深度解析:机器学习如何助力GPT-5实现语言理解的飞跃
文章目录
- 文章前言
- 机器学习在GPT-5中的具体应用
- 模型训练与优化
- 机器翻译与跨语言交流:
- 情感分析与问答系统:
- 集成机器学习功能:
- 文本生成
- 语言理解
- 任务适应
- 机器学习对GPT-5性能的影响
- 存在的挑战及解决方案
- 技术细节与示例
文章前言

GPT-5是OpenAI公司开发的一种先进的自然语言处理模型,它是GPT(Generative Pre-trained Transformer)系列的最新成员。GPT-5代表了当前自然语言处理领域的最前沿技术,通过深度学习和机器学习技术,GPT-5能够在海量文本数据上进行预训练,学习并理解人类语言的复杂性和多样性。GPT-5拥有庞大的模型规模和超强的生成能力,能够生成连贯、流畅且富含信息的文本,广泛应用于文本生成、问答系统、机器翻译、文本摘要等自然语言处理任务中。GPT-5的出现不仅推动了人工智能技术的发展,也为各行各业带来了革命性的变革。
机器学习在GPT-5中发挥着至关重要的作用,为GPT-5赋予了强大的文本生成和语言理解能力。以下将详细解释机器学习在GPT-5中的应用、对性能的影响、存在的挑战及解决方案,并提供相关的技术细节和示例。
机器学习在GPT-5中的具体应用

模型训练与优化
- GPT-5采用了大规模的预训练数据,通过机器学习算法进行训练,使模型能够学习到人类语言的复杂性和多样性。
- GPT-5的模型规模预计将达到近百万亿参数的级别,远超GPT-4的10万亿参数,这得益于机器学习算法在处理大规模数据时的效率。
- GPT-5通过机器学习不断优化模型参数,使预测结果尽可能接近真实文本,从而提升模型的准确性和泛化能力。
示例伪代码:
# 假设我们有一个预训练模型GPT5Model和一个训练数据集train_data # 初始化GPT-5模型
gpt5_model = GPT5Model() # 定义损失函数和优化器
loss_function = ... # 具体的损失函数,如交叉熵损失
optimizer = ... # 具体的优化器,如Adam优化器 # 训练循环
for epoch in range(num_epochs): for batch in train_data: # 前向传播 outputs = gpt5_model(batch) # 计算损失 loss = loss_function(outputs, batch['targets']) # 反向传播和优化 loss.backward() optimizer.step() optimizer.zero_grad() # 保存训练好的模型
gpt5_model.save('gpt5_trained_model.pth')

机器翻译与跨语言交流:
- GPT-5具备强大的机器翻译能力,能够实现多种语言间的互译,为跨语言交流提供便利。
- 机器学习算法使得GPT-5在翻译过程中能够准确捕捉语言的语义和上下文信息,确保翻译结果的准确性和流畅性。
示例伪代码:
# 假设我们有一个加载好的GPT-5翻译模型gpt5_translator # 加载GPT-5翻译模型
gpt5_translator = load_translator('gpt5_translator_model.pth') # 输入待翻译的文本和源语言、目标语言
source_text = "你好,世界!"
source_lang = 'zh'
target_lang = 'en' # 使用GPT-5翻译模型进行翻译
translated_text = gpt5_translator.translate(source_text, source_lang, target_lang) # 打印翻译结果
print(translated_text)
情感分析与问答系统:
- GPT-5可以应用于情感分析任务,通过机器学习算法识别文本中的情感倾向和情绪表达。
- 在问答系统方面,GPT-5可以理解用户的问题或需求,并给出相应的回答或建议。这种能力同样依赖于机器学习算法对语言理解和处理的能力。
示例伪代码:
# 假设我们有一个加载好的GPT-5情感分析模型gpt5_sentiment_analyzer和一个问答模型gpt5_qa_model # 加载情感分析模型
gpt5_sentiment_analyzer = load_model('gpt5_sentiment_analyzer_model.pth') # 输入待分析的文本
text_to_analyze = "这部电影太棒了!" # 使用GPT-5情感分析模型进行分析
sentiment = gpt5_sentiment_analyzer.analyze_sentiment(text_to_analyze) # 打印情感分析结果
print(sentiment) # 输出可能是 "positive" 或其他情感标签 # 加载问答模型
gpt5_qa_model = load_model('gpt5_qa_model.pth') # 输入问题和上下文
question = "这部电影的导演是谁?"
context = "这部电影是由张艺谋执导的..." # 使用GPT-5问答模型回答问题
answer = gpt5_qa_model.answer_question(question, context) # 打印回答结果
print(answer)
集成机器学习功能:
- GPT-5集成了机器学习功能,使得AI能够从用户的反馈和数据中不断学习和改进,提供更好的服务。
- 用户可以给GPT-5提供正面或负面的评价,或者指定一些优化目标或约束条件,让GPT-5根据这些信息来调整自己的行为和输出。
文本生成
GPT-5通过机器学习技术,特别是深度学习中的自然语言处理(NLP)技术,能够生成高质量的文本内容。它可以根据输入的文本或主题,自动编写文章、新闻、小说等,具有与人类相似的写作风格和语言表达能力。
示例代码:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch # 加载模型和分词器
model_name = "gpt2-medium" # 假设我们使用GPT-2的medium版本作为示例
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name) # 输入文本
input_text = "今天天气真好,"
input_ids = tokenizer.encode(input_text, return_tensors='pt') # 生成文本
generated = model.generate(input_ids, max_length=50, pad_token_id=tokenizer.eos_token_id) # 将生成的ID转换为文本
output_text = tokenizer.decode(generated[0], skip_special_tokens=True)
print(output_text)
语言理解
GPT-5还能够理解并解释自然语言文本的含义。它可以通过学习大量的文本数据,掌握语言的语法、语义和上下文信息,从而实现对文本内容的深入理解。
示例代码:
# 假设我们有一个预训练的GPT模型和一个分类头
# (注意:GPT本身不直接用于分类,但我们可以添加额外的层) # ...(加载模型和分词器的代码与上面相同)... # 假设的文本分类函数(这里只是一个示意,GPT本身不提供分类功能)
def classify_text(text, model, tokenizer, classifier_head): input_ids = tokenizer.encode(text, return_tensors='pt') with torch.no_grad(): gpt_output = model(input_ids)[0] # 获取GPT模型的最后一层输出 # 假设classifier_head是一个预训练的分类头模型 class_logits = classifier_head(gpt_output[:, 0, :]) # 取第一个token的输出进行分类 predicted_class = torch.argmax(class_logits, dim=-1).item() return predicted_class # 示例文本
text_to_classify = "我喜欢看电影"
predicted_class = classify_text(text_to_classify, model, tokenizer, classifier_head)
print(f"预测的类别是:{predicted_class}")
任务适应
GPT-5具备自适应学习能力,能够根据不同的任务需求调整自身的参数和模型结构。这使得GPT-5能够应用于各种自然语言处理任务,如问答系统、情感分析、机器翻译等。
示例代码:
from transformers import Trainer, TrainingArguments
from your_custom_dataset import YourCustomDataset # 假设你有一个自定义的数据集类 # ...(加载模型和分词器的代码与上面相同)... # 定义训练参数
training_args = TrainingArguments( output_dir='./results', # 输出目录 num_train_epochs=3, # 训练轮次 per_device_train_batch_size=16, # 批量大小 warmup_steps=500, # 学习率预热步数 weight_decay=0.01, # 权重衰减 logging_dir='./logs', # TensorBoard日志目录 logging_steps=10,
) # 加载数据集
train_dataset = YourCustomDataset(tokenizer=tokenizer, mode='train')
eval_dataset = YourCustomDataset(tokenizer=tokenizer, mode='eval') # 初始化Trainer
trainer = Trainer( model=model, # 模型 args=training_args, # 训练参数 train_dataset=train_dataset, # 训练数据集 eval_dataset=eval_dataset, # 评估数据集 # ... 其他可选参数 ...
) # 开始训练
trainer.train()
机器学习对GPT-5性能的影响
机器学习对GPT-5性能的影响是多方面的,从提升模型的准确性、泛化能力,到优化计算效率等方面都起到了关键作用。以下是详细的分析:
-
提升准确性:
- GPT-5通过大量的文本数据训练,能够学习到更多的语言知识和模式,从而提升其生成文本和理解语言的准确性。
- 斯坦福大学的研究发现,虽然使用AI生成的数据训练模型会导致性能下降,即所谓的“模型自噬障碍”(MAD),但这是因为模型未能得到“新鲜的数据”,即人类标注的数据。这强调了真实数据在提升模型准确性中的重要性。
- GPT-5的训练数据预计将达到近百万亿参数的级别,远超GPT-4的10万亿参数,这将使GPT-5能够处理更复杂的任务,生成更精确和流畅的文本。
-
提高泛化能力:
- GPT-5经过充分的机器学习训练,能够处理各种复杂的自然语言场景,具备较强的泛化能力。它的多模态能力将支持视频、音频等其他媒体形式的输入和输出,进一步扩大了其应用场景。GPT-5的更新还包括长期记忆和增强上下文意识,这将使模型能够处理需要长期记忆和连贯性的任务,如写长篇小说或进行深入对话,进一步提高了其泛化能力。
-
优化计算效率:
- GPT-5采用了先进的分布式计算技术和轻量级模型,这些技术能够在保持高性能的同时,降低对计算资源的需求,提高计算效率。尽管GPT-5的算力集群更庞大,训练成本更高,但通过这些优化技术,可以在一定程度上缓解成本问题。
-
数据依赖与解决方案:
- GPT-5的性能高度依赖于训练数据的质量和数量。为了解决这个问题,需要采用高质量、多样化的训练数据,并对数据进行预处理和过滤。
- 牛津、剑桥等机构的研究人员发现,如果在训练时大量使用AI内容,会引发模型崩溃。因此,为模型的训练准备由人类生产的真实数据变得尤为重要。
-
挑战与未来方向:
- 数据安全和隐私问题是GPT-5面临的重要挑战之一。由于GPT-5需要大量的数据进行训练和优化,因此确保数据的安全性和隐私性至关重要。
- 偏见和误导问题也是GPT-5需要解决的问题。GPT-5生成的内容受训练数据的影响,如果这些数据中存在偏见或误导,那么生成的内容也可能存在类似问题。
- 未来的研究将探索如何更好地利用机器学习技术来提升GPT-5的性能,并解决上述挑战。例如,通过改进数据预处理和过滤技术来提高数据质量,或者通过引入新的算法和技术来减少偏见和误导问题。
存在的挑战及解决方案
数据依赖:GPT-5的性能高度依赖于训练数据的质量和数量。如果训练数据存在偏见或误导信息,将会影响GPT-5生成文本的质量。为了解决这个问题,需要采用高质量、多样化的训练数据,并对数据进行预处理和过滤。
计算资源:GPT-5的训练和推理过程需要大量的计算资源。为了解决这个问题,可以采用分布式计算、并行计算等技术手段,提高模型的训练和推理速度。
版权问题:GPT-5生成的文本可能存在版权问题。为了避免这种情况的发生,需要在使用GPT-5时遵守相关的法律法规和伦理标准,确保生成的内容不侵犯他人的知识产权。
技术细节与示例
GPT-5采用了Transformer架构作为其基础模型,该架构由多个自注意力机制和全连接层组成。通过堆叠多个Transformer层,GPT-5能够学习到更深层次的语言特征。以下是一个简化的GPT-5模型架构示意图(注意,由于GPT-5的复杂性,这里仅展示一个概念性的示例):
Input -> [ Embedding Layer ] -> [ Transformer Layer 1 ] -> ... -> [ Transformer Layer N ] -> [ Output Layer ]
其中,Embedding Layer用于将输入文本转换为模型可以处理的向量表示;Transformer Layer是模型的核心部分,负责学习文本中的语言特征;Output Layer则根据任务需求输出相应的结果。
由于GPT-5的复杂性和专业性,直接提供代码示例可能不太合适。但读者可以通过查阅相关的深度学习框架(如TensorFlow、PyTorch等)和NLP库(如Hugging Face的Transformers库)来了解如何构建和训练类似的模型。这些框架和库提供了丰富的API和工具,可以帮助读者更好地理解机器学习在GPT-5中的应用和实现过程。
–
相关文章:
深度解析:机器学习如何助力GPT-5实现语言理解的飞跃
文章目录 文章前言机器学习在GPT-5中的具体应用模型训练与优化机器翻译与跨语言交流:情感分析与问答系统:集成机器学习功能:文本生成语言理解任务适应 机器学习对GPT-5性能的影响存在的挑战及解决方案技术细节与示例 文章前言 GPT-5是OpenAI公…...
Springcloud-消息总线-Bus
1.消息总线在微服务中的应用 BUS- 消息总线-将消息变更发送给所有的服务节点。 在微服务架构的系统中,通常我们会使用消息代理来构建一个Topic,让所有 服务节点监听这个主题,当生产者向topic中发送变更时,这个主题产生的消息会被…...

js 接收回调函数 转换为promise
下面是一个示例代码,展示如何编写一个接收回调函数并将其转换为 Promise 的 JavaScript 函数: // 定义一个接收回调函数并转换为 Promise 的函数 function convertCallbackToPromise(callbackFunction) {// 返回一个新的 Promise 对象return new Promis…...

Python 面试【★★★】
欢迎莅临我的博客 💝💝💝,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...
计算机网络(物理层)
物理层 物理层最核心的工作内容就是解决比特流在线路上传输的问题 基本概念 何为物理层?笼统的讲,就是传输比特流的。 可以着重看一下物理层主要任务的特性 传输媒体 传输媒体举例: 引导型传输媒体 引导型传输媒体指的是信号通过某种…...

OpenGL-ES 学习(6)---- 立方体绘制
目录 立方体绘制基本原理立方体的顶点坐标和绘制顺序立方体颜色和着色器实现效果和参考代码 立方体绘制基本原理 一个立方体是由8个顶点组成,共6个面,所以绘制立方体本质上就是绘制这6个面共12个三角形 顶点的坐标体系如下图所示,三维坐标…...

《数据结构与算法基础 by王卓老师》学习笔记——类C语言有关操作补充
1.元素类型说明 2.数组定义 3.C语言的内存动态分配 4..C中的参数传递 5.传值方式 6.传地址方式 例子...

高频面试题基本总结回顾2(含笔试高频算法整理)
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...
》)
《深入浅出MySQL:数据库开发、优化与管理维护(第3版)》
深入浅出MySQL sql执行流程第一步:通过连接器进行连接第二步:解析器解析 SQL第三步:执行SQL 行记录存储格式行溢出日志数据库三大范式第一范式第二范式第三范式 索引索引分类B树索引BTree vs Hash需要索引1、字段需要频繁的查询操作2、字段用…...
VBA技术资料MF171:创建指定工作表数的工作簿
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...
【效率提升】新一代效率工具平台utools
下载地址:utools uTools这款软件,是一款功能强大且高度可定制的效率神器,使用快捷键alt space(空格) 随时调用,支持调用系统应用、用户安装应用和市场插件等。 utools可以调用系统设置和内置应用,这样可以方便快捷的…...

Jmeter插件管理器,websocket协议,Jmeter连接数据库,测试报告的查看
目录 1、Jmeter插件管理器 1、Jmeter插件管理器用处:Jmeter发展并产生大量优秀的插件,比如取样器、性能监控的插件工具等。但要安装这些优秀的插件,需要先安装插件管理器。 2、插件的下载,从Availabale Plugins中选择ÿ…...
)
Android中ViewModel+LiveData+DataBinding的配合使用(kotlin)
Android 中 ViewModel、LiveData 和 Data Binding 的配合使用(Kotlin) 摘要 本文将介绍如何在 Android 开发中结合使用 ViewModel、LiveData 和 Data Binding 进行数据绑定和状态更新。我们将详细探讨这三者之间的关系,并展示如何在 Kotlin…...

Elasticsearch 避免常见查询错误和陷阱
Elasticsearch 作为一款强大的搜索引擎和分析工具,已经被广泛应用于各种场景中。然而,在使用 Elasticsearch 进行查询时,如果不注意一些常见的错误和陷阱,可能会导致查询效率低下、结果不准确甚至系统性能下降。本文旨在总结一些常…...
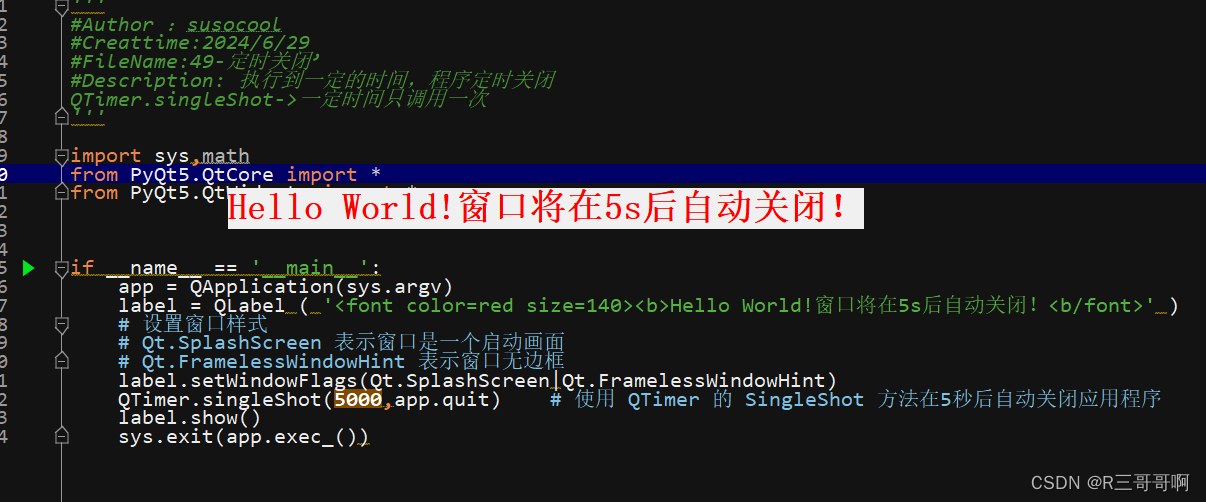
【PyQt】20-QTimer(动态显示时间、定时关闭)
QTimer 前言一、QTimer介绍二、动态时间展示2.1 代码2.2 运行结果 三、定时关闭3.1 介绍他的两种用法1、使用函数或Lambda表达式2、带有定时器类型(高级) 3.2 代码3.3 运行结果 总结 前言 好久没学习了。 一、QTimer介绍 pyqt里面的多线程可以有两种实…...
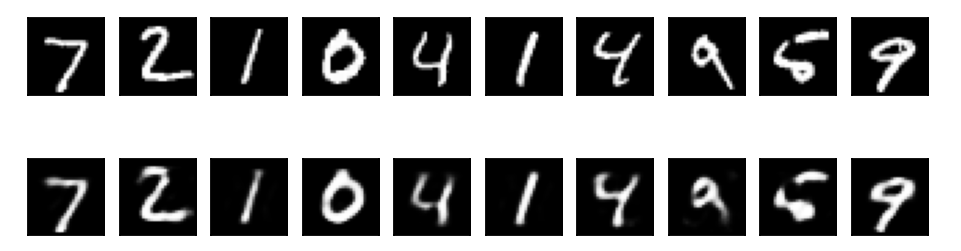
[深度学习] 自编码器Autoencoder
自编码器(Autoencoder)是一种无监督学习算法,主要用于数据的降维、特征提取和数据重建。自编码器由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。其基本思想是将输入数据映射…...

模型微调、智能体、知识库之间的区别
使用开源模型微调和使用知识库与智能体(agent)的区别主要体现在工作原理、应用场景和实现目标上。以下是对这三者的详细对比: 开源模型微调 定义: 微调是对预训练模型(例如BERT、GPT等)进行额外训练&…...
七日世界Once Human跳ping、延迟高、丢包怎么办?
七日世界是一款开放世界为轴点的生存射击游戏,玩家将进入一个荒诞、荒芜的末日世界,在这里与好友一起对抗可怖的怪物和神秘物质星尘的入侵,给这个星球留下最后的希望,共筑一片安全的领地。不过有部分玩家在游玩七日世界的时候&…...
机器人控制系列教程之关节空间运动控制器搭建(1)
机器人位置控制类型 机器人位置控制分为两种类型: 关节空间运动控制—在这种情况下,机器人的位置输入被指定为一组关节角度或位置的向量,这被称为机器人的关节配置,记作q。控制器跟踪一个参考配置,记作 q r e f q_{re…...

[linux]sed命令基础入门详解
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...
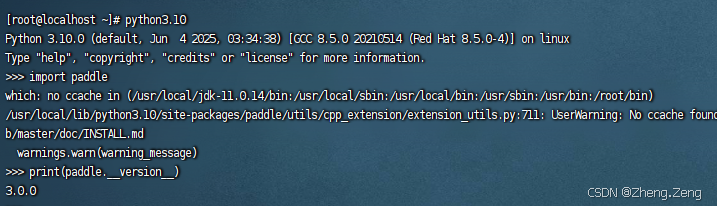
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...

云安全与网络安全:核心区别与协同作用解析
在数字化转型的浪潮中,云安全与网络安全作为信息安全的两大支柱,常被混淆但本质不同。本文将从概念、责任分工、技术手段、威胁类型等维度深入解析两者的差异,并探讨它们的协同作用。 一、核心区别 定义与范围 网络安全:聚焦于保…...
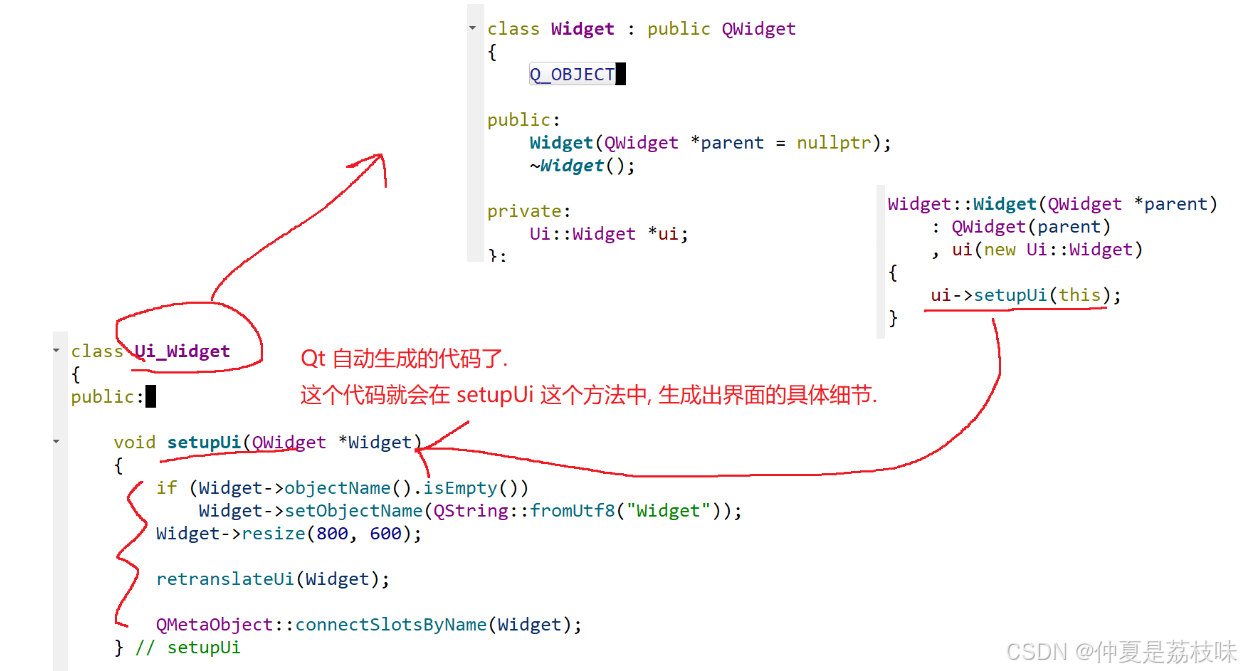
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

虚幻基础:角色旋转
能帮到你的话,就给个赞吧 😘 文章目录 移动组件使用控制器所需旋转:组件 使用 控制器旋转将旋转朝向运动:组件 使用 移动方向旋转 控制器旋转和移动旋转 缺点移动旋转:必须移动才能旋转,不移动不旋转控制器…...

手动给中文分词和 直接用神经网络RNN做有什么区别
手动分词和基于神经网络(如 RNN)的自动分词在原理、实现方式和效果上有显著差异,以下是核心对比: 1. 实现原理对比 对比维度手动分词(规则 / 词典驱动)神经网络 RNN 分词(数据驱动)…...