LLM主流架构和模型
本文参考自https://github.com/HqWu-HITCS/Awesome-Chinese-LLM?tab=readme-ov-file和Huggingface中的ModelCard(https://huggingface.co/)
LLM主要类别架构
LLM本身基于transformer架构。自2017年,attention is all you need诞生起,transformer模型为不同领域的模型提供了灵感和启发。基于原始的Transformer框架,衍生出了一系列模型,一些模型仅仅使用encoder或decoder,有些模型同时使encoder+decoder。
LLM分类一般分为三种:自编码模型(encoder)、自回归模型(decoder)和编解码器模型(encoder-decoder)。
自编码器模型(AutoEncoder model,AE)
BERT
BERT base model (uncased)
使用掩码语言建模 (masked language modeling-MLM) 目标对英语进行预训练的模型。该模型不区分大小写:它不会区分english和English。
模型描述
BERT 是一个以自监督方式在大量英语数据上进行预训练的 Transformer 模型。这意味着它只在原始文本上进行预训练,没有任何人工标记(这就是它可以使用大量公开数据的原因),并有一个自动流程从这些文本中生成输入和标签。更准确地说,它进行了两个预训练目标:
掩码语言建模 (MLM):取一个句子,模型随机掩码输入中的 15% 的单词,然后通过模型运行整个掩码句子,并预测被掩码的单词。这与通常一个接一个地看到单词的传统循环神经网络 (RNN) 或内部掩码未来标记的 GPT 等自回归模型不同。它允许模型学习句子的双向表示。
下一句预测 (NSP):模型在预训练期间将两个掩码句子连接起来作为输入。有时它们对应于原文中彼此相邻的句子,有时则不是。然后,模型必须预测这两个句子是否彼此相连。
通过这种方式,模型可以学习英语的内部表征,然后可以使用该表征提取对下游任务有用的特征:例如,如果您有一个带标签的句子数据集,则可以使用 BERT 模型生成的特征作为输入来训练标准分类器。
请注意,此模型主要针对使用整个句子(可能被屏蔽)进行决策的任务进行微调,例如序列分类、标记分类或问答。对于文本生成等任务,您应该考虑 GPT2 之类的模型。
模型变体

如何使用
以下是如何在 PyTorch 中使用该模型获取给定文本的特征:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
训练数据
BERT 模型在 BookCorpus 上进行了预训练,BookCorpus 是一个包含 11,038 本未出版的书籍和英文维基百科(不包括列表、表格和标题)的数据集。
训练过程
Preprocessing
使用 WordPiece 将文本小写化并标记化,词汇量为 30,000。模型的输入形式如下:
[CLS] Sentence A [SEP] Sentence B [SEP]
句子 A 和句子 B 对应于原始语料库中的两个连续句子的概率为 0.5,在其他情况下,则是语料库中的另一个随机句子。请注意,这里所指的句子是一段连续的文本,通常比单个句子长。唯一的限制是,包含两个“句子”的结果的总长度小于 512 个标记。
每个句子的掩蔽过程的细节如下:
- 15% 的 token 被屏蔽。
- 在 80% 的情况下,屏蔽的 token 被 [MASK] 替换。
- 在 10% 的情况下,屏蔽的 token 被替换为与它们所替换的 token 不同的随机 token。
- 在剩余的 10% 的情况下,屏蔽的 token 保持原样。
Pretraining
该模型在 4 个云 TPU(共 16 个 TPU 芯片)上进行训练,训练步骤为 100 万步,批处理大小为 256。90% 的步骤的序列长度限制为 128 个标记,其余 10% 的步骤的序列长度限制为 512 个标记。使用的优化器是 Adam,学习率为 1e-4, β 1 = 0.9 \beta_1=0.9 β1=0.9 和 β 2 = 0.999 \beta_2=0.999 β2=0.999,权重衰减为 0.01,学习率预热 10,000 步,之后学习率线性衰减。
Evaluation results
在下游任务上进行微调后,该模型可实现以下结果:
Glue test results:
| Task | MNLI-m/mm | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|---|---|---|---|---|---|---|---|---|---|
| Score | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
自回归模型(Autoregressive model,AR)
GPT
GPT-2
在此处测试整个生成功能:https://transformer.huggingface.co/doc/gpt2-large
使用因果语言建模 (CLM) 目标对英语进行预训练的模型。
模型描述
GPT-2 是一个以自监督方式在大量英语数据上进行预训练的 transformers 模型。这意味着它只在原始文本上进行预训练,没有任何人以任何方式标记它们(这就是它可以使用大量公开数据的原因),并自动从这些文本中生成输入和标签。更准确地说,它被训练来猜测句子中的下一个单词。
更准确地说,输入是一定长度的连续文本序列,目标是相同的序列,向右移动一个标记(单词或单词片段)。该模型在内部使用掩码机制来确保对标记 i 的预测仅使用从 1 到 i 的输入,而不使用未来的标记。
这样,该模型学习了英语的内部表示,然后可用于提取对下游任务有用的特征。然而,该模型最擅长的是它预训练的目的,即根据提示生成文本。
这是 GPT-2 的最小版本,具有 124M 个参数。
如何使用
以下是如何在 PyTorch 中使用该模型获取给定文本的特征:
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
训练数据
OpenAI 团队希望在尽可能大的语料库上训练这个模型。为了构建它,他们从 Reddit 上获得至少 3 个 karma 的出站链接中抓取了所有网页。请注意,所有维基百科页面都已从此数据集中删除,因此该模型未在维基百科的任何部分上进行训练。生成的数据集(称为 WebText)重达 40GB 文本,但尚未公开发布。您可以在此处找到 WebText 中存在的前 1,000 个域的列表。
训练过程
Preprocessing
使用字节级版本的字节对编码 (BPE)(用于 Unicode 字符)和 50,257 个词汇量对文本进行标记。输入是 1024 个连续标记的序列。
较大的模型在 256 个云 TPU v3 核心上进行训练。训练持续时间未披露,训练的具体细节也未披露。
Evaluation results
该模型无需任何微调(零样本)即可实现以下结果:
| Dataset | LAMBADA (PPL) | LAMBADA (ACC) | CBT-CN (ACC) | CBT-NE (ACC) | WikiText2 (PPL) | PTB (PPL) | enwiki8 (BPB) | text8 (BPC) | WikiText103 (PPL) | 1BW (PPL) |
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 0.17 | 37.50 | 75.20 |
序列到序列模型(Sequence to Sequence Model)
T5
模型描述
Text-To-Text Transfer Transformer (T5) 的开发人员写道:
借助 T5,我们建议将所有 NLP 任务重新定义为统一的文本到文本格式,其中输入和输出始终是文本字符串,而 BERT 样式的模型只能输出类标签或输入的跨度。我们的文本到文本框架允许我们在任意 NLP 任务上使用相同的模型、损失函数和超参数。
T5-Base 是具有 2.2 亿个参数的检查点。
直接利用和下游利用
开发人员在一篇博客文章中写道,该模型:
我们的文本到文本框架允许我们在任何 NLP 任务上使用相同的模型、损失函数和超参数,包括机器翻译、文档摘要、问答和分类任务(例如情绪分析)。我们甚至可以将 T5 应用于回归任务,通过训练它来预测数字的字符串表示而不是数字本身。
有关更多详细信息,请参阅博客文章和研究论文。
训练数据
该模型在 Colossal Clean Crawled Corpus (C4) 上进行了预训练,该语料库是在与 T5 相同的研究论文背景下开发和发布的。
该模型在无监督 (1.) 和监督任务 (2.) 的多任务混合上进行了预训练。因此,以下数据集用于 (1.) 和 (2.):
- 用于无监督去噪目标的数据集:
- C4
- Wiki-DPR
- 用于监督文本到文本语言建模目标的数据集
- 句子可接受性判断
CoLA Warstadt et al., 2018 - 情感分析
SST-2 Socher et al., 2013 - 释义/句子相似性
MRPC Dolan and Brockett, 2005
STS-B Ceret al., 2017
QQP Iyer et al., 2017 - 自然语言推理
MNLI Williams et al., 2017
QNLI Rajpurkar et al.,2016
RTE Dagan et al., 2005
CB De Marneff et al., 2019 - 句子完成
COPA Roemmele et al., 2011 - 词义消歧
WIC Pilehvar and Camacho-Collados, 2018 - 问答
MultiRC Khashabi et al., 2018
ReCoRD Zhang et al., 2018
BoolQ Clark et al., 2019
训练过程
模型开发人员在摘要中写道:
在本文中,我们通过引入一个统一的框架来探索 NLP 迁移学习技术的前景,该框架将每个语言问题转换为文本到文本格式。我们的系统研究比较了数十种语言理解任务的预训练目标、架构、未标记数据集、迁移方法和其他因素。
引入的框架 T5 框架涉及一个将本文研究的方法结合在一起的训练程序。有关更多详细信息,请参阅研究论文。
Evaluation
测试数据、因素和指标
开发人员根据 24 项任务评估该模型,请参阅研究论文了解详细信息(https://jmlr.org/papers/volume21/20-074/20-074.pdf)。
结果
有关 T5-Base 的完整结果,请参阅研究论文表 14(https://jmlr.org/papers/volume21/20-074/20-074.pdf)。
相关文章:
LLM主流架构和模型
本文参考自https://github.com/HqWu-HITCS/Awesome-Chinese-LLM?tabreadme-ov-file和Huggingface中的ModelCard(https://huggingface.co/) LLM主要类别架构 LLM本身基于transformer架构。自2017年,attention is all you need诞生起&#x…...
为企业提供动力:用于大型组织的WordPress
可扩展且灵活的架构可通过主题、插件和集成进行定制内置 SEO 功能和营销功能内容管理和协作工具支持多站点安装托管解决方案和面向平台的提供商采用现代前端技术的 Headless CMS 功能 拥有强大、灵活且可扩展的内容管理系统 (CMS) 对于大型组织至关重要。作为最受欢迎和广泛使用…...

Django框架数据库ORM查询操作
Django框架在生成数据库的models模型文件后,旧可以在应用中通过ORM来操作数据库了。今天抽空试了下查询语句。以下是常用的查询语句。 以下查询需要引入django的Sum,Count,Q模块 from django.db.models import Sum,Count,Q 导入生成的mode…...
font-spider按需生成字体文件
font-spider可以全局安装,也可以单个项目内安装,使用npm run xxxx的形式 npm i font-spider "dev": "font-spider ./*.html" <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name&…...
双叒叕-一个-Android-MVVM-组件化架构框架?
LifecycleViewModelLiveDataViewBindingAndroid KTXOkHttp:网络请求Retrofit:网络请求MMKV:腾讯基于 mmap 内存映射的 key-value 本地存储组件Glide:快速高效的Android图片加载库ARoute:阿里用于帮助 Android App 进行组件化改造的框架 —— 支持模块间的路由、通信、解耦BaseR…...
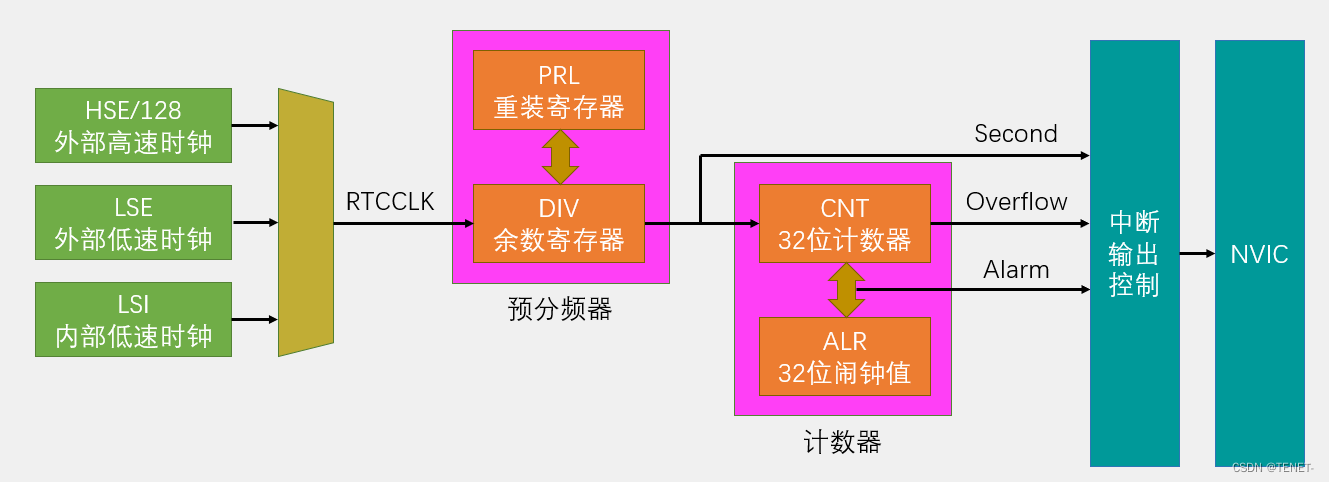
STM32单片机BKP备份寄存器和RTC实时时钟详解
文章目录 1. Unix时间戳 2. UTC/GMT 3. 时间戳转换 4. BKP简介 5. BKP基本结构 6. RTC简介 7. RTC框架图 8. RTC基本结构 9. 代码示例 1. Unix时间戳 实时时钟,本质上是一个定时器,专门用来产生年月日时分秒。 Unix 时间戳(Unix T…...

vue3+ts 使用vue3-ace-editor实现Json编辑器
1、效果图 输入代码,点击格式化就出现以上效果,再点击压缩,是以下效果2、安装 npm i vue3-ace-editor 3、使用 新建aceConfig.js文件 // ace配置,使用动态加载来避免第一次加载开销 import ace from ace-builds// 导入不同的主…...

黑马HarmonyOS-NEXT星河版实战
"黑马HarmonyOS-NEXT星河版实战"课程旨在帮助学员深入了解HarmonyOS-NEXT星河版操作系统的开发和实际应用。学员将学习操作系统原理、应用开发技巧和界面设计,通过实战项目提升技能。课程注重实践与理论相结合,为学员提供全面的HarmonyOS开发经…...

PCL 三次样条插值(二维点)
一、简介 在插值计算中,最简单的分段多项式近似应该是分段线性插值,它由连接一组数据点组成,仅仅只需要将这些点一一用直线进行顺序相连即可。不过线性函数插值的缺点也很明显,就是在两个子区间变化的比较突兀,也就是没有可微性(不够光滑)。因此我们需要更为符合物理情况…...

HTTP/3 协议学习
前一篇: HTTP/2 协议学习-CSDN博客 HTTP/3 协议介绍 HTTP/3 是互联网上用于传输超文本的协议 HTTP 的第三个主要版本。它是 HTTP/2 的后继者,旨在进一步提高网络性能和安全性。HTTP/3 与前两个版本的主要区别在于它使用了一个完全不同的底层传输协议—…...

数据库-数据定义和操纵-DML语言的使用
为表的所有字段插入数据: INSERT INTO 表名 (字段名) VALUES (内容); 更新表中指定的内容: update语句三要素: 需要更新的表(table)名; 需要更新的字段(column)名和它的新内容(valu…...
的用法总结)
BeanUtils.populate()的用法总结
BeanUtils.populate()的用法总结 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java中,BeanUtils.populate()是Apache Commons BeanUtils库提供…...
)
IDEA 学习之 热加载问题(Hot Swap)
目录 1. IDEA 自带热加载1.1. 热加载快捷键1.2. 热加载范围 1. IDEA 自带热加载 1.1. 热加载快捷键 系统快捷键WINCtrl F9MACOPTIOIN F9 1.2. 热加载范围 资源类型是否影响影响范围Java部分方法签名内...

计算机组成原理----指令系统课后习题
对应的知识点: 指令系统 扩展操作码的计算: 公式: 对扩展操作码而言,若地址长度为n,上一层留出m种状态,下一层可扩展出 mx2^n 种状态 1.设计某指令系统时,假设采用 16 位定长指令字格式&#…...

yolov8环境搭建+训练自己数据集
一、yolov8环境搭建 1. 安装miniconda环境 地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda 选择Python3.8版本 最好安装在C盘 勾选自动添加环境变量 ***以下操作安装过程中关闭代理软件 *** 2. 创建虚拟环境 conda create -n yolov8 python3…...
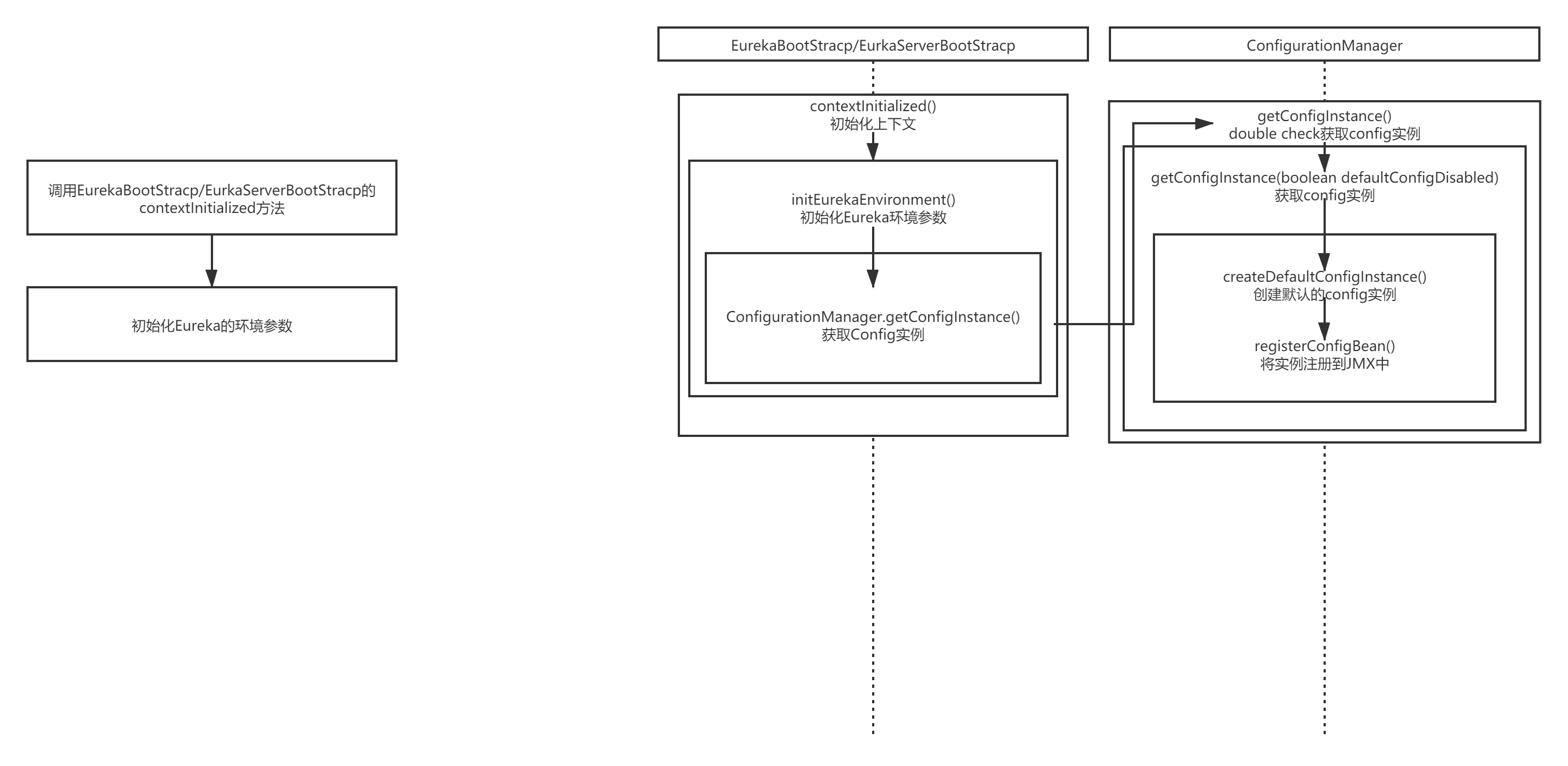
Eureka 学习笔记(1)
一 、contextInitialized() eureka-core里面,监听器的执行初始化的方法,是contextInitialized()方法,这个方法就是整个eureka-server启动初始化的一个入口。 Overridepublic void contextInitialized(ServletContextEvent event) {try {init…...

视觉新纪元:解码LED显示屏的视角、可视角、最佳视角的最终奥秘
在璀璨夺目的LED显示屏世界里,每一个绚烂画面的背后,都离不开三个关键概念:视角、可视角与最佳视角。这些术语不仅是衡量显示效果的重要标尺,也是连接观众与精彩内容的桥梁。让我们一起走进这场视觉盛宴,探索那些让LED…...
Benchmarking Panoptic Scene Graph Generation (PSG), ECCV‘22 场景图生成,利用PSG数据集
2080-ti显卡复现 源代码地址 Jingkang50/OpenPSG: Benchmarking Panoptic Scene Graph Generation (PSG), ECCV22 (github.com) 安装 pytorch 1.7版本 cuda10.1 按照readme的做法安装 我安装的过程如下图所示,这个截图是到了pip install openmim这一步 下一步 下一步 这一步…...
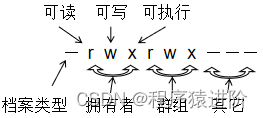
Linux 文件权限
优质博文:IT-BLOG-CN 一、使用者与群组的概念 【1】在Linux里面,任何一个文件都具有[User,Group及Other]三种身份的个别权限:不过需要注意的是root用户,具有所有权限。 ✔ User(文件拥有者):只有文件拥有者…...

IOS Swift 从入门到精通:算术运算,运算符重载,符合赋值运算,比较运算,条件,结合条件,三元运算,Swift语句,范围运算
目录 算术运算符 运算符重载 复合赋值运算符 比较运算符 条件 结合条件 三元运算符 Switch 语句 范围运算符 总结 算术运算符 现在您已经了解了 Swift 中的所有基本类型,我们可以开始使用运算符将它们组合在一起。运算符是那些像和 这样的小数学符号-&…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...