大数据面试题之HBase(1)
目录
介绍下HBase
HBase优缺点
说下HBase原理
介绍下HBase架构
HBase读写数据流程
HBase的读写缓存
在删除HBase中的一个数据的时候,它什么时候真正的进行删除呢?当你进行删除操作,它是立马就把数据删除掉了吗?
HBase中的二级索引
HBase的RegionServer宕机以后怎么恢复的?
HBase的一个region由哪些东西组成?
HBase高可用怎么实现的?
为什么HBase适合写多读少业务?
介绍下HBase
HBase是一个开源的、分布式的、面向列的NoSQL数据库,它模仿了Google的Bigtable数据存储模型,并在Apache Hadoop生态系统中
运行。HBase的设计目标是为了处理非常大的数据集,即所谓的“大数据”,能够在商用硬件集群上实现高度的可伸缩性和可靠性。下面是
HBase的一些关键特性与概念:1、核心特点:1) 分布式存储:HBase利用Hadoop Distributed File System (HDFS)作为底层存储,数据分散存储在集群中的多个节点上,支持
水平扩展。2) 面向列族:数据以列族(Column Family)的形式组织,列族内的列可以动态增加,每个列族可以有多个列,不同的列族可以有不同
的存储属性。3) 稀疏存储:HBase表是稀疏的,即表中的每个行不必有每一列的数据,未赋值的列不会占用存储空间。4) 键值存储:在更高层次上,HBase可以被视为一个巨大的键值存储系统,其中行键(Row Key)作为键,而每个Cell(由行键、列族、
列限定符和时间戳唯一确定)存储实际的数据值。5) 实时读写:支持低延迟的随机读写操作,适用于实时数据处理场景。6) 强一致性:HBase提供了“强一致性”读取,意味着读操作总是返回最新的已提交数据。7) 自动分区:表会被自动分割成多个区域(Region),随着数据的增长,Region会自动分裂并重新分配,从而实现负载均衡。
2、关键组件:1) Region Server:负责处理对特定Region的读写请求。2) HMaster:管理整个集群的Region分配、负载均衡、Region Server故障检测等,但HBase设计为无单点故障,即使HMaster挂掉
也不影响数据读写。3) ZooKeeper:用于集群的协调服务,如维护集群元数据、协助进行Leader选举等。
3、适用场景:1) 大规模数据存储,特别是非结构化和半结构化的数据。2) 需要快速随机访问数据的应用,例如实时分析、Web索引、社交网络数据存储等。3) 高并发读写操作的环境,HBase能够通过水平扩展应对大量读写请求。HBase不支持复杂的SQL查询,而是使用基于行键和列族的简单API进行数据访问,适合那些需要极高扩展性和高吞吐量,但对事务性要求不
高的应用场景。HBase优缺点
优点:
1、大规模数据存储能力:HBase可以轻松地扩展到数百台甚至数千台服务器,以满足大规模数据存储和并发访问的需求。
2、高可靠性:
WAL(预写式日志)机制确保了在数据写入时,即使集群出现异常也不会导致数据丢失。
Replication机制保证了在集群出现严重问题时,数据不会丢失或损坏。
HBase底层使用HDFS,HDFS本身也有备份机制,进一步增强了数据的可靠性。
3、高性能:
底层的LSM(Log-Structured Merge-Tree)数据结构和Rowkey有序排列等设计,使得HBase具有非常高的写入性能。
Region切分、主键索引和缓存机制使得HBase在海量数据下也具备一定的随机读取性能,针对Rowkey的查询能达到毫秒级别。
4、面向列存储:
面向列(簇)的存储和权限控制,列(簇)独立检索,提高了数据检索的灵活性。
对于为空的列并不占用内存空间,因此表可以设计的非常稀疏,节省存储空间。
5、多版本数据:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳。
6、灵活的数据模型:提供了灵活的列族和列的数据模型,可以根据实际需求进行数据建模,支持动态添加列。
7、强大的数据处理能力:支持丰富的数据操作和查询功能,包括范围查询、过滤器、聚合函数等。缺点:
1、不支持SQL语句:虽然HBase是一个非关系型数据库,但它不支持SQL语句,这可能会增加一些用户的学习成本。
2、单一RowKey的局限性:单一RowKey的局限性决定了它不可能有效地支持多条件查询,这可能会限制其在某些复杂查询场景下的应用。
3、配置和管理复杂:HBase的配置和管理需要一定的专业知识和经验,对于非技术人员来说,上手和维护成本较高。
4、不支持复杂的事务操作:HBase不支持跨行的事务操作,只能保证单行的原子性,对于涉及多行事务操作的场景,无法提供完整的事务支
持。
5、查询性能:相对于传统关系型数据库,HBase的查询性能可能会有所下降,特别是在复杂的查询场景下。
6、存储空间占用较大:由于HBase需要维护大量的索引和元数据,以及数据的冗余复制,所以相比于传统数据库,HBase的存储空间占用较
大。综上所述,HBase在提供大规模数据存储、高可靠性、高性能和灵活数据模型的同时,也存在一些局限性和挑战,用户需要根据自身需求和技
术背景进行权衡选择。说下HBase原理
HBase的工作原理基于几个核心组件和设计理念,旨在提供一个高性能、可扩展、分布式的存储系统。以下是HBase的关键原理:1. 分布式架构
HMaster: 负责集群的管理工作,包括表的创建、删除、分区(Region)的分配与负载均衡、故障检测与恢复等。HBase设计为可以运行多
个HMaster实例,但只有一个处于Active状态,其他为Standby模式,以保证高可用性。
RegionServer: 存储并处理数据的服务器,每个RegionServer负责一组Region的读写操作。当某个Region的数据量增大到一定阈值
时,该Region会被分割成两个更小的Region并重新分配。
ZooKeeper: 作为分布式协调服务,用于管理集群元数据、Leader选举、故障恢复等,确保集群的一致性和稳定性。
2. 数据模型
RowKey: 每一行数据的唯一标识,决定了数据的存储位置和排序。RowKey设计极为关键,因为它直接影响数据的分布和访问性能。
Column Families: 数据按列族组织,每个列族可以有多个列,列族内的列可以动态增加,不同列族可以有不同的存储和缓存策略。
Timestamps: 每个单元格(Cell)都包含一个时间戳,用于版本控制,使得HBase能够存储同一数据的不同版本。
3. 存储机制
MemStore & Flush: 写入的数据首先存储在内存中的MemStore,当MemStore达到一定阈值时,数据会被“Flush”到磁盘上的HFile
中,以HFile格式持久化存储。
HFile: HBase在HDFS上的存储格式,是一种高效的、可持久化的、具有索引结构的文件格式,支持快速查找。
Write-Ahead Log (WAL): 在数据写入MemStore之前,会先写入预写日志(WAL),确保在系统崩溃时能够恢复数据。
4. 读写流程
写操作: 客户端写入数据时,先与ZooKeeper交互找到RowKey对应的RegionServer,然后将数据写入该RegionServer的MemStore并
记录到WAL,以保证数据的持久性。
读操作: 客户端读取数据时同样先定位到正确的RegionServer,然后直接从MemStore或HFile中读取数据。MemStore作为读缓存加速读
取速度,未命中时则从磁盘读取。
5. 容错与恢复
Region自动平衡: HMaster会监控各RegionServer的负载,自动进行Region的迁移和负载均衡。
故障恢复: 当RegionServer故障时,HMaster会重新分配其上的Region到其他健康的RegionServer上,并利用WAL恢复未持久化到
HFile的数据。综上所述,HBase通过高度分布式的架构、列族存储模型、高效的读写机制以及严格的容错恢复策略,实现了对海量数据的高效存储与处理。介绍下HBase架构
HBase的架构是一个分布式、可扩展的NoSQL数据库系统,其核心组件协同工作以支持海量数据存储和高效的数据访问。以下是对HBase架构
的详细介绍:1. 总体概述
HBase是一个基于Hadoop构建的分布式、面向列的NoSQL数据库。
底层物理存储以Key-Value的数据格式存储在Hadoop的HDFS文件系统上。2. 主要组件
(1)Client
提供了访问HBase的一系列API接口,如Java Native API、Rest风格http API、Thrift API、scala等。
客户端会维护cache来加快对HBase的访问。
(2)ZooKeeper
HBase通过ZooKeeper来做Master的高可用,保证任何时候集群中只有一个Master。
实时监控RegionServer的上线和下线信息,并实时通知Master。
存储元数据的入口以及集群配置的维护等工作。
(3)HDFS
为HBase提供最终的底层数据存储服务。
为HBase提供高可用的支持。
(4)Master(HMaster)
负责RegionServer的管理,为RegionServer分配Region。
负责RegionServer的负载均衡。
发现失效的RegionServer并重新分配其上的Region。
管理用户对table的增删改操作(DDL操作:create, delete, alter)。
(5)RegionServer(HRegionServer)
RegionServer维护Region,处理对这些Region的IO请求,向HDFS文件系统中读写数据。
一个RegionServer由多个Region组成,一个Region由多个Store组成,一个Store对应一个CF(列族)。
写操作先写入Mem Store,当Mem Store中的数据达到某个阈值时,RegionServer会启动flashcache进程写入StoreFile。
RegionServer负责切分在运行过程中变得过大的Region。3. 特殊表
.META.:记录了用户所有表拆分出来的Region映射信息,可以有多个Regoin。
-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个Region,不会分裂。4. 数据访问流程
Client访问用户数据前需要首先访问ZooKeeper,找到-ROOT-表的Region所在的位置。
然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问。
中间需要多次网络操作,但client端会做cache缓存。5. 底层存储
HBase的底层存储采用的是LSM树(Log-Structured Merge-Tree)。
数据以HFile格式保存在HDFS上。6. 数据处理
支持丰富的数据操作和查询功能,包括范围查询、过滤器、聚合函数等。7. 事务和并发控制
HBase提供了对事务的支持,包括事务原子性的保证、写写并发控制和读写并发控制。以上就是HBase架构的详细介绍,通过Client、ZooKeeper、HDFS、Master和RegionServer等组件的协同工作,HBase能够支持海量
数据存储和高效的数据访问。HBase读写数据流程
HBase的读写数据流程体现了其分布式、列式存储的特点,以及如何利用ZooKeeper进行协调以实现高效的数据操作。下面是HBase读写数
据的主要流程:1、写数据流程:1) 客户端请求:客户端通过Row Key确定要写入的数据应该归属的Region。首先,它通过与ZooKeeper通信找到.META.表,该表存储
了所有Region的位置信息,从而定位到目标Region所在的RegionServer。2) 验证与写入:客户端向目标RegionServer发送写请求。RegionServer验证请求的合法性及表的存在性后,将数据写入该Region的
MemStore中。同时,为了确保数据的持久性,操作也会被记录到Write-Ahead Log (WAL)中,以防RegionServer故障导致数据丢失。3) MemStore满载与Flush:当MemStore达到预设的大小阈值时,其内容会被“Flush”到磁盘上,生成一个新的HFile。HFile是HBase用于持久化存储数据的文件格式,包含数据和索引,便于快速查找。4) Compact合并:随着HFile数量的增加,会触发Compact操作,将多个较小的HFile合并成较大的文件,同时进行数据版本合并和删除
标记数据,以优化存储空间和查询性能。5) Region分裂:当Region的大小超过一定阈值时,会触发Region的Split操作,将大Region分裂成两个或更多的新Region,以维持
数据分布的均衡。2、读数据流程:1) 定位Region:客户端根据Row Key通过ZooKeeper查询.META.表,找到包含目标数据的Region的位置信息,进而定位到正确的
RegionServer。2) 读取数据:客户端向该RegionServer发送读请求。首先尝试从Region的MemStore中读取最新数据,这是因为MemStore存储的是最
近的更新,访问速度最快。3) 查询StoreFile:如果MemStore中没有找到数据,则继续查询该Region下的StoreFile(即之前Flush生成的HFile)。在这个过
程中,Block Cache(一种基于LRU策略的缓存)会被用来加速数据访问,如果所需数据在Block Cache中存在,则直接返回。4) 数据返回:一旦找到数据,就将其返回给客户端。如果开启了读取缓存策略,查询到的数据也可能被加入到Block Cache中,以便下次
更快地访问。通过上述流程,HBase实现了高效、可靠的读写操作,特别是在处理大规模数据集时,能够满足低延迟和高吞吐量的需求。HBase的读写缓存
HBase的读写缓存是其性能优化的关键部分,主要包括两种缓存机制:MemStore(写缓存)和BlockCache(读缓存)。以下是关于这两种
缓存机制的详细解释:1、MemStore(写缓存)1) 作用:MemStore是HBase的写缓存,用于缓存写入的数据。当客户端向HBase写入数据时,数据首先会被写入MemStore,而不是直接
写入磁盘。这样可以提高写入的性能,因为写入内存的速度远快于写入磁盘。2) 工作机制:
写入数据时,数据首先被写入MemStore,并同时写入WAL(Write-Ahead Log)以确保数据的持久性。WAL用于在系统崩溃时恢复数据。
当MemStore中的数据达到一定的阈值(例如,当MemStore的大小达到HRegionServer的heapsize的某个百分比时),会触发flush操
作,将数据从MemStore写入HDFS上的HFile中。
HBase为每个Region提供一个MemStore,因此可以有多个MemStore同时运行,以支持并发的写操作。3) 优化建议:对于写密集型的应用,可以通过调整MemStore的大小和flush策略来优化性能。例如,可以增加MemStore的大小以减少
flush的频率,或者调整flush的触发条件以平衡内存使用和写入性能。2、BlockCache(读缓存)1) 作用:BlockCache是HBase的读缓存,用于缓存从HDFS读取的数据块。当HBase需要读取数据时,它首先会检查BlockCache中是否
已经有该数据块的缓存。如果有,则直接从缓存中读取,避免了对HDFS的I/O操作,从而提高了读取性能。2) 工作机制:
BlockCache在HRegionServer的JVM堆上管理,它将表中最常访问的文件块缓存到内存中。
当HBase读取数据时,如果请求的数据块已经缓存在BlockCache中,则可以直接从缓存中读取,避免了查询HDFS的开销。
BlockCache采用LRU(Least Recently Used)策略来管理缓存,当缓存达到其最大大小时,会淘汰最近最少使用的数据块。3) 优化建议:对于读密集型的应用,可以通过增加BlockCache的大小来提高缓存命中率,从而进一步提高读取性能。但是,需要注意的
是,BlockCache和MemStore的大小之和不能超过HRegionServer的JVM堆大小的某个限制(通常为80%),否则HBase将无法启动。综上所述,HBase通过MemStore和BlockCache两种缓存机制来优化读写性能。合理地配置和调整这两种缓存的大小和策略,可以根据应用
的需求来平衡读写性能和资源使用。在删除HBase中的一个数据的时候,它什么时候真正的进行删除呢?当你进行删除操作,它是立马就把数据删除掉了吗?
在HBase中,当你执行一个删除操作时,数据并不会立即从磁盘上删除。HBase采取的是逻辑删除的方式,也就是说,它实际上是对要删除的
数据打上一个删除标记,这个标记被称为"Tombstone"(墓碑标记)。这个过程包括:1、客户端请求删除:客户端通过HBase API发出一个删除请求,指定要删除的行的RowKey以及可选的列族和列限定符。
2、插入Tombstone标记:HBase接收到删除请求后,会在MemStore中为该条目插入一个特殊的删除标记(Tombstone),这个标记记录了
删除的时间戳,表明对应的数据版本在此时间点之后被视为已删除。
3、数据读取时的处理:当后续有读取请求到达时,HBase会在检索数据时检查这些Tombstone标记,确保任何带有删除标记的数据不会被包
含在查询结果中。
Major Compaction触发真正删除:只有当Major Compaction过程发生时,这些带有Tombstone标记的数据才会被物理地从HFile中移
除,从而真正释放磁盘空间。Major Compaction是一个合并多个StoreFile(HFiles)的过程,它会创建一个新的、不包含已删除数据
的HFile,并替换旧的文件。因此,HBase中的数据在删除操作后,并不是立刻从磁盘上消失,而是经过一段时间,待到Major Compaction操作时,才会被彻底清理
掉。这样设计既保证了删除操作的高效性,也减少了数据删除对系统即时性能的影响。HBase中的二级索引
HBase作为一个分布式、列式存储的NoSQL数据库,其数据主要通过RowKey进行访问,这相当于一级索引。然而,HBase本身并不直接支持
二级索引(Secondary Index),这意味着无法直接高效地根据非RowKey字段进行查询。为了解决这一限制,开发人员采用了多种策略和
技术来实现二级索引,以下是几种常见的方法:1、Coprocessors(协处理器):
协处理器是HBase提供的一种机制,允许用户代码在RegionServer上运行,与数据存储紧密集成。通过使用协处理器,可以在数据变更时
维护一个辅助索引表,该表的RowKey为二级索引字段的值,而存储的内容包含指向原始数据RowKey的指针。查询时,先通过索引表找到
RowKey,再通过RowKey访问实际数据。2、Phoenix:
Phoenix是一个基于SQL的HBase查询引擎,它在HBase之上提供了一层SQL抽象。Phoenix支持创建二级索引,通过创建额外的HBase表来
维护索引,并在后台自动管理索引的更新。当执行查询时,Phoenix能够利用这些索引来加速非RowKey字段的查找。3、MapReduce或Spark作业:
可以通过批处理框架如MapReduce或Spark定期重建或更新二级索引表。这种方法通常适用于索引更新不频繁或可以接受一定延迟的场景。4、ITHBase (Indexed-Transactional HBase):
虽然这个项目较老且基于较旧的HBase版本,但它展示了如何在HBase上实现事务和二级索引的结合。通过额外的机制来维护索引与数据的一
致性。5、列族索引:
另一种方法是在相同的表中使用不同的列族来存储索引数据,这种方式适用于某些特定的数据模型,比如一个行内包含大量Qualifier的情
况。二级索引的引入显著增强了HBase的查询灵活性,使得用户可以根据非RowKey字段执行高效查询,但同时也带来了数据一致性和维护成本的
挑战。开发者在选择二级索引实现时需权衡各种方案的优缺点,考虑数据量、查询模式、更新频率等因素。HBase的RegionServer宕机以后怎么恢复的?
HBase的RegionServer宕机后的恢复过程主要包括以下几个步骤:1、故障检测:
HBase利用ZooKeeper来检测RegionServer的健康状况。每个RegionServer会周期性地向ZooKeeper发送心跳。如果ZooKeeper在预
定的时间间隔(Session Timeout)内没有收到心跳,它会认为该RegionServer已经宕机,并将此信息通知给HMaster。2、任务接管与资源分配:
HMaster检测到RegionServer宕机后,会开始接管该RegionServer上的所有Region。HMaster会遍历故障RegionServer托管的所有
Region,并将它们重新分配给集群中其他健康的RegionServer。这个过程涉及停用旧Region,分配新Region,以及更新元数据信息。3、数据恢复:
新的RegionServer在接收分配的Region后,会读取对应Region的HLog(Write-Ahead Log)文件,这些日志文件包含了宕机前对该
Region的所有更改操作。通过重放这些日志,新的RegionServer能够恢复那些在RegionServer宕机时尚未持久化到HFile的数据。
对于WALs,可能需要进行日志切分(SplitLog)过程,以确保所有未完成的日志都被正确处理和应用,尤其是当存在部分写入的日志片段
时。4、负载均衡:
一旦数据恢复完成,HMaster可能会启动负载均衡器来重新调整Region分布,确保集群的资源得到合理分配,避免某些RegionServer过
载。5、服务恢复:
经过上述步骤,原来在故障RegionServer上的数据和服务就被恢复到了新的RegionServer上,此时HBase可以继续对外提供服务。
整个恢复过程是自动化的,不需要人工干预,但是根据集群的大小、数据量以及故障的具体情况,恢复的时间可能会有所不同。如果配置了
Region自动均衡功能,集群会逐渐趋向于均衡状态,但如果需要快速恢复负载均衡,管理员也可以手动触发负载均衡操作。HBase的一个region由哪些东西组成?
HBase的一个region主要由以下几个部分组成:1、Stores:
每一个region由一个或多个store组成,每个store对应HBase表中的一个column family。HBase会把一起访问的数据放在一个store
里面,即为每个ColumnFamily建一个store。也就是说,一个表中有多少个ColumnFamily,那么该表的一个region中就有多少个
Store。2、MemStore:
MemStore是HBase的写缓存,用于缓存写入的数据。它保存在内存中,用于保存修改的数据即key-value对。
当MemStore的大小达到一个阈值(最新版本默认128MB,由参数hbase.hregion.memstore.flush.size配置)时,MemStore会被
flush到文件,即生成一个快照。3、StoreFiles:
MemStore内存中的数据写到文件后就成为StoreFile。memstore的每次flush操作都会生成一个新的StoreFile。
但是,当一个store上默认超过3个StoreFile时,会对StoreFile进行合并成一个新的StoreFile,这个过程由
hbase.hstore.compactionThreshold参数控制。4、HFiles:
StoreFile底层是以HFile的格式保存。HFile是HBase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。
一个StoreFile对应着一个HFile,而HFile是存储在HDFS之上的。HFile文件格式是基于Google Bigtable中的SSTable。总结来说,HBase的一个region主要由多个store组成,每个store对应一个column family,并包含一个MemStore用于写缓存和0至多
个StoreFile用于存储实际的数据文件(HFile)。这种结构使得HBase能够有效地管理和访问大量数据。HBase高可用怎么实现的?
HBase的高可用性主要通过以下几个方面来实现:1、数据的复制和分布:
HBase使用Hadoop的HDFS作为底层存储,数据被分散存储在多个RegionServer上。每个RegionServer都负责管理一部分数据,这些数
据通过HBase的分区机制进行划分。
HBase还使用了Hadoop的复制机制,将数据复制到多个RegionServer上,以实现数据的冗余备份。通常,数据会被复制三份(默认配
置),确保在部分节点故障时,系统仍可以从其他节点获取备份数据。2、ZooKeeper的协调:
HBase使用ZooKeeper作为分布式协调服务,用于管理和协调HBase集群中的各个组件。ZooKeeper可以监控HBase集群的状态,并在出现
故障时进行自动的故障转移和恢复。
当一个RegionServer宕机时,ZooKeeper会检测到宕机事件,并将该RegionServer上的数据分配给其他可用的RegionServer,以保证
数据的可用性。3、Master-Slave架构:
HBase采用了Master-Slave架构,其中Master节点负责管理整个HBase集群,包括表的创建、删除、分区的调整等操作。而
RegionServer节点负责实际的数据存储和读写操作。
当Master节点发生故障时,系统会自动选举一个新的Master节点来接管管理任务,保证系统的可用性。这个选举过程由ZooKeeper负责协
调。4、数据一致性和容错:
HBase通过多副本复制和ZooKeeper的数据同步机制来确保数据在多个节点之间的一致性。当写入操作发生时,HBase会将数据同时写入多
个副本中,并在所有副本都成功写入后才返回写入成功的响应。
HBase还提供了容错机制,以应对节点故障和网络问题。当一个节点发生故障时,系统可以自动从其他节点获取备份数据,并重新分配
RegionServer,确保数据的高可用性。5、一致性哈希:
HBase使用一致性哈希算法来实现数据的分区和负载均衡。一致性哈希算法可以将数据均匀地分布到不同的节点上,从而实现数据的负载均衡
和高可用性。当一个节点发生故障时,一致性哈希算法可以自动将该节点上的数据重新分布到其他节点上,以保证数据的一致性。综上所述,HBase通过数据的复制和分布、ZooKeeper的协调、Master-Slave架构、数据一致性和容错以及一致性哈希等机制,实现了高
可用性。这些机制确保了HBase在部分节点故障时,系统仍能继续提供服务,并自动进行故障恢复和数据重新分配。为什么HBase适合写多读少业务?
HBase适合写多读少业务的原因主要包括以下几点:1、LSM树结构(Log-Structured Merge-Tree):
HBase使用LSM树作为其存储引擎的核心。LSM树通过将数据先写入内存中的MemStore,然后合并到磁盘上的SSTable(Sorted String
Table)文件中,这样的过程对于写操作非常友好。写入时,大部分操作是顺序写入内存和磁盘,避免了随机I/O,提高了写入速度和吞吐
量。2、预分区和负载均衡:
HBase的表会被预先分割成多个Region,这些Region可以分布在不同的RegionServer上。合理的预分区和动态负载均衡机制确保了写入
负载能被均匀地分散到集群的各个节点,即使在高并发写入场景下也能保持较好的性能。3、Write-Ahead Log (WAL):
HBase使用WAL机制保证数据的持久性和可靠性。在数据写入MemStore之前,会先记录到WAL中,这是一个顺序写入的过程,保证了即使在
RegionServer故障时也不会丢失数据,同时也降低了写操作的延迟。4、减少读取开销的努力:
虽然HBase默认仅通过RowKey提供高效的查询,缺乏直接的二级索引支持,使得复杂的查询(特别是非RowKey查询)效率较低。这意味着
对于读操作密集型的应用,可能需要额外的优化措施,如利用Coprocessors、Phoenix或外部索引系统(如Elasticsearch)来提升读
性能。综上所述,HBase的设计特别优化了写入性能,通过LSM树结构、预分区、负载均衡和WAL机制,使得它在处理大量写入操作时表现出色。然
而,对于读操作,特别是非主键查询,可能需要额外的技术手段来优化,因此它更适合那些写多读少的业务场景。引用:https://www.nowcoder.com/discuss/353159520220291072
通义千问、文心一言
相关文章:
)
大数据面试题之HBase(1)
目录 介绍下HBase HBase优缺点 说下HBase原理 介绍下HBase架构 HBase读写数据流程 HBase的读写缓存 在删除HBase中的一个数据的时候,它什么时候真正的进行删除呢?当你进行删除操作,它是立马就把数据删除掉了吗? HBase中的二级索引 HBa…...

git回退commit的方式
在Git中,回退commit(即撤销之前的提交)可以通过多种方式来实现。以下是一些常见的方法,以及它们的详细步骤和注意事项: ### 1. 使用git revert命令 git revert命令用于撤销某次commit,但它并不会删除该comm…...
[Information Sciences 2023]用于假新闻检测的相似性感知多模态提示学习
推荐的一个视频:p-tuning P-tunning直接使用连续空间搜索 做法就是直接将在自然语言中存在的词直接替换成可以直接训练的输入向量。本身的Pretrained LLMs 可以Fine-Tuning也可以不做。 这篇论文也解释了为什么很少在其他领域结合知识图谱的原因:就是因…...

自定义vue3 hooks
文章目录 hooks目录结构demo hooks 当页面内有很多的功能,js代码太多,不好维护,可以每个功能都有写一个js或者ts,这样的话,代码易读,并且容易维护,组合式setup写法与此结合👍&#…...
《昇思25天学习打卡营第21天 | 昇思MindSporePix2Pix实现图像转换》
21天 本节学习了通过Pix2Pix实现图像转换。 Pix2Pix是基于条件生成对抗网络(cGAN)实现的一种深度学习图像转换模型。可以实现语义/标签到真实图片、灰度图到彩色图、航空图到地图、白天到黑夜、线稿图到实物图的转换。Pix2Pix是将cGAN应用于有监督的图…...
【文档+源码+调试讲解】科研经费管理系统
目 录 目 录 摘 要 ABSTRACT 1 绪论 1.1 课题背景 1.2 研究现状 1.3 研究内容 2 系统开发环境 2.1 vue技术 2.2 JAVA技术 2.3 MYSQL数据库 2.4 B/S结构 2.5 SSM框架技术 3 系统分析 3.1 可行性分析 3.1.1 技术可行性 3.1.2 操作可行性 3.1.3 经济可行性 3.1…...

linux 下 rm 为什么要这么写?
下面代码中的rm 为什么要写成/bin/rm? 大文件清理,高宿主含量样本可节约>90%空间/bin/rm -rf temp/qc/*contam* temp/qc/*unmatched* temp/qc/*.fqls -l temp/qc/ 这是一个很好的问题,观察很仔细, 也带着了自己的思考。 rm是 Linux 下的一个危险…...

【Spring Boot】Spring AOP中的环绕通知
目录 一、什么是AOP?二、AOP 的环绕通知2.1 切点以及切点表达式2.2 连接点2.3 通知(Advice)2.4 切面(Aspect)2.5 不同通知类型的区别2.5.1 正常情况下2.5.2异常情况下 2.6 统一管理切点PointCut 一、什么是AOP? Aspect Oriented Programmingÿ…...
docker部署前端,配置域名和ssl
之前使用80端口部署前端项目后,可以使用IP端口号在公网访问到部署的项目。 进行ICP域名备案后,可以通过域名解析将IP套壳,访问域名直接访问到部署的项目~ 如果使用http协议可以很容易实现这个需求,对nginx.conf文件进行修改&#…...
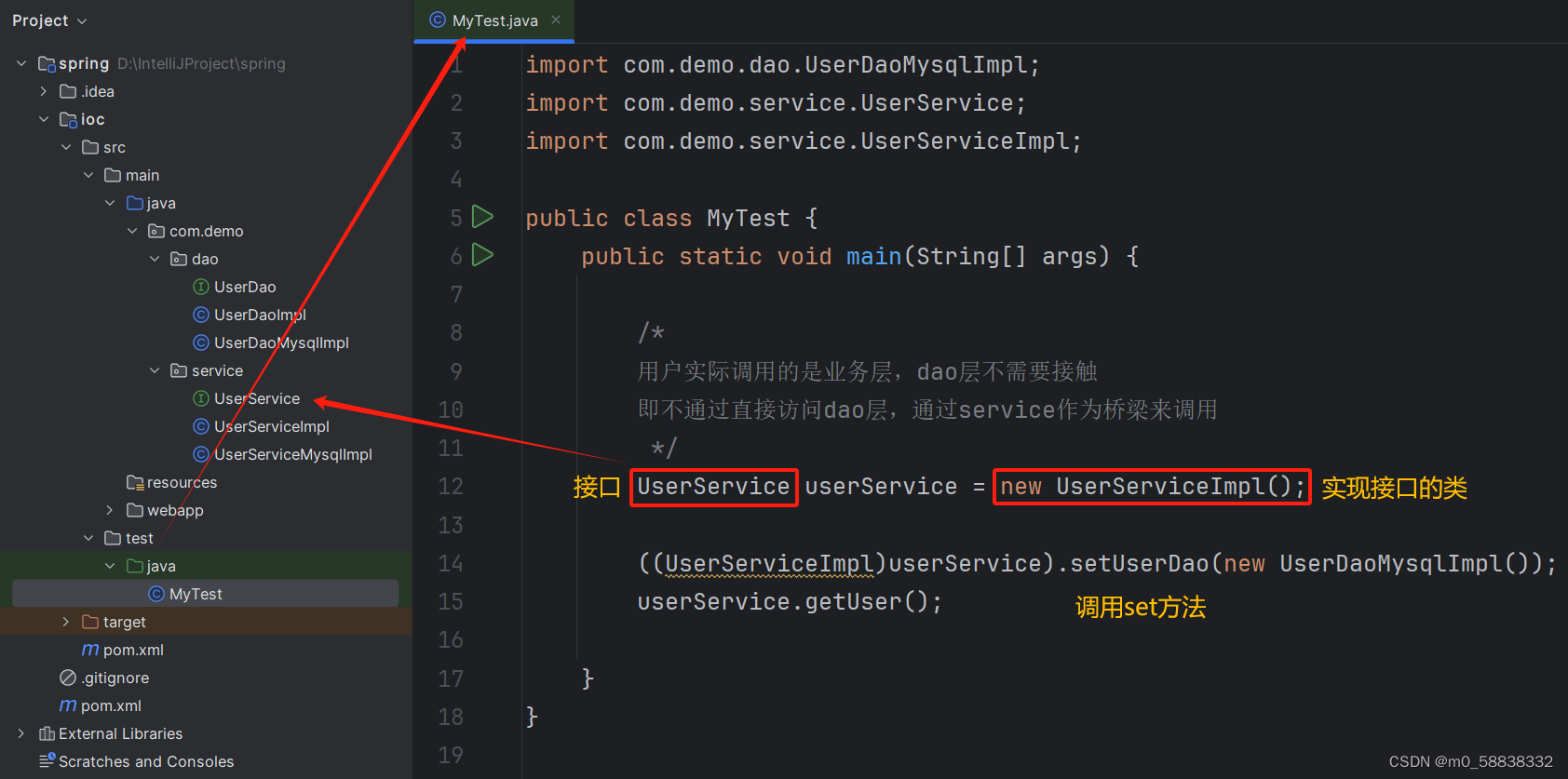
初学Spring之 IOC 控制反转
Spring 是一个轻量级的控制反转(IOC)和面向切面编程(AOP)的框架 导入 jar 包:spring-webmvc、spring-jdbc <dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc&…...

rpc的仅有通信的功能,在网断的情况下,比网通情况下,内存增长会是什么原因
RPC(Remote Procedure Call,远程过程调用)主要负责在分布式系统中透明地调用远程服务,就像调用本地函数一样。它封装了网络通信的细节,使得开发者可以专注于业务逻辑而非底层通信协议。RPC通信通常包括序列化、网络传输…...

从零开始:如何设计一个现代化聊天系统
写在前面: 此博客内容已经同步到我的博客网站,如需要获得更优的阅读体验请前往https://mainjaylai.github.io/Blog/blog/system/chat-system 在当今数字化时代,聊天系统已成为我们日常生活和工作中不可或缺的一部分。从个人交流到团队协作,从客户服务到社交网络,聊天应用…...

香橙派OrangePi AIpro初体验:当小白拿到一块开发板第一时间会做什么?
文章目录 香橙派OrangePi AIpro初体验:当小白拿到一块高性能AI开发板第一时间会做什么前言一、香橙派OrangePi AIpro概述1.简介2.引脚图开箱图片 二、使用体验1.基础操作2.软件工具分析 三、香橙派OrangePi AIpro.测试Demo1.测试Demo1:录音和播音(USB接口…...
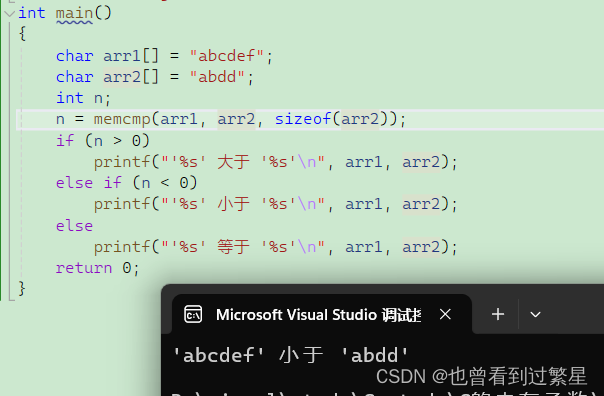
【C语言内存函数】
目录 1.memcpy 使用 模拟实现 2.memmove 使用 模拟实现 3.memset 使用 4.memcmp 使用 1.memcpy 使用 void * memcpy ( void * destination, const void * source, size_t num );目的地址 源地址 字节数 destination:指向要复制内…...
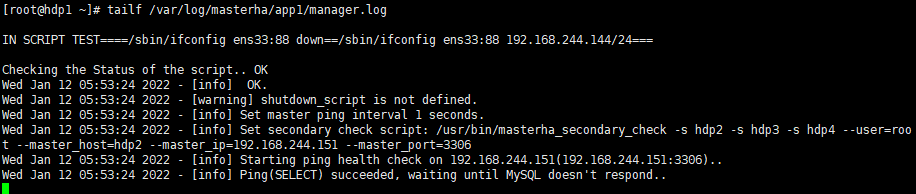
Mysql部署MHA高可用
部署前准备: mysql-8.0.27下载地址:https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.27-1.el7.x86_64.rpm-bundle.tar mha-manager下载地址:https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-mana…...
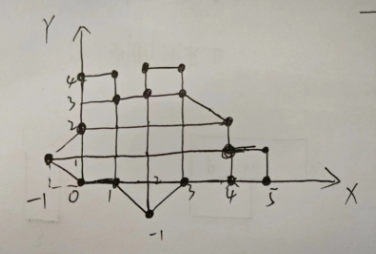
【算法学习】射线法判断点在多边形内外(C#)以及确定内外两点连线与边界的交点
1.前言: 在GIS开发中,经常会遇到确定一个坐标点是否在一块区域的内部这一问题。 如果这个问题不是一个单纯的数学问题,例如:在判断DEM、二维图像像素点、3D点云点等含有自身特征信息的这些点是否在一个区域范围内部的时候&#x…...

SQL语句(DML)
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增删改等操作 DML-添加数据 insert into employee(id, workno, name, gender, age, idcard) values (1,1,Itcast,男,10,123456789012345678);select *…...

uniapp小程序打开地图导航
uniapp uni.getLocation({type: gcj02, //返回可以用于uni.openLocation的经纬度success: function (res) {const latitude res.latitude;const longitude res.longitude;uni.openLocation({latitude: latitude,longitude: longitude,success: function () {console.log(suc…...
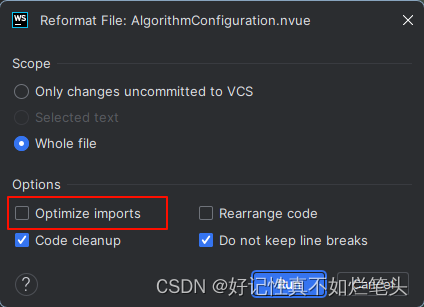
webstorm格式化或保存时 vue3引入的组件被删除了
解决办法 保存时设置 格式化设置...

Java时间转换
一、线程不安全 Date date new Date(); SimpleDateFormat dateFormat new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String prefix dateFormat.format(date);二、线程安全,建议使用 String t1 LocalDateTime.now().format(DateTimeFormatter.ofPattern("y…...

深入解析原生HTTP与MCP服务器的交互机制
1. 原生HTTP与MCP服务器交互的核心机制 当你第一次听说MCP服务器时,可能会觉得这是个高大上的概念。其实简单来说,MCP(Model Context Protocol)就是一种让客户端和AI模型服务端进行高效通信的协议。而HTTP作为互联网最基础的通信协…...

Clover Bootloader虚拟化环境部署终极指南:QEMU、KVM、Xen全平台支持
Clover Bootloader虚拟化环境部署终极指南:QEMU、KVM、Xen全平台支持 【免费下载链接】CloverBootloader Bootloader for macOS, Windows and Linux in UEFI and in legacy mode 项目地址: https://gitcode.com/gh_mirrors/cl/CloverBootloader Clover Bootl…...

多模态融合避坑手册:为什么你的跨模态模型总掉进‘语义鸿沟’?
多模态融合避坑手册:为什么你的跨模态模型总掉进‘语义鸿沟’? 当你兴奋地将精心设计的跨模态模型投入训练,却发现验证集指标像过山车一样剧烈波动时,问题往往出在那些容易被忽视的工程细节里。上周有位工程师向我展示了他的视频…...
)
一加手机Root后玩机指南:用Magisk Delta模块实现这些实用功能(附模块推荐)
一加手机Root后进阶玩法:Magisk Delta模块实战指南 当你成功为一加手机解锁BL并获取Root权限后,真正的玩机之旅才刚刚开始。作为一款以极客精神著称的品牌,一加手机在Root后的可玩性远超普通设备。本文将聚焦Magisk Delta这一强大工具&#x…...
】五、从逻辑门到LEG:指令集与条件跳转的构建)
【图灵完备(Turing Complete)】五、从逻辑门到LEG:指令集与条件跳转的构建
1. 从逻辑门到处理器:LEG架构的诞生之路 记得我第一次用面包板搭建简单逻辑电路时,连个LED灯闪烁都要折腾半天。而现在我们要做的,是把这些基础逻辑门像乐高积木一样拼接成真正的处理器核心。LEG架构的设计初衷就是要解决原始图灵机指令宽度受…...

大语言模型,视觉模型,全模态模型,语音模型和向量模型的区别和使用
1. 大语言模型(Large Language Model, LLM)定义:以文本为输入,生成文本的模型。特点:输入输出都是自然语言(或包含少量结构化的 prompt)。擅长对话、写作、推理、代码生成等任务。在 LangChain …...

协议数采网关在智慧水务场景中的应用与功能
水资源管理作为生态文明建设的关键组成部分,其重要性不言而喻。在智慧水务建设不断深化的当下,水质监测、水量调度以及设备运维等各个环节,都对智能化水平提出了更为严苛的要求。然而,当前水务行业面临着诸多难题,监测…...

ScanTailor Advanced终极指南:免费开源扫描文档处理完整解决方案
ScanTailor Advanced终极指南:免费开源扫描文档处理完整解决方案 【免费下载链接】scantailor-advanced ScanTailor Advanced is the version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and fixes. …...

MogFace人脸检测模型Java后端服务实战:SpringBoot集成与高并发优化
MogFace人脸检测模型Java后端服务实战:SpringBoot集成与高并发优化 最近在做一个智能门禁系统的项目,需要用到人脸检测功能。选型的时候,MogFace模型以其高精度和不错的速度进入了我们的视线。但问题来了,怎么把这个用Python写的…...
)
Altium Designer新手必看:5分钟搞定PCB封装库创建(附3D模型导入技巧)
Altium Designer新手实战:从零构建PCB封装库与3D模型高效导入 刚接触Altium Designer的工程师常被PCB封装库的创建难住——焊盘尺寸怎么定?丝印如何对齐?3D模型能否可视化验证?这些问题直接关系到后期PCB设计的成功率。本文将用最…...