四十篇:内存巨擘对决:Redis与Memcached的深度剖析与多维对比
内存巨擘对决:Redis与Memcached的深度剖析与多维对比

1. 引言
在现代的系统架构中,内存数据库已经成为了信息处理的核心技术之一。这类数据库系统的高效性主要来源于其对数据的即时访问能力,这是因为数据直接存储在RAM中,而非传统的基于磁盘的存储系统。内存数据库通过避免磁盘I/O,极大地缩短了数据访问时间,从而提供了显著的性能优势。这种技术特别适用于需要高速数据读写和高并发处理的场景,例如实时分析、广告技术和高频交易系统。
在众多内存数据库系统中,Redis和Memcached是最为人所熟知和广泛使用的两种技术。它们各自具有独特的特点和优势,但也有不少人在选择时会感到困惑。Redis,常被比喻为“内存中的瑞士军刀”,它不仅支持多种数据结构如字符串、列表、集合、散列表等,还提供了持久化、事务、和复制等功能。相比之下,Memcached则更像是一位“内存的轻盈舞者”,它以其简洁高效的键值存储能力在处理高并发场景下的缓存需求时表现卓越。
从数学的角度来看,Redis和Memcached的设计和运作原理也可以引入一系列有趣的数学模型和分析方法。例如,对于Redis中的数据结构,可以通过概率模型来优化其性能表现。考虑到集合操作,如并集或交集,我们可以用概率论中的集合理论来预测操作的效率,其中集合的大小可以表示为随机变量 ∣ S ∣ |S| ∣S∣,操作的时间复杂度可以用期望值 E [ f ( ∣ S ∣ ) ] E[f(|S|)] E[f(∣S∣)] 来评估,其中 f f f 是相关操作的时间复杂性函数。
此外,对于Memcached,其内部使用Slab分配器来管理内存,这涉及到一系列内存分配和回收的策略,这可以通过排队论中的M/M/1队列模型来描述。在这个模型中,内存请求到达和处理的过程可以被建模为具有指数分布的到达间隔和服务时间。这样的数学模型不仅帮助我们理解和预测系统行为,还能指导我们进行更有效的系统设计和优化。
在接下来的章节中,我们将深入探讨Redis和Memcached在系统架构和数学模型层面的多维对比,以及它们在不同使用场景下的表现和适用性,以帮助读者更好地理解这两种技术的特点,并作出更为明智的技术选型决策。

2. Redis:内存中的瑞士军刀
2.1 Redis的系统架构艺术
Redis,作为内存数据库的佼佼者,其系统架构的艺术体现在其对数据结构的匠心设计和持久化机制的架构智慧上。在这一节中,我们将深入探讨Redis如何在系统架构层面实现高效、可靠的数据处理。
数据结构的匠心设计
Redis支持多种数据结构,包括字符串(Strings)、列表(Lists)、集合(Sets)、散列(Hashes)、有序集合(Sorted Sets)等。每种数据结构都针对特定的使用场景进行了优化,使得Redis能够灵活应对各种数据操作需求。
例如,Redis的列表数据结构采用了双向链表实现,这使得在列表两端进行插入和删除操作的时间复杂度为 O ( 1 ) O(1) O(1),非常适合实现队列或栈。而对于集合数据结构,Redis使用了哈希表来保证元素的唯一性和快速的成员检查,时间复杂度同样为 O ( 1 ) O(1) O(1)。
持久化机制的架构智慧
Redis提供了两种主要的持久化机制:RDB(Redis Database Backup)和AOF(Append Only File)。RDB通过定期生成数据集的时间点快照来实现持久化,而AOF则通过记录服务器接收到的每一个写操作命令来实现持久化。
RDB的优点在于其生成的文件紧凑,适合用于备份和灾难恢复。其背后的数学原理是基于概率的数据压缩技术,通过选择合适的保存间隔,可以在数据丢失风险和存储空间之间找到平衡点。例如,如果每小时保存一次RDB文件,那么最多可能丢失一小时的数据,但存储空间的使用会更加高效。
AOF则提供了更高的数据安全性,因为它记录了所有的写操作。AOF文件的体积可能会比RDB文件大,但其重写机制可以定期压缩AOF文件,减少其体积。AOF的重写过程可以通过数学模型来优化,例如使用增量更新的策略,只记录自上次重写以来的变化,从而减少I/O操作和磁盘空间的占用。
复制与高可用性的架构蓝图
Redis的复制功能允许创建多个从服务器来复制主服务器的数据,这一机制不仅提高了数据的读取能力,还增强了系统的可用性和容错性。Redis的复制过程是异步的,这意味着从服务器不需要实时与主服务器保持同步,从而减少了网络带宽和主服务器的负载。
在高可用性方面,Redis提供了Sentinel系统,这是一个分布式系统,用于监控和管理Redis实例,自动进行故障转移。Sentinel系统通过选举机制来选择新的主服务器,确保在主服务器故障时,系统能够快速恢复服务。这一过程涉及到分布式系统中的共识算法,如Raft或Paxos,确保在网络分区或节点故障的情况下,系统仍能保持一致性和可用性。
通过这些精心设计的系统架构特性,Redis不仅提供了强大的数据处理能力,还确保了数据的安全性和系统的稳定性,使其成为现代系统架构中不可或缺的一部分。
2.2 Redis的数学魔法
Redis不仅在系统架构上展现了其艺术性,其在数学层面的应用也同样引人入胜。本节将深入探讨Redis如何利用数学原理来优化其数据结构、持久化机制以及复制和高可用性功能。
数据结构的数学语言
Redis的数据结构设计不仅考虑了功能性和效率,还融入了丰富的数学原理。例如,Redis的散列(Hashes)数据结构使用了哈希表来实现快速的键值查找,其平均时间复杂度为 O ( 1 ) O(1) O(1)。哈希表的核心在于哈希函数的选择和冲突解决策略,这涉及到数论和概率论的知识。一个好的哈希函数应该能够将键均匀地分布到哈希表的槽中,减少冲突的概率。
对于有序集合(Sorted Sets),Redis使用了跳跃表(Skip List)这一数据结构,它在保持有序性的同时,提供了平均 O ( log n ) O(\log n) O(logn) 的插入、删除和查找时间复杂度。跳跃表的数学基础在于其层级结构的构建,每一层都是一个有序链表,高层的节点是低层节点的随机抽样,这一过程可以用几何分布来描述。
持久化与概率的数学编织
Redis的持久化机制,特别是AOF(Append Only File),涉及到概率论的应用。AOF通过记录每个写操作来保证数据的持久性,但频繁的写操作会导致磁盘I/O成为性能瓶颈。为了优化这一过程,Redis引入了AOF重写机制,即定期将内存中的数据集以紧凑的形式写入新的AOF文件。
AOF重写的触发时机可以通过概率模型来优化。例如,可以使用泊松分布来描述写操作的到达率,从而确定重写的最佳间隔。此外,AOF文件的压缩过程也可以通过信息论中的熵编码技术来进一步优化,减少文件大小,提高存储效率。
复制和高可用性的数学解析
Redis的复制功能和高可用性机制同样蕴含着深刻的数学原理。复制过程中的数据一致性问题可以通过共识算法如Paxos或Raft来解决,这些算法基于概率论和图论,确保在网络分区或节点故障的情况下,系统仍能达成一致。
在高可用性方面,Redis的Sentinel系统通过监控Redis实例的健康状态,并在主节点故障时自动进行故障转移。这一过程涉及到选举算法,其核心在于多数派原则,确保在任何时候都有足够数量的节点达成共识,这一原则可以用图论中的连通性理论来解释。
通过这些数学模型的应用,Redis不仅在性能上达到了极致,还在数据一致性和系统可用性方面提供了坚实的保障,使其成为现代系统架构中的重要组成部分。

3. Memcached:内存的轻盈舞者
3.1 Memcached的系统架构精髓
Memcached,作为内存缓存领域的轻盈舞者,其系统架构的精髓体现在其简洁高效的键值存储、精细的内存管理策略以及强大的分布式系统实现上。在这一节中,我们将深入探讨Memcached如何在系统架构层面实现高性能和高效率。
键值存储的架构哲学
Memcached的核心设计理念是提供一个简单而高效的键值存储系统。其架构哲学在于“简单即高效”,通过最小化功能集来减少复杂性,从而提升性能。Memcached的数据模型非常直观,每个键对应一个值,且不支持复杂的数据结构,如列表、集合等。这种设计简化了内部的数据管理和操作逻辑,使得Memcached能够专注于提供极致的读写速度。
例如,Memcached使用了一个固定大小的哈希表来存储键值对,这使得查找操作的时间复杂度为 O ( 1 ) O(1) O(1)。哈希表的设计和实现涉及到哈希函数的选择和冲突解决策略,Memcached采用了链地址法来处理冲突,即每个哈希槽指向一个链表,链表中存储所有哈希到该槽的键值对。
内存管理的架构策略
Memcached的内存管理策略是其另一个核心优势。Memcached使用了一种称为“slab allocator”的内存分配机制,这种机制将内存划分为多个大小固定的块(slab),每个slab包含多个相同大小的内存页(chunk)。当新的键值对需要存储时,Memcached会从合适的slab中分配一个chunk,而不是直接从操作系统申请内存。
这种内存管理策略的优点在于减少了内存碎片,提高了内存使用效率。每个slab的大小是2的幂次方,这使得内存分配和释放操作更加高效。此外,Memcached还引入了LRU(Least Recently Used)算法来淘汰最近最少使用的键值对,从而在有限的内存空间中保持数据的活跃性。
分布式系统的架构实现
Memcached的分布式特性是其另一个亮点。Memcached通过客户端的哈希算法来决定键值对存储在哪个服务器上,这种分布式架构简化了服务器的管理,同时也提高了系统的可扩展性。客户端的哈希算法通常采用一致性哈希(Consistent Hashing),这种算法能够在服务器增减时最小化键的重新分布,从而减少数据迁移的开销。
一致性哈希的数学基础在于环形哈希空间的使用,每个服务器和键都被映射到这个环上。当需要查找一个键时,客户端沿着环顺时针查找,直到找到第一个服务器。这种设计确保了在服务器变化时,只有部分键需要重新映射,而不是所有的键。
通过这些精心设计的系统架构特性,Memcached不仅提供了高效的键值存储和内存管理,还实现了强大的分布式能力,使其成为处理大规模并发读取和缓存场景的理想选择。
3.2 Memcached的数学韵律
Memcached不仅在系统架构上展现了其简洁高效的特点,其在数学层面的应用也同样引人入胜。本节将深入探讨Memcached如何利用数学原理来优化其键值存储、内存管理以及分布式系统功能。
键值存储的数学基础
Memcached的键值存储机制基于哈希表实现,这一数据结构的核心在于哈希函数的选择和冲突解决策略。一个好的哈希函数应该能够将键均匀地分布到哈希表的槽中,减少冲突的概率。Memcached通常使用MurmurHash或Jenkins Hash等高效的哈希函数,这些函数在保持低冲突率的同时,提供了快速的计算速度。
哈希表的性能可以通过负载因子(load factor)来衡量,即哈希表中已存储的键值对数量与哈希表槽数的比值。理想情况下,负载因子应保持在较低的水平,以确保查找操作的时间复杂度接近 O ( 1 ) O(1) O(1)。当负载因子过高时,可以通过动态调整哈希表的大小来优化性能,这一过程涉及到动态数组的增长策略,通常采用倍增法,即每次扩容时将哈希表的大小翻倍。
内存管理的概率旋律
Memcached的内存管理策略,特别是其slab allocator机制,涉及到概率论的应用。slab allocator将内存划分为多个大小固定的块(slab),每个slab包含多个相同大小的内存页(chunk)。这种内存分配策略的优点在于减少了内存碎片,提高了内存使用效率。
slab allocator的数学基础在于其对内存大小的分组策略,每个slab的大小是2的幂次方,这使得内存分配和释放操作更加高效。此外,Memcached还引入了LRU(Least Recently Used)算法来淘汰最近最少使用的键值对,从而在有限的内存空间中保持数据的活跃性。LRU算法的实现涉及到队列和链表的操作,其时间复杂度为 O ( 1 ) O(1) O(1),确保了高效的内存管理。
分布式系统的数学分析
Memcached的分布式特性是其另一个亮点。Memcached通过客户端的哈希算法来决定键值对存储在哪个服务器上,这种分布式架构简化了服务器的管理,同时也提高了系统的可扩展性。客户端的哈希算法通常采用一致性哈希(Consistent Hashing),这种算法能够在服务器增减时最小化键的重新分布,从而减少数据迁移的开销。
一致性哈希的数学基础在于环形哈希空间的使用,每个服务器和键都被映射到这个环上。当需要查找一个键时,客户端沿着环顺时针查找,直到找到第一个服务器。这种设计确保了在服务器变化时,只有部分键需要重新映射,而不是所有的键。一致性哈希的性能可以通过虚拟节点(virtual nodes)的数量来优化,虚拟节点是物理服务器的多个副本,分布在哈希环上,从而提高了负载均衡的效果。
通过这些数学模型的应用,Memcached不仅在性能上达到了极致,还在内存管理和分布式系统方面提供了坚实的保障,使其成为处理大规模并发读取和缓存场景的理想选择。

4. Redis与Memcached:多维对比的交响曲
4.1 系统架构层面的对比
在内存数据库的世界中,Redis和Memcached作为两大巨头,各自展现了独特的系统架构特点。本节将从数据结构的架构丰富性、持久化能力的架构分析以及复制和高可用性的架构视角,对这两者进行深入的对比分析。
数据结构的架构丰富性
Redis以其丰富的数据结构著称,支持字符串(Strings)、列表(Lists)、集合(Sets)、有序集合(Sorted Sets)、哈希(Hashes)等多种数据类型。这种多样性使得Redis能够灵活地处理各种复杂的数据操作,如范围查询、交并集运算等。Redis的数据结构设计不仅考虑了功能性,还融入了高效的内存管理和操作逻辑,确保了高性能的读写操作。
相比之下,Memcached仅支持简单的键值存储,其数据模型更为简洁。这种设计简化了内部的数据管理和操作逻辑,使得Memcached能够专注于提供极致的读写速度。虽然Memcached在数据结构的丰富性上不及Redis,但其简洁的架构哲学在处理大规模并发读取和缓存场景时表现出色。
持久化能力的架构分析
Redis提供了两种持久化机制:RDB(Redis Database)和AOF(Append Only File)。RDB通过定期快照的方式将内存中的数据集保存到磁盘,而AOF则通过记录每个写操作来保证数据的持久性。这两种机制各有优劣,RDB提供了高效的快照功能,但可能会丢失最后一次快照后的数据;AOF提供了更高的数据安全性,但频繁的写操作会导致磁盘I/O成为性能瓶颈。
Memcached则不提供内置的持久化功能,其设计理念是作为纯内存缓存系统,不承担数据持久化的责任。这种设计使得Memcached在性能上更为出色,但在数据持久化方面则需要依赖外部系统或应用层的实现。
复制和高可用性的架构视角
Redis的复制功能和高可用性机制通过主从复制和Sentinel系统实现。主从复制允许将数据从主节点复制到多个从节点,从而提高数据的可用性和读取性能。Sentinel系统则负责监控Redis实例的健康状态,并在主节点故障时自动进行故障转移,确保系统的高可用性。
Memcached的分布式特性通过客户端的哈希算法实现,这种架构简化了服务器的管理,同时也提高了系统的可扩展性。然而,Memcached本身并不提供内置的复制和高可用性机制,这需要通过外部系统或应用层的实现来补充。
通过这些系统架构层面的对比,我们可以看到Redis和Memcached在数据结构、持久化能力以及复制和高可用性方面各有千秋。Redis提供了更为丰富的功能和更高的灵活性,适合处理复杂的数据操作和持久化需求;而Memcached则以其简洁高效的架构哲学,在处理大规模并发读取和缓存场景时表现出色。
4.2 数学模型层面的对比
在内存数据库的世界中,Redis和Memcached不仅在系统架构上展现了各自的特色,其在数学模型的应用上也各有千秋。本节将从数据结构的数学丰富性、持久化能力的数学分析以及复制和高可用性的数学视角,对这两者进行深入的对比分析。
数据结构的数学丰富性
Redis的数据结构设计不仅考虑了功能性,还融入了高效的数学模型。例如,Redis的有序集合(Sorted Sets)通过使用跳表(Skip List)和哈希表的组合,实现了高效的插入、删除和范围查询操作。跳表是一种概率性数据结构,其平均时间复杂度为 O ( log n ) O(\log n) O(logn),非常适合用于实现有序集合。
P ( x ) = 1 2 i P(x) = \frac{1}{2^i} P(x)=2i1
其中, P ( x ) P(x) P(x) 表示节点 x x x 在第 i i i 层的概率。跳表的这种概率性设计使得其性能在大多数情况下接近平衡树,但实现和维护更为简单。
相比之下,Memcached的数据模型更为简洁,仅支持简单的键值存储。这种设计简化了内部的数据管理和操作逻辑,使得Memcached能够专注于提供极致的读写速度。虽然Memcached在数据结构的数学丰富性上不及Redis,但其简洁的架构哲学在处理大规模并发读取和缓存场景时表现出色。
持久化能力的数学分析
Redis的持久化机制涉及到概率论的应用。例如,AOF(Append Only File)持久化机制通过记录每个写操作来保证数据的持久性。AOF的重写(rewrite)过程涉及到对现有AOF文件的分析和优化,这一过程可以通过数学模型来预测和优化。
E [ T ] = S μ E[T] = \frac{S}{\mu} E[T]=μS
其中, E [ T ] E[T] E[T] 表示重写过程的期望时间, S S S 表示AOF文件的大小, μ \mu μ 表示重写操作的速率。通过这种数学模型,可以预测和优化AOF重写过程的性能。
Memcached则不提供内置的持久化功能,其设计理念是作为纯内存缓存系统,不承担数据持久化的责任。这种设计使得Memcached在性能上更为出色,但在数据持久化方面则需要依赖外部系统或应用层的实现。
复制和高可用性的数学视角
Redis的复制功能和高可用性机制涉及到概率论和排队论的应用。例如,主从复制过程中的数据同步涉及到网络延迟和数据传输速率的数学模型。
E [ D ] = L λ E[D] = \frac{L}{\lambda} E[D]=λL
其中, E [ D ] E[D] E[D] 表示数据同步的期望延迟, L L L 表示数据包的大小, λ \lambda λ 表示数据传输的速率。通过这种数学模型,可以预测和优化主从复制过程的性能。
Memcached的分布式特性通过客户端的哈希算法实现,这种架构简化了服务器的管理,同时也提高了系统的可扩展性。然而,Memcached本身并不提供内置的复制和高可用性机制,这需要通过外部系统或应用层的实现来补充。
通过这些数学模型层面的对比,我们可以看到Redis和Memcached在数据结构、持久化能力以及复制和高可用性方面各有千秋。Redis提供了更为丰富的数学模型和更高的灵活性,适合处理复杂的数据操作和持久化需求;而Memcached则以其简洁高效的数学模型,在处理大规模并发读取和缓存场景时表现出色。
4.3 性能与效率的数学与架构交响
在内存数据库的领域中,性能和效率是衡量系统优劣的关键指标。Redis和Memcached在这两个维度上展现了各自的特色,其背后蕴含的数学模型和架构设计值得深入探讨。本节将从读写速度的数学模型与架构实现以及内存使用效率的数学分析与架构策略两个方面,对这两者进行对比分析。
读写速度的数学模型与架构实现
Redis以其高效的读写性能著称,这得益于其精心设计的数据结构和内存管理策略。例如,Redis的字符串(Strings)类型支持高效的二进制安全字符串操作,其读写操作的时间复杂度为 O ( 1 ) O(1) O(1)。此外,Redis的列表(Lists)类型通过使用双向链表或压缩列表(ziplist)实现,确保了高效的插入和删除操作。
T ( n ) = O ( 1 ) T(n) = O(1) T(n)=O(1)
其中, T ( n ) T(n) T(n) 表示操作的时间复杂度, n n n 表示数据集的大小。这种常数时间复杂度的设计使得Redis在处理大量读写请求时能够保持高性能。
Memcached同样以其卓越的读写速度闻名,其简洁的键值存储模型和高效的内存管理策略是其性能的保障。Memcached使用slab allocator机制来管理内存,将内存划分为多个大小固定的块(slab),每个slab包含多个相同大小的内存页(chunk)。这种内存分配策略减少了内存碎片,提高了内存使用效率。
M = S × N M = S \times N M=S×N
其中, M M M 表示总的内存大小, S S S 表示每个slab的大小, N N N 表示slab的数量。通过这种数学模型,可以优化内存分配和管理的效率。
内存使用效率的数学分析与架构策略
Redis的内存使用效率得益于其丰富的数据结构和高效的内存管理策略。例如,Redis的哈希(Hashes)类型通过使用压缩列表(ziplist)或哈希表实现,确保了高效的内存使用。压缩列表是一种紧凑的数据结构,适用于存储小规模的键值对,其内存使用效率远高于传统的哈希表。
E = S C E = \frac{S}{C} E=CS
其中, E E E 表示内存使用效率, S S S 表示数据集的大小, C C C 表示压缩列表的压缩率。通过这种数学模型,可以优化内存使用效率。
Memcached的内存管理策略同样值得称道,其slab allocator机制通过将内存划分为多个大小固定的块,减少了内存碎片,提高了内存使用效率。此外,Memcached还引入了LRU(Least Recently Used)算法来淘汰最近最少使用的键值对,从而在有限的内存空间中保持数据的活跃性。
P ( x ) = 1 N P(x) = \frac{1}{N} P(x)=N1
其中, P ( x ) P(x) P(x) 表示键值对被淘汰的概率, N N N 表示键值对的数量。通过这种数学模型,可以优化内存管理和淘汰策略。
通过这些数学模型和架构策略的对比,我们可以看到Redis和Memcached在性能和效率方面各有千秋。Redis以其丰富的数据结构和高效的内存管理策略,在处理复杂的数据操作和持久化需求时表现出色;而Memcached则以其简洁高效的架构哲学,在处理大规模并发读取和缓存场景时表现出色。
4.4 扩展性和灵活性的多维协奏
在内存数据库的世界中,扩展性和灵活性是衡量系统适应性和生命力的重要指标。Redis和Memcached在这两个维度上展现了各自的特色,其背后蕴含的数学模型和架构设计值得深入探讨。本节将从Redis的模块和扩展的数学与架构模型以及Memcached的简单性和一致性的数学与架构分析两个方面,对这两者进行对比分析。
Redis的模块和扩展的数学与架构模型
Redis以其高度的扩展性和灵活性著称,这得益于其模块化架构和丰富的扩展机制。Redis支持通过模块(Modules)扩展其功能,这些模块可以由用户自定义开发,从而实现对Redis功能的增强或定制。例如,Redis的搜索模块(RediSearch)通过高效的倒排索引和压缩技术,实现了高性能的全文搜索功能。
E = F C E = \frac{F}{C} E=CF
其中, E E E 表示扩展效率, F F F 表示新增功能的复杂度, C C C 表示扩展成本。通过这种数学模型,可以评估和优化模块化扩展的效率。
此外,Redis的集群(Cluster)模式通过分片(Sharding)技术实现了水平扩展,将数据分布到多个节点上,从而提高了系统的吞吐量和可用性。分片技术涉及到数据分布的均匀性和负载均衡的数学模型。
P ( x ) = 1 N P(x) = \frac{1}{N} P(x)=N1
其中, P ( x ) P(x) P(x) 表示数据分布到节点 x x x 的概率, N N N 表示节点的数量。通过这种数学模型,可以优化数据分布和负载均衡的策略。
Memcached的简单性和一致性的数学与架构分析
Memcached以其简洁高效的架构哲学和一致性模型著称,这使得其在扩展性和灵活性方面同样表现出色。Memcached的分布式特性通过客户端的哈希算法实现,这种架构简化了服务器的管理,同时也提高了系统的可扩展性。
H ( k ) = k m o d N H(k) = k \mod N H(k)=kmodN
其中, H ( k ) H(k) H(k) 表示键 k k k 的哈希值, N N N 表示节点的数量。通过这种简单的哈希算法,可以实现数据的均匀分布和负载均衡。
此外,Memcached的一致性哈希(Consistent Hashing)算法通过引入虚拟节点(Virtual Nodes),进一步提高了数据分布的均匀性和系统的可扩展性。一致性哈希算法通过减少节点变动时数据迁移的范围,确保了系统的一致性和稳定性。
D = M V D = \frac{M}{V} D=VM
其中, D D D 表示数据分布的均匀度, M M M 表示实际数据分布, V V V 表示理想数据分布。通过这种数学模型,可以评估和优化数据分布的均匀性。
通过这些数学模型和架构策略的对比,我们可以看到Redis和Memcached在扩展性和灵活性方面各有千秋。Redis以其模块化架构和丰富的扩展机制,在处理复杂的数据操作和持久化需求时表现出色;而Memcached则以其简洁高效的架构哲学和一致性模型,在处理大规模并发读取和缓存场景时表现出色。
4.5 社区和支持的多维共鸣
在开源软件的世界中,社区的活跃度和支持资源是衡量项目成功与否的重要指标。Redis和Memcached作为内存数据库领域的佼佼者,其背后的社区和支持资源同样值得深入探讨。本节将从Redis的活跃社区与数学资源以及Memcached的社区和数学资源两个方面,对这两者进行对比分析。
Redis的活跃社区与数学资源
Redis拥有一个庞大且活跃的社区,这为其持续的发展和创新提供了强大的动力。社区成员不仅贡献了大量的代码和文档,还积极参与到Redis的讨论和问题解决中。这种社区的活跃度可以通过以下数学模型进行量化:
A = C T A = \frac{C}{T} A=TC
其中, A A A 表示社区活跃度, C C C 表示社区贡献的数量, T T T 表示时间。通过这种数学模型,可以评估和优化社区的活跃度。
此外,Redis社区还提供了丰富的数学资源,包括算法优化、性能调优和数据分析等方面的文档和教程。这些资源不仅帮助用户更好地理解和使用Redis,还促进了Redis在数学模型和算法层面的深入研究。
R = D U R = \frac{D}{U} R=UD
其中, R R R 表示数学资源的丰富度, D D D 表示数学资源的数量, U U U 表示用户的需求。通过这种数学模型,可以评估和优化数学资源的丰富度。
Memcached的社区和数学资源
Memcached同样拥有一个活跃的社区,尽管其规模和活跃度可能不及Redis,但其社区成员同样为Memcached的发展和维护做出了重要贡献。社区的活跃度可以通过以下数学模型进行量化:
A = C T A = \frac{C}{T} A=TC
其中, A A A 表示社区活跃度, C C C 表示社区贡献的数量, T T T 表示时间。通过这种数学模型,可以评估和优化社区的活跃度。
Memcached社区也提供了一定数量的数学资源,包括内存管理、分布式系统和性能优化等方面的文档和教程。这些资源帮助用户更好地理解和使用Memcached,同时也促进了Memcached在数学模型和算法层面的深入研究。
R = D U R = \frac{D}{U} R=UD
其中, R R R 表示数学资源的丰富度, D D D 表示数学资源的数量, U U U 表示用户的需求。通过这种数学模型,可以评估和优化数学资源的丰富度。
通过这些数学模型和资源对比,我们可以看到Redis和Memcached在社区和支持资源方面各有千秋。Redis以其庞大且活跃的社区和丰富的数学资源,在推动项目发展和创新方面表现出色;而Memcached则以其简洁高效的社区和数学资源,在满足用户需求和问题解决方面表现出色。

5. 使用场景的多维交响
5.1 Redis的适用场景
Redis以其丰富的数据结构和强大的功能,在多种应用场景中展现了其独特的优势。本节将从复杂数据结构需求的数学与架构模型、持久化和复制需求的数学与架构分析以及实时分析和处理的数学与架构视角三个方面,详细探讨Redis的适用场景。
复杂数据结构需求的数学与架构模型
Redis支持多种复杂的数据结构,如列表(Lists)、集合(Sets)、有序集合(Sorted Sets)、哈希(Hashes)等,这些数据结构为处理复杂的数据操作提供了强大的支持。例如,有序集合通过使用跳跃表(Skip List)和压缩列表(ziplist)实现,确保了高效的插入和查询操作。
T ( n ) = O ( log n ) T(n) = O(\log n) T(n)=O(logn)
其中, T ( n ) T(n) T(n) 表示操作的时间复杂度, n n n 表示数据集的大小。通过这种数学模型,可以评估和优化复杂数据结构的操作效率。
此外,Redis的发布/订阅(Pub/Sub)功能通过使用队列和消息传递机制,实现了高效的消息传递和处理。这种机制涉及到消息传递的数学模型和队列管理的算法优化。
P ( m ) = 1 N P(m) = \frac{1}{N} P(m)=N1
其中, P ( m ) P(m) P(m) 表示消息传递到订阅者的概率, N N N 表示订阅者的数量。通过这种数学模型,可以评估和优化消息传递的效率。
持久化和复制需求的数学与架构分析
Redis提供了多种持久化机制,如RDB(Redis Database)和AOF(Append Only File),这些机制确保了数据的安全性和可靠性。例如,RDB通过定期快照的方式,将数据持久化到磁盘,而AOF则通过记录每个写操作,实现了数据的实时持久化。
D = S T D = \frac{S}{T} D=TS
其中, D D D 表示持久化效率, S S S 表示数据集的大小, T T T 表示持久化时间。通过这种数学模型,可以评估和优化持久化机制的效率。
此外,Redis的复制功能通过主从复制(Master-Slave Replication)和哨兵(Sentinel)机制,实现了数据的高可用性和故障转移。这种机制涉及到数据同步的数学模型和故障检测的算法优化。
R = M S R = \frac{M}{S} R=SM
其中, R R R 表示复制效率, M M M 表示主节点的数据量, S S S 表示从节点的数据量。通过这种数学模型,可以评估和优化复制机制的效率。
实时分析和处理的数学与架构视角
Redis在实时分析和处理方面同样表现出色,其高效的内存操作和丰富的数据结构为实时数据处理提供了强大的支持。例如,Redis的流(Streams)数据结构通过使用日志和队列机制,实现了高效的数据流处理和分析。
P ( x ) = 1 N P(x) = \frac{1}{N} P(x)=N1
其中, P ( x ) P(x) P(x) 表示数据流处理到节点的概率, N N N 表示节点的数量。通过这种数学模型,可以评估和优化数据流处理的效率。
此外,Redis的聚合操作(Aggregation Operations)通过使用哈希表和压缩列表,实现了高效的实时数据聚合和分析。这种机制涉及到数据聚合的数学模型和算法优化。
A = F T A = \frac{F}{T} A=TF
其中, A A A 表示聚合效率, F F F 表示聚合功能的复杂度, T T T 表示聚合时间。通过这种数学模型,可以评估和优化聚合操作的效率。
通过这些数学模型和架构策略的分析,我们可以看到Redis在复杂数据结构需求、持久化和复制需求以及实时分析和处理方面具有显著的优势。这些优势使得Redis成为处理复杂数据操作和高并发实时处理的理想选择。
5.2 Memcached的适用场景
Memcached以其简洁高效的架构和出色的性能,在多种应用场景中展现了其独特的优势。本节将从简单键值存储的数学与架构模型、高并发读取的数学与架构分析以及缓存层优化的数学与架构视角三个方面,详细探讨Memcached的适用场景。
简单键值存储的数学与架构模型
Memcached的核心功能是提供简单的键值存储服务,其设计哲学在于简洁性和高效性。这种设计使得Memcached在处理大规模的简单键值存储需求时表现出色。例如,Memcached通过使用哈希表(Hash Table)来存储键值对,确保了高效的插入和查询操作。
T ( n ) = O ( 1 ) T(n) = O(1) T(n)=O(1)
其中, T ( n ) T(n) T(n) 表示操作的时间复杂度, n n n 表示数据集的大小。通过这种数学模型,可以评估和优化简单键值存储的操作效率。
此外,Memcached的内存管理机制通过使用Slab Allocator,实现了高效的内存分配和回收。这种机制涉及到内存分配的数学模型和算法优化。
M = S P M = \frac{S}{P} M=PS
其中, M M M 表示内存使用效率, S S S 表示数据集的大小, P P P 表示内存页的大小。通过这种数学模型,可以评估和优化内存管理机制的效率。
高并发读取的数学与架构分析
Memcached在处理高并发读取场景时同样表现出色,其高效的内存操作和简洁的架构设计为高并发读取提供了强大的支持。例如,Memcached通过使用多线程和非阻塞I/O,实现了高效的并发处理。
C = R T C = \frac{R}{T} C=TR
其中, C C C 表示并发处理效率, R R R 表示请求的数量, T T T 表示处理时间。通过这种数学模型,可以评估和优化高并发读取的处理效率。
此外,Memcached的一致性哈希(Consistent Hashing)算法通过引入虚拟节点(Virtual Nodes),进一步提高了数据分布的均匀性和系统的可扩展性。这种机制涉及到数据分布的数学模型和算法优化。
D = M V D = \frac{M}{V} D=VM
其中, D D D 表示数据分布的均匀度, M M M 表示实际数据分布, V V V 表示理想数据分布。通过这种数学模型,可以评估和优化数据分布的均匀性。
缓存层优化的数学与架构视角
Memcached在缓存层优化方面同样表现出色,其高效的内存操作和简洁的架构设计为缓存层优化提供了强大的支持。例如,Memcached通过使用LRU(Least Recently Used)算法,实现了高效的缓存淘汰策略。
E = U T E = \frac{U}{T} E=TU
其中, E E E 表示缓存淘汰效率, U U U 表示缓存使用率, T T T 表示淘汰时间。通过这种数学模型,可以评估和优化缓存淘汰策略的效率。
此外,Memcached的分布式特性通过客户端的哈希算法实现,这种架构简化了服务器的管理,同时也提高了系统的可扩展性。这种机制涉及到数据分布的数学模型和算法优化。
H ( k ) = k m o d N H(k) = k \mod N H(k)=kmodN
其中, H ( k ) H(k) H(k) 表示键 k k k 的哈希值, N N N 表示节点的数量。通过这种简单的哈希算法,可以实现数据的均匀分布和负载均衡。
通过这些数学模型和架构策略的分析,我们可以看到Memcached在简单键值存储需求、高并发读取需求以及缓存层优化方面具有显著的优势。这些优势使得Memcached成为处理大规模简单键值存储和高并发读取的理想选择。

6. 结论
在深入探讨了Redis与Memcached的系统架构、数学模型以及适用场景后,我们可以得出一些关键的结论和选择建议。同时,我们也将对未来发展趋势进行多维预测。
Redis与Memcached的选择建议
在选择Redis或Memcached时,应根据具体的应用需求和场景进行权衡。以下是一些关键的选择建议:
-
复杂数据结构需求:如果应用需要处理复杂的数据结构,如列表、集合、有序集合等,Redis是更合适的选择。其丰富的数据结构和强大的功能可以满足复杂的数据操作需求。
-
持久化和复制需求:如果应用对数据的持久化和复制有较高要求,Redis同样是一个更好的选择。其提供的RDB和AOF持久化机制以及主从复制和哨兵机制,确保了数据的安全性和高可用性。
-
高并发读取需求:如果应用主要面临高并发读取的挑战,Memcached可能是一个更合适的选择。其简洁高效的架构和出色的性能,可以有效应对高并发读取的场景。
-
缓存层优化需求:如果应用主要用于缓存层优化,Memcached的简洁性和高效性使其成为一个理想的选择。其LRU缓存淘汰策略和高效的内存管理机制,可以有效提高缓存层的性能和效率。
未来发展趋势的多维预测
随着技术的不断进步和应用需求的不断变化,Redis和Memcached都将继续发展和演进。以下是一些未来发展趋势的多维预测:
-
性能优化:随着硬件技术的进步,如更快的CPU和更大的内存,Redis和Memcached都将继续优化其性能,提高读写速度和内存使用效率。
-
功能扩展:为了满足更多样化的应用需求,Redis和Memcached都将继续扩展其功能,如增加新的数据结构、优化持久化机制和复制机制等。
-
分布式系统:随着分布式系统的普及,Redis和Memcached都将继续优化其分布式特性,提高系统的可扩展性和容错性。
-
人工智能和机器学习:随着人工智能和机器学习的兴起,Redis和Memcached可能会集成更多与AI和ML相关的功能,如实时数据分析、预测模型等。
-
云原生和容器化:随着云原生和容器化技术的发展,Redis和Memcached都将继续优化其云原生和容器化支持,提高系统的灵活性和可管理性。
通过这些选择建议和未来发展趋势的预测,我们可以更好地理解和把握Redis与Memcached的应用场景和发展方向,从而做出更明智的技术选择和规划。
相关文章:
四十篇:内存巨擘对决:Redis与Memcached的深度剖析与多维对比
内存巨擘对决:Redis与Memcached的深度剖析与多维对比 1. 引言 在现代的系统架构中,内存数据库已经成为了信息处理的核心技术之一。这类数据库系统的高效性主要来源于其对数据的即时访问能力,这是因为数据直接存储在RAM中,而非传统…...
HTML5的多线程技术:Web Worker API
Web Workers API 是HTML5的一项技术,它允许在浏览器后台独立于主线程运行脚本,即允许进行多线程处理。这对于执行密集型计算任务特别有用,因为它可以防止这些任务阻塞用户界面,从而保持网页的响应性和交互性。Web Workers在自己的…...
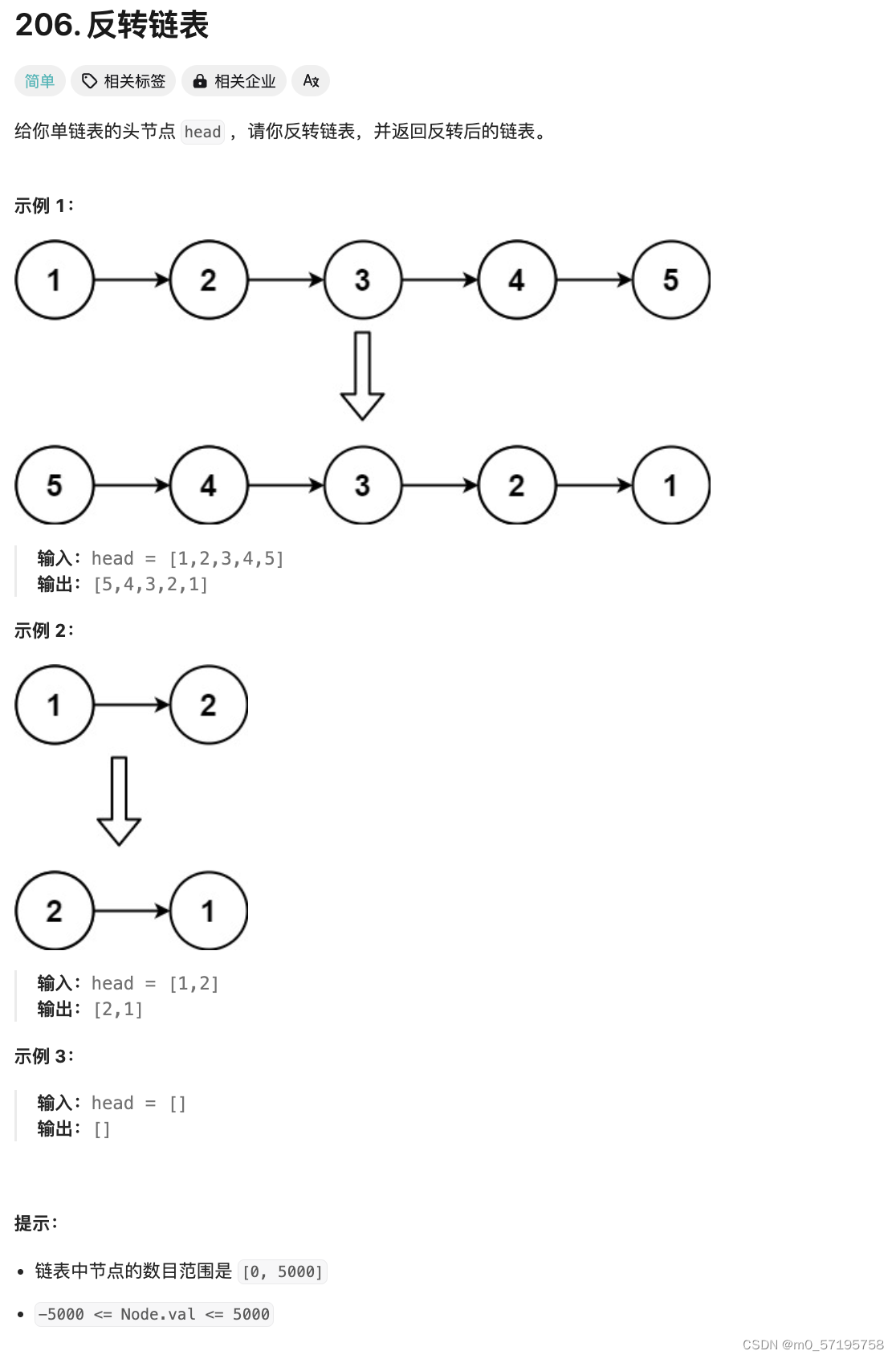
Java | Leetcode Java题解之第206题反转链表
题目: 题解: class Solution {public ListNode reverseList(ListNode head) {if (head null || head.next null) {return head;}ListNode newHead reverseList(head.next);head.next.next head;head.next null;return newHead;} }...

660错题
不能局部求导,局部洛必达...
GAMES104:04游戏引擎中的渲染系统1:游戏渲染基础-学习笔记
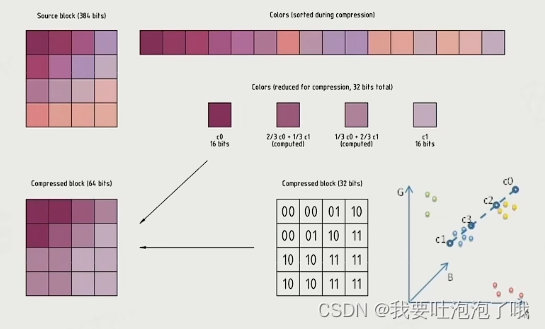
文章目录 概览:游戏引擎中的渲染系统四个课时概览 一,渲染管线流程二,了解GPUSIMD 和 SIMTGPU 架构CPU到GPU的数据传输GPU性能限制 三,可见性Renderable可渲染对象提高渲染效率Visibility Culling 可见性裁剪 四,纹理压…...
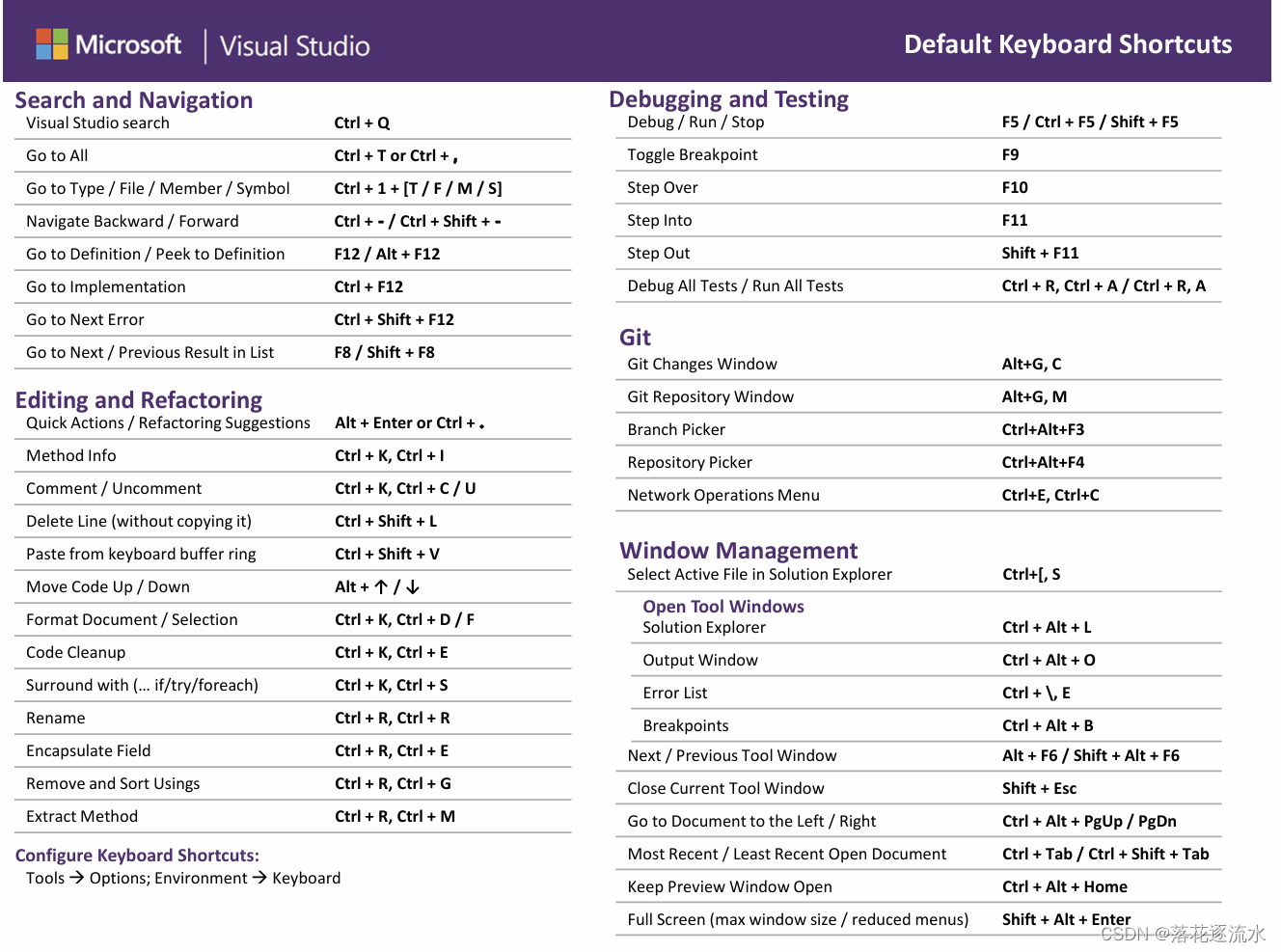
Visual Studio 中的键盘快捷方式
1. Visual Studio 中的键盘快捷方式 1.1. 可打印快捷方式备忘单 1.2. Visual Studio 的常用键盘快捷方式 本部分中的所有快捷方式都将全局应用(除非另有指定)。 “全局”上下文表示该快捷方式适用于 Visual Studio 中的任何工具窗口。 生成࿱…...

K8S中的某个容器突然出现内存和CPU占用过高的情况解决办法
当K8S中的某个容器突然出现内存和CPU占用过高的情况时,可以采取以下步骤进行处理: 观察和分析: 使用kubectl top pods命令查看集群中各个Pod的CPU和内存占用情况,找出占用资源高的Pod。使用kubectl describe pod <pod-name>…...

Pointnet++改进即插即用系列:全网首发GLSA聚合和表示全局和局部空间特征|即插即用,提升特征提取模块性能
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入GLSA,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步骤三 1.理论介…...

如何选择适合自己的虚拟化技术?
虚拟化技术已成为现代数据中心和云计算环境的核心组成部分。本文将帮助您了解如何选择适合自己需求的虚拟化技术,以实现更高的效率、资源利用率和灵活性。 理解虚拟化技术 首先,让我们了解虚拟化技术的基本概念。虚拟化允许将一个物理服务器划分为多个虚…...

Spring动态代理详解
一,动态代理 我发现Spring框架中的动态代理是一种非常强大的机制,它可以在运行时为接口或类创建动态代理,然后通过这些代理在方法调用前后添加额外的行为。在后续Spring的AOP(面向切面编程)支持中扮演了关键角色。 二…...

Java微服务架构中的消息总线设计
Java微服务架构中的消息总线设计 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨在Java微服务架构中的消息总线设计。 一、什么是消息总线&…...
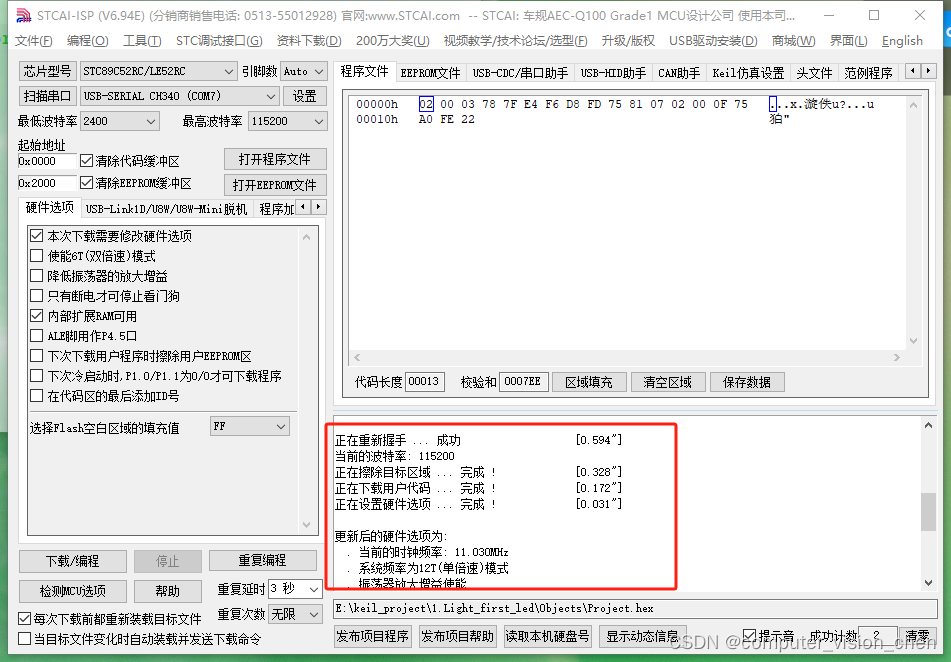
51单片机项目-点亮第一个LED灯(涉及:进制转换表、创建项目、生成HEX文件、下载程序到单片机、二极管区分正负极)
目录 新建项目选择型号添加新文件到该项目设置字体和utf-8编码二极管如何区分正负极原理:CPU通过寄存器来控制硬件电路 用P2寄存器的值控制第一个灯亮进制转换编译查看P2寄存器的地址生成HEX文件把代码下载到单片机中下载程序到单片机 新建项目 选择型号 stc是中国…...

安全管理中心测评项
安全管理中心 系统管理 应对系统管理员进行身份鉴别,只允许其通过特定的命令或操作界面进行系统管理操作,并对这些操作进行审计; 应通过系统管理员对系统的资源和运行进行配置、控制和管理,包括用户身份、系统资源配置、系统加…...
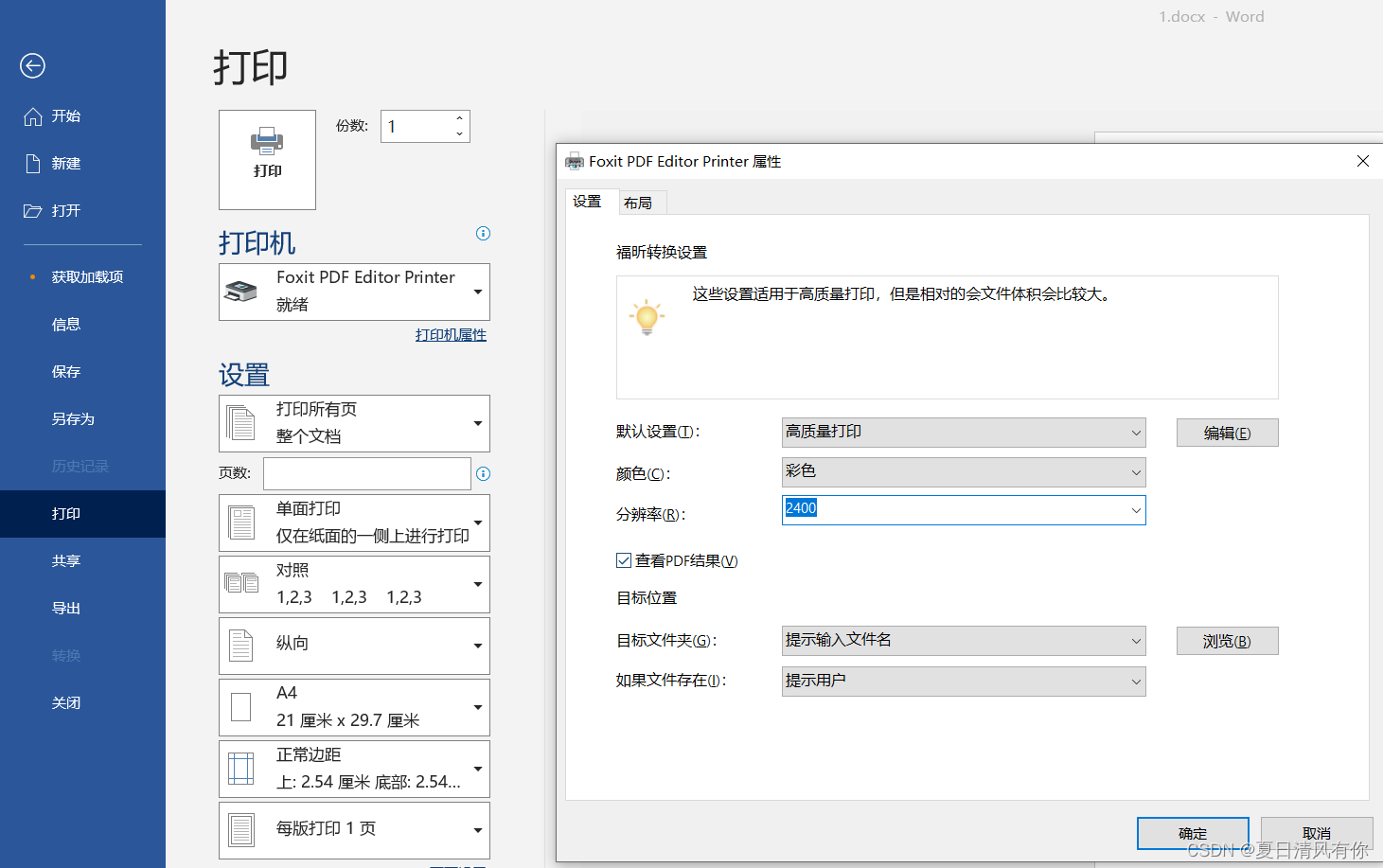
word 转pdf 中图片不被压缩的方法
word 转pdf 中图片不被压缩的方法 法1: 调节word 选项中的图片格式为不压缩、高保真 法2: 1: word 中的图片尽可能使用高的分辨率,图片存为pnd或者 tif 格式(最高清) 2: 转化为pdf使用打印机器,参数如下…...
Springboot+Vue3开发学习笔记《1》
SpringbootVue3开发学习笔记《1》 博主正在学习SpringbootVue3开发,希望记录自己学习过程同时与广大网友共同学习讨论。 一、前置条件 博主所用版本: IDEA需要破解,破解工具链接容易挂,关注私聊我单发。 Spring Boot是Spring提…...
grpc编译
1、cmake下载 Download CMakehttps://cmake.org/download/cmake老版本下载 Index of /fileshttps://cmake.org/files/2、gprc源码下载,发现CMAKE报错 3、使用git下载 1)通过git打开一个目录:如下grpc将放在D盘src目录下 cd d: cd src2&am…...

echarts-wordcloud:打造个性化词云库
前言 在当今信息爆炸的时代,如何从海量的文本数据中提取有用的信息成为了一项重要的任务。词云作为一种直观、易于理解的数据可视化方式,被广泛应用于文本分析和可视化领域。本文将介绍一种基于 echarts-wordcloud 实现的词云库,通过其丰富的…...
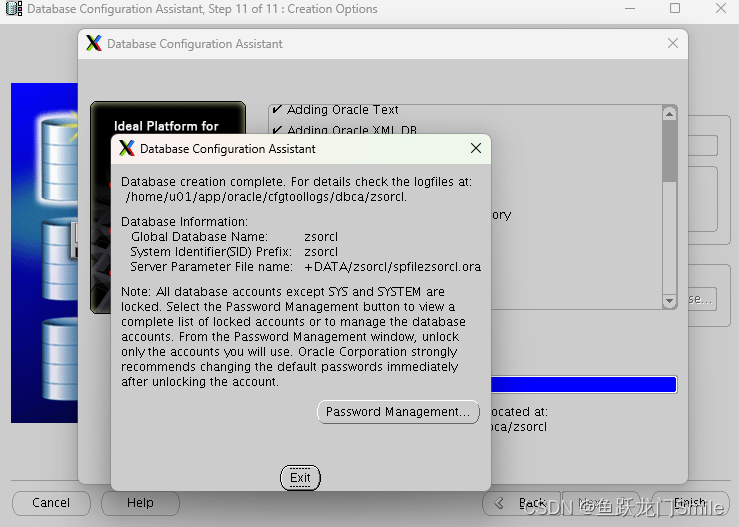
VMware虚拟机安装CentOS7.9 Oracle 11.2.0.4 RAC+单节点RAC ADG
目录 一、参考资料 二、RAC环境配置清单 1.主机环境 2.共享存储 3.IP地址 4.虚拟机 三、系统参数配置 1. 配置网卡 1.1 配置NAT网卡 1.2 配置HostOnly网卡 2. 修改主机名 3. 配置/etc/hosts 4. 关闭防火墙 5. 关闭Selinux 6. 配置内核参数 7. 配置grid、oracle…...
iOS 视图实现渐变色背景
需求 目的是要实现视图的自定义的渐变背景色,实现一个能够随时使用的工具。 实现讨论 在 iOS 中,如果设置视图单一的背景色,是很简单的。可是,如果要设置渐变的背景色,该怎么实现呢?其实也没有很是麻烦&…...

hive命令和参数
一.命令行模式 hive命令行 hive -H 查询hive的可用参数 hive -e "" 在hive命令中直接执行简单的sql语句 在hive命令中执行sql文件 hive -f 文件地址 在hive命令中新建hive变量 hive --hivevar mykey"myvalue" beeline命令行 先得启动hiveserver…...

如何将B站碎片化缓存视频合并为完整MP4?这个Android工具给你答案
如何将B站碎片化缓存视频合并为完整MP4?这个Android工具给你答案 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 想象一下这样的场景:你在地铁上打开手机,准备观看…...

VirtualLab进阶实验指南:单缝衍射参数优化与动态仿真
1. VirtualLab单缝衍射实验入门指南 第一次接触VirtualLab进行单缝衍射仿真时,我完全被那些复杂的参数搞懵了。后来才发现,只要掌握几个关键点,就能轻松看到漂亮的衍射条纹。先说说最基本的实验搭建: 在VirtualLab中新建一个空白项…...

利用快马平台快速生成蓝桥杯python算法题原型,加速备赛效率
今天在准备蓝桥杯Python竞赛时,发现一个很实用的技巧——用InsCode(快马)平台快速生成算法题原型。就拿"三数之和"这道经典题来说,平台能帮我们快速搭建解题框架,特别适合赛前突击训练。 先说说这个题目的具体要求:给定…...

RePKG高效资源处理工具完全指南:从功能解析到实战应用
RePKG高效资源处理工具完全指南:从功能解析到实战应用 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 功能探秘:RePKG如何解决游戏资源处理难题?…...
)
告别二维图纸!用管线大师3分钟搞定地下管网三维建模(附Cesium加载教程)
告别二维图纸!用管线大师3分钟搞定地下管网三维建模(附Cesium加载教程) 市政工程师老张盯着屏幕上密密麻麻的CAD线条已经三个小时了。这些代表地下管网的二维线段,在他眼里逐渐模糊成一片灰色的迷宫。"要是能直接看到立体的管…...

夸克网盘自动化助手:告别手动操作,享受智能云存储管理
夸克网盘自动化助手:告别手动操作,享受智能云存储管理 【免费下载链接】quark_auto_save 夸克网盘签到、自动转存、命名整理、发推送提醒和刷新媒体库一条龙 项目地址: https://gitcode.com/gh_mirrors/qu/quark_auto_save 还在为每天重复检查夸克…...

BilibiliDown:高效下载B站视频的3步实战指南
BilibiliDown:高效下载B站视频的3步实战指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibil…...

TrollInstallerX深度解析:iOS 14-16.6.1 TrollStore安装解决方案
TrollInstallerX深度解析:iOS 14-16.6.1 TrollStore安装解决方案 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 问题象限:iOS用户的安装困境与技…...

抖音视频智能下载器:企业级内容管理解决方案的技术架构与效率革命
抖音视频智能下载器:企业级内容管理解决方案的技术架构与效率革命 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fal…...

颠覆传统下载体验:3步解锁全平台资源获取
颠覆传统下载体验:3步解锁全平台资源获取 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字内容爆炸的时代&a…...