【代码发布】Quantlab4.3:lightGBM应用于全球大类资产的多因子智能策略(代码+数据)
原创文章第566篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。
昨天,Quantlab整合Alpha158因子集,为机器学习大类资产配置策略做准备(代码+数据),我们完成了因子集构建,并尝试给数据做了预处理。
今天我们开始引入机器学习——树模型,以lightGBM为主。

代码已经发布。
今天,需要先 pip install lightgbm。
之前我们有分享过类似的文章:
Quantlab3.3代码发布:全新引擎 | 静态花开:年化13.9%,回撤小于15% | lightGBM实现排序学习
今天我们要把lightgbm应用于全球大类资产配置的排序上。
LightGBM 是由微软开发的一个开源机器学习库,它基于决策树算法,特别适用于处理大规模数据集。LightGBM 的核心优势在于其高性能、低内存消耗和高准确率,这些特点使得它在多个领域,包括量化投资,都非常受欢迎。
-
处理大规模数据:量化投资经常涉及到处理大量的历史交易数据和其他市场数据。LightGBM 能够有效地处理这些数据,并从中学习。
-
快速模型训练:量化策略需要快速迭代和测试。LightGBM 的训练速度使得研究人员能够快速评估不同策略的效果。
-
模型解释性:虽然不是 LightGBM 的主要优势,但决策树模型的可解释性可以帮助量化分析师理解模型的决策过程,这对于合规性和策略调整非常重要。
lightGBM有sklearn的接口:
加载内置的房价数据,做回归分析:
"""第三方库导入"""
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import r2_score, mean_squared_errorfrom sklearn.datasets import fetch_california_housing
data = fetch_california_housing()
"""训练集 验证集构建"""
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2,random_state=42)
"""模型训练"""
model = LGBMRegressor()
model.fit(X_train, y_train)def calc_metrics(model, X, y):y_pred = model.predict(X)mse = mean_squared_error(y, y_pred)r2 = r2_score(y, y_pred)print('r2:',r2,'mse:',mse)print('训练集:')
calc_metrics(model, X_train, y_train)
print("测试集")
calc_metrics(model, X_test, y_test)
训练集和测试集,在默认参数下,均获得不错的拟合:
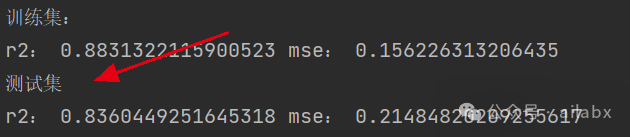
模型调参,调参后训练集r2达到0.94, 测试集也提升至0.85

调参代码如下:
def adj_params():"""模型调参"""params = {'n_estimators': [100, 200, 300, 400],# 'learning_rate': [0.01, 0.03, 0.05, 0.1],'max_depth': [5, 8, 10, 12]}other_params = {'learning_rate': 0.1, 'seed': 42}model_adj = LGBMRegressor(**other_params)# sklearn提供的调参工具,训练集k折交叉验证(消除数据切分产生数据分布不均匀的影响)optimized_param = GridSearchCV(estimator=model_adj, param_grid=params, scoring='r2', cv=5, verbose=1)# 模型训练optimized_param.fit(X_train, y_train)# 对应参数的k折交叉验证平均得分means = optimized_param.cv_results_['mean_test_score']params = optimized_param.cv_results_['params']for mean, param in zip(means, params):print("mean_score: %f, params: %r" % (mean, param))# 最佳模型参数print('参数的最佳取值:{0}'.format(optimized_param.best_params_))# 最佳参数模型得分print('最佳模型得分:{0}'.format(optimized_param.best_score_))
代码在如下位置:
我们来代入大类资产的因子数据,由于量化投资,使用的价量数据是时序数据,因些不能按照train_test_split这样随机划分,我们需要按时间分成两段。
def train(self, train_func):df = self.dfsplit_date = self.split_datedf_train = df.loc[:split_date]df_val = df.loc[split_date:]fields, names = self.alpha.get_fields_names()train_func(df_train, df_val, feature_cols=names)
总体训练代码如下:
symbols = ['CL', # 原油'^TNX', # 美十年期国债'GOLD', # 黄金'^NDX', # 纳指100'000300.SH', # 沪深300'000905.SH', # 中证500'399006.SZ', # 创业板指数'000012.SH', # 国债指数'000832.SH', # 中证转债指数'HSI', # 香港恒生'N225', # 日经225'GDAXI' # 德国DAX指数 ] m = ModelTrainer(symbols=symbols, alpha=Alpha158()) from models.lightgbm_models import trainm.train(train_func=train)
在未进行数据预处理时,容易出现过拟合的情况:

代码在如下位置:
历史文章:

Quantlab整合Alpha158因子集,为机器学习大类资产配置策略做准备(代码+数据)
【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
AI量化实验室——2024量化投资的星辰大海
相关文章:
【代码发布】Quantlab4.3:lightGBM应用于全球大类资产的多因子智能策略(代码+数据)
原创文章第566篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。 昨天,Quantlab整合Alpha158因子集,为机器学习大类资产配置策略做准备(代码数据),我们完成了因子集构建,并尝试…...

【毕业设计】Django 校园二手交易平台(有源码+mysql数据)
此项目有完整实现源码,有需要请联系博主 Django 校园二手交易平台开发项目 项目选择动机 本项目旨在开发一个基于Django的校园二手交易平台,为大学生提供一个安全便捷的二手物品买卖平台。该平台将提供用户注册和认证、物品发布和搜索、交易信息管理等…...
文章自动生成器,在线AI写作工具
随着人工智能AI技术的发展,AI技术被应用到越来越多的场景。对于需要创作内容的同学来说,AI写作-文章内容自动生成器是一个非常好的辅助工具。AI写作工具可以提升我们的创作效率,快速的生成文章,然后在根据需求进行调整修改即可。下…...

Matlab初识:什么是Matlab?它的历史、发展和应用领域
目录 一、什么是Matlab? 二、Matlab的历史与发展 三、Matlab的应用领域 四、安装和启动Matlab 五、界面介绍 六、第一个Matlab程序 七、总结 一、什么是Matlab? Matlab 是由 MathWorks 公司开发的一款用于数值计算、可视化以及编程的高级技术计算…...
大模型之-Seq2Seq介绍
大模型之-Seq2Seq介绍 1. Seq2Seq 模型概述 Seq2Seq(Sequence to Sequence)模型是一种用于处理序列数据的深度学习模型,常用于机器翻译、文本摘要和对话系统等任务。它的核心思想是将一个输入序列转换成一个输出序列。 Seq2Seq模型由两个主…...

NSSCTF-Web题目12
目录 [SWPUCTF 2021 新生赛]finalrce 1、题目 2、知识点 3、思路 [UUCTF 2022 新生赛]ez_rce 1、题目 2、知识点 3、思路 [羊城杯 2020]easycon 1、题目 2、知识点 3、思路 [SWPUCTF 2021 新生赛]finalrce 1、题目 2、知识点 命令执行,tee命令 3、思路…...

22、架构-资源与调度
1、资源与调度 调度是容器编排系统最核心的功能之一,“编排”一词本身便包 含“调度”的含义。调度是指为新创建的Pod找到一个最恰当的宿主机 节点来运行它,这个过程成功与否、结果恰当与否,关键取决于容器 编排系统是如何管理与分配集群节点…...

mac 常用工具命令集合
Iterm2 Command T:新建标签 Command W:关闭当前标签 Command ← →:在标签之间切换 Control U:清除当前行 Control A:跳转到行首 Control E:跳转到行尾 Command F:查找 Command …...

服务器雪崩的应对策略之----限流
限流是一种控制流量的技术,旨在防止系统在高并发请求下被压垮。通过限流,可以确保系统在负载高峰期依然能保持稳定运行。常见的限流策略包括令牌桶算法、漏桶算法、计数器算法和滑动窗口算法。 常见的限流方法 1. 令牌桶算法 (Token Bucket Algorithm)2…...

Python12 列表推导式
1.什么是列表推导式 Python的列表推导式(list comprehension)是一种简洁的构建列表(list)的方法,它可以从一个现有的列表中根据某种指定的规则快速创建一个新列表。这种方法不仅代码更加简洁,执行效率也很…...

threejs 光影投射-与场景进行交互(六)
效果 场景中有三个立方体,三种颜色.点击变成红色,再点恢复自身原有颜色 代码 import ./style.css import * as THREE from three import { OrbitControls } from three/examples/jsm/controls/OrbitControls.js import { log } from three/examples/jsm/nodes/Nodes.js//…...
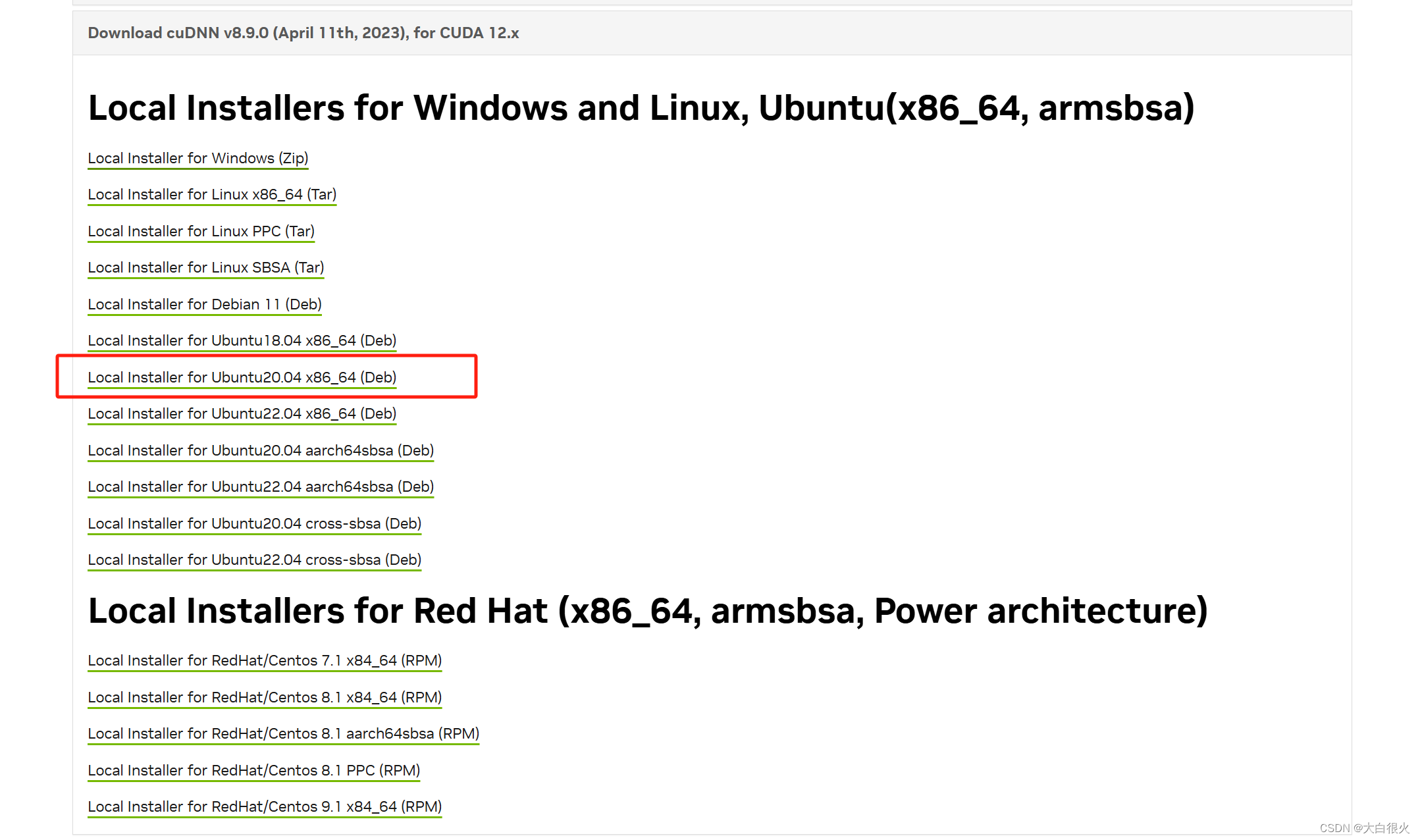
Ubuntu 20.04安装显卡驱动、CUDA和cuDNN(2024.06最新)
一、安装显卡驱动 1.1 查看显卡型号 lspci | grep -i nvidia我们发现输出的信息中有Device 2230,可以根据这个信息查询显卡型号 查询网址:https://admin.pci-ids.ucw.cz/mods/PC/10de?actionhelp?helppci 输入后点击Jump查询 我们发现显卡型号为RTX …...
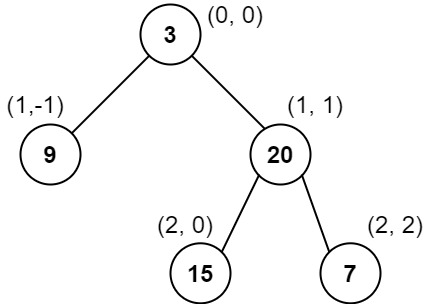
二叉树的这五种遍历方法你们都会了吗?
说在前面 🎈二叉树大家应该都很熟了吧,那二叉树的这五种遍历方式你们都会了吗? 以这一二叉树为例子,我们来看看不同遍历方式返回的结果都是怎样的。 前序遍历 前序遍历的顺序是:首先访问根节点,然后递归地…...

使用模数转换器的比例电阻测量基础知识
A/D 转换器是比率式的,也就是说,它们的结果与输入电压与参考电压的比值成正比。这可用于简化电阻测量。 测量电阻的标准方法是让电流通过电阻并测量其压降 (见图 1)。然后,欧姆定律(V I x R) 可用于计算电压和电流的…...

(C++语言的设计和演化) C++的设计理念
文章目录 前言📖C 语言设计规则📐规则和原理📐一般性规则📐设计支持规则📐语言的技术性规则📐低级程序设计支持规则 📖标准化(扩充评判准则)📐它精确吗&#…...

AI音乐:创新引擎还是创意终结者?
✨作者主页: Mr.Zwq✔️个人简介:一个正在努力学技术的Python领域创作者,擅长爬虫,逆向,全栈方向,专注基础和实战分享,欢迎咨询! 您的点赞、关注、收藏、评论,是对我最大…...

20240621每日后端---------如何优化项目中的10000个if-else 语句?
如何优化 10000 个 if-else 语句?有没有好的解决方案? 额,本身问题就很奇怪,怎么可能有这种代码。。。世界你让我陌生,但是我们还是假象着看看能不能解决一下。 解决方案1:策略模式 使用策略模式确实可以…...
【STM32】时钟树系统
1.时钟树简介 1.1五个时钟源 LSI是低速内部时钟,RC振荡器,频率为32kHz左右。供独立看门狗和自动唤醒单元使用。 LSE是低速外部时钟,接频率为32.768kHz的石英晶体。这个主要是RTC的时钟源。 HSE是高速外部时钟,可接石英*/陶瓷谐振…...
docker换源
文章目录 前言1. 查找可用的镜像源2. 配置 Docker 镜像源3. 重启 Docker 服务4. 查看dock info是否修改成功5. 验证镜像源是否更换成功注意事项 前言 在pull镜像时遇到如下报错: ┌──(root㉿kali)-[/home/longl] └─# docker pull hello-world Using default …...
百度在线分销商城小程序源码系统 分销+会员组+新用户福利 前后端分离 带完整的安装代码包以及搭建部署教程
系统概述 百度在线分销商城小程序源码系统是一款集分销、会员组管理和新用户福利于一体的前后端分离的系统。它采用先进的技术架构,确保系统的稳定性、高效性和安全性。该系统的前端基于小程序开发,为用户提供了便捷的购物体验和交互界面。用户可以通过…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...

终极音乐解锁指南:3步让加密音乐在任何设备自由播放
终极音乐解锁指南:3步让加密音乐在任何设备自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

C++的单例模式及其作用
什么是单例模式?无论是在面向对象编程还是软件架构中,单例模式都扮演着至关重要的角色。它不仅能够确保一个类只有一个实例存在,还能够提供全局访问点,使得我们可以方便地在程序的任何地方使用该实例。但有几个设计模式并非解决抽…...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...

Android Compose 图层的合成 : BlendMode
1. 图形的合成是什么 ? Compose中,图层的合成,通过BlendMode来控制 “显示谁、保留哪部分”,常用于裁剪、遮罩、图层叠加。 1.1 初始界面 Preview Composable fun MyBlendModeTest() {Box {Box(Modifier.size(100.dp).background(Color.R…...