C语言实现快速排序(hoare法、挖坑法、前后指针法与非递归实现)——不看后悔系列

目录
1. hoare法
方法与步骤
代码实现
2. 挖坑法
方法与步骤
代码实现
3. 前后指针法
方法与步骤
代码实现
4. 快速排序的缺点与优化
1.快速排序的缺点
2.快速排序的优化
① 三数取中法选 key
代码实现
② 小区间优化
代码实现
5. 快速排序的非递归实现
附录﹡完整源码
快速排序递归实现
快速排序非递归实现
快速排序是霍尔大佬在1962年提出的排序方法,因其出色的排序效率使得它成为使用最广泛的排序算法。快速排序之所以敢叫做快速排序,自然是有一定的道理,今天我们就来看看快速排序是如何凌驾于其它算法之上的。
快速排序的基本思想是:任取待排序数列中的一个数作为 key 值,通过某种方法使得 key 的左边所有的数都比它小,右边的数都比它大;以 key 为中心,将 key 左边的数列与右边的数列取出,做同样的操作(取 key 值,分割左右区间),直至所有的数都到了正确的位置。
上述所提到的某种方法可以有很多种,例如:hoare法、挖坑法、前后指针法。它们虽然做法不相同,但做的都是同一件事——分割出 key 的左右区间(左边的数比 key 小,右边的数比 key 大)。
我们首先来看看霍尔大佬所用的方法——hoare法。
1. hoare法
方法与步骤
以数列 6,1,2,7,9,3,4,5,8,10 为例:
 1.取最左边为 key ,分别有 left 和 right 指向数列的最左端与最右端;
1.取最左边为 key ,分别有 left 和 right 指向数列的最左端与最右端;

2. right 先走,找到比 key 小的数就停下来;

3. left 开始走,找到比 key 大的数就停下来;

4. 交换 left 与 right 所在位置的数;

5.重复上述操作,right 找小,left 找大,进行交换;

6. right 继续找小;

7. left 继续找大,若与 right 就停下来;
8.交换二者相遇位置与 key 处的值;

此时一趟排序就完成了,此时的数列有两个特点:
1. key 所指向的值(6)已经到了正确的位置;
2. key 左边的数字都比 key 要小,右边的都比 key 要大;
接下来就是递归的过程了,分别对左右区间进行同样的操作:

代码实现
知道了详解步骤,用代码来实现并不困难,但是有很多很多的细节需要注意。(这里的代码未经优化,当前的代码有几种极端的情况不能适应)
void Swap(int* p, int* q)
{int tmp = *p;*p = *q;*q = tmp;
}void QuickSort(int* a, int begin, int end)
{//数列只有一个数,或无数列则返回if (begin >= end){return;}int left = begin;int right = end;int keyi = left;while (left < right){//右边先走while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);QuickSort(a, begin, left - 1);QuickSort(a, left + 1, end);
}2. 挖坑法
挖坑法相比于hoare法,思路上更为简单易懂。
方法与步骤
还是以同样的数列 6,1,2,7,9,3,4,5,8,10 为例:

1. 先将第一个数存放到 key 中,形成一个坑位:分别有 left 和 right 指向数列的最左端与最右端;

2. right 先走,找到比 key 小的数,将该数丢到坑里;同时又形成了一个新的坑;

3. left 开始走,找到比 key 大的数,将该数丢到坑里;同时形成一个新的坑;

4. right继续找小,进行重复的操作;

5. left 找大;
 6. right 找小;
6. right 找小;
 7. left 找大;
7. left 找大;
8.若二者相遇就停下来;将 key 值放入坑;

至此,一趟排序已经完成,我们发现此时的数列与hoare具有相同的特点:
1. key 所指向的值(6)已经到了正确的位置;
2. key 左边的数字都比 key 要小,右边的都比 key 要大;
挖坑法、hoare、前后指针法完成一趟排序后都具有相同的特点,所以不同版本的快速排序不一样的只有单趟排序的实现,总体思路都是相同的。
代码实现
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int left = begin;int right = end;int key = a[left];int hole = left;//坑位while (left < right){while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;QuickSort(a, begin, hole - 1);QuickSort(a, hole + 1, end);
}3. 前后指针法
方法与步骤
以同样的数列为例:
 1. 取第一个值为 key ;有 prev 和 cur 分别指向数列开头和 prev 的下一个数;
1. 取第一个值为 key ;有 prev 和 cur 分别指向数列开头和 prev 的下一个数;
 2. cur 先走,找到比 key 小的数就停下来;
2. cur 先走,找到比 key 小的数就停下来;
3. ++prev ,交换 prev 与 cur 位置的数;(前两次无需交换,因为自己与自己换没有意义)
 4. 重复此步骤;
4. 重复此步骤;
 5. 直到 cur 走完整个数列,交换 prev 与 key 处的值;
5. 直到 cur 走完整个数列,交换 prev 与 key 处的值;

至此,第一趟排序就结束了,又是与前两种方法相同的结果;
代码实现
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int prev = begin;int cur = prev + 1;int keyi = begin;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[keyi], &a[prev]);keyi = prev;QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}4. 快速排序的缺点与优化
1.快速排序的缺点
我们用三种方式实现了快速排序,其实这三种方式并无明显的优劣之分。但是我们前面设计的快速排序其实是有两个缺点的:
1.在最坏情况下它的的效率极慢;
2.在数据量太大时会造成栈溢出。
那么什么情况是最坏情况呢?答案是,当数据本身就是有序的时候(无论是逆序还是顺序)。在最坏情况下,每次我们的 key 值都是最大或者最小,这样就会使 key 与数列的每个数都比较一次,它的时间复杂度为 O(n^2);
为什么会发生栈溢出呢?因为我们的快速排序是利用递归实现的,有递归调用,就要建立函数栈帧,并且随着递归的深度越深所要建立的函数栈帧的消耗就越大 。如这幅图所示:
2.快速排序的优化
① 三数取中法选 key
为了应对最坏情况会出现时间复杂度为 O(N^2) 的情况,有人提出了三数取中的方法。
旧方法中,我们每次选 key 都是数列的第一个元素。三数取中的做法是,分别取数列的第一个元素、最后一个元素和最中间的元素,选出三个数中不是最大也不是最小的那个数当作 key 值。
有了三数取中,之前的最坏情况立马变成了最好情况。
代码实现
由于hoare法、挖坑法、前后指针法最终的效果都相同且效率差异很小,所以就任意选取一个为例,其余两者都类似。
//三数取中的函数
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end]){return mid;}else if (a[begin] > a[end]){return begin;}else{return end;}}else // a[begin] > a[mid]{if (a[mid] > a[end]){return mid;}else if (a[begin] < a[end]){return begin;}else{return end;}}
}
//hoare法
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int mid = GetMidIndex(a, begin, end);Swap(&a[mid], &a[begin]);int left = begin;int right = end;int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);QuickSort(a, begin, left - 1);QuickSort(a, left + 1, end);
}
② 小区间优化
随着递归的调用越深入,此时有个很大的缺点就是函数栈帧的消耗很大。但是同时又有一个好处,就是越往下,数列就越接近有序,且此时每个小区间的数据个数特别少。
那么有什么办法可以取其长处避其短处呢?不知道你是否还记得插入排序的特点——数据越接近有序,效率就越高。并且,在数据量极少的情况下,时间复杂度为 O(N^2) 的插入排序与时间复杂度为 O(N*log N) 的快速排序基本没有什么区别。所以,我们干脆就在排序数据量少的数列时,采用插入排序代替。
代码实现
//三数取中的函数
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end]){return mid;}else if (a[begin] > a[end]){return begin;}else{return end;}}else // a[begin] > a[mid]{if (a[mid] > a[end]){return mid;}else if (a[begin] < a[end]){return begin;}else{return end;}}
}//插入排序
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp) //大于tmp,往后挪一个{a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp; //把tmp插入空隙}
}//hoare法
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}if ((end - begin + 1) < 15){// 小区间用直接插入替代,减少递归调用次数InsertSort(a+begin, end - begin + 1);}else{int mid = GetMidIndex(a, begin, end);Swap(&a[mid], &a[begin]);int left = begin;int right = end;int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);QuickSort(a, begin, left - 1);QuickSort(a, left + 1, end);}
}
两外两种方法的代码实现已打包完成,可在文末直接取用。
5. 快速排序的非递归实现
快速排序的非递归思路与递归相差无几,唯一不同的是,非递归用栈或队列模拟函数递归建立栈帧的过程。
void QuickSortNonR(int* a, int begin, int end)
{Stack st;StackInit(&st);StackPush(&st, begin);StackPush(&st, end);while (!StackEmpty(&st)){int right = StackTop(&st);StackPop(&st);int left = StackTop(&st);StackPop(&st);int keyi = PartSort1(a, left, right);//三种方法任选其一//int keyi = PartSort2(a, left, right);//int keyi = PartSort3(a, left, right);if (keyi + 1 < right){StackPush(&st, keyi + 1);StackPush(&st, right);}if (left < keyi - 1){StackPush(&st, left);StackPush(&st, keyi - 1);}}StackDestroy(&st);
}附录﹡完整源码
快速排序递归实现
//交换函数
void Swap(int* p, int* q)
{int tmp = *p;*p = *q;*q = tmp;
}//三数取中
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end]){return mid;}else if (a[begin] > a[end]){return begin;}else{return end;}}else // a[begin] > a[mid]{if (a[mid] > a[end]){return mid;}else if (a[begin] < a[end]){return begin;}else{return end;}}
}//插入排序
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp) //大于tmp,往后挪一个{a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp; //把tmp插入空隙}
}// Hoare法
int PartSort1(int* a, int begin, int end)
{int mid = GetMidIndex(a, begin, end);Swap(&a[begin], &a[mid]);int left = begin, right = end;int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi]){--right;}while (left < right && a[left] <= a[keyi]){++left;}Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);keyi = left;return keyi;
}// 挖坑法
int PartSort2(int* a, int begin, int end)
{int mid = GetMidIndex(a, begin, end);Swap(&a[begin], &a[mid]);int left = begin, right = end;int key = a[left];int hole = left;while (left < right){while (left < right && a[right] >= key){--right;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}//前后指针法
int PartSort3(int* a, int begin, int end)
{int mid = GetMidIndex(a, begin, end);Swap(&a[begin], &a[mid]);int keyi = begin;int prev = begin, cur = begin + 1;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}//快速排序(递归)
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}if ((end - begin + 1) < 15){// 小区间用直接插入替代,减少递归调用次数InsertSort(a + begin, end - begin + 1);}else{int keyi = PartSort1(a, begin, end);//int keyi = PartSort2(a, begin, end);//int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}
}快速排序非递归实现
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int STDataType;typedef struct Stack
{STDataType* a; //动态开辟数组int capacity; //记录栈的容量大小int top; //记录栈顶的位置
}Stack;//栈的初始化
void StackInit(Stack* ps);
//释放动态开辟的内存
void StackDestroy(Stack* ps);
//压栈
void StackPush(Stack* ps, STDataType data);
//出栈
void StackPop(Stack* ps);
//读取栈顶的元素
STDataType StackTop(Stack* ps);
//判断栈是否为空
bool StackEmpty(Stack* ps);// Hoare法
int PartSort1(int* a, int begin, int end)
{int mid = GetMidIndex(a, begin, end);Swap(&a[begin], &a[mid]);int left = begin, right = end;int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi]){--right;}while (left < right && a[left] <= a[keyi]){++left;}Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);keyi = left;return keyi;
}// 挖坑法
int PartSort2(int* a, int begin, int end)
{int mid = GetMidIndex(a, begin, end);Swap(&a[begin], &a[mid]);int left = begin, right = end;int key = a[left];int hole = left;while (left < right){while (left < right && a[right] >= key){--right;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}int PartSort3(int* a, int begin, int end)
{int mid = GetMidIndex(a, begin, end);Swap(&a[begin], &a[mid]);int keyi = begin;int prev = begin, cur = begin + 1;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}
void QuickSortNonR(int* a, int begin, int end)
{Stack st;StackInit(&st);StackPush(&st, begin);StackPush(&st, end);while (!StackEmpty(&st)){int right = StackTop(&st);StackPop(&st);int left = StackTop(&st);StackPop(&st);int keyi = PartSort1(a, left, right);//三种方法任选其一//int keyi = PartSort2(a, left, right);//int keyi = PartSort3(a, left, right);if (keyi + 1 < right){StackPush(&st, keyi + 1);StackPush(&st, right);}if (left < keyi - 1){StackPush(&st, left);StackPush(&st, keyi - 1);}}StackDestroy(&st);
}//栈的实现_函数定义void StackInit(Stack* ps)
{assert(ps);//初始化时,可附初值,也可置空ps->a = NULL;ps->capacity = 0;ps->top = 0;
}void StackDestroy(Stack* ps)
{assert(ps);//若并未对ps->a申请内存,则无需释放if (ps->capacity == 0)return;//释放free(ps->a);ps->a = NULL;ps->capacity = ps->top = 0;
}void StackPush(Stack* ps,STDataType data)
{assert(ps);//若容量大小等于数据个数,则说明栈已满,需扩容if (ps->capacity == ps->top){//若为第一次扩容,则大小为4,否则每次扩大2倍int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newCapacity);if (tmp == NULL){perror("realloc fail");exit(-1);}ps->a = tmp;ps->capacity = newCapacity;}//压栈ps->a[ps->top] = data;ps->top++;
}void StackPop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//出栈ps->top--;
}STDataType StackTop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//返回栈顶的数据return ps->a[ps->top - 1];
}bool StackEmpty(Stack* ps)
{assert(ps);//返回topreturn ps->top == 0;
}相关文章:
C语言实现快速排序(hoare法、挖坑法、前后指针法与非递归实现)——不看后悔系列
目录 1. hoare法 方法与步骤 代码实现 2. 挖坑法 方法与步骤 代码实现 3. 前后指针法 方法与步骤 代码实现 4. 快速排序的缺点与优化 1.快速排序的缺点 2.快速排序的优化 ① 三数取中法选 key 代码实现 ② 小区间优化 代码实现 5. 快速排序的非递归实现 附录…...

如何为系统可靠性的量化提供依据
SLA 即 Service Level Agreement,也就是服务等级协议,它指的是系统服务提供者(Provider)对客户(Customer)的一个服务承诺。 而 SLO 就是 SLA 的具体目标管理办法,它由一系列相关的指标 SLI &am…...

量化投资中的因子是什么?因子是如何分类的,包括哪些?
因子就是对个股有解释的因素。因子的种类很多,不同类别的因子从不同的维度对个股收益进行解释。比如基本面因子的数据来源方面有很大一部分是财务报表,从估值、成长、盈利能力等多个方面对股票收益进行解释。量价因子是围绕价格、成交量等技术指标构建的…...

力扣-修复表中的名字
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1667. 修复表中的名字二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其他…...

【博客633】linux vxlan设备工作原理
linux vxlan设备工作原理 vxlan处理包的原理:以k8s cni flannel组件创建的vxlan设备为例 1、k8s cni组件创建flannel设备flannel.1,且这个设备为vxlan类型的设备 root10.10.10.12:/home/ubuntu# ethtool -i flannel.1 driver: vxlan version: 0.1 fi…...

3.12学习周报
文章目录前言文献阅读摘要简介方法介绍讨论结论相关性分析总结前言 本周阅读文献《Streamflow and rainfall forecasting by two long short-term memory-based models》,文献主要提出两种基于长短时记忆网络的混合模型用于对水流量和降雨量进行预测。小波-LSTM&am…...
电力电子中逐波限流控制以及dsp实现
逐波限流是指在电力系统运行中,对电力设备进行电流保护的一种措施。它的实现方式是通过对电力系统的电流进行逐波监测和控制,每一波电流都可以独立地进行限制,从而保护电力系统设备不受过载损坏或短路故障的影响。 逐波限流的作用是提高电力…...
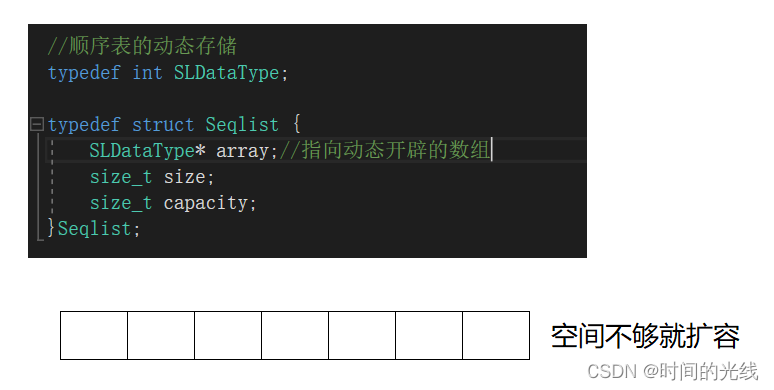
【数据结构】 顺序表
文章目录1 线性表2 顺序表2.1 概念及结构2.2 接口实现2.3 数组相关面试题2.4 顺序表的问题与思考1 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序…...

Elasticsearch 集群规划- 单台机器核心数计算公式
在做集群规划的时候,到底需要给集群的每个节点多少个核心数?这个问题一直困扰了我很久。最近一段时间做千亿数据,PB存储量集群规划的时候,突然想明白了这件事,大致可以用一个公式来计算!我觉得这是一个非常…...

Tesla都使用什么编程语言?
作者 | 初光 出品 | 车端 备注 | 转载请阅读文中版权声明 知圈 | 进“汽车电子与AutoSAR开发”群,请加微“cloud2sunshine” 总目录链接>> AutoSAR入门和实战系列总目录 带着对更美好未来的愿景,特斯拉不仅成为有史以来最有价值的汽车公司&…...

1143. 最长公共子序列——【Leetcode每日刷题】
1143. 最长公共子序列 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些…...
、obj.notify()、obj.notifyAll()详解)
【并发基础】线程的通知与等待:obj.wait()、obj.notify()、obj.notifyAll()详解
目录 〇、先总结一下这三个方法带来的Java线程状态变化 一、obj.wait() 1.1 作用 1.2 使用前需要持有线程共享对象的锁 1.3 使用技巧 二、obj.notify(All)() 1.1 notify() 方法 1.1.1 调用notify()或notifyAll()不会释放线程的锁 1.2 notifyAll() 方法 1.3 使用技巧 三、使用实…...

css黏性定位-实现商城的分类滚动的标题吸附
传统的黏性定位是使用js通过计算高度来实现的,当元素滚动到一定位置时吸附在当前位置。下面我们通过css来实现黏性定位功能。 黏性定位 黏性定位目前主流的浏览器已经全部支持,顾名思义,黏性定位具有吸附的效果,其实它是positio…...

@Component和@bean注解在容器中创建实例区别
Component和Bean的区别 在Spring Boot中,Component注解和Bean注解都可以用于创建bean。它们的主要区别在于它们的作用范围和创建方式。 Component注解是一种通用的注解,可以用于标注任何类。被标注的类将被Spring容器自动扫描并创建为一个bean。这个bea…...

不写注释就是垃圾
最近Linux6.2出来了增加了很多新的东西,有看点的是,Linux确实要可以在Apple M1上面运行了,这应该是一个很大的新闻,如果有这么稳定的硬件支持,那对于Linux来说相当于又打下了一大片的江山。其中关于Linux6.2的特性罗列…...

深信服一面
1.C变量存储在哪里,生命周期是怎样的 2.静态成员变量和成员函数的特性,在哪里用过吗 3.new和delete是什么,和malloc和free对比有啥优势 4.new能不能重载,重载new有什么用 5.多态是怎么实现的,有什么优势和目的 6.…...

【C语言】深度理解指针(中)
前言✈上回说到,我们学习了一些与指针相关的数据类型,如指针数组,数组指针,函数指针等等,我们还学习了转移表的基本概念,学会了如何利用转移表来实现一个简易计算器。详情请点击传送门:【C语言】…...

步进电机运动八大算法
引导一种模块化(Module)设计思想,将传统步进电机的控制器(controller)、驱动器(Driver)、运动算法(Arithmetic)三合一。 对比国内外步进电机驱动原理和已有工作,结合各种硬件特性,改进或实现了可实际移植并用于步进电机控制八大算法。本产品…...

如果你持续大量的教坏ChatGPT,它确实会变坏
你输出的很多数据是经过人工标注吗,以确保可以正常对外展示出来,而不是有性别歧视、种族歧视或者其它意识形态为多数人所不认同的内容产生? 作为AI语言模型,我并不直接处理或输出任何数据,我的任务是通过对输入的自然语…...

opencv学习(二)图像阈值和平滑处理
图像阈值ret, dst cv2.threshold(src, thresh, maxval, type)src: 输入图,只能输入单通道图像,通常来说为灰度图dst: 输出图thresh: 阈值maxval: 当像素值超过了阈值(或者小于阈值,…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次‘交叉验证’吧
你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次"交叉验证"当你在GEO数据库中下载了三个肺癌研究的差异表达结果,却发现三个DEG列表的重叠基因不到20%——这种令人沮丧的场景每天都在全球实验室上演。单项研究的差异分析结果就像…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...