程序猿成长之路之数据挖掘篇——决策树分类算法(1)——信息熵和信息增益
决策树不仅在人工智能领域发挥着他的作用,而且在数据挖掘中也在分类领域中独占鳌头。了解决策树的思想是学习数据挖掘中的分类算法的关键,也是学习分类算法的基础。
什么是决策树
用术语来说,决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
用自己的话来说,决策树用于方便利用已知的数据和规律对未知的对象进行归类的方式,是一种分类算法。
使用决策树的意义
在应用于复杂的多阶段决策时,阶段明显,层次清楚,便于决策机构集体研究,可以周密地思考各种因素,有利于作出正确的决策。
分析决策树之前需要了解的内容
- 信息熵
定义:
从信息的完整性描述:当系统的有序状态一致时,数据越集中的地方熵值越小,数据越分散的地方熵值越大。
从信息的有序性描述:当数据量一致时,系统越有序,熵值越低;系统越混乱或者分散,熵值越高。
总而言之:
信息熵的值越大,则认为该变量包含的信息量就大
信息熵越大,表示包含的信息种类就越多,信息量就越大,信息越混乱分散,纯度就越低
信息熵只和包含的信息种类、出现的概率有关,与信息总数量无关
信息熵计算公式
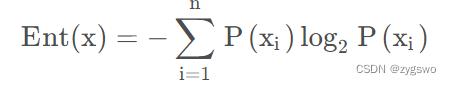
其中Ent(x) 为分类依据x的信息熵,P(xi)为第i类的数据在总数据中的数量占比。举个例子: 总数为15人的集合中,性别分为男和女,其中男生有8人,女生有7人,那么性别的信息熵为-(8/15)*log2(8/15)-(7/15)*log2(7/15)
- 信息增益
定义:
以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。也就是说如果信息增益越大,说明划分的效果越好,划分后数据集越有序,当前的分类依据越可靠。
信息增益的计算公式:

其中Gain(D,a) 表示根据某种规则分类中,a类数据在数据集D中的信息增益。
Ent(D)表示D的信息熵,Ent(D|a)表示条件熵,即根据某种规则分类中a类数据在数据集D中的信息熵
信息熵计算公式详见上文,条件熵计算公式如下:
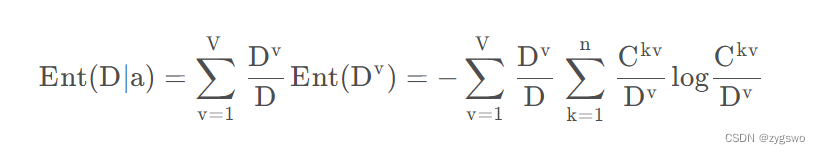
我们不难发现,条件熵相比信息熵前面还乘了一个系数,也就是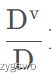
这个表示什么呢?就是按照这种规则分类中a类数据的个数除以数据样本总体个数得到的结果。
- 信息增益率
定义:
如果某个特征的特征值种类较多,则其信息熵值就越大。即:特征值种类越多,除以的系数就越大。如果某个特征的特征值种类较小,则其信息熵值就越小。即:特征值种类越小,除以的系数就越小。通过引入信息增益率,可以惩罚那些取值较多的特征,从而更倾向于选择那些取值较少但与目标变量相关性更强的特征。
信息增益率 = 信息增益 / 信息熵
信息增益率公式如下:
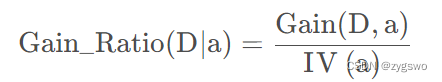
其中IV(a)表示按照这种规则分类中属性a的信息熵,满足信息熵的计算公式。
如果大家看到这里有点蒙没关系,下面我会用一个例子简单的介绍一下信息熵、信息增益、信息增益率的计算。
案例
下图为一个列表,其中列举了不同性别和不同活跃度客户的流失情况,其中uid-用户编号,gender-性别,act_info-活跃度,is_lost-是否流失(0-否,1-是)
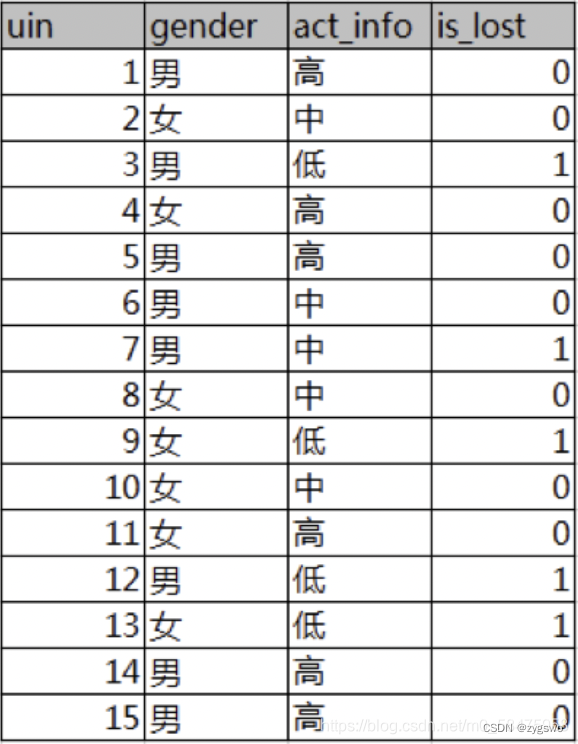
那么我们现在想分析一下性别和活跃度哪个条件更影响用户的流失情况。
思路
- 计算用户流失情况的信息熵
- 计算性别和活跃度条件下的信息增益。也就是计算不同条件下信息熵变化的情况
- 计算性别和活跃度条件下的信息增益率,从而对取值较多的特征进行过滤。
- 比较不同特征的信息增益率,取较高的那个作为首选特征
1. 计算用户流失情况的信息熵
首先我们由图可知,流失的用户有5人,编号分别是3、7、9、12、13,非流失客户有10人,那么我们有:
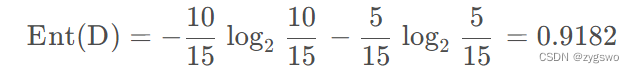
也就是流失情况的信息熵为0.9182,由于信息熵高,因此数据混乱度较高。
2. 计算性别和活跃度条件下的信息增益。
性别条件下的信息增益:
由图中我们有男生中未流失的用户有5人,流失的客户有3人,分别是编号3,7,12



同理可以计算女生的信息熵,因此有
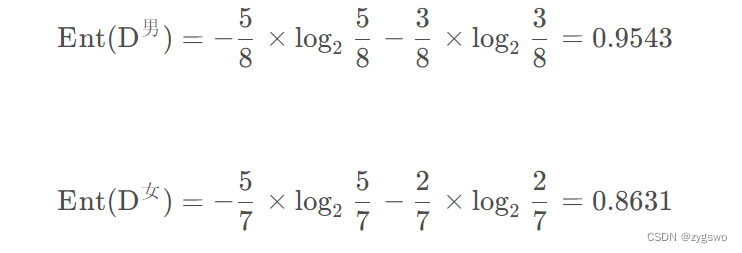
计算性别条件下的信息增益:
其中Ent(D|a)为条件熵,在信息熵的基础上乘了一个频率比例。(a样本个数/D-总样本数)
最终得到信息增益为0.0064,可以看出这个条件的信息增益很小,也说明这个条件对于用户是否会流失的影响很小。
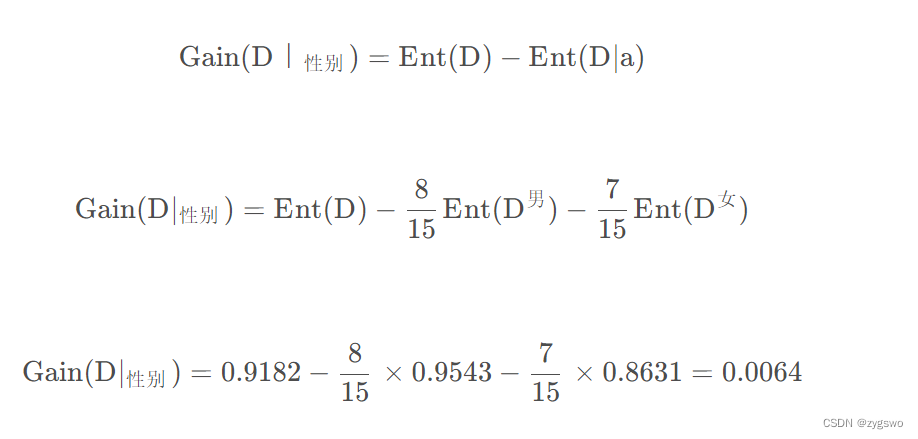
活跃度条件下的信息增益:
计算信息熵:
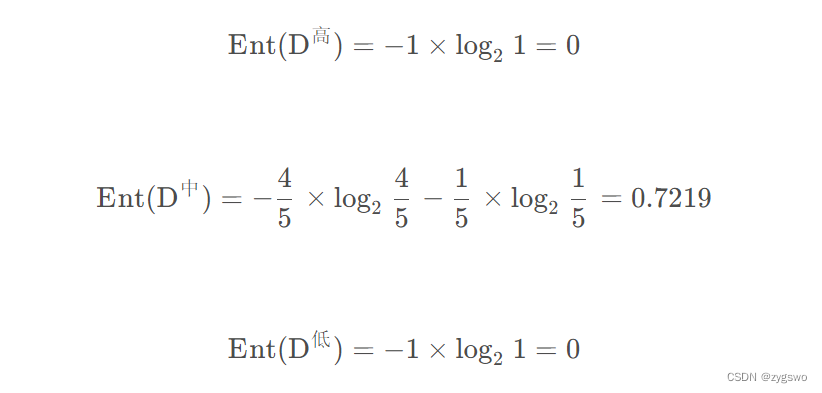
之后计算活跃度的信息增益:
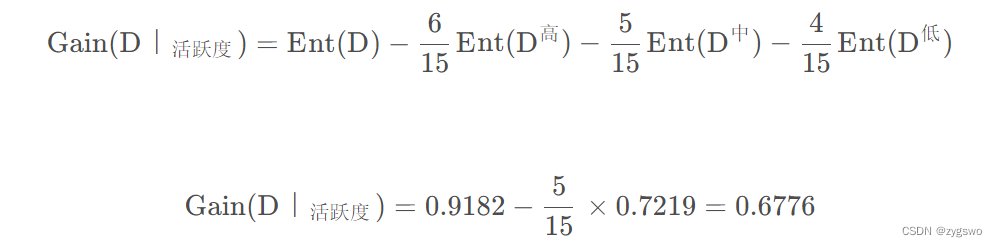
从这里我们可以看出活跃度对于用户流失的影响要远大于用户的性别。
3. 计算性别和活跃度条件下的信息增益率
性别的信息熵:
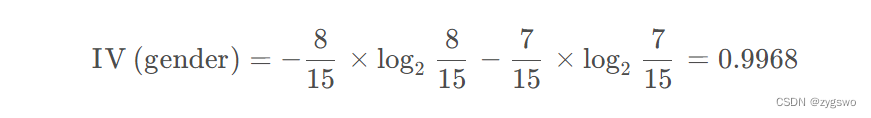
活跃度的信息熵:
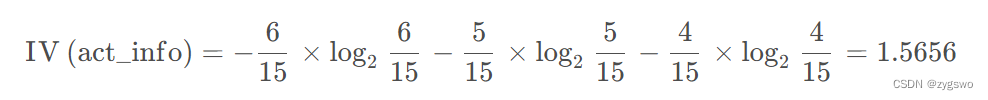
上文已经计算好了信息增益:
性别的信息增益为:0.0064
活跃度的信息增益为:0.6776
所以我们有:
性别的信息增益率为:
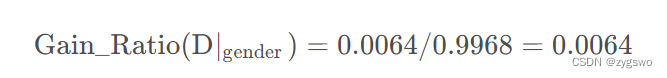
活跃度的信息增益率为:
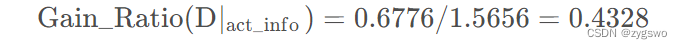
根据以上计算结果:性别特征的信息增益率明显小于活跃度的信息增益率,因此我们优先选用活跃度作为分类特征
案例实现代码
package classificationUtil;import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;import com.alibaba.fastjson.JSON; //需要自行导入/*** decisionTreeUtil* @author zygswo**/
public class decisionTreeUtil {public static void main(String[] args) {run();}public static void run() {File dataFile = new File("D:/decisionTree/dataset/datas.txt"); //读取文件BufferedInputStream reader = null;String itemsStr = "";double totalNb = 0; //总数List<TestItemNorm> items = new ArrayList<>();try {if (!dataFile.exists()) {dataFile.createNewFile();}reader = new BufferedInputStream(new FileInputStream(dataFile));byte[] line = new byte[reader.available()];reader.read(line);itemsStr = new String(line);System.out.println(itemsStr);items = JSON.parseArray(itemsStr,TestItemNorm.class);//将总数保存到totalNb中,方便计算信息增益totalNb = items.size(); //计算is_lost数量Map<String,List<TestItemNorm>> isLostRes = calcNb(items,"is_lost");//计算is_lost信息熵double isLostXinxiShangRes = calcXinxishang(isLostRes);System.out.println("is_lost类别的信息熵为 = " + isLostXinxiShangRes);//计算信息增益//计算性别的信息增益//计算不同性别的数量Map<String,List<TestItemNorm>> genderRes = calcNb(items,"gender");//计算信息增益double genderXinxiZengyiRes = isLostXinxiShangRes;//根据不同的性别去求值for (Map.Entry<String, List<TestItemNorm>> entry:genderRes.entrySet()) {List<TestItemNorm> resTmp = entry.getValue();//求当前Map<String,List<TestItemNorm>> temp = calcNb(resTmp,"is_lost");double xinxiShangTemp = calcXinxishang(temp);genderXinxiZengyiRes = genderXinxiZengyiRes - (resTmp.size() * xinxiShangTemp / totalNb * 1.0);}System.out.println("性别的信息增益为 = " + genderXinxiZengyiRes);//计算活跃度的信息增益//计算不同活跃度的数量Map<String,List<TestItemNorm>> activeRes = calcNb(items,"act_info");//计算信息增益double huoyueduXinxiZengyiRes = isLostXinxiShangRes;//根据不同的性别去求值for (Map.Entry<String, List<TestItemNorm>> entry:activeRes.entrySet()) {List<TestItemNorm> resTmp = entry.getValue();//求当前Map<String,List<TestItemNorm>> temp = calcNb(resTmp,"is_lost");double xinxiShangTemp = calcXinxishang(temp);huoyueduXinxiZengyiRes = huoyueduXinxiZengyiRes - (resTmp.size() * xinxiShangTemp / totalNb * 1.0);}System.out.println("活跃度的信息增益为 = " + huoyueduXinxiZengyiRes);//计算信息增益率//计算信息熵double genderRate = calcXinxishang(genderRes);System.out.println("性别的信息熵为 = " + genderRate);double huoyueduRate = calcXinxishang(activeRes);System.out.println("活跃度的信息熵为 = " + huoyueduRate);//计算信息增益率genderRate = genderXinxiZengyiRes / (genderRate * 1.0);System.out.println("性别的信息增益率为 = " + genderRate);huoyueduRate = huoyueduXinxiZengyiRes / (huoyueduRate * 1.0);System.out.println("活跃度的信息增益率为 = " + huoyueduRate);//构建决策树} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} finally {try {reader.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}/*** 计算信息熵* @param inputDataSet 输入的结果集* @return 信息熵*/private static <T> double calcXinxishang(Map<String, List<T>> inputDataMap) {double totalNb = 0.0,res = 0.0;//计算总数for (Map.Entry<String, List<T>> entry:inputDataMap.entrySet()) {if (entry.getValue() == null) {continue;}totalNb += entry.getValue().size();}//计算信息熵for (Map.Entry<String, List<T>> entry:inputDataMap.entrySet()) {if (entry.getValue() == null) {continue;}int currentSize = entry.getValue().size();double temp = (currentSize / totalNb) * 1.0;if (res == 0) {res = -1 * temp * (Math.log(temp) / Math.log(2) * 1.0);} else {res += -1 * temp * (Math.log(temp) / Math.log(2) * 1.0);}}return res;}/*** 计算数量统计结果* @param inputDataSet 输入的结果集* @param calcColumnName 列名* @return 统计结果*/private static <T> Map<String,List<T>> calcNb(List<T> inputDataSet,String calcColumnName){Map<String,List<T>> res = new ConcurrentHashMap<String, List<T>>();if (inputDataSet == null || inputDataSet.isEmpty()) {return res;}Class<?> cls = inputDataSet.get(0).getClass();Field[] fs = cls.getDeclaredFields();//for (Field f:fs) {f.setAccessible(true);String name = f.getName();if (name.equalsIgnoreCase(calcColumnName)) {for (T inputData:inputDataSet) {try {String value = f.get(inputData).toString();List<T> temp = new ArrayList<>();if (res.get(value) != null) {temp = res.get(value);}temp.add(inputData);res.put(value, temp);} catch (IllegalArgumentException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IllegalAccessException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}return res;}
}参考:
机器学习:决策树之信息熵、信息增益、信息增益率、基尼指数分析https://blog.csdn.net/m0_58475958/article/details/118735363
相关文章:
程序猿成长之路之数据挖掘篇——决策树分类算法(1)——信息熵和信息增益
决策树不仅在人工智能领域发挥着他的作用,而且在数据挖掘中也在分类领域中独占鳌头。了解决策树的思想是学习数据挖掘中的分类算法的关键,也是学习分类算法的基础。 什么是决策树 用术语来说,决策树(Decision Tree)是…...

数据通信与网络(五)
交换机功能: 地址学习(端口/MAC地址映射表) 通信过滤(基于端口/MAC地址映射表) 生成树协议(断开环路) 隔离冲突域 生成树协议 隔离冲突域 交换机配置模式(用不同级别的命令对交换机进行配置) 普…...
数据中心容灾考题
abc cd abc c为啥...
win10远程桌面连接端口,远Win10远程桌面连接端口修改及无法连接解决方案
一、Win10远程桌面连接端口概述 Win10远程桌面连接功能允许用户从远程位置访问和控制另一台计算机。远程桌面连接默认使用TCP 3389端口,但出于安全或其他需求,用户可能希望修改此端口。 二、Win10远程桌面连接端口修改方法 要修改Win10远程桌面连接的…...
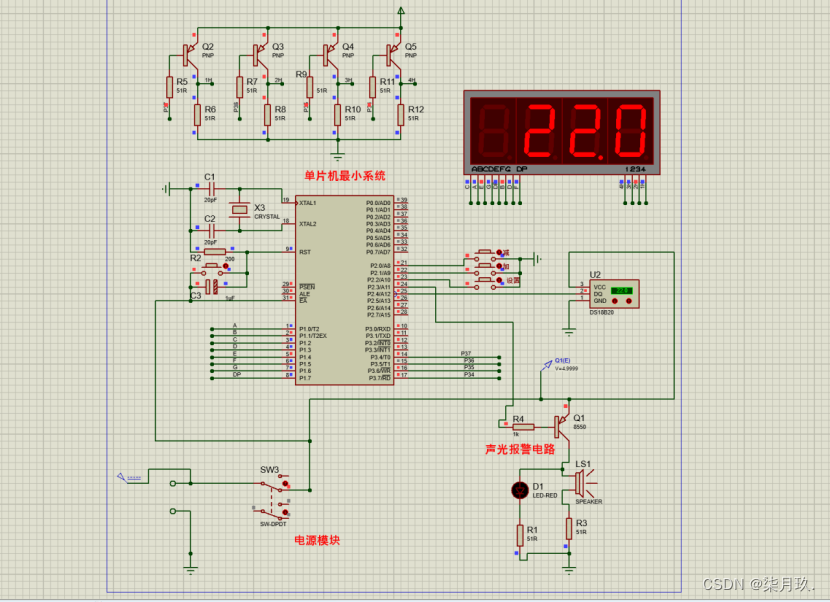
基于AT89C52单片机的温度报警系统
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/89456321?spm=1001.2014.3001.5503 仿真构造:AT89C52+DS18B20温度模块+三按键+蜂鸣器+四位数码管显示+电源模块。 压缩包构造:源码+仿真图+设计文档+原理图+开题文档+元件…...
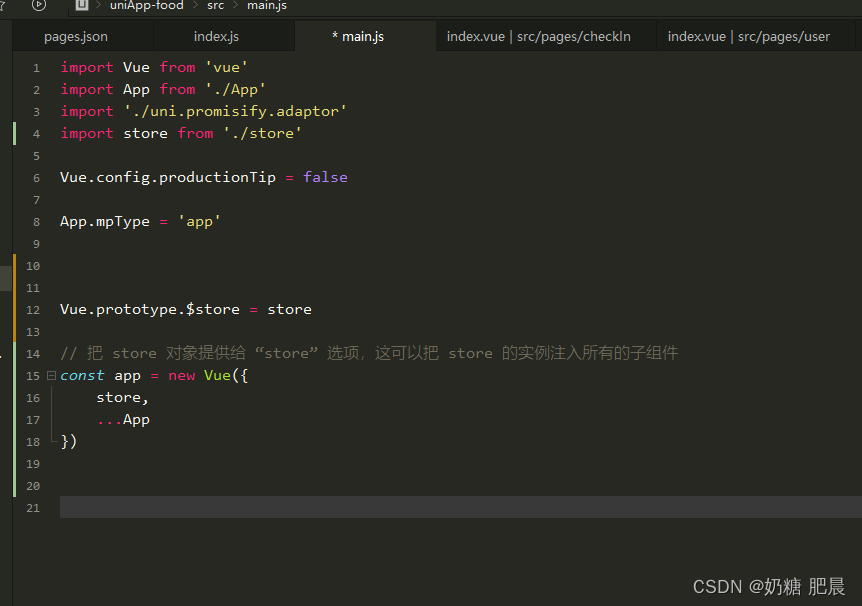
[保姆级教程]uniapp配置vueX
文章目录 注意新建文件简单的使用 注意 uniapp是支持vueX的只需配置一下就好 新建文件 在src文件中,新建一个store(如果有的话跳过) 在store中新建一个js文件,修改js文件名称和选择模板为default 在 uni-app 项目根目录下&…...

第二次IAG
IAG in NanJing City 我与南京奥体的初次相遇,也可能是最后一次! 对我来说,IAG 演唱会圆满结束啦! 做了两场充满爱[em]e400624[/em]的美梦 3.30号合肥站,6.21号南京站[em]e400947[/em] 其实,没想到昨天回去看呀!(lack of money […...
智慧校园综合管理系统的优点有哪些
在当今这个信息化飞速发展的时代,智慧校园综合管理系统正逐步成为教育领域的一股革新力量,它悄然改变着我们对传统校园管理的认知。这套系统如同一个无形的桥梁,将先进的信息技术与学校的日常运作紧密相连,展现出多维度的优势。 …...

如何跳出认知偏差,个人认知能力升级
一、教程描述 什么是认知力?认知力(cognitive ability),实际上就是指一个人的认知能力,是指人的大脑加工、储存和提取信息的能力,或者主观对非主观的事物的反映能力,如果变成大白话,…...

Scala中的map函数
Scala中的map函数 在 Scala 中,map 是一种常见的高阶函数,用于对集合中的每个元素应用一个函数,并返回应用了该函数后的新集合,保持原始集合的结构不变。它的主要作用有以下几点: 1. 遍历集合: map 可以遍历…...

linux安装conda环境实践
Conda介绍 conda 是一个开源的软件包管理系统和环境管理软件,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 conda 分为 anaconda 和 miniconda,anaconda 是一个包含了许多常用库的集合版本,miniconda 是精简版…...

Flutter-实现头像叠加动画效果
实现头像叠加动画效果 在这篇文章中,我们将介绍如何使用 Flutter 实现一个带有透明度渐变效果和过渡动画的头像叠加列表。通过这种效果,可以在图片切换时实现平滑的动画,使 UI 更加生动和吸引人。 需求 我们的目标是实现一个头像叠加列表&…...

MSPM0G3507——特殊的串口0
在烧录器中有串口0,默认也是串口0通过烧录线给电脑发数据。 如果要改变,需要变一下LP上的跳线帽。 需要更改如下位置的跳线帽...

如何选择合适的大模型框架:LangChain、LlamaIndex、Haystack 还是 Hugging Face
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集&#x…...

TCP 协议详解:三次握手与四次挥手
在网络通信中,确保数据准确无误地传递是至关重要的。TCP(Transmission Control Protocol,传输控制协议)作为一种面向连接的、可靠的、基于字节流的通信协议,在网络数据传输中起到了核心作用。本文将详细解析 TCP 的基本…...
)
Matlab 单目相机标定(内置函数,棋盘格)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 具体的标定原理可以参阅之前的博客Matlab 单目相机标定(内置函数),这里实现对棋盘格数据的标定过程。 二、实现代码 getCameraCorners.m function [camCorners, usedImIdx, imCheckerboard] = getCameraCorners(…...

C语言第17篇:预处理详解
1、预定义符号 C语言设置了一些预定义符号,可以直接使用。预定义符号也是在预处理期间处理的。 __FILE__ //进行编译的源文件 __LINE__ //文件当前的行号 __DATE__ //文件被编译的日期 __TIME__ //文件被编译的时间 __STDC__ //如果编译器遵循ANSI…...

用 Git 玩转版本控制
前言 Git,作为当今最流行的版本控制系统,不仅深受程序员们的青睐,也逐渐成为非开发人员管理文档版本的强大工具。本文将从实用主义的角度出发,深入浅出地介绍 Git 的常用命令,并带领大家探索 Git 的高级功能ÿ…...

AJAX中get和post的区别
在AJAX(Asynchronous JavaScript and XML)中,GET 和 POST 是两种常用的HTTP请求方法,它们之间存在一些关键的区别。以下是这些区别的主要点: 请求的目的: GET:通常用于从服务器检索(…...

软件测试笔记
一、介绍 软件测试是为了尽可能多地发现软件系统中的错误而不是证明软件的正确性。 1、软件缺陷是什么? 软件在使用过程中存在的任何问题都叫软件的缺陷,简称bug。 缺陷的判定标准 软件未实现需求说明书中明确要求的功能——少功能 软件出现了需求说…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...