Apache Paimon系列之:Append Table和Append Queue
Apache Paimon系列之:Append Table和Append Queue
- 一、Append Table
- 二、Data Distribution
- 三、自动小文件合并
- 四、Append Queue
- 五、压缩
- 六、Streaming Source
- 七、Watermark Definition
- 八、Bounded Stream
一、Append Table
如果表没有定义主键,则默认为追加表。
您只能以流式方式将完整记录插入到表中。此类表适合不需要流式更新的用例(例如日志数据同步)。
CREATE TABLE my_table (product_id BIGINT,price DOUBLE,sales BIGINT
);
二、Data Distribution
默认情况下,append table没有bucket的概念。它的作用就像一个 Hive 表。数据文件放置在分区下,可以在其中重新组织和重新排序以加快查询速度。
三、自动小文件合并
在流式写入作业中,如果没有bucket定义,则writer中不会进行压缩,而是使用Compact Coordinator扫描小文件并将压缩任务传递给Compact Worker。在流模式下,如果在flink中运行insert sql,拓扑将是这样的:
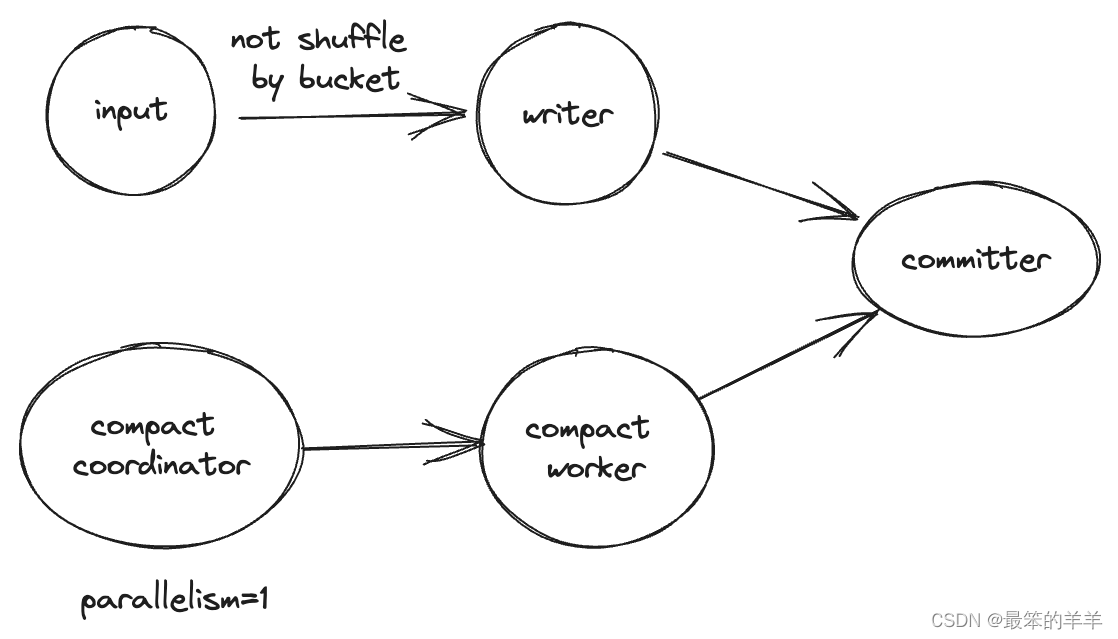
不用担心反压,压实永远不会反压。
如果将 write-only 设置为 true,Compact Coordinator 和 Compact Worker 将在拓扑中删除。
自动压缩仅在 Flink 引擎流模式下支持。您还可以通过 paimon 中的 flink 操作在 flink 中启动压缩作业,并通过 set write-only 禁用所有其他压缩。
四、Append Queue
在这种模式下,您可以将append table视为一个由bucket分隔的队列。同一个桶中的每条记录都是严格排序的,流式读取会严格按照写入的顺序将记录传输到下游。使用此模式,不需要进行特殊配置,所有数据都会以队列的形式放入一个桶中。您还可以定义bucket和bucket-key以实现更大的并行性和分散数据。
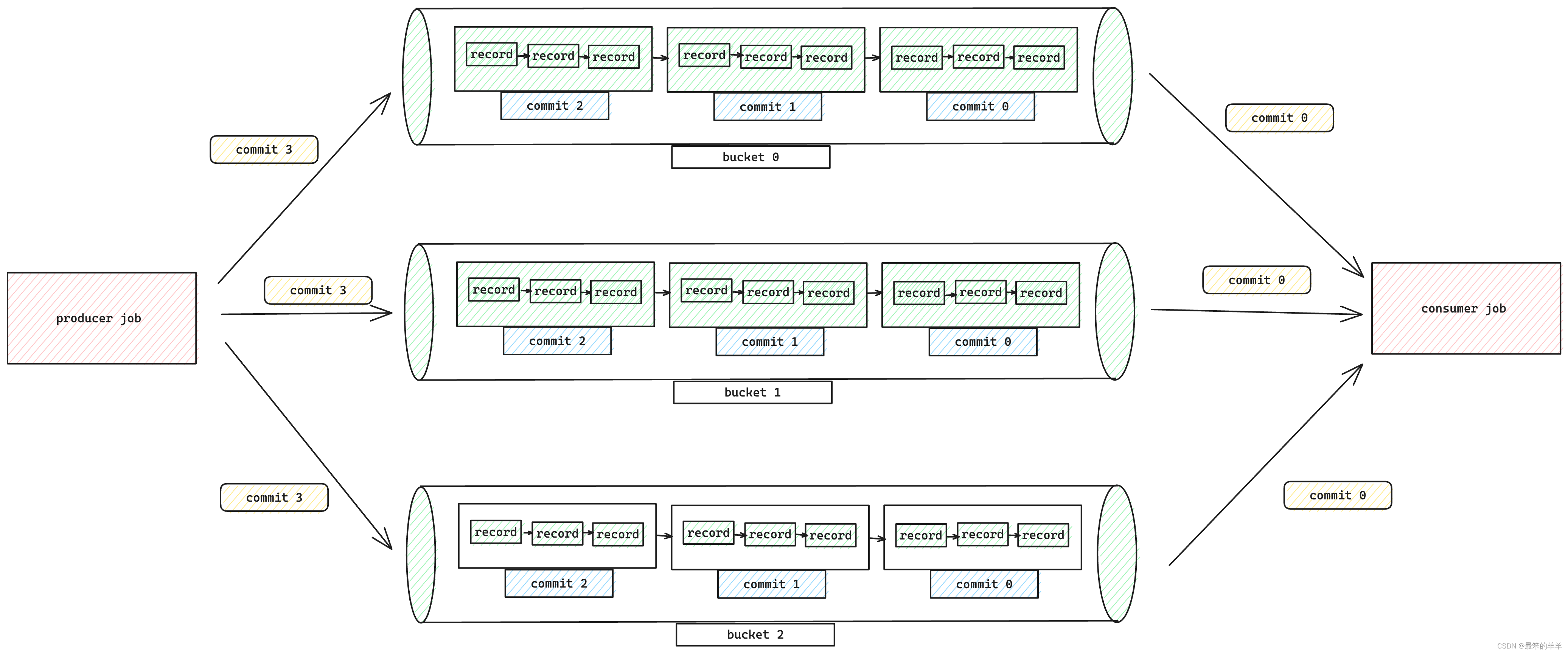
CREATE TABLE my_table (product_id BIGINT,price DOUBLE,sales BIGINT
) WITH ('bucket' = '8','bucket-key' = 'product_id'
);
五、压缩
默认情况下,sink节点会自动进行compaction来控制文件数量。以下选项控制压缩策略:
| Key | Default | Type | Description |
|---|---|---|---|
| write-only | false | Boolean | 如果设置为 true,将跳过压缩和快照过期。此选项与专用紧凑作业一起使用。 |
| compaction.min.file-num | 5 | Integer | 对于文件集 [f_0,…,f_N],满足 sum(size(f_i)) >= targetFileSize 触发追加表压缩的最小文件号。该值避免了几乎完整的文件被压缩,这是不划算的。 |
| compaction.max.file-num | 50 | Integer | 对于文件集 [f_0,…,f_N],触发追加表压缩的最大文件数,即使 sum(size(f_i)) < targetFileSize。该值可以避免挂起太多小文件,从而降低性能。 |
| full-compaction.delta-commits | (none) | Integer | 增量提交后将不断触发完全压缩。 |
六、Streaming Source
目前仅 Flink 引擎支持流式源行为。
Streaming Read Order
对于流式读取,记录按以下顺序生成:
- 对于来自两个不同分区的任意两条记录
- 如果 scan.plan-sort-partition 设置为 true,则首先生成分区值较小的记录。
- 否则,将先产生分区创建时间较早的记录。
- 对于来自同一分区、同一桶的任意两条记录,将首先产生第一条写入的记录。
- 对于来自同一分区但两个不同桶的任意两条记录,不同的桶由不同的任务处理,它们之间没有顺序保证。
七、Watermark Definition
您可以定义读取 Paimon 表的水印:
CREATE TABLE t (`user` BIGINT,product STRING,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);-- launch a bounded streaming job to read paimon_table
SELECT window_start, window_end, COUNT(`user`) FROM TABLE(TUMBLE(TABLE t, DESCRIPTOR(order_time), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end;
给定的代码创建了一个名为"t"的表,它包含了三个列:“user”(BIGINT类型),“product”(STRING类型),和"order_time"(TIMESTAMP类型,精确到毫秒)。它还为"order_time"列定义了一个水印(WATERMARK),表示事件的时间戳早于水印的事件被认为是延迟事件,可以被丢弃。
在创建表之后,该代码启动了一个有界的流作业来读取"t"表中的数据。它使用TUMBLE函数将数据按照"order_time"列分组为固定大小的滚动窗口,窗口大小为10分钟。window_start和window_end表示每个窗口的起始和结束时间戳,COUNT函数用于计算每个窗口内不同用户的数量。结果按照window_start和window_end进行分组。
您还可以启用 Flink Watermark 对齐,这将确保没有源/拆分/分片/分区将其水印增加得远远超出其他部分:
| Key | Default | Type | Description |
|---|---|---|---|
| scan.watermark.alignment.group | (none) | String | 一组用于对齐水印的源。 |
| scan.watermark.alignment.max-drift | (none) | Duration | 在我们暂停从源/任务/分区进行消耗之前,对齐水印的最大漂移。 |
八、Bounded Stream
Streaming Source 也可以是有界的,您可以指定 scan.bounded.watermark 来定义有界流模式的结束条件,流读取将结束,直到遇到更大的水印快照。
快照中的水印是由writer生成的,例如,您可以指定kafka源并声明水印的定义。当使用此kafka源写入Paimon表时,Paimon表的快照将生成相应的水印,以便您在流式读取此Paimon表时可以使用有界水印的功能。
CREATE TABLE kafka_table (`user` BIGINT,product STRING,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka'...);-- launch a streaming insert job
INSERT INTO paimon_table SELECT * FROM kakfa_table;-- launch a bounded streaming job to read paimon_table
SELECT * FROM paimon_table /*+ OPTIONS('scan.bounded.watermark'='...') */;
这段代码包含了几个步骤:
- 创建一个名为"kafka_table"的表,该表包含了三个列:“user”(BIGINT类型),“product”(STRING类型),和"order_time"(TIMESTAMP类型,精确到毫秒)。它还为"order_time"列定义了一个水印(WATERMARK),表示事件的时间戳早于水印的事件被认为是延迟事件,可以被丢弃。该表的连接器(connector)被指定为"kafka",意味着数据将从Kafka中读取。
- 启动一个流式插入作业。这个作业将从"kafka_table"中选择所有的数据,并插入到名为"paimon_table"的表中。
- 启动一个有界的流作业来读取"paimon_table"表中的数据。该作业将返回"paimon_table"表中的所有数据。注释中的"scan.bounded.watermark"选项可以指定有界流作业的水印,用于确定数据的处理范围。
- 总的来说,这段代码创建了一个从Kafka读取数据的表,并通过流式插入将数据插入到另一个表中。然后,通过有界流作业从目标表中读取数据。
相关文章:
Apache Paimon系列之:Append Table和Append Queue
Apache Paimon系列之:Append Table和Append Queue 一、Append Table二、Data Distribution三、自动小文件合并四、Append Queue五、压缩六、Streaming Source七、Watermark Definition八、Bounded Stream 一、Append Table 如果表没有定义主键,则默认为…...

Vue使用vue-esign实现在线签名 加入水印
Vue在线签名 一、目的二、样式三、代码1、依赖2、代码2.1 在线签名组件2.1.1 基础的2.1.2 携带时间水印的 2.2父组件 一、目的 又来了一个问题,直接让我在线签名(还不能存储base64),并且还得上传,我直接***违禁词。 好…...

与码无关:分数限制下,选好专业还是选好学校?
本文的目标读者:24届的高考生和家长。 写这篇非技术性文章,是因为我看到了24届考生和21年的我同样迷茫。 事先声明,本文带有强烈的个人思考色彩,可能会引起不适,如有不同观点,欢迎在评论区讨论。 一、前言…...

什么是负载均衡技术?
随着网络技术的快速发展,互联网行业也越来越广泛,人们的日常生活中也离不开网络技术,大量的用户进行浏览访问网站时,企业会使用负载均衡技术,降低当前网站的负载,以此来提高网站的访问速度。 今天小编就来给…...

存在重复元素Ⅱ python3
存在重复元素Ⅱ 问题描述解题思路代码实现复杂度 问题描述 给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] nums[j] 且 abs(i - j) < k 。如果存在,返回 true ;否则ÿ…...
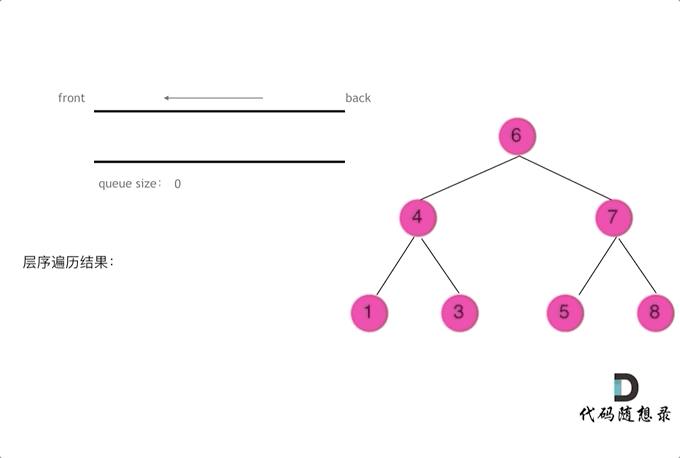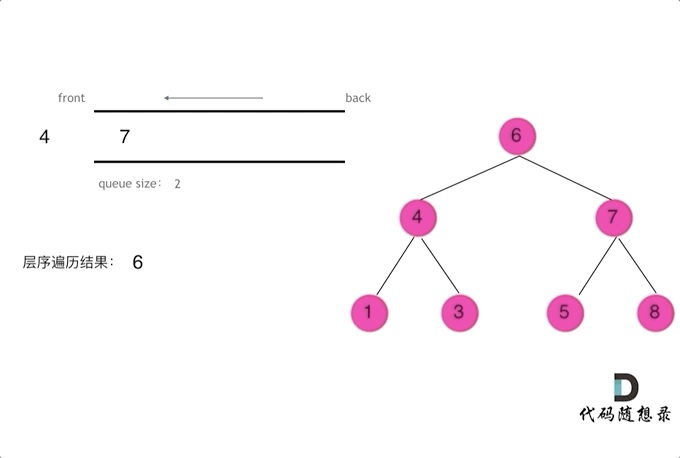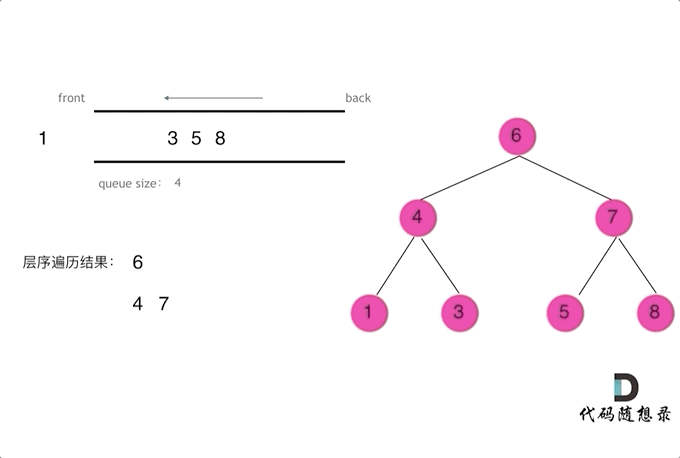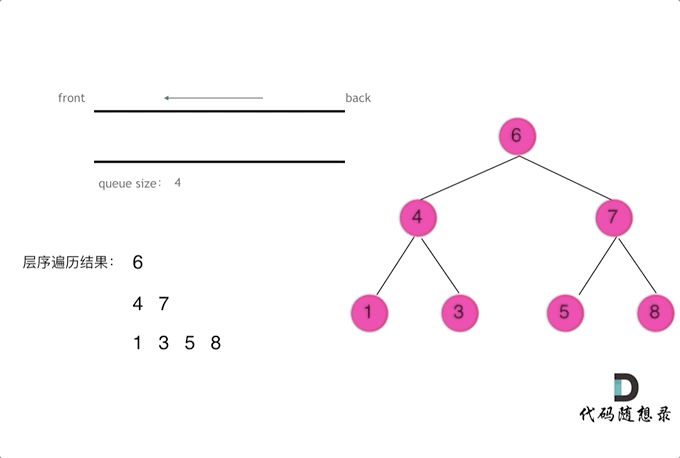
【CV炼丹师勇闯力扣训练营 Day13:§6二叉树1】
CV炼丹师勇闯力扣训练营 代码随想录算法训练营第13天 二叉树的递归遍历 二叉树的迭代遍历、统一迭代 二叉树的层序遍历 一、二叉树的递归遍历(深度优先搜索) 【递归步骤】 1.确定递归函数的参数和返回值:确定哪些参数是递归的过程中需要处理…...

代码随想录算法训练营第46天 [ 121. 买卖股票的最佳时机 122.买卖股票的最佳时机II 123.买卖股票的最佳时机III ]
代码随想录算法训练营第46天 [ 121. 买卖股票的最佳时机 122.买卖股票的最佳时机II 123.买卖股票的最佳时机III ] 一、121. 买卖股票的最佳时机 链接: 代码随想录. 思路:dp[i][0] 第i天持有股票的最大利润 dp[i][1] 第i天不持有股票的最大利润 做题状态:…...

基于IDEA的Maven简单工程创建及结构分析
目录 一、用 mvn 命令创建项目 二、用 IDEA 的方式来创建 Maven 项目。 (1)首先在 IDEA 下的 Maven 配置要已经确保完成。 (2)第二步去 new 一个 project (创建一个新工程) (3)…...
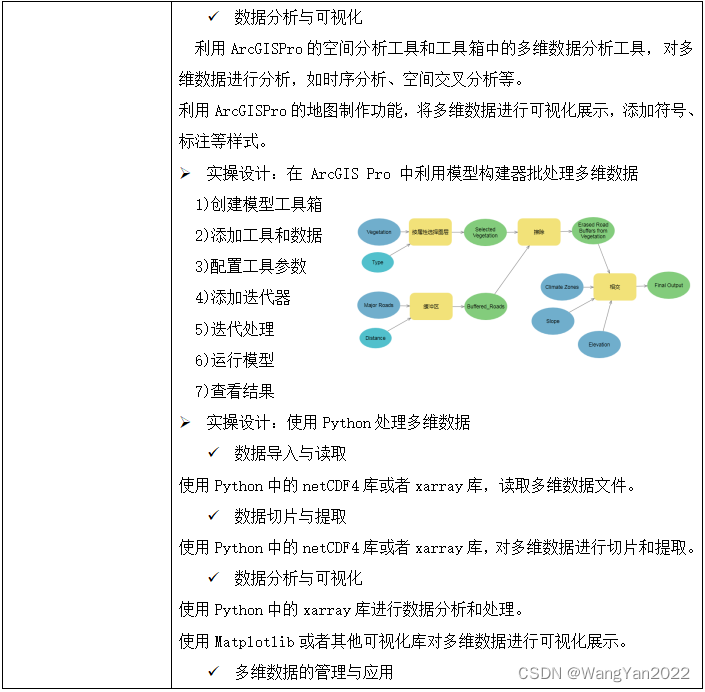
解锁空间数据奥秘:ArcGIS Pro与Python双剑合璧,处理表格数据、矢量数据、栅格数据、点云数据、GPS数据、多维数据以及遥感云平台数据等
ArcGISPro提供了用户友好的图形界面,适合初学者快速上手进行数据处理和分析。它拥有丰富的工具和功能,支持各种数据格式的处理和分析,适用于各种规模的数据处理任务。ArcGISPro在地理信息系统(GIS)领域拥有广泛的应用&…...

后端路线指导(4):后端春招秋招经验分享
后端春招&秋招经验分享 春招(暑期实习) /秋招是应届生非常重要的应聘时间,每一个想就业的同学一定要有所了解! 本篇内容,老白将与大家分享暑期实习和秋招如何应对招聘的个人经验,希望每个同学看完都能有所收获! 首先说明一下老白对于面试核心竞争力的…...

面完小红书算法岗,心态崩了。。。
暑期实习基本结束了,校招即将开启。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。提前准备才是完全之策。 最近,我们又陆续整理了很多大厂的面试题,…...
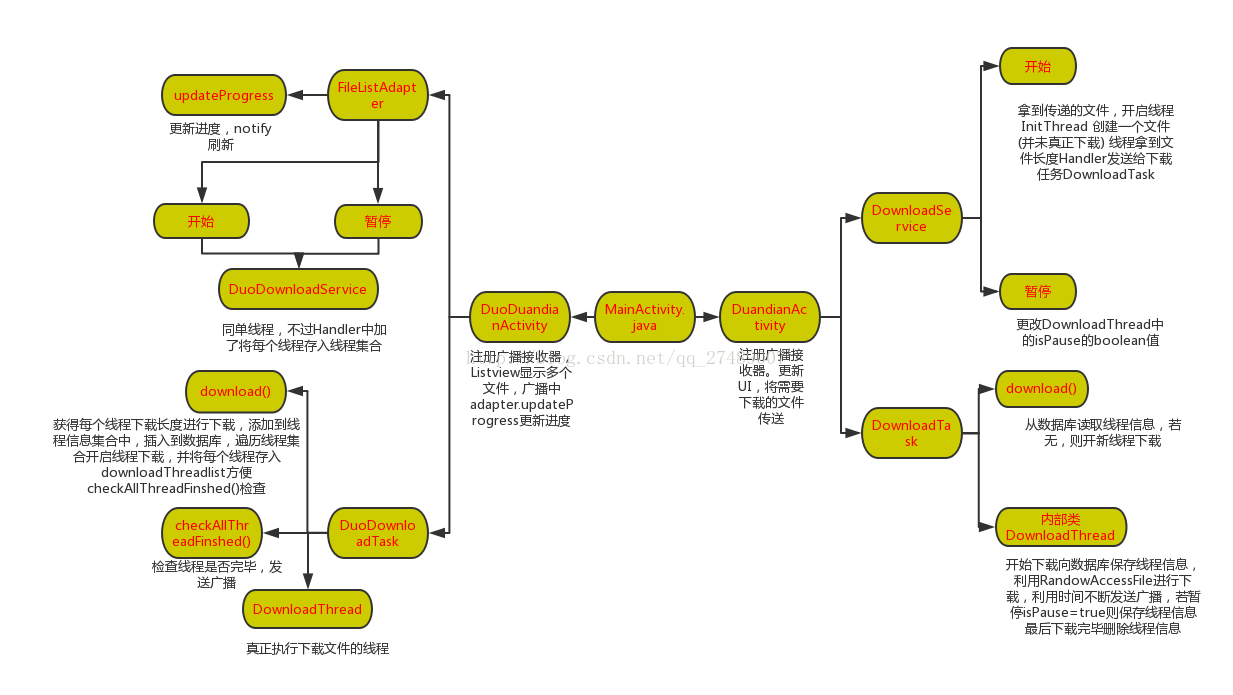
Android 断点续传进阶之多线程下载
今天继续下载的风骚走位内容—多线程多文件断点续传 Android 断点续传基础之单线程下载:http://blog.csdn.net/qq_27489007/article/details/53897653 效果图: 文件关系: 所需内容 多文件下载列表的显示 启动多个线程分段下载 使用通知栏…...

Python爬虫学习 | Scrapy框架详解
一.Scrapy框架简介 何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分&am…...
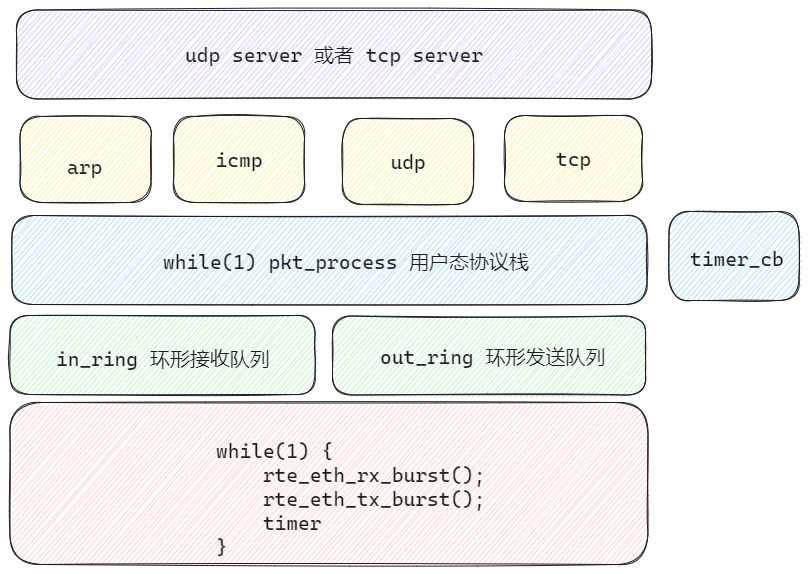
用户态协议栈05—架构优化
优化部分 添加了in和out两个环形缓冲区,收到数据包后添加到in队列;经过消费者线程处理之后,将需要发送的数据包添加到out队列。添加数据包解析线程(消费者线程),架构分层 #include <rte_eal.h> #inc…...

模拟退火算法
模拟退火算法(Simulated Annealing, SA)是一种用于全局优化问题的概率搜索算法,其灵感来自于金属退火过程。在金属退火中,材料被加热到高温,然后缓慢冷却,以减少其晶格中的缺陷并达到最小能量状态。模拟退火…...

Java匿名类
Java 匿名类是一种特殊的内部类,它没有名字,并且通常用来简化代码实现,尤其是在实现接口或者抽象类的实例时。匿名类可以在实例化时定义其行为,而不需要创建单独的类文件。 匿名类的特点 没有名字:匿名类是没有名字的…...

G7易流赋能化工物流,实现安全、环保与效率的共赢
近日,中国物流与采购联合会在古都西安举办了备受瞩目的第七届化工物流安全环保发展论坛。以"坚守安全底线,追求绿色发展,智能规划化工物流未来"为主题,该论坛吸引了众多政府部门、行业专家和企业代表的参与。G7易流作为…...
)
y=sin(2x)
函数 \( y \sin(2x) \) 是一个正弦函数,其中 \( x \) 是自变量,\( y \) 是因变量。这个函数描述了一个周期性波动的波形,其特点是: 1. **振幅**:正弦函数的振幅是 1,这意味着波形在 \( y \) 轴上的最大值…...

快捷方式(lnk)--加载HTA-CS上线
免责声明:本文仅做技术交流与学习... 目录 CS: HTA文档 文件托管 借助mshta.exe突破 本地生成lnk快捷方式: 非系统图标路径不同问题: 关于lnk的上线问题: CS: HTA文档 配置监听器 有效载荷---->HTA文档--->选择监听器--->选择powershell模式----> 默认生成一…...

从同—视角理解扩散模型(Understanding Diffusion Models A Unified Perspective)
从同—视角理解扩散模型 Understanding Diffusion Models A Unified Perspective【全公式推导】【免费视频讲解】 B站视频讲解 视频的论文笔记 从同一视角理解扩散模型【视频讲解笔记】 配合视频讲解的同步笔记。 整个系列完整的论文笔记内容如下,仅为了不用—一回复…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...