Python 中的 Pandas(数据分析与处理)
Pandas 是 Python 中最受欢迎的数据处理库之一,其名字源自于“Panel Data”(面板数据)的缩写。它提供了三种主要的数据结构:Series , DataFrame , Panel(在新版本已经被弃用)
数据操作与基本技巧
- 数据读取与加载:Pandas 支持从多种数据源加载数据,包括 CSV 文件、Excel 文件、SQL 数据库、JSON 文件等。使用 pd.read_csv()、pd.read_excel() 等函数可以方便地将数据加载到 DataFrame 中进行后续处理。
- 数据探索与预览:通过 head()、tail()、info()、describe() 等方法可以快速查看数据的前几行、后几行、基本信息以及统计摘要。
- 数据选择与过滤:使用行索引、列索引、布尔条件等方式选择感兴趣的数据子集。例如,通过 df[column_name] 或 df.loc[row_index, column_name] 可以选取指定的列或行。
- 数据清洗与处理:处理缺失值、重复值、异常值等,使用 dropna()、fillna()、drop_duplicates()、replace() 等方法对数据进行清洗和处理,保证数据质量。
- 数据重塑与转换:使用 pivot_table()、stack()、unstack() 等方法对数据进行重塑和转换,以满足不同的分析需求
高级数据分析与处理技巧
- 数据统计与聚合:使用 groupby() 方法按照某些条件对数据进行分组,然后通过聚合函数如 sum()、mean()、count() 等进行统计计算。
- 时间序列数据分析:对于时间序列数据,Pandas 提供了丰富的处理功能,包括日期范围生成、日期索引设置、时间重采样、滚动计算等,方便用户进行时间序列数据分析与预测。
- 数据可视化:Pandas 结合 Matplotlib、Seaborn 等可视化库,可以方便地绘制折线图、柱状图、散点图等各种图表,直观展示数据的分布和趋势。
- 高效计算与优化:Pandas 支持向量化操作,通过使用 NumPy 数组和 Pandas 的内置函数,可以实现高效的数据处理和计算。此外,还可以通过并行计算、内存优化等方式进一步提高计算效率
Series:
类似于一维数组,由一组数据和与之相关的索引组成。每个元素都有对应的标签,可以通过标签进行索引和操作。
1,创建Series
使用列表或数组创建Series:可以通过传递Python列表或NumPy数组来创建Series
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
使用字典创建Series:字典的键将成为Series的索引
data = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
s = pd.Series(data)
2,索引
# 使用位置索引:可以使用整数位置来访问Series中的元素
s[0] # 访问第一个元素# 使用自定义索引:可以使用自定义的标签索引访问元素
s['a'] # 访问标签为'a'的元素
3,基本属性
| values | 返回Series的数据部分(一个NumPy数组) |
| index | 返回Series的索引部分(一个Index对象) |
| dtype | 返回Series中的数据类型 |
4,基本操作
# 算术操作:支持基本的算术运算,如加法、减法、乘法和除法
s1 + s2
s1 * 2# 索引与切片:可以使用位置索引或自定义索引进行索引和切片操作
s[1:3] # 选择第2到第3个元素
s['a':'c'] # 选择标签从'a'到'c'的元素
5,数据对齐
当对两个Series进行操作时,Pandas会根据索引自动对齐数据
s1 = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.Series([4, 5, 6], index=['b', 'c', 'd'])
result = s1 + s2
6,其他
Pandas提供了多种方法处理缺失数据,如isnull()、fillna()等
可以使用apply()方法应用函数到Series的每个元素上
提供了一系列统计函数,如sum()、mean()、max()等,用于计算Series的统计信息
Series对象提供了plot()方法,可以直接绘制数据的图表
DataFrame:
类似于电子表格或 SQL 数据库中的表格数据结构,由多个 Series 组成,每一列可以是不同的数据类型。DataFrame 提供了强大的数据操作和处理功能,适用于各种复杂的数据分析任务。
1,创建DataFrame
通过传递字典创建:可以使用字典来创建DataFrame,其中字典的键将成为DataFrame的列标签
import pandas as pd
data = {'Name': ['zzz', 'xxx', 'ddd'],'Age': [25, 30, 35],'City': ['New York', 'Los Angeles', 'Shanghai']}
df = pd.DataFrame(data)
也可以通过读取外部数据创建:可以从文件(如CSV、Excel等)或数据库中读取数据创建DataFrame
2,基本属性
# shape:返回DataFrame的行数和列数
df.shape# columns:返回DataFrame的列标签
df.columns# index:返回DataFrame的行索引
df.index
3,索引与选择数据
# 使用列标签选择列:可以通过列标签直接选择DataFrame中的列
df['Name']# 使用loc和iloc选择行和列
df.loc[0] # 选择索引为0的行
df.loc[:, 'Age'] # 选择名为'Age'的列的所有行
df.iloc[0] # 使用整数位置选择行# 使用布尔索引进行条件选择
df[df['Age'] > 25]
4,基本操作
# 添加列
df['Gender'] = ['Female', 'Male', 'Male']# 删除列
df.drop('City', axis=1, inplace=True)# 行列转置
df.T
5,数据排序
# 按列或行的值进行排序
df.sort_values(by='Age')
6,其他
处理缺失数据:可以使用dropna()删除包含缺失值的行或列,或使用fillna()填充缺失值。
处理重复数据:使用drop_duplicates()删除重复行使用groupby()方法对数据进行分组并应用聚合函数
使用concat()、merge()或join()方法将多个DataFrame合并成一个
使用pivot_table()方法创建数据透视表
使用plot()方法进行数据可视化,例如绘制柱状图、折线图等
相关文章:
)
Python 中的 Pandas(数据分析与处理)
Pandas 是 Python 中最受欢迎的数据处理库之一,其名字源自于“Panel Data”(面板数据)的缩写。它提供了三种主要的数据结构:Series , DataFrame , Panel(在新版本已经被弃用) 数…...
【文档智能 RAG】RAG增强之路-智能文档解析关键技术难点及PDF解析工具PDFlux
前言 在私域知识问答和企业知识工程领域,结合Retrieval-Augmented Generation(RAG)模型和大型语言模型(LLM)已成为主流方法。然而,企业中存在着大量的PDF文件,PDF解析的低准确性显著影响了基于…...

五大API接口:提升你的应用性能与用户体验
引言: 简述API接口的重要性引入API接口对于提升应用性能和用户体验的贡献 API接口简介: 定义:解释什么是API接口作用:概述API接口在软件开发中的作用 1. 数据访问API 功能描述:提供快速、安全的数据存取功能提升性…...

RabbitMQ实践——在Ubuntu上安装并启用管理后台
大纲 环境安装启动管理后台 RabbitMQ是一款功能强大、灵活可靠的消息代理软件,为分布式系统中的通信问题提供了优秀的解决方案。无论是在大规模数据处理、实时分析还是微服务架构中,RabbitMQ都能发挥出色的性能,帮助开发者构建高效、稳定的系…...

Ubuntu中防火墙的使用 和 开放 关闭 端口
目录 1.查看防火墙的状态 2.开启ufw防火墙 3.重启ufw防火墙 4.关闭ufw防火墙 5.设置外来访问默认权限 6.开放普通端口 7.关闭普通端口 8.开放规定协议的端口 9.关闭指定协议端口 10.重启防火墙,是配置生效 1.查看防火墙的状态 sudo ufw status 2.开启uf…...

ansible 模块进阶及变量
yum 模块进阶 - name: install pkgs hosts: webservers tasks: - name: install web pkgs # 此任务通过yum安装三个包 yum: name: httpd,php,php-mysqlnd state: present # 根据功能等,可以将一系列软件放到一个组中,安装软件包组,将会把很…...

MYSQL数据库安装
一.编译安装MySQL服务 1.安装环境依赖包 2.将安装mysql 所需软件包传到/opt目录下 mysql-boost-5.7.44.tar tar zxvf mysql-boost-5.7.44.tar.gz 3.配置软件模块 cd /opt/mysql-5.7.44/ cmake \ -DCMAKE_INSTALL_PREFIX/usr/local/mysql \ -DMYSQL_UNIX_ADDR/usr/local/mysq…...

Pycharm配置远程调试
第1步:添加SSH Inerpreter 打开Settings --> Project interpreter配置项,配置如下两项 Project Interpreter添加SSH inerpreter 首次使用的远程环境需要填写ip及账号密码,建立ssh连接,然后选择对应的远端python路径 Path mapp…...

【Java面试】二十二、JVM篇(下):JVM参数调优与排查
文章目录 1、JVM的参数在哪里设置2、常见的JVM调优参数有哪些3、常见的JVM调优工具有哪些4、Java内存泄漏的排查思路5、CPU飙高的排查思路 1、JVM的参数在哪里设置 war包部署,在tomcat中设置,修改TOMCAT_HOME/bin/catalina.sh 文件 jar包启动࿰…...
统计信号处理基础 习题解答10-17
题目: 在选择不含信息的或者不假设任何先验知识的先验PDF时,我们需要从数据中得到最大的信息量。在这种方式下,数据是了解未知参数的主要贡献者。利用习题10.15的结果,这种方法可以通过选择使I最大的来实现。对于例10.1的高斯先验PDF,该如何选择和2使得 是不含信息…...

嵌套使用模板类
#include<iostream> using namespace std;template <class Datatype> class Stack { private:Datatype* items;//栈数组int stacksize;//栈的实际大小int top;//栈顶指针 public://构造函数:1)分配栈数组内存,2)把栈顶…...

adb卸载系统应用
1.进入shell adb shell2.查看所有包 pm list packages3.查找包 如查找vivo相关的包 pm list packages | grep vivo发现包太多了,根本不知道哪个是我们想卸载的应用 于是可以打开某应用,再查看当前运行应用的包名 如下: 4.查找当前前台运行的包名 打开某应用,在亮屏状态输入 …...

Rapidfuzz,一个高效的 Python 模糊匹配神器
目录 01初识 Rapidfuzz 什么是 Rapidfuzz? 为什么选择 Rapidfuzz? 安装 Rapidfuzz 配置 Rapidfuzz 02基本操作 简单比率计算 03高级功能 查找单个最佳匹配 查找多个最佳匹配 使用阈值优化性能 04实战案例…...

【猫狗分类】Pytorch VGG16 实现猫狗分类1-数据清洗+制作标签文件
Pytorch 猫狗分类 用Pytorch框架,实现分类问题,好像是学习了一些基础知识后的一个小项目阶段,通过这个分类问题,可以知道整个pytorch的工作流程是什么,会了一个分类,那就可以解决其他的分类问题࿰…...

磁盘管理 磁盘介绍 MBR
track:磁道,就是磁盘上同心圆,从外向里,依次1号、2号磁道..... sector:扇区,将磁盘分成一个一个扇形区域,每个扇区大小是512字节,从外向里,依次是1号扇区、2号扇区... cy…...

JSON响应中提取特定的信息——6.14山大软院项目实训2
在收到的JSON响应中提取特定的信息(如response字段中的文本)并进行输出,需要进行JSON解析。在Unity中,可以使用JsonUtility进行简单的解析,但由于JsonUtility对嵌套对象的支持有限,通常推荐使用第三方库如N…...

【C++高阶】高效搜索的秘密:深入解析搜索二叉树
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:C多态 🌹🌹期待您的关注 🌹🌹 ❀二叉搜索树 📒1. 二叉搜索树&…...

《软件定义安全》之七:SDN安全案例
第7章 SDN安全案例 1.DDoS缓解 1.1 Radware DefenseFlow/Defense4All Radware在开源的SDN控制器平台OpenDaylight(ODL)上集成了一套抗DDoS的模块和应用,称为Defense4ALL。其架构如下图,主要有两部分:控制器中的安全…...
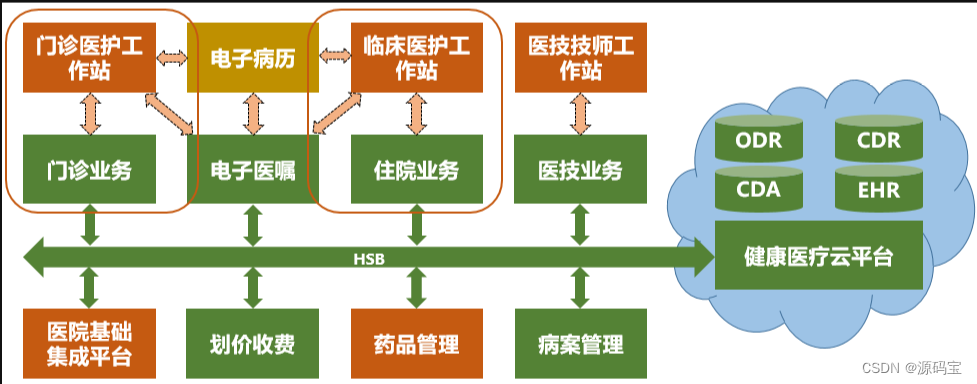
java语言his系统医保接口 云HIS系统首页功能实现springboot框架+Saas模式 his系统项目源码
java语言his系统医保接口 云HIS系统首页功能实现springboot框架Saas模式 his系统项目源码 HIS系统的实施旨在整个医院建设企业级的计算机网络系统,并在其基础上构建企业级的应用系统,实现整个医院的人、财、物等各种信息的顺畅流通和高度共享,…...
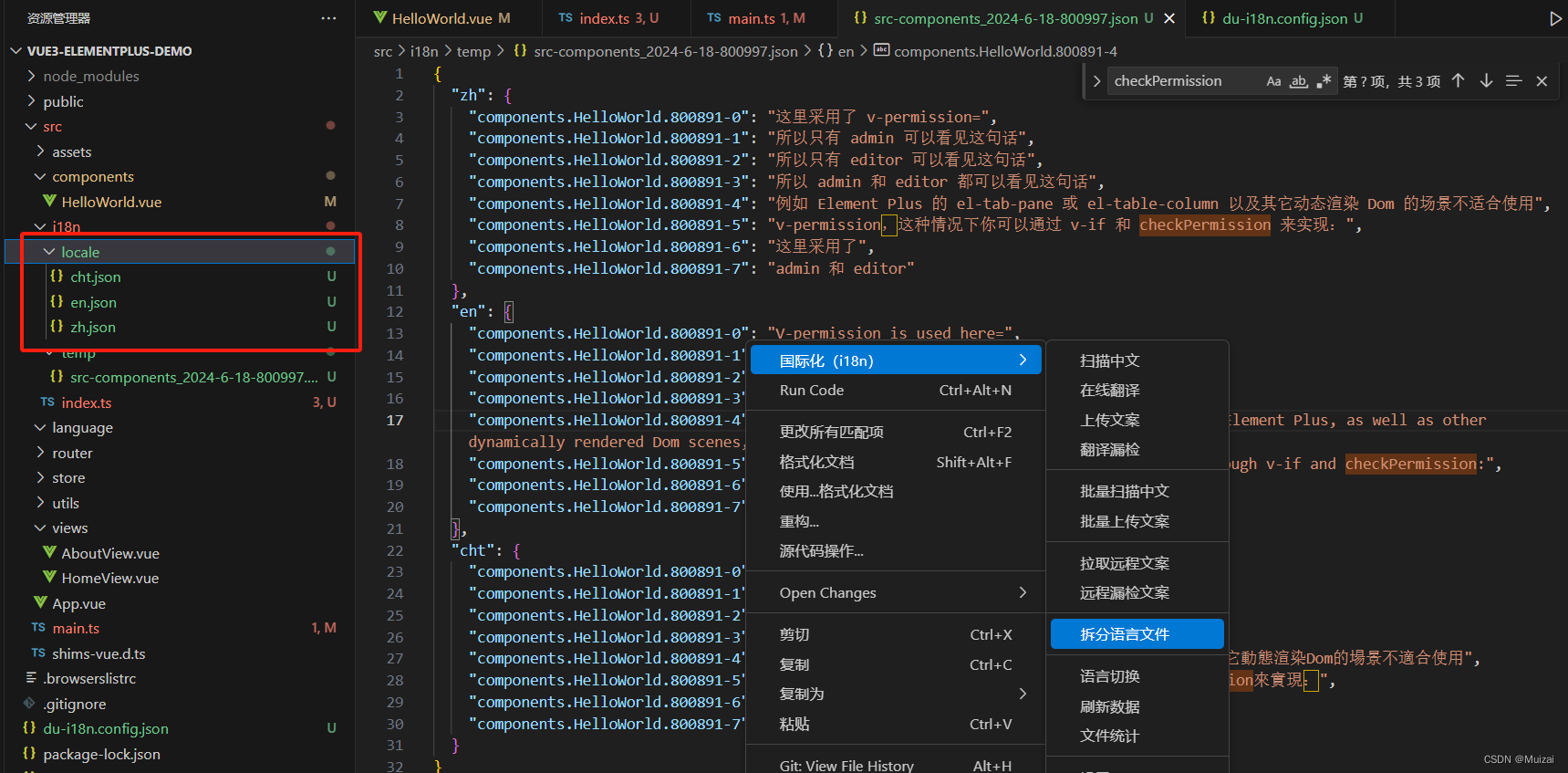
使用vscode插件du-i18n处理前端项目国际化翻译多语言
前段时间我写了一篇关于项目国际化使用I18n组件的文章,Vue3 TS 使用国际化组件I18n,那个时候还没真正在项目中使用,需求排期还没有定,相当于是预研。 当时就看了一下大概怎么用,改了一个简单的页面,最近需…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...