Python 高级实战:基于自然语言处理的情感分析系统
前言
在大数据和人工智能迅猛发展的今天,自然语言处理(NLP)作为人工智能的重要分支,已经深入到我们的日常生活和工作中。情感分析作为NLP中的一个重要应用,广泛应用于市场分析、舆情监控和客户反馈等领域。本文将讲述一个基于Python实现的情感分析系统,旨在帮助大家进一步提升在NLP领域的技能。
一:工具准备
“工欲善其事,必先利其器。”在开始我们的实战之前,首先需要准备好必备的工具。我们将使用的主要工具有Python编程语言及其相关库。
1.1 Python安装与环境配置
首先,确保你已经安装了Python。如果尚未安装,可以从Python官网下载并安装最新版本。在终端中运行以下命令确认安装成功:
python --version
1.2 安装必要的库
我们将使用一些常用的库来实现情感分析的功能,主要包括nltk、sklearn、pandas和matplotlib。可以通过以下命令安装这些库:
pip install nltk scikit-learn pandas matplotlib
以下是每个库的作用:
| 库 | 作用 |
|---|---|
| nltk | 提供丰富的自然语言处理工具和数据集,用于文本处理、分词、词性标注、情感分析等任务。 |
| sklearn | 提供一系列机器学习算法和工具,用于数据预处理、特征提取、模型训练和评估。 |
| pandas | 提供高效的数据结构和数据分析工具,常用于数据清洗、处理和分析。 |
| matplotlib | 提供灵活和强大的绘图工具,用于生成各种图表和可视化数据。 |
1.3 下载NLTK数据
NLTK库提供了丰富的自然语言处理工具和数据集。在使用前,我们需要下载一些必要的数据集:
import nltk
nltk.download('punkt')
nltk.download('vader_lexicon')
NLTK库中的punkt和vader_lexicon的作用:
| 库/工具 | 作用 |
|---|---|
| NLTK库 | 提供丰富的自然语言处理工具和数据集,适用于文本处理、分类、标注、解析、语义推理等任务 |
| punkt | 用于句子分割和单词分割,使用无监督学习方法识别句子边界和单词边界 |
| vader_lexicon | VADER情感词典,用于从文本中提取情感得分(正面、负面、中性)并计算综合情感得分 |
二:数据获取与预处理
“做工的人,常以苦力相期。”获取和清洗数据是情感分析中的重要步骤。我们将从网络上抓取用户评论数据,并对其进行预处理。
2.1 确定数据源
我们以IMDb电影评论为例,抓取其评论数据。目标网址为:IMDb Movie Reviews
2.2 编写数据抓取代码
以下是一个抓取IMDb电影评论的示例代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd# 获取单个页面的评论数据
def get_reviews(url):response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')reviews = soup.find_all('div', class_='text show-more__control')data = [review.get_text() for review in reviews]return data# 爬取多页的评论数据
def scrape_all_reviews(base_url, pages):all_reviews = []for i in range(pages):url = f"{base_url}&page={i+1}"reviews = get_reviews(url)all_reviews.extend(reviews)return all_reviews# 主程序
if __name__ == '__main__':base_url = 'https://www.imdb.com/title/tt0111161/reviews?ref_=tt_ql_3'pages = 5 # 爬取前5页的评论reviews = scrape_all_reviews(base_url, pages)# 保存数据到CSV文件df = pd.DataFrame(reviews, columns=['Review'])df.to_csv('imdb_reviews.csv', index=False)print("数据已保存到imdb_reviews.csv")
以上代码展示了如何利用requests获取网页内容,通过BeautifulSoup解析网页,并提取评论数据。最后,将数据保存到CSV文件中,以便后续分析使用。
三:情感分析模型构建
在获取了数据之后,我们需要构建一个情感分析模型,对评论进行情感分类。
3.1 数据读取与预处理
首先我们读取刚才保存的CSV文件,并对数据进行简单的预处理。
import pandas as pd
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import string# 读取数据
df = pd.read_csv('imdb_reviews.csv')# 数据清洗与预处理
def preprocess_text(text):tokens = word_tokenize(text.lower())tokens = [t for t in tokens if t.isalpha() and t not in stopwords.words('english')]return ' '.join(tokens)df['ProcessedReview'] = df['Review'].apply(preprocess_text)
print(df.head())
3.2 构建情感分析模型
我们将使用VADER情感分析器,这是一种基于规则的情感分析工具,适用于社交媒体文本。
from nltk.sentiment.vader import SentimentIntensityAnalyzer# 初始化VADER情感分析器
sid = SentimentIntensityAnalyzer()# 计算每条评论的情感得分
df['SentimentScore'] = df['ProcessedReview'].apply(lambda x: sid.polarity_scores(x)['compound'])# 根据情感得分分类
df['Sentiment'] = df['SentimentScore'].apply(lambda x: 'positive' if x > 0 else ('negative' if x < 0 else 'neutral'))
print(df.head())
3.3 模型评估
为了评估我们的情感分析模型,我们可以使用一些统计指标和可视化工具。这里代码的作用是统计情感分析结果中各情感类别的数量,并绘制情感分布图。
import matplotlib.pyplot as plt# 统计各情感类别的数量
sentiment_counts = df['Sentiment'].value_counts()# 绘制情感分布图
plt.figure(figsize=(8, 6))
plt.bar(sentiment_counts.index, sentiment_counts.values, color=['green', 'red', 'grey'])
plt.title('Sentiment Distribution')
plt.xlabel('Sentiment')
plt.ylabel('Count')
plt.show()
四:高级应用与优化
在实际应用中,我们还可以进一步优化和扩展情感分析模型,以满足不同的需求。
4.1 使用机器学习模型
除了基于规则的方法,我们还可以使用机器学习模型来进行情感分析。以下是一个使用sklearn库中LogisticRegression模型的示例。这里的代码展示了如何使用机器学习模型进行情感分析。它包含了特征提取、数据集划分、模型训练和评估的完整流程。:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report# 特征提取
vectorizer = TfidfVectorizer(max_features=5000)
X = vectorizer.fit_transform(df['ProcessedReview'])
y = df['Sentiment'].map({'positive': 1, 'negative': 0, 'neutral': 2})# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练逻辑回归模型
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)# 预测并评估模型
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['negative', 'neutral', 'positive']))
4.2 实时情感分析系统
我们还可以构建一个实时情感分析系统,利用Flask框架将其部署为Web服务。
from flask import Flask, request, jsonifyapp = Flask(__name__)# 预加载模型和向量化器
vectorizer = TfidfVectorizer(max_features=5000)
model = LogisticRegression(max_iter=1000)
# 假设我们已经训练并保存了模型和向量化器
# vectorizer.fit_transform(...)
# model.fit(...)@app.route('/predict', methods=['POST'])
def predict():data = request.get_json()review = data['review']processed_review = preprocess_text(review)X = vectorizer.transform([processed_review])prediction = model.predict(X)sentiment = 'positive' if prediction == 1 else ('negative' if prediction == 0 else 'neutral')return jsonify({'sentiment': sentiment})if __name__ == '__main__':app.run(debug=True)
五:总结
“世事洞明皆学问,人情练达即文章。”通过本次实战案例,我们从数据抓取入手,构建了一个基于Python的情感分析系统,并展示了如何使用VADER和机器学习模型进行情感分析。希望通过这篇文章,能够帮助高级开发者更好地理解和掌握NLP在情感分析中的应用。
在这个数据驱动的时代,情感分析作为NLP的重要应用,具有广泛的实际意义。希望大家在不断学习和实践中,能够在NLP领域开拓出属于自己的天地,推动技术的发展和应用。
附录:完整代码
以下是本文涉及的完整代码,方便读者参考与学习。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.sentiment.vader import SentimentIntensityAnalyzer
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from flask import Flask, request, jsonify# 下载必要的NLTK数据
nltk.download('punkt')
nltk.download('vader_lexicon')# 获取单个页面的评论数据
def get_reviews(url):response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')reviews = soup.find_all('div', class_='text show-more__control')data = [review.get_text() for review in reviews]return data# 爬取多页的评论数据
def scrape_all_reviews(base_url, pages):all_reviews = []for i in range(pages):url = f"{base_url}&page={i+1}"reviews = get_reviews(url)all_reviews.extend(reviews)return all_reviews# 数据预处理
def preprocess_text(text):tokens = word_tokenize(text.lower())tokens = [t for t in tokens if t.isalpha() and t not in stopwords.words('english')]return ' '.join(tokens)# 主程序:数据抓取与保存
if __name__ == '__main__':base_url = 'https://www.imdb.com/title/tt0111161/reviews?ref_=tt_ql_3'pages = 5 # 爬取前5页的评论reviews = scrape_all_reviews(base_url, pages)# 保存数据到CSV文件df = pd.DataFrame(reviews, columns=['Review'])df.to_csv('imdb_reviews.csv', index=False)print("数据已保存到imdb_reviews.csv")# 读取数据
df = pd.read_csv('imdb_reviews.csv')
df['ProcessedReview'] = df['Review'].apply(preprocess_text)# 初始化VADER情感分析器
sid = SentimentIntensityAnalyzer()# 计算每条评论的情感得分
df['SentimentScore'] = df['ProcessedReview'].apply(lambda x: sid.polarity_scores(x)['compound'])# 根据情感得分分类
df['Sentiment'] = df['SentimentScore'].apply(lambda x: 'positive' if x > 0 else ('negative' if x < 0 else 'neutral'))# 统计各情感类别的数量
sentiment_counts = df['Sentiment'].value_counts()# 绘制情感分布图
plt.figure(figsize=(8, 6))
plt.bar(sentiment_counts.index, sentiment_counts.values, color=['green', 'red', 'grey'])
plt.title('Sentiment Distribution')
plt.xlabel('Sentiment')
plt.ylabel('Count')
plt.show()# 使用机器学习模型进行情感分析
vectorizer = TfidfVectorizer(max_features=5000)
X = vectorizer.fit_transform(df['ProcessedReview'])
y = df['Sentiment'].map({'positive': 1, 'negative': 0, 'neutral': 2})# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练逻辑回归模型
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)# 预测并评估模型
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['negative', 'neutral', 'positive']))# 构建实时情感分析系统
app = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.get_json()review = data['review']processed_review = preprocess_text(review)X = vectorizer.transform([processed_review])prediction = model.predict(X)sentiment = 'positive' if prediction == 1 else ('negative' if prediction == 0 else 'neutral')return jsonify({'sentiment': sentiment})if __name__ == '__main__':app.run(debug=True)
相关文章:

Python 高级实战:基于自然语言处理的情感分析系统
前言 在大数据和人工智能迅猛发展的今天,自然语言处理(NLP)作为人工智能的重要分支,已经深入到我们的日常生活和工作中。情感分析作为NLP中的一个重要应用,广泛应用于市场分析、舆情监控和客户反馈等领域。本文将讲述…...

ruby面试题
ruby 基础 1、each、map、collect的区别 each: 仅遍历数组,并做相应操作,数组本身不发生改变。 map:遍历数组,并做相应操作后,返回新数组(处理),原数组不变。 collect: 跟map作用一样。 collect! map!: 多了一个作…...

Android U Settings 应用中 APN 菜单实现的代码逻辑
功能简介 MobileNetwork移动网络设置页面下有【接入点设置】(APN)。 问题:为什么Controller初始化找不到pref,然后报错。 Note:什么时候切换成Controller的呢?在Android T&U 上还没有更新成kt实现 ,但是已经有Controller的方案。 流程逻辑 1、界面“telephony_a…...

java时间处理工具类
效果 最近7天:2024年6月21日-2024年6月27日过去一周、最近一周:2024年6月16日-2024年6月22日过去三个月:2024年3月-2024年6月近半年、过去半年:2023年12月-2024年6月去年:2023年1月-2023年12月过去3年:202…...
Android高级面试_2_IPC相关
Android 高级面试-3:语言相关 1、Java 相关 1.1 缓存相关 问题:LruCache 的原理? 问题:DiskLruCache 的原理? LruCache 用来实现基于内存的缓存,LRU 就是最近最少使用的意思,LruCache 基于L…...

docker封禁对外端口映射
docker比linux防火墙规则优先级要高,一旦在docker里面配置了对外服务端口的话在iptable里面封不掉,需要通过下面的方法进行封禁: 这里我的宿主机IP地址是10.5.1.244,docker 内部网络ip段是默认的172.17段的,以下为命令࿱…...
)
【leetcode系列】567.字符串的排列(滑动窗口)
题目 给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。如果是,返回 true ;否则,返回 false 。 换句话说,s1 的排列之一是 s2 的 子串 。 示例 示例 1: 输入:s1 “ab” s2…...

情感分析方法与实践
第1关:情感分析的基本方法 情感分析简介 情感分析,又称意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。在日常生活中,情感分析的应用非常普遍,下面列举几种常见的…...

迁移学习——CycleGAN
CycleGAN 1.导入需要的包2.数据加载(1)to_img 函数(2)数据加载(3)图像转换 3.随机读取图像进行预处理(1)函数参数(2)数据路径(3)读取文…...

【软件测试】对于测试中的bug,我们真正了解了吗?
目录 1.软件测试的生命周期 1.1.软件测试阶段流程 1.2.各流程的任务 2.什么是bug 2.1.bug的概念 2.2.怎么描述bug 2.3.bug的级别 2.4.bug的生命周期 1.软件测试的生命周期 在学习bug前,我们先来学习一下软件测试的生命周期,也就是测试人员进行测…...

Packer-Fuzzer一款好用的前端高效安全扫描工具
★★免责声明★★ 文章中涉及的程序(方法)可能带有攻击性,仅供安全研究与学习之用,读者将信息做其他用途,由Ta承担全部法律及连带责任,文章作者不承担任何法律及连带责任。 1、Packer Fuzzer介绍 Packer Fuzzer是一款针对Webpack…...

解决卸载TabX explorer软件后导致系统文件资源管理器无法正常使用问题
最近安装了最新版本的鲁大师,安装过程中不小心同时安装了捆绑软件TabX explorer。这个软件和系统自带的文件资源管理器很像,最后弹出会员到期才发现,这个不是系统文件资源管理器,是第三方的文件资源管理器,就按正常流程…...

qt for android 使用打包sqlite数据库文件方法
1.在使用sqlite数据库时,先将数据库文件打包,放置在assets中如下图: 将文件放置下android中的assets下的所有文件都会打包在APK中,可以用7zip查看apk文件 2.在qt代码读取数据文件,注意在assets下的文件都是Read-Only,需…...

MYBATIS大于等于、小于等于的写法
mybatis使用的是xml格式的文件。使用>和<号的时候,会存在与xml的标签的规范冲突。需要写成如下形式,否则会报错。 第一种写法 原符号 替换符号 < < < <> > > >& & &…...

基于堆叠长短期记忆网络 Stacked LSTM 预测A股股票价格走势
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...
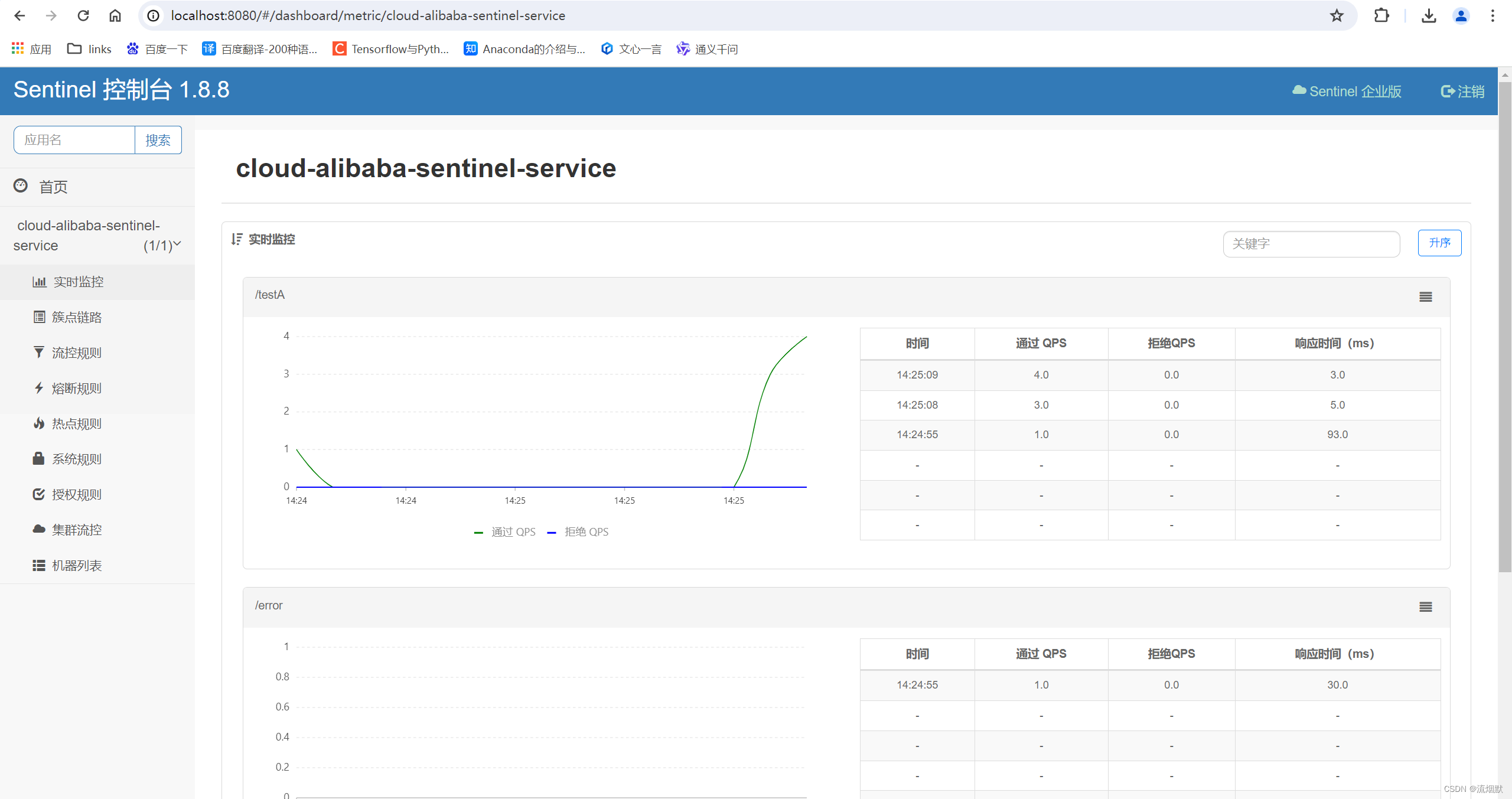
SpringCloud Alibaba Sentinel基础入门与安装
GitHub地址:https://github.com/alibaba/Sentinel 中文文档:https://sentinelguard.io/zh-cn/docs/introduction.html 下载地址:https://github.com/alibaba/Sentinel/releases Spring Cloud Alibaba 官方说明文档:Spring Clou…...
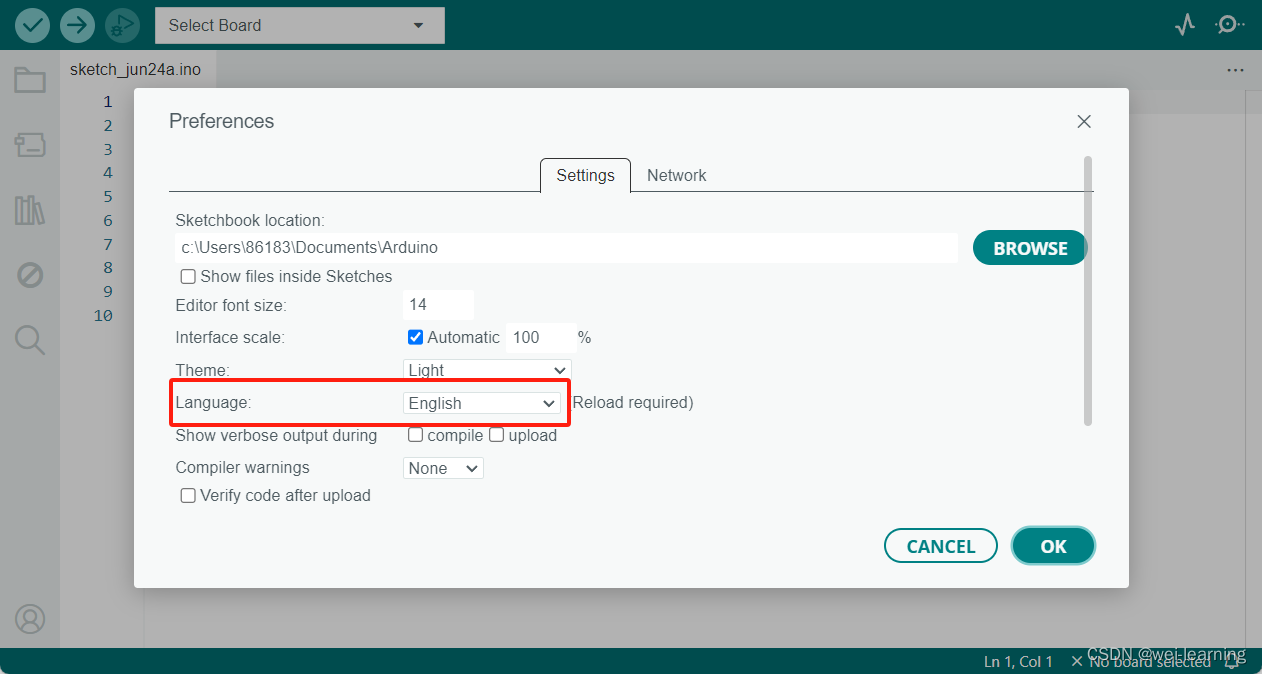
Arduino IDE下载、安装和配置
文章开始先把我自己网盘里的安装包分享给大家,链接:https://pan.baidu.com/s/1cb2_3m0LnuSKLnWP_YoWPw?pwdwwww 提取码:wwww 里面一个是Arduino IDE的安装包,另一个是即将发布的版本。 第一个安装包打开直接按照我的步骤安装就…...
SOBEL图像边缘检测器的设计
本项目使用FPGA设计出SOBEL图像边缘检测器,通过分析项目在使用过程中的工作原理和相关软硬件设计进行分析详细介绍SOBEL图像边缘检测器的设计。 资料获取可联系wechat 号:comprehensivable 边缘可定义为图像中灰度发生急剧变化的区域边界,它是图像最基本…...

Day35:2734. 执行字串操作后的字典序最小字符串
Leetcode 2734. 执行字串操作后的字典序最小字符串 给你一个仅由小写英文字母组成的字符串 s 。在一步操作中,你可以完成以下行为: 选择 s 的任一非空子字符串,可能是整个字符串,接着将字符串中的每一个字符替换为英文字母表中的前…...

【高考志愿】机械工程
目录 一、专业概述 二、学科特点 三、就业前景 四、机械工程学科排名 五、专业选择建议 高考志愿选择机械工程,这是一个需要深思熟虑的决定,因为它不仅关乎未来的学习和职业发展,更是对自我兴趣和潜能的一次重要考量。 一、专业概述 机…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...
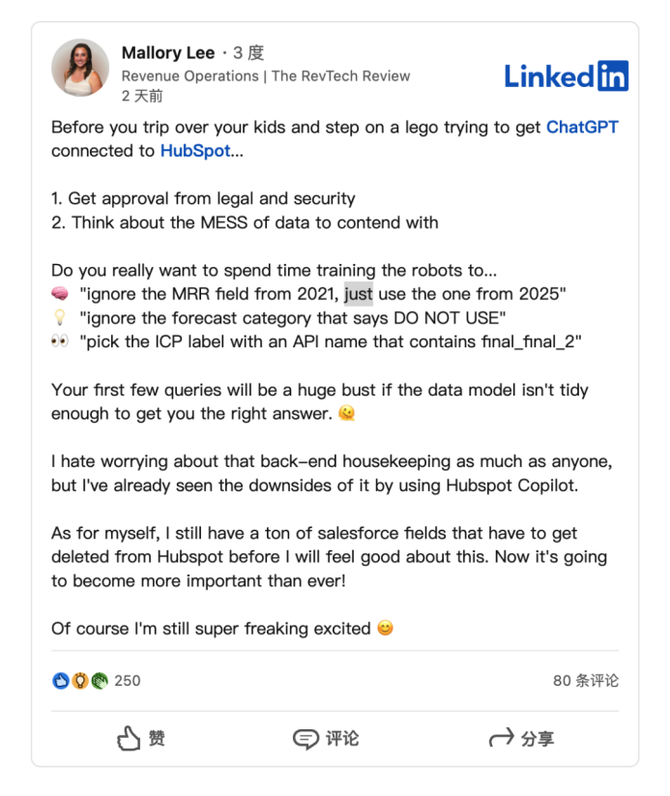
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...