谈谈kafaka的并行处理,顺带讲讲rabbitmq
简介
Kafka 是一个分布式流处理平台,它支持高效的并行处理。Kafka 的并行处理能力主要体现在以下几个方面:
分区(Partition)并行
- Kafka 将数据存储在称为"分区"的逻辑单元中。
- 每个分区可以独立地并行地进行读写操作。
- 生产者可以根据分区策略,将数据写入到指定的分区中。
- 这样可以实现对同一主题的并行写入。
消费者组(Consumer Group)并行:
- 消费者组是一组共享同一个消费者组 ID 的消费者。
- 每个分区只能被同一个消费者组中的一个消费者消费。
- 通过增加消费者组的数量,可以实现对同一主题的并行消费。
- 每个消费者组中的消费者,可以独立地并行地从分区中读取数据。
分区再均衡(Partition Rebalance)机制:
- 当消费者加入或退出消费者组时,Kafka 会自动进行分区再均衡。
- 分区会被重新分配给消费者组中的其他消费者。
- 这确保了负载均衡,提高了整体的并行处理能力。
多线程消费
- 每个消费者都可以使用多个线程来并行地处理消息。
- 这可以进一步提高单个消费者的并行处理能力。
Kafka Streams
- Kafka Streams 是一个用于构建实时应用程序和微服务的库。
- 它提供了高度可扩展和容错的流处理能力,可以利用 Kafka 的并行特性。
- Kafka Streams 应用程序可以自动进行并行处理和负载均衡。
数据流
Kafka 是一个分布式流处理平台。整个 Kafka 的数据流可以概括为:生产者将数据写入 Kafka 的主题分区,broker 负责存储和管理这些数据,消费者从分区中读取数据进行处理。Zookeeper 负责协调整个集群的状态和元数据。它的数据流主要包括以下几个关键组件:
主题(Topic)
主题是 Kafka 中的数据流单位,类似于数据库中的表。
每个主题都被划分为多个分区(Partition),数据以日志的形式存储在这些分区中。
主题可以被多个生产者写入,多个消费者消费。
生产者(Producer):
- 生产者是向 Kafka 主题发送数据的应用程序。
- 生产者负责将数据写入到指定的主题和分区中。
- 生产者可以配置消息的分区策略,以控制数据的分布。
消费者(Consumer):
- 消费者是从 Kafka 主题读取数据的应用程序。
- 消费者按照自己的消费进度从分区中读取数据,并将已读取的数据标记为已提交。
- 消费者可以组成消费者组,共享同一个主题的消费负载。
broker:
- broker 是 Kafka 集群中的服务节点,负责存储和管理主题的数据。
- 每个 broker 可以容纳多个主题的分区,并提供数据复制和容错能力。
- broker 接收生产者的写入请求,并为消费者提供数据读取服务。
Zookeeper:
- Zookeeper 是 Kafka 集群的协调者,负责管理集群的元数据和配置信息。
- Zookeeper 跟踪 broker 节点的状态,并协调消费者组的分区再平衡。
kafaka的分区
在 Kafka 中,分区是针对生产者提交消息到 Broker 的概念,而消费者是无法指定分区的。
生产者分区
- 生产者在向 Kafka 主题(Topic)发送消息时,可以指定消息的分区。
- 生产者可以根据业务需求,将相关的消息发送到同一个分区,以便后续的消费者进行处理。
- 生产者也可以使用 Kafka 提供的分区策略,比如轮询、哈希或自定义的分区器,来决定消息应该被发送到哪个分区。
消费者无法指定分区:
- 消费者在消费 Kafka 主题时,是无法指定要消费哪个分区的。
- 消费者会自动从主题的所有分区中读取消息,并由 Kafka 的负载均衡机制将分区分配给不同的消费者实例。
- 当有新的消费者加入或者现有消费者退出时,Kafka 会自动进行分区的再均衡,以确保各个消费者实例能够公平地消费分区中的消息。
这种设计的好处是:
- 解耦了生产者和消费者,使得系统更加灵活和可扩展。
- 消费者无需关心消息存储在哪些分区,只需要关注从主题中消费数据即可。
- Kafka 的负载均衡机制能够自动管理分区的分配,降低了开发和运维的复杂度。
总的来说,Kafka 的分区机制是针对生产者的,而消费者无法指定分区,这是 Kafka 设计中的一个重要特点,也是它能够支持大规模数据处理的关键所在。
并行处理策略的本质
Kafka 采用的并行处理策略确实是一种"空间换时间"的设计思路。具体体现在以下几个方面:
分区(Partition)的空间换时间
- Kafka 将数据划分为多个分区,这需要占用更多的存储空间。
- 但这样做可以实现对分区的并行读写,提高整体的吞吐量和处理能力,从而换取更快的数据处理速度。
消费者组(Consumer Group)的空间换时间
- 通过增加消费者组的数量,可以实现对同一主题的并行消费。
- 这需要更多的消费者实例,占用更多的资源(CPU、内存等)。
- 但这样做可以大幅提高数据消费的并行度和处理速度。
分区再均衡(Partition Rebalance)的空间换时间
- 在消费者加入或退出时,Kafka 需要执行分区再均衡操作。
- 这需要消耗一定的计算资源和时间来重新分配分区。
- 但这种动态的分区再平衡,可以确保负载均衡,提高整体的并行处理能力。
kafaka的消费机制
Kafka 中,一个消费实例通常会被多个消费者同时消费,这主要取决于以下几个因素:
消费者组配置
- Kafka 中,消费者是以消费者组的形式存在的。
- 同一个消费者组内的消费者实例,会被分配到不同的分区进行消费。
分区数量
- Kafka 的每个主题都会被划分为多个分区。
- 分区数量决定了同时可以有多少个消费者实例来消费这个主题。
负载均衡策略
- Kafka 会根据消费者组内的消费者实例数量,自动将分区平均分配给它们。
这样可以确保每个消费者实例都有自己独立的分区来消费。 - 通常情况下,如果一个主题有N个分区,而一个消费者组里有M个消费者实例,那么每个实例通常会被分配到 N/M 个分区。
例如,如果一个主题有 12 个分区,而消费者组里有 4 个实例,那么每个实例通常会被分配到 3 个分区进行消费。
这样的分配方式可以充分利用系统资源,确保负载均衡,提高整体的消费吞吐量。当然,具体的分配情况还会根据不同的场景和配置而有所不同。
kafaka的各种消费场景
Kafka 的消费者实例是如何被消费的,并结合不同的消费场景进行分析。
基本消费模式:
- 在最基本的消费模式下,每个消费者实例从 Kafka 主题(Topic)的所有分区中读取消息。
- Kafka 的负载均衡机制会将分区的所有权分配给不同的消费者实例。
- 当有新的消费者加入或者现有消费者退出时,Kafka 会自动进行分区的再均衡,确保各个消费者实例能够公平地消费分区中的消息。
消费者组:
- 消费者组是Kafka中更常见的消费模式。
- 同一个消费者组内的消费者实例会共享主题的所有分区,但每个分区只会被组内的一个消费者实例消费。
- 当有新的消费者加入或者现有消费者退出时,Kafka 会自动进行分区的再均衡,确保组内的所有消费者实例都能平均分摊分区的消费任务。
不同场景下的应用:
- 高吞吐场景:如果需要实现高吞吐的数据处理,可以创建多个消费者实例,并将它们划分到不同的消费者组中。这样可以充分利用Kafka的并行处理能力,提高整体的吞吐量。
- 故障恢复场景:如果某个消费者实例发生故障,其他组内的实例可以自动接管该实例负责的分区,确保数据不会丢失。这种容错性是Kafka的一大优势。
- 数据重复消费场景:有时需要对数据进行重复消费,比如进行日志分析。这时可以将消费者划分到不同的消费者组中,每个组负责不同的数据处理任务。
消费位移(Offset)管理
- Kafka会自动记录每个消费者实例消费到的位移(Offset),确保数据不会被重复消费。
- 消费者可以手动提交位移,也可以让Kafka自动提交。合理的位移管理策略可以确保数据的一致性和可靠性。
rabbitmq为什么不这么做
RabbitMQ 确实也可以通过创建多个队列来实现某些程度的并行处理,但与 Kafka 的设计方式还是存在一些差异:
消息分区机制不同
- Kafka 的设计重点是基于分区的并行处理,每个分区可以独立读写。
- RabbitMQ 的队列是更简单的消息存储单元,没有类似的分区概念。
消费者组机制不同:
- Kafka 有专门的消费者组概念,可以实现同一队列的并行消费。
- RabbitMQ 没有类似的消费者组机制,多个消费者消费同一队列时,消息会被平均分配。
分区再均衡机制不同:
- Kafka 有自动的分区再均衡机制,可以应对消费者的动态变化。
- RabbitMQ 需要手动管理多个队列之间的消息负载均衡。
吞吐量和扩展性差异:
- Kafka 的分区和消费者组机制使其具有更高的吞吐量和可扩展性。
- RabbitMQ 依赖于单个队列,在高吞吐量场景下可能会成为性能瓶颈。
小结
总的来说,Kafka 的设计目标是针对大规模数据处理,因此它从架构层面引入了分区和消费者组等机制,来实现更高效的并行处理。这种设计思路确实可以带来更好的性能和扩展性。
而 RabbitMQ 则更偏向于经典的消息队列模型,适用于一般的异步消息处理场景。多队列的方式虽然也能实现一定程度的并行,但与 Kafka 的整体设计思路还是有所不同。
所以,在选择消息队列系统时,需要结合具体的业务需求和性能要求,从而选择最合适的技术方案。Kafka 和 RabbitMQ 都是优秀的消息队列系统,适用于不同的场景。
rabbitmq的消费机制
RabbitMQ 的消息消费机制与 Kafka 有一些不同:
单一消费者消费模式
- 在 RabbitMQ 中,一条消息同一时间只会被一个消费者消费。
- 这是 RabbitMQ 的默认行为,称为"公平分发"(Fair Dispatch)。
负载均衡机制
- 当有多个消费者监听同一个队列时,RabbitMQ 会将消息平均分配给各个消费者。
- 这种机制可以实现简单的负载均衡,但无法像 Kafka 那样做到真正的并行消费。
手动确认机制
- 在 RabbitMQ 中,消费者需要手动确认(Ack)已经处理完毕的消息。
- 这样可以避免消息丢失,但需要消费者自行管理确认逻辑。
与 Kafka 的并行消费模型不同,RabbitMQ 更倾向于"一个消息,一个消费者"的方式。这种设计适用于一般的异步消息处理场景,但在需要高吞吐量和大规模并行处理的场景下,可能会成为性能瓶颈。
rabbit确实不大适合分布式
从消息消费机制来看,RabbitMQ 确实相对不太友好于分布式系统的构建。这主要体现在以下几个方面:
可扩展性限制
RabbitMQ 的"一个消息,一个消费者"的机制,会限制其在分布式场景下的可扩展性。
如果需要提高处理能力,只能通过增加消费者实例的数量,而无法像 Kafka 那样做到真正的并行消费。
负载均衡困难
RabbitMQ 自身的负载均衡机制较为简单,主要依赖于将消息平均分配给各个消费者。
在分布式场景下,需要更复杂的负载均衡策略来应对动态的消费者变化。
容错性较弱
由于消息的处理依赖于单一消费者,一旦某个消费者实例故障,该实例处理的消息将无法被其他实例消费。
这可能会导致消息丢失或处理延迟等问题。
消费者管理复杂
在分布式环境中,需要自行管理多个消费者实例之间的状态协调和消息确认逻辑。
这增加了开发和运维的复杂度。
小结
相比之下,Kafka 的分区和消费者组机制更加适合分布式系统的构建。它可以实现真正的并行消费,并提供自动的分区再均衡等功能,大大简化了分布式场景下的开发和运维工作。
当然,RabbitMQ 也提供了一些分布式特性,如集群部署、镜像队列等,但仍然无法完全匹配 Kafka 在大规模分布式处理场景下的优势。
所以,对于需要高吞吐量、高扩展性的分布式系统,Kafka 可能会是一个更合适的选择。而对于中小型的异步消息处理需求,RabbitMQ 的传统消息队列模型也是一个不错的选择。
kafaka简单实例
假设我们有一个电商网站,需要处理来自不同渠道的订单信息。我们可以使用 Kafka 来实现这个场景:
生产者
- 电商网站的各个渠道(如移动应用、PC 网站、第三方平台等)将订单信息发送到 Kafka。
- 每个渠道都有自己的 Kafka 生产者,向不同的 Kafka 主题(Topic)发送消息。
分区
- 我们为订单主题(Topic)创建多个分区,比如按照订单来源渠道划分。
- 这样可以实现对不同渠道的订单数据进行并行处理。
消费者
- 我们有多个消费者实例,负责消费订单主题的消息。
- 每个消费者实例都会消费主题的所有分区,但是会被分配到不同的分区进行处理。
消费者组
- 我们将这些消费者实例划分到不同的消费者组中。
- 同一个消费者组内的消费者实例会协调分区的消费,实现负载均衡。
- 如果有新的消费者加入或退出,Kafka 会自动进行分区再均衡。
示例代码(伪代码):
# 生产者
for order in orders_from_channel:producer.send(topic='orders', key=order['channel'], value=order)# 消费者
consumer = KafkaConsumer(topic='orders',group_id='order_processing_group',bootstrap_servers=['kafka1:9092', 'kafka2:9092', 'kafka3:9092']
)for message in consumer:process_order(message.value)在这个场景中,Kafka 的分区和消费者组机制发挥了重要作用:
分区确保了不同渠道的订单数据能够被并行处理,提高了整体的吞吐量。
消费者组机制实现了消费者实例之间的负载均衡,并能应对动态的消费者变化。
整个系统具有较强的可扩展性和容错性,能够应对订单量的增长和中间件故障。
相关文章:

谈谈kafaka的并行处理,顺带讲讲rabbitmq
简介 Kafka 是一个分布式流处理平台,它支持高效的并行处理。Kafka 的并行处理能力主要体现在以下几个方面: 分区(Partition)并行 Kafka 将数据存储在称为"分区"的逻辑单元中。每个分区可以独立地并行地进行读写操作。生产者可以根据分区策略,将数据写入到指定的分…...

P3056 [USACO12NOV] Clumsy Cows S
[USACO12NOV] Clumsy Cows S 题目描述 Bessie the cow is trying to type a balanced string of parentheses into her new laptop, but she is sufficiently clumsy (due to her large hooves) that she keeps mis-typing characters. Please help her by computing the min…...

智赢选品,OZON数据分析选品利器丨萌啦OZON数据
在电商行业的激烈竞争中,如何快速准确地把握市场动态、洞察消费者需求、实现精准选品,是每个电商卖家都面临的挑战。而在这个数据驱动的时代,一款强大的数据分析工具无疑是电商卖家们的得力助手。今天,我们就来聊聊这样一款选品利…...

Canal自定义客户端
一、背景 在Canal推送数据变更信息至MQ(消息队列)时,我们遇到了特定问题,尤其是当消息体的大小超过了MQ所允许的最大限制。这种限制导致数据推送过程受阻,需要相应的调整或处理。 二、解决方法 采用Canal自定义客户…...
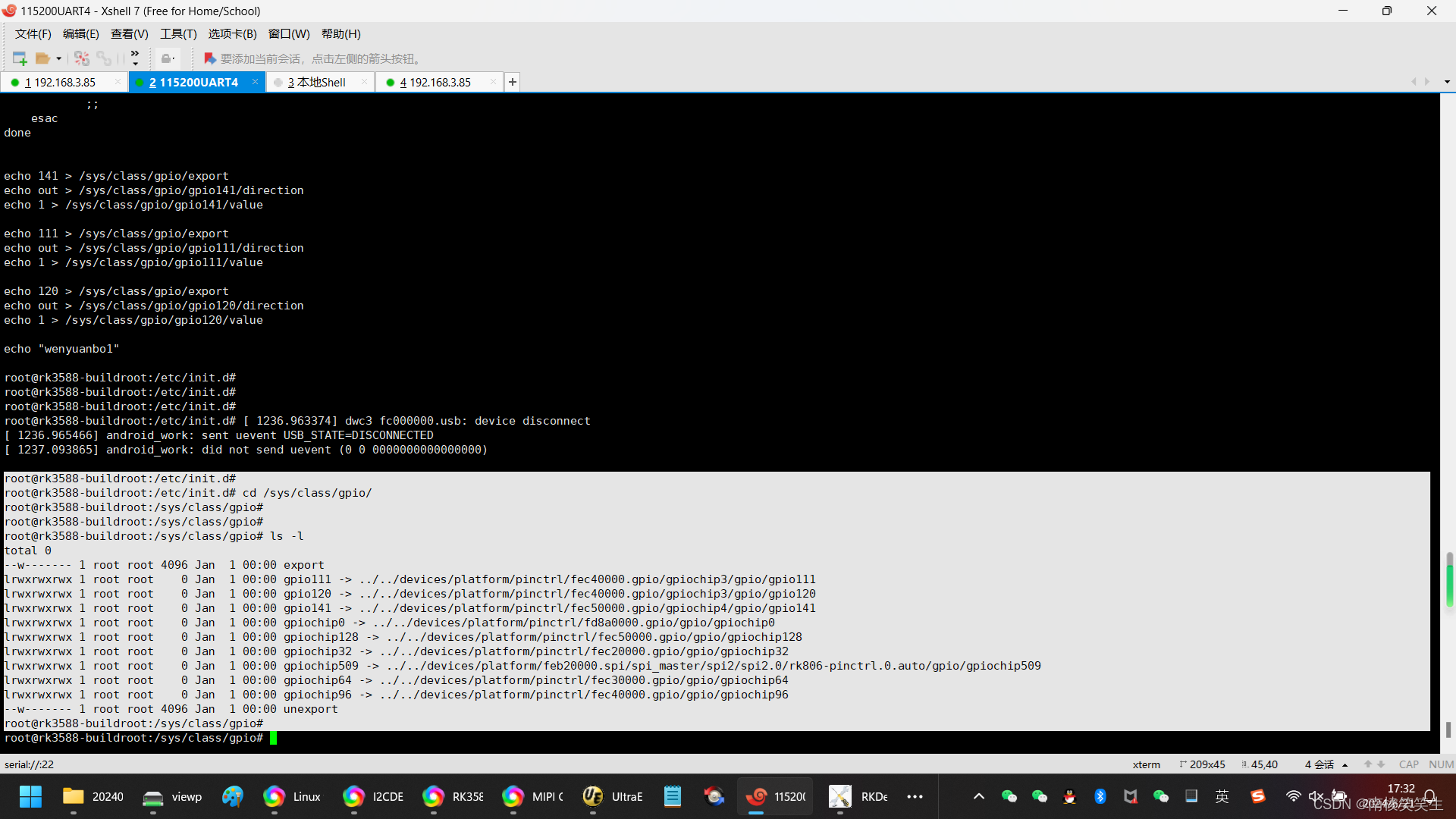
20240621将需要自启动的部分放到RK3588平台的Buildroot系统的rcS文件中
20240621将需要自启动的部分放到RK3588平台的Buildroot系统的rcS文件中 2024/6/21 17:15 开发板:飞凌OK3588-C SDK:Rockchip原厂的Buildroot 缘起:在凌OK3588-C的LINUX R4系统启动的时候,需要拉高GPIO4_B5、GPIO3_B7和GPIO3_D0。…...
掌握数据魔方:Xinstall引领ASA全链路数据归因新纪元
一、引言 在数字化时代,数据是App推广和运营的核心驱动力。然而,如何准确获取、分析并应用这些数据,却成为了许多开发者和营销人员面临的痛点。Xinstall作为一款专业的App全渠道统计服务商,致力于提供精准、高效的数据解决方案&a…...

IIS代理配置-反向代理
前后端分离项目,前端在开发中使用proxy代理解决跨域问题,打包之后无效。 未配置前无法访问 部署环境为windows IIS,要在iis设置反向代理 安装代理模块 需要在iis中实现代理,需要安装Application Request Routing Cache和URL重…...
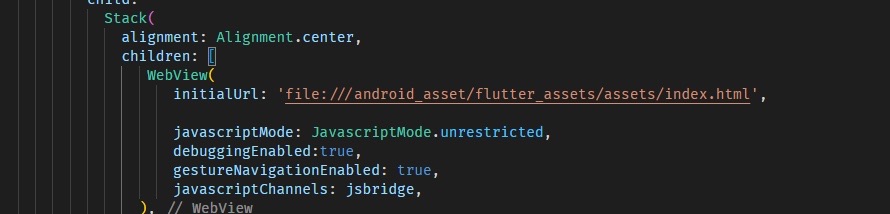
Flutter调用本地web
前言: 在目前Flutter 环境中,使用在线 webview 是一种很常见的行为 而在 app 环境中,离线使用则更有必要 1.环境准备 将依赖导入 2.引入前端代码 前端代码有两种情况 一种是使用打包工具 build 而来的前端代码 另一种情况是直接使用 HTML 文件 …...

AI大模型部署Ubuntu服务器攻略
一、下载Ollama 在线安装: 在linux中输入命令curl -fsSL https://ollama.com/install.sh | sh 由于在linux下载ollama需要经过外网,网络会不稳定,很容易造成连接超时的问题。 离线安装: 步骤一: 下载Ollama离线版本…...

vlan、vxlan、vpc学习
文章目录 前言VLAN (Virtual Local Area Network)定义工作原理优点应用场景限制 VXLAN (Virtual eXtensible Local Area Network)工作原理优点应用场景与VLAN的区别 VPC (Virtual Private Cloud)定义特点优势应用场景与VLAN/VXLAN的关联 总结 前言 VLAN(Virtual Lo…...

低代码开发:加速工业数智化转型发展
引言 在当今全球经济一体化和信息化的深度融合的大环境下,工业数智化转型已经成为推动制造业高质量发展的关键因素。这一转型不仅涉及生产过程的智能化、网络化,还涉及到企业管理、市场服务等全方位的数字化升级,其最终目标是为了实现更高效能…...

python“__main__“的解读
Tutorial Gross tutorial 有些模块包含了仅供脚本使用的代码,比如解析命令行参数或从标准输入获取数据。 如果这样的模块被从不同的模块中导入,例如为了单元测试,脚本代码也会无意中执行。 这就是 if name ‘main’ 代码块的用武之地。除非…...
Linux Debian12使用podman安装pikachu靶场环境
一、pikachu简介 Pikachu是一个带有漏洞的Web应用系统,在这里包含了常见的web安全漏洞。 二、安装podman环境 Linux Debian系统如果没有安装podman容器环境,可以参考这篇文章先安装podman环境, Linux Debian11使用国内源安装Podman环境 三…...
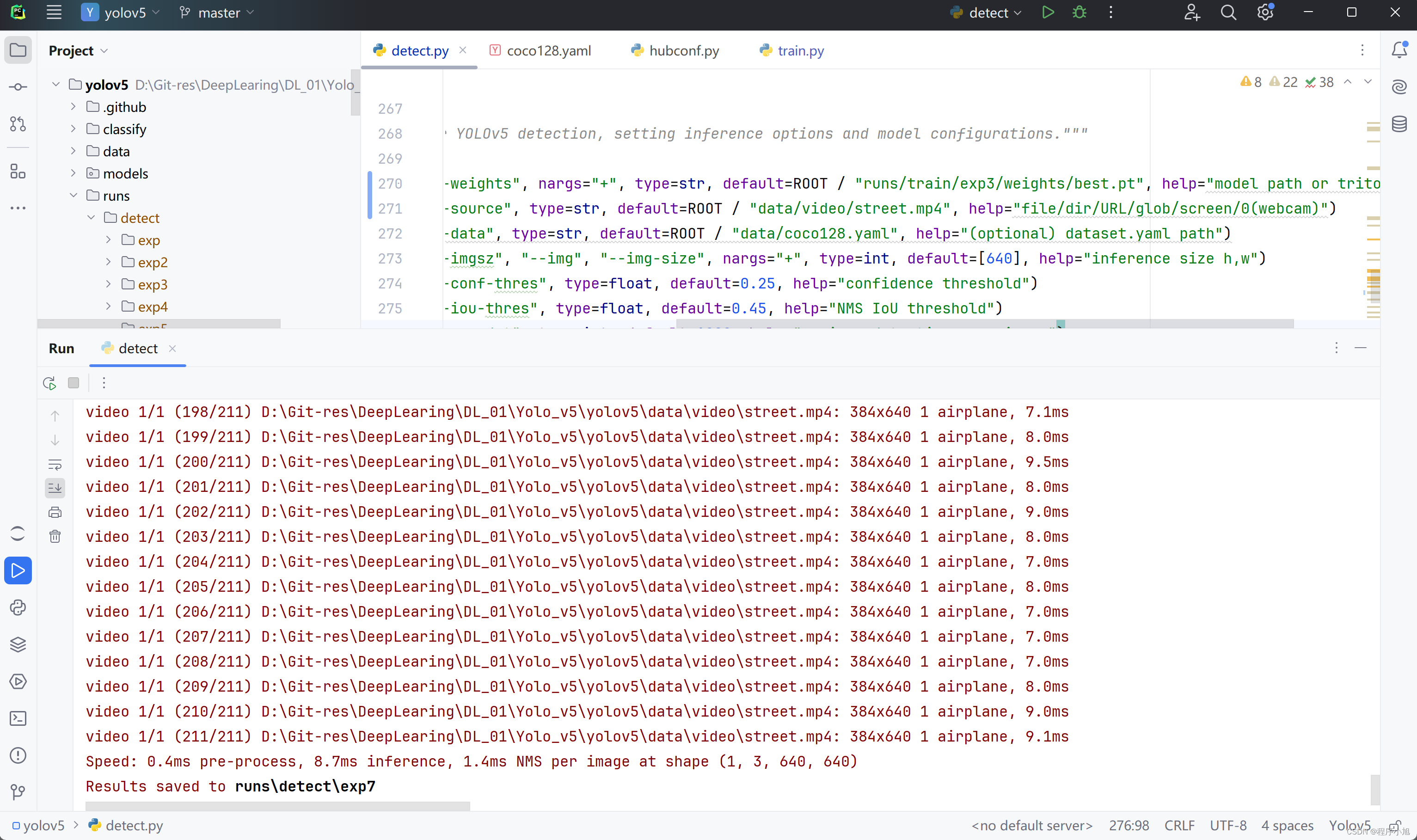
跑通并使用Yolo v5的源代码并进行训练—目标检测
跑通并使用Yolo v5的源代码并进行训练 摘要:yolo作为目标检测计算机视觉领域的核心网络模型,虽然到24年已经出到了v10的版本,但也很有必要对之前的核心版本v5版本进行进一步的学习。在学习yolo v5的时候因为缺少论文所以要从源代码入手来体验…...
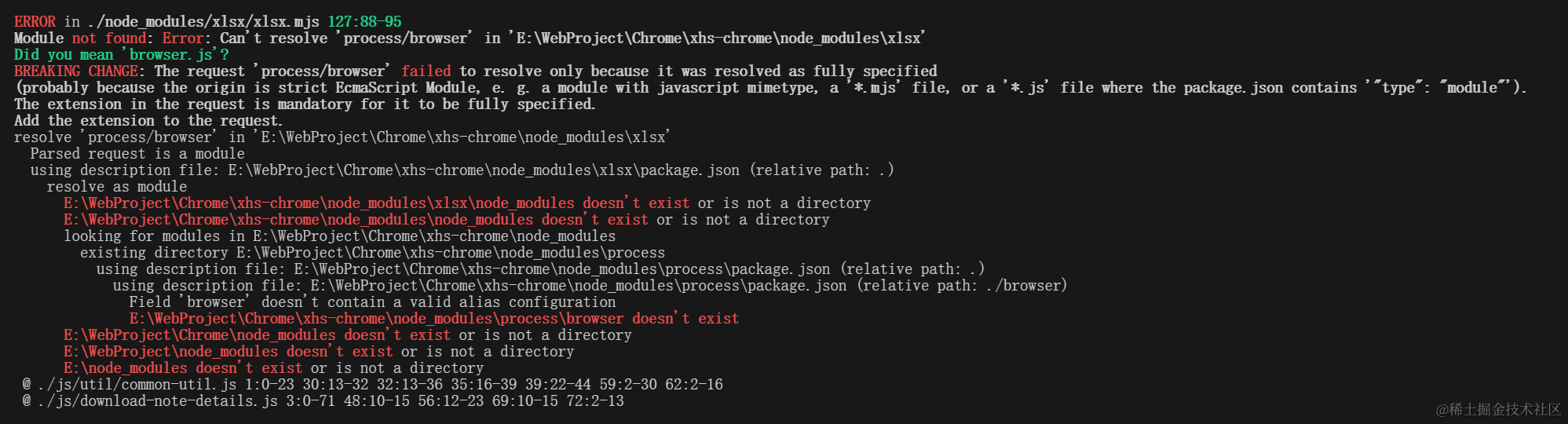
需求虽小但是问题很多,浅谈JavaScript导出excel文件
最近我在进行一些前端小开发,遇到了一个小需求:我想要将数据导出到 Excel 文件,并希望能够封装成一个函数来实现。这个函数需要接收一个二维数组作为参数,数组的第一行是表头。在导出的过程中,要能够确保避免出现中文乱…...
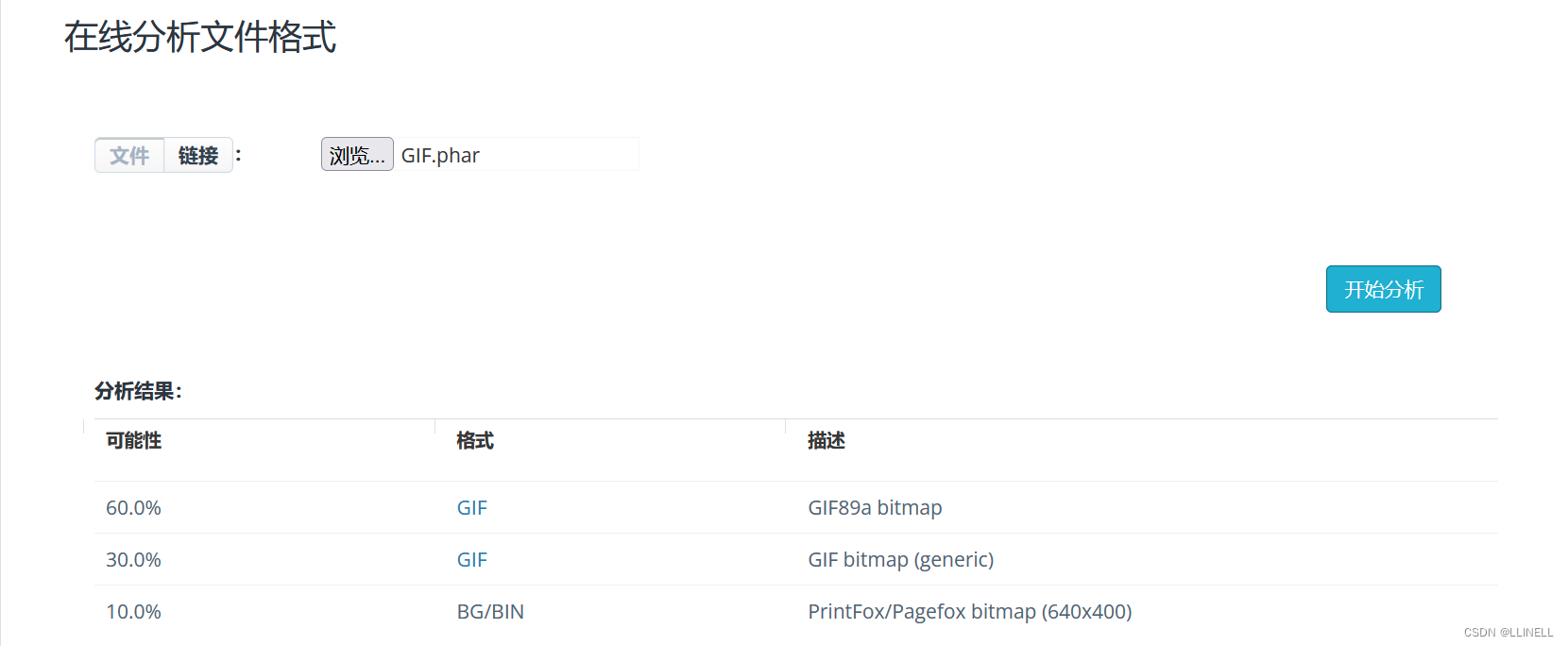
phar反序列化及绕过
目录 一、什么是phar phar://伪协议格式: 二、phar结构 1.stub phar:文件标识。 格式为 xxx; *2、manifest:压缩文件属性等信息,以序列化存 3、contents:压缩文件的内容。 4、signature:签名&#…...
:视频图像滚动问题分析(imx6+TVP5150+Camera))
汽车IVI中控开发入门及进阶(三十):视频图像滚动问题分析(imx6+TVP5150+Camera)
前言: DA主控SOC采用imx6,TVP5150作为camera摄像头视频的解码decode芯片,imx6采用linux系统。 关于imx6,请参阅:汽车IVI中控开发入门及进阶(二十九):i.MX6-CSDN博客 Contributor III:...

给PDF添加书签的通解-姜萍同款《偏微分方程》改造手记
背景 网上找了一本姜萍同款的《偏微分方程》,埃文斯,英文版,可惜没有书签,洋洋七百多页,没有书签,怎么读?用福昕编辑器自然能手工一个个加上,可是劳神费力,非程序员所为…...
在寻找电子名片在线制作免费生成?5个软件帮助你快速制作电子名片
在寻找电子名片在线制作免费生成?5个软件帮助你快速制作电子名片 当你需要快速制作电子名片时,有几款免费在线工具可以帮助你实现这个目标。这些工具提供了丰富的设计模板和元素,让你可以轻松地创建个性化、专业水平的电子名片。 1.一键logo…...

Github 2024-06-16 php开源项目日报 Top10
根据Github Trendings的统计,今日(2024-06-16统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量PHP项目10Livewire: Laravel中构建动态UI组件的全栈框架 创建周期:1818 天开发语言:PHP协议类型:MIT LicenseStar数量:21388 个Fork数量:1…...

快速原型实践:用快马平台十分钟搭建静电地板施工模拟器
快速原型实践:用快马平台十分钟搭建静电地板施工模拟器 静电地板施工是机房、实验室等场所装修的重要环节,涉及基层处理、支架安装、地板铺设、接地检测等多个步骤。传统方式下,施工团队需要反复核对图纸、计算材料用量,过程繁琐…...

m4s-converter:5分钟搞定B站缓存视频永久保存
m4s-converter:5分钟搞定B站缓存视频永久保存 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的烦恼?收…...
)
告别VPN切换!用Docker在Windows上同时挂载两个EasyConnect(保姆级图文教程)
Windows双开EasyConnect的容器化解决方案:告别VPN切换烦恼 早上九点,刚泡好的咖啡还冒着热气,你正通过公司内网VPN处理OA系统里的报销流程。突然钉钉弹出消息——项目服务器出现异常,需要立即排查。你不得不退出办公VPNÿ…...

【OpenClaw】OpenClaw 配置完全指南:从入门到精通
【OpenClaw】OpenClaw 配置完全指南:从入门到精通一、配置文件基础1.1 配置文件位置1.2 配置文件结构二、核心配置详解2.1 Agents 配置2.1.1 基本配置2.1.2 模型配置2.2 Channels 配置2.2.1 飞书配置2.2.2 WebChat 配置2.3 Bindings 配置2.4 Gateway 配置2.5 Plugin…...

怎么部署OpenClaw?2026年京东云10分钟保姆级安装OpenClaw及大模型百炼APIKey指南
怎么部署OpenClaw?2026年京东云10分钟保姆级安装OpenClaw及大模型百炼APIKey指南。OpenClaw作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群聊、个人工作流中自动执行任…...

保姆级教程:在ROS Noetic下用OCS2让Unitree A1/Go1四足机器人站起来并走两步
从零到行走:OCS2与Unitree四足机器人实战指南 1. 环境准备与基础概念 四足机器人控制一直是机器人学中最具挑战性的领域之一。Unitree A1/Go1作为国产开源四足机器人的代表,结合OCS2(Optimal Control for Switched Systems)这一强…...

STM32F103 HAL库实战:用DMA+485实现稳定串口收发,解决方向切换的坑
STM32F103 HAL库实战:用DMA485实现稳定串口收发,解决方向切换的坑 在嵌入式开发中,RS485通信因其抗干扰能力强、传输距离远等优势,被广泛应用于工业控制、楼宇自动化等领域。然而,许多开发者在使用STM32F103系列MCU配合…...

B站缓存视频转换与媒体处理全攻略:从本地存储到高效管理
B站缓存视频转换与媒体处理全攻略:从本地存储到高效管理 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过B站缓存视频无法…...

自媒体效率革命:OpenClaw+Phi-3-vision自动生成图文内容
自媒体效率革命:OpenClawPhi-3-vision自动生成图文内容 1. 为什么选择OpenClawPhi-3组合 去年我刚开始做科技类自媒体时,每天要花4-5小时在内容创作上——从全网搜索素材、筛选图片、写文案到排版发布,整个过程繁琐又耗时。直到发现OpenCla…...

别再只用ROS_LOCALHOST_ONLY了:手把手教你为CycloneDDS写一份高级本地通信配置
突破ROS_LOCALHOST_ONLY局限:CycloneDDS高级本地通信配置实战指南 当你在ROS2开发中遇到网络波动导致通信中断时,是否曾简单粗暴地设置ROS_LOCALHOST_ONLY1,却发现这像一把双刃剑——虽然隔离了外部干扰,却也切断了必要的CLI工具连…...