java -- stream流
stream流一直在使用,但是感觉还不够精通,现在深入研究一下。 stream这个章节中,会用到
函数式接口–lambda表达式–方法引用的相关知识
介绍
是jdk8引进的新特性。
stream流是类似一条流水线一样的操作,每次对数据进行一个操作。
可以简化操作
我觉得还是以官方文档来说比较好
官方介绍
部分分散到后面去了,有的我用我自己的话换了一下
初步介绍
支持顺序和并行聚合操作的元素序列。以下示例说明了使用 和 IntStream的Stream聚合操作:
int sum = widgets.stream() .filter(w -> w.getColor() == RED).mapToInt(w -> w.getWeight()).sum();
在此示例中, widgets是一个单列集合。我们通过创建一个Collection.stream()对象流,过滤它以生成仅包含红色小部件的流 Widget,然后将其转换为代表每个红色小部件权重的值流 int。然后将此流相加以生成总重量。
流的组成
为了执行计算,流操作被组合到流管道中。
流管道组成:
- 源(可能是数组、集合、生成器函数、I/O 通道等)
- 零个或多个中间操作
- 一个终端操作组成。
流是懒惰的;仅在启动终端操作时对源数据执行计算,并且仅在需要时使用源元素。
实现
没看懂
流实现在优化结果计算方面允许很大的自由度。例如,流实现可以自由地从流管道中执行操作(或整个阶段),因此可以免除行为参数的调用,如果它可以证明它不会影响计算结果。这意味着行为参数的副作用可能并不总是被执行,也不应该被依赖,除非另有规定(例如通过终端操作 forEach 和 forEachOrdered)。
和集合的区别
集合和流虽然具有一些表面上的相似之处,但具有不同的目标。
流主要关注其元素的有效管理和访问。相比之不提供直接访问或操作其元素的方法,而是关注以声明方式描述其源以及将在该源上聚合执行的计算操作。但是,如果提供的流操作不提供所需的功能,则和 iterator() spliterator() 操作可用于执行受控遍历。
并发
流管道可以被视为对流源的查询。除非源明确设计为并发修改(例如 ConcurrentHashMap),否则在查询流源时修改流源可能会导致不可预测或错误的行为。
除了明确说可以修改的,一般都可以对其进行修改,向迭代器一样,下面是对上面的解释
大多数流操作接受描述用户指定行为的参数,例如在上面的示例中传递给 mapToInt的 lambda 表达式 w -> w.getWeight()。为了保持正确的行为,这些行为参数:
必须是非干扰的(它们不修改流源);和
在大多数情况下,必须是无状态的(其结果不应依赖于在流管道执行期间可能更改的任何 状态 )。
参数
此类参数始终是函数接口(如 Function)的实例,并且通常是 lambda 表达式或方法引用。除非另有指定,否则这些参数必须为非空值。
一个流只能操作一次(调用中间流或终端流操作)。
不可用重复操作,stream对象不可用第二次,所以我们一般使用链式编程。
例如,这排除了“分叉”流,其中同一源馈送两个或多个管道,或同一流的多个遍历。如果流实现检测到流正在重用,则可能会引发 IllegalStateException 。但是,由于某些流操作可能会返回其接收器而不是新的流对象,因此可能无法在所有情况下都检测到重用。
最后
流有一个 close() 方法并实现 AutoCloseable.在流关闭后对其进行操作将引发 IllegalStateException。
自动关闭
大多数流实例在使用后实际上并不需要关闭,因为它们由集合、数组或生成函数支持,不需要特殊的资源管理。通常,只有源为 IO 通道的流(例如 返回 Files.lines(Path)的流)才需要关闭。如果流确实需要关闭,则必须在 try-with-resources 语句或类似控制结构中将其作为资源打开,以确保在其操作完成后立即关闭它。
流管道可以按顺序或并行执行。此执行模式是流的属性。流是通过顺序执行或并行执行的初始选择创建的。
(例如,创建一个顺序流, Collection.stream() 并 Collection.parallelStream() 创建一个并行流。这种执行模式的选择可以由 or sequential() parallel() 方法修改,也可以用该方法 isParallel() 查询。
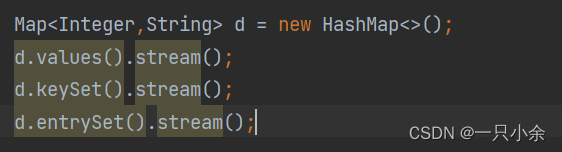
获取stream流
双列集合是不可用直接获取的。
| 数据类型 | 获取方法 |
|---|---|
| 数组 | Arrays.stream(数组); |
| 单列集合 | 直接调用Collection的stream方法 |
| 双列集合 | 转换为单列在获取,如keyset/entryset |
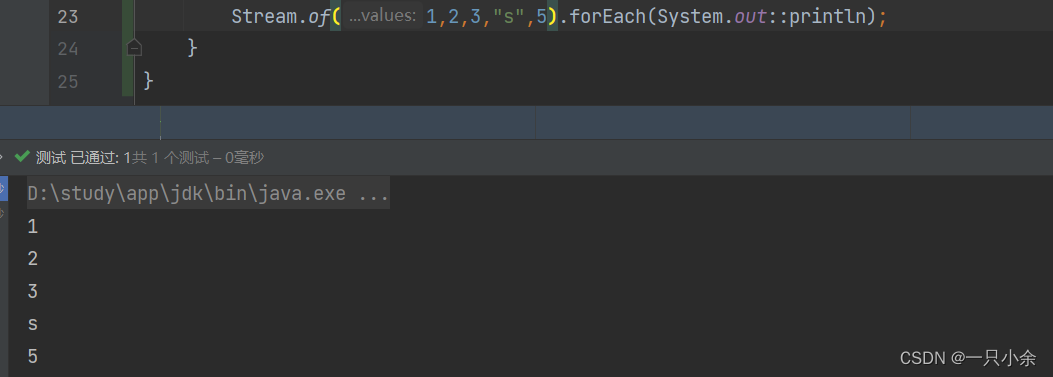
| 零散数据 | stream.of(T…values); |
数组

单列集合

双列集合
零散数据
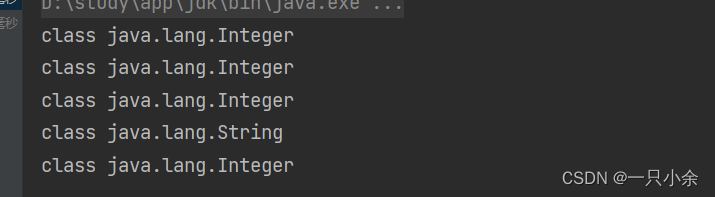
不过不理解为什么不是一个类型也可以

获取其class对象,发现就是不同类型
除了 Stream对象引用流之外,还有LongStream和 的IntStream原始专用化,所有这些都称为“流”,并符合此处描述的特征和DoubleStream限制。
那么如果固定类型的话
选取固定的stream来进行封装
方法
中间方法
filter
过滤,只保留符合条件的数据
Stream<T> filter(Predicate<? super T> predicate);

limit
限制流元素的大小
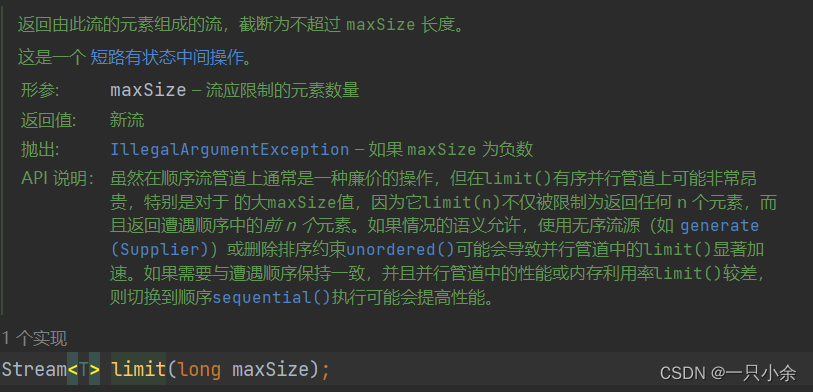
skip
舍弃前面的n个元素,如果少于n则返回空流

limit和skip可以组合使用,获取n-maxsize中的元素
distinct
去重,依靠hashcode和equals

依靠hashset去重
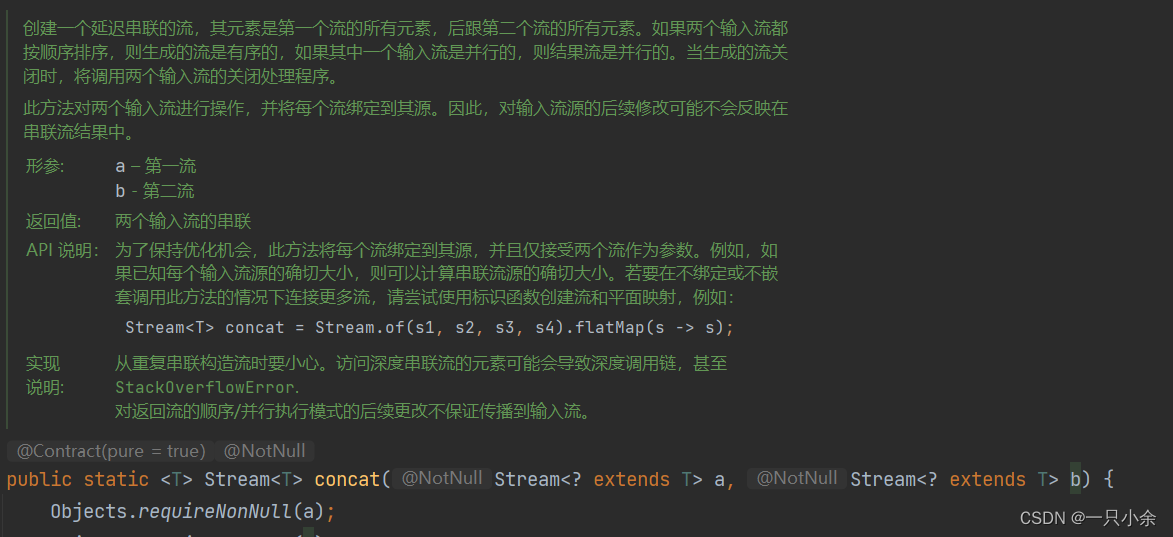
concat
将2个流合成一个
静态方法,需要类名调用
map
类型转换/对每一个进行操作
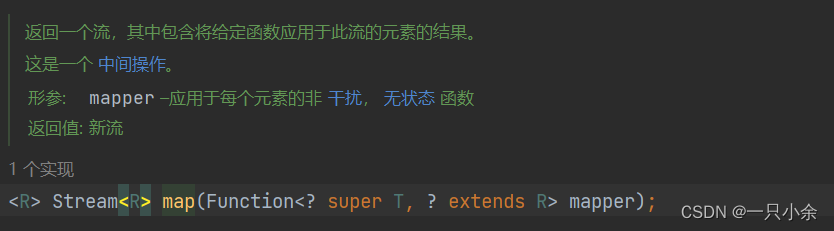
类型转换,T和R类型不相同
如果只是操作则T和R类型相同
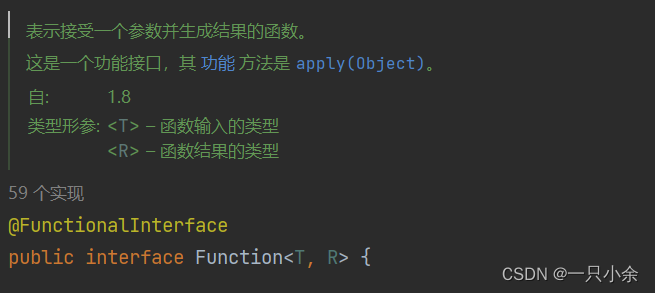
同类型的
Stream.of(2,3,4,5,6,7,8,9).map(i -> i++).forEach(System.out::println);
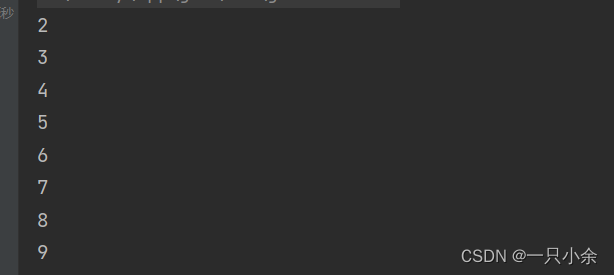
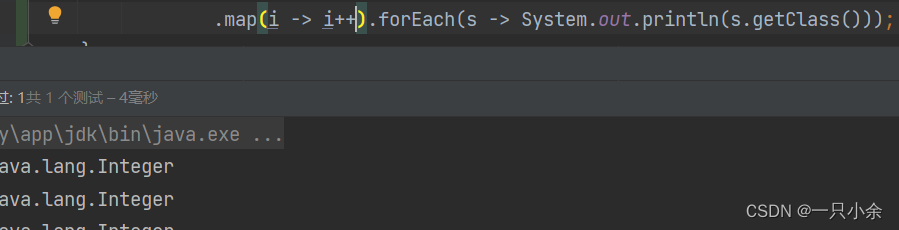
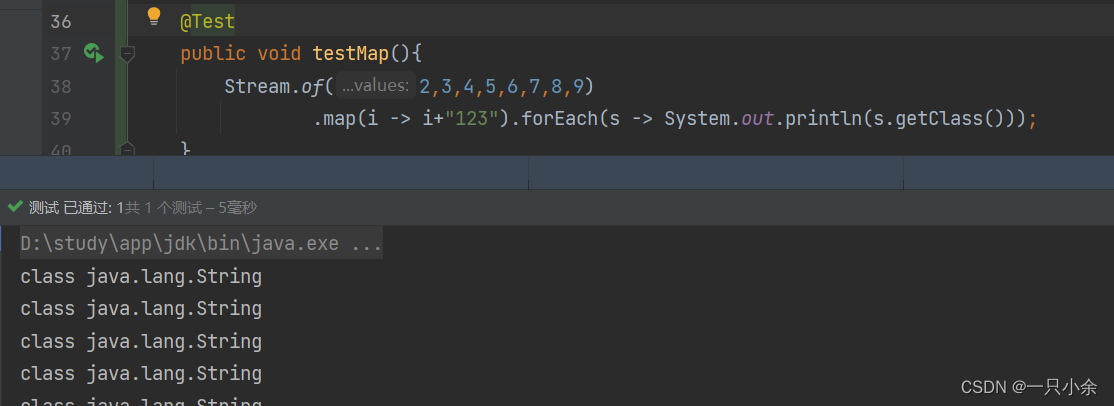
不同类型
终结方法
forEach
遍历,这个上面用过了
void forEach(Consumer<? super T> action);
count
返回此流中的元素计数
long count = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).map(i -> i++).count();System.out.println(count);
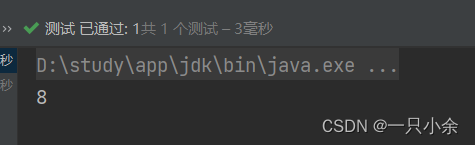
toArray
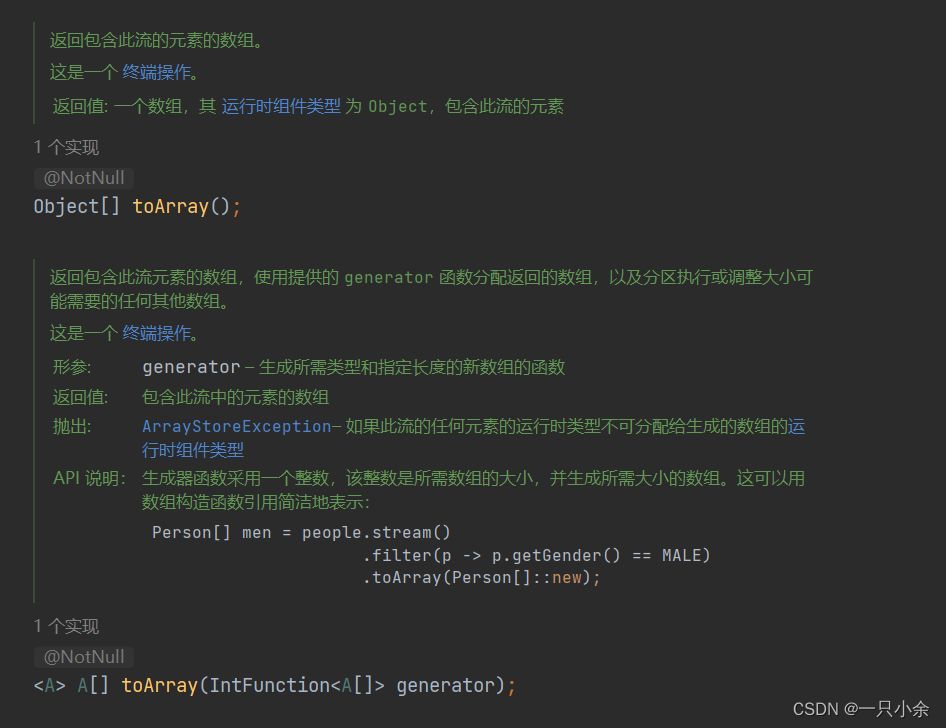
Object[] array =Stream.of(2, 3, 4, 5, 6, 7, 8, 9).map(i -> i++).toArray();System.out.println(Arrays.toString(array));
Integer[] arr = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).map(i -> i++).toArray(Integer[]::new);System.out.println(Arrays.toString(arr));
collect
收集成集合,如set,list,map
list
List<Integer> list = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).filter(s -> s % 2 == 0).collect(Collectors.toList());Assert.assertEquals(list,List.of(2,4,6,8));
set
Set<Integer> set = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).filter(s -> s % 2 == 0).collect(Collectors.toSet());Assert.assertEquals(set,Set.of(2,4,6,8));
map
Stream.of("zhangsan-18","lisi-20","wangwu-22").map(s -> s.split("-")).collect(Collectors.toMap(s -> s[0], s -> s[1])).forEach((k,v) -> System.out.println(k + " : " + v));
这个代码呢,是我写完方法名和开头zhangsan自动生成的。
我开始还在疑惑,咦forEach和collect怎么可能继续用,后来我才想起,collect之后就变成Map集合了,后面这个forEach方法是map集合里面的,不是流里面的了。
测试结果,set和list通过了,map打印也正确

相关文章:
java -- stream流
写在前面: stream流一直在使用,但是感觉还不够精通,现在深入研究一下。 stream这个章节中,会用到 函数式接口–lambda表达式–方法引用的相关知识 介绍 是jdk8引进的新特性。 stream流是类似一条流水线一样的操作,每次对数据进…...

【Spring6】| Bean的四种获取方式(实例化)
目录 一:Bean的实例化方式 1. 通过构造方法实例化 2. 通过简单工厂模式实例化 3. 通过factory-bean实例化 4. 通过FactoryBean接口实例化 5. BeanFactory和FactoryBean的区别(面试题) 6. 使用FactoryBean注入自定义Date 一:…...
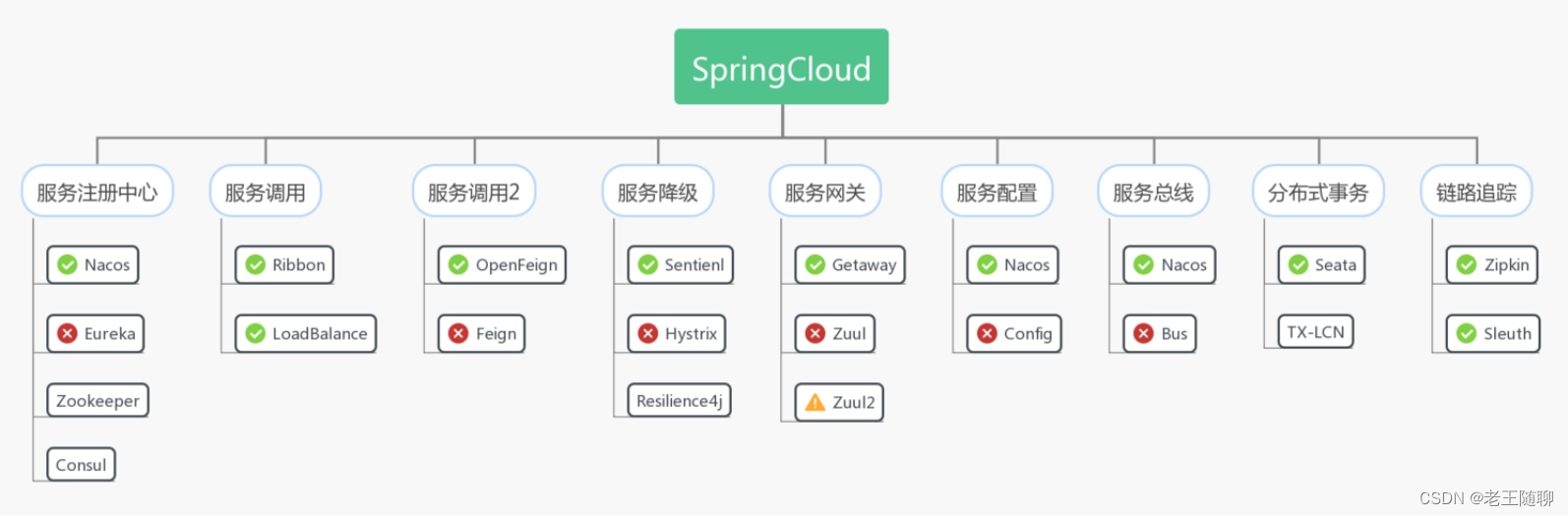
01: 新手学SpringCloud前需知道的5点
目录 第一点: 什么是微服务架构 第二点:为什么需要学习Spring Cloud 第三点: Spring Cloud 是什么 第四点: SpringCloud的优缺点 1、SpringCloud优点 2、SpringCloud缺点 第五点: SpringCloud由什么组成 1&…...

ubuntu apt安装arm交叉编译工具
查找查找编译目标为32位的gcc-arm交叉编译器命令apt-cache search arm|awk index($1,"arm")!0 {print}|grep gcc-arm\|g-arm #或者 apt-cache search arm|awk index($1,"arm")!0 {print}|grep -E gcc-arm|g\\-arm输出如下g-arm-linux-gnueabihf - GNU C co…...

阿里云一面经历
文章目录 ES 查询方式都有哪些?1 基于词项的查询term & terms 查询Fuzzy QueryWildcard Query2 基于全文的查询Match QueryQuery String QueryMatch Phrase Query3 复合查询Bool QueryElasticsearch 删除原理ES 大文章怎么存arthas 常用命令arthas 排查问题过程arthas 工作…...

Java Stream中 用List集合统计 求和 最大值 最小值 平均值
对集合数据的统计,是开发中常用的功能,掌握好Java Stream提供的方法,避免自己写代码统计,可以提高工作效率。 先造点数据: pigs.add(new Pig(1, "猪爸爸", 31, "M", false)); pigs.add(new Pig(…...
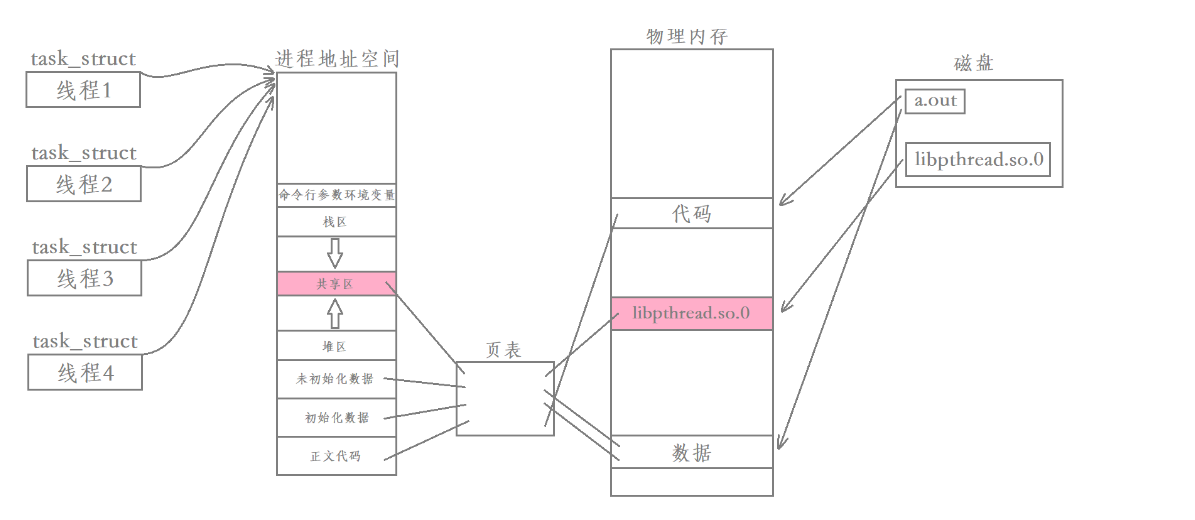
【Linux】多线程---线程控制
进程在前面已经讲过了,所以这次我们来讨论一下多线程。前言:线程的背景进程是Linux中资源及事物管理的基本单位,是系统进行资源分配和调度的一个独立单位。但是实现进程间通信需要借助操作系统中专门的通信机制,但是只这些机制将占…...
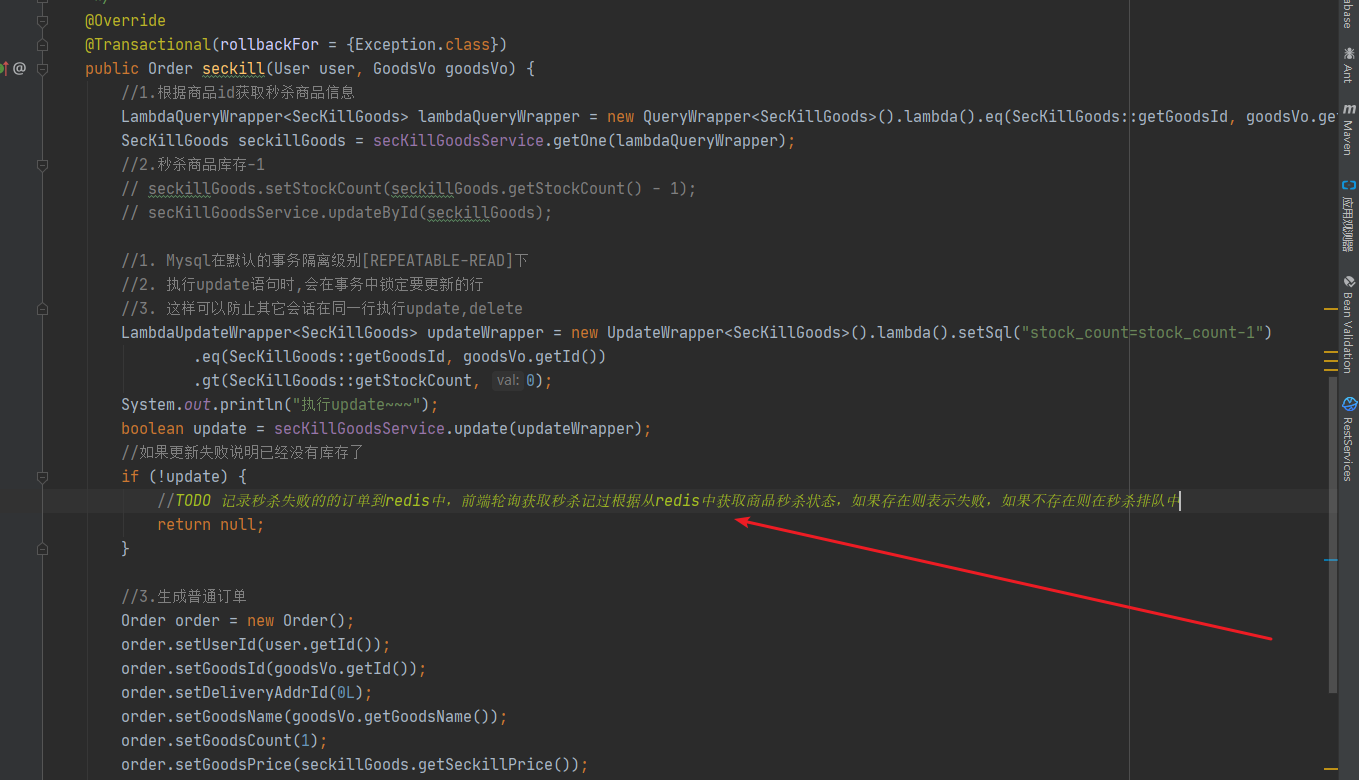
秒杀高并发解决方案
秒杀高并发解决方案 1.秒杀/高并发方案-介绍 秒杀/高并发 其实主要解决两个问题,一个是并发读,一个是并发写并发读的核心优化理念是尽量减少用户到 DB 来"读"数据,或者让他们读更少的数据, 并 发写的处理原则也一样针对秒杀系统需…...

【每日一题】蓝桥杯加练 | Day07
文章目录一、三角回文数1、问题描述2、解题思路3、AC代码一、三角回文数 原题链接:三角回文数 1、问题描述 对于正整数 n, 如果存在正整数 k 使得n123⋯k k(k1)2\frac{k(k1)}{2}2k(k1) , 则 n 称为三角数。例如, 66066 是一个三角数, 因为 66066123⋯363 。 如果一…...

条件语句(分支语句)——“Python”
各位CSDN的uu们你们好呀,最近总是感觉特别特别忙,但是却又不知道到底干了些什么,好像啥也没有做,还忙得莫名其妙,言归正传,今天,小雅兰的内容还是Python呀,介绍一些顺序结构的知识点…...

论文投稿指南——中文核心期刊推荐(国家财政)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...
面向数据安全共享的联邦学习研究综述
开放隐私计算 摘 要:跨部门、跨地域、跨系统间的数据共享是充分发挥分布式数据价值的有效途径,但是现阶段日益严峻的数据安全威胁和严格的法律法规对数据共享造成了诸多挑战。联邦学习可以联合多个用户在不传输本地数据的情况下协同训练机器学习模型&am…...
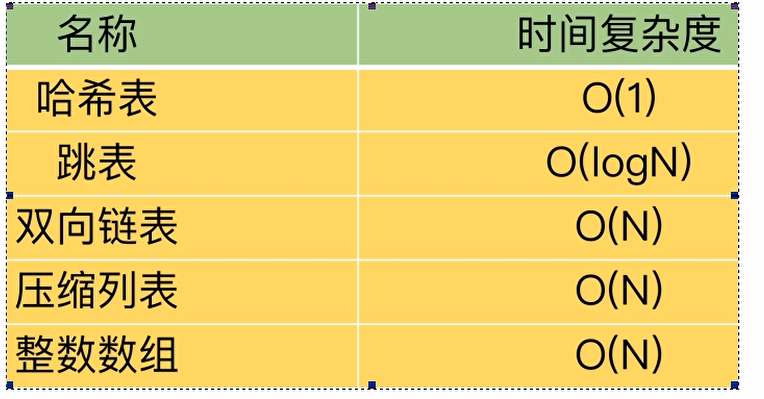
Redis经典五种数据类型底层实现原理解析
目录总纲redis的k,v键值对新的三大类型五种经典数据类型redisObject结构图示结构讲解数据类型与数据结构关系图示string数据类型三大编码格式SDS详解代码结构为什么要重新设计源码解析三大编码格式hash数据类型ziplist和hashtable编码格式ziplist详解结构剖析ziplist的优势(为什…...

Jackson 返回前端的 Response结果字段大小问题
目录 1、问题产生的背景 2、出现的现象 3、解决方案 4、成果展现 5、总结 6、参考文章 1、问题产生的背景 因为本人最近工作相关的对接外部项目,在我们国内有很多程序员都是使用汉语拼音或者部分字母加上英文复合体定义返回实体VO,这样为了能够符合…...

每天五分钟机器学习:你理解贝叶斯公式吗?
本文重点 贝叶斯算法是机器学习算法中非常经典的算法,也是非常古老的一个算法,但是它至今仍然发挥着重大的作用,本节课程及其以后的专栏将会对贝叶斯算法来做一个简单的介绍。 贝叶斯公式 贝叶斯公式是由联合概率推导而来 其中p(Y|X)称为后验概率,P(Y)称为先验概率…...

C++的入门
C的关键字 C总计63个关键字,C语言32个关键字 命名空间 我们C的就是建立在C语言之上,但是是高于C语言的,将C语言的不足都弥补上了,而命名空间就是为了弥补C语言的不足。 看一下这个例子。在C语言中会报错 #include<stdio.h>…...

数据的存储
类型的意义:使用这个类型开辟内存空间的大小(大小决定了使用范围)如何看待内存空间视角类型的基本归类整型家族浮点数家族构造类型指针类型空类型整型存储解构:整型在计算机中占用四个字节,整型分为无符号整型和有符号整型在计算机…...

Linux查看UTC时间
先了解一下几个时间概念。 GMT时间:Greenwich Mean Time,格林尼治平时,又称格林尼治平均时间或格林尼治标准时间。是指位于英国伦敦郊区的皇家格林尼治天文台的标准时间。 GMT时间存在较大误差,因此不再被作为标准时间使用。现在…...
SpringBoot修改启动图标(详细步骤)
目录 一、介绍 二、操作步骤 三、介绍Java学习(题外话) 四、关于基础知识 一、介绍 修改图标就是在资源加载目录(resources)下放一个banner.txt文件。这样运行加载的时候就会扫描到这个文件,然后启动的时候就会显…...

【每日一题Day143】面试题 17.05. 字母与数字 | 前缀和+哈希表
面试题 17.05. 字母与数字 给定一个放有字母和数字的数组,找到最长的子数组,且包含的字母和数字的个数相同。 返回该子数组,若存在多个最长子数组,返回左端点下标值最小的子数组。若不存在这样的数组,返回一个空数组。…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...

Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析
Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析 一、第一轮基础概念问题 1. Spring框架的核心容器是什么?它的作用是什么? Spring框架的核心容器是IoC(控制反转)容器。它的主要作用是管理对…...

医疗AI模型可解释性编程研究:基于SHAP、LIME与Anchor
1 医疗树模型与可解释人工智能基础 医疗领域的人工智能应用正迅速从理论研究转向临床实践,在这一过程中,模型可解释性已成为确保AI系统被医疗专业人员接受和信任的关键因素。基于树模型的集成算法(如RandomForest、XGBoost、LightGBM)因其卓越的预测性能和相对良好的解释性…...