大数据面试题之Hive(3)
目录
Hive的函数:UDF、UDAF、UDTF的区别?
UDF是怎么在Hive里执行的
row_number,rank,dense_rank的区别
Hive count(distinct)有几个reduce,海量数据会有什么问题
HQL:行转列、列转行
一条HQL从代码到执行的过程
了解Hive SQL吗?讲讲分析函数?
分析函数中加Order By和不加Order By的区别?
Hive优化方法
Hive里metastore是干嘛的
HiveServer2是什么?
Hive表字段换类型怎么办
parquet文件优势
Hive的函数:UDF、UDAF、UDTF的区别?
Hive中的UDF(User-Defined Functions)、UDAF(User-Defined Aggregate Functions)、UDTF
(User-Defined Table-Generating Functions)都是用于扩展Hive SQL语言功能的自定义函数,它们分
别用于不同的场景和数据处理需求。下面是它们的区别:UDF (User-Defined Function):
用途: UDFs用于处理单个行的数据,将一行输入映射到一行输出。它们可以用于执行自定义的计算、转换和操
作,如数学运算、字符串处理或日期时间函数。
示例: 创建一个计算两个数字之和的函数。
调用方式: 在Hive查询中,你可以像使用内置函数一样调用UDF。UDAF (User-Defined Aggregate Function):
用途: UDAFs用于聚合数据,它们接受多行输入数据,并产生一个输出数据行。它们通常在GROUP BY子句中使
用,用于求和、求平均数、最大值、最小值等操作。
示例: 创建一个计算平均值的函数。
调用方式: 在Hive查询中,你可以在SELECT语句中使用UDAF,通常与GROUP BY一起使用。UDTF (User-Defined Table-Generating Function):
用途: UDTFs用于生成多行数据,它们可以将一行输入数据转换为多行输出数据。它们常用于数据拆分、解析或转
换,比如将一个逗号分隔的字符串转换为多行数据。示例: 创建一个函数,用于将一个包含多个值的字符串拆分成多行。
调用方式: 在Hive查询中,UDTFs通常在SELECT语句中使用,可能需要与LATERAL VIEW配合使用,以便处理生成的多行数据。
总结而言,UDF用于处理单行数据,UDAF用于聚合多行数据到单一结果,而UDTF用于将单行数据转换为多行数
据。这些函数允许Hive用户根据特定的需求定制数据处理逻辑,从而增强Hive的功能性和灵活性。UDF是怎么在Hive里执行的
在Hive中执行UDF(用户定义函数)涉及一系列步骤,以下是这些步骤的详细解释:1、创建UDF:
首先,你需要创建一个Java类来实现UDF的逻辑。这个类通常会继承Hive提供的UDF类,并覆盖其evaluate方
法。在evaluate方法中,你将定义UDF的具体操作。
例如,如果你想要创建一个计算字符串长度的UDF,你可以创建一个名为StringLengthUDF的类,并在其中实现
evaluate方法以返回输入字符串的长度。2、编译UDF:
将Java类编译成JAR文件。这通常是通过使用Maven或Gradle等构建工具来完成的。3、将JAR文件添加到Hive的classpath:
将编译好的JAR文件上传到Hive可以访问的位置。这可以通过多种方式完成,例如将JAR文件上传到HDFS
(Hadoop Distributed FileSystem)或使用ADD JAR命令将本地JAR文件添加到Hive的classpath中。
例如,使用ADD JAR /path/to/StringLengthUDF.jar;命令将JAR文件添加到Hive中。4、注册UDF:
在Hive中注册UDF,以便在查询中使用它。这通常是通过CREATE TEMPORARY FUNCTION语句完成的,其中需要
指定UDF的名称和JAR文件中类的全限定名。
例如,CREATE TEMPORARY FUNCTION string_length AS 'com.example.udf.StringLengthUDF';5、在查询中使用UDF:
一旦UDF被注册,你就可以在Hive查询中像使用内置函数一样使用它。在查询中,只需调用UDF的名称并传入必要
的参数即可。
例如,SELECT name, string_length(description) AS length FROM table_name;6、处理结果:
Hive将执行查询,并在结果中包括UDF的返回值。你可以像处理查询的其他部分一样处理这些返回值。7、注意事项:
如果UDF需要在多个Hive会话或集群节点上执行,你需要确保JAR文件在所有相关节点上都是可用的。
对于更复杂的UDF(例如需要处理多个输入参数或返回复杂数据类型的UDF),你可能需要实现Hive的
GenericUDF接口而不是简单的UDF接口。
通过遵循以上步骤,你可以在Hive中成功执行UDF,并利用自定义函数来增强你的数据处理能力。row_number,rank,dense_rank的区别
在 Hive 中,ROW_NUMBER、RANK 和 DENSE_RANK 这三个窗口函数的主要区别在于对相同值的处理以及生成
的排名连续性。ROW_NUMBER:为结果集中的每一行分配一个唯一的连续整数序号,无论值是否相同。
例如,对于成绩相同的学生,ROW_NUMBER 会为他们分配不同的连续序号。RANK:为相同值的行分配相同的排名,但排名可能不连续。即如果有多个相同的值,它们会得到相同的排名,而
后续的排名会跳过中间的数字。
例如,如果有三个学生成绩相同并列第 5 名,那么下一个不同成绩的学生排名将是第 8 名。DENSE_RANK:为相同值的行分配相同的排名,并且排名是连续的。Hive count(distinct)有几个reduce,海量数据会有什么问题
在Hive中,COUNT(DISTINCT)操作默认情况下只使用一个reduce task来完成。这是因为COUNT(DISTINCT)
需要对所有不同的值进行计数,在MapReduce模型中,所有的“distinct”计算必须在一个地方进行汇总,以便
正确地计算出唯一的值数量。因此,尽管你可以设置更多的reduce tasks,但对于COUNT(DISTINCT)操作来
说,它仍然会被限制为一个reduce task,因为它需要全局汇总所有map task的结果。当处理海量数据时,这种设计会导致一些问题:1、数据倾斜:如果数据分布不均匀,大量的数据可能会集中在少数几个map task上,而这些map task的输出又
都需要被同一个reduce task处理,这会导致该reduce task负载过重,成为瓶颈。
2、内存溢出:由于所有不同的值需要在reduce阶段被处理,如果唯一值的数量非常大,这可能导致reduce
task的内存溢出,尤其是在资源有限的情况下。
3、执行时间长:一个reduce task处理大量数据会导致执行时间显著增加,尤其是当数据量远远超过reduce task的处理能力时。为了优化COUNT(DISTINCT)在海量数据上的性能,可以采取以下几种策略:1) 采样:使用采样来近似计算COUNT(DISTINCT),牺牲一定的准确性以换取性能。2) 分组预处理:在COUNT(DISTINCT)之前,可以通过添加GROUP BY语句来对数据进行预分组,减少需要在最
终COUNT(DISTINCT)中处理的数据量。但要注意,这可能会引入新的数据倾斜问题。3) 使用Map端聚合:通过设置mapreduce.job.reduces属性到一个较大的数值,并且使用DISTRIBUTE BY和
SORT BY来尝试在多个reduce tasks上更均匀地分配数据,虽然最终的汇总仍然需要一个额外的步骤,但这可
以减轻单个reduce task的压力。4) BitMap或HyperLogLog:利用Bitmap Index或者HyperLogLog这样的概率数据结构来估算
COUNT(DISTINCT),这可以大大减少内存消耗和计算时间,代价是结果会有一定误差。在实际应用中,选择哪种策略取决于具体的数据规模、可用资源以及对结果精确度的要求。HQL:行转列、列转行
在Hive SQL(HQL)中,行转列(也称为透视或透视表)和列转行(也称为逆透视或解构)是常见的操作,通常
用于数据重塑以适应不同的分析需求。这些操作在SQL中通常通过聚合函数、条件语句和LATERAL
VIEW/EXPLODE等Hive特有的功能来实现。行转列(透视)行转列通常涉及将行中的值转换为列标题,并将相关的值填充到这些列中。这通常通过CASE语句和聚合函数(如
SUM、MAX、MIN等)来实现。例如,假设我们有一个名为sales的表,其中包含销售数据,如下所示:CREATE TABLE sales ( year INT, quarter INT, amount DECIMAL(10, 2)
); INSERT INTO sales VALUES (2020, 1, 100), (2020, 2, 150), (2021, 1, 200), (2021, 2, 250);我们想要将这个表透视,以便每个年份都有一个对应的“Q1”和“Q2”列:SELECT year, SUM(CASE WHEN quarter = 1 THEN amount ELSE 0 END) AS Q1, SUM(CASE WHEN quarter = 2 THEN amount ELSE 0 END) AS Q2
FROM sales
GROUP BY year;列转行(逆透视)列转行是行转列的逆操作,它通常涉及将列标题转换为行值,并将相关的列值转换为行中的值。在Hive中,这通
常通过LATERAL VIEW和EXPLODE来实现,特别是当处理数组或映射等复杂数据类型时。但是,对于简单的列转行操作,我们可以使用UNION ALL或UNION(如果需要去重)来实现。假设我们有一个透视后的表sales_pivot,如下所示:CREATE TABLE sales_pivot ( year INT, Q1 DECIMAL(10, 2), Q2 DECIMAL(10, 2)
);
INSERT INTO sales_pivot VALUES (2020, 100, 150), (2021, 200, 250);我们想要将这个表逆透视回原始的sales表结构:SELECT year, 1 AS quarter, Q1 AS amount FROM sales_pivot
UNION ALL
SELECT year, 2 AS quarter, Q2 AS amount FROM sales_pivot;注意:在实际应用中,如果列转行操作涉及的数据量很大,使用UNION ALL可能会导致性能问题。在这种情况
下,可能需要考虑使用更高效的方法,如Hive的LATERAL VIEW和EXPLODE功能来处理数组或映射数据。一条HQL从代码到执行的过程
一条 HQL(Hive Query Language)从代码到执行通常经历以下过程:1、语法解析:Hive 接收到用户输入的 HQL 语句后,会对其进行语法解析,检查语句的语法结构是否正确。2、语义分析:在语法正确的基础上,进行语义分析,例如检查表和列是否存在、数据类型是否匹配等。3、生成逻辑计划:根据语义分析的结果,生成逻辑查询计划。这个逻辑计划描述了查询的基本操作和关系,但还没有考虑具体的执行细节。4、优化逻辑计划:Hive 的优化器会对逻辑计划进行优化,例如选择合适的连接算法、调整表的扫描顺序等,以提高查询性能。5、生成物理计划:将优化后的逻辑计划转换为可执行的物理计划,确定具体的执行步骤和使用的执行引擎(如
MapReduce、Tez 或 Spark)。6、任务提交与执行:物理计划被提交到对应的执行引擎中进行任务的分配和执行。7、结果返回:执行引擎完成任务后,将结果返回给 Hive,Hive 再将结果展示给用户。整个过程中,Hive 会尽力优化查询计划以提高执行效率,为用户提供准确和快速的查询结果。了解Hive SQL吗?讲讲分析函数?
Hive SQL中的分析函数,也被称为窗口函数,是一种强大的功能,用于执行复杂的分析和数据透视,而无需复杂
的子查询或自连接。分析函数允许你在一组相关的行(通常由PARTITION BY和ORDER BY限定的窗口)上执行计
算。这使得分析函数非常适合于计算排名、百分比、累计总和、移动平均等统计指标。在Hive中,分析函数分为几类,包括但不限于:1、排名函数:ROW_NUMBER(): 为每一行分配一个唯一的数字,通常与PARTITION BY和ORDER BY一起使用。
RANK(): 类似于ROW_NUMBER(),但是在遇到重复值时,会跳过随后的数字。
DENSE_RANK(): 类似于RANK(),但是不会跳过数字,即使有重复值。2、偏移函数:LEAD(): 返回当前行之后的第n行的值。
LAG(): 返回当前行之前的第n行的值。3、聚集函数:SUM(), AVG(), MIN(), MAX(), COUNT(): 这些函数通常与OVER子句结合使用,以在窗口范围内执行聚集
操作。4、累积和差分函数:
SUM() OVER (ORDER BY ... ROWS BETWEEN ... AND ... ): 计算累计总和。
FIRST_VALUE(), LAST_VALUE(): 返回窗口中第一个或最后一个值。
NTILE(): 将窗口中的行划分为指定数量的桶。
使用分析函数的一般语法包括OVER子句,这个子句定义了函数应该应用于哪个窗口:OVER ([PARTITION BY <column_list>] [ORDER BY <column_list>] [ROWS | RANGE <window_frame>])其中:
PARTITION BY将数据分割成独立的组。
ORDER BY确定窗口内的行顺序。
ROWS或RANGE定义了窗口的大小和位置。
例如,如果我们有一个销售记录表sales,并且我们想要计算每个月每个产品的累计销售额,我们可以使用如下查询:SELECT product_id, sale_date, total_sales,SUM(total_sales) OVER (PARTITION BY product_id ORDER BY sale_date) AS running_total
FROM sales
ORDER BY product_id, sale_date;在这个查询中,SUM(total_sales) OVER (...)是一个分析函数,它计算了每个产品从最早销售日期到当前日
期的累计销售额。分析函数在大数据分析中非常有用,因为它们提供了在不进行额外数据复制或复杂联接的情况下执行复杂计算的能
力。分析函数中加Order By和不加Order By的区别?
在分析函数(Analytic Functions)中使用ORDER BY子句与不使用它有着显著的区别。分析函数通常用于执
行跨行计算,为结果集中的每一行返回一个值,这个值是基于与当前行相关的其他行的。这些函数包括
ROW_NUMBER(), RANK(), DENSE_RANK(), LEAD(), LAG(), FIRST_VALUE(), LAST_VALUE(),
NTILE(), SUM() OVER(), AVG() OVER(), MIN() OVER(), MAX() OVER()等。不加ORDER BY的情况:当你在分析函数中不使用ORDER BY子句时,函数通常按照数据在结果集中的默认顺序(通常是物理存储顺序或查
询的扫描顺序)进行操作。
这可能会导致结果的不一致性和不可预测性,因为默认的排序顺序可能会随着数据的插入、删除或更新而改变。
在某些情况下,不使用ORDER BY可能是有意为之,特别是当你只关心与当前行相关的其他行的聚合值时,而不关
心这些行的具体顺序。加ORDER BY的情况:当你在分析函数中使用ORDER BY子句时,你可以明确指定函数应该按照哪个列或多个列的顺序进行操作。
这确保了结果的一致性和可预测性,因为无论数据的物理存储顺序如何,函数都会按照你指定的顺序进行操作。
ORDER BY子句在分析函数中非常重要,因为它决定了哪些行被认为是“当前行”的“之前”或“之后”的行。例如,LEAD()和LAG()函数分别返回结果集中当前行的下一行和上一行的值。没有ORDER BY子句,这些函数将
不知道哪一行是“下一行”或“上一行”。示例:
假设我们有一个名为employees的表,其中包含员工的ID、姓名和工资。如果我们想要为每个员工计算其工资在
部门内的排名(假设表中还有一个department_id列),我们可以使用RANK()分析函数。不使用ORDER BY:SELECT employee_id, salary, RANK() OVER (PARTITION BY department_id) AS salary_rank
FROM employees;
这个查询将会失败,因为RANK()函数需要一个ORDER BY子句来指定如何对员工进行排序以计算排名。使用ORDER BY:SELECT employee_id, salary, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS salary_rank FROM employees;这个查询将会成功,并为每个部门的员工按照工资从高到低的顺序计算排名。Hive优化方法
1、合理设计表结构
选择合适的数据类型:尽量使用占用存储空间小的数据类型,避免过度使用大字段。
分区和分桶:根据业务需求进行合理的分区和分桶,提高查询效率。2、优化查询语句
减少不必要的列:只选择需要的列,避免使用 SELECT * 。
条件过滤前置:将能过滤掉大量数据的条件放在 WHERE 子句的前面。
避免子查询:尽量将子查询改写为连接操作。3、利用索引
如果适用,可以为经常用于查询和连接的列创建索引。4、选择合适的连接方式
对于小表和大表的连接,优先考虑 MAPJOIN 。5、调整配置参数
例如调整 hive.exec.reducers.bytes.per.reducer 控制 Reducer 的数量。6、数据压缩
对数据进行压缩存储,减少数据量和存储空间。7、缓存表或中间结果
对于经常使用且不经常变化的数据,可以使用缓存提高查询速度。8、并行执行
开启并行执行任务,提高执行效率。9、定期清理无用数据
减少数据量,提高查询性能。10、监控和分析执行计划
使用 EXPLAIN 命令查看查询的执行计划,分析并优化执行流程。Hive里metastore是干嘛的
在Apache Hive中,MetaStore是一个核心组件,它负责存储Hive表的元数据(metadata)。元数据是关于数
据的数据,它描述了数据的结构、属性、位置等信息。对于Hive来说,元数据主要包括表名、列名、数据类型、
分区信息、表存储的位置(HDFS路径)等。以下是MetaStore的主要职责和功能:1、存储元数据:MetaStore将Hive表的元数据存储在关系型数据库中(如MySQL、Derby、PostgreSQL等),
这样Hive就可以通过查询MetaStore来获取表的结构和其他相关信息。2、提供元数据服务:Hive客户端(如Beeline、JDBC/ODBC驱动等)通过HiveServer2与MetaStore交互,
以获取表的元数据。这样,客户端就可以知道如何查询或操作数据。3、支持表的演化:当表的结构发生变化(如添加/删除列、修改数据类型等)时,MetaStore会更新相应的元数
据。4、提供事务支持(对于支持ACID的Hive版本):对于支持ACID(原子性、一致性、隔离性、持久性)的Hive版
本,MetaStore还负责跟踪和管理事务相关的元数据,以确保数据的一致性和可恢复性。5、支持授权和访问控制(可选):虽然MetaStore本身不直接处理授权和访问控制,但它可以与其他安全框架
(如Apache Ranger)集成,以支持更细粒度的数据访问控制。6、高可用性和可扩展性:为了支持大规模的数据仓库应用,MetaStore可以配置为高可用性(HA)模式,并使用
分布式数据库来存储元数据,以提供更高的可扩展性和容错性。总之,MetaStore是Hive中不可或缺的一部分,它负责存储和管理Hive表的元数据,为Hive客户端提供元数据服务,并支持表的演化和事务等功能。HiveServer2是什么?
HiveServer2是Apache Hive的一个关键组件,它作为一个服务运行,负责处理来自客户端的SQL请求。
HiveServer2是HiveServer1的升级版,旨在提供更稳定、更安全且更高效的服务,支持多种客户端连接方式和
更高的并发性。以下是HiveServer2的一些主要特点和功能:1、多客户端支持:HiveServer2提供了多种客户端接口,包括JDBC、ODBC、Thrift API以及CLI(命令行界
面),这使得不同的应用程序和工具能够以各自合适的方式连接到Hive。2、并发性:HiveServer2支持多客户端并发请求,这意味着多个客户端可以同时向HiveServer2发送查询,而
不必等待其他查询完成。3、安全性:HiveServer2支持Kerberos认证,允许在企业级环境中实施更严格的安全措施。4、改进的性能:HiveServer2在内部实现了更好的优化,以提高查询处理速度和资源管理。5、Web UI:HiveServer2可以提供一个Web UI界面,用于监控服务状态和执行简单的查询。6、执行引擎:HiveServer2可以与多种执行引擎集成,如MapReduce、Tez和Spark,以优化查询执行。7、远程执行:HiveServer2允许远程客户端执行SQL语句并接收结果,这使得跨集群或跨数据中心的数据查询和
分析成为可能。8、命令行接口(CLI):HiveServer2提供了新的CLI工具,如beeline,它是一个轻量级的命令行接口,用于
提交SQL语句和获取结果。HiveServer2的启动通常涉及到配置Hive的hive-site.xml文件,设置监听端口、主机地址以及与安全和执行
相关的参数。一旦配置完成,HiveServer2就可以通过运行特定的启动脚本来启动,这通常是在Hive安装目录下
的bin/hiveserver2脚本。在企业环境中,HiveServer2是Hive集群的关键组成部分,它使得Hive成为一个可扩展且高度可用的数据仓库
解决方案。Hive表字段换类型怎么办
在 Hive 中,如果要更改表字段的数据类型,可以使用 ALTER TABLE 语句。但需要注意的是,并非所有的数
据类型转换都是直接可行的,而且某些转换可能会导致数据丢失或不准确。以下是更改表字段数据类型的一般语法:ALTER TABLE table_name CHANGE column_name old_column_type new_column_type;例如,如果要将表 your_table 中的字段 your_column 从 INT 类型更改为 STRING 类型,可以使用以下
语句:ALTER TABLE your_table CHANGE your_column INT STRING;
在执行类型更改操作之前,请务必谨慎考虑可能产生的影响,并对数据进行备份以防万一。parquet文件优势
Parquet 文件具有以下显著优势:1、高效存储:采用列式存储格式,只读取需要的列,大幅减少了 I/O 开销,尤其在处理大规模数据时性能提升明显。2、压缩效率高:支持多种高效的压缩算法,如 Snappy、Gzip 等,能显著减少数据存储空间。3、自描述性:文件包含了自身的元数据信息,如数据类型、列名等,便于数据的解析和处理。4、兼容性好:能够与多种大数据处理框架和工具良好兼容,如 Hive、Spark 等。5、支持嵌套结构:可以很好地处理复杂的嵌套数据结构,适合存储具有多层级关系的数据。6、数据类型丰富:支持多种常见的数据类型,包括整数、浮点数、字符串、日期时间等。7、分区友好:与 Hive 等工具的分区机制配合良好,便于数据的管理和查询优化。8、易于并行处理:可以被多个任务并行读取和处理,提高了数据处理的效率。引用:https://www.nowcoder.com/discuss/353159520220291072
通义千问、文心一言、豆包
相关文章:
)
大数据面试题之Hive(3)
目录 Hive的函数:UDF、UDAF、UDTF的区别? UDF是怎么在Hive里执行的 row_number,rank,dense_rank的区别 Hive count(distinct)有几个reduce,海量数据会有什么问题 HQL:行转列、列转行 一条HQL从代码到执行的过程 了解Hive S…...

华为OD机考题HJ17 坐标移动
前言 应广大同学要求,开始以OD机考题作为练习题,看看算法和数据结构掌握情况。有需要练习的可以关注下。 描述 开发一个坐标计算工具, A表示向左移动,D表示向右移动,W表示向上移动,S表示向下移动。从&am…...

redis修改密码
在Redis中,修改密码通常涉及编辑Redis配置文件或者在运行时通过Redis命令动态修改。 温馨提示:(运行时直接参考第2条) 1.编辑配置文件: 找到Redis配置文件redis.conf,通常位于/etc/redis/或/usr/local/e…...

《昇思 25 天学习打卡营第 7 天 | 模型训练 》
《昇思 25 天学习打卡营第 7 天 | 模型训练 》 活动地址:https://xihe.mindspore.cn/events/mindspore-training-camp 签名:Sam9029 模型训练 本章节-结合前几张的内容所讲-算是一节综合实践 mindscope 框架使用张量 数据类型数据集下载与加载网络构建函…...

HTML/CSS 基础
1、<input type"checkbox" checked> checked 默认选中为复选框 2、表格中的标题<caption> 3、文字标签直接加 title 4、<dl>为自定义列表的整体,包裹<dt><dd> <dt>自定义列表的主题 <dd>主题的每一项内容 5、…...

Linux系统安装Lua语言及Lua外部库
安装Lua Lua语言是一种轻量级、高效且可扩展的脚本语言,具有简洁易学的语法和占用资源少的特点。它支持动态类型,提供了丰富的表达式和运算符,同时具备自动垃圾回收机制和跨平台性。Lua语言易于嵌入到其他应用程序中,并可与其他语…...

前端技术栈学习:Vue2、Vue cli脚手架、ElementUI组件库、Axios
1 基本介绍 (1)Vue 是一个前端框架, 易于构建用户界面 (2)Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或项目整合 (3)支持和其它类库结合使用 (4&#…...
pycharm中取消Typo:In word ‘xxx‘提示(绿色波浪线提示)的方法
#事故现场 使用pycharm写python代码出现绿色波浪线的提示,并提示Typo:In word ‘xxx’,这是pycharm检测到单词拼写错误、不规范; 那如何取消这种提示呢? #解决方法 方法一:Settings → Editor → Inspections → P…...

js中的浅拷贝和深拷贝
浅拷贝Shallow Copy 浅拷贝只复制对象的顶层属性及其引用,而不复制这些引用所指向的对象。如果原始对象中的某个属性是一个对象或数组,那么浅拷贝后的对象将包含对这个内部对象或数组的引用,而不是这个对象或数组的一个新副本。 let obj1 …...

【Linux】常用基本命令
wget网址用于直接从网上下载某个文件到服务器,当然也可以直接从网上先把东西下到本地然后用filezilla这个软件来传输到服务器上。 当遇到不会的命令时候,可以使用man “不会的命令”来查看这个命令的详细信息。比如我想要看看ls这个命令的详细用法&…...
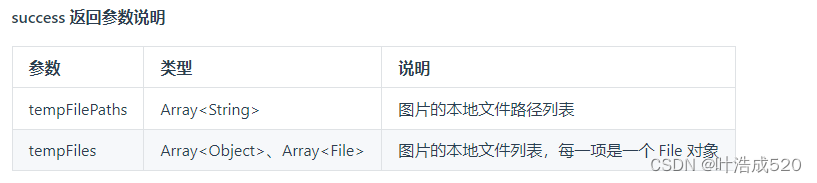
uniapp——上传图片获取到file对象而非临时地址——基础积累
最近在看uniapp的代码,遇到一个需求,就是要实现上传图片的功能 uniapp 官网地址:https://uniapp.dcloud.net.cn/ 上传图片有对应的API: uni.chooseImage方法:https://uniapp.dcloud.net.cn/api/media/image.html#choo…...
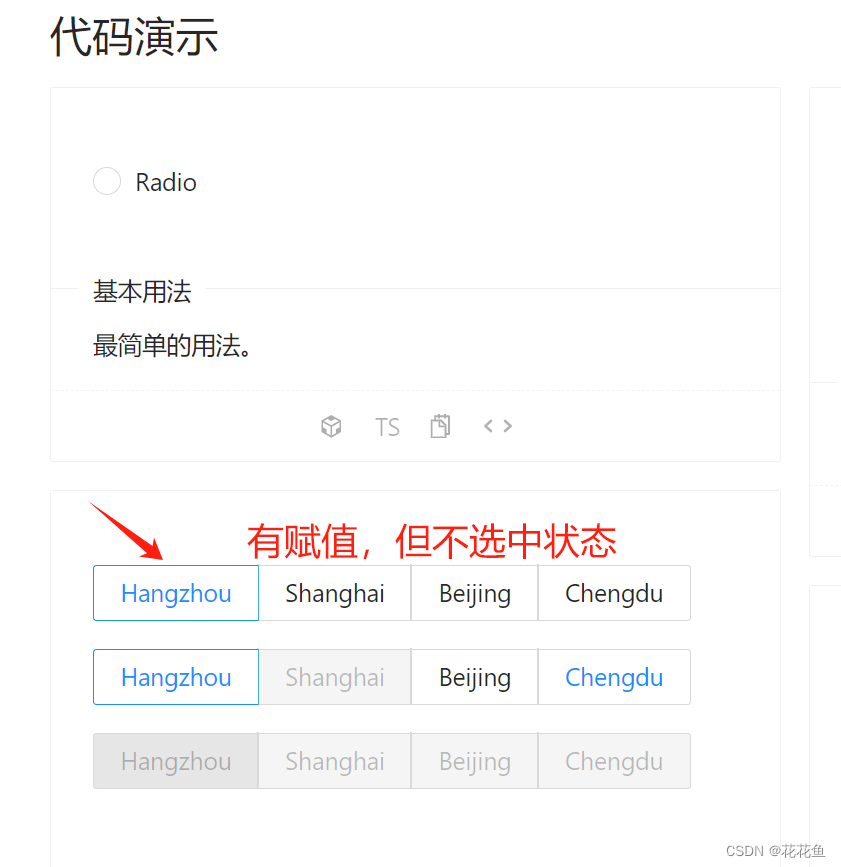
vue3 antdv RadioButton默认值选择问题处理
1、先上官方文档: Ant Design Vue — An enterprise-class UI components based on Ant Design and Vue.js 官方代码: <template><div><div><a-radio-group v-model:value"value1"><a-radio-button value"a…...

最佳实践,一款基于 Flutter 的桌面应用
前言 这篇文章介绍作为一名后端开发人员,快速的入门前端或者客户端一些相关的技术的心得。先来说说为什么作为一名后端开发人员也需要学习一些前端或者客户端相关的技术。通常来说,深耕一个领域没有错,因为社会常常就是这样分工的࿰…...

python第一个多进程爬虫
使用 multiprocessing 模块实现多进程爬取股票网址买卖数据的基本思路是: 定义爬虫函数,用于从一个或多个股票网址上抓取数据。创建多个进程,每个进程执行爬虫函数,可能针对不同的股票或不同的网页。使用 multiprocessing.Queue …...

在Ubuntu 18.04上安装和配置Ansible的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 配置管理系统旨在简化对大量服务器的控制,适用于管理员和运维团队。它们允许您从一个中央位置以自动化的方式控制许多…...
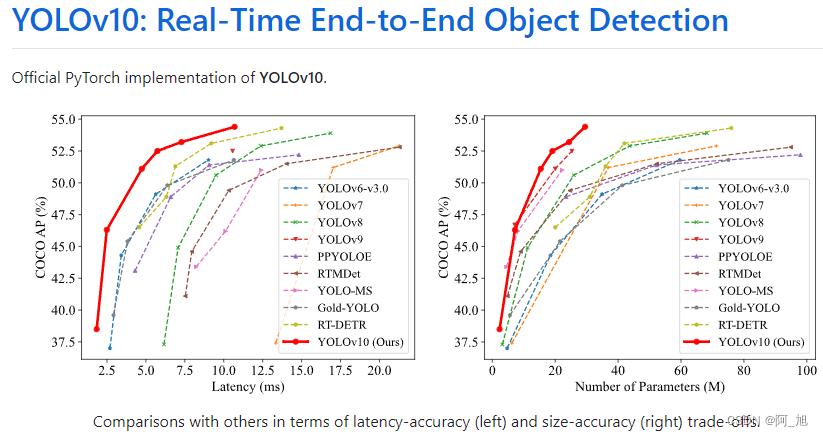
【详细教程】如何使用YOLOv10进行图片与视频的目标检测
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

LLM大语言模型-AI大模型全面介绍
简介: 大语言模型(LLM)是深度学习的产物,包含数十亿至数万亿参数,通过大规模数据训练,能处理多种自然语言任务。LLM基于Transformer架构,利用多头注意力机制处理长距离依赖,经过预训…...
瑜伽馆管理系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,教练管理,用户管理,瑜伽管理,套餐管理,体测报告管理,基础数据管理 前台账户功能包括:系统首页࿰…...

JAVA【案例5-2】模拟默认密码自动生成
【模拟默认密码自动生成】 1、案例描述 本案例要求编写一个程序,模拟默认密码的自动生成策略,手动输入用户名,根据用户名自动生成默认密码。在生成密码时,将用户名反转即为默认的密码。 2、案例目的 (1)…...

小区业主管理系统
摘 要 随着城市化进程的加速和人口的不断增加,小区的数量也在不断增加。小区作为城市居民居住的主要场所,其管理工作也变得越来越重要。传统的小区业主管理方式存在诸多问题,如信息传递不畅、业务处理效率低下等。因此,开发一个高…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...