昇思MindSpore学习总结九——FCN语义分割
1、语义分割
图像语义分割(semantic segmentation)是图像处理和机器视觉技术中关于图像理解的重要一环,AI领域中一个重要分支,常被应用于人脸识别、物体检测、医学影像、卫星图像分析、自动驾驶感知等领域。
语义分割的目的是对图像中每个像素点进行分类。 要识别出整张图片的每个部分,就意味着要精确到像素点,所以语义分割实际上是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人、汽车、马等),从而进行区域划分。
与普通的分类任务只输出某个类别不同,语义分割任务输出与输入大小相同的图像,输出图像的每个像素对应了输入图像每个像素的类别。语义在图像领域指的是图像的内容,对图片意思的理解,下图是一些语义分割的实例:

2、全卷积网络
全卷积网络(Fully Convolutional Networks,FCN)是UC Berkeley的Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation[1]一文中提出的用于图像语义分割的一种框架。
核心思想:
1.不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
2.增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
3.结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
FCN是首个端到端(end to end)进行像素级(pixel level)预测的全卷积网络。

3、模型简介
FCN主要用于图像分割领域,是一种端到端的分割方法,是深度学习应用在图像语义分割的开山之作。通过进行像素级的预测直接得出与原图大小相等的label map。因FCN丢弃全连接层替换为全卷积层,网络所有层均为卷积层,故称为全卷积网络。
全卷积神经网络主要使用以下三种技术:
3.1 卷积化(Convolutional)
使用VGG-16作为FCN的backbone。VGG-16的输入为224*224的RGB图像,输出为1000个预测值。VGG-16只能接受固定大小的输入,丢弃了空间坐标,产生非空间输出。VGG-16中共有三个全连接层,全连接层也可视为带有覆盖整个区域的卷积。将全连接层转换为卷积层能使网络输出由一维非空间输出变为二维矩阵,利用输出能生成输入图片映射的heatmap。

3*3 conv, 64:使用64个size是3*3,stride步长为1,padding填充为1的卷积核。
池化:最大池化,使用size是2*2,stride步长为2,padding填充为0进行池化。
第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,7,7)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
3.2 上采样(Upsample)
在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图的大小的稠密图像预测,需要对得到的特征图进行上采样操作。使用双线性插值的参数来初始化上采样逆卷积的参数,后通过反向传播来学习非线性上采样。在网络中执行上采样,以通过像素损失的反向传播进行端到端的学习。

3.3 跳跃结构(Skip Layer)
利用上采样技巧对最后一层的特征图进行上采样得到原图大小的分割是步长为32像素的预测,称之为FCN-32s。由于最后一层的特征图太小,损失过多细节,采用skips结构将更具有全局信息的最后一层预测和更浅层的预测结合,使预测结果获取更多的局部细节。将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。 Skips结构将深层的全局信息与浅层的局部信息相结合。

4、数据处理
由于PASCAL VOC 2012数据集中图像的分辨率大多不一致,无法放在一个tensor中,故输入前需做标准化处理。
4.2 加载数据集
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar"download(url, "./dataset", kind="tar", replace=True)4.2 数据预处理
import numpy as np
import cv2
import mindspore.dataset as dsclass SegDataset:def __init__(self,image_mean, #图像的均值,用于图像标准化。通常是一个列表或数组,包含每个通道的均值值。image_std,#图像的标准差,也用于图像标准化。通常是一个列表或数组,包含每个通道的标准差值。data_file='',#数据文件的路径。这个参数默认是一个空字符串,表示可能的默认值或未提供文件路径。batch_size=32,#批处理大小,表示一次训练中使用的样本数量。32是一个常见的默认值。crop_size=512,#裁剪大小,表示图像在训练或测试时裁剪的尺寸。512通常用于高分辨率图像。max_scale=2.0,#最大缩放比例,用于数据增强,通过随机缩放图像来增加模型的鲁棒性。min_scale=0.5,#最小缩放比例,同样用于数据增强。ignore_label=255,#忽略标签,通常用于语义分割任务,表示某些像素点不参与训练的标签值。num_classes=21,#类别数量,表示数据集中不同类别的数量。21个类别可能用于某个特定的数据集,比如Pascal VOC。num_readers=2,#读取器数量,表示用于读取数据文件的并行读取器数量,可以加快数据加载速度。num_parallel_calls=4):#并行调用数量,用于数据预处理的并行调用次数,可以加快数据预处理过程。self.data_file = data_fileself.batch_size = batch_sizeself.crop_size = crop_sizeself.image_mean = np.array(image_mean, dtype=np.float32)self.image_std = np.array(image_std, dtype=np.float32)self.max_scale = max_scaleself.min_scale = min_scaleself.ignore_label = ignore_labelself.num_classes = num_classesself.num_readers = num_readersself.num_parallel_calls = num_parallel_callsmax_scale > min_scaledef preprocess_dataset(self, image, label):# np.frombuffer(image, dtype=np.uint8):将原始字节数据转换为NumPy数组,以便OpenCV可以处理。# cv2.imdecode(..., cv2.IMREAD_COLOR):使用OpenCV解码这个NumPy数组,并将其转换为一个图像矩阵,以便后续的图像处理操作。image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)#生成一个在self.min_scale和self.max_scale之间的随机浮点数。sc = np.random.uniform(self.min_scale, self.max_scale)new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])#将图像 image_out 的大小调整为 new_w 宽和 new_h 高,并使用(nterpolation=cv2.INTER_CUBIC)双三次插值方法进行插值。image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)image_out = (image_out - self.image_mean) / self.image_stdout_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)pad_h, pad_w = out_h - new_h, out_w - new_wif pad_h > 0 or pad_w > 0:# cv2.copyMakeBorder:这是OpenCV中的一个函数,用于为图像添加边框。image_out:这是要添加边框的输入图像矩阵。# 0, pad_h, 0, pad_w:这些参数指定了边框的大小:image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)offset_h = np.random.randint(0, out_h - self.crop_size + 1)offset_w = np.random.randint(0, out_w - self.crop_size + 1)image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]if np.random.uniform(0.0, 1.0) > 0.5:image_out = image_out[:, ::-1, :]label_out = label_out[:, ::-1]image_out = image_out.transpose((2, 0, 1))image_out = image_out.copy()label_out = label_out.copy()label_out = label_out.astype("int32")return image_out, label_outdef get_dataset(self):ds.config.set_numa_enable(True)dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],shuffle=True, num_parallel_workers=self.num_readers)transforms_list = self.preprocess_datasetdataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],output_columns=["data", "label"],num_parallel_workers=self.num_parallel_calls)dataset = dataset.shuffle(buffer_size=self.batch_size * 10)dataset = dataset.batch(self.batch_size, drop_remainder=True)return dataset# 定义创建数据集的参数
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"# 定义模型训练参数
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)dataset = dataset.get_dataset()4.3 训练集可视化
import numpy as np
import matplotlib.pyplot as pltplt.figure(figsize=(16, 8))# 对训练集中的数据进行展示
for i in range(1, 9):plt.subplot(2, 4, i)show_data = next(dataset.create_dict_iterator())show_images = show_data["data"].asnumpy()show_images = np.clip(show_images, 0, 1)
# 将图片转换HWC格式后进行展示plt.imshow(show_images[0].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0)
plt.show()【运行结果】

5、网络构建
FCN网络的流程如下图所示:
- 输入图像image,经过pool1池化后,尺寸变为原始尺寸的1/2。
- 经过pool2池化,尺寸变为原始尺寸的1/4。
- 接着经过pool3、pool4、pool5池化,大小分别变为原始尺寸的1/8、1/16、1/32。
- 经过conv6-7卷积,输出的尺寸依然是原图的1/32。
- FCN-32s是最后使用反卷积,使得输出图像大小与输入图像相同。
- FCN-16s是将conv7的输出进行反卷积,使其尺寸扩大两倍至原图的1/16,并将其与pool4输出的特征图进行融合,后通过反卷积扩大到原始尺寸。
- FCN-8s是将conv7的输出进行反卷积扩大4倍,将pool4输出的特征图反卷积扩大2倍,并将pool3输出特征图拿出,三者融合后通反卷积扩大到原始尺寸。

5.1 构建代码
import mindspore.nn as nnclass FCN8s(nn.Cell):def __init__(self, n_class):super().__init__()self.n_class = n_classself.conv1 = nn.SequentialCell(nn.Conv2d(in_channels=3, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU())self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.SequentialCell(nn.Conv2d(in_channels=64, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(in_channels=128, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU())self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.SequentialCell(nn.Conv2d(in_channels=128, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU())self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.SequentialCell(nn.Conv2d(in_channels=256, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv5 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv6 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=4096,kernel_size=7, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)self.conv7 = nn.SequentialCell(nn.Conv2d(in_channels=4096, out_channels=4096,kernel_size=1, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=16, stride=8, weight_init='xavier_uniform')def construct(self, x):x1 = self.conv1(x)p1 = self.pool1(x1)x2 = self.conv2(p1)p2 = self.pool2(x2)x3 = self.conv3(p2)p3 = self.pool3(x3)x4 = self.conv4(p3)p4 = self.pool4(x4)x5 = self.conv5(p4)p5 = self.pool5(x5)x6 = self.conv6(p5)x7 = self.conv7(x6)sf = self.score_fr(x7)u2 = self.upscore2(sf)s4 = self.score_pool4(p4)f4 = s4 + u2u4 = self.upscore_pool4(f4)s3 = self.score_pool3(p3)f3 = s3 + u4out = self.upscore8(f3)return out6、训练准备
导入VGG-6部分预训练权重,使用下面代码导入VGG-16预训练模型的部分预训练权重。
from download import download
from mindspore import load_checkpoint, load_param_into_neturl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/fcn8s_vgg16_pretrain.ckpt"
download(url, "fcn8s_vgg16_pretrain.ckpt", replace=True)
def load_vgg16():ckpt_vgg16 = "fcn8s_vgg16_pretrain.ckpt"param_vgg = load_checkpoint(ckpt_vgg16)load_param_into_net(net, param_vgg)7、损失函数
语义分割是对图像中每个像素点进行分类,仍是分类问题,故损失函数选择交叉熵损失函数来计算FCN网络输出与mask之间的交叉熵损失。这里我们使用的是mindspore.nn.CrossEntropyLoss()作为损失函数。
7.1 自定义评价指标Metrics
这一部分主要对训练出来的模型效果进行评估,为了便于解释,假设如下:共有 𝑘+1 个类(从 𝐿0 到 𝐿𝑘, 其中包含一个空类或背景), 𝑝𝑖𝑗 表示本属于𝑖类但被预测为𝑗类的像素数量。即, 𝑝𝑖𝑖 表示真正的数量, 而 𝑝𝑖𝑗𝑝𝑗𝑖则分别被解释为假正和假负, 尽管两者都是假正与假负之和。
- Pixel Accuracy(PA, 像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。

- Mean Pixel Accuracy(MPA, 均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。

- Mean Intersection over Union(MloU, 均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之,在语义分割的问题中,这两个集合为真实值(ground truth) 和预测值(predicted segmentation)。这个比例可以变形为正真数 (intersection) 比上真正、假负、假正(并集)之和。在每个类上计算loU,之后平均。

- Frequency Weighted Intersection over Union(FWIoU, 频权交井比):为MloU的一种提升,这种方法根据每个类出现的频率为其设置权重。

import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.train as trainclass PixelAccuracy(train.Metric):def __init__(self, num_class=21):# 初始化方法,设置类别数,并调用父类的初始化方法super(PixelAccuracy, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):# 掩码,仅保留有效类别范围内的像素mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]# 计算标签count = np.bincount(label, minlength=self.num_class**2)# 统计每个类别组合的频数confusion_matrix = count.reshape(self.num_class, self.num_class)# 重塑为混淆矩阵return confusion_matrixdef clear(self):# 将混淆矩阵重置为全零矩阵self.confusion_matrix = np.zeros((self.num_class,) * 2)def update(self, *inputs):# 更新混淆矩阵y_pred = inputs[0].asnumpy().argmax(axis=1)# 获取预测类别y = inputs[1].asnumpy().reshape(4, 512, 512) # 获取真实类别并重塑self.confusion_matrix += self._generate_matrix(y, y_pred) # 更新混淆矩阵def eval(self):# 计算并返回像素准确率pixel_accuracy = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()return pixel_accuracyclass PixelAccuracyClass(train.Metric):def __init__(self, num_class=21):super(PixelAccuracyClass, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def eval(self):mean_pixel_accuracy = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)mean_pixel_accuracy = np.nanmean(mean_pixel_accuracy)return mean_pixel_accuracyclass MeanIntersectionOverUnion(train.Metric):def __init__(self, num_class=21):super(MeanIntersectionOverUnion, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def eval(self):mean_iou = np.diag(self.confusion_matrix) / (np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -np.diag(self.confusion_matrix))mean_iou = np.nanmean(mean_iou)return mean_iouclass FrequencyWeightedIntersectionOverUnion(train.Metric):def __init__(self, num_class=21):super(FrequencyWeightedIntersectionOverUnion, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def eval(self):freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)iu = np.diag(self.confusion_matrix) / (np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -np.diag(self.confusion_matrix))frequency_weighted_iou = (freq[freq > 0] * iu[freq > 0]).sum()return frequency_weighted_iou8、模型训练
导入VGG-16预训练参数后,实例化损失函数、优化器,使用Model接口编译网络,训练FCN-8s网络。
import mindspore
from mindspore import Tensor
import mindspore.nn as nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, Modeldevice_target = "Ascend"
mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target=device_target)train_batch_size = 4
num_classes = 21
# 初始化模型结构
net = FCN8s(n_class=21)
# 导入vgg16预训练参数
load_vgg16()
# 计算学习率
min_lr = 0.0005
base_lr = 0.05
train_epochs = 1
iters_per_epoch = dataset.get_dataset_size()
total_step = iters_per_epoch * train_epochslr_scheduler = mindspore.nn.cosine_decay_lr(min_lr, # 最低学习率base_lr, # 基础学习率total_step, # 总步数iters_per_epoch, # 每个 epoch 的迭代次数decay_epoch=2) # 开始衰减的 epoch
# 从学习率调度器中取出最后一个学习率值,并将其转换为 Tensor
lr = Tensor(lr_scheduler[-1])# 定义损失函数
loss = nn.CrossEntropyLoss(ignore_index=255)
# 定义优化器
optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.0001)
# 定义loss_scale
scale_factor = 4
scale_window = 3000
loss_scale_manager = ms.amp.DynamicLossScaleManager(scale_factor, scale_window)
# 初始化模型
if device_target == "Ascend":model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})# 设置ckpt文件保存的参数
time_callback = TimeMonitor(data_size=iters_per_epoch)
loss_callback = LossMonitor()
callbacks = [time_callback, loss_callback]
save_steps = 330
keep_checkpoint_max = 5
config_ckpt = CheckpointConfig(save_checkpoint_steps=10,keep_checkpoint_max=keep_checkpoint_max)
ckpt_callback = ModelCheckpoint(prefix="FCN8s",directory="./ckpt",config=config_ckpt)
callbacks.append(ckpt_callback)
model.train(train_epochs, dataset, callbacks=callbacks)【运行结果】

FCN网络在训练的过程中需要大量的训练数据和训练轮数,这里只提供了小数据单个epoch的训练来演示loss收敛的过程,下文中使用已训练好的权重文件进行模型评估和推理效果的展示。
9、模型评估
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"# 下载已训练好的权重文件
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/FCN8s.ckpt"
download(url, "FCN8s.ckpt", replace=True)
net = FCN8s(n_class=num_classes)ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)if device_target == "Ascend":model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)
dataset_eval = dataset.get_dataset()
model.eval(dataset_eval)10、模型推理
使用训练的网络对模型推理结果进行展示。
import cv2
import matplotlib.pyplot as pltnet = FCN8s(n_class=num_classes)
# 设置超参
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
eval_batch_size = 4
img_lst = []
mask_lst = []
res_lst = []
# 推理效果展示(上方为输入图片,下方为推理效果图片)
plt.figure(figsize=(8, 5))
show_data = next(dataset_eval.create_dict_iterator())
show_images = show_data["data"].asnumpy()
mask_images = show_data["label"].reshape([4, 512, 512])
show_images = np.clip(show_images, 0, 1)
for i in range(eval_batch_size):img_lst.append(show_images[i])mask_lst.append(mask_images[i])
res = net(show_data["data"]).asnumpy().argmax(axis=1)
for i in range(eval_batch_size):plt.subplot(2, 4, i + 1)plt.imshow(img_lst[i].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)plt.subplot(2, 4, i + 5)plt.imshow(res[i])plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.show()【运行结果】自己电脑没运行出来

打卡

相关文章:
昇思MindSpore学习总结九——FCN语义分割
1、语义分割 图像语义分割(semantic segmentation)是图像处理和机器视觉技术中关于图像理解的重要一环,AI领域中一个重要分支,常被应用于人脸识别、物体检测、医学影像、卫星图像分析、自动驾驶感知等领域。 语义分割的目的是对图…...

js数据库多级分类按树形结构打印
可以使用 JavaScript 来按层级打印 categories 数组。首先,需要将这个数组转换成一个树形结构,然后再进行递归或者迭代来打印每个层级的内容。 以下是一个示例代码,用来实现这个功能: const categories [{ id: 2, name: "…...

centos下编译安装redis最新稳定版
一、目标 编译安装最新版的redis 二、安装步骤 1、redis官方下载页面 Downloads - Redis 2、下载最新版的redis源码包 注:此时的最新稳定版是 redis 7.2.5 wget https://download.redis.io/redis-stable.tar.gz 3、安装编译环境 yum install -y gcc gcc-c …...

如何让自动化测试更加灵活简洁?
简化的架构对于自动化测试和主代码一样重要。冗余和不灵活性可能会导致一些问题:比如 UI 中的任何更改都需要更新多个文件,测试可能在功能上相互重复,并且支持新功能可能会变成一项耗时且有挑战性的工作来适应现有测试。 页面对象模式如何理…...

linux 下载依赖慢和访问github代码慢
1 pip install 下载依赖慢,添加清华镜像源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 2 git 出现错误 Could not resolve host: github.com 原来是因为github.com没有被主机给解析, 第一步 先 ping 看一下主机地址 …...
奥比中光astra_pro相机使用记录
一、信息获取 1、官网 用于了解产品信息 http://www.orbbec.com.cn/sys/37.html 2、开发者社区 咨询问题下载开发部https://developer.orbbec.com.cn/ 二 、windowvs19 1、相机型号 orbbec_astro_pro 根据对应的型号找到需要的包工具 踩坑1,因为这个相机型号…...

【MindSpore学习打卡】应用实践-计算机视觉-深入解析 Vision Transformer(ViT):从原理到实践
在近年来的深度学习领域,Transformer模型凭借其在自然语言处理(NLP)中的卓越表现,迅速成为研究热点。尤其是基于自注意力(Self-Attention)机制的模型,更是推动了NLP的飞速发展。然而,…...

Debezium系列之:支持在一个数据库connector采集中过滤某些表的删除事件
Debezium系列之:支持在一个数据库connector采集中过滤某些表的删除事件 一、需求二、相关技术三、参数设置四、消费数据一、需求 在一个数据库的connector中采集了多张表,部分表存在数据归档的业务场景,会定期从表中删除历史数据,希望能过滤掉存在数据归档这些表的删除事件…...

SQL Server端口配置指南:最佳实践与技巧
1. 引言 SQL Server通常使用默认端口1433进行通信。为了提高安全性和性能,正确配置SQL Server的端口非常重要。本指南将帮助您了解如何配置和优化SQL Server的端口设置,以满足不同环境和需求。 2. 端口配置基础 2.1 默认端口 SQL Server的默认端口是…...
)
FastGPT 报错:undefined 该令牌无权使用模型:gpt-3.5-turbo (request id: xxx)
目录 一、FastGPT 报错 二、解决方法 一、FastGPT 报错 进行对话时 FastGPT 报错如下所示。 [Error] 2024-07-01 09:25:23 sse error: undefined 该令牌无权使用模型:gpt-3.5-turbo (request id: xxxxx) {message: 403 该令牌无权使用模型:gpt-3.5-turbo (request id: x…...

springboot系列八: springboot静态资源访问,Rest风格请求处理, 接收参数相关注解
文章目录 WEB开发-静态资源访问官方文档基本介绍快速入门注意事项和细节 Rest风格请求处理基本介绍应用实例注意事项和细节思考题 接收参数相关注解基本介绍应用实例PathVariableRequestHeaderRequestParamCookieValueRequestBodyRequestAttributeSessionAttribute ⬅️ 上一篇…...

# 职场生活之道:善于团结
在职场这个大舞台上,每个人都是演员,也是观众。要想在这个舞台上站稳脚跟,除了专业技能,更要学会如何与人相处,如何团结他人。团结,是职场生存的重要法则之一。 1. 主动团结:多一个朋友&#x…...

go sync包(五) WaitGroup
WaitGroup sync.WaitGroup 可以等待一组 Goroutine 的返回,一个比较常见的使用场景是批量发出 RPC 或者 HTTP 请求: requests : []*Request{...} wg : &sync.WaitGroup{} wg.Add(len(requests))for _, request : range requests {go func(r *Reque…...

基于深度学习的相机内参标定
基于深度学习的相机内参标定 相机内参标定(Camera Intrinsic Calibration)是计算机视觉中的关键步骤,用于确定相机的内部参数(如焦距、主点位置、畸变系数等)。传统的标定方法依赖于已知尺寸的标定板,通常…...

适合金融行业的国产传输软件应该是怎样的?
对于金融行业来说,正常业务开展离不开文件传输场景,一般来说,金融行业常用的文件传输工具有IM通讯、邮件、自建文件传输系统、FTP应用、U盘等,这些传输工具可以基础实现金融机构的文件传输需求,但也存在如下问题&#…...

昇思25天学习打卡营第9天|MindSpore使用静态图加速(基于context的开启方式)
在Graph模式下,Python代码并不是由Python解释器去执行,而是将代码编译成静态计算图,然后执行静态计算图。 在静态图模式下,MindSpore通过源码转换的方式,将Python的源码转换成中间表达IR(Intermediate Repr…...

class类和style内联样式的绑定
这里的绑定其实就是v-bind的绑定,如代码所示,div后面的引号就是v-bind绑定,然后大括号将整个对象括起来,对象内先是属性,属性后接的是变量,这个变量是定义在script中的,后通过这个变量ÿ…...

3033.力扣每日一题7/5 Java
博客主页:音符犹如代码系列专栏:算法练习关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 目录 思路 解题方法 时间复杂度 空间复杂度 Code 思路 首先创建一个与…...

GPT-5:下一代AI如何彻底改变我们的未来
GPT-5 发布前瞻:技术突破与未来展望 随着科技的飞速发展,人工智能领域不断迎来新的突破。根据最新消息,OpenAI 的首席技术官米拉穆拉蒂在一次采访中确认,GPT-5 将在一年半后发布,并描述了其从 GPT-4 到 GPT-5 的飞跃如…...

重载一元运算符
自增运算符 #include<iostream> using namespace std; class CGirl { public:string name;int ranking;CGirl() { name "zhongge"; ranking 5; }void show() const{ cout << "name : "<<name << " , ranking : " <…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...
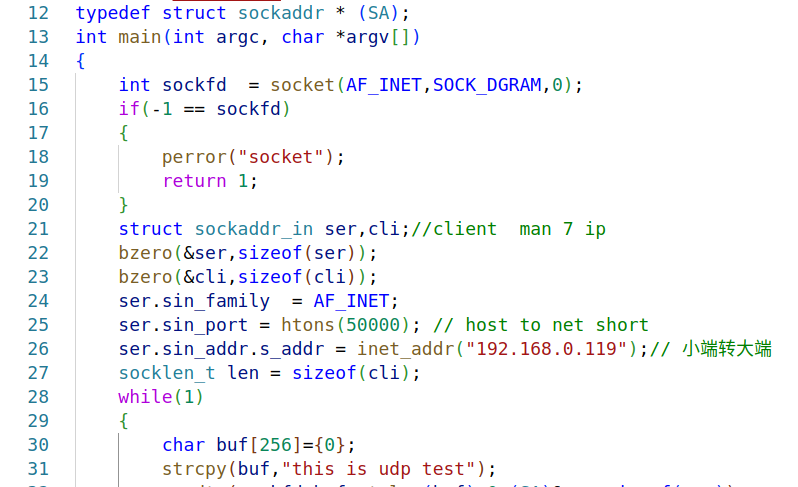
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...