算法金 | 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost 算法大全

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
决策树是一种简单直观的机器学习算法,它广泛应用于分类和回归问题中。它的核心思想是将复杂的决策过程分解成一系列简单的决策,通过不断地将数据集分割成更小的子集来进行预测。本文将带你详细了解决策树系列算法的定义、原理、构建方法、剪枝与优化技术,以及它的优缺点。

一、决策树
1.1 决策树的定义与原理
决策树的定义:决策树是一种树形结构,其中每个节点表示一个特征的测试,每个分支表示一个测试结果,每个叶子节点表示一个类别或回归值。决策树的目标是通过一系列的特征测试,将数据分成尽可能纯的子集。
决策树的原理:决策树通过递归地选择最优特征进行分割来构建。最优特征的选择通常基于某种度量标准,如信息增益、基尼指数或方差减少。每次分割都会将数据集分成更小的子集,直到满足停止条件(如达到最大深度或子集纯度)为止。
1.2 决策树的构建方法
构建方法:
- 选择最优特征:使用信息增益、基尼指数或方差减少等标准来选择最优特征进行分割
- 分割数据集:根据最优特征的不同取值将数据集分割成若干子集
- 递归构建子树:对每个子集递归地选择最优特征进行分割,直到满足停止条件
- 生成叶子节点:当满足停止条件时,生成叶子节点并标记类别或回归值
1.3 决策树的剪枝与优化
剪枝技术:
- 预剪枝:在构建过程中提前停止树的生长,如限制树的最大深度、最小样本数或最小增益
- 后剪枝:在构建完成后,通过剪去不重要的子树来简化模型,如通过交叉验证选择最优剪枝点
优化方法:
- 特征选择:使用基于统计显著性的特征选择方法来减少特征数量
- 参数调整:通过网格搜索或随机搜索优化超参数,如最大深度、最小样本数等
- 集成方法:结合多个决策树(如随机森林、梯度提升树)来提高模型性能
1.4 决策树的优缺点
优点:
- 直观简单,易于理解和解释
- 适用于数值型和类别型数据
- 可以处理多输出问题
缺点:
- 容易过拟合,尤其是深树
- 对噪声和小变动敏感
- 计算复杂度高,尤其是在特征数多时
更多内容,见微*公号往期文章: 突破最强算法模型,决策树算法!!
防失联,进免费知识星球交流。算法知识直达星球:t.zsxq.com/ckSu3https://t.zsxq.com/ckSu3

更多内容,见免费知识星球
二、集成学习概述
集成学习是通过结合多个学习器的预测结果来提高模型性能的一种方法。它的核心思想是集成多个模型,通过投票、加权等方式获得更稳定、更准确的预测结果。集成学习在处理高维数据、降低过拟合和提高模型泛化能力方面具有显著优势。
2.1 集成学习的基本概念
集成学习的定义:集成学习(Ensemble Learning)是一种将多个基模型组合在一起的方法,其目标是通过结合多个模型的优点来提高整体性能。集成学习通常分为两类:同质集成(基模型相同,如随机森林)和异质集成(基模型不同,如堆叠模型)。
集成学习的原理:集成学习的基本原理是通过组合多个弱模型(即性能不佳的单个模型)来构建一个强模型(即性能优异的集成模型)。这种组合可以通过多种方式实现,常见的方法包括:Bagging、Boosting和Stacking。
以下是集成学习的一些常用方法:
- Bagging(Bootstrap Aggregating):通过对数据集进行有放回的随机抽样,生成多个子数据集,并在每个子数据集上训练基模型。最终的预测结果通过对所有基模型的预测结果进行平均或投票来确定
- Boosting:通过迭代地训练基模型,每个基模型在前一个基模型的基础上进行改进。每次迭代时,增加错误分类样本的权重,使得新模型能够更好地处理这些样本
- Stacking:通过训练多个基模型,并使用这些基模型的预测结果作为输入,训练一个次级模型来进行最终预测
2.2 Bagging 和 Boosting 的区别
Bagging(Bootstrap Aggregating):
- 通过对数据集进行有放回的随机抽样,生成多个子数据集
- 在每个子数据集上训练基模型
- 通过对所有基模型的预测结果进行平均或投票来确定最终结果
- 主要用于减少方差,防止过拟合
Boosting:
- 通过迭代地训练基模型,每个基模型在前一个基模型的基础上进行改进
- 每次迭代时,增加错误分类样本的权重,使得新模型能够更好地处理这些样本
- 通过加权平均或加权投票来确定最终结果
- 主要用于减少偏差,提高模型的准确性
主要区别:
- 训练方式:Bagging 是并行训练多个基模型,Boosting 是串行训练多个基模型
- 数据处理:Bagging 使用有放回的随机抽样,Boosting 根据错误率调整样本权重
- 目标:Bagging 主要减少方差,Boosting 主要减少偏差
2.3 集成学习在机器学习中的重要性
提高模型性能:集成学习通过结合多个基模型的预测结果,可以显著提高模型的准确性和稳定性。这在处理复杂问题和高维数据时尤为重要
降低过拟合风险:集成学习通过对多个模型的预测结果进行综合,减少了单个模型的过拟合风险,使得模型具有更好的泛化能力
增强模型鲁棒性:集成学习可以通过结合不同的模型,提高模型对噪声和异常值的鲁棒性,增强模型在实际应用中的可靠性
三、Bagging
Bagging 是集成学习中的一种方法,通过并行训练多个基模型来提高整体性能。它通过对数据集进行有放回的随机抽样,生成多个子数据集,并在每个子数据集上训练基模型。最终的预测结果通过对所有基模型的预测结果进行平均或投票来确定。Bagging 主要用于减少模型的方差,防止过拟合。
3.1 Bagging 的定义与原理
Bagging 的定义:Bagging(Bootstrap Aggregating)是一种通过并行训练多个基模型来提高模型性能的集成学习方法。它通过对原始数据集进行有放回的随机抽样,生成多个子数据集,并在每个子数据集上训练基模型。
Bagging 的原理:Bagging 的核心思想是通过减少模型的方差来提高模型的泛化能力。具体步骤如下:
- 从原始数据集中有放回地随机抽样生成多个子数据集
- 在每个子数据集上训练一个基模型
- 对每个基模型的预测结果进行平均(回归任务)或投票(分类任务)以得到最终预测结果
3.2 Bagging 的具体算法与流程
Bagging 的具体流程:
- 数据集生成:对原始数据集进行有放回的随机抽样,生成多个子数据集
- 模型训练:在每个子数据集上训练一个基模型(如决策树)
- 结果综合:对每个基模型的预测结果进行平均或投票,得到最终的预测结果
3.3 Bagging 的优缺点
优点:
- 减少方差:通过对多个基模型的预测结果进行综合,Bagging 能有效减少模型的方差,提升模型的泛化能力
- 防止过拟合:由于每个基模型是在不同的子数据集上训练的,Bagging 能有效防止单个模型过拟合
- 简单易用:Bagging 方法实现简单,适用于多种基模型
缺点:
- 计算复杂度高:由于需要训练多个基模型,Bagging 的计算复杂度较高,训练时间较长
- 模型解释性差:由于 Bagging 是对多个基模型的结果进行综合,单个基模型的解释性较差,难以解释最终模型的预测结果
Bagging 方法在处理高维数据和防止过拟合方面具有显著优势,适用于多种机器学习任务。
抱个拳,送个礼

四、随机森林
随机森林是 Bagging 的一种改进版本,通过构建多个决策树并结合它们的预测结果来提高模型的准确性和稳定性。与 Bagging 不同的是,随机森林在每次分割节点时还会随机选择部分特征进行考虑,从而进一步增加模型的多样性。
4.1 随机森林的定义与原理
随机森林的定义:随机森林(Random Forest)是一种基于决策树的集成学习方法,通过构建多个决策树并结合它们的预测结果来提高模型的性能。每棵树在训练时都使用了不同的样本和特征,从而增加了模型的多样性和鲁棒性。
随机森林的原理:随机森林的核心思想是通过引入随机性来减少模型的方差和过拟合风险。具体步骤如下:
- 对原始数据集进行有放回的随机抽样,生成多个子数据集
- 在每个子数据集上训练一棵决策树。在每个节点分割时,随机选择部分特征进行考虑
- 对所有决策树的预测结果进行平均(回归任务)或投票(分类任务)以得到最终预测结果
4.2 随机森林的构建方法
构建方法:
- 数据集生成:对原始数据集进行有放回的随机抽样,生成多个子数据集
- 决策树训练:在每个子数据集上训练一棵决策树,在每个节点分割时随机选择部分特征进行考虑
- 结果综合:对所有决策树的预测结果进行平均或投票,得到最终的预测结果
4.3 随机森林的优化技术
优化方法:
- 特征选择:通过分析特征重要性,选择最有价值的特征进行训练
- 参数调整:使用网格搜索或随机搜索优化超参数,如树的数量(n_estimators)、最大深度(max_depth)、最小样本数(min_samples_split)等
- 样本加权:在训练时对样本进行加权处理,使得模型对不同样本的重要性有所区别
- 交叉验证:通过交叉验证评估模型性能,选择最优参数配置
4.4 随机森林的优缺点
优点:
- 高准确率:通过集成多个决策树,随机森林具有较高的预测准确率
- 抗过拟合:通过引入随机性,随机森林能有效减少过拟合风险
- 特征重要性评估:随机森林可以评估各个特征的重要性,帮助理解数据
缺点:
- 计算复杂度高:由于需要训练多个决策树,随机森林的计算复杂度较高,训练时间较长
- 内存占用大:随机森林需要存储多个决策树模型,占用较多内存
- 模型解释性差:由于随机森林是对多个决策树的结果进行综合,单个决策树的解释性较差,难以解释最终模型的预测结果
随机森林在处理高维数据和防止过拟合方面具有显著优势,适用于多种机器学习任务。
更多内容,见微*公号往期文章:突破最强算法模型!!学会随机森林,你也能发表高水平SCI
防失联,进免费知识星球交流。算法知识直达星球:t.zsxq.com/ckSu3

免费知识星球,欢迎加入交流
五、Boosting
Boosting 是另一种强大的集成学习方法,通过逐步改进弱模型的性能来构建一个强模型。与 Bagging 不同,Boosting 是一种串行过程,每个基模型在训练时都会关注前一个模型中被错误分类的样本,从而不断提高整体模型的准确性。
5.1 Boosting 的定义与原理
Boosting 的定义:Boosting 是一种集成学习方法,通过逐步训练多个弱模型,每个模型在前一个模型的基础上进行改进,最终将这些弱模型组合成一个强模型。常见的 Boosting 算法包括 AdaBoost、GBDT 和 XGBoost。
Boosting 的原理:Boosting 的核心思想是通过逐步减小模型的偏差来提高整体性能。具体步骤如下:
- 初始化模型,将所有样本的权重设为相等
- 训练第一个基模型,计算每个样本的误差
- 根据误差调整样本的权重,使得错误分类的样本权重增加
- 训练下一个基模型,并继续调整样本权重,直至达到指定的模型数量或误差阈值
- 最终将所有基模型的预测结果进行加权平均或加权投票,得到最终预测结果
5.2 Boosting 的具体算法与流程
Boosting 的具体流程:
- 初始化权重:将所有样本的权重设为相等
- 训练基模型:在当前样本权重下训练基模型,计算每个样本的误差
- 调整权重:根据误差调整样本的权重,错误分类的样本权重增加
- 重复步骤 2 和 3:直至达到指定的基模型数量或误差阈值
- 加权综合:将所有基模型的预测结果进行加权平均或加权投票,得到最终预测结果
5.3 Boosting 的优缺点
优点:
- 高准确率:通过逐步改进模型性能,Boosting 能显著提高模型的预测准确率
- 减少偏差:通过关注前一个模型的错误分类样本,Boosting 能有效减少模型的偏差
- 灵活性强:Boosting 可以与多种基模型结合,具有较高的灵活性
缺点:
- 计算复杂度高:由于需要逐步训练多个基模型,Boosting 的计算复杂度较高,训练时间较长
- 易过拟合:如果基模型过于复杂或迭代次数过多,Boosting 可能会导致过拟合
- 对噪声敏感:由于 Boosting 会增加错误分类样本的权重,可能会对噪声样本过度拟合
Boosting 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务
六、Adaboost
Adaboost 是 Boosting 家族中最早提出的一种算法,通过逐步调整样本权重来训练一系列弱分类器,从而组合成一个强分类器。它的核心思想是让后续的分类器重点关注前面被错误分类的样本,从而提高模型的准确性。
6.1 Adaboost 的定义与原理
Adaboost 的定义:Adaboost(Adaptive Boosting)是一种自适应 Boosting 算法,通过调整样本权重来逐步提高模型性能。每个弱分类器的权重根据其错误率进行调整,错误率低的分类器权重较高,错误率高的分类器权重较低。
Adaboost 的原理:Adaboost 的核心思想是通过逐步调整样本权重,使得每个弱分类器能够更好地处理前一个分类器错误分类的样本。具体步骤如下:
- 初始化样本权重,使得每个样本的权重相等
- 训练弱分类器,并计算其错误率
- 根据错误率调整分类器权重,错误率越低的分类器权重越高
- 根据错误分类情况调整样本权重,错误分类的样本权重增加
- 迭代上述步骤,直到达到指定的弱分类器数量或误差阈值
- 最终将所有弱分类器的预测结果进行加权综合,得到最终预测结果
6.2 Adaboost 的构建方法
构建方法:
- 初始化权重:将所有样本的权重设为相等
- 训练弱分类器:在当前样本权重下训练弱分类器,计算每个样本的误差
- 调整分类器权重:根据弱分类器的错误率调整其权重,错误率越低的分类器权重越高
- 调整样本权重:根据错误分类情况调整样本权重,错误分类的样本权重增加
- 重复步骤 2-4:直到达到指定的弱分类器数量或误差阈值
- 加权综合:将所有弱分类器的预测结果进行加权综合,得到最终预测结果
6.3 Adaboost 的优化技术
优化方法:
- 参数调整:通过网格搜索或随机搜索优化超参数,如弱分类器数量(n_estimators)、学习率(learning_rate)等
- 弱分类器选择:选择合适的弱分类器,如决策树、线性模型等,根据具体问题选择最优模型
- 样本加权:在训练时对样本进行加权处理,使得模型对不同样本的重要性有所区别
- 交叉验证:通过交叉验证评估模型性能,选择最优参数配置
6.4 Adaboost 的优缺点
优点:
- 高准确率:通过逐步改进模型性能,Adaboost 能显著提高模型的预测准确率
- 减少偏差:通过关注前一个模型的错误分类样本,Adaboost 能有效减少模型的偏差
- 适用于多种基模型:Adaboost 可以与多种基模型结合,具有较高的灵活性
缺点:
- 计算复杂度高:由于需要逐步训练多个弱分类器,Adaboost 的计算复杂度较高,训练时间较长
- 易过拟合:如果弱分类器过于复杂或迭代次数过多,Adaboost 可能会导致过拟合
- 对噪声敏感:由于 Adaboost 会增加错误分类样本的权重,可能会对噪声样本过度拟合
Adaboost 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务
抱个拳,送个礼

七、GBDT
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是一种基于决策树的 Boosting 方法,通过逐步构建一系列决策树来提升模型的预测性能。每棵树都在前面所有树的残差上进行拟合,从而不断减小整体模型的误差。
7.1 GBDT 的定义与原理
GBDT 的定义:GBDT 是一种通过逐步构建一系列决策树来提升模型性能的集成学习方法。每棵树都在前面所有树的残差上进行拟合,以减小整体模型的误差。GBDT 适用于回归和分类任务,在许多实际应用中表现出色。
GBDT 的原理:GBDT 的核心思想是通过逐步减小残差来提高模型的准确性。具体步骤如下:
- 初始化模型,将所有样本的预测值设为目标值的均值(回归)或初始概率(分类)
- 计算当前模型的残差,即目标值与当前预测值之间的差异
- 训练一棵决策树来拟合残差,得到新的预测值
- 更新模型的预测值,将新的预测值加到当前预测值上
- 重复步骤 2-4,直到达到指定的树数量或误差阈值
7.2 GBDT 的构建方法
构建方法:
- 初始化预测值:将所有样本的预测值设为目标值的均值(回归)或初始概率(分类)
- 计算残差:计算当前模型的残差,即目标值与当前预测值之间的差异
- 训练决策树:在当前残差上训练一棵决策树,得到新的预测值
- 更新预测值:将新的预测值加到当前预测值上
- 重复步骤 2-4:直到达到指定的树数量或误差阈值
7.3 GBDT 的优化技术
优化方法:
- 参数调整:通过网格搜索或随机搜索优化超参数,如树的数量(n_estimators)、学习率(learning_rate)、最大深度(max_depth)等
- 特征选择:通过分析特征重要性,选择最有价值的特征进行训练
- 正则化:通过添加正则化项来控制模型的复杂度,防止过拟合
- 早停:通过监控验证集上的误差,在误差不再显著降低时提前停止训练
7.4 GBDT 的优缺点
优点:
- 高准确率:通过逐步减小残差,GBDT 能显著提高模型的预测准确率
- 减少偏差:通过在残差上训练决策树,GBDT 能有效减少模型的偏差
- 处理非线性关系:GBDT 能处理复杂的非线性关系,适用于多种数据类型
缺点:
- 计算复杂度高:由于需要逐步训练多个决策树,GBDT 的计算复杂度较高,训练时间较长
- 易过拟合:如果决策树过于复杂或迭代次数过多,GBDT 可能会导致过拟合
- 对参数敏感:GBDT 对参数设置较为敏感,需要仔细调整超参数以获得最佳性能
GBDT 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务。接下来我们会详细探讨 XGBoost 及其具体实现。

免费知识星球,欢迎加入,一起交流切磋
八、XGBoost
XGBoost 是一种高效的梯度提升算法,被广泛应用于各种机器学习竞赛和实际项目中。它在 GBDT 的基础上进行了多种优化,包括正则化、并行处理和树结构的改进,使得其在精度和效率上均有显著提升。
8.1 XGBoost 的定义与原理
XGBoost 的定义:XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升决策树的增强版算法,具有更高的效率和准确性。XGBoost 通过引入二阶导数信息、正则化项和并行处理等技术,显著提升了模型的性能和训练速度。
XGBoost 的原理:XGBoost 的核心思想与 GBDT 类似,通过逐步减小残差来提高模型的准确性。不同的是,XGBoost 引入了以下优化:
- 正则化项:通过添加 L1 和 L2 正则化项来控制模型复杂度,防止过拟合
- 二阶导数信息:在优化目标函数时引入二阶导数信息,提高优化精度
- 并行处理:通过并行计算和分布式计算加速模型训练
- 树结构优化:使用贪心算法和剪枝技术优化树的结构
8.2 XGBoost 的构建方法
构建方法:
- 数据准备:将数据转换为 DMatrix 格式,XGBoost 专用的数据结构
- 设置参数:配置 XGBoost 的超参数,如目标函数、最大深度、学习率等
- 训练模型:使用训练数据训练 XGBoost 模型
- 预测结果:使用训练好的模型进行预测
- 评估性能:计算预测结果的准确性等指标
8.3 XGBoost 的优化技术
优化方法:
- 参数调整:通过网格搜索或随机搜索优化超参数,如树的数量(num_round)、学习率(eta)、最大深度(max_depth)等
- 特征选择:通过分析特征重要性,选择最有价值的特征进行训练
- 正则化:通过添加 L1 和 L2 正则化项来控制模型的复杂度,防止过拟合
- 早停:通过监控验证集上的误差,在误差不再显著降低时提前停止训练
8.4 XGBoost 的优缺点
优点:
- 高准确率:通过引入多种优化技术,XGBoost 具有极高的预测准确率
- 快速训练:通过并行计算和分布式计算,XGBoost 的训练速度非常快
- 正则化控制:通过添加 L1 和 L2 正则化项,XGBoost 能有效控制模型复杂度,防止过拟合
- 处理缺失值:XGBoost 能自动处理数据中的缺失值,提高模型的鲁棒性
缺点:
- 参数调整复杂:XGBoost 具有大量超参数,需要仔细调整以获得最佳性能
- 内存占用大:XGBoost 需要存储大量中间结果,内存占用较大
- 对数据预处理敏感:XGBoost 对数据预处理要求较高,需确保数据规范化和特征选择合理
XGBoost 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务
更多内容,见微*公号往期文章:不愧是腾讯,问基础巨细节 。。。
[ 抱个拳,总个结 ]
集成学习算法通过结合多个基模型的预测结果来提高模型的性能。常见的集成学习算法包括 Bagging、Boosting、随机森林、Adaboost、GBDT 和 XGBoost。每种算法都有其独特的优势和适用场景。
9.1 各算法的比较
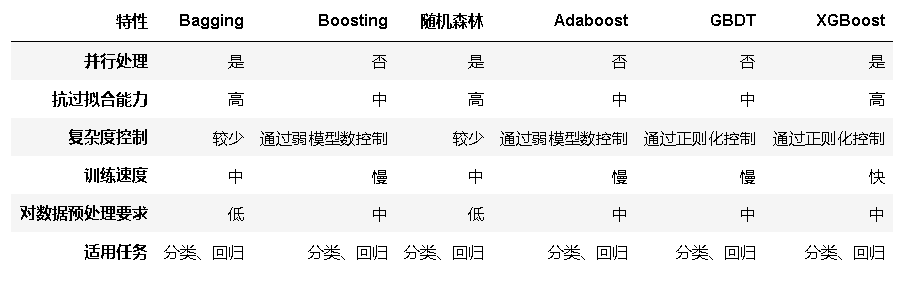
Bagging vs Boosting:
- Bagging(如随机森林)主要通过并行训练多个基模型来减少方差,防止过拟合。它在处理高维数据和噪声数据时表现出色,适用于多种任务
- Boosting(如 Adaboost 和 GBDT)通过串行训练多个基模型来逐步减少模型偏差。它更适合处理复杂的非线性关系,但训练时间较长,对数据预处理要求较高
随机森林 vs GBDT:
- 随机森林是 Bagging 的一种实现,通过构建大量的决策树来提高模型性能。它具有较高的抗过拟合能力和训练速度,但在处理复杂非线性关系时可能表现不如 GBDT
- GBDT 是 Boosting 的一种实现,通过逐步拟合残差来提高模型性能。它在处理复杂非线性关系和高维数据方面表现出色,但训练时间较长,参数调整复杂
XGBoost:
- XGBoost 是 GBDT 的增强版,通过引入正则化、并行处理和二阶导数信息等技术,显著提高了模型的准确性和训练速度。它在各种机器学习竞赛和实际项目中表现优异,适用于多种任务
9.2 实际应用中的选择指南
选择集成学习算法时应考虑以下因素:
- 数据特性:
- 数据维度较高且噪声较多时,Bagging 和随机森林表现较好
- 数据关系复杂且存在非线性特征时,Boosting、GBDT 和 XGBoost 更为适用
- 模型性能:
- 需要高准确率和稳定性的任务,优先选择 XGBoost 或 GBDT
- 需要快速训练和较低复杂度的任务,可以选择 Bagging 或随机森林
- 计算资源:
- 有足够的计算资源和时间,可以选择 XGBoost 或 GBDT 以获得最佳性能
- 资源有限或时间紧迫时,Bagging 和随机森林是更好的选择
- 过拟合风险:
- 数据量较小或过拟合风险较高时,选择具有较高抗过拟合能力的算法,如 Bagging、随机森林和 XGBoost
综合考虑,在实际应用中选择合适的集成学习算法可以显著提高模型的性能和鲁棒性。以下是一个简要的选择指南:
- Bagging:适用于高维、噪声较多的数据,快速训练,防止过拟合
- Boosting:适用于复杂的非线性关系,逐步减少偏差,提高准确性
- 随机森林:适用于各种任务,具有较高的抗过拟合能力和训练速度
- Adaboost:适用于分类任务,逐步调整样本权重,提高模型性能
- GBDT:适用于处理复杂数据和高维数据,提高模型准确性,但训练时间较长
- XGBoost:适用于各种任务,具有最高的准确性和训练速度,但参数调整复杂
通过合理选择和应用集成学习算法,可以有效提升机器学习模型的性能,为各种实际任务提供强大的解决方案。
接下来,大侠可以具体选定某个算法进行更深入的研究或实践应用。山高路远,江湖再会
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
相关文章:
算法金 | 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost 算法大全
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 决策树是一种简单直观的机器学习算法,它广泛应用于分类和回归问题中。它的核心思想是将复杂的决策过程分解成一系列简单的决…...

[每周一更]-(第103期):GIT初始化子模块
文章目录 初始化和更新所有子模块分步骤操作1. 克隆包含子模块的仓库2. 初始化子模块3. 更新子模块 查看子模块状态提交子模块的更改处理子模块路径错误的问题 该问题的缘由是因为:在写某些代码的时候,仓库中有些文件夹,只提交了文件夹名称到…...

单例模式---线程安全实现
文章目录 1.单例模式的特点😊2.单例模式两种实现🤣🤗😊2.1 饿汉式2.2 懒汉式 3.传统单例模式的线程安全问题4.解决方法4.1静态局部变量4.2加锁4.3双重检查锁(DCL)4.4pthread_once 1.单例模式的特点…...

Agent技术在现代软件开发与应用中的探索
一、引言 随着计算机科学的快速发展,Agent技术作为人工智能和分布式计算领域的重要分支,已经渗透到软件开发的各个方面。Agent技术通过赋予软件实体自主性和交互性,使得软件系统能够更加智能、灵活地响应环境变化和用户需求。本文将对Agent技…...
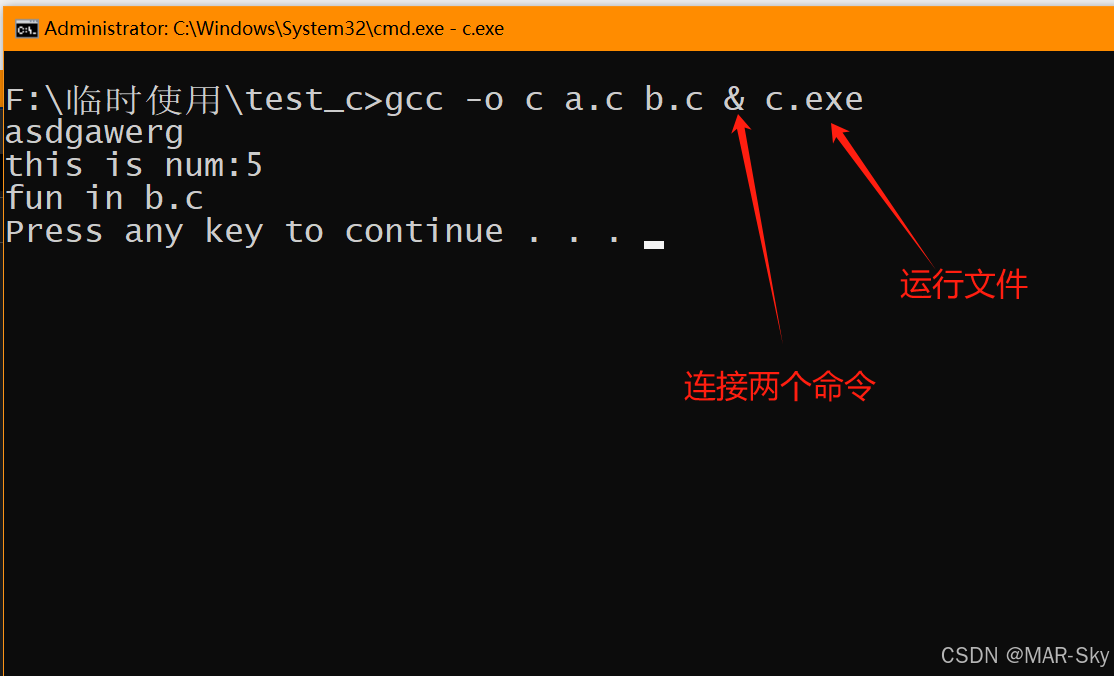
c语言中extern定义和引用其他文件的变量,(sublime text)单独一个文件编译不会成功
关键字extern的作用 这个很常见的都知道是定义一个外部变量或函数,但并不是简单的建立两个文件,然后在用extern 定义在另一个非最初定义变量的文件里 区分文件和编译运行的文件 例如,一个文件夹里有文件a.c和文件b.c,在sublime text中直接…...

时序数据中的孤立野点、异常值识别及处理方法
目录 参考资料 对时序数据做差分; 参考资料 [1] 离群点(孤立点、异常值)检测方法 2017.6;...

JetBrains PyCharm 2024 mac/win版编程艺术,智慧新篇
JetBrains PyCharm 2024是一款功能强大的Python集成开发环境(IDE),专为提升开发者的编程效率和体验而设计。这款IDE不仅继承了前代版本的优秀特性,还在多个方面进行了创新和改进,为Python开发者带来了全新的工作体验。 JetBrains PyCharm 20…...

MCU解决800V电动汽车牵引逆变器的常见设计挑战的3种方式
电动汽车 (EV) 牵引逆变器是电动汽车的。它将高压电池的直流电转换为多相(通常为三相)交流电以驱动牵引电机,并控制制动产生的能量再生。电动汽车电子产品正在从 400V 转向 800V 架构,这有望实现: 快速充电 – 在相同…...

《逆向投资 邓普顿的长赢投资法》
接下来跟大家一起学习《逆向投资 邓普顿的长赢投资法》。邓普顿被誉为20世纪最伟大的选股人之一,我非常确信林奇在他的《战胜华尔街》里也提到了邓普顿,可惜实在想不起来林奇是怎么形容邓普顿的。 邓普顿拥有70多年的投资生涯,在他晚年时曾总…...

C++中main函数的参数、返回值分别什么意思?main函数返回值跟普通函数返回值一样吗?
在C中,main函数是程序的入口点,即程序开始执行的地方。main函数可以有两种形式的签名(signature): 标准的main函数,不接受任何参数,也不返回任何值: int main() {// 代码... }带有参…...

Java程序员学习Go开发Higress的WASM插件
Java程序员学习Go开发Higress的WASM插件 契机 ⚙ 今年天池大赛有higress相关挑战,研究一下。之前没搞过go,踩了很多坑,最主要的就是tinygo打包,多方寻求解决无果,结论是tinygo0.32go1.19无法在macos arm架构下打包。…...

Python入门-基本数据类型-数字类型
数字类型是指表示数字或者数值的数据类型。在Python语言中,数字类型有整型(int)、 浮点型(float)、复数型(complex),对应数学中的整数、小数和复数,此外还有一种特殊 的整型,即布尔型(bool)。本节将对这4种数字类型进行详细介绍。…...
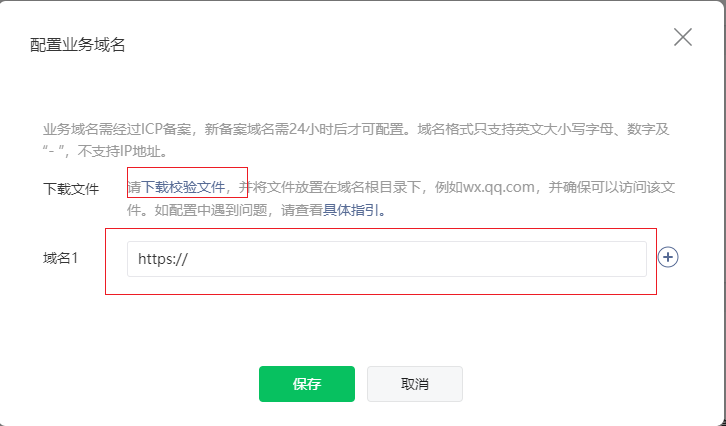
小程序web-view无法打开该页面的解决方法
问题:开发者工具可以正常打开,正式上线版小程序使用 web-view 组件测试时提示:“无法打开该页面,不支持打开 https://xxxxxx,请在“小程序右上角更多->反馈与投诉”中和开发者反馈。” 解决方法:需要配…...

海外媒体发稿:媒体宣发套餐的作用分享-华媒舍
一、神奇媒体宣发套餐 神奇媒体宣发套餐是一项专业的多媒体宣传推广服务,旨在帮助企业、个人快速提升品牌知名度和曝光度。它通过全面覆盖主流媒体、社交网络以及各大网络平台,将您的宣传信息传递给广泛的受众群体,实现全方位、多角度的宣传…...
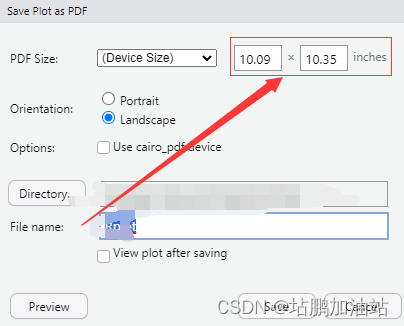
【R语言】plot输出窗口大小的控制
如果需要输出png格式的图片并设置dpi,可采用以下代码 png("A1.png",width 10.09, height 10.35, units "in",res 300) 为了匹配对应的窗口大小,在输出的时候保持宽度和高度一致即可,步骤如下: 如上的“10…...

【shell脚本实战案例】数据磁盘初始化
文章目录 一、案例应用场景二、案例需求三、案例算法四、代码实现五、实现验证 🌈你好呀!我是 山顶风景独好 🎈欢迎踏入我的博客世界,能与您在此邂逅,真是缘分使然!😊 🌸愿您在此停留…...

1.7 计算机体系结构分类
Flynn分类法 CISC与RISC...

数据结构之B树:深入了解与应用
目录 1. B树的基本概念 1.1 B树的定义 1.2 B树的性质 1.3 B树的阶 2. B树的结构 2.1 节点结构 2.2 节点分裂 2.3 节点合并 3. B树的基本操作 3.1 搜索 3.2 插入 3.3 删除 4. B树的应用 4.1 数据库索引 4.2 文件系统 4.3 内存管理 5. B树的优势和局限 5.1 优势…...
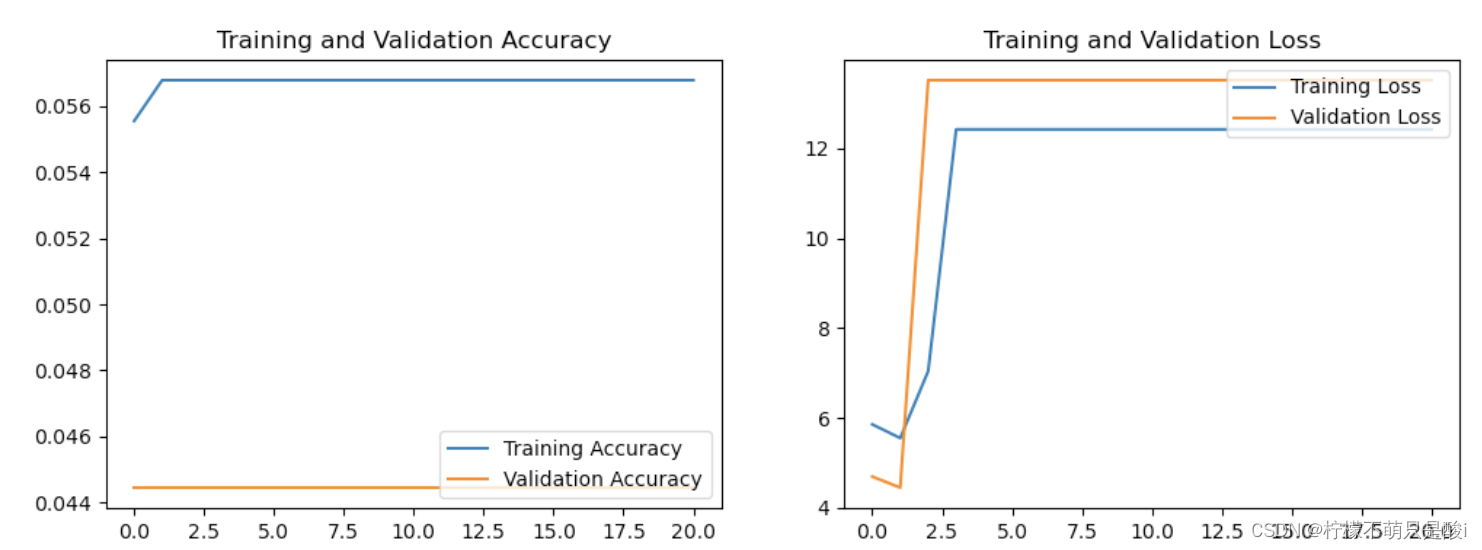
Tensorflow入门实战 T06-Vgg16 明星识别
目录 1、前言 2、 完整代码 3、运行过程结果 4、遇到的问题 5、小结 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 1、前言 这周主要是使用VGG16模型,完成明星照片识别。 2、 完整代…...

SpringBoot 3.3.1 + Minio 实现极速上传和预览模式
统一版本管理 <properties><minio.version>8.5.10</minio.version><aws.version>1.12.737</aws.version><hutool.version>5.8.28</hutool.version> </properties><!--minio --> <dependency><groupId>io.m…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...
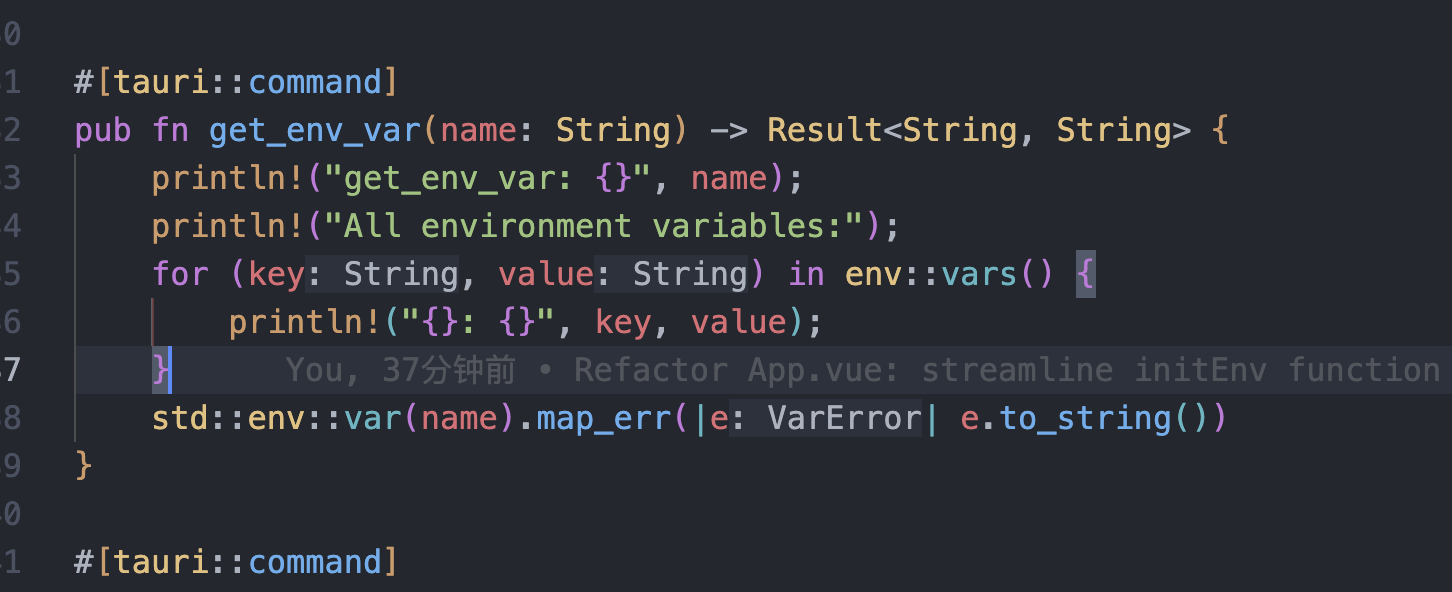
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...