机械学习 - 基础概念 - scikit-learn - 数据预处理 - 1
目录
- 安装 scikit-learn
- 术语理解
- 1. 特征(feature )和样本( sample / demo)的区别?
- 2. 关于模型的概念
- 一、机械学习概念
- 1. 监督学习
- 总结:
- 2. 非监督学习
- 总结:
- 3. 强化学习
- 总结:
- 三种学习的特点总结
- scikit-learn 说明
- 二、机械学习的基本实操逻辑
- 1. 采集数据
- 2. 数据预处理(Preprocessing)
- 预处理算法:
- 归一化:
- 1.normalize()
- 3. 数据降维处理 (Dimensionality reduction)
- 4. 分类(Classification)、回归(Regression)、聚类(Clustering)处理 三选一
- 5. 模型选择 (Model selection)
- 三、数据预处理 —— 数据分析
- 数据规范化详解 —— 归一化 / 标准化
- 如何区分归一化和标准化
- 数据归一化 —— 范围缩放(scale)及映射
- 1. 最大最小规范化(归一化)(Min-Max Normalization) [0,1] / 范围缩放(Scaling)
- 功能:
- 2. Mean normalization (均值归一化)[-1,1]:
- 前两种归一化方法应用场景:
- 前两种归一化方法不适用场景:
- 3. 小数定标规范化(归一化) (normalization by decimal scaling)
- 功能:
- 什么时候用归一化?
- 数据标准化 std
- 1. 零-均值规范化 (标准化)(z-score standardization)/ 均值移除(Mean removal)
- 功能:
- 意义:
- 应用场景:
- 什么时候用标准化?
- 归一化 与 标准化资料链接:
- 下一章节跳转链接
安装 scikit-learn
记得在虚拟环境下安装,这里推荐 Virtualenv
pip install scikit-learn
链接:Windows 10 - Python 的虚拟环境 Virtualenv - 全局 python 环境切换问题
在这里 scikit-learn框架的核心模块 —— sklearn,而不是 scikit
import sklearn
测试环境:(请注意这里是虚拟环境 Virtualenv)
操作系统: Window 10
工具:Pycharm
Python: 3.7
scikit-learn: 1.0.2
numpy: 1.21.6
scipy: 1.7.3
threadpoolctl: 3.1.0
joblib: 1.1.0
术语理解
1. 特征(feature )和样本( sample / demo)的区别?
- 一个样本由多个特征组成,而特征是一个样本的元素;
- 对于数据的处理,通过设置轴参数axis 为 0 或 1 ,可以选择对样本们,进行特征向量运算(纵向)或样本特征运算(横向);
- 样本指横向的元素,特征指纵向的元素。这句话的意思是,当你设置axis = 0 或 axis = 1时,那么当为 0 时,指向纵向的特征元素,为 1 时,则指向横向的样本元素,举个例子,假如有样本 A 和 样本 B,其中样本 A 和样本 B 都有特征 a、b、c ,那么当axis = 0 时,则按顺序取样本 A 和 样本 B 的特征 [Aa, Ba],[Ab, Bb],[Ac, Bc],当 axis = 1 时,则按顺序取样本 A 的特征 [Aa, Ab, Ac] ,然后再取样本 B 的 [Ba, Bb, Bc]
具体演示:
0|1 a b c
样本 A Aa Ab Ac
样本 B Ba Bb Bc- 某个矩阵内的所有的输入值 x ,最终经过算法转换,得到输出值特征 y
2. 关于模型的概念
所谓的机器学习模型,本质上是一个函数,其作用是实现从一个样本 XXX 到样本的标记值 f(x)→xf(x) \rightarrow xf(x)→x 的映射
通俗概括:可以从数据中学习到的,可以实现特定功能(映射)的函数。
进一步专业性概括:模型是在指定的假设空间中,确定学习策略,通过优化算法去学习到的由输入 到输出的映射。
现实中,我们可以看到一些用塑料制造出来的人物、机器等模型,这就是相当于一个映射,从脑海里的想法 x 中,映射为塑料模型 y ,还有3D模型,也是同理,通过构建模型 y,映射出脑海里的 x ,但是机械学习的模型,也是一样的吗?
那是自然,通过已知的数据 x 映射出未知的数据 y, 来构建出一个预测模型,该模型是通过监督、非监督、强化等学习策略,以算法为工具,来构建一个模型。
实际理解:编程语言的函数f(x)f(x)f(x),输入矩阵XXX ,也就是样本 XXX,返回值是一个模型对样本的转换后的映射 YYY,YYY 是一个预测值。
一、机械学习概念
机械学习共分为三种学习:
- 监督学习
- 非监督学习
- 强化学习
1. 监督学习
监督学习(
Supervised Learning)的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。
即:利用训练数据集学习一个模型,再用模型对测试样本集进行预测。通俗理解:每个数据点都被标记或关联一个类别或者分值。
例(类别):输入一张图片,判断该图片中的动物是猫还是狗;
例(分值):通过大量数据预测一辆二手车的出售价格;
监督学习的目的就是学习大量的样本(称作训练数据),从而对未来的数据点做出预测(称作测试数据)。
分类和回归,从根本上来说,分类是预测一个标签,回归是预测一个数量。
分类是给一个样本预测离散型类别标签的问题。
回归是给一个样本预测连续输出量的问题。
这段引用,笔者个人理解是,模型是具备输入值和输出值的,即 XXX 和 YYY ,当统计完这个模型内的一般规律,就可以用这个统计出来的一般规律,来预测其他的输入值 XXX 的可能性,即输出值 YYY,当然这一点,其实就很麻烦,现实世界可无法仅仅通过一个模型的规律,就能预测的了结果,所以只能说模型多多益善。
对于分类,笔者认为是点状预测,一个点一个点的预测出来,而不是像一条线那样;
回归则是线性预测,例如可以预测股票的线性变化,笔者个人大致是这样认为的。
总结:
监督学习,需要人去找模型去喂给它,还要多多观察该模型的准确性,也就是要监督并观察该算法的性能及准确度,就好比如有的小孩子需要我们大人去监督它们的学习,这样它们会在我们的监督下,认真学习,并提高成绩,这里指的是提升算法的性能和模型的准确度。
所以哪些需要模型的,都是监督学习。
2. 非监督学习
非监督学习(
Unsupervised Learning)为直接对数据进行建模。没有给定事先标记过的训练范例,所用的数据没有属性或标签这一概念。事先不知道输入数据对应的输出结果是什么。自动对输入的资料进行分类或分群,以寻找数据的模型和规律。
例:聚类
总结:
非监督学习,孩子需要靠自己自学成才,不应该需要我们去监督它们学习,这样才能独立自主,由于现实生活中的变化,我们不太可能拥有全部的现实模型,在某种情况下,我们不太可能一直监督它们学习,所以需要它拥有自学的能力,通过自主收集现实的样本特征,自动的对自己进行变量输入,从而获取一个又一个的模型,然后对于模型进行一个性能或准确度的评估等等。
3. 强化学习
强化学习(
Reinforcement Learning)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
总结:
强化学习,孩子在学会了自主学习后,对它们进行一个激励的学习奖励措施,那么其会有可能形成一个应激性的行为,然后孩子就会容易去做某种对自己有利的事,比如设计一个撞墙的强化学习算法,那么对于撞墙就会执行一个闪避的有利选择,所以我们可以利用这一点,设计出一个符合该设想的机器学习算法,即强化学习。
三种学习的特点总结
有监督学习、无监督学习、强化学习具有不同的特点:
监督学习是有一个
label(标记)的,这个label告诉算法什么样的输入对应着什么样的输出,常见的算法是分类、回归等;
无监督学习则是没有label(标记),常见的算法是聚类;
强化学习强调如何基于环境而行动,以取得最大化的预期利益。
scikit-learn 说明
scikit-learn库主要功能分六大部分:分类,回归,聚类,降维,模型选择,数据预处理
分类、回归 ——> 监督学习
聚类 ——> 非监督学习
二、机械学习的基本实操逻辑
1. 采集数据
这里先不介绍采集数据,笔者还没涉猎。
2. 数据预处理(Preprocessing)
在真实的世界中,经常需要处理大量的原始数据,这些原始数据是机器学习算法无法理解的,为了让机器学习算法理解原始数据,需要对数据进行预处理。
所谓的预处理,也叫规范化,其实就是提取复杂数据里的有价值的内容,这里用到了归一化或标准化:
- 数据归一化/标准化 —— 将原始数据分为训练用数据和测试数据,测试数据是从原始数据中抽出一部分充当测试用的数据 (这在监督学习中很常见)
预处理算法:
归一化:
1.normalize()
3. 数据降维处理 (Dimensionality reduction)
通常而言,做机器学习时,你的数据量越大,维度越多,考虑的因素越多,你的分类、回归的预测就会越准确,但也因为是考虑的太多了,你的计算也就会越慢,所以在这里就会考虑要怎么权衡预测的准确度和计算速度。
在保证最大信息量的情况下,减少维度,降低计算的时间。
减少维度,可以更好的可视化,超过了三维,人就会难以理解,所以降维可以将数据更好的可视化,还有提升计算的效率(机器学习最根本的一点)
降维算法:
4. 分类(Classification)、回归(Regression)、聚类(Clustering)处理 三选一
分类算法:
回归算法:
聚类算法:
5. 模型选择 (Model selection)
三、数据预处理 —— 数据分析
数据规范化详解 —— 归一化 / 标准化
数据规范化处理是数据挖掘的一项基础工作。不同评价指标往往具有不同的量纲,数值见的差别可能很大,不进行处理可能会影响到数据分析的结果。为了消除指标之间的量纲(不同的物理量)和取值范围差异的影响,需要进行标准化处理(对数据进行预处理),将数据按照比例进行缩放(归一化处理),使之落入一个特定的区域,便于进行综合分析。如将工资收入属性值映射到[−1,1][-1,1][−1,1]或者[0,1][0, 1][0,1]内 (这是归一化例子)
数据规范化对于基于距离的挖掘算法尤为重要。(这里的基于距离指的是变量输出值之间的距离)
规范化 指归一化 或 标准化
如何区分归一化和标准化
归一化和标准化都是对数据做变换的方式,将原始的一列数据转换到某个范围,或者某种形态,具体的:
归一化(Normalization):数据归一化用于需要对特征向量的值进行调整时,以保证每个特征向量的值都缩放到相同的数值范围,将一列数据变化到某个固定区间(范围)中,通常,这个区间是 [0,1][0, 1][0,1],广义的讲,可以是各种区间,比如映射到 [0,1][0,1][0,1]一样可以继续映射到其他范围,图像中可能会映射到 [0,255][0,255][0,255],其他情况可能映射到 [−1,1][-1,1][−1,1];
标准化(Standardization):将数据变换为均值为0,标准差为1的分布[0,1][0, 1][0,1],切记,并非一定是正态的;
中心化:另外,还有一种处理叫做中心化,也叫零均值处理,就是将每个原始数据减去这些数据的均值。(其实也就是上面的标准化)
有时候会看到标准归一化,其实也差不多,说是标准化,其实这个定义早就被归一化的概念给覆盖了,标准化归一化都可以这么叫,但是具体到它们的实现公式就得考虑清楚,名字随意,实现它们时,就得看看是怎么个处理方法。
一个是等比例缩放、一个是去均值中心化缩放。
数据归一化 —— 范围缩放(scale)及映射
scale n. 天平,磅秤;;刻度,标度;标尺,刻度尺;v 缩放
广义的说,标准化和归一化同为对数据的线性变化,所以我们没必要规定死,归一化难道就必须到[0,1][0,1][0,1]之间,我到 [0,1][0,1][0,1] 之间后,然后再乘一个255,你奈我何?所以切记不要被概念所束缚住,常见的有以下几种:
1. 最大最小规范化(归一化)(Min-Max Normalization) [0,1] / 范围缩放(Scaling)
功能:
归一化的最通用模式Normalization,也称线性归一化、最小-最大规范化,也称为离散标准化,是对原始数据的线性变换,将数据值映射到 [0,1][0, 1][0,1] 之间
转换公式如下:
Xnew=Xi−XminXmax−XminX_{new}=\frac{X_{i}-X_{min}}{X_{max}-X_{min}}Xnew=Xmax−XminXi−Xmin ,范围 [0,1][0,1][0,1]
- XiX_{i}Xi : 指的是要归一化的数据,通常是二维矩阵
- XmaxX_{max}Xmax : 每列中的最大值组成的行向量
- XminX_{min}Xmin : 每列中的最小值组成的行向量
- XnewX_{new}Xnew : 指的是占比结果,到了这一步其实还不算完整,看下面的公式中的 XscaledX_{scaled}Xscaled
或
Xstd=X−X.min(axis=0)X.max(axis=0)−X.min(axis=0)X_{std}=\frac{X_{}-X_{.}min(axis=0)}{X_{.}max(axis=0)-X_{.}min(axis=0)}Xstd=X.max(axis=0)−X.min(axis=0)X−X.min(axis=0)
Xscaled=Xstd×(max−min)+minX_{scaled}=X_{std}\times(max-min)+minXscaled=Xstd×(max−min)+min ,范围 [0,1][0,1][0,1]
乍看一下很懵逼,解释一下:
- XXX:要归一化的数据,通常是二维矩阵,例如
[[4,2,3]
[1,5,6]]
-
X.min(axis=0)X.min(axis=0)X.min(axis=0):每列中的最小值组成的行向量,如上面的例子中应该是
[1,2,3] -
X.max(axis=0)X.max(axis=0)X.max(axis=0):每列中的最大值组成的行向量,如上面的例子中应该是
[4,5,6] -
maxmaxmax: 要映射到的区间最大值,默认是1 ,可以根据情况更改,不要被束缚住
-
minminmin:要映射到的区间最小值,默认是0 ,可以根据情况更改,不要被束缚住
-
XstdX_{std}Xstd : 占比结果
-
XscaledX_{scaled}Xscaled: 最终的归一化结果,映射到范围 [0,1][0,1][0,1]而已,借助XstdX_{std}Xstd 完成最后一步的 XscaledX_{scaled}Xscaled ,minminmin 为 0.
再用朴实的语言描述一下上面公式所做的事:
- 第一步求每个列中元素到最小值距离占该列最大值和最小值距离的比例,这实际上已经是将数据放缩到了 [0,1][0,1][0,1] 区间上
- 第二步将占比结果数据按同等比例缩放映射到指定的 [min,max][min,max][min,max] 区间
2. Mean normalization (均值归一化)[-1,1]:
若要转换到 [−1,1][-1,1][−1,1] 之间,则
Xstd=X−XmeanXmax−XminX_{std}=\frac{X-X_{mean}}{X_{max}-X_{min}}Xstd=Xmax−XminX−Xmean
Xscaled=Xstd×(max−min)+minX_{scaled}=X_{std}\times(max-min)+minXscaled=Xstd×(max−min)+min ,范围 [−1,1][-1,1][−1,1]
- XstdX_{std}Xstd : 去除均值的占比结果
- XmeanX_{mean}Xmean 代表了 XXX的每一列的均值
- X.min(axis=0)X.min(axis=0)X.min(axis=0):每列中的最小值组成的行向量
- X.max(axis=0)X.max(axis=0)X.max(axis=0):每列中的最大值组成的行向量
- XscaledX_{scaled}Xscaled: 最终的归一化结果,所谓的映射,本质是放大了 XstdX_{std}Xstd 的数值,映射到范围 [−1,1][-1,1][−1,1]而已
- maxmaxmax: 要映射到的区间最大值,默认是1 ,可以根据情况更改,不要被束缚住
- minminmin:要映射到的区间最小值,默认是0 ,可以根据情况更改,不要被束缚住
前两种归一化方法应用场景:
- 在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用该方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在 [0−255][0 - 255][0−255] 的范围
前两种归一化方法不适用场景:
- 原始数据存在小部分很大或很小的数据时,会造成大部分数据规范化后接近于 0 或 1,区分度不大,比如 (
1, 1.2, 1.3, 1.4, 1.5, 1.6,8.4)这组数据。若将来遇到超过目前属性[min, max]取值范围的时候,会引起系统报错,需要重新确定 minminmin 和 maxmaxmax —— 将这组数据标准化(归一化),然后得到的一组规范化后各值接近于0的数据,假如以后加入新的数据,会有可能超过该数据标准化后的最大最小的范围,就需要重新确定 minminmin 和 maxmaxmax
3. 小数定标规范化(归一化) (normalization by decimal scaling)
功能:
通过移动属性值的小数位数,将属性值映射到[-1, 1]之间,移动的小数位数取决于属性值绝对值的最大值。
转化公式为: 原始值 / 10^k
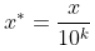
Xnew=X10kX_{new}=\frac{X}{10^k}Xnew=10kX
- k 取决于 XXX 内的属性取值中的最大绝对值
- 小数定标规范化就是通过移动小数点的位置来进行规范化。
- 小数点移动多少位取决于 XXX 内的属性的取值中的最大绝对值。
这里的 XXX 内的属性代指样本实例的某种属性,比如长度、宽度、数量等。
也就是说找的是矩阵内绝对值化后的最大的输入值元素x,并且使用恰当的对数函数方法 log10 ,以10为底,值为该绝对值化的最大值 max(x) ,即 log10max(X)=klog_{10} max(X) = klog10max(X)=k ,得到 k 值,还要注意的一点是 kkk 值必须是向上取整,这里提供一个方法是numpy模块的ceil(k)方法,向上取整方法,注意不是四舍五入,而是整个小数点后的值都被舍去了。完整公式:Xnew=ceil(log10max(abs(X)))X_{new} = ceil(log_{10} max(abs(X)))Xnew=ceil(log10max(abs(X))) ,abs()是绝对值函数
什么时候用归一化?
- 如果对输出结果范围有要求,用归一化。
- 如果数据较为稳定,不存在极端的最大最小值,用归一化。
数据标准化 std
1. 零-均值规范化 (标准化)(z-score standardization)/ 均值移除(Mean removal)
通常我们会把每个特征的平均值移除,以保证特征均值为0(即标准化处理)。这样做可以消除特征彼此之间的偏差(
bias)。
功能:
零-均值规范化也称标准差标准化,经过处理的数据的均值为0,标准差为1,是当前用得最多的数据标准化方式。
转化公式为: (原始值 - 均值)/ 标准差
Xnew=X−XmeanXstdX_{new}=\frac{X-X_{mean}}{X_{std}}Xnew=XstdX−Xmean
符号解释:
XnewX_{new}Xnew 为标准化后的值
XmeanX_{mean}Xmean 为 XXX 的均值
XstdX_{std}Xstd 为 XXX 的标准差
意义:
- 变换后数据的 均值为0,方差为1
- 结果没有实际意义,仅用于比较
应用场景:
- 在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,
Z-score standardization表现更好。
什么时候用标准化?
- 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
归一化 与 标准化资料链接:
如何理解归一化(normalization)?
最大最小化标准化
标准化和归一化,请勿混为一谈,透彻理解数据变换
常用数据规范化方法: min-max规范化,零-均值规范化等
数据挖掘实验(一)数据规范化【最小-最大规范化、零-均值规范化、小数定标规范化】
【机器学习】数据归一化——MinMaxScaler理解
python中axis=0 axis=1的理解
参考链接:
6_Python机器学习库Scikit-Learn介绍
下一章节跳转链接
机械学习 - scikit-learn - 数据预处理 - 2
相关文章:
机械学习 - 基础概念 - scikit-learn - 数据预处理 - 1
目录安装 scikit-learn术语理解1. 特征(feature )和样本( sample / demo)的区别?2. 关于模型的概念一、机械学习概念1. 监督学习总结:2. 非监督学习总结:3. 强化学习总结:三种学习的…...
)
OLCNE cluster 配置 NFS Storage(英文)
OLCNE cluster 配置 NFS Storage(英文)Create an OLCNE cluster.Create an NFS server.a. Install the NFS utility package on the server and client instances.b. Create a directory for your shared files. Make sure that the server does not hav…...
RabbitMQ高级特性
RabbitMQ高级特性 消息可靠性投递 Consumer ACK 消费端限流 TTL 死信队列 延迟队列 日志与监控 消息可靠性分析与追踪 管理 消息可靠性投递 在使用 RabbitMQ 的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ 为我们提供了两种方式用来控制…...
利用Dockerfile开发定制镜像实战.
Dockerfile的原理 dockerfile是一种文本格式的文件,用于描述如何构建Docker镜像。在Dockerfile中,我们可以定义基础镜像、安装依赖、添加文件等操作,最终生成一个可以直接运行的容器镜像。 Dockerfile的原理可以分为以下几个步骤:…...

PyInstaller 将DLL文件打包进exe
PyInstaller 将DLL文件打包进exe方法1:通过--add-data命令方法2:通过修改 .spec扩展:博主热门文章推荐:方法1:通过–add-data命令 注意:这里 dll末尾添加的.为当前目录,则该dll要放到main.py同一…...
【JVM篇2】垃圾回收机制
目录 一、GC的作用 申请变量的时机&销毁变量的时机 内存泄漏 内存溢出(oom) 垃圾回收的劣势 二、GC的工作过程 回收垃圾的过程 第一阶段:找垃圾/判定垃圾 方案1:基于引用计数(非Java语言) 引用计数方式的缺陷 方案2:可达性分析…...
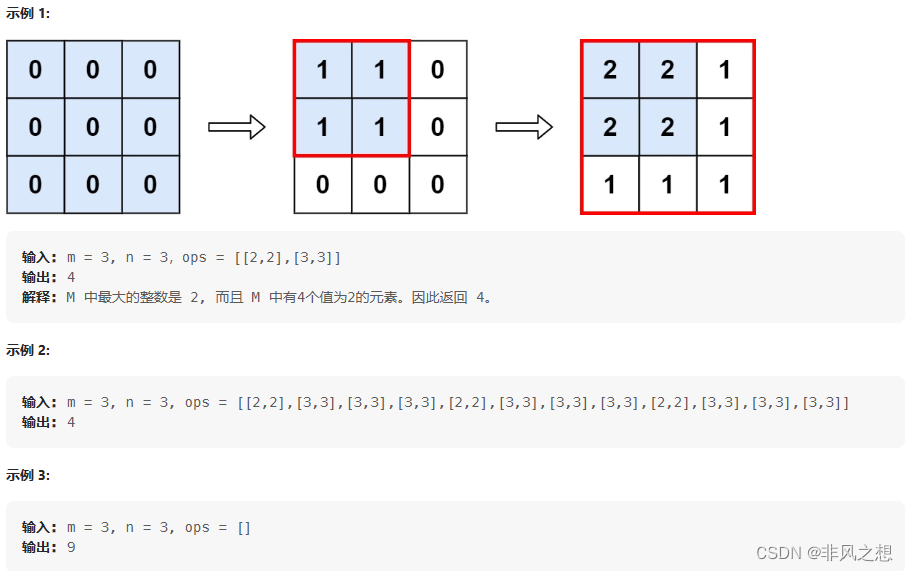
LeetCode598. 范围求和 II(python)
题目 给你一个 m x n 的矩阵 M ,初始化时所有的 0 和一个操作数组 op ,其中 ops[i] [ai, bi] 意味着当所有的 0 < x < ai 和 0 < y < bi 时, M[x][y] 应该加 1。 提示: 1 < m, n < 4 * 104 0 < ops.length < 104 o…...

观察者模式与发布订阅模式
前言 我的任督二脉终于被打通了,现在该你了 区别 观察者模式 就2个角色:观察者和被观察者(重要)明确知道状态源,明确知道对方是谁一对多关系 发布订阅模式 有3个角色:发布者,订阅者和发布订阅…...

磨金石教育摄影技能干货分享|烟花三月下扬州,是时候安排了!
人间三月最柔情,杨柳依依水波横。三月的风将要吹来,春天的门正式打开。对中国人来说,古往今来,赏春最好的地方是江南。人人都说江南好,可是江南哪里好呢?古人在这方面早就给出了答案:故人西辞黄…...

Kafka 消费组位移
Kafka 消费组位移消费者 API命令行Kafka : 基于日志结构(log-based)的消息引擎 消费消息时,只是从磁盘文件上读取数据,不会删除消息数据位移数据能由消费者控制,能很容易修改位移的值,实现重复消费历史数据…...

Python|数学|贪心|数组|动态规划|单选记录:实现保留3位有效数字(四舍六入五成双规则)|用Python来创造一个提示用户输入数字的乘法表|最小路径和
1、实现保留3位有效数字(四舍六入五成双规则)(数学,算法) 贡献者:weixin_45782673 输入:1234 输出:1234 12 12.0 4 4.00 0.2 0.200 0.32 0.320 1.3 1.30 1.235 1.24 1.245 1.24 1.…...

【MySQL】MySQL的索引
目录 介绍 索引的分类 索引的操作-创建索引-单列索引-普通索引 格式 操作 索引的操作-创建索引-单列索引-唯一索引 索引的操作-创建索引-单列索引-主键索引 索引的操作-创建索引-组合索引 索引的操作-全文索引 索引的操作-空间索引 索引的验证 索引的特点 介绍…...
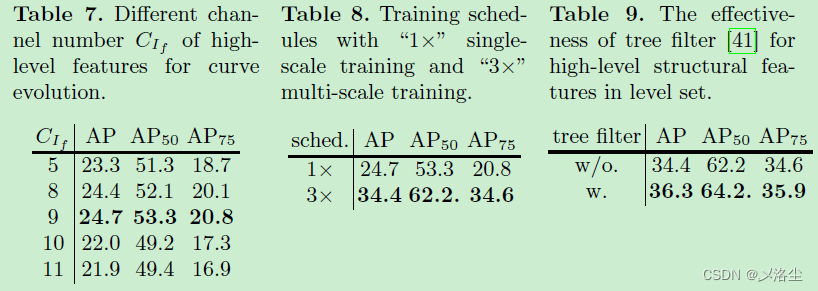
弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记
弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记一、Abstract二、引言三、相关工作3.1 基于 Box 的实例分割3.2 基于层级的分割四、提出的方法4.1 图像分割中的层级模型4.2 基于 Box 的实例分割在 Bounding Box 内的层级进化输入的数据…...
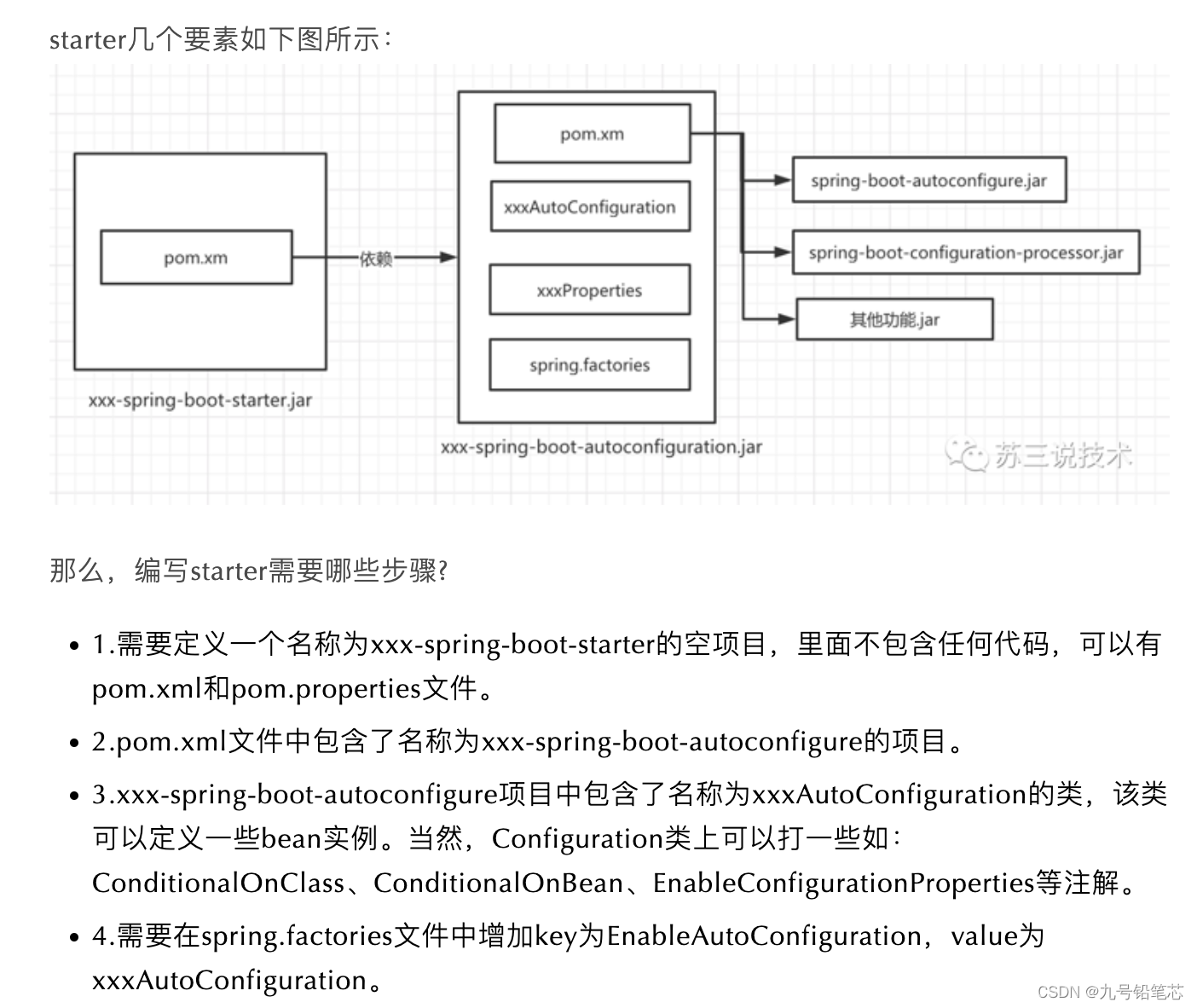
Springboot是什么
目录 为什么会要用springboot 1、之前 2、现在 springboot优点 springboot四大核心 自动装配介绍 1、自动装配作用是什么 2、自动装配原理 springboot starter是什么 1、starter作用 2、比如:我们想搭建java web框架 3、starter原理 SpringBootApplica…...
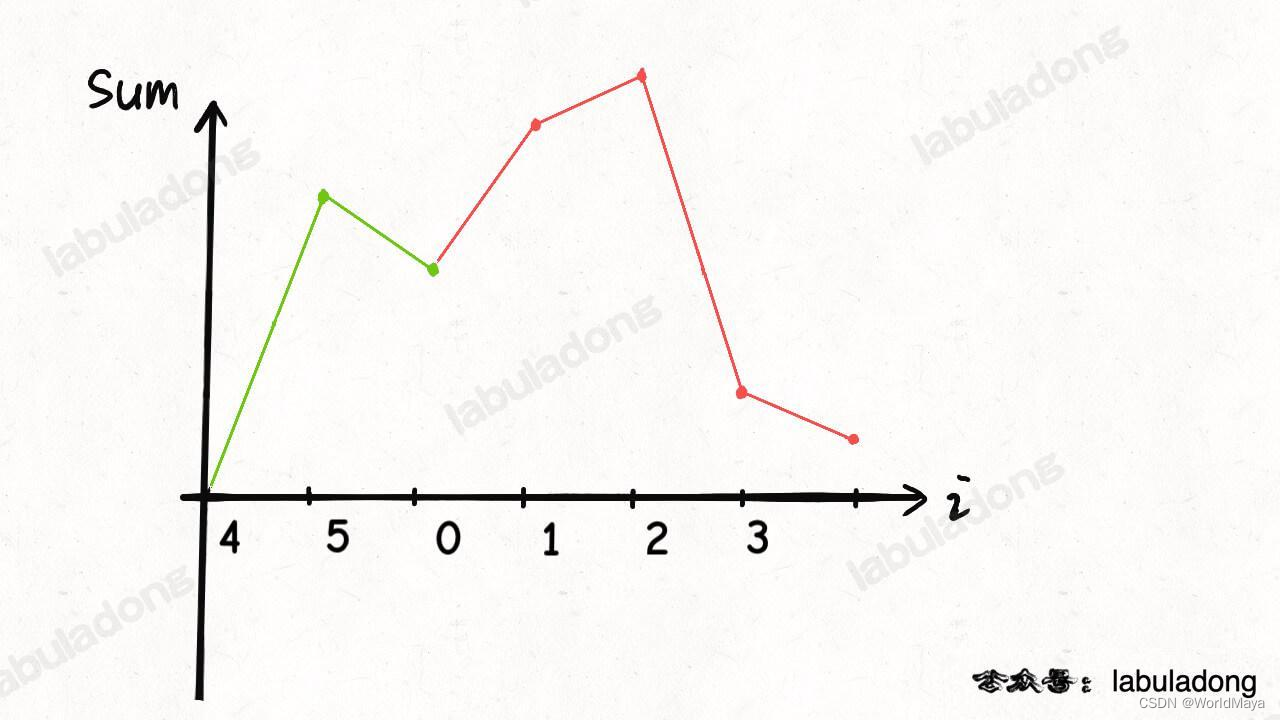
LeetCode 134. 加油站(函数图像法 / 贪心)
题目: 链接:LeetCode 134. 加油站 难度:中等 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中…...

王道计算机组成原理课代表 - 考研计算机 第三章 存储系统 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 计算机组成 知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!! 关于对 存储系统 章节知识点总结的十分全面,涵括了《计算机组成原理》课程里…...
Flask-mock接口数据流程
背景:由于在开发过程中,会遇到以下的痛点 1.服务端接口提测延期,具体接口逻辑未完成实现,接口未能正常调通,导致客户端提测停滞; 2.因为前期已在技术评审上已与客户端开发定好接口字段,客户端比…...

springboot项目配置序列化,反序列化器
介绍本文介绍在项目中时间类型、枚举类型的序列化和反序列化自定义的处理类,也可以使用注解。建议枚举都实现一个统一的接口,方便处理。我这定义了一个Dict接口。枚举类型注解处理这种方式比较灵活,可以让枚举按照自己的方式序列化࿰…...
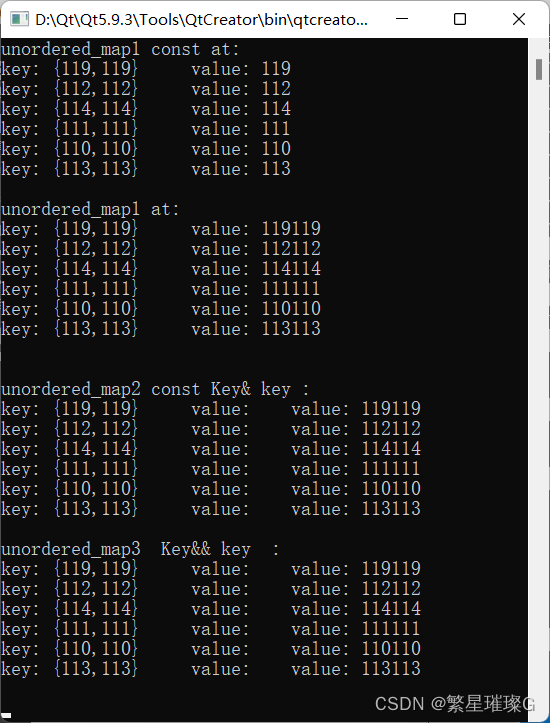
c++11 标准模板(STL)(std::unordered_map)(九)
定义于头文件 <unordered_map> template< class Key, class T, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator< std::pair<const Key, T> > > class unordered…...

Seay代码审计工具
一、简介Seay是基于C#语言开发的一款针对PHP代码安全性审计的系统,主要运行于Windows系统上。这款软件能够发现SQL注入、代码执行、命令执行、文件包含、文件上传、绕过转义防护、拒绝服务、XSS跨站、信息泄露、任意URL跳转等漏洞,基本上覆盖常见PHP漏洞…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...