深度剖析现阶段的多模态大模型做不了医疗
导读
在人工智能的这波浪潮中,以ChatGPT为首的大语言模型(LLM)不仅在自然语言处理(NLP)领域掀起了一场技术革命,更是在计算机视觉(CV)乃至多模态领域展现出了令人瞩目的潜力。
这些先进的技术,以其强大的数据处理能力和深度学习算法,正在被广泛应用于医疗影像分析、辅助诊断、个性化治疗计划制定等多个方面。相信大多数小伙伴都坚定不移地认为大语言模型(LLM)和图文多模态大模型的崛起无疑为医疗领域带来了革命性的变革。
然而,作为一线医疗AI从业者,本文作者(廖方舟,知乎@https://www.zhihu.com/people/liao-fang-zhou-31)却提出了一种截然不同的观点,即在当前的技术和数据储备下,多模态大模型在医疗辅助诊断领域难以取得重大突破。
今天的文章将为大家揭示多模态大模型在辅助诊断、异常检测等方面的潜力与局限,作者不仅分享了对当前技术的深刻见解,还提出了关于数据质量和模型训练的重要思考。如果您对AI在医疗领域的应用充满好奇,或者正在寻找行业内部的深度分析,欢迎深入阅读本文,详情请移步至文末阅读原文。
背景
2023-2024年,科技领域最引人注目的进展无疑是大语言模型(LLM)和图文多模态大模型的飞速发展。除了通用模型的突破,各垂直领域的大模型也如雨后春笋般涌现。医学作为一个至关重要的垂直领域,也见证了多项关键进展。例如,Google Health的Med-PaLM 2 和 OpenAI 的ChatGPT 声称能够通过美国医生资格考试,并具备一定的多模态能力来进行基础的读片工作。
大语言模型在众多自然语言处理(NLP)任务中表现出色,逐渐统合了许多独立的NLP领域。随着数据规模的增加,大语言模型的表现遵循“Scaling Law”不断提升。在翻译、编写代码等应用场景中,ChatGPT 已经迅速推广,取代了许多旧有工具。
这种趋势迫使尚未涉足大模型领域的人们重新思考:是否也应该投入大模型的开发?大模型是否会对现有行业带来巨大冲击?作为医疗AI从业者,我在这些问题上进行了反思。本文将分享我对大模型在医疗领域的一些看法,欢迎大家批评指正。
我得出的基本结论是:在当前的技术和数据储备下,多模态大模型在医疗辅助诊断领域难以取得重大突破。
定义
多模态大模型是指能够同时处理和整合来自多种输入形式(如文本、图像、音频等)的大型机器学习模型。这些模型通过理解和生成多种形式的数据,能够执行跨模态任务,例如从图像生成描述性文本,或根据文本生成相关的图像。这类模型结合了视觉和语言理解能力,使得它们能够在多种应用场景中发挥作用,从而突破单一模态的限制,提供更加丰富和交互性强的用户体验。
多模态大模型的技术架构
多模态大模型通常由一个多模态嵌入模块、跨模态注意力机制和解码器组成:
- 多模态嵌入模块:将不同模态的数据转换为共同的向量表示。这可以通过独立的编码器(如卷积神经网络用于图像,变压器模型用于文本)实现。
- 跨模态注意力机制:允许模型关注不同模态数据中的相关信息,使得一个模态的特征可以增强或补充另一个模态的特征。例如,在图像描述生成中,模型可以利用图像的特征来聚焦生成文本的内容。
- 解码器:将整合后的多模态特征转化为具体的输出形式,如生成自然语言描述、生成图像或其他形式的数据。
在医学应用中,常见的场景是智能读片,即输入X光或CT图像,由模型解读后自动生成报告。患者可以根据模型的反馈进一步提问,深入咨询预期的病情变化、疾病成因、治疗手段等。
一个例子:https://stanford-aimi.github.io/chexagent.html
根据上述技术架构,我们可以看到,大模型在进行描述时,类似于人类,边看图边说话,它的“眼睛”会寻找图像中与问题最相关的部分,提取该区域的特征并进行语言组织。
难点1:微小目标识别
模型要准确描述图像内容的前提是“注意”到图像中的异常之处,这个过程基本等同于“异常检测”或“显著性检测”。医学图像与自然图像的主要区别在于对小目标检测的重视,例如在肺部CT中,结节检测的下限通常是3-4毫米,即4-5像素。考虑到典型的薄层CT图像尺寸为300x512x512像素,这种结节在原图中所占比例仅为1/1e6,在二维图像上相当于1080p照片上的一个像素。

以这张照片为例,普通自然语言描述的输出可能是:
一个人穿着正式服饰,拿着一张演讲稿纸,准备在麦克风前发表演讲。
而模仿医生写报告的方式,输出结果可能是:
下巴有一颗痣,色淡,半球状,无危,直径4mm
这一简单描述综合了器官检测、异常检测、细粒度识别、分割测量等任务,这也是医学AI软件常用的模型拆解思路。在异常检测中,可以使用密集锚点(dense anchor)和相对简单的骨干网络(backbone)提取所有可能的位置点,在细粒度识别中,则只用关注异常位点,使用较复杂的骨干网络以达到更好的诊断效果。
要将这些步骤整合到一个端到端的大模型中,需要一个极大的图像特征图(feature map),确保微小物体特征不被遗漏,同时融合多尺度特征进行复杂计算以保证特征提取的完备性,这意味着巨大的计算量。此外,在巨大的特征图上进行跨注意力(cross-attention)同样计算代价高昂。
这个计算过程也表明,大模型的“看图说话”能力受限于“异常检测”步骤的准确性。如果检测不到异常,就会漏诊;如果假阳性过多,说错话的概率也会显著增加。这一能力的提升,与模型是否多模态、是否大规模关系不大,关键在于视觉模型本身的检测能力。
难点2:语义模糊、风格不一的医生报告
表面上看,医学影像与医生报告似乎是一个天然的图像-文本数据对,而且数据量也不缺乏:每个三甲医院都能轻松提供上百万套CT图像与对应的文本报告。似乎只要多收集几个医院的数据,利用规模效应(scaling law),问题就能迎刃而解。然而,实际情况并非如此。我们来看看一些真实的影像科报告,他们都是骨折病例,来自不同的医院:
双侧胸廓对称,气管及纵隔居中。双肺纹理增强模糊,双下肺背侧胸膜下可见斑片状模糊影。双肺胸膜下可见线样模糊影。气管及支气管通畅。心脏不大。纵隔及肺门未见明显肿大的淋巴结。双侧胸腔可见少许积液。骨窗示右侧锁骨中段似见透亮线影。胸骨下段骨质不连续,局部可见小骨碎片影。TH11椎体骨质不连续,稍变扁。前纵隔脂肪间隙模糊,可见絮状渗出影。双侧诸肋骨未见明显移位性骨折征象。
“1.右肺中叶、左肺上叶下舌段、两肺下叶轻度慢性炎症;2.两肺上叶混合型肺气肿并肺大疱形成;3.两侧胸膜肥厚;4.右侧第4肋陈旧性骨折。”
1.胸骨骨折,右侧第2-5前肋及左侧第6前肋骨折,左肺下叶及右肺中下叶膨胀不全伴挫伤,请结合临床,必要时复查。2.两侧胸腔少量积液。3.附见:脾脏肿大;胆囊周围少量积液。,两肺纹理增多,走向自然,左肺下叶及右肺中下叶膨胀不全伴条片状模糊影,余肺野内未见明显异常密度阴影。所见各级支气管腔通畅,管腔无狭窄。两侧肺门未见肿大淋巴结,纵隔未见肿大淋巴结。胸廓两侧对称,胸膜无增厚,两侧胸腔少量积液。心脏和大血管无异常。胸骨骨折,右侧第2-5前肋及左侧第6前肋骨折。附见:脾脏肿大;胆囊周围少量积液。"
左肺上叶尖后段(Img63)见磨玻璃结节,内似见小泡影,大小为13mm×11mm。左肺上叶尖后段(Img31)、右肺下叶背段(Img126)见实性结节,较大者位于右肺下叶背段,大小为6mm×4mm。右肺上叶尖段、下叶背段(Img122)见类圆形薄/无壁透亮区。双肺下叶背段近胸膜处见少许斑片状、条索状高密度影及胸膜下线影,以右侧为著。双侧肺门无增大,所见气道通畅。心脏大小正常。纵隔无占位性病变,淋巴结不大。左侧胸腔少量积液。肋骨3D重建、曲面重建左侧第7-12肋多发骨皮质连续性中断,断端对位对线尚可;余所示各肋骨未见明确错位骨折。
胸廓对称,胸壁光滑。肺纹理清晰,走行正常,右肺中叶见小结节影(im30)。肺门影不大,气管及各支气管通畅,气管内见稍高密度影。心影不大,各层面未见肿大淋巴结影。骨窗右侧第11肋见骨折线。
患者屏气不佳,伪影较重,影响观察。胸廓两侧对称,支气管血管束部分模糊。双肺可见数个小结节,直径约0.2cm-0.4cm,较大者位于右肺中叶外段(Img38);右肺中叶及左肺下叶后基底段可见少许索条影。主气管、双肺主支气管及其分支管腔通畅。双侧肺门及纵隔内未见明显增大淋巴结。心脏大,局部心包增厚。未见明确胸膜病变。右侧第5前肋局部形态欠规则。
这些报告清晰地展示了语义上的显著差异:1. 不同医院在风格和详细程度上差异很大,报告的行文顺序也没有固定模式。2. 病灶定位方法各异:有些仅基于解剖位置(如“胸骨下段”),有些则使用图像层数(如“img31”)。3. 名词使用习惯差异大:“骨质不连续”=“局部形态欠规则”,“肺门影不大”=“双侧肺门无增大”。
除此之外,如果直接让机器学习模型从这些文本中学习,你将遇到如下问题:
- 需要同时描述全局和注意微小物体 :这意味着需要维护多尺度的特征。
- 缺乏某个病症的描述并不意味着病症不存在 :可能是医生未检查到,或漏诊。这些报告中都提到了骨折,如果你的模型学习了检查骨折的技能,但在新医院的数据中发现这个医院的医生默认不检查微小骨折(因为检查费时且发生率低),模型就无法适应。
- 数据极为长尾和稀疏 :虽然这里选取的都是骨折病例,但实际上骨折发生率仅为1%。如果按照自然分布训练,难以充分训练模型。这些报告中涉及肺、心、肝、骨、脾、胆、气管、淋巴等多个器官,每个器官的病变发生率都不高,难以形成一个在各个疾病上都均衡的训练集。
- 医生的定位描述非常抽象 :如“左侧第6前肋”,“下叶背段(Img122)”,“胆囊周围”,这些位置普通人甚至无法定位。要让大模型从这些报告中学习,前提是模型必须熟悉各种解剖位置,这本身就是一个不小的挑战。还有更模糊的描述,如“双肺可见数个小结节”,面对这么大的肺,模型该如何设置注意力?
在自然图像的描述任务中,尽管不同人对图像的描述角度、详略、指向方式各异,大模型似乎仍能较好地处理这些差异,原因是大家都认可 image caption 是没有标准答案的,我不会因为模型没有对毛泽东下巴上的痣进行细致描述和准确分类而苛责它。然而,医学影像诊断本质上仍然是一个检测和分类任务,使用的指标是 MAP 和 AUC。据我所知,目前还没有证据表明,多模态训练能显著提升 COCO 小目标检测能力?事实上,现有的各类 SOTA 的 open-vocabulary 论文都尚未达到监督学习的水平。
难点3:医生报告并非金标准
即便前两个难点(微小物体检测和报告语言风格问题)可以通过技术手段克服,如在模型结构中引入从粗到细的分级注意力机制,或通过清洗数据统一报告格式,并通过补充标注解决指向不明确的问题,第三个难点却超出了纯技术解决方案的范畴。这一难题,乃是医学AI领域最核心的挑战所在。所有涉足诊断相关产品(如胸部CT、乳腺钼靶、胸部X光)的医学AI公司,几乎无一例外地都经历过一个深刻而苦涩的教训:
医生的标注不可完全依赖。
在行业的早期阶段,大家普遍认可医生的权威性,认为诊断任务需要深厚的经验和长期训练。经验丰富的医生被视为高质量数据集的关键,因此,常用的策略是让低年资医生进行初步标注,高年资医生对有分歧的部分进行质量控制。我们曾投入十余名医生,花费三十余万元标注费用,希望快速扩充数据集,结果训练出来的模型效果却非常垃圾,不得不推翻重来。问题的原因如下:
- 医生之间缺乏共识 :不同医院的医生在诊断标准上存在显著差异。在医院内部,科主任通常具有权威性,可以在科室内推行他的标准。然而,在多医院医生合作时,矛盾便会显现。A医院的年轻医生往往不愿接受B医院高年资医生的标准,因为他们的主任教的标准不同。即使是A医院和B医院的高年资医生之间,也难以达成共识。影像科学领域缺乏一部公认的权威百科全书来解决诊断标准问题,因为该学科本身就面临“同影异病”和“同病异影”的复杂情况。我们统计过,两位初标医生的一致率仅约70%。即便有高年资医生进行校验,也只是将个人偏好注入数据集,而无法真正拉齐初标医生的看法。
2.漏标现象严重 :许多微小病灶只有3-5个像素,容易被人眼忽略。尽管医生接受过专业训练,漏诊仍然不可避免。作为参考,我们从医院报告系统中寻找骨折病例,发生率约为1%,而配备了AI辅助诊断之后,骨折的发病率提高到了10%,原因是医生报告中只会写有临床意义的骨折位点,一些微小骨折,要么没有看见,要么看见了也没有提一下的必要。而机器学习算法,追求的是“标准一致”的训练集,与医生平时的工作习惯进行标注是大不一样的。
- 医生难以约束 :在公司主导的产品开发中,外聘医生的主要动力是通过标注更多数据获取更高报酬。AI公司往往通过数据量考核标注工作,导致标注速度优先于标注质量。此外,由于医生在疾病解释方面具有天然的权威性,即使标注出现错误,算法工程师们也难以提出反驳。即使公司方配备了内部专家控制标注质量,他们也难以全面监督大量标注人员的工作。
因为上述问题的存在,医疗 AI 公司普遍采用了“少数全职精英医生制定标准 + 大量经过培训的非专业人员执行标注 + 使用模型把控标注质量 + 反复迭代清洗数据”的技术路线。一般来说,达到一个勉强可用的水平,所需的数据量如下:
器官分割任务: 约 100 例病例
病灶检测任务: 约 2000 例病例
病灶分类任务: 约 50000 例病例
此外,还需要将各种 corner case 加入,总数据量大致翻倍后,才能达到较高的实用水平。这些数字看起来并不大,似乎触手可及,但实际上,只有亲身参与过这个行业的人才知道,数据的高质量背后需要经历许多轮的模型-标注交叉检查,算法、医生、测试、标注、产品经理之间的反复讨论,修订标注标准,以及无数次标注培训会。这通常需要数个月的辛勤工作,才能沉淀出高质量的数据。
在项目实践中,我深刻体会到,数据的质量远比数量重要。通常,多加新数据来训练效果不如对现有数据进行清洗,甚至由于新数据未经反复清洗,数据质量差,反而可能拉低分数。因此,对于在医学领域如何有效应用 scaling law,我仍然没有完全想明白。
对现在工作的一些讨论
下面我对今年新出的一些工作做一些解读,来辅助验证一下我的观点。
CT-Clip
A foundation model utilizing chest CT volumes and radiology reports for supervised-level zero-shot detection of abnormalities
这篇工作的亮点,是收集了两万多ct图像,和它们的报告文本,使用clip的范式来做训练。我非常钦佩作者将数据开源的举动,要知道对于敏感的医疗数据,开源两万数据+报告,是比发几篇cvpr或者radiology 更加能推动行业进展的事情,其中要经过非常繁琐的数据伦理审查流程。在中国,我们号称数据很多,但是各个医院都拿着自己的数据当个宝,还从来没有过这个级别的开源数据集。
讲完了优点,我们看看作者做了啥,作者在摘要中自豪的宣称,
CT-CLIP outperforms state-of-the-art, fully supervised methods in multi-abnormality detection across all key metrics
主要是这张图:
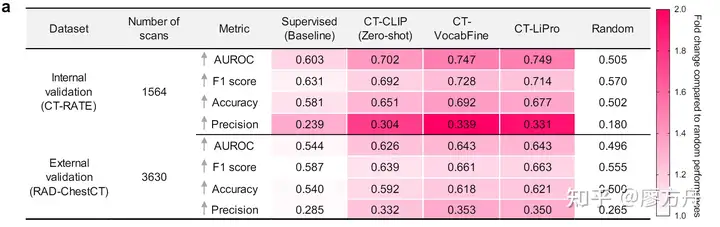
乍一看,比监督学习的baseline 高了14个点,牛逼!但是且慢,你看看这个AUC的数字,0.75,比瞎猜好不了太多,作为baseline 的supervised learning auc 只能做到0.6,这只能说这个baseline 过于垃圾,老中医望闻问切的auc没准都比他高。
chexagent
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
这篇工作的思路和上面那个并没有本质区别,无非是从胸部ct换成了胸部x光。因为胸部x光很早就有开源数据,从有image caption 这个任务以来,就不停有人尝试拿nlp的各种image caption 算法套用到x光上来水论文。我们且不看作者做了多少辛勤的数据和模型工作,看看它的结果(图片中结果是accuracy):
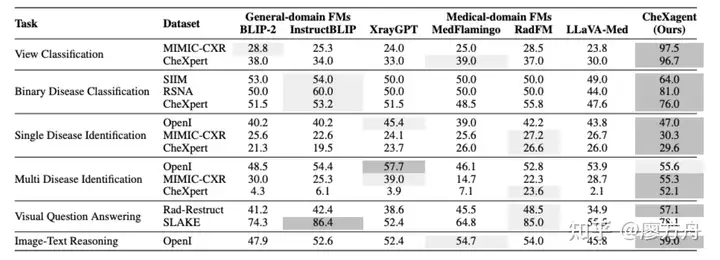
这一堆五五六六的分数…要是我都不好意思发这论文。现在所有做大模型+医疗的单位,都喜欢做一个对着x光做报告生成、患者对答的demo,证明自己有一个会说话的数字医生,似乎取代医生指日可待。实际上这些case都是精挑细选,根本经不起生产环境的考验,看完本文之后,希望各位看官加一个心眼,看看他paper里边的算法指标。
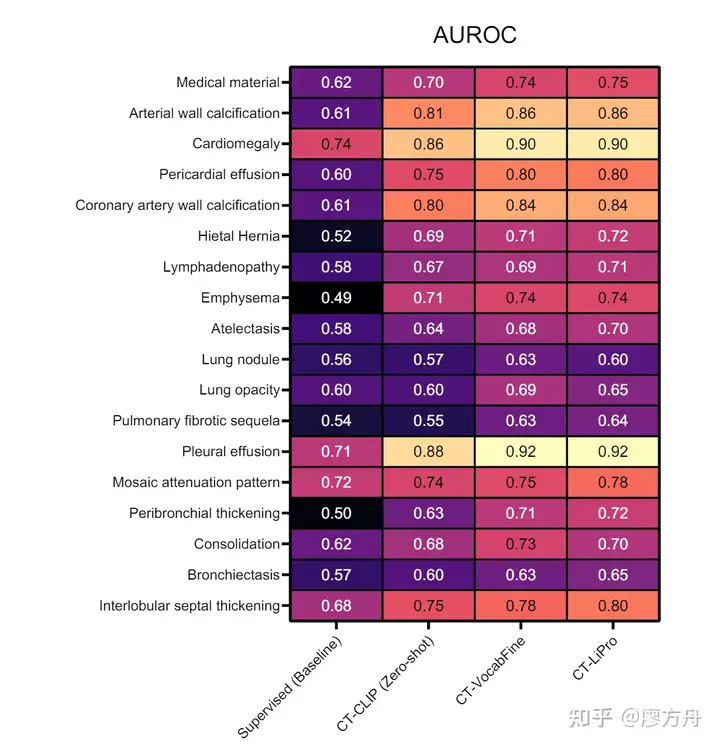
除了指标上的问题,我们找一些细节证据,是如何反映我刚才提到的几个难点的。这是ct-clip中各个病种的auc分数,它分数最高的病种是心肌肥大 Cardiomegaly 和 胸腔积液Pleural effusion ,得分超过0.9,已经摸到勉强可用的边了,分数最低的是肺结节 Lung nodule 和 纤维化后遗症 Pulmonary fibrotic sequela,基本还在瞎猜的范围。
给大家感受一下这几个病怎么看:
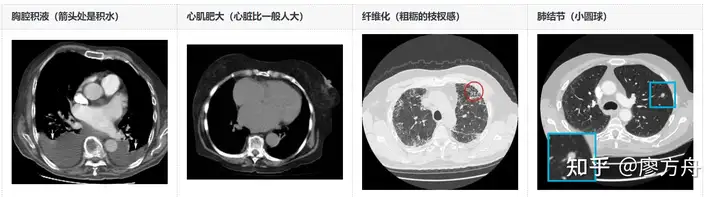
胸腔积液和心肌肥大是较为宏观的图像特征,且基本没有歧义,属于普通人一教就会的类型。纤维化则是类似于图像纹理的弥散特征,它之所以得分低,并非因为难以判别,而是因为纤维化程度较低时,医生往往结合患者是否有肺炎或结核病史后再决定是否记录,如果没有特别病史,可能就不写了。肺结节是一个典型的小目标检测任务,正如我之前提到的,这类端到端模型难以处理得很好。
结合我前面提到的难点,纤维化问题反映了“医生报告并非金标准”的挑战,而肺结节检测则属于“微小目标识别”的难题。至于“语义模糊、风格不一的医生报告”问题,这个数据集仅来源于一家医院,还尚未遇到此类问题。在我们自己的项目中,我会对训练集进行验证,观察其拟合情况,即对训练集进行一次validation,以评估其指标表现。对于一般的检测和分类任务,如果训练集的指标都不高,通常意味着可能存在大量的标注错误。这几篇论文并未提供详细的数据,因此无法进行深入分析。
监督学习做到哪一步了?
那么一般来说,监督学习是什么水平呢,医生自己又是什么水平呢?这个数字的真值其实很难获得,我们以FDA的认证报告作为参考吧。qxr-LN 是 Qure.ai 开发的胸部x光结节检测产品,这是它的FDA 认证报告 总结一下:纯医生:auc=0.73,纯模型:auc=0.94,模型+医生:auc=0.81。这组数字说明了几点:医生是废物,模型比医生强了两个次元,当医生用模型辅助诊断的时候,他甚至还会将正确答案改错。
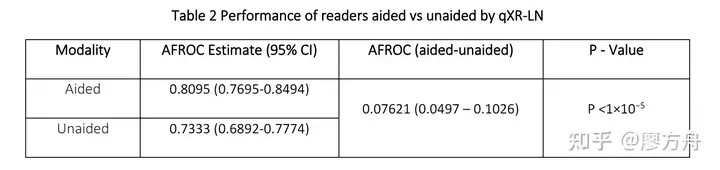
这种乐子数据屡见不鲜,在早期的 FDA 报告里边,Qure还报告过0.99的模型 auc (脑平扫认证报告),属于是华佗再世了。
在辅助诊断产品方面,学术界的成果普遍不如工业界的实用产品。但工业界的测试集和数据往往不公开,因此很难有统一的衡量标准来比较各家AI公司的水平。所谓的临床试验数据,由于各家公司独立进行,也缺乏可比性。此外,临床试验的金标准由医生制定,其标注质量也需要打一个大问号。真的要按照严格的临床试验流程来搞,数字可能不会特别好看,所以 QURE 估计是掺了些水分在指标里的。
抛开可能的水分,实际情况如何呢?正如之前提到的,医生之间的一致性非常低,因此如果细致地评估医生报告的AUC,可能真的只有0.7多。模型的表现通常会比医生高一些,Qure的这款产品在我们的简单评测中表现尚可,基本能用。
然而,从体验和可用性来看,医生的报告仍有优势。医生尽管容易犯一些小错误,比如漏掉小结节或不判别模棱两可的病例,但极少犯严重的错误。模型虽然擅长小微病灶检测,但有时会在大问题上出错,例如,有段时间我们的模型有千分之一的概率将心脏误认为肿瘤(这是胸部CT和胸部X光类产品中常见的bug,几乎家家都出现过)。这种问题虽然在AUC上无足轻重,但对用户的信任度有很大影响。
因此,尽管从得分上看,模型在单病种上的表现不输医生,但从实际体验来看,模型也从未完全胜过医生。现在的医疗AI产品,即使在单病种检测上,也还不能完全替代医生,只能作为辅助工具使用。(跟自动驾驶有点像吧。。。)
多模态大模型的发展路径?
多模态大模型的最大优势,就是能以统一的任务范式,吃下各种数据集,用大语言模型把未经整理、来源各异的标注消化嚼碎了喂给视觉backbone,让模型有极强的“通用“能力。因此他的最大使用场景,是在一些低犯错成本、高数据来源异质性、开放可交互的情景中使用。比如说医生的教学、科研场景,要从医院数据库里边做相似病例检索,以前要花大把金钱和人力做数据清洗,把非结构化的病例进行结构化,有了大模型可能直接做向量数据库检索就行。这是我能想到的现在的技术水平就能马上使用的。
至于大模型能不能更进一步,把我们从监督学习无尽清洗数据的泥潭中拯救出来,还需要大家一起努力
总结
文章有点长,简单帮大家总结下:
首先,对于微小目标识别,医疗影像中的微小病灶(如肺部结节)在图像中占比极小,要求模型具备极高的分辨能力;此外,不同的病灶需要多尺度特征和巨大的特征图,这不仅增加了计算量,还要求极高的精确度。
其次,在实际临床应用中,医生的报告往往风格各异,描述的详细程度和顺序没有固定标准,这使得模型难以统一学习和理解。不仅如此,报告中对病灶的定位方式多样,有些基于解剖位置,有些基于图像层数,这进一步增加了模型训练的复杂性。
除此之外,不同医生和医院之间的诊断标准差异较大,导致标注数据的一致性和可靠性不足,何况医生的漏标现象也很严重,尤其是对一些微小病灶,导致标注数据的质量不高。这导致标注数据的高质量要求反复的模型-标注交叉检查和不断的迭代清洗,这需要大量时间和资源。
因此,高质量的数据远比数量更重要。有效的数据清洗和标准化是提升模型性能的关键。然而,在医学影像中,数据获取和清洗的复杂性使得这一过程尤为艰难。从作者例举的几篇文章(如CT-Clip和CheXagent)来看,即使是多模态大模型在医疗影像分析中的应用,其效果仍然不尽如人意。模型在某些宏观特征(如心肌肥大、胸腔积液)上的表现较好,但在微小病灶(如肺结节、纤维化后遗症)上的检测能力仍显不足。
总的来说,小编认为,多模态大模型在医疗辅助诊断领域的应用仍然是前景广阔,但正如本文作者所述,受限于技术和数据储备的瓶颈,当前还难以取得重大突破。为此,后续对于提高模型在微小病灶检测上的能力、统一医生报告的标准、以及提高数据标注的质量,是未来发展的关键方向。同时,未来需要更加注重数据质量的提升和技术的逐步改进,才能更好地推动多模态大模型在医疗领域的应用和发展。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
相关文章:
深度剖析现阶段的多模态大模型做不了医疗
导读 在人工智能的这波浪潮中,以ChatGPT为首的大语言模型(LLM)不仅在自然语言处理(NLP)领域掀起了一场技术革命,更是在计算机视觉(CV)乃至多模态领域展现出了令人瞩目的潜力。 这些…...
Zabbix 监控 Kubernetes 集群
Zabbix 监控 Kubernetes 集群 Zabbix作为一个成熟且功能强大的监控系统,被许多企业广泛采用。它能够对各种IT基础设施进行全面的监控,包括服务器、网络设备、应用程序等。而将Zabbix与Kubernetes结合,可以实现对Kubernetes集群的全面监控&am…...

网上预约就医取号系统
摘 要 近年来,随着信息技术的发展和普及,我国医疗信息产业快速发展,各大医院陆续推出自己的信息系统来实现医疗服务的现代化转型。不可否认,对一些大型三级医院来说,其信息服务质量还是广泛被大众所认可的。这就更需要…...
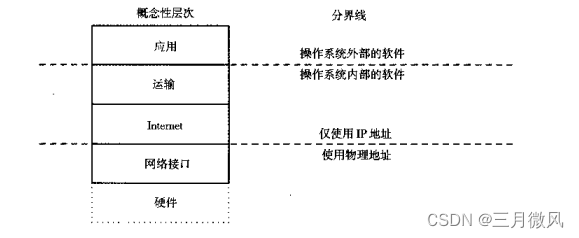
概念描述——TCP/IP模型中的两个重要分界线
TCP/IP模型中的两个重要分界线 协议的层次概念包含了两个也许不太明显的分界线,一个是协议地址分界线,区分出高层与低层寻址操作;另一个是操作系统分界线,它把系统与应用程序区分开来。 高层协议地址界限 当我们看到TCP/P软件的…...

ECharts,拿来吧你!
作为一名前端程序员,在日常的项目开发中,我们会遇到各种各样的图表设计,那么,为了提高我们的开发效率,ECharts便应运而生了!它提供了丰富的图表样式和多浏览器支持的API接口,不仅能够将静态的数据转换为图表,还可以动态的请求后端传递过来的数据,将其以可视化的形式展现给用户,…...

【DICOM】BitsAllocated字段值为8和16时区别
一、读取dicom C# 使用fo-dicom操作dicom文件-CSDN博客 二、DICOM中BitsAllocated字段值为8和16时区别 位深度差异: 当BitsAllocated为8时,意味着每个像素使用8位来表示其灰度值。这允许每个像素有2^8256种不同的灰度等级,适用于那些不需要高…...
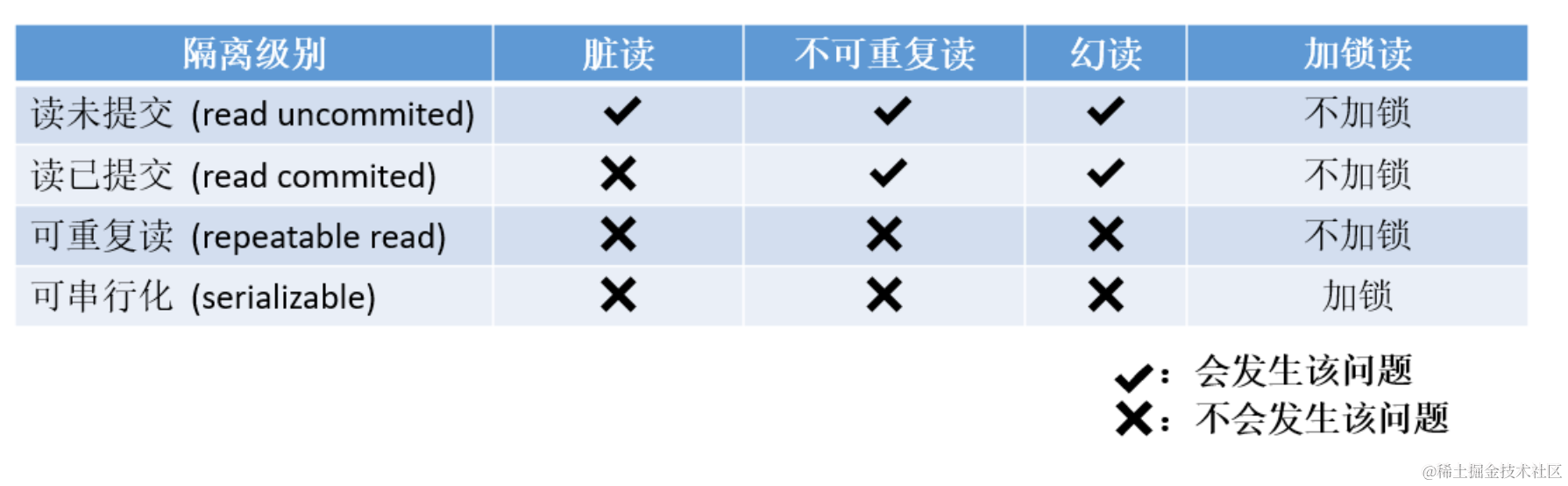
【MySQL】 -- 事务
如果对表中的数据进行CRUD操作时,不加控制,会带来一些问题。 比如下面这种场景: 有一个tickets表,这个数据库被两个客户端机器A和B用时连接对此表进行操作。客户端A检查tickets表中还有一张票的时候,将票出售了&#x…...

c#调用c++生成的dll,c++端使用opencv, c#端使用OpenCvSharp, 返回一张图像
c代码: // OpenCVImageLibrary.cpp #include <opencv2/opencv.hpp> #include <vector> extern "C" { __declspec(dllexport) unsigned char* ReadImageToBGR(const char* filePath, int* width, int* height, int* step) { cv::Mat i…...

【Android面试八股文】你能说一说View绘制流程与自定义View注意点吗?
文章目录 一、自定义View的构造函数以及各参数的用法二、自定义View的几种方式三、自定义View的绘制流程四、自定义View需要注意的一些点五、举个例子一、自定义View的构造函数以及各参数的用法 在Android中,自定义View通常需要提供多个构造函数,以适应不同的使用场景。主要…...
【第24章】Vue实战篇之用户信息展示
文章目录 前言一、准备1. 获取用户信息2. 存储用户信息3. 加载用户信息 二、用户信息1.昵称2.头像 三、展示总结 前言 这里我们来展示用户昵称和头像。 一、准备 1. 获取用户信息 export const userInfoService ()>{return request.get(/user/info) }2. 存储用户信息 i…...
“打造智能售货机系统,基于ruoyi微服务版本生成基础代码“
目录 # 开篇 1. 菜单 2. 字典配置 3. 表配置 3.1 导入表 3.2 区域管理 3.3 合作商管理 3.4 点位管理 4. 代码导入 4.1 后端代码生成 4.2 前端代码生成 5. 数据库代码执行 6. 点位管理菜单顺序修改 7. 页面展示 8. 附加设备表 8.1 新增设备管理菜单 8.2 创建字…...
oracle12c到19c adg搭建(五)dg搭建后进行切换19c进行数据字典升级
一、备库切主库升级 12c切换为19c主库的时候是由低版本到高版本所以cdb和pdb的数据字典需要进行升级才可以让数据与软件版本兼容。 1.1切换 SQL> alter database recover managed standby database finish; Database altered. SQL> alter database commit to switcho…...

在公司的一些笔记
6.19 记住挂载在windows上的账户是DAHUATECH\401593,不是401593Windows与linux不能同时挂载在虚拟盘上 6.21 /******************************************************************************* pdc_ledSy7806e.c* * Description: 提供I2C访问sy7806e。 * * …...

2020C++等级考试二级真题题解
202012数组指定部分逆序重放c #include <iostream> using namespace std; int main() {int a[110];int n, k;cin >> n >> k;for (int i 0; i < n; i) {cin >> a[i];}for (int i 0; i < k / 2; i) {swap(a[i], a[k - 1 - i]);}for (int i 0…...

面试官:聊聊 nextTick
前言 在最近的面试中,不少面试官叫我聊聊 nextTick,nextTick 是个啥,这篇文章咱来好好聊聊! 我的回答 nextTick 是官方提供的一个异步方法,用于在 DOM 更新之后执行回调。正好在我的项目中用到了,就拿它来形容一下,大概的场景是渲染一个列表,每次点击按钮就会往列表后…...
)
shell编程之条件语句(shell脚本)
条件测试操作 要使shell脚本程序具备一定的“智能”,面临的第一个问题就是如何区分不同的情况以确定执行何种操作。例如,当磁盘使用率超过95%时,发送告警信息;当备份目录不存在时,能够自动创建;当源码编译程序时,若配置失败则不再继续安装等。 shell环境根据命令执行后…...

QT中QSettings的使用系列之二:保存和恢复应用程序主窗口
1、核心代码 #include "widget.h" #include "ui_widget.h" #include <QSettings> #include <QDebug> #include <QColo...

Linux系统上安装Miniconda并安装特定版本的Python
要在Linux系统上安装Miniconda并安装特定版本的Python(例如3.10.12),请按照以下步骤进行操作: 1. 下载并安装Miniconda 下载Miniconda安装脚本: 使用wget或curl下载Miniconda安装脚本。以下是使用wget的命令ÿ…...

解决Qt中 -lGL无法找到的问题
在使用Qt Creator创建并编译新项目时,可能会遇到以下错误: /usr/bin/ld: cannot find -lGL collect2: error: ld returned 1 exit status make: *** [untitled1] Error 1 18:07:41: The process "/usr/bin/make" exited with code 2. Error w…...

【重要】《HTML趣味编程》专栏内资源的下载链接
目录 关于专栏 博主简介 专栏内资源的下载链接 写在后面 关于专栏 本专栏将持续更新,至少含有30个案例,后续随着案例的增加可能会涨价,欢迎大家尽早订阅!(订阅后可查看专栏内所有文章,并且可以下载专栏内的所有资源) 博主简介 ⭐ 2024年百度文心智能体大赛 Top1⭐…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...
VisualXML全新升级 | 新增数据库编辑功能
VisualXML是一个功能强大的网络总线设计工具,专注于简化汽车电子系统中复杂的网络数据设计操作。它支持多种主流总线网络格式的数据编辑(如DBC、LDF、ARXML、HEX等),并能够基于Excel表格的方式生成和转换多种数据库文件。由此&…...