深度学习 - Transformer 组成详解
整体结构
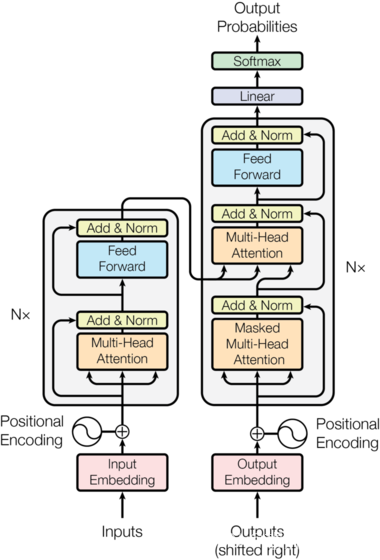
1. 嵌入层(Embedding Layer)
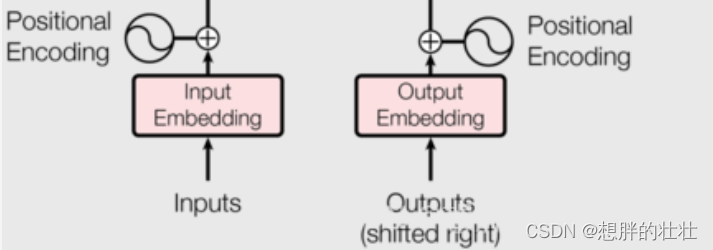
生活中的例子:字典查找
想象你在读一本书,你不认识某个单词,于是你查阅字典。字典为每个单词提供了一个解释,帮助你理解这个单词的意思。嵌入层就像这个字典,它将每个单词(或输入序列中的每个标记)映射到一个高维向量(解释),这个向量包含了单词的各种语义信息。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import mathclass EmbeddingLayer(nn.Module):def __init__(self, vocab_size, d_model, max_seq_length=512):super(EmbeddingLayer, self).__init__()# vocab_size: 词汇表的大小,即输入序列中可能的不同标记的总数。# d_model: 每个嵌入向量的维度,即词嵌入向量的长度。# max_seq_length: 序列的最大长度,用于位置嵌入。self.embedding = nn.Embedding(vocab_size, d_model) # 词嵌入层self.pos_embedding = nn.Embedding(max_seq_length, d_model) # 位置嵌入层self.d_model = d_model# 初始化位置编码pe = torch.zeros(max_len, d_model)# 生成词位置列表position = torch.arange(0, max_len).unsqueeze(1)# 根据公式计算词位置参数div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))# 生成词位置矩阵my_matmulres = position * div_term# 给位置编码矩阵奇数列,赋值sin曲线特征pe[:, 0::2] = torch.sin(my_matmulres)# 给位置编码矩阵偶数列,赋值cos曲线特征pe[:, 1::2] = torch.cos(my_matmulres)# 形状变化 [max_seq_length,d_model]-->[1,max_seq_length,d_model]pe = pe.unsqueeze(0)# 把pe位置编码矩阵 注册成模型的持久缓冲区buffer; 模型保存再加载时,可以根模型参数一样,一同被加载# 什么是buffer: 对模型效果有帮助的,但是却不是模型结构中超参数或者参数,不参与模型训练self.register_buffer('pe', pe)def forward(self, x):seq_length = x.size(1) # 序列长度pos = torch.arange(0, seq_length, device=x.device).unsqueeze(0) # 生成位置索引return self.embedding(x) * math.sqrt(self.d_model) + self.pe[:,:x.size()[-1], :] # 词嵌入和位置嵌入相加
2. 多头自注意力机制(Multi-Head Self-Attention)

生活中的例子:小组讨论
想象你在一个小组讨论中,每个人(每个位置上的单词)都提出自己的观点(Query),并听取其他人的意见(Key和Value)。每个人对所有其他人的观点进行加权平均,以形成自己的新观点。多头注意力机制类似于多个小组同时进行讨论,每个小组从不同的角度(头)讨论问题,然后将所有讨论结果合并在一起。
class MultiHeadSelfAttention(nn.Module):def __init__(self, d_model, nhead):super(MultiHeadSelfAttention, self).__init__()# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。self.nhead = nheadself.d_model = d_model# 定义线性变换层self.q_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.out_linear = nn.Linear(d_model, d_model)self.scale = (d_model // nhead) ** 0.5 # 缩放因子def forward(self, x):batch_size = x.size(0) # 获取批大小# 线性变换并分成多头q = self.q_linear(x).view(batch_size, -1, self.nhead, self.d_model // self.nhead).transpose(1, 2)k = self.k_linear(x).view(batch_size, -1, self.nhead, self.d_model // self.nhead).transpose(1, 2)v = self.v_linear(x).view(batch_size, -1, self.nhead, self.d_model // self.nhead).transpose(1, 2)# 计算注意力得分scores = torch.matmul(q, k.transpose(-2, -1)) / self.scaleattn = torch.nn.functional.softmax(scores, dim=-1) # 计算注意力权重context = torch.matmul(attn, v).transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) # 加权求和out = self.out_linear(context) # 最后一层线性变换return out
3. 前馈神经网络(Feed-Forward Network)

生活中的例子:信息过滤和处理
想象你在整理会议纪要,需要对会议地录音进行归纳、总结和补充。前馈神经网络类似于这个过程,它对输入的信息进行进一步处理和转换,以提取重要特征。
class FeedForwardNetwork(nn.Module):def __init__(self, d_model, dim_feedforward, dropout=0.1):super(FeedForwardNetwork, self).__init__()# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# dim_feedforward: 前馈神经网络的隐藏层维度。# dropout: 在前馈神经网络中使用的dropout比率,用于正则化。self.linear1 = nn.Linear(d_model, dim_feedforward) # 第一个线性层self.dropout = nn.Dropout(dropout) # dropout层self.linear2 = nn.Linear(dim_feedforward, d_model) # 第二个线性层def forward(self, x):return self.linear2(self.dropout(torch.nn.functional.relu(self.linear1(x)))) # 激活函数ReLU和dropout
4. 层归一化(Layer Normalization)

生活中的例子:团队合作中的标准化
想象你在一个团队中工作,每个人都有不同的工作习惯和标准。为了更好地合作,团队决定采用统一的工作标准(如文档格式、命名规范等)。层归一化类似于这种标准化过程,它将输入归一化,使得每个特征的均值为0,标准差为1,以稳定和加速训练。
class LayerNorm(nn.Module):def __init__(self, d_model, eps=1e-6):super(LayerNorm, self).__init__()# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# eps: 用于数值稳定的小值,防止除以零。self.gamma = nn.Parameter(torch.ones(d_model)) # 缩放参数self.beta = nn.Parameter(torch.zeros(d_model)) # 偏移参数self.eps = eps # epsilon,用于数值稳定def forward(self, x):mean = x.mean(dim=-1, keepdim=True) # 计算均值std = x.std(dim=-1, keepdim=True) # 计算标准差return self.gamma * (x - mean) / (std + self.eps) + self.beta # 归一化
5. 残差连接(Residual Connection)
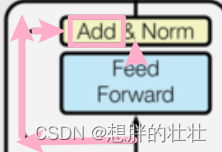
生活中的例子:备忘录
想象你在会议上记了很多笔记。为了确保不会遗漏任何重要信息,你在总结时会参照这些笔记。残差连接类似于这个过程,它将每层的输入直接加到输出上,确保信息不会在层与层之间丢失。
class ResidualConnection(nn.Module):def __init__(self, d_model, dropout=0.1):super(ResidualConnection, self).__init__()# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# dropout: 在残差连接中使用的dropout比率,用于正则化。self.norm = LayerNorm(d_model) # 层归一化self.dropout = nn.Dropout(dropout) # dropout层def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x))) # 残差连接
6. 编码器层(Encoder Layer)
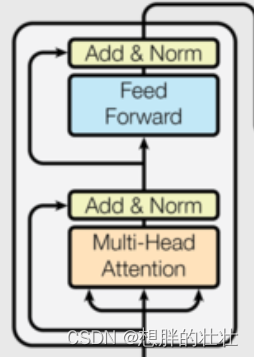
生活中的例子:多轮面试
想象你在参加多轮面试,每轮面试都有不同的考官,考察不同的方面(如专业知识、沟通能力等)。每轮面试都帮助你更全面地展示自己。编码器层类似于这种多轮面试的过程,每层处理输入序列的不同方面,逐层提取和增强特征。
class EncoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1):super(EncoderLayer, self).__init__()# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。# dim_feedforward: 前馈神经网络的隐藏层维度。# dropout: 在各层中使用的dropout比率,用于正则化。self.self_attn = MultiHeadSelfAttention(d_model, nhead) # 多头自注意力机制self.feed_forward = FeedForwardNetwork(d_model, dim_feedforward, dropout) # 前馈神经网络self.sublayers = nn.ModuleList([ResidualConnection(d_model, dropout) for _ in range(2)]) # 两个子层(注意力和前馈网络)def forward(self, src):src = self.sublayers[0](src, lambda x: self.self_attn(x)) # 应用自注意力机制src = self.sublayers[1](src, self.feed_forward) # 应用前馈神经网络return src
7. 解码器层(Decoder Layer)
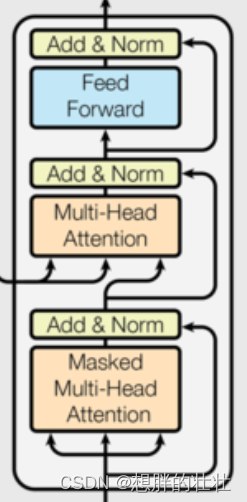
生活中的例子:逐步解谜
想象你在玩一个解谜游戏,每解决一个谜题(每层解码器),你都会得到新的线索,逐步解开整个谜题。解码器层类似于这种逐步解谜的过程,每层结合当前解码的结果和编码器的输出,逐步生成目标序列。
class DecoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1):super(DecoderLayer, self).__init__()# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。# dim_feedforward: 前馈神经网络的隐藏层维度。# dropout: 在各层中使用的dropout比率,用于正则化。self.self_attn = MultiHeadSelfAttention(d_model, nhead) # 多头自注意力机制self.cross_attn = MultiHeadSelfAttention(d_model, nhead) # 编码器-解码器注意力self.feed_forward = FeedForwardNetwork(d_model, dim_feedforward, dropout) # 前馈神经网络self.sublayers = nn.ModuleList([ResidualConnection(d_model, dropout) for _ in range(3)]) # 三个子层(自注意力、交叉注意力、前馈网络)def forward(self, tgt, memory):tgt = self.sublayers[0](tgt, lambda x: self.self_attn(x)) # 应用自注意力机制tgt = self.sublayers[1](tgt, lambda x: self.cross_attn(x, memory)) # 应用编码器-解码器注意力tgt = self.sublayers[2](tgt, self.feed_forward) # 应用前馈神经网络return tgt
8. 编码器(Encoder)
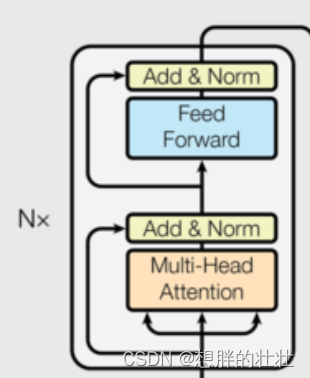
class Encoder(nn.Module):def __init__(self, num_layers, d_model, nhead, dim_feedforward, dropout=0.1):super(Encoder, self).__init__()# num_layers: 编码器层的数量,即堆叠的编码器层数。# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。# dim_feedforward: 前馈神经网络的隐藏层维度。# dropout: 在各层中使用的dropout比率,用于正则化。self.layers = nn.ModuleList([EncoderLayer(d_model, nhead, dim_feedforward, dropout) for _ in range(num_layers)]) # 堆叠多个编码器层def forward(self, src):for layer in self.layers:src = layer(src) # 依次通过每个编码器层return src
9. 解码器(Decoder)
class Decoder(nn.Module):def __init__(self, num_layers, d_model, nhead, dim_feedforward, dropout=0.1):super(Decoder, self).__init__()# num_layers: 解码器层的数量,即堆叠的解码器层数。# d_model: 输入和输出的维度,即每个位置的特征向量的长度。# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。# dim_feedforward: 前馈神经网络的隐藏层维度。# dropout: 在各层中使用的dropout比率,用于正则化。self.layers = nn.ModuleList([DecoderLayer(d_model, nhead, dim_feedforward, dropout) for _ in range(num_layers)]) # 堆叠多个解码器层def forward(self, tgt, memory):for layer in self.layers:tgt = layer(tgt, memory) # 依次通过每个解码器层return tgt
10. Transformer模型
class TransformerModel(nn.Module):def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout=0.1):super(TransformerModel, self).__init__()# vocab_size: 词汇表的大小,即输入序列中可能的不同标记的总数。# d_model: 每个嵌入向量的维度,即词嵌入向量的长度。# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。# num_encoder_layers: 编码器层的数量,即堆叠的编码器层数。# num_decoder_layers: 解码器层的数量,即堆叠的解码器层数。# dim_feedforward: 前馈神经网络的隐藏层维度。# dropout: 在各层中使用的dropout比率,用于正则化。self.embedding = EmbeddingLayer(vocab_size, d_model) # 嵌入层self.encoder = Encoder(num_encoder_layers, d_model, nhead, dim_feedforward, dropout) # 编码器self.decoder = Decoder(num_decoder_layers, d_model, nhead, dim_feedforward, dropout) # 解码器self.fc = nn.Linear(d_model, vocab_size) # 最后一层线性变换,将输出维度映射到词汇表大小def forward(self, src, tgt):src = self.embedding(src) # 嵌入输入序列tgt = self.embedding(tgt) # 嵌入目标序列memory = self.encoder(src) # 编码器处理输入序列output = self.decoder(tgt, memory) # 解码器处理目标序列output = self.fc(output) # 映射到词汇表大小return output
训练示例
# 参数
# vocab_size: 词汇表的大小,即输入序列中可能的不同标记的总数。
# d_model: 每个嵌入向量的维度,即词嵌入向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# num_encoder_layers: 编码器层的数量,即堆叠的编码器层数。
# num_decoder_layers: 解码器层的数量,即堆叠的解码器层数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
# batch_size: 每个训练批次中的样本数量。
# seq_length: 输入序列的长度。
# num_epochs: 训练的轮数,即遍历整个训练集的次数。
vocab_size = 1000
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
dropout = 0.1
batch_size = 32
seq_length = 10
num_epochs = 10# 数据集
src = torch.randint(0, vocab_size, (batch_size, seq_length))
tgt = torch.randint(0, vocab_size, (batch_size, seq_length))dataset = TensorDataset(src, tgt)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 模型实例
model = TransformerModel(vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练
for epoch in range(num_epochs):for src_batch, tgt_batch in dataloader:tgt_input = tgt_batch[:, :-1] # 目标输入tgt_output = tgt_batch[:, 1:] # 目标输出optimizer.zero_grad()output = model(src_batch, tgt_input) # 前向传播output = output.permute(1, 2, 0) # 调整形状以匹配损失函数loss = criterion(output, tgt_output) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")print("训练完成")
代码说明
- EmbeddingLayer:将输入序列和位置嵌入映射到高维空间。
- MultiHeadSelfAttention:实现多头自注意力机制,包括查询、键和值的线性变换和注意力计算。
- FeedForwardNetwork:前馈神经网络,用于进一步处理特征。
- LayerNorm:层归一化,用于稳定训练过程。
- ResidualConnection:残差连接,帮助训练更深的网络。
- EncoderLayer:将多头自注意力机制和前馈神经网络组合在一起,形成编码器层。
- DecoderLayer:包括多头自注意力机制、编码器-解码器注意力和前馈神经网络,形成解码器层。
- Encoder:由多个编码器层堆叠而成。
- Decoder:由多个解码器层堆叠而成。
- TransformerModel:将编码器和解码器组合在一起,形成完整的Transformer模型。
相关文章:
深度学习 - Transformer 组成详解
整体结构 1. 嵌入层(Embedding Layer) 生活中的例子:字典查找 想象你在读一本书,你不认识某个单词,于是你查阅字典。字典为每个单词提供了一个解释,帮助你理解这个单词的意思。嵌入层就像这个字典…...
ONLYOFFICE 8.1编辑器桌面应用程序来袭——在线全面测评
目录 ✈下载✈ 👀界面👀 👊功能👊 🧠幻灯片版式的重大改进🧠 ✂无缝切换文档编辑、审阅和查看模式✂ 🎵在演示文稿中播放视频和音频文件🎵 🤗版本 8.1:…...

《Windows API每日一练》6.4 程序测试
前面我们讨论了鼠标的一些基础知识,本节我们将通过一些实例来讲解鼠标消息的不同处理方式。 本节必须掌握的知识点: 第36练:鼠标击中测试1 第37练:鼠标击中测试2—增加键盘接口 第38练:鼠标击中测试3—子窗口 第39练&…...
[C#]基于opencvsharp实现15关键点人体姿态估计
数据集 正确选择数据集以对结果产生适当影响也是非常必要的。在此姿势检测中,模型在两个不同的数据集即COCO关键点数据集和MPII人类姿势数据集上进行了预训练。 1. COCO:COCO关键点数据集是一个多人2D姿势估计数据集,其中包含从Flickr收集的…...

lambda-map.merge
map.merge 结论: 1.当前传入的 key ,value biFunction 2.如果之前map不存在则直接put(当前key,当前value) 3.如果之前map已经有了,老value与 当前value 进入function处理后再 put(当前key,处理后的value)...

pppd 返回错误码 含义
错误码 00: pppd已经断开,或者已经成功建立连接后请求方又中 断了。 01: 发成了一个严重错误,例如系统调用失败或者访问非法内存。 02: 处理给定操作是检测到错误,例如使用两个互斥的操作。 03:…...

XML 技术
XML 技术 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它由万维网联盟(W3C)开发,并在1998年成为正式标准。XML的设计目标是既易于人类阅读,也易于机器解析。它是一种自描述的语言,允许用户定义自己的标签和文档结构。XML被广泛应用于各种领域,包括网络服…...
基于RabbitMQ的异步消息传递:发送与消费
引言 RabbitMQ是一个流行的开源消息代理,用于在分布式系统中实现异步消息传递。它基于Erlang语言编写,具有高可用性和可伸缩性。在本文中,我们将探讨如何在Python中使用RabbitMQ进行消息发送和消费。 安装RabbitMQ 在 Ubuntu 上安装 Rabbi…...

Golang | Leetcode Golang题解之第201题数字范围按位与
题目: 题解: func rangeBitwiseAnd(m int, n int) int {for m < n {n & (n - 1)}return n }...
)
竞争性谈判中,主要谈判什么内容?(电子化招采系统)
问:竞争性谈判中,主要谈判什么内容? 答:竞争性谈判是指采购人或代理机构通过与多家供应商(不少于3家)进行谈判,最后从中确定中标供应商的一种采购方式。在谈判的过程中,谈判的主要内…...

youlai-boot项目的学习(4) 前后端本地部署
环境 1、macOS, brew, IntelliJ IDEA, WebStrom 2、后端:https://gitee.com/youlaiorg/youlai-boot.git , master, 9a753a2e94985ed4cbbf214156ca035082e02723 3、前端:https://gitee.com/youlaiorg/vue3-element-admin.git, master, 66b913ef01dc880ad…...
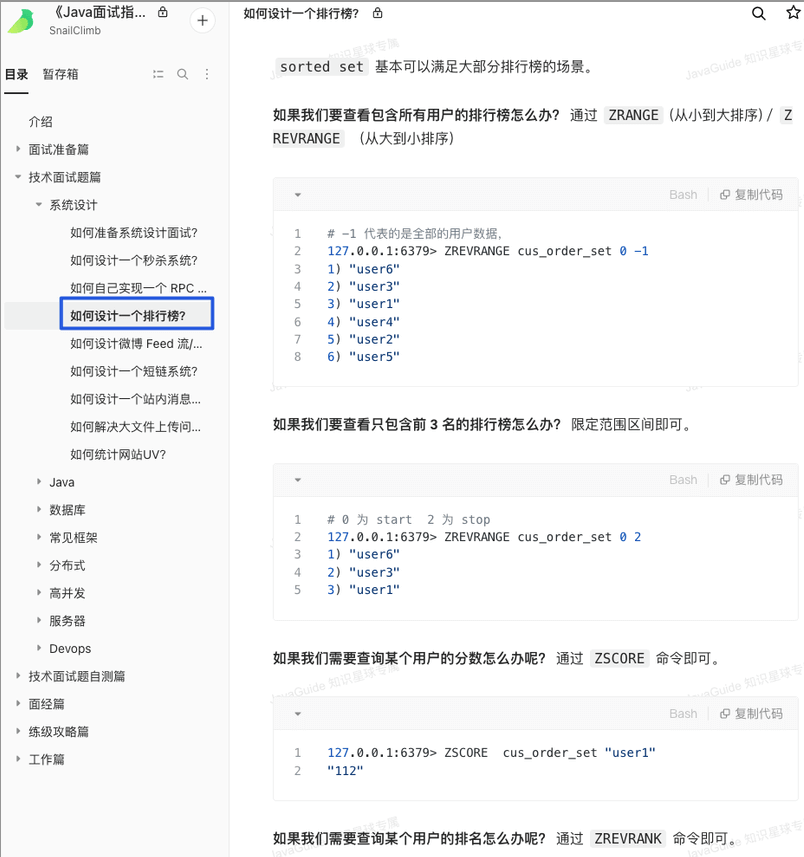
Redis 5 种基础数据结构?
Redis 5 种基本数据结构(String、List、Hash、Set、Sorted Set)在面试中经常会被问到,这篇文章我们一起来回顾温习一下。 还有几种比较特殊的数据结构(HyperLogLogs、Bitmap 、Geospatial、Stream)也非常重要,我们后面下次再聊! 下面是正文。…...

搜维尔科技:SenseGlove Nova2国内首款支持手掌心力回馈手套开售
《SenseGlove Nova 2》现正全球发行中! 搜维尔科技独家代理最新上市的 SenseGlove Nova 2 是世上首款,也是目前市面上唯一一款提供手掌力回馈的无缐VR力回馈手套,它结合了三种最先进的反馈技术,包括主动反馈、强力反馈及震动反馈,…...

Java中的函数式编程入门
Java中的函数式编程入门 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我来为大家介绍一下Java中的函数式编程。随着Java 8的发布,函数式编程成…...
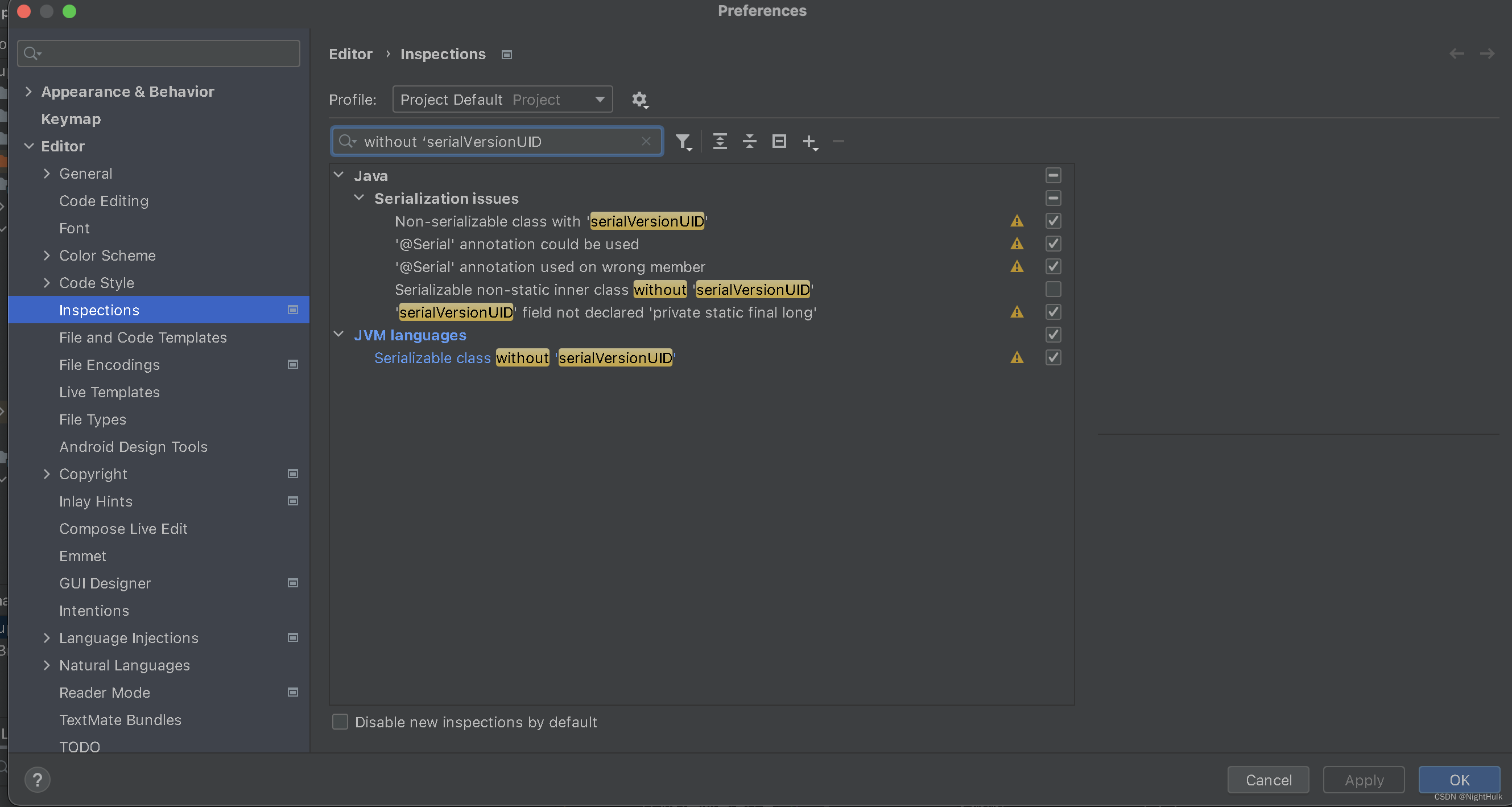
idea 自动生成序列化数字
目标:当类继承Serializable后自动生成序列化Uid 网上查了很多说勾选class without ‘serialVersionUID’ 但是我勾选没用 最后发现,我勾选的是Serialization issues里面的配置,要勾选的是JVM languages下的 如下图所示,记录一下…...
)
Java数据结构算法(最长递增序列二分查找)
前言: 最长递增子序列(Longest Increasing Subsequence, LIS)是指在一个给定的序列中,找到一个最长的子序列,使得这个子序列中的元素是单调递增的。子序列不要求在原序列中连续。 实现原理 使用一个 tails 列表,其中…...

编译VTK静态库
编译VTK静态库遇到问题 vtkCommonCore-9.3d.lib(vtkSMPToolsAPI.obj) : error LNK2019: unresolved external symbol "public: bool __cdecl vtk::detail::smp::vtkSMPToolsImpl<1>::IsParallelScope(void)" (?IsParallelScope?$vtkSMPToolsImpl$00smpdetai…...

Python中的@property装饰器:深入理解与应用
Python中的property装饰器:深入理解与应用 在Python中,property装饰器是一个强大的工具,它允许我们将方法作为属性来访问,使得代码更加简洁、清晰,并提供了更好的封装性。本文将深入探讨property装饰器的工作原理、应…...
)
springCloudalibabaAI孵化(一)
目录 1、what 1、简介 2、核心概念 3、高级特性 Prompt 和 AiResponse 4、功能 2、How 1、前言 2、在项目 pom.xml 中加入 2023.0.1.0 版本 Spring Cloud Alibaba 依赖: 3、在 配置文件中加入以下配置:application.yml 4、编写聊天服务实现类&a…...

【封装】Unity编辑器模式GUID加载资源
介绍 在编辑器模式下通过GUID获取工程目录下的指定资源的接口工具封装 工具原理 借助AssetDatabaseAPI FindAssets : 获取 GUID GUIDToAssetPath : 通过GUID获取路径LoadAssetAtPath<T>: 通过路径加载资源 代码: public static class GetAssetUtil {pub…...

设计系统文本化:用YAML/JSON统一管理设计令牌,实现多端一致与自动化
1. 项目概述:当设计系统遇上纯文本 最近在跟一个跨职能团队协作时,我们遇到了一个典型的老大难问题:设计师在Figma里更新了一个按钮的主色调,前端工程师在代码库里改了对应的CSS变量,但负责撰写产品文档和营销材料的同…...

14602开源|黄大年茶思屋第146期第二题:支持采集内容运动的静态3DGS重建
AI无偏差版脱敏题目标准化解题详解(第二题:支持采集内容运动的静态3DGS重建) 模块一:脱敏题目原文复刻 【脱敏题目原文】 支持采集内容运动的静态3DGS重建 基于3DGS及其扩展形式,支持动态建模和静态渲染,输…...

面壁智能开源端侧多模态大模型MiniCPM-V 4.6,性能登顶同尺寸榜首,降低开发门槛
【导语:5月13日,面壁智能联合清华大学与OpenBMB开源社区,发布并开源新一代端侧多模态大模型MiniCPM-V 4.6。该模型以轻量级参数实现性能与效率突破,在评测中超越竞品,还降低了运行内存需求和计算成本,支持多…...

基于MCP协议构建AI工具服务器:从原理到企业级实践
1. 项目概述:一个连接上下文与工具的智能服务器最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“聪明”地使用外部工具和数据。我发现,很多项目要么是把工具调用逻辑硬编码在提示词里,要么就是搞一套…...

基于PM波谱的二级海浪三维数值建模与可视化仿真
摘要:海浪的数值建模与三维可视化仿真在海洋工程、船舶设计及海上作业安全评估等领域具有重要的应用价值。针对二级海况(有义波高约 1.0 m、风速约7 m/s)条件下的不规则海浪模拟需求,本文提出了一种基于Pierson-Moskowitz…...

Xshell6启动报错0xc000007b:从DLL缺失到Visual C++库修复的完整排障指南
1. 当Xshell6突然罢工:0xc000007b报错初体验 那天早上我像往常一样双击Xshell6图标,准备连接服务器,结果突然弹出一个冰冷的错误窗口:"应用程序无法正常启动(0xc000007b)"。这种系统级错误代码对很多Windows用户来说就…...

深入GORM源码:手把手教你为自定义字段打造专属‘Clause钩子’
深入GORM源码:手把手教你为自定义字段打造专属‘Clause钩子’ 在当今快速迭代的业务场景中,数据库操作早已不再是简单的CRUD。当我们面对复杂的状态流转、多租户隔离或敏感数据加密时,往往需要在数据持久化层植入特定的业务逻辑。GORM作为Go生…...

AgentDock:构建可控AI智能体的开源框架与工程实践
1. 项目概述:构建可控的智能体应用框架如果你正在寻找一个既能利用大语言模型(LLM)的创造力,又能确保关键业务流程稳定可靠的开发框架,那么 AgentDock 的出现可能正合你意。我最近深度体验了这个开源项目,它…...

TIA Portal 多版本下载与安装全攻略
1. TIA Portal版本选择与下载准备 第一次接触西门子TIA Portal的工程师,面对从V15.1到V18多个版本时,往往会陷入选择困难。我刚开始用TIA Portal时也踩过不少坑,后来发现版本选择主要取决于两个因素:项目需求和硬件兼容性。如果是…...
)
AI全领域热点速递(2026年5月11日)
💌 关心家人,从每日报平安开始。万年历提醒微信小程序,您值得体验。📰 每日整理AI领域核心动态,精选有价值资讯,精简可读,适合收藏备查。🤖 AI全领域热点速递(2026年5月1…...