【Linux】—Apache Hive 安装部署
文章目录
- 前言
- 认识Metadata
- 认识Metastore
- metastore三种配置方式
- 一、安装前准备
- 二、下载hive-3.1.2安装包
- 三、下载完成后,通过xftp6上传到Linux服务器上
- 四、解压Hive安装包
- 五、配置Hive
- 六、内嵌模型安装—Hive元数据配置到Derby
- 七、本地模式安装—Hive元数据配置到MySQL
- 八、远程模型安装—使用元数据服务的方式访问Hive
- 九、Hive客户端使用
- hive客户端
- HiveServer、HiveServer2服务
- Hive客户端与服务的关系
- Hive客户机使用—Hive Client
- Hive客户机— Hive Beeline Client
前言
本文主要介绍在Linux环境下安装Hive的过程。
- 使用Linux 工具/版本 :
- xshell6、xftp6
- Centos7:CentOS Linux release 7.6.1810 (Core)
- 安装Hive版本:
- hive-3.1.2
认识Metadata
Metadata即元数据。元数据包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。元数据存储在关系型数据库中,如hive内置的Derby、或者第三方如MySQL等。
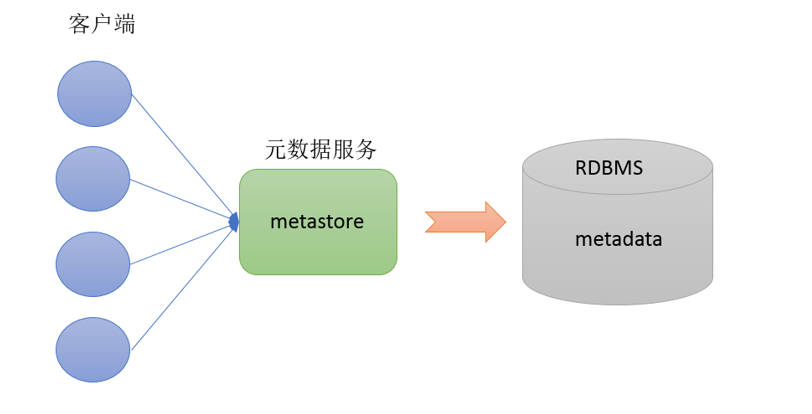
认识Metastore
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。某种程序上也保证上了hive元数据的安全。
metastore三种配置方式
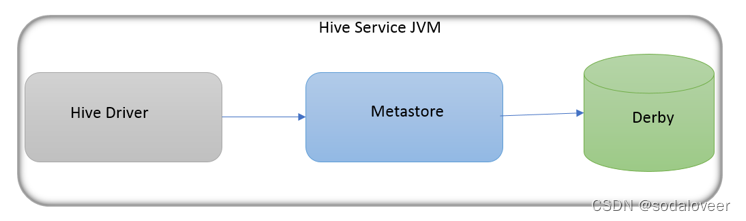
- 内嵌模式
内嵌模式(Embedded Metastore)是metastore默认部署模式。此种模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。不需要额外起Metastore服务。
但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。
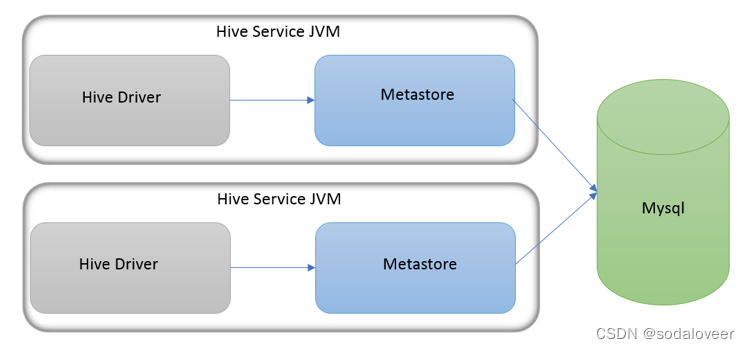
- 本地模式
本地模式(Local Metastore)下,Hive Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。本地模式采用外部数据库来存储元数据,推荐使用MySQL。
hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
缺点是:每启动一次hive服务,都内置启动了一个metastore。
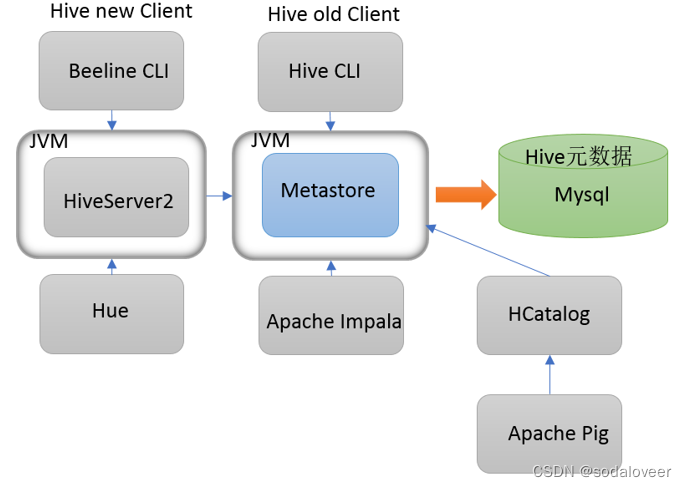
- 远程模式
远程模式(Remote Metastore)下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。
- 三种模式对比
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| Metastore单独配置、启动 | 否 | 否 | 是 |
| Metastore存储介质 | Derby | Mysql | Mysql |
一、安装前准备
由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
-
服务器基础环境
-
集群时间同步
-
防火墙关闭,执行"systemctl status firewalld.service“命令查看防火墙的状态;如果没有关闭,则执行"systemctl stop firewalld.service"命令关闭防火墙。

-
主机Host映射
-
免密登录
-
JDK安装
-
-
Hadoop集群
-
启动Hive之前必须先启动Hadoop集群,需等待HDFS安全模式关闭之后再启动运行Hive。执行"myhadoop start"命令启动集群,执行"jpsall"命令查看集群启动状态。


-
二、下载hive-3.1.2安装包
hive安装包下载地址:https://archive.apache.org/dist/hive/
三、下载完成后,通过xftp6上传到Linux服务器上
将hive-3.1.2安装包上传到 /opt/software 路径下面。
1、打开xshell6,连接要安装hive的Linux服务器,执行 “cd /opt/software” 命令。

2、打开xftp6,选择下载好的hive安装包,点击上传到 /opt/software下面。

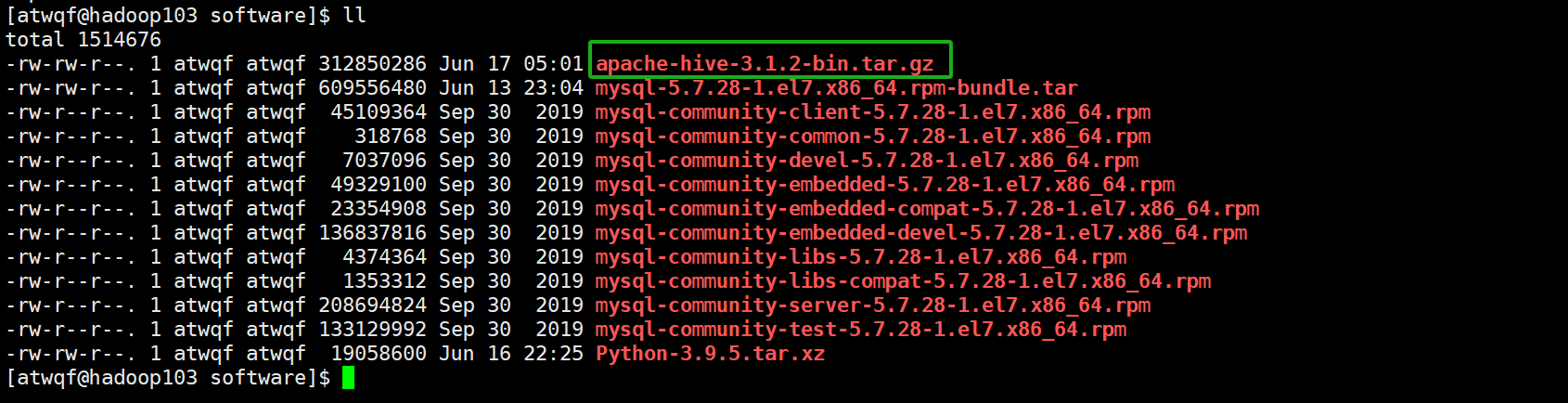
3、关闭xftp6,在刚刚连接Linux服务器的 /opt/software 路径下执行 “ll” 命令,可以查看到hive安装包已经上传成功。
四、解压Hive安装包
1、解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面,执行"tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/"命令。

2、修改apache-hive-3.1.2-bin.tar.gz 的名称为 hive,执行"mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive"命令。

五、配置Hive
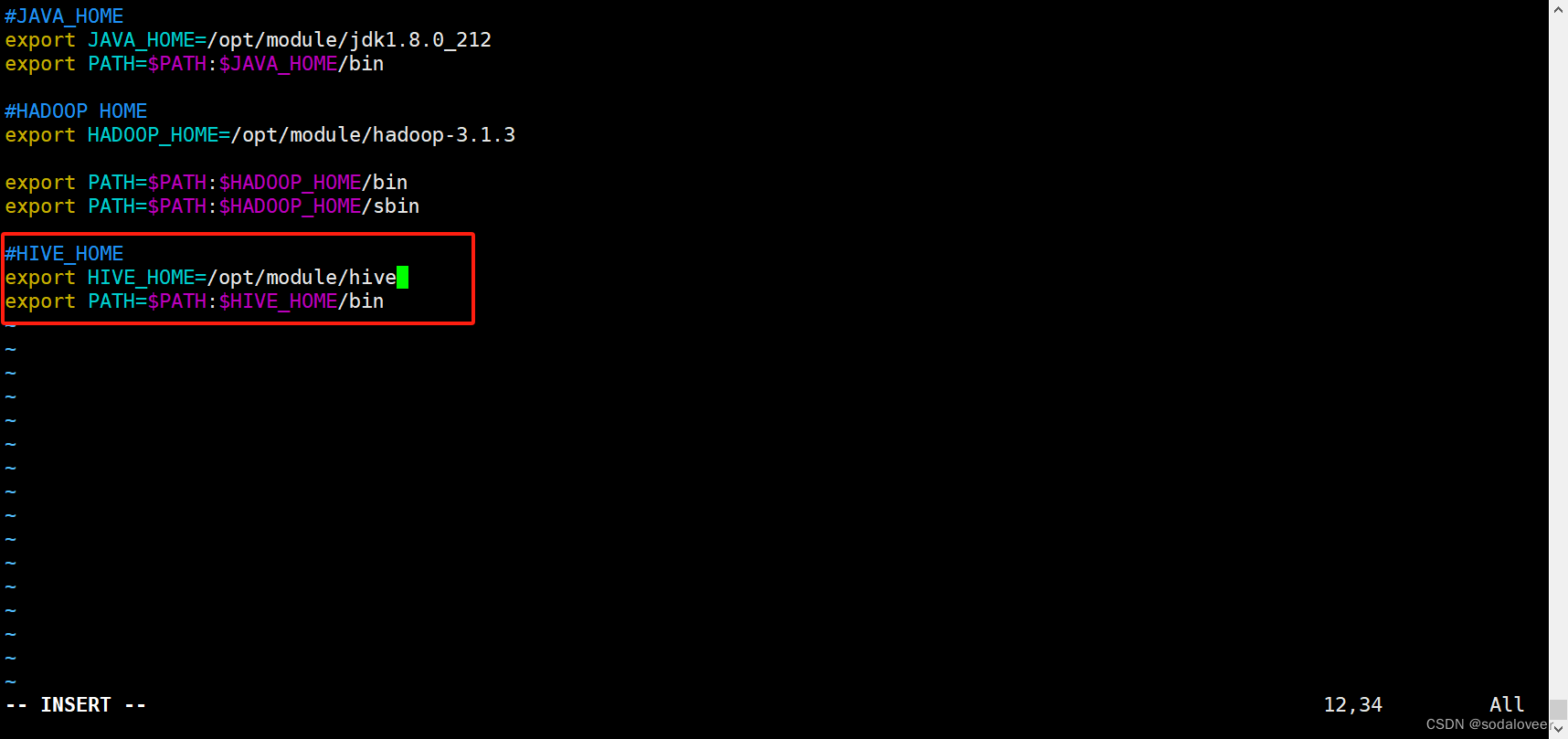
1、添加环境变量,执行"vim /etc/profile.d/my_env.sh"命令。
- 添加以下内容:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
2、解决日志冲突,执行"mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak”命令。

六、内嵌模型安装—Hive元数据配置到Derby
Derby是内置的数据库,无需下载。
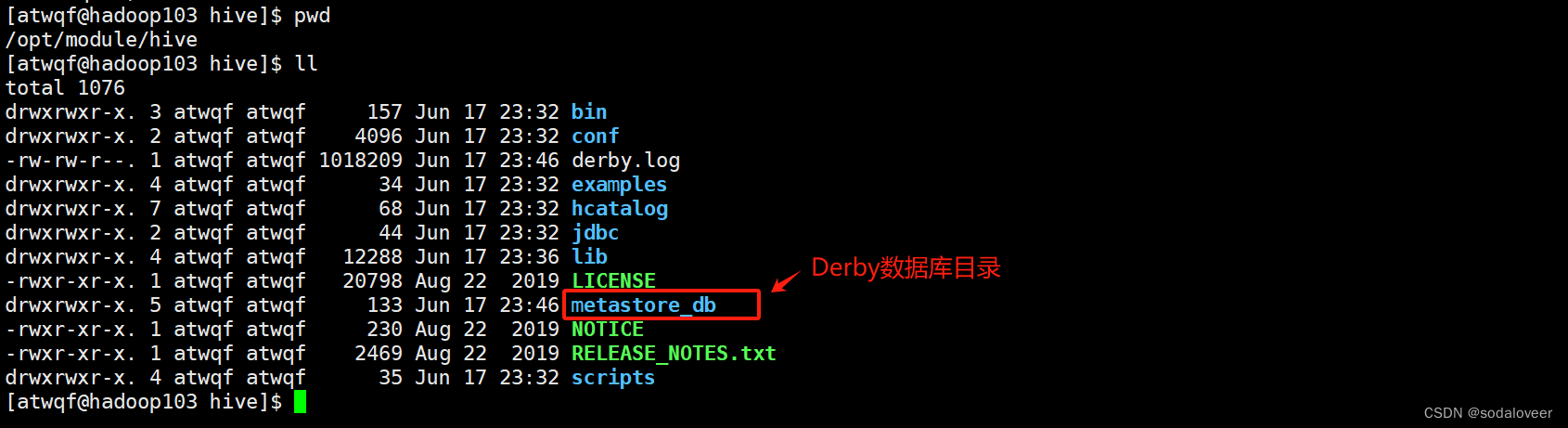
1、初始化元数据库。执行"bin/schematool -dbType derby -initSchema"命令 。


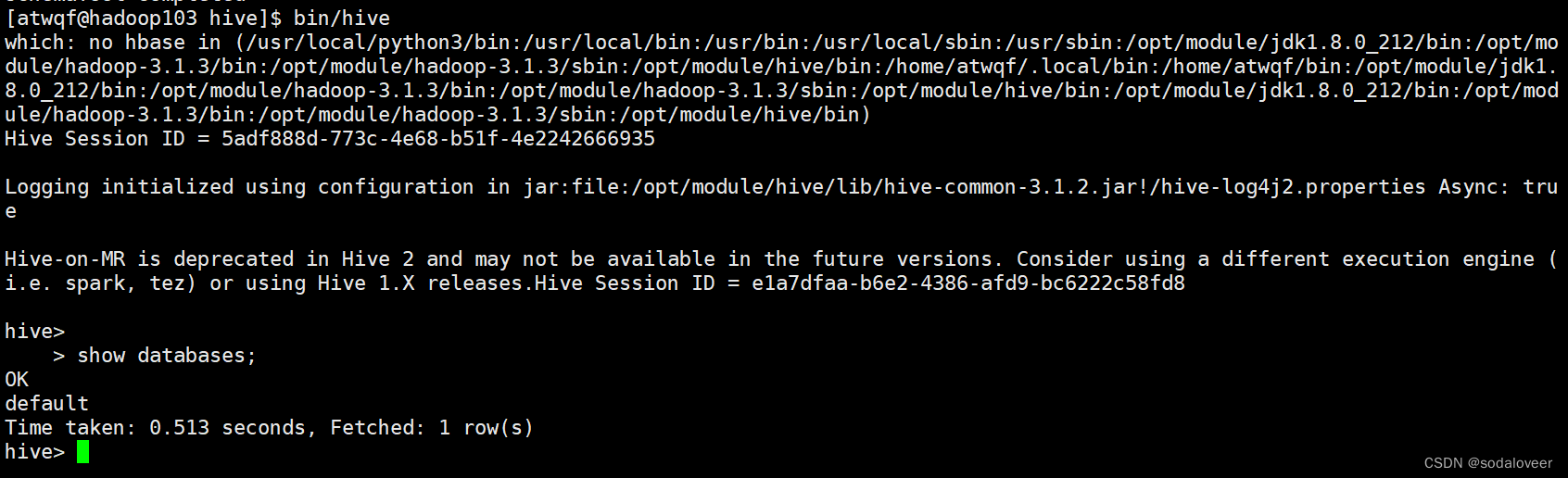
2、启动使用hive,执行"bin/hive"命令。
3、开启另一个窗口,执行"cat /tmp/atwqf/hive.log"命令查看日志文件。
注意:
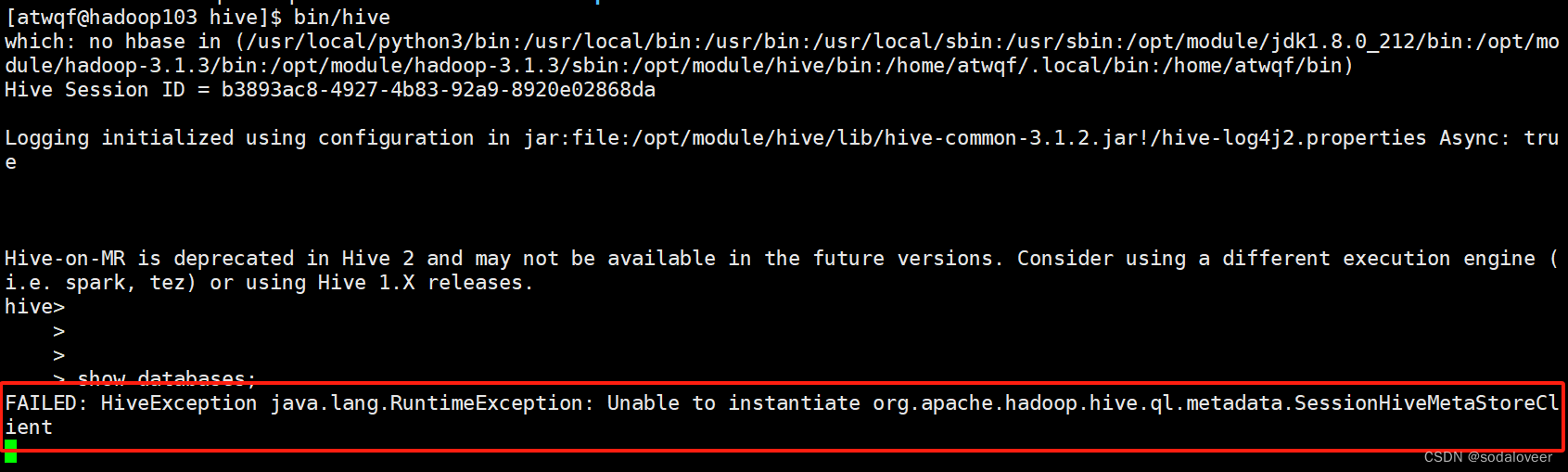
Hive默认使用的元数据库为derby,开启Hive之后就会占用元数据库,且不与其他客户端共享数据。
例如:另外开一个窗口使用hive,会报错FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
七、本地模式安装—Hive元数据配置到MySQL
本地模式安装前先进行MySQL安装,参考链接:https://blog.csdn.net/sodaloveer/article/details/139674393,确定MySQL数据库安装成功后,才将Hive元数据配置到MySQL。
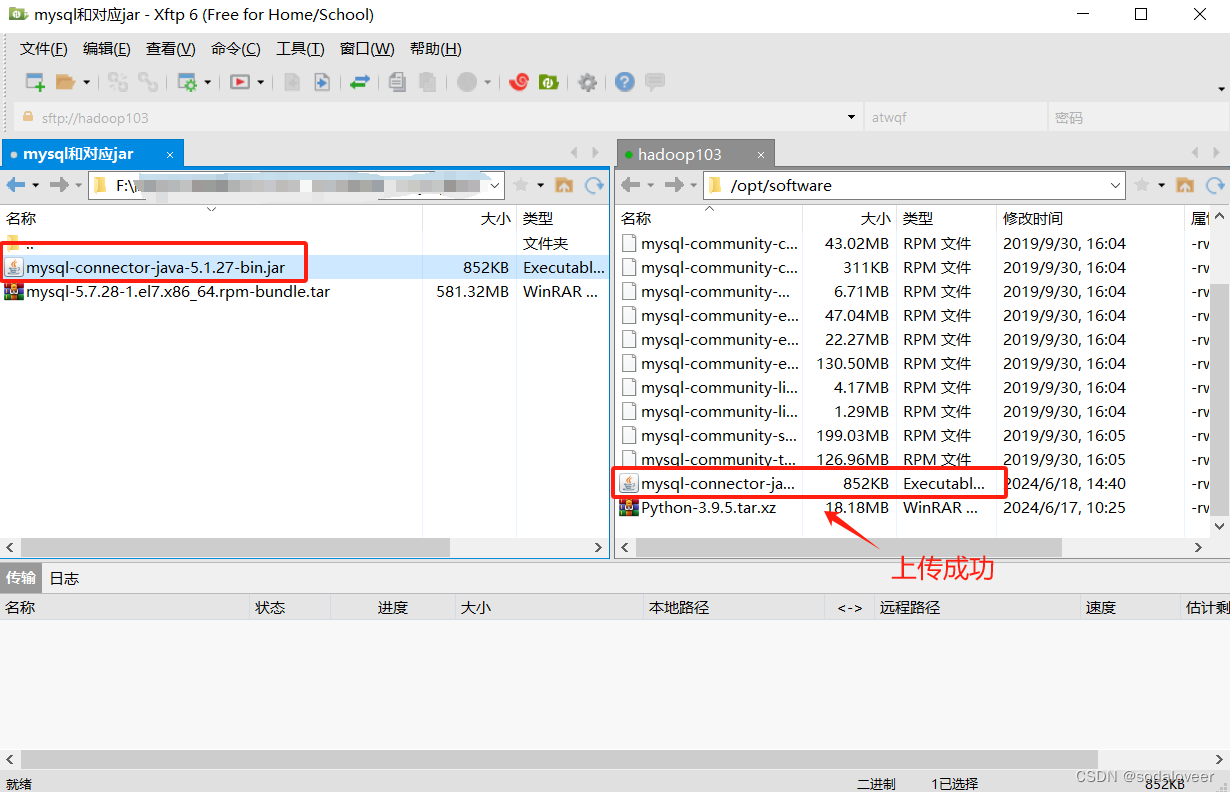
1、上传MySQL的JDBC驱动(通过xftp6上传),将MySQL的JDBC驱动拷贝到Hive的lib目录下,执行"cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib"命令。

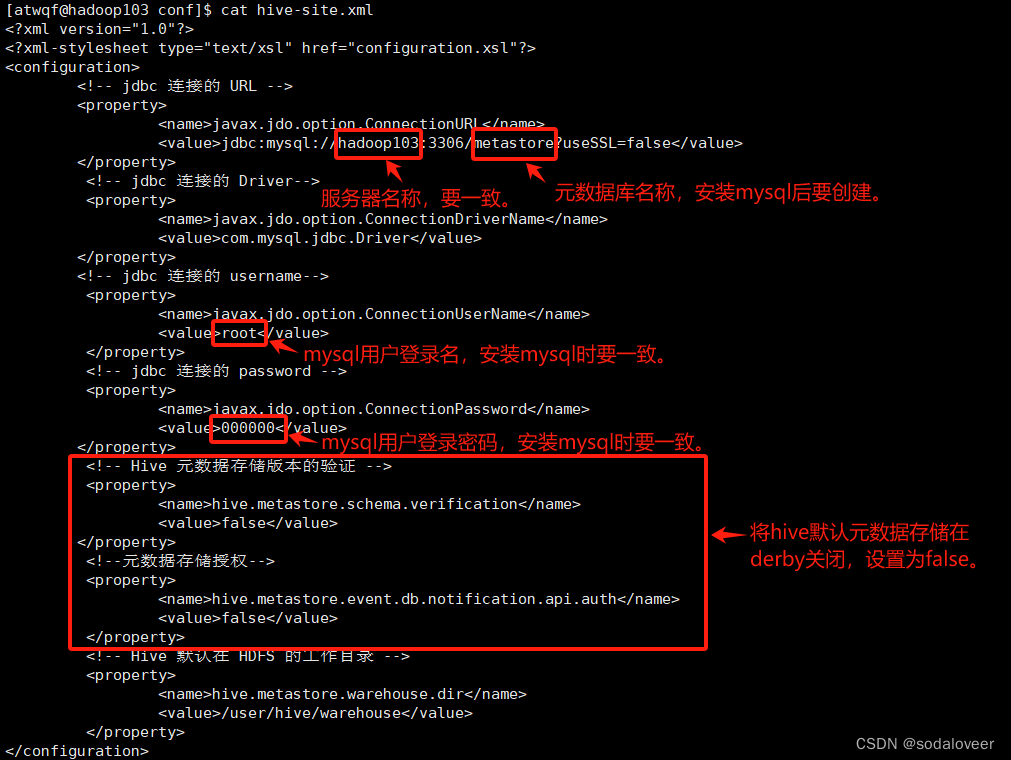
2、配置Metastore到MySQL,在/opt/module/hive/conf目录下新建hive-site.xml文件。执行"vim /opt/module/hive/conf/hive-site.xml",添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc 连接的 URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop103:3306/metastore?useSSL=false</value></property> <!-- jdbc 连接的 Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property> <!-- jdbc 连接的 username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property> <!-- jdbc 连接的 password --><property><name>javax.jdo.option.ConnectionPassword</name><value>000000</value></property> <!-- Hive 元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property> <!--元数据存储授权--><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property> <!-- Hive 默认在 HDFS 的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property>
</configuration>
复制粘贴上面的内容需要注意:<?xml version="1.0"?>这里需要注意,这一行必须在第一行,并且需要顶格,前面没有任何空格或其他字符。多余空格需去掉,特殊字符需转义),否则会报错:
Illegal processing instruction target ("xml"); xml (case insensitive) is reserved by the specs.
3、登陆MySQL,执行"mysql -uroot -p000000"

4、新建Hive元数据库,元数据库的名称要和配置文件hive-site.xml一致。
> create database metastore;
> show databases;
> quit;

5、初始化元数据库,执行"schematool -initSchema -dbType mysql -verbose"命令。
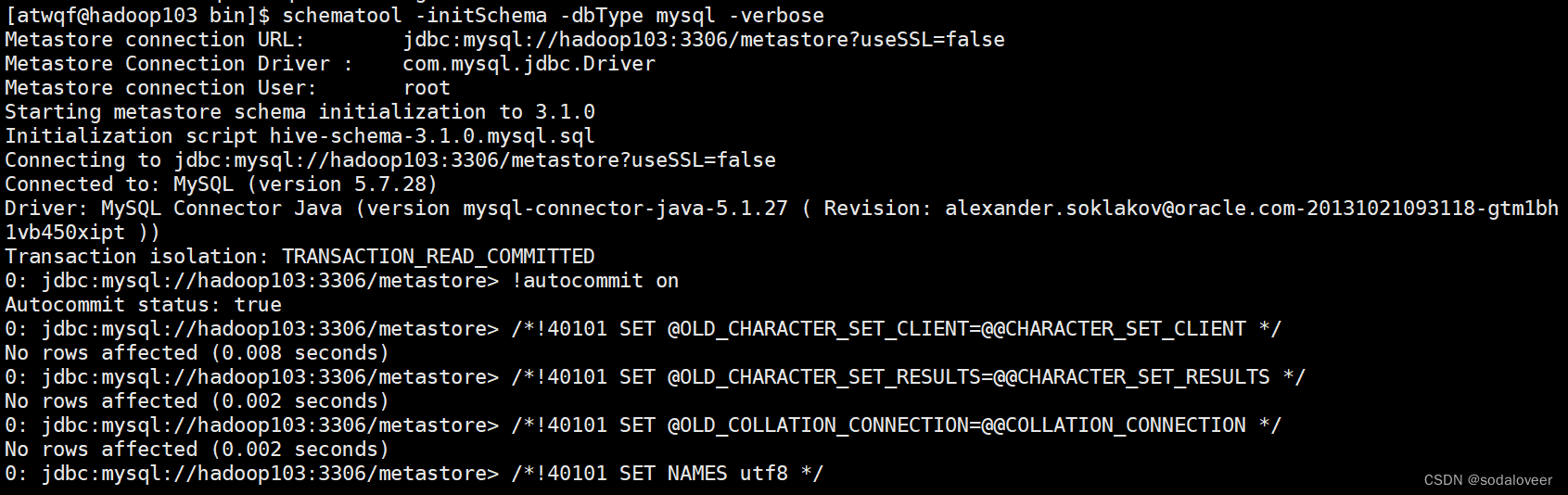
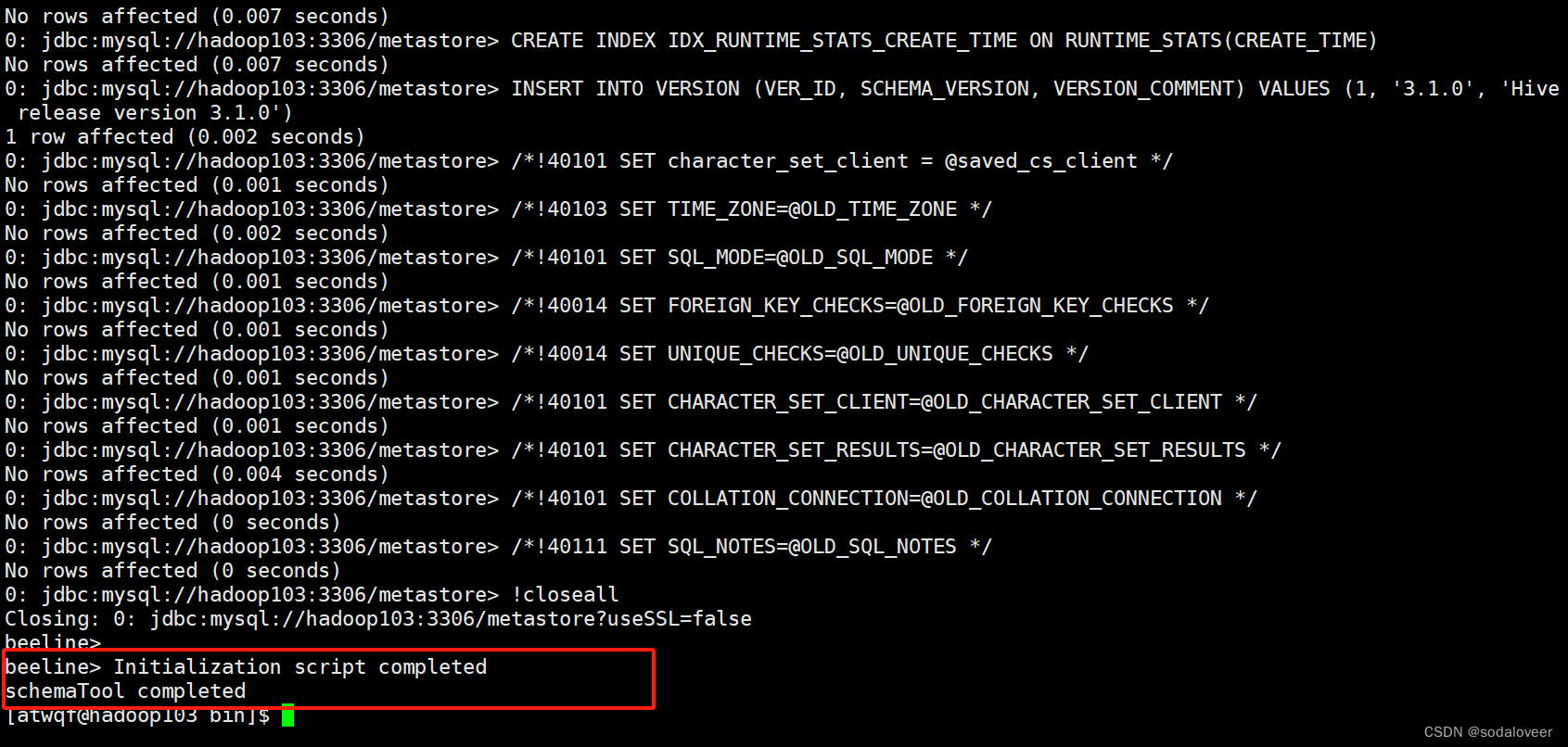
初始化完成。
6、再次启动Hive,执行"bin/hive"命令。
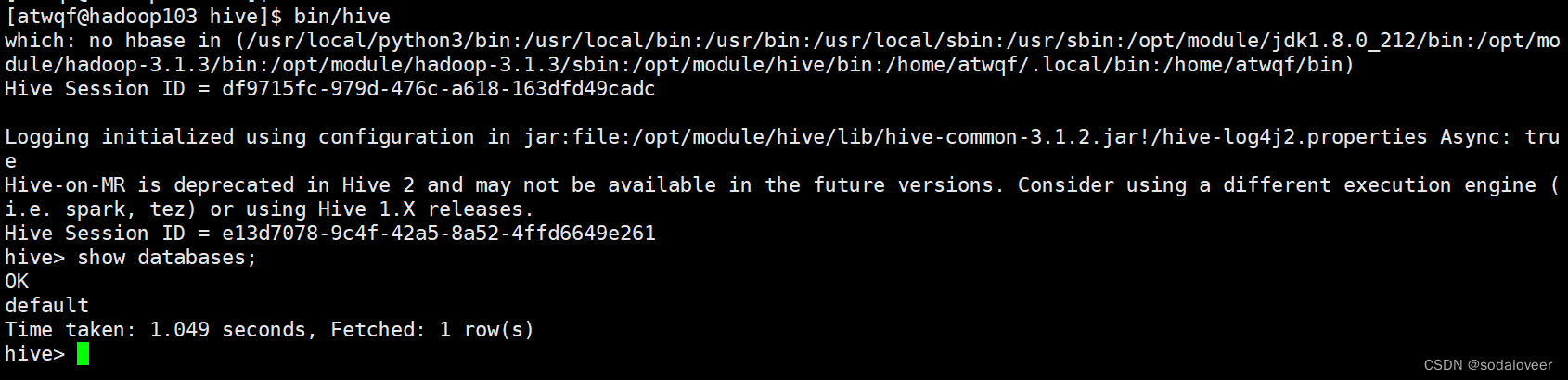
另一个窗口开启hive,执行"bin/hive"命令。

八、远程模型安装—使用元数据服务的方式访问Hive
1、执行"vim /opt/module/hive/conf/hive-site.xml",添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc 连接的 URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop103:3306/metastore?useSSL=false</value></property> <!-- jdbc 连接的 Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property> <!-- jdbc 连接的 username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property> <!-- jdbc 连接的 password --><property><name>javax.jdo.option.ConnectionPassword</name><value>000000</value></property> <!-- Hive 元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property> <!--元数据存储授权--><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property> <!-- Hive 默认在 HDFS 的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property> <!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop103:9083</value></property>
</configuration>
与本地模式相比,hive-site.xml文件主要是在增加了下面的内容:
<!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop103:9083</value></property>
要给hive起一个服务,主要是提供端口使第三方框架可以连接使用。
2、启动metastore,三种方式:
- 前台启动,执行"hive --service metastore"命令。

另起一个窗口:

后台启动,进程挂起,执行"nohup /opt/module/hive/bin/hive --service metastore &"命令,后台启动的输出日志信息,在/root目录下,nohup.out。
也可以使用脚本管理服务的启动和关闭。
1.执行"vim $HIVE_HOME/bin/hiveservices.sh"命令新建脚本,脚本内容如下;
2.执行"chmod +x $HIVE_HOME/bin/hiveservices.sh"命令,添加执行权限;
3.执行"hiveservices.sh start"启动 Hive 后台服务.
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数 1 为进程名,参数 2 为进程端口
function check_process()
{pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print
$2}')ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)echo $pid[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}function hive_start()
{metapid=$(check_process HiveMetastore 9083)cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1
&"[ -z "$metapid" ] && eval $cmd || echo "Metastroe 服务已启动"server2pid=$(check_process HiveServer2 10000)cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)[ "$metapid" ] && kill $metapid || echo "Metastore 服务未启动"server2pid=$(check_process HiveServer2 10000)[ "$server2pid" ] && kill $server2pid || echo "HiveServer2 服务未启动"
}
case $1 in
"start")hive_start;;
"stop")hive_stop;;
"restart")hive_stopsleep 2hive_start;;
"status")check_process HiveMetastore 9083 >/dev/null && echo "Metastore 服务运行
正常" || echo "Metastore 服务运行异常"check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 服务运
行正常" || echo "HiveServer2 服务运行异常";;
*)echo Invalid Args!echo 'Usage: '$(basename $0)' start|stop|restart|status';;
esac
-
注意:
- 前台启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作。
在远程模式下,必须首先启动Hive metastore服务才可以使用hive。因为metastore服务和hive server是两个单独的进程了。否则会报错:

九、Hive客户端使用
hive客户端
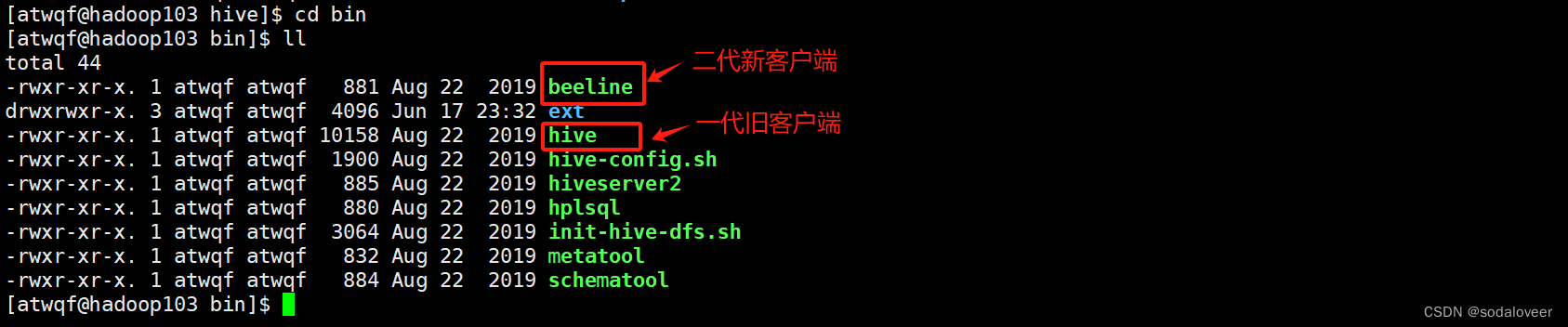
第一代客户端(deprecated不推荐使用):$HIVE_HOME/bin/hive。
第二代客户端(recommended 推荐使用):$HIVE_HOME/bin/beeline,是一个JDBC客户端。
HiveServer、HiveServer2服务
HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果。
区别:
HiveServer不能处理多于一个客户端的并发请求。
HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。所以更加推荐使用第二代客户端($HIVE_HOME/bin/beeline)。
Hive客户端与服务的关系

Hiveserver2通过metastore服务读写元数据,所以在远程模式下启动Hiveserver2之前必须先启动metastore服务。
Beeline客户端只能通过Hiveserver2服务访问Hive,而Hive Cline是通过Metastore服务访问的。
Hive客户机使用—Hive Client
bin/hive客户端是hive第一代客户端,可以访问metastore服务,从而达到操作hive目的。
内嵌和本地模式下直接执行"$HIVE_HOME/bin/hive"命令,metastore服务会内嵌一起启动。
如果需要在其他机器上(远程模式)通过bin/hive访问hive metastore服务,只需要在该机器的hive-site.xml配置中添加metastore服务地址即可。(参考上面:远程模型安装—使用元数据服务的方式访问Hive)
Hive客户机— Hive Beeline Client
Beeline客户端是hive第二代客户端(推荐使用),不是直接访问metastore服务的,需要单独启动hiveserver2服务。
Beeline是JDBC客户端面,通过JDBC协议与HIveserver2服务进行通信,协议的地址是:jdbc:hive2://hadoop103:10000。
1、使用JDBC方式访问Hive,执行"vim /opt/module/hive/conf/hive-site.xml",添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc 连接的 URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop103:3306/metastore?useSSL=false</value></property> <!-- jdbc 连接的 Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc 连接的 username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property> <!-- jdbc 连接的 password --><property><name>javax.jdo.option.ConnectionPassword</name><value>000000</value></property> <!-- Hive 元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property> <!--元数据存储授权--><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property> <!-- Hive 默认在 HDFS 的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop103:9083</value></property><!-- 指定 hiveserver2 连接的 host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop103</value></property> <!-- 指定 hiveserver2 连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
</configuration>
与远程模式相比,hive-site.xml文件主要是在增加了下面的内容:
<!-- 指定 hiveserver2 连接的 host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop103</value></property><!-- 指定 hiveserver2 连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
2、先启动metastore服务,执行"$HIVE_HOME/bin/hive --service metastore"命令。
然后启动hiveserver2,执行"$HIVE_HOME/bin/hive --service hiveserver2"命令。


3、启动beeline客户端,执行"$HIVE_HOME/bin/beeline -u jdbc:hive2://hadoop103:10000 -natwqf"命令。

安装过程中可能出现的报错:
“schematool -initSchema -dbType mysql -verbose” 报错!!!
安装Hive后执行“$HIVE_HOME/bin/hive”命令时,报错Connection refused
相关文章:
【Linux】—Apache Hive 安装部署
文章目录 前言认识Metadata认识Metastoremetastore三种配置方式 一、安装前准备二、下载hive-3.1.2安装包三、下载完成后,通过xftp6上传到Linux服务器上四、解压Hive安装包五、配置Hive六、内嵌模型安装—Hive元数据配置到Derby七、本地模式安装—Hive元数据配置到M…...
组装盒示范程序
代码; #include <gtk-2.0/gtk/gtk.h> #include <glib-2.0/glib.h> #include <stdio.h>int main(int argc, char *argv[]) {gtk_init(&argc, &argv);GtkWidget *window;window gtk_window_new(GTK_WINDOW_TOPLEVEL);gtk_window_set_title(GTK_WINDO…...
推荐一款AI修图工具,支持AI去水印,AI重绘,AI抠图...
不知道大家有没有这样的一个痛点,发现了一张不错的“素材”, 但是有水印,因此不能采用,但找来找去,还是觉得初见的那个素材不错,怎么办? 自己先办法呗。 二师兄发现了一款功能强大的AI修图工具…...

2024广东省职业技能大赛云计算赛项实战——容器化部署Nginx
容器化部署Nginx 前言 编写Dockerfile文件构建nginx镜像,要求基于centos完成Nginx服务的安装和配置,并设置服务开机自启。 编写Dockerfile构建镜像erp-nginx:v1.0,要求使用centos7.9.2009镜像作为基础镜像,完成Nginx服务的安装&…...

压缩pdf文件大小在线,在线免费压缩pdf
在现在办公中,PDF文档已经成为我们日常工作中不可或缺的一部分。然而,随着文档内容的不断丰富,PDF文件的大小也逐渐增大,这不仅占用了大量的存储空间,而且在传输和共享时也显得尤为不便。所以有时候我们需要把pdf压缩小…...

薄冰英语语法学习--名词1
我用来教我自己3岁的小孩的。 有特殊的情况,暂时先不用管,3岁小孩,只用全部按非特殊情况算就ok了,以后长大了,遇到问题了,再微调一下。先解决百分之90的问题。 一般的复数,直接加s 特殊的词尾…...

oracle12c到19c adg搭建(六)切换后12c备库服务器安装19c软件在19c主库升级数据字典后尝试同步
一、安装19c软件 参考文章oracle12c到19c adg搭建(三)oracle19c数据库软件安装 二、原主库尝试通过19c软件启动数据库 2.1复制12c的相关参数文件和密码文件到19c目录 注意:密码文件需要从已切换主库19c传过来 [oracleo12u19p ~]$ cd /u01/app/oracle…...
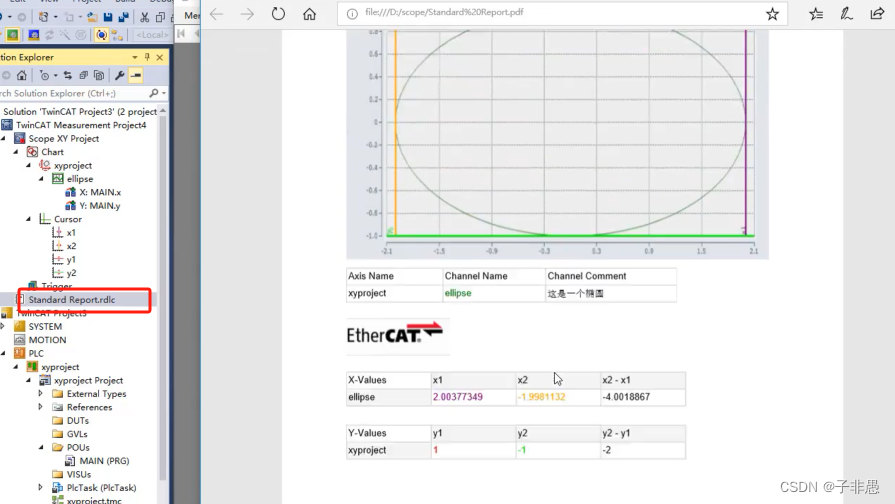
Scope XY Project的使用
1.Scope XY Project的功能介绍与使用方法 添加监控变量 绘制成一个三角形 XY进行对调操作 修改XY轴的比例修改显示输出 2.Cursor的使用方法 游标线的添加测量 3.Reporting功能的使用方法 到处对应的报表数据 添加对应的报告数据...
Pytorch Geometric(PyG)入门
PyG (PyTorch Geometric) 是建立在 PyTorch 基础上的一个库,用于轻松编写和训练图形神经网络 (GNN),适用于与结构化数据相关的各种应用。官方文档 Install PyG PyG适用于python3.8-3.12 一般使用场景:pip install torch_geometric 或conda …...
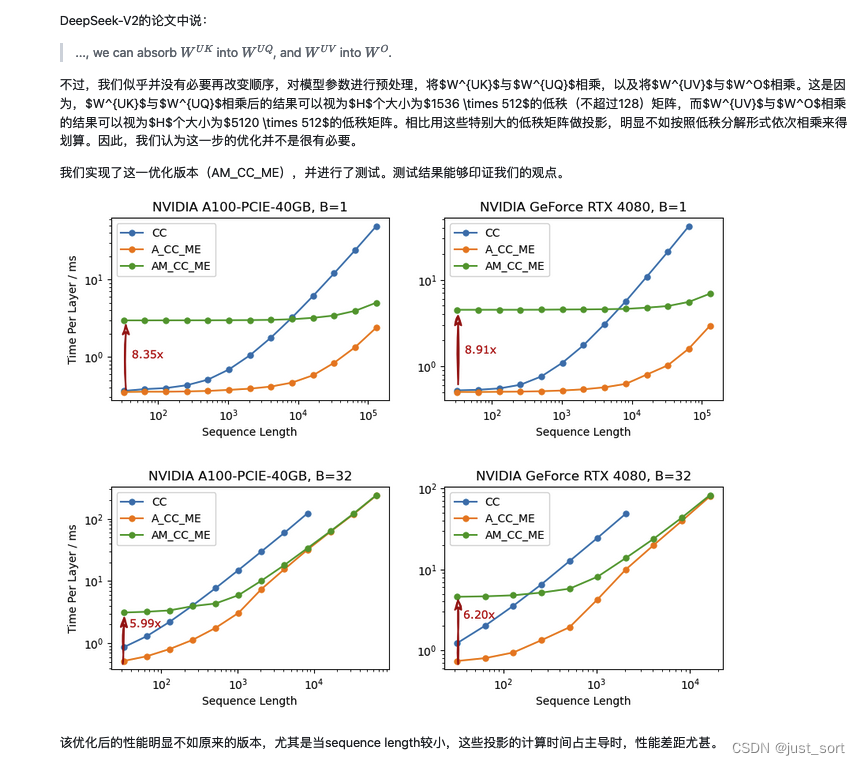
大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应…...
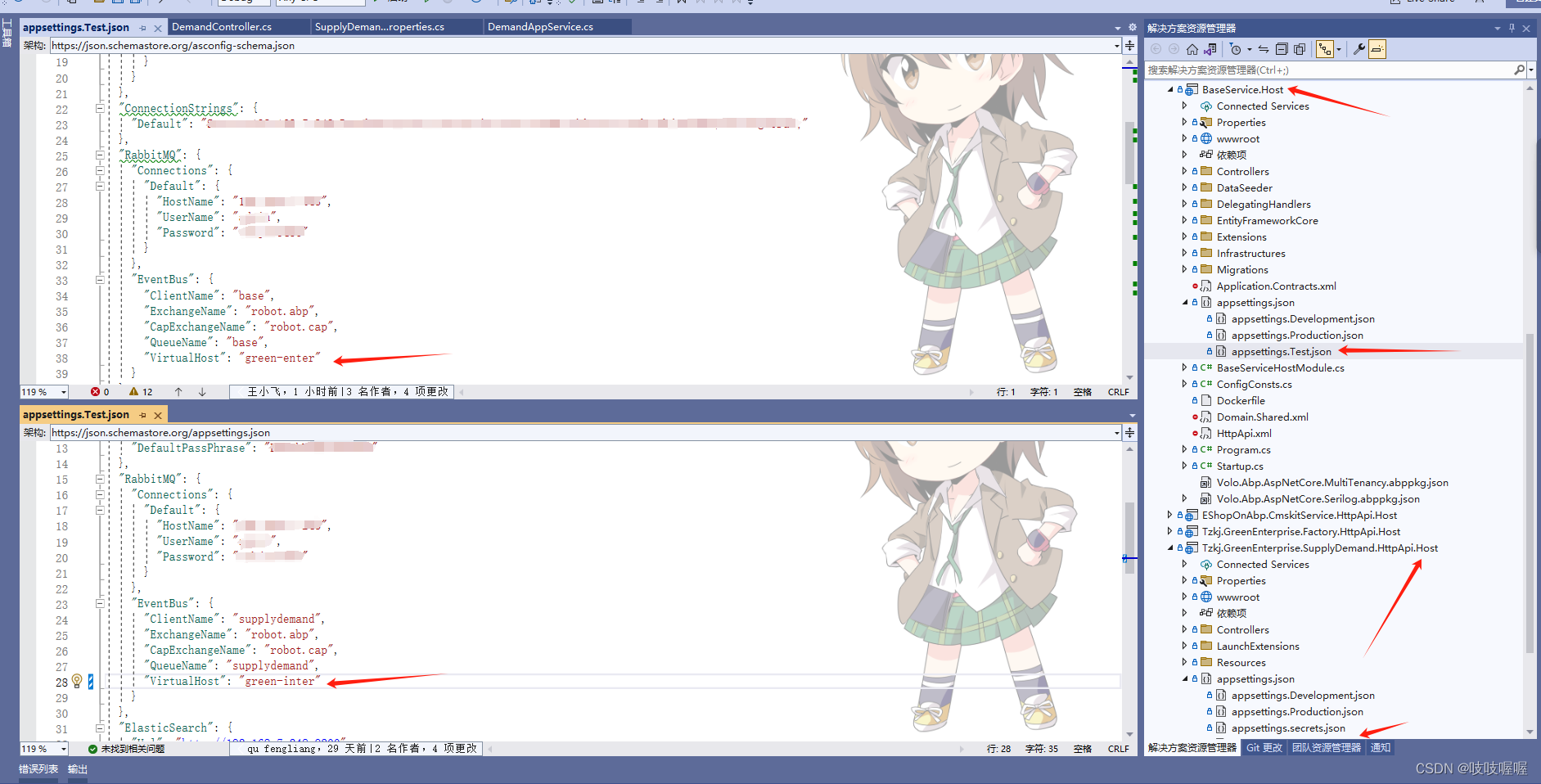
项目中eventbus和rabbitmq配置后,不起作用
如下:配置了baseService层和SupplyDemand层得RabbitMQ和EventBus 但是在执行订阅事件时,发送得消息在base项目中没有执行,后来发现是虚拟机使用得不是一个,即上图中得EventBus下得VirtualHost,修改成一直就可以了...

文库小程序搭建部署:实现资源共享正向反馈
文档库相信大家应该不陌生,日常我们的工作模板、会议模板、求职时的简历模板、教育界的教学模板等来源方式都出自于文档库,随着互联网的发展和工作需求,文档模板开启了新型的知识变现新途径,通过文库小程序,我们不仅能…...
ONLYOFFICE 桌面编辑器8.1---一个高效且强大的办公软件
软件介绍 ONLYOFFICE 桌面编辑器经过不断的更新换代现在迎来了,功能更加强大的ONLYOFFICE 桌面编辑器8.1是一个功能强大的办公套件,专为多平台设计,包括Windows、Linux和macOS。它提供了一套全面的办公工具,包括文档处理、电子表…...
QThread 与QObject::moveToThread利用Qt事件循环在子线程执行多个函数
1. QThread的两种用法 第一种用法就是继承QThread,然后覆写 virtual void run(), 这种用法的缺点是不能利用信号槽机制。 第二种用法就是创建一个线程,创建一个对象,再将对象moveToThread, 这种可以充分利用信号槽机制ÿ…...

6-2 归并排序
6-2 归并排序 分数 10 全屏浏览 切换布局 作者 软件工程DS&A课程组 单位 燕山大学 以下代码采用分而治之算法实现归并排序。请补充函数mergesort()的代码。提示:mergesort()函数可用递归实现,其中参…...
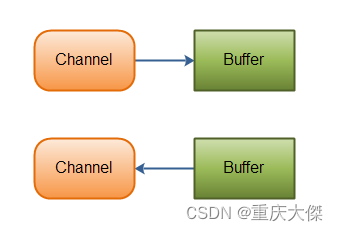
Java NIO(一) 概述
NIO主要用于以少量线程来管理多个网络连接,处理其上的读写等事件。在大量连接情况下,不管是效率还是空间占用都要优于传统的BIO。 Java NIO 由以下几个核心部分组成: Channel Buffer Selector Selector 如果你的应用打开了多个连接&#x…...

JUC线程池最佳实践
参考:Java 线程池最佳实践 | JavaGuide 使用构造函数创建线程池。【使用有界队列,控制线程创建数量】 SpringBoot 中的 Actuator 组件 / ThreadPoolExecutor 的相关 API监控线程池运行状态 是不同的业务使用不同的线程池【父子任务用同一个线程池容易死…...
2024最新版Node.js下载安装及环境配置教程(非常详细)
一、进入官网地址下载安装包 官网:Node.js — Run JavaScript Everywhere 其他版本下载:Node.js — Download Node.js (nodejs.org) 选择对应你系统的Node.js版本 二、安装程序 (1)下载完成后,双击安装包…...
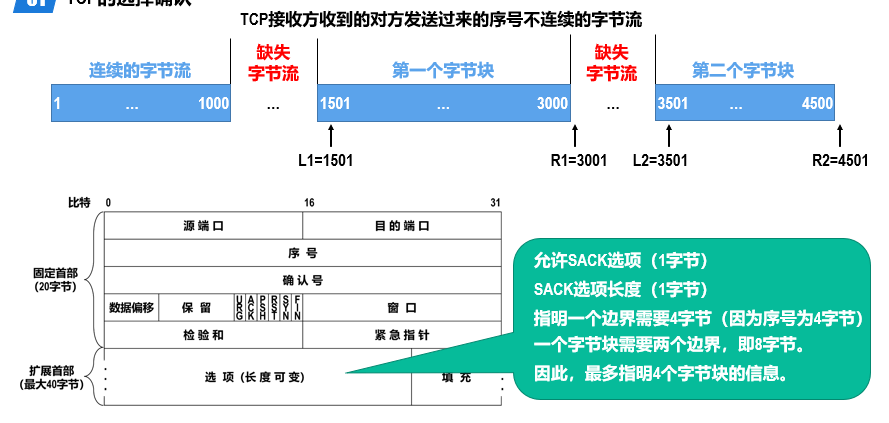
计算机网络5:运输层
概述 进程间基于网络的通信 计算机网络中实际进行通信的真正实体,是位于通信两端主机中的进程。 如何为运行在不同主机上的应用进程提供直接的逻辑通信服务,就是运输层的主要任务。运输层协议又称为端到端协议。 运输层向应用层实体屏蔽了下面网络核心…...

昂科烧录器支持HangShun航顺芯片的32位微控制器HK32F030C8T6
芯片烧录行业领导者-昂科技术近日发布最新的烧录软件更新及新增支持的芯片型号列表,其中HangShun航顺芯片的32位微控制器HK32F030C8T6已经被昂科的通用烧录平台AP8000所支持。 HK32F030C8T6使用ARM Cortex-M0内核,最高工作频率96 MHz,内置最…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...
如何把工业通信协议转换成http websocket
1.现状 工业通信协议多数工作在边缘设备上,比如:PLC、IOT盒子等。上层业务系统需要根据不同的工业协议做对应开发,当设备上用的是modbus从站时,采集设备数据需要开发modbus主站;当设备上用的是西门子PN协议时…...
未授权访问事件频发,我们应当如何应对?
在当下,数据已成为企业和组织的核心资产,是推动业务发展、决策制定以及创新的关键驱动力。然而,未授权访问这一隐匿的安全威胁,正如同高悬的达摩克利斯之剑,时刻威胁着数据的安全,一旦触发,便可…...