万物皆可爬——亮数据代理IP+Python爬虫批量下载百度图片助力AI训练
- 💂 个人网站:【 摸鱼游戏】【神级代码资源网站】【导航大全】
- 🤟 一站式轻松构建小程序、Web网站、移动应用:👉注册地址
- 🤟 基于Web端打造的:👉轻量化工具创作平台
- 💅 想寻找共同学习交流,摸鱼划水的小伙伴,请点击【全栈技术交流群】
项目背景
本文档详细介绍了一个网络爬虫项目的准备和实现过程。该项目的目标是从百度图片搜索中获取图片链接并下载图片。此类爬虫项目通常用于收集大量的图片数据,以便用于训练各种人工智能模型,特别是计算机视觉模型。计算机视觉领域的研究需要大量的图像数据来训练和测试模型,以便实现图像分类、对象检测、图像生成等功能。
一、项目准备
环境配置
在开始编写爬虫之前,确保已经完成以下环境配置:
Python安装: 确保已安装Python 3.x版本。Python是一种功能强大且易于学习的编程语言,适合于各种编程任务,包括网络爬虫开发。
需要的库: Python有一个庞大的第三方库生态系统,我们将使用几个核心库来开发我们的爬虫:
- requests: 用于发送HTTP请求和处理响应。
- json: 用于处理JSON格式的数据。
- urllib: 提供了在网络上获取数据的一些功能,我们主要用来进行URL编码。
- os: 提供了与操作系统交互的功能,用于创建文件夹等文件操作。
- time: 提供了时间相关的功能,例如休眠程序以及计时等。
可以使用以下命令通过pip安装这些库:
pip install requests
如果你使用的是Anaconda等集成环境,可以使用conda命令:
conda install requests
这些库将帮助我们处理HTTP请求、解析和存储数据,以及进行一些基本的系统操作。
二、爬虫设计与实现
爬虫设计思路
目标网站分析
本爬虫目标是从百度图片搜索获取图片链接并下载。百度图片搜索返回的结果是JSON格式的数据,其中包含了图片的缩略图链接。
数据获取流程
- 构建百度图片搜索的URL,通过GET请求获取JSON数据。
- 解析JSON数据,提取缩略图链接。
- 下载图片到本地存储。
代码实现
初始化爬虫类(BaiduImageSpider)
import requests
import json
from urllib import parse
import os
import timeclass BaiduImageSpider(object):def __init__(self):self.json_count = 0 # 请求到的json文件数量(一个json文件包含30个图像文件)self.url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5179920884740494226&ipn=rj&ct' \'=201326592&is=&fp=result&queryWord={' \'}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word={' \'}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={' \'}&rn=30&gsm=1e&1635054081427= 'self.directory = r"C:\价值一个亿\python-mini-projects\projects\baidutupian\{}" # 存储目录 这里需要修改为自己希望保存的目录 {}不要丢self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3','Accept-Language': 'en-US,en;q=0.9','Referer': 'https://image.baidu.com'}
创建存储文件夹
# 创建存储文件夹def create_directory(self, name):self.directory = self.directory.format(name)# 如果目录不存在则创建if not os.path.exists(self.directory):os.makedirs(self.directory)self.directory += r'\{}'
获取图像链接
# 获取图像链接
def get_image_link(self, url):list_image_link = []strhtml = requests.get(url, headers=self.header) # Get方式获取网页数据print(f"Response content for URL {url}:\n{strhtml.text}\n")try:jsonInfo = json.loads(strhtml.text)except json.JSONDecodeError:print("Error decoding JSON")return list_image_linkif 'data' in jsonInfo:for index in range(len(jsonInfo['data'])):if 'thumbURL' in jsonInfo['data'][index]:list_image_link.append(jsonInfo['data'][index]['thumbURL'])else:print("No 'data' key in the response JSON")return list_image_link
下载图片
# 下载图片
def save_image(self, img_link, filename):try:res = requests.get(img_link, headers=self.header)if res.status_code == 404:print(f"图片 {img_link} 下载出错")else:with open(filename, "wb") as f:f.write(res.content)print("存储路径:" + filename)except requests.RequestException as e:print(f"Error downloading image: {e}")
主运行函数
# 入口函数
def run(self):searchName = input("查询内容:")searchName_parse = parse.quote(searchName) # 编码self.create_directory(searchName)pic_number = 0 # 图像数量for index in range(self.json_count):pn = index * 30request_url = self.url.format(searchName_parse, searchName_parse, str(pn))list_image_link = self.get_image_link(request_url)for link in list_image_link:pic_number += 1self.save_image(link, self.directory.format(str(pic_number) + '.jpg'))time.sleep(1) # 休眠1秒,防止封ipprint(searchName + "----图像下载完成--------->")
三、代码详解
__init__ 方法
init 方法用于初始化爬虫类的属性。在这个方法中,我们定义了以下几个重要的属性:
- json_count: 用于指定要请求的JSON文件数量,每个JSON文件包含多个图像条目。
- url: 百度图片搜索的API URL,包含了多个参数用于构造请求。
- directory: 存储下载图片的目录路径。这个路径在 create_directory 方法中被初始化和修改。
- header: 请求头信息,包括用户代理、接受语言和引用页,用于模拟浏览器发送请求。
create_directory 方法
create_directory 方法根据提供的名称创建存储图片的文件夹。具体步骤如下:
- 将 directory 属性格式化为指定的存储目录路径。
- 使用 os.makedirs() 方法创建多层目录,如果目录不存在的话。
- 将 directory 属性更新为包含图片文件名格式的路径,以便后续保存图片时直接在该路径下生成文件。
get_image_link 方法
get_image_link 方法负责发送GET请求获取百度图片搜索返回的JSON数据,并解析数据提取图片的缩略图链接。具体步骤如下:
- 使用 requests.get() 方法发送GET请求,获取包含图片信息的JSON数据。
- 尝试解析返回的JSON数据,如果解析失败则捕获 json.JSONDecodeError 异常并打印错误信息。
- 如果JSON数据中包含 data 键,遍历数据条目并提取每个条目中的 thumbURL(缩略图链接),将其添加到 list_image_link 列表中。
- 如果JSON数据中不存在 data 键,则打印相应的错误信息并返回空列表。
save_image 方法
save_image 方法用于下载图片到本地存储。具体步骤如下:
- 使用 requests.get() 方法发送GET请求,获取包含图片数据的响应。
- 检查响应状态码,如果返回的状态码是404,则打印错误信息表示图片下载失败。
- 如果响应正常,将图片数据写入以指定文件名 filename 打开的二进制文件中(使用 “wb” 模式)。
- 打印存储图片的路径信息,表示图片已成功保存到本地。
run 方法
run 方法是爬虫的主运行函数,负责处理用户输入的查询内容,循环获取图片链接并下载到本地存储。具体步骤如下:
- 提示用户输入要查询的内容,并对用户输入的内容进行URL编码,以便构造百度图片搜索的查询URL。
- 调用 create_directory 方法创建存储图片的目录,目录名与用户输入的查询内容相关联。
- 初始化 pic_number 变量,用于记录已下载的图片数量。
- 使用循环从0到 json_count (设定的请求的JSON文件数量)遍历,构造不同页数的百度图片搜索URL,发送请求并获取图片链接。
- 遍历获取的图片链接列表,逐个下载图片到本地存储,并在每次下载后休眠1秒以防止IP被封禁。
- 下载完成后打印提示信息,指示所有图片已成功下载并存储到指定目录中。
以上详细解释了每个方法在爬虫实现中的作用和具体实现步骤,确保了爬虫能够有效地从百度图片搜索中获取指定数量的图片并保存到本地。
四、亮数据代理IP的使用
为什么需要代理IP
在爬取网站数据时,频繁的请求会被网站识别为异常流量,可能导致IP被封禁。使用代理IP可以隐藏真实IP,降低被封禁的风险。
如何在爬虫中配置代理IP
可以使用第三方代理IP服务商提供的代理IP池,例如requests库中的proxies参数。这里我采用的是亮数据IP代理服务。

修改代码以支持代理IP
在请求中添加代理IP,例如:
proxies = {'http': 'http://user:password@proxy_ip:port','https': 'https://user:password@proxy_ip:port',
}
requests.get(url, headers=self.header, proxies=proxies)
五、完整代码及运行结果
以下是完整的Python代码实现:
# -*- coding:utf8 -*-
import requests
import json
from urllib import parse
import os
import timeclass BaiduImageSpider(object):def __init__(self):self.json_count = 0 # 请求到的json文件数量(一个json文件包含30个图像文件)self.url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5179920884740494226&ipn=rj&ct' \'=201326592&is=&fp=result&queryWord={' \'}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word={' \'}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={' \'}&rn=30&gsm=1e&1635054081427= 'self.directory = r"C:\价值一个亿\python-mini-projects\projects\baidutupian\{}" # 存储目录 这里需要修改为自己希望保存的目录 {}不要丢self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3','Accept-Language': 'en-US,en;q=0.9','Referer': 'https://image.baidu.com'}# 创建存储文件夹def create_directory(self, name):self.directory = self.directory.format(name)# 如果目录不存在则创建if not os.path.exists(self.directory):os.makedirs(self.directory)self.directory += r'\{}'# 获取图像链接def get_image_link(self, url):list_image_link =[]strhtml = requests.get(url, headers=self.header) # Get方式获取网页数据print(f"Response content for URL {url}:\n{strhtml.text}\n")try:jsonInfo = json.loads(strhtml.text)except json.JSONDecodeError:print("Error decoding JSON")return list_image_linkif 'data' in jsonInfo:for index in range(len(jsonInfo['data'])):if 'thumbURL' in jsonInfo['data'][index]:list_image_link.append(jsonInfo['data'][index]['thumbURL'])else:print("No 'data' key in the response JSON")return list_image_link# 下载图片def save_image(self, img_link, filename):try:res = requests.get(img_link, headers=self.header)if res.status_code == 404:print(f"图片 {img_link} 下载出错")else:with open(filename, "wb") as f:f.write(res.content)print("存储路径:" + filename)except requests.RequestException as e:print(f"Error downloading image: {e}")# 入口函数def run(self):searchName = input("查询内容:")searchName_parse = parse.quote(searchName) # 编码self.create_directory(searchName)pic_number = 0 # 图像数量for index in range(self.json_count):pn = index * 30request_url = self.url.format(searchName_parse, searchName_parse, str(pn))list_image_link = self.get_image_link(request_url)for link in list_image_link:pic_number += 1self.save_image(link, self.directory.format(str(pic_number) + '.jpg'))time.sleep(1) # 休眠1秒,防止封ipprint(searchName + "----图像下载完成--------->")if __name__ == '__main__':spider = BaiduImageSpider()spider.json_count = 10 # 定义下载10组图像,也就是三百张spider.run()
演示爬虫的运行
运行以上代码,按照提示输入查询内容,爬虫将开始从百度图片搜索下载相关图片。

下载的图片展示

六、总结
本文详细介绍了如何使用Python编写一个简单的爬虫,用于从百度图片搜索下载图片。通过分析目标网站、设计爬虫流程、实现代码以及配置代理IP,使得爬虫能够有效地获取图片数据。通过本项目,读者可以学习到基本的爬虫原理和实现方法,同时也了解到了如何处理异常情况和优化爬虫效率的方法。
相关文章:
万物皆可爬——亮数据代理IP+Python爬虫批量下载百度图片助力AI训练
💂 个人网站:【 摸鱼游戏】【神级代码资源网站】【导航大全】🤟 一站式轻松构建小程序、Web网站、移动应用:👉注册地址🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交…...

OpenCv形态学(一)
目录 形态学转换 结构元素 腐蚀 膨胀 开运算 闭运算 形态学梯度 顶帽 黑帽 图像轮廓 查找轮廓 绘制轮廓 形态学转换 形态变换是一些基于图像形状的简单操作。通常在二值图像上执行。它需要两个输入,一个是我们的原始图像,第二个是决定操作性…...

CSS基础汇总
CSS 1. 选择器 标签选择器 通过标签名找标签(把指定的样式应用到某一个、组、类标签上) id选择器 通过id属性值找标签,关键符号#id值{样式} 复合选择器 1、并列选择器:关键符号,用法:选择器1,…...

cocos creator让所有button点击时播放音效
原理: 利用prototype属性,通过重写 cc.Button.prototype._onTouchEnded 方法,以便在按钮被点击时播放音频。通过重写其 _onTouchEnded 方法,可以添加自定义行为,如播放音频。 概念解释: prototype&#…...

mybatisplus自带的雪花算法(IdType.ASSIGN_ID)无法自动生成弊端缺点,以及改进方法
前言 今日在使用mybatisplus的雪花算法自动给id赋值时发现怎么都是null的情况,这尼玛测了半天,终于发现巨坑,废话不多说,直接上干货 IService.save 只有调用IService中的save方法才能正常生成id,像IService.saveBatc…...

单位转换:将kb转换为 MB ,GB等形式
写法一: function formatSizeUnits(kb) {let units [KB, MB, GB, TB, PB,EB,ZB,YB];let unitIndex 0;while (kb > 1024 && unitIndex < units.length - 1) {kb / 1024;unitIndex;}return ${kb.toFixed(2)} ${units[unitIndex]}; } console.log(for…...

优思学院|「按计划推动型」与「需求拉动型」的生产模式
针对生产架构做对比分类的用语,主要有按计划推进型与需求拉动型。 「按计划推动型」与「需求拉动型」两者乃是生产架构上常使用、成对比的两个用语。不过,有时不只用来指单纯的生产现场架构,也有人把它应用在更广泛的生产架构设计上。 按计划…...

解释什么是lambda函数?它有什么好处?
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

码农:如何快速融入团队
问题: 码农如何快速融入团队? 记住一个标准:能干事、能抗事。 总结一个字: 靠谱。 适用范围:新手码农、老司机码农、测试、DBA、运维、产品经理、项目经理、架构师、技术专家、。。。。适用于任何行业的打工者。 下面要…...

Android 通知组
一. 通知组简介 从 Android 7.0(API 级别 24)开始,您可以在一个组中显示相关通知。如下所示: 图 1. 收起(顶部)和展开(底部)的通知组。 注意 :如果应用发出 4 条或更多条通知且未…...

【机器学习】ChatTTS:开源文本转语音(text-to-speech)大模型天花板
目录 一、引言 二、TTS(text-to-speech)模型原理 2.1 VITS 模型架构 2.2 VITS 模型训练 2.3 VITS 模型推理 三、ChatTTS 模型实战 3.1 ChatTTS 简介 3.2 ChatTTS 亮点 3.3 ChatTTS 数据集 3.4 ChatTTS 部署 3.4.1 创建conda环境 3.4.2 拉取源…...
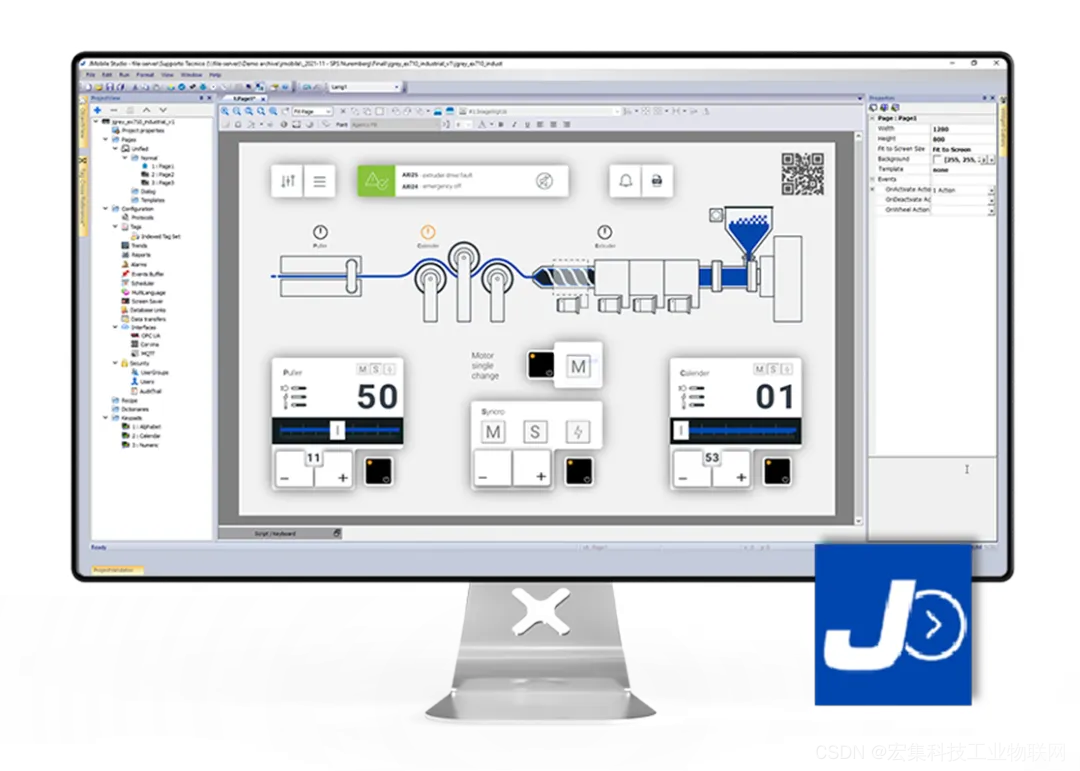
宏集物联网工控屏通过 S7 ETH 协议采集西门子 1200 PLC 数据
前言 为了实现和西门子PLC的数据交互,宏集物联网HMI集成了S7 PPI、S7 MPI、S7 Optimized、S7 ETH等多个驱动来适配西门子200、300、400、1200、1500、LOGO等系列PLC。 本文主要介绍宏集物联网HMI如何通过S7 ETH协议采集西门子1200 PLC的数据,文中详细介…...
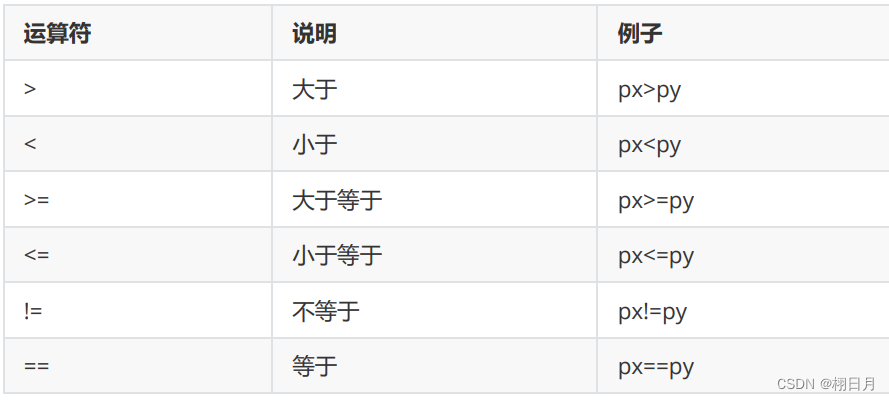
C语言学习记录(十一)——指针基本知识及运算
文章目录 前言1. 指针的概念2.指针变量的说明3. 指针的含义4. 指针运算①指针加减:②指针的关系运算符 前言 一个学习嵌入式的小白~ 有问题评论区或私信指出~ 提示:以下是本篇文章正文内容,下面案例可供参考 1. 指针的概念 在C语言中&…...
的语法及在对应不同需求下应如何使用)
Oracle中 ROW_NUMBER()的语法及在对应不同需求下应如何使用
Oracle数据库中的ROW_NUMBER()函数是一个窗口函数,它为查询结果集中的每一行分配一个唯一的序号。这个函数在数据分析、分页查询、数据去重和排名问题等方面非常有用。ROW_NUMBER()函数的语法如下: ROW_NUMBER() OVER ( [ PARTITION BY column ] ORDER …...

德邦快递大件可以寄2米长物品吗?大件跨省行李用哪个快递便宜?
搬家或寄送特殊尺寸物品时,快递的选择尤为关键。特别是2米长的大件物品,是否能够承运?哪家快递在跨省大件行李方面更经济?今天,就为你解答这些疑问。 1、祺祺寄快递小程序: “祺祺寄快递”小程序ÿ…...

C# 在WPF .net8.0框架中使用FontAwesome 6和IconFont图标字体
文章目录 一、在WPF中使用FontAwesome 6图标字体1.1 下载FontAwesome1.2 在WPF中配置引用1.2.1 引用FontAwesome字体文件1.2.2 将字体文件已资源的形式生成 1.3 在项目中应用1.3.1 使用方式一:局部引用1.3.2 使用方式二:单个文件中全局引用1.3.3 使用方式…...
万能自定义预约小程序源码系统 适合任何行业在线预约报名 前后端分离 带完整的安装代码包以及搭建教程
系统概述 在当今数字化时代,线上预约已成为各行各业不可或缺的一部分。为满足广大企业和个人对在线预约系统的需求,我们特别推出了这款“万能自定义预约小程序源码系统”。该系统以其高度的灵活性和可扩展性,为各行各业提供了完美的在线预约…...

【MySQL备份】mysqldump篇
目录 1.简介 2.基本用途 3.命令格式 3.1常用选项 3.2常用命令 4.备份脚本 5.定时执行备份脚本 1.简介 mysqldump 是 MySQL 数据库管理系统的命令行实用程序,用于创建数据库的逻辑备份。它能够导出数据库的结构(如表结构、视图、触发器等…...
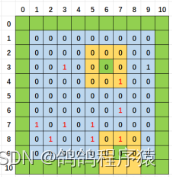
控制台扫雷(C语言实现)
目录 博文目的实现思路项目创建文件解释 具体实现判断玩家进行游戏还是退出扫雷棋盘的确定地图初始化埋雷玩家扫雷的实现雷判断函数 源码game.cgame.h扫雷.c 博文目的 相信不少人都学习了c语言的函数,循环,分支那我们就可以写一个控制台的扫雷小游戏来检…...

操作系统期末复习 | 批处理程序 | PV实现同步互斥 | 调度算法 | 页面置换算法 | 磁盘调度算法
操作系统引论 批处理程序 单道批处理:引入脱机输入/输出技术,并由监督程序负责控制作业的输入、输出。主要优点是缓解了一定程度的人机速度矛盾,资源利用率有所提升。主要缺点是内存中仅能有一道程序运行,只有该程序运行结束之后…...
 第一章:AWS IAM 配置详解)
对接亚马逊 SP-API(Amazon Selling Partner API) 第一章:AWS IAM 配置详解
1. AWS IAM 基础概念扫盲 第一次接触亚马逊SP-API的开发者,往往会在IAM配置环节卡壳。我见过不少团队在这个阶段浪费两三周时间反复调试,其实只要理解几个核心概念就能事半功倍。IAM(Identity and Access Management)就像亚马逊AW…...

IDM激活开源工具:永久使用Internet Download Manager的完整指南
IDM激活开源工具:永久使用Internet Download Manager的完整指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 当你发现下载工具突然停用࿰…...

MDIN380芯片高清视频处理方案:SDI转VGA与LVDS转换,专业PCB设计与源码集成
MDIN380 SDI转VGA 转LVDS VGA转SDI 高清视频处理 MDIN380芯片 PCB代码方案资料 3G-SDI转VGA ?3G-SDI转LVDS ?高清视频 MDIN380、GV7601 芯片方案(PCB图和源码)。 此方案是韩国视频处理芯片MDIN380的整合应用方案。 3G-SDI转VGA或3G-SDI转LVDS。 方案共有两块电路板(一块底板…...

5大核心功能深度解析:AltDrag如何重新定义Windows窗口管理效率
5大核心功能深度解析:AltDrag如何重新定义Windows窗口管理效率 【免费下载链接】altdrag :file_folder: Easily drag windows when pressing the alt key. (Windows) 项目地址: https://gitcode.com/gh_mirrors/al/altdrag 在Windows系统中,窗口管…...

如何快速配置MangoHud快捷键:从零开始的游戏性能监控终极指南
如何快速配置MangoHud快捷键:从零开始的游戏性能监控终极指南 【免费下载链接】MangoHud A Vulkan and OpenGL overlay for monitoring FPS, temperatures, CPU/GPU load and more. 项目地址: https://gitcode.com/gh_mirrors/ma/MangoHud 你是否厌倦了游戏性…...

树莓派Ubuntu系统无显示器配置全攻略:VNC远程桌面与虚拟显示器实战
1. 树莓派Ubuntu系统初始化配置 第一次接触树莓派的朋友可能会觉得这个小玩意儿很神奇,巴掌大的板子居然能跑完整的桌面系统。我当初拿到树莓派4B时也兴奋了好一阵子,但很快发现一个现实问题:不是每个人都有多余的显示器可以长期接在树莓派上…...

基于模糊控制的改进DWA算法功能详解
改进动态窗口DWA算法,模糊控制自适应调整评价因子权重,matlab代码 这段代码是一个基于动态窗口法(Dynamic Window Approach,DWA)的路径规划算法的实现。下面我将对代码进行分析,并解释算法的优势、需要注意…...
Elsevier Tracker:解放科研作者的审稿状态智能追踪方案
Elsevier Tracker:解放科研作者的审稿状态智能追踪方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否曾经历过这样的科研投稿循环:每天早晨第一件事就是登录Elsevier系统,…...

零基础入门:星图平台私有化部署Qwen3-VL:30B,Clawdbot飞书接入完整指南
零基础入门:星图平台私有化部署Qwen3-VL:30B,Clawdbot飞书接入完整指南 1. 项目概述与准备工作 1.1 为什么选择Qwen3-VL:30B? Qwen3-VL:30B是目前最强的多模态大模型之一,具备以下核心优势: 强大的视觉理解能力&am…...

三步快速上手Bootstrap Datepicker:打造专业级网页日期选择器
三步快速上手Bootstrap Datepicker:打造专业级网页日期选择器 【免费下载链接】bootstrap-datepicker A datepicker for twitter bootstrap (twbs) 项目地址: https://gitcode.com/gh_mirrors/bo/bootstrap-datepicker Bootstrap Datepicker是一款基于Bootst…...