MapReduce的执行流程排序
MapReduce 是一种用于处理大规模数据集的分布式计算模型。它将作业分成多个阶段,以并行处理和分布式存储的方式来提高计算效率。以下是 MapReduce 的执行流程以及各个阶段的详细解释:
1. 作业提交(Job Submission)
用户通过客户端提交 MapReduce 作业。客户端指定作业的输入数据、输出位置、Map 和 Reduce 函数以及其他配置参数。作业提交后,客户端与集群的资源管理器(如 YARN 的 ResourceManager)进行通信,申请资源并提交作业。
2. 作业初始化(Job Initialization)
资源管理器接收作业请求并启动作业管理器(JobManager),在 YARN 中叫做 ApplicationMaster。作业管理器负责进一步分解作业并为每个任务申请资源。
3. 任务分配(Task Assignment)
作业管理器将作业分解成多个任务(Tasks),包括多个 Map 任务和 Reduce 任务。资源管理器根据资源情况分配容器(Containers)来执行这些任务。
4. Map 阶段(Map Phase)
4.1. 输入分片(Input Splitting)
作业管理器将输入数据集分成若干个数据分片(Splits),每个分片通常对应一个 Map 任务。分片是逻辑上的划分,具体的数据读取由记录读取器(RecordReader)完成。
4.2. Map 任务执行
每个 Map 任务处理一个输入分片。Map 函数读取输入数据(通常是键值对),并产生中间键值对(key-value pairs)。
4.3. 本地排序(In-Memory Sort)
Map 任务在本地内存中对输出的中间键值对进行排序。如果输出数据超过内存限制,数据会溢出到磁盘,并进行合并和排序。
并且会将产生的中间键值对写入内存缓冲区(环形缓冲区),缓冲区的大小默认是100MB,存储阈值是80%,当存储的数据达到80%的时候会触发溢写(spill)操作,溢写会对环形缓冲区中的数据写入磁盘文件中,这个过程就被称为溢写文件。
在写入磁盘时,数据会被分区,排序,这个排序的过程也就是接下来提到的第二次排序,在maptask执行过程中,可能会发生多次溢写,生成多个溢写文件,在maptask结束之后,这些溢写文件会被合并成为一个或者少量文件。
5. Shuffle 和 Sort 阶段(Shuffle and Sort Phase)
5.1. Shuffle
在 Map 任务完成后,中间键值对会传输到 Reducer 节点。Shuffle 阶段负责将这些中间数据从 Mapper 节点传输到合适的 Reducer 节点。
5.2. Sort
Reducer 接收到来自多个 Mapper 的中间数据后,会进行排序。这个排序是基于键的全局排序,确保相同键的所有值聚集在一起。
6. Reduce 阶段(Reduce Phase)
6.1. Reduce 任务执行
每个 Reduce 任务接收到排序后的中间数据,调用 Reduce 函数处理每个键及其对应的值。Reduce 函数产生最终的输出键值对。
7. 输出阶段(Output Phase)
Reduce 任务的输出被写入到指定的输出位置(通常是分布式文件系统,如 HDFS)。
8. 作业完成(Job Completion)
当所有的 Map 和 Reduce 任务都完成后,作业管理器向资源管理器报告作业完成状态。客户端可以查询作业的状态和统计信息。作业的输出数据现在可以供用户使用。
执行流程图解
- 作业提交:客户端 -> 资源管理器
- 作业初始化:资源管理器 -> 作业管理器(JobManager/ApplicationMaster)
- 任务分配:作业管理器 -> Map 任务和 Reduce 任务
- Map 阶段:
- 输入分片 -> Map 任务 -> 本地排序
- Shuffle 和 Sort 阶段:Map 输出 -> Shuffle -> Sort
- Reduce 阶段:Reduce 任务执行
- 输出阶段:Reduce 输出写入 -> 输出位置
- 作业完成:作业管理器报告 -> 资源管理器 -> 客户端查询
通过这种结构化的执行流程,MapReduce 实现了对大规模数据的高效处理和分析。
总结:
总结一下,整个mapreduce的执行过程会包含大致三次排序过程,第一次发生在maptask阶段,map阶段会对输入的数据进行读取并产生中间键值对,maptask在本地内存中对输出的中间键值对进行排序。如果输出数据超过内存限制,就会触发第二次排序,此时数据会溢出到磁盘,并进行合并和排序。第三次排序:数据在进行shuffer和sort阶段的合并排序之后,会发送到对应的reducer节点,此时会进行最后的归并排序,将所有键值对按照相同的键进行合并,保证拥有相同键的值存放在一起,这次的排序是全局排序,reducetask会将排序好的结果进行输出。
相关文章:

MapReduce的执行流程排序
MapReduce 是一种用于处理大规模数据集的分布式计算模型。它将作业分成多个阶段,以并行处理和分布式存储的方式来提高计算效率。以下是 MapReduce 的执行流程以及各个阶段的详细解释: 1. 作业提交(Job Submission) 用户通过客户端…...

雅思词汇及发音积累 2024.7.3
银行 check (美)支票 cheque /tʃek/ (英)支票 ATM 自动取款机 cashier 收银员 teller /ˈtelə(r)/ (银行)出纳员 loan 贷款 draw/withdraw money 提款 pin number/passsword/code …...

Vue2和Vue3的区别Vue3的组合式API
一、Vue2和Vue3的区别 1、创建方式的不同: (1)、vue2:是一个构造函数,通过该构造函数创建一个Vue实例 new Vue({})(2)、Vue3:是一个对象。并通过该对象的createApp()方法,创建一个vue实例。 Vue…...

ML307R OpenCPU HTTP使用
一、函数介绍 二、示例代码 三、代码下载地址 一、函数介绍 具体函数可以参考cm_http.h文件,这里给出几个我用到的函数 1、创建客户端实例 /*** @brief 创建客户端实例** @param [in] url 服务器地址(服务器地址url需要填写完整,例如(服务器url仅为格式示…...

【状态估计】线性高斯系统的状态估计——离散时间的递归滤波
前两篇文章介绍了离散时间的批量估计、离散时间的递归平滑,本文着重介绍离散时间的递归滤波。 前两篇位置:【状态估计】线性高斯系统的状态估计——离散时间的批量估计、【状态估计】线性高斯系统的状态估计——离散时间的递归平滑。 离散时间的递归滤波…...
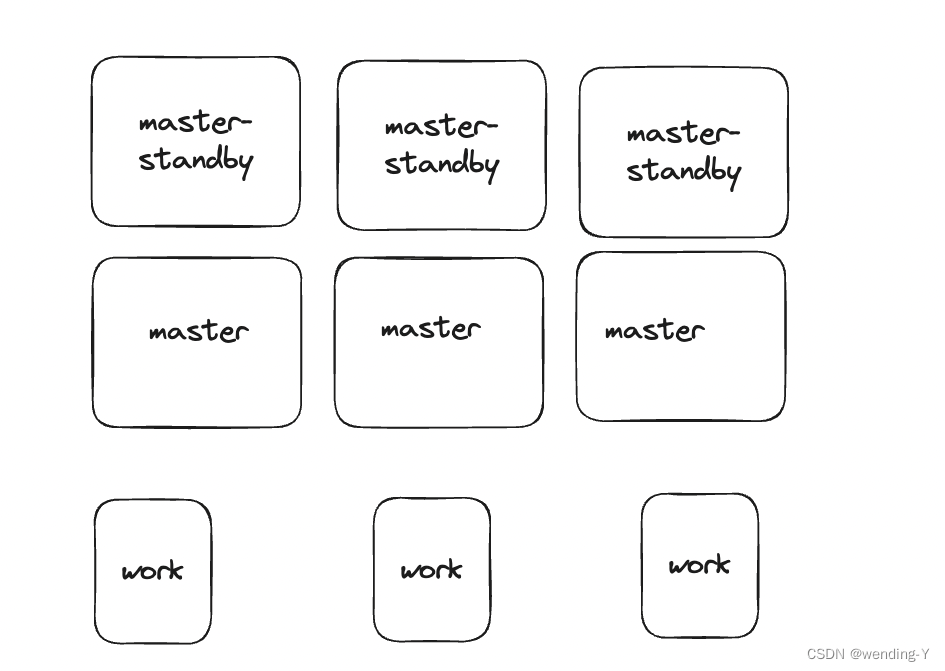
架构设计上中的master三种架构,单节点,主从节点,多节点分析
文章目录 背景单节点优点缺点 主从节点优点缺点 多节点优点缺点 多节点,多backup设计优点缺点 总结 背景 在很多分布式系统里会有master,work这种结构。 master 节点负责管理资源,分发任务。下面着重讨论下master 数量不同带来的影响 单节点 优点 1.设…...

如何在 SQL 中删除一条记录?
如何在 SQL 中删除一条记录? 在 SQL 中,您可以使用DELETE查询和WHERE子句删除表中的一条记录。在本文中,我将向您介绍如何使用DELETE查询和WHERE子句删除记录。我还将向您展示如何一次从表中删除多条记录 如何在 SQL 中使用 DELETE 这是使…...
JavaSE (Java基础):面向对象(上)
8 面向对象 面向对象编程的本质就是:以类的方法组织代码,以对象的组织(封装)数据。 8.1 方法的回顾 package com.oop.demo01;// Demo01 类 public class Demo01 {// main方法public static void main(String[] args) {int c 10…...

flink使用StatementSet降低资源浪费
背景 项目中有很多ods层(mysql 通过cannal)kafka,需要对这些ods kakfa做一些etl操作后写入下一层的kafka(dwd层)。 一开始采用的是executeSql方式来执行每个ods→dwd层操作,即类似: def main(…...

FineDataLink4.1.9支持Kettle调用
FDL更新至4.1.9后,新增kettle调用功能,支持不增加额外负担的情况下,将现有的Kettle任务平滑迁移到FineDataLink。 一、更新版本前存在的问题与痛点 在此次功能更新前,用户可能会遇到以下问题: 1.对于仅使用kettle的…...

SwanLinkOS首批实现与HarmonyOS NEXT互联互通,软通动力子公司鸿湖万联助力鸿蒙生态统一互联
在刚刚落下帷幕的华为开发者大会2024上,伴随全场景智能操作系统HarmonyOS Next的盛大发布,作为基于OpenHarmony的同根同源系统生态,软通动力子公司鸿湖万联全域智能操作系统SwanLinkOS首批实现与HarmonyOS NEXT互联互通,率先攻克基…...

Win11禁止右键菜单折叠的方法
背景 在使用windows11的时候,会发现默认情况下,右键菜单折叠了。以至于在使用一些软件的右键菜单时总是要点击“显示更多选项”菜单展开所有菜单,然后再点击。而且每次在显示菜单时先是全部展示,再隐藏一下,看着着实难…...
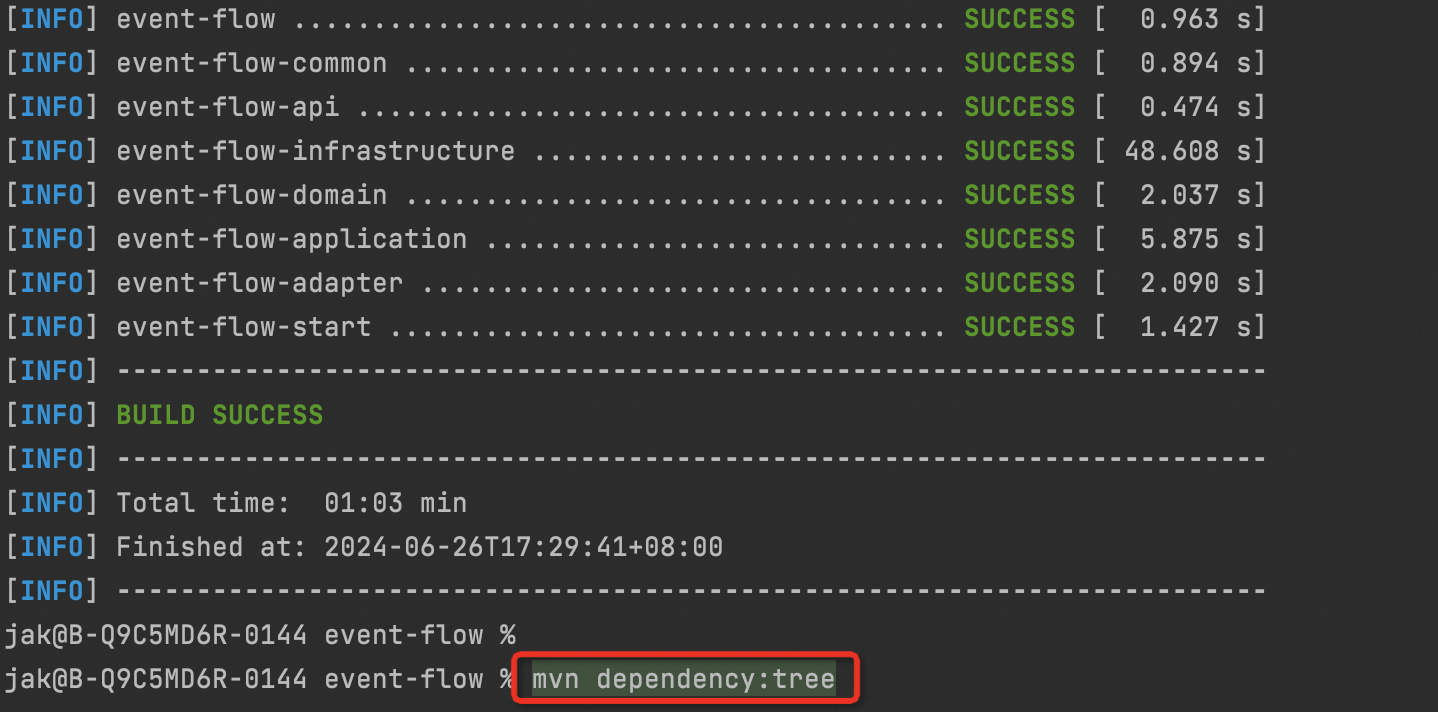
Maven列出所有的依赖树
在 IntelliJ IDEA 中,你可以使用 Maven 插件来列出项目的依赖树。Maven 插件提供了一个名为dependency:tree的目标,可以帮助你获取项目的依赖树详细信息。 要列出项目的依赖树,可以执行以下步骤: 打开 IntelliJ IDEA,…...

测试开发面试题和答案
Python 请解释Python中的列表推导式(List Comprehension)是什么,并给出一个示例。 答案: 列表推导式是Python中一种简洁的构建列表的方法。它允许从一个已存在的列表创建新列表,同时应用一个表达式来修改或选择元素。…...

llm学习-3(向量数据库的使用)
1:数据读取和加载 接着上面的常规操作 加载环境变量---》获取所有路径---》加载文档---》切分文档 代码如下: import os from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv()) # 获取folder_path下所有文件路径,储存在…...
【01-02】Mybatis的配置文件与基于XML的使用
1、引入日志 在这里我们引入SLF4J的日志门面,使用logback的具体日志实现;引入相关依赖: <!--日志的依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version&g…...
)
Linux-进程间通信(IPC)
进程间通信(IPC)介绍 进程间通信(IPC,InterProcess Communication)是指在不同的进程之间传播或交换信息。IPC 的方式包括管道(无名管道和命名管道)、消息队列、信号量、共享内存、Socket、Stre…...

C++ STL: std::vector与std::array的深入对比
什么是 std::vector 和 std::array 首先,让我们简要介绍一下这两种容器: • std::vector:一个动态数组,可以根据需要动态调整其大小。 • std::array:一个固定大小的数组,其大小在编译时确定。 虽然…...

哈哈看到这条消息感觉就像是打开了窗户
在这个信息爆炸的时代,每一条动态可能成为我们情绪的小小触发器。今天,当我无意间滑过那条由杜海涛亲自发布的“自曝式”消息时,不禁心头一颤——如果这是我的另一半,哎呀,那画面,简直比烧烤摊还要“热辣”…...

10、matlab中字符、数字、矩阵、字符串和元胞合并为字符串并将字符串以不同格式写入读出excel
1、前言 在 MATLAB 中,可以使用不同的数据类型(字符、数字、矩阵、字符串和元胞)合并为字符串,然后将字符串以不同格式写入 Excel 文件。 以下是一个示例代码,展示如何将不同数据类型合并为字符串,并以不…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...