一文包学会ElasticSearch的大部分应用场合
ElasticSearch
 官网下载地址:Download Elasticsearch | Elastic
官网下载地址:Download Elasticsearch | Elastic
历史版本下载地址1:Index of elasticsearch-local/7.6.1
历史版本下载地址2:Past Releases of Elastic Stack Software | Elastic
ElasticSearch的安装(windows)
安装前所需环境,jdk1.8以上,最好也要有node环境。
-
安装解压即可
-
启动进入bin目录,点击
启动日志
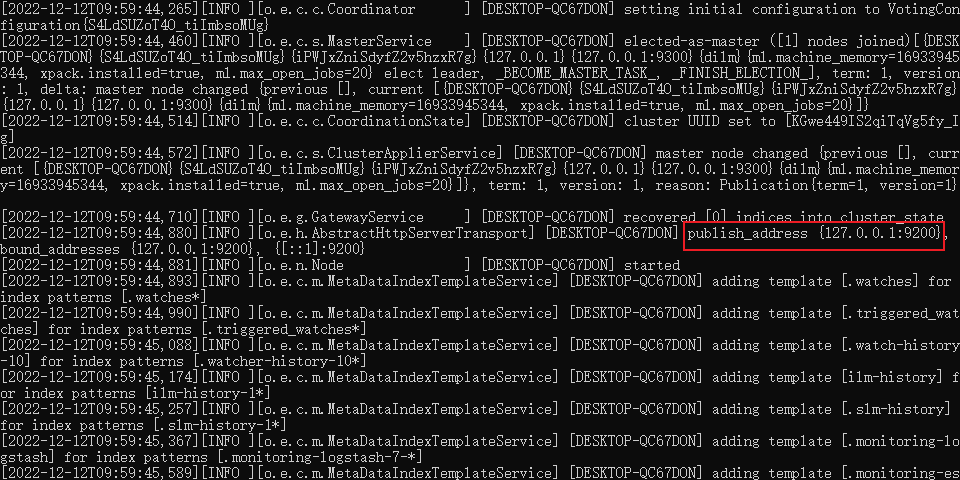
访问端口:http://localhost:9200/

安装可视化界面
下载地址:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster
#下载依赖
cnpm install
#启动
cnpm run start
#默认启动本地的9100端口连接ElasticSearch
这里会出现跨域问题
修改ElasticSearch配置文件(在elasticsearch解压目录config下elasticsearch.yml中添加)
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"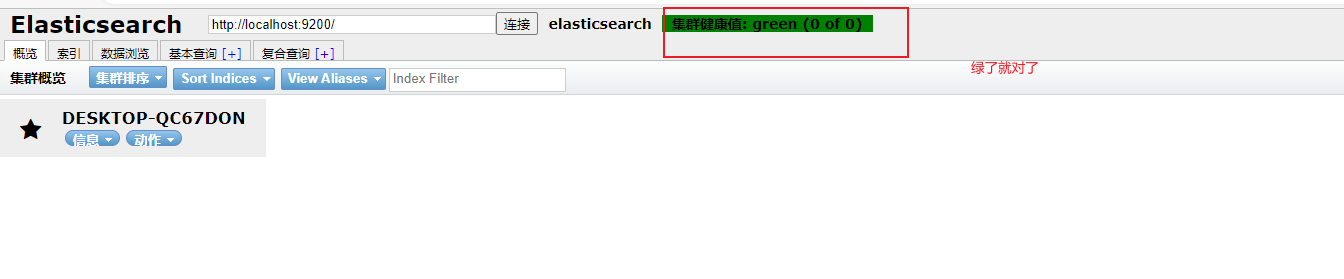
安装kibana
官网地址:下载 Elastic 产品 | Elastic
历史版本地址:Index of kibana-local/7.6.1
下载的版本要和ElasticSearch版本一致
解压,进入斌、目录启动。

汉化
修改config文件下的kibana.yml配置文件。
i18n.locale: "zh-CN"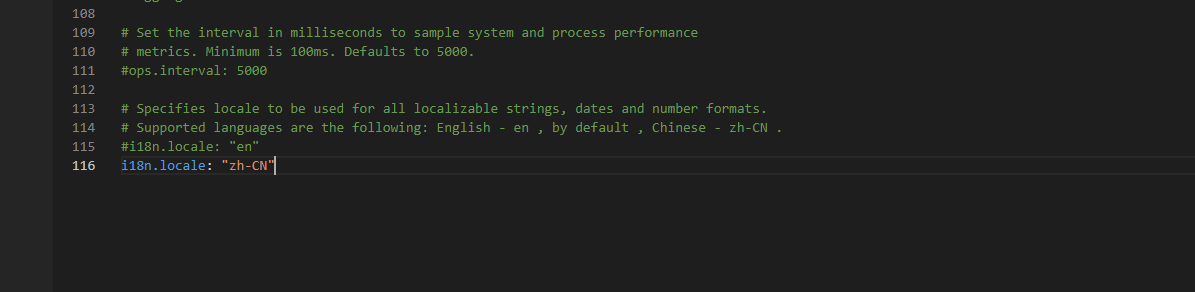

docker安装(单点)
链接: 百度网盘 请输入提取码 提取码: cf82
1.将三个tar放置/tmp下
2.在该目录下执行
docker load -i es.tar #上到到容器
docker load -i kibana.tar 3.执行启动
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1命令解释:
-
-e "cluster.name=es-docker-cluster":设置集群名称 -
-e "http.host=0.0.0.0":监听的地址,可以外网访问 -
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小 -
-e "discovery.type=single-node":非集群模式 -
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录 -
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录 -
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录 -
--privileged:授予逻辑卷访问权 -
--network es-net:加入一个名为es-net的网络中 -
-p 9200:9200:端口映射配置
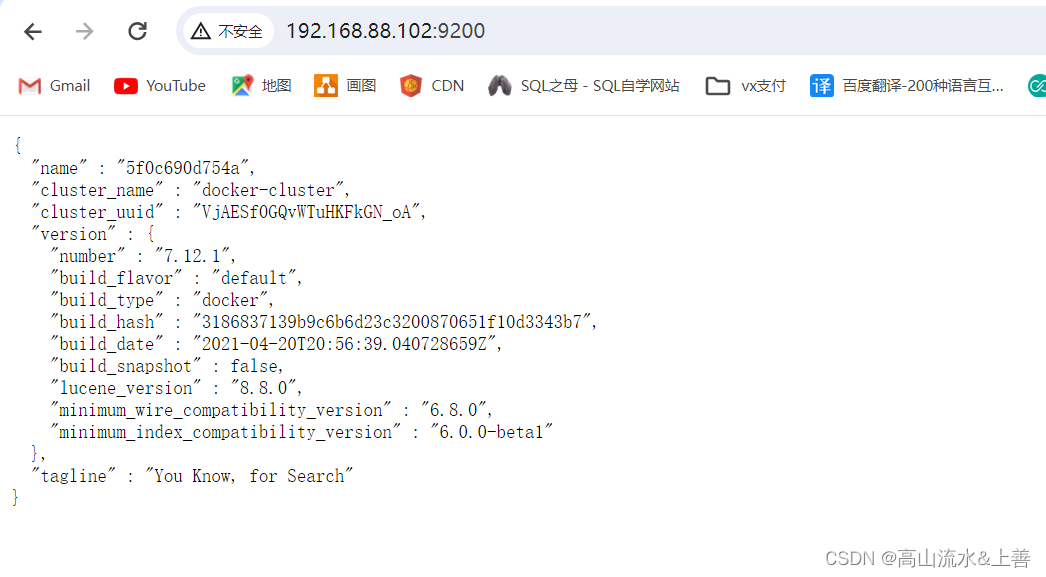
在浏览器中输入:http://IP地址:9200 即可看到elasticsearch的响应结果
4.接下来安装kibana
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1-
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中 -
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch -
-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana查看运行日志,当查看到下面的日志,说明成功:
 此时,在浏览器输入地址访问:http://192.168.150.101:5601,即可看到结果
此时,在浏览器输入地址访问:http://192.168.150.101:5601,即可看到结果
docker安装分词器(在线安装)
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearchdocker安装ik分词器(离线安装)
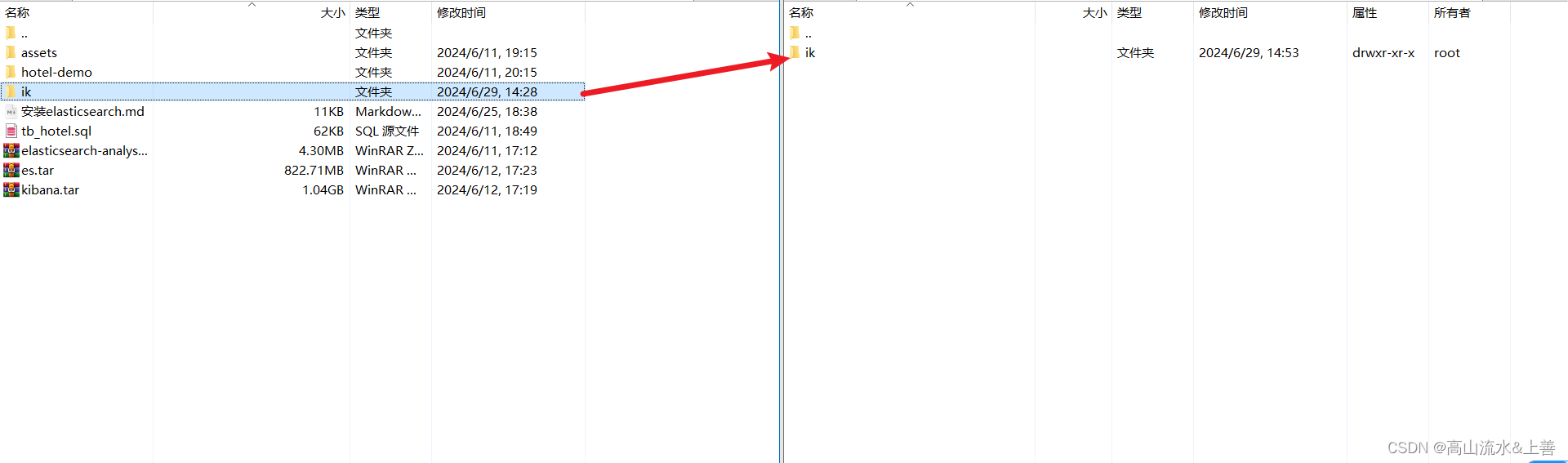
在百度网盘中提出ik文件夹或者自己解压elasticsearch-analysis-ik-7.12.1.zip重命名为ik,如下操作:
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins显示结果:
[{"CreatedAt": "2022-05-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中。
然后进入该文件夹将ik文件夹放置该目录即可:
 依次执行以下指令:
依次执行以下指令:
# 重启容器docker restart es# 查看es日志
docker logs -f es踩坑:

我的是虚拟机,暂停之后,docker无法挂载导致。
#重启docker
systemctl restart docker
#重启容器
systemctl restart es
systemctl restart kibana测试:
 IK分词器
IK分词器
什么是ik分词器?
IK分词器是ES的一个插件,主要用于把一段中文或者英文的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词器是将每个字看成一个词,比如"我爱技术"会被分为"我","爱","技","术",这显然不符合要求,所以我们需要安装中文分词器IK来解决这个问题;
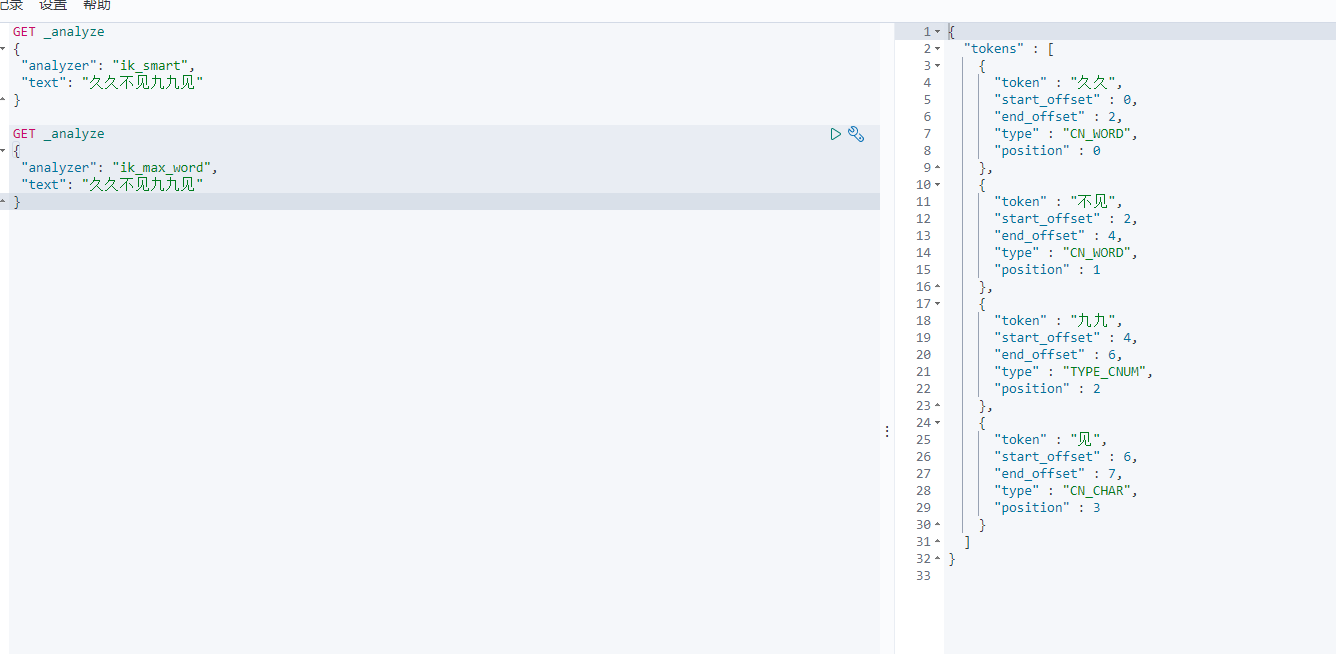
IK提供了两个分词算法:ik_smart和ik_max_word
ik_smart为最少切分,添加了歧义识别功能,推荐;
ik_max_word为最细切分,能切的都会被切掉;
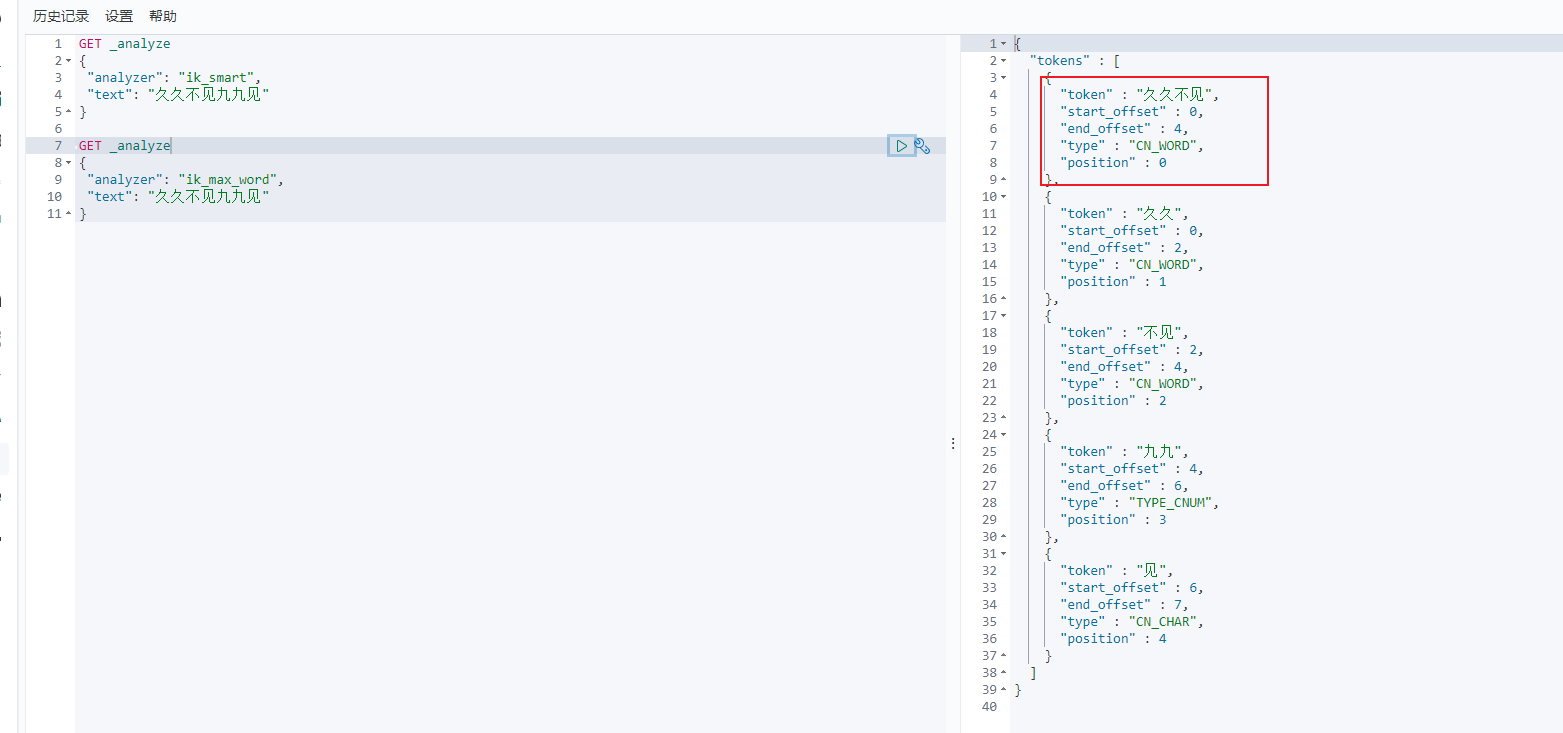
示例:对“买一台笔记本” 进行分词 K提供了两个分词算法: ik_smart和ik_max_word ,其中ik_smart为最少切分, ik_max_word为最细粒度划分!
ik_smart分词结果:

ik_max_word分词结果:
{"tokens" : [{"token" : "买一","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "一台","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "一","start_offset" : 1,"end_offset" : 2,"type" : "TYPE_CNUM","position" : 2},{"token" : "台笔","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "台","start_offset" : 2,"end_offset" : 3,"type" : "COUNT","position" : 4},{"token" : "笔记本","start_offset" : 3,"end_offset" : 6,"type" : "CN_WORD","position" : 5},{"token" : "笔记","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 6},{"token" : "本","start_offset" : 5,"end_offset" : 6,"type" : "CN_CHAR","position" : 7}]
}
安装
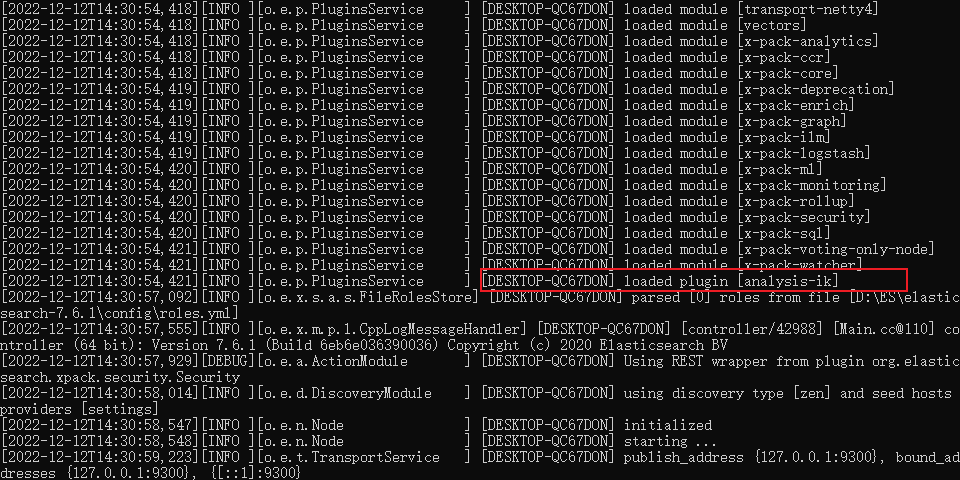
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.1
下载完成后解压到,在elasticSearch的plugins目录下创建ik文件目录并解压。
配置完成使用kibanna进行测试:
仔细观察可发现es会将一个一个的词去分开,那么他是根据什么去分词的呢?
我们进入下载的ik分词器插件中可见有很多的.dic文件,其实这些文件就是为了分词所诞生的。
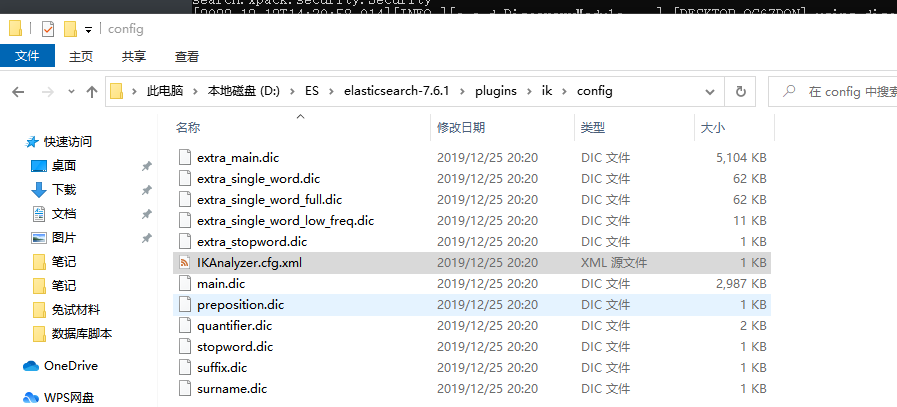
自定义分词
例子:此时我们想让上图中的久久不见为一组
-
在config目录下创建my.dic
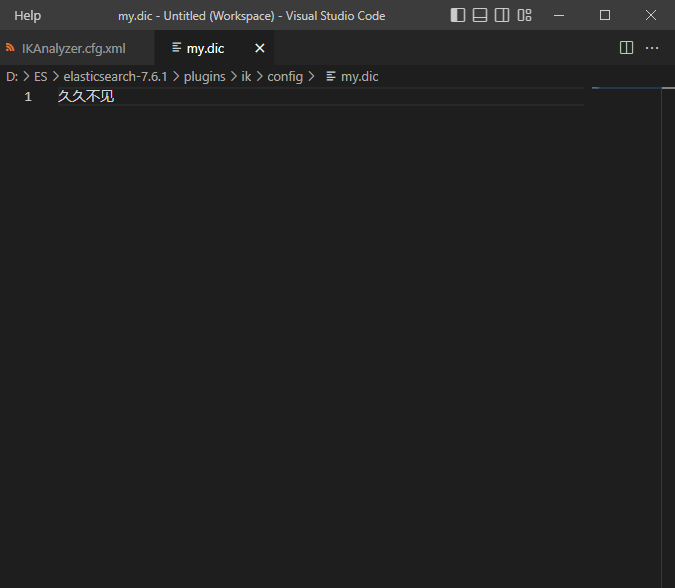
-
然后在
IKAnalyzer.cfg.xml
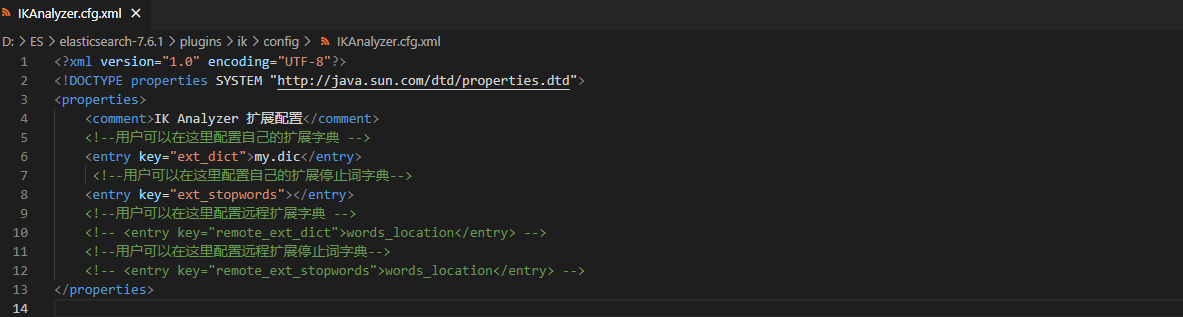
3.重启测试
Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明:
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
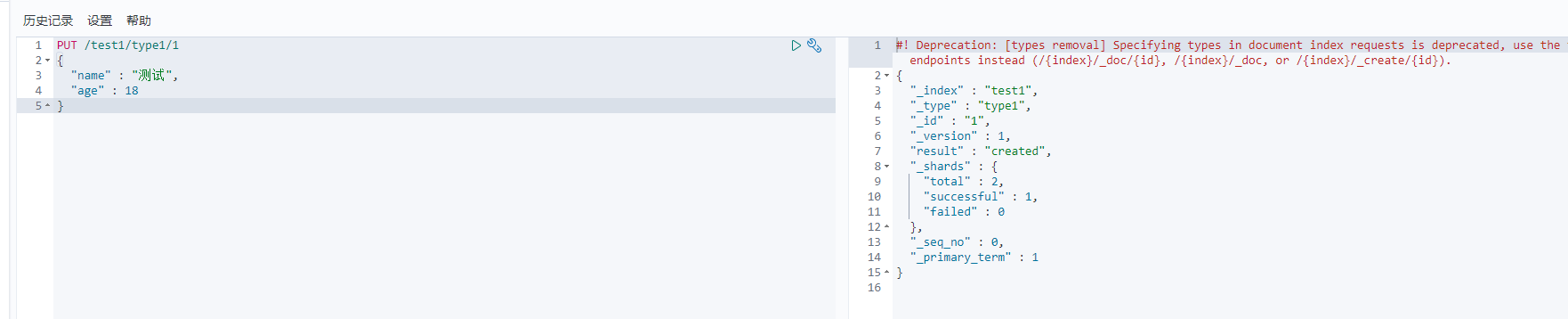
测试
PUT /test1/type1/1
{"name" : "测试","age" : 18
}

字段数据类型(Mapping)
-
字符串类型
-
text、
keyword
-
text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
-
keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
-
-
-
数值型
-
long、Integer、short、byte、double、float、half float、scaled float
-
-
日期类型
-
date
-
-
te布尔类型
-
boolean
-
-
二进制类型
-
binary
-
-
等等…
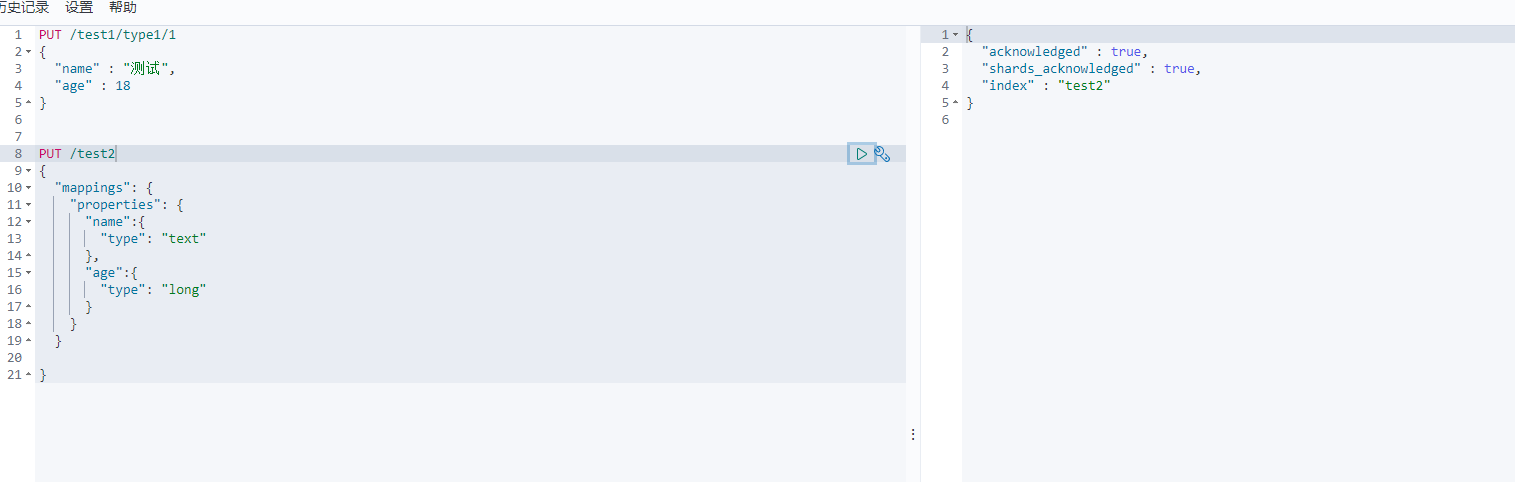
指定字段的类型(put)
PUT /test2
{"mappings": {"properties": {"name":{ #类似数据库字段名"type": "text" #类似数据库字段类型},"age":{"type": "long"}}}}
crud例子
# 创建索引库
PUT /estest
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_max_word" #使用text类型需要指定ik分词器类型},"email": {"type": "keyword","index": false #是够开启分词,默认开启},"name": {"type": "object","properties": {"firstName": {"type": "keyword","index": false},"lastName":{"type": "keyword","index": false}}}}}
}
# 查询
get /estest
#修改结构 在原结构的基础上添加age属性并指定类型
PUT /estest/_mapping
{"properties":{"age":{"type":"integer"}}
}
#删除索引
DELETE /estest关于索引的基本操作
1.添加数据
PUT test/_doc/2
{"name":"王五","age":35,"desc":"啦啦啦啦啦测试啦","tag":["标签一","标签二","标签三"]
}//在原来的结构上添加字段
POST /hotel/_update/2048671293
{"doc": {"isAD":true}
}
2.修改数据
#指定所有的字段做修改操作
POST test/_doc/2/_update
{
"name":"修改的名字"
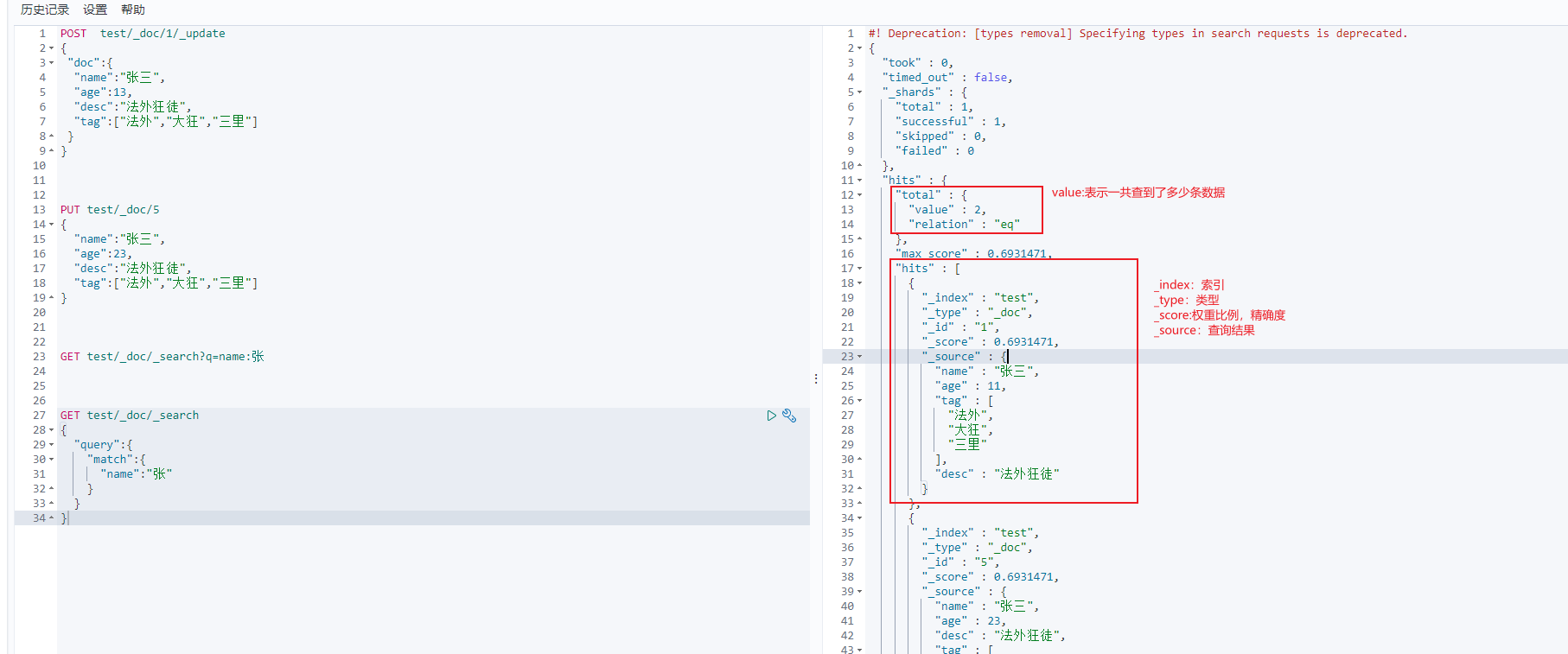
}3.模糊查询
GET test/_doc/_search?q=name:张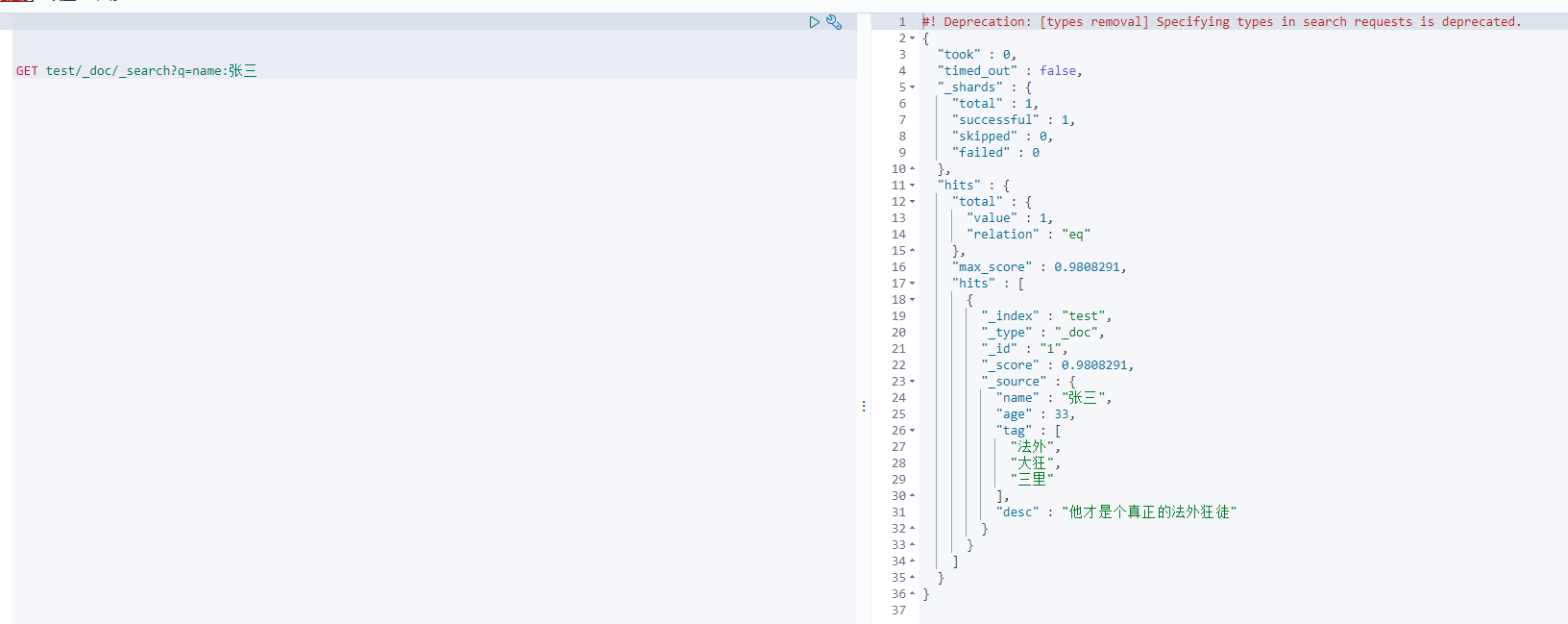
GET test/_doc/_search
{"query":{"match":{"name":"张"}}
}
查询匹配
-
match:匹配(会使用分词器解析(先分析文档,然后进行查询)) -
_source:过滤字段 -
sort:排序 -
form、size分页
4._source:过滤字段
GET test/_doc/_search
{"query":{"match":{"name":"张"}},"_source":["name","tag"] #只需要name和tag属性
}5.sort排序
GET test/_doc/_search
{"query":{"match":{"name":"张"}},"sort":[{"age":{"order":"desc" #asc desc }}]
}6.form、size 分页
GET test/_doc/_search
{"query":{"match":{"name":"张"}},"sort":[{"age":{"order":"desc"}}],"from":1, #from相当于 limit(pageNnm) 第几页"size":1 #size 相当于 pageSize 每页显示多少条数据
}7.布尔值查询(must)
GET test/_doc/_search
{"query":{"bool":{"must":[ #must表示必须符合的意思{"match":{"name":"张"}},{"match":{"age":23}}]}}
}
#上面相当于mysql的 where name='张' and age=238.相当于sql的or语句(should)
GET /test/_doc/_search
{"query":{"bool": {"should": [{"match":{"name":"张三"}},{"match":{"age":88}}]} }
}
#相当于mysql的 where name="张三" or age=88 9.不包含(must_not)
GET /test/_doc/_search
{"query":{"bool":{"must_not":{ #不包含"match":{"age":88 #排除88岁的}} }}
}10.过滤器(lt)
GET /test/_doc/_search
{"query":{"bool": {"should": [{"match":{"name":"张三"}},{"match":{"age":88}}],"filter":{"range":{"age":{"lt":88, # 小于88"gt":23 # 大于23 }}}} }
}-
gt 大于
-
gte 大于等于
-
lt 小于
-
lte 小于等于
11.匹配多个条件查询
GET /test/_doc/_search
{"query":{"match":{"tag":"小 大"}}
}
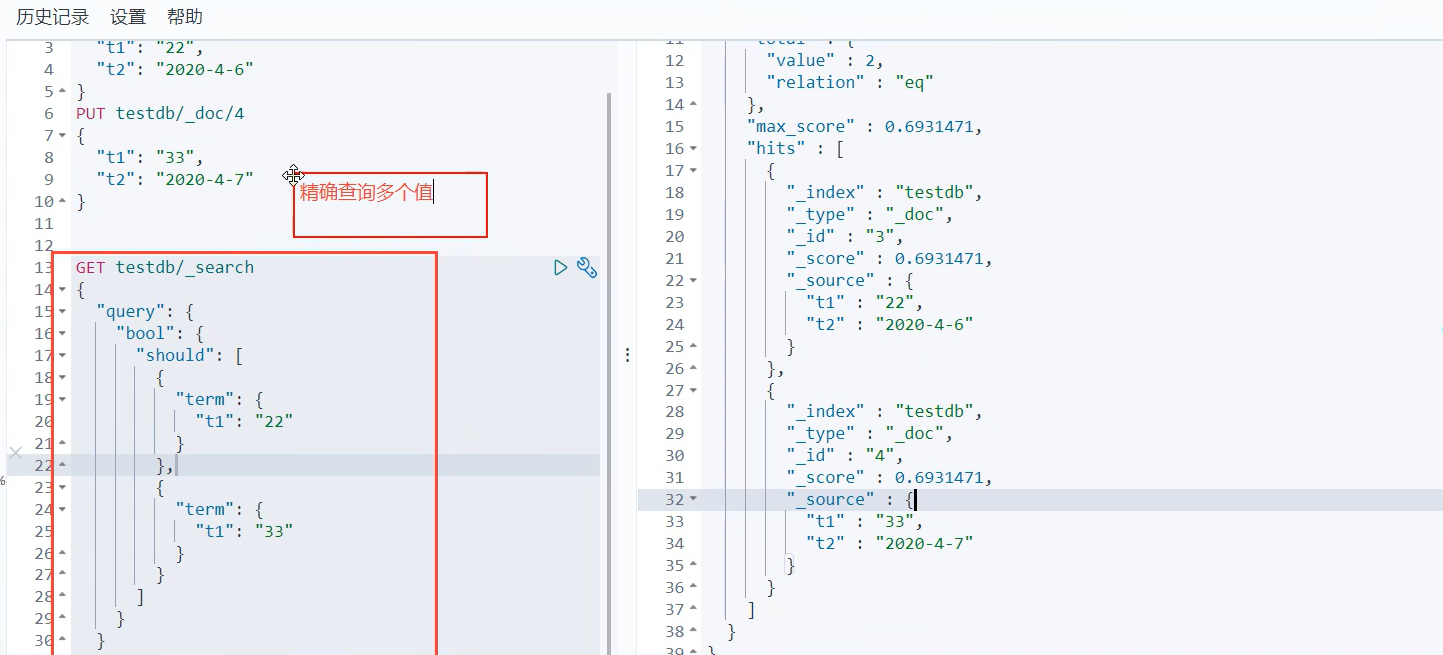
12.精确查询
-
term 查找是通过倒排索引去查询的
查询快 -
match 会使用分词器解析,通过分词查询
注意类型:其中keyword类型是不会被分词器解析拆分的,而text会被拆分。
GET /test3/_doc/_search
{"query":{"term": {#使用term必须精确,因为desc这个字段的类型的keyword"desc": "无语了..."}}
}
GET /test3/_doc/_search
{"query":{"match":{ "name":"老"}}
}精确查询多个值
例子
# 创建索引库
PUT /estest
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_max_word"},"email": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstName": {"type": "keyword","index": false},"lastName":{"type": "keyword","index": false}}}}}
}
# 查询
#get /estest
#修改结构 在原结构的基础上添加age属性并指定类型
PUT /estest/_mapping
{"properties":{"age":{"type":"integer"}}
}
#删除索引
DELETE /estest#添加文档1
PUT /estest/_doc/1
{"age":10,"email":"24112869@qq.com","info":"这是一段分词的内容!","name":{"firstName":"张","lastName":"三"}
}
#添加文档2
PUT /estest/_doc/2
{"age":50,"email":"78945669@qq.com","info":"这是一段分词的内容2!","name":{"firstName":"张","lastName":"四"}
}#查询文档
#get /estest/_doc/2#模糊查询方式1
GET /estest/_doc/_search?q=info:这是#模糊查询方式2
POST /estest/_search
{"query": {"match": {"info": "这是"}}
}
#过滤字段
POST /estest/_search
{"query": {"match": {"info": "这是"}},"_source": ["name","info","age"],"sort": [{"age": {"order": "desc"}}]
}
# 代码高亮
GET /estest/_search
{"query":{"match":{"info":"这是"}},"highlight":{"pre_tags":"<i class='key' style='color:red'>","post_tags":"</i>","fields":{"info":{}}}
}代码高亮
GET /test3/_doc/_search
{"query":{"match":{"name":"李"}},"highlight":{"fields":{"name":{}}}
}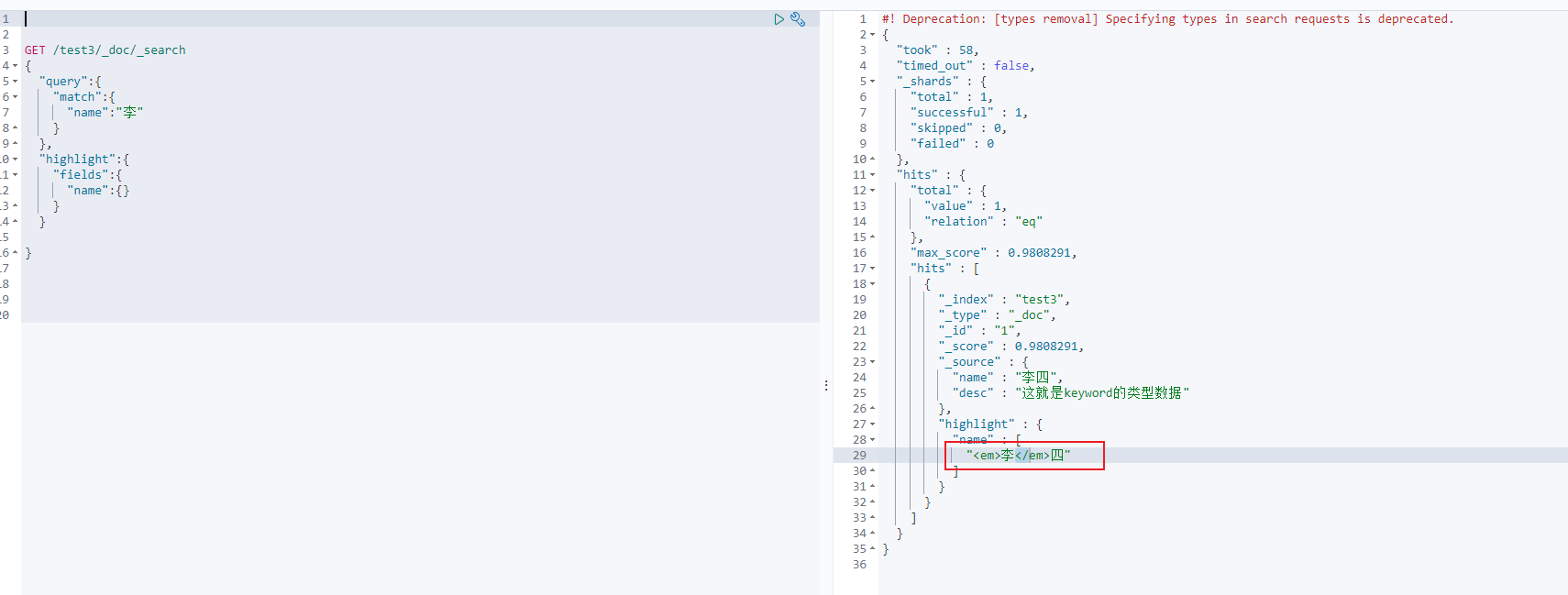
返回前端,前端通过em标签即可实现高亮!
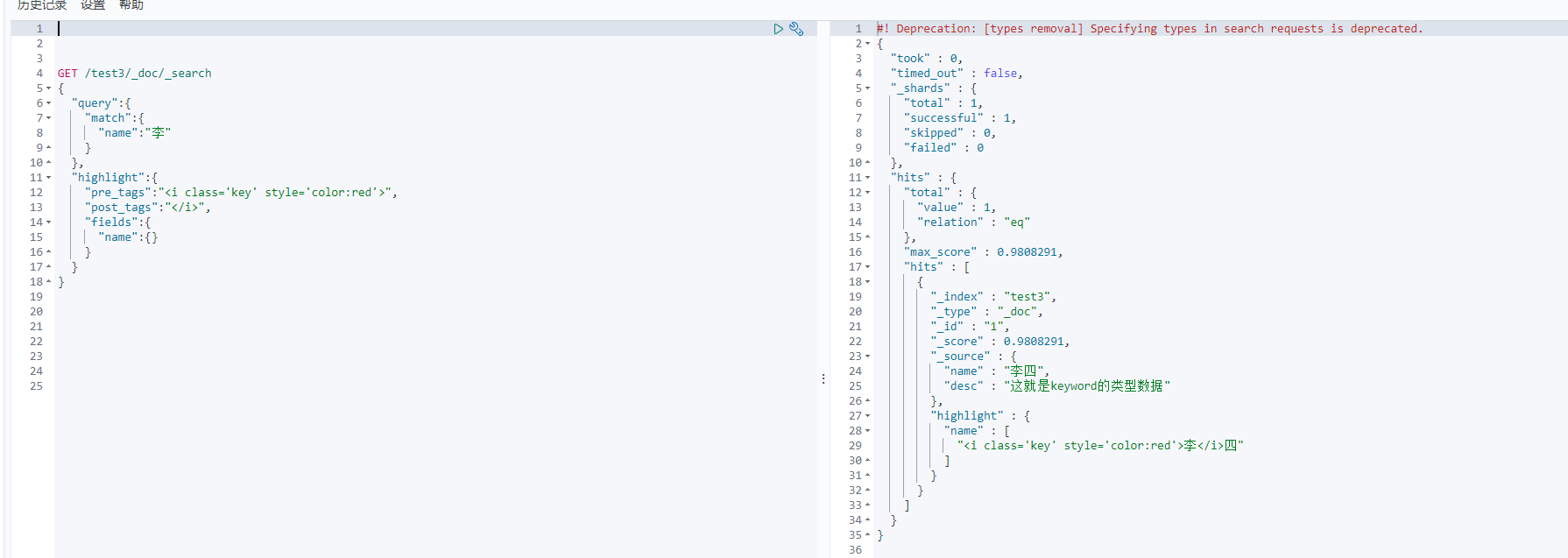
也可以自定义标签或者样式
GET /test3/_doc/_search
{"query":{"match":{"name":"李"}},"highlight":{"pre_tags":"<i class='key' style='color:red'>","post_tags":"</i>","fields":{"name":{}}}
}
集成sprigboot(2.2.6)
依赖
<properties><java.version>1.8</java.version><elasticsearch.version>7.6.1</elasticsearch.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>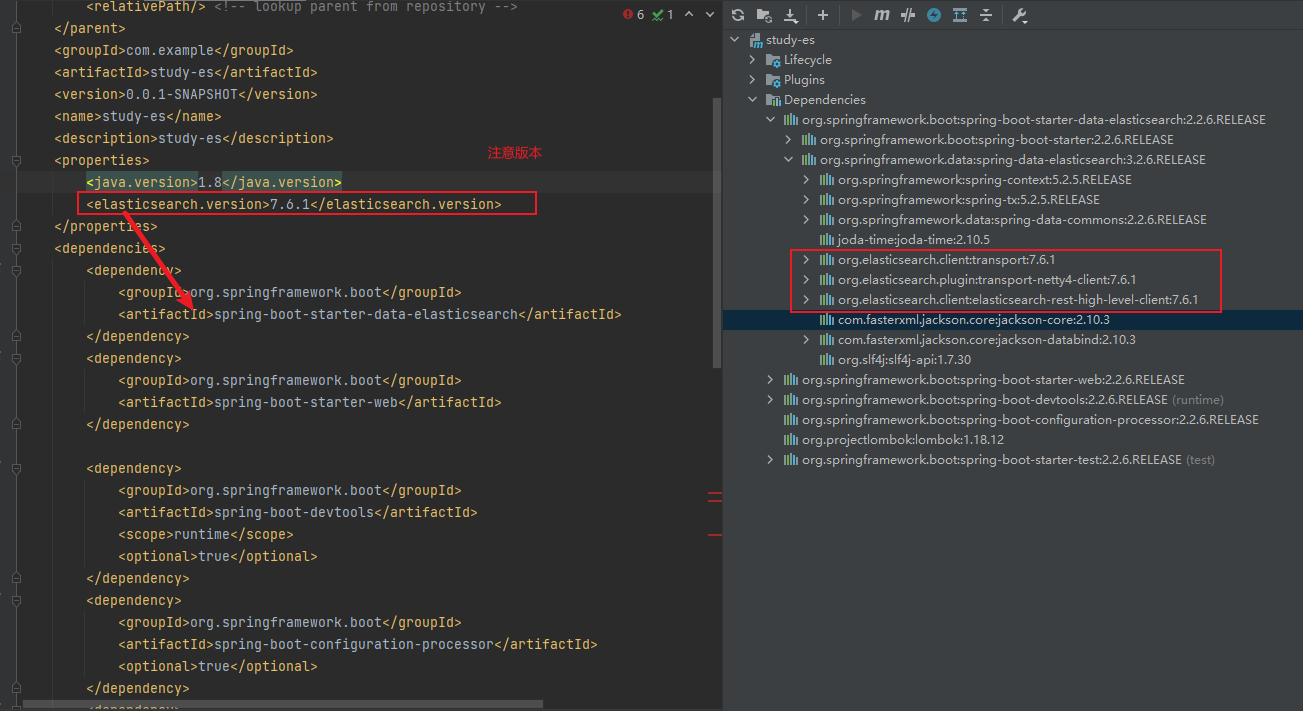
注意这里的版本要和本地的版本对应
编写配置类
@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));return client;}
}Es的api使用
索引
//添加索引
@SpringBootTest
class StudyEsApplicationTests {@Autowired@Qualifier("restHighLevelClient")RestHighLevelClient client;@Testvoid contextLoads() throws IOException {// 创建客户端CreateIndexRequest createIndexRequest = new CreateIndexRequest("cws_test1");// 执行请求,获取请求响应CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);System.out.println(createIndexResponse);}
}
/*** @param* @return void* @author cws* @date 2022/12/15 10:39* 判断索引是否存在*/
@Test
void getText() throws IOException {GetIndexRequest getIndexRequest = new GetIndexRequest("cws_test1");boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);System.out.println(exists);
}
/*** 删除索引*/
@Test
void DelText() throws IOException {DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("cws_test1");AcknowledgedResponse delete = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);System.out.println(delete);
}文档
//添加文档
@Test
void AddText() throws IOException {User user = new User("李四",50);// 创建请求 put /cws_test1/_doc/1IndexRequest indexRequest = new IndexRequest("cws_test1");indexRequest.id("2"); //设置索引idindexRequest.timeout(TimeValue.timeValueSeconds(1l));// 将数据放入请求indexRequest.source(JSONUtil.toJsonStr(user), XContentType.JSON);// 使用客户端发送请求IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println(indexResponse.status().getStatus());System.out.println(indexResponse.toString());
}/*** 删除文档*/@Testvoid del() throws IOException {DeleteRequest deleteRequest = new DeleteRequest("cws_test1");deleteRequest.id("1");DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);System.out.println(delete);}
/*** 获取单个文档*/
@Test
void getDocument() throws IOException {GetRequest getRequest = new GetRequest("cws_test1");getRequest.id("2");GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT);System.out.println(documentFields.getSource());
}
/*** 修改文档*/
@Test
void update() throws IOException {UpdateRequest updateRequest = new UpdateRequest("cws_test1","2");User user = new User("测试",5);updateRequest.doc(JSONUtil.toJsonStr(user), XContentType.JSON);UpdateResponse response = client.update(updateRequest, RequestOptions.DEFAULT);System.out.println(response.status());
}
/*** 判断是否文档
*/
@Test
void exitDocument() throws IOException {GetRequest getRequest = new GetRequest("cws_test1","2");// 设置不返回_sourcegetRequest.fetchSourceContext(new FetchSourceContext(false));getRequest.storedFields("_none_");boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);System.out.println(exists);
}批量添加数据
@Test
void addListOfDocument() throws IOException {//批量apiBulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");List<User> list = new ArrayList<>();list.add(new User("ls", 1));list.add(new User("ws", 2));list.add(new User("ww", 3));list.add(new User("历史", 4));list.add(new User("pp", 5));for (int i = 0; i < list.size(); i++) {bulkRequest.add(new IndexRequest("cws_test1").id("" + (i + 1)).source(JSONUtil.toJsonStr(list.get(i)), XContentType.JSON));}BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.hasFailures());//是否出现异常? false表示没有出现(成功),System.out.println(bulk.status());//状态
}批量删除
@Test
void dels() throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");List<String> list = new ArrayList<>();list.add("1");list.add("2");list.add("3");for (int i = 0; i < list.size(); i++) {bulkRequest.add( new DeleteRequest("cws_test1").id(list.get(i)));}BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.status());
}批量更新,批量删除,批量添加操作基本一致,差别在 bulkRequest.add()传的参数
查询(searchRequest)
| 构建添加类 | 作用 |
|---|---|
| SearchSourceBuilder | 条件构造 |
| HighlightBuilder | 构建高亮 |
| TermsQueryBuilder | 精确查询 |
| MatchAllQueryBuilder | 查询全部 |
以此类推,把索引构建号的xxxQueryBuilder放置sourceBuilder.query()中即可 |
@Testvoid search() throws IOException {
// 创建所需apiSearchRequest searchRequest = new SearchRequest();//创建搜索条件SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// QueryBuilders.matchAllQuery() 匹配所有
// 使用QueryBuilders工具类快速构建TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name", "ww");sourceBuilder.query(termsQueryBuilder);sourceBuilder.timeout(new TimeValue(10l, TimeUnit.SECONDS));searchRequest.source(sourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println(JSONUtil.toJsonStr(searchResponse.getHits()));for (SearchHit hit : searchResponse.getHits().getHits()) {System.out.println(hit.getSourceAsMap());}}
相当用java构建了GET /cws_test1/_doc/_search
{"query":{"term":{#精确匹配"name":"ww"}}
}
实战(springboot2.2.6)
爬取京东数据,进行es实现练习。
依赖
<properties><java.version>1.8</java.version><elasticsearch.version>7.6.1</elasticsearch.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.17</version></dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency>
</dependencies>客户端工具类
注意版本匹配
@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));return client;}
}爬取数据
//爬取数据类
@Component
public class HtmlParseUtils {public List<Title> getDataJD(String keyWord) throws IOException {List<Title> list = new ArrayList<>();String url = "https://search.jd.com/Search?keyword=" + keyWord;//获取整个页面Document document = Jsoup.parse(new URL(url), 30000);
// System.out.println(document);//选择所需要的部分Element goodsList = document.getElementById("J_goodsList");
// 获取所有的liElements lis = goodsList.getElementsByTag("li");for (Element li : lis) {
// 获取图片String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img");
// 获取价格String price = li.getElementsByClass("p-price").eq(0).text();
// 获取书名String bookName = li.getElementsByClass("p-name").eq(0).text();
// System.out.println("------------------------------------------------------");
// System.out.println(img);
// System.out.println(price);
// System.out.println(bookName);Title title = new Title(bookName, price, img);list.add(title);}return list;}
}编写实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Title {private String name;private String price;private String imgUrl;
}将数据添加到es
@Service
public class ContentService {@AutowiredRestHighLevelClient restHighLevelClient;public String addEs(String keyword) throws IOException {List<Title> list = new HtmlParseUtils().getDataJD(keyword);BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");for (int i = 0; i < list.size(); i++) {bulkRequest.add(new IndexRequest("cws_jd").source(JSONUtil.toJsonStr(list.get(i)), XContentType.JSON));}BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);boolean b = bulk.hasFailures();if (!b) {return "成功!";}return "失败";}
}编写service搜索接口
p
ublic List<Map<String,Object>> search(String keyWord,int pageNum,int pageSize) throws IOException {if(pageNum==0){pageNum=1;}SearchRequest searchRequest = new SearchRequest();SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//设置分页sourceBuilder.from(pageNum);sourceBuilder.size(pageSize);// 构建查询条件TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name", keyWord);sourceBuilder.query(termsQueryBuilder);searchRequest.source(sourceBuilder);SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);// 封装返回的数据List<Map<String,Object>> list=new ArrayList<>();for (SearchHit hit : search.getHits().getHits()) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();list.add(sourceAsMap);}return list;
}controller
@RestController
@SuppressWarnings("all")
public class ContentController {@AutowiredContentService contentService;@GetMapping("/Content/{keyWord}")public String setContent(@PathVariable("keyWord") String keyWord) throws IOException {return contentService.addEs(keyWord);}@GetMapping("/search/{keyWord}/{pageNum}/{pageSize}")public List<Map<String,Object>> searchKeyList(@PathVariable("keyWord") String keyWord,@PathVariable("pageNum") int pageNum,@PathVariable("pageSize") int pageSize) throws IOException {return contentService.search(keyWord,pageNum,pageSize);}
}设置高亮
public List<Map<String, Object>> searchHighlightFields(String keyWord, int pageNum, int pageSize) throws IOException {if (pageNum == 0) {pageNum = 1;}SearchRequest searchRequest = new SearchRequest();SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//设置分页sourceBuilder.from(pageNum);sourceBuilder.size(pageSize);// 构建查询条件TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name", keyWord);//设置高亮HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("name");//要高亮的字段名highlightBuilder.preTags("<span class='key' style='color:red'>");highlightBuilder.postTags("</span>");highlightBuilder.requireFieldMatch(false);//取消多个字段显示sourceBuilder.highlighter(highlightBuilder);sourceBuilder.query(termsQueryBuilder);searchRequest.source(sourceBuilder);SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 封装返回的数据List<Map<String, Object>> list = new ArrayList<>();for (SearchHit hit : search.getHits().getHits()) {Map<String, HighlightField> highlightFields = hit.getHighlightFields();//高亮的结果HighlightField name = highlightFields.get("name");//获取到高亮的字段Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果//如果name不等于空调换数据if (name != null) {Text[] fragments = name.fragments();String new_name = "";for (Text text : fragments) {new_name += text;}sourceAsMap.put("name", new_name);}list.add(sourceAsMap);}return list;}集成练习二
数据库结构:
CREATE TABLE `NewTable` (
`id` bigint(20) NOT NULL COMMENT '酒店id' ,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店名称' ,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店地址' ,
`price` int(10) NOT NULL COMMENT '酒店价格' ,
`score` int(2) NOT NULL COMMENT '酒店评分' ,
`brand` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店品牌' ,
`city` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '所在城市' ,
`star_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店星级,1星到5星,1钻到5钻' ,
`business` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '商圈' ,
`latitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '纬度' ,
`longitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '经度' ,
`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店图片' ,
PRIMARY KEY (`id`)
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8mb4 COLLATE=utf8mb4_general_ci
ROW_FORMAT=COMPACT
;更具数据库结构创建es的mapping
PUT /hotel
{"mappings": {"properties": {"id":{"type": "keyword" #在es中id比较特殊,不进行分词所以这样用keyword},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"adderss":{"type": "text","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword", "copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}注明:在上面结构中多出了location和all字段。
location字段主要用于处理地理坐标,那么在es中支持两种坐标数据类型:geo_point: 此类型用于存储地理位置点,通常由经度和纬度组成。一个 geo_point 字段可以以两种方式存储坐标: 作为数组 [lon, lat],其中 lon 是经度,lat 是纬度。作为对象 {"lat": lat, "lon": lon} 或 {"lat": lat, "lon": lon, "geohash": geohash},其中可选的 geohash 是对经纬度进行编码的字符串,便于区间查询。 geo_shape: 这种类型用于存储更复杂的地理形状,如多边形、圆形、线等。它支持对地理空间区域进行索引和查询,适用于处理区域覆盖、邻近判断等复杂的空间关系查询。
all字段用于搜索,在实现中我们想通过酒店名称、酒店品牌和商圈同时去搜索,那么通过单个字段是实现不了的,所以es提供了copy_to功能,将需要的字段全部拷贝到一个字段中,我们通过这个字段去进行检索即可。
接入RestClient
注意自己的es版本,我使用的是7.12.1
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependency><properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version></properties> 创建索引库
创建索引库
@SpringbootTest
public class RestClientTest {private RestHighLevelClient client;@Testvoid testCreateHotelIndex() throws IOException {
// 创建request对象CreateIndexRequest request = new CreateIndexRequest("hotel");request.source(HOTEL_TEMP, XContentType.JSON);client.indices().create(request, RequestOptions.DEFAULT);}@BeforeEachvoid setUp(){this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.88.102:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}package cn.itcast.hotel.estemp;public class IndexTemplate {public static final String HOTEL_TEMP = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"adderss\":{\n" +" \"type\": \"text\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" , \"copy_to\": \"all\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}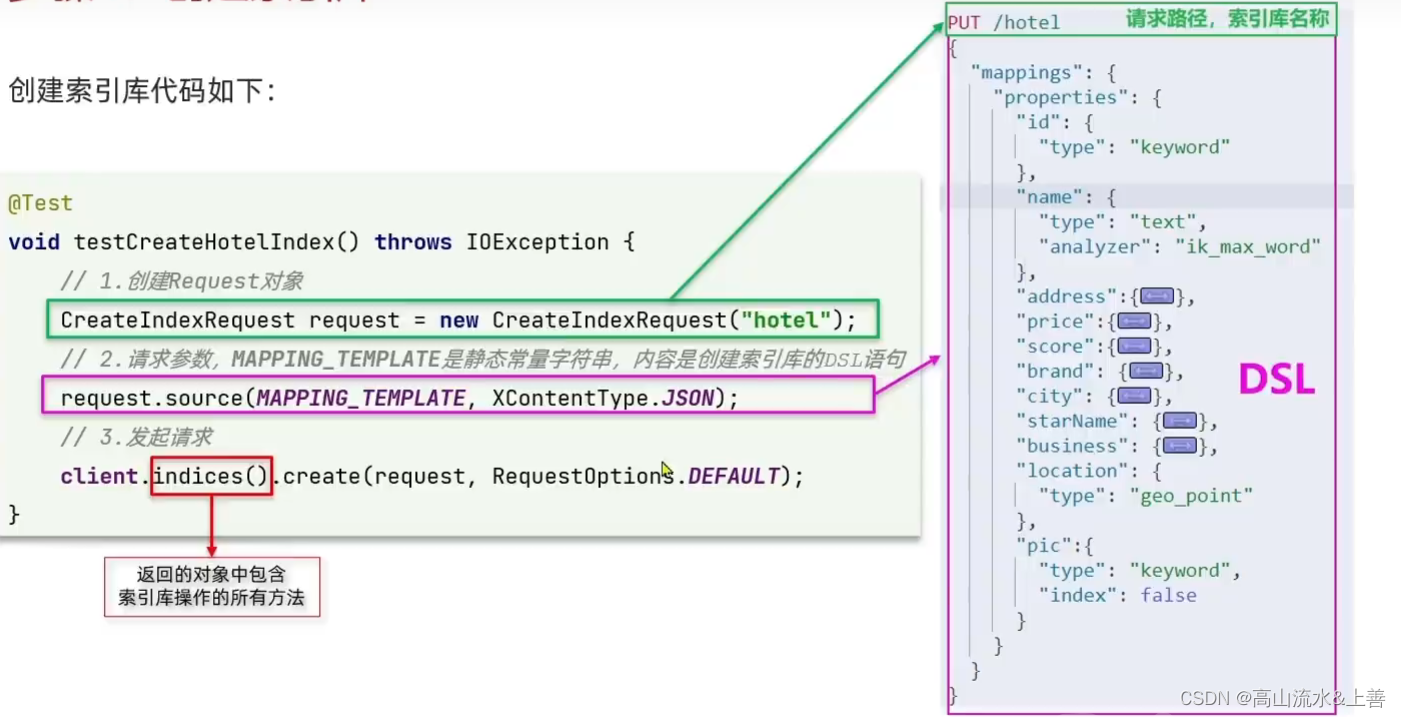 使用RestClient操作文档(CRUD)
使用RestClient操作文档(CRUD)
添加文档
@Testvoid setHotelOfDoc() throws IOException {
// put /hotel/_doc/36934IndexRequest indexRequest = new IndexRequest("hotel");indexRequest.timeout("1s");//设置超时时间Hotel hotel = hotelService.getById(36934L);indexRequest.id(hotel.getId().toString());//设置idHotelDoc hotelDoc = new HotelDoc(hotel);indexRequest.source(JSON.toJSONString(hotelDoc), XContentType.JSON);client.index(indexRequest, RequestOptions.DEFAULT);}查询文档
/*** 获取文档* @throws IOException*/@Testvoid testGetHotelOfDoc() throws IOException {
// get /hotel/_doc/36934GetRequest getRequest = new GetRequest();getRequest.index("hotel");getRequest.id("36934");GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT);String sourceAsString = documentFields.getSourceAsString();System.out.println(sourceAsString);}修改文档
/*** 修改文档* @throws IOException*/@Testvoid testUpdateHotelOfDoc() throws IOException {UpdateRequest updateRequest = new UpdateRequest();updateRequest.index("hotel");updateRequest.id("36934");updateRequest.doc("price", 200,"brand","8天");client.update(updateRequest, RequestOptions.DEFAULT);}
//这里是用的部分修改,其实也可以使用client.index()进行修改删除文档
/*** 删除文档* @throws IOException*/@Testvoid testDelHotelOfDoc() throws IOException {DeleteRequest deleteRequest = new DeleteRequest();deleteRequest.id("36934");deleteRequest.index("hotel");client.delete(deleteRequest, RequestOptions.DEFAULT);}批量导入文档
@Testvoid addListOfDocument() throws IOException {//批量apiBulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");List<HotelDoc> list = hotelService.list().stream().map(hotel -> {HotelDoc hotelDoc = new HotelDoc(hotel);return hotelDoc;}).collect(Collectors.toList());for (int i = 0; i < list.size(); i++) {bulkRequest.add(new IndexRequest("hotel").id(list.get(i).getId().toString()).source(JSON.toJSONString(list.get(i)), XContentType.JSON));}BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.hasFailures());//是否出现异常? false表示没有出现(成功),System.out.println(bulk.status());//状态}DSL查询语法
ElasticSearch提供了基于JSON来定义的查询。常见包括:
查询所有
:查询出所有数据,一般测试用。例如:match_all
查询所有
get /hotel/_search
{"query":{"match_all": {}}
}全文检索(fuul text) 查询
利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
-
match_query
-
multi_match_query
全文检索查询
#推荐,上面我们将字段全部copy到了all这个字段中,所以两个查询是一样的,但是效率不同
get /hotel/_search
{"query":{"match": {"all": "如家北京"}}
}
#效率低字段较多
get /hotel/_search
{"query":{"multi_match": {"query": "如家北京","fields": ["name","brand","business"]}}
}精确查询
:根据精确词条值查找数据,一般是查找keyword、数值、boolean等类型的字段。例如:
-
ids
-
range
-
term
精确查询
#查询为city为北京的酒店
get /hotel/_search
{"query":{"term": {"city": {"value": "北京"}}}
}
# 查询price在大于等于100小于等于2000
get /hotel/_search
{"query":{"range": {"price": {"gte": 100,"lte": 2000}}}
}地理(geo)查询
:根据精确维度查询。例如:
-
geo_distance
-
geo_bounding_box
get /hotel/_search
{"query":{"geo_distance":{"distance":"3km", #范围"location":"31.21,121.5" #自己所在位置的地理坐标}}
}复合查询
:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
-
bool
-
function_score
function_score查询
 应用场景:例如百度为什么查询企业出来的这个企业会排第一条呢?首先一定匹配查询的结果,然后有些企业花钱让你查的数据的score的评分较高。
应用场景:例如百度为什么查询企业出来的这个企业会排第一条呢?首先一定匹配查询的结果,然后有些企业花钱让你查的数据的score的评分较高。
案例:
get /hotel/_search
{"query":{"function_score": {"query": {"match": {"all": "外滩"}}}}
}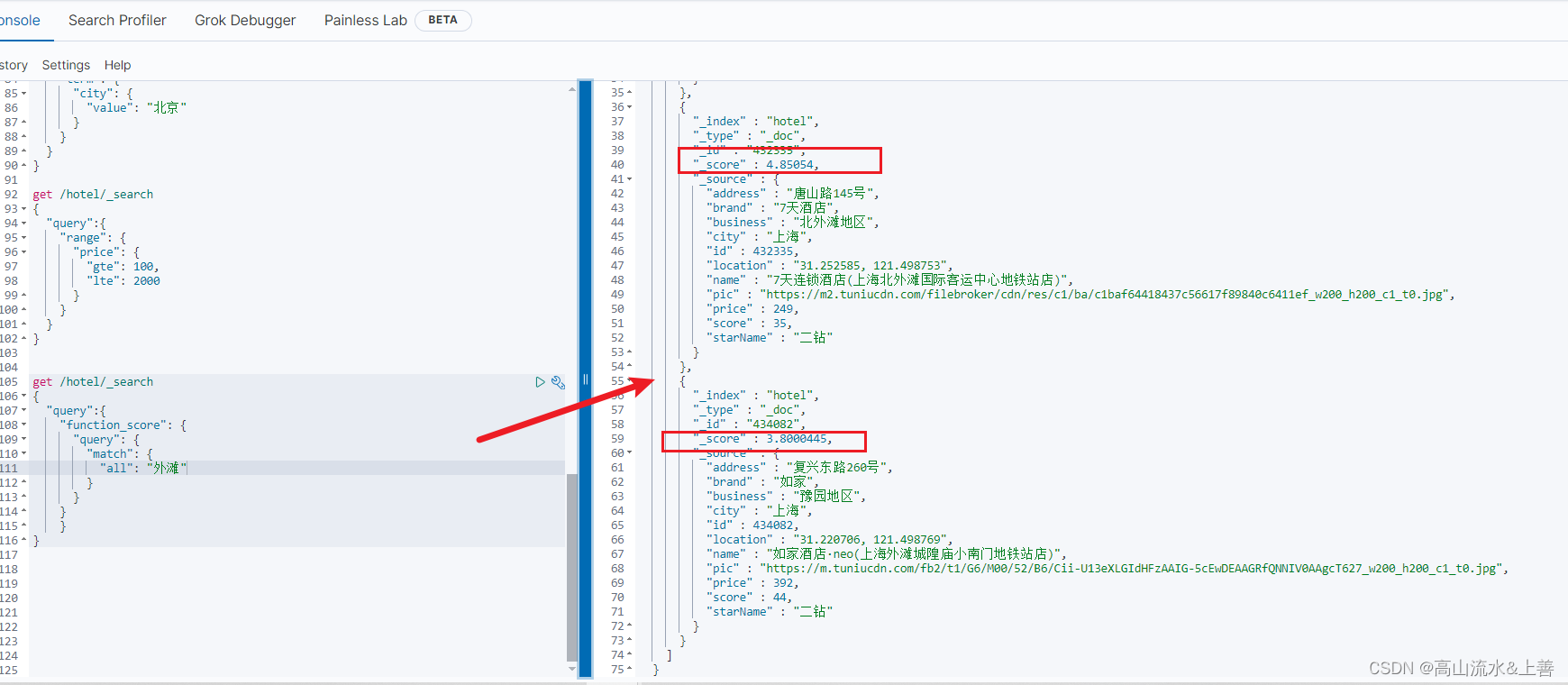
此时我们想让最后这家的排名靠前就可以如下操作:
get /hotel/_search
{"query":{"function_score": {"query": {"match": {"all": "外滩"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10}]}}
}
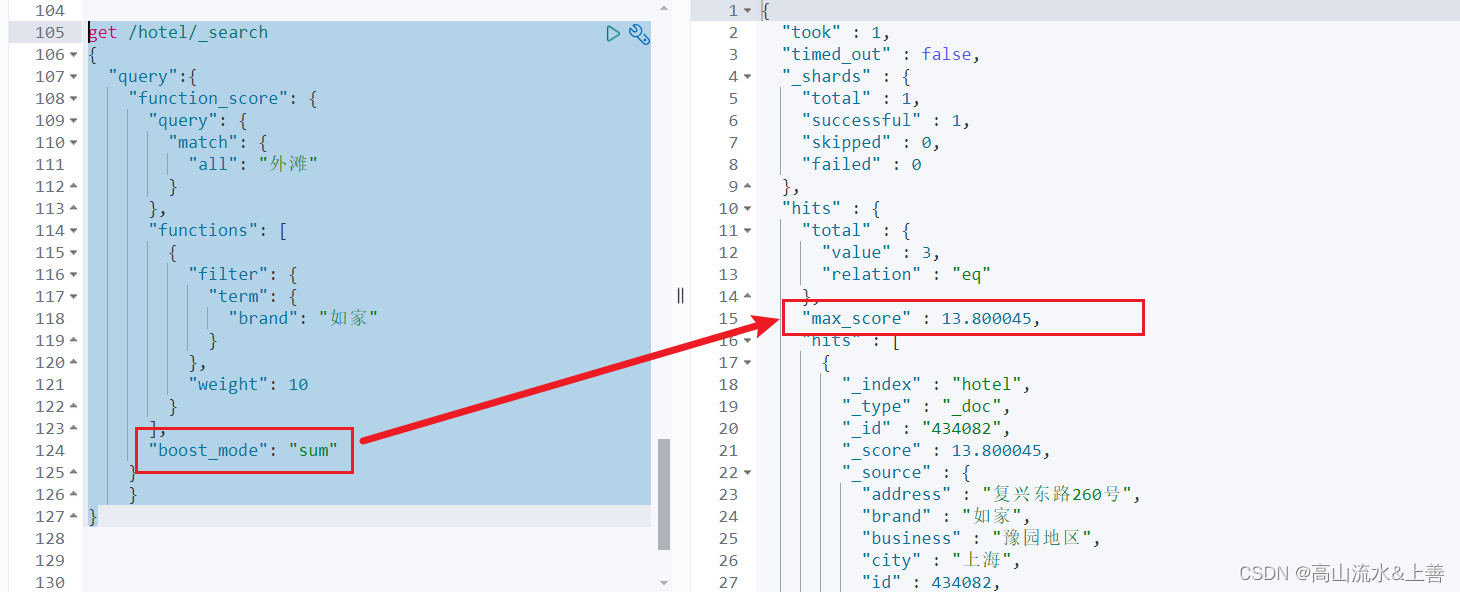
默认是乘于weight,那么就是38,还可以通过boost_mode控制:
get /hotel/_search
{"query":{"function_score": {"query": {"match": {"all": "外滩"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10}],"boost_mode": "sum" #这里是相加,可以有很多参数,可见上图}}
}
bool查询
布尔查询是一个或者多个查询子句的组合。方式有:
-
must:必须匹配每个子查询,类似“与” -
should:选择性匹配子查询,类型“或” -
must_not:必须不匹配,不参与算分,类"非" -
filter:必须匹配,不参与算分
案例
#查询名称包含如家,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
get /hotel/_search
{"query":{"bool": {"must": [{"match": {"name":"如家"}}],"must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": "31.21,121.5"}}]}}
}排序
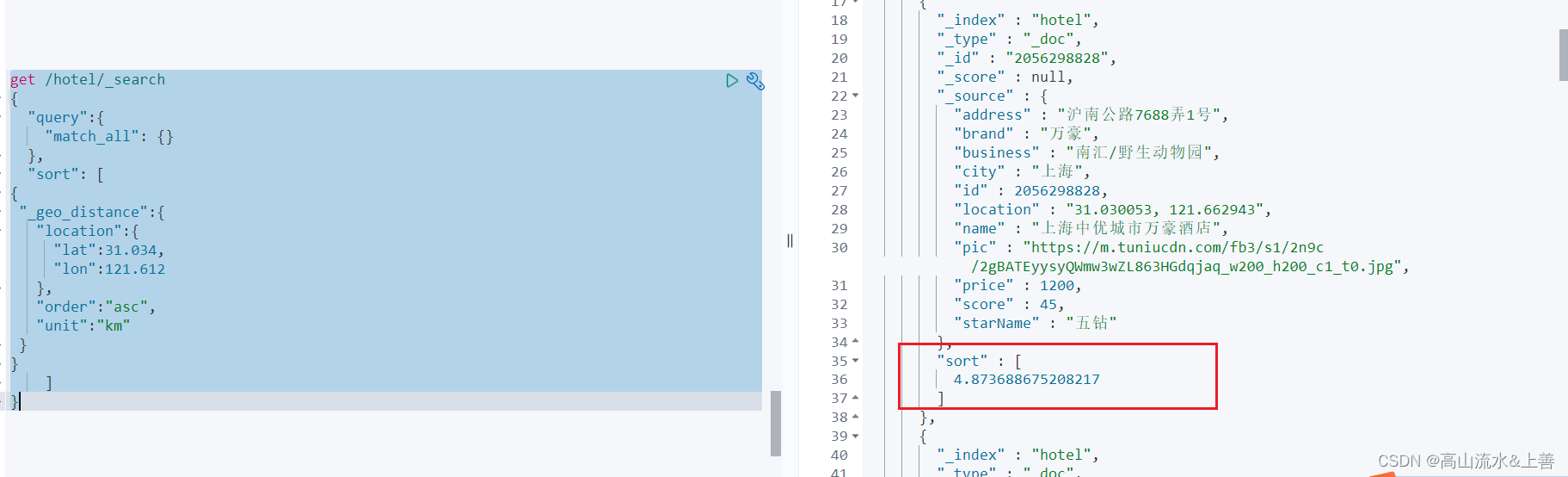
例子:在我们选择酒店是我们可以看到酒店可我们的距离,以升序排,我们就可以在es中使用sort进行操作。
get /hotel/_search
{"query":{"match_all": {}},"sort": [
{"_geo_distance":{"location":{"lat":31.034, #纬度"lon":121.612 #经度},"order":"asc","unit":"km"}
}]
}
使用RestClient操作DSL
RestClient查询所有
get /hotel/_search
{"query":{"match_all": {}},"from":1,"size":50
}/*** 查询所有数据* @throws IOException*/@Testvoid testSearchAll() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数request.source().query(QueryBuilders.matchAllQuery()).size(50);search(request);}private void search(SearchRequest request) throws IOException {// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.处理响应SearchHits hits = response.getHits();long value = hits.getTotalHits().value;System.out.println(value);SearchHit[] hits1 = hits.getHits();for (SearchHit hit : hits1) {HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);System.out.println(hotelDoc);}}RestClient全文检索
/*** 全文检索 matchQuery* @param* @throws IOExceptionget /hotel/_search
{"query":{"match": {"all": "如家"}}
}*/@Testvoid testMatchQuery() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数request.source().query(QueryBuilders.matchQuery("all", "如家"));search(request);}/*** 全文检索 multi_match_query* @param* @throws IOExceptionget /hotel/_search
{"query":{"multi_match": {"query": "如家","fields": ["name","brand"]}}
}*/@Testvoid testMultiMatchQueryQuery() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数request.source().query(QueryBuilders.multiMatchQuery("如家", "name", "brand"));search(request);}
RestClient精确查询(term,range)
/*** 精确查询* @param* @throws IOException*/@Testvoid testTermQuery() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数
// request.source().query(QueryBuilders.termQuery("city", "上海"));request.source().query(QueryBuilders.rangeQuery("price").lt(300));search(request);}RestClient地理查询
/*** 精确查询* @param* @throws IOException*/@Testvoid testGeoDistanceQuery() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数request.source().query(QueryBuilders.geoDistanceQuery("location").distance("50km").point(31.197804,121.498618));search(request);}RestClient复合查询
/*** 复合查询* @param* @throws IOException*/@Testvoid testBoolQueryBuilder() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.termQuery("city", "上海"));boolQuery.filter(QueryBuilders.rangeQuery("price").lte(200));request.source().query(boolQuery);search(request);}RestClient排序与分页
/*** 排序与分页* @param* @throws IOException*/@Testvoid testSortAndPage() throws IOException {// 1.准备RequestSearchRequest searchRequest = new SearchRequest("hotel");searchRequest.source().query(QueryBuilders.matchAllQuery()).from(1).size(10).sort("price", SortOrder.DESC);search(searchRequest);}RestClient(词语高亮)
在默认情况下检索字段需要和高亮字段一致,如果碰到特殊情况可以使用require_field_match改为false
/*** 代码高亮* @param* @throws IOException*/@Testvoid testHighlighter() throws IOException {// 1.准备RequestSearchRequest searchRequest = new SearchRequest("hotel");HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("name");highlightBuilder.preTags("<font color='red'>");highlightBuilder.postTags("</font>");highlightBuilder.requireFieldMatch(false);searchRequest.source().query(QueryBuilders.matchQuery("all", "如家")).highlighter(highlightBuilder);SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);search.getHits().forEach(hit -> {System.out.println(hit.getHighlightFields());});}聚合
聚合可以实现对文档数据的统计、分析、运算。常见的三类:
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组
-
Date Histogram:按照日期阶梯,例如一周为一组或者一月为一组
度量(Metric)聚合:用以计算一些值、比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:最小值
-
Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其他聚合的结果为基础做聚合
桶聚合Bucket
get /hotel/_search
{"size":0,"aggs":{"brandAgg":{ #设置聚合名称"terms": {"field": "brand", #选择聚合字段"size": 20 #页数}}}
}
#类似mysql group by
在上图中我们可以看出分组对的文档数量是按照降序排序的,我们可以进行修改:
get /hotel/_search
{"size":0,"aggs":{"brandAgg":{"terms": {"order": {"_count": "asc" #更具count数量升序排}, "field": "brand","size": 20}}}
}我可也可以加上query条件,锁定范围:
get /hotel/_search
{"query":{"range": {"price": {"lte": 200}}},"size":0,"aggs":{"brandAgg":{"terms": {"order": {"_count": "asc"}, "field": "brand","size": 20}}}
}度量(Metric)聚合
#查询每种牌子的酒店的min、max、avg,并通过平均分排序
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": { #结合bucket聚合"terms": {"order": { "scoreAgg.avg": "asc" }, "field": "brand","size": 20},"aggs": {"scoreAgg": { #Metric自定义名称"stats": { #这个的stats就包含了min、max、avg"field": "score" #Metric聚合字段}}}}}
}
#类似数据库的 先分组然后再求聚合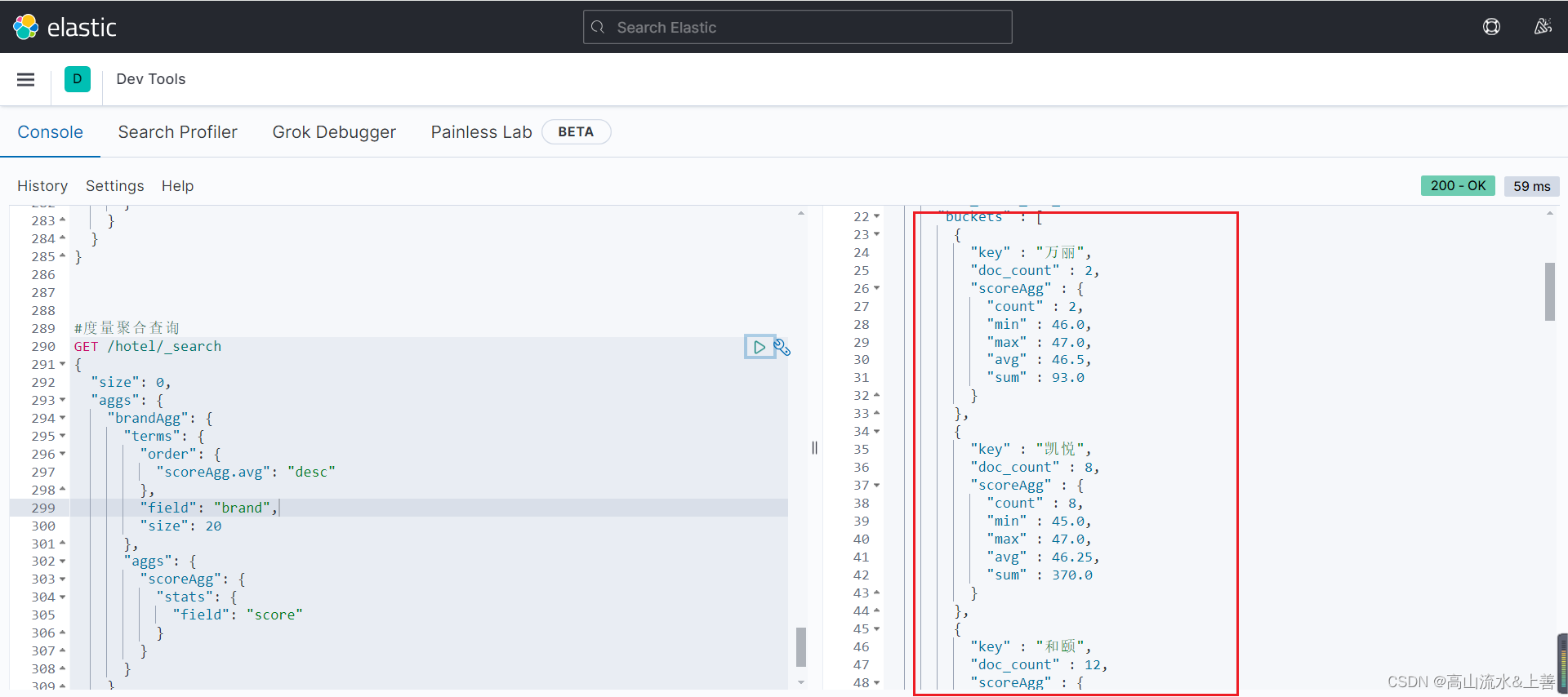
RestClient操作聚合
/*** 聚合操作*/@Testvoid testAggregation() throws IOException {SearchRequest request = new SearchRequest("hotel");
// 不需要具体内容request.source().size(0);request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(20).order(BucketOrder.aggregation("_count", false)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);Aggregations aggregations = response.getAggregations();Terms brandAgg = aggregations.get("brandAgg");List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();buckets.forEach(bucket -> {String keyAsString = bucket.getKeyAsString();System.out.println(keyAsString);});}自动补全
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:GitHub - infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
在京东等平台搜索框输入拼音或者关键子会有提示效果那么大多数都是基于es的自动补全实现的。这里需要拼音分词器插件:
拼音分词器安装
将py文件夹上传到es映射的目录下和ik分词器一样的方法。也可以自己解压elasticsearch-analysis-pinyin-7.12.1.zip命名为py。

测试:
自定义分词器
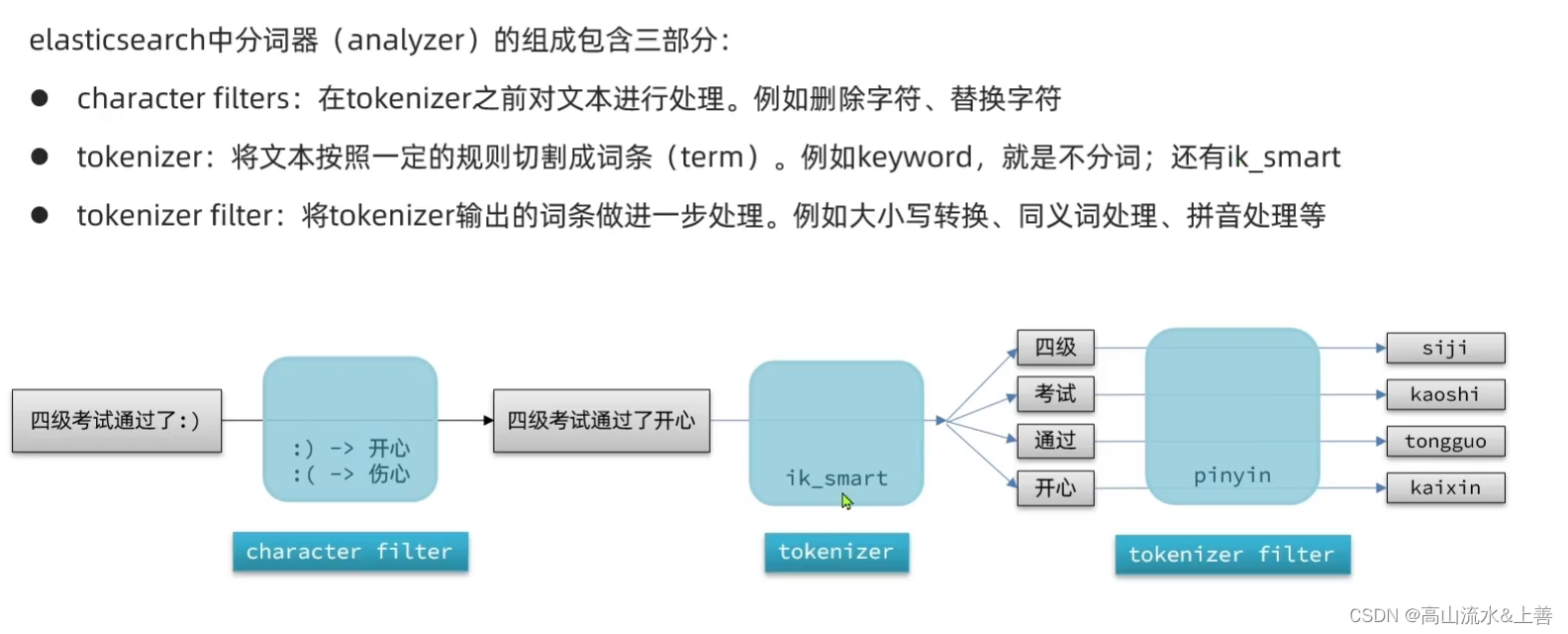
为什么要自定义分词器呢?如果单独使用ik或者拼音分词器并不能满足我们的需求,例如我使用拼音分词器那么结果只有拼音结果没有中文结果且拼音首字母拼接,这样无法满足我们的搜索。
自定义使用
主要:需要在创建索引时指定。
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": { "properties": {"title":{ #指定字段"type":"text","analyzer": "my_analyzer", #调用自定义分词器"search_analyzer": "ik_smart" #搜索时使用 ik}}}
}解释:
PUT /test 这是一个HTTP的PUT请求,目标是Elasticsearch中的一个索引,这里索引名为test。这意味着你正在更新或创建名为test的索引,并为其指定特定的设置。 请求体内容详解 settings:这部分包含索引的配置信息,重点在于定义分析器设置。 analysis:分析模块的配置,用于定义如何对文本进行分析处理,包括分词、过滤等。 analyzer: "my_analyzer" 定义了一个名为my_analyzer的自定义分析器。分析器决定了如何将文本分解成词语(tokens)以便于搜索和索引。 tokenizer: "ik_max_word" 指定了分析器使用的分词器为ik_max_word。IK分词器是针对中文文本设计的,ik_max_word模式会尽可能地进行词语切分,生成最细粒度的词语组合。 filter: "py" 定义了一个名为py的过滤器,该过滤器应用于分词结果。这里的py是一个拼音过滤器,用于生成中文字符的拼音表示。 py过滤器的参数说明: keep_full_pinyin: 设为false表示不保留全拼形式。 keep_joined_full_pinyin: 设为true表示保留连接的全拼音形式,比如"zhongguo"。 keep_original: 设为true表示保留原始的中文字符。 limit_first_letter_length: 设置首字母拼音的最大长度为16,超过的会被截断。 remove_duplicated_term: 设为true表示移除重复的拼音项,避免索引膨胀。 none_chinese_pinyin_tokenize: 设为false表示不对非中文字符进行拼音处理。
测试
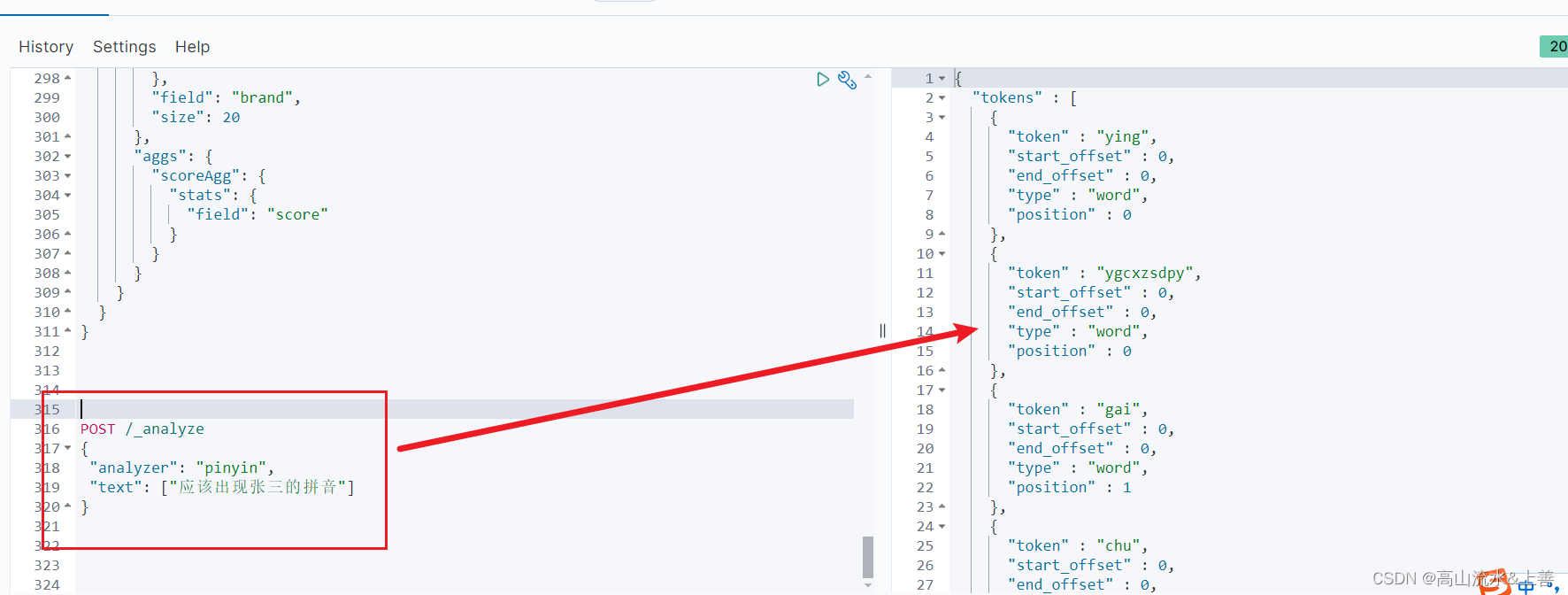
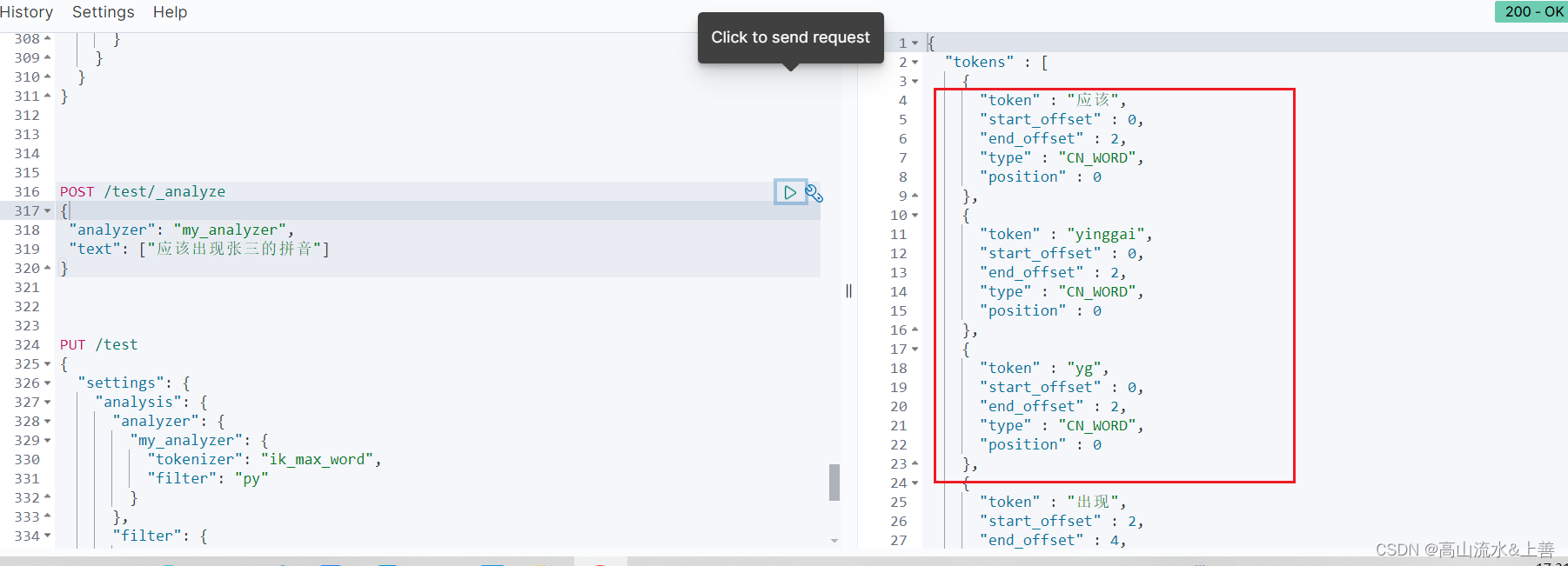
POST /test/_analyze
{"analyzer": "my_analyzer","text": ["应该出现张三的拼音"]
}
自动补全类型及查询功能(Completion Suggester)
官网地址:Suggesters | Elasticsearch Guide [7.6] | Elastic
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:参与补全查询的字段必须是completion类型。字段的内容一般是用来补全的多个词条形成的数组。
案例
// 自动补全的索引库
PUT test2
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
// 示例数据
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{"title": ["Nintendo", "switch"]
}// 自动补全查询
POST /test2/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
注意:自动补全的类型必须是completion
综合案例
我们基于集成练习二里面的数据库结构做个自动补全的综合案例。
1.修改索引
// 创建名为"hotel"的Elasticsearch索引,并定义其设置和映射规则。
PUT /hotel
{"settings": {"analysis": { // 分析器与过滤器配置区域"analyzer": { // 自定义分析器定义"text_anlyzer": { // 用于全文本分析的分析器"tokenizer": "ik_max_word", // 使用IK分词器的最细粒度分词模式"filter": "py" // 应用自定义的拼音过滤器},"completion_analyzer": { // 专用于自动补全字段的分析器"tokenizer": "keyword", // 使用keyword分词器,保持整个输入作为单个token"filter": "py" // 同样应用拼音过滤器以支持拼音补全}},"filter": { // 自定义过滤器定义"py": { // 拼音过滤器配置"type": "pinyin", // 指定过滤器类型为拼音处理"keep_full_pinyin": false, // 不保留全拼形式"keep_joined_full_pinyin": true, // 保留连接的全拼音形式"keep_original": true, // 保留原始中文字符"limit_first_letter_length": 16, // 首字母拼音最大长度限制"remove_duplicated_term": true, // 移除重复的拼音项"none_chinese_pinyin_tokenize": false // 对非中文字符不进行拼音处理}}}},"mappings": { // 映射定义,描述文档字段的数据类型和属性"properties": { // 具体字段定义"id": { // 唯一标识符"type": "keyword" // 关键词类型,适合唯一ID},"name": { // 酒店名称"type": "text", // 文本类型,用于全文搜索"analyzer": "text_anlyzer", // 搜索时使用自定义的text_anlyzer"search_analyzer": "ik_smart", // 查询时使用ik_smart分词器,支持智能分词"copy_to": "all" // 将此字段内容复制到"all"字段,便于综合搜索},"address": { // 地址信息"type": "keyword", // 作为关键词存储,不参与全文搜索"index": false // 不建立索引,提高写入性能},"price": { // 价格"type": "integer" // 整型数据},"score": { // 评分"type": "integer"},"brand": { // 品牌"type": "keyword","copy_to": "all" // 同样复制到"all"字段},"city": { // 所在城市"type": "keyword"},"starName": { // 星级名称"type": "keyword"},"business": { // 商圈"type": "keyword","copy_to": "all"},"location": { // 地理位置坐标"type": "geo_point"},"pic": { // 图片链接"type": "keyword","index": false // 图片链接不需要搜索,故不建立索引},"all": { // 综合全文搜索字段"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion": { // 自动补全字段"type": "completion", // 使用completion类型"analyzer": "completion_analyzer" // 应用专为补全设计的分析器}}}
}2.修改构造器
@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();//这里是应该我们是数据中有/我们做了下处理,这里主要将brand和business加到自动补全自动中if(this.business.contains("/")){String[] arr = this.business.split("/");this.suggestion=new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion, arr);}else{this.suggestion= Arrays.asList(this.brand,this.business);}}
}3.重新同步数据库数据
@Testvoid addListOfDocument() throws IOException {//批量apiBulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");List<HotelDoc> list = hotelService.list().stream().map(hotel -> {HotelDoc hotelDoc = new HotelDoc(hotel);return hotelDoc;}).collect(Collectors.toList());for (int i = 0; i < list.size(); i++) {bulkRequest.add(new IndexRequest("hotel").id(list.get(i).getId().toString()).source(JSON.toJSONString(list.get(i)), XContentType.JSON));}BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.hasFailures());//是否出现异常? false表示没有出现(成功),System.out.println(bulk.status());//状态} 
4.测试
POST /hotel/_search
{"suggest": {"title_suggest": {"text": "w","completion": {"field": "suggestion", "skip_duplicates": true, "size": 10 }}}
} 
4.RestCline操作自动补全
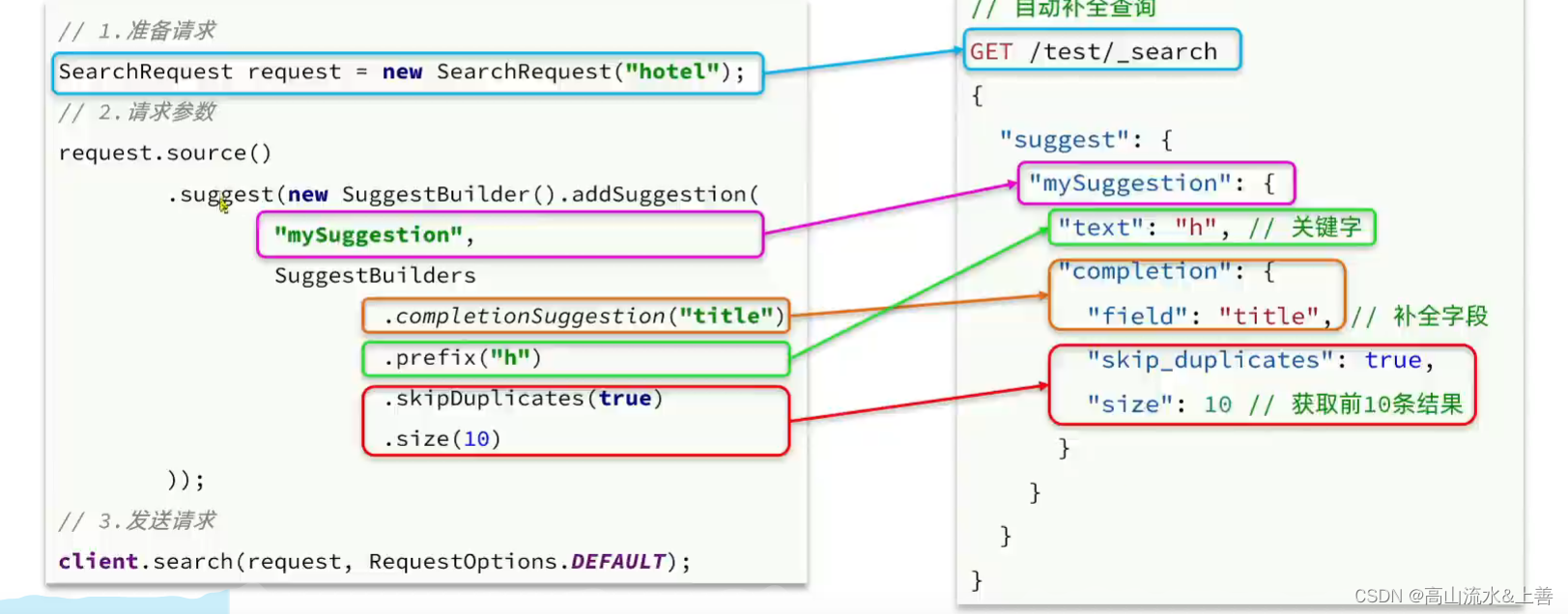
/*** 自动补全*/
@Test
void testSuggest() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().suggest(new SuggestBuilder().addSuggestion("MySuggestion",SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);Suggest suggest = response.getSuggest();Suggest.Suggestion<? extends Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option>> suggestion = suggest.getSuggestion("MySuggestion");suggestion.forEach(entry -> {entry.getOptions().forEach(option -> {String text = option.getText().string();System.out.println(text);});});
}
微服务ES数据同步
方案一
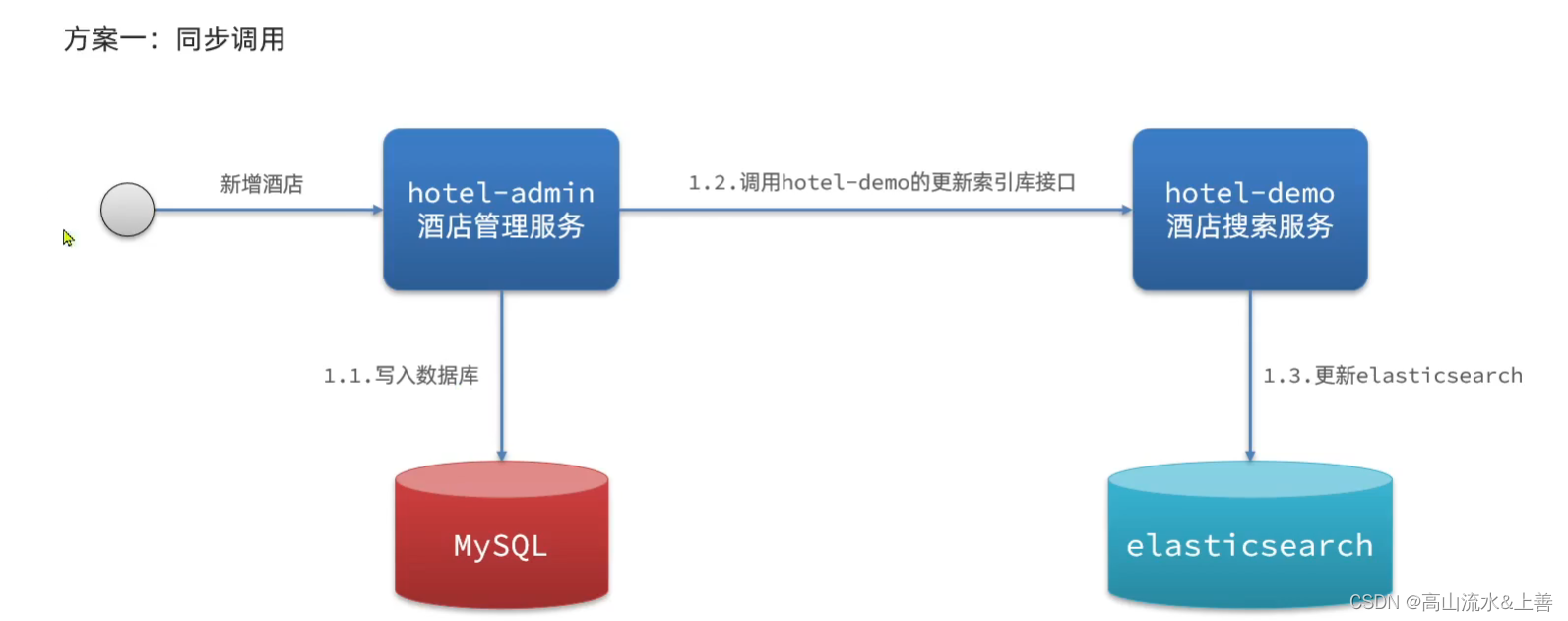
缺陷:冗余,无法保证一定成功,耦合性差,性能差。
方案二
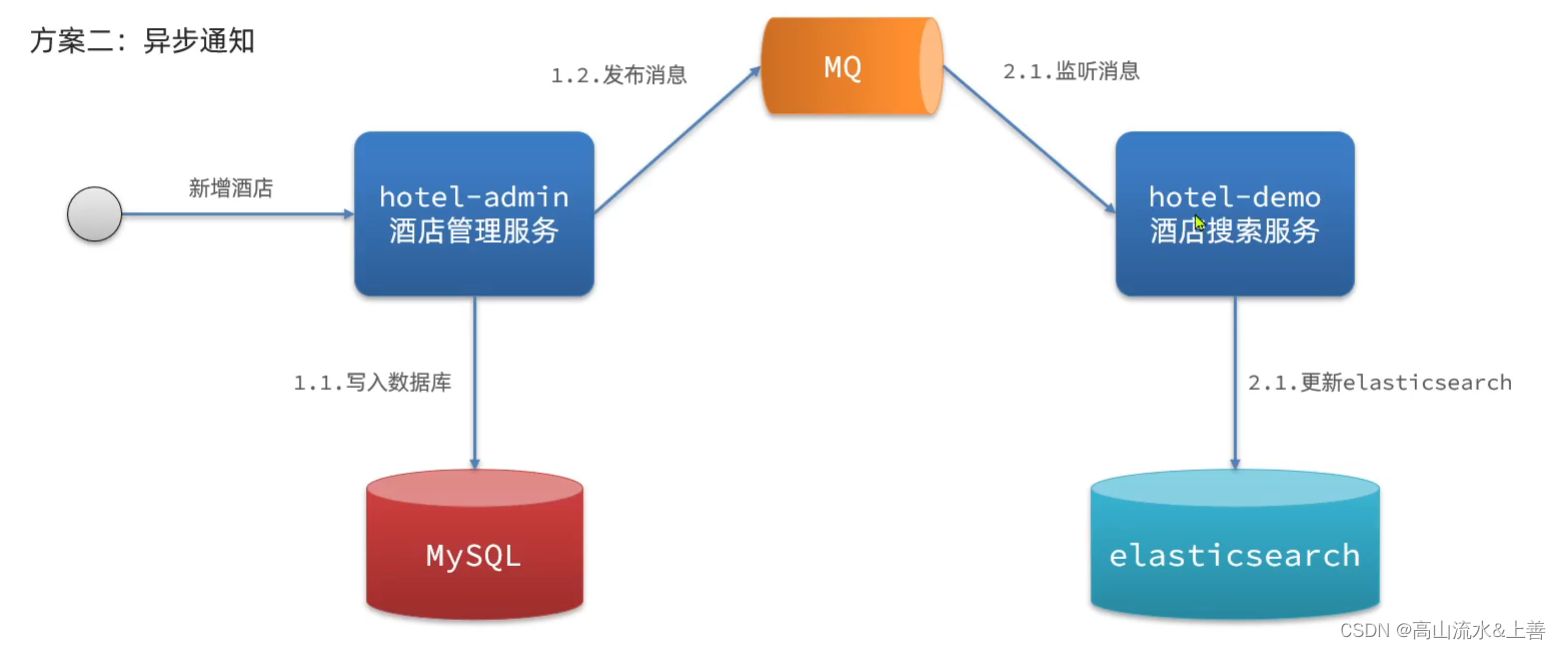
这里我们使用方案二实现
@Component
public class MqGeneratorOfEsData {@Resourceprivate RabbitTemplate rabbitTemplate;public void testSendMessageTopicQueue(String exchange, String routingKey, String message) {rabbitTemplate.convertAndSend(exchange,routingKey,message);}
}
//后台crud是发送消息
@PostMappingpublic void saveHotel(@RequestBody Hotel hotel){hotelService.save(hotel);mqGeneratorOfEsData.testSendMessageTopicQueue("hotel.topic", "hotel.addOrUpdate", hotel.getId().toString());}
@PutMapping()public void updateById(@RequestBody Hotel hotel){if (hotel.getId() == null) {throw new InvalidParameterException("id不能为空");}hotelService.updateById(hotel);mqGeneratorOfEsData.testSendMessageTopicQueue("hotel.topic", "hotel.addOrUpdate", hotel.getId().toString());}
@DeleteMapping("/{id}")public void deleteById(@PathVariable("id") Long id) {hotelService.removeById(id);mqGeneratorOfEsData.testSendMessageTopicQueue("hotel.topic", "hotel.del", id.toString());}//es服务去处理
@Component
public class MqListenerEsData {@Resourceprivate RabbitTemplate rabbitTemplate;@Resourceprivate RestHighLevelClient client;@ResourceIHotelService iHotelService;/*** 监听新增或者修改* @param msg* @throws InterruptedException*/@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "hotel.addOrUpdate"),exchange = @Exchange(name = "hotel.topic", type = ExchangeTypes.TOPIC),key = {"hotel.addOrUpdate"}))public void listenTopicQueue1(String msg) throws InterruptedException {try {System.out.println("hotel.addOrUpdate接收到消息:" + msg);Long id = Long.valueOf(msg);Hotel hotel = iHotelService.getById(id);HotelDoc hotelDoc = new HotelDoc(hotel);IndexRequest indexRequest = new IndexRequest("hotel");indexRequest.timeout("1s");//设置超时时间indexRequest.id(hotel.getId().toString());//设置idindexRequest.source(JSON.toJSONString(hotelDoc), XContentType.JSON);IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);if (index.getResult().name().equals("CREATED")) {System.out.println("新增成功");} else if (index.getResult().name().equals("UPDATED")) {System.out.println("修改成功");}} catch (IOException e) {e.printStackTrace();throw new RuntimeException("保存数据失败");}}/*** 删除* @param id* @throws InterruptedException*/@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "hotel.del"),exchange = @Exchange(name = "hotel.topic", type = ExchangeTypes.TOPIC),key = {"hotel.del"}))public void listenTopicQueue2(String id) throws InterruptedException {try {DeleteRequest deleteRequest = new DeleteRequest();deleteRequest.id(id);deleteRequest.index("hotel");client.delete(deleteRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();throw new RuntimeException("删除失败");}}
}ES集群
因为设备原因这里我们在单台机器上搭建集群。
首先编写一个docker-compose文件,内容如下:
version: '2.2'
services:es01:image: elasticsearch:7.12.1container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster- discovery.seed_hosts=es02,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data01:/usr/share/elasticsearch/dataports:- 9200:9200networks:- elastices02:image: elasticsearch:7.12.1container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data02:/usr/share/elasticsearch/dataports:- 9201:9200networks:- elastices03:image: elasticsearch:7.12.1container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data03:/usr/share/elasticsearch/datanetworks:- elasticports:- 9202:9200
volumes:data01:driver: localdata02:driver: localdata03:driver: local
networks:elastic:driver: bridge
es运行需要修改一些linux系统权限,修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
添加下面的内容:
vm.max_map_count=262144
然后执行命令,让配置生效:
sysctl -p
通过docker-compose启动集群:
docker-compose up -d
集群状态监控
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能,配置比较复杂。
这里推荐使用cerebro来监控es集群状态,官方网址:https://github.com/lmenezes/cerebro
解压后进入bin目录双击cerebro.bat即可,访问http://localhost:9000/#!/connect即可。

输入你的elasticsearch的任意节点的地址和端口,点击connect即可:

绿色的条,代表集群处于绿色(健康状态)。
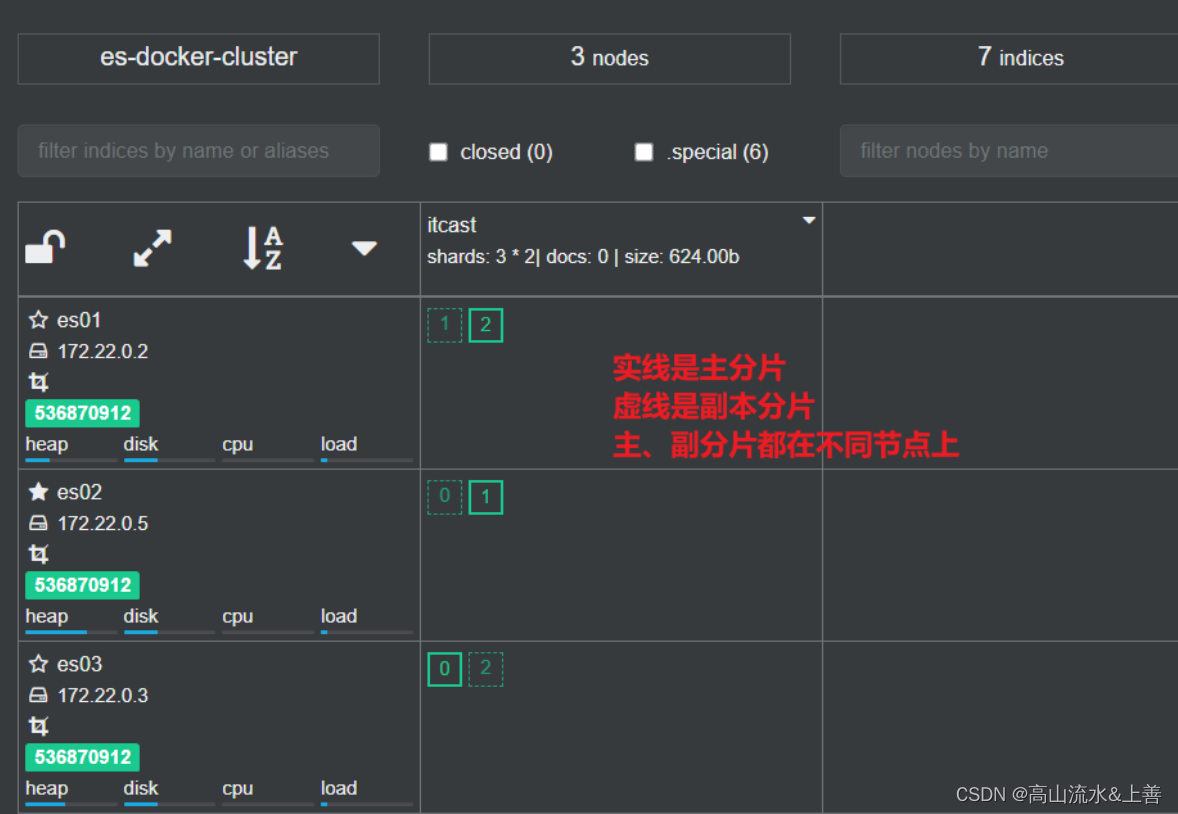
分片
为了数据的原子性,我们把各个es的数据存放在不用的es上例如:es01可以存放es02的数据,当es02宕机了那么额可以利用es01这台恢复数据。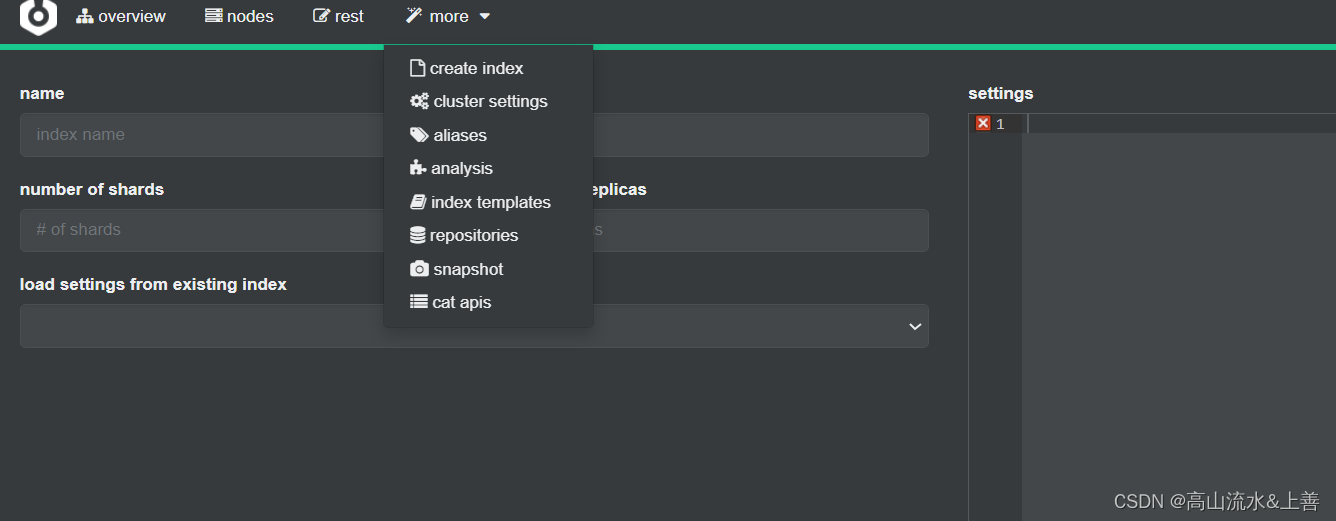

相关文章:
一文包学会ElasticSearch的大部分应用场合
ElasticSearch 官网下载地址:Download Elasticsearch | Elastic 历史版本下载地址1:Index of elasticsearch-local/7.6.1 历史版本下载地址2:Past Releases of Elastic Stack Software | Elastic ElasticSearch的安装(windows) 安装前所…...

创建kobject
1、kobject介绍 kobject的全称是kernel object,即内核对象。每一个kobject都会对应系统/sys/下的一个目录。 2、相关结构体和api介绍 2.1 struct kobject // include/linux/kobject.h 2.2 kobject_create_and_add kobject_create_and_addkobject_createkobj…...

数据结构 - C/C++ - 树
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 树的概念 结构特性 树的样式 树的存储 树的遍历 节点增删 二叉搜索树 平衡二叉树 树的概念 二叉树是树形结构,是一种非线性结构。 非线性结构:在二叉树中&#x…...
Linux源码阅读笔记12-RCU案例分析
在之前的文章中我们已经了解了RCU机制的原理和Linux的内核源码,这里我们要根据RCU机制写一个demo来展示他应该如何使用。 RCU机制的原理 RCU(全称为Read-Copy-Update),它记录所有指向共享数据的指针的使用者,当要修改构想数据时&…...

【C++】双线性差值算法实现RGB图像缩放
双线性差值算法 双线性插值(Bilinear Interpolation)并不是“双线性差值”,它是一种在二维平面上估计未知数据点的方法,通常用于图像处理中的图像缩放。 双线性插值的基本思想是:对于一个未知的数据点,我…...
计算机网络知识普及之四元组
在涉及到TCP/UDP等IP类通信协议时,存在四元组概念 这里只是普及使用 先来一些前置知识,什么是IP协议? IP协议全称为互联网协议,处于网络层中,主要作用是标识网络中的设备,每个设备的IP地址是唯一的。 在网…...

深度探讨网络安全:挑战、防御策略与实战案例
目录 编辑 一、引言 二、网络安全的主要挑战 恶意软件与病毒 数据泄露 分布式拒绝服务攻击(DDoS) 内部威胁 三、防御策略与实战案例 恶意软件防护 网络钓鱼防护 数据泄露防护 总结 一、引言 随着信息技术的迅猛发展,网络安全问…...

“穿越时空的机械奇观:记里鼓车的历史与科技探秘“
在人类文明的发展历程中,科技的创新与进步不仅仅推动了社会的进步,也为我们留下了丰富的文化遗产。记里鼓车,作为一种古老的里程计量工具,其历史地位和技术成就在科技史上具有重要的意义。本文将详细介绍记里鼓车的起源、结构原理…...

DevOps CMDB平台整合Jira工单
背景 在DevOps CMDB平台建设的过程中,我们可以很容易的将业务应用所涉及的云资源(WAF、K8S、虚拟机等)、CICD工具链(Jenkins、ArgoCD)、监控、日志等一次性的维护到CMDB平台,但随着时间的推移,…...
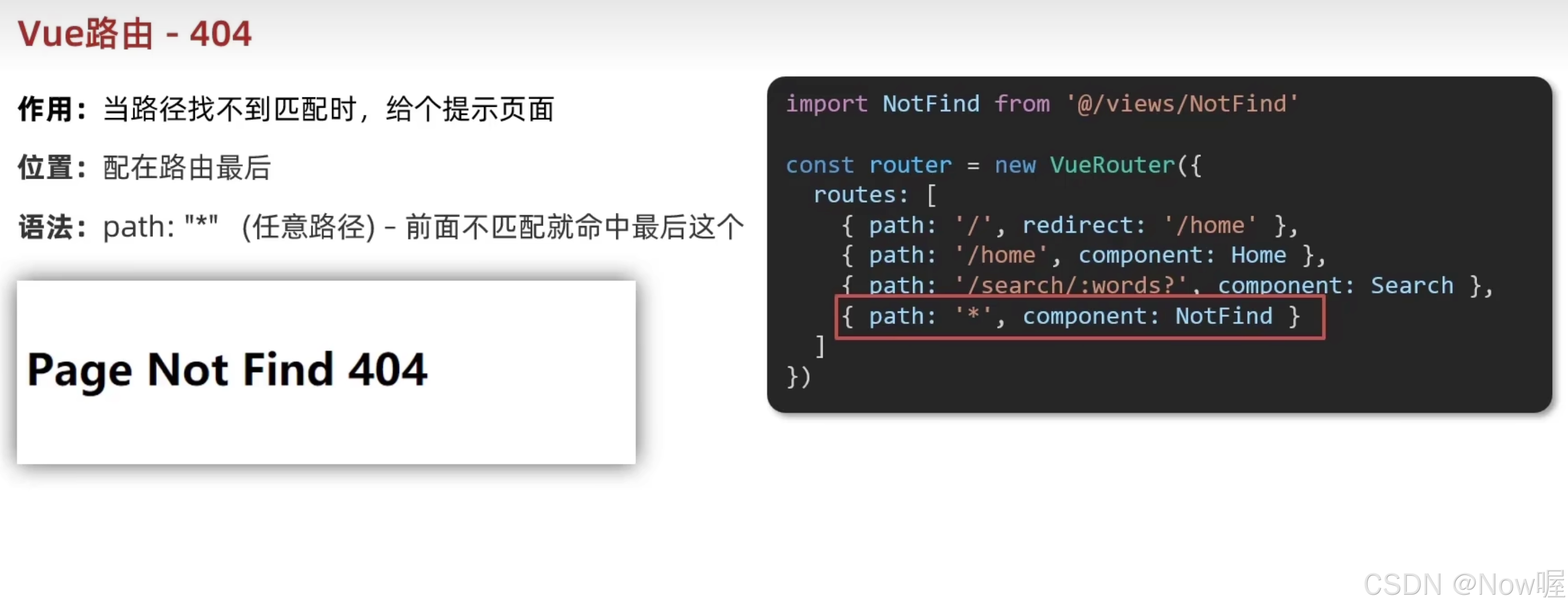
Vue-路由
路由简介 SPA单页面应用。导航区和展示区 单页Web应用整个应用只有一个完整的页面点击页面中的导航连接不会刷新页面,只会做页面的局部更新数据需要通过ajax请求获取 路由:路由就是一组映射关系,服务器接收到请求时,根据请求路…...

【Rust入门教程】安装Rust
文章目录 前言Rust简介Rust的安装更新与卸载rust更新卸载 总结 前言 在当今的编程世界中,Rust语言以其独特的安全性和高效性吸引了大量开发者的关注。Rust是一种系统编程语言,专注于速度、内存安全和并行性。它具有现代化的特性,同时提供了低…...

Character.ai因内容审查流失大量用户、马斯克:Grok-3用了10万块英伟达H100芯片
ChatGPT狂飙160天,世界已经不是之前的样子。 更多资源欢迎关注 1、爆火AI惨遭阉割,1600万美国年轻人失恋?Character.ai被爆资金断裂 美国流行的社交软件Character.ai近期对模型进行大幅度内容审查,导致用户感到失望并开始流失。…...

Spring源码九:BeanFactoryPostProcessor
上一篇Spring源码八:容器扩展一,我们看到ApplicationContext容器通过refresh方法中的prepareBeanFactory方法对BeanFactory扩展的一些功能点,包括对SPEL语句的支持、添加属性编辑器的注册器扩展解决Bean属性只能定义基础变量的问题、以及一些…...

大模型笔记1: Longformer环境配置
论文: https://arxiv.org/abs/2004.05150 目录 库安装 LongformerForQuestionAnswering 库安装 首先保证电脑上配置了git. git环境配置: https://blog.csdn.net/Andone_hsx/article/details/87937329 3.1、找到git安装路径中bin的位置,如:D:\Prog…...
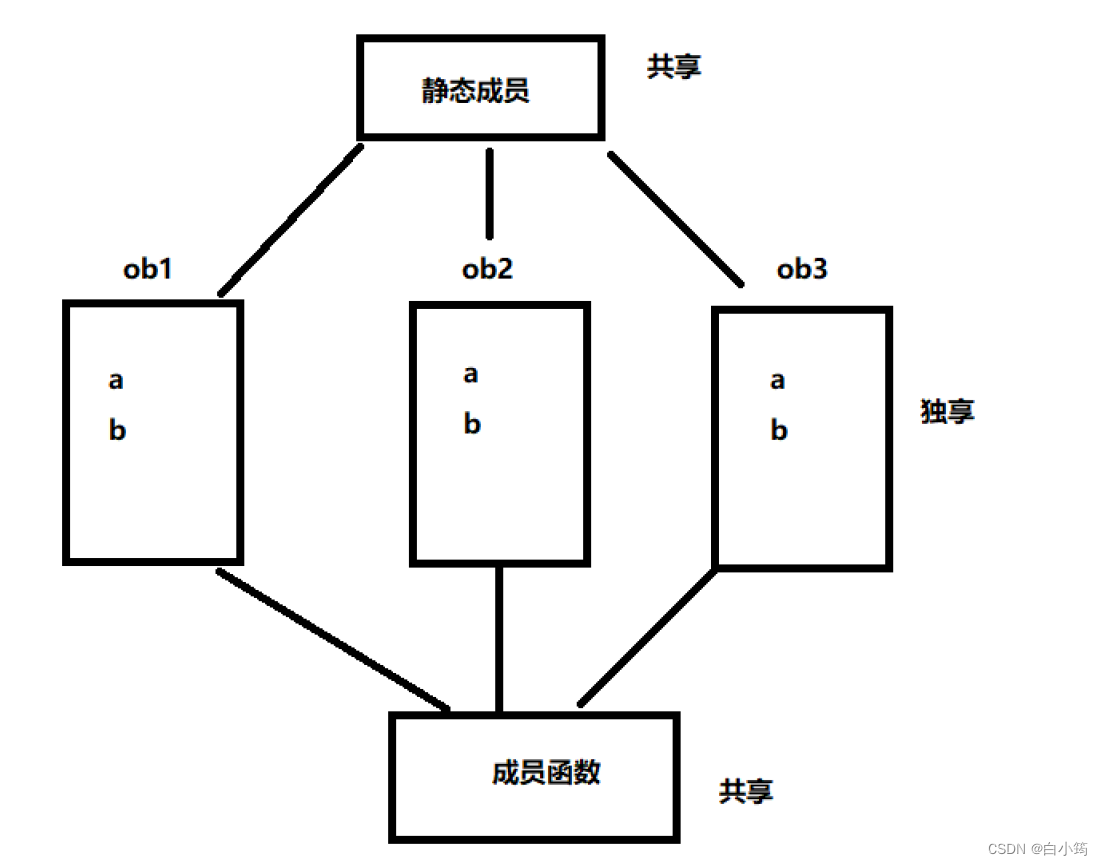
类和对象(提高)
类和对象(提高) 1、定义一个类 关键字class 6 class Data1 7 { 8 //类中 默认为私有 9 private: 10 int a;//不要给类中成员 初始化 11 protected://保护 12 int b; 13 public://公共 14 int c; 15 //在类的内部 不存在权限之分 16 void showData(void)…...

免费最好用的证件照制作软件,一键换底+老照片修复+图片动漫化,吊打付费!
这款软件真的是阿星用过的,最好用的证件照制作软件,没有之一! 我是阿星,今天要给大家安利一款超实用的证件照工具,一键换底,自动排版,免费无广告,让你在家就能轻松搞定证件照&#…...

antfu/ni 在 Windows 下的安装
问题 全局安装 ni 之后,第一次使用会有这个问题 解决 在 powershell 中输入 Remove-Item Alias:ni -Force -ErrorAction Ignore之后再次运行 ni Windows 11 下的 Powershell 环境配置 可以参考 https://github.com/antfu-collective/ni?tabreadme-ov-file#how …...

Linux 生产消费者模型
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:Linux初窥门径⏪ 🚚代码仓库:Linux代码练习🚚 🌹关注我🫵带你学习更多Linux知识 🔝 前言 1. 生产消费者模型 1.1 什么是生产消…...

深入浅出:MongoDB中的背景创建索引
深入浅出:MongoDB中的背景创建索引 想象一下,你正忙于将成千上万的数据塞入你的MongoDB数据库中,你的用户期待着实时的响应速度。此时,你突然想到:“嘿,我应该给这些查询加个索引!” 没错&…...

Spring事务十种失效场景
首先我们要明白什么是事务?它的作用是什么?它在什么场景下在Spring框架下会失效? 事务:本质上是由数据库和程序之间交互的过程中的衍生物,它是一种控制数据的行为规则。有几个特性 1、原子性:执行单元内,要…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...