人工智能—美国加利福尼亚州房价预测实战
引言
在当今快速发展的房地产市场中,房价预测已成为一个至关重要的领域。它不仅关系到投资者的决策,也直接影响到普通购房者的生活质量。特别是在美国加利福尼亚州,这个以其高房价和房地产市场的波动性而闻名的地方,准确的房价预测显得尤为重要。本文将通过实战案例,深入探讨如何利用数据分析和机器学习技术来预测加利福尼亚州的房价走势。
背景信息
加利福尼亚州房地产市场概况
加利福尼亚州,作为美国经济最发达的地区之一,其房地产市场长期以来一直是国内外投资者关注的焦点。从硅谷的高科技产业到洛杉矶的娱乐业,再到旧金山的金融中心,加利福尼亚州的经济多元化为房地产市场提供了坚实的基础。然而,与经济活力相伴的是房价的高涨和快速波动,这给市场参与者带来了不小的挑战。
数据集信息
美国加利福尼亚州房价数据集是一个公开的数据集,通常用于机器学习和数据科学项目中的回归分析。根据搜索结果,这个数据集包含以下特征(本文涉及数据集已绑定上传,可免费获取):
- 经度(Longitude):表示房屋所在位置的经度坐标。
- 纬度(Latitude):表示房屋所在位置的纬度坐标。
- Housing Median Age:区域中房屋的中位年龄,即一半房屋比这个年龄新,一半房屋比这个年龄旧。
- Total Rooms:该区域内所有房屋的房间总数。
- Total Bedrooms:该区域内所有房屋的卧室总数,这个特征可能存在缺失值。
- Population:该区域内的总人口数。
- Households:该区域内的家庭总数。
- Median Income:该区域内家庭的收入中位数。
- Median House Value:该区域内房屋的中位数价格,通常作为目标变量用于预测。
数据挖掘目标
通过房子的信息特征,预测Median House Value(该区域房价中位数)。
数据的读入和初步分析
数据读入:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as py
import plotly.graph_objs as go
import warnings
import os
warnings.filterwarnings("ignore")
data = pd.read_csv('housing.csv')
data.head()
展示前五行数据:

描述性统计:

分割测试集与训练集:
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(data, test_size=0.2, random_state=42)
老规矩80%数据用于训练,20%数据用于测试。
数据的初步分析:
# 设置图形窗口的大小为宽度15英寸,高度9英寸。
plt.figure(3 , figsize = (15 , 9))
# 初始化一个计数器n,用于跟踪当前正在处理的列(或子图)的索引。
n = 0
# 遍历DataFrame data的所有列名。
for x in data.columns.to_list(): # 对每一列,增加计数器n的值。 n += 1 # 创建一个子图,在3行3列的网格中,位置由n决定(注意:这里需要确保n的值在1到9之间,否则会出现错误)。 plt.subplot(3 , 3 , n) # 调整子图之间的间距。注意:通常最好在循环外只调用一次subplots_adjust,因为它会调整整个图形中所有子图的布局。 # 这里的调用可能不会有预期的效果,因为它在每次迭代时都会重新设置。 plt.subplots_adjust(hspace =0.5 , wspace = 0.5) # 使用seaborn的distplot函数绘制data中当前列x的分布图,并设置直方图的bin数量为20。 # 注意:seaborn的distplot函数在较新版本中已被displot取代。 sns.distplot(data[x] , bins = 20) # 为当前子图设置标题,标题内容为“Distplot of ”,后面跟着当前列的名称x。 plt.title('Distplot of {}'.format(x))
# 显示所有子图。
plt.show()
9个变量的直方图展示:

直方图是一种统计图表,用于表示数据分布的可视化。它通常用于展示数据集中数值型数据的分布情况。以下是直方图的一些关键特点和解释方法:
- 数据分组:首先,将数据分成若干个连续的、通常是等宽的区间或“箱子”(bins)。
- 箱子高度:每个箱子的高度表示落在该区间内的数据点的数量,即频数。
- 连续性:与条形图不同,直方图的箱子是连续的,没有间隙,因为它们表示的是数值型数据的连续区间。
- 范围:每个箱子覆盖一个特定的数值范围,例如,在房价数据中,一个箱子可能代表20万美元到30万美元的价格区间。
- 频率分布:直方图可以展示数据的频率分布,即不同数值区间内数据点的集中程度。
- 形状识别:通过直方图的形状,可以识别数据的分布特性,如是否对称、是否存在偏斜(右偏或左偏)、是否有双峰(双模态)等。
- 密度曲线:有时在直方图上叠加一个平滑的曲线,称为核密度估计(KDE),它可以更平滑地展示数据的分布。
分析:
- 通过观察直方图,可以快速了解数据的中心趋势、分散程度和分布形态,为进一步的统计分析提供直观信息。
- 多变量比较:直方图也可以用来比较不同组别的数据分布,只需为每组数据创建一个直方图并并排显示。
- 局限性:直方图的一个局限性是选择箱子的宽度和位置可能会影响图表的解释。不同的箱子设置可能会展示出数据的不同特征。
直方图是数据分析中的重要工具,特别是在探索性数据分析(EDA)阶段,它帮助数据分析师快速把握数据的关键特征。
绘制经度和纬度的散点图:经纬度的二维分布也就是实际的地形分布。
散点图多用于相关性分析,具体介绍请查看我的专栏《从0开始学统计》内的从0开始学统计-什么是相关?
# 经度与纬度关系图
sns.relplot(data=data,x="longitude",y="latitude")

绘制房价随人口数量变化的折线图:
# 房价随人口变化折线图
data.plot('population', 'medianHouseValue')
plt.show()
 简单的图形我就不介绍了,感兴趣可以在网上查。
简单的图形我就不介绍了,感兴趣可以在网上查。
绘制皮尔逊相关系数热力图:
# 设置seaborn的绘图样式和字体,这里设置了绘图上下文为"paper"(适合论文的样式)和字体为"monospace"(等宽字体)
sns.set(context="paper",font="monospace")
# 计算DataFrame 'data' 中各列之间的相关系数,并将结果存储在'housing_corr_matrix'中
housing_corr_matrix = data.corr() # 注意:这里假设'data'是已经加载好的一个DataFrame
# 设置matplotlib的图形和坐标轴。这里创建了一个图形对象'fig'和一个坐标轴对象'axe'(但注意,这里应该是'ax'而不是'axe')
# figsize参数设置了图形的大小为12x8英寸
fig, ax = plt.subplots(figsize=(12,8)) # 修改'axe'为'ax'
# 使用seaborn的diverging_palette函数生成一个颜色映射(cmap),从颜色220(接近蓝色)渐变到颜色10(接近红色)
# center参数设置为"light",表示颜色映射的中心是亮色
# as_cmap=True表示返回的是一个颜色映射对象
cmap = sns.diverging_palette(220,10,center = "light", as_cmap=True)
# 使用seaborn的heatmap函数绘制热力图。这里使用了之前计算的相关系数矩阵'housing_corr_matrix'
# vmax参数设置了颜色映射的最大值,这里为1(因为相关系数范围是-1到1)
# square=True表示每个单元格都是正方形
# cmap参数指定了使用的颜色映射
# annot=True表示在每个单元格中显示数值
sns.heatmap(housing_corr_matrix, vmax=1, square=True, cmap=cmap, annot=True)
# 显示图形
plt.show()

之前的案例有介绍怎样辨识相关热图,这里就不再重复了,感兴趣可以翻下以前的案例。
在经纬图上绘制房屋价格和人口分布:
# 使用Pandas的DataFrame.plot()方法绘制散点图
# kind="scatter" 指定了绘制的是散点图
# x="longitude" 指定了x轴的数据是'longitude'列
# y="latitude" 指定了y轴的数据是'latitude'列
# alpha=0.4 设置了点的透明度,使得重叠的点可以部分可见
# s=data["population"]/50 设置了点的大小,大小与'population'列的值成正比,但除以50是为了缩放大小
# label="population" 设置了图例的标签为"population"(但通常这个标签可能更适合用于s参数,表示大小与人口相关)
# figsize=(10,7) 设置了图形的大小为10x7英寸
# c=data["medianHouseValue"] 设置了点的颜色,颜色由'medianHouseValue'列的值决定
# cmap=plt.get_cmap("jet") 设置了颜色映射为"jet"
# colorbar=True 在图上显示颜色条,表示不同的颜色对应的'medianHouseValue'值
# sharex=False (在.plot()方法中,sharex通常不是有效的参数,除非您在子图网格中使用subplot_kws或gridspec_kws)
# 如果是在使用subplot或subplots时,sharex可能用于控制x轴是否共享
data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, s=data["population"]/50, label="population (size)", figsize=(10,7), c=data["medianHouseValue"], cmap=plt.get_cmap("jet"), colorbar=True, # sharex=False # 在这个上下文中,sharex参数不适用,可以移除
)
# plt.legend() 显示图例,图例通常显示在图的某个角落,根据label参数来标识不同的数据系列
plt.legend()
 上图点越密集,对应区域的颜色就越深,通过颜色深浅就可以看出数据的几种区域。越大、透明度越低的地方代表人口越多,越接近colorbar顶端的颜色的地方代表房产价格越高。经过这一系列分析后,对数据可以有非常直观的了解。
上图点越密集,对应区域的颜色就越深,通过颜色深浅就可以看出数据的几种区域。越大、透明度越低的地方代表人口越多,越接近colorbar顶端的颜色的地方代表房产价格越高。经过这一系列分析后,对数据可以有非常直观的了解。
拆分数据:
housing=train_set.drop("medianHouseValue",axis=1)
labels=train_set["medianHouseValue"].copy()
得到输入数据和目标变量(label)。
数据标准化:采用z-score标准化,之前博客有过介绍,感兴趣的可以点超链接进入。
# 从 sklearn.impute 模块中导入 SimpleImputer 类,这个类用于填充数据集中的缺失值。
from sklearn.impute import SimpleImputer
# 从 sklearn.preprocessing 模块中导入 StandardScaler 类,这个类用于数据的标准化处理,即将数据转换为均值为0,标准差为1的分布。
from sklearn.preprocessing import StandardScaler
# 从 sklearn.pipeline 模块中导入 Pipeline 类,这个类用于构建数据处理的流水线,可以按照定义的顺序依次执行多个数据转换步骤。
from sklearn.pipeline import Pipeline
# 创建一个 Pipeline 对象,其中包含了 SimpleImputer 和 StandardScaler
pipeline = Pipeline([ ('imputer', SimpleImputer(strategy="median")), # 使用 SimpleImputer,策略为中位数填充 ('scaler', StandardScaler()), # 使用 StandardScaler 进行标准化
])
data_prepared = pipeline.fit_transform(housing)#最终的结果,为numpy数组

上图为标准化后的5组数据。
模型构建
查看不同模型的表现
# 从 sklearn.linear_model 模块中导入 LinearRegression, ElasticNet, 和 Lasso 类。这些类分别代表线性回归、弹性网络(结合了L1和L2正则化的线性回归)和Lasso回归(L1正则化的线性回归)。
from sklearn.linear_model import LinearRegression, ElasticNet, Lasso
# 从 sklearn.ensemble 模块中导入 RandomForestRegressor 类。这是一个基于随机森林的回归模型。
from sklearn.ensemble import RandomForestRegressor
# 从 sklearn.pipeline 模块中导入 make_pipeline 函数(尽管在您的代码中并未直接使用它)。make_pipeline 是一个快捷方式来创建 pipeline。
from sklearn.pipeline import make_pipeline
# 从 sklearn.model_selection 模块中导入 KFold 和 cross_val_score 函数。KFold 用于生成K折交叉验证的索引,cross_val_score 用于计算模型的交叉验证得分。
from sklearn.model_selection import KFold, cross_val_score
# 设定交叉验证的折数为10
n_folds = 10
# 定义一个函数 get_rmse,该函数接收一个模型作为参数,并返回模型在数据上的均方根误差(RMSE)。
# RMSE 是通过计算 cross_val_score 的负均方误差的平方根来获得的,因为 cross_val_score 默认返回的是负指标,所以需要先取负值再平方根。
def get_rmse(model): rmse = np.sqrt(-cross_val_score(model, data_prepared, labels, scoring="neg_mean_squared_error", cv=n_folds)) return rmse
# 创建四个不同的回归模型实例:
# linreg 是线性回归模型
linreg = LinearRegression()
# forest 是随机森林回归模型,设置了10个决策树估计器和随机状态为42
forest = RandomForestRegressor(n_estimators=10, random_state=42)
# lasso 是Lasso回归模型,设置了正则化强度为0.0005和随机状态为1
lasso = Lasso(alpha=0.0005, random_state=1)
# enet 是弹性网络模型,设置了正则化强度为0.0005,L1和L2正则化的比例为0.9,以及随机状态为3
enet = ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3)
# 使用之前定义的 get_rmse 函数来计算并打印每个模型的RMSE
print(get_rmse(linreg))
print(get_rmse(forest))
print(get_rmse(lasso))
print(get_rmse(enet))
在一般的训练中,通常可以选取多个模型,通过计算误差得出最好的模型。在本案例中,对线性回归、随机森林、Lasso、ElasticNet模型进行训练,得出了随机森林(random forest regressor)的效果是最好的,因为它的均方根误差最小。

选择效果最好的模型进行展示:
# 从测试数据集 test_set 中删除 "medianHouseValue" 列(这通常是因为我们要对这部分数据进行预测,而不是作为特征),
# axis=1 表示我们是在列的方向上进行操作(即删除列)。
# 结果存储在 test_housing 变量中,它只包含用于预测的特征,但不包含目标变量 "medianHouseValue"。
test_housing = test_set.drop("medianHouseValue", axis=1)
# 从测试数据集 test_set 中复制 "medianHouseValue" 列的值,这列通常是我们想要预测的目标变量。
# 使用 copy() 方法是为了确保我们得到的是原始数据的副本,而不是视图或引用,以避免后续可能的数据修改。
# 结果存储在 test_labels 变量中,它包含了与 test_housing 对应的真实目标值。
test_labels = test_set["medianHouseValue"].copy()
# 使用之前定义的 pipeline 对象(它可能包含了数据预处理步骤,如缺失值填充和标准化)来拟合(fit)并转换(transform)
# test_housing 数据集。注意,这里我们只使用了 transform 方法而不是 fit_transform,
# 因为 pipeline 已经通过训练集进行了拟合(通常在之前的数据准备步骤中)。
# 结果(即预处理后的特征)存储在 test_data 变量中,这些特征将用于后续的模型预测。
test_data = pipeline.transform(test_housing)

下面代码对测试集数据进行处理:
# 使用RandomForestRegressor(随机森林回归模型)的fit方法,将预处理后的训练数据(data_prepared)和对应的标签(labels)作为输入,
# 对模型进行训练。fit方法会计算每个决策树所需的参数,并构建整个随机森林模型。
forest.fit(data_prepared, labels)
# 使用训练好的RandomForestRegressor模型的predict方法,对预处理后的测试数据(test_data)进行预测。
# predict方法会返回测试数据集中每个样本的预测值,这些预测值存储在predict_labels变量中。
predict_labels = forest.predict(test_data)
训练数据和预测:
# 使用RandomForestRegressor(随机森林回归模型)的fit方法,将预处理后的训练数据(data_prepared)和对应的标签(labels)作为输入,
# 对模型进行训练。fit方法会计算每个决策树所需的参数,并构建整个随机森林模型。
forest.fit(data_prepared, labels)
# 使用训练好的RandomForestRegressor模型的predict方法,对预处理后的测试数据(test_data)进行预测。
# predict方法会返回测试数据集中每个样本的预测值,这些预测值存储在predict_labels变量中。
predict_labels = forest.predict(test_data)
对实际数据和预测数据进行可视化:
# 假设您已经导入了NumPy库(import numpy as np)和Matplotlib的pyplot模块(import matplotlib.pyplot as plt)。
# 这行代码将test_labels(可能是一个Pandas Series或列表)转换为NumPy数组,并存储在origin_labels变量中。
# 这样做是为了确保数据类型与Matplotlib兼容,并可能为了后续的数值操作。
origin_labels = np.array(test_labels)
# 使用Matplotlib的plot函数绘制origin_labels数组的前100个值。
# 这通常用于可视化原始数据的标签值,以便与预测值进行比较。
# label参数为这条线指定了一个标签,该标签稍后会显示在图例中。
plt.plot(origin_labels[0:100], label='origin_labels')
# 使用Matplotlib的plot函数绘制predict_labels数组的前100个值。
# 这用于可视化模型的预测值,以便观察预测结果与实际标签之间的差异。
# 同样,通过label参数为这条线指定了一个标签。
plt.plot(predict_labels[0:100], label='predict_labels')
# 显示图例,其中包含了之前通过label参数指定的标签。
# 图例会解释图中的每条线分别代表什么。
plt.legend()

比较预测和实际结果(红棕色线为预测数据,蓝色为实际数据),可以看出模型的预测能力还是相当不错的,当然有更多的数据,我相信预测结果会更加准确。
大家可能觉得看图没有感觉,我就给大家把预测数据合并到表内,给大家展示预测完全正确的部分数据(见下图,倒数第二列为实际结果,最后一列为预测结果)。

创作不易,点赞、关注、评论、转发4连!
相关文章:
人工智能—美国加利福尼亚州房价预测实战
引言 在当今快速发展的房地产市场中,房价预测已成为一个至关重要的领域。它不仅关系到投资者的决策,也直接影响到普通购房者的生活质量。特别是在美国加利福尼亚州,这个以其高房价和房地产市场的波动性而闻名的地方,准确的房价预…...
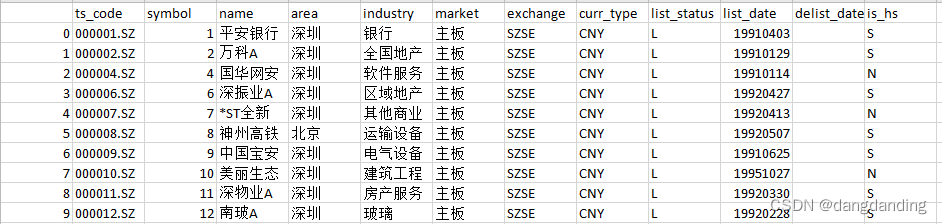
python pandas处理股票量化数据:笔记2
有一个同学用我的推荐链接注册了tushare社区帐号https://tushare.pro/register?reg671815,现在有了170分积分。目前使用数据的频率受限制。不过可以在调试期间通过python控制台获取数据,将数据保存在本地以后使用不用高频率访问tushare数据接口…...

enum库
Python enum 模块教程 enum 是 Python 3.4 引入的一个模块,用于定义枚举类型。枚举类型是一种特殊的数据类型,由一组命名的值组成,这些值称为枚举成员。使用 enum 可以提高代码的可读性和可维护性,特别是在处理一组相关的常量值时…...

【CT】LeetCode手撕—141. 环形链表
目录 题目1- 思路2- 实现⭐141. 环形链表——题解思路 3- ACM实现 题目 原题连接:141. 环形链表 1- 思路 模式识别 模式1:判断链表的环 ——> 快慢指针 思路 快指针 ——> 走两步慢指针 ——> 走一步判断环:若快慢相遇则有环&a…...

python,自定义token生成
1、使用的包PyJWT来实现token生成 安装:pip install PyJWT2.8.0 2、使用例子: import jwt import time pip install pyJWT2.8.0 SECRET_KEY %^ES*E&Ryurehuie9*7^%$#$EDFGHUYTRE#$%^&%$##$RTYGHIK DEFAULT_EXP 7 * 24 * 60def create_token(…...

小米SU7遇冷,下一代全新车型被官方意外曝光
不知道大伙儿有没有发现,最近小米 SU7 热度好像突然之间就淡了不少? 作为小米首款车型,SU7 自上市以来一直承载着新能源轿车领域流量标杆这样一个存在。 发售 24 小时订单量破 8 万,2 个月后累计交付破 2 万台。 看得出来限制它…...

JavaScript 函数与事件
1. JavaScript自定义函数 语法: function 函数名(参数列表){ 方法体; } 在函数被调用时,一个 arguments 对象就会被创建,它只能使用在函数体中,以数组的形式来管理函数的实际…...

Qt 焦点系统关键点总结
1.1 焦点窗口 指的是当前时刻拥有键盘输入的窗口。 Qt提供了如下接口,用于设置窗口是否是”可获取焦点“窗口: void QWidget::setFocusPolicy(Qt::FocusPolicy policy); Qt::FocusPolicy Qt::TabFocus 与焦点链相关,详解见下一…...
SpringBoot+Maven项目的配置构建
文章目录 1、application.properties2、pom.xml 1、application.properties 也可使用yml yaml #静态资源 spring.mvc.static-path-pattern/images/** #上传文件大小设置 spring.http.multipart.max-file-size10MB spring.http.multipart.max-request-size10MBspring.mvc.path…...
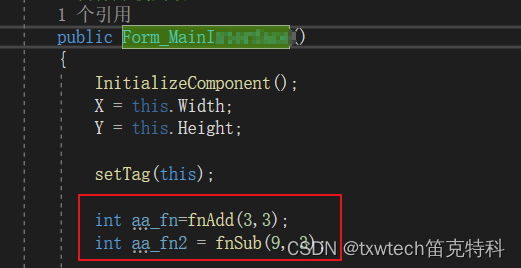
c#调用c++dll方法
添加dll文件到debug目录,c#生成的exe的相同目录 就可以直接使用了,放在构造函数里面测试...

ACM算法学习路线、清单
入门 模拟、暴力、贪心、高精度、排序 图论 搜索 BFS、DFS、IDDFS、IDA*、A*、双向BFS、记忆化 最短路 SPFA、bellman-fort(队列优化)、Dijkstra(堆优化)、Johnson、Floyd、差分约束、第k短路 树 树的重心和直径、dfs序、树链刨分与动态树、LCA、Prufer编码及Cayley定理…...
sqoop的安装配置
1. 上传并解压安装包 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C ../server/ 重命名:mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop 2. 配置环境变量 sudo vim /etc/profile # 配置sqoop的环境变量 export SQOOP_HOME/export/server/sqoop export PATH$PATH…...

代码随想录算法训练营第六十四天 | 图论理论基础、深搜理论基础、广搜理论基础、98. 所有可达路径
图论理论基础 我写在了个人语雀笔记中 https://www.yuque.com/yuqueyonghu8mml9e/bmbl71/ex473q4y0ebs0l3r?singleDoc# 深搜理论基础 https://www.yuque.com/yuqueyonghu8mml9e/bmbl71/zamfikz08c2haptn?singleDoc# 98. 所有可达路径 题目链接:98. 所有可达…...

【教师资格证考试综合素质——法律专项】教师法笔记以及练习题
《中华人民共和国教师法》 一.首次颁布:第一部《中华人民共和国教师法》于1993年10月31日由第八届全国人民代表大会常务委员会第四次会议通过,1994年1月1日起执行。 二.历次修改:2009年8月27日第十一届全国人民代表…...
图卷积网络(Graph Convolutional Network, GCN)
图卷积网络(Graph Convolutional Network, GCN)是一种用于处理图结构数据的深度学习模型。GCN编码器的核心思想是通过邻接节点的信息聚合来更新节点表示。 图的表示 一个图 G通常表示为 G(V,E),其中: V 是节点集合,…...
】pipeline 实际调用的是什么? __call__ 方法!)
【diffusers 极速入门(一)】pipeline 实际调用的是什么? __call__ 方法!
在使用 diffusers 库进行图像生成时,你可能会发现管道(pipeline)对象可以像函数一样被调用。这背后的魔法是什么呢?答案是:__call__ 方法!本文将通过简单的案例代码,带你快速了解 diffusers 管道…...

【DPDK学习路径】二、DPDK简介
DPDK(Data Plane Development Kit)是一个框架,用于快速报文处理。 在linux内核提供的报文处理模型中,接收报文的处理路径为:首先由网卡硬件接收,产生硬中断,触发网卡驱动程序注册的中断函数处理,之后产生软…...
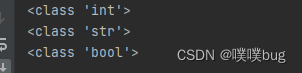
python基础 002 - 2 常用数据类型
python的常用数据类型 int , 整型 1,2,3float ,小数,浮点类型1.2bool , boolean 布尔,真假。判断命题。True Flasestr ,字符串 list , 列表 a []tuple, 元组 a ()dict , dictionary, 字典 a {}set , 集合 a {} 1 查看数据类型 typ…...

爆赞!GitHub首本Python开发实战背记手册,标星果然百万名不虚传
Python (发音:[ paiθ(ə) n; (US) paiθɔn ] n. 蟒蛇,巨蛇 ),是一种面向对象的解释性的计算机程序设计语言,也是一种功能强大而完善的通用型语言,已经具有十多年的发展历史,成熟且稳定。Python 具有脚本语言中最丰富…...

Spring源码-xxxAware实现类和BeanPostProcessor接口调用过程
xxxAware实现类作用 以ApplicationContextAware接口为例 ApplicationContextAware的作用是可以方便获取Spring容器ApplicationContext,从而可以获取容器内的Bean package org.springframework.context;import org.springframework.beans.BeansException; import or…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...