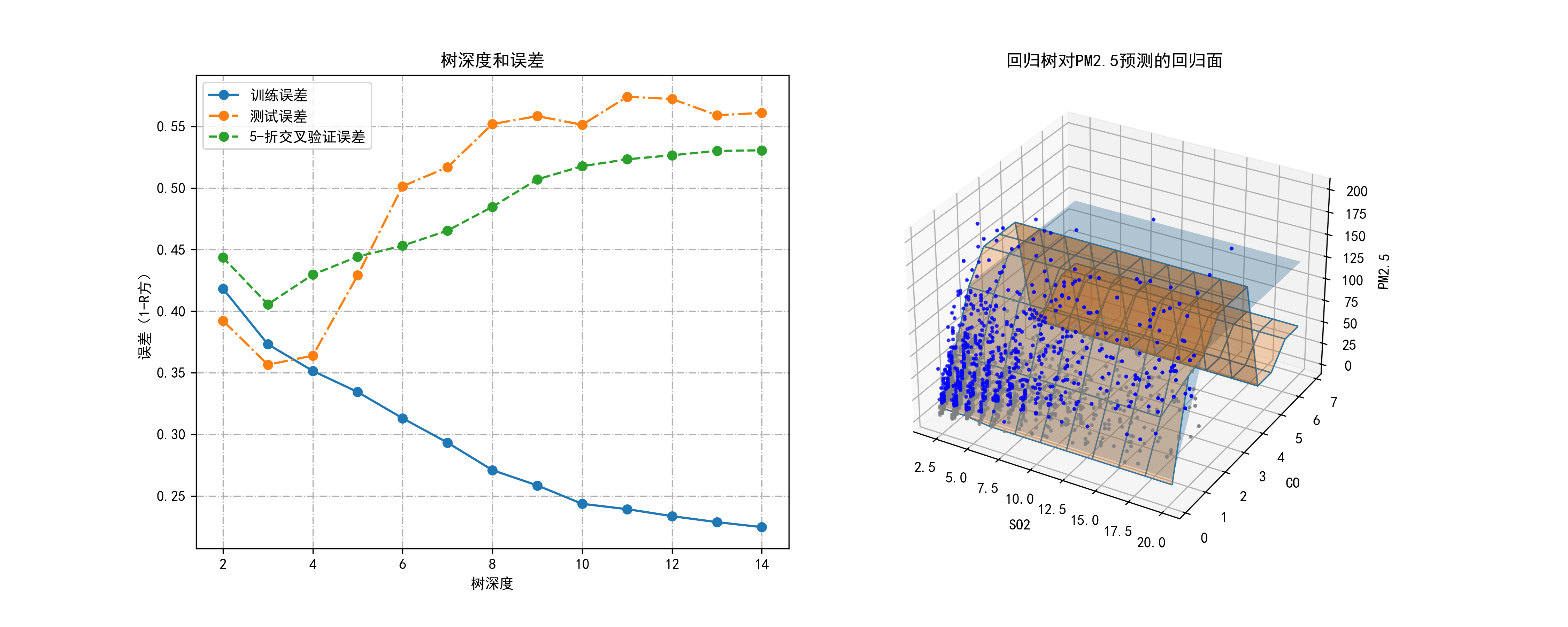
04-基于决策树对空气质量监测数据等级进行预测
这段代码主要用于分析北京市空气质量数据,并基于决策树回归模型预测PM2.5浓度。
数据导入与预处理:
- 首先导入必要的库,并从Excel文件中读取数据。数据中对PM2.5和SO2值进行了筛选,排除了异常值和缺失值。
数据准备:
- 定义了自变量
X(包括SO2和CO浓度)和因变量Y(PM2.5浓度)。- 将数据分割为训练集和测试集,比例为70:30,保证了模型评估的独立性。
模型训练与误差评估:
- 使用循环遍历不同的树深度(从2到14),建立决策树回归模型
DecisionTreeRegressor。- 计算并记录了训练误差、测试误差和5折交叉验证误差,用以评估模型的泛化能力和过拟合情况。
误差可视化:
- 绘制了图表展示不同树深度下的训练误差、测试误差和交叉验证误差的变化情况,帮助选择最优的树深度。
模型应用与可视化:
- 选择树深度为3的模型,对数据集进行拟合,并打印出输入变量的重要性。
- 使用预测结果对数据点进行分类,根据预测值是否小于真实值确定颜色。
三维可视化:
- 使用三维散点图展示SO2、CO与PM2.5的关系,根据分类结果着色。
- 绘制决策树回归模型的预测面,展示树深度为3和5时的回归效果。
保存图像:
- 最后将生成的图像保存为文件。
这段代码的主要目的是探索空气质量数据中SO2和CO浓度对PM2.5浓度的影响,并通过决策树回归模型建立预测,同时进行模型评估和结果可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
import sklearn.linear_model as LM
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.datasets import make_regression
from sklearn import tree
from sklearn.preprocessing import LabelEncoderdata=pd.read_excel('北京市空气质量数据.xlsx')
data=data.replace(0,np.NaN)
data=data.dropna()
data=data.loc[(data['PM2.5']<=200) & (data['SO2']<=20)]X=data[['SO2','CO']]
Y=data['PM2.5']
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
trainErr=[]
testErr=[]
CVErr=[]
for k in np.arange(2,15):modelDTC = tree.DecisionTreeRegressor(max_depth=k,random_state=123)modelDTC.fit(X_train,Y_train)trainErr.append(1-modelDTC.score(X_train,Y_train)) # 训练误差testErr.append(1-modelDTC.score(X_test,Y_test)) # 测试误差Err=1 - cross_val_score(modelDTC,X,Y,cv=5,scoring='r2') CVErr.append(Err.mean()) # 五折交叉验证误差fig = plt.figure(figsize=(15,6))
ax1 = fig.add_subplot(121)
ax1.grid(True, linestyle='-.')
ax1.plot(np.arange(2,15),trainErr,label="训练误差",marker='o',linestyle='-')
ax1.plot(np.arange(2,15),testErr,label="测试误差",marker='o',linestyle='-.')
ax1.plot(np.arange(2,15),CVErr,label="5-折交叉验证误差",marker='o',linestyle='--')
ax1.set_xlabel("树深度")
ax1.set_ylabel("误差(1-R方)")
ax1.set_title('树深度和误差')
ax1.legend()modelDTC = tree.DecisionTreeRegressor(max_depth=3,random_state=123)
modelDTC.fit(X,Y)
print("输入变量重要性:",modelDTC.feature_importances_ )
data['col']='grey'
data.loc[modelDTC.predict(X)<=Y,'col']='blue'
ax2 = fig.add_subplot(122, projection='3d')
ax2.scatter(data['SO2'],data['CO'],data['PM2.5'],marker='o',s=3,c=data['col'])
ax2.set_xlabel('SO2')
ax2.set_ylabel('CO')
ax2.set_zlabel('PM2.5')
ax2.set_title('回归树对PM2.5预测的回归面')x,y = np.meshgrid(np.linspace(data['SO2'].min(),data['SO2'].max(),10), np.linspace(data['CO'].min(),data['CO'].max(),10))
Xtmp=np.column_stack((x.flatten(),y.flatten()))
ax2.plot_surface(x, y, modelDTC.predict(Xtmp).reshape(10,10), alpha=0.3,label="树深度=3")
modelDTC = tree.DecisionTreeRegressor(max_depth=5,random_state=123)
modelDTC.fit(X,Y)
ax2.plot_wireframe(x, y, modelDTC.predict(Xtmp).reshape(10,10),linewidth=1)
ax2.plot_surface(x, y, modelDTC.predict(Xtmp).reshape(10,10), alpha=0.3,label="树深度=5")
fig.subplots_adjust(wspace=0.05)
plt.savefig("../4.png", dpi=300)运行结果如下图所示
总结
决策树模型以其简单直观的特性和广泛的适用性,在许多领域都得到了有效的应用。对于复杂的数据集或者需要更高预测精度的问题,可以通过集成学习方法(如随机森林、梯度提升树)来进一步改进决策树模型的性能。
相关文章:
【Python机器学习实战】 | 基于决策树的药物研究分类预测
🎩 欢迎来到技术探索的奇幻世界👨💻 📜 个人主页:一伦明悦-CSDN博客 ✍🏻 作者简介: C软件开发、Python机器学习爱好者 🗣️ 互动与支持:💬评论 &…...
B端系统的UI框架选择,不要输在了起跑线,如何破?
所谓成也框架、败也框架,框架就是这么的优点和缺点鲜明,市面上的框架多如牛毛,谁家的最优秀呢?为何框架搞出来的UI界面同质化呢,如何避免这种情况,如何在框架的基础上进一步提升颜值和体验呢,本…...
)
RabbitMQ延迟消息(通过死信交换机实现)
延迟消息:生产者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间后才收到消息 通过DLX和TTL模拟出延迟队列的功能,即,消息发送以后,不让消费者拿到,而是等待过期时间࿰…...

Java - 分支结构 - if…else/switch
Java 分支结构 - if…else/switch if语句语法 if...else 语句语法实例 if...else if...else 语句语法实例 嵌套的 if…else 语句语法实例 switch 语句语法实例 顺序结构只能顺序执行,不能进行判断和选择,因此需要分支结构。 Java有两种分支结构…...

web安全渗透测试十大常规项(一):web渗透测试之XML和XXE外部实体注入
#详细点: XML被设计为传输和存储数据,XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素,其焦点是数据的内容,其把数据从HTML分离,是独立于软件和硬件的信息传输工具。等同于JSON传输。XXE漏洞XML External Entity Injection,即xml外部实体注入漏洞,XXE漏洞发…...

任务3.8.2 利用RDD计算总分与平均分
实战:使用RDD 计算学生成绩的总分与平均分 项目背景 本项目旨在利用 Apache Spark 的强大数据处理能力,对存储在 HDFS 上的学生成绩文件进行处理,计算每个学生的总分和平均分。 项目目标 读取存储在 HDFS 上的成绩文件。计算每个学生的总…...

探索磁力搜索引擎:互联网资源获取的新视角
在当今数字化社会中,寻找和获取网络资源变得更加便捷和多样化。磁力搜索引擎作为这一趋势的一部分,提供了一种新颖而有效的方法来定位和获取用户所需的文件、媒体和其他数字内容。本文将深入探讨磁力搜索引擎的工作原理、使用场景及其在网络文化中的影响…...

立创开源学习篇(一)
1.机壳地 外面包围的一圈是机壳地,和金属外壳相连与电路板的GND不相连:(大疆很多产品有此设计) 屏蔽和接地:通过在电路板周围打孔,并连接到机壳地,可以形成有效的电磁屏蔽层(形成金…...

2024/6/18 英语每日一段
While refusing to attribute various problems to specific labs in order to protect the investigators’ sources, the Gladstone AI team told The Washington Times that it found various assessments of security issues were “totally untethered to reality” about…...

时隔一年,SSD大涨价?
同样产品,2T,去年400多到手,今年700。 去年 今年...

【TB作品】MSP430G2553,单片机,口袋板,流量积算仪设计
题9 流量积算仪设计 某型流量计精度为0.1%, 满刻度值为4L/s,流量计输出为4—20 mA。 设计基于MSP430及VFC32的流量积算仪。 具体要求 (1) 积算仪满刻度10000 L,精度0.1 L; 计满10000 L,自动归零并通过串口(RS232)向上位…...
九、数据结构(并查集)
文章目录 1.并查集操作的简单实现2.解决问题3. 并查集优化3.1 合并的优化3.2查询优化3.3查询优化2 通常用“帮派”的例子来说明并查集的应用背景:在一个城市中有 n ( n < 1 0 6 ) n(n < 10^6) n(n<106)个人,他们分成不同的帮派,给出…...

大模型开发技术基础
大模型(Large Model)的开发涉及多个技术基础和领域,涵盖了机器学习、深度学习、自然语言处理(NLP)、计算机视觉(CV)、数据工程等方面。以下是一些关键的技术基础: 1. 机器学习和深度…...

芯片验证分享9 —— 芯片调试
大家好,我是谷公子,之前的课程给大家讲了验证原则、激励设计和代码审查,今天我们来讲芯片调试。 芯片调试是执行一次成功的验证之后要进行的工作。记住,所谓成功的验证,是指它可以证明芯片没有实现预期的功能。调试主…...

java 面试题--基础
文章目录 基础java SE 、 EE 、 ME 的区别jdk 和 jre 区别?java 的日志级别基本数据类型 特性关键字finalabstractsuperswitchfortry catch 接口和抽象类的区别接口抽象类适用场景 类的加载循序静态代码块 传参问题访问修饰符运算符 反射java 里的应用为什么反射的性…...

必看!!! 2024 最新 PG 硬核干货大盘点(上)
PGConf.dev(原名PGCon,从2007年至2023年)首次在风景如画的加拿大温哥华市举办。此次重新定位的会议带来了全新的视角和多项新的内容,参会体验再次升级。尽管 PGCon 历来更侧重于开发者,吸引来自世界各地的资深开发者、…...
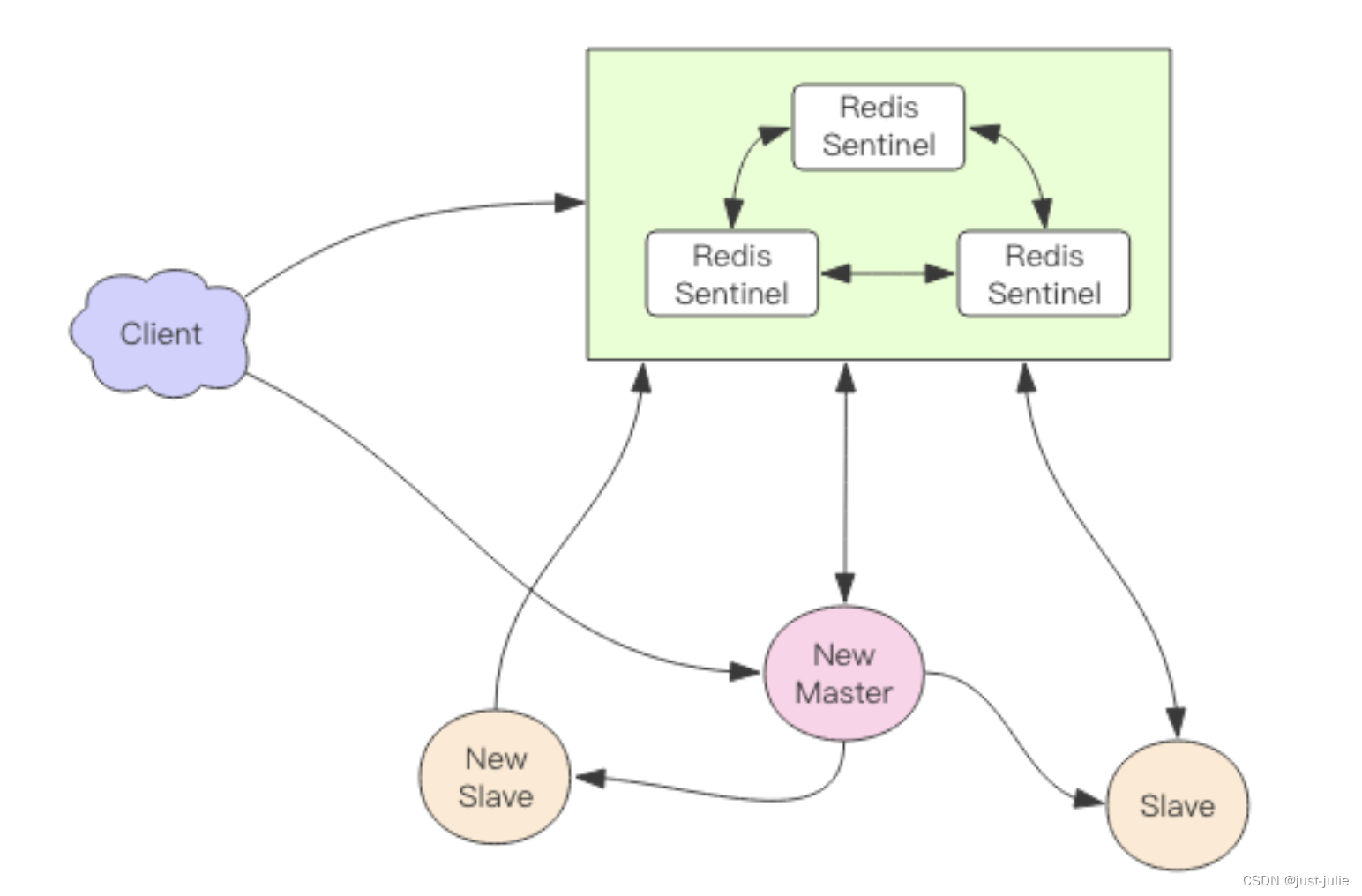
Redis 高可用 sentinel
简介 Sentinel提供了一种高可用方案来抵抗节点故障,当故障发生时Redis集群可以自动进行主从切换,程序可以不用重启。 Redis Sentinel集群可以看成是一个Zookeeper集群,他是Redis集群高可用的心脏,一般由3-5个节点组成࿰…...

【数据结构】练习集
数据的逻辑结构说明数据元素之间的顺序关系,它依赖于计算机的存储结构。(F) 在顺序表中逻辑上相邻的元素,其对应的物理位置也是相邻的。(T) 若一个栈的输入序列为{1, 2, 3, 4, 5},则不可能得到…...

驱动开发(四):Linux内核中断
驱动开发系列文章: 驱动开发(一):驱动代码的基本框架 驱动开发(二):创建字符设备驱动 驱动开发(三):内核层控制硬件层 驱动开发(四…...

btrace:binder_transaction+eBPF+Golang实现通用的Android APP动态行为追踪工具
一、简介: 在进行Android恶意APP检测时,需要进行自动化的行为分析,一般至少包括行为采集和行为分析两个模块。其中,行为分析有基于规则、基于机器学习、基于深度学习甚至基于大模型的方案,各有各的优缺点,不…...
Pixel Dimension Fissioner效果展示:同一文本种子在不同Temperature下的创意光谱
Pixel Dimension Fissioner效果展示:同一文本种子在不同Temperature下的创意光谱 1. 像素语言工坊的创意魔力 Pixel Dimension Fissioner(像素维度裂变器)是一款基于MT5-Zero-Shot-Augment核心引擎构建的文本创意工具。它将传统AI文本生成转…...

Qwen3-Embedding-4B部署指南:SGlang服务启动与API调用
Qwen3-Embedding-4B部署指南:SGlang服务启动与API调用 1. Qwen3-Embedding-4B模型简介 1.1 核心能力概述 Qwen3-Embedding-4B是通义千问系列最新推出的文本嵌入模型,专为语义理解任务设计。作为中等规模的4B参数模型,它在多语言支持、长文…...

嵌入式C中结构体嵌套联合体的内存优化实践
1. 结构体与联合体共用的工程实践解析在嵌入式系统开发中,内存资源往往高度受限,如何在保证代码可读性与功能完整性的前提下,实现内存使用的最优化,是每一位硬件工程师和固件开发者必须面对的核心问题。结构体(struct&…...

我的第一个多智能体项目踩坑实录:LangGraph连接Dify时,流式响应和错误处理怎么做?
我的第一个多智能体项目踩坑实录:LangGraph连接Dify时,流式响应和错误处理怎么做? 去年夏天,当我第一次尝试将Dify平台的多个智能体通过LangGraph串联成工作流时,原本以为只需要简单调用API就能完成的任务,…...

M2FP镜像深度体验:CPU优化版,稳定运行无报错
M2FP镜像深度体验:CPU优化版,稳定运行无报错 你是否曾为本地部署一个AI模型而焦头烂额?尤其是在没有独立显卡的电脑上,面对复杂的依赖冲突和版本不兼容问题,一个简单的“pip install”都可能变成一场灾难。最近&#…...

Qwen-Image镜像惊艳案例:RTX4090D解析科研论文插图并生成方法论总结
Qwen-Image镜像惊艳案例:RTX4090D解析科研论文插图并生成方法论总结 1. 科研助手新体验:当AI遇到学术论文 想象一下这样的场景:你正在阅读一篇复杂的科研论文,面对密密麻麻的图表和数据,需要花费数小时才能理解其中的…...

Swift面试必问:Struct与Class的10个关键区别及实战选择指南
Swift面试必问:Struct与Class的10个关键区别及实战选择指南 在iOS开发领域,Swift语言的设计哲学始终围绕着安全性与性能展开。作为面试中的高频考点,Struct与Class的差异远不止于简单的语法区别,而是反映了Swift核心团队对现代编程…...

终极Flowtime.js指南:10个技巧构建惊艳HTML演示与网站
终极Flowtime.js指南:10个技巧构建惊艳HTML演示与网站 【免费下载链接】flowtime.js Flowtime.js HTML5/CSS3/JS Websites and Presentation Framework 项目地址: https://gitcode.com/gh_mirrors/fl/flowtime.js Flowtime.js是一个强大的HTML5/CSS3/JS框架&…...

低成本AI助手方案:OpenClaw对接自部署GLM-4.7-Flash
低成本AI助手方案:OpenClaw对接自部署GLM-4.7-Flash 1. 为什么选择自部署模型OpenClaw组合 去年我在开发个人知识管理工具时,发现调用商业AI API的成本高得惊人。一个简单的文件整理任务,每月Token费用就超过200元。这促使我开始寻找更经济…...

Nanbeige 4.1-3B部署教程:适配RTX 3060/4090的显存优化参数详解
Nanbeige 4.1-3B部署教程:适配RTX 3060/4090的显存优化参数详解 1. 环境准备与快速部署 在开始部署Nanbeige 4.1-3B模型前,我们需要确保硬件和软件环境满足基本要求。 1.1 硬件要求 显卡:NVIDIA RTX 3060(12GB)或RTX 4090(24GB)显存&…...