DETRs Beat YOLOs on Real-time Object Detection论文翻译
cvpr 2024
论文名称 DETRs在实时目标检测上击败YOLO
地址 https://arxiv.longhoe.net/abs/2304.08069
代码 https://github.com/lyuwenyu/RT-DETR
目录
摘要
1介绍
2.相关工作
2.1实时目标探测器
2.2.端到端物体探测器
3.检测器的端到端速度
3.1.NMS分析
3.2.端到端速度基准
4.实时DETR
4.1.模型概述
4.3.不确定性最小查询选择
5.实验
5.1.与SOTA的比较
5.2.混合编码器的消融研究
5.3.查询选择的消融研究
5.4.解码器的消融研究
6.限制和讨论
7.结论
附录
1.实验设置数据集和指标。
2.与较轻的YOLO探测器相比
3.RT-DETR的大规模预训练
4.不同后处理阈值预测的可视化
5.RT-DETR预测的可视化
摘要
YOLO系列已经成为最流行的实时目标检测框架,因为它在速度和准确性之间做出了合理的权衡。然而,我们观察到YOLO的速度和准确性受到NMS的负面影响。最近,端到端基于转换器的检测器(DETR)提供了消除NMS的替代方案。然而,高计算成本限制了它们的实用性,并阻碍了它们充分发挥排除NMS的优势。在本文中,我们提出了实时检测Transformer(RT-DETR),第一个实时端到端对象检测器,以我们所知,解决了上述困境。我们借鉴先进的DETR,分两步构建RT-DETR:首先,我们专注于在提高速度的同时保持准确性,其次是在提高准确性的同时保持速度。具体来说,我们设计了一个高效的混合编码器,通过解耦尺度内交互和跨尺度融合来快速处理多尺度特征,以提高速度。然后,我们提出了不确定性最小的查询选择提供高质量的初始查询的解码器,从而提高准确性。此外,RT-DETR支持灵活的速度调整,通过调整解码器层的数量来适应各种场景,而无需重新训练。我们的RT-DETR-R50 / R101在COCO上实现了53.1% / 54.3%的AP,在T4 GPU上实现了108 / 74 FPS,无论是速度还是精度都超过了之前先进的YOLO。此外,RT-DETR-R50在准确性方面优于DINO-R50 2.2%AP,FPS约为21倍。经过Objects 365的预训练后,RTDETR-R50 / R101分别达到了55.3% / 56.2%的AP。代码:https://zhao-yian.github.io/RTDETR。
1介绍
实时目标检测是一个重要的研究领域,有着广泛的应用,如目标跟踪[43]、视频监控[28]、自动驾驶[2]等,现有的实时检测器一般采用基于CNN的架构,其中最著名的是YOLO检测器[1,10-12,15,16,25,30,38,40]由于它们在速度和准确性之间的合理权衡。然而,这些检测器通常需要非最大值抑制(NMS)进行后处理,这不仅降低了推理速度,而且还引入了超参数,导致速度和精度不稳定。此外,考虑到不同场景对查全率和准确率的重视程度不同,需要仔细选择合适的NMS阈值,这阻碍了实时检测器的发展。
最近,端到端基于transformer的检测器(DETR)[4,17,23,27,36,39,44,45]由于其精简的架构和消除手工制作的组件而受到学术界的广泛关注。然而,它们的高计算成本使它们无法满足实时检测要求,因此无NMS架构没有表现出推理速度优势。这启发我们探索DETR是否可以扩展到实时场景,并在速度和准确性方面优于先进的YOLO检测器,消除NMS对实时对象检测造成的延迟。
为实现上述目标,我们重新考虑DETR并对关键组件进行详细分析,以减少不必要的计算冗余并进一步提高准确性。对于前者,我们观察到,虽然多尺度特征的引入有利于加速训练收敛[45],但它会导致输入编码器的序列长度显着增加。由于多尺度特征的交互作用导致的高计算成本使得Transformer编码器成为计算瓶颈。因此,实现实时DETR需要重新设计编码器。对于后者,以前的工作[42,44,45]表明难以优化的对象查询阻碍了DETR的性能,并提出了查询选择方案,以用编码器特征取代香草可学习嵌入。然而,我们观察到,目前的查询选择直接采用分类分数进行选择,忽略了这样一个事实,即检测器需要同时建模的类别和对象的位置,这两者都决定了功能的质量。这不可避免地导致具有低定位置信度的编码器特征被选择作为初始查询,从而导致相当大程度的不确定性并损害DETR的性能。我们将查询初始化视为进一步提高性能的突破口。
在本文中,我们提出了实时检测Transformer(RT-DETR),第一个实时端到端的对象检测器,以我们最好的知识。为了快速处理多尺度特征,我们设计了一个高效的混合编码器来代替香草Transformer编码器,通过解耦尺度内交互和不同尺度特征的跨尺度融合来显著提高推理速度。为了避免低定位置信度的编码器特征被选择为对象查询,我们提出了不确定性最小查询选择,通过显式优化不确定性,为解码器提供高质量的初始查询,从而提高准确性。此外,RT-DETR支持灵活的速度调整,以适应各种实时场景,而无需重新训练,这要归功于DETR的多层解码器架构。
RT-DETR在速度和精度之间实现了理想的平衡。具体来说,RT-DETR-R50在COCO val 2017上实现了53.1%的AP,在T4 GPU上实现了108 FPS,而RTDETR-R101实现了54.3%的AP和74 FPS,在速度和准确性方面都优于之前先进的YOLO探测器的L和X型号,图1。我们还通过使用更小的主干扩展编码器和解码器来开发扩展的RT-DETR,其性能优于更轻的YOLO检测器(S和M模型)。此外,RT-DETR-R50在准确度上比DINO-Deformable-DETR-R50高出2.2% AP(53.1% AP vs 50.9% AP),在FPS上高出约21倍(108 FPS vs 5 FPS),显着提高了DETR的准确度和速度。在使用Objects 365 [35]进行预训练后,RTDETR-R50 / R101实现了55.3% / 56.2%的AP,从而实现了令人惊讶的性能提升。更多实验结果见附录。
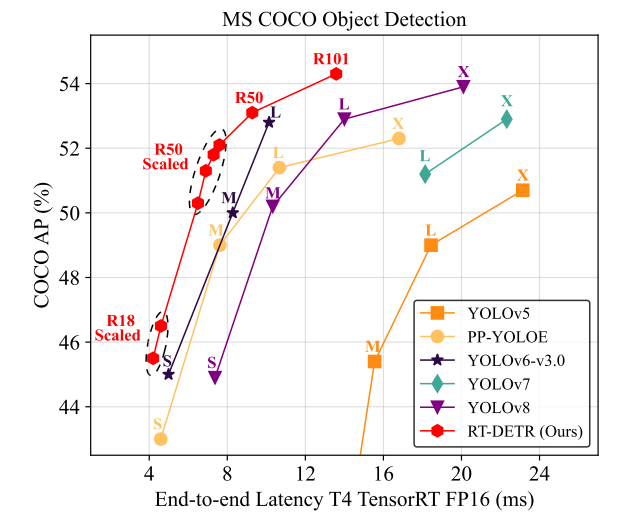
图1.与以前先进的实时目标检测器相比,我们的RT-DETR实现了最先进的性能。
主要贡献归纳如下:(一)。我们提出了第一个称为RTDETR的实时端到端对象检测器,它不仅在速度和准确性方面优于以前先进的YOLO检测器,而且还消除了NMS后处理对实时对象检测造成的负面影响;(ii)。定量分析NMS对YOLO检测器速度和精度的影响,建立端到端速度基准测试实时检测器的端到端推理速度;(iii).所提出的RT-DETR通过调整解码器层的数量来支持灵活的速度调整,以适应各种情况,而无需重新训练。
2.相关工作
2.1实时目标探测器
YOLOv1 [31]是第一个基于CNN的单阶段对象检测器,可以实现真正的实时对象检测。经过多年的不断发展,YOLO探测器已经超越了其他单级目标探测器[21,24],成为实时目标探测器的代名词。YOLO检测器可以分为两类:基于锚点的[1,11,15,25,29,30,37,38]和无锚点的[10,12,16,40],它们在速度和精度之间实现了合理的权衡,并广泛应用于各种实际场景。这些先进的实时检测器会产生许多重叠的盒子,需要NMS后处理,这会降低它们的速度。
2.2.端到端物体探测器
端到端物体探测器以其流线型的管道而闻名。Carion等人[4]首先提出了基于Transformer的端到端检测器,称为DETR,由于其独特的特性而引起了广泛的关注。特别是,DETR消除了手工制作的锚和NMS组件。相反,它采用二分匹配,并直接预测一对一的对象集。尽管DETR具有明显的优势,但它存在一些问题:训练收敛速度慢,计算成本高,难以优化查询。已经提出了许多DETR变体来解决这些问题。加速融合。Deformable-DETR [45]通过提高注意力机制的效率来加速多尺度特征的训练收敛。DAB-DETR [23]和DN-DETR [17]通过引入迭代细化方案和去噪训练进一步提高了性能。Group-DETR [5]引入了分组一对多分配。降低计算成本。高效DETR [42]和稀疏DETR [33]通过减少编码器和解码器层的数量或更新查询的数量来降低计算成本。Lite DETR [18]通过以交错方式降低低级特征的更新频率来提高编码器的效率。优化查询初始化。条件DETR [27]和锚DETR [39]降低了查询的优化难度。Zhu等人。[45]提出了两阶段DETR的查询选择,DINO [44]建议混合查询选择以帮助更好地初始化查询。目前的DETR仍然是计算密集型的,并且没有被设计为真实的时间检测。我们的RT-DETR积极探索计算成本的降低,并试图优化查询初始化,优于最先进的实时检测器。
3.检测器的端到端速度
3.1.NMS分析
NMS是一种在目标检测中广泛使用的后处理算法,用于消除重叠的输出框。NMS中需要两个阈值:置信阈值和IoU阈值。具体来说,得分低于置信度阈值的盒子被直接过滤掉,并且每当任何两个盒子的IoU超过IoU阈值时,得分较低的盒子将被丢弃。迭代地执行该过程,直到处理完每个类别的所有框。因此,NMS的执行时间主要取决于盒子的数量和两个阈值。为了验证这一观察结果,我们利用YOLOv5 [11](基于锚)和YOLOv8 [12](无锚)进行分析。
我们首先计算在同一输入上过滤具有不同置信度阈值的输出框后剩余的框的数量。我们从0.001到0.25之间采样值作为置信度阈值,以计算两个检测器的剩余框的数量,并将它们绘制在条形图上,这直观地反映了NMS对其超参数的敏感性,图2。随着置信度阈值的增加,更多的预测框被过滤掉,需要计算IoU的剩余框的数量减少,从而减少NMS的执行时间。
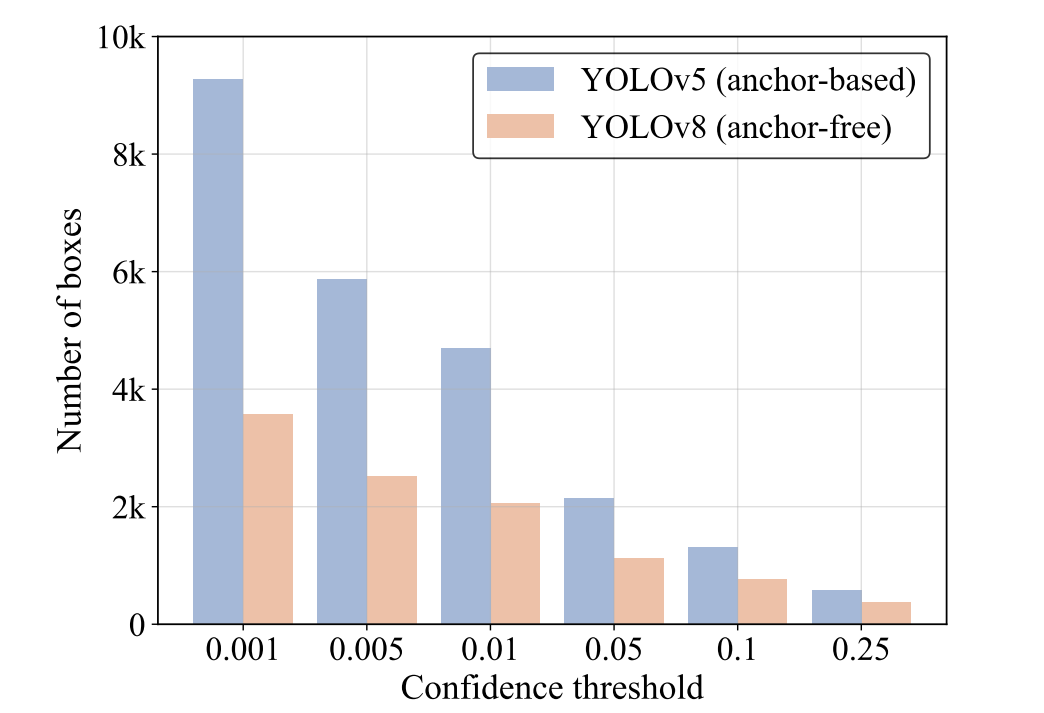
图2.不同置信度阈值下的盒子数量。
此外,我们使用YOLOv8在COCO val2017上评估了准确性,并测试了不同超参数下NMS操作的执行时间。注意,我们采用的NMS操作是指TensorRT efficientNMSPlugin,它涉及多个内核,包括EfficientNMSFilter、RadixSort、EfficientNMS等,我们只报告EfficientNMS内核的执行时间。我们使用TensorRT FP16在T4 GPU上测试了速度,输入和预处理保持一致。超参数和相应的结果如表1所示。从结果中,我们可以得出结论,EfficientNMS内核的执行时间随着置信度阈值的降低或IoU阈值的增加而增加。原因是高置信度阈值直接过滤掉更多的预测框,而高IoU阈值在每轮筛选中过滤掉的预测框较少。我们还在附录中可视化了具有不同NMS阈值的YOLOv8的预测。结果表明,不适当的置信度阈值会导致检测器产生明显的误报或漏报。在置信度阈值为0.001,IoU阈值为0.7的情况下,YOLOv8实现了最佳AP结果,但相应的NMS时间处于较高水平。考虑到YOLO检测器通常报告模型速度并排除NMS时间,因此需要建立端到端速度基准。
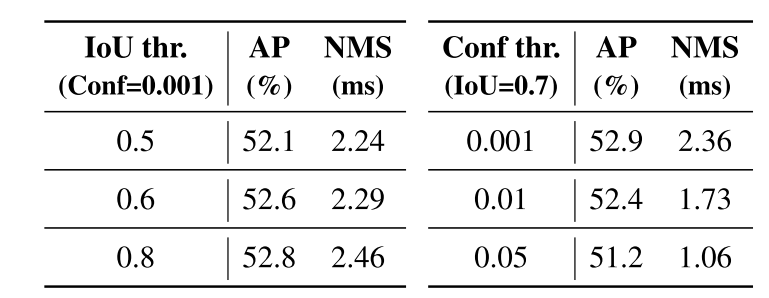
表1.IoU阈值和置信度阈值对准确性和NMS执行时间的影响。
3.2.端到端速度基准
为了能够公平地比较各种实时检测器的端到端速度,我们建立了一个端到端速度基准。考虑到NMS的执行时间受输入的影响,需要选择基准数据集并计算多个图像的平均执行时间。我们选择COCO val 2017 [20]作为基准数据集,并如上所述为YOLO检测器添加TensorRT的NMS后处理插件。具体来说,我们根据基准数据集上相应准确度的NMS阈值测试检测器的平均推理时间,不包括I/O和MemoryCopy操作。我们利用基准测试在T4 GPU上使用TensorRT FP 16测试基于锚的检测器YOLOv 5 [11]和YOLOv 7 [38]以及无锚检测器PP-YOLOE [40],YOLOv 6 [16]和YOLOv 8 [12]的端到端速度。根据结果(cf。表2),我们得出结论,无锚检测器优于基于锚的检测器,具有与YOLO检测器相同的精度,因为前者需要比后者更少的NMS时间。原因是基于锚的检测器比无锚检测器产生更多的预测框(在我们测试的检测器中是三倍)。

表2.与SOTA的比较(仅YOLO探测器的L和X型号,与S和M型号的比较见附录)。我们不测试其他DETR的速度,除了DINO-Deformable-DETR [44]用于比较,因为它们不是实时检测器。我们的RT-DETR在速度和准确性方面优于最先进的YOLO探测器和DETR。
4.实时DETR
4.1.模型概述
RT-DETR由一个主干、一个高效的混合编码器和一个带辅助预测头的Transformer解码器组成。RT-DETR的概述如图4所示。具体来说,我们将来自主干的最后三个阶段{S3,S4,S5}的特征馈送到编码器中。高效的混合编码器通过尺度内特征交互和跨尺度特征融合将多尺度特征变换成图像特征序列(参见图1)。秒4.2)。随后,采用不确定性最小查询选择来选择固定数量的编码器特征以用作解码器的初始对象查询(参见图1)。秒4.3)。最后,具有辅助预测头的解码器迭代地优化对象查询以生成类别和框。4.2.高效的混合编码器计算瓶颈分析。多尺度特征的引入加速了训练收敛并提高了性能[45]。然而,尽管可变形注意力降低了计算成本,但急剧增加的序列长度仍然导致编码器成为计算瓶颈。如Lin等人[19]所述,编码器占GFLOP的49%,但在可变形DETR中仅占AP的11%。为了克服这个瓶颈,我们首先分析了计算冗余存在于多尺度Transformer编码器。直观的,包含丰富的语义信息的对象的高级功能提取低级别的功能,使它多余的级联多尺度功能上执行功能交互。因此,我们设计了一组具有不同类型编码器的变体,以证明同时进行尺度内和跨尺度特征交互是低效的,图3。特别地,我们使用DINO-Deformable-R50与RT-DETR中使用的更小尺寸的数据读取器和更轻的解码器进行实验,并且首先去除DINO-Deformable-R50中的多尺度Transformer编码器作为变体A。然后,插入不同类型的编码器以基于A产生一系列变体,详细说明如下(每个变体的详细指示符参见表3):
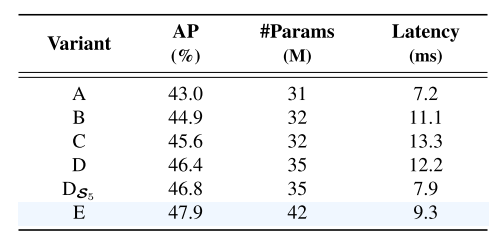
表3.图3中示出了变型集合的指示符。
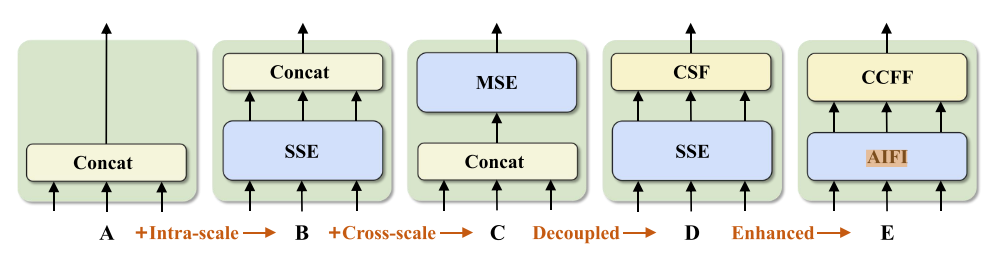
图3.每个变体的编码器结构。SSE表示单尺度Transformer编码器,MSE表示多尺度Transformer编码器,CSF表示跨尺度融合。AIFI和CCFF是设计到我们的混合编码器的两个模块。
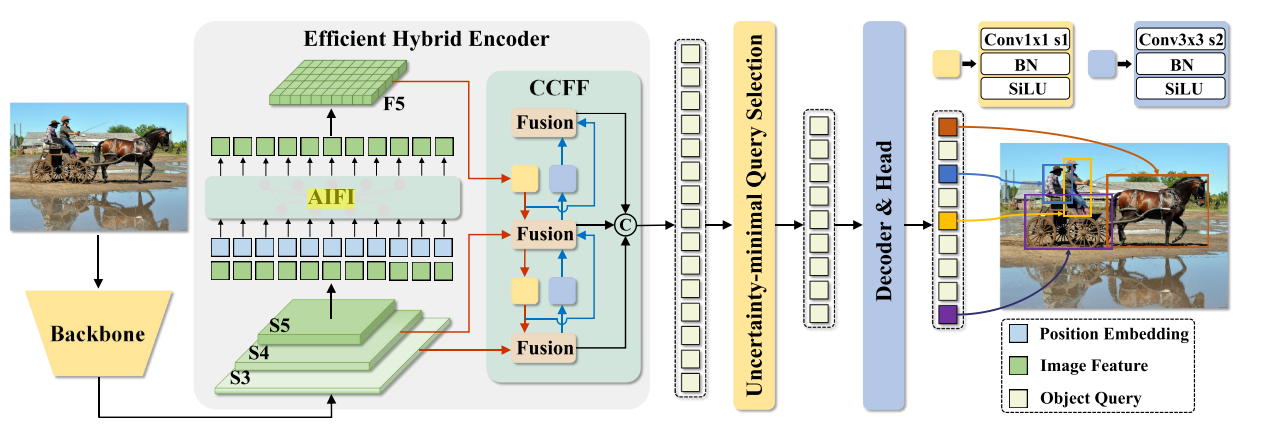
图3.每个变体的编码器结构。SSE表示单尺度Transformer编码器,MSE表示多尺度Transformer编码器,CSF表示跨尺度融合。AIFI和CCFF是设计到我们的混合编码器的两个模块。
· A → B:变体B将单尺度Transformer编码器插入到A中,其使用一层Transformer块。多尺度特征共享编码器以进行尺度内特征交互,然后连接为输出。
· B → C:变体C引入基于B的跨尺度特征融合,并将级联特征馈送到多尺度Transformer编码器中以执行同时的尺度内和跨尺度特征交互。
· C → D:变体D通过利用用于前者的单尺度Transformer编码器和用于后者的PANet风格[22]结构来实现尺度内交互和跨尺度融合。
· D→ E:变体E在D的基础上增强了尺度内交互和跨尺度融合,采用了我们设计的高效混合编码器。
混合设计。在此基础上,我们对编码器的结构进行了重新思考,提出了一种高效的混合编码器,该编码器由基于注意力的尺度内特征交互(AIFI)和基于CNN的跨尺度特征融合(CCFF)两个模块组成。具体地,AIFI通过利用单尺度Transformer编码器仅在S5上执行尺度内交互来进一步降低基于变型D的计算成本。原因在于,将自注意操作应用于具有更丰富语义概念的高级特征,捕获了概念实体之间的联系,这有利于后续模块对对象的定位和识别。然而,由于缺乏语义概念以及与高级特征交互的重复和混淆的风险,较低级别特征的尺度内交互是不必要的。为了验证这一观点,我们仅对变体D中的S5进行尺度内相互作用,实验结果报告在表3中(见DS5行)。与D相比,DS5不仅显著降低了延迟(快35%),而且提高了准确性(AP高0.4%)。CCFF基于跨尺度融合模块进行优化,在融合路径中插入几个由卷积层组成的融合块,融合块的作用是将两个相邻尺度特征融合成一个新特征,其结构如图5所示。融合块包含两个1 × 1卷积来调整通道数量,由RepConv [8]组成的N个RepBlocks用于特征融合,两个路径输出通过逐元素相加进行融合。我们将混合编码器的计算公式化为:
其中Reshape表示将展平特征的形状恢复为与S5相同的形状。

图5.CCFF中的融合阻滞。
4.3.不确定性最小查询选择
为了降低在DETR中优化对象查询的难度,一些后续的工作[42,44,45]提出了查询选择方案,它们的共同点是使用置信度得分从编码器中选择前K个特征来初始化对象查询(或只是位置查询)。置信度分数表示特征包括前景对象的可能性。然而,检测器需要同时对对象的类别和位置进行建模,这两者都决定了特征的质量。因此,特征的性能得分是与分类和定位两者共同相关的潜在变量。基于分析,当前的查询选择导致所选择的特征具有相当程度的不确定性,从而导致解码器的次优初始化并阻碍检测器的性能。
为了解决这个问题,我们提出了不确定性最小查询选择方案,明确地构建和优化认知的不确定性建模的联合潜在变量的编码器功能,从而为解码器提供高质量的查询。具体地,特征不确定性U被定义为在等式中定位P和分类C的预测分布之间的差异。(2).为了最小化查询的不确定性,我们将不确定性集成到等式中的基于梯度的优化的损失函数中。(3).
其中,Y表示预测和基础事实,Y表示= {k c,k B},k c和k B分别表示类别和边界框,X表示编码器特征。
有效性分析。为了分析不确定性最小查询选择的有效性,我们在COCO val2017上可视化了所选特征的分类得分和IoU得分,图6。我们绘制了分类分数大于0.5的散点图。紫色和绿色点分别表示从使用不确定性最小查询选择和普通查询不确定性最小查询选择解码器和头部选择训练的模型中选择的特征。点越靠近图的右上方,对应特征的质量越高,即,预测的类别和框越可能描述真实的对象。顶部和右侧的密度曲线反映了两种类型的点的数量。
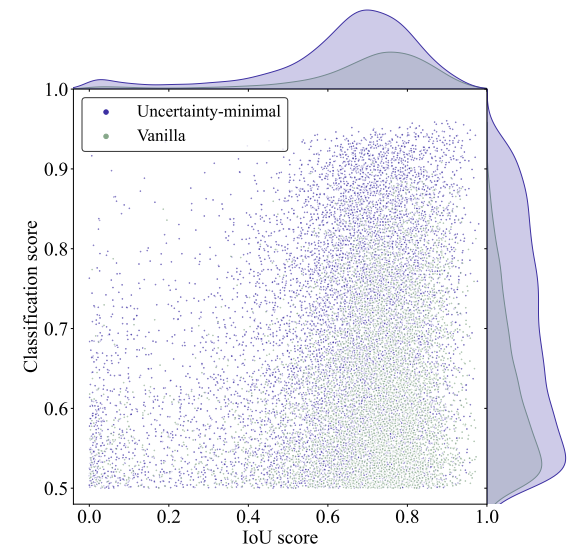
图6.所选编码器功能的分类和IoU分数。紫色和绿色点分别表示从使用不确定性最小查询选择和普通查询选择训练的模型中选择的特征。
散点图最显著的特点是紫色的点集中在图的右上方,而绿色的点集中在右下方。这表明不确定性最小查询选择产生更多高质量的编码器特征。此外,我们进行定量分析两个查询选择方案。紫色点比绿色点多138%,即,具有小于或等于0.5的分类分数的更多绿色点,其可被认为是低质量特征。并且有120%的紫色点比绿色点的分数都大于0.5。从密度曲线也可以得出同样的结论,紫色和绿色之间的差距在图的右上方最明显。定量结果进一步表明,不确定性最小查询选择提供了更多的特征,具有准确的分类和查询的精确位置,从而提高了检测器的准确性(参见图1)。秒5.3)。
4.4.定标RT-DETR
由于实时检测器通常提供不同尺度的模型以适应不同的场景,因此RT-DETR还支持灵活的缩放。具体来说,对于混合编码器,我们通过调整嵌入维数和通道数来控制宽度,通过调整Transformer层和RepBlocks的数量来控制深度。解码器的宽度和深度可以通过操纵对象查询和解码器层的数量来控制。此外,RT-DETR的速度支持通过调整解码器层的数量来灵活调整。我们观察到,在最后删除一些解码器层对准确性的影响最小,但大大提高了推理速度(参见。秒5.4)。我们将配备ResNet 50和ResNet 101的RT-DETR [13,14]与YOLO探测器的L和X型号进行了比较。更轻的RT-DETR可以通过应用其他更小的(例如,ResNet 18/34)或可扩展(例如,CSPResNet [40])具有缩放编码器和解码器的骨干。我们在附录中将缩放的RT-DETR与更轻的(S和M)YOLO探测器进行了比较,它们在速度和精度方面都优于所有S和M模型。
5.实验
5.1.与SOTA的比较
表2将RT-DETR与当前的实时(YOLO)和端到端(DETR)检测器进行了比较,其中仅比较了YOLO检测器的L和X型号,S和M型号的比较见附录。我们的RT-DETR和YOLO检测器共享一个共同的输入大小(640,640),其他DETR使用的输入大小为(800,1333)。FPS在T4 GPU上使用TensorRT FP 16进行报告,并根据第12节中提出的端到端速度基准使用官方预训练模型用于YOLO检测器。3.2.我们的RT-DETR-R50实现了53.1%的AP和108 FPS,而RTDETR-R101实现了54.3%的AP和74 FPS,在速度和准确性方面优于具有类似规模的最先进的YOLO探测器和具有相同主干的DETR。实验设置见附录。与实时探测器比较。我们比较了端到端速度(参见秒3.2)和使用YOLO探测器的RTDETR的准确性。我们将RT-DETR与YOLOv 5 [11]、PP-YOLOE [40]、YOLOv6v3.0 [16](以下简称YOLOv 6)、YOLOv 7 [38]和YOLOv 8 [12]进行比较。与YOLOv 5-L / PP-YOLOE-L /YOLOv 6-L相比,RT-DETR-R50的准确度提高了4.1% / 1.7% /0.3%AP,FPS提高了100.0% / 14.9% /9.1%,参数数量减少了8.7% / 19.2% /28.8%。与YOLOv 5-X / PP-YOLOE-X相比,RTDETR-R101的精度提高了3.6% /2.0%,FPS提高了72.1% /23.3%,参数数量减少了11.6% /22.4%。与YOLOv 7-L /YOLOv 8-L相比,RT-DETR-R50将准确度提高了1.9% /0.2%AP,FPS提高了96.4% /52.1%。与YOLOv 7-X /YOLOv 8-X相比,RT-DETR-R101的准确度提高了1.4% /0.4%AP,FPS提高了64.4% /48.0%。这表明我们的RT-DETR实现了最先进的实时检测性能。
与端到端检测器的比较。我们还比较RT-DETR与现有的DETR使用相同的骨干。我们根据COCO val 2017上相应精度的设置来测试DINO-Deformable-DETR的速度[44],以进行比较,即:使用TensorRT FP 16测试速度,输入大小为(800,1333)。表2显示,RT-DETR在速度和准确性方面优于所有具有相同主干的DETR。与DINO-Deformable-DETR-R50相比,RT-DETR-R50的准确度提高了2.2%AP,速度提高了21倍(108 FPS vs 5 FPS),两者都有明显的提高。
5.2.混合编码器的消融研究
我们评估了第二节中设计的变体的指标。4.2,包括AP(用1×配置训练),参数数量和延迟,表3。与基线A相比,变体B将准确性提高了1.9% AP,并将潜伏期增加了54%。这证明了尺度内特征交互是显著的,但是单尺度Transformer编码器在计算上是昂贵的。变体C比B提供0.7%的AP改进,并将延迟增加20%。这表明跨尺度特征融合也是必要的,但多尺度Transformer编码器需要更高的计算成本。变体D比C提供了0.8%的AP改进,但将延迟降低了8%,这表明解耦尺度内交互和跨尺度融合不仅降低了计算成本,而且提高了准确性。与变体D相比,DS5将延迟减少了35%,但提供了0.4%的AP改善,表明不需要较低级别特征的尺度内交互。最后,变体E比D提供1.5%的AP改善。尽管参数数量增加了20%,但延迟减少了24%,使编码器更高效。这表明,我们的混合编码器实现了更好的速度和精度之间的权衡。
5.3.查询选择的消融研究
我们对不确定性最小查询选择进行消融研究,结果报告在RT-DETR-R50上,1×配置,表4。RT-DETR中的查询选择根据分类得分选择前K(K = 300)个编码器特征作为内容查询,并将所选特征对应的预测框作为初始位置查询。我们比较了COCO val 2017上两种查询选择方案选择的编码器特征,并分别计算了分类得分大于0.5以及分类和IoU得分大于0.5的比例。实验结果表明,不确定性最小查询选择算法选择的编码器特征不仅提高了高分类分数的比例(0.82%vs0.35%),而且提供了更多的高质量特征(0.67%vs0.30%)。我们还评估了在COCO val 2017上使用两种查询选择方案训练的检测器的准确性,其中不确定性最小查询选择实现了0.8% AP的改进(48.7% AP vs 47.9% AP)。

表4.不确定性最小查询选择的消融研究结果。Propcls和Propboth分别表示分类得分的比例和得分均大于0.5的比例。
5.4.解码器的消融研究
表5显示了用不同数量的解码器层训练的RT-DETR-R50的每个解码器层的推理延迟和准确性。当解码器层数设置为6时,RT-DETR-R50达到最佳精度53.1%AP。此外,我们观察到,随着解码器层的索引的增加,相邻解码器层之间的精度差异逐渐减小。以列RTDETR-R50-Det 6为例,使用第5个解码器层进行推理仅损失0.1%的AP(53.1% AP vs 53.0% AP)的准确性,同时将延迟减少0.5 ms(9.3 ms vs 8.8 ms)。因此,RT-DETR通过调整解码器层数而无需重新训练来支持灵活的速度调整,从而提高了其实用性。
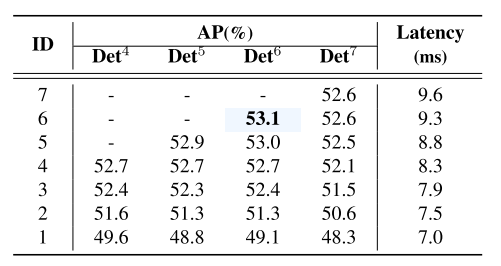
表5.解码器的消融研究结果。ID指示解码器层索引。Detk表示具有k个解码器层的检测器。所有结果均报告在RT-DETR-R50(6×配置)上。
6.限制和讨论
限制。尽管所提出的RT-DETR在速度和准确性方面优于具有类似尺寸的最先进的实时检测器和端到端检测器,但它与其他DETR具有相同的限制,即,对小物体的性能仍然不如强实时检测器。根据表2,RT-DETR-R50比L模型(YOLOv 8-L)中的最高APval S低0.5%AP,RTDETR-R101比X模型(YOLOv 7-X)中的最高APval S低0.9%AP。我们希望,这一问题将在今后的工作中得到解决。
讨论。现有的大型DETR模型[3,6,32,41,44,46]在COCO测试开发[20]排行榜上表现出令人印象深刻的性能。所提出的不同尺度的RT-DETR保留了与其他DETR相同的解码器,这使得我们可以用高精度的预训练大型DETR模型来提取我们的轻量级检测器。我们相信这是RT-DETR相对于其他实时检测器的优势之一,可能是未来探索的一个有趣方向。
7.结论
在这项工作中,我们提出了一个实时端到端检测器,称为RT-DETR,它成功地扩展了DETR的实时检测场景,并达到了最先进的性能。RT-DETR包括两个关键的增强:一个高效的混合编码器,可以快速处理多尺度特征,以及提高初始对象查询质量的不确定性最小查询选择。此外,RT-DETR支持灵活的速度调整,无需重新训练,消除了两个NMS阈值带来的不便,便于实际应用。RTDETR,沿着其模型缩放策略,拓宽了实时对象检测的技术方法,为不同的实时场景提供了超越YOLO的新可能性。我们希望RT-DETR能够付诸实践。致谢。本研究得到了国家重点研发计划(No.2022ZD0118201)、国家自然科学基金(No.61972217,32071459,62176249,62006133,62271465)和深圳市医学科研基金(No.B2302037)的部分资助。感谢刘畅、王振南和李克汉在写作和演示方面提出的有益建议。
附录
1.实验设置数据集和指标。
我们在COCO[20]和Objects365[35]上进行了实验,其中RT-DETR在COCO Train 2017上进行了训练,并在COCO val2017数据集上进行了验证。我们报告了标准的COCO指标,包括AP(在均匀采样的IOU阈值范围内从0.50到0.95的平均值,步长为0.05),AP50,AP75,以及不同尺度的AP:APS,APM,APL。实施细节。我们使用在ImageNet[7,34]上预先训练的ResNet[13,14]作为主干,主干的学习速率策略遵循[4]。在混合编码器中,AIFI由1个变换器层组成,CCFF中的融合块由3个RepBlock组成。我们利用不确定的最小查询选择来选择前300个编码器特征来初始化解码器的对象查询。解码器的训练策略和超参数几乎遵循Dino[44]。我们使用四个批次大小为16的NVIDIA Tesla V100 GPU使用AdamW[26]优化器训练RT-DETR,并应用指数移动平均衰减=0.9999。1×组态意味着总历元为12,最终报告的结果采用6×组态。在训练期间应用的数据增强包括随机{颜色扭曲、扩展、裁剪、翻转、调整大小}操作,遵循[40]。RT-DETR的主要超参数如表A所示(详细配置请参考RT-DETRR50)。
2.与较轻的YOLO探测器相比
为了适应不同的实时检测场景,我们通过使用ResNet50/34/18[13]对编码器和解码器进行缩放来开发更轻规模的RT-DETR。具体地说,我们在保持其他组件不变的情况下,将RepBlock中的通道数量减半,并在推理过程中通过调整解码器层的数量来获得一组RT-DETR。我们将定标的RT-DETR与表B中的S和M型号的YOLO探测器进行了比较。定标的RT-DETR-R50/34/18在训练时使用的解码器层数分别为6/4/3,而Deck表示在推理过程中使用了k个解码器层。我们的RT-DETR-R50-DEC2−5在速度和精度上都优于所有M型号的YOLO探测器,而RT-DETR-R18-DEC2则优于所有S型号的探测器。与最先进的M模型(YOLOv8-M[12])相比,RT-DETR-R50-DEC5的准确率提高了0.9%,FPS提高了36%。与最先进的S模型(YOLOv6-S[16])相比,RT-DETR-R18-DEC2的准确率提高了0.5%,FPS提高了18%。这表明,通过简单的定标,RT-DETR在速度和精度上都能够超过较轻的YOLO探测器。
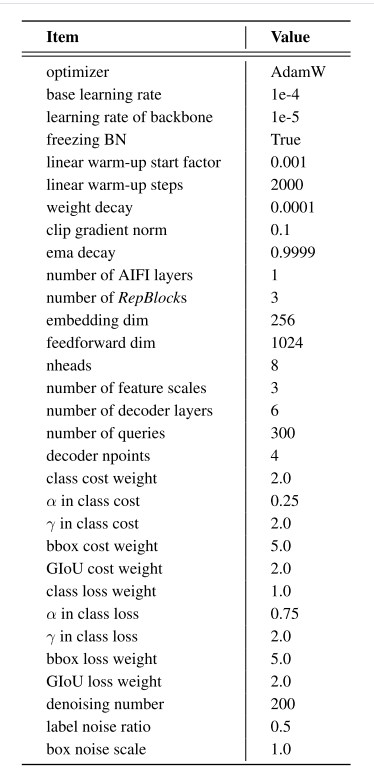
表A.RT-DETR的主要超参数。

表B与S和M型YOLO探测器的比较。根据建议的端到端速度基准,YOLO探测器的FPS在采用TensorRT FP16的T4 GPU上使用官方预先训练的模型进行报告。†表示训练过程中的参数数量,而不是推理。
3.RT-DETR的大规模预训练
我们在较大的Objects365[35]数据集上对RT-DETR进行预训练,然后在COCO上对其进行微调,以获得更高的性能。如表C所示,我们分别在RT-DETR-R18/50/101上进行了实验。所有三个模型都在Objects365上预训练了12个时期,RT-DETR-R18在COCO上微调了60个时期,而RT-DETR-R50和RT-DETR-R101则微调了24个时期。实验结果表明,RT-DETR-R18/50/101在COCO val2017上的性能提高了2.7%/2.2%/1.9%。这一令人惊讶的改进进一步展示了RTDETR的潜力,并为行业内各种实时场景提供了最强的实时物体探测器。

表C.对COCO val2017进行了微调,并对目标365进行了预培训。
4.不同后处理阈值预测的可视化
为了直观地展示后处理对检测器的影响,我们使用不同的后处理阈值可视化了YOLOv8[12]和RT-DETR产生的预测,分别如图A和图B所示。我们通过为YOLOv8-L设置不同的NMS阈值和为RT-DETR-R50设置分数阈值来显示对COCO val2017中随机选择的两个样本的预测。NMS有两个阈值:置信度阈值和IOU阈值,这两个阈值都会影响检测结果。置信度阈值越高,过滤出的预测框越多,假阴性的数量也就越多。然而,使用较低的置信度阈值,例如0.001,会导致大量的冗余框并增加假阳性的数量。欠条门槛越高,每轮筛查中筛选出的重叠框越少,假阳性数量就越多(图A中红圈标记的位置)。然而,如果输入中存在重叠或相互遮挡的对象,采用较低的IOU阈值将导致删除真正的正面。置信度阈值对于处理预测框相对简单,因此很容易设置,而IOU阈值很难准确设置。考虑到不同场景对召回率和准确率的重视程度不同,例如,一般检测场景需要较低的置信度阈值和较高的IOU阈值来提高召回率,而专用检测场景需要较高的置信度阈值和较低的IOU阈值来提高准确率,因此有必要针对不同的场景仔细选择合适的网管阈值。RT-DETR利用二部匹配来预测Oneto-One对象集,消除了抑制重叠框的需要。取而代之的是,它直接过滤出带有分数阈值的低置信度框。与NMS中使用的置信度阈值类似,分数阈值可以根据特定的侧重点在不同的场景中进行调整,以实现最佳的检测性能。因此,在RT-DETR中设置后处理阈值是简单的,并且不影响推理速度,增强了实时检测器对各种场景的适应性。
图A.YOLOv8-L[12]不同NMS阈值预报的可视化。

图B.不同得分阈值的RT-DETR-R50预测的可视化。
5.RT-DETR预测的可视化
我们从COCO val2017中选择了几个样本来展示RT-DETR在复杂场景和挑战性条件下的检测性能(参见图C和图D)。在复杂的场景中,RT-DETR展示了其检测各种对象的能力,即使它们是小的或密集的包装,例如杯子、酒杯和个人。此外,RT-DETR成功地检测到了各种困难条件下的目标,包括运动模糊、旋转和遮挡。这些预测证实了RT-DETR良好的检测性能。
图C.复杂场景中RT-DETR-R101预测的可视化(得分阈值=0.5)。
 图D.困难条件下RT-DETR-R101预测的可视化,包括运动模糊、旋转和遮挡(得分阈值=0.5)。
图D.困难条件下RT-DETR-R101预测的可视化,包括运动模糊、旋转和遮挡(得分阈值=0.5)。
相关文章:
DETRs Beat YOLOs on Real-time Object Detection论文翻译
cvpr 2024 论文名称 DETRs在实时目标检测上击败YOLO 地址 https://arxiv.longhoe.net/abs/2304.08069 代码 https://github.com/lyuwenyu/RT-DETR 目录 摘要 1介绍 2.相关工作 2.1实时目标探测器 2.2.端到端物体探测器 3.检测器的端到端速度 3.1.NMS分析 3.2.端到端速度…...
SpringBoot 多数据源配置
目录 一. 引入maven依赖包 二. 配置yml 三、创建 xml 分组文件 四、切换数据源 一. 引入maven依赖包 <dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.6.1&…...

RK3568驱动指南|第十六篇 SPI-第192章 mcp2515驱动编写:完善write和read函数
瑞芯微RK3568芯片是一款定位中高端的通用型SOC,采用22nm制程工艺,搭载一颗四核Cortex-A55处理器和Mali G52 2EE 图形处理器。RK3568 支持4K 解码和 1080P 编码,支持SATA/PCIE/USB3.0 外围接口。RK3568内置独立NPU,可用于轻量级人工…...

#BI建模与数仓建模有什么区别?指标体系由谁来搭建?
问题1: 指标体系是我们数仓来搭建还是分析师来做,如何去推动? 问题2:BI建模与数仓建模有什么区别? 指标体系要想做好,其实是分两块内容的,一块是顶层设计阶段,业务指标体系的搭建&am…...
如何用Python实现三维可视化?
Python拥有很多优秀的三维图像可视化工具,主要基于图形处理库WebGL、OpenGL或者VTK。 这些工具主要用于大规模空间标量数据、向量场数据、张量场数据等等的可视化,实际运用场景主要在海洋大气建模、飞机模型设计、桥梁设计、电磁场分析等等。 本文简单…...
chrome.storage.local.set 未生效
之前chrome.storage.local.set 和 get 一直不起作用 使用以下代码运行成功。 chrome.storage.local.set({ pageState: "main" }).then(() > {console.log("Value is set");});chrome.storage.local.get(["pageState"]).then((result) > …...

泛微开发修炼之旅--30 linux-Ecology服务器运维脚本
文章链接:30 linux-ecology服务器运维脚本...

LeetCode 全排列
思路:这是一道暴力搜索问题,我们需要列出答案的所有可能组合。 题目给我们一个数组,我们很容易想到的做法是将数组中的元素进行排列,如何区分已选中和未选中的元素,容易想到的是建立一个标记数组,已经选中的…...

python实现支付宝异步回调验签
说明 python实现支付宝异步回调验签,示例中使用Django框架。 此方案使用了支付宝的pythonSDK,请一定装最新版本的,支付宝官网文档不知道多久没更新了,之前的版本pip安装会报一些c库不存在的错误; pip install alipay-…...
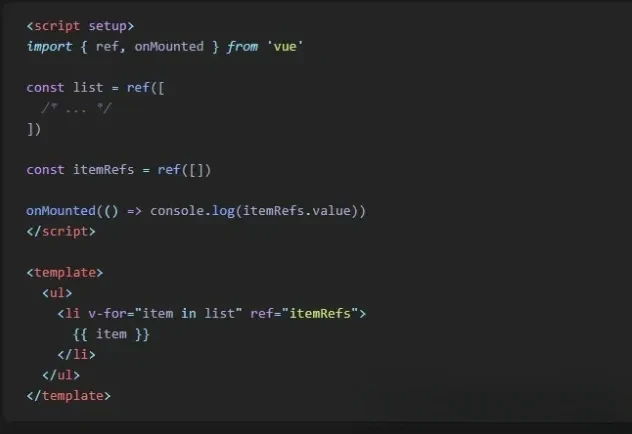
注意!Vue.js 或 Nuxt.js 中请停止使用.value
大家好,我是CodeQi! 一位热衷于技术分享的码仔。 当您在代码中使用.value时,必须每次都检查变量是否存在并且是引用。 这可能很麻烦,因为在运行时使用.value可能会导致错误。然而,有一个简单的解决方法,即使用unref()而不是.value。 unref()会检查变量是否是引用,并自…...

Java:JDK、JRE和JVM 三者关系
文章目录 一、JDK是什么二、JRE是什么三、JDK、JRE和JVM的关系 一、JDK是什么 JDK(Java Development Kit):Java开发工具包 JRE:Java运行时环境开发工具:javac(编译工具)、java(运行…...

Radio专业术语笔记
在收音机的 RDS (Radio Data System) 功能中,CT 代表 “Clock Time”。RDS 是一种数字广播标准,用于在调频广播中传输辅助数据,如电台名称、节目类型、交通信息等。CT 功能是其中的一部分,用于同步和显示广播电台发送的当前时间。…...

cocosCreator找出未用到的图片
最近整理项目的时候发现有些资源文件夹有点轮乱(一些历史原因导致的),而且有很多图片都是没用了的,但是没有被删除掉,还一直放在项目中,导致项目的资源文件夹比较大,而且还冗余。于是今天想着整理一下。 公开免费链接 找出未使用的图片 有好几种方法可以找出未使用的图片…...
一览 Anoma 上的有趣应用概念
撰文:Tia,Techub News 本文来源香港Web3媒体:Techub News Anoma 的目标是为应用提供通用的意图机器接口,这意味着使用 Anoma,开发人员可以根据意图和分布式意图机编写应用,而不是根据事务和特定状态机进行…...

Spring Boot集成fastjson2快速入门Demo
1.什么是fastjson2? fastjson2是阿里巴巴开发的一个高性能的Java JSON处理库,它支持将Java对象转换成JSON格式,同时也支持将JSON字符串解析成Java对象。本文将介绍fastjson2的常见用法,包括JSON对象、JSON数组的创建、取值、遍历…...

Three.js机器人与星系动态场景(二):强化三维空间认识
在上篇博客中介绍了如何快速利用react搭建three.js平台,并实现3D模型的可视化。本文将在上一篇的基础上强化坐标系的概念。引入AxesHelper辅助工具及文本绘制工具,带你快速理解camer、坐标系、position、可视区域。 Three.js机器人与星系动态场景&#x…...

java顺序查找
其中有一个常用的编程思想: 由于是遍历查找,不能用if-else来输出没有找到,而应该设置一个索引index,如果找到就将index的值设置成下标的值,如果遍历结束后index仍为初始值,才是没有找到 //2024.07.03impor…...
提升学生职务执行力的智慧校园学工管理策略
智慧校园的学工管理系统匠心独运地融入了“学生职务”这一创新模块,它紧密贴合学生的实际需求,致力于在校期间的实践经验积累和个人能力的全面提升。这个模块化身为一个便捷的综合平台,让学生们能够轻松发掘并参与到丰富多彩的校内职务中去&a…...

系统运维面试总结(shell编程)
SYNDDOS攻击,需要判断这个访问是正常访问还是信包攻击,当前这个信包发起的访问数量是多少,例如看到30个信包同时再访问时设置监控报警。 一般选用/dev/urandom生成,但其生成的随机数带有二进制乱码,所以需要tr命令…...

在数据库中,什么是主码、候选码、主属性、非主属性?
在数据库中,主码、候选码、主属性和非主属性是几个重要的概念,它们对于理解数据库的结构和数据的完整性至关重要。以下是对这些概念的详细解释: 一、主码(Primary Key) 定义:主码,也被称为主键…...

jetson_yolo_deployment 01_linux_dev_env
01 — Linux 开发环境搭建作者:智汇嵌入式实验室 7yewh 本文件是 Jetson YOLO 部署系列的第 1 篇。 目标:从"能用 Linux"到"能在 Linux 上高效开发"。你现在的水平 vs 部署需要的水平 你现在会的: 部署 YO…...

专科生收藏!口碑爆棚的降AIGC网站 —— 千笔·降AIGC助手
在AI技术迅速渗透学术写作领域的当下,越来越多的学生和研究者开始依赖AI工具进行论文撰写与内容生成。然而,随着各大查重系统对AI生成内容的识别能力不断提升,AI率超标已成为困扰无数学子的“隐形炸弹”——轻则被要求修改,重则影…...

隧道衬砌损伤多场耦合分析
COMSOL案例实现隧道衬砌结构多场耦合细观损伤 本案例以混凝土衬砌的损伤为主线,从细观角度,在多场耦合分析方程中引入损伤变量,应用COMSOL实现衬砌损伤过程中的热-湿-力场三场耦合模型。 利用COMSOL实现衬砌混凝土温度、湿度、气动荷载相互作…...

航空航天需求:Vue3如何扩展百度WebUploader支持卫星遥感数据的分片校验上传?
大文件上传方案探索:从WebUploader到自定义分片上传的实践 作为一名前端开发工程师,最近遇到了一个颇具挑战性的需求:需要在Vue项目中实现4GB左右大文件的稳定上传,且要兼容Chrome、Firefox、Edge等主流浏览器,后端使…...

保姆级教程:用Ollama快速部署Yi-Coder-1.5B代码生成模型
保姆级教程:用Ollama快速部署Yi-Coder-1.5B代码生成模型 1. 引言 作为一名开发者,你是否经常遇到这样的场景:面对一个复杂功能时,脑海中已经有了大致思路,却卡在具体实现细节上?或者需要快速验证某个算法…...

零基础部署Qwen2.5-7B-Instruct:5分钟搭建本地智能对话助手
零基础部署Qwen2.5-7B-Instruct:5分钟搭建本地智能对话助手 想体验专业级大模型的强大能力,但又担心云端服务的隐私问题和高昂成本?今天,我们就来手把手教你,如何在5分钟内,零基础搭建一个完全运行在你本地…...

Qwen3系统数据库设计:使用MySQL存储任务与字幕数据
Qwen3系统数据库设计:使用MySQL存储任务与字幕数据 今天咱们来聊聊怎么给一个智能字幕对齐系统——比如叫它Qwen3吧——设计一个靠谱的后端数据库。你可能已经用上了各种AI模型来处理视频和字幕,但生成的结果、处理的任务状态,这些数据总得有…...

Moondream2在网络安全中的应用:恶意图片内容检测
Moondream2在网络安全中的应用:恶意图片内容检测 1. 当图片成为攻击入口:一个被忽视的安全盲区 你有没有想过,一张看似普通的图片,可能正悄悄携带恶意代码?在日常工作中,我们习惯性地把注意力放在文件后缀…...

ESP32-S3全功能学习平台:USB双模+电源管理+LVGL触控一体化设计
1. 项目概述ESP-POCKET2 是一款面向嵌入式开发者与硬件学习者的全功能 ESP32-S3 开发平台,其设计目标并非仅满足基础烧录与外设驱动验证,而是构建一个可长期伴随工程能力成长的“系统级学习载体”。该开发板以 ESP32-S3-WROOM-01(N16R8&#…...

威拉里发布多款金属3D打印新材料!三期项目与国外工厂全力推进!
当前,3D打印正迈入规模化生产新阶段,金属粉末的品质一致性与供应稳定性,直接决定了规模化生产的可行性与经济性。近日,国内3D打印金属粉末领域的龙头企业威拉里,接连发布多款针对不同高端制造领域的新型金属粉末材料&a…...