[机器学习算法]决策树
1. 理解决策树的基本概念
决策树是一种监督学习算法,可以用于分类和回归任务。决策树通过一系列规则将数据划分为不同的类别或值。树的每个节点表示一个特征,节点之间的分支表示特征的可能取值,叶节点表示分类或回归结果。

2. 决策树的构建过程
2.1. 特征选择
特征选择是构建决策树的第一步,通常使用信息增益、基尼指数或增益率等指标。
- 信息增益(Information Gain)
信息增益表示通过某个特征将数据集划分后的纯度增加量,公式如下:
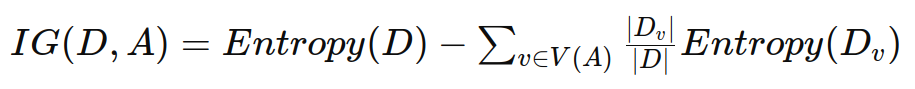
其中:
D 是数据集。
A 是特征。
V(A) 是特征 A 的所有可能取值。
Dv 是数据集中特征 A 取值为 v 的子集。
∣Dv∣ 是 Dv 中样本的数量。
∣D∣ 是数据集 D 中样本的总数量。
Entropy(D) 是数据集 D 的熵,表示数据集本身的纯度。
选择信息增益最大的特征作为当前节点的划分特征。
熵的计算公式为:
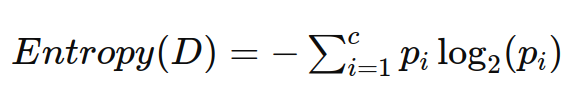
其中:
c 是类别的数量。
pi 是数据集中属于第 i 类的样本所占的比例。
以下代码展示了如何计算熵、信息增益,并选择最优特征。
import numpy as np
from collections import Counter
from sklearn.datasets import load_irisdef entropy(y):hist = np.bincount(y)ps = hist / len(y)return -np.sum([p * np.log2(p) for p in ps if p > 0])def information_gain(X, y, feature):# Entropy before splitentropy_before = entropy(y)# Values and countsvalues, counts = np.unique(X[:, feature], return_counts=True)# Weighted entropy after splitentropy_after = 0for v, count in zip(values, counts):entropy_after += (count / len(y)) * entropy(y[X[:, feature] == v])return entropy_before - entropy_afterdef best_feature_by_information_gain(X, y):features = X.shape[1]gains = [information_gain(X, y, feature) for feature in range(features)]return np.argmax(gains), max(gains)# Load dataset
iris = load_iris()
X = iris.data
y = iris.target# Find best feature
best_feature, best_gain = best_feature_by_information_gain(X, y)
print(f'Best feature: {iris.feature_names[best_feature]}, Information Gain: {best_gain}')- 基尼指数(Gini Index)
也称为基尼不纯度(Gini Impurity),是一种衡量数据集纯度的指标。基尼指数越小,数据集的纯度越高。
基尼指数的计算公式:
对于一个包含 k 个类别的分类问题,基尼指数 G(D) 定义如下:
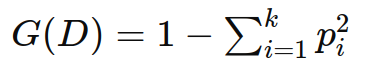
其中:
D 是数据集。
k 是类别的数量。
pi 是数据集中属于第 i 类的样本所占的比例。
条件基尼指数:
在某个特征 A 的条件下,数据集 D 的条件基尼指数 G(D∣A) 定义如下:
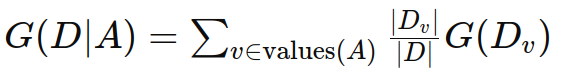
其中:
values(A) 是特征 A 的所有可能取值。
Dv 是数据集中特征 A 取值为 v 的子集。
∣Dv∣ 是 Dv 中样本的数量。
∣D∣ 是数据集 D 中样本的总数量。
G(Dv) 是子集 Dv 的基尼指数。
基尼增益(Gini Gain):
基尼增益 GG(D,A) 是通过特征 A 划分数据集 D 后基尼指数的减少量。计算公式如下:
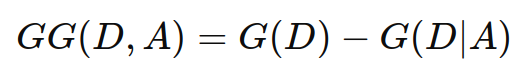
参数解释
D:整个数据集,包含了所有的样本。
A:某个特征,用于划分数据集。
G(D):数据集 D 的基尼指数,表示数据集本身的纯度。
G(D∣A):在特征 A 的条件下,数据集 D 的条件基尼指数,表示在特征 A 的条件下数据集的纯度。
选择基尼增益最大的特征及其分割点作为当前节点的划分特征。
以下代码展示如何使用上述步骤来选择基尼增益最大的特征:
import numpy as np
from sklearn.datasets import load_irisdef gini(y):hist = np.bincount(y)ps = hist / len(y)return 1 - np.sum([p**2 for p in ps if p > 0])def gini_gain(X, y, feature):# Gini index before splitgini_before = gini(y)# Values and countsvalues, counts = np.unique(X[:, feature], return_counts=True)# Weighted gini after splitgini_after = 0for v, count in zip(values, counts):gini_after += (count / len(y)) * gini(y[X[:, feature] == v])return gini_before - gini_afterdef best_feature_by_gini_gain(X, y):features = X.shape[1]gains = [gini_gain(X, y, feature) for feature in range(features)]return np.argmax(gains), max(gains)# Load dataset
iris = load_iris()
X = iris.data
y = iris.target# Find best feature
best_feature, best_gain = best_feature_by_gini_gain(X, y)
print(f'Best feature: {iris.feature_names[best_feature]}, Gini Gain: {best_gain}')- 增益率(Gain Ratio)
决策树中的增益率(Gain Ratio)用于选择最优的划分属性,以便构建决策树。增益率是基于信息增益(Information Gain)的一个修正版本,用于克服信息增益在处理属性取值多样性时可能出现的偏向问题。
信息增益是指选择某一属性划分数据集后,信息熵的减少量。信息增益公式为:
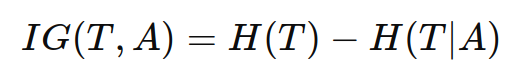
其中:
IG(T,A):属性 A 对数据集 T 的信息增益。
H(T):数据集 T 的熵。
H(T∣A):在给定属性 A 的条件下数据集 T 的条件熵。
增益率通过将信息增益除以属性的固有值(Intrinsic Value)来计算。固有值是衡量属性取值多样性的一种指标。增益率公式为:
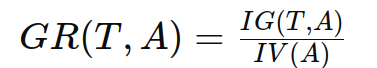
其中:
GR(T,A):属性 A 对数据集 T 的增益率。
IG(T,A):属性 A 对数据集 T 的信息增益。
IV(A):属性 A 的固有值。
固有值(Intrinsic Value)
固有值反映了属性的取值多样性,计算公式为:
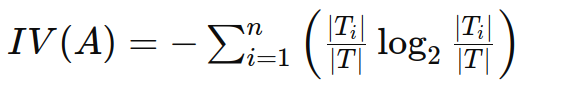
其中:
Ti:属性 A 的第 i 个取值所对应的样本子集。
∣Ti∣:属性 A 的第 i 个取值所对应的样本子集的样本数量。
∣T∣:数据集 T 的总样本数量。
n:属性 A 取值的个数。
通过计算每个属性的增益率,选择增益率最高的属性作为决策树节点的划分属性,从而构建最优的决策树。
2.2. 划分节点
根据选定的特征和阈值,数据集被划分成多个子集。
2.3. 递归构建
递归地对每个子集进行特征选择和划分,直到满足停止条件(如当前数据子集中的所有实例都属于同一个类别,或达到预设的最大树深度)。
特征选择以增益率为例,在决策树构建过程中,选择每个节点的分裂特征是基于当前数据集的增益率计算结果的。对于每个分裂点,我们都会重新计算剩余特征的增益率,并选择其中最高的作为下一个分裂特征。
import numpy as np
import pandas as pd# 计算熵
def entropy(y):unique_labels, counts = np.unique(y, return_counts=True)probabilities = counts / counts.sum()return -np.sum(probabilities * np.log2(probabilities))# 计算信息增益
def information_gain(data, split_attribute, target_attribute):total_entropy = entropy(data[target_attribute])values, counts = np.unique(data[split_attribute], return_counts=True)weighted_entropy = np.sum([(counts[i] / np.sum(counts)) * entropy(data[data[split_attribute] == values[i]][target_attribute])for i in range(len(values))])info_gain = total_entropy - weighted_entropyreturn info_gain# 计算固有值
def intrinsic_value(data, split_attribute):values, counts = np.unique(data[split_attribute], return_counts=True)probabilities = counts / counts.sum()return -np.sum(probabilities * np.log2(probabilities))# 计算增益率
def gain_ratio(data, split_attribute, target_attribute):info_gain = information_gain(data, split_attribute, target_attribute)iv = intrinsic_value(data, split_attribute)return info_gain / iv if iv != 0 else 0# 递归构建决策树
def build_decision_tree(data, original_data, features, target_attribute, parent_node_class=None):# 条件1: 所有数据点属于同一类别if len(np.unique(data[target_attribute])) <= 1:return np.unique(data[target_attribute])[0]# 条件2: 数据子集为空elif len(data) == 0:return np.unique(original_data[target_attribute])[np.argmax(np.unique(original_data[target_attribute], return_counts=True)[1])]# 条件3: 没有更多的特征可以分裂elif len(features) == 0:return parent_node_classelse:parent_node_class = np.unique(data[target_attribute])[np.argmax(np.unique(data[target_attribute], return_counts=True)[1])]gain_ratios = {feature: gain_ratio(data, feature, target_attribute) for feature in features}best_feature = max(gain_ratios, key=gain_ratios.get)tree = {best_feature: {}}features = [i for i in features if i != best_feature]for value in np.unique(data[best_feature]):sub_data = data[data[best_feature] == value]subtree = build_decision_tree(sub_data, original_data, features, target_attribute, parent_node_class)tree[best_feature][value] = subtreereturn tree# 可视化决策树
def visualize_tree(tree, depth=0):if isinstance(tree, dict):for attribute, subtree in tree.items():if isinstance(subtree, dict):for value, subsubtree in subtree.items():print(f"{'| ' * depth}|--- {attribute} = {value}")visualize_tree(subsubtree, depth + 1)else:print(f"{'| ' * depth}|--- {attribute} = {value}: {subtree}")else:print(f"{'| ' * depth}|--- {tree}")# 示例数据
data = pd.DataFrame({'Outlook': ['Sunny', 'Sunny', 'Overcast', 'Rain', 'Rain', 'Rain', 'Overcast', 'Sunny', 'Sunny', 'Rain', 'Sunny', 'Overcast', 'Overcast', 'Rain'],'Temperature': ['Hot', 'Hot', 'Hot', 'Mild', 'Cool', 'Cool', 'Cool', 'Mild', 'Cool', 'Mild', 'Mild', 'Mild', 'Hot', 'Mild'],'Humidity': ['High', 'High', 'High', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'High'],'Wind': ['Weak', 'Strong', 'Weak', 'Weak', 'Weak', 'Strong', 'Strong', 'Weak', 'Weak', 'Weak', 'Strong', 'Strong', 'Weak', 'Strong'],'PlayTennis': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No']
})# 构建决策树
features = ['Outlook', 'Temperature', 'Humidity', 'Wind']
target_attribute = 'PlayTennis'
tree = build_decision_tree(data, data, features, target_attribute)# 可视化决策树
print("Decision Tree:")
visualize_tree(tree)通过运行代码,可以看到每个节点选择的分裂特征以及决策树的结构:
Decision Tree:
|--- Temperature = Cool
| |--- PlayTennis = Yes
|--- Temperature = Hot
| |--- PlayTennis = No
|--- Temperature = Mild
| |--- Outlook = Sunny
| | |--- Humidity = High
| | | |--- PlayTennis = No
| | |--- Humidity = Normal
| | | |--- PlayTennis = Yes
| |--- Outlook = Rain
| | |--- Wind = Weak
| | | |--- PlayTennis = Yes
| | |--- Wind = Strong
| | | |--- PlayTennis = No
| |--- Outlook = Overcast
| | |--- PlayTennis = Yes
解释决策树的结构:
根节点是 Temperature,这是第一个选择的分裂特征。
Temperature 的每个取值(Cool, Hot, Mild)对应一个子节点。
如果 Temperature 是 Cool,则 PlayTennis 是 Yes。
如果 Temperature 是 Hot,则 PlayTennis 是 No。
如果 Temperature 是 Mild,则继续分裂 Outlook 属性:Outlook 是 Sunny 时,进一步分裂 Humidity 属性:Humidity 是 High 时,PlayTennis 是 No。Humidity 是 Normal 时,PlayTennis 是 Yes。Outlook 是 Rain 时,进一步分裂 Wind 属性:Wind 是 Weak 时,PlayTennis 是 Yes。Wind 是 Strong 时,PlayTennis 是 No。Outlook 是 Overcast 时,PlayTennis 是 Yes。
通过这种方式,决策树会根据每个节点选择最佳的分裂特征,直到所有数据点都被正确分类或没有更多的特征可供分裂。
2.4. 防止过拟合
防止决策树过拟合的方法主要包括剪枝、设置深度限制和样本数量限制。以下是一些常用的方法及其实现:
- 预剪枝 (Pre-pruning)
预剪枝是在构建决策树时限制树的增长。常用的方法包括:
设置最大深度:限制树的深度,防止树过深导致过拟合。
设置最小样本分裂数:如果节点中的样本数小于某个阈值,则不再分裂该节点。
设置最小信息增益:如果信息增益小于某个阈值,则不再分裂该节点。
- 后剪枝 (Post-pruning)
后剪枝是在决策树完全生长后,剪去一些不重要的分支。常用的方法包括:
代价复杂度剪枝 (Cost Complexity Pruning):基于一个代价复杂度参数 α,剪去那些对降低训练误差贡献较小但增加了模型复杂度的分支。
代价复杂度剪枝 (CCP) 是一种后剪枝技术,用于简化已经完全生长的决策树。CCP 通过引入一个复杂度惩罚参数 α 来权衡决策树的复杂度与其在训练集上的误差。通过调整 α,我们可以控制模型的复杂度,防止过拟合。
原理
CCP 的基本思想是通过最小化以下代价复杂度函数来选择最佳的子树:
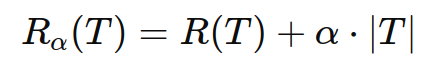
其中:
Rα(T) 是带有复杂度惩罚项的代价复杂度。
R(T)是子树 T 的误差。
α 是复杂度惩罚项,控制模型复杂度与误差之间的权衡。
∣T∣ 是子树 T 的叶节点数量。
较小的 α 值允许更多的节点,使树更加复杂;较大的 α 值会剪去更多的节点,使树更加简单。
代价复杂度剪枝步骤:
构建完全生长的决策树:首先,生成一棵完全生长的决策树,使其充分拟合训练数据。
计算每个子树的误差:对子树中的所有节点计算其误差 R(T)。
计算代价复杂度:对于每个子树,计算其代价复杂度 Rα(T)。
选择合适的 α:通过关系图或交叉验证结果选择最佳的 α 值。
剪枝:根据选定的 α 值,剪去那些对降低误差贡献不大但增加了复杂度的节点。
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_text
import matplotlib.pyplot as plt# 示例数据
data = pd.DataFrame({'Outlook': ['Sunny', 'Sunny', 'Overcast', 'Rain', 'Rain', 'Rain', 'Overcast', 'Sunny', 'Sunny', 'Rain', 'Sunny', 'Overcast', 'Overcast', 'Rain'],'Temperature': ['Hot', 'Hot', 'Hot', 'Mild', 'Cool', 'Cool', 'Cool', 'Mild', 'Cool', 'Mild', 'Mild', 'Mild', 'Hot', 'Mild'],'Humidity': ['High', 'High', 'High', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'High'],'Wind': ['Weak', 'Strong', 'Weak', 'Weak', 'Weak', 'Strong', 'Strong', 'Weak', 'Weak', 'Weak', 'Strong', 'Strong', 'Weak', 'Strong'],'PlayTennis': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No']
})# 将特征和目标变量转换为数值编码
data_encoded = pd.get_dummies(data[['Outlook', 'Temperature', 'Humidity', 'Wind']])
target = data['PlayTennis'].apply(lambda x: 1 if x == 'Yes' else 0)# 拆分数据集
X = data_encoded
y = target# 构建完全生长的决策树
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X, y)# 导出决策树规则
tree_rules = export_text(clf, feature_names=list(data_encoded.columns))
print("Original Decision Tree Rules:")
print(tree_rules)# 计算代价复杂度剪枝路径
path = clf.cost_complexity_pruning_path(X, y)
ccp_alphas, impurities = path.ccp_alphas, path.impurities# 训练不同复杂度惩罚项的决策树
clfs = []
for ccp_alpha in ccp_alphas:clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)clf.fit(X, y)clfs.append(clf)# 绘制复杂度惩罚项与树结构的关系图
node_counts = [clf.tree_.node_count for clf in clfs]
depth = [clf.tree_.max_depth for clf in clfs]fig, ax = plt.subplots(3, 1, figsize=(10, 10))
ax[0].plot(ccp_alphas, node_counts, marker='o', drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("number of nodes")
ax[0].set_title("Number of nodes vs alpha")ax[1].plot(ccp_alphas, depth, marker='o', drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("depth")
ax[1].set_title("Depth vs alpha")ax[2].plot(ccp_alphas, impurities, marker='o', drawstyle="steps-post")
ax[2].set_xlabel("alpha")
ax[2].set_ylabel("impurity")
ax[2].set_title("Impurity vs alpha")plt.tight_layout()
plt.show()# 选择合适的 alpha 进行剪枝并可视化决策树,例如选择 impurity 最小对应的 alpha
# Impurity 反映了决策树在分裂节点时的纯度,纯度越高(impurity 越低),节点中样本越一致,分类效果越好。
optimal_alpha = ccp_alphas[np.argmin(impurities)]
pruned_tree = DecisionTreeClassifier(random_state=0, ccp_alpha=optimal_alpha)
pruned_tree.fit(X, y)# 导出剪枝后的决策树规则
pruned_tree_rules = export_text(pruned_tree, feature_names=list(data_encoded.columns))print("Pruned Decision Tree Rules:")
print(pruned_tree_rules)3. 使用集成方法
- 随机森林:通过构建多棵决策树并结合它们的预测结果,可以减少单棵树的过拟合。
使用随机森林(Random Forest)是一种有效的方法来防止单个决策树模型的过拟合问题。随机森林通过构建多棵决策树并集成它们的预测结果,从而提高模型的泛化能力。
随机森林防止过拟合的机制:
1. 集成学习:随机森林是一种集成学习方法,通过构建多棵决策树,并将它们的预测结果进行投票或平均,从而得到最终的预测结果。这种方式可以有效地减少单棵决策树的高方差,提高模型的稳定性和泛化能力。2. 随机特征选择:在每棵决策树的节点分裂时,随机森林不会考虑所有特征,而是从所有特征中随机选择一个子集来进行分裂。这样可以减少树之间的相关性,提高集成效果。3. Bootstrap 重采样:每棵决策树都是通过对原始训练数据进行 bootstrap 重采样(有放回抽样)得到的不同样本集进行训练。这样每棵树都有不同的训练数据,进一步减少了树之间的相关性。
- 梯度提升树:通过逐步构建一系列决策树,每棵树修正前一棵树的错误,可以提高模型的泛化能力。
梯度提升树(Gradient Boosting Trees, GBT)是一种集成学习方法,通过逐步构建一系列决策树来提高模型的预测性能。每棵新树的构建是为了修正之前所有树的误差。
梯度提升树防止过拟合的机制:
1. 分阶段训练:梯度提升树采用逐步训练的方法。每次构建新树时,模型会根据之前所有树的预测误差来调整新树的结构。这种逐步优化的方法可以有效减少过拟合。2. 学习率:学习率(learning rate)控制每棵树对最终模型的贡献。较小的学习率使得每棵树的影响较小,从而需要更多的树来拟合训练数据。尽管这会增加计算成本,但可以显著降低过拟合的风险。3. 树的深度:限制每棵树的最大深度可以防止单棵树过于复杂,从而避免过拟合。浅层树(通常 3-5 层)虽然不能完全拟合数据,但可以捕捉到数据的主要结构,从而与其他树一起构成一个强大的集成模型。4. 子样本采样:在构建每棵树时,梯度提升树可以对训练数据进行子样本采样(subsampling)。这种方法通过引入训练数据的随机性,减少了模型的方差,从而防止过拟合。5. 正则化:梯度提升树可以引入正则化参数,如 L1 和 L2 正则化,来进一步防止模型的过拟合。
4. 实际应用中的决策树
决策树可以用于多个实际应用,如客户分类、疾病诊断、风险评估等。在实际应用中,需要根据具体问题调整决策树的参数(如树的最大深度、最小样本分裂数等),以达到最佳效果。
使用 TensorFlow 和 NumPy 实现一个简单的决策树分类器
相关文章:
[机器学习算法]决策树
1. 理解决策树的基本概念 决策树是一种监督学习算法,可以用于分类和回归任务。决策树通过一系列规则将数据划分为不同的类别或值。树的每个节点表示一个特征,节点之间的分支表示特征的可能取值,叶节点表示分类或回归结果。 2. 决策树的构建…...

springboot应用cpu飙升的原因排除
1、通过top或者jps命令查到是那个java进程, top可以看全局那个进程耗cpu,而jps则默认是java最耗cpu的,比如找到进程是196 1.1 top (推荐)或者jps命令均可 2、根据第一步获取的进程号,查询进程里那个线程最占用cpu,发…...
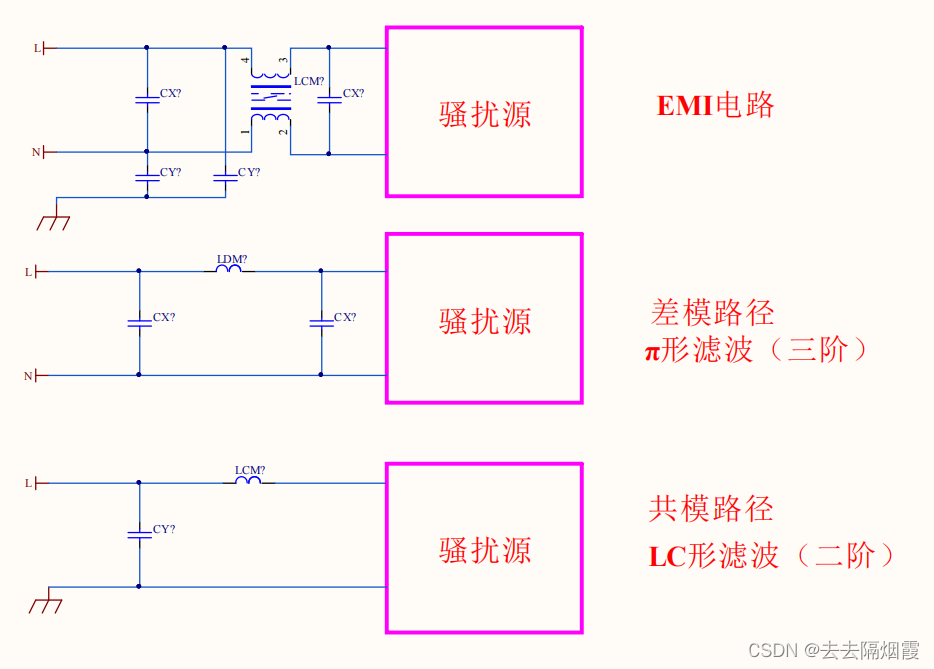
反激开关电源EMI电路选型及计算
EMI :开关电源对电网或者其他电子产品的干扰 EMI :传导与辐射 共模电感的滤波电路,La和Lb就是共模电感线圈。这两个线圈绕在同一铁芯上,匝数和相位都相 同(绕制反向)。 这样,当电路中的正常电流(差模&…...

vue3前端对接后端的图片验证码
vue3前端对接后端的图片验证码 <template> <image :src"captchaUrl" alt"图片验证码" click"refreshCaptcha"></image> </template><script setup>import {ref} from "vue";import {useCounterStore} …...
【Unity】RPG2D龙城纷争(四)要诀、要诀数据集
更新日期:2024年6月20日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介要诀数据集(AbilityDataSet)一、定义要诀数据集类二、要诀属性1.要诀类型2.攻击距离3.基础命中、暴击率4.基础属性加成5.…...
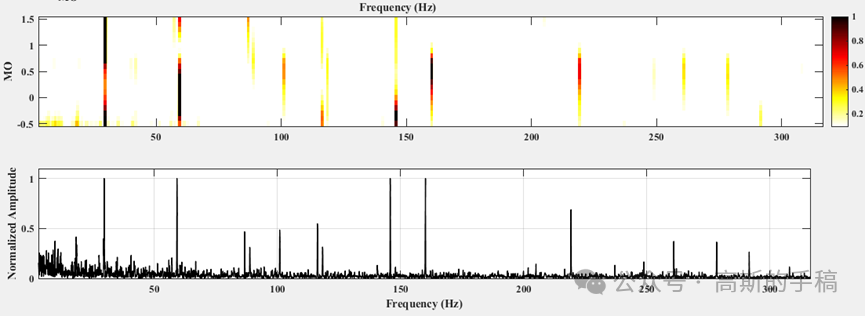
一种基于非线性滤波过程的旋转机械故障诊断方法(MATLAB)
在众多的旋转机械故障诊断方法中,包络分析,又称为共振解调技术,是目前应用最为成功的方法之一。首先,对激励引起的共振频带进行带通滤波,然后对滤波信号进行包络谱分析,通过识别包络谱中的故障相关的特征频…...

HarmonyOS Next 系列之从手机选择图片或拍照上传功能实现(五)
系列文章目录 HarmonyOS Next 系列之省市区弹窗选择器实现(一) HarmonyOS Next 系列之验证码输入组件实现(二) HarmonyOS Next 系列之底部标签栏TabBar实现(三) HarmonyOS Next 系列之HTTP请求封装和Token…...

如果xml在mapper目录下,如何扫描到xml
如果xml在mapper目录下,如何扫描到xml 项目结构 src├── main│ ├── java│ │ └── com│ │ └── bg│ │ ├── Application.java│ │ ├── domain│ │ │ └── User.java│ │ …...
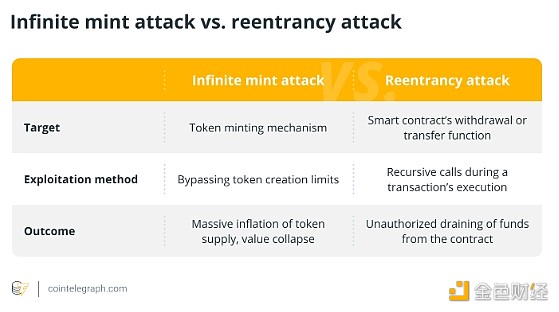
什么是无限铸币攻击?它是如何运作的?
一、无限铸币攻击解释 无限铸币攻击是指攻击者操纵合约代码不断铸造超出授权供应限制的新代币。 这种黑客行为在去中心化金融 (DeFi) 协议中最为常见。这种攻击通过创建无限数量的代币来损害加密货币或代币的完整性和价值。 例如,一名黑客利用了 Paid 网络的智能…...

【Android】怎么使APP进行开机启动
项目需求 在Android系统开启之后,目标app可以在系统开机之后启动。 项目实现 使用广播的方式 首先我们要创建一个广播(这里是启动了一个Service服务) public class BootReceiver extends BroadcastReceiver {Overridepublic void onReceive(Context context, I…...

详细分析Element Plus的el-pagination基本知识(附Demo)
目录 前言1. 基本知识2. Demo3. 实战 前言 需求:从无到有做一个分页并且附带分页的导入导出增删改查等功能 前提一定是要先有分页,作为全栈玩家,先在前端部署一个分页的列表 相关后续的功能,是Java,推荐阅读&#x…...

ubuntu换镜像源方法
查看ubuntu的版本,不同的版本对应的不同的镜像源 cat /etc/issue Ubuntu 18.04.6 LTS \n \l 先备份一个,防止更改错误 cobol cp /etc/apt/sources.list /etc/apt/sources.list.backup 先进入清华源,搜索ubuntu,点击问号 点进来可以看到可以…...

python flask配置邮箱发送功能,使用flask_mail模块
🌈所属专栏:【Flask】✨作者主页: Mr.Zwq✔️个人简介:一个正在努力学技术的Python领域创作者,擅长爬虫,逆向,全栈方向,专注基础和实战分享,欢迎咨询! 您的点…...

Flask快速入门(路由、CBV、请求和响应、session)
Flask快速入门(路由、CBV、请求和响应、session) 目录 Flask快速入门(路由、CBV、请求和响应、session)安装创建页面Debug模式快速使用Werkzeug介绍watchdog介绍快速体验 路由系统源码分析手动配置路由动态路由-转换器 Flask的CBV…...
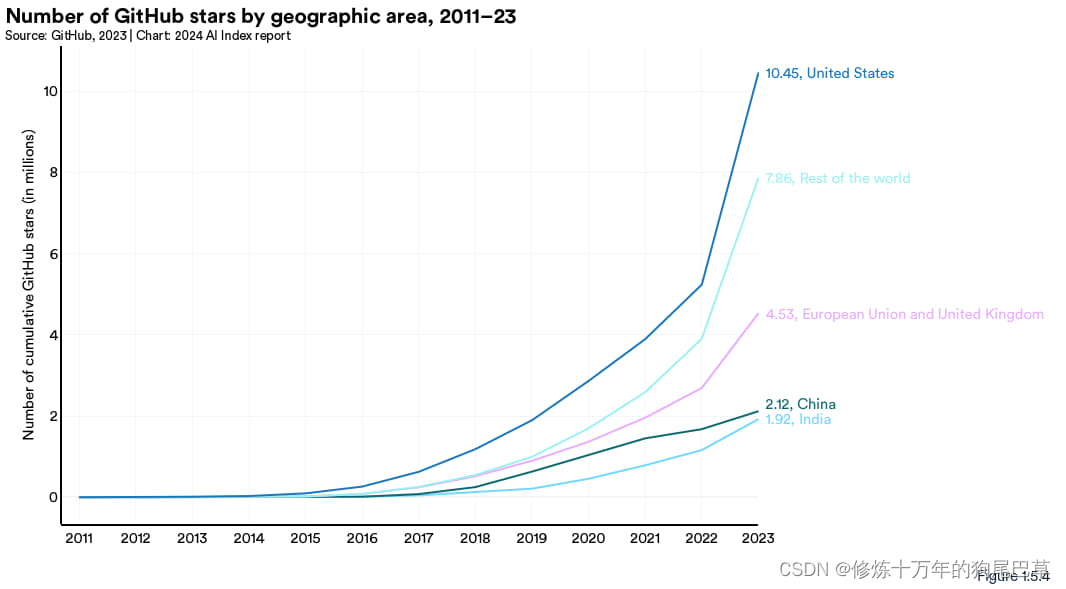
人工智能指数报告
2024人工智能指数报告(一):研发 前言 全面分析人工智能的发展现状。 从2017年开始,斯坦福大学人工智能研究所(HAI)每年都会发布一份人工智能的研究报告,人工智能指数报告(AII&…...
聊聊 Mybatis 动态 SQL
这篇文章,我们聊聊 Mybatis 动态 SQL ,以及我对于编程技巧的几点思考 ,希望对大家有所启发。 1 什么是 Mybatis 动态SQL 如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼…...

【windows|004】BIOS 介绍及不同品牌电脑和服务器进入BIOS设置的方法
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社…...
lvgl的应用:移植MusicPlayer(基于STM32F407)
目录 概述 1 软硬件环境 1.1 UI开发版本 1.2 MCU开发环境 1.3 注意点 2 GUI Guider开发UI 2.1 使用GUI Guider创建UI 2.2 GUI Guider编译项目和测试 2.2.1 GUI Guider编译项目 2.2.2 编译 2.3 了解GUI Guider生成代码 3 移植项目 3.1 Keil中加载代码 3.2 调用G…...
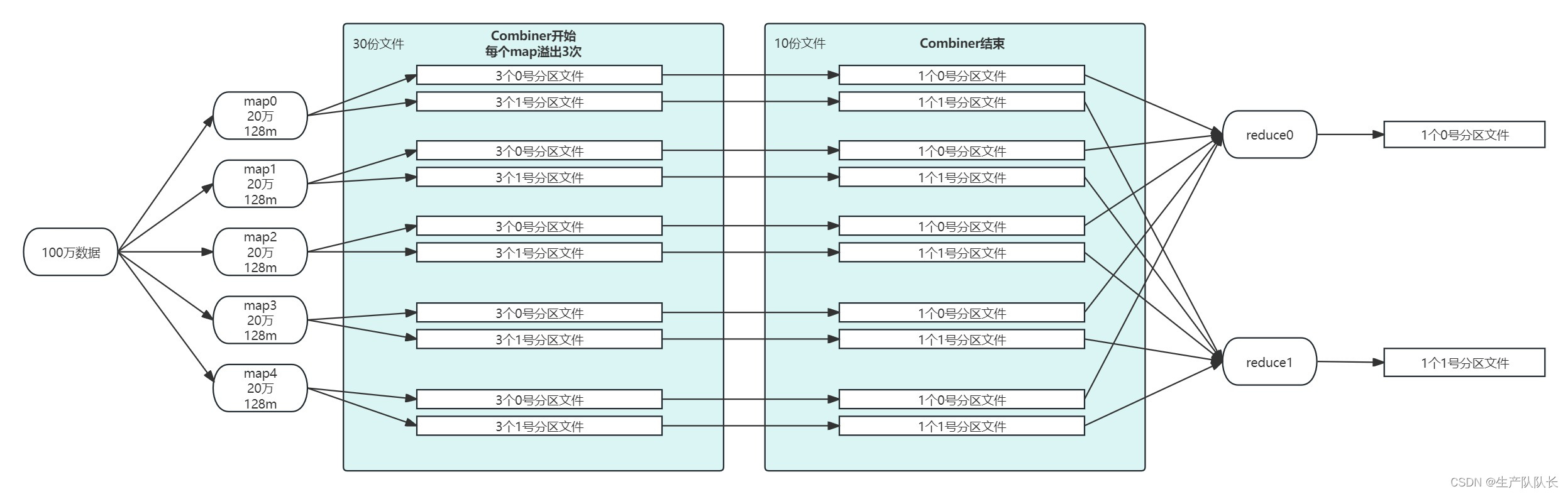
Hadoop3:MapReduce中的Shuffle机制
一、流程图 Shuffle是Map方法之后,Reduce方法之前的数据处理过程称。 二、图解说明 1、数据流向 map方法中context.write(outK, outV);开始,写入环形缓冲区,再进行分区排序,写到磁盘 reduce方法拉取磁盘上的数据,…...
从设计到实践:高速公路监控技术架构全剖析
随着高速公路网络的迅速扩展和交通流量的日益增加,高效的监控系统成为保障交通安全、提升管理效率的重要手段。本文将深入探讨高速公路监控技术架构,从设计理念到实际应用,全面解析这一关键技术的各个环节。 ### 一、系统设计理念 #### 1. 高…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...