实现VOC数据集与COCO数据集格式转换
实现VOC数据集与COCO数据集格式转换
- 2、将voc数据集的xml转化为coco数据集的json格式
- 2、COCO格式的json文件转化为VOC格式的xml文件
- 3、将 txt 文件转换为 Pascal VOC 的 XML 格式

<annotation><folder>文件夹目录</folder><filename>图片名.jpg</filename><path>path_to\at002eg001.jpg</path><source><database>Unknown</database></source><size><width>550</width><height>518</height><depth>3</depth></size><segmented>0</segmented><object><name>Apple</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>292</xmin><ymin>218</ymin><xmax>410</xmax><ymax>331</ymax></bndbox></object><object>...</object>
</annotation>
coco
|______annotations # 存放标注信息
| |__train.json
| |__val.json
| |__test.json
|______trainset # 存放训练集图像
|______valset # 存放验证集图像
|______testset # 存放测试集图像一个标准的json文件包含如下信息:
{ "info" : info,"licenses" : [license],"images" : [image],"annotations" : [annataton],"categories" : [category]
}
(1)images字段列表元素的长度 = 划入训练集(或者测试集)的图片的数量;
(2)annotations字段列表元素的数量 = 训练集(或者测试集)中bounding box的数量;
(3)categories字段列表元素的数量 = 类别的数量
接下来我们看每个key对应的内容:
(1)info
info{
"year" : int, # 年份
"version" : str, # 版本
"description" : str, # 详细描述信息
"contributor" : str, # 作者
"url" : str, # 协议链接
"date_created" : datetime, # 生成日期
}(2)images
"images": [
{"id": 0, # int 图像id,可从0开始"file_name": "0.jpg", # str 文件名"width": 512, # int 图像的宽"height": 512, # int 图像的高"date_captured": "2020-04-14 01:45:07.508146", # datatime 获取日期"license": 1, # int 遵循哪个协议"coco_url": "", # str coco图片链接url"flickr_url": "" # str flick图片链接url
}](3)licenses
"licenses": [
{"id": 1, # int 协议id号 在images中遵循的license即1"name": null, # str 协议名 "url": null # str 协议链接
}]
(4)annotations
"annotations": [
{"id": 0, # int 图片中每个被标记物体的id编号"image_id": 0, # int 该物体所在图片的编号"category_id": 2, # int 被标记物体的类别id编号"iscrowd": 0, # 0 or 1 目标是否被遮盖,默认为0"area": 4095.9999999999986, # float 被检测物体的面积(64 * 64 = 4096)"bbox": [200.0, 416.0, 64.0, 64.0], # [x, y, width, height] 目标检测框的坐标信息"segmentation": [[200.0, 416.0, 264.0, 416.0, 264.0, 480.0, 200.0, 480.0]]
}]
(5)categories
"categories":[
{"id": 1, # int 类别id编号"name": "rectangle", # str 类别名字"supercategory": "None" # str 类别所属的大类,如卡车和轿车都属于机动车这个class
},
{"id": 2,"name": "circle", "supercategory": "None"}
]
2、将voc数据集的xml转化为coco数据集的json格式

# create_xml_list.py
import os
xml_list = os.listdir('C:/Users/user/Desktop/train')
with open('C:/Users/user/Desktop/xml_list.txt','a') as f:for i in xml_list:if i[-3:]=='xml':f.write(str(i)+'\n')

# voc2coco.py# pip install lxmlimport sys
import os
import json
import xml.etree.ElementTree as ETSTART_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = {}
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,# "motorbike": 14, "person": 15, "pottedplant": 16,# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}def get(root, name):vars = root.findall(name)return varsdef get_and_check(root, name, length):vars = root.findall(name)if len(vars) == 0:raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))if length > 0 and len(vars) != length:raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))if length == 1:vars = vars[0]return varsdef get_filename_as_int(filename):try:filename = os.path.splitext(filename)[0]return int(filename)except:raise NotImplementedError('Filename %s is supposed to be an integer.'%(filename))def convert(xml_list, xml_dir, json_file):list_fp = open(xml_list, 'r')json_dict = {"images":[], "type": "instances", "annotations": [],"categories": []}categories = PRE_DEFINE_CATEGORIESbnd_id = START_BOUNDING_BOX_IDfor line in list_fp:line = line.strip()print("Processing %s"%(line))xml_f = os.path.join(xml_dir, line)tree = ET.parse(xml_f)root = tree.getroot()path = get(root, 'path')if len(path) == 1:filename = os.path.basename(path[0].text)elif len(path) == 0:filename = get_and_check(root, 'filename', 1).textelse:raise NotImplementedError('%d paths found in %s'%(len(path), line))## The filename must be a numberimage_id = get_filename_as_int(filename)size = get_and_check(root, 'size', 1)width = int(get_and_check(size, 'width', 1).text)height = int(get_and_check(size, 'height', 1).text)image = {'file_name': filename, 'height': height, 'width': width,'id':image_id}json_dict['images'].append(image)## Cruuently we do not support segmentation# segmented = get_and_check(root, 'segmented', 1).text# assert segmented == '0'for obj in get(root, 'object'):category = get_and_check(obj, 'name', 1).textif category not in categories:new_id = len(categories)categories[category] = new_idcategory_id = categories[category]bndbox = get_and_check(obj, 'bndbox', 1)xmin = int(get_and_check(bndbox, 'xmin', 1).text) - 1ymin = int(get_and_check(bndbox, 'ymin', 1).text) - 1xmax = int(get_and_check(bndbox, 'xmax', 1).text)ymax = int(get_and_check(bndbox, 'ymax', 1).text)assert(xmax > xmin)assert(ymax > ymin)o_width = abs(xmax - xmin)o_height = abs(ymax - ymin)ann = {'area': o_width*o_height, 'iscrowd': 0, 'image_id':image_id, 'bbox':[xmin, ymin, o_width, o_height],'category_id': category_id, 'id': bnd_id, 'ignore': 0,'segmentation': []}json_dict['annotations'].append(ann)bnd_id = bnd_id + 1for cate, cid in categories.items():cat = {'supercategory': 'none', 'id': cid, 'name': cate}json_dict['categories'].append(cat)json_fp = open(json_file, 'w')json_str = json.dumps(json_dict)json_fp.write(json_str)json_fp.close()list_fp.close()if __name__ == '__main__':if len(sys.argv) <= 1:print('3 auguments are need.')print('Usage: %s XML_LIST.txt XML_DIR OUTPU_JSON.json'%(sys.argv[0]))exit(1)convert(sys.argv[1], sys.argv[2], sys.argv[3])

import os
img_dir='F:/Billboard/dataset/images/'
lab_dir='F:/Billboard/dataset/labels/'
name_list = os.listdir(img_dir)
for i,name in enumerate(name_list):os.rename(img_dir+name,img_dir+str(i)+'.jpg')os.rename(lab_dir+name[:-4]+'.txt',lab_dir+str(i)+'.txt')
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text)) - 1
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text)) - 1
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))2、COCO格式的json文件转化为VOC格式的xml文件

# coco2voc.py# pip install pycocotools
import os
import time
import json
import pandas as pd
from tqdm import tqdm
from pycocotools.coco import COCO#json文件路径和用于存放xml文件的路径
anno = 'C:/Users/user/Desktop/val/instances_val2017.json'
xml_dir = 'C:/Users/user/Desktop/val/xml/'coco = COCO(anno) # 读文件
cats = coco.loadCats(coco.getCatIds()) # 这里loadCats就是coco提供的接口,获取类别# Create anno dir
dttm = time.strftime("%Y%m%d%H%M%S", time.localtime())def trans_id(category_id):names = []namesid = []for i in range(0, len(cats)):names.append(cats[i]['name'])namesid.append(cats[i]['id'])index = namesid.index(category_id)return indexdef convert(anno,xml_dir): with open(anno, 'r') as load_f:f = json.load(load_f)imgs = f['images'] #json文件的img_id和图片对应关系 imgs列表表示多少张图cat = f['categories']df_cate = pd.DataFrame(f['categories']) # json中的类别df_cate_sort = df_cate.sort_values(["id"], ascending=True) # 按照类别id排序categories = list(df_cate_sort['name']) # 获取所有类别名称print('categories = ', categories)df_anno = pd.DataFrame(f['annotations']) # json中的annotationfor i in tqdm(range(len(imgs))): # 大循环是images所有图片,Tqdm是可扩展的Python进度条,可以在长循环中添加一个进度提示信息xml_content = []file_name = imgs[i]['file_name'] # 通过img_id找到图片的信息height = imgs[i]['height']img_id = imgs[i]['id']width = imgs[i]['width']version =['"1.0"','"utf-8"'] # xml文件添加属性xml_content.append("<?xml version=" + version[0] +" "+ "encoding="+ version[1] + "?>")xml_content.append("<annotation>")xml_content.append(" <filename>" + file_name + "</filename>")xml_content.append(" <size>")xml_content.append(" <width>" + str(width) + "</width>")xml_content.append(" <height>" + str(height) + "</height>")xml_content.append(" <depth>"+ "3" + "</depth>")xml_content.append(" </size>")# 通过img_id找到annotationsannos = df_anno[df_anno["image_id"].isin([img_id])] # (2,8)表示一张图有两个框for index, row in annos.iterrows(): # 一张图的所有annotation信息bbox = row["bbox"]category_id = row["category_id"]cate_name = categories[trans_id(category_id)]# add new objectxml_content.append(" <object>")xml_content.append(" <name>" + cate_name + "</name>")xml_content.append(" <truncated>0</truncated>")xml_content.append(" <difficult>0</difficult>")xml_content.append(" <bndbox>")xml_content.append(" <xmin>" + str(int(bbox[0])) + "</xmin>")xml_content.append(" <ymin>" + str(int(bbox[1])) + "</ymin>")xml_content.append(" <xmax>" + str(int(bbox[0] + bbox[2])) + "</xmax>")xml_content.append(" <ymax>" + str(int(bbox[1] + bbox[3])) + "</ymax>")xml_content.append(" </bndbox>")xml_content.append(" </object>")xml_content.append("</annotation>")x = xml_contentxml_content = [x[i] for i in range(0, len(x)) if x[i] != "\n"]### list存入文件#xml_path = os.path.join(xml_dir, file_name.replace('.xml', '.jpg'))xml_path = os.path.join(xml_dir, file_name.split('j')[0]+'xml')print(xml_path)with open(xml_path, 'w+', encoding="utf8") as f:f.write('\n'.join(xml_content))xml_content[:] = []if __name__ == '__main__':convert(anno,xml_dir)
3、将 txt 文件转换为 Pascal VOC 的 XML 格式
比如从OpenImageV5下载下来的BIllboard数据集,目录如下:
Billboard
|______images # 存放训练集图像
| |__train|__train.jpg
| |__val|__val.jpg
|______labels # 存放标注信息
| |__train|__train.txt
| |__val|__val.txt
将 txt 文件转换为 Pascal VOC 的 XML 格式的代码如下:
#! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
from PIL import Image# VEDAI 图像存储位置
src_img_dir = "F:/Billboard/dataset/images/val"
# VEDAI 图像的 ground truth 的 txt 文件存放位置
src_txt_dir = "F:/Billboard/dataset/labels/val"
src_xml_dir = "F:/Billboard/dataset/xml/val"
name=['billboard']img_Lists = glob.glob(src_img_dir + '/*.jpg')img_basenames = [] # e.g. 100.jpg
for item in img_Lists:img_basenames.append(os.path.basename(item))img_names = [] # e.g. 100
for item in img_basenames:temp1, temp2 = os.path.splitext(item)img_names.append(temp1)for img in img_names:im = Image.open((src_img_dir + '/' + img + '.jpg'))width, height = im.size# open the crospronding txt filegt = open(src_txt_dir + '/' + img + '.txt').read().splitlines()#gt = open(src_txt_dir + '/gt_' + img + '.txt').read().splitlines()# write in xml file#os.mknod(src_xml_dir + '/' + img + '.xml')xml_file = open((src_xml_dir + '/' + img + '.xml'), 'w')xml_file.write('<annotation>\n')xml_file.write(' <folder>VOC2007</folder>\n')xml_file.write(' <filename>' + str(img) + '.jpg' + '</filename>\n')xml_file.write(' <size>\n')xml_file.write(' <width>' + str(width) + '</width>\n')xml_file.write(' <height>' + str(height) + '</height>\n')xml_file.write(' <depth>3</depth>\n')xml_file.write(' </size>\n')# write the region of image on xml filefor img_each_label in gt:spt = img_each_label.split(' ') #这里如果txt里面是以逗号‘,’隔开的,那么就改为spt = img_each_label.split(',')。xml_file.write(' <object>\n')xml_file.write(' <name>' + str(name[int(spt[0])]) + '</name>\n')xml_file.write(' <pose>Unspecified</pose>\n')xml_file.write(' <truncated>0</truncated>\n')xml_file.write(' <difficult>0</difficult>\n')xml_file.write(' <bndbox>\n')xml_file.write(' <xmin>' + str(float(spt[1])*width) + '</xmin>\n')xml_file.write(' <ymin>' + str(float(spt[3])*height) + '</ymin>\n')xml_file.write(' <xmax>' + str(float(spt[2])*width) + '</xmax>\n')xml_file.write(' <ymax>' + str(float(spt[4])*height) + '</ymax>\n')xml_file.write(' </bndbox>\n')xml_file.write(' </object>\n')xml_file.write('</annotation>')相关文章:
实现VOC数据集与COCO数据集格式转换
实现VOC数据集与COCO数据集格式转换2、将voc数据集的xml转化为coco数据集的json格式2、COCO格式的json文件转化为VOC格式的xml文件3、将 txt 文件转换为 Pascal VOC 的 XML 格式<annotation><folder>文件夹目录</folder><filename>图片名.jpg</file…...

常用的密码算法有哪些?
我们将密码算法分为两大类。 对称密码(密钥密码)——算法只有一个密钥。如果多个参与者都知道该密钥,该密钥 也称为共享密钥。非对称密码(公钥密码)——参与者对密钥的可见性是非对称的。例如,一些参与者仅…...
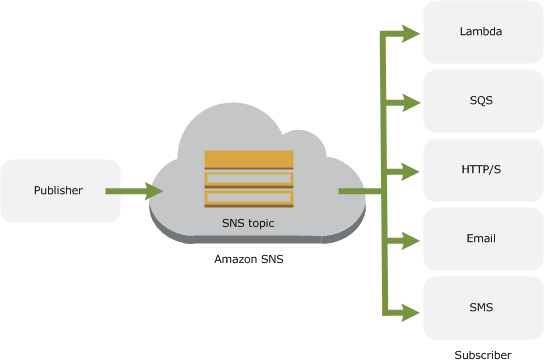
SNS (Simple Notification Service)简介
SNS (Simple Notification Service) 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。 和SQS (Simple Queue Service)一样,SNS也可以轻松分离和扩展微服务,分布式系统和无服务应用程序…...

JVM初步理解浅析
一、JVM的位置 JVM的位置 JVM在操作系统的上一层,是运行在操作系统上的。JRE是运行环境,而JVM是包含在JRE中 二、JVM体系结构 垃圾回收主要在方法区和堆,所以”JVM调优“大部分也是发生在方法区和堆中 可以说调优就是发生在堆中…...

【巨人的肩膀】MySQL面试总结(一)
💪 目录💪1、什么是ER图2、数据库范式了解吗3、超键、候选键、主键、外键分别是什么?4、为什么不推荐使用外键与级联5、什么是存储过程6、drop、delete与truncate区别7、数据库设计通常分为那几步8、什么是关系型数据库9、什么是SQL10、MySQL…...
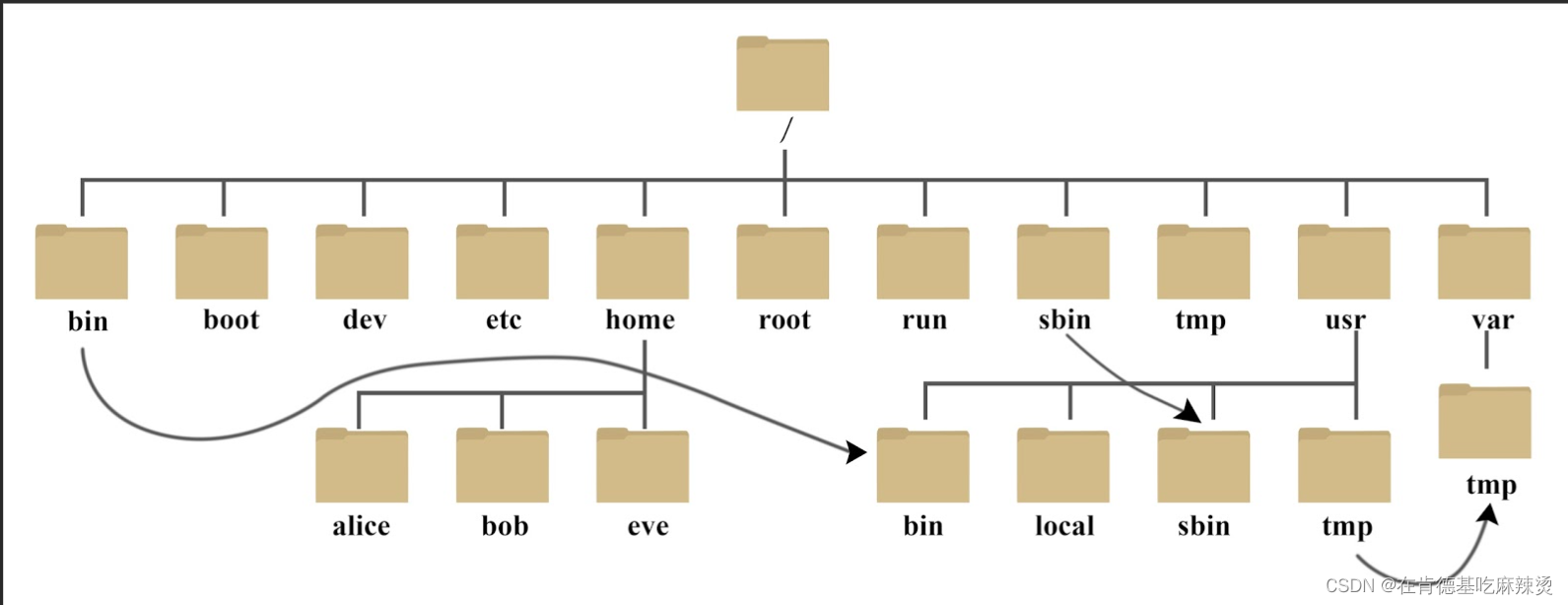
【数据结构之树】——什么是树,树的特点,树的相关概念和表示方法以及在实际的应用。
文章目录一、1.树是什么?2.树的特点二、树的相关概念三、树的表示方法1.常规方法表示树2.使用左孩子右兄弟表示法3. 使用顺序表来存储父亲节点的下标三、树在实际的应用总结一、1.树是什么? 树是一种非线性的数据结构,它是由n(n&…...
JavaScript语法
文章目录一、JavaScript是什么?JavaScript引入方式二、基础语法书写语法输出语句变量数据类型运算符流程控制语句数组函数JS变量作用域对象一、JavaScript是什么? JavaScript:是一门跨平台的脚本语言,用来控制网页行为࿰…...

【BIOS/UEFI】HII 基本框架及概述
HII(Human Interface Infrastructure )定义了一套管理用户输入的基础框架。HII数据库主要提供用户安装、卸载以及使用各种字符串、字体和图片等资源的接口。 HID Devices 是用户输入设备,如键盘、串口和网络;Display Devices 是输…...
溢出边界导致程序崩溃的问题)
sprintf(...)溢出边界导致程序崩溃的问题
文章目录小结问题及解决参考小结 使用sprintf(...)进行格式化是一种标准的做法,但是这样做是有一个极大的风险,由于sprintf(...)不进行边界检查,这样会有写操作溢出边界的风险,并导致程序崩溃。本文进行了简单写操作溢出边界的测…...

公式推导+dfs简版
写在前面的话:心可以冷,但手不能停 第一题:C. Flexible String 题目大意:给一个aaa字符串和bbb字符串和数字kkk,首先设置一个计数器cntcntcnt,其中可以对aaa字符串做以下操作:替换aaa中的一个字母xxx&#…...

论文笔记 | 标准误聚类问题
关于标准误的选择,如是否选择稳健性标准误、是否采取聚类标准误。之前一直是困惑的,惯用的做法是类似主题的文献做法。所以这一次,借计量经济学课程之故,较深入学习了标准误的选择问题。 在开始之前推荐一个知乎博主。他阅读了很…...
银行管理系统--课后程序(Python程序开发案例教程-黑马程序员编著-第7章-课后作业)
实例1:银行管理系统 从早期的钱庄到现如今的银行,金融行业在不断地变革;随着科技的发展、计算机的普及,计算机技术在金融行业得到了广泛的应用。银行管理系统是一个集开户、查询、取款、存款、转账、锁定、解锁、退出等一系列的功…...
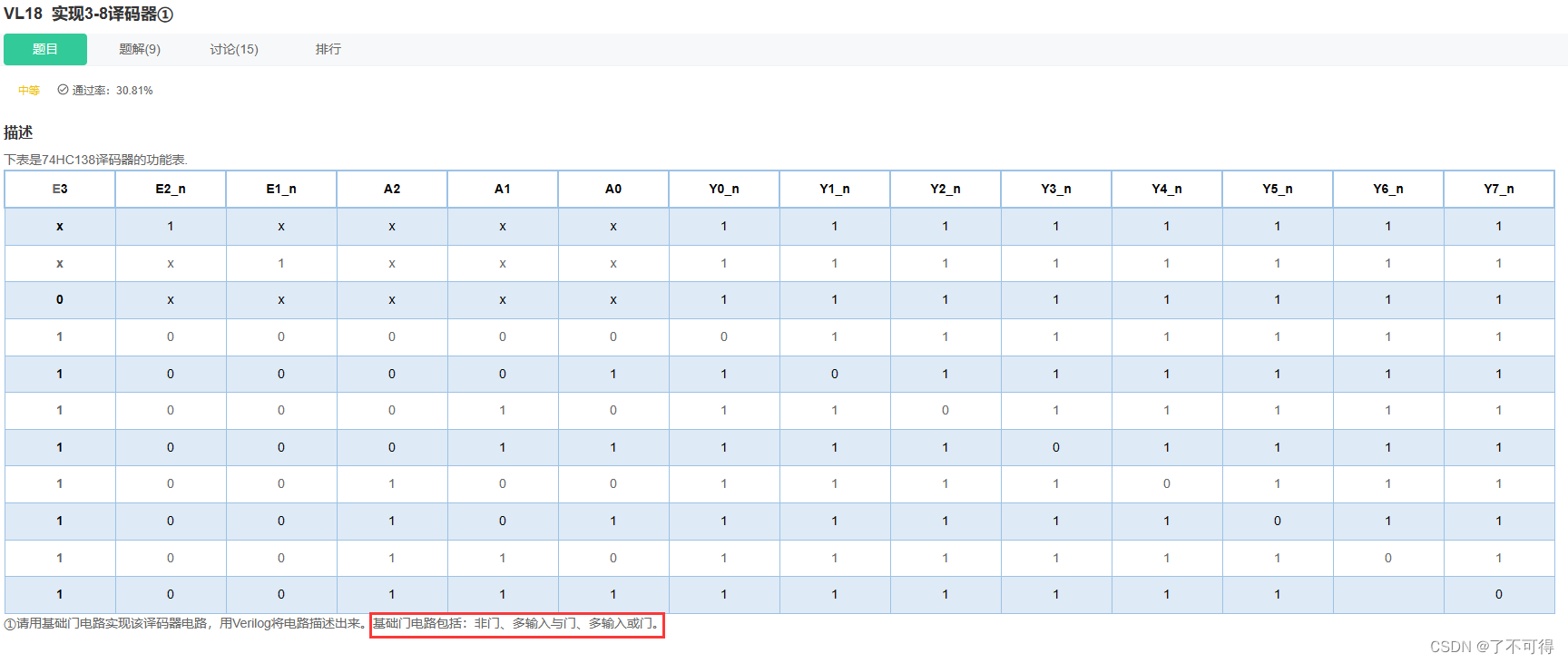
【18】组合逻辑 - VL18 实现3-8译码器①
VL18 实现3-8译码器① 1 题目 【这题我的思路非常绝境】奈斯 !! 看真值表的思路:Yi所在列【0仅一个其余全1】,故【以0为对象求解】 观察发现:E3 E2_n E1_n = 100 时 是 译码的使能信号 ; 并且E3 E2_n E1_n为其他值时,都不使能译码 然后就很简单,没有仿真就成功了 2 代…...

2020蓝桥杯真题最长递增 C语言/C++
题目描述 在数列a_1 ,a_2,⋯,a_n 中,如果a_i <a_i1 <a_i2<⋯<a_j,则称 a_i至 a_j为一段递增序列,长度为 j−i1。 定一个数列,请问数列中最长的递增序列有多长。 输入描述 输入的第一行包含一个整数 n。 第二行包含…...
| 机考必刷)
华为OD机试题 - 寻找连续区间(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:寻找连续区间题目输入输出示例一输入输出说明示例二输入输出Cod…...

一次疲惫的调试--累了及时透气
原创 射频清茶 深山小老虎 2023-03-11 14:32发表于广东 收录于合集 #射频调试3个 #网分4个 #Wi-Fi 2个 进来透透气 道不尽红尘舍恋 诉不完人间恩怨 世世代代都是缘 喝着相同的水 留着相同的血 这条路漫漫又长远 红花当然配绿叶 这一辈子谁来陪 渺渺茫茫来又回 往日情景再…...
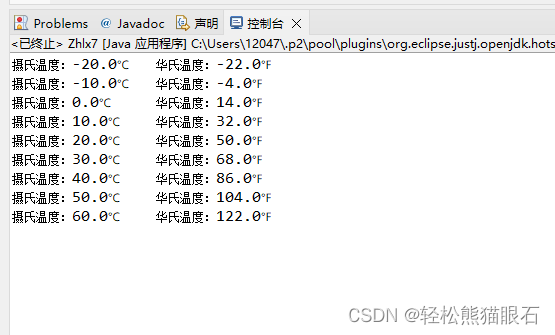
综合练习7 摄氏度转华氏温度(“\t“的使用,循环语句)
综合练习7 摄氏度转华氏温度 使用do…while循环,在控制台输入摄氏温度与华氏温度的对照表。 对照表从摄氏温度-30℃到50℃,每行间隔10℃,运行如下: 摄氏温度:-30℃ 华氏温度:-22.0℉ 摄氏温度:…...

AWS数据库总结
RDS – 联机事务处理OLTP(Online Transaction Processing),包括: SQL ServerOracleMySQL ServerPostgreSQLAuroraMariaDB非关系数据库DynamoDB数据仓库RedShift – 联机分析处理OLAP(Online Analytics Processing&…...
2个步骤就能批量给视频添加滚动字幕
现在很多小伙伴在剪辑视频的时候都会给自己的视频添加适配的字幕,但是有很多的视频想要添加一样的滚动字幕时,有一个能批量添加剪辑的工具非常重要,今天小编就给大家分享一个可以批量剪辑大量视频的工具,下面一起看看具体的操作步…...
PHP 的运行方式有哪些?
PHP本质上的运行方式可以分为两种: 基于命令行的基于PHP-FPM的 但实际上,PHP能做的事很多,很多场景下,不同的运行方式能让开发更方便,减轻各种工作。 测试开发 PHP内置了一个HTTP 的server。这意味着,很…...
)
Simulink新手必看:从零搭建四轴飞行器仿真模型(附完整代码)
Simulink实战:四轴飞行器仿真建模全流程解析 四轴飞行器作为无人机领域的经典构型,其控制系统的设计与验证一直是工程师和科研人员的重点课题。对于刚接触Simulink的开发者而言,如何将复杂的飞行动力学转化为可视化的仿真模型往往令人望而生畏…...

Phi-3-mini-4k-instruct-gguf步骤详解:supervisor服务管理与错误日志定位方法
Phi-3-mini-4k-instruct-gguf步骤详解:supervisor服务管理与错误日志定位方法 1. 模型概述 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本,特别适合问答、文本改写、摘要整理和简短创作等场景。这个开箱即用的解决方案已…...

7步构建个性化定制:Degrees of Lewdity中文整合包深度改造指南
7步构建个性化定制:Degrees of Lewdity中文整合包深度改造指南 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS DOL-CHS-MODS是一款基于Degrees of Lewdity中文汉化版的自动化构建系统&am…...

技术解码:ViGEmBus虚拟手柄驱动框架 - 重新定义Windows输入设备模拟的底层架构
技术解码:ViGEmBus虚拟手柄驱动框架 - 重新定义Windows输入设备模拟的底层架构 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款基…...

Mac用户福音:Qwen3-TTS声音克隆在ComfyUI上的M芯片优化方案
Mac用户福音:Qwen3-TTS声音克隆在ComfyUI上的M芯片优化方案 1. 为什么Mac用户需要特别优化方案 苹果M系列芯片凭借其出色的能效比和统一内存架构,已经成为许多创意工作者的首选。然而,在运行AI模型时,特别是像Qwen3-TTS这样的语…...

SiameseAOE模型多模态扩展探索:结合图像信息的属性抽取
SiameseAOE模型多模态扩展探索:结合图像信息的属性抽取 最近在做一个项目,需要从一堆产品说明书里自动提取技术参数。这些说明书五花八门,有的是纯文本PDF,有的则是图文混排,甚至有些关键参数就印在产品图片的标签上。…...

小白也能搞定:CYBER-VISION零号协议智能助盲系统部署全流程
小白也能搞定:CYBER-VISION零号协议智能助盲系统部署全流程 1. 系统介绍与准备工作 CYBER-VISION零号协议是一款专为视障人士设计的智能助盲系统,它通过先进的计算机视觉技术,将周围环境实时转化为可理解的语音提示。想象一下,当…...

Anything to RealCharacters效果评测:与Stable Diffusion ControlNet写实方案对比
Anything to RealCharacters效果评测:与Stable Diffusion ControlNet写实方案对比 1. 项目概述 Anything to RealCharacters是一款专为RTX 4090显卡优化的2.5D转真人图像转换系统。这个工具基于通义千问Qwen-Image-Edit-2511图像编辑底座,集成了专门的…...

百川2-13B-Chat-4bits应用场景:开发者日常——代码审查、错误诊断、技术文档润色实战
百川2-13B-Chat-4bits应用场景:开发者日常——代码审查、错误诊断、技术文档润色实战 1. 引言:当大模型成为你的开发伙伴 想象一下这个场景:深夜,你盯着屏幕上那段运行了三次、报错信息却完全不同的代码,咖啡已经凉透…...

Word文档自动更新日期技巧
设置Word文档自动显示当天日期打开Word文档后,可以通过插入日期字段实现每次打开时自动更新为当天日期。方法1:使用日期字段在Word文档中定位光标到需要显示日期的位置。点击菜单栏"插入"→"文本"→"日期和时间"。在弹出的…...