完美解决ValueError: column index (256) not an int in range(256)的正确解决方法,亲测有效!!!
完美解决ValueError: column index (256) not an int in range(256)的正确解决方法,亲测有效!!!

亲测有效
- 完美解决ValueError: column index (256) not an int in range(256)的正确解决方法,亲测有效!!!
- 报错问题
- 解决思路
- 解决方法
- 1. 检查数据框的列数量
- 2. 验证列索引范围
- 3. 检查数据格式和内容
- 4. 修复数据读取过程
- 示例代码
- 常见场景分析
- 解决思路与总结
报错问题
在处理数据或使用Pandas等数据处理库时,可能会遇到以下报错信息:
ValueError: column index (256) not an int in range(256)
这个错误通常表明你试图访问一个超出有效范围的列索引,或者传递了一个不在允许范围内的列索引。常见的情况包括:
- 列索引超出范围:访问的列索引超出了数据框中实际存在的列范围。
- 数据格式错误:数据格式不正确,导致列索引计算错误。
- 数据读取错误:在读取数据时出现错误,导致列索引不正确。
解决思路
解决这个错误的关键在于确保访问的列索引在有效范围内。以下是一些解决思路:
- 检查数据框的列数量:确认数据框的实际列数量。
- 验证列索引范围:确保访问的列索引在数据框的列范围内。
- 检查数据格式和内容:验证数据格式是否正确,确保没有数据损坏或读取错误。
- 修复数据读取过程:确保数据读取过程正确,避免读取错误导致的列索引问题。
下滑查看解决方法
解决方法
1. 检查数据框的列数量
确认数据框的实际列数量,确保访问的列索引在范围内。
错误示例:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
print(df.iloc[:, 256]) # 错误:访问的列索引超出范围
解决方法:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)# 检查数据框的列数量
print("Number of columns:", df.shape[1])# 正确访问范围内的列
if df.shape[1] > 1:print(df.iloc[:, 1])
else:print("Column index out of range")
2. 验证列索引范围
确保访问的列索引在数据框的列范围内,避免超出有效范围。
错误示例:
import pandas as pddf = pd.read_csv('data.csv')
print(df.iloc[:, 256]) # 错误:访问的列索引超出范围
解决方法:
import pandas as pddf = pd.read_csv('data.csv')# 验证列索引范围
if df.shape[1] > 255:print(df.iloc[:, 255])
else:print("Column index out of range")
3. 检查数据格式和内容
验证数据格式是否正确,确保没有数据损坏或读取错误。
错误示例:
import pandas as pddata = '1,2,3\n4,5,6\n7,8,9'
df = pd.read_csv(data)
print(df.iloc[:, 256]) # 错误:数据格式错误导致的列索引问题
解决方法:
import pandas as pd
from io import StringIOdata = 'A,B,C\n1,2,3\n4,5,6\n7,8,9'
df = pd.read_csv(StringIO(data))# 检查数据格式和内容
print(df)# 正确访问范围内的列
if df.shape[1] > 2:print(df.iloc[:, 2])
else:print("Column index out of range")
4. 修复数据读取过程
确保数据读取过程正确,避免读取错误导致的列索引问题。
错误示例:
import pandas as pddf = pd.read_csv('data_with_errors.csv')
print(df.iloc[:, 256]) # 错误:数据读取错误导致的列索引问题
解决方法:
import pandas as pdtry:df = pd.read_csv('data_with_errors.csv')
except pd.errors.ParserError:print("Error parsing CSV file")# 修复数据读取过程
if 'df' in locals() and df.shape[1] > 255:print(df.iloc[:, 255])
else:print("Column index out of range or data read error")
示例代码
以下是一个完整的示例,演示如何避免ValueError: column index (256) not an int in range(256)错误:
import pandas as pd
from io import StringIO# 模拟读取数据
data = 'A,B,C\n1,2,3\n4,5,6\n7,8,9'
df = pd.read_csv(StringIO(data))# 检查数据框的列数量
print("Number of columns:", df.shape[1])# 验证列索引范围
if df.shape[1] > 2:print(df.iloc[:, 2])
else:print("Column index out of range")# 修复数据读取过程
try:df = pd.read_csv(StringIO(data))if df.shape[1] > 255:print(df.iloc[:, 255])else:print("Column index out of range")
except pd.errors.ParserError:print("Error parsing CSV file")
常见场景分析
-
列索引超出范围
错误示例:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data) print(df.iloc[:, 256]) # 错误:访问的列索引超出范围解决方法:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data)# 检查数据框的列数量 print("Number of columns:", df.shape[1])# 正确访问范围内的列 if df.shape[1] > 1:print(df.iloc[:, 1]) else:print("Column index out of range") -
数据格式错误
错误示例:
import pandas as pddata = '1,2,3\n4,5,6\n7,8,9' df = pd.read_csv(data) print(df.iloc[:, 256]) # 错误:数据格式错误导致的列索引问题解决方法:
import pandas as pd from io import StringIOdata = 'A,B,C\n1,2,3\n4,5,6\n7,8,9' df = pd.read_csv(StringIO(data))# 检查数据格式和内容 print(df)# 正确访问范围内的列 if df.shape[1] > 2:print(df.iloc[:, 2]) else:print("Column index out of range") -
数据读取错误
错误示例:
import pandas as pddf = pd.read_csv('data_with_errors.csv') print(df.iloc[:, 256]) # 错误:数据读取错误导致的列索引问题解决方法:
import pandas as pdtry:df = pd.read_csv('data_with_errors.csv') except pd.errors.ParserError:print("Error parsing CSV file")# 修复数据读取过程 if 'df' in locals() and df.shape[1] > 255:print(df.iloc[:, 255]) else:print("Column index out of range or data read error")
解决思路与总结
- 检查数据框的列数量:确认数据框的实际列数量。
- 验证列索引范围:确保访问的列索引在数据框的列范围内。
- 检查数据格式和内容:验证数据格式是否正确,确保没有数据损坏或读取错误。
- 修复数据读取过程:确保数据读取过程正确,避免读取错误导致的列索引问题。
通过以上步骤,可以有效解决ValueError: column index (256) not an int in range(256)相关的错误,确保代码能够正常运行。如果问题依旧存在,请进一步检查代码逻辑,确保在所有需要正确参数的地方都使用了正确的参数。
以上内容仅供参考,具体问题具体分析,如果对你没有帮助,深感抱歉。
相关文章:
完美解决ValueError: column index (256) not an int in range(256)的正确解决方法,亲测有效!!!
完美解决ValueError: column index (256) not an int in range(256)的正确解决方法,亲测有效!!! 亲测有效 完美解决ValueError: column index (256) not an int in range(256)的正确解决方法,亲测有效!&…...
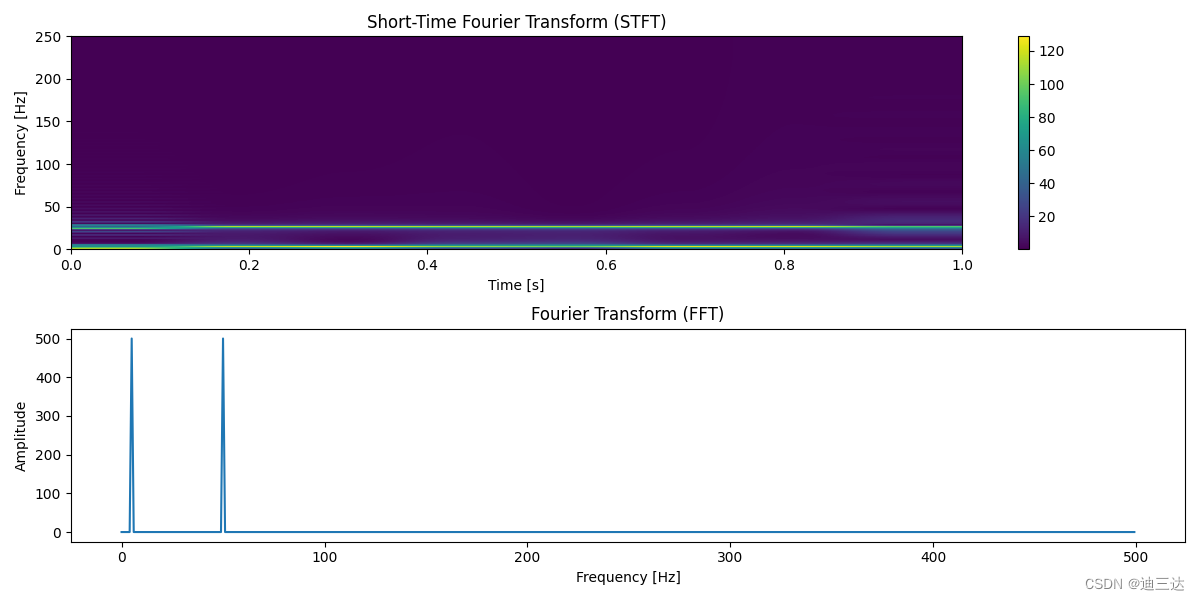
# 音频处理4_傅里叶变换
1.离散傅里叶变换 对于离散时域信号 x[n]使用离散傅里叶变换(Discrete Fourier Transform, DFT)进行频域分析。 DFT 将离散信号 x[n] 变换为其频谱表示 X[k],定义如下: X [ k ] ∑ n 0 N − 1 x [ n ] e − j 2 π k n N X[k]…...

提升网络速度的几种有效方法
在数字化时代,网络速度对于我们的日常生活和工作至关重要。无论是观看高清视频、在线游戏,还是进行视频会议,快速稳定的网络连接都是不可或缺的。如果你发现自己当前的网络速度不尽如人意,那么不妨尝试以下几种方法来提升它。 升…...
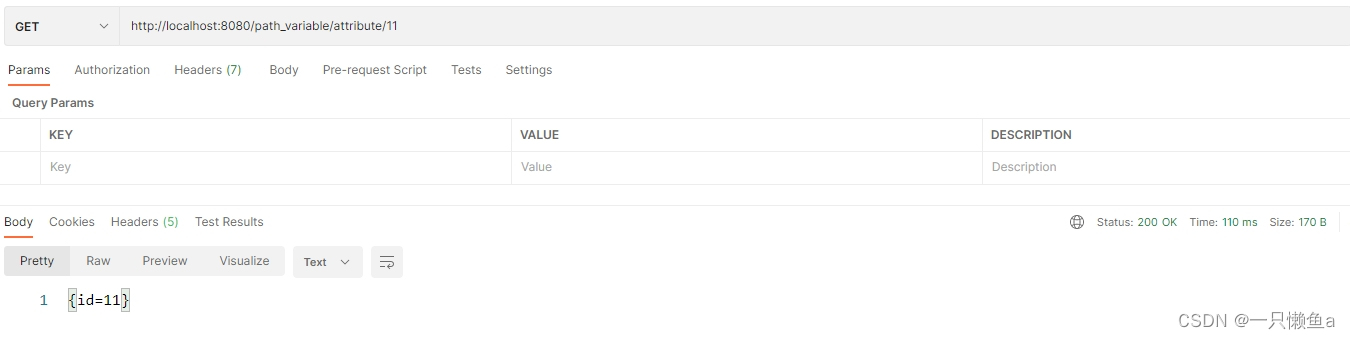
@PathVariable注解的使用及源码解析
前言 PathVariable 注解是我们进行JavaEE开发,最常见的几个注解之一,这篇博文我们以案例和源码相结合,帮助大家更好的了解PathVariable 注解 使用案例 1.获取 URL 上的值 RequestMapping("/id/{id}") public Object getId(Path…...

服务器配置重点看哪些参数
对服务器有需求时,应重点考虑以下几个关键参数,以下仅供参考: 处理器(CPU):包括CPU的品牌(如Intel或AMD)、型号、核心数、线程数、主频和缓存大小。核心数越多,处理并发请…...

WSL Ubuntu 如何设置中文语言?
本章教程,主要介绍如何在WSL Ubuntu 如何设置中文语言。 操作系统:Windows 10 Pro 64 WSL子系统:Ubuntu 20.04 LTS 一、安装中文语言包 sudo apt install language-pack-zh-hans二、设置中文语言 sudo dpkg-reconfigure locales选择en_US.UTF-8 和 zh_CN.UTF-8 选择zh_CN.…...

「51媒体」政企活动媒体宣发如何做?
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 媒体宣传加速季,100万补贴享不停,一手媒体资源,全国100城线下落地执行。详情请联系胡老师。 政企活动媒体宣发是一个系统性的过程,需要明确…...

K近邻回归原理详解及Python代码示例
K近邻回归原理详解 K近邻回归(K-Nearest Neighbors Regression, KNN)是一种基于实例的学习算法,用于解决回归问题。它通过找到输入数据点在特征空间中最相似的K个邻居(即最近的K个数据点),并使用这些邻居的…...
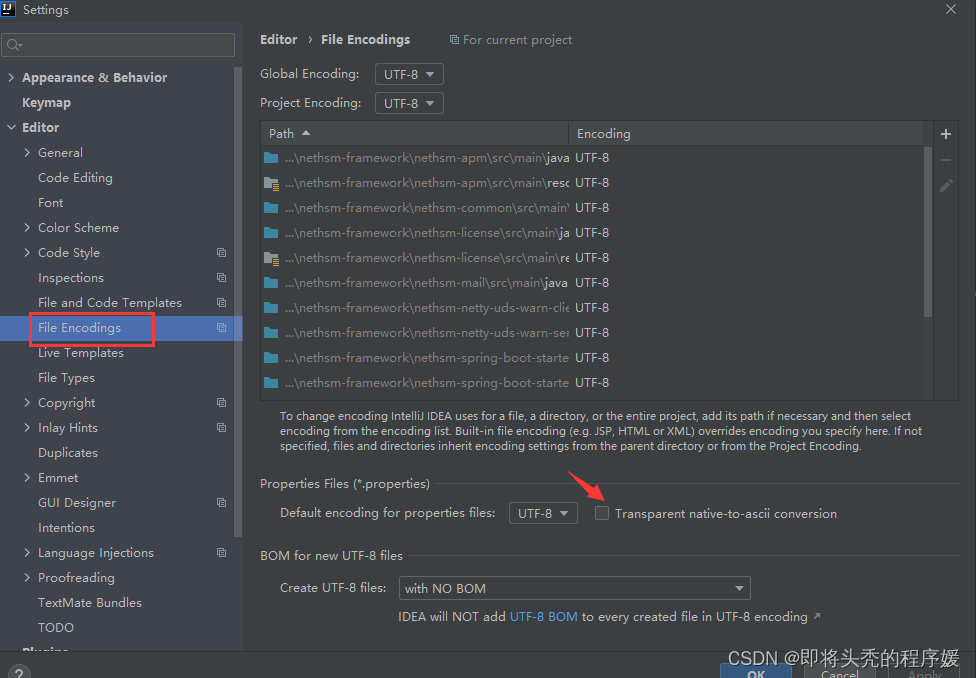
idea 开发工具properties文件中的中文不显示
用idea打开一个项目,配置文件propertise中的中文都不展示,如图: 可修改idea配置让中文显示: 勾选箭头指向的框即可,点击应用保存,重新打开配置文件,显示正常...

让DroidVNC-NG支持中文输入
DroidVNC-NG支持控制端输入内容,但是仅支持英文字符,如果需要控制输入法软键盘输入中文的话就没办法了,经过摸索找到了解决办法。 这个解决办法有个条件就是让DroidVNC-NG成为系统级应用(这个条件比较苛刻)ÿ…...

android dialog 显示时 activity 是否会执行 onPause onStop
当一个 Android Dialog 显示时,当前 Activity 通常不会执行 onPause 或 onStop 方法。Dialog 是附加到 Activity 上的一个窗口,它不会中断或替换当前的 Activity,因此 Activity 的生命周期方法 onPause 和 onStop 不会被调用。 然而…...
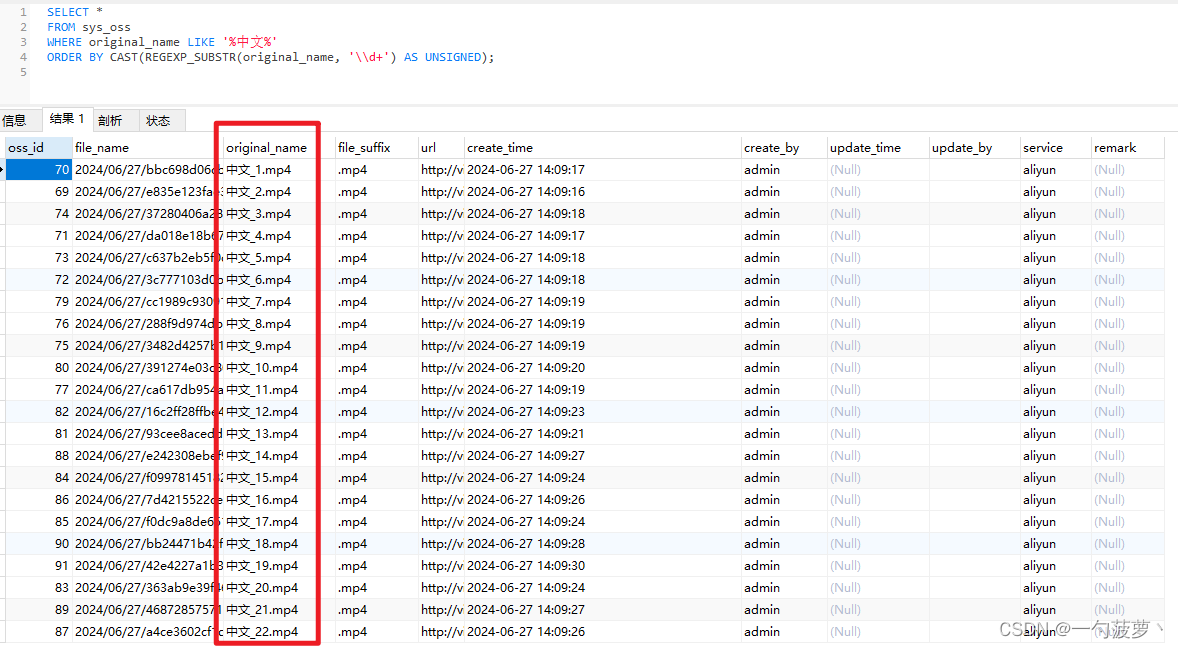
如何在MySQL中按字符串中的数字排序
在管理数据库时,我们经常遇到需要按嵌入在字符串中的数字进行排序的情况。这在实际应用中尤为常见,比如文件名、代码版本号等字段中通常包含数字,而这些数字往往是排序的关键。本文将详细介绍如何在MySQL中利用正则表达式提取字符串中的数字并…...
memcacheredis构建缓存服务器
Memcached&Redis构建缓存服务器 前言 许多Web应用都将数据保存到 RDBMS中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、 网站显示延迟等重大影响。Memcached/redis是高性能…...
Linux基础- 使用 Apache 服务部署静态网站
目录 零. 简介 一. linux安装Apache 二. 创建网页 三. window访问 修改了一下默认端口 到 8080 零. 简介 Apache 是世界使用排名第一的 Web 服务器软件。 它具有以下一些显著特点和优势: 开源免费:可以免费使用和修改,拥有庞大的社区支…...
接口自动化测试框架实战(Pytest+Allure+Excel)
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1. Allure 简介 Allure 框架是一个灵活的、轻量级的、支持多语言的测试报告工具,它不…...

如何预防和处理他人盗用IP地址?
IP地址的定义及作用 解释 IP 地址在互联网中的作用。它是唯一标识网络设备的数字地址,类似于物理世界中的邮政地址。 1、IP地址盗窃的定义 解释一下什么是IP地址盗用,即非法使用他人的IP地址或者伪造IP地址的行为,这种行为可能引发法律和安…...
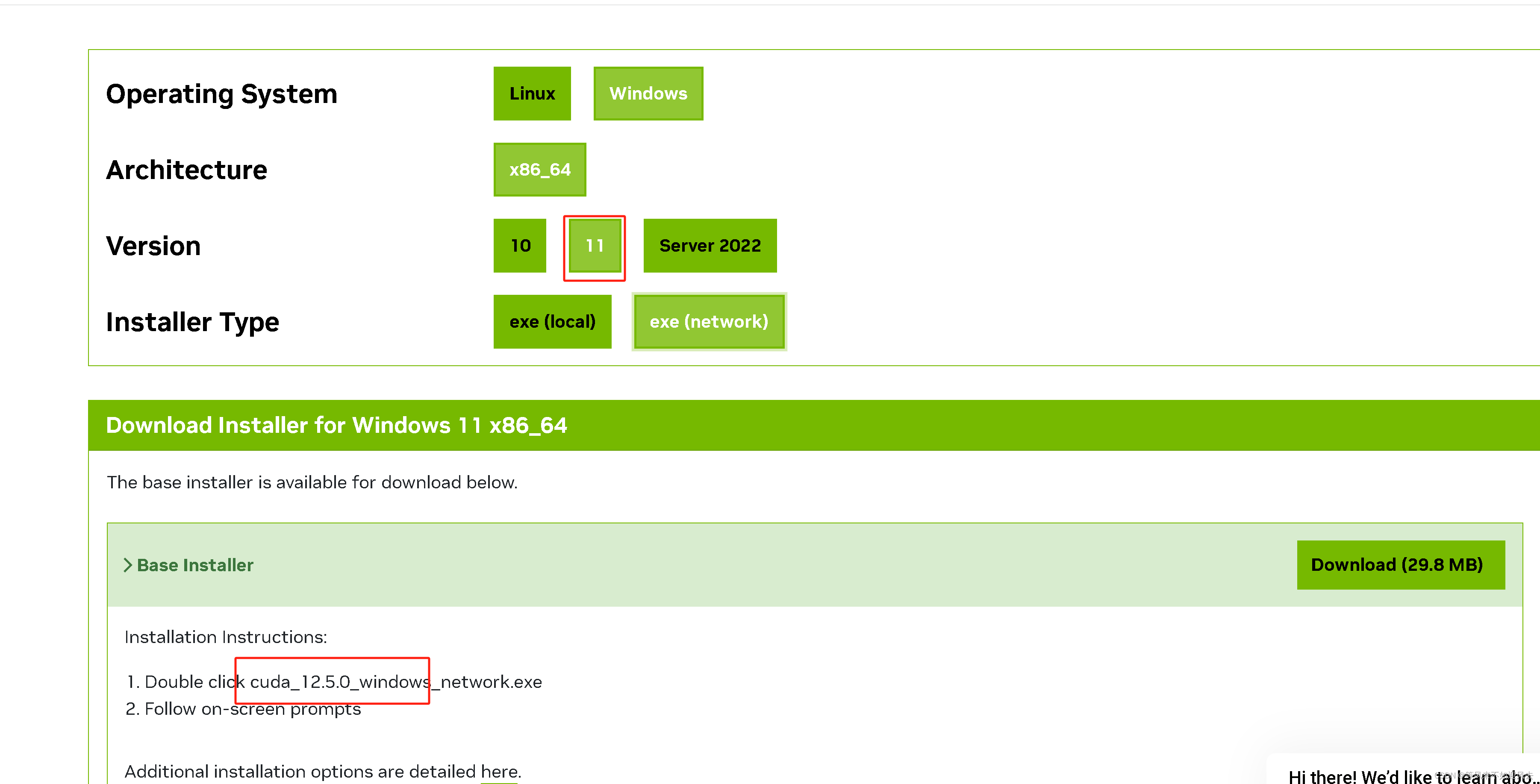
【ai】李沐 动手深度学学v2 环境安装:anaconda3、pycharm、d2
cuda-toolkit cuda_12.5.0_windows_network.exe 官方课程网站 第二版资源下载release版本 pycharm版本 李沐 【动手学深度学习v2 PyTorch版】 课程笔记 CUDA 选择11, 实际下载 12.5.0...

前后端分离对软件行业及架构设计的影响
在软件开发领域,前后端分离是一种越来越流行的架构设计模式。这种方法将用户界面(前端)与服务器逻辑(后端)分离开来,允许它们独立开发、测试和部署。本文将探讨前后端分离对软件行业和架构设计的影响&#…...

深入解析Dubbo架构层次
什么是Dubbo? Dubbo是阿里巴巴开源的一款高性能优秀的服务框架,致力于提供高性能和透明化的 RPC 远程服务调用方案,以及 SOA 服务治理方案。它的主要功能包括: 远程通信:提供高效的远程通信能力。负载均衡࿱…...

关于GPIO的上拉、下拉,无上下拉
1.GPIO_PULLUP(上拉) 作用和原理 作用:上拉模式会在GPIO引脚和电源电压(Vcc)之间连接一个内部上拉电阻。原理:当引脚配置为输入模式时,如果引脚没有连接到其他外部电路,内部上拉电…...

DPO vs PPO:两种AI对齐技术到底选哪个?我全试了一遍
整整一个月的实验,四块4090烧了不知道多少电费。这不算什么,真正让我崩溃的是——跑了三天的PPO训练,在最后一刻因为reward model打分偏差炸了。 那一刻我真的很想摔键盘。 但后来换上DPO重新跑,12小时搞定,效果还更…...

一文看懂 Hermes Agent 的 Prompt Builder:系统提示词到底拼进了什么?
一、先说结论:Prompt Builder 是 Hermes 的“提示词总装车间”普通 Chatbot 的系统提示词往往是一段固定文字,告诉模型“你是谁、怎么回答”。Hermes Agent 的 Prompt Builder 更像一条总装线:它会把身份、记忆、用户画像、项目规则、技能目录…...

NLP之BERT预训练模型详解
摘要: BERT(Bidirectional Encoder Representations from Transformers)是谷歌于2018年提出的革命性自然语言处理模型,首次将基于Transformer的双向编码器架构成功应用于预训练语言模型,在多项NLP基准任务上刷新了最优…...

《技术底稿 40》别只看文件大小:一次 “反常 OOM” 背后的内存缓存重构
一、反常现象:小文件报错,大文件反倒正常业务场景需批量导入文献类 ZIP 压缩包。本次测试出现诡异问题:一个 282MB 的 ZIP 包导入时,直接抛出 java.lang.OutOfMemoryError: Java heap space 堆内存溢出。当前服务 JVM 堆内存固定配…...

Supermask:冻结权重+二值掩码的神经网络子结构发现方法
1. 什么是 Supermasks?——不是“超级面具”,而是神经网络里的“先天直觉” 你有没有试过教一个刚学会走路的孩子认苹果?你不需要从零开始教他光谱分析、细胞结构或者植物分类学,只要拿个红彤彤的苹果在他眼前晃一晃,再…...

Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案
Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans 你是否曾经在设计网页或应用时,…...

平均 CPU 利用率指标为何该摒弃?多个案例揭示真相!
1. 作者信息与文章背景Jeremy Theocharis 是《平凡即卓越》作者、UMH 联合创始人兼首席技术官。文章基于其在 2026 年 4 月云原生亚琛聚会上的演讲,探讨为何应摒弃平均 CPU 利用率指标。2. 应用程序问题引出我们应用程序中的一个 Go 函数在生产环境总是被取消执行。…...
)
从CRUD到AI:普通程序员转型大模型应用开发指南(收藏版)
本文针对有3-5年Java、前端或PHP开发经验的程序员,探讨了如何转型AI大模型应用开发。文章指出,虽然表面看起来与现有工作不同,但CRUD经验反而是转型优势,如API调用、业务流程理解、数据库知识和调试能力等。转型只需掌握Python基础…...

FRED的光路和光路历史记录
对于杂散光分析,通常会使用“高级光线追迹”对话框,并选择“创建/使用光线历史文件”和“确定光路”选项。下面是对这两个选项的简要解释。确定光线路径选择此选项会使得FRED存储所有光路信息。这允许用户之后使用诊断工具,如光路追迹路径报告…...

G-Helper终极指南:如何用免费开源工具彻底替代Armoury Crate
G-Helper终极指南:如何用免费开源工具彻底替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...