使用langchain打造自己的大型语言模型(LLMs)

我们知道Openai的聊天机器人可以回答用户提出的绝大多数问题,它几乎无所不知,无所不能,但是由于有机器人所学习到的是截止到2021年9月以前的知识,所以当用户询问机器人关于2021年9月以后发送的事情时,它无法给出正确的答案,另外用户向机器人提问的字符串(prompt)长度被限制在4096个token(token可以看作是一种词语单位)。如果用户的prompt的长度超过4096个token时,机器人通常会抛出一个“异常”提示信息:

我们想要做的是让像openai聊天机器人这样的大型语言模型(LLMs)学习特定领域内的知识,这些特定的领域的知识可能是几本电子书,几十个文本文件,或者是关系型数据库,我们想要LLMs模型学习用户给定的数据,并且只回答给定数据范围内的相关问题,如果问题超出范围,一律告知用户问题超出范围无法回答,也就是我们要限制LLMs模型自由发挥,不能让它随便乱说。能否执行这样的功能呢?
LangChain
LangChain 是一种LLMs接口框架,它允许用户围绕大型语言模型快速构建应用程序和管道。 它直接与 OpenAI 的 GPT-3 和 GPT-3.5 模型以及 Hugging Face 的开源替代品(如 Google 的 flan-t5 模型)集成。
LangChain可用于聊天机器人、生成式问答(GQA)、本文摘要等。
LangChain的核心思想是我们可以将不同的组件“链接”在一起,以围绕 LLM 创建更高级的用例。 链(chain)可能由来自多个模块的多个组件组成。
今天我们要实现的功能是,让LLMs模型(如openai的聊天机器人)学习我提供的3个文本文件中的内容,并根据这些文件中的内容来回答相关问题,当问题超出范围时一律给出提示,并且机器人不会有任何自由发挥的空间。而我们提供的3个文本文件都是百度百科中拷贝下来的2022年发生的国内外时事新闻:
- 2022年卡塔尔世界杯。
- 日本请首相安倍晋三遇刺案。
- 埃隆·马斯克收购推特案。
为此我们从百度百科中将上述三个2022年的时事新闻网页中的内容拷贝出来,分别存储为三个文本文件:
- 2022世界杯.txt
- 埃隆·马斯克收购推特案.txt
- 安倍晋三遇刺案.txt
由于我们从百度百科上下载的这3篇时事新闻均发生在2022年,而ChatGPT只学习到了截止2021年9月之前的知识,因此它将无法准确回答关于这3个时事新闻的以外的其他问题。并且这些时事新闻都有较大的篇幅,且长度均超过了4096个token的长度,这正好被用来测试ChatGPT对特定数据的学习能力以及回答相关问题的能力。
这里我们会用到一种称为文本嵌入(Embeddings)的技术:

安装依赖包
我们需要安装如下依赖包:
pip install langchain
pip install openai
pip install chromadb
pip install jieba
pip install unstructured 导入依赖包
import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import TokenTextSplitter
from langchain.llms import OpenAI
from langchain.chains import ChatVectorDBChain
from langchain.document_loaders import DirectoryLoader
import jieba as jb文档预处理
由于中文的语法的特殊性,对于中文的文档必须要做一些预处理工作:词语的拆分,也就是要把中文的语句拆分成一个个基本的词语单位,这里我们会用的一个分词工具:jieba,它会帮助我们对资料库中的所有文本文件进行分词处理。不过我们首先将这3个时事新闻的文本文件放置到Data文件夹下面,然后在data文件夹下面再建一个子文件夹:cut, 用来存放被分词过的文档:
files=['2022世界杯.txt','埃隆·马斯克收购推特案.txt','安倍晋三遇刺案.txt']for file in files:#读取data文件夹中的中文文档my_file=f"./data/{file}"with open(my_file,"r",encoding='utf-8') as f: data = f.read()#对中文文档进行分词处理cut_data = " ".join([w for w in list(jb.cut(data))])#分词处理后的文档保存到data文件夹中的cut子文件夹中cut_file=f"./data/cut/cut_{file}"with open(cut_file, 'w') as f: f.write(cut_data)f.close()文本嵌入(Embeddings)
接下来我们要按照LangChain的流程来处理这些经过中文分词处理的数据,首先是加载文档,然后要对文档进行切块处理,切块处理完成以后需要调用openai的Embeddings方法进行文本嵌入操作和向量化操作,最后我们需要创建一个聊天机器人的chain, 这个chain可以加载openai的各种语言模型,这里我们加载gpt-3.5-turbo模型。
#加载文档
loader = DirectoryLoader('./data/cut',glob='**/*.txt')
docs = loader.load()
#文档切块
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
doc_texts = text_splitter.split_documents(docs)
#调用openai Embeddings
os.environ["OPENAI_API_KEY"] = "your-openai_api_key"
embeddings = OpenAIEmbeddings(openai_api_key=os.environ["OPENAI_API_KEY"])
#向量化
vectordb = Chroma.from_documents(doc_texts, embeddings, persist_directory="./data/cut")
vectordb.persist()
#创建聊天机器人对象chain
chain = ChatVectorDBChain.from_llm(OpenAI(temperature=0, model_name="gpt-3.5-turbo"), vectordb, return_source_documents=True)创建聊天函数
接下来我们要创建一个聊天函数,用来让机器人回答用户提出的问题,这里我们让机器人每次只针对当前问题进行回答,并没有将历史聊天记录保存起来一起喂给机器人。
def get_answer(question):chat_history = []result = chain({"question": question, "chat_history": chat_history});return result["answer"]下面是我和机器人之间就2022年3个时事新闻进行针对性聊天的内容:







总结
今天我们用LangChain对接了大型语言模型(LLMs), 并让LMMs可以针对性的学习用户给定的特定数据,这些数据可以是文本文件,数据库,知识库等结构化或者非结构化的数据。当用户询问的问题超出范围时,机器人不会给出任何答案,只会给出相关的提示信息显示用户的问题超出了范围,这样可以有效限制机器人自由发挥,使机器人不能让它随便乱说。
相关文章:
使用langchain打造自己的大型语言模型(LLMs)
我们知道Openai的聊天机器人可以回答用户提出的绝大多数问题,它几乎无所不知,无所不能,但是由于有机器人所学习到的是截止到2021年9月以前的知识,所以当用户询问机器人关于2021年9月以后发送的事情时,它无法给出正确的答案&#x…...
宏函数)
assert()宏函数
assert()宏函数 assert是宏,而不是函数。在C的assert.h文件中 #include <assert.h> void assert( int expression );assert的作用是先计算表达式expression, 如果其值为假(即为0),那么它会打印出来assert的内容…...

Docker圣经:大白话说Docker底层原理,6W字实现Docker自由
说在前面: 现在拿到offer超级难,甚至连面试电话,一个都搞不到。 尼恩的技术社群(50)中,很多小伙伴凭借 “左手云原生右手大数据”的绝活,拿到了offer,并且是非常优质的offer&#…...
Redis+Caffeine多级(二级)缓存,让访问速度纵享丝滑
目录多级缓存的引入多级缓存的优势CaffeineRedis实现多级缓存V1.0版本V2.0版本V3.0版本多级缓存的引入 在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中࿰…...
C#和.net框架之第一弹
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录C# 简介一、微软平台的编程二、使用VS创建第一个c#程序1、第一步2、第二步3、第三步4、第四步5、第五步C# 简介 C# 是一个现代的、通用的、面向对象的编程语言&…...
)
C++---背包模型---潜水员(每日一道算法2023.3.12)
注意事项: 本题是"动态规划—01背包"和"背包模型—二维费用的背包问题"的扩展题,优化思路不多赘述,dp思路会稍有不同,下面详细讲解。 题目: 潜水员为了潜水要使用特殊的装备。 他有一个带2种气体…...

C++类的成员变量和成员函数详解
类可以看做是一种数据类型,它类似于普通的数据类型,但是又有别于普通的数据类型。类这种数据类型是一个包含成员变量和成员函数的集合。 类的成员变量和普通变量一样,也有数据类型和名称,占用固定长度的内存。但是,在定义类的时候不能对成员变量赋值,因为类只是一种数据类…...
(模拟)(位运算)116. 飞行员兄弟)
(枚举)(模拟)(位运算)116. 飞行员兄弟
目录 题目链接 一些话 切入点 流程 套路 ac代码 题目链接 116. 飞行员兄弟 - AcWing题库 我草,又~在~水~字~数~啦!我草,又~在~水~字~数~啦…...
详解Array.prototype.shift.call(arguments)
经常看到如下代码: function foo() {let k Array.prototype.shift.call(arguments);console.log(k) } foo(11,22) //11 Array.prototype.shift.call(arguments)的作用是: 取 arguments 中的第一个参数 一、为啥要这么写,不直接使用argume…...
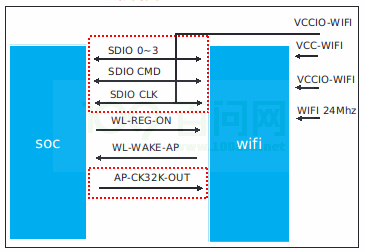
Tina_Linux_Wi-Fi_开发指南
Tina Linux Wi-Fi 开发指南 1 前言 1.1 文档简介 介绍Allwinner 平台上Wi-Fi 驱动移植,介绍Tina Wi-Fi 管理框架,包括Station,Ap 以及Wi-Fi 常见问题。 1.2 目标读者 适用Tina 平台的广大客户和对Tina Wi-Fi 感兴趣的同事。 1.3 适用范…...
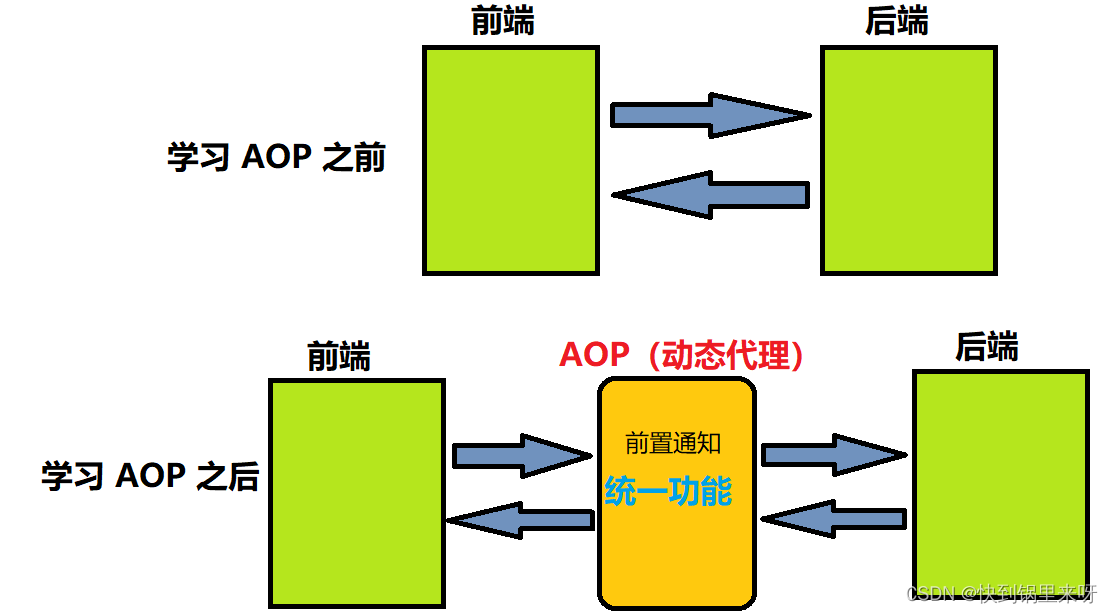
Spring AOP(AOP概念、组成、Spring AOP实现及实现原理)
文章目录1. Spring AOP 是什么2. 为什么要用 AOP3. 怎么学 Spring AOP4. AOP 组成5. Spring AOP 实现5.1 添加 Spring AOP 框架支持5.2 定义切面和切点5.3 实现通知方法5.4 使⽤ AOP 统计 UserController 每个⽅法的执⾏时间 StopWatch5.4 切点表达式说明 AspectJ6. Spring AOP…...
8.条件渲染指令
目录 1 v-if v-show 2 v-if v-else-if v-else 1 v-if v-show v-if与v-show都可以控制DOM的显示与隐藏 由于flag是布尔值,所以这里可以直接写 v-if"flag" 当flag为true的时候,v-if与v-show控制的div都会被显示出来 当flag为false的时候&a…...
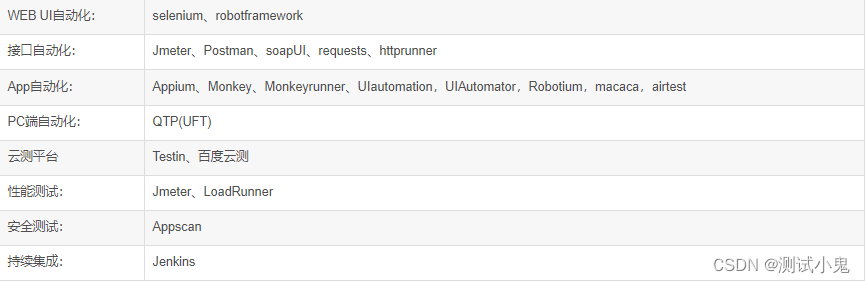
2023年全网最全最细最流行的自动化测试工具有哪些?你都知道吗!
下面就是我个人整理的一些比较常用的自动化测试工具,并且还有视频版本的详细介绍,同时在线学习人数超过1000人! B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)一:前言 随着测试工程师技能和…...

网络安全——数据链路层安全协议
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.数据链路层安全协议简介 1.数据链路安全性 二.局域网数据链路层协议 1.…...
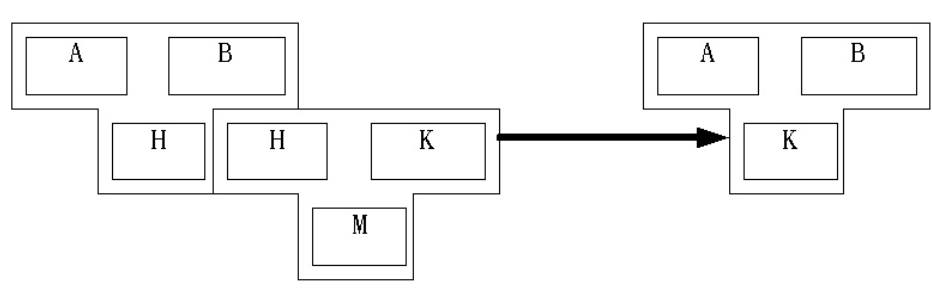
编译原理基础概念
一、什么是编译程序编译程序是一种程序,能够将某一种高级语言编写的源程序改造成另一种低级语言编写的目标程序,他们在逻辑上等价、完成相同的工作二、编译阶段1、当目标程序是机器语言时,编译阶段:(1)编译…...
蔬菜视觉分拣机器人的设计与实现(RoboWork参赛方案)
蔬菜视觉分拣机器人的设计与实现 文章目录蔬菜视觉分拣机器人的设计与实现1. 技术栈背景2. 整体设计3. 机械结构3.1 整体结构3.2 底座结构3.3 小臂结构3.4 大臂结构3.5 负载组件结构3.6 末端执行器结构4. 硬件部分4.1 视觉系统4.1.1 光源4.1.2 海康工业相机4.2 传送带系统4.2.1…...
【LVGL移植】STM32F1基于STM32CubeMX配置硬件SPI驱动1.8寸TFT ST7735S跑LVGL图形demo
【LVGL移植】STM32F1基于STM32CubeMX配置硬件SPI驱动1.8寸TFT ST7735S屏幕跑LVGL图形demo🎬运行LVGL 按键组件demo ✨基于STM32CubeMX配置工程是因为方便移植,只要是STM32芯片,拿到我的这个工程源码就可以根据自己的stm32芯片,自…...
写给20、21级学生的话
写给20、21级学生的话前言一、关于招聘变招生,你怎么看?二、对于即将实习/已经实习的学生,你有什么建议?1.学习方面2.提升方面三、思想成年真的很重要前言 最近,有一些同学遇到的实习问题,我统一回复下&…...
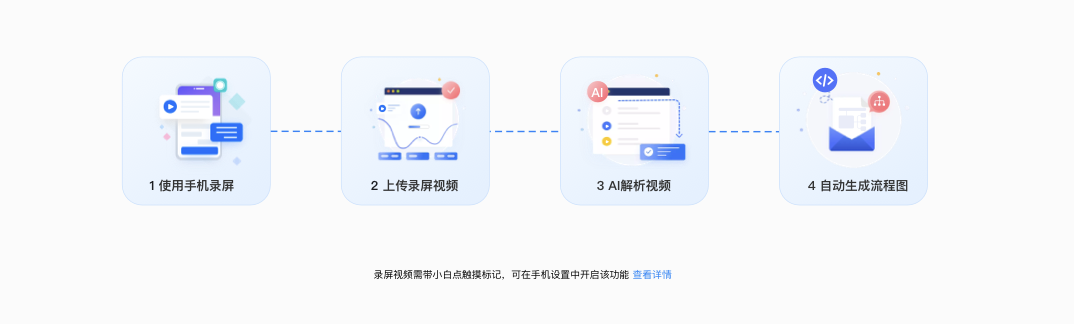
功能测试用例多次录制后,我丢掉了selenium,选择龙测AI-TestOps云平台
目录一、如何使用龙测AI-TestOps云平台1、进入龙测AI-TestOps云平台2、新建项目3、新建流程图4、创建任务5、查看任务状态6、查看报告、图片7、下载流程图、测试报告、excel用例二、龙测AI-TestOps云平台AI功能介绍1、NLP2、视频AI转流程图三、总结功能测试用例多次录制后&…...

【C++知识点】C++20 常用新特性总结
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...