[论文笔记]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
引言
我们知道Transformer很好用,但它设定的最长长度是512。像一篇文章超过512个token是很容易的,那么我们在处理这种长文本的情况下也想利用Transformer的强大表达能力需要怎么做呢?
本文就带来一种处理长文本的Transformer变种——Transformer-XL,它也是XLNet的基石。这里的XL取自EXTRAL LONG。
论文题目:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
论文地址:https://arxiv.org/pdf/1901.02860.pdf
Transformer
我们先来简单回顾下Transformer,不熟悉的可以先看关于Transformer论文全文翻译——[论文翻译]Attention Is All You Need
。

我们重点回顾输入向量的计算方式,如上图底部所示,词嵌入(Embedding) ➕ 位置编码(Positional Encoding)。
假设有两个输入token,它们的位置分别在i,ji,ji,j处,用xi,xjx_i,x_jxi,xj相应地表示。
记
ExiT∈R1×dE_{x_i}^T \in \Bbb R^{1 \times d}ExiT∈R1×d为token xix_ixi的词嵌入,ExjE_{x_j}Exj为 token xjx_jxj的词嵌入;
UiT∈R1×dU_i^T \in \Bbb R^{1 \times d}UiT∈R1×d和UjT∈R1×dU_j^T \in \Bbb R^{1 \times d}UjT∈R1×d分别为第iii和第jjj处的位置编码。
这里ddd为嵌入大小。
一般向量默认是列向量,而行向量表示需要加上个转置。所以,上面两个记号上有转置。
那么在计算token xjx_jxj相对于token xjx_jxj的Self-Attention时,首先会计算出qiq_iqi和kjk_jkj:
qi=(ExiT+UiT)WqT∈R1×dkj=(Exj+Uj)WkT∈R1×d(1)q_i = (E_{x_i}^T + U_i^T)W_q^T \in \Bbb R^{1\times d}\\ k_j = (E_{x_j} + U_j)W_k^T \in \Bbb R^{1\times d} \tag 1 qi=(ExiT+UiT)WqT∈R1×dkj=(Exj+Uj)WkT∈R1×d(1)
其中WqTW_q^TWqT和WkT∈Rd×dW_k^T \in \Bbb R^{d \times d}WkT∈Rd×d。
这里把词嵌入+位置编码分开写,后面会看到为什么这么做。
接下来,在计算它们两之间的注意力得分时,直接拿这两个向量做点积得到一个标量,注意维度:
qi⋅kjT=(ExiT+UiT)WqT⋅((ExjT+UjT)WkT)T=(ExiTWqT+UiTWqT)⋅(WkExj+WkUj)=ExiTWqTWkExj+ExiTWqTWkUj+UiTWqTWkExj+UiTWqTWkUj(2)\begin{aligned} q_i \cdot k_j^T &= (E_{x_i}^T + U_i^T)W_q^T \cdot \left ( (E_{x_j}^T + U_j^T)W_k^T \right)^T \\ &= (E_{x_i}^TW_q^T + U_i ^TW_q^T) \cdot ( W_k E_{x_j} + W_kU_j) \\ &= E_{x_i}^TW^T_qW_k E_{x_j} + E_{x_i}^TW^T_qW_kU_j + U_i ^TW_q^T W_k E_{x_j} + U_i ^TW_q^T W_kU_j \end{aligned} \tag 2 qi⋅kjT=(ExiT+UiT)WqT⋅((ExjT+UjT)WkT)T=(ExiTWqT+UiTWqT)⋅(WkExj+WkUj)=ExiTWqTWkExj+ExiTWqTWkUj+UiTWqTWkExj+UiTWqTWkUj(2)
相当于把它们进行了展开,整个过程应该没什么问题。
下面进入本文的主题。
Transformer-XL
我们先来看如果想在Transformer中处理长文本的话,要怎么做呢?
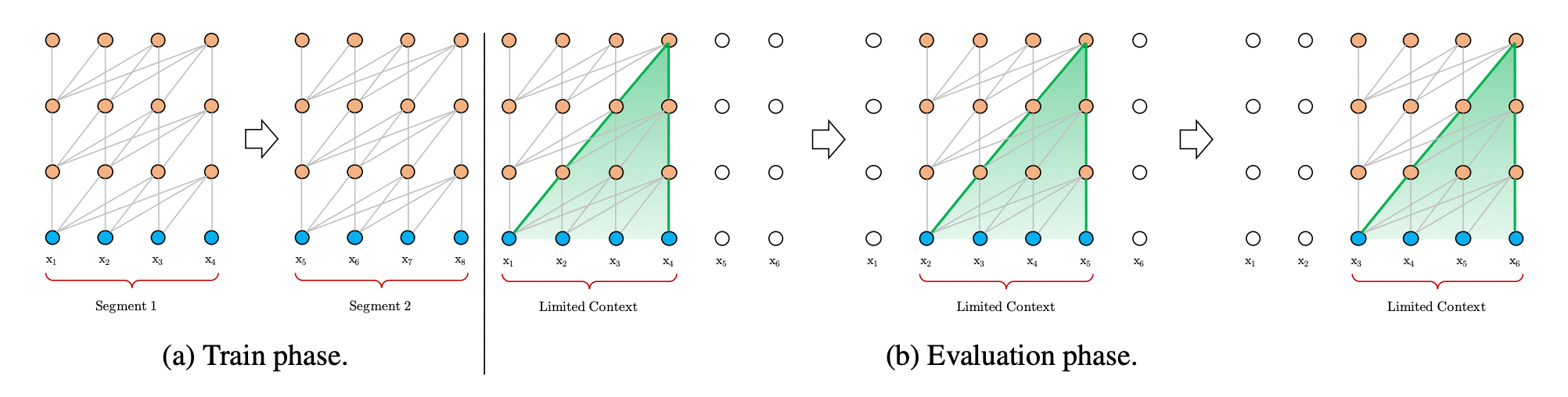
图1: Transformer中处理长文本的传统方法
而Transformer-XL的提出就是为了处理(address)上面的两个问题。
上图给出了块长度为4时的一个示例,可以看到,在训练阶段,Transformer分别对第一个块中的序列x1,x2,x3,x4x_1,x_2,x_3,x_4x1,x2,x3,x4和第二块中的序列x5,x6,x7,x8x_5,x_6,x_7,x_8x5,x6,x7,x8进行建模(modeling)。
而在评估(evaluation)阶段,为了不将文本切成块,会通过类似移动窗口的方式,一个一个token地向后移动,这种方法效率非常低下。
为此,Transformer-XL提出了两种改进策略——块级别循环(Segment-level Recurrent)和相对位置编码(Relative Positional Encoding)。
我们先来看第一个。
块级别循环
块级别循环,全称是状态复用的块级别循环(Segment-Level Recurrence with State Reuse)。如下图(a)部分:
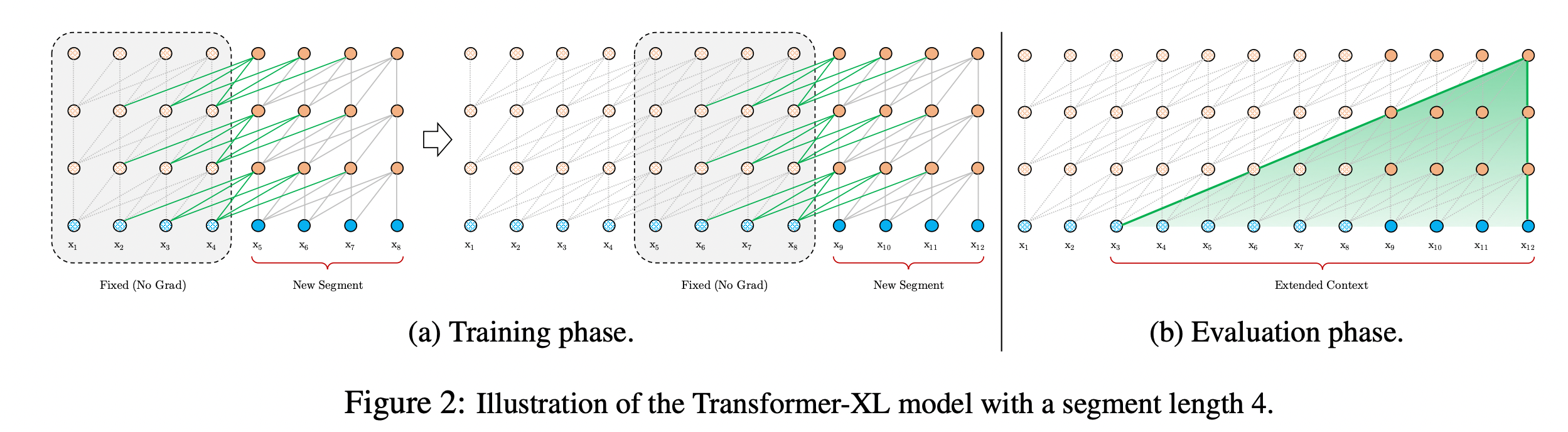
图2: Transformer-XL中处理长文本的方法
上面有两个块,每个块都会做Self-Attention,块之间有一些绿色的连线。在第二个块的时候,可以把第一个块的某些信息通过绿色的连线传递过来,那么它是怎么实现的呢?
实际上非常简单,它的思想是,在跑完第一个块的信息后,把它中间所有的隐藏层向量都缓存起来,然后跑第二个块的信息时,可以拿到这些缓存向量。
下面用公式描述一下,假设两个连续长度为LLL的块分别为sτ=xτ,1,⋯,xτ,L\pmb s_{\tau}=\pmb x_{\tau,1}, \cdots,x_{\tau,L}sτ=xτ,1,⋯,xτ,L和sτ+1=xτ+1,1,⋯,xτ+1,L\pmb s_{\tau+1}=\pmb x_{\tau+1,1}, \cdots,x_{\tau+1,L}sτ+1=xτ+1,1,⋯,xτ+1,L。记由第τ\tauτ个块sτ\pmb s_{\tau}sτ在第nnn层上产生的隐藏状态序列hτn∈RL×d\pmb h_{\tau}^n \in \Bbb R^{L\times d}hτn∈RL×d,ddd为隐藏层维度大小。
那么对于片段sτ+1\pmb s_{\tau +1}sτ+1在第nnn层上的隐藏状态hτ+1n\pmb h_{\tau+1}^nhτ+1n计算如下:
h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1](3)\pmb {\tilde h _{\tau +1}^{n-1}} = [\text{SG}(\pmb {h _{\tau}^{n-1}}) \circ \pmb { h _{\tau +1}^{n-1}} ] \tag 3 h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1](3)
qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvT(4)\pmb q_{\tau +1}^n, \pmb k_{\tau +1}^n,\pmb v_{\tau +1}^n = \pmb h_{\tau+1}^{n-1}W^T_q , \pmb { \tilde h_{\tau+1}^{n-1}}W^T_k, \pmb { \tilde h_{\tau+1}^{n-1}}W^T_v \tag 4 qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvT(4)
hτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)(5)\pmb h_{\tau+1}^n = \text{Transformer-Layer}(\pmb q_{\tau +1}^n, \pmb k_{\tau +1}^n,\pmb v_{\tau +1}^n) \tag 5 hτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)(5)
其中函数SG(⋅)\text{SG}(\cdot)SG(⋅)表示停止梯度传输;记号[hu∘hv][\pmb h_u \circ \pmb h_v][hu∘hv]表示沿着长度(时间步)维度拼接两个隐藏状态序列;WWW表示全连接权重。
这里通过拼接当前块第n−1n-1n−1层的隐藏状态和缓存的前一块第n−1n-1n−1层的隐藏状态来生成扩展的上下文h~τ+1n−1\pmb {\tilde h _{\tau +1}^{n-1}}h~τ+1n−1。
与传统的Transformer的主要不同点在于键kτ+1n\pmb k_{\tau +1}^nkτ+1n和值vτ+1n\pmb v_{\tau +1}^nvτ+1n的计算依赖于扩展的上下文h~τ+1n−1\pmb {\tilde h _{\tau +1}^{n-1}}h~τ+1n−1,即用到了前一块的缓存信息hτn−1\pmb {h _{\tau}^{n-1}}hτn−1。
同时可以看到在计算查询qτ+1n\pmb q_{\tau +1}^nqτ+1n时只会基于当前块来计算。这种设计体现在了上图(a)的绿线中。
这种状态复用的块级别循环机制应用于语料库中每两个连续的块,本质上是在隐藏状态下产生一个块级别的循环。在这种机制下,Transformer利用的有效上下文可以远远超出两个块。注意到这种在hτ+1n\pmb h_{\tau +1}^nhτ+1n和hτn−1\pmb h_{\tau}^{n-1}hτn−1的循环依赖每块间向下移动一层,与传统RNN中的同层循环不同。因此,最大可能的依赖长度随块的长度LLL和层数NNN呈线性增长。这种机制和RNN中常用的随时间反向传播机制(Back Propagation Through Time,BPTT)类似。然而,在这里是将整个序列的隐藏层状态全部缓存,而不是像BPTT机制中只会保留最后一个状态。
在训练的时候,先训练第一块,更新完第一块的权重后,然后固定中间的隐藏状态向量。在训练第二块的时候,读取刚才保存那些向量,在训练第二块的时候,还是只更新第二块的权重,不过可以隐式地用到第一块的信息(通过绿线传递过来)。梯度不会沿着绿线进行更新,因此实际上学的还是一个块之间的信息。
通过这种方式可以延长依赖的长度到N倍,N就是网络的深度(块的个数)。
这样解决了上下文碎片问题,让模型可以捕获到长期依赖的信息。而评估阶段就更简单了,此时可以直接拿到全部的上下文信息,沿着上面的绿线将信息向后传递,而不需要像图1(b)那样从头开始计算。每次可以以块进行移动,而不是以token为单位进行移动,大大加快了推理过程。
虽然它的思想很简单,但如果直接实现的话会发现表现很差,因为这里还有一个问题,就是不连贯的位置编码问题。这就涉及到了第二个改进策略,相对位置编码。
相对位置编码
如果直接简单地把原来Transformer的绝对位置编码信息应用到块级别的循环上就会很奇怪:
[0,1,2,3]→[0,1,2,3,0,1,2,3][0,1,2,3] \rightarrow [0,1,2,3,0,1,2,3] [0,1,2,3]→[0,1,2,3,0,1,2,3]
假设和上面的例子一样,块长度限制为4。现在长度为8之后就会变成两个单独的块,对应的位置编码就成了[0,1,2,3,0,1,2,3][0,1,2,3,0,1,2,3][0,1,2,3,0,1,2,3]。
这样模型无法区分第一个块的第2个位置编码和第二个块的第2个位置编码,认为是一样的,这显然是不合理的。因为位置编码的目的是为了引入位置信息。Transformer-XL针对这种情况提出了相对位置编码。
位置信息的重要性体现在注意力分数的计算上面,在传统Transformer中,同一块(segment)内的查询qiq_iqi和键向量kjk_jkj的注意力分数计算如下:

就是上文公式(2)(2)(2),拆分成四项后,为每项进行编号,从(a)(a)(a)到(d)(d)(d)。
ExiT∈R1×dE_{x_i}^T \in \Bbb R^{1 \times d}ExiT∈R1×d为token xix_ixi的词嵌入,ExjE_{x_j}Exj为 token xjx_jxj的词嵌入;
UiT∈R1×dU_i^T \in \Bbb R^{1 \times d}UiT∈R1×d和UjT∈R1×dU_j^T \in \Bbb R^{1 \times d}UjT∈R1×d分别为第iii和第jjj处的绝对位置编码。
原本的做法里面,位置嵌入是绝对位置,因此如果是第i个位置,这个UiU_iUi都会是一样的(不管是哪个块)。
基于仅依赖相对位置信息的思想,Transformer-XL提出了改进如下:

其中为每项进行编号,从下面展开描述一下它的改进点:
- 将(b)(b)(b)和(d)(d)(d)项中计算key向量的绝对位置嵌入UjU_jUj替换为相对位置Ri−jR_{i-j}Ri−j,代表一个相对距离信息。注意这里的RRR是传统Transformer中的正弦函数编码模式,是不需要学习的。
- 引入一个可学习的参数uuu∈Rd\in \Bbb R^d∈Rd去替换(c)(c)(c)项中的query向量UiTWqTU_i^TW_q^TUiTWqT。这样新的query向量uuu对于所有的位置都是一样的,因为是以位置iii为基准点,所以iii使用的位置嵌入是一个固定的嵌入,只需要考虑iii和jjj之间相关位置的关系。同理,用可学习的参数vvv∈Rd\in \Bbb R^d∈Rd去替换(d)(d)(d)项中的UiTWqTU_i^TW_q^TUiTWqT。
- 将WkW_kWk分成两个权重矩阵Wk,EW_{k,E}Wk,E和Wk,RW_{k,R}Wk,R,以分别产生基于内容的key向量和基于位置的key向量。
在新的计算公式中,每项都有直观的意义:
- (a)(a)(a)项表示基于内容的相关度,计算query xix_ixi和key xjx_jxj内容之间的关联信息;
- (b)(b)(b)项捕获内容相关的位置偏置,计算query xix_ixi的内容与key xjx_jxj的位置编码之间的关联信息,Ri−jR_{i-j}Ri−j表示两者的相对位置信息,取RRR中的第i−ji-ji−j行;
- (c)(c)(c)项表示全局内容偏置,计算query xix_ixi的位置编码与key xjx_jxj的内容之间的关联信息;
- (d)(d)(d)项表示全局位置偏置,计算query xix_ixi与key xjx_jxj的位置编码之间的关联信息;
把块级别循环和相对位置编码的信息合并后,我们就得到了Transformer-XL的最终架构。对于一个NNN层的Transformer-XL的单个注意力头,对于n=1,⋯,Nn=1,\cdots,Nn=1,⋯,N有:

这样对于每个query,所有的位置嵌入都是一样的,对于不同的token注意力偏差也是一样的。
这里的注意力偏差怎么理解?原始的Transformer中的位置编码,对于每个位置都会学一个向量,假设某个token经常出现在第一个位置,比如“今年”这个token,那么模型学到的位置编码可能会包含“今年”这个token的意思,而没有其他不常出现在第一个位置的token信息。也就说第一个位置编码对“今年”产生了偏差。
相关文章:
[论文笔记]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
引言 我们知道Transformer很好用,但它设定的最长长度是512。像一篇文章超过512个token是很容易的,那么我们在处理这种长文本的情况下也想利用Transformer的强大表达能力需要怎么做呢? 本文就带来一种处理长文本的Transformer变种——Transf…...
| 机考必刷)
华为OD机试题 - 找目标字符串(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:找目标字符串题目输入输出示例一输入输出说明Code解题思路版权说…...

C++面向对象编程之六:重载操作符(<<,>>,+,+=,==,!=,=)
重载操作符C允许我们重新定义操作符(例如:,-,*,/)等,使其对于我们自定义的类类型对象,也能像内置数据类型(例如:int,float,double&…...

JS_wangEditor富文本编辑器
官网:https://www.wangeditor.com/ 引入 CSS 定义样式 <link href"https://unpkg.com/wangeditor/editorlatest/dist/css/style.css" rel"stylesheet"> <style>#editor—wrapper {border: 1px solid #ccc;z-index: 100; /* 按需定…...

Django实践-06导出excel/pdf/echarts
文章目录Django实践-06导出excel/pdf/echartsDjango实践-06导出excel/pdf/echarts导出excel安装依赖库修改views.py添加excel导出函数修改urls.py添加excel/运行测试导出pdf安装依赖库修改views.py添加pdf导出函数修改urls.py添加pdf/生成前端统计图表修改views.py添加get_teac…...

java并发入门(一)共享模型—Synchronized、Wait/Notify、pack/unpack
一、共享模型—管程 1、共享存在的问题 1.1 共享变量案例 package com.yyds.juc.monitor;import lombok.extern.slf4j.Slf4j;Slf4j(topic "c.MTest1") public class MTest1 {static int counter 0;public static void main(String[] args) throws InterruptedEx…...

Ast2500增加用户自定义功能
备注:这里使用的AMI的开发环境MegaRAC进行AST2500软件开发,并非openlinux版本。1、添加上电后自动执行的任务在PDKAccess.c中列出了系统启动过程中的所有任务,若需要添加功能,在相应的任务中添加自定义线程。一般在两个任务里面添…...

用Python暴力求解德·梅齐里亚克的砝码问题
文章目录固定个数的砝码可称量重量砝码的组合方法40镑砝码的组合问 一个商人有一个40磅的砝码,由于跌落在地而碎成4块。后来,称得每块碎片的重量都是整磅数,而且可以用这4 块来称从1 至40 磅之间的任意整数磅的重物。问这4 块砝码片各重多少&…...

离散Hopfield神经网络的分类——高校科研能力评价
离散Hopfield网络离散Hopfield网络是一种经典的神经网络模型,它的基本原理是利用离散化的神经元和离散化的权值矩阵来实现模式识别和模式恢复的功能。它最初由美国物理学家John Hopfield在1982年提出,是一种单层的全连接神经网络,被广泛应用于…...
- Call逻辑分析和扩展机制)
Retrofit核心源码分析(三)- Call逻辑分析和扩展机制
在前面的两篇文章中,我们已经对 Retrofit 的注解解析、动态代理、网络请求和响应处理机制有了一定的了解。在这篇文章中,我们将深入分析 Retrofit 的 Call 逻辑,并介绍 Retrofit 的扩展机制。 一、Call 逻辑分析 Call 是 Retrofit 中最基本…...

源码分析spring如和对@Component注解进行BeanDefinition注册的
Spring ioc主要职责为依赖进行处理(依赖注入、依赖查找)、容器以及托管的(java bean、资源配置、事件)资源声明周期管理;在ioc容器启动对元信息进行读取(比如xml bean注解等)、事件管理、国际化等处理;首先…...
C语言--字符串函数1
目录前言strlenstrlen的模拟实现strcpystrcatstrcat的模拟实现strcmpstrcmp的模拟实现strncpystrncatstrncmpstrstrstrchr和strrchrstrstr的模拟实现前言 本章我们将重点介绍处理字符和字符串的库函数的使用和注意事项。 strlen 我们先来看一个我们最熟悉的求字符串长度的库…...
Webstorm使用、nginx启动、FinalShell使用
文章目录 主题设置FinalShellFinalShell nginx 启动历史命令Nginx页面发布配置Webstorm的一些常用快捷键代码生成字体大小修改Webstorm - gitCode 代码拉取webstorm 汉化webstorm导致CPU占用率高方法一 【忽略node_modules】方法二 【设置 - 代码编辑 - 快速预览文档 - 关闭】主…...

源码分析Spring @Configuration注解如何巧夺天空,偷梁换柱。
前言 回想起五年前的一次面试,面试官问Configuration注解和Component注解有什么区别?记得当时的回答是: 相同点:Configuration注解继承于Component注解,都可以用来通过ClassPathBeanDefinitionScanner装载Spring bean…...
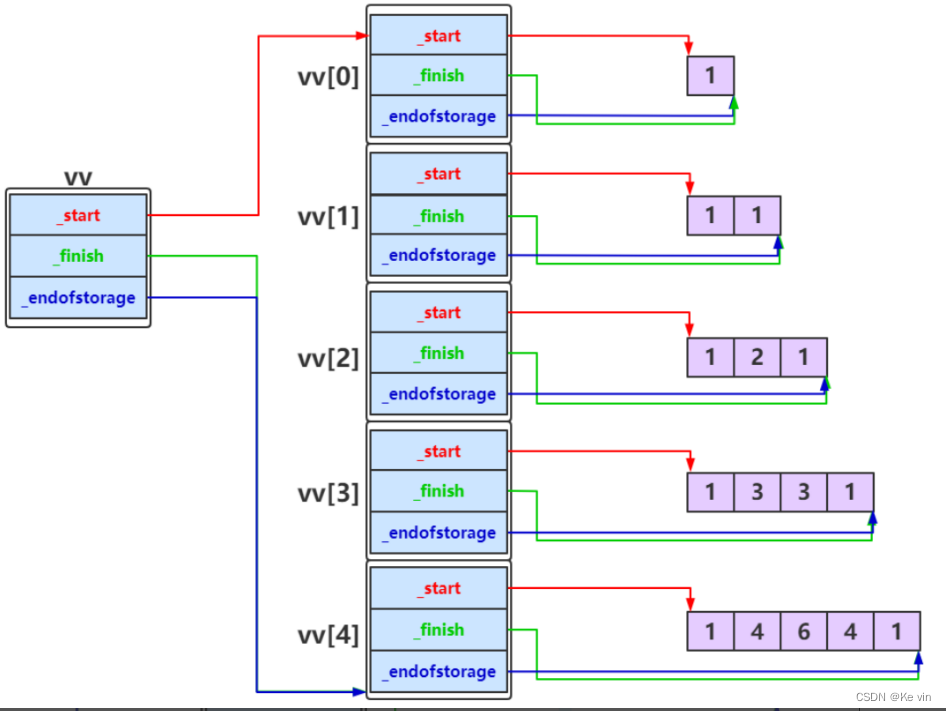
vector的使用及模拟实现
目录 一.vector的介绍及使用 1.vector的介绍 2.vector的使用 1.vector的定义 2.vector iterator的使用 3. vector 空间增长问题 4.vector 增删查改 3.vector 迭代器失效问题(重点) 1. 会引起其底层空间改变的操作 2.指定位置元素的删除操作--erase 3. Li…...
)
“华为杯”研究生数学建模竞赛2007年-【华为杯】A题:基于自助法和核密度估计的膳食暴露评估模型(附获奖论文)
赛题描述 我国是一个拥有13亿人口的发展中国家,每天都在消费大量的各种食品,这批食品是由成千上万的食品加工厂、不可计数的小作坊、几亿农民生产出来的,并且经过较多的中间环节和长途运输后才为广大群众所消费,加之近年来我国经济发展迅速而环境治理没有能够完全跟上,以…...
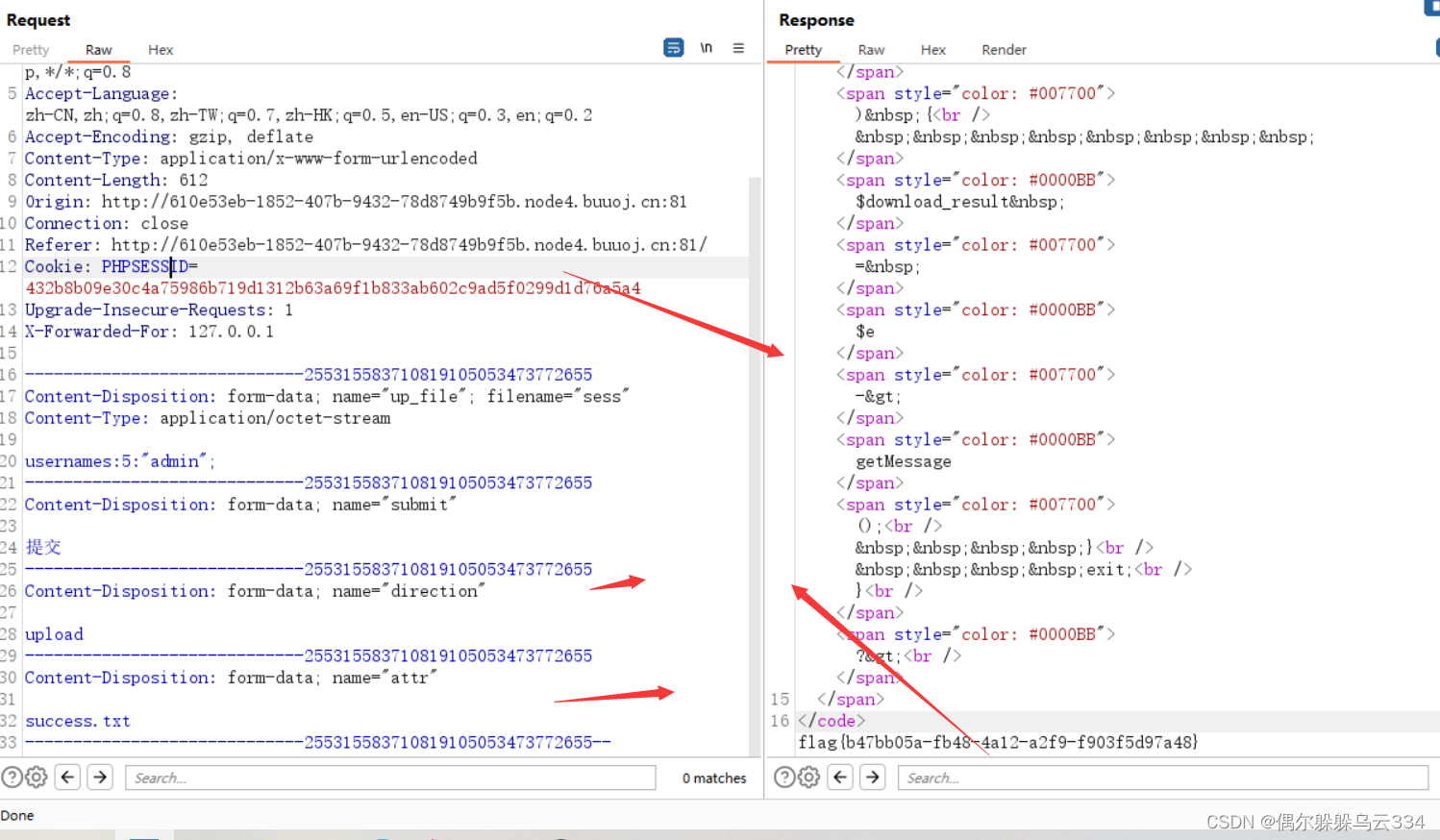
刷题(第三周)
目录 [CISCN2021 Quals]upload [羊城杯 2020]EasySer [网鼎杯 2020 青龙组]notes [SWPU2019]Web4 [Black Watch 入群题]Web [HFCTF2020]BabyUpload [CISCN2021 Quals]upload 打开界面以后,发现直接给出了源码 <?php if (!isset($_GET["ctf"]))…...

新C++(14):移动语义与右值引用
当你在学习语言的时候,是否经常听到过一种说法,""左边的叫做左值,""右边的叫做右值。这句话对吗?从某种意义上来说,这句话只是说对了一部分。---前言一、什么是左右值?通常认为:左值是一个表示数据的表达式(…...
TCP相关概念
目录 一.滑动窗口 1.1概念 1.2滑动窗口存在的意义 1.3 滑动窗口的大小变化 1.4丢包问题 二.拥塞控制 三.延迟应答 四.捎带应答 五.面向字节流 六.粘包问题 七.TIME_WAIT状态 八.listen第2个参数 九.TCP总结 一.滑动窗口 1.1概念 概念:双方在进行通信时&a…...

MySQL锁篇
MySQL锁篇 一、一条update语句 我们的故事继续发展,我们还是使用t这个表: CREATE TABLE t (id INT PRIMARY KEY,c VARCHAR(100) ) EngineInnoDB CHARSETutf8;现在表里的数据就是这样的: mysql> SELECT * FROM t; —------- | id | c | —…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...