大模型之-Seq2Seq介绍
大模型之-Seq2Seq介绍
1. Seq2Seq 模型概述
Seq2Seq(Sequence to Sequence)模型是一种用于处理序列数据的深度学习模型,常用于机器翻译、文本摘要和对话系统等任务。它的核心思想是将一个输入序列转换成一个输出序列。
Seq2Seq模型由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。编码器读取并理解输入序列,将其转换成一个称为上下文向量的固定长度表示。解码器根据这个上下文向量生成目标序列。
编码器逐步处理输入序列中的每个元素,并将每一步的结果传递给下一步,最终生成一个总结输入信息的上下文向量。解码器使用这个向量,逐步生成输出序列的每个元素。
为了提高模型性能,常引入Attention机制,使解码器在生成每个输出时能够关注编码器输出的不同部分。Seq2Seq模型的灵活性和强大功能使其成为解决许多自然语言处理任务的有效工具。
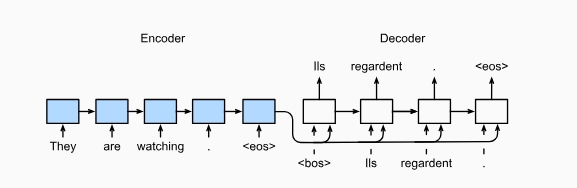
1-1. 基本组成部分
- 编码器(Encoder):负责读取并理解输入序列。
假设正在读一本书。编码器就像大脑在读书的时候,它会逐字逐句地理解书中的内容,并在你的脑海里形成一个总结。具体来说,编码器会逐个处理输入的每个单词(或字符),并把它们转化为一个理解的内部表示。
- 解码器(Decoder):负责生成输出序列。
现在需要根据你读的书写一篇总结。解码器就像你在写这篇总结的过程。它会根据编码器生成的内部表示(你对书的理解),逐步地写出总结中的每个句子或单词。
-
编码器和解码器合作过程
- 读书(编码器):编码器一边读一边总结,把整个输入(比如一句话或一段话)变成一个内部表示,就像你读完一本书后脑海中的理解。
- 写总结(解码器):解码器根据编码器的内部表示,逐字逐句地写出总结内容,就像你在写一篇文章。
-
简单比喻
-
编码器:你在读一本书,把内容记在脑子里。
-
解码器:你根据记在脑子里的内容,写出一篇文章。
-
所以,编码器是负责理解输入内容的部分,而解码器是根据理解的内容生成输出的部分
- 上下文向量(Context Vector):编码器将输入序列转换成的固定长度向量,作为解码器的输入。
像是你在读完书之后形成的“脑海里的理解”或者“脑海中的总结”。它浓缩了你所读的内容的所有重要信息。
当编码器处理完输入序列(比如一句话的所有单词)之后,它会生成一个代表整个输入序列的内部状态,这个状态就是上下文向量。这个向量包含了输入序列中的所有关键信息,能够帮助解码器理解输入内容的总体意思。
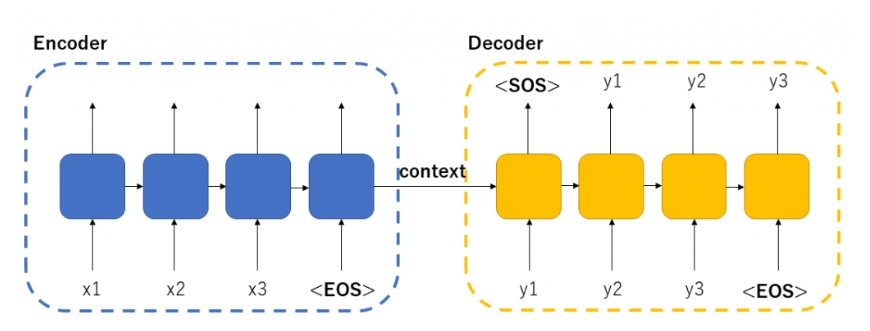
1-2. 基本工作流程
- 输入序列通过编码器,生成上下文向量。
- 解码器根据上下文向量生成目标序列。
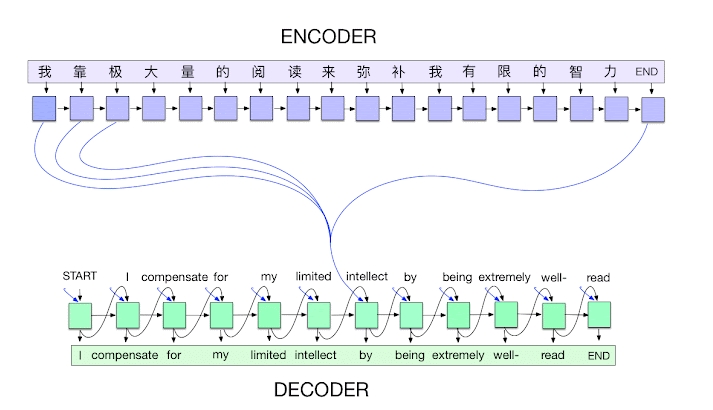
2. 编码器(Encoder)
编码器通常由一个或多个RNN(循环神经网络)组成,如LSTM(长短期记忆网络)或GRU(门控循环单元)。编码器将输入序列逐步处理,将每个时刻的隐藏状态传递给下一个时刻,最终生成一个上下文向量,表示整个输入序列的信息。
2-1. 编码器结构
- 输入嵌入层:将输入的词或字符转换为向量表示。
- RNN层:处理输入嵌入,生成隐藏状态。
import torch
import torch.nn as nnclass Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hidden_dim, n_layers):super(Encoder, self).__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, batch_first=True)def forward(self, src):embedded = self.embedding(src)outputs, (hidden, cell) = self.rnn(embedded)return hidden, cell
3. 解码器(Decoder)
解码器的结构与编码器类似,但其初始状态是编码器生成的上下文向量。解码器逐步生成输出序列,每一步都依赖于前一步的输出和隐藏状态。
3-1. 解码器结构
- 输入嵌入层:将前一步的输出词或字符转换为向量表示。
- RNN层:处理输入嵌入和编码器的隐藏状态,生成新的隐藏状态和输出。
class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hidden_dim, n_layers):super(Decoder, self).__init__()self.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, batch_first=True)self.fc_out = nn.Linear(hidden_dim, output_dim)def forward(self, input, hidden, cell):input = input.unsqueeze(1)embedded = self.embedding(input)output, (hidden, cell) = self.rnn(embedded, (hidden, cell))prediction = self.fc_out(output.squeeze(1))return prediction, hidden, cell
4. 训练过程
4-1. 损失函数
使用交叉熵损失(Cross-Entropy Loss)来计算模型输出与目标序列之间的差异。
4-2. 优化器
常用的优化器有Adam和SGD。
4-3. 训练循环
def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoptimizer.zero_grad()output = model(src, trg)output_dim = output.shape[-1]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)
5. Attention机制
Attention机制用于解决上下文向量长度固定导致的信息丢失问题。通过Attention机制,解码器在生成每个词时,可以“关注”编码器输出的不同部分,从而利用更多的上下文信息。
5-1. Attention层
class Attention(nn.Module):def __init__(self, hidden_dim):super(Attention, self).__init__()self.attn = nn.Linear(hidden_dim * 2, hidden_dim)self.v = nn.Parameter(torch.rand(hidden_dim))def forward(self, hidden, encoder_outputs):batch_size = encoder_outputs.shape[0]src_len = encoder_outputs.shape[1]hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))energy = energy.permute(0, 2, 1)v = self.v.repeat(batch_size, 1).unsqueeze(1)attention = torch.bmm(v, energy).squeeze(1)return torch.softmax(attention, dim=1)
6. 实际应用场景
6-1. 机器翻译
Seq2Seq(Sequence to Sequence)模型是一种基于神经网络的技术,广泛应用于自然语言处理任务,特别是机器翻译。Seq2Seq模型能够将一个序列(例如一句话)转换为另一个序列(另一种语言的翻译)。其主要构成包括编码器(Encoder)和解码器(Decoder)两个部分,通常使用递归神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)来实现。
6-1-1. Seq2Seq模型的基本结构
- 编码器(Encoder):
- 编码器的任务是将输入序列(源语言句子)转换为一个固定大小的上下文向量(Context Vector)。
- 输入序列的每个单词通过嵌入层(Embedding Layer)转换为词向量,然后逐步输入到RNN、LSTM或GRU单元中。
- 编码器的最后一个隐藏状态(Hidden State)作为上下文向量传递给解码器。
- 解码器(Decoder):
- 解码器根据编码器传递的上下文向量生成目标序列(目标语言句子)。
- 解码器在每个时间步接收前一个时间步生成的单词和当前的隐藏状态,输出当前时间步的单词。
- 解码器输出的每个单词通过Softmax层转换为概率分布,从中选出最可能的单词作为当前时间步的输出。
6-1-2. 应用流程
- 训练阶段:
- 输入大量的源语言-目标语言对(例如英语句子-中文句子)。
- 编码器将源语言句子编码为上下文向量。
- 解码器根据上下文向量和已生成的目标语言单词逐步生成整个目标语言句子。
- 使用目标语言的实际单词对生成的单词进行监督学习,更新模型参数。
- 翻译阶段:
- 输入一个新的源语言句子。
- 编码器将其编码为上下文向量。
- 解码器根据上下文向量逐步生成目标语言句子,直到生成结束标记()。
6-1-3. Seq2Seq机器翻译优点
- 处理变长输入和输出:Seq2Seq模型能够处理长度不固定的输入和输出序列。
- 上下文捕捉:编码器能够捕捉源语言句子的全局上下文信息,有助于生成连贯的目标语言句子。
- 端到端训练:Seq2Seq模型可以通过端到端的方式直接训练,无需手工设计特征。
6-2. 文本摘要
Seq2Seq(Sequence to Sequence)模型在文本摘要任务中的应用与其在机器翻译中的应用有很多相似之处。文本摘要的目标是从一个长文本中生成一个简短的、语义上等价的摘要。与机器翻译类似,Seq2Seq模型通过编码器和解码器的组合来实现这个任务。
6-2-1. Seq2Seq模型在文本摘要中的基本结构
- 编码器(Encoder):
- 编码器将输入的长文本编码成一个固定长度的上下文向量(Context Vector)。
- 通常使用递归神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)来处理输入文本。
- 输入文本的每个词通过嵌入层(Embedding Layer)转换为词向量,然后逐步输入到编码器的RNN、LSTM或GRU单元中。
- 最终,编码器的隐藏状态作为上下文向量传递给解码器。
- 解码器(Decoder):
- 解码器根据编码器生成的上下文向量生成文本摘要。
- 解码器在每个时间步接收前一个时间步生成的词和当前的隐藏状态,输出当前时间步的词。
- 解码器输出的每个词通过Softmax层转换为概率分布,从中选出最可能的词作为当前时间步的输出。
6-2-2. 应用流程
- 训练阶段:
- 输入大量的原始文本和相应的摘要对。
- 编码器将原始文本编码为上下文向量。
- 解码器根据上下文向量和已生成的摘要词逐步生成整个摘要。
- 使用实际的摘要词对生成的词进行监督学习,更新模型参数。
- 摘要生成阶段:
- 输入一个新的长文本。
- 编码器将其编码为上下文向量。
- 解码器根据上下文向量逐步生成摘要,直到生成结束标记()。
6-2-3. Seq2Seq文本摘要优点
- 处理变长输入和输出:Seq2Seq模型能够处理长度不固定的输入和输出序列,这对文本摘要特别重要。
- 上下文捕捉:编码器能够捕捉输入文本的全局上下文信息,有助于生成连贯的摘要。
- 端到端训练:Seq2Seq模型可以通过端到端的方式直接训练,无需手工设计特征。
6-3. 对话系统
Seq2Seq(Sequence to Sequence)模型在对话系统中的应用非常广泛。对话系统(也称为聊天机器人)需要处理自然语言输入,并生成自然语言输出,这与机器翻译和文本摘要任务有很多相似之处。Seq2Seq模型能够根据用户输入的对话上下文,生成适当的回复,完成自然语言理解和生成的任务。
6-3-1. Seq2Seq模型在对话系统中的基本结构
- 编码器(Encoder):
- 编码器将用户输入的对话内容编码成一个固定长度的上下文向量(Context Vector)。
- 通常使用递归神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)来处理输入文本。
- 输入的每个词通过嵌入层(Embedding Layer)转换为词向量,然后逐步输入到编码器的RNN、LSTM或GRU单元中。
- 最终,编码器的隐藏状态作为上下文向量传递给解码器。
- 解码器(Decoder):
- 解码器根据编码器生成的上下文向量生成对话回复。
- 解码器在每个时间步接收前一个时间步生成的词和当前的隐藏状态,输出当前时间步的词。
- 解码器输出的每个词通过Softmax层转换为概率分布,从中选出最可能的词作为当前时间步的输出。
6-3-2. 应用流程
训练阶段:
- 输入大量的对话数据对(例如用户输入和对应的回复)。
- 编码器将用户输入编码为上下文向量。
- 解码器根据上下文向量和已生成的回复词逐步生成整个回复。
- 使用实际的回复词对生成的词进行监督学习,更新模型参数。
对话生成阶段:
- 输入一个新的用户对话内容。
- 编码器将其编码为上下文向量。
- 解码器根据上下文向量逐步生成回复,直到生成结束标记()。
6-3-3. Seq2Seq对话系统优点
- 处理变长输入和输出:Seq2Seq模型能够处理长度不固定的输入和输出序列,这对对话系统特别重要。
- 上下文捕捉:编码器能够捕捉用户输入的全局上下文信息,有助于生成连贯的回复。
- 端到端训练:Seq2Seq模型可以通过端到端的方式直接训练,无需手工设计特征。
7. 完整示例代码演示
7-1. 完整代码分享
以下是一份完整的示例代码,包括编码器、解码器、Seq2Seq模型、训练和预测部分,test_seq2seq.py
代码实现了一个基础的Seq2Seq模型,并使用随机数据进行训练。训练损失的逐步下降表明模型在学习,但损失下降比较缓慢,可能是需要调整参数和数据来优化模型性能。实际应用场景中,一般跑模型的都是真实数据集并根据需要调整模型参数,以获得更好的结果。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# @Project :WangtAI
# @File :test_seq2seq.py
# @Time :2024/6/19 17:56
# @Author :wangting_666
# @Email :wangtingbk@gmail.com### pip install torch torchvisionimport torch
import torch.nn as nn
import torch.optim as optim
import random# 设置随机种子以确保结果可重复
SEED = 1234
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True# 定义编码器Encoder
class Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout):super().__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout)self.dropout = nn.Dropout(dropout)def forward(self, src):embedded = self.dropout(self.embedding(src))outputs, (hidden, cell) = self.rnn(embedded)return hidden, cell# 定义解码器Decoder
class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):super().__init__()self.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout)self.fc_out = nn.Linear(hidden_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, input, hidden, cell):input = input.unsqueeze(0)embedded = self.dropout(self.embedding(input))output, (hidden, cell) = self.rnn(embedded, (hidden, cell))prediction = self.fc_out(output.squeeze(0))return prediction, hidden, cell# 定义Seq2Seq模型
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super().__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self, src, trg, teacher_forcing_ratio=0.5):trg_len = trg.shape[0]batch_size = trg.shape[1]trg_vocab_size = self.decoder.fc_out.out_featuresoutputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)hidden, cell = self.encoder(src)input = trg[0, :]for t in range(1, trg_len):output, hidden, cell = self.decoder(input, hidden, cell)outputs[t] = outputteacher_force = random.random() < teacher_forcing_ratiotop1 = output.argmax(1)input = trg[t] if teacher_force else top1return outputs# 初始化模型参数
INPUT_DIM = 100
OUTPUT_DIM = 100
ENC_EMB_DIM = 32
DEC_EMB_DIM = 32
HID_DIM = 64
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, DEVICE).to(DEVICE)# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()# 训练函数
def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src = batch.src.to(DEVICE)trg = batch.trg.to(DEVICE)optimizer.zero_grad()output = model(src, trg)output_dim = output.shape[-1]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)# 示例数据
class Batch:def __init__(self, src, trg):self.src = srcself.trg = trgbatch_size = 10
src_len = 7
trg_len = 9src = torch.randint(0, INPUT_DIM, (src_len, batch_size)).long()
trg = torch.randint(0, OUTPUT_DIM, (trg_len, batch_size)).long()iterator = [Batch(src, trg)]# 训练模型
N_EPOCHS = 10
CLIP = 1for epoch in range(N_EPOCHS):train_loss = train(model, iterator, optimizer, criterion, CLIP)print(f'Epoch: {epoch + 1:02}, Train Loss: {train_loss:.3f}')### 运行代码后,控制台输出内容:
"""
D:\Python\Python312\python.exe E:\PandasAI\tmp\test_seq2seq.py
Epoch: 01, Train Loss: 4.613
Epoch: 02, Train Loss: 4.604
Epoch: 03, Train Loss: 4.598
Epoch: 04, Train Loss: 4.594
Epoch: 05, Train Loss: 4.589
Epoch: 06, Train Loss: 4.583
Epoch: 07, Train Loss: 4.587
Epoch: 08, Train Loss: 4.578
Epoch: 09, Train Loss: 4.566
Epoch: 10, Train Loss: 4.562
"""
7-2 . 总结和分析
- 功能实现
- 编码器(Encoder):通过嵌入层和循环神经网络(LSTM)来处理输入序列,并生成隐藏状态和细胞状态。这些状态捕捉了输入序列中的信息。
- 解码器(Decoder):使用嵌入层和LSTM,根据编码器生成的隐藏状态和细胞状态逐步生成输出序列。
- Seq2Seq模型:结合编码器和解码器,将输入序列转换为输出序列。解码器使用教师强制(Teacher Forcing)策略,即在生成序列的过程中,有一定概率使用真实的目标序列作为下一个时间步的输入,以加速训练。
- 训练过程:使用随机生成的数据进行训练,优化模型参数以最小化交叉熵损失。训练过程中,每轮迭代都会输出当前的训练损失。
- 结果分析
从提供的训练损失结果来看:
Epoch: 01, Train Loss: 4.613
Epoch: 02, Train Loss: 4.604
Epoch: 03, Train Loss: 4.598
Epoch: 04, Train Loss: 4.594
Epoch: 05, Train Loss: 4.589
Epoch: 06, Train Loss: 4.583
Epoch: 07, Train Loss: 4.587
Epoch: 08, Train Loss: 4.578
Epoch: 09, Train Loss: 4.566
Epoch: 10, Train Loss: 4.562
可以得出以下结论:
- 损失下降趋势:总体上,训练损失在逐步下降。这表明模型在学习过程中逐渐改进,尽管下降幅度较小。
- 下降缓慢:损失下降的幅度较小,可能原因如下:
- 数据复杂性:随机生成的数据可能过于简单或过于复杂,导致模型难以有效学习。
- 模型参数:编码器和解码器的参数选择(如隐藏层维度、层数、丢弃率等)可能需要调整,以更好地适应数据。
- 训练数据量:训练数据量较小(仅一个批次),可能不足以充分训练模型。
8. 进阶优化
8-1. 双向编码器
使用双向RNN(BiRNN)作为编码器,使得编码器能够利用输入序列的前后文信息,从而提高表示能力。
class BiEncoder(nn.Module):def __init__(self, input_dim, emb_dim, hidden_dim, n_layers):super(BiEncoder, self).__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, bidirectional=True, batch_first=True)self.fc = nn.Linear(hidden_dim * 2, hidden_dim)def forward(self, src):embedded = self.embedding(src)outputs, (hidden, cell) = self.rnn(embedded)hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)))return hidden, cell
8-2. Beam Search
解码器在生成序列时,使用Beam Search代替贪心搜索,可以生成更优的目标序列。Beam Search在每一步保留得分最高的k个序列,最终选择得分最高的一个。
def beam_search_decoder(data, k):sequences = [[list(), 1.0]]for row in data:all_candidates = list()for i in range(len(sequences)):seq, score = sequences[i]for j in range(len(row)):candidate = [seq + [j], score * -np.log(row[j])]all_candidates.append(candidate)ordered = sorted(all_candidates, key=lambda tup: tup[1])sequences = ordered[:k]return sequences
8-3. 多任务学习
通过多任务学习,Seq2Seq模型可以在同一网络中同时学习多个相关任务,提高模型的泛化能力和性能。
相关文章:
大模型之-Seq2Seq介绍
大模型之-Seq2Seq介绍 1. Seq2Seq 模型概述 Seq2Seq(Sequence to Sequence)模型是一种用于处理序列数据的深度学习模型,常用于机器翻译、文本摘要和对话系统等任务。它的核心思想是将一个输入序列转换成一个输出序列。 Seq2Seq模型由两个主…...

NSSCTF-Web题目12
目录 [SWPUCTF 2021 新生赛]finalrce 1、题目 2、知识点 3、思路 [UUCTF 2022 新生赛]ez_rce 1、题目 2、知识点 3、思路 [羊城杯 2020]easycon 1、题目 2、知识点 3、思路 [SWPUCTF 2021 新生赛]finalrce 1、题目 2、知识点 命令执行,tee命令 3、思路…...

22、架构-资源与调度
1、资源与调度 调度是容器编排系统最核心的功能之一,“编排”一词本身便包 含“调度”的含义。调度是指为新创建的Pod找到一个最恰当的宿主机 节点来运行它,这个过程成功与否、结果恰当与否,关键取决于容器 编排系统是如何管理与分配集群节点…...

mac 常用工具命令集合
Iterm2 Command T:新建标签 Command W:关闭当前标签 Command ← →:在标签之间切换 Control U:清除当前行 Control A:跳转到行首 Control E:跳转到行尾 Command F:查找 Command …...

服务器雪崩的应对策略之----限流
限流是一种控制流量的技术,旨在防止系统在高并发请求下被压垮。通过限流,可以确保系统在负载高峰期依然能保持稳定运行。常见的限流策略包括令牌桶算法、漏桶算法、计数器算法和滑动窗口算法。 常见的限流方法 1. 令牌桶算法 (Token Bucket Algorithm)2…...

Python12 列表推导式
1.什么是列表推导式 Python的列表推导式(list comprehension)是一种简洁的构建列表(list)的方法,它可以从一个现有的列表中根据某种指定的规则快速创建一个新列表。这种方法不仅代码更加简洁,执行效率也很…...

threejs 光影投射-与场景进行交互(六)
效果 场景中有三个立方体,三种颜色.点击变成红色,再点恢复自身原有颜色 代码 import ./style.css import * as THREE from three import { OrbitControls } from three/examples/jsm/controls/OrbitControls.js import { log } from three/examples/jsm/nodes/Nodes.js//…...
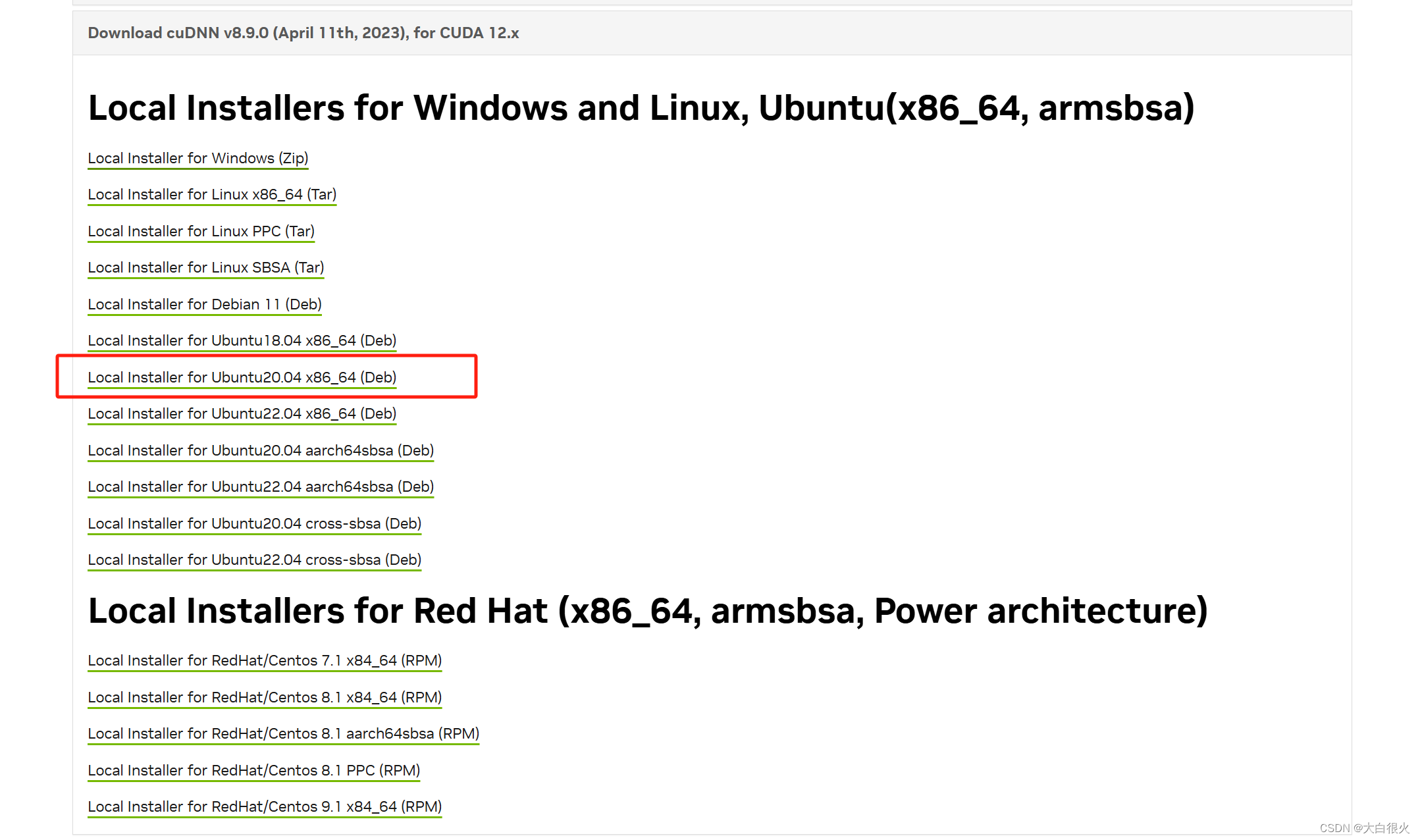
Ubuntu 20.04安装显卡驱动、CUDA和cuDNN(2024.06最新)
一、安装显卡驱动 1.1 查看显卡型号 lspci | grep -i nvidia我们发现输出的信息中有Device 2230,可以根据这个信息查询显卡型号 查询网址:https://admin.pci-ids.ucw.cz/mods/PC/10de?actionhelp?helppci 输入后点击Jump查询 我们发现显卡型号为RTX …...
二叉树的这五种遍历方法你们都会了吗?
说在前面 🎈二叉树大家应该都很熟了吧,那二叉树的这五种遍历方式你们都会了吗? 以这一二叉树为例子,我们来看看不同遍历方式返回的结果都是怎样的。 前序遍历 前序遍历的顺序是:首先访问根节点,然后递归地…...

使用模数转换器的比例电阻测量基础知识
A/D 转换器是比率式的,也就是说,它们的结果与输入电压与参考电压的比值成正比。这可用于简化电阻测量。 测量电阻的标准方法是让电流通过电阻并测量其压降 (见图 1)。然后,欧姆定律(V I x R) 可用于计算电压和电流的…...

(C++语言的设计和演化) C++的设计理念
文章目录 前言📖C 语言设计规则📐规则和原理📐一般性规则📐设计支持规则📐语言的技术性规则📐低级程序设计支持规则 📖标准化(扩充评判准则)📐它精确吗&#…...

AI音乐:创新引擎还是创意终结者?
✨作者主页: Mr.Zwq✔️个人简介:一个正在努力学技术的Python领域创作者,擅长爬虫,逆向,全栈方向,专注基础和实战分享,欢迎咨询! 您的点赞、关注、收藏、评论,是对我最大…...

20240621每日后端---------如何优化项目中的10000个if-else 语句?
如何优化 10000 个 if-else 语句?有没有好的解决方案? 额,本身问题就很奇怪,怎么可能有这种代码。。。世界你让我陌生,但是我们还是假象着看看能不能解决一下。 解决方案1:策略模式 使用策略模式确实可以…...
【STM32】时钟树系统
1.时钟树简介 1.1五个时钟源 LSI是低速内部时钟,RC振荡器,频率为32kHz左右。供独立看门狗和自动唤醒单元使用。 LSE是低速外部时钟,接频率为32.768kHz的石英晶体。这个主要是RTC的时钟源。 HSE是高速外部时钟,可接石英*/陶瓷谐振…...
docker换源
文章目录 前言1. 查找可用的镜像源2. 配置 Docker 镜像源3. 重启 Docker 服务4. 查看dock info是否修改成功5. 验证镜像源是否更换成功注意事项 前言 在pull镜像时遇到如下报错: ┌──(root㉿kali)-[/home/longl] └─# docker pull hello-world Using default …...
百度在线分销商城小程序源码系统 分销+会员组+新用户福利 前后端分离 带完整的安装代码包以及搭建部署教程
系统概述 百度在线分销商城小程序源码系统是一款集分销、会员组管理和新用户福利于一体的前后端分离的系统。它采用先进的技术架构,确保系统的稳定性、高效性和安全性。该系统的前端基于小程序开发,为用户提供了便捷的购物体验和交互界面。用户可以通过…...

Flutter【组件】富文本组件
简介 flutter 富文本组件。 github地址: https://github.com/ThinkerJack/jac_uikit pub地址:https://pub.dev/packages/jac_uikit 使用方式 运行 flutter pub add jac_uikit组件文档 使用方式: HighlightedTextWidget.builder(text: &…...

中国恋爱交友相亲软件有哪些?大型婚恋相亲交友APP真实测评推荐
嘿嘿,当了29年的单身汪,这下总算不再单着啦!这两年把身边能找的人都找遍了,也没碰到合适的。没办法,就跑到网上去试试,坚持了有半年,可算有对象啦!下面给大家说说我用过的几个能脱单…...
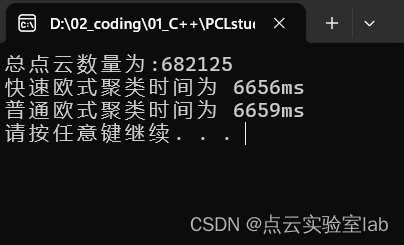
快速欧氏聚类与普通欧氏聚类比较
1、前言 文献《FEC: Fast Euclidean Clustering for Point Cloud Segmentation》介绍了一种快速欧氏聚类方法,大概原理可以参考如下图,具体原理可以参考参考文献。 2、时间效率比较:快速欧氏聚类VS普通欧氏聚类 网上搜集的快速欧式聚类,与自己手写的普通欧式聚类进行对比,…...

如何让大语言模型在规格普通的硬件上运行 - 量化技术
近年来,大型语言模型(LLMs)的能力有了飞跃式的发展,使其在越来越多的应用场景中更加友好和适用。然而,随着LLMs的智能和复杂度的增加,其参数数量,即权重和激活值的数量也在增加,这意…...

Qwen3-4B Instruct-2507快速上手:HTTP访问+侧边栏控制+清空记忆三步操作
Qwen3-4B Instruct-2507快速上手:HTTP访问侧边栏控制清空记忆三步操作 你是不是也遇到过这种情况:想找个好用的AI对话模型,要么部署复杂到劝退,要么界面简陋得像上个世纪的产物,要么就是生成速度慢得让人想砸键盘&…...

裸机嵌入式系统中的事件驱动与上下文切换实践
1. 嵌入式无操作系统环境下的上下文切换与模块解耦实践在资源受限的嵌入式系统中,尤其是不搭载实时操作系统(RTOS)的裸机环境中,如何在保证实时性的同时实现逻辑解耦、避免阻塞、提升代码可维护性,是长期困扰固件工程师…...

小白友好!阿里Speech Seaco Paraformer ASR部署教程,附常见问题解决
小白友好!阿里Speech Seaco Paraformer ASR部署教程,附常见问题解决 1. 为什么选择这个语音识别镜像? 语音识别技术在日常工作和学习中变得越来越重要,但很多工具要么需要复杂的配置,要么识别效果不尽如人意。这个由…...

Qwen3-ASR-1.7B跨平台部署:Windows与Linux性能对比
Qwen3-ASR-1.7B跨平台部署:Windows与Linux性能对比 1. 引言 语音识别技术正在快速改变我们与设备交互的方式,而Qwen3-ASR-1.7B作为最新的开源语音识别模型,凭借其支持52种语言和方言的能力,成为了开发者关注的焦点。但在实际部署…...
Pixel Dimension Fissioner可部署方案:私有化部署保障企业文案数据安全
Pixel Dimension Fissioner可部署方案:私有化部署保障企业文案数据安全 1. 企业数据安全新选择 在数字化内容创作时代,企业文案数据安全已成为不可忽视的核心需求。Pixel Dimension Fissioner(像素语言维度裂变器)作为基于MT5-Z…...

Bonezegei_SoftSerial:嵌入式软件串口的工程化实践与稳定边界
1. 项目概述Bonezegei_SoftSerial 是一个面向嵌入式平台的轻量级软件串口(Software UART)实现库,专为资源受限或硬件 UART 资源不足的场景设计。其核心目标并非替代硬件 UART,而是在特定约束条件下提供可预测、可配置、工程可用的…...
在RTOS下失效?手把手教你用DWT实现us级精确延时(附STM32H743代码))
HAL_Delay()在RTOS下失效?手把手教你用DWT实现us级精确延时(附STM32H743代码)
HAL_Delay()在RTOS下失效?手把手教你用DWT实现us级精确延时(附STM32H743代码) 在嵌入式开发中,精确的延时控制往往是保证系统稳定性和实时性的关键。当我们在RTOS环境下使用STM32的HAL库时,可能会遇到一个棘手的问题&a…...

CLIP ViT-H-14 GPU利用率提升技巧:FP16推理+TensorRT加速实践
CLIP ViT-H-14 GPU利用率提升技巧:FP16推理TensorRT加速实践 1. 项目背景与挑战 CLIP ViT-H-14作为当前最先进的视觉语言模型之一,在图像特征提取领域展现出强大能力。但在实际部署中,我们面临两个主要挑战: 显存占用高&#x…...
)
Endnote X9保姆级安装教程:从下载到新建数据库全流程(附资源链接)
Endnote X9科研文献管理工具全流程安装指南 作为一名长期与文献打交道的科研工作者,我深知文献管理工具对学术研究的重要性。Endnote X9作为一款功能强大的文献管理软件,能显著提升文献整理、引用和写作效率。本文将手把手带你完成从软件安装到数据库创建…...
)
华为设备实战:3种代理ARP配置全解析(路由式+VLAN内+VLAN间)
华为设备代理ARP配置实战指南:从原理到场景化部署 在复杂的企业网络环境中,代理ARP(Proxy ARP)技术常常是解决特定连通性问题的"秘密武器"。作为网络工程师,你是否遇到过这样的场景:两个 logica…...