【论文阅读】-- TSR-TVD:时变数据分析和可视化的时间超分辨率

TSR-TVD: Temporal Super-Resolution for Time-Varying Data Analysis and Visualization
- 摘要
- 1 引言
- 2 相关工作
- 3 我们的循环生成方法
- 3.1 损失函数
- 3.2 网络架构
- 4 结果与讨论
- 4.1 数据集和网络训练
- 4.2 结果
- 4.3 讨论
- 5 结论和未来工作
- 致谢
- 参考文献
- 附录
- 1 训练算法及优化
- 2 网络分析
- 3 补充讨论
摘要
我们提出了 TSR-TVD,这是一种新颖的深度学习框架,它使用对抗性学习生成时变数据 (TVD) 的时间超分辨率 (TSR)。 TSR-TVD 是第一个应用循环生成网络(RGN)(循环神经网络(RNN)和生成对抗网络(GAN)的组合)从低分辨率体积序列生成时间高分辨率体积序列的工作。 TSR-TVD 的设计包括发生器和鉴别器。生成器以一对体积作为输入,并通过前向和后向预测输出合成的中间体积序列。鉴别器将合成的中间体积作为输入并产生指示体积真实性的分数。我们的方法还可以处理多变量数据,其中一个变量的训练网络应用于生成另一个变量的 TSR。为了证明 TSR-TVD 的有效性,我们用几个时变多元数据集展示了定量和定性结果,并将我们的方法与标准线性插值和仅基于 RNN 或 CNN 的解决方案进行了比较。
1 引言
在许多科学领域,科学家每天都会进行大规模的科学模拟并生成时变的多元数据。在本文中,我们专注于增强这些数据的时间分辨率,因为科学家经常模拟涉及许多变量的长时间序列,但只能存储非常有限数量的时间步长(例如,每一百个时间步长)以供后期处理。专门分析。我们的目标是在后处理过程中通过生成精细的时间分辨率来增强这些减少的模拟数据,从而能够更准确地研究基础数据的动态时空特征。也就是说,给定一个低分辨率体积序列,例如 100 个时间步长,我们的目标是生成例如 500 个时间步长的高分辨率体积序列,同时保持空间分辨率不变。
为时变数据生成时间上精细的体积序列提出了两个主要挑战。第一个挑战是体数据随时间的动态变化通常是非线性的。传统方法采用标准线性插值 (LERP) 来生成中间体积。这些插值仅基于插值位置周围的局部信息,因此可能无法捕获体积的复杂演化和非线性变化。第二个挑战是如何考虑视觉质量。将典型的基于递归的神经网络设计应用于我们的问题只会测量体素距离,即使 PSNR 很高,也可能不会产生高质量的渲染结果。例如,张等人。 [61]指出,仅使用像素级损失函数来训练神经网络可能会生成带有噪声和伪影的图像。
为了应对这些挑战,我们提出了 TSR-TVD,这是一种新颖的深度学习框架,用于从时变数据 (TVD) 生成时间超分辨率 (TSR)。我们利用循环生成网络(RGN)(循环神经网络(RNN)和生成对抗网络(GAN)的组合)来实现 TSR。这是因为 RNN 和 GAN 可以非均匀、非局部地学习不同体积之间的时空关系,从而高质量地对中间体积进行插值。受序列学习(例如天气预报和机器翻译)和图像生成(例如帧插值和视频预测)技术的启发,我们的解决方案由生成器和鉴别器组成,用于使用对抗性学习生成卷序列的时间相干 TSR 。 TSR-TVD 将采样体积作为输入并生成中间体积。我们通过优化损失函数(包括对抗性损失、体积损失和特征损失)来训练 TSR-TVD。我们的 TSR-TVD 还可以处理多变量数据,其中一个变量的训练网络应用于生成另一个变量的 TSR。为了证明 TSRTVD 的有效性,我们用几个不同特征的时变多元数据集展示了定量和定性结果。我们将 TSR-TVD 与广泛使用的 LERP 以及仅基于 RNN 或 CNN 的解决方案进行比较。我们表明,我们的方法在数据级别的 PSNR 方面实现了比 LERP 更好的质量,在图像级别的 SSIM 方面实现了最佳质量。
本文的贡献如下。首先,我们的工作是第一个应用 RGN(RNN 和 GAN 的组合)来生成体积序列的 TSR 的工作。其次,我们应用 ConvLSTM 层来捕获时空关系,并提出一个新的体素洗牌层来加速训练过程。第三,我们为 TSR 任务设计了一种新的架构,它不仅支持同变量推理,还支持异变量推理。第四,我们研究了几种超参数设置并分析它们如何影响 TSR-TVD 的性能。
2 相关工作
时变多元数据分析和可视化是科学可视化的一个关键主题。我们建议感兴趣的读者参阅调查论文 [24] 以了解概述。现有的时变数据分析和可视化工作重点关注高效组织和渲染[44,52,59]、传递函数规范[20]、插图启发[23]和重要性驱动[54]技术。对于时变多元数据,研究人员研究了查询驱动的可视化[47, 9]、变量相关性探索[43]、变量分组[4]、变量之间的信息流[53, 29]以及导航界面[2, 48]。接下来,我们将注意力集中在视频时间超分辨率、相关 GAN 和 RNN 技术以及科学可视化深度学习的相关工作上。
视频的 TSR。深度学习在生成视频 TSR 方面取得了巨大成功。例如,尼克劳斯等人。 [35]引入了用于帧插值的卷积神经网络(CNN),其中网络通过输入帧学习内核,然后应用学习的内核来生成丢失的帧。阮等人。 [34]提出了一种深度线性嵌入模型来插值中间帧。他们将每一帧变换到一个特征空间,然后在特征空间中对中间帧进行线性插值,最后将插值后的特征恢复到相应的帧中。江等人。 [21]建立了一个CNN来通过两个给定帧估计前向和后向光流。然后,他们将这些光流包装到帧中以生成任意的中间帧。
我们的工作与上述工作不同。首先,我们利用 RNN 来捕获时间关系,而不是使用 CNN,因为 RNN 可以学习跨时间的潜在模式。其次,与图像生成任务不同,研究人员可以使用预先训练的图像分类模型来提高合成结果的视觉质量,但没有这样的体积模型。第三,许多深度学习模型计算光流以生成中间帧,但这些模型需要大量标记的光流数据进行训练,或者需要额外的子网络以无监督的方式计算光流。因此,我们应用 GAN 来确保合成体积的高质量。有些作品使用 RNN 或 GAN 来实现类似的目的 [18,30,6],但与我们的工作不同时。我们的方法不需要大量标记数据或附加模块,这降低了其复杂性和训练时间。我们结合 ConvLSTM 来实现时间一致性。基于这种机制,TSR-TVD使用时间步i、i+1、···、i+j−1中的所有信息来对时间步i+j进行插值。
GAN 和 RNN 技术。由 Goodfellow 等人提出。 [10],GAN包括两个网络:生成器G和鉴别器D。G试图从噪声或观察中合成数据样本来欺骗D,而D的目的是将G生成的数据与真实样本区分开。 GAN 已应用于图像翻译 [19, 55]、风格迁移 [22]、图像修复 [37] 和图像超分辨率 [28] 任务。由于训练不稳定的问题,在训练过程中考虑了不同的技术,例如L2损失[37]、梯度正则化[32]以及G和D的单独学习率[42]。 RNN 接受序列作为输入,并通过内部状态构建时间关系。最常用的 RNN 架构之一是长短期记忆(LSTM)[15],它已应用于视频着色[27]和视频字幕[51]。由于梯度消失和爆炸问题,RNN 训练中应用了不同的技术,例如堆叠 LSTM [51] 和梯度裁剪 [36]。
科学可视化的深度学习。越来越多的作品应用深度学习来解决科学可视化问题。曾等人。 [49, 50] 率先使用人工神经网络对 3D 体积数据集进行分类。 Ma[31]指出使用神经网络作为可视化研究的一个有前途的方向。随着现代深度学习技术的爆炸性增长,研究人员最近开始探索深度神经网络(DNN)解决各种问题的能力。
对于体积可视化,Zhou 等人。 [62]提出了一种基于 CNN 的体积放大解决方案,它比线性放大更好地保留了结构细节和体积质量。拉吉等人。 [39]利用 CNN 迭代地细化传递函数,旨在将相似体积数据集的渲染图像中的视觉特征与目标图像中的视觉特征进行匹配。程等人。 [7]提出了一种深度学习辅助的解决方案,它描述和探索使用传统方法难以捕获的复杂结构。伯杰等人。 [3] 设计了一个 GAN,根据视点和传递函数的大量体渲染图像来计算模型。 Shi和Tao[45]提出了一种基于CNN的视点估计方法,该方法在使用不同传递函数和渲染参数渲染的图像上取得了良好的性能。谢等人。 [60]设计了一种时间相干方法来生成空间超分辨率体积,其中通过时间鉴别器保证时间相干性。韦斯等人。 [57]提出了一种图像空间解决方案,它学习将低分辨率等值面几何特性的采样表示升级到更高分辨率。他们通过添加帧间运动损失来考虑时间变化,以实现改进的时间相干性。
对于流量可视化,Hong 等人。 [16] 使用 LSTM 来学习和预测粒子追踪中的数据访问模式,以隐藏分布式并行流可视化中的 I/O 延迟。维维尔等人。 [58]采用基于 LSTM 的方法使用自动编码器框架来预测物理系统的密集 3D+时间函数。 Kim 和 G̈ unther [25] 使用 CNN 以端到端的方式将滤波器和特征提取结合起来,从不稳定的 2D 矢量场中提取鲁棒的参考帧。韩等人。 [12]提出了一种用于矢量场重建的深度学习方法,该方法将从原始矢量场追踪的流线作为输入,并应用两阶段过程来重建高质量的矢量场。韩等人。 [11]设计了一个自动编码器来学习潜在空间中流线或表面的特征,并进行降维和交互式聚类以进行代表性选择。
尽管已经研究了从低分辨率体积生成空间高分辨率体积[62, 60],但据我们所知,在时变数据分析和可视化的背景下,尚未完成生成时间高分辨率体积的工作从低分辨率的卷序列开始,这是这项工作的重点。
3 我们的循环生成方法
我们将 TSR 问题定义如下。给定时间步 i 和 i + k(其中 k > 1)的一对体积 (Vi,Vi+k),我们寻求满足 φ (Vi,Vi+k) ≈ V 的函数 φ,其中 V = {Vi +1,Vi+2,···,Vi+k−1} 是 Vi 和 Vi+k 之间的中间体积。
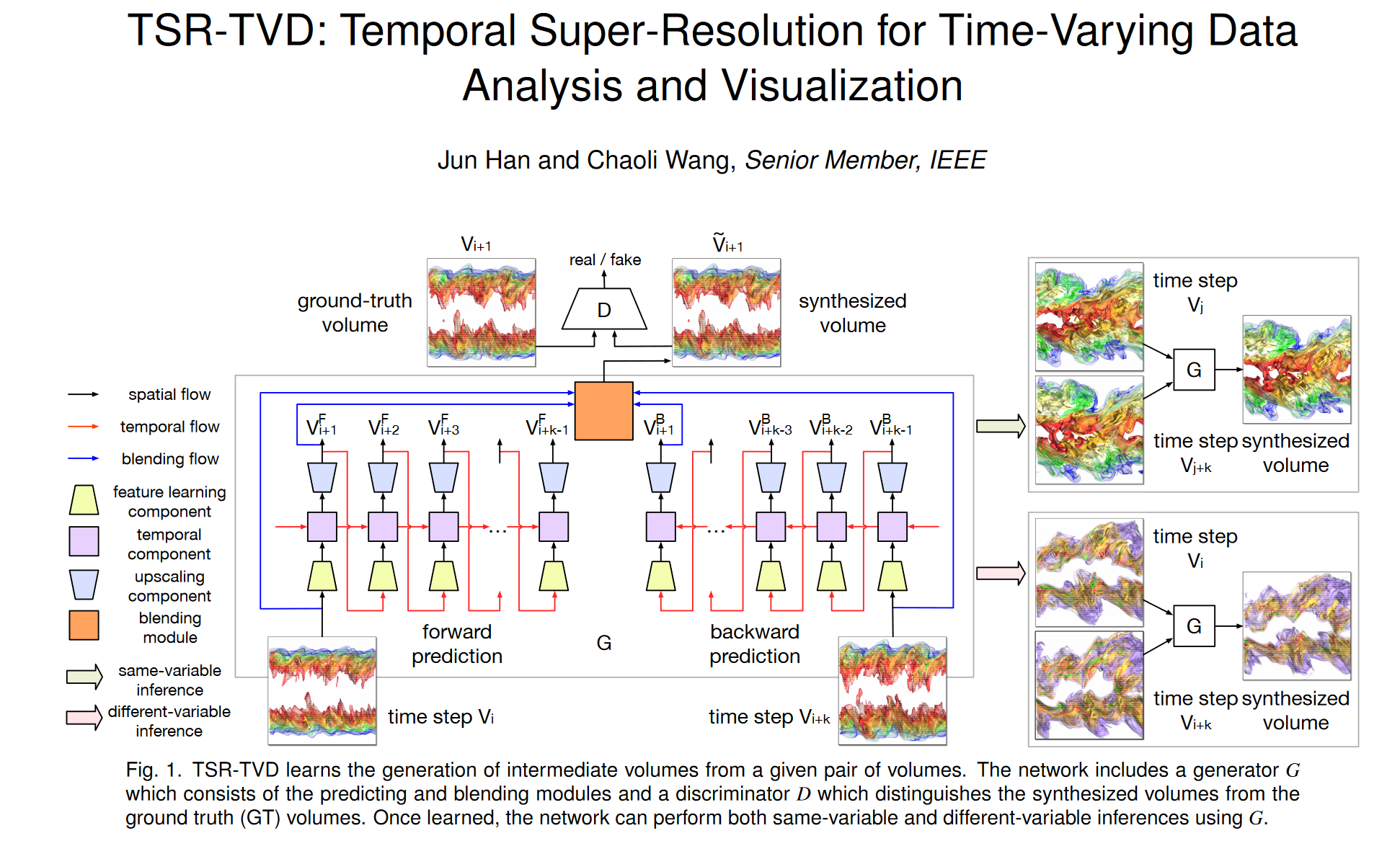
我们提出了一种新颖的循环生成网络(RGN),它是 RNN 和 GAN 的组合。 RGN 包括生成器 G 和判别器 D。G 使用两个模块来估计函数 φ ,如图 1 所示。第一个模块,即预测模块 (φPREDICT),是一个体积预测网络,通过以下方式生成前向预测 VF: Vi 和分别通过 Vi+k 的后向预测 VB。即,
V F = ϕ P R E D I C T F ( V i ) , ( 1 ) V B = ϕ P R E D I C T B ( V i + k ) , (2) ϕ P R E D I C T = { ϕ P R E D I C T F , ϕ P R E D I C T B } . (3) \begin{aligned} \mathbf{V}^{\mathbf{F}}& =\boldsymbol{\phi}_{\mathrm{PREDICT}}^\mathrm{F}(V_i), && \begin{pmatrix}1\end{pmatrix} \\ \mathbf{V}\mathbf{B}& =\boldsymbol{\phi}_{\mathrm{PREDICT}}^\mathrm{B}(V_{i+k}), && \text{(2)} \\ \phi_{\mathrm{PREDICT}}& =\{\boldsymbol{\phi}_{\mathrm{PREDICT}}^{\mathrm{F}},\boldsymbol{\phi}_{\mathrm{PREDICT}}^{\mathrm{B}}\}. && \text{(3)} \end{aligned} VFVBϕPREDICT=ϕPREDICTF(Vi),=ϕPREDICTB(Vi+k),={ϕPREDICTF,ϕPREDICTB}.(1)(2)(3)
第二个模块,混合模块 (φBLEND),采用 Vi、Vi+k 以及来自 VF 和 VB 的共享相同时间步长的相应体积对(为清楚起见,图 1 仅说明了时间步长 i 的混合流连接) + 1) 作为输入,并将它们混合成代表最终预测 ̃ V 的体积,即
V ~ = ϕ B L E N D ( V i , V i + k , V F , V B ) . ( 4 ) \mathbf{\tilde{V}}=\phi_{\mathrm{BLEND}}(V_i,V_{i+k},\mathbf{V}^\mathrm{F},\mathbf{V}^\mathrm{B}).\quad(4) V~=ϕBLEND(Vi,Vi+k,VF,VB).(4)
当我们使用下采样和上采样框架来重建中间体积时,下采样期间可能会丢失详细特征,而这些特征在上采样期间无法完美恢复。将 Vi 和 Vi+k 添加到混合中将有助于消除预测产生的噪声。判别器 D 区分 ̃ V 和 V。也就是说,给定 D 不同的输入,D 输出一个分数来指示输入的真实性。理想情况下,D(V) ≈ 1 且 D(̃ V) ≈ 0。在这方面,D 可以被视为二元分类器。 D 的分数可以指导 G 合成高质量的体积,因为 G 的目标是愚弄 D,使 D 无法将 V 区分为假体积。
下面,我们描述 TSR-TVD 的细节,包括损失函数的定义以及 G 和 D 的架构。训练算法和优化细节可以在附录的第 1 节中找到。
3.1 损失函数
注意。让我们将 VT = {(V1,Vk1 ), (Vk1 ,Vk2 ), · · · , (Vkn−1 ,Vkn )} 表示为我们的 TSR-TVD 框架的一组输入量对,并且 VI = {{V2 , · · · ,Vk1−1}, {Vk1+1, · · · ,Vk2−1}, · · · , {Vkn−1+1, · · · ,Vkn−1}} 作为基本事实 (GT )我们旨在插值的中间体积。令 θG 和 θD 分别为 G 和 D 中的可学习参数,K 为最大插值步长(即 ki+1 − ki 6 K + 1,i ∈ [0, n − 1])。
对抗性损失。遵循 GAN [10] 中的定义,我们将 G 和 D 的对抗性损失定义如下
min θ G L G = E V ∈ V T [ log D ( G ( V ) ) ] , (5) min θ D L D = 1 2 E V ∈ V ′ [ log D ( V ) ] + 1 2 E V ∈ V T [ log ( 1 − D ( G ( V ) ) ) ] , ( 6 ) \operatorname*{min}_{\theta_{G}}\mathcal{L}_{G}=\mathbb{E}_{V\in\mathbf{V}^{T}}\big[\log D(G(V))\big],\text{(5)}\\\operatorname*{min}_{\theta_{D}}\mathcal{L}_{D}=\frac{1}{2}\mathbb{E}_{V\in\mathbf{V}^{\prime}}\big[\log D(V)\big]+\frac{1}{2}\mathbb{E}_{V\in\mathbf{V}^{T}}\big[\log\big(1-D(G(V))\big)\big], (6) θGminLG=EV∈VT[logD(G(V))],(5)θDminLD=21EV∈V′[logD(V)]+21EV∈VT[log(1−D(G(V)))],(6)
其中E[·]表示期望运算。
这个公式背后的想法是,我们让 G 和 D 相互竞争,以便 G 可以产生合成体积,在训练过程中完全愚弄 D,而 D 的目标是将合成体积区分为假的,并将此信息返回给G迫使G变得更强大,直到D和G达到平衡。通过这个过程,G可以学习如何合成高度接近GT的高质量音量。对抗性损失背后的竞争理念通过最小化体素损失(例如 L1 损失)来鼓励感知解决方案,而不是面向 PSNR 或 SSIM 的解决方案。请注意,单独使用对抗性损失会导致 G 和 D 的训练不稳定。因此,我们进一步考虑体积损失和特征损失,如下所述。
体积损失。由于对抗性损失只考虑感知结果,因此我们在 LG 中添加了体积损失,这意味着 G 的任务不仅是愚弄 D,而且要接近 L2 意义上的 GT 输出,而 D 的工作保持不变。此外,还可以通过添加体积损失来提高训练稳定性[37, 19]。因此,我们利用 L2 距离作为 G 损失函数的一部分
L V = E V ′ ∈ V T , V ∈ V I [ ∥ G ( V ′ ) − V ∥ 2 ] , ( 7 ) \mathscr{L}_V=\mathbb{E}_{V'\in\mathbf{V}^T,V\in\mathbf{V}^I}\big[\|G(V')-V\|_2\big],\quad(7) LV=EV′∈VT,V∈VI[∥G(V′)−V∥2],(7)
|| · ||2 表示 L2 范数。
特征损失。张等人。 [61]建议从 DNN 中提取的特征可以用作评估生成模型输出的指标。遵循这一准则,我们还基于 D 计算 VI 和 G(VT ) 之间的特征差异。这种特征损失强制 G 在不同尺度的 G(VT ) 和 VI 之间产生相似的特征。具体来说,特征是从 D 的每个卷积 (Conv) 层中提取的,除了最终的 Conv 层,G 可以尝试最小化真实体积和合成体积之间的这些中间表示。我们将从第 k 个 Conv 层提取的特征表示表示为 Fk。那么特征损失定义为
L F = E V ′ ∈ V T , V ∈ V I ∑ k = 1 N − 1 1 N k [ ∥ F k ( G ( V ′ ) ) − F k ( V ) ∥ 2 ] , ( 8 ) \mathscr{L}_F=\mathbb{E}_{V'\in\mathbf{V}^T,V\in\mathbf{V}^I}\sum_{k=1}^{N-1}\frac{1}{N_k}\big[\|F^k(G(V'))-F^k(V)\|_2\big],\quad(8) LF=EV′∈VT,V∈VIk=1∑N−1Nk1[∥Fk(G(V′))−Fk(V)∥2],(8)
其中 N 是 D 中 Conv 层的总数,Nk 表示第 k 个 Conv 层中的元素数量。这种特征损失与 VGG 损失[22, 55]有关,后者在图像超分辨率和风格迁移任务中取得了令人印象深刻的结果。
考虑到所有三个损失,我们将 G 的最终损失函数定义为
min θ G L G = λ 1 ( E V ∈ V T [ ( D ( G ( V ) ) − 1 ) 2 ] ) + λ 2 L V + λ 3 L F , ( 9 ) \min\limits_{\theta_G}\mathcal{L}_G=\lambda_1\big(\mathbb{E}_{V\in\mathbf{V}^T}\big[\big(D(G(V))-1\big)^2\big]\big)+\lambda_2\mathcal{L}_V+\lambda_3\mathcal{L}_F,\quad(9) θGminLG=λ1(EV∈VT[(D(G(V))−1)2])+λ2LV+λ3LF,(9)
其中λ1、λ2和λ3是超参数,它们控制这三个损失的相对重要性。

3.2 网络架构
Generator。如图 1 所示,生成器 G 包含两个模块:预测模块和混合模块。预测模块由三个组件组成:特征学习组件、具有多个 ConvLSTM 层的时间组件和升级组件,如图 2 (a) 所示。特征学习组件从体积中提取特征表示,时间组件桥接不同体积之间的空间和时间信息,而升级组件则从时空特征中恢复体积。混合模块将预测模块的所有输出作为输入并生成最终的合成体积。
由于传统的残差块无法改变输入的分辨率[14],因此我们提出了一种高级残差块(在本文的其余部分中仍称为残差块),它允许缩小或放大其输入。这种治疗方法为 TSR-TVD 训练带来了诸多好处。首先,它捕获多尺度特征。其次,它防止网络梯度消失。第三,它使我们能够构建更深层次的神经网络来提高性能。
特征学习组件的核心是四个残差块。每个残差块包含两部分(P1和P2):P1由四个Conv层组成,后面是谱归一化(SN)[32](对Conv层中的参数进行归一化以稳定训练)和ReLU [33],P2包含一个 Conv 层,后跟 SN 和 ReLU。这两个部分通过跳跃连接[41]桥接,如图2(c)所示。我们将第一个残差块的内核大小设置为 5 × 5 × 5,将最后三个残差块的内核大小设置为 3 × 3 × 3。我们将步幅设置为 2,这意味着每个残差中输入的分辨率减半堵塞。我们将这四个残差块中的特征图分别设置为16、32、64和64。
1 f t = σ ( W x f ⋆ x t + W h f ⋆ h t − 1 + b f ) , (10) i t = σ ( W x i ⋆ x t + W h i ⋆ h t − 1 + b i ) , ( 11 ) 0 t = σ ( W x o ⋆ x t + W h o ⋆ h t − 1 + b o ) , ( 12 ) c ′ t = tanh ( W x c ⋆ x t + W h c ⋆ h t − 1 + b c ) , ( 13 ) c t = i t ⊙ c t ′ + f t ⊙ c t − 1 , ( 14 ) h t = o t ⊙ tanh ( c t ) , (15) \begin{gathered} \text{1} \mathbf{f}_t=\boldsymbol{\sigma}(\mathbf{W}_{xf}\star\mathbf{x}_t+\mathbf{W}_{hf}\star\mathbf{h}_{t-1}+\mathbf{b}_f), \text{(10)} \\ \mathbf{i}_t=\sigma(\mathbf{W}_{xi}\star\mathbf{x}_t+\mathbf{W}_{hi}\star\mathbf{h}_{t-1}+\mathbf{b}_i), \begin{pmatrix}11\end{pmatrix} \\ \text{0} t=\boldsymbol{\sigma}(\mathbf{W}_{xo}\star\mathbf{x}_t+\mathbf{W}_{ho}\star\mathbf{h}_{t-1}+\mathbf{b}_o), (12) \\ \mathbf{c'}_{t} =\tanh(\mathbf{W}_{xc}\star\mathbf{x}_t+\mathbf{W}_{hc}\star\mathbf{h}_{t-1}+\mathbf{b}_c), (13) \\ c_t =\mathbf{i}_t\odot\mathbf{c}^{\prime}_t+\mathbf{f}_t\odot\mathbf{c}_{t-1}, (14) \\ \mathbf{h}_t =\mathbf{o}_t\odot\tanh(\mathbf{c}_t), \text{(15)} \end{gathered} 1ft=σ(Wxf⋆xt+Whf⋆ht−1+bf),(10)it=σ(Wxi⋆xt+Whi⋆ht−1+bi),(11)0t=σ(Wxo⋆xt+Who⋆ht−1+bo),(12)c′t=tanh(Wxc⋆xt+Whc⋆ht−1+bc),(13)ct=it⊙ct′+ft⊙ct−1,(14)ht=ot⊙tanh(ct),(15)
对于时间部分,我们应用 ConvLSTM [46] 将空间特征转换为时空特征,以便 TSR-TVD 可以通过先前的体积来预测下一个体积。与传统的LSTM[15]相比,卷积中的权重共享机制允许我们使用更少的参数来训练ConvLSTM,从而节省大量内存并加快训练过程。 ConvLSTM 共有三种状态:输入状态、忘记状态和输出状态。这三个状态决定了我们是否应该让新的输入进入(输入状态)、因为输入不重要而删除信息(忘记状态),或者让输入影响当前时间步的输出(输出状态)。以数据 (xt )、先前隐藏状态 (ht−1) 和记忆状态 (ct−1) 作为输入,ConvLSTM 定义如下
其中 it 、 ft 、 ct 、 ot 、 ht 分别是 ConvLSTM 第 t 步的输入、遗忘、记忆、输出和隐藏状态。 σ (·)、tanh(·)、? 和 分别表示逻辑 sigmoid 激活函数、双曲正切激活函数、Conv 运算和元素乘法。 (Wx f , Wh f , b f )、(Wxi, Whi, bi)、(Wxo, Who, bo) 和 (Wxc, Whc, bc) 是 ConvLSTM 中的可学习参数。默认情况下,我们设置 h0 = 0 和 c0 = 0。请注意,ConvLSTM 不会更改输入的分辨率。 ConvLSTM 的示例如图 3 (a) 所示。
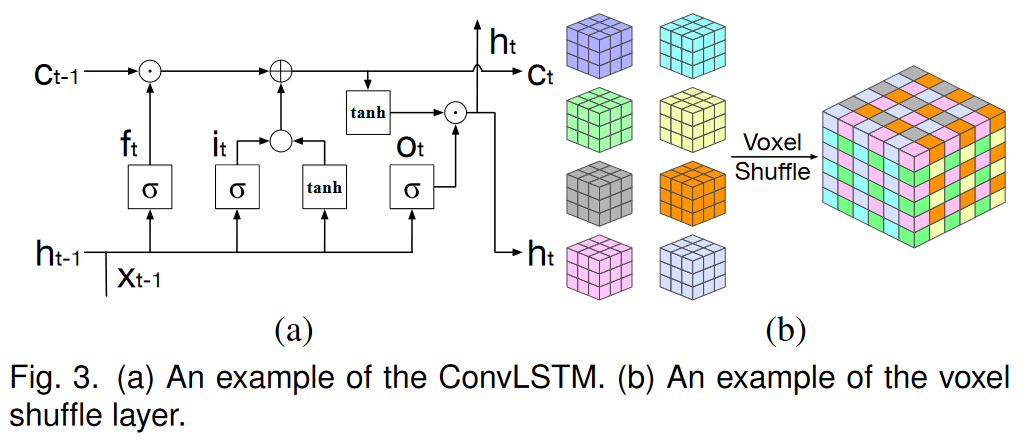
升级组件将 ConvLSTM 的时空特征作为输入并输出合成体积。从最大池化或卷积层恢复分辨率的常见方法是使用反卷积 (DeConv) 层。然而,这种方法带来了两个问题:高计算成本和不必要的零填充。例如,如果我们需要使用因子 f 来放大尺寸为 [L,W, H] 的特征,DeConv 操作将首先将该特征扩展到 [ f L + S − 1, fW + S − 1, fW + S − 1, f H + S − 1] 通过补零,其中 S 是内核大小,然后应用 Conv 运算来生成大小为 [ f L, fW, f H] 的输出。为了解决这些问题,我们提出了一个有效的子体素Conv层,我们称之为体素洗牌层,用于放大。定义如下
O = S ( W ⋆ I + b ) , ( 16 ) \mathbf{O}=\mathscr{S}(\mathbf{W}\star\mathbf{I}+\mathbf{b}),\quad(16) O=S(W⋆I+b),(16)
其中 I 和 O 分别是输入和输出,W 和 b 是可学习参数,S 是周期性洗牌操作,它将 [C f 3, L,W, H] 张量的元素重新排列为大小的张量[C,f L,fW,f H](C表示通道数)。图 3 (b) 说明了此操作的示例。
我们将特征学习组件中使用的相同架构应用于升级组件。不同之处在于,我们在 P1 和 P2 中的最后一个 SN 层之后添加了体素洗牌层。至于超参数设置,前三个残差块中的内核大小设置为 3 × 3 × 3,最后一个残差块中的内核大小设置为 5 × 5 × 5。我们将每个体素洗牌层的放大因子设置为 2,并将这四个残差块中的特征图分别设置为 64、32、16 和 1。请注意,我们在最终残差块之后应用 tanh(·)。
通过预测模块,我们得到前向预测ViF和后向预测ViB。混合模块接受 Vki 、 Vki+1 、 ViF 和 ViB 作为输入,以产生最终的合成体积 ̃ Vi
V ~ i = w i V k i + ( 1 − w i ) V k i + 1 + 1 2 ( V i F + V i B ) , \mathbf{\tilde{V}}_i=w_iV_{k_i}+(1-w_i)V_{k_{i+1}}+\frac12(\mathbf{V}_i^\mathrm{F}+\mathbf{V}_i^\mathrm{B}), V~i=wiVki+(1−wi)Vki+1+21(ViF+ViB),
其中 wi 是控制 Vki 和 Vki+1 重要性的权重。
Discriminator。为了区分真实体积和合成体积,我们训练了一个鉴别器网络 D。该架构如图 2 (b) 所示。遵循 Radford 等人的指南。 [38] 和 Miyato 等人。 [32],我们使用多个带有泄漏 ReLU 激活的 Conv 和 SN 层(α = 0.2),并避免在整个网络中使用池化层。 D 包括 5 个内核大小为 4 × 4 × 4 的 Conv 层,分别包含 64、128、256、512 和 1 个特征图。跨步卷积用于降低除最后一层之外的每个 Conv 层的体积分辨率。前四个 Conv 层的步幅设置为 2。在最后一个 Conv 层,它产生大小为 1 × 1 × 1 的输出,并且我们不应用激活函数。
4 结果与讨论
4.1 数据集和网络训练
我们使用表1中列出的数据集对TSR-TVD进行了实验。气候数据集来自动力核心模型比对项目(DCMIP)中对地球气候的模拟[1]。我们获得了由不同模型(camfv 和 fim)生成的两个集成运行。在这些模型中,体积在早期时间步长中相当静态,随后出现两个湍流分支。燃烧数据集来自对随时间演变的湍流非预混火焰的直接数值模拟,其中燃烧反应发生在两层内。这些层最初是薄的平面层,然后当它们与周围的湍流相互作用时演变成复杂的结构。模拟生成多个变量,我们使用了其中三个:放热 (HR)、化学计量混合分数 (MF) 和 OH 质量分数 (YOH)。电离数据集通过 IEEE 可视化 2008 竞赛提供。该模拟涉及电离前沿不稳定性的 3D 辐射流体动力学计算,用于研究星际介质中的各种现象,例如恒星的形成。模拟生成多个变量,我们使用其中两个:He 质量丰度 (He) 和 He+ 质量丰度 (He+)。太阳羽流数据集来自模拟,旨在研究太阳羽流在太阳热量、动量和磁场传输中的作用。模拟生成一个速度矢量场,我们计算了速度大小以供我们使用。超新星数据集来自模拟爆炸恒星动力学的模拟,该模拟揭示了冲击波爆炸的不稳定性,从而使核心中的新生中子星旋转。模拟生成熵 (E) 标量场和速度矢量场,我们计算出速度大小 (VM) 供我们使用。最后,涡数据集在特征提取和跟踪中得到了广泛的应用。该数据集来自涡旋结构的伪谱模拟。我们使用了涡度幅度标量变量。
使用单个 NVIDIA TITAN Xp 1080 GPU 进行训练。对于每个时期,我们从卷对 (Vki ,Vki+1 ) 中随机裁剪出四个大小为 64 × 64 × 64 的子卷。这种裁剪机制可以加快训练过程并减少内存需求。我们将 V 中的输入范围缩放为 [−1, 1],将输出量的范围缩放为 [−1, 1](因为最终激活函数 tanh(·) 的输出值范围为 [−1, 1] ])。为了优化,我们使用 He 等人建议的参数初始化了 TSR-TVD 中的参数。 [13]并应用Adam优化器[26]来更新参数。我们为每个小批量设置一个训练样本。我们为G和D设置不同的学习率,以减少训练时间并稳定训练过程[42]。 G 和 D 的学习率分别为 10−4 和 4 × 10−4。 β1 = 0.0,β2 = 0.999。 λ1 = 10−3,λ2 = 1,且 λ3 = 5 × 10−2。我们发现,如果 λ1 大于 λ2 和 λ3,TSRTVD 将无法生成与 GT 体积相似的合成体积。
这是因为 TSR-TVD 将更关注对抗性损失而不是体积和特征损失,并且对抗性损失的目标是合成新颖的体积而不是接近 GT 体积的体积。我们将 SN 中的 ε 设置为 10−4,将 nG 和 nD 分别设置为 1 和 2(请参阅附录中的第 1 节)。在训练过程中,我们将最大插值步长 K 设置为 3,因为较大的 K 会导致 ConvLSTM 中的梯度消失并阻止 TSR-TVD 找到全局最优解。然而,在推理过程中,我们可以增加 K 来插值更直接的时间步,因为不需要梯度计算。
4.2 结果
由于页面限制,我们无法在论文中显示多个时间步长的 TSR-TVD 结果。这些结果可以在随附的视频中找到,该视频显示了整个序列的可视化结果,并强调了使用 TSR-TVD 生成的合成体积比 LERP、RNN 和 CNN 的质量更好。除非另有说明,本文中提出的由 TSR-TVD 合成的体积的所有可视化结果都是推断结果(即网络在训练期间看不到这些体积)。这些影响结果来自远离训练数据的体积子序列,并且在该子序列中,我们在两个结束时间步长处选择距离 GT 体积最远的时间步长(即,我们显示了可能的最差结果) TSR-TVD 结果)。同一数据集的所有可视化都使用相同的照明、查看和传递函数(用于体渲染)设置。网络分析请参见附录第2节。
评估指标。我们利用峰值信噪比(PSNR)来评估数据级别的合成体积的质量。 PSNR 定义为
P S N R ( V , V ′ ) = 20 log 10 I ( V ) − 10 log 10 M S E ( V , V ′ ) , ( 18 ) \mathrm{PSNR}(\mathbf{V},\mathbf{V}^{\prime})=20\log_{10}I(\mathbf{V})-10\log_{10}\mathrm{MSE}(\mathbf{V},\mathbf{V}^{\prime}),\quad(18) PSNR(V,V′)=20log10I(V)−10log10MSE(V,V′),(18)
其中V和V’是原始体积和合成体积,I(V)是V的最大值和最小值之间的差,MSE(V, V’)是V和V’之间的均方误差。
我们应用结构相似性指数(SSIM)[56]来评估图像级别渲染图像的质量。 SSIM 定义为
S S I M ( I , I ′ ) = ( 2 μ I μ I ′ + c 1 ) ( 2 σ I , I ′ + c 2 ) ( μ I 2 + μ I ′ 2 + c 1 ) ( σ I 2 + σ I 2 + c 2 ) , ( 19 ) \mathrm{SSIM}(\mathbf{I},\mathbf{I}^{\prime})=\frac{(2\boldsymbol{\mu}_\mathbf{I}\boldsymbol{\mu}_{\mathbf{I}^{\prime}}+c_1)(2\boldsymbol{\sigma}_{\mathbf{I},\mathbf{I}^{\prime}}+c_2)}{(\boldsymbol{\mu}_\mathbf{I}^2+\boldsymbol{\mu}_{\mathbf{I}^{\prime}}^2+c_1)(\boldsymbol{\sigma}_\mathbf{I}^2+\boldsymbol{\sigma}_\mathbf{I}^2+c_2)},\quad(19) SSIM(I,I′)=(μI2+μI′2+c1)(σI2+σI2+c2)(2μIμI′+c1)(2σI,I′+c2),(19)
其中I和I′是V和V′渲染图像的子图像,μI和μI′是I和I′的平均值,σ 2 I和σ 2 I′是I和I′的方差, σI,I′是I和I′的协方差,c1和c2是两个小常数,用于稳定与分母的除法。
为了量化分别从合成体积和 GT 体积中提取的两个等值面之间的相似性,我们计算了它们相应距离场的互信息 [5]。通过构建两个距离场的联合直方图来计算互信息,其中联合直方图中的每个条目 (i, j) 分别包含落入第一和第二距离场中的 bin i 和 j 的体素数量。等值面相似度 (IS) 越大,两个曲面越相似。
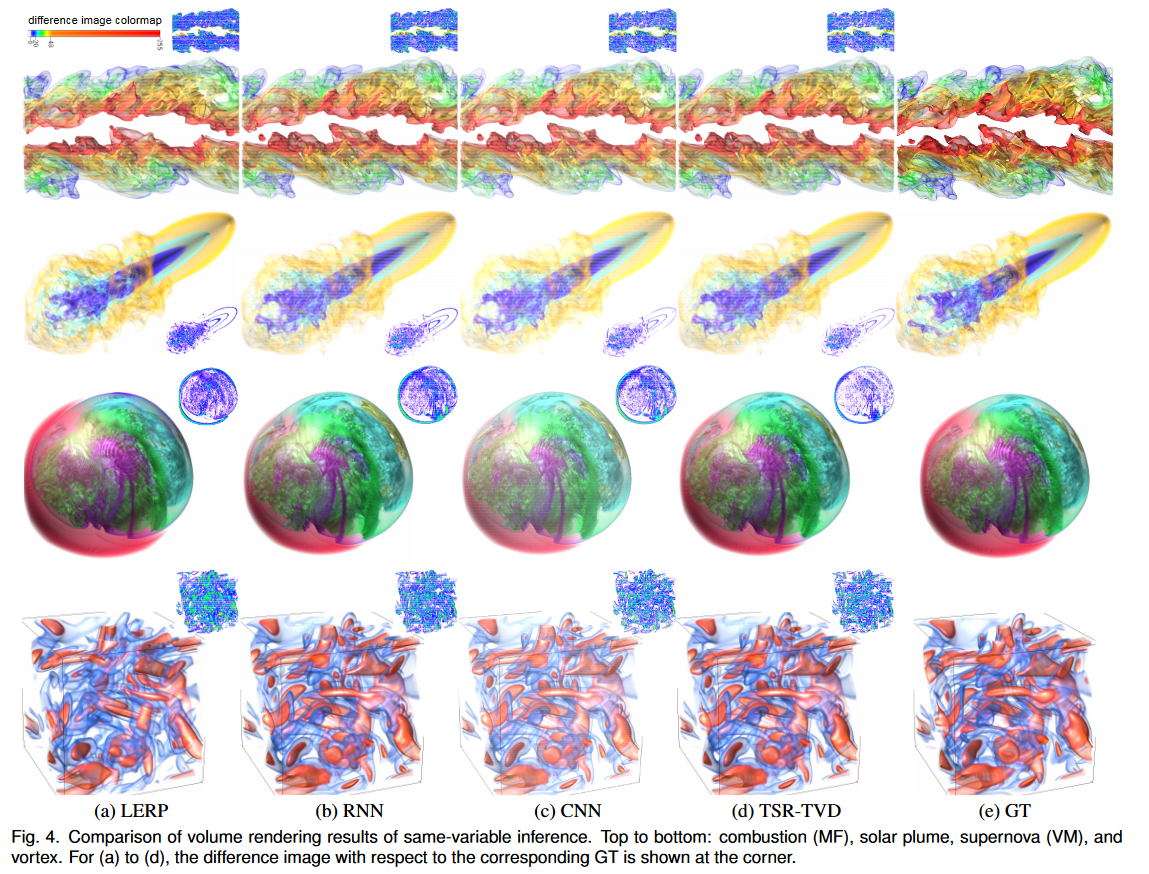
定性和定量分析。在图 4 中,我们比较了 LERP、RNN 和 TSR-TVD 生成的合成体积的渲染结果。为了训练 RNN,我们仍然使用 TSR-TVD 的架构,但消除了判别器。为了训练 CNN,我们使用相同的 TSR-TVD 架构,但不使用 ConvLSTM 作为内置时间相干性预测器。为了便于比较,我们计算了 CIELUV 颜色空间中合成体积和原始体积生成的图像的像素差异(欧几里德距离)。我们将明显的像素差异(Δ > 6.0)映射到非白色(钳位差异大于 255),并在角落显示差异图像。 GT 是为了进行公平比较而提供的。对于燃烧(MF)数据集,与LERP相比,RNN、CNN和TSR-TVD可以生成更多细节,例如左角的红色小分量。但 TSR-TVD 的渲染结果比 RNN 或 CNN 的结果具有更少的伪影。对于太阳羽流数据集,所有四种方法都会生成相似的结果,但 TSR-TVD 最接近 GT。很明显,TSR-TVD 为超新星 (VM) 数据集带来了最佳的视觉质量,而 LERP 最差,RNN 或 CNN 在右侧生成了许多伪影。对于涡流数据集,LERP 生成最差的结果,而 RNN、CNN 和 TSR-TVD 生成相似的结果。经过仔细检查,我们可以看到 TSR-TVD 在左下角产生最接近的结果。
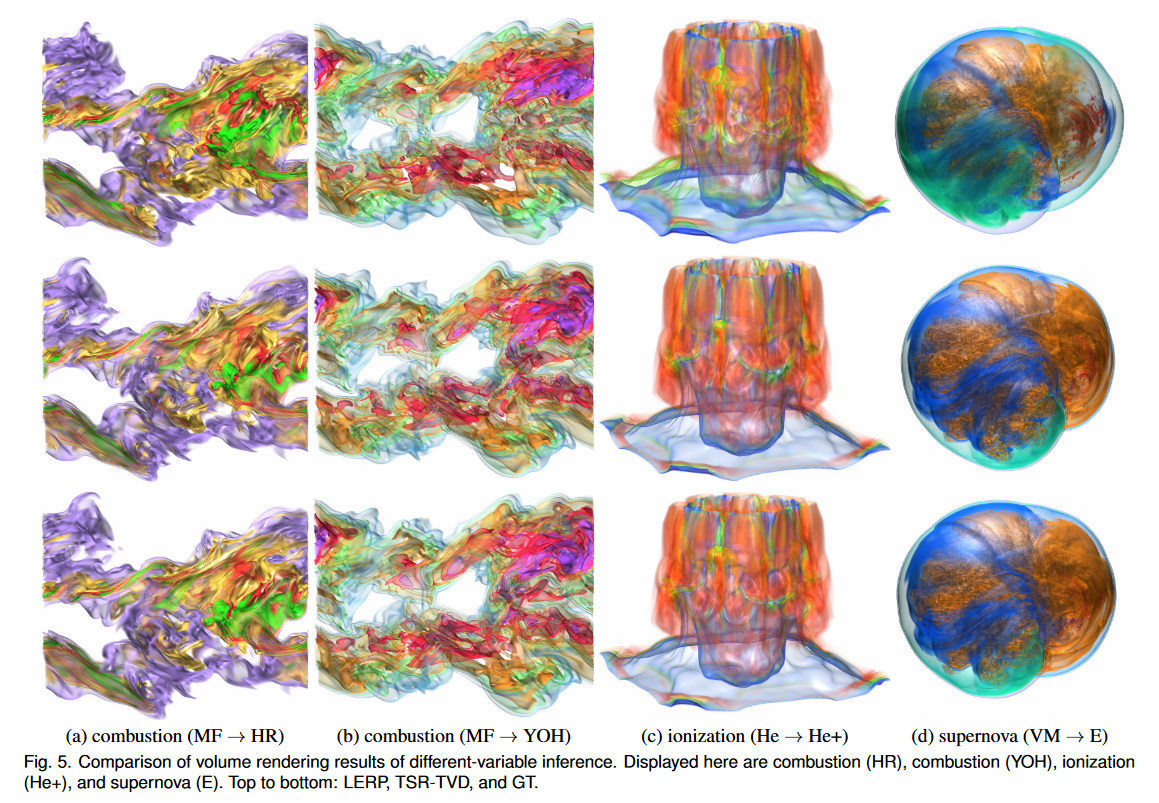
在图5中,我们通过不同变量推理比较了LERP和TSR-TVD生成的合成体积的渲染结果。对于异变量推理,我们使用数据集的变量 X 进行训练,并使用同一数据集的另一个变量 Y 进行推理 (X → Y )。对于燃烧数据集的 MF → HR,TSR-TVD 在左上角的紫色部分和右中角的绿色和黄色部分产生高质量且详细的视觉结果,而 LERP 产生不太准确的结果。对于燃烧数据集的MF→YOH,与LERP相比,TSR-TVD生成更准确的渲染结果。比如右上角的紫色部分和右下角的绿色部分就更接近GT。对于电离数据集的He→He+,很明显TSR-TVD在中层和底层给出了高质量的视觉结果,而LERP由于内容变化而导致颜色偏移(即使使用相同的传递函数)渲染 GT 和合成体积)。很明显,TSR-TVD 对超新星数据集的 VM → E 产生了更好的视觉结果。 TSRTVD 在橙色、海军蓝和青色部分产生更准确的细节。然而,LERP 无法忠实地恢复这些部分,因为我们可以清楚地看到由于内容变化而导致的颜色变化。
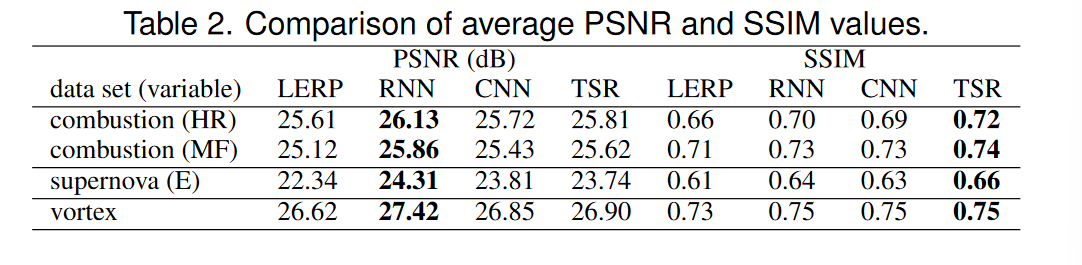
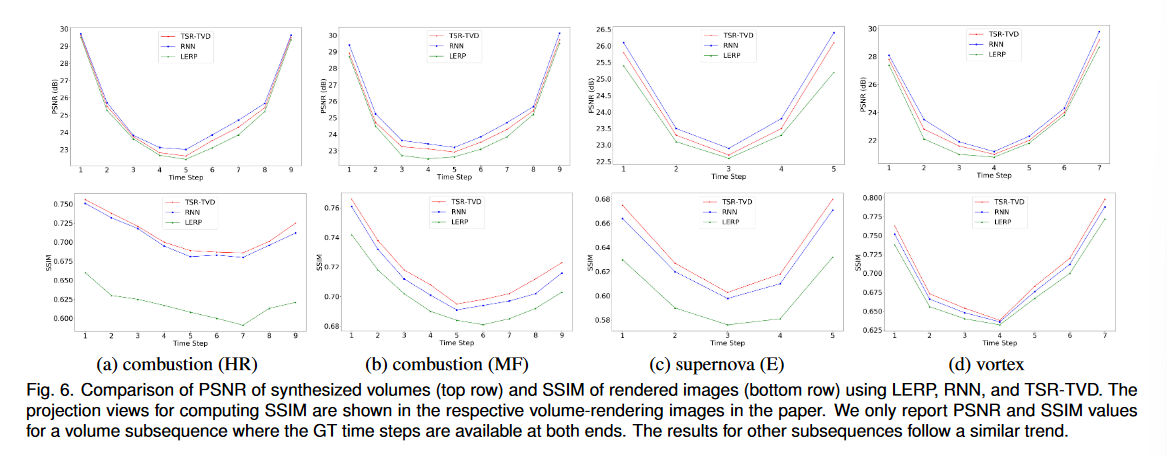
在图 6 中,我们在数据 (PSNR) 和图像 (SSIM) 级别将 TSR-TVD 结果与 LERP 和 RNN 结果进行比较。在数据层面,我们可以看到 RNN 实现了最高的 PSNR 值。这是因为 RNN 是面向 PSNR 的解决方案,而 TSR-TVD 不仅受到体积损失(面向 PSNR 的损失)的约束,还受到对抗性(面向感知的损失)和特征损失的约束,这可能导致较低的 PSNR 值。对于这四个数据集,PSNR 曲线遵循类似的趋势:PSNR 值在 GT 时间步可用的体积子序列的两端达到峰值,并随着我们向间隔中间的时间步移动而稳定下降。我们还发现超新星 (E) 数据集的三种方法的 PSNR 值较低。这是因为超新星表现出快节奏的旋转行为,与其他两个数据集表现出的其他行为相比,这种行为更难以捕捉。在图像级别,TSR-TVD 产生最高的 SSIM 值。它是燃烧 (HR)、燃烧 (MF) 和超新星 (E) 数据集的明显赢家。 TSR-TVD 产生的平均 SSIM 值分别为 ∼ 0.72、∼ 0.72、∼ 0.65,但 LERP 产生的平均 SSIM 值分别为 ∼ 0.62、∼ 0.70、∼ 0.60。对于涡流数据集,TSR-TVD 仍然略优于 LERP 和 RNN。在表 2 中,我们报告了 LERP、RNN、CNN 和 TSR-TVD 整个体积序列的平均 PSNR 和 SSIM 值。同样,RNN 在 PSNR 方面表现最好,而 TSR-TVD 在 SSIM 方面表现最好。
在图 7 中,我们展示了使用燃烧 (YOH) 数据集的 TSR-TVD 变体。我们可以看到,仅使用前向或后向预测仍然可以很好地生成合成体积,但结果缺乏细节。例如,右中角的 GT 体积中有一个封闭的浅青色部分,图 7(d) 中在全模式下捕获了该部分,但在图 7(a) 和 (b) 中都遗漏了该部分。此外,我们发现,如果不将原始体积添加到混合模块中,渲染结果会导致明显的噪声,如图7(c)所示。这是因为我们使用传统的下采样和上采样框架来重建中间体积。在下采样阶段,TSR-TVD会压缩体积并丢失一些信息,但是在上采样阶段,丢失的信息无法完美恢复。这种信息丢失导致渲染图像质量较差。

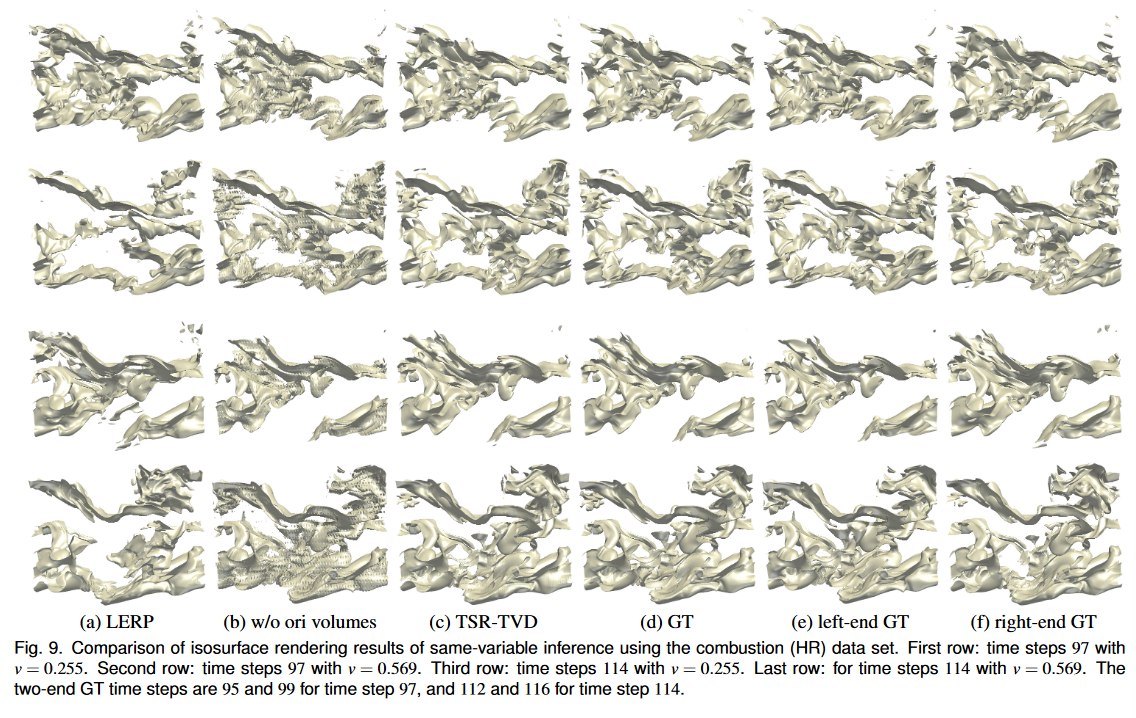
在图 8 和图 9 中,我们比较了 LERP 生成的合成体积、未混合原始体积的 TSR-TVD 以及使用超新星 (E) 和燃烧 (HR) 数据集的 TSR-TVD 的等值面渲染结果。对于每个数据集,值范围标准化为 [−1, 1],我们选择两个时间步长和两个等值线来显示等值面。对于超新星 (E) 数据集,我们可以观察到,当 v = 0 时,TSR-TVD 生成的等值面包含更多细节(例如,时间步长 39 的右下角和时间步长 55 的右上角) )。对于 v = 0.176,TSR-TVD 产生更高质量的等值面,因为 LERP 完全无法在时间步 39 构造接近 GT 的等值面(我们可以看到该表面在值空间中严重移动)。添加向后和向前预测以及使用体素体积损失,TSR-TVD 能够在很大程度上缓解这一问题并产生非常接近 GT 的表面。对于燃烧(HR)数据集,TSR-TVD仍然可以生成比LERP更接近的等值面,例如左下角(v = 0.255)和右上角(v = 0.569)。对于这两个数据集,很明显,TSR-TVD 的完整模式比未将原始体积添加到混合模块中的模式产生更好的结果。此外,我们在表 3 中报告了这两个数据集整个体积序列的平均 IS 值。定量结果还证实,TSRTVD 产生的等值面质量优于 LERP。

失败案例。如图 10 所示,LERP 和 TSR-TVD 都无法很好地对气候 (fim) 数据集的中间时间步进行插值。我们可以看到两个结果中的体素值都发生了变化。例如,在LERP和TSR-TVD的结果中,GT中的绿色部分变成黄色,蓝色部分几乎消失。这是由于 TSR-TVD 在估计相邻时间步的数据分布之间的差异方面存在局限性。请参阅附录中的第 3 节以进行进一步讨论。

4.3 讨论
作为一种深度学习技术,TSR-TVD 需要大量的时间进行训练。在附录的图 2 中,我们报告了不同超参数设置下选定数据集的训练时间曲线。训练样本数为40%,子体积大小为64×64×64,训练燃烧数据集(100个epoch)需要近6个小时,训练超新星数据集(200个epoch)需要半天时间。训练时间与训练样本数量或子体积大小的增加形成近乎线性的关系。我们注意到,体积的实际大小(即数据的空间维度)并不是网络训练的关键限制因素,因为我们在 TSR-TVD 训练中应用了裁剪机制。因此,训练时间主要取决于(裁剪的)子体积大小而不是体积大小。推理时间取决于插值时间步数和体积分辨率。由于 GPU 内存有限,我们推断各个子卷以形成整个卷。时间在一小时(涡流)到一天(燃烧)之间。请参阅附录中的第 3 节以进行进一步讨论。我们当前的 TSR-TVD 框架具有以下局限性。首先,我们的解决方案没有考虑输入传递函数或可视化过程。我们只是将输入 3D 体积视为数值数据,以生成时间解析结果。在可视化方面,我们使用一维传递函数将标量值映射到颜色和不透明度。体积渲染器还实现光照计算。尽管如此,定性和定量评估显示了 TSR-TVD 相对于 LERP 和 RNN 的整体优势。虽然合并传递函数,特别是不透明度传递函数,可能有助于提高图像级别的性能,但其代价是使训练过程依赖于输入传递函数,这需要在传递函数满足时从头开始训练。变化。其次,TSR-TVD 只能推断任意整数时间步长的中间体积,而不能推断任意时间步长的中间体积。我们将进一步研究如何通过解缠结表示从两个给定体积推断任意中间体积[8, 17]。第三,TSR-TVD 通过循环模块考虑时间一致性。更好的方法是将时间相干性纳入损失函数设计中。我们将研究时间和循环损失,考虑相邻时间步骤的一致性,以实现更好的时间一致性。
5 结论和未来工作
我们提出了 TSR-TVD,一种用于生成时变数据的时间超分辨率的深度学习解决方案。给定一个卷对作为输入,其中间卷作为 GT,我们利用 RGN 进行前向和后向预测并训练 TSR-TVD。然后,经过训练的网络能够通过同变量推理或不同变量推理为其余时间序列生成时间解析的体积序列。与 LERP、RNN 和 CNN 相比,TSR-TVD 生成的合成中间体具有更好的视觉质量。 TSR-TVD 是我们所谓的科学可视化数据增强研究工作的一部分。在这种情况下,数据增强是指通过合并来自内部和外部来源的信息,向缩减的数据添加空间、时间和可变细节。除了时间超分辨率(TSR)之外,我们还会考虑时变数据的空间超分辨率(SSR)。我们的最终目标是通过生成具有更高空间和时间分辨率和细节的体序列来实现时空超分辨率(STSR)。在空间和时间维度上扩展时变数据的能力对于大规模科学模拟和应用至关重要。由于存储空间有限,科学家通常不得不稀疏地保存模拟数据,我们的研究将为他们提供一个有前途的替代方案,让他们根据模拟的性质和数据的特征做出更好的决策。
致谢
这项研究得到了美国国家科学基金会的 IIS-1455886、CNS-1629914 和 DUE1833129 拨款以及 NVIDIA GPU 拨款计划的部分支持。作者要感谢匿名审稿人富有洞察力的评论.
参考文献


附录
1 训练算法及优化
算法。如算法 1 所示,我们的 TSR-TVD 训练算法包含两部分:优化 D(判别器)和 G(生成器)。该算法运行一定数量的 epoch T,并且对于每个 epoch,它分别以 nD 和 nG 次优化两个网络。为了生成高质量的结果,鉴别器必须强大,这意味着 D 应该将合成结果区分为假结果,即使它们只有很少的差异。因此,我们通常设置nD > nG。

优化。我们应用随时间反向传播 (BPTT),这是一种基于梯度的方法来优化 TSR-TVD。与进化优化等传统优化技术相比,BPTT 可以加速训练过程。我们将第 i 个 ConvLSTM (Li) 到第 (i + j) 个 ConvLSTM (Li+ j) 的 BPTT 公式如下
∂ L i + j ∂ L i = ∏ t = i + 1 i + j ∂ L t ∂ L t − 1 . ( 20 ) \frac{\partial L^{i+j}}{\partial L^i}=\prod_{t=i+1}^{i+j}\frac{\partial L^t}{\partial L^{t-1}}.\quad(20) ∂Li∂Li+j=t=i+1∏i+j∂Lt−1∂Lt.(20)
计算 ∂ Lt ∂ Lt−1 的详细信息参见 Hochreiter 和 Schmidhuber [15]。
然后我们通过以下方式更新生成器参数 θG
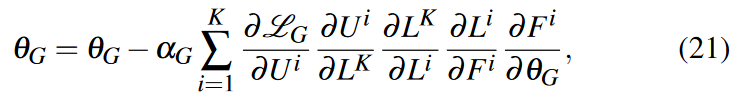
其中 Fi 和 Ui 是第 i 个特征学习和放大组件,K 是最大插值步骤,αG 是 G 的学习率。
2 网络分析
为了评估 TSR-TVD,我们分析了以下超参数设置:训练周期、训练样本、子体积大小、ConvLSTM 层数、最大插值步长和放大方法。详细讨论如下。
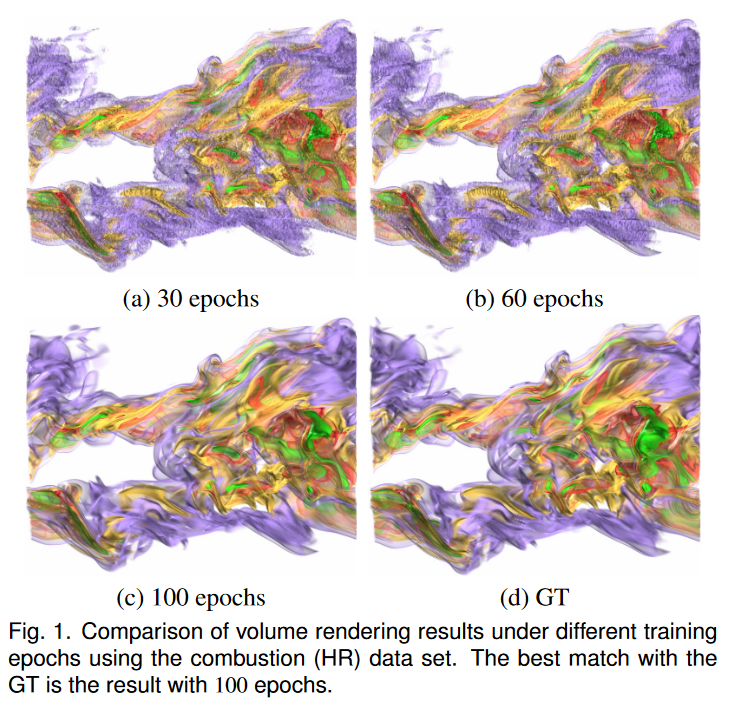
训练周期与视觉质量。我们研究了使用 TSR-TVD 合成体积的视觉质量如何随着燃烧 (HR) 数据集的不同训练时期而变化。图 1 展示了不同数量的训练 epoch 后获得的体积的渲染。我们可以观察到,与 100 epoch 下的结果相比,30 和 60 epoch 下的渲染图像具有更多的模糊伪影。例如,随着训练的进行,左上角的紫色部分和右中角的绿色部分的伪影越来越少。此外,我们发现超过 100 个 epoch,综合结果之间没有显着差异。因此,我们选择 100 个 epoch 来训练燃烧数据集。采用相同的实验来确定其他数据集的训练时期。
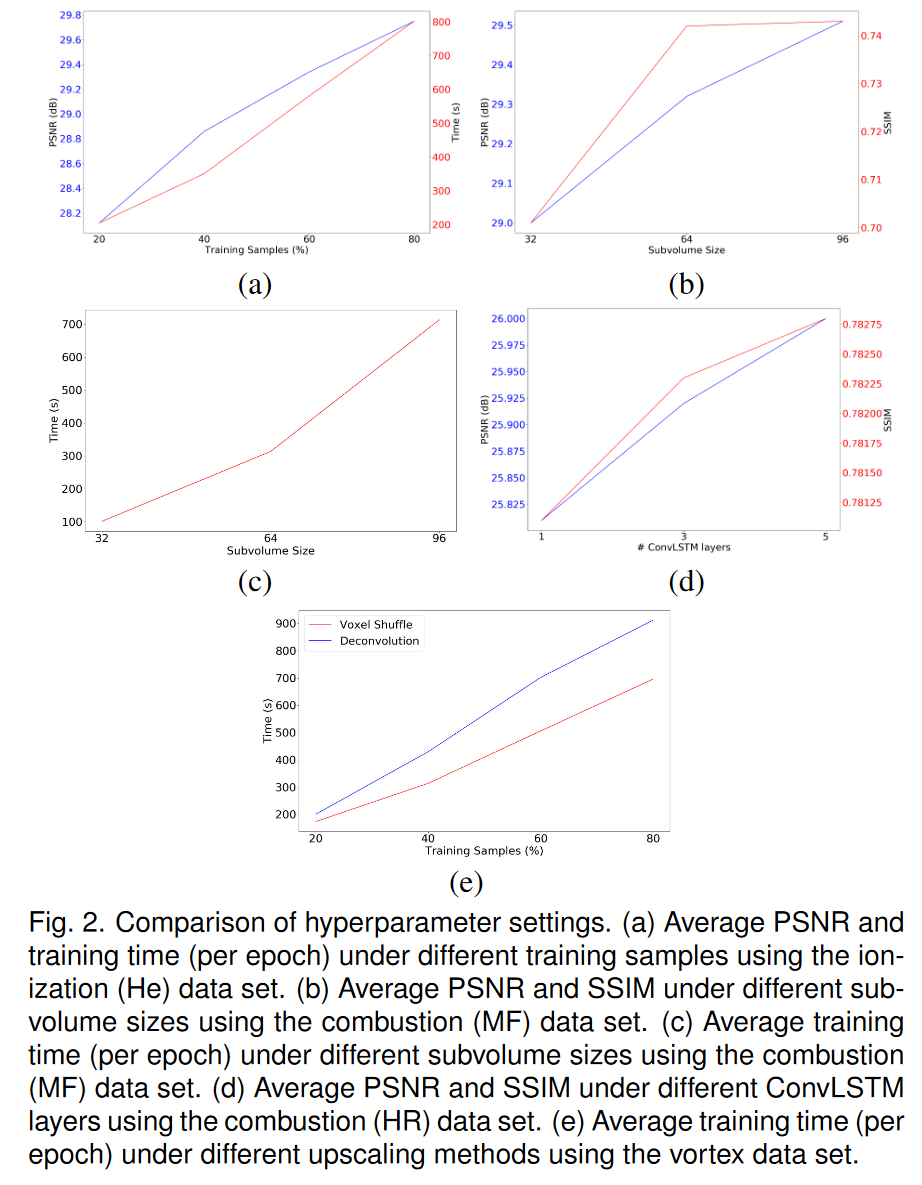
训练样本与 PSNR。我们研究了训练样本数量对 PSNR 和训练时间的影响。例如,100 个时间步的时变数据集的 20% 训练样本意味着我们在训练期间可以将前 20 个时间步用作 GT 数据。我们使用 20%、40%、60% 和 80% 的训练样本来使用电离 (He) 数据集训练 TSR-TVD。我们绘制了不同训练样本数量下的 PSNR 和平均训练时间曲线,如图 2(a)所示。我们可以看到使用更多的训练样本可以提高 PSNR。然而,这需要更长的训练时间。此外,我们观察到使用更多训练样本并没有显着提高视觉质量。为了达到质量和速度之间的平衡,我们使用 40% 的样本来训练 TSR-TVD。
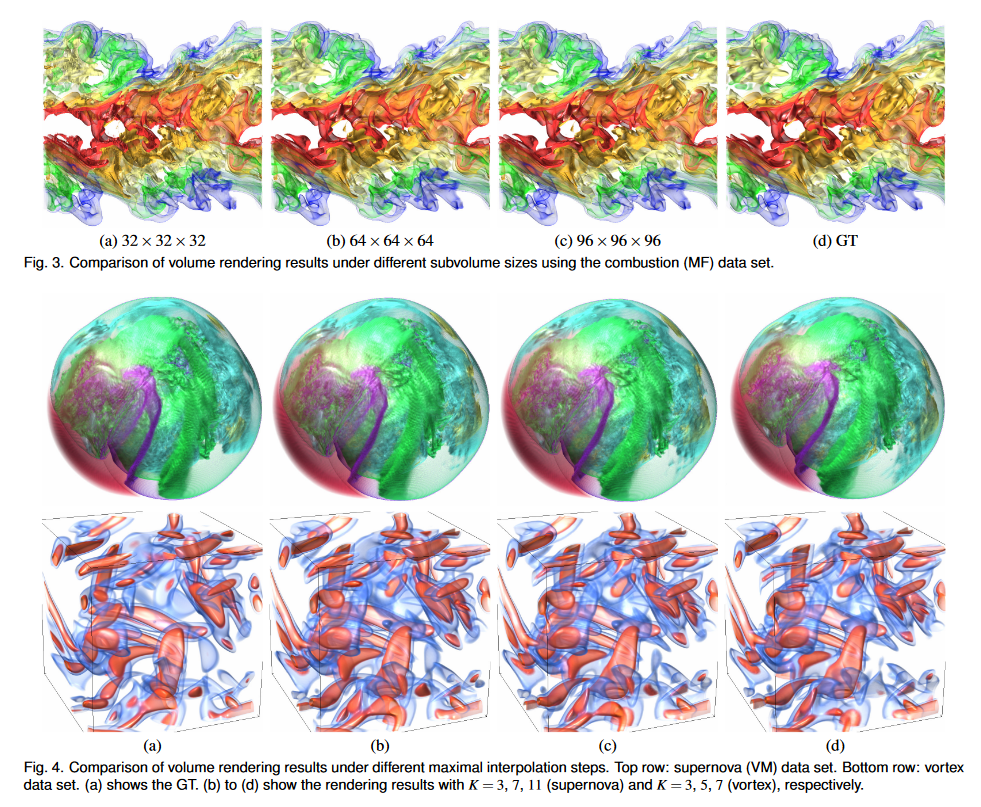
子体积大小与视觉质量和 PSNR。我们使用燃烧(MF)数据集训练子体积大小为 32 × 32 × 32、64 × 64 × 64 和 96 × 96 × 96 的 TSR-TVD。渲染结果如图3所示。我们可以看到,渲染图像的伪影较多,子体积大小为32×32×32。例如左上角的黄色部分和底部的绿色部分——左角不够光滑,如图 3 (a) 所示。 PSNR和SSIM曲线如图2(b)所示。我们可以观察到,使用更大的子体积可以提高 PSNR,因为扩大的感受野有助于 TSR-TVD 捕获更多语义信息。然而,较大的子卷大小需要更多的时间来训练并消耗更多的计算资源,如图2©所示。然而,当我们将子体积大小从 64 × 64 × 64 更新到 96 × 96 × 96 时,SSIM 并没有显着改善。作为权衡,我们使用 64 × 64 × 64 的子体积大小来训练 TSR-TVD。
ConvLSTM 层数与 PSNR 和 SSIM。我们使用燃烧(HR)数据集研究了不同数量的 ConvLSTM 层下 TSR-TVD 的性能。我们选择1、3和5个ConvLSTM层来训练TSR-TVD并绘制平均PSNR和SSIM曲线,如图2(d)所示。我们可以观察到,使用更多的 ConvLSTM 层可以实现更高的 PSNR,但是,该参数对实际渲染结果影响很小,因为平均 SSIM 值没有表现出显着差异。此外,使用更多的ConvLSTM层需要更多的计算资源。作为一种权衡,我们使用一个 ConvLSTM 层来训练 TSR-TVD。
最大插值步长与视觉质量。在推理阶段,我们使用不同数量的最大插值步骤 K 来使用超新星 (VM) 和涡流数据集对中间体积进行插值。渲染结果如图4所示。对于超新星数据集,我们可以观察到随着K的增加,视觉内容逐渐扭曲,尽管幅度不是很大。对于涡旋数据集,很明显,随着 K 的增加,不同的蓝色和红色分量会增大或缩小。对于我们探索的大多数数据集,K 的适当值是 5 或 7。由于这些数据集可能是从模拟中稀疏输出的(请参阅随附的视频),如果我们考虑实际的模拟时间步长,K 的适当值将成比例地大于此处建议的值。
体素洗牌/DeConv 层与训练时间。我们使用涡数据集研究了基于 TSR-TVD 不同升级方法的训练速度。平均训练时间曲线如图2(e)所示。显然,使用体素洗牌层可以加速训练过程。这是因为体素洗牌操作仅增加张量中的通道数而不是张量大小。与改变张量大小进行放大相比,增加通道数可以更有效地使用 GPU 资源并减少乘法次数。
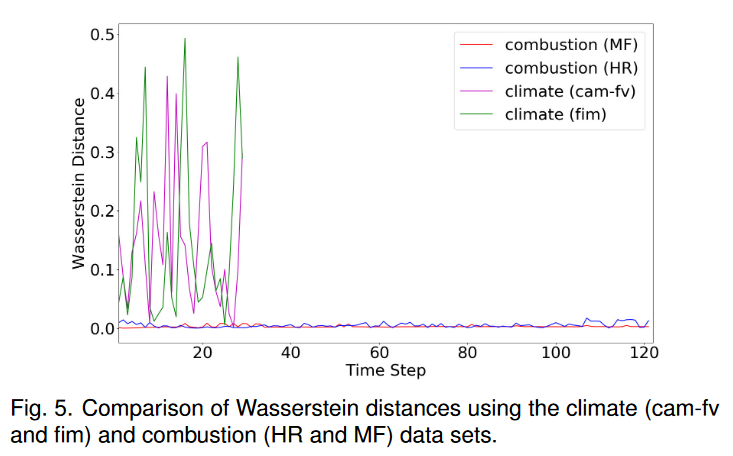
3 补充讨论
失败案例。论文中图 10 所示的气候(fim)数据集的失败案例是由于 TSR-TVD 在估计数据分布差异方面的限制。为了验证,我们使用 Wasserstein 距离 [40] 来测量两个不同数据集的两个相邻时间步的相似性,如图 5 所示。我们观察到燃烧(HR 和 MF)数据集显示两个相邻时间之间的距离很小脚步。然而,对于气候(cam-fv 和 dim)数据集,距离波动剧烈。此外,气候(fim)数据集的平均 Wasserstein 距离为 0.14702,而燃烧(MF)数据集的平均 Wasserstein 距离为 0.00347。该估计显示了 TSR-TVD 在捕获数据分布之间的波动方面的局限性。
推理时间。论文第 4.3 节中报告的推理时间是针对整个剩余体积序列的(即,除了用于训练的时间步长之外的所有时间步长)。以燃烧数据集为例,在训练过程中,我们总共裁剪了 19、200 个子体积。这是因为我们训练了 100 个 epoch;在每个 epoch 中,我们为每个卷对裁剪 4 个子卷;我们有 48 个卷对用于训练(1 ∼ 5, 2 ∼ 6, …, 48 ∼ 52)。在推理过程中,我们需要裁剪 170、100 个子体积才能生成中间体积。这是因为我们有 18 个卷对用于推理(52 ∼ 56, 56 ∼ 60, …, 118 ∼ 122);对于每一对,我们沿 x 维度裁剪 30 次,沿 y 维度裁剪 45 次,沿 z 维度裁剪 7 次。请注意,这些裁剪的子体积在空间上有重叠,以避免空间不连续。然后通过加权串联算法将推断出的子体积连接起来以形成整个体积。
相关文章:
【论文阅读】-- TSR-TVD:时变数据分析和可视化的时间超分辨率
TSR-TVD: Temporal Super-Resolution for Time-Varying Data Analysis and Visualization 摘要1 引言2 相关工作3 我们的循环生成方法3.1 损失函数3.2 网络架构 4 结果与讨论4.1 数据集和网络训练4.2 结果4.3 讨论 5 结论和未来工作致谢参考文献附录1 训练算法及优化2 网络分析…...

《web应用技术》第12次课后作业
1、了解servlet技术 Servlet(server applet):运行在服务器的小程序,Servlet就是一个接口,定义了Java类被浏览器访问到的规则。将来我们自定义一个类,实现Servlet接口,复写方法。 Servlet本身不能独立运行,…...

【初阶数据结构】深入解析带头双向循环链表:探索底层逻辑
🔥引言 本篇将介绍带头双向循环链表底层实现以及在实现中需要注意的事项,帮助各位在使用过程中根据底层实现考虑到效率上问题和使用时可能会导致的错误使用 🌈个人主页:是店小二呀 🌈C语言笔记专栏:C语言笔…...

【面试干货】Java中的访问修饰符与访问级别
【面试干货】Java中的访问修饰符与访问级别 1、public2、protected3、默认(没有访问修饰符)4、private 💖The Begin💖点点关注,收藏不迷路💖 在Java中,访问修饰符用于控制类、变量、方法和构造器…...

Oracle最终还是杀死了MySQL
起因 大约15年前,Oracle收购了Sun公司,从而也拥有了MySQL,互联网上关于Oracle何时会“扼杀MySQL”的讨论此起彼伏。 当时流传着各种理论:从彻底扼杀 MySQL 以减少对 Oracle 专有数据库的竞争,到干掉 MySQL 开源项目&…...

【Python的随机数汇总】
我们写python代码的时候,很少能用得上随机数,但是随机数有很多妙用。例如,在我们做测试数据集的时候,可以构建一个随机的dataframe; 或者在保存数据的时候,可以在每条数据前插入一列作为,不重…...

[状态压缩 广搜BFS]Saving Tang Monk
描述 《Journey to the West》(also 《Monkey》) is one of the Four Great Classical Novels of Chinese literature. It was written by Wu Chengen during the Ming Dynasty. In this novel, Monkey King Sun Wukong, pig Zhu Bajie and Sha Wujing, escorted Tang Monk to…...

Flutter 实现软鼠标
文章目录 前言一、如何实现?1、记录鼠标偏移2、MouseRegion获取偏移3、Transform移动图标 二、完整代码三、使用示例总结 前言 flutter在嵌入式系统中运行时,有可能遇到drm鼠标无法使用的情况,但鼠标事件却可以正常接收,此时如果…...
使用 MLRun 和 MinIO 设置开发机器
MLOps 之于机器学习,就像 DevOps 之于传统软件开发一样。两者都是一组旨在改善工程团队(开发或 ML)和 IT 运营 (Ops) 团队之间协作的实践和原则。目标是使用自动化来简化开发生命周期,从规划和开发到部署和…...

资质申请表详解:填写《建筑幕墙工程设计专项资质申请表》的要点
填写《建筑幕墙工程设计专项资质申请表》的要点如下,按照清晰、分点表示和归纳的方式整理,并参考了文章中的相关数字和信息: 一、封面 申报企业名称:按照工商营业执照内容填写全称,并加盖企业公章。填报日期…...
华为手机怎么找回删除的照片?掌握3个方法,恢复不是梦
由于误删、设备故障、软件更新等原因,我们有时可能会不慎丢失这些宝贵的照片。当面对空空如也的相册时,那种失落感无法言喻。华为手机该怎么找回删除的照片呢?但是,请不要绝望!在科技的帮助下,我们可以采取…...

数据结构试题 20-21
真需要就死记吧 二叉树遍历-先序(非递归)【图解代码】_哔哩哔哩_bilibili 解释一下步骤: 一个循环为: 1.取节点 2.放右子树 3.放左子树 每次循环,都要从栈里取出一个节点 先放右子树,再放左子树 那这道题就是,先放1&am…...
vscode插件开发之 - TestController
TesController概要介绍 TestController 组件是用于实现自定义测试框架和集成测试结果的。它允许开发者定义自己的测试运行器,以支持在VSCode中运行和展示测试。以下是一些使用 TestController 组件的主要场景: 自定义测试框架:如果你正在开发…...

QBitArray使用详解
QBitArray使用详解 一、创建和初始化 QBitArray1.1 QBitArray默认构造1.2 QBitArray指定大小的构造1.3 QBitArray指定大小和初始值的构造 二、设置和访问位2.1 QBitArray设置单个位2.2 QBitArray访问单个位2.3 QBitArray使用下标操作符 三、设置所有位3.1 QBitArray将所有位设置…...

基于Python的自然语言处理项目 ChatTTS 推荐
**项目名称:ChatTTS** ChatTTS是一个基于Python的自然语言处理项目,旨在实现一个简单的文本到语音转换系统。它使用深度学习技术,通过自然语言处理和语音合成算法,将文本转换为语音输出。 **项目介绍**: Chat…...

论 To B 产品:从概念到市场实践
本文作者为 360 奇舞团产品经理 论 To B 产品:从概念到市场实践 To B 产品在商业世界中扮演着至关重要的角色。相较于面向消费者的To C市场,To B市场更专注于为其他企业提供产品和服务。理解和成功运营To B产品需要对其特定的市场需求和运作方式有深刻的…...

如何通过自定义模块DIY出专属个性化的CSDN主页?一招教你搞定!
个人主页:学习前端的小z 个人专栏:HTML5和CSS3悦读 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! 文章目录 💯如何通过HTMLCSS自定义模板diy出自己的个性化csdn主页&#x…...
[BSidesCF 2020]Had a bad day1
看到页面有两个按钮 先随便点一个试一下,当我们点击之后发现url是有变动的 感觉url是有点东西的,可能是某种注入,先尝试一下sql注入,发现给出了报错 通过报错我们可以确定是文件包含漏洞,那我们试试php伪协议去读取一下…...

从媒体网站的频道划分看媒体邀约的分类?
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 媒体宣传加速季,100万补贴享不停,一手媒体资源,全国100城线下落地执行。详情请联系胡老师。 在我们举行活动的时候,通常会邀请媒体到现场来…...

Day40
Day40 监听器 概念: 监听器用于监听web应用中某些对象信息的创建、销毁、增加,修改,删除等动作的 发生,然后作出相应的响应处理。当范围对象的状态发生变化的时候,服务器自动调用 监听器对象中的方法。 常用于统计在线…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...