使用Dropout大幅优化PyTorch模型,实现图像识别
大家好,在机器学习模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络时,过拟合具体表现在模型训练数据损失函数较小,预测准确率较高,但是在测试数据上损失函数比较大,预测准确率较低。Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
1.机器学习中的Dropout正则化
Dropout正则化是机器学习领域中一种有效的技术,通过随机丢弃神经网络中的某些单元,实现对多个不同网络架构的并行训练。
这种方法对于减少模型在训练过程中的过拟合现象非常关键,有助于提升模型的泛化能力。

深度网络
2.在PyTorch模型中集成Dropout
要在PyTorch模型中加入Dropout正则化,可以使用torch.nn.Dropout类来实现。这个类需要一个Dropout率作为输入参数,表示神经元被关闭的可能性,这可以应用于任何非输出层。
self.dropout = nn.Dropout(0.25)
3.观察Dropout对模型性能的影响
为了研究Dropout的效果,这里将训练一个用于图像分类的模型。最初,训练一个经过正则化的网络,然后是一个没有Dropout正则化的网络。两个模型都将在Cifar-10数据集上训练8个周期。
步骤1:首先,将导入需要实现网络的依赖项和库。
import torch
from torch import nn
from torch import optim
from torch.nn import functional as F
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoaderimport matplotlib.pyplot as plt
import numpy as npdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
步骤2:将加载数据集并准备数据加载器。
BATCH_SIZE = 32transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])trainset = torchvision.datasets.CIFAR10(root="./data", train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root="./data", train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE,shuffle=False, num_workers=2)CLASS_NAMES = ("plane", "car", "bird", "cat","deer", "dog", "frog", "horse", "ship", "truck")
步骤3:加载并可视化一些数据
def show_batch(image_batch, label_batch):plt.figure(figsize=(10,10))for n in range(25):ax = plt.subplot(5,5,n+1)img = image_batch[n] / 2 + 0.5 # 取消归一化img = img.numpy()plt.imshow(np.transpose(img, (1, 2, 0)))plt.title(CLASS_NAMES[label_batch[n]])plt.axis("off")
sample_images, sample_labels = next(iter(trainloader))
show_batch(sample_images, sample_labels)
输出:

步骤4:在Dropout正则化中实现网络
class Net(nn.Module):def __init__(self, input_shape=(3,32,32)):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3)self.conv2 = nn.Conv2d(32, 64, 3)self.conv3 = nn.Conv2d(64, 128, 3)self.pool = nn.MaxPool2d(2,2)n_size = self._get_conv_output(input_shape)self.fc1 = nn.Linear(n_size, 512)self.fc2 = nn.Linear(512, 10)self.dropout = nn.Dropout(0.25)def _get_conv_output(self, shape):batch_size = 1input = torch.autograd.Variable(torch.rand(batch_size, *shape))output_feat = self._forward_features(input)n_size = output_feat.data.view(batch_size, -1).size(1)return n_sizedef _forward_features(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = self.pool(F.relu(self.conv3(x)))return xdef forward(self, x):x = self._forward_features(x)x = x.view(x.size(0), -1)x = self.dropout(x)x = F.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return x
步骤5:实现训练
def train(model, device, train_loader, optimizer, criterion, epoch, steps_per_epoch=20):# 将模型切换到训练模式。这对于像dropout、batchnorm等在训练和评估模式下表现不同的层是必要的model.train()train_loss = 0train_total = 0train_correct = 0# 我们循环遍历数据迭代器,并将输入数据提供给网络并调整权重。for batch_idx, (data, target) in enumerate(train_loader, start=0):# 从训练数据集中加载输入特征和标签data, target = data.to(device), target.to(device)# 将所有可学习权重参数的梯度重置为0optimizer.zero_grad()# 前向传播:传递训练数据集中的图像数据,预测图像所属的类别(在本例中为0-9)output = model(data)# 定义我们的损失函数,并计算损失loss = criterion(output, target)train_loss += loss.item()scores, predictions = torch.max(output.data, 1)train_total += target.size(0)train_correct += int(sum(predictions == target))# 将所有可学习权重参数的梯度重置为0optimizer.zero_grad()# 反向传播:计算损失相对于模型参数的梯度loss.backward()# 更新神经网络权重optimizer.step()acc = round((train_correct / train_total) * 100, 2)print("Epoch [{}], Loss: {}, Accuracy: {}".format(epoch, train_loss/train_total, acc), end="")
步骤6:实现测试函数
def test(model, device, test_loader, criterion, classes):# 将模型切换到评估模式。这对于像dropout、batchnorm等在训练和评估模式下表现不同的层是必要的model.eval()test_loss = 0test_total = 0test_correct = 0example_images = []with torch.no_grad():for data, target in test_loader:# 从测试数据集中加载输入特征和标签data, target = data.to(device), target.to(device)# 进行预测:传递测试数据集中的图像数据,预测图像所属的类别(在本例中为0-9)output = model(data)# 计算损失,累加批次损失test_loss += criterion(output, target).item()scores, predictions = torch.max(output.data, 1)test_total += target.size(0)test_correct += int(sum(predictions == target))acc = round((test_correct / test_total) * 100, 2)print("Test_loss: {}, Test_accuracy: {}".format(test_loss/test_total, acc))
步骤7:初始化网络的损失和优化器
net = Net().to(device)
print(net)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
输出:
Net((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc1): Linear(in_features=512, out_features=512, bias=True)(fc2): Linear(in_features=512, out_features=10, bias=True)(dropout): Dropout(p=0.25, inplace=False)
)
步骤8:开始训练
for epoch in range(8):train(net, device, trainloader, optimizer, criterion, epoch)test(net, device, testloader, criterion, CLASS_NAMES)print("Finished Training")
输出:
Epoch [0], Loss: 0.0461193907892704, Accuracy: 45.45 Test_loss: 0.036131812924146654, Test_accuracy: 58.58
Epoch [1], Loss: 0.03446852257728577, Accuracy: 60.85 Test_loss: 0.03089196290373802, Test_accuracy: 65.27
Epoch [2], Loss: 0.029333480607271194, Accuracy: 66.83 Test_loss: 0.027052838513255118, Test_accuracy: 70.41
Epoch [3], Loss: 0.02650276515007019, Accuracy: 70.21 Test_loss: 0.02630699208676815, Test_accuracy: 70.99
Epoch [4], Loss: 0.024451716771125794, Accuracy: 72.41 Test_loss: 0.024404651895165445, Test_accuracy: 73.03
Epoch [5], Loss: 0.022718262011408807, Accuracy: 74.35 Test_loss: 0.023125074282288553, Test_accuracy: 74.86
Epoch [6], Loss: 0.021408387248516084, Accuracy: 75.76 Test_loss: 0.023151200053095816, Test_accuracy: 74.43
Epoch [7], Loss: 0.02033562403023243, Accuracy: 76.91 Test_loss: 0.023537022879719736, Test_accuracy: 73.93
Finished Training4.没有Dropout正则化的网络
在这里将构建相同的网络,但是没有dropout层。在相同的数据集和周期数上训练网络,并评估Dropout对网络性能的影响,使用相同的训练和测试函数。
步骤1:实现网络
class Net(nn.Module):def __init__(self, input_shape=(3,32,32)):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3)self.conv2 = nn.Conv2d(32, 64, 3)self.conv3 = nn.Conv2d(64, 128, 3)self.pool = nn.MaxPool2d(2,2)n_size = self._get_conv_output(input_shape)self.fc1 = nn.Linear(n_size, 512)self.fc2 = nn.Linear(512, 10)def _get_conv_output(self, shape):batch_size = 1input = torch.autograd.Variable(torch.rand(batch_size, *shape))output_feat = self._forward_features(input)n_size = output_feat.data.view(batch_size, -1).size(1)return n_sizedef _forward_features(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = self.pool(F.relu(self.conv3(x)))return xdef forward(self, x):x = self._forward_features(x)x = x.view(x.size(0), -1)x = F.relu(self.fc1(x))x = self.fc2(x)return x
步骤2:损失和优化器
net = Net().to(device)
print(net)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
输出:
Net((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc1): Linear(in_features=512, out_features=512, bias=True)(fc2): Linear(in_features=512, out_features=10, bias=True)
)
步骤3:开始训练
for epoch in range(8):train(net, device, trainloader, optimizer, criterion, epoch)test(net, device, testloader, criterion, CLASS_NAMES)print("Finished Training")
输出:
Epoch [0], Loss: 0.04425342482566833, Accuracy: 48.29 Test_loss: 0.03506121407747269, Test_accuracy: 59.93
Epoch [1], Loss: 0.0317487561249733, Accuracy: 63.97 Test_loss: 0.029791217082738877, Test_accuracy: 66.4
Epoch [2], Loss: 0.026000032302737237, Accuracy: 70.83 Test_loss: 0.027046055325865747, Test_accuracy: 69.97
Epoch [3], Loss: 0.022179243130385877, Accuracy: 75.11 Test_loss: 0.02481114484965801, Test_accuracy: 72.95
Epoch [4], Loss: 0.01933788091301918, Accuracy: 78.26 Test_loss: 0.024382170912623406, Test_accuracy: 73.55
Epoch [5], Loss: 0.016771901984512807, Accuracy: 81.04 Test_loss: 0.024696413831412793, Test_accuracy: 73.53
Epoch [6], Loss: 0.014588635778725148, Accuracy: 83.41 Test_loss: 0.025593858751654625, Test_accuracy: 73.94
Epoch [7], Loss: 0.01255791916936636, Accuracy: 85.94 Test_loss: 0.026889967443048952, Test_accuracy: 73.69
Finished Training相关文章:
使用Dropout大幅优化PyTorch模型,实现图像识别
大家好,在机器学习模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络时,过拟合具体表现在模型训练数据损失函数较小,预测准确率较高,但是在测…...

Vue3中的常见组件通信(超详细版)
Vue3中的常见组件通信 概述 在vue3中常见的组件通信有props、mitt、v-model、 r e f s 、 refs、 refs、parent、provide、inject、pinia、slot等。不同的组件关系用不同的传递方式。常见的撘配形式如下表所示。 组件关系传递方式父传子1. props2. v-model3. $refs4. 默认…...
Stm32的DMA的学习
一,介绍 二,DMA框图 三,DMA通道 四,相关HAL库函数 五,配置DMA 六,Stm32CubeMX配置 【13.1】减少CPU传输负载 DMA直接存储器访问—Kevin带你读《STM32Cube高效开发教程基础篇》_哔哩哔哩_bilibili...
)
应用安全(补充)
Nessus是目前全世界最多人使用的系统漏洞扫描与分析软件。NMAP是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。X-SCAN安全漏洞扫描工具AppScan是IBM的一款web安全扫描工具,可以利用爬虫技术进行网站安全渗透测试,根据网站入口自…...

鸿蒙开发Ability Kit(程序框架服务):【FA模型切换Stage模型指导】 app和deviceConfig的切换
app和deviceConfig的切换 为了便于开发者维护应用级别的属性配置,Stage模型将config.json中的app和deviceConfig标签提取到了app.json5中进行配置,并对部分标签名称进行了修改,具体差异见下表。 表1 配置文件app标签差异对比 配置项FA模型…...

通过命令行配置调整KVM的虚拟网络
正文共:1234 字 20 图,预估阅读时间:2 分钟 在上篇文章中(最小化安装的CentOS7部署KVM虚拟机),我们介绍了如何在最小化安装的CentOS 7系统中部署KVM组件和相关软件包。因为没有GUI图形界面,我们…...

Apache POI操作excel
第1部分:引言 1.1 Apache POI简介 Apache POI是一个开源的Java库,用于处理Microsoft Office文档。自2001年首次发布以来,它已经成为Java社区中处理Office文档事实上的标准。Apache POI支持HSSF(用于旧版本的Excel格式࿰…...

Python错误集锦:faker模块生成xml文件时提示:`xml` requires the `xmltodict` Python library
原文链接:http://www.juzicode.com/python-error-faker-exceptions-unsupportedfeature-xml-requires-the-xmltodict-python-library 错误提示: faker模块生成xml文件时提示: xml requires the xmltodict Python library Traceback (most r…...

Vue3-尚硅谷笔记
1. Vue3简介 2020年9月18日,Vue.js发布版3.0版本,代号:One Piece(n 经历了:4800次提交、40个RFC、600次PR、300贡献者 官方发版地址:Release v3.0.0 One Piece vuejs/core 截止2023年10月,最…...

RockChip Android12 System之MultipleUsers
一:概述 System中的MultipleUsers不同于其他Preference采用system_dashboard_fragment.xml文件进行加载,而是采用自身独立的xml文件user_settings.xml加载。 二:Multiple Users 1、Activity packages/apps/Settings/AndroidManifest.xml <activityandroid:name="S…...

第12天:前端集成与Django后端 - 用户认证与状态管理
第12天:前端集成与Django后端 - 用户认证与状态管理 目标 整合Django后端与Vue.js前端,实现用户认证和应用状态管理。 任务概览 设置Django后端用户认证。创建Vue.js前端应用。使用Vuex进行状态管理。实现前端与后端的用户认证流程。 详细步骤 1. …...

在ROS2中蓝牙崩溃的原因分析
在ROS2中,如果蓝牙模块没有成功启动,可能的原因有几个方面: 1. **硬件问题**:首先需要确认蓝牙硬件本身是否正常工作,包括检查蓝牙模块是否正确连接到系统,以及模块是否存在物理损坏。 2. **驱动问题**&a…...

【PythonWeb开发】Flask中间件钩子函数实现封IP
在 Flask 框架中, 提供了几种类型的钩子(类似于Django的中间件),它们是在请求的不同阶段自动调用的函数。这些钩子让你能够对请求和响应的处理流程进行扩展,而无需修改核心代码。 Flask钩子的四种类型 before_first_r…...

可以一键生成热点营销视频的工具,建议收藏
在当今的商业环境中,热点营销已经成为了一种非常重要的营销策略。那么,什么是热点营销呢?又怎么做热点营销视频呢? 最近高考成绩慢慢公布了,领导让结合“高考成绩公布”这个热点,做一个关于企业或产品的营销…...

Unity Meta Quest 开发:关闭 MR 应用的安全边界
社区链接: SpatialXR社区:完整课程、项目下载、项目孵化宣发、答疑、投融资、专属圈子 📕教程说明 这期教程我将介绍如何在应用中关闭 Quest 系统的安全边界。 视频讲解: https://www.bilibili.com/video/BV1Gm42157Zi …...
)
4.sql注入攻击(OWASP实战训练)
4.sql注入攻击(OWASP实战训练) 引言1,实验环境owasp,kali Linux。2,sql注入危害3,sql基础回顾4,登录owasp5,查询实例(1)简单查询实例(2࿰…...

前端Web开发HTML5+CSS3+移动web视频教程 Day1
链接 HTML 介绍 写代码的位置:VSCode 看效果的位置:谷歌浏览器 安装插件 open in browser: 接下来要保证每次用 open in browser 打开的是谷歌浏览器。只需要将谷歌浏览器变为默认的浏览器就可以了。 首先进入控制面板,找到默…...

中医实训室:在传统针灸教学中的应用与创新
中医实训室是中医教育体系中的重要组成部分,尤其在传统针灸教学中,它扮演着无可替代的角色。这里是理论与实践的交汇点,是传统技艺与现代教育理念的碰撞之地。本文将探讨中医实训室在传统针灸教学中的应用与创新实践。 首先,实训室…...
_useReducer)
React Hooks 小记(七)_useReducer
useReducer usereducer 相当于 复杂的 useState 当状态更新逻辑较复杂时可以考虑使用 useReducer。useReducer 可以同时更新多个状态,而且能把对状态的修改从组件中独立出来。 相比于 useState,useReducer 可以更好的描述“如何更新状态”。例如&#…...

甲子光年专访天润融通CEO吴强:客户经营如何穿越低速周期?
作者|陈杨、编辑|栗子 社会的发展从来都是从交流和联络开始的。 从结绳记事到飞马传信,从电话电报到互联网,人类的联络方式一直都在随着时代的发展不断进步。只是传统社会通信受限于技术导致效率低下,对经济社会产生影…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...
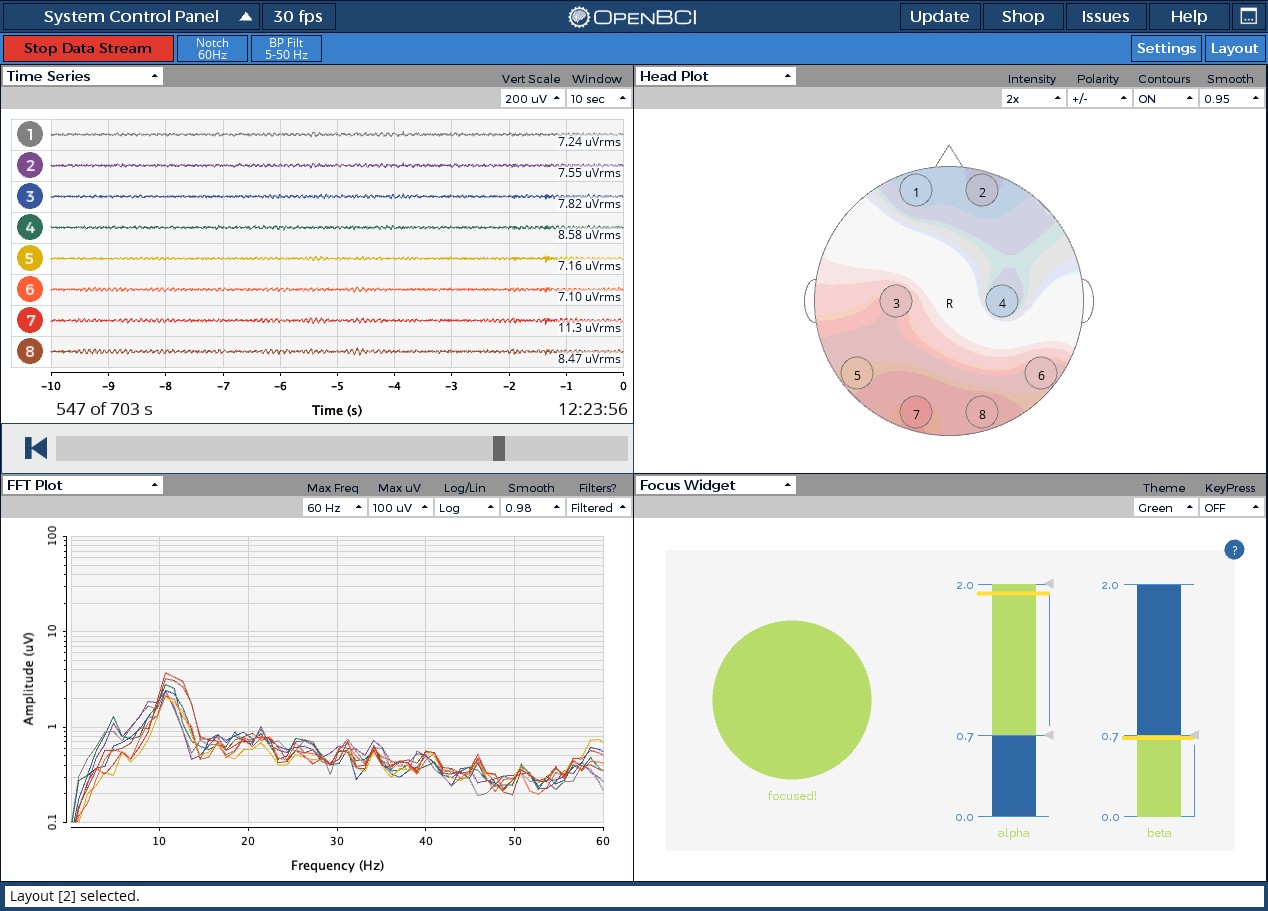
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...