Python-爬虫 下载天涯论坛帖子

为了爬取的高效性,实现的过程中我利用了python的threading模块,下面是threads.py模块,定义了下载解析页面的线程,下载图片的线程以及线程池
import threading
import urllib2
import Queue
import re
thread_lock = threading.RLock()
#下载页面的一个函数,header中没有任何内容也可以顺利的下载,就省去了
def download_page(html_url):
try:
req = urllib2.Request(html_url)
response = urllib2.urlopen(req)
page = response.read()
return page
except Exception:
print ‘download %s failed’ % html_url
return None
#下载图片的一个方法,和上面的函数很像,只不过添加了一个文件头
#因为在测试的过程中发现天涯对于没有如下文件头的图片链接是不会返回正确的图片的
def download_image(image_url, referer):
try:
req = urllib2.Request(image_url)
req.add_header(‘Host’, ‘img3.laibafile.cn’)
req.add_header(‘User-Agent’, ‘Mozilla/5.0 (Windows NT 6.3; WOW64; rv:33.0) Gecko/20100101 Firefox/33.0’)
req.add_header(‘Accept’, ‘image/png,image/*;q=0.8,*/*;q=0.5’)
req.add_header(‘Accept-Language’, ‘zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3’)
req.add_header(‘Referer’, referer)
req.add_header(‘Origin’, ‘http://bbs.tianya.cn’)
req.add_header(‘Connection’, ‘keep-alive’)
response = urllib2.urlopen(req)
image = response.read()
return image
except Exception:
print ‘download %s failed’ % image_url
return None
#下载和解析一个页面的线程类
class download_html_page(threading.Thread):
#name:线程的名字
#page_range:用户输入的页面范围
#page_contents:解析之后楼主的内容
#img_urls:解析之后楼主贴的图的链接
#html_url:输入的页面url
#first_page:第一次已经下载好的页面,主要是考虑效率,不重复下载
def __init__(self, name, page_range, page_contents, img_urls, html_url, first_page):
threading.Thread.__init__(self)
self.name = name
self.page_range = page_range
self.page_contents = page_contents
self.img_urls = img_urls
self.html\_url = html\_url self.first\_page = first\_page #判断是不是楼主的内容
def is\_louzhu(self, s): result = re.search(r'<!-- <div class="host-ico">(.\*?)</div> -->', s, re.S) return (result is not None) #获得页面里属于楼主图片的url
def get\_img\_url(self, s, page\_url): #判断是不是楼主给其他用户的评论,如果是的话,直接过滤掉(本人从不看评论) is\_louzhu\_answer = re.search(r'-{15,}<br>', s, re.S) if is\_louzhu\_answer is None: imgurl = re.findall(r'<img.\*?original="(?P<imgurl>.\*?)".\*?/><br>', s, flags = re.S) url\_path = \[\] for one\_url in imgurl: self.img\_urls.put(one\_url + '|' + page\_url) path = re.search('\\w+\\.jpg', one\_url).group(0) url\_path.append('img/' + path) segments = re.split(r'<img .\*?/><br>', s.strip()) content = segments\[0\].strip() for i in range(len(url\_path)): content += '\\n<img src = "' + url\_path\[i\] + '" />\\n<br>' content += segments\[i+1\].strip() return content #解析夜歌页面
def parse\_page(self, html\_page, page\_url): html\_page.decode('utf-8') Items = re.findall(r'<div class="atl-content">(?P<islouzhu>.+?)<div class="bbs-content.\*?">(?P<content>.+?)</div>', html\_page, re.S) page\_content = '' for item in Items: if self.is\_louzhu(item\[0\]): one\_div = self.get\_img\_url(item\[1\], page\_url) if one\_div is not None: page\_content += one\_div return page\_content def run(self): while self.page\_range.qsize() > 0: page\_number = self.page\_range.get() page\_url = re.sub('-(\\d+?)\\.shtml', '-' + str(page\_number) + '.shtml', self.html\_url) page\_content = '' print 'thread %s is downloading %s' % (self.name, page\_url) if page\_url == self.html\_url: page\_content = self.parse\_page(self.first\_page, page\_url) else: page = download\_page(page\_url) if page is not None: page\_content = self.parse\_page(page, page\_url) #thread\_lock.acquire() #self.page\_contents\[page\_number\] = page\_content #thread\_lock.release() self.page\_contents.put(page\_content, page\_number) self.img\_urls.put('finished')
#下载图片的线程
class fetch_img(threading.Thread):
def __init__(self, name, img_urls, download_img):
threading.Thread.__init__(self)
self.name = name
self.img_urls = img_urls
self.download_img = download_img
def run(self): while True: message = self.img\_urls.get().split('|') img\_url = message\[0\] if img\_url == 'finished': self.img\_urls.put('finished') break else: thread\_lock.acquire() if img\_url in self.download\_img: thread\_lock.release() continue else: thread\_lock.release() print 'fetching image %s' % img\_url referer = message\[1\] image = download\_image(img\_url, referer) image\_name = re.search('\\w+\\.jpg', img\_url).group(0) with open(r'img\\%s' % image\_name, 'wb') as img: img.write(image) thread\_lock.acquire() self.download\_img.add(img\_url) thread\_lock.release()
#定义了一个线程池
class thread_pool:
def __init__(self, page_range, page_contents, html_url, first_page):
self.page_range = page_range
self.page_contents = page_contents
self.img_urls = Queue.Queue()
self.html_url = html_url
self.first_page = first_page
self.download_img = set()
self.page\_thread\_pool = \[\] self.image\_thread\_pool = \[\] def build\_thread(self, page, image): for i in range(page): t = download\_html\_page('page thread%d' % i, self.page\_range, self.page\_contents, self.img\_urls, self.html\_url, self.first\_page) self.page\_thread\_pool.append(t) for i in range(image): t = fetch\_img('image thread%d' % i, self.img\_urls, self.download\_img) self.image\_thread\_pool.append(t) def all\_start(self): for t in self.page\_thread\_pool: t.start() for t in self.image\_thread\_pool: t.start() def all\_join(self): for t in self.page\_thread\_pool: t.join() for t in self.image\_thread\_pool: t.join()
下面是主线程的代码:
# -*- coding: utf-8 -*-
import re
import Queue
import threads
if __name__ == ‘__main__’:
html_url = raw_input('enter the url: ')
html_page = threads.download_page(html_url)
max\_page = 0
title = ''
if html\_page is not None: search\_title = re.search(r'<span class="s\_title"><span style="\\S+?">(?P<title>.+?)</span></span>', html\_page, re.S) title = search\_title.groupdict()\['title'\] search\_page = re.findall(r'<a href="/post-\\S+?-\\d+?-(?P<page>\\d+?)\\.shtml">(?P=page)</a>', html\_page, re.S) for page\_number in search\_page: page\_number = int(page\_number) if page\_number > max\_page: max\_page = page\_number print 'title:%s' % title
print 'max page number: %s' % max\_page start\_page = 0
while start\_page < 1 or start\_page > max\_page: start\_page = input('input the start page number:') end\_page = 0
while end\_page < start\_page or end\_page > max\_page: end\_page = input('input the end page number:') page\_range = Queue.Queue()
for i in range(start\_page, end\_page + 1): page\_range.put(i) page\_contents = {}
thread\_pool = threads.thread\_pool(page\_range, page\_contents, html\_url, html\_page)
thread\_pool.build\_thread(1, 1)
thread\_pool.all\_start()
thread\_pool.all\_join()
本文仅作项目练习,且勿商用!!!
由于文章篇幅有限,文档资料内容较多,需要这些文档的朋友,可以加小助手微信免费获取,【保证100%免费】,中国人不骗中国人。

全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
今天就分享到这里啦,感谢大家收看!
相关文章:
Python-爬虫 下载天涯论坛帖子
为了爬取的高效性,实现的过程中我利用了python的threading模块,下面是threads.py模块,定义了下载解析页面的线程,下载图片的线程以及线程池 import threading import urllib2 import Queue import re thread_lock threading.RL…...
创建github个人博客
文章目录 安装Hexo安装git安装Node.js安装 Hexo git配置SSH key配置ssh 搭建个人博客新建博客生成静态网页 本文主要参考 【保姆级】利用Github搭建自己的个人博客,看完就会 安装Hexo 参考官方文档:https://hexo.io/zh-cn/docs/ Hexo 是一个快速、简洁且…...

【五子棋game】
编写一个五子棋游戏程序可以分为几个步骤:设计棋盘、定义规则、实现人机交互、判断胜负。下面是一个简化的五子棋游戏程序示例,使用Python语言编写。 首先,我们需要一个棋盘。可以使用一个二维数组来表示棋盘,其中0表示空位&#…...

从入门到精通:使用Python的Watchdog库监控文件系统的全面指南
从入门到精通:使用Python的Watchdog库监控文件系统的全面指南 引言Watchdog库概述核心组件工作原理 快速开始:设置Watchdog安装Watchdog创建一个简单的监控脚本设置和启动Observer 事件处理:如何响应文件系统的变化基本事件处理处理复杂的场景…...

Linux 进程管理指令
Linux 进程管理是系统管理的重要部分,通过各种工具和命令,你可以查看、控制、调试和管理进程。以下是一些常用的 Linux 进程管理命令和工具。 查看进程 1. ps ps 命令用于列出当前系统的进程。 查看当前用户的所有进程: ps -u $USER查看…...

Java OA系统通知公告模块
### 使用Spring Boot实现OA通知公告模块 使用Spring Boot框架实现一个支持多种形式公告发布、设置发布时间和有效期,以及公告发布后推送通知的模块。 #### 项目结构 结构组织项目: OA_Notification_Module/ ├── src/ │ ├── main/ │ │ …...
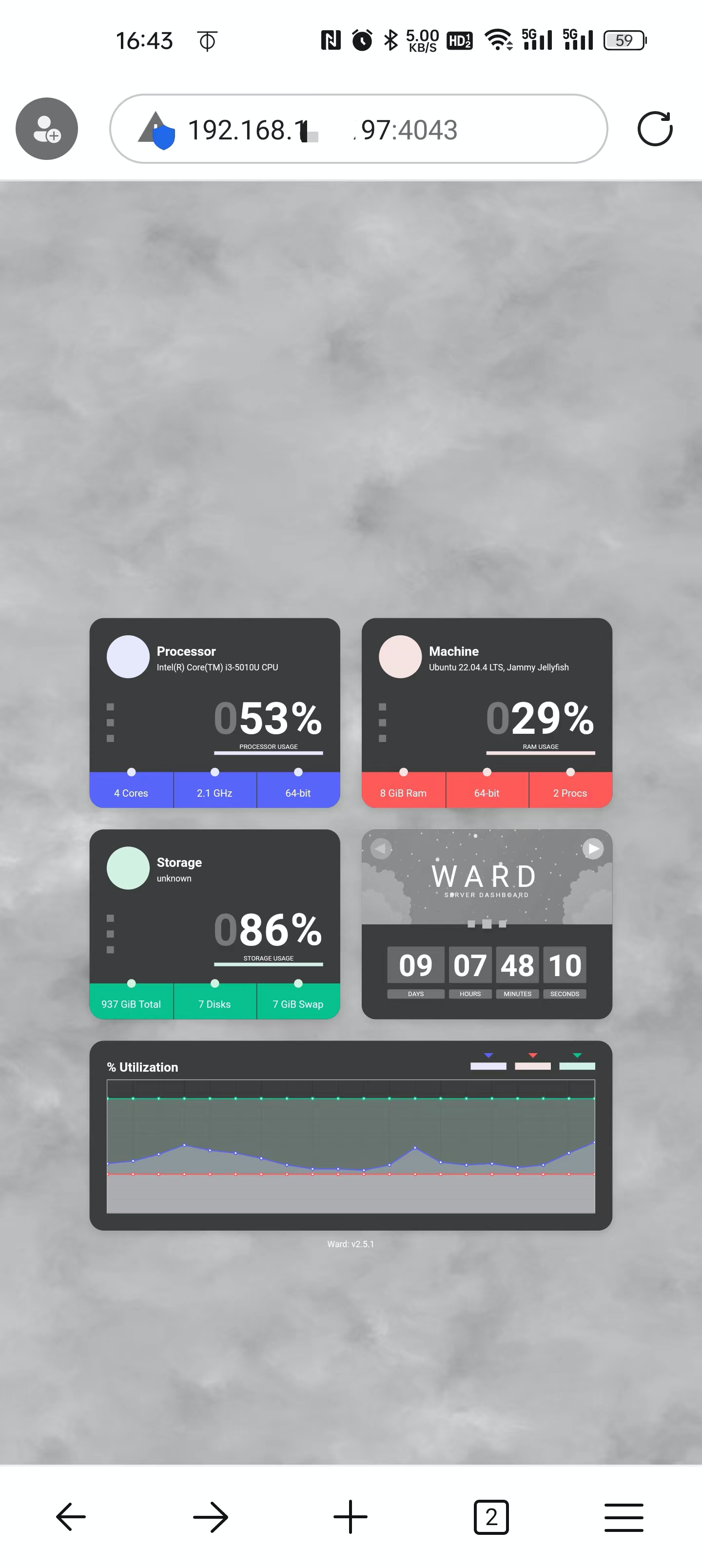
简约的服务器监控工具Ward
什么是 Ward ? Ward 是一个简单简约的服务器监控工具。 Ward 支持自适应设计系统。此外,它还支持深色主题。它仅显示主要信息,如果您想查看漂亮的仪表板而不是查看一堆数字和图表,则可以使用它。 Ward 在所有流行的操作系统上都能…...

新能源发电乙级资质所需办理标准
企业资历与信誉: 必须具有独立企业法人资格。社会信誉良好,注册资本不少于100万元人民币。 技术条件: 专业技术人员配置齐全、合理,数量需满足资质标准要求。主要技术负责人或总工程师应具有大学本科以上学历、10年以上设计经历&a…...
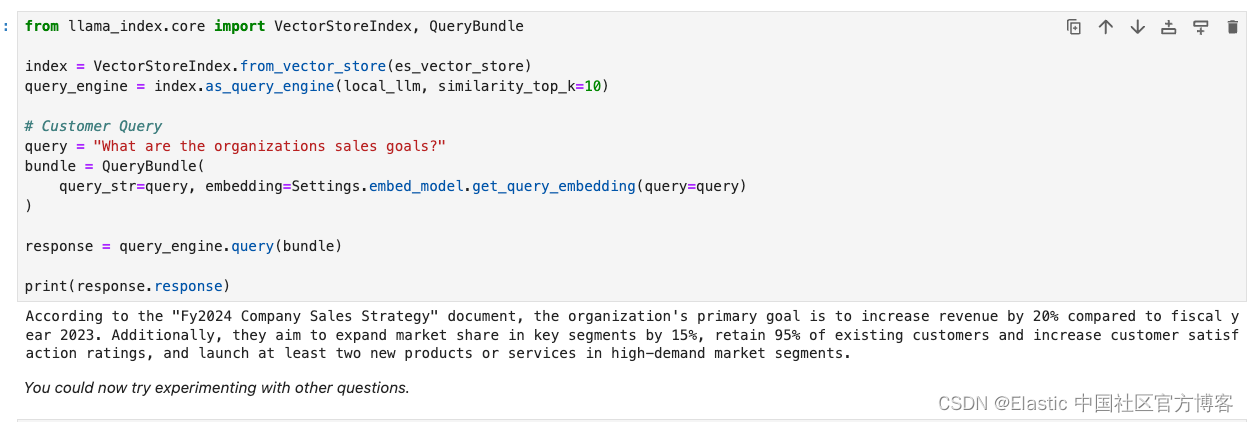
Elasticsearch:使用 Llamaindex 的 RAG 与 Elastic 和 Llama3
这篇文章是对之前的文章 “使用 Llama 3 开源和 Elastic 构建 RAG” 的一个补充。我们可以在本地部署 Elasticsearch,并进行展示。我们将一步一步地来进行配置并展示。你还可以参考我之前的另外一篇文章 “Elasticsearch:使用在本地计算机上运行的 LLM 以…...
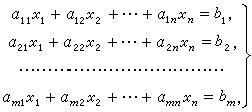
AcWing算法基础课笔记——高斯消元
高斯消元 用来求解方程组 a 11 x 1 a 12 x 2 ⋯ a 1 n x n b 1 a 21 x 1 a 22 x 2 ⋯ a 2 n x n b 2 … a n 1 x 1 a n 2 x 2 ⋯ a n n x n b n a_{11} x_1 a_{12} x_2 \dots a_{1n} x_n b_1\\ a_{21} x_1 a_{22} x_2 \dots a_{2n} x_n b_2\\ \dots \\ a…...

【JavaScript脚本宇宙】图形魔术:探索领先的图像处理库及其独特功能
深入了解HTML5视频:最受欢迎的库及其功能 前言 图像处理是现代数字媒体开发中不可或缺的一部分,从调整图像大小到创建复杂的图形场景。有许多库可用,每个库都有其特定的优点和适用场景。在本文中,我们将探讨六种流行的图像处理库…...

Nemotron-4
Nemotron-4是英伟达(NVIDIA)发布的一系列高级人工智能模型,特别着重于大尺度语言模型(LLMs)的发展。这些模型在不同的参数量级上展现出了卓越的性能和效率,其中特别提到了150亿参数的Nemotron-4 15B和3400亿…...

【神经网络】神经元的基本结构和训练过程
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 神经元的基本结构和训练过程 …...
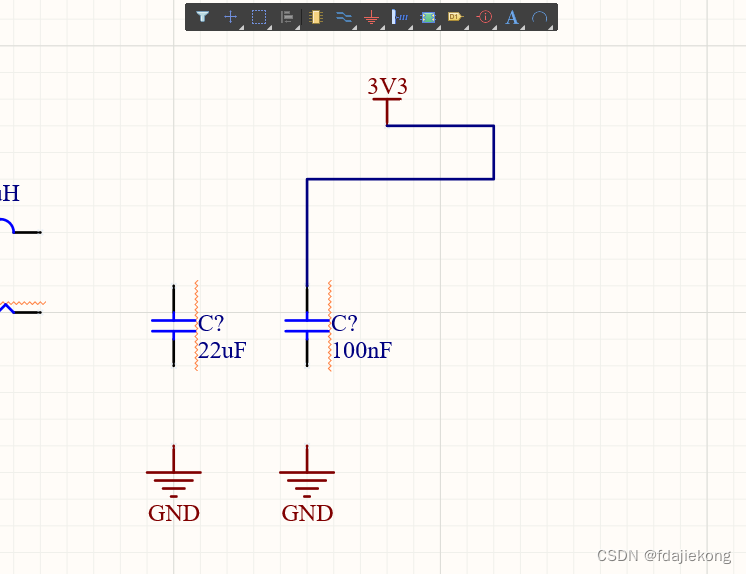
第28课 绘制原理图——绘制导线
概述 放置完元器件之后,接着就要用导线将元器件的管脚一个一个连起来了。 绘制导线的方法 点击快速工具条上的“线”命令,进入绘制导线的过程。 点击选择某个管脚或电源端口,作为导线的起始端。 再点击选择另一个管脚或电源端口,…...

NLP 相关知识
NLP 相关知识 NLPLLMPrompt ChainingLangChain NLP NLP(Natuarl Language Processing)是人工智能的一个分支,中文名自然语言处理,专注于处理和理解人类使用的自然语言。它涵盖了多个子领域,如文本分类、情感分析、机器…...

Java中的设计模式:实战案例分享
Java中的设计模式:实战案例分享 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 设计模式是软件开发中的宝贵工具,它们为常见的问题提供…...
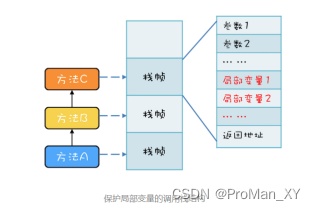
并发编程理论基础——合适的线程数量和安全的局部变量(十)
多线程的提升方向 主要方向在于优化算法和将硬件的性能发挥到极致想要发挥出更多的硬件性能,最主要的就是提升I/O的利用率和CPU的利用率以及综合利用率操作系统已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免 CPU 轮询 I/O 状态,也提…...

Python使用抽象工厂模式和策略模式的组合实现生成指定长度的随机数
设计模式选择理由: 抽象工厂模式: 抽象工厂模式适合于创建一组相关或依赖对象的场景。在这里,我们可以定义一个抽象工厂来创建不同类型(数字、字母、特殊符号)的随机数据生成器。 策略模式: 策略模式允许你…...

python-17-零基础自学python-
学习内容:《python编程:从入门到实践》第二版 知识点: 类、子类、继承、调用函数 练习内容: 练习9-6:冰激凌小店 冰激凌小店是一种特殊的餐馆。编写一个名为IceCreamStand的类,让它继承为完成练习9-1或…...

Web应用和Tomcat的集成鉴权1-BasicAuthentication
作者:私语茶馆 1.Web应用与Tomcat的集成式鉴权 Web应用部署在Tomcat时,一般有三层鉴权: (1)操作系统鉴权 (2)Tomcat容器层鉴权 (3)应用层鉴权 操作系统层鉴权包括但不限于:Tomcat可以和Windows的域鉴权集成,这个适合企业级的统一管理。也可以在Tomcat和应用层独立…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...
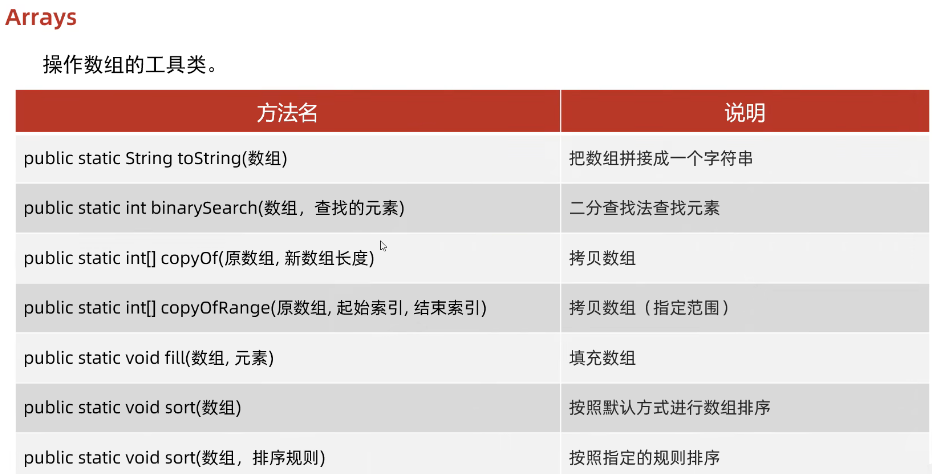
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...

Canal环境搭建并实现和ES数据同步
作者:田超凡 日期:2025年6月7日 Canal安装,启动端口11111、8082: 安装canal-deployer服务端: https://github.com/alibaba/canal/releases/1.1.7/canal.deployer-1.1.7.tar.gz cd /opt/homebrew/etc mkdir canal…...

用 FFmpeg 实现 RTMP 推流直播
RTMP(Real-Time Messaging Protocol) 是直播行业中常用的传输协议。 一般来说,直播服务商会给你: ✅ 一个 RTMP 推流地址(你推视频上去) ✅ 一个 HLS 或 FLV 拉流地址(观众观看用)…...
docker容器互联
1.docker可以通过网路访问 2.docker允许映射容器内应用的服务端口到本地宿主主机 3.互联机制实现多个容器间通过容器名来快速访问 一 、端口映射实现容器访问 1.从外部访问容器应用 我们先把之前的删掉吧(如果不删的话,容器就提不起来,因…...