掌握Python编程的深层技能
一、Python基础语法、变量、列表、字典等运用
1.运行python程序的两种方式
1.交互式即时得到程序的运行结果
2.脚本方式把程序写到文件里(约定俗称文件名后缀为.py),然后用python解释器解释执行其中的内容
2.python程序运行的三个步骤
python3.8 C:\a\b\c.py
1.先启动python3.8解释器,此时相当于启动了一个文本编辑器
2.解释器会发送系统调用,把c.py的内容从硬盘读入内存,此时c.py中的内容全部为普通字符,没有任何语法意义
3.解释器开始解释执行刚刚读入内存的c.py的代码,开始识别python语法
3.变量
变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
#为什么要有变量?
答:为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的
详细地说:
程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,
所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化。
#如何使用变量
1.变量基本使用
# 原则:先定义,后引用
name = 'egon' #定义-》存
print(name) #引用-》取
2.内存管理:垃圾回收机制
垃圾:当一个变量值被绑定的变量名的个数为0时,该变量值无法被访问到---垃圾
3.变量名的命名规则
原则:变量名的命名应该见名知意
1. 变量名只能是 字母、数字或下划线的任意组合
2. 变量名的第一个字符不能是数字
3. 关键字不能声明为变量名,常用关键字如下
['and', 'as', 'assert', 'break', 'class',
'continue', 'def', 'del', 'elif', 'else',
'except', 'exec', 'finally', 'for', 'from',
'global', 'if', 'import', 'in', 'is', 'lambda',
'not', 'or', 'pass', 'print', 'raise', 'return',
'try', 'while', 'with', 'yield']
4.变量名的命名风格
#1.纯小写加下划线的方式
age_of_alex = 73
print(age_of_alex)
#2.驼峰体
AgeOfAlex=73
print(AgeOfAlex)
5.变量值的三大特性
name = 'egon'
#1、id
反应的是变量在内存中的唯一编号,内存地址不同id肯定不同
print(id(name))
#2、type
变量值的类型
print(type(name))
#3、value
变量值
print(name)
4.is与==
is:比较左右两个值身份id是否相等
==:比较左右两个值他们的值是否相等
5.数字类型
5.1整型int
作用:用来记录人的年龄,出生年份,学生人数等整数相关的状态
5.2 float浮点型
作用:用来记录人的身高,体重,薪资等小数相关的状态
6.字符串类型str
作用:用来记录人的名字,家庭住址,性别等描述性质的状态
用单引号、双引号、多引号,都可以定义字符串,本质上是没有区别的,但是
#1、需要考虑引号嵌套的配对问题
msg = "My name is Tony , I'm 18 years old!" #内层有单引号,外层就需要用双引号
#2、多引号可以写多行字符串
msg = '''天下只有两种人。比如一串葡萄到手,一种人挑最好的先吃,另一种人把最好的留到最后吃。照例第一种人应该乐观,因为他每吃一颗都是吃剩的葡萄里最好的;第二种人应该悲观,因为他每吃一颗都是吃剩的葡萄里最坏的。不过事实却适得其反,缘故是第二种人还有希望,第一种人只有回忆。'''
7.列表
索引对应值,索引从0开始,0代表第一个
作用:记录多个值,并且可以按照索引取指定位置的值
定义:在[]内用逗号分隔开多个任意类型的值,一个值称之为一个元素
# 1、列表类型是用索引来对应值,索引代表的是数据的位置,从0开始计数
>>> stu_names=['张三','李四','王五']
>>> stu_names[0]
'张三'
>>> stu_names[1]
'李四'
>>> stu_names[2]
'王五'
# 2、列表可以嵌套,嵌套取值如下
>>> students_info=[['tony',18,['jack',]],['jason',18,['play','sleep']]]
>>> students_info[0][2][0] #取出第一个学生的第一个爱好
'play'
内置方法:
1.按索引存取值(正向存取+反向存取)
l = [111, 'egon', 'hello']# 正向取
print(l[0])
# 反向取
print(l[-1])
# 可以取也可以改
l[0] = 222 # 索引存在则修改对应的值
print(l)
# 2.切片(顾头顾尾,步长)
print(l[0:5:2])
# 3.长度
print(len(l))
# 4.成员运算in和not in
print('aaa' in ['aaa', 1, 2])
print(1 in ['aaa', 1, 2])
# 5.追加
l.append(3333)
print(l)
# 6.插入值
l.insert(1, 'alex')
print(l)# 7.extend
new_l = [1,2,3]
for i in new_l:l.append(i)
print(l)
# 用extend 实现了上述代码
l.extend(new_l)
print(l)# 8.删除
del l[1]
print(l)
# 方式二:pop根据索引删除,不指定索引默认删除最后一个,会返回删除的值
l.pop(0)
print(l)
# 方式三:remove()根据元素删除,返回None
l.remove('egon')
print(l)
8.字典
key对应值,其中key通常为字符串类型,所以key对值可以有描述性的功能
作用:用来存多个值,每个值都有唯一一个key与其对应,key对值有描述性功能
定义:在{}内用逗号分开各多个key:value
# 1、字典类型是用key来对应值,key可以对值有描述性的功能,通常为字符串类型
>>> person_info={'name':'tony','age':18,'height':185.3}
>>> person_info['name']
'tony'
>>> person_info['age']
18
>>> person_info['height']
185.3
# 2、字典可以嵌套,嵌套取值如下
>>> students=[
... {'name':'tony','age':38,'hobbies':['play','sleep']},
... {'name':'jack','age':18,'hobbies':['read','sleep']},
... {'name':'rose','age':58,'hobbies':['music','read','sleep']},
... ]
>>> students[1]['hobbies'][1] #取第二个学生的第二个爱好
'sleep'
9.bool类型
作用:用来记录真假这两种状态
定义:
>>> is_ok = True
>>> is_ok = False
通常用来当作判断的条件,我们将在if判断中用到它
二、垃圾回收机制、格式化输出、基本运算符
1.垃圾回收机制
#1.引用计数
x=10 # 直接引用
print(id(x))
y=x
z=xl=['a', 'b', x] # 间接引用
print(id(l[2]))d = {'mmm': x}
print(id(d['mmm']))# 2.标记清除
# 循环引用=》导致内存泄露
l1 = [111, ]
l2 = [222, ]l1.append(l2) # l1=[值111的内存地址,l2列表的内存地址]
l2.append(l1) # l2=[值222的内存地址,l1列表的内存地址]print(id(l1[1]))
print(id(l2))print(id(l2[1]))
print(id(l1))print(l2)
print(l1[1])del l1
del l2#3.分代回收
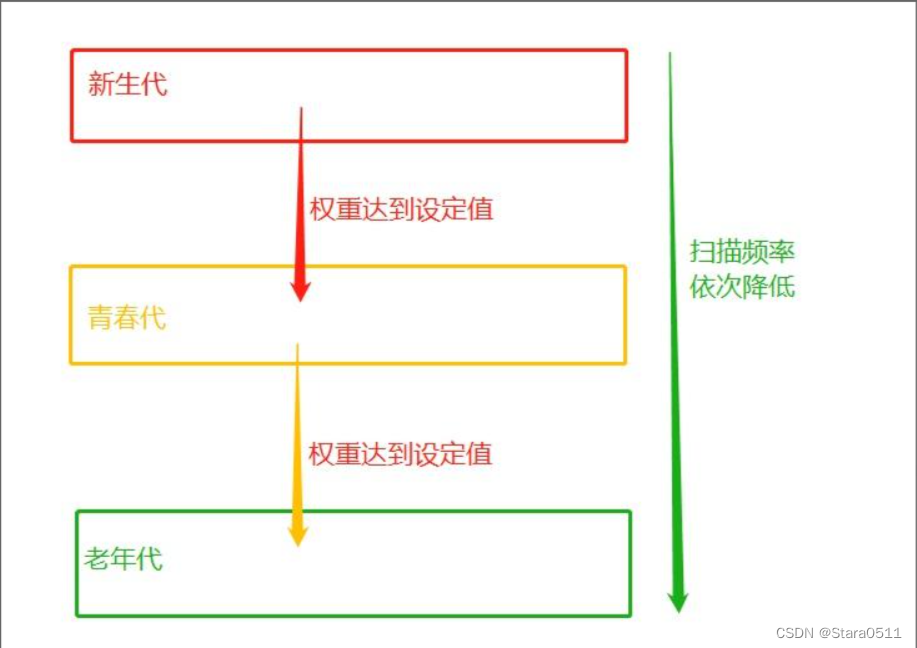
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,
如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,
当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,
青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,
这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,
接下来,青春代中的对象,也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低
2.格式化输出
1.%号
# 1、格式的字符串(即%s)与被格式化的字符串(即传入的值)必须按照位置一一对应
# ps:当需格式化的字符串过多时,位置极容易搞混
print('%s asked %s to do something' % ('egon', 'lili')) # egon asked lili to do something
print('%s asked %s to do something' % ('lili', 'egon')) # lili asked egon to do something# 2、可以通过字典方式格式化,打破了位置带来的限制与困扰
print('我的名字是 %(name)s, 我的年龄是 %(age)s.' % {'name': 'egon', 'age': 18})kwargs={'name': 'egon', 'age': 18}
print('我的名字是 %(name)s, 我的年龄是 %(age)s.' % kwargs)
2.str.format
2.1 使用位置参数
# 按照位置一一对应
print('{} asked {} to do something'.format('egon', 'lili')) # egon asked lili to do something
print('{} asked {} to do something'.format('lili', 'egon')) # lili asked egon to do something
2.2 使用索引
# 使用索引取对应位置的值
print('{0}{0}{1}{0}'.format('x','y')) # xxyx
2.3 使用关键字参数or字典
# 可以通过关键字or字典方式的方式格式化,打破了位置带来的限制与困扰
print('我的名字是 {name}, 我的年龄是 {age}.'.format(age=18, name='egon'))kwargs = {'name': 'egon', 'age': 18}
print('我的名字是 {name}, 我的年龄是 {age}.'.format(**kwargs)) # 使用**进行解包操作
2.4 填充与格式化
# 先取到值,然后在冒号后设定填充格式:[填充字符][对齐方式][宽度]# *<10:左对齐,总共10个字符,不够的用*号填充
print('{0:*<10}'.format('开始执行')) # 开始执行******# *>10:右对齐,总共10个字符,不够的用*号填充
print('{0:*>10}'.format('开始执行')) # ******开始执行# *^10:居中显示,总共10个字符,不够的用*号填充
print('{0:*^10}'.format('开始执行')) # ***开始执行***
2.5 精度与进制
print('{salary:.3f}'.format(salary=1232132.12351)) #精确到小数点后3位,四舍五入,结果为:1232132.124
print('{0:b}'.format(123)) # 转成二进制,结果为:1111011
print('{0:o}'.format(9)) # 转成八进制,结果为:11
print('{0:x}'.format(15)) # 转成十六进制,结果为:f
print('{0:,}'.format(99812939393931)) # 千分位格式化,结果为:99,812,939,393,931
3.f-Strings
3.1 {}中可以是变量名
name = 'egon'
age = 18
print(f'{name} {age}') # egon 18
print(F'{age} {name}') # 18 egon
3.2 {}中可以是表达式
# 可以在{}中放置任意合法的Python表达式,会在运行时计算
# 比如:数学表达式
print(f'{3*3/2}') # 4.5# 比如:函数的调用
def foo(n):print('foo say hello')return nprint(f'{foo(10)}') # 会调用foo(10),然后打印其返回值# 比如:调用对象的方法
name='EGON'
print(f'{name.lower()}') # egon
3.3 在类中的使用
>>> class Person(object):
... def __init__(self, name, age):
... self.name = name
... self.age = age
... def __str__(self):
... return f'{self.name}:{self.age}'
... def __repr__(self):
... return f'===>{self.name}:{self.age}<==='
...
>>>
>>> obj=Person('egon',18)
>>> print(obj) # 触发__str__
egon:18
>>> obj # 触发__repr__
===>egon:18<===
>>>
>>> # 在f-Strings中的使用
>>> f'{obj}' # 触发__str__
'egon:18'
>>> f'{obj!r}' # 触发__repr__
'===>egon:18<==='
3.4 多行f-Stings
# 当格式化字符串过长时,如下列表info
name = 'Egon'
age = 18
gender = 'male'
hobbie1='play'
hobbie2='music'
hobbie3='read'
info = [f'名字:{name}年龄:{age}性别:{gender}',f'第一个爱好:{hobbie1}第二个爱好:{hobbie2}第三个爱好:{hobbie3}'] # 我们可以回车分隔到多行,注意每行前都有一个f
info = [# 第一个元素f'名字:{name}'f'年龄:{age}'f'性别:{gender}',# 第二个元素f'第一个爱好:{hobbie1}'f'第二个爱好:{hobbie2}'f'第三个爱好:{hobbie3}'
]print(info)
# ['名字:Egon年龄:18性别:male', '第一个爱好:play第二个爱好:music第三个爱好:read']
4.基本运算符
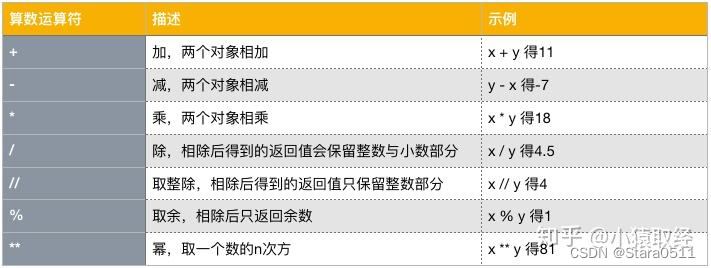
4.1 算术运算符
4.2比较运算符

4.3赋值运算符
4.3.1 增量赋值

4.3.2 链式赋值
>>> z=10
>>> y=z
>>> x=y
>>> x,y,z
(10, 10, 10)>>> x=y=z=10
>>> x,y,z
(10, 10, 10)
4.3.3交叉赋值
>>> m=10
>>> n=20
>>> temp=m
>>> m=n
>>> n=temp
>>> m,n
(20, 10)>>> m=10
>>> n=20
>>> m,n=n,m # 交叉赋值
>>> m,n
(20, 10)
4.3.4解压赋值
>>> nums=[11,22,33,44,55]
>>>
>>> a=nums[0]
>>> b=nums[1]
>>> c=nums[2]
>>> d=nums[3]
>>> e=nums[4]
>>> a,b,c,d,e
(11, 22, 33, 44, 55)>>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
注意,上述解压赋值,等号左边的变量名个数必须与右面包含值的个数相同,否则会报错
#1、变量名少了
>>> a,b=nums
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)#2、变量名多了
>>> a,b,c,d,e,f=nums
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 6, got 5)但如果我们只想取头尾的几个值,可以用*_匹配
>>> a,b,*_=nums
>>> a,b
(11, 22)ps:字符串、字典、元组、集合类型都支持解压赋值
4.4逻辑运算符

4.4.1连续多个and
>>> 2 > 1 and 1 != 1 and True and 3 > 2 # 判断完第二个条件,就立即结束,得的最终结果为False
False
4.4.2连续多个or
>>> 2 > 1 or 1 != 1 or True or 3 > 2 # 判断完第一个条件,就立即结束,得的最终结果为True
True
4.4.3优先级not>and>or
#1、三者的优先级关系:not>and>or,同一优先级默认从左往右计算。
>>> 3>4 and not 4>3 or 1==3 and 'x' == 'x' or 3 >3
False#2、最好使用括号来区别优先级,其实意义与上面的一样
'''
原理为:
(1) not的优先级最高,就是把紧跟其后的那个条件结果取反,所以not与紧跟其后的条件不可分割(2) 如果语句中全部是用and连接,或者全部用or连接,那么按照从左到右的顺序依次计算即可(3) 如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算
'''
>>> (3>4 and (not 4>3)) or (1==3 and 'x' == 'x') or 3 >3
False
#3、短路运算:逻辑运算的结果一旦可以确定,那么就以当前处计算到的值作为最终结果返回
>>> 10 and 0 or '' and 0 or 'abc' or 'egon' == 'dsb' and 333 or 10 > 4
我们用括号来明确一下优先级
>>> (10 and 0) or ('' and 0) or 'abc' or ('egon' == 'dsb' and 333) or 10 > 4
短路: 0 '' 'abc' 假 假 真返回: 'abc'#4、短路运算面试题:
>>> 1 or 3
1
>>> 1 and 3
3
>>> 0 and 2 and 1
0
>>> 0 and 2 or 1
1
>>> 0 and 2 or 1 or 4
1
>>> 0 or False and 1
False
4.5 成员运算符

注意:虽然下述两种判断可以达到相同的效果,但我们推荐使用第二种格式,因为not in语义更加明确
>>> not 'lili' in ['jack','tom','robin']
True
>>> 'lili' not in ['jack','tom','robin']
True
4.6 身份运算符

需要强调的是:==双等号比较的是value是否相等,而is比较的是id是否相等
#1. id相同,内存地址必定相同,意味着type和value必定相同
#2. value相同type肯定相同,但id可能不同,如下
>>> x='Info Tony:18'
>>> y='Info Tony:18'
>>> id(x),id(y) # x与y的id不同,但是二者的值相同
(4327422640, 4327422256)>>> x == y # 等号比较的是value
True
>>> type(x),type(y) # 值相同type肯定相同
(<class 'str'>, <class 'str'>)
>>> x is y # is比较的是id,x与y的值相等但id可以不同
False
三、可变不可变类型、三大循环
1.可变不可变类型
可变类型: 值改变,id不变,证明改的是原值,证明原值是可以被改变的
不可变类型:值改变,id也变,证明产生了新的值,压根没有改变原值,证明原值是不可以被修改的
int float str bool tuple 不可变类型
list dict 可变类型
0、None、空(空字符串、空列表、空字典)=》代表的bool值为false,其余都为真
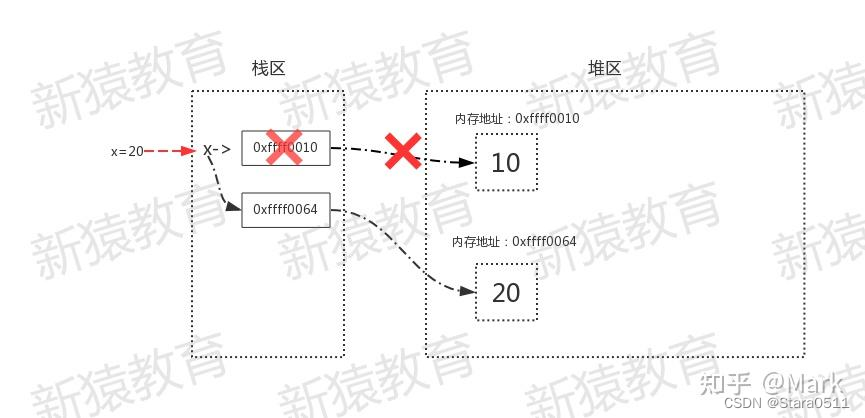
1.1数字类型
x = 10
id(x)
1830448896
x = 20
id(x)
1830448928
内存地址改变了,说明整型是不可变数据类型,浮点型也一样
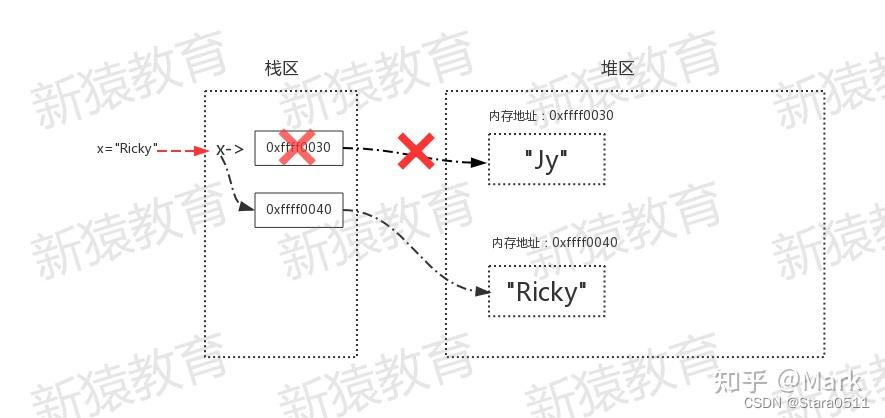
1.2字符串
x = "Jy"
id(x)
938809263920
x = "Ricky"
id(x)
938809264088
内存地址改变了,说明字符串是不可变数据类型
1.3列表
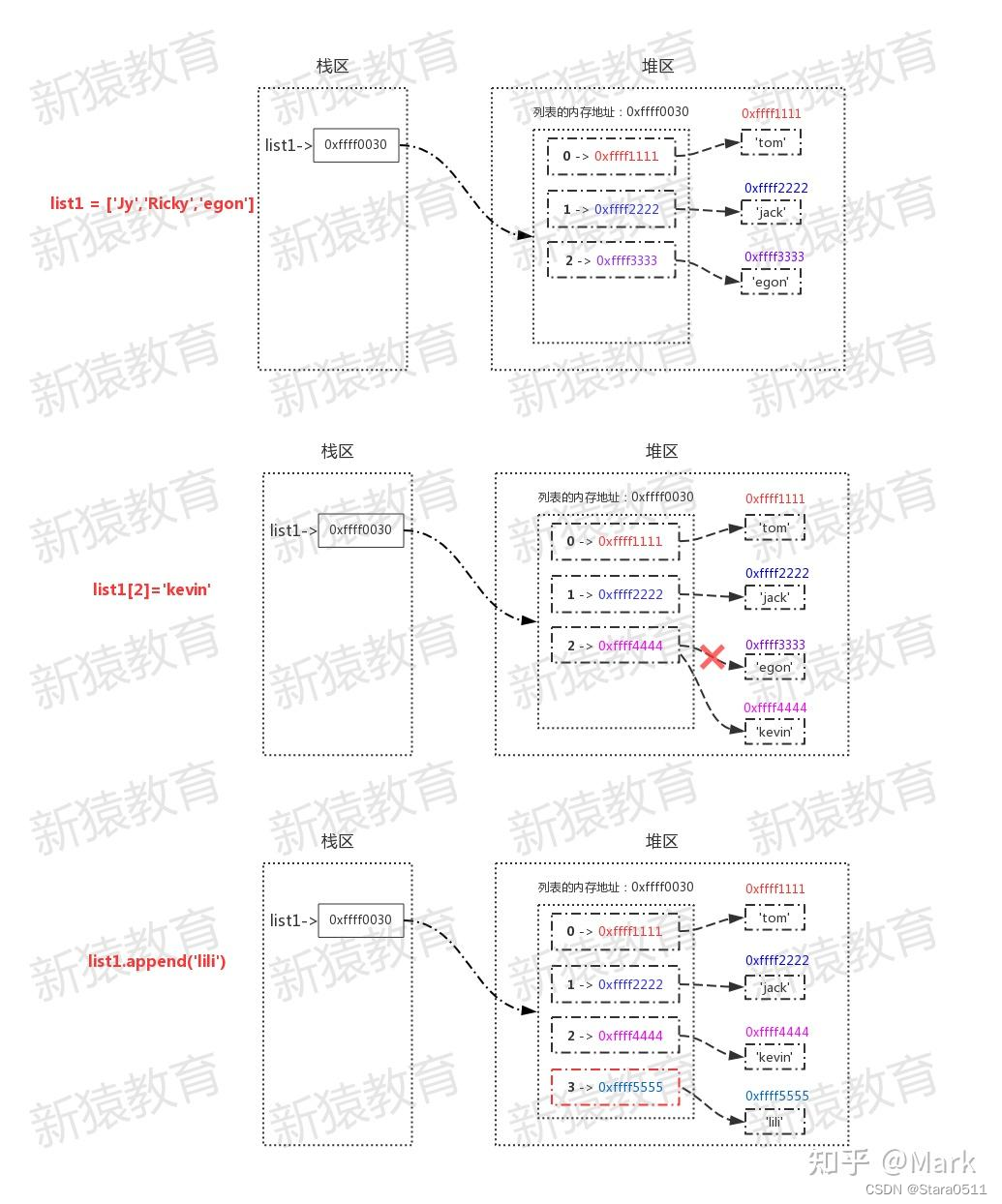
list1 = ['tom','jack','egon']
id(list1)
486316639176
list1[2] = 'kevin'
id(list1)
486316639176
list1.append('lili')
id(list1)
486316639176
对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型
1.4元组
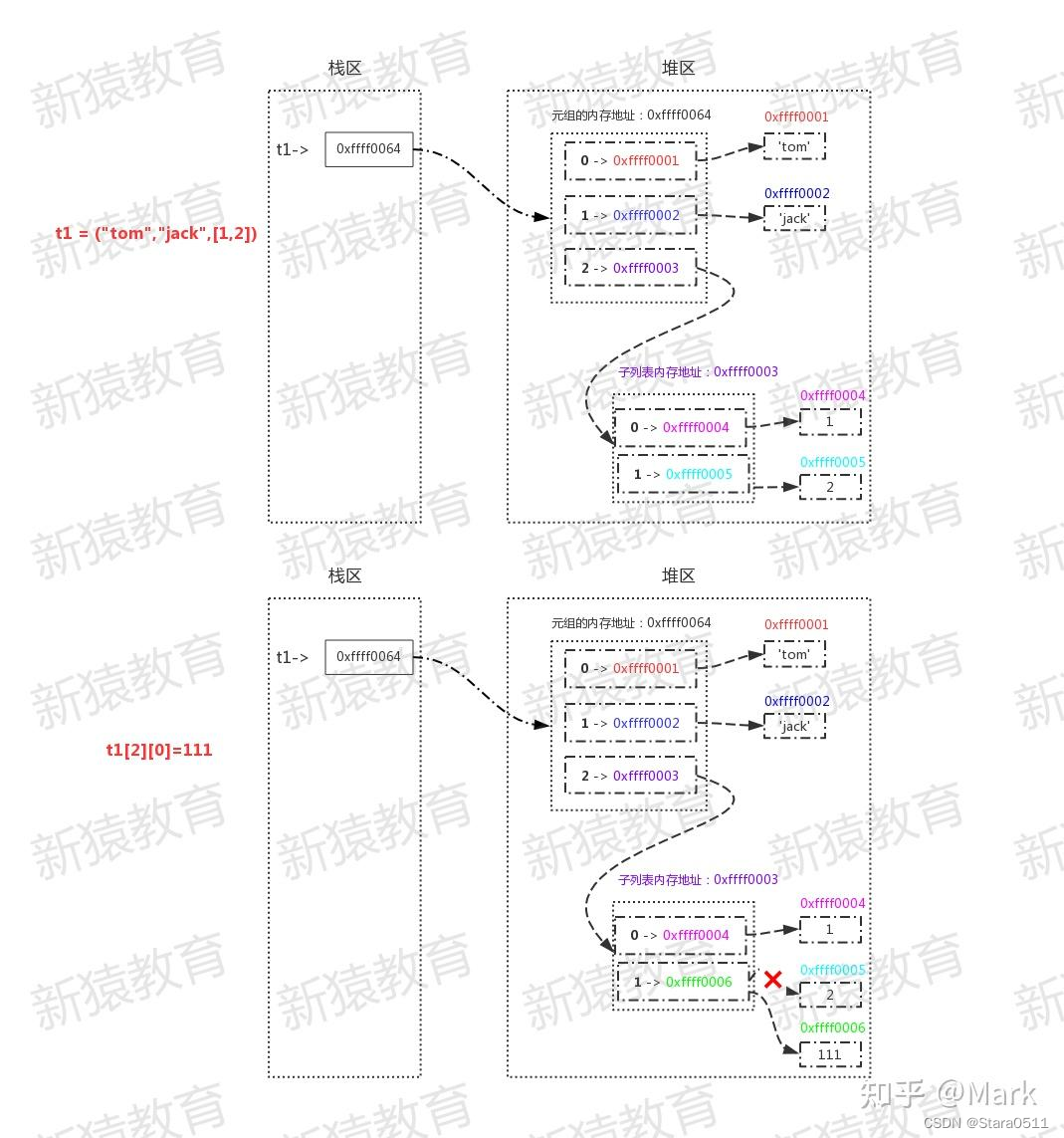
t1 = ("tom","jack",[1,2])
t1[0]='TOM' # 报错:TypeError
t1.append('lili') # 报错:TypeError
元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改
t1 = ("tom","jack",[1,2])
id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
t1[2][0]=111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变
t1
('tom', 'jack', [111, 2])
id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不变
(4327403152, 4327403072, 4327422472)
1.5字典
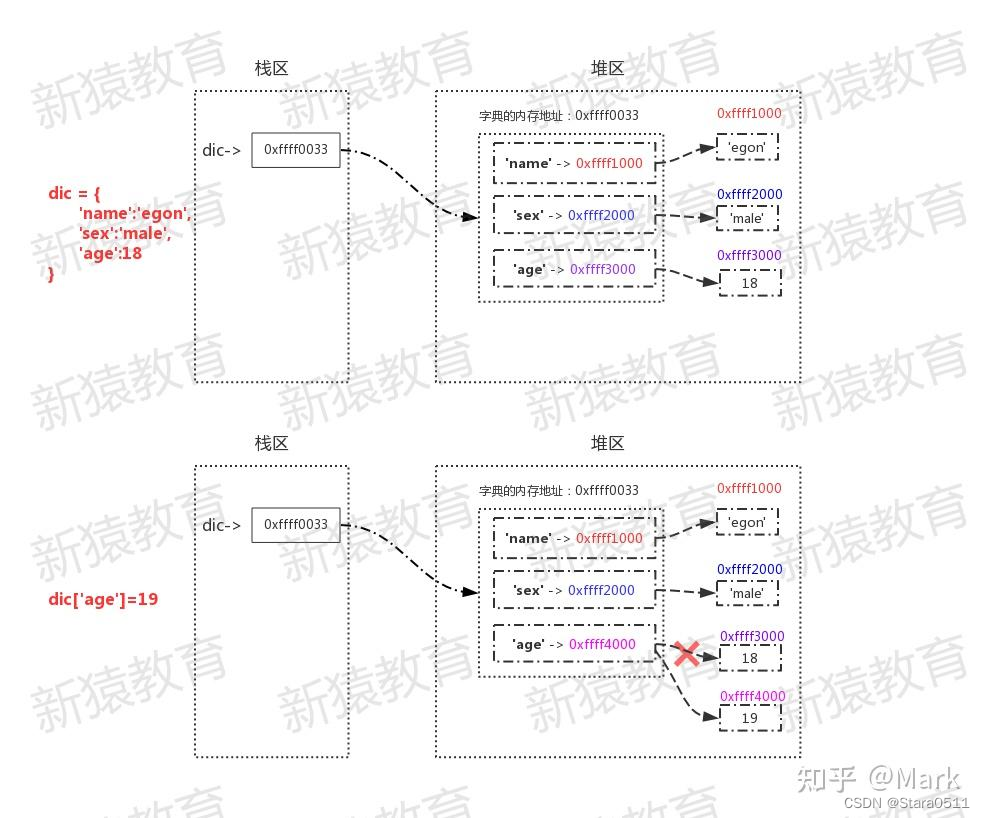
dic = {'name':'egon','sex':'male','age':18}id(dic)
4327423112
dic['age']=19
dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
id(dic)
4327423112
对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型
关于字典:
定义:{}内用逗号分隔开多key:value,其中value可以是任意类型,但是key必须是不可变类型
dict = {'k1':111'k2':3.1'k3':[333,]'k4':{'name':'egon'}}
2.if判断
语法1:
if 条件:代码1代码2.....
语法2:
if 条件:代码1代码2.....
else:代码1代码2.....
语法3:
if 条件:代码1代码2.....
elif 条件2:代码1代码2....
else:代码1代码2....
import random # 随机模块player = int(input("请输入(0-剪刀 1-石头 2-布)")) # 玩家输入
computer = random.randint(0,2) # 0-2之间随机产生一个数作为电脑的输入if (player == 0 and computer == 2) or (player == 1 and computer == 0) or (player == 2 and computer == 1):print("恭喜玩家你赢了") # 加上小括号
elif (player == 0 and computer == 0) or (player == 1 and computer == 1) or (player == 2 and computer == 2):print("平局")
else:print("很可惜,你输了")
2.1 if 的嵌套
语法:
if 条件 1:条件 1 满足执行的代码……if 条件 1 基础上的条件 2:条件 2 满足时,执行的代码…… # 条件 2 不满足的处理else:条件 2 不满足时,执行的代码# 条件 1 不满足的处理
else:条件1 不满足时,执行的代码……
# 定义布尔型变量 has_ticket 表示是否有车票
has_ticket = True# 定义整数型变量 knife_length 表示刀的长度,单位:厘米
knife_length = 20# 首先检查是否有车票,如果有,才允许进行 安检
if has_ticket:print("有车票,可以开始安检...")# 安检时,需要检查刀的长度,判断是否超过 20 厘米# 如果超过 20 厘米,提示刀的长度,不允许上车if knife_length >= 20:print("不允许携带 %d 厘米长的刀上车" % knife_length)# 如果不超过 20 厘米,安检通过else:print("安检通过,祝您旅途愉快……")# 如果没有车票,不允许进门
else:print("大哥,您要先买票啊")
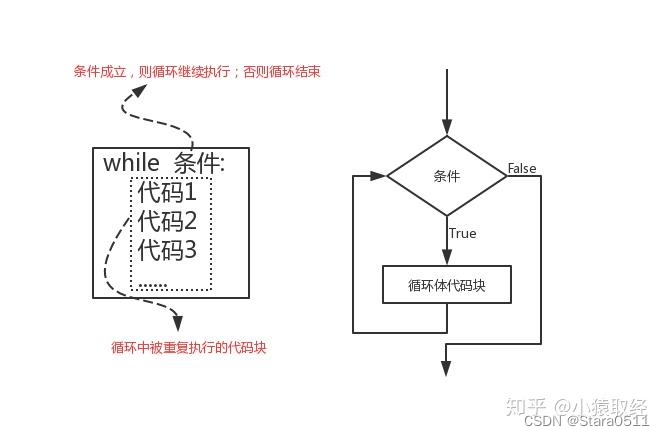
3.while循环
while 条件:代码1 代码2 代码3
while的运行步骤:
步骤1:如果条件为真,那么依次执行:代码1、代码2、代码3、......
步骤2:执行完毕后再次判断条件,如果条件为True则再次执行:代码1、代码2、代码3、......,如果条件为False,则循环终止
username = "jason"
password = "123"
# 记录错误验证的次数
count = 0
while count < 3:inp_name = input("请输入用户名:")inp_pwd = input("请输入密码:")if inp_name == username and inp_pwd == password:print("登陆成功")breakelse:print("输入的用户名或密码错误!")count += 1
3.1 while循环嵌套
username = "jason"
password = "123"
count = 0
while count < 3: # 第一层循环inp_name = input("请输入用户名:")inp_pwd = input("请输入密码:")if inp_name == username and inp_pwd == password:print("登陆成功")while True: # 第二层循环cmd = input('>>: ')if cmd == 'quit':break # 用于结束本层循环,即第二层循环print('run <%s>' % cmd)break # 用于结束本层循环,即第一层循环else:print("输入的用户名或密码错误!")count += 1
3.2 while continue
结束本次循环,直接进入下一次
# 强调在continue之后添加同级代码毫无意义,因为永远无法运行
count = 0
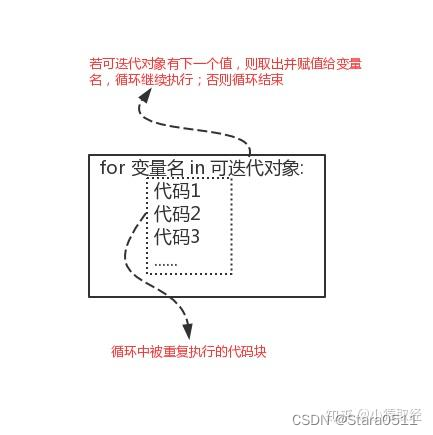
while count < 6:if count == 4:count += 1continueprint(count)count += 14.for循环语法
语法:
for 变量名 in 可迭代对象: # 此时只需知道可迭代对象可以是字符串\列表\字典,我们之后会专门讲解可迭代对象代码一代码二...#例1
for item in ['a','b','c']:print(item)
# 运行结果
a
b
c# 参照例1来介绍for循环的运行步骤
# 步骤1:从列表['a','b','c']中读出第一个值赋值给item(item=‘a’),然后执行循环体代码
# 步骤2:从列表['a','b','c']中读出第二个值赋值给item(item=‘b’),然后执行循环体代码
# 步骤3: 重复以上过程直到列表中的值读尽
打印金字塔
# 分析
'''
#max_level=5* # current_level=1,空格数=4,*号数=1*** # current_level=2,空格数=3,*号数=3***** # current_level=3,空格数=2,*号数=5******* # current_level=4,空格数=1,*号数=7********* # current_level=5,空格数=0,*号数=9# 数学表达式
空格数=max_level-current_level
*号数=2*current_level-1
'''
# 实现:
max_level=5
for current_level in range(1,max_level+1):for i in range(max_level-current_level):print(' ',end='') #在一行中连续打印多个空格for j in range(2*current_level-1):print('*',end='') #在一行中连续打印多个空格print()
四、字符串、队列、堆栈、元组、集合
1.字符串类型
1.按索引取值(正向取+反向取):只能取
str = 'hello world'
# 正向取
print(str[0])
# 反向取
print(str[-1])# 只能取,不能改2.切片:索引的拓展应用,从一个大字符串中拷贝出一个子字符串(顾头不顾尾,步长)
str = 'hello world'
res = str[0:5]
print(res)
print(str)# 步长
res = str[0:5:2]
print(res)
# 反向步长
res = str[5:0:-1]
print(res)# 长度len
print(len(str))# 成员运算in和not in
# 判断一个子字符串是否存在于一个大字符穿
print('alex' in 'alex' is 'sb')
print(not 'alex' in "alex is sb") # 不推荐使用
print('alex' not in "alex is sb")# 移除空白strip
str = ' egon '
res = str.strip() # 默认去掉的空格
print(res)
str = '@@@@@@@@@egon***************' # 去掉左右两侧的@和*
print(str.strip('@,*'))# 切分split:把一个字符串按照某种分隔符进行切分,得到一个列表
info = 'egon 18 male'
print(info.split()) # 默认分隔符是空格info = 'egon:18:male'
print(info.split(':')) # 指定分隔符# 指定分隔次数(了解)
info = 'egon:18:male'
print(info.split(':',1))# 循环
info = 'egon:18:male'
for x in info:print(x)
需要掌握:
# 1.strip lstrip rstrip
str = '*****egon**********'
print(str.strip('*'))
print(str.lstrip('*'))
print(str.rstrip('*'))
# 2.lower,upper
str = 'AAADDDFRFRFR'
print(str.lower())
print(str.upper())
# 3.startwith, endswith
print("alex is sb".startswith('alex'))
print("alex is sb".endswith('sb'))
# 4.format的三种玩法# 5.split, rsplit
info = "egon:18:male"
print(info.split(':', 1))
print(info.rsplit(':', 1))
# 6.join:把列表拼接成字符串
l = ['egon', '18', 'male']
print(l[0] + ":" + l[1] + ":" + l[2])
print(":".join(l)) # 按照某个分隔符号,把元素全为字符串的列表拼接成一个大字符串# 7.replace
str = "you can you np no can no bb"
print(str.replace("you", "YOU", 1))# 8.isdigit
# 判断字符串是否由纯数字组成
print('123'.isdigit())
print("12.3".isdigit())age = input("请输入你的年龄:").strip()
if age.isdigit():age = int(age)if age > 18:print("猜大了")elif age < 18:print("猜小了")else:print('猜小了')
else:print("必须输入数字")
2.队列堆栈
队列:FIFO,先进先出
l = []
# 入队操作
l.append('first')
l.append('second')
l.append('third')
print(l)
# 出队操作
print(l.pop(0))
print(l.pop(0))
print(l.pop(0))
# 堆栈:LIFO,后进先出
# 入栈操作
l.append('first')
l.append('second')
l.append('third')
# 出栈操作
print(l.pop())
print(l.pop())
print(l.pop())
3.元组
按照索引存放多个值,只用于读不用于改
tuple = (1, 1.3, 6, 99, 'shun')
print(tuple,type(tuple))
# 类型转换
print(tuple('hello'))
print(tuple([1, 2, 3]))
print(tuple({'a1': 111, 'a2': 222}))# 内置方法
tuple = (1, 2, 9)
print(tuple.count(1))
print(tuple.index(1))
# 1.按索引取值(正向取+反向取)
tuple = ('aa', 'bbb', 'ccc')
print(tuple[0])
print(tuple[-1])# 2.切片
tuple = ('aaa', "dd+1", 'python', '2387')
print(tuple[0:3])
print(tuple[::-1])
# 3.长度
print(len(tuple))# 4.成员运算in和not in
print('aaa' in tuple)# 5.循环
for x in tuple:print(x)
4.集合类型
作用:集合、list、tuple、dict一样都可以存放多个值,但是集合主要用于:去重、关系运算
定义:
"""
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:1:每个元素必须是不可变类型2:集合内没有重复的元素3:集合内元素无序
"""
s = {1,2,3,4} # 本质 s = set({1,2,3,4})# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合类型转换:
# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
4.1关系运算

# 1.关系运算
friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
l = []
for x in friends1:if x in friends2:l.append(x)
print(l)
4.2 内置方法
friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
# 1.取交集
print(friends1 & friends2)
print(friends1.intersection(friends2))
# 2.取并集/合集:
print(friends1 | friends2)
print(friends1.union(friends2))
# 3.取差集:取friend1独有的
print(friends1 - friends2)
print(friends1.difference(friends2))
# 取friend2独有
print(friends2 - friends1)
print(friends2.difference(friends1))
# 4.取对称差集:求两个用户独有的,即去掉共有的好友
print(friends1 ^ friends2)
print(friends1.symmetric_difference(friends2))
# 5.父子集:包含的关系
s1 = {1, 2, 3}
s2 = {1, 2, 4}
print(s1 > s2) # 不存在包含关系,输出为Falses1 = {1, 2, 3}
s2 = {1, 2}
print(s1 > s2) # 当s1大于或等于s2时,才能说s1是s2他爹
print(s1.issuperset(s2))
print(s2.issubset(s1)) # s2 < s1 =》 Ture
s1 = {1, 2, 3}
s2 = {1, 2, 3}
print(s1 == s2) # s1与s2互为父子
print(s1.issuperset(s2))
print(s2.issuperset(s1))
4.3去重
集合去重复有局限性
- 只能针对不可变类型
- 集合本身是无序的,去重之后无法保留原来的顺序
# 1.只能针对不可变量类型去重
print(set([111, 1, 1, 1111, 2, 6666]))
# 2.无法保证原来的顺序
l = [1, 'a', 'b', 'z', 1111, 5]
print(list(set(l)))
print(l)
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[{'name':'lili','age':18,'sex':'male'},{'name':'jack','age':73,'sex':'male'},{'name':'tom','age':20,'sex':'female'},{'name':'lili','age':18,'sex':'male'},{'name':'lili','age':18,'sex':'male'},
]
new_l=[]for dic in l:if dic not in new_l:new_l.append(dic)print(new_l)# 其他内置方法
s = {1, 2, 3}
s.discard(4) # 删除元素不存在 do nothing
print(s)
s.remove(4) # 删除元素不存在则报错s.update({1, 3, 5})
print(s)# 了解
s.difference_update({3, 4, 5}) # s= s.difference({3, 4, 5}) # 求差集并赋值
print(s)res = s.isdisjoint({4,5,6,8}) #两个集合完全独立、没有共同部分,返回Ture
print(res)
五、字符编码以及乱码处理
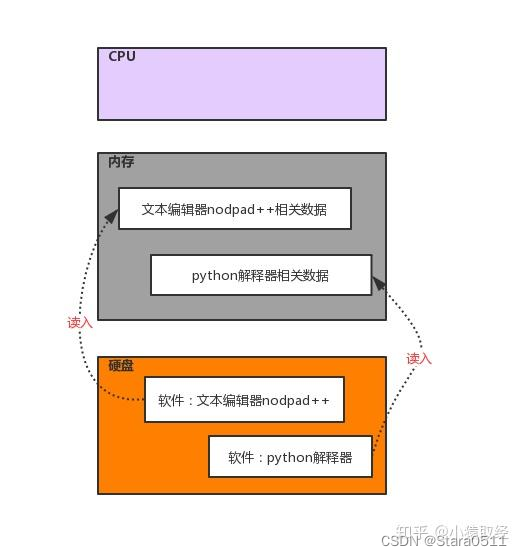
1.字符编码
#1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的#2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行#3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
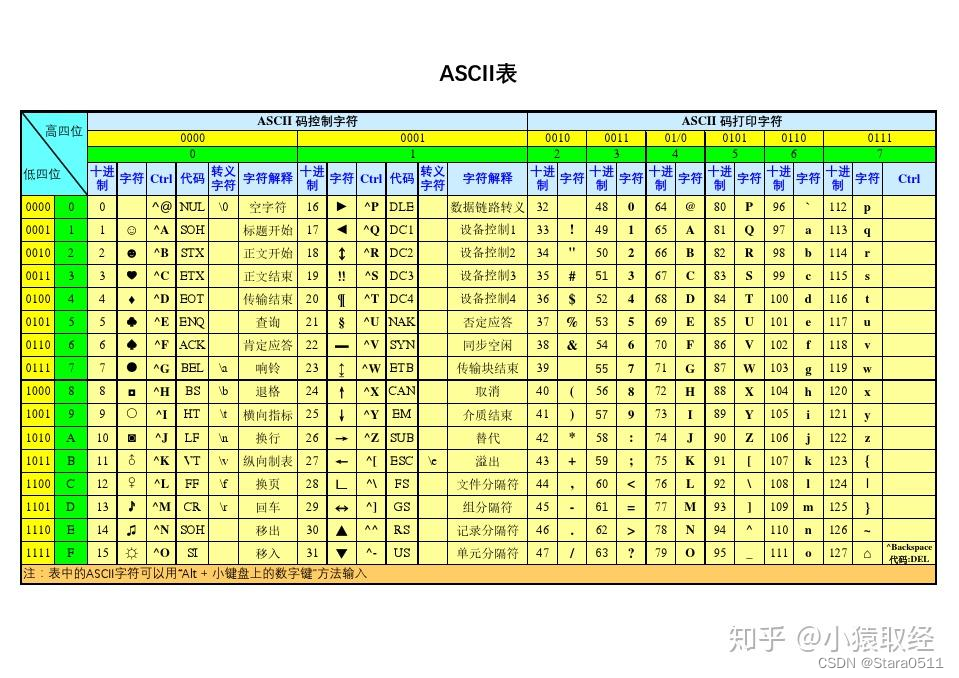
1.1阶段一:一家独大
ASCII表的特点:1、只有英文字符与数字的一一对应关系2、一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符3、采用8位二进制数对应一个英文字符串
1.2 阶段二:诸侯割据、天下大乱
# GBK表的特点:1、只有中文字符、英文字符与数字的一一对应关系2、一个英文字符对应1Bytes一个中文字符对应2Bytes 补充说明:1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
1.3 阶段三:分久必合
unicode(内存中统一使用Unicode):1、兼容万国字符,与万国字符都有对应关系2、采用16位(16bit=2Bytes) 二进制对应一个中文字符串,个别生僻会采用4Bytes、8Bytes3、老的字符编码都可以转换成Unicode,但是不能通过Unicode互转
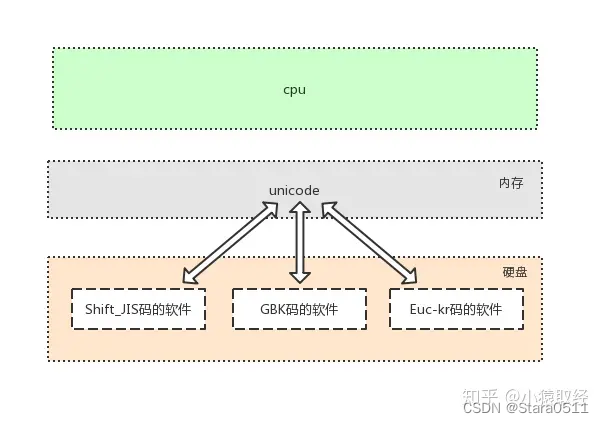
1.4 utf-8:unicode transform format-8编码
那为何在内存中不直接使用utf-8呢?
utf-8是针对Unicode的可变长度字符编码:一个英文字符占1Bytes,一个中文字符占3Bytes,生僻字用更多的Bytes存储unicode更像是一个过渡版本,我们新开发的软件或文件存入硬盘都采用utf-8格式,等过去几十年,所有老编码的文件都淘汰掉之后,会出现一个令人开心的场景,即硬盘里放的都是utf-8格式,此时unicode便可以退出历史舞台,内存里也改用utf-8,天下重新归于统一
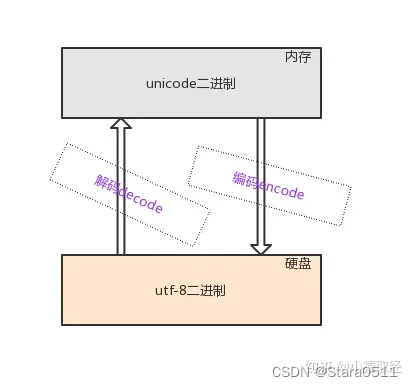
2.文本文件存取乱码问题
存乱了,解决办法是,编码格式应该设置成支持文件内字符串的格式
取乱了,解决办法是,文件是以什么编码格式存入硬盘的,就应该以什么编码格式读入
python解释器默认的文件的编码
python3默认:utf-8
python2默认:ASCII
2.1 保证运行python程序前两个阶段不乱码的核心法则
指定文件头修改默认的编码
在py文件的首行写:
# coding utf-8
# coding 文件当初存入硬盘时所采用的编码格式
六、文件处理
1.文件处理
# 1. 打开文件,由应用程序向操作系统发起系统调用open(...),操作系统打开该文件,对应一块硬盘空间,并返回一个文件对象赋值给一个变量f
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r# 2. 调用文件对象下的读/写方法,会被操作系统转换为读/写硬盘的操作
data=f.read()# 3. 向操作系统发起关闭文件的请求,回收系统资源
f.close()
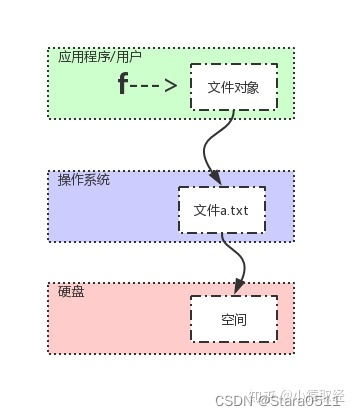
回收方法为:
1、f.close() #回收操作系统打开的文件资源
2、del f #回收应用程序级的变量
with关键字
# 1、在执行完子代码块后,with 会自动执行f.close()
with open('a.txt','w') as f:pass # 2、可用用with同时打开多个文件,用逗号分隔开即可
with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data = read_f.read()write_f.write(data)
2.指定操作文本文件的字符编码
f = open(...)是由操作系统打开文件,如果打开的是文本文件,会涉及到字符编码问题,如果没有为open指定编码,那么打开文本文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。f = open('a.txt','r',encoding='utf-8')
3.控制文件读写操作的模式
r(默认的):只读
w:只写
a:只追加写
3.1 r 模式的使用
# r只读模式: 在文件不存在时则报错,文件存在文件内指针直接跳到文件开头with open('a.txt',mode='r',encoding='utf-8') as f:res=f.read() # 会将文件的内容由硬盘全部读入内存,赋值给res# 小练习:实现用户认证功能inp_name=input('请输入你的名字: ').strip()inp_pwd=input('请输入你的密码: ').strip()with open(r'db.txt',mode='r',encoding='utf-8') as f:for line in f:# 把用户输入的名字与密码与读出内容做比对u,p=line.strip('\n').split(':')if inp_name == u and inp_pwd == p:print('登录成功')breakelse:print('账号名或者密码错误')
3.2 w 模式的使用
# w只写模式: 在文件不存在时会创建空文档,文件存在会清空文件,文件指针跑到文件开头
with open('b.txt',mode='w',encoding='utf-8') as f:f.write('你好\n')f.write('我好\n') f.write('大家好\n')f.write('111\n222\n333\n')
#强调:
# 1 在文件不关闭的情况下,连续的写入,后写的内容一定跟在前写内容的后面
# 2 如果重新以w模式打开文件,则会清空文件内容
3.3 a 模式的使用
# a只追加写模式: 在文件不存在时会创建空文档,文件存在会将文件指针直接移动到文件末尾with open('c.txt',mode='a',encoding='utf-8') as f:f.write('44444\n')f.write('55555\n')
#强调 w 模式与 a 模式的异同:
# 1 相同点:在打开的文件不关闭的情况下,连续的写入,新写的内容总会跟在前写的内容之后
# 2 不同点:以 a 模式重新打开文件,不会清空原文件内容,会将文件指针直接移动到文件末尾,新写的内容永远写在最后# 小练习:实现注册功能:name=input('username>>>: ').strip()pwd=input('password>>>: ').strip()with open('db1.txt',mode='a',encoding='utf-8') as f:info='%s:%s\n' %(name,pwd)f.write(info)
3.4 + 模式的使用(了解)
# r+ w+ a+ :可读可写
#在平时工作中,我们只单纯使用r/w/a,要么只读,要么只写,一般不用可读可写的模式
4.控制文件读写内容的模式
大前提: tb模式均不能单独使用,必须与r/w/a之一结合使用
t(默认的):文本模式1. 读写文件都是以字符串为单位的2. 只能针对文本文件3. 必须指定encoding参数
b:二进制模式:1.读写文件都是以bytes/二进制为单位的2. 可以针对所有文件3. 一定不能指定encoding参数
4.1 t 模式的使用
# t 模式:如果我们指定的文件打开模式为r/w/a,其实默认就是rt/wt/atwith open('a.txt',mode='rt',encoding='utf-8') as f:res=f.read() print(type(res)) # 输出结果为:<class 'str'>with open('a.txt',mode='wt',encoding='utf-8') as f:s='abc'f.write(s) # 写入的也必须是字符串类型#强调:t 模式只能用于操作文本文件,无论读写,都应该以字符串为单位,而存取硬盘本质都是二进制的形式,当指定 t 模式时,内部帮我们做了编码与解码
4.2 b 模式的使用
# b: 读写都是以二进制位单位with open('1.mp4',mode='rb') as f:data=f.read()print(type(data)) # 输出结果为:<class 'bytes'>with open('a.txt',mode='wb') as f:msg="你好"res=msg.encode('utf-8') # res为bytes类型f.write(res) # 在b模式下写入文件的只能是bytes类型#强调:b模式对比t模式
1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便
2、针对非文本文件(如图片、视频、音频等)只能使用b模式# 小练习: 编写拷贝工具
src_file=input('源文件路径: ').strip()
dst_file=input('目标文件路径: ').strip()
with open(r'%s' %src_file,mode='rb') as read_f,open(r'%s' %dst_file,mode='wb') as write_f:for line in read_f:# print(line)write_f.write(line)
5.操作文件的方法(重点)
# 读操作
f.read() # 读取所有内容,执行完该操作后,文件指针会移动到文件末尾
f.readline() # 读取一行内容,光标移动到第二行首部
f.readlines() # 读取每一行内容,存放于列表中# 强调:
# f.read()与f.readlines()都是将内容一次性读入内容,如果内容过大会导致内存溢出,若还想将内容全读入内存,则必须分多次读入,有两种实现方式:
# 方式一
with open('a.txt',mode='rt',encoding='utf-8') as f:for line in f:print(line) # 同一时刻只读入一行内容到内存中# 方式二
with open('1.mp4',mode='rb') as f:while True:data=f.read(1024) # 同一时刻只读入1024个Bytes到内存中if len(data) == 0:breakprint(data)# 写操作
f.write('1111\n222\n') # 针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) # 针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) # 文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式f.readable() # 文件是否可读
f.writable() # 文件是否可读
f.closed # 文件是否关闭
f.encoding # 如果文件打开模式为b,则没有该属性
f.flush() # 立刻将文件内容从内存刷到硬盘
f.name
6.主动控制文件内指针移动
#大前提:文件内指针的移动都是Bytes为单位的,唯一例外的是t模式下的read(n),n以字符为单位
with open('a.txt',mode='rt',encoding='utf-8') as f:data=f.read(3) # 读取3个字符with open('a.txt',mode='rb') as f:data=f.read(3) # 读取3个Bytes# 之前文件内指针的移动都是由读/写操作而被动触发的,若想读取文件某一特定位置的数据,则则需要用f.seek方法主动控制文件内指针的移动,详细用法如下:
# f.seek(指针移动的字节数,模式控制):
# 模式控制:
# 0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的
# 1: 该模式代表指针移动的字节数是以当前所在的位置为参照的
# 2: 该模式代表指针移动的字节数是以文件末尾的位置为参照的
# 强调:其中0模式可以在t或者b模式使用,而1跟2模式只能在b模式下用
6.1 0模式详解
# a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节)
abc你好# 0模式的使用
with open('a.txt',mode='rt',encoding='utf-8') as f:f.seek(3,0) # 参照文件开头移动了3个字节print(f.tell()) # 查看当前文件指针距离文件开头的位置,输出结果为3print(f.read()) # 从第3个字节的位置读到文件末尾,输出结果为:你好# 注意:由于在t模式下,会将读取的内容自动解码,所以必须保证读取的内容是一个完整中文数据,否则解码失败with open('a.txt',mode='rb') as f:f.seek(6,0)print(f.read().decode('utf-8')) #输出结果为: 好
6.2 1模式详解
# 1模式的使用
with open('a.txt',mode='rb') as f:f.seek(3,1) # 从当前位置往后移动3个字节,而此时的当前位置就是文件开头print(f.tell()) # 输出结果为:3f.seek(4,1) # 从当前位置往后移动4个字节,而此时的当前位置为3print(f.tell()) # 输出结果为:7
6.3 2模式详解
# a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节)
abc你好# 2模式的使用
with open('a.txt',mode='rb') as f:f.seek(0,2) # 参照文件末尾移动0个字节, 即直接跳到文件末尾print(f.tell()) # 输出结果为:9f.seek(-3,2) # 参照文件末尾往前移动了3个字节print(f.read().decode('utf-8')) # 输出结果为:好# 小练习:实现动态查看最新一条日志的效果
import time
with open('access.log',mode='rb') as f:f.seek(0,2)while True:line=f.readline()if len(line) == 0:# 没有内容time.sleep(0.5)else:print(line.decode('utf-8'),end='')
7.文件的修改
# 文件a.txt内容如下
张一蛋 山东 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422# 执行操作
with open('a.txt',mode='r+t',encoding='utf-8') as f:f.seek(9)f.write('<妇女主任>')# 文件修改后的内容如下
张一蛋<妇女主任> 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422# 强调:
# 1、硬盘空间是无法修改的,硬盘中数据的更新都是用新内容覆盖旧内容
# 2、内存中的数据是可以修改的
7.1文件修改方式一
# 实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件
# 优点: 在文件修改过程中同一份数据只有一份
# 缺点: 会过多地占用内存
with open('db.txt',mode='rt',encoding='utf-8') as f:data=f.read()with open('db.txt',mode='wt',encoding='utf-8') as f:f.write(data.replace('kevin','SB'))
7.2 文件修改方式二
# 实现思路:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容,修改完后写入临时文件...,删掉原文件,将临时文件重命名原文件名
# 优点: 不会占用过多的内存
# 缺点: 在文件修改过程中同一份数据存了两份
import oswith open('db.txt',mode='rt',encoding='utf-8') as read_f,\open('.db.txt.swap',mode='wt',encoding='utf-8') as wrife_f:for line in read_f:wrife_f.write(line.replace('SB','kevin'))os.remove('db.txt')
os.rename('.db.txt.swap','db.txt')
七、函数
1.函数
定义函数:def 函数名(参数1,参数2,...):"""文档描述"""函数体return 值1.def: 定义函数的关键字;
2.函数名:函数名指向函数内存地址,是对函数体代码的引用。函数的命名应该反映出函数的功能;
3.括号:括号内定义参数,参数是可有可无的,且无需指定参数的类型;
4.冒号:括号后要加冒号,然后在下一行开始缩进编写函数体的代码;
"""文档描述""": 描述函数功能,参数介绍等信息的文档,非必要,但是建议加上,从而增强函数的可读性;
6.函数体:由语句和表达式组成;
7.return 值:定义函数的返回值,return是可有可无的。
参数是函数的调用者向函数体传值的媒介,若函数体代码逻辑依赖外部传来的参数时则需要定义为参函数
def my_min(x,y):res=x if x < y else yreturn res
否则定义为无参函数
def interactive():user=input('user>>: ').strip()pwd=input('password>>: ').strip()return (user,pwd)
1.1 调用函数与函数返回值
#定义阶段
def foo():print('in the foo')bar()def bar():print('in the bar')#调用阶段
foo()
相关文章:
掌握Python编程的深层技能
一、Python基础语法、变量、列表、字典等运用 1.运行python程序的两种方式 1.交互式即时得到程序的运行结果 2.脚本方式把程序写到文件里(约定俗称文件名后缀为.py),然后用python解释器解释执行其中的内容2.python程序运行的三个步骤 python3.8 C:\a\b\c.py 1.先启动python3…...
Echarts地图实现:各省市计划录取人数
Echarts地图实现:各省市计划录取人数 实现功能 本文将介绍如何使用 ECharts 制作一个展示中国人民大学2017年各省市计划录取人数的地图。我们将实现以下图表形式: 地图:基础的地图展示,反映不同省市的录取人数。散点图…...

shell脚本if/else使用示例
if判断字符串是否为空实例if判断整数是否为奇数实例if判断整数是否为偶数实例if判断整数是否为正数实例if判断整数是否为负数实例输入两个字符串,输出字符串的大小关系输入学生的成绩判断是否合法输入学生的成绩判断是否及格判断平年闰年输入文件判断文件是否是普通…...

【D3.js in Action 3 精译】1.2.2 可缩放矢量图形(二)
当前内容所在位置 第一部分 D3.js 基础知识 第一章 D3.js 简介 1.1 何为 D3.js?1.2 D3 生态系统——入门须知 1.2.1 HTML 与 DOM1.2.2 SVG - 可缩放矢量图形 ✔️ 第一部分【第二部分】✔️第三部分(精译中 ⏳) 1.2.3 Canvas 与 WebGL&#x…...

Java中的Monad设计模式及其实现
Java中的Monad设计模式及其实现 在函数式编程中,Monad是一种重要的设计模式,用于处理包含隐含计算信息(如计算顺序、环境、状态、错误处理等)的计算。Monad提供了一种结构,使得可以将计算链式连接起来,每一…...

Dahlia Hart: Stylized Casual Character(休闲角色模型)
此包包含两个发型和两个服装,每个都有多种颜色选择。每个发型都适合与物理资源一起使用,并包含各种表情和音素混合形状。 下载:Unity资源商店链接资源下载链接 效果图:...
vector容器
以下是关于vector容器的总结 1、构造容器 2、容器赋值 3、获取容量capacity和大小size 4、插入和删除 5、数据存取 6、互换容器和预留空间 #include <iostream> #include <vector>using namespace std; // vector数据结构和数组非常相似,也称为单端数组…...

二进制常用知识整理<java>
1、进制转换: int转二进制: public static void main(String[] args) {int a 0b100;//0b表示后面的为二进制表示,0开始表示八进制System.out.println(a);System.out.println(Integer.toBinaryString(a));System.out.println(Integer.toStr…...

基于Docker的淘客返利平台部署
基于Docker的淘客返利平台部署 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!在本文中,我们将探讨如何利用Docker技术来部署一个淘客返利平台。Doc…...
【涵子来信科技潮流】——WWDC24回顾与暑假更新说明
期末大关,即将来袭。在期末之前,我想发一篇文章,介绍有关WWDC24的内容和暑假中更新的说明。本篇文章仅为个人看法和分享,如需了解更多详细内容,请通过官方渠道或者巨佬文章进行进一步了解。 OK, Lets go. 一、WWDC24 …...
)
重温react-08(createContext使用方式)
react中的createContext使用方式 简介一下,就是组件之间可以互相通信的比较好用的传值方式,话不多说直接上代码。 以下介绍的是类组件中的方式,在函数组件中不是如此使用的。 定义一个通用的方法 import { createContext } from "react…...

LInux后台运行程序
测试c代码 #include <stdio.h> #include <unistd.h> int main() {for (int i;; i) {printf("b数值 %d\n", i);fflush(stdout);sleep(3);} }使用CtrlZ可以将当前正在运行的程序放到后台并暂停它。如果你想要继续这个暂停的程序,可以使用fg命令…...

DEBOPIE框架:打造最好的ChatGPT交易机器人
本文介绍了如何利用 DEBOPIE 框架并基于 ChatGPT 创建高效交易机器人,并强调了在使用 AI 辅助交易时需要注意的限制以及操作步骤。原文: Build the Best ChatGPT Trading Bots with my “DEBOPIE” Framework 如今有大量文章介绍如何通过 ChatGPT 帮助决定如何以及在…...

C++ Thead多线程 condition_variable 与其使用场景---C++11多线程快速学习
std::condition_variable 的步骤如下: 创建一个 std::condition_variable 对象。 创建一个互斥锁 std::mutex 对象,用来保护共享资源的访问。 在需要等待条件变量的地方 使用 std::unique_lock<std::mutex> 对象锁定互斥锁 并调用 std::conditio…...

什么是前端开发?
前端开发是什么一种工作?这里以修房子举例: jquery根据数据去生成对应的html代码。首先得有一个html代码的“房屋构造”,然后根据数据去填充“房屋构造”的“血肉”,最后JavaScript通过事件等方法给一砖一瓦修好的房屋添加“灵魂…...
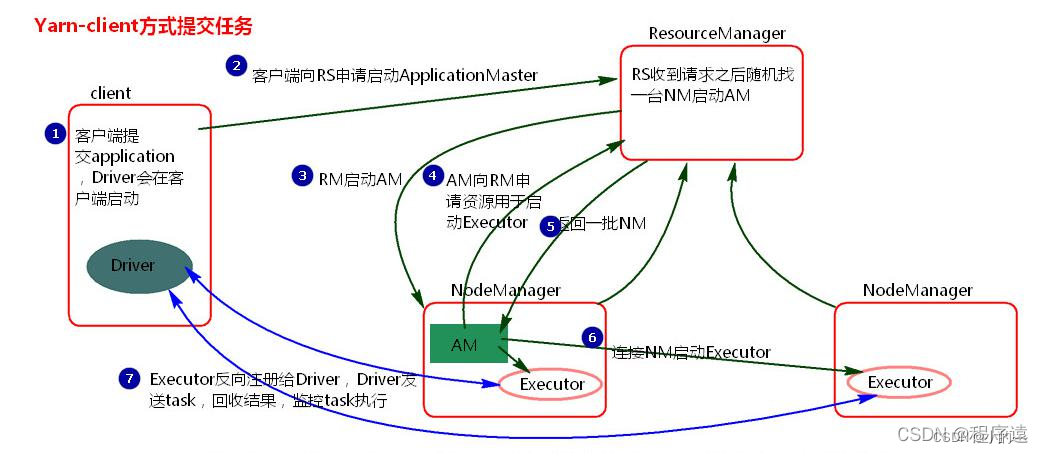
大数据面试题之Spark(1)
目录 Spark的任务执行流程 Spark的运行流程 Spark的作业运行流程是怎么样的? Spark的特点 Spark源码中的任务调度 Spark作业调度 Spark的架构 Spark的使用场景 Spark on standalone模型、YARN架构模型(画架构图) Spark的yarn-cluster涉及的参数有哪些? Spark提交jo…...

Spring Boot 和 Spring Framework 的区别是什么?
SpringFramework和SpringBoot都是为了解决在Java开发过程中遇到的各种问题而出现的。了解它们之间的差异,能够更好的帮助我们使用它们。 SpringFramework SpringFramework是一个开源的Java平台,它提供了一种全面的架构和基础设施来支持Java应用程序的开…...
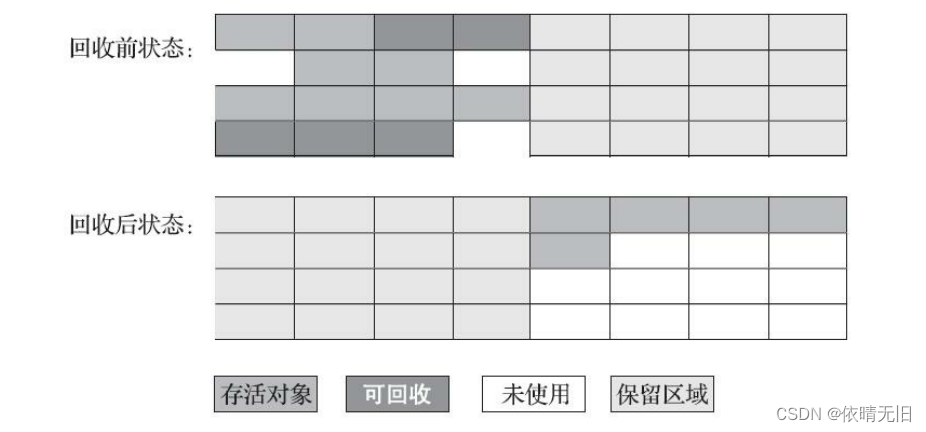
JVM原理(四):JVM垃圾收集算法与分代收集理论
从如何判定消亡的角度出发,垃圾收集算法可以划分为“引用计数式垃圾收集”和“追踪式垃圾收集”两大类。 本文主要介绍的是追踪式垃圾收集。 1. 分代收集理论 当代垃圾收集器大多遵循“分代收集”的理论进行设计,它建立在两个假说之上: 弱分…...
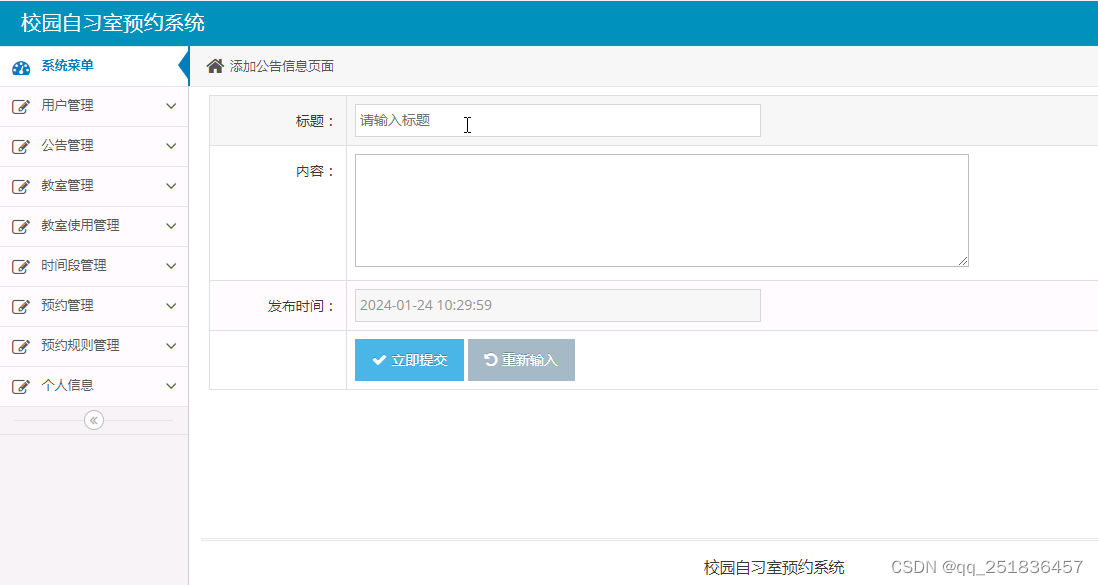
1961 Springboot自习室预约系统idea开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 自习室预约管理系统是一套完善的信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发),系统具有完整的源代码和数据库…...
答案版)
前端面试题(12)答案版
1. H5的新特性? 1) 更加语义化的标签,如<header>、<nav>、<article>等,便于网页结构的表达。 2) 新的多媒体标签,如<video>和<audio>,支持本地视频和音频的播放。 3) 本地存储API,如localStorage和sessionStorage,用于在客户端保存数…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...
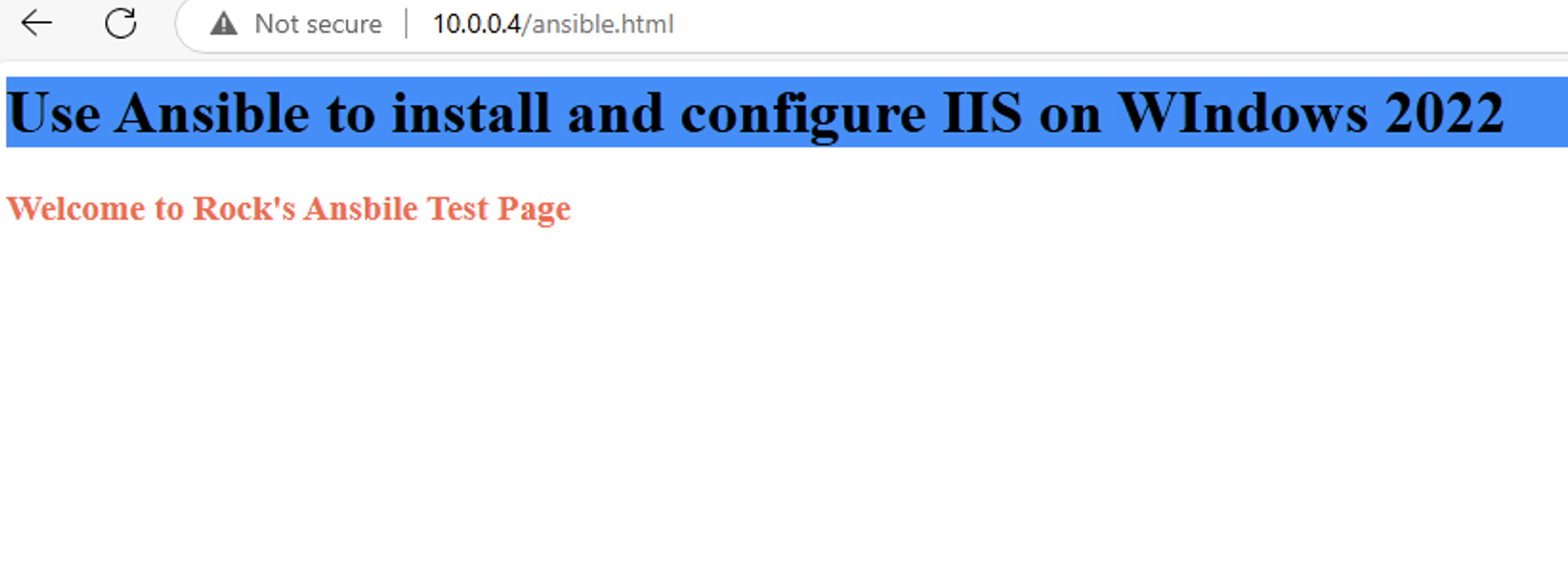
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...