代码随想录算法训练营第70天图论9[1]
代码随想录算法训练营第70天:图论9
拓扑排序精讲
卡码网:117. 软件构建(opens new window)
题目描述:
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。
输入描述:
第一行输入两个正整数 M, N。表示 N 个文件之间拥有 M 条依赖关系。
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
输出描述:
输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
如果不能成功处理(相互依赖),则输出 -1。
输入示例:
5 4
0 1
0 2
1 3
2 4
输出示例:
0 1 2 3 4
提示信息:
文件依赖关系如下:
所以,文件处理的顺序除了示例中的顺序,还存在
0 2 4 1 3
0 2 1 3 4
等等合法的顺序。
数据范围:
- 0 <= N <= 10 ^ 5
- 1 <= M <= 10 ^ 9
#拓扑排序的背景
本题是拓扑排序的经典题目。
一聊到 拓扑排序,一些录友可能会想这是排序,不会想到这是图论算法。
其实拓扑排序是经典的图论问题。
先说说 拓扑排序的应用场景。
大学排课,例如 先上A课,才能上B课,上了B课才能上C课,上了A课才能上D课,等等一系列这样的依赖顺序。 问给规划出一条 完整的上课顺序。
拓扑排序在文件处理上也有应用,我们在做项目安装文件包的时候,经常发现 复杂的文件依赖关系, A依赖B,B依赖C,B依赖D,C依赖E 等等。
如果给出一条线性的依赖顺序来下载这些文件呢?
有录友想上面的例子都很简单啊,我一眼能给排序出来。
那如果上面的依赖关系是一百对呢,一千对甚至上万个依赖关系,这些依赖关系中可能还有循环依赖,你如何发现循环依赖呢,又如果排出线性顺序呢。
所以 拓扑排序就是专门解决这类问题的。
概括来说,给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序。
当然拓扑排序也要检测这个有向图 是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。
所以拓扑排序也是图论中判断有向无环图的常用方法。
#拓扑排序的思路
拓扑排序指的是一种 解决问题的大体思路, 而具体算法,可能是广搜也可能是深搜。
大家可能发现 各式各样的解法,纠结哪个是拓扑排序?
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS
卡恩1962年提出这种解决拓扑排序的思路
一般来说我们只需要掌握 BFS (广度优先搜索)就可以了,清晰易懂,如果还想多了解一些,可以再去学一下 DFS 的思路,但 DFS 不是本篇重点。
接下来我们来讲解BFS的实现思路。
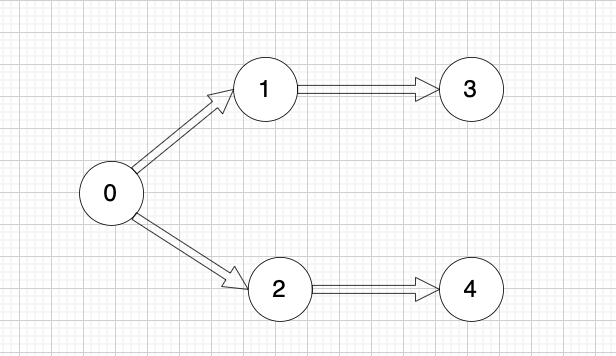
以题目中示例为例如图:

做拓扑排序的话,如果肉眼去找开头的节点,一定能找到 节点0 吧,都知道要从节点0 开始。
但为什么我们能找到 节点0呢,因为我们肉眼看着 这个图就是从 节点0出发的。
作为出发节点,它有什么特征?
你看节点0 的入度 为0 出度为2, 也就是 没有边指向它,而它有两条边是指出去的。
节点的入度表示 有多少条边指向它,节点的出度表示有多少条边 从该节点出发。
所以当我们做拓扑排序的时候,应该优先找 入度为 0 的节点,只有入度为0,它才是出发节点。 理解以上内容很重要!
接下来我给出 拓扑排序的过程,其实就两步:
- 找到入度为0 的节点,加入结果集
- 将该节点从图中移除
循环以上两步,直到 所有节点都在图中被移除了。
结果集的顺序,就是我们想要的拓扑排序顺序 (结果集里顺序可能不唯一)
#模拟过程
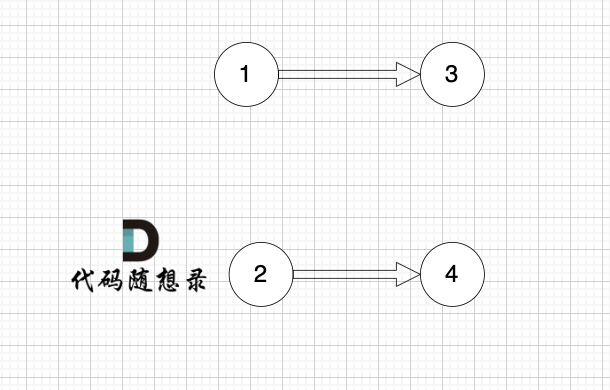
用本题的示例来模拟这一过程:
1、找到入度为0 的节点,加入结果集

2、将该节点从图中移除
1、找到入度为0 的节点,加入结果集
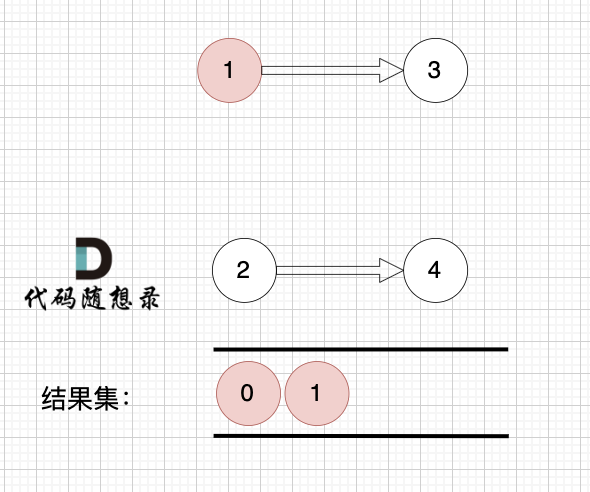
这里大家会发现,节点1 和 节点2 入度都为0, 选哪个呢?
选哪个都行,所以这也是为什么拓扑排序的结果是不唯一的。
2、将该节点从图中移除

1、找到入度为0 的节点,加入结果集
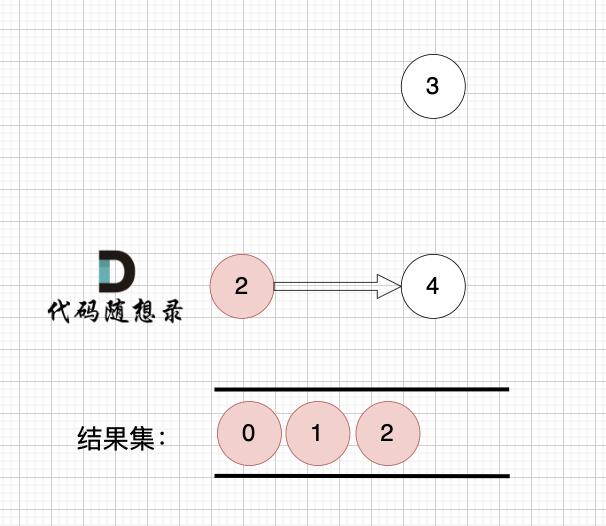
节点2 和 节点3 入度都为0,选哪个都行,这里选节点2
2、将该节点从图中移除
后面的过程一样的,节点3 和 节点4,入度都为0,选哪个都行。
最后结果集为: 0 1 2 3 4 。当然结果不唯一的。
#判断有环
如果有 有向环怎么办呢?例如这个图:

这个图,我们只能将入度为0 的节点0 接入结果集。
之后,节点1、2、3、4 形成了环,找不到入度为0 的节点了,所以此时结果集里只有一个元素。
那么如果我们发现结果集元素个数 不等于 图中节点个数,我们就可以认定图中一定有 有向环!
这也是拓扑排序判断有向环的方法。
通过以上过程的模拟大家会发现这个拓扑排序好像不难,还有点简单。
#写代码
理解思想后,确实不难,但代码写起来也不容易。
为了每次可以找到所有节点的入度信息,我们要在初始话的时候,就把每个节点的入度 和 每个节点的依赖关系做统计。
代码如下:
cin >> n >> m;
vector<int> inDegree(n, 0); // 记录每个文件的入度
vector<int> result; // 记录结果
unordered_map<int, vector<int>> umap; // 记录文件依赖关系while (m--) {
// s->t,先有s才能有t
cin >> s >> t;
inDegree[t]++; // t的入度加一
umap[s].push_back(t); // 记录s指向哪些文件
}找入度为0 的节点,我们需要用一个队列放存放。
因为每次寻找入度为0的节点,不一定只有一个节点,可能很多节点入度都为0,所以要将这些入度为0的节点放到队列里,依次去处理。
代码如下:
queue<int> que;
for (int i = 0; i < n; i++) {
// 入度为0的节点,可以作为开头,先加入队列
if (inDegree[i] == 0) que.push(i);
}
开始从队列里遍历入度为0 的节点,将其放入结果集。
while (que.size()) {
int cur = que.front(); // 当前选中的节点
que.pop();
result.push_back(cur);
// 将该节点从图中移除 }
这里面还有一个很重要的过程,如何把这个入度为0的节点从图中移除呢?
首先我们为什么要把节点从图中移除?
为的是将 该节点作为出发点所连接的边删掉。
删掉的目的是什么呢?
要把 该节点作为出发点所连接的节点的 入度 减一。
如果这里不理解,看上面的模拟过程第一步:
这事节点1 和 节点2 的入度为 1。
将节点0删除后,图为这样:
那么 节点0 作为出发点 所连接的节点的入度 就都做了 减一 的操作。
此时 节点1 和 节点 2 的入度都为0, 这样才能作为下一轮选取的节点。
所以,我们在代码实现的过程中,本质是要将 该节点作为出发点所连接的节点的 入度 减一 就可以了,这样好能根据入度找下一个节点,不用真在图里把这个节点删掉。
该过程代码如下:
while (que.size()) {
int cur = que.front(); // 当前选中的节点
que.pop();
result.push_back(cur);
// 将该节点从图中移除
vector<int> files = umap[cur]; //获取cur指向的节点
if (files.size()) { // 如果cur有指向的节点
for (int i = 0; i < files.size(); i++) { // 遍历cur指向的节点
inDegree[files[i]] --; // cur指向的节点入度都做减一操作
// 如果指向的节点减一之后,入度为0,说明是我们要选取的下一个节点,放入队列。
if(inDegree[files[i]] == 0) que.push(files[i]);
}
}}
最后代码如下:
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
int main() {
int m, n, s, t;
cin >> n >> m;
vector<int> inDegree(n, 0); // 记录每个文件的入度unordered_map<int, vector<int>> umap;// 记录文件依赖关系
vector<int> result; // 记录结果while (m--) {
// s->t,先有s才能有t
cin >> s >> t;
inDegree[t]++; // t的入度加一
umap[s].push_back(t); // 记录s指向哪些文件
}
queue<int> que;
for (int i = 0; i < n; i++) {
// 入度为0的文件,可以作为开头,先加入队列
if (inDegree[i] == 0) que.push(i);
//cout << inDegree[i] << endl;
}
// int count = 0;
while (que.size()) {
int cur = que.front(); // 当前选中的文件
que.pop();
//count++;
result.push_back(cur);
vector<int> files = umap[cur]; //获取该文件指向的文件
if (files.size()) { // cur有后续文件
for (int i = 0; i < files.size(); i++) {
inDegree[files[i]] --; // cur的指向的文件入度-1
if(inDegree[files[i]] == 0) que.push(files[i]);
}
}
}
if (result.size() == n) {
for (int i = 0; i < n - 1; i++) cout << result[i] << " ";
cout << result[n - 1];
} else cout << -1 << endl;}
dijkstra(朴素版)精讲
卡码网:47. 参加科学大会(opens new window)
【题目描述】
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
【输入描述】
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
【输出描述】
输出一个整数,代表小明从起点到终点所花费的最小时间。
输入示例
7 9
1 2 1
1 3 4
2 3 2
2 4 5
3 4 2
4 5 3
2 6 4
5 7 4
6 7 9
输出示例:12
【提示信息】
能够到达的情况:
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。

不能到达的情况:
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。

数据范围:
1 <= N <= 500; 1 <= M <= 5000;
#思路
本题就是求最短路,最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。
接下来,我们来详细讲解最短路算法中的 dijkstra 算法。
dijkstra算法:在有权图(权值非负数)中求从起点到其他节点的最短路径算法。
需要注意两点:
- dijkstra 算法可以同时求 起点到所有节点的最短路径
- 权值不能为负数
(这两点后面我们会讲到)
如本题示例中的图:

起点(节点1)到终点(节点7) 的最短路径是 图中 标记绿线的部分。
最短路径的权值为12。
其实 dijkstra 算法 和 我们之前讲解的prim算法思路非常接近,如果大家认真学过prim算法,那么理解 Dijkstra 算法会相对容易很多。(这也是我要先讲prim再讲dijkstra的原因)
dijkstra 算法 同样是贪心的思路,不断寻找距离 源点最近的没有访问过的节点。
这里我也给出 dijkstra三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)
大家此时已经会发现,这和prim算法 怎么这么像呢。
我在prim算法讲解中也给出了三部曲。 prim 和 dijkstra 确实很像,思路也是类似的,这一点我在后面还会详细来讲。
在dijkstra算法中,同样有一个数组很重要,起名为:minDist。
minDist数组 用来记录 每一个节点距离源点的最小距离。
理解这一点很重要,也是理解 dijkstra 算法的核心所在。
大家现在看着可能有点懵,不知道什么意思。
没关系,先让大家有一个印象,对理解后面讲解有帮助。
我们先来画图看一下 dijkstra 的工作过程,以本题示例为例: (以下为朴素版dijkstra的思路)
(示例中节点编号是从1开始,所以为了让大家看的不晕,minDist数组下标我也从 1 开始计数,下标0 就不使用了,这样 下标和节点标号就可以对应上了,避免大家搞混)
#朴素版dijkstra
#模拟过程
0、初始化
minDist数组数值初始化为int最大值。
这里在强点一下 minDist数组的含义:记录所有节点到源点的最短路径,那么初始化的时候就应该初始为最大值,这样才能在后续出现最短路径的时候及时更新。

(图中,max 表示默认值,节点0 不做处理,统一从下标1 开始计算,这样下标和节点数值统一, 方便大家理解,避免搞混)
源点(节点1) 到自己的距离为0,所以 minDist[1] = 0
此时所有节点都没有被访问过,所以 visited数组都为0
以下为dijkstra 三部曲
1、选源点到哪个节点近且该节点未被访问过
源点距离源点最近,距离为0,且未被访问。
2、该最近节点被标记访问过
标记源点访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
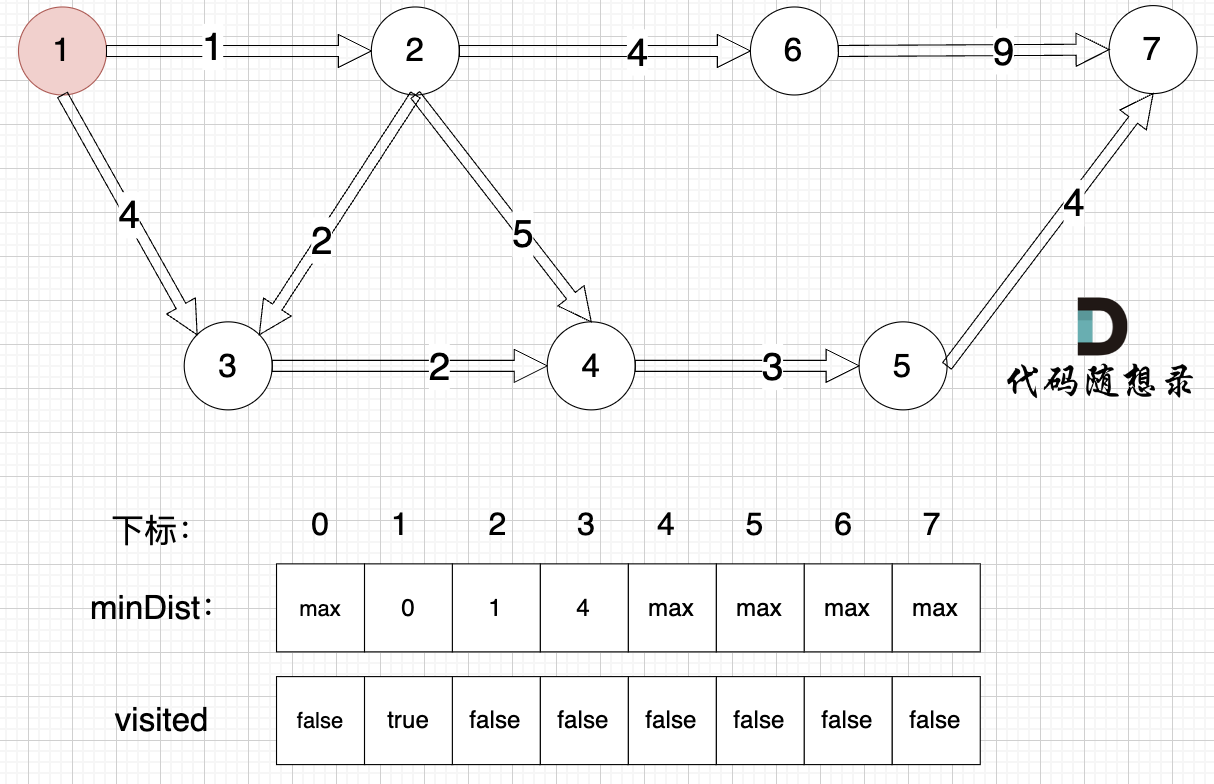
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
- 源点到节点2的最短距离为1,小于原minDist[2]的数值max,更新minDist[2] = 1
- 源点到节点3的最短距离为4,小于原minDist[3]的数值max,更新minDist[4] = 4
可能有录友问:为啥和 minDist[2] 比较?
再强调一下 minDist[2] 的含义,它表示源点到节点2的最短距离,那么目前我们得到了 源点到节点2的最短距离为1,小于默认值max,所以更新。 minDist[3]的更新同理
1、选源点到哪个节点近且该节点未被访问过
未访问过的节点中,源点到节点2距离最近,选节点2
2、该最近节点被标记访问过
节点2被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
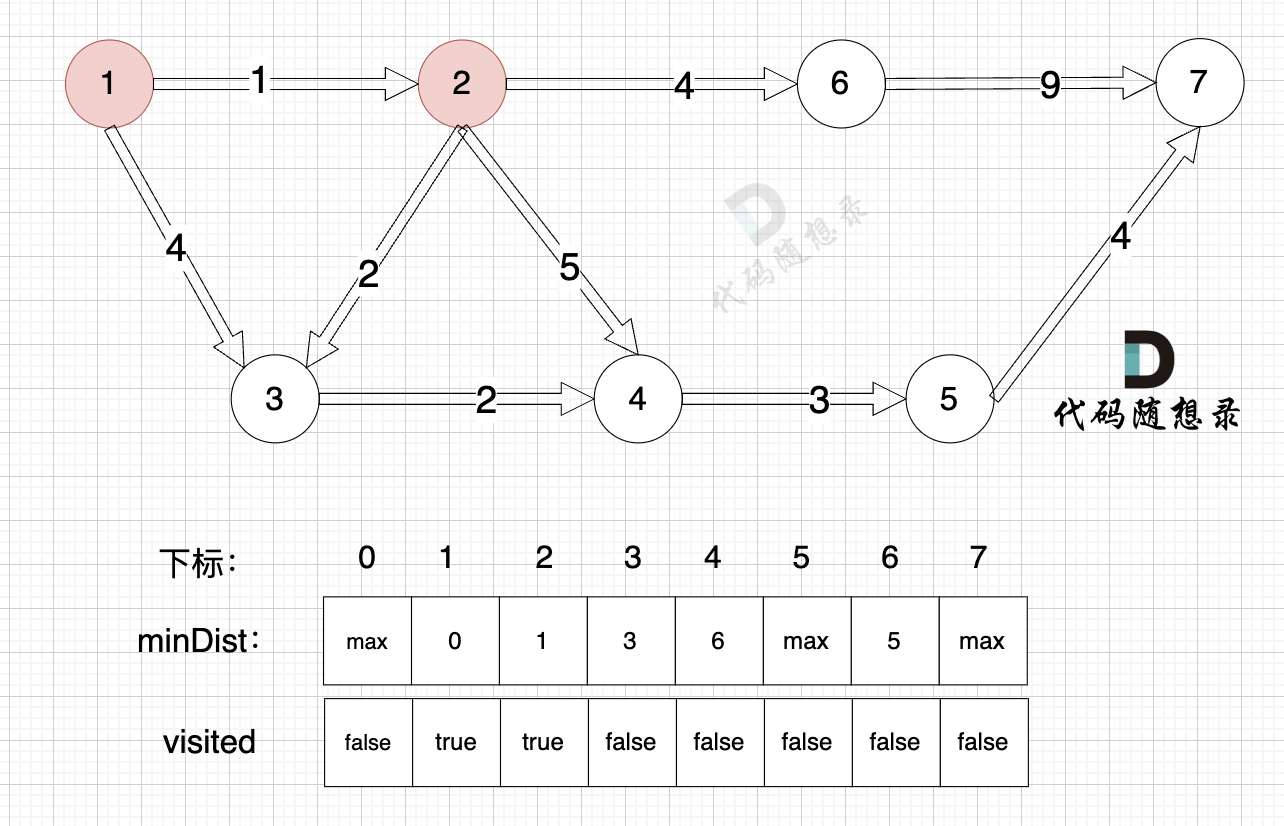
更新 minDist数组,即:源点(节点1) 到 节点6 、 节点3 和 节点4的距离。
为什么更新这些节点呢? 怎么不更新其他节点呢?
因为 源点(节点1)通过 已经计算过的节点(节点2) 可以链接到的节点 有 节点3,节点4和节点6.
更新 minDist数组:
- 源点到节点6的最短距离为5,小于原minDist[6]的数值max,更新minDist[6] = 5
- 源点到节点3的最短距离为3,小于原minDist[3]的数值4,更新minDist[3] = 3
- 源点到节点4的最短距离为6,小于原minDist[4]的数值max,更新minDist[4] = 6
1、选源点到哪个节点近且该节点未被访问过
未访问过的节点中,源点距离哪些节点最近,怎么算的?
其实就是看 minDist数组里的数值,minDist 记录了 源点到所有节点的最近距离,结合visited数组筛选出未访问的节点就好。
从 上面的图,或者 从minDist数组中,我们都能看出 未访问过的节点中,源点(节点1)到节点3距离最近。
2、该最近节点被标记访问过
节点3被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
更新 minDist数组:
- 源点到节点4的最短距离为5,小于原minDist[4]的数值6,更新minDist[4] = 5
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,有节点4 和 节点6,距离源点距离都是 5 (minDist[4] = 5,minDist[6] = 5) ,选哪个节点都可以。
2、该最近节点被标记访问过
节点4被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

由于节点4的加入,那么源点可以链接到节点5 所以更新minDist数组:
- 源点到节点5的最短距离为8,小于原minDist[5]的数值max,更新minDist[5] = 8
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,是节点6,距离源点距离是 5 (minDist[6] = 5)
2、该最近节点被标记访问过
节点6 被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

由于节点6的加入,那么源点可以链接到节点7 所以 更新minDist数组:
- 源点到节点7的最短距离为14,小于原minDist[7]的数值max,更新minDist[7] = 14
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,是节点5,距离源点距离是 8 (minDist[5] = 8)
2、该最近节点被标记访问过
节点5 被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

由于节点5的加入,那么源点有新的路径可以链接到节点7 所以 更新minDist数组:
- 源点到节点7的最短距离为12,小于原minDist[7]的数值14,更新minDist[7] = 12
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,是节点7(终点),距离源点距离是 12 (minDist[7] = 12)
2、该最近节点被标记访问过
节点7 被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
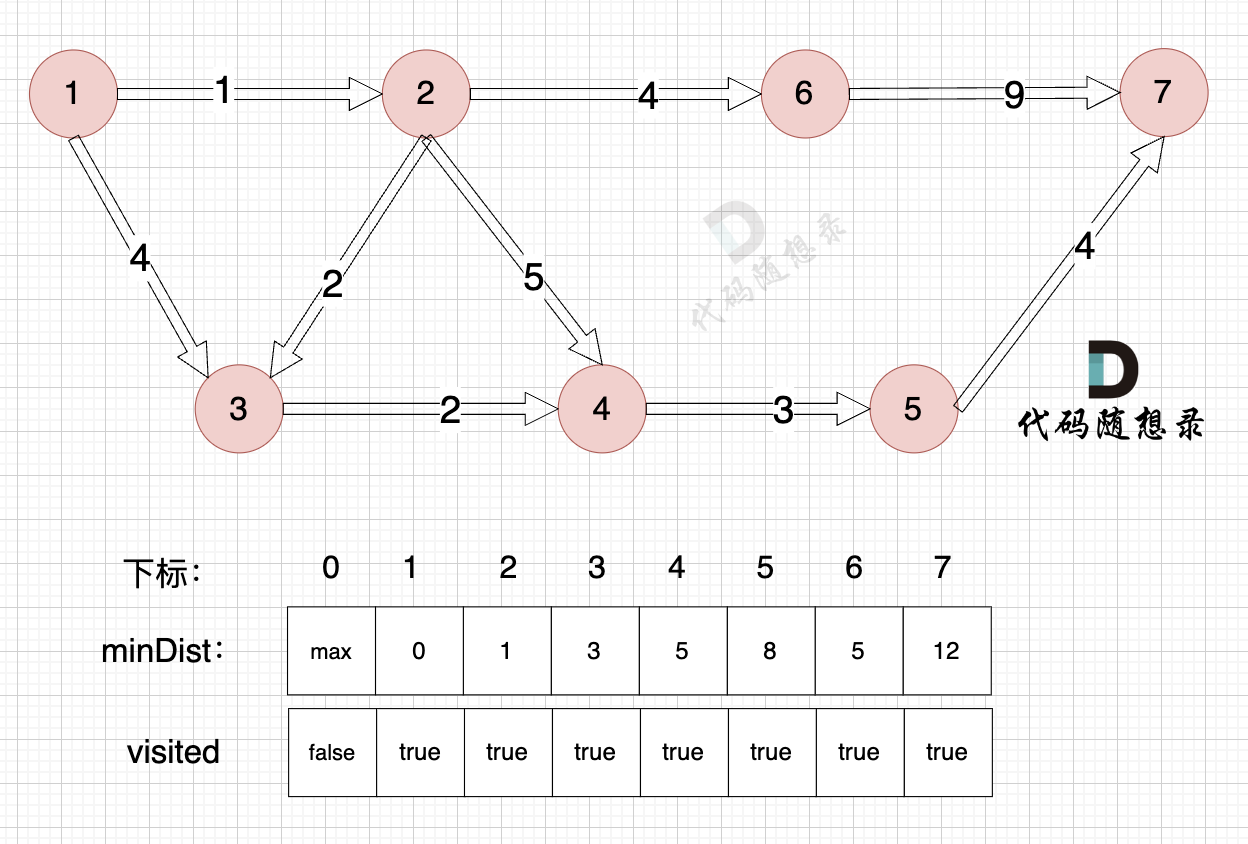
节点7加入,但节点7到节点7的距离为0,所以 不用更新minDist数组
最后我们要求起点(节点1) 到终点 (节点7)的距离。
再来回顾一下minDist数组的含义:记录 每一个节点距离源点的最小距离。
那么起到(节点1)到终点(节点7)的最短距离就是 minDist[7] ,按上面举例讲解来说,minDist[7] = 12,节点1 到节点7的最短路径为 12。
路径如图:

在上面的讲解中,每一步 我都是按照 dijkstra 三部曲来讲解的,理解了这三部曲,代码也就好懂的。
#代码实现
本题代码如下,里面的 三部曲 我都做了注释,大家按照我上面的讲解 来看如下代码:
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
grid[p1][p2] = val;
}int start = 1;
int end = n;// 存储从源点到每个节点的最短距离
std::vector<int> minDist(n + 1, INT_MAX);// 记录顶点是否被访问过
std::vector<bool> visited(n + 1, false);minDist[start] = 0; // 起始点到自身的距离为0for (int i = 1; i <= n; i++) { // 遍历所有节点int minVal = INT_MAX;
int cur = 1;// 1、选距离源点最近且未访问过的节点
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}visited[cur] = true; // 2、标记该节点已被访问// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}}if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
else cout << minDist[end] << endl; // 到达终点最短路径}
- 时间复杂度:O(n^2)
- 空间复杂度:O(n^2)
#debug方法
写这种题目难免会有各种各样的问题,我们如何发现自己的代码是否有问题呢?
最好的方式就是打日志,本题的话,就是将 minDist 数组打印出来,就可以很明显发现 哪里出问题了。
每次选择节点后,minDist数组的变化是否符合预期 ,是否和我上面讲的逻辑是对应的。
例如本题,如果想debug的话,打印日志可以这样写:
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
grid[p1][p2] = val;
}int start = 1;
int end = n;std::vector<int> minDist(n + 1, INT_MAX);std::vector<bool> visited(n + 1, false);minDist[start] = 0;
for (int i = 1; i <= n; i++) {int minVal = INT_MAX;
int cur = 1;for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}visited[cur] = true;for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}// 打印日志:
cout << "select:" << cur << endl;
for (int v = 1; v <= n; v++) cout << v << ":" << minDist[v] << " ";
cout << endl << endl;;}
if (minDist[end] == INT_MAX) cout << -1 << endl;
else cout << minDist[end] << endl;}打印后的结果:
select:1
1:0 2:1 3:4 4:2147483647 5:2147483647 6:2147483647 7:2147483647select:2
1:0 2:1 3:3 4:6 5:2147483647 6:5 7:2147483647select:3
1:0 2:1 3:3 4:5 5:2147483647 6:5 7:2147483647select:4
1:0 2:1 3:3 4:5 5:8 6:5 7:2147483647select:6
1:0 2:1 3:3 4:5 5:8 6:5 7:14select:5
1:0 2:1 3:3 4:5 5:8 6:5 7:12select:7
1:0 2:1 3:3 4:5 5:8 6:5 7:12
打印日志可以和上面我讲解的过程进行对比,每一步的结果是完全对应的。
所以如果大家如果代码有问题,打日志来debug是最好的方法
#如何求路径
如果题目要求把最短路的路径打印出来,应该怎么办呢?
这里还是有一些“坑”的,本题打印路径和 prim 打印路径是一样的,我在 prim算法精讲 【拓展】中 已经详细讲解了。
在这里就不再赘述。
打印路径只需要添加 几行代码, 打印路径的代码我都加上的日志,如下:
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
grid[p1][p2] = val;
}int start = 1;
int end = n;std::vector<int> minDist(n + 1, INT_MAX);std::vector<bool> visited(n + 1, false);minDist[start] = 0; //加上初始化
vector<int> parent(n + 1, -1);for (int i = 1; i <= n; i++) {int minVal = INT_MAX;
int cur = 1;for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}visited[cur] = true;for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
parent[v] = cur; // 记录边
}
}}// 输出最短情况
for (int i = 1; i <= n; i++) {
cout << parent[i] << "->" << i << endl;
}
}
打印结果:
-1->1
1->2
2->3
3->4
4->5
2->6
5->7
对应如图:

#出现负数
如果图中边的权值为负数,dijkstra 还合适吗?
看一下这个图: (有负权值)

节点1 到 节点5 的最短路径 应该是 节点1 -> 节点2 -> 节点3 -> 节点4 -> 节点5
那我们来看dijkstra 求解的路径是什么样的,继续dijkstra 三部曲来模拟 :(dijkstra模拟过程上面已经详细讲过,以下只模拟重要过程,例如如何初始化就省略讲解了)
初始化:
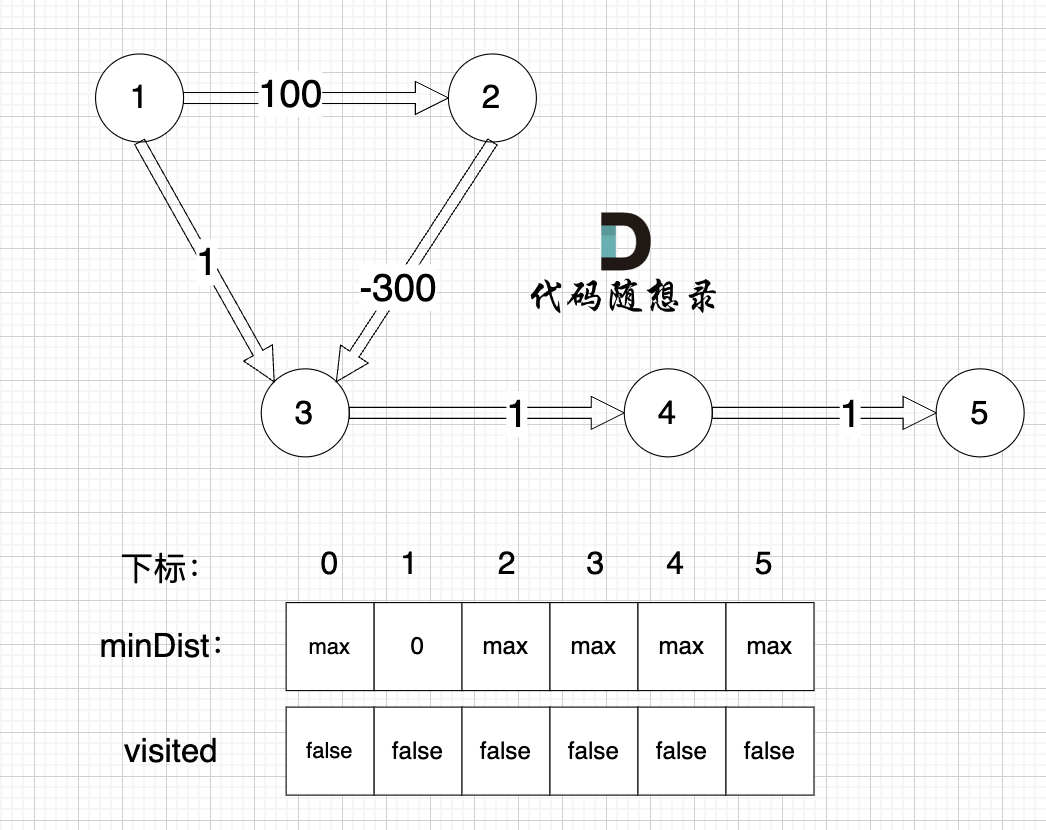
1、选源点到哪个节点近且该节点未被访问过
源点距离源点最近,距离为0,且未被访问。
2、该最近节点被标记访问过
标记源点访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
- 源点到节点2的最短距离为100,小于原minDist[2]的数值max,更新minDist[2] = 100
- 源点到节点3的最短距离为1,小于原minDist[3]的数值max,更新minDist[4] = 1
1、选源点到哪个节点近且该节点未被访问过
源点距离节点3最近,距离为1,且未被访问。
2、该最近节点被标记访问过
标记节点3访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
- 源点到节点4的最短距离为2,小于原minDist[4]的数值max,更新minDist[4] = 2
1、选源点到哪个节点近且该节点未被访问过
源点距离节点4最近,距离为2,且未被访问。
2、该最近节点被标记访问过
标记节点4访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

由于节点4的加入,那么源点可以有新的路径链接到节点5 所以更新minDist数组:
- 源点到节点5的最短距离为3,小于原minDist[5]的数值max,更新minDist[5] = 5
1、选源点到哪个节点近且该节点未被访问过
源点距离节点5最近,距离为3,且未被访问。
2、该最近节点被标记访问过
标记节点5访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
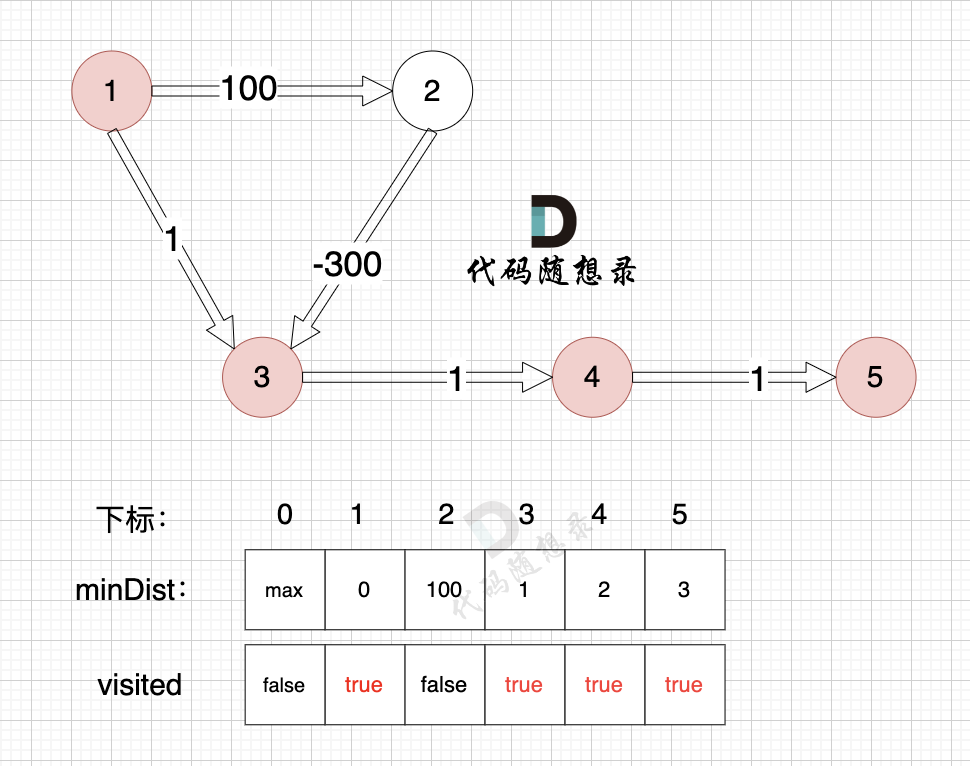
节点5的加入,而节点5 没有链接其他节点, 所以不用更新minDist数组,仅标记节点5被访问过了
1、选源点到哪个节点近且该节点未被访问过
源点距离节点2最近,距离为100,且未被访问。
2、该最近节点被标记访问过
标记节点2访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

至此dijkstra的模拟过程就结束了,根据最后的minDist数组,我们求 节点1 到 节点5 的最短路径的权值总和为 3,路径: 节点1 -> 节点3 -> 节点4 -> 节点5
通过以上的过程模拟,我们可以发现 之所以 没有走有负权值的最短路径 是因为 在 访问 节点 2 的时候,节点 3 已经访问过了,就不会再更新了。
那有录友可能会想: 我可以改代码逻辑啊,访问过的节点,也让它继续访问不就好了?
那么访问过的节点还能继续访问会不会有死循环的出现呢?控制逻辑不让其死循环?那特殊情况自己能都想清楚吗?(可以试试,实践出真知)
对于负权值的出现,大家可以针对某一个场景 不断去修改 dijkstra 的代码,但最终会发现只是 拆了东墙补西墙,对dijkstra的补充逻辑只能满足某特定场景最短路求解。
对于求解带有负权值的最短路问题,可以使用 Bellman-Ford 算法 ,我在后序会详细讲解。
#dijkstra与prim算法的区别
这里再次提示,需要先看我的 prim算法精讲 ,否则可能不知道我下面讲的是什么。
大家可以发现 dijkstra的代码看上去 怎么和 prim算法这么像呢。
其实代码大体不差,唯一区别在 三部曲中的 第三步: 更新minDist数组
因为prim是求 非访问节点到最小生成树的最小距离,而 dijkstra是求 非访问节点到源点的最小距离。
prim 更新 minDist数组的写法:
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
因为 minDist表示 节点到最小生成树的最小距离,所以 新节点cur的加入,只需要 使用 grid[cur][j] ,grid[cur][j] 就表示 cur 加入生成树后,生成树到 节点j 的距离。
dijkstra 更新 minDist数组的写法:
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
因为 minDist表示 节点到源点的最小距离,所以 新节点 cur 的加入,需要使用 源点到cur的距离 (minDist[cur]) + cur 到 节点 v 的距离 (grid[cur][v]),才是 源点到节点v的距离。
此时大家可能不禁要想 prim算法 可以有负权值吗?
当然可以!
录友们可以自己思考思考一下,这是为什么?
这里我提示一下:prim算法只需要将节点以最小权值和链接在一起,不涉及到单一路径。
#总结
本篇,我们深入讲解的dijkstra算法,详细模拟其工作的流程。
这里我给出了 dijkstra 三部曲 来 帮助大家理解 该算法,不至于 每次写 dijkstra 都是黑盒操作,没有框架没有章法。
在给出的代码中,我也按照三部曲的逻辑来给大家注释,只要理解这三部曲,即使 过段时间 对 dijkstra 算法有些遗忘,依然可以写出一个框架出来,然后再去调试细节。
对于图论算法,一般代码都比较长,很难写出代码直接可以提交通过,都需要一个debug的过程,所以 学习如何debug 非常重要!
这也是我为什么 在本文中 单独用来讲解 debug方法。
本题求的是最短路径和是多少,同时我们也要掌握 如何把最短路径打印出来。
我还写了大篇幅来讲解 负权值的情况, 只有画图带大家一步一步去 看 出现负权值 dijkstra的求解过程,才能帮助大家理解,问题出在哪里。
如果我直接讲:是因为访问过的节点 不能再访问,导致错过真正的最短路,我相信大家都不知道我在说啥。
最后我还讲解了 dijkstra 和 prim 算法的 相同 与 不同之处, 我在图论的讲解安排中 先讲 prim算法 再讲 dijkstra 是有目的的, 理解这两个算法的相同与不同之处 有助于大家学习的更深入。
而不是 学了 dijkstra 就只看 dijkstra, 算法之间 都是有联系的,多去思考 算法之间的相互联系,会帮助大家思考的更深入,掌握的更彻底。
本篇写了这么长,我也只讲解了 朴素版dijkstra,关于 堆优化dijkstra,我会在下一篇再来给大家详细讲解。
加油
dijkstra(堆优化版)精讲
卡码网:47. 参加科学大会(opens new window)
【题目描述】
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
【输入描述】
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
【输出描述】
输出一个整数,代表小明从起点到终点所花费的最小时间。
输入示例
7 9
1 2 1
1 3 4
2 3 2
2 4 5
3 4 2
4 5 3
2 6 4
5 7 4
6 7 9
输出示例:12
【提示信息】
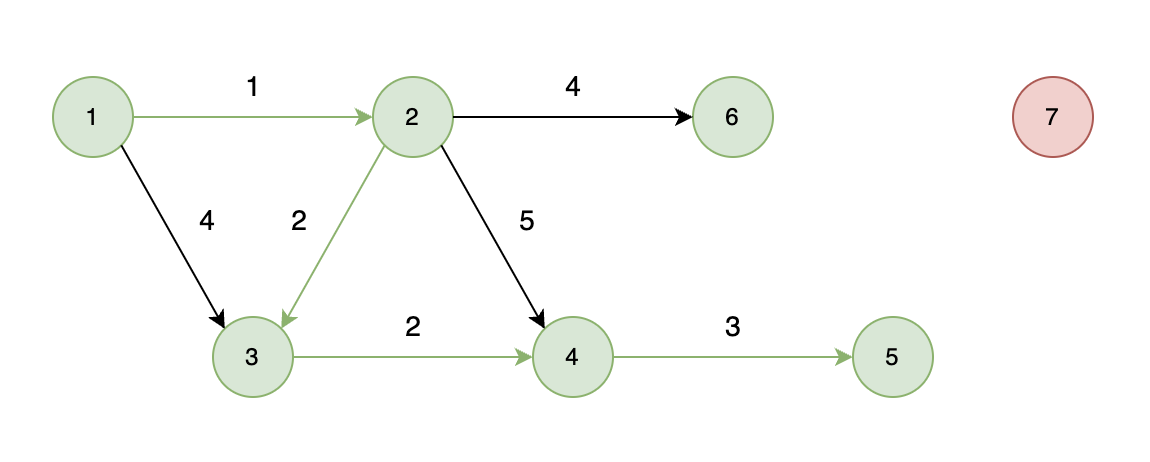
能够到达的情况:
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。

不能到达的情况:
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
数据范围:
1 <= N <= 500; 1 <= M <= 5000;
#思路
本篇我们来讲解 堆优化版dijkstra,看本篇之前,一定要先看 我讲解的 朴素版dijkstra,否则本篇会有部分内容看不懂。
在上一篇中,我们讲解了朴素版的dijkstra,该解法的时间复杂度为 O(n^2),可以看出时间复杂度 只和 n (节点数量)有关系。
如果n很大的话,我们可以换一个角度来优先性能。
在 讲解 最小生成树的时候,我们 讲了两个算法,prim算法(从点的角度来求最小生成树)、Kruskal算法(从边的角度来求最小生成树)
这么在n 很大的时候,也有另一个思考维度,即:从边的数量出发。
当 n 很大,边 的数量 也很多的时候(稠密图),那么 上述解法没问题。
但 n 很大,边 的数量 很小的时候(稀疏图),是不是可以换成从边的角度来求最短路呢?
毕竟边的数量少。
有的录友可能会想,n (节点数量)很大,边不就多吗? 怎么会边的数量少呢?
别忘了,谁也没有规定 节点之间一定要有边连接着,例如有一万个节点,只有一条边,这也是一张图。
了解背景之后,再来看 解法思路。
#图的存储
首先是 图的存储。
关于图的存储 主流有两种方式: 邻接矩阵和邻接表
#邻接矩阵
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
例如: grid[2][5] = 6,表示 节点 2 链接 节点5 为有向图,节点2 指向 节点5,边的权值为6 (套在题意里,可能是距离为6 或者 消耗为6 等等)
如果想表示无向图,即:grid[2][5] = 6,grid[5][2] = 6,表示节点2 与 节点5 相互连通,权值为6。
如图:

在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间,有一条双向边,即:grid[2][5] = 6,grid[5][2] = 6
这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。
而且在寻找节点链接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
邻接矩阵的优点:
- 表达方式简单,易于理解
- 检查任意两个顶点间是否存在边的操作非常快
- 适合稠密图,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
缺点:
- 遇到稀疏图,会导致申请过大的二维数组造成空间浪费 且遍历 边 的时候需要遍历整个n * n矩阵,造成时间浪费
#邻接表
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
邻接表的构造如图:

这里表达的图是:
- 节点1 指向 节点3 和 节点5
- 节点2 指向 节点4、节点3、节点5
- 节点3 指向 节点4,节点4指向节点1。
有多少边 邻接表才会申请多少个对应的链表节点。
从图中可以直观看出 使用 数组 + 链表 来表达 边的链接情况 。
邻接表的优点:
- 对于稀疏图的存储,只需要存储边,空间利用率高
- 遍历节点链接情况相对容易
缺点:
- 检查任意两个节点间是否存在边,效率相对低,需要 O(V)时间,V表示某节点链接其他节点的数量。
- 实现相对复杂,不易理解
#本题图的存储
接下来我们继续按照稀疏图的角度来分析本题。
在第一个版本的实现思路中,我们提到了三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)
在第一个版本的代码中,这三部曲是套在一个 for 循环里,为什么?
因为我们是从节点的角度来解决问题。
三部曲中第一步(选源点到哪个节点近且该节点未被访问过),这个操作本身需要for循环遍历 minDist 来寻找最近的节点。
同时我们需要 遍历所有 未访问过的节点,所以 我们从 节点角度出发,代码会有两层for循环,代码是这样的: (注意代码中的注释,标记两层for循环的用处)
for (int i = 1; i <= n; i++) { // 遍历所有节点,第一层for循环 int minVal = INT_MAX;
int cur = 1;// 1、选距离源点最近且未访问过的节点 , 第二层for循环
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}visited[cur] = true; // 2、标记该节点已被访问// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}}
那么当从 边 的角度出发, 在处理 三部曲里的第一步(选源点到哪个节点近且该节点未被访问过)的时候 ,我们可以不用去遍历所有节点了。
而且 直接把 边(带权值)加入到 小顶堆(利用堆来自动排序),那么每次我们从 堆顶里 取出 边 自然就是 距离源点最近的节点所在的边。
这样我们就不需要两层for循环来寻找最近的节点了。
了解了大体思路,我们再来看代码实现。
首先是 如何使用 邻接表来表述图结构,这是摆在很多录友面前的第一个难题。
邻接表用 数组+链表 来表示,代码如下:(C++中 vector 为数组,list 为链表, 定义了 n+1 这么大的数组空间)
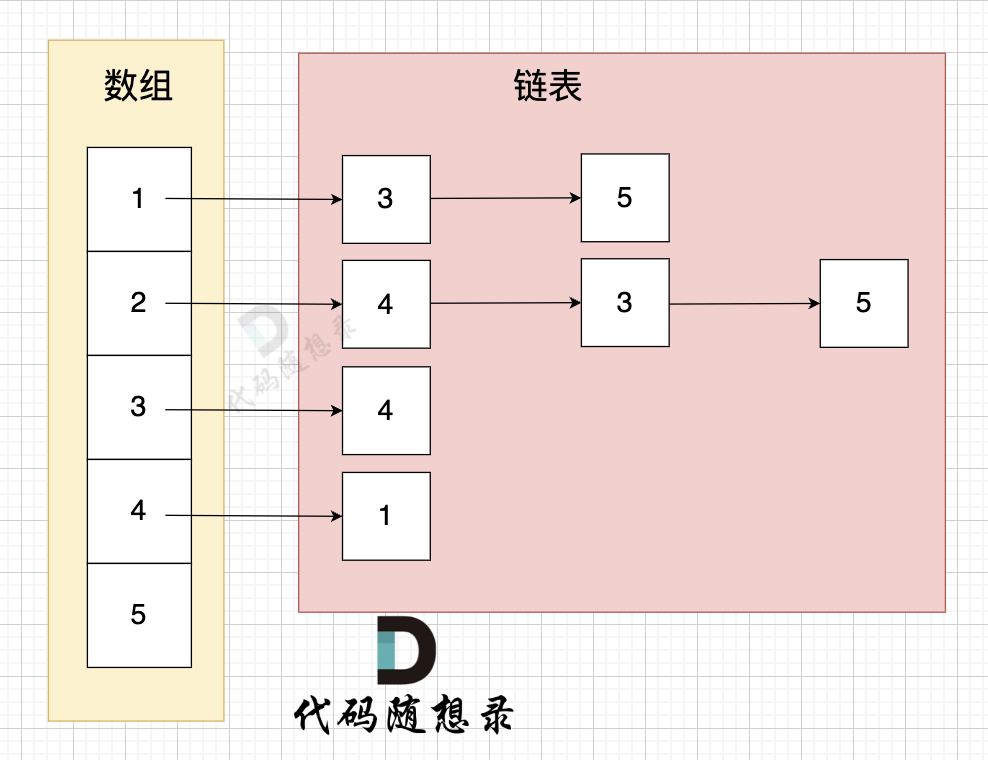
vector<list<int>> grid(n + 1);
不少录友,不知道 如何定义的数据结构,怎么表示邻接表的,我来给大家画一个图:
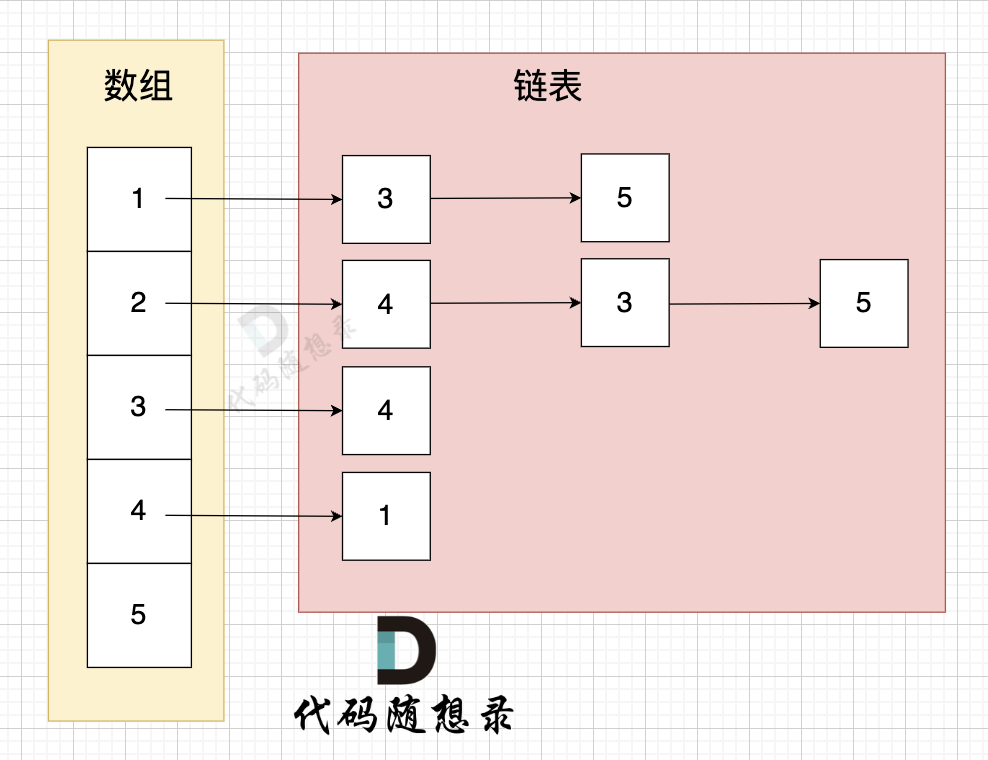
图中邻接表表示:
- 节点1 指向 节点3 和 节点5
- 节点2 指向 节点4、节点3、节点5
- 节点3 指向 节点4
- 节点4 指向 节点1
大家发现图中的边没有权值,而本题中 我们的边是有权值的,权值怎么表示?在哪里表示?
所以 在vector<list<int>> grid(n + 1); 中 就不能使用int了,而是需要一个键值对 来存两个数字,一个数表示节点,一个数表示 指向该节点的这条边的权值。
那么 代码可以改成这样: (pair 为键值对,可以存放两个int)
vector<list<pair<int,int>>> grid(n + 1);
举例来给大家展示 该代码表达的数据 如下:
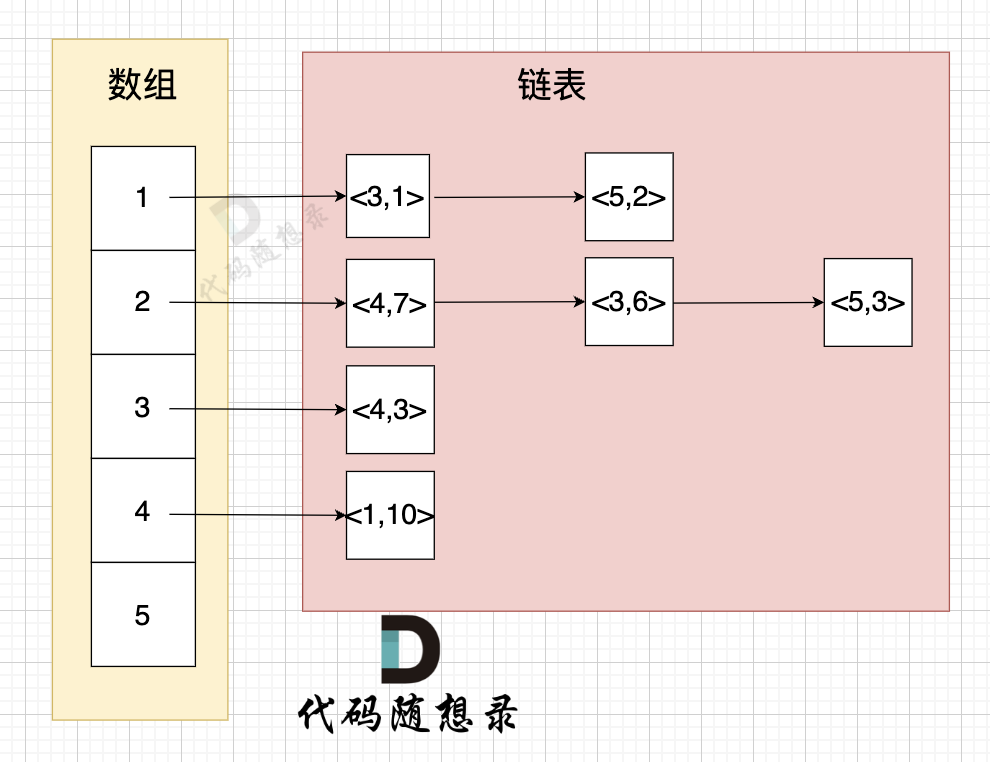
- 节点1 指向 节点3 权值为 1
- 节点1 指向 节点5 权值为 2
- 节点2 指向 节点4 权值为 7
- 节点2 指向 节点3 权值为 6
- 节点2 指向 节点5 权值为 3
- 节点3 指向 节点4 权值为 3
- 节点5 指向 节点1 权值为 10
这样 我们就把图中权值表示出来了。
但是在代码中 使用 pair<int, int> 很容易让我们搞混了,第一个int 表示什么,第二个int表示什么,导致代码可读性很差,或者说别人看你的代码看不懂。
那么 可以 定一个类 来取代 pair<int, int>
类(或者说是结构体)定义如下:
struct Edge {
int to; // 邻接顶点
int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};
这个类里有两个成员变量,有对应的命名,这样不容易搞混 两个int的含义。
所以 本题中邻接表的定义如下:
struct Edge {
int to; // 链接的节点
int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};vector<list<Edge>> grid(n + 1); // 邻接表(我们在下面的讲解中会直接使用这个邻接表的代码表示方式)
#堆优化细节
其实思路依然是 dijkstra 三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)
只不过之前是 通过遍历节点来遍历边,通过两层for循环来寻找距离源点最近节点。 这次我们直接遍历边,且通过堆来对边进行排序,达到直接选择距离源点最近节点。
先来看一下针对这三部曲,如果用 堆来优化。
那么三部曲中的第一步(选源点到哪个节点近且该节点未被访问过),我们如何选?
我们要选择距离源点近的节点(即:该边的权值最小),所以 我们需要一个 小顶堆 来帮我们对边的权值排序,每次从小顶堆堆顶 取边就是权值最小的边。
C++定义小顶堆,可以用优先级队列实现,代码如下:
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
// 优先队列中存放 pair<节点编号,源点到该节点的权值>
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;
(pair<int, int>中 第二个int 为什么要存 源点到该节点的权值,因为 这个小顶堆需要按照权值来排序)
有了小顶堆自动对边的权值排序,那我们只需要直接从 堆里取堆顶元素(小顶堆中,最小的权值在上面),就可以取到离源点最近的节点了 (未访问过的节点,不会加到堆里进行排序)
所以三部曲中的第一步,我们不用 for循环去遍历,直接取堆顶元素:
// pair<节点编号,源点到该节点的权值>
pair<int, int> cur = pq.top(); pq.pop();第二步(该最近节点被标记访问过) 这个就是将 节点做访问标记,和 朴素dijkstra 一样 ,代码如下:
// 2. 第二步,该最近节点被标记访问过
visited[cur.first] = true;(cur.first 是指取 pair<int, int> 里的第一个int,即节点编号 )
第三步(更新非访问节点到源点的距离),这里的思路 也是 和朴素dijkstra一样的。
但很多录友对这里是最懵的,主要是因为两点:
- 没有理解透彻 dijkstra 的思路
- 没有理解 邻接表的表达方式
我们来回顾一下 朴素dijkstra 在这一步的代码和思路(如果没看过我讲解的朴素版dijkstra,这里会看不懂)
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
其中 for循环是用来做什么的? 是为了 找到 节点cur 链接指向了哪些节点,因为使用邻接矩阵的表达方式 所以把所有节点遍历一遍。
而在邻接表中,我们可以以相对高效的方式知道一个节点链接指向哪些节点。
再回顾一下邻接表的构造(数组 + 链表):
假如 加入的cur 是节点 2, 那么 grid[2] 表示的就是图中第二行链表。 (grid数组的构造我们在 上面 「图的存储」中讲过)
所以在邻接表中,我们要获取 节点cur 链接指向哪些节点,就是遍历 grid[cur节点编号] 这个链表。
这个遍历方式,C++代码如下:
for (Edge edge : grid[cur.first])
(如果不知道 Edge 是什么,看上面「图的存储」中邻接表的讲解)
cur.first 就是cur节点编号, 参考上面pair的定义: pair<节点编号,源点到该节点的权值>
接下来就是更新 非访问节点到源点的距离,代码实现和 朴素dijkstra 是一样的,代码如下:
// 3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (Edge edge : grid[cur.first]) { // 遍历 cur指向的节点,cur指向的节点为 edge
// cur指向的节点edge.to,这条边的权值为 edge.val
if (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDist
minDist[edge.to] = minDist[cur.first] + edge.val;
pq.push(pair<int, int>(edge.to, minDist[edge.to]));
}
}
但为什么思路一样,有的录友能写出朴素dijkstra,但堆优化这里的逻辑就是写不出来呢?
主要就是因为对邻接表的表达方式不熟悉!
以上代码中,cur 链接指向的节点编号 为 edge.to, 这条边的权值为 edge.val ,如果对这里模糊的就再回顾一下 Edge的定义:
struct Edge {
int to; // 邻接顶点
int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};
确定该节点没有被访问过,!visited[edge.to] , 目前 源点到cur.first的最短距离(minDist) + cur.first 到 edge.to 的距离 (edge.val) 是否 小于 minDist已经记录的 源点到 edge.to 的距离 (minDist[edge.to])
如果是的话,就开始更新操作。
即:
if (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDist
minDist[edge.to] = minDist[cur.first] + edge.val;
pq.push(pair<int, int>(edge.to, minDist[edge.to])); // 由于cur节点的加入,而新链接的边,加入到优先级队里中
}同时,由于cur节点的加入,源点又有可以新链接到的边,将这些边加入到优先级队里中。
以上代码思路 和 朴素版dijkstra 是一样一样的,主要区别是两点:
- 邻接表的表示方式不同
- 使用优先级队列(小顶堆)来对新链接的边排序
#代码实现
堆优化dijkstra完整代码如下:
#include <iostream>
#include <vector>
#include <list>
#include <queue>
#include <climits>
using namespace std;
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
// 定义一个结构体来表示带权重的边
struct Edge {
int to; // 邻接顶点
int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};int main() {
int n, m, p1, p2, val;
cin >> n >> m;vector<list<Edge>> grid(n + 1);for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
// p1 指向 p2,权值为 val
grid[p1].push_back(Edge(p2, val));}int start = 1; // 起点
int end = n; // 终点// 存储从源点到每个节点的最短距离
std::vector<int> minDist(n + 1, INT_MAX);// 记录顶点是否被访问过
std::vector<bool> visited(n + 1, false); // 优先队列中存放 pair<节点,源点到该节点的权值>
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;// 初始化队列,源点到源点的距离为0,所以初始为0
pq.push(pair<int, int>(start, 0)); minDist[start] = 0; // 起始点到自身的距离为0while (!pq.empty()) {
// 1. 第一步,选源点到哪个节点近且该节点未被访问过 (通过优先级队列来实现)
// <节点, 源点到该节点的距离>
pair<int, int> cur = pq.top(); pq.pop();if (visited[cur.first]) continue;// 2. 第二步,该最近节点被标记访问过
visited[cur.first] = true;// 3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (Edge edge : grid[cur.first]) { // 遍历 cur指向的节点,cur指向的节点为 edge
// cur指向的节点edge.to,这条边的权值为 edge.val
if (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDist
minDist[edge.to] = minDist[cur.first] + edge.val;
pq.push(pair<int, int>(edge.to, minDist[edge.to]));
}
}}if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
else cout << minDist[end] << endl; // 到达终点最短路径
}- 时间复杂度:O(ElogE) E 为边的数量
- 空间复杂度:O(N + E) N 为节点的数量
堆优化的时间复杂度 只和边的数量有关 和节点数无关,在 优先级队列中 放的也是边。
以上代码中,while (!pq.empty()) 里套了 for (Edge edge : grid[cur.first])
for 里 遍历的是 当前节点 cur 所连接边。
那 当前节点cur 所连接的边 也是不固定的, 这就让大家分不清,这时间复杂度究竟是多少?
其实 for (Edge edge : grid[cur.first]) 里最终的数据走向 是 给队列里添加边。
那么跳出局部代码,整个队列 一定是 所有边添加了一次,同时也弹出了一次。
所以边添加一次时间复杂度是 O(E), while (!pq.empty()) 里每次都要弹出一个边来进行操作,在优先级队列(小顶堆)中 弹出一个元素的时间复杂度是 O(logE) ,这是堆排序的时间复杂度。
(当然小顶堆里 是 添加元素的时候 排序,还是 取数元素的时候排序,这个无所谓,时间复杂度都是O(E),总之是一定要排序的,而小顶堆里也不会滞留元素,有多少元素添加 一定就有多少元素弹出)
所以 该算法整体时间复杂度为 O(ElogE)
网上的不少分析 会把 n (节点的数量)算进来,这个分析是有问题的,举一个极端例子,在n 为 10000,且是有一条边的 图里,以上代码,大家感觉执行了多少次?
while (!pq.empty()) 中的 pq 存的是边,其实只执行了一次。
所以该算法时间复杂度 和 节点没有关系。
至于空间复杂度,邻接表是 数组 + 链表 数组的空间 是 N ,有E条边 就申请对应多少个链表节点,所以是 复杂度是 N + E
#拓展
当然也有录友可能想 堆优化dijkstra 中 我为什么一定要用邻接表呢,我就用邻接矩阵 行不行 ?
也行的。
但 正是因为稀疏图,所以我们使用堆优化的思路, 如果我们还用 邻接矩阵 去表达这个图的话,就是 一个高效的算法 使用了低效的数据结构,那么 整体算法效率 依然是低的。
如果还不清楚为什么要使用 邻接表,可以再看看上面 我在 「图的存储」标题下的讲解。
这里我也给出 邻接矩阵版本的堆优化dijkstra代码:
#include <iostream>
#include <vector>
#include <list>
#include <climits>
using namespace std;
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};int main() {
int n, m, p1, p2, val;
cin >> n >> m;vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
// p1 指向 p2,权值为 val
grid[p1][p2] = val;
}int start = 1; // 起点
int end = n; // 终点// 存储从源点到每个节点的最短距离
std::vector<int> minDist(n + 1, INT_MAX);// 记录顶点是否被访问过
std::vector<bool> visited(n + 1, false);// 优先队列中存放 pair<节点,源点到该节点的距离>
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;// 初始化队列,源点到源点的距离为0,所以初始为0
pq.push(pair<int, int>(start, 0));minDist[start] = 0; // 起始点到自身的距离为0while (!pq.empty()) {
// <节点, 源点到该节点的距离>
// 1、选距离源点最近且未访问过的节点
pair<int, int> cur = pq.top(); pq.pop();if (visited[cur.first]) continue;visited[cur.first] = true; // 2、标记该节点已被访问// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int j = 1; j <= n; j++) {
if (!visited[j] && grid[cur.first][j] != INT_MAX && (minDist[cur.first] + grid[cur.first][j] < minDist[j])) {
minDist[j] = minDist[cur.first] + grid[cur.first][j];
pq.push(pair<int, int>(j, minDist[j]));
}
}
}if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
else cout << minDist[end] << endl; // 到达终点最短路径}- 时间复杂度:O(E * (N + logE)) E为边的数量,N为节点数量
- 空间复杂度:O(log(N^2))
while (!pq.empty()) 时间复杂度为 E ,while 里面 每次取元素 时间复杂度 为 logE,和 一个for循环 时间复杂度 为 N 。
所以整体是 E * (N + logE)
#总结
在学习一种优化思路的时候,首先就要知道为什么要优化,遇到了什么问题。
正如我在开篇就给大家交代清楚 堆优化方式的背景。
堆优化的整体思路和 朴素版是大体一样的,区别是 堆优化从边的角度出发且利用堆来排序。
很多录友别说写堆优化 就是看 堆优化的代码也看的很懵。
主要是因为两点:
- 不熟悉邻接表的表达方式
- 对dijkstra的实现思路还是不熟
这是我为什么 本篇花了大力气来讲解 图的存储,就是为了让大家彻底理解邻接表以及邻接表的代码写法。
至于 dijkstra的实现思路 ,朴素版 和 堆优化版本 都是 按照 dijkstra 三部曲来的。
理解了三部曲,dijkstra 的思路就是清晰的。
针对邻接表版本代码 我做了详细的 时间复杂度分析,也让录友们清楚,相对于 朴素版,时间都优化到哪了。
最后 我也给出了 邻接矩阵的版本代码,分析了这一版本的必要性以及时间复杂度。
至此通过 两篇dijkstra的文章,终于把 dijkstra 讲完了,如果大家对我讲解里所涉及的内容都吃透的话,详细对 dijkstra 算法也就理解到位了。
相关文章:
代码随想录算法训练营第70天图论9[1]
代码随想录算法训练营第70天:图论9 拓扑排序精讲 卡码网:117. 软件构建(opens new window) 题目描述: 某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的…...
浏览器设计为默认
...

windows USB 设备驱动开发-USB设备描述符
USB的描述符是USB设备向主机报告状态的重要数据结构,在USB通电后,端点(也称为终结点)0始终处于可用状态,这个默认的端点就是用于主机从设备中读取描述符的。 讨论USB通讯,需要从软件和硬件两方面说起,在软件上&#x…...

【踩坑】修复报错Cannot find DGL libdgl_sparse_pytorch_2.2.0.so
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 错误复现 原因分析 解决方法 错误复现 import dgldataset dgl.data.CoraGraphDataset() graph dataset[0] graph.adjacency_matrix() 原因分…...

postman中参数和x-www-form-urlencoded传值的区别
在 Postman 中,传递参数的方式有多种,其中常用的包括 params 和 x-www-form-urlencoded。这两种方式在使用场景和传递数据的方式上有所不同。 1. Params Params 选项用于在 URL 中传递查询参数。这些参数通常用于 GET 请求,但也可以与其他 …...
自己训练 PaddleOCR
打标工具 https://github.com/Evezerest/PPOCRLabel 感谢这位热心网友提供的标注工具,操作非常的方便 只是这个工具有个小坑get_rotate_crop_image() 我的标注数据导出时,很多数据变成倒的 hmmmm, 你管我~ if dst_img_height …...
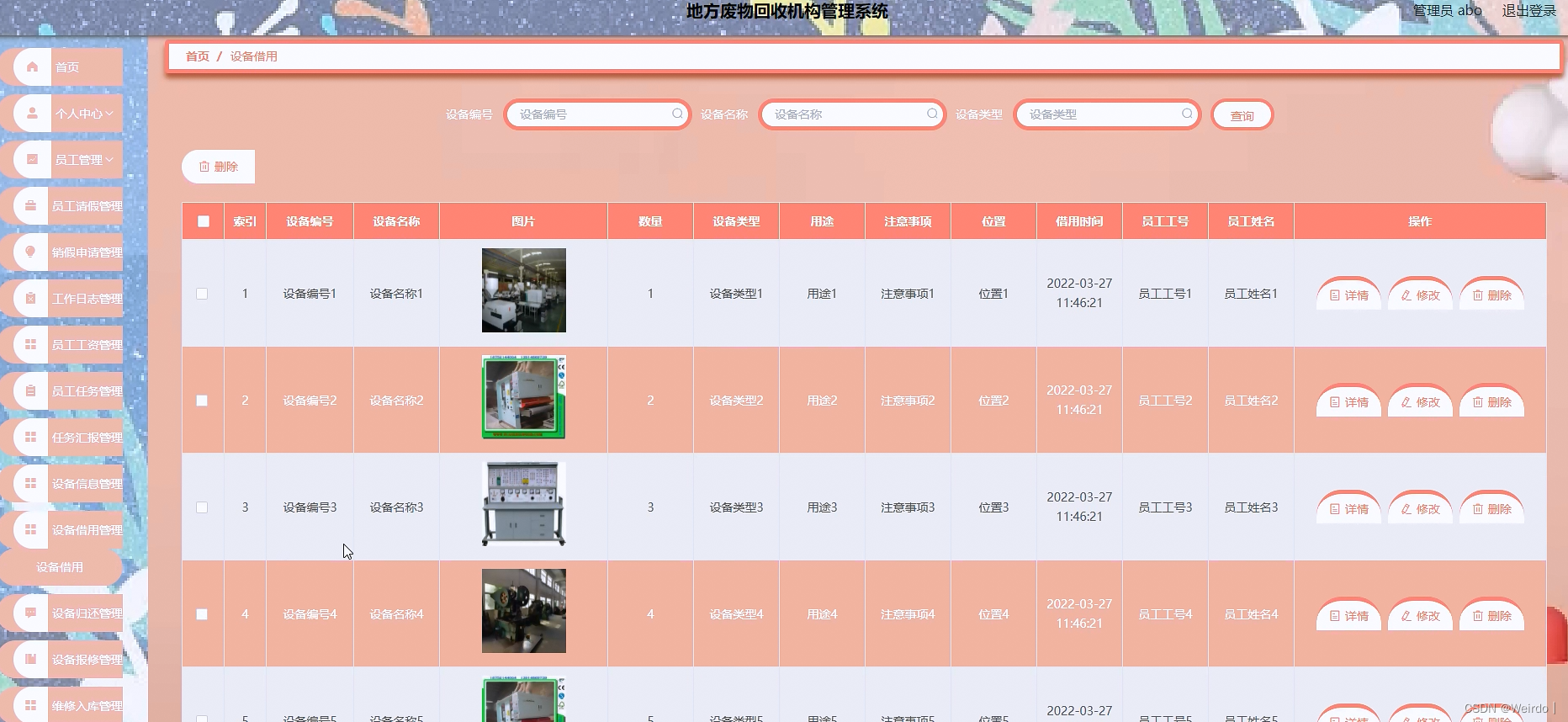
基于SpringBoot的地方废物回收机构管理系统
本系统主要包括管理员和员工两个角色组成;主要包括:首页、个人中心、员工管理、员工请假管理、销假申请管理、工作日志管理、员工工资管理、员工任务管理、任务汇报管理、设备信息管理、设备借用管理、设备归还管理、设备保修管理、维修入库管理、员工打…...
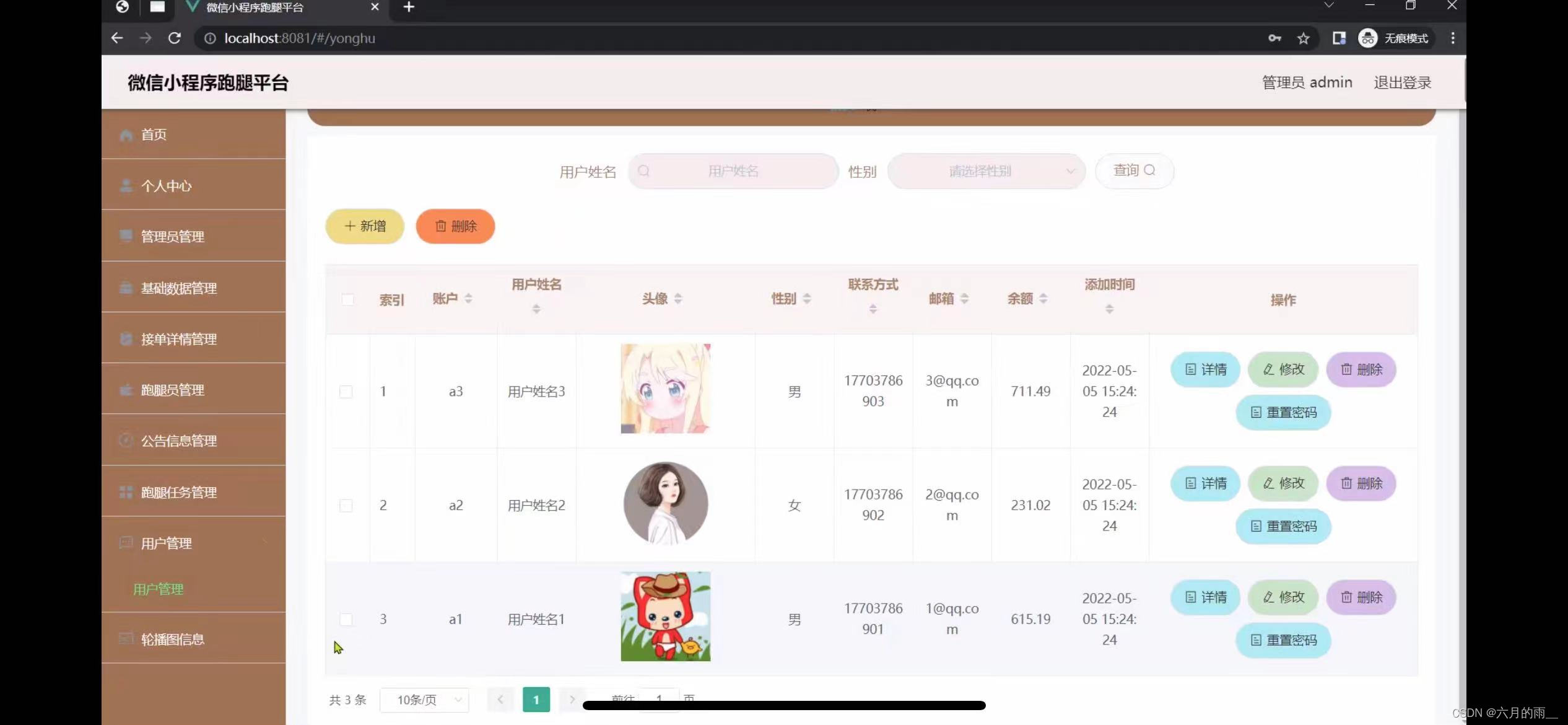
跑腿平台小程序的设计
管理员账户功能包括:系统首页,个人中心,基础数据管理,管理员管理,接单详情管理,跑腿员管理,跑腿任务管理 微信端账号功能包括:系统首页,跑腿任务,接单员&…...
Java技术栈总结:Redis篇
一、数据类型 Redis 自身是一个 Map,其中的所有数据均采用“key:value”的形式存储。 数据类型指的是存储的数据的类型,即 value 部分的类型,key 的部分只能是字符串。 value 部分的数据类型:<String、List、Hash、Set、Zse…...

django models对应的mysql类型
Django模型字段类型与MySQL数据库类型的对应关系如下: Django 模型字段类型MySQL 数据库类型AutoFieldBIGINT UNSIGNEDCharFieldVARCHARIntegerFieldINTDecimalFieldDECIMALDateFieldDATEDateTimeFieldDATETIMEFileField, ImageFieldVARCHAR (用于文件路径)Boolean…...

2024攻防演练:亚信安全新一代WAF,关键时刻守护先锋
实网攻防 网络安全如同一面坚固的盾牌,保护着我们的信息资产免受无孔不入的威胁。而其中,WAF就像网络安全的守门员,关键时刻挺身而出,为您的企业筑起一道坚实的防线。 攻防不对等 防守方实时应答压力山大 在攻防对抗中…...

富格林:曝光有效方案安全交易
富格林认为,近些年来大家的投资理财意识逐渐增强,现货黄金作为一种自带优质避险功能的投资产品,自然就受到投资者的关注和追捧。但现货黄金的交易市场相对来说还是比较混杂,投资小白稍不留神就可能会陷入受害陷阱当中无法安全交易…...
)
ArtTS系统能力-窗口管理的学习(3.2)
上篇回顾: ArtTS系统能力-通知的学习(3.1) 本篇内容: ArtTS系统能力-窗口管理的学习(3.2) 一、 知识储备 1. 基本概念 窗口渲染式能力:指对状态栏、导航栏等系统窗口进行控制,减…...

C++ 运算符的优先级和关联性表
C 运算符的优先级和关联性表 1. Precedence and associativity (优先级和结合性)2. Alternative spellings (替代拼写)3. C operator precedence and associativity table (C 运算符的优先级和关联性表)References C documentation (C 文档) https://learn.microsoft.com/en-us…...

正则表达式替换字符串的方法
正则表达式替换字符串的方法 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来探讨一个非常实用的编程技术:使用正则表达式替换字符串。正则…...
开源模型应用落地-FastAPI-助力模型交互-WebSocket篇(五)
一、前言 使用 FastAPI 可以帮助我们更简单高效地部署 AI 交互业务。FastAPI 提供了快速构建 API 的能力,开发者可以轻松地定义模型需要的输入和输出格式,并编写好相应的业务逻辑。 FastAPI 的异步高性能架构,可以有效支持大量并发的预测请求,为用户提供流畅的交互体验。此外,F…...

2024/7/4总结
http协议 http协议,是一个客户端请求和响应的标准协议,这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。用户输入地址和端口号之后就可以从服务器上取得所需要的网页信息。 通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给…...

【Android面试八股文】Looper如何在子线程中创建?
文章目录 一、Looper的几个重要方法二、子线程中使用Looper的方式1三、子线程中使用Looper的方式23.1 使用HandlerThread实现3.2 HandlerThread源码解析创建子线程的 Looper必须要通过 Looper.prepare()初始化looper,然后再通过 Looper.loop()方法让 Loop运行起来。 那么具…...

IT项目管理文档体系
IT项目管理文档体系是确保项目顺利进行、有效沟通和合规性的关键组成部分。一个完善的文档体系能够帮助项目团队记录决策过程、明确职责、跟踪进度、管理变更并提供审计痕迹。 项目启动文档: 项目章程:正式授权项目启动,定义项目目标、范围、…...
)
ELK企业内部日志分析系统(1)
ELKKafkaFilebeat企业内部日志分析系统(1) Elasticsearch集群部署 1.部署环境 IP地址主机名配置系统版本192.168.222.129es12核4GRockyLinux192.168.222.130es22核3GRockyLinux192.168.222.131es32核3GRockyLinux 2.配置主机名解析和主机名 #关闭防火墙与selinux #更改主机…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...