大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应了完整公式中的具体行并且对每个操作前后的Tensor Shape变化也进行了解析。我们可以看到目前的官方实现在存储KV Cache的时候并不是存储隐向量,而是把隐向量都解压缩变成了标准的MHA的KV Cache,实际上是完全不能节省显存的。接着,就继续学习了一下清华大学的ZHANG Mingxing组实现的MLA矩阵吸收的工程实现,在这一节也详细分析了原理包括 W U K W^{UK} WUK和 W U V W_{UV} WUV分别如何吸收到 W U Q W_{UQ} WUQ和 W o W_o Wo中,分析了实现了矩阵吸收的每行代码的原理以及操作发生前后相关Tensor的维度变化。接着,对矩阵吸收代码实现里的矩阵乘法的性质进行分析,可以看到MLA在大多数阶段都是计算密集型而非访存密集型的。最后引用了作者团队的Benchmark结果,以及说明为何不是直接保存吸收后的大投影矩阵,而是在forward里面重新计算两个矩阵的吸收。
这里提一下,我维护的几个记录个人学习笔记以及社区中其它大佬们的优秀博客链接的仓库都获得了不少star,感谢读者们的认可,我也会继续在开源社区多做贡献。github主页:https://github.com/BBuf ,欢迎来踩

0x0. 前言
这篇文章主要是对Deepseek2提出的优化KV Cache的MLA方法做个人理解,特别是关于MLA的矩阵吸收部分,这部分Paper以及官方开源实现没有给出。然后,开源社区大佬确实出手很快,在知乎的《如何看待 DeepSeek 发布的 MoE 大模型 DeepSeek-V2?》问题下清华大学的ZHANG Mingxing组就提出了MLA的矩阵吸收实现并且给出了一个兼容现有Transformers实现的PR(https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat/discussions/12)。
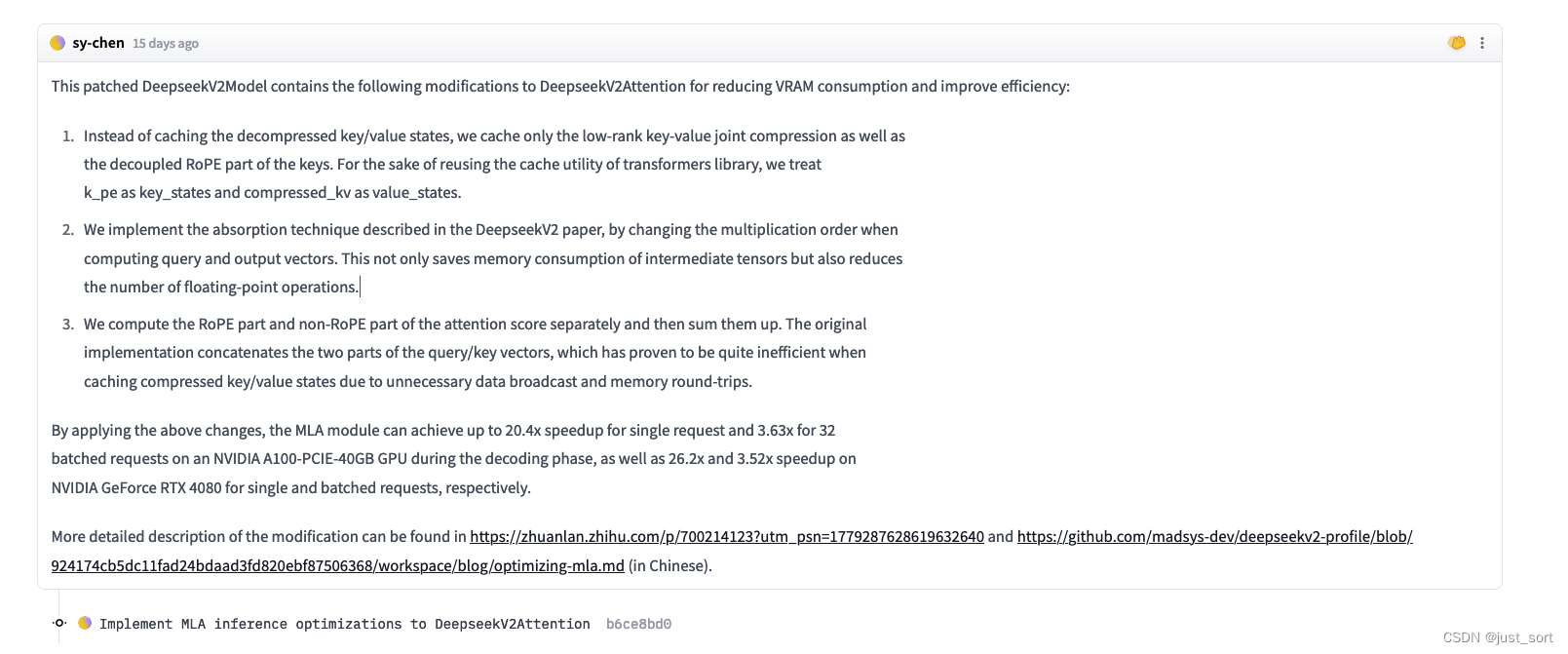
翻译:
这个修补过的DeepseekV2Model包含了对DeepseekV2Attention的以下修改,以减少VRAM消耗并提高效率:
- 不再缓存解压缩的Key/Value状态,而仅缓存低秩Key-Value联合压缩以及Key的解耦RoPE部分。 为了重用transformers库的缓存实用程序,我们将k_pe视为key_states,将compressed_kv视为value_states。
- 采用DeepseekV2论文中描述的吸收技术,通过改变计算Query和Output向量时的乘法顺序。这不仅节省了中间张量的内存消耗,还减少了浮点运算的次数。
- 分别计算RoPE部分和非RoPE部分的注意力分数,然后将它们相加。原始实现将Query/Key向量的两部分连接起来,但在缓存压缩Key/Value状态时由于不必要的数据广播和内存往返而被证明效率较低。
通过应用上述更改,MLA模块在解码阶段可以在NVIDIA A100-PCIE-40GB GPU上对单个请求实现高达20.4倍的加速,对32个批处理请求实现3.63倍的加速;在NVIDIA GeForce RTX 4080上,对单个和批处理请求分别实现26.2倍和3.52倍的加速。
这篇博客就是以我的视角来理解清楚这个PR中矩阵吸收的工程实现以及为何它可以加速现有的Deepseek2 MLA实现。本文先回顾一下MHA的Decode阶段KV Cache由来,然后根据paper的公式去理解Transformers中的DeepseekV2Attention类的实现。再接下来就学习一下ZHANG Mingxing大佬组所提出的MLA矩阵吸收工程实现。
Paper Link:https://arxiv.org/pdf/2405.04434
0x1. MHA 解码阶段KV Cache由来
首先回顾一下 MHA 机制在Decode阶段的原理和实现。
下面的公式来源也是DeepSeek2 paper,我做了更精细的解释。
假设batch_size为1,另外由于是解码阶段,输入只有一个token,所以序列的长度也是1,所以输入可以表示为 h t ∈ R d h_t \in \mathbb{R}^d ht∈Rd。接着假设embedding词表维度为 d d d,并且有 n h n_h nh表示注意力头的数量, d h d_h dh表示每个注意力头的维度。
t表示解码阶段当前是第几个token。
然后通过 W Q , W K , W V ∈ R d h n h × d W^Q, W^K, W^V \in \mathbb{R}^{d_h n_h \times d} WQ,WK,WV∈Rdhnh×d三个参数矩阵得到 q t , k t , v t ∈ R d h n h q_t, k_t, v_t \in \mathbb{R}^{d_h n_h} qt,kt,vt∈Rdhnh,具体方法就是三个矩阵乘:
q t = W Q h t , k t = W K h t , v t = W V h t , q_t = W^Q h_t, \newline k_t = W^K h_t, \newline v_t = W^V h_t, qt=WQht,kt=WKht,vt=WVht,
在 MHA 的计算中,这里的 q t , k t , v t q_t, k_t, v_t qt,kt,vt 又会分割成 n h n_h nh 个注意力头,即:
[ q t , 1 ; q t , 2 ; ⋯ ; q t , n h ] = q t [ k t , 1 ; k t , 2 ; ⋯ ; k t , n h ] = k t [ v t , 1 ; v t , 2 ; ⋯ ; v t , n h ] = v t \begin{bmatrix} q_{t,1}; q_{t,2}; \cdots ; q_{t,n_h} \end{bmatrix} = q_t \newline \begin{bmatrix} k_{t,1}; k_{t,2}; \cdots ; k_{t,n_h} \end{bmatrix} = k_t \newline \begin{bmatrix} v_{t,1}; v_{t,2}; \cdots ; v_{t,n_h} \end{bmatrix} = v_t [qt,1;qt,2;⋯;qt,nh]=qt[kt,1;kt,2;⋯;kt,nh]=kt[vt,1;vt,2;⋯;vt,nh]=vt
这里 q t , i , k t , i , v t , i ∈ R d h q_{t,i}, k_{t,i}, v_{t,i} \in \mathbb{R}^{d_h} qt,i,kt,i,vt,i∈Rdh 分别表示query、key和value的第 i i i个头的计算结果。
接下来就是计算注意力分数和输出了,公式如下:
o t , i = ∑ j = 1 t Softmax j ( q t , i k j , i d h ) v j , i , u t = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] o_{t,i} = \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{q_{t,i} k_{j,i}}{\sqrt{d_h}} \right) v_{j,i}, \newline u_t = W^O [o_{t,1}; o_{t,2}; \cdots ; o_{t,n_h}] ot,i=j=1∑tSoftmaxj(dhqt,ikj,i)vj,i,ut=WO[ot,1;ot,2;⋯;ot,nh]
这里 W O ∈ R d × d h n h W^O \in \mathbb{R}^{d \times d_h n_h} WO∈Rd×dhnh 表示输出映射矩阵。从上面的公式可以看出来,对于当前的第 t t t 个 token的query,会和 t t t之前所有token的key, value做注意力计算,并且由于token by token的生成 t t t之前所的有token对应的 k k k, v v v我们都可以Cache下来,避免重复计算,这就是KV Cache的由来。
对于一个 l l l层的标准MHA的网络来说,每个token需要的KV Cache大小为 2 n h d h l 2n_hd_hl 2nhdhl,其中2表示bf16的字节。
为了改进KV Cache,演化了一系列AI Infra的工作,比如Paged Attention, GQA, MLA包括最新的GQA,MLA之外的另一种KV Cache压缩方式:动态内存压缩(DMC),vAttention:用于在没有Paged Attention的情况下Serving LLM 。
0x2. DeepSeek2 MLA 原理介绍
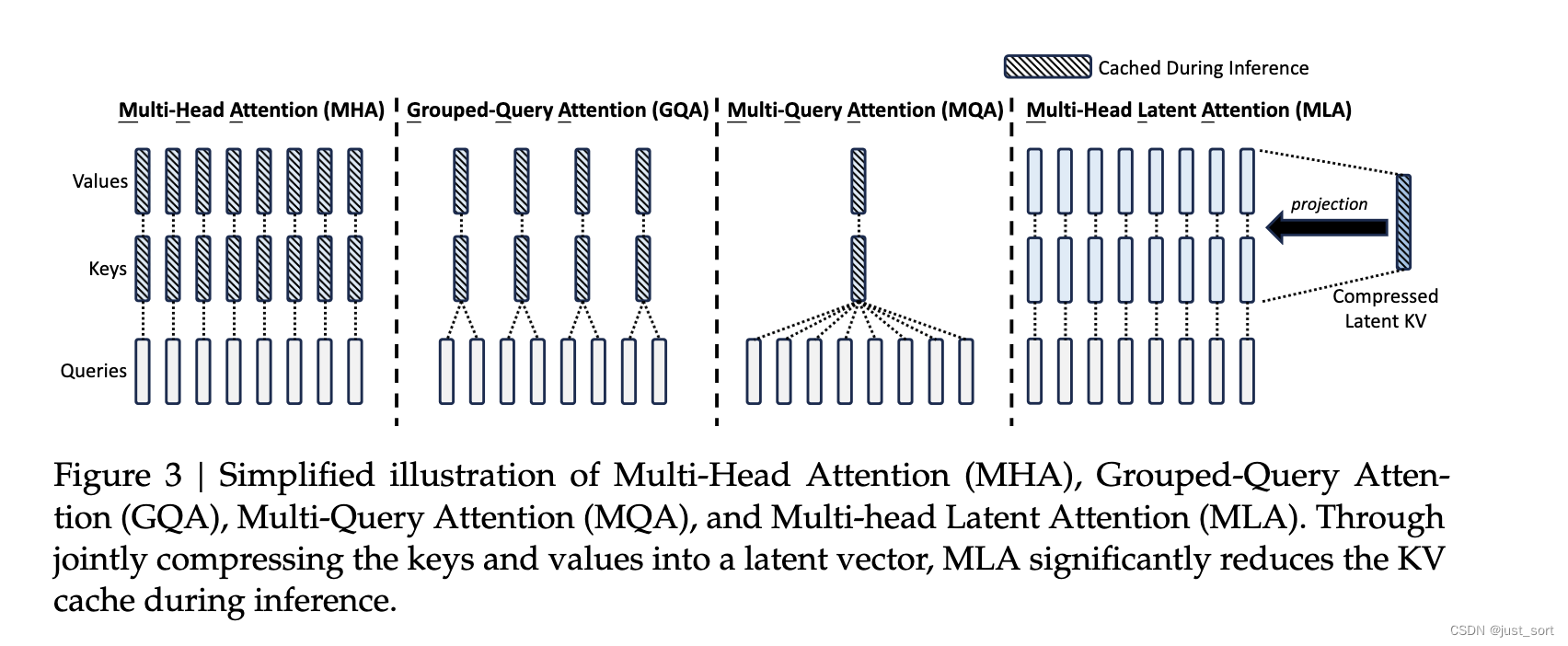
上面的图是Deepseek2 paper中对集中常见KV Cache压缩方法的对比,可以看到MLA的核心是对keys和values进行低秩联合压缩来减少KV Cache。对应paper的公式9-11。
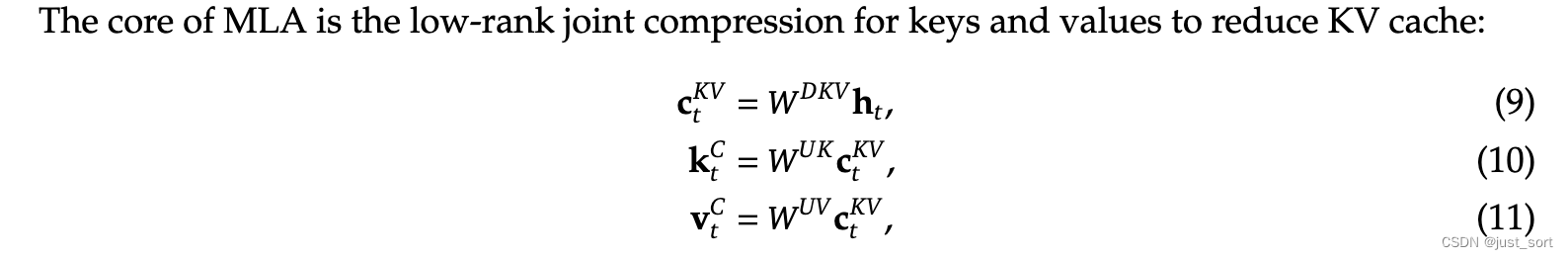
其中,
- c t K V ∈ R d c \mathbf{c}_{t}^{KV} \in \mathbb{R}^{d_c} ctKV∈Rdc:表示对 key 和 value 压缩后的隐向量 latent vector ,这里 d c ( ≪ d h n h ) d_c (\ll d_h n_h) dc(≪dhnh) 表示 KV Cache压缩的维度。
- W D K V ∈ R d c × d \mathbf{W}^{DKV} \in \mathbb{R}^{d_c \times d} WDKV∈Rdc×d:表示向下映射 down-projection 矩阵
- W U K , W U V ∈ R d h n h × d c \mathbf{W}^{UK}, \mathbf{W}^{UV} \in \mathbb{R}^{d_h n_h \times d_c} WUK,WUV∈Rdhnh×dc:表示向上映射 up-projection 矩阵
这样在推理时,只需要缓存隐向量 c t K V \mathbf{c}_{t}^{KV} ctKV 即可,因此 MLA 对应的每一个 token 的 KV Cache 参数只有 2 d c l 2d_c l 2dcl 个,其中 l l l是网络层数, 2 2 2是bfloat16的字节。
此外,为了降低训练过程中的激活内存,DeepSeek2还对query进行低秩压缩,即便这并不能降低KV Cache:
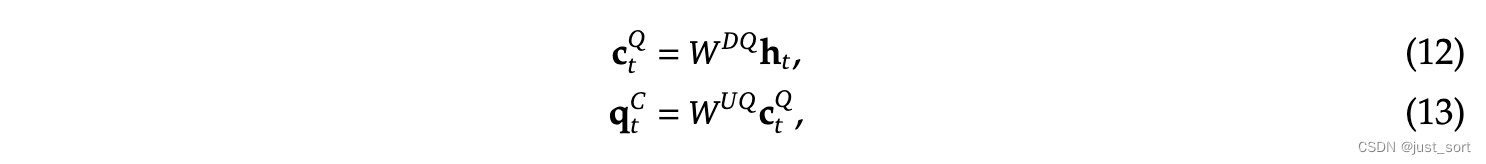
其中,
- c t Q ∈ R d c ′ \mathbf{c}_{t}^{Q} \in \mathbb{R}^{d'_c} ctQ∈Rdc′:表示将 queries 压缩后的隐向量, d c ′ ( ≪ d h n h ) d'_c (\ll d_h n_h) dc′(≪dhnh) 表示 query 压缩后的维度
- W D Q ∈ R d c ′ × d , W U Q ∈ R d h n h × d c ′ \mathbf{W}^{DQ} \in \mathbb{R}^{d'_c \times d}, \mathbf{W}^{UQ} \in \mathbb{R}^{d_h n_h \times d'_c} WDQ∈Rdc′×d,WUQ∈Rdhnh×dc′ 分别表示 down-projection 和 up-projection 矩阵
接下来MLA讨论的一个问题是,在上面的压缩过程中我们并没有考虑到RoPE。原始的RoPE需要在query和key中融入相对位置信息。在MLA中,在query中融入相对位置信息是比较容易的,但是由于KV Cache缓存的是压缩后的低秩key-value信息,这里面是没办法融入相对位置信息的。
关于RoPE为何不兼容MLA,苏神的博客里有更深刻的解释,建议阅读 https://kexue.fm/archives/10091
下面是对 Paper 的 Decoupled Rotary Position Embedding 章节进行解释。
识别图中的所有文本和公式如下:
由于对 query 和 key 来说,RoPE 都是位置敏感的。如果对 k t C \mathbf{k}_{t}^{C} ktC 采用 RoPE,那么当前生成 token 相关的 RoPE 矩阵会在 W Q \mathbf{W}^{Q} WQ 和 W U K \mathbf{W}^{UK} WUK 之间,并且矩阵乘法不遵循交换律,因此在推理时 W U K \mathbf{W}^{UK} WUK 就无法整合到 W Q \mathbf{W}^{Q} WQ 中。这就意味着,推理时我们必须重新计算所有之前 tokens 的 keys,这将大大降低推理效率。
这里的 W U K \mathbf{W}^{UK} WUK 就整合到 W Q \mathbf{W}^{Q} WQ 请看下面截图的解释,来自苏神的博客。我会在下一大节再仔细讨论这个原理。

因此,DeepSeek2提出了解耦 RoPE 策略,具体来说:
使用额外的多头 queries q t , i R ∈ R d h R \mathbf{q}_{t, i}^{R} \in \mathbb{R}^{d_h^R} qt,iR∈RdhR 以及共享的 key k t R ∈ R d h R \mathbf{k}_{t}^{R} \in \mathbb{R}^{d_h^R} ktR∈RdhR 来携带 RoPE 信息,其中 d h R d_h^R dhR 表示解耦的 queries 和 key 的一个 head 的维度。
基于这种解耦的 RoPE 策略,MLA 遵循的计算逻辑为:
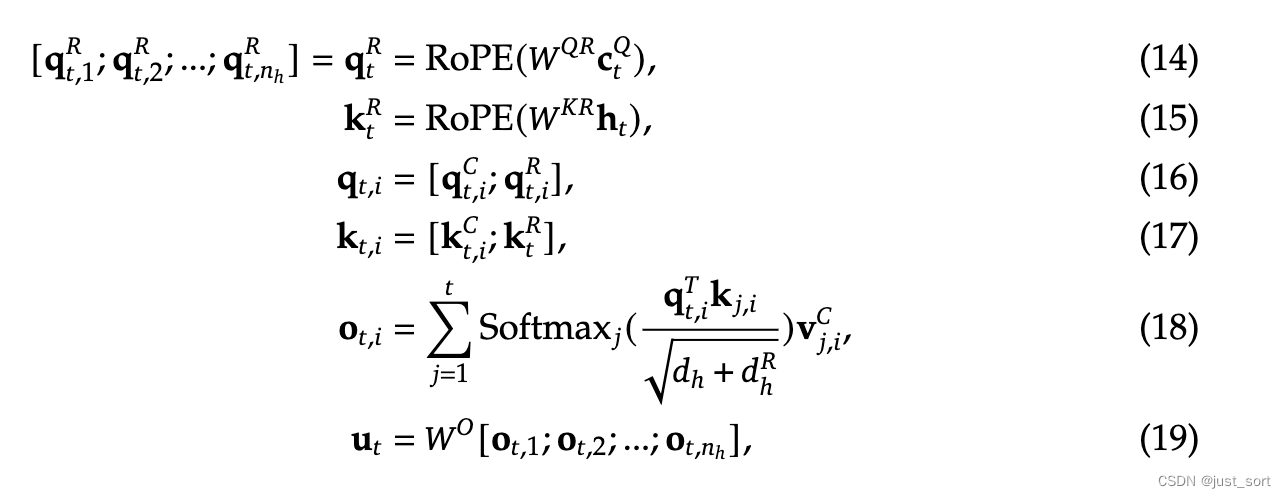
其中:
- W Q R ∈ R d h R n h × d c ′ \mathbf{W}^{QR} \in \mathbb{R}^{d_h^R n_h \times d_c'} WQR∈RdhRnh×dc′ 和 W K R ∈ R d h R × d \mathbf{W}^{KR} \in \mathbb{R}^{d_h^R \times d} WKR∈RdhR×d 分别表示计算解耦后的 queries 和 key 的矩阵
- RoPE( ⋅ \cdot ⋅) 表示应用 RoPE 的操作; [ ⋅ ; ⋅ ] [ \cdot ; \cdot ] [⋅;⋅] 表示拼接操作
推理时,只需要缓存解耦后的 key 即可,当然还有上面的隐向量 c t K V \mathbf{c}_{t}^{KV} ctKV,因此对于单个 token 的 KV Cache 只包含 ( d c + d h R ) l (d_c + d_h^R)l (dc+dhR)l 个元素,这里没考虑层数和bf16的字节数。具体可以看一下Table 1的数据对比:

翻译一下:
表1 | 各种注意力机制中每个token的KV Cache对比。 n h n_h nh 表示注意力头的数量, d h d_h dh 表示每个注意力头的维度, l l l 表示层数, n g n_g ng 表示GQA中的组数, d c d_c dc 和 d h R d_h^R dhR 分别表示KV压缩维度和MLA中解耦后queries和key的每头维度。KV Cache的数量以元素的数量来衡量,而不考虑存储精度。对于DeepSeek-V2, d c d_c dc 被设置为 4 d h 4d_h 4dh 而 d h R d_h^R dhR 被设置为 d h 2 \frac{d_h}{2} 2dh。因此,其KV Cache等于只有2.25组的GQA,但其性能强于MHA。
原理的话应该就是这些了,接下来就带着原理阅读DeepseekV2Attention的实现。
这里再特别说明一下Paper中相比于Dense的Deepseek 67B(或者LLaMa3 70B)节省93.3% KV Cache的计算方法:

首先是层数,DeepSeek2是60层,而Deepseek 67B为95层,层数的节省比例为 60 / 95
然后是单层的KV Cache,比例是(4.5 x 128) / (2 x 8 x 128),其中2表示K和V,8表示num_attention_heads,128表示head_size,4.5则是上面MLA中的9/2的压缩隐向量。
此外,DeepSeek2针对KV Cache使用了6Bit量化,节省比例为 6 / 16
把这三个比例乘起来,再用1减掉就是93.3%的由来。
这里的6bit感觉是考虑了量化参数 scale 和 zero-point, 如果采用4bit量化, 而scale / zero-point 为fp32, 则当group_size=32时, 根据group-wise量化规则,每32个元素对应一组float32的scale和zero_point,那么每个元素平摊的位宽就多了2Bit,量化位宽等同于6Bit。
0x3. MLA HuggingFace官方实现代码解读
为了便于描述代码,这里直接把完整的公式贴出来,Paper的附录C:
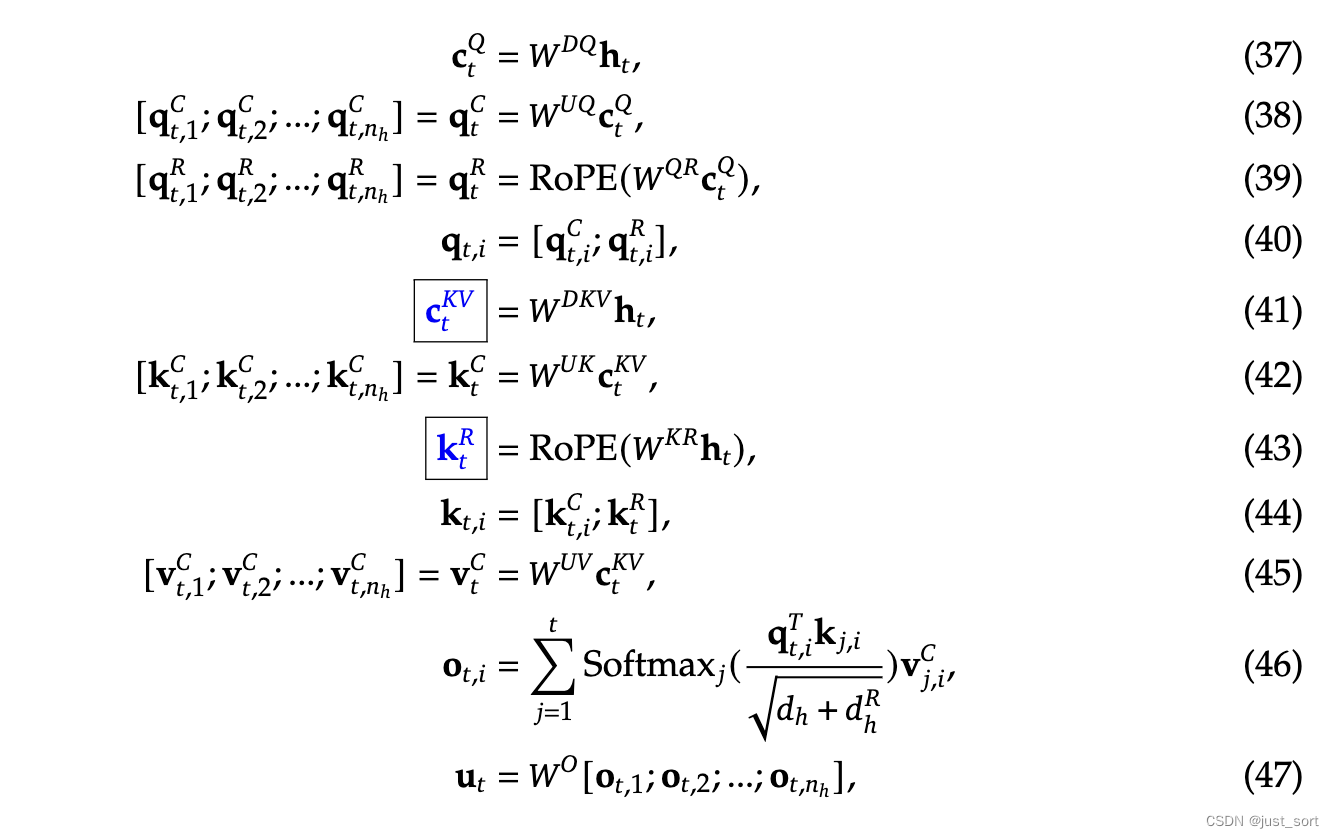
对照上面的原理介绍下面对 DeepseekV2Attention 模块进行解读,代码链接:https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat/blob/main/modeling_deepseek.py#L680
首先来看初始化部分,为了快速理解代码直接忽略掉RoPE计算相关的代码部分。
# Copied from transformers.models.llama.modeling_llama.LlamaAttention with Llama->DeepseekV2
class DeepseekV2Attention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def __init__(self, config: DeepseekV2Config, layer_idx: Optional[int] = None):super().__init__()self.attention_dropout = config.attention_dropoutself.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.max_position_embeddings = config.max_position_embeddingsself.rope_theta = config.rope_theta# 对应 query 压缩后的隐向量的维度 d'_cself.q_lora_rank = config.q_lora_rank# 对应$d_h^R$, 表示应用了rope的 queries 和 key 的一个 head 的维度。self.qk_rope_head_dim = config.qk_rope_head_dim# 对应 key-value 压缩后的隐向量维度 d_cself.kv_lora_rank = config.kv_lora_rank# value 的一个注意力头的隐藏层为度self.v_head_dim = config.v_head_dim# 表示query和key的隐藏向量中应用rope部分的维度self.qk_nope_head_dim = config.qk_nope_head_dim# 每一个注意力头的维度应该是两部分只和self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dimself.is_causal = True# MLA 中对 Q 投影矩阵也做了一个低秩分解,对应生成 q_a_proj 和 q_b_proj 两个矩阵。# 其中 q_a_proj 大小为 [hidden_size, q_lora_rank] = [5120, 1536],# 对应上面公式中的W^DQself.q_a_proj = nn.Linear(self.hidden_size, config.q_lora_rank, bias=config.attention_bias)self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)# q_b_proj 大小为 [q_lora_rank, num_heads * q_head_dim] = # [q_lora_rank, num_attention_heads * (qk_nope_head_dim + qk_rope_head_dim)] = [1536, 128*(128+64)] = [1536, 24576] # 对应上述公式中的W^UQ和W^QR合并后的大矩阵self.q_b_proj = nn.Linear(config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False)# 与Q向量类似,KV向量的生成也是先投影到一个低维的 compressed_kv 向量(对应c_t^{KV})# 再升维展开。具体的代码涉及 kv_a_proj_with_mqa 和 kv_b_proj 两个参数矩阵。# 其中 kv_a_proj_with_mqa 大小为 [hidden_size, kv_lora_rank + qk_rope_head_dim]# = [5120, 512 + 64] = [5120, 576],对应上述公式中的W^{DKV}和W^{KR}。self.kv_a_proj_with_mqa = nn.Linear(self.hidden_size,config.kv_lora_rank + config.qk_rope_head_dim,bias=config.attention_bias,)self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)# kv_b_proj 大小为 [kv_lora_rank, num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim)] # = [512, 128*((128+64)-64+128)] = [512, 32768],对应上述公式中的W^{UK}和W^{UV}。# 由于 W^{UK} 只涉及 non rope 的部分所以维度中把 qk_rope_head_dim 去掉了。self.kv_b_proj = nn.Linear(config.kv_lora_rank,self.num_heads* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),bias=False,)# 对应完整公式的第 47 行self.o_proj = nn.Linear(self.num_heads * self.v_head_dim,self.hidden_size,bias=config.attention_bias,)
根据0x2节的原理介绍,现在已经可以把 DeepseekV2Attention 模块里面所有的权重矩阵都和初始化的代码对应起来了,如果你想继续看下去一定要理解到初始化的每行代码。
为了方便理解forward代码时回看公式,这里再重复贴一下完整公式:
接下来再看一下forward的代码,这对应了完整公式里面的详细计算过程:
def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,**kwargs,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:if "padding_mask" in kwargs:warnings.warn("Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`")# hidden_states对应公式中的h_t,的shape是(batch_size, seq_length, # hidden_size),其中 hidden_size 具体为 5120,假设batch_size和seq_length都为1bsz, q_len, _ = hidden_states.size()# 计算Q:对应完整公式中的 37-39 行,先降维再升维,好处是相比直接使用大小为 [5120, 24576] 的矩阵# [5120, 1536] * [1536, 24576] 这样的低秩分解在存储空间和计算量上都大幅度降低q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)# 切分 rope 和非 rope 部分,完整公式中 40 行反过来q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)# 对应公式中的 41 和 43 行只是还没有加 rope# 一个优化的 MLA KVCache 实现只需要缓存这个 compressed_kv 就行# kv_a_proj_with_mqa shape 为[hidden_size, kv_lora_rank + qk_rope_head_dim]# = [5120, 512 + 64] = [5120, 576]# 所以compressed_kv的shape就是[1, 1, 576]compressed_kv = self.kv_a_proj_with_mqa(hidden_states)# 对应完整公式的 44 行反过来compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)# 这里的 k_pe 和 上面的 q_pe 要扔给 RoPE模块,所以需要重整下shapek_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)# 对应公式中的 42 和 45 行,将 MLA 展开成标准 MHA 的形式kv = (self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))# 因为 kv_b_proj 打包了 W^{UK} 和 W^{UV} 把他们分离出来k_nope, value_states = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)# 获取key/value的序列长度kv_seq_len = value_states.shape[-2]if past_key_value is not None:if self.layer_idx is None:raise ValueError(f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} ""for auto-regressive decoding with k/v caching, please make sure to initialize the attention class ""with a layer index.")kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)# 给需要 rope 的部分加 ropecos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)# 更新和拼接历史 KVCache,可以看到这里存储的是展开后的 MHA KVCache# 其中 q_head_dim 等于 qk_nope_head_dim + qk_rope_head_dimquery_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)query_states[:, :, :, : self.qk_nope_head_dim] = q_nopequery_states[:, :, :, self.qk_nope_head_dim :] = q_pekey_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)key_states[:, :, :, : self.qk_nope_head_dim] = k_nopekey_states[:, :, :, self.qk_nope_head_dim :] = k_pe# Transformers库中标准的 KV Cache 更新代码if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)# 后续就是标准的多头自注意力计算了,为了篇幅,忽略这部分代码...
读完这一节基本就能将MLA完整公式的每一行都搞清楚了,并且我们可以看到目前的官方实现在存储KV Cache的时候并不是存储隐向量,而是把隐向量都解压缩变成了标准的MHA的KV Cache,实际上是完全不能节省显存的。
0x4. 矩阵吸收
这一节就是学习和理解一下清华大学的ZHANG Mingxing组实现的MLA矩阵吸收( https://zhuanlan.zhihu.com/p/700214123 )。它的代码是直接应用在HF实现上的,所以可以很方便进行应用。为了理解再重复贴一下完整公式:
以及Paper中提到的矩阵吸收,

0x4.1 W^{UK}的吸收
对于 W U K \mathbf{W}^{UK} WUK 矩阵我们有:
atten_weights = q t ⊤ k t = ( W U Q c t Q ) ⊤ W U K c t K V = c t Q ⊤ W U Q ⊤ W U K c t K V \text{atten\_weights} = \mathbf{q}_{t}^\top \mathbf{k}_{t} = (\mathbf{W}^{UQ} \mathbf{c}_{t}^{Q})^\top \mathbf{W}^{UK} \mathbf{c}_{t}^{KV} = \mathbf{c}_{t}^{Q^\top} \mathbf{W}^{UQ^\top} \mathbf{W}^{UK} \mathbf{c}_{t}^{KV} atten_weights=qt⊤kt=(WUQctQ)⊤WUKctKV=ctQ⊤WUQ⊤WUKctKV
也就是说我们实际上不需要将低维的 c t K V \mathbf{c}_{t}^{KV} ctKV 展开再计算,而是直接将 W U K \mathbf{W}^{UK} WUK 通过结合律先和左边做乘法。
# 以下和上一节的MLA forward部分实现相同
# hidden_states对应公式中的h_t,的shape是(batch_size, seq_length,
# hidden_size),其中 hidden_size 具体为 5120,假设batch_size为1,seq_length为q_len
bsz, q_len, _ = hidden_states.size()# 计算Q:对应完整公式中的 37-39 行,先降维再升维,好处是相比直接使用大小为 [5120, 24576] 的矩阵
# [5120, 1536] * [1536, 24576] 这样的低秩分解在存储空间和计算量上都大幅度降低
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
# 切分 rope 和非 rope 部分,完整公式中 40 行反过来
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)# 对应公式中的 41 和 43 行只是还没有加 rope
# 一个优化的 MLA KVCache 实现只需要缓存这个 compressed_kv 就行,不过后面实际上展开
# hidden_states 的 shape 为 (1, past_len, hidden_size)
# kv_a_proj_with_mqa shape 为[hidden_size, kv_lora_rank + qk_rope_head_dim]
# = [5120, 512 + 64] = [5120, 576]
# 所以compressed_kv的shape就是[1, past_len, 576]
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
# 对应完整公式的 44 行反过来
compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
# 这里的 k_pe 和 上面的 q_pe 要扔给 RoPE模块,所以需要重整下shape
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
以下部分是 W U K W^{UK} WUK的吸收需要做的改动,省略掉了把compressed_kv和k_pe加入到Transformers KV Cache的改动:
# 从 kv_b_proj 中分离的 W^{UK} 和 W^{UV} 两部分,他们要分别在不同的地方吸收
kv_b_proj = self.kv_b_proj.weight.view(self.num_heads, -1, self.kv_lora_rank)
q_absorb = kv_b_proj[:, :self.qk_nope_head_dim,:]
out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]cos, sin = self.rotary_emb(q_pe)
q_pe = apply_rotary_pos_emb(q_pe, cos, sin, q_position_ids)
# W^{UK} 即 q_absorb 被 q_nope 吸收
q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope)
# 吸收后 attn_weights 直接基于 compressed_kv 计算不用展开。
attn_weights = torch.matmul(q_pe, k_pe.transpose(2, 3)) + torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)
attn_weights *= self.softmax_scale
主要是吸收这里的代码需要仔细理解:
- 从0x4节的讲解已经知道kv_b_proj就是 W U K W^{UK} WUK 和 W U V W^{UV} WUV两部分,这里是把 W U K W^{UK} WUK吸收到 W U Q W^{UQ} WUQ,所以需要先把两者分离出来。注意到
self.kv_b_projweight shape为[kv_lora_rank, num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim)] = [512, 128*((128+64)-64+128)] = [512, 32768],所以kv_b_proj的shape为[num_heads,q_head_dim - qk_rope_head_dim + v_head_dim , kv_lora_rank],q_absorb的shape为[num_heads, qk_nope_head_dim , kv_lora_rank]=[128, 128, 512],同样out_absorb的shape为[num_heads, v_head_dim , kv_lora_rank]=[128, 128, 512]。 q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope)这行代码中,q_nope的shape是[batch_size, num_heads, q_len, q_head_dim]。所以这行代码就是一个矩阵乘法,把 W U K W^{UK} WUK吸收到 W U Q W^{UQ} WUQ。- 吸收后 attn_weights 直接基于 compressed_kv 计算不用展开。对应
torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)这行代码。其中q_nope 的维度是[batch_size, num_heads, q_len, kv_lora_rank],compressed_kv 是[batch_size, past_len, kv_lora_rank],输出的维度是[batch_size, num_heads, q_len, past_len]。 - 此外,我们还可以观察到
torch.matmul(q_pe, k_pe.transpose(2, 3))这行代码是分开计算了RoPE部分的q和k的注意力计算再求和,没有和原本的实现一样将加上了 rope 的 q_pe/k_pe 和没加 rope 的 q_nope/k_nope 拼接起来一起,也就是下面的代码。作者团队把这个拆分叫做 Move Elision 的优化,后续有性能对比。
# 更新和拼接历史 KVCache,可以看到这里存储的是展开后的 MHA KVCache
# 其中 q_head_dim 等于 qk_nope_head_dim + qk_rope_head_dim
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pekey_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
除了压缩KV Cache之外,我们还可以观察到上面涉及到的2个矩阵乘法实际上都来到了计算密集的领域,例如对于
torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)。由于不同 head 的 q_nope 部分 share 了共同的 compressed_kv 部分,实际计算的是 batch_size 个 [num_heads * q_len, kv_lora_rank] 和 [past_len, kv_lora_rank] 的矩阵乘法。计算等价于一个 MQA 操作,计算强度正比于 num_heads 的也就是 128。
0x4.2 W^{UV}的吸收
对于 W U V W^{UV} WUV我们有:
v = W U V c t K V v= W^{UV}c_t^{KV} v=WUVctKV (对应公式的45行)
u = u= u= attn_weights 和 v v v 的矩阵乘法
o = u W o o = uW_o o=uWo
这里把 attn_weights 记作 M M M,那么有:
o = M W U V c t K V W o o = MW^{UV}c_t^{KV}W_o o=MWUVctKVWo
和 W U K W^{UK} WUK的吸收过程类似,利用结合律改变计算顺序,那么有:
o = M c t K V W U V W o o = Mc_t^{KV}W^{UV}W_o o=MctKVWUVWo
我们可以把 W U V W^{UV} WUV吸收到 W o W_o Wo中,对应的代码实现:
# attn_weight的shape是[batch_size, num_heads, q_len, past_len]
# compressed_kv的shape是[batch_size, past_len, kv_lora_rank]
# attn_output的shape是[batch_size, num_heads, q_len, kv_lora_rank]
attn_output = torch.einsum('bhql,blc->bhqc', attn_weights, compressed_kv)
# out_absorb的shape是[num_heads, v_head_dim , kv_lora_rank]
# out_absorb.mT的shape是[num_heads, kv_lora_rank, v_head_dim]
# 最终attn_output的shape是[batch_size, num_heads, q_len, v_head_dim]
attn_output = torch.matmul(attn_output, out_absorb.mT)
注意:.mT 方法用于获取张量的转置(transpose)。对于二维张量(矩阵),转置操作会交换其行和列。而对于高维张量,.mT 会交换最后两个维度。
同样,这里除了压缩KV Cache之外,我们还可以观察到上面涉及到的2个矩阵乘法实际上也来到了计算密集的领域,例如对于
attn_output = torch.einsum('bhql,blc->bhqc', attn_weights, compressed_kv)。由于不同 head 的 attn_weights 部分 share 了共同的 compressed_kv 部分,实际计算的是 batch_size 个 [num_heads * q_len, kv_lora_rank] 和 [past_len, kv_lora_rank] 的矩阵乘法。计算等价于一个 MQA 操作,计算强度正比于 num_heads 的也就是 128。因此相比 MHA,吸收后的 MLA 计算强度要大得多,因此也可以更加充分的利用 GPU 算力。
0x4.3 MLA MatMul的性质
上面几乎分析了每个矩阵乘法的计算shape,可以发现除了在对q做计算时涉及到gemv之外,也就是q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states))),其它地方的矩阵乘运算q_len维度都是和num_heads在一起做计算,而num_heads在Deepseek2的配置里面已经是128了,导致其它的Matmul几乎都落在了计算密集的范畴。
综上,对于MLA模块来说,有很大比例的MatMul都达到了计算密集的范畴,这改变了之前MHA的访存密集的性质。然而,在整个网络中间,由于有MoE模块的存在,如果BatchSize不够大(无法激活所有的expert,导致计算和访存比=计算密度低)还是无法整体达到计算密集的范围,但MLA节省的KV Cache本就可以让DeepSeek2的Batch大幅度提升,所以均摊到每个token的带宽需求相比于Dense的LLaMa3 70B也会大幅度下降。
0x4.4 Benchmark
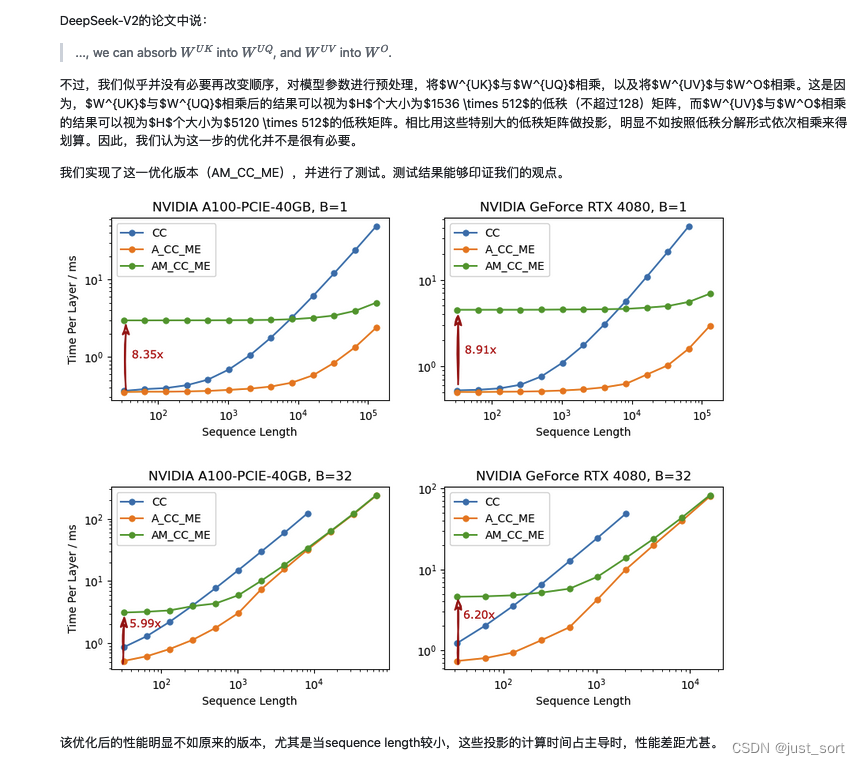
最后,作者团队在他们的Blog中给出了一些Benchmark结果,可以看到这个矩阵吸收的有效性。
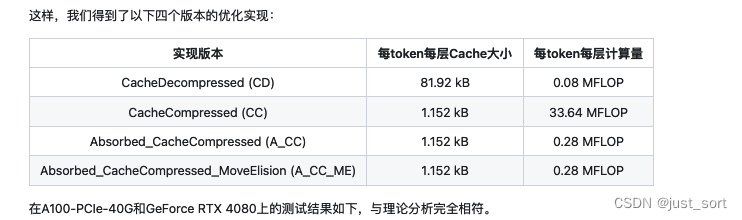
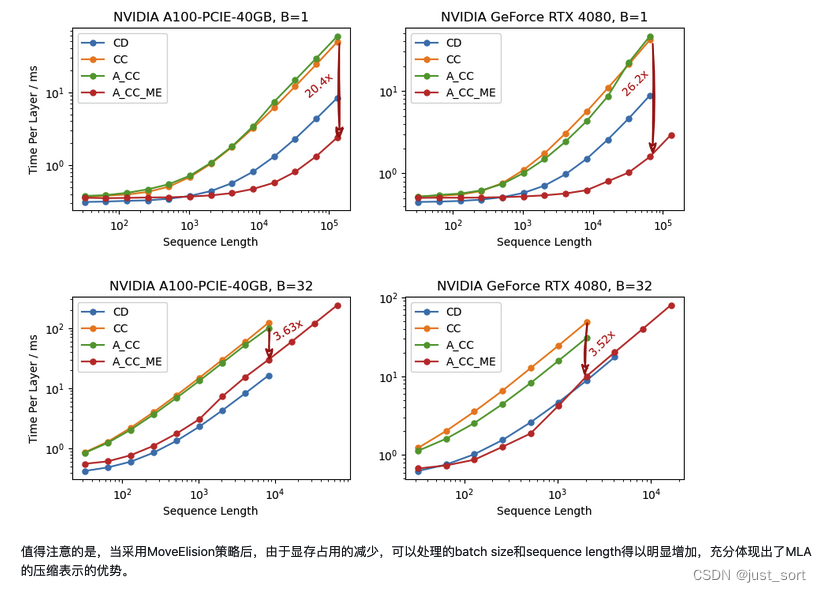
图中的标签分别表示 原始的解压缩版本CacheDecompressed (CD),KV缓存压缩后的CacheCompressed(CC),吸收后直接使用 compressed_kv 计算的 Absorbed_CacheCompressed (A_CC) 版本,和增加了 move elision 优化的最终版本 Absorbed_CacheCompressed_MoveElision (A_CC_ME)。
0x4.5 是否需要重计算
以 W U K W^{UK} WUK的吸收为例子,这里实际上是说在矩阵吸收的时候是否要提前把 W U K W^{UK} WUK和 W U Q W^{UQ} WUQ的矩阵乘结果保存下来,而不是在forward的时候重计算。作者在评论区回复过这个问题,意思就是直接在forward的时候重计算速度会更优。博客里面的解释如下:
0x5. 总结
这就是本篇博客的全部内容了,这里总结一下。首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应了完整公式中的具体行并且对每个操作前后的Tensor Shape变化也进行了解析。我们可以看到目前的官方实现在存储KV Cache的时候并不是存储隐向量,而是把隐向量都解压缩变成了标准的MHA的KV Cache,实际上是完全不能节省显存的。接着,就继续学习了一下清华大学的ZHANG Mingxing组实现的MLA矩阵吸收的工程实现,在这一节也详细分析了原理包括 W U K W^{UK} WUK和 W U V W_{UV} WUV分别如何吸收到 W U Q W_{UQ} WUQ和 W o W_o Wo中,分析了实现了矩阵吸收的每行代码的原理以及操作发生前后相关Tensor的维度变化。接着,对矩阵吸收代码实现里的矩阵乘法的性质进行分析,可以看到MLA在大多数阶段都是计算密集型而非访存密集型的。最后引用了作者团队的Benchmark结果,以及说明为何不是直接保存吸收后的大投影矩阵,而是在forward里面重新计算两个矩阵的吸收。
0x6. 参考资料
- https://www.zhihu.com/question/655172528
- https://arxiv.org/pdf/2405.04434
相关文章:
大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应…...
项目中eventbus和rabbitmq配置后,不起作用
如下:配置了baseService层和SupplyDemand层得RabbitMQ和EventBus 但是在执行订阅事件时,发送得消息在base项目中没有执行,后来发现是虚拟机使用得不是一个,即上图中得EventBus下得VirtualHost,修改成一直就可以了...

文库小程序搭建部署:实现资源共享正向反馈
文档库相信大家应该不陌生,日常我们的工作模板、会议模板、求职时的简历模板、教育界的教学模板等来源方式都出自于文档库,随着互联网的发展和工作需求,文档模板开启了新型的知识变现新途径,通过文库小程序,我们不仅能…...
ONLYOFFICE 桌面编辑器8.1---一个高效且强大的办公软件
软件介绍 ONLYOFFICE 桌面编辑器经过不断的更新换代现在迎来了,功能更加强大的ONLYOFFICE 桌面编辑器8.1是一个功能强大的办公套件,专为多平台设计,包括Windows、Linux和macOS。它提供了一套全面的办公工具,包括文档处理、电子表…...
QThread 与QObject::moveToThread利用Qt事件循环在子线程执行多个函数
1. QThread的两种用法 第一种用法就是继承QThread,然后覆写 virtual void run(), 这种用法的缺点是不能利用信号槽机制。 第二种用法就是创建一个线程,创建一个对象,再将对象moveToThread, 这种可以充分利用信号槽机制ÿ…...

6-2 归并排序
6-2 归并排序 分数 10 全屏浏览 切换布局 作者 软件工程DS&A课程组 单位 燕山大学 以下代码采用分而治之算法实现归并排序。请补充函数mergesort()的代码。提示:mergesort()函数可用递归实现,其中参…...
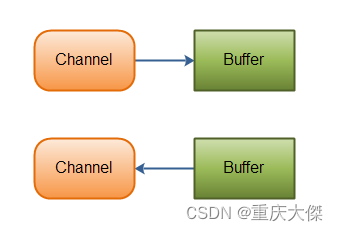
Java NIO(一) 概述
NIO主要用于以少量线程来管理多个网络连接,处理其上的读写等事件。在大量连接情况下,不管是效率还是空间占用都要优于传统的BIO。 Java NIO 由以下几个核心部分组成: Channel Buffer Selector Selector 如果你的应用打开了多个连接&#x…...

JUC线程池最佳实践
参考:Java 线程池最佳实践 | JavaGuide 使用构造函数创建线程池。【使用有界队列,控制线程创建数量】 SpringBoot 中的 Actuator 组件 / ThreadPoolExecutor 的相关 API监控线程池运行状态 是不同的业务使用不同的线程池【父子任务用同一个线程池容易死…...
2024最新版Node.js下载安装及环境配置教程(非常详细)
一、进入官网地址下载安装包 官网:Node.js — Run JavaScript Everywhere 其他版本下载:Node.js — Download Node.js (nodejs.org) 选择对应你系统的Node.js版本 二、安装程序 (1)下载完成后,双击安装包…...
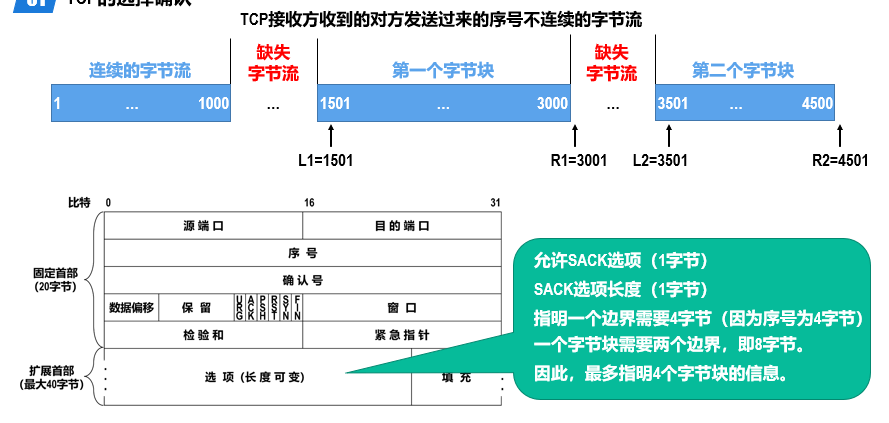
计算机网络5:运输层
概述 进程间基于网络的通信 计算机网络中实际进行通信的真正实体,是位于通信两端主机中的进程。 如何为运行在不同主机上的应用进程提供直接的逻辑通信服务,就是运输层的主要任务。运输层协议又称为端到端协议。 运输层向应用层实体屏蔽了下面网络核心…...

昂科烧录器支持HangShun航顺芯片的32位微控制器HK32F030C8T6
芯片烧录行业领导者-昂科技术近日发布最新的烧录软件更新及新增支持的芯片型号列表,其中HangShun航顺芯片的32位微控制器HK32F030C8T6已经被昂科的通用烧录平台AP8000所支持。 HK32F030C8T6使用ARM Cortex-M0内核,最高工作频率96 MHz,内置最…...

纯css星空动画
让大家实现一个这样的星空动画效果,大家会怎么做? js,不! 其实使用css就能写 我也不藏着掖着,源码直接放下面了 <script setup></script><template><div class"box"><div v-for"i in 5" :key"i" :class"layer…...
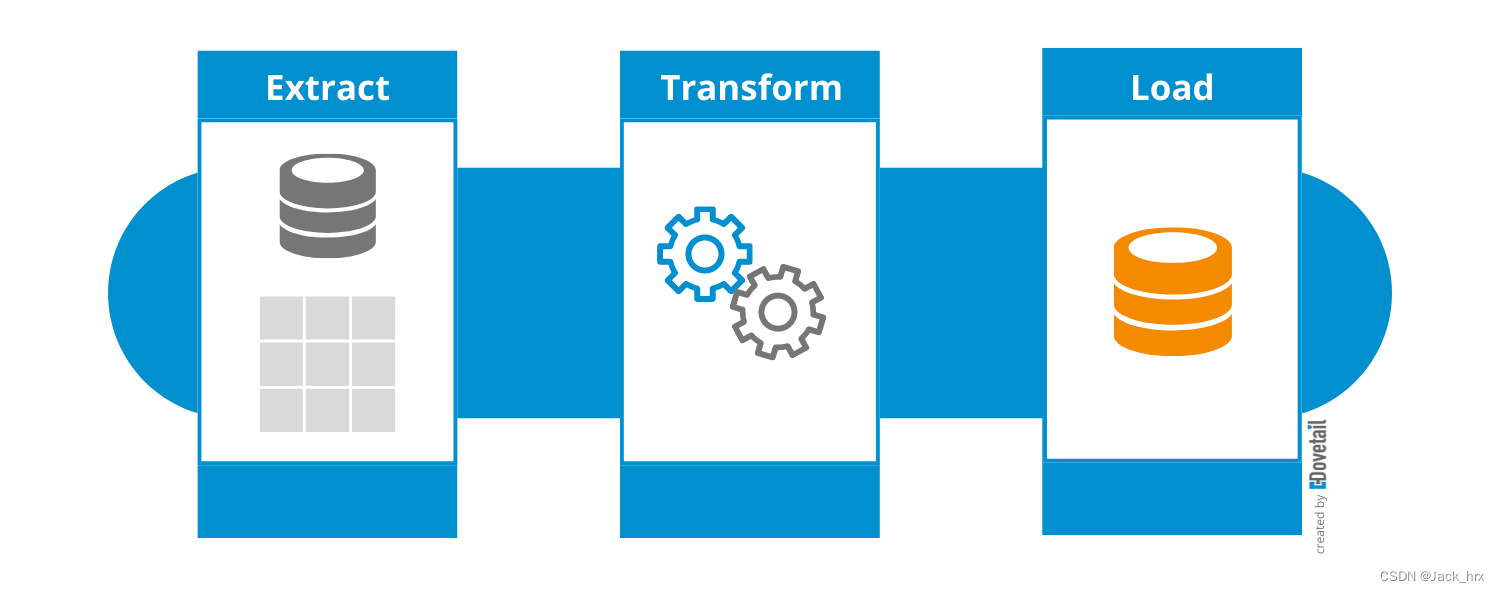
使用Apache Flink实现实时数据同步与清洗:MySQL和Oracle到目标MySQL的ETL流程
使用Apache Flink实现实时数据同步与清洗:MySQL和Oracle到目标MySQL的ETL流程 实现数据同步的ETL(抽取、转换、加载)过程通常涉及从源系统(如数据库、消息队列或文件)中抽取数据,进行必要的转换࿰…...

postman教程-22-Newman结合Jenkins执行自动化测试
上一小节我们学习了Postman Newman运行集合生成测试报告的方法,本小节我们讲解一下Postman Newman结合Jenkins执行自动化测试的方法。 在软件开发过程中,持续集成(CI)是一种实践,旨在通过自动化的测试和构建过程来频繁…...

uniapp实现tabBar功能常见的方法
在 UniApp 中实现 Tab 功能通常涉及到使用 <navigator> 组件结合 tabBar 配置,或者通过自定义的视图切换逻辑来实现。以下是两种常见的实现方式: 1. 使用 tabBar 配置 UniApp 支持在 pages.json 文件中配置 tabBar,以在应用的底部或顶…...

智慧在线医疗在线诊疗APP患者端+医生端音视频诊疗并开处方
智慧在线医疗:音视频诊疗新纪元 🌐 智慧医疗新篇章 随着科技的飞速发展,智慧医疗正逐步走进我们的生活。特别是在线医疗,凭借其便捷、高效的特点,已成为许多患者的首选。而其中的“智慧在线医疗患者端医生端音视频诊疗…...

攻防平台搭建与简易渗透工具箱编写
知识点:攻防平台搭建,虚拟机的网络模式详解,安全脚本编写 虚拟机的网络模式: 虚拟机(VM)的网络模式决定了虚拟机与宿主机以及外部网络之间的连接方式。不同的虚拟化平台(如VMware, VirtualBox,…...

SQL EXISTS 关键字的使用与理解
SQL EXISTS 关键字的使用与理解 SQL(Structured Query Language)是一种用于管理关系数据库管理系统(RDBMS)的标准编程语言。在SQL中,EXISTS关键字是一个逻辑运算符,用于检查子查询中是否存在至少一行数据。…...
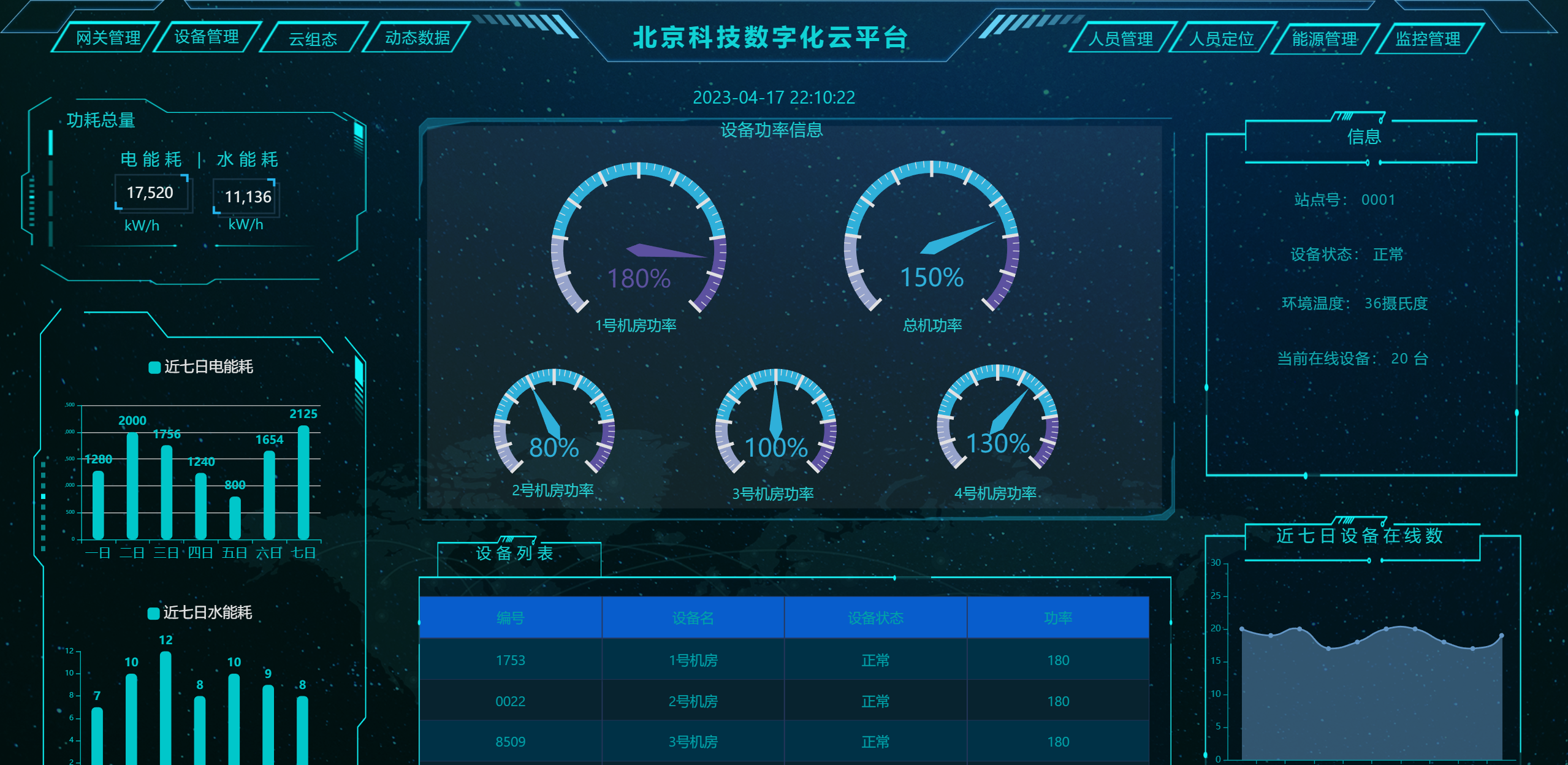
开源低代码平台,JeecgBoot v3.7.0 里程碑版本发布
项目介绍 JeecgBoot是一款企业级的低代码平台!前后端分离架构 SpringBoot2.x,SpringCloud,Ant Design&Vue3,Mybatis-plus,Shiro,JWT 支持微服务。强大的代码生成器让前后端代码一键生成! JeecgBoot引领…...

名侦探李先生第一话:谁是真正的凶手(只出现一次的数字相关题解(力扣)+位操作符回忆)
引子:我们在之前的案子中破解过基础的单身狗问题,那面对更有挑战的案子,且看李先生如何破局,那下凶手! 复习: 1,位操作符: 正整数原,反,补码都相同 首位是…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...
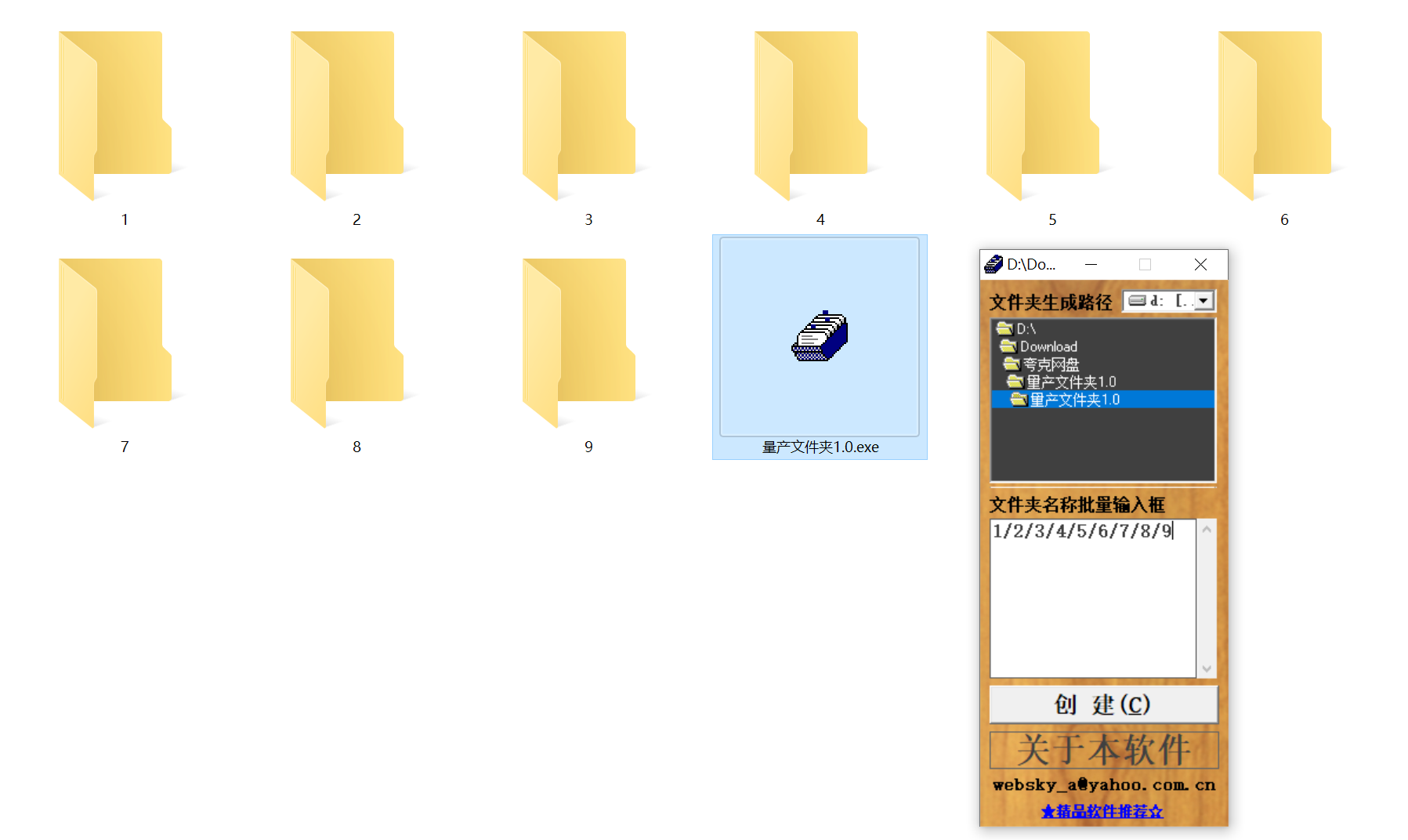
结构化文件管理实战:实现目录自动创建与归类
手动操作容易因疲劳或疏忽导致命名错误、路径混乱等问题,进而引发后续程序异常。使用工具进行标准化操作,能有效降低出错概率。 需要快速整理大量文件的技术用户而言,这款工具提供了一种轻便高效的解决方案。程序体积仅有 156KB,…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...

接口 RESTful 中的超媒体:REST 架构的灵魂驱动
在 RESTful 架构中,** 超媒体(Hypermedia)** 是一个核心概念,它体现了 REST 的 “表述性状态转移(Representational State Transfer)” 的本质,也是区分 “真 RESTful API” 与 “伪 RESTful AP…...