Redis+Caffeine多级(二级)缓存,让访问速度纵享丝滑
目录
- 多级缓存的引入
- 多级缓存的优势
- Caffeine+Redis实现多级缓存
- V1.0版本
- V2.0版本
- V3.0版本
多级缓存的引入
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
在先不考虑并发等复杂问题的情况下,两级缓存的访问流程可以用下面这张图来表示:

多级缓存的优势
那么,使用两级缓存相比单纯使用远程缓存,具有什么优势呢?
本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
但是在设计中,还是要考虑一些问题的,例如数据一致性问题。首先,两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
另外,如果是分布式环境下,一级缓存之间也会存在一致性问题,当一个节点下的本地缓存修改后,需要通知其他节点也刷新本地缓存中的数据,否则会出现读取到过期数据的情况,这一问题可以通过类似于Redis中的发布/订阅功能解决。
此外,缓存的过期时间、过期策略以及多线程访问的问题也都需要考虑进去,不过我们今天暂时先不考虑这些问题,先看一下如何简单高效的在代码中实现两级缓存的管理。
Caffeine+Redis实现多级缓存
在简单梳理了一下要面对的问题后,下面开始两级缓存的代码实战,我们整合号称最强本地缓存的Caffeine作为一级缓存、性能之王的Redis作为二级缓存。首先建一个springboot项目,引入缓存要用到的相关的依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.1</version>
</dependency>
在application.yml中配置Redis的连接信息:
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
在下面的例子中,我们将使用RedisTemplate来对redis进行读写操作,RedisTemplate使用前需要配置一下ConnectionFactory和序列化方式,这一过程比较简单就不贴出代码了,有需要本文全部示例代码的可以在文末获取。
下面我们在单机环境下,将按照对业务侵入性的不同程度,分三个版本来实现两级缓存的使用。
V1.0版本
@Configuration
public class CaffeineConfig {
@Bean
public Cache<String,Object> caffeineCache(){
return Caffeine.newBuilder()
.initialCapacity(128)//初始大小
.maximumSize(1024)//最大数量
.expireAfterWrite(60, TimeUnit.SECONDS)//过期时间
.build();
}
}
简单解释一下Cache相关的几个参数的意义:
initialCapacity:初始缓存空大小
maximumSize:缓存的最大数量,设置这个值可以避免出现内存溢出
expireAfterWrite:指定缓存的过期时间,是最后一次写操作后的一个时间,这里
此外,缓存的过期策略也可以通过expireAfterAccess或refreshAfterWrite指定。
在创建完成Cache后,我们就可以在业务代码中注入并使用它了。在没有使用任何缓存前,一个只有简单的Service层代码是下面这样的,只有crud操作:
@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;@Override
public Order getOrderById(Long id) {
Order order = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return order;
}@Override
public void updateOrder(Order order) {
orderMapper.updateById(order);
}@Override
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
}
接下来,对上面的OrderService进行改造,在执行正常业务外再加上操作两级缓存的代码,先看改造后的查询操作:
public Order getOrderById(Long id) {
String key = CacheConstant.ORDER + id;
Order order = (Order) cache.get(key,
k -> {
//先查询 Redis
Object obj = redisTemplate.opsForValue().get(k);
if (Objects.nonNull(obj)) {
log.info("get data from redis");
return obj;
}// Redis没有则查询 DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(k, myOrder, 120, TimeUnit.SECONDS);
return myOrder;
});
return order;
}
在Cache的get方法中,会先从缓存中进行查找,如果找到缓存的值那么直接返回。如果没有找到则执行后面的方法,并把结果加入到缓存中。
因此上面的逻辑就是先查找Caffeine中的缓存,没有的话查找Redis,Redis再不命中则查询数据库,写入Redis缓存的操作需要手动写入,而Caffeine的写入由get方法自己完成。
在上面的例子中,设置Caffeine的过期时间为60秒,而Redis的过期时间为120秒,下面进行测试,首先看第一次接口调用时,进行了数据库的查询:

而在之后60秒内访问接口时,都没有打印打任何sql或自定义的日志内容,说明接口没有查询Redis或数据库,直接从Caffeine中读取了缓存。
等到距离第一次调用接口进行缓存的60秒后,再次调用接口:

可以看到这时从Redis中读取了数据,因为这时Caffeine中的缓存已经过期了,但是Redis中的缓存没有过期仍然可用。
下面再来看一下修改操作,代码在原先的基础上添加了手动修改Redis和Caffeine缓存的逻辑:
public void updateOrder(Order order) {
log.info("update order data");
String key=CacheConstant.ORDER + order.getId();
orderMapper.updateById(order);
//修改 Redis
redisTemplate.opsForValue().set(key,order,120, TimeUnit.SECONDS);
// 修改本地缓存
cache.put(key,order);
}
看一下下面图中接口的调用、以及缓存的刷新过程。可以看到在更新数据后,同步刷新了缓存中的内容,再之后的访问接口时不查询数据库,也可以拿到正确的结果:

最后再来看一下删除操作,在删除数据的同时,手动移除Reids和Caffeine中的缓存:
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
String key= CacheConstant.ORDER + id;
redisTemplate.delete(key);
cache.invalidate(key);
}
我们在删除某个缓存后,再次调用之前的查询接口时,又会出现重新查询数据库的情况:
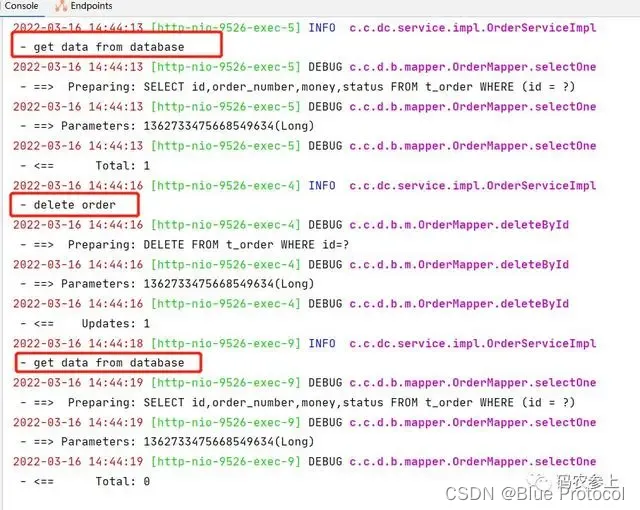
简单的演示到此为止,可以看到上面这种使用缓存的方式,虽然看起来没什么大问题,但是对代码的入侵性比较强。在业务处理的过程中要由我们频繁的操作两级缓存,会给开发人员带来很大负担。那么,有什么方法能够简化这一过程呢?我们看看下一个版本。
V2.0版本
在spring项目中,提供了CacheManager接口和一些注解,允许让我们通过注解的方式来操作缓存。先来看一下常用几个注解说明:
@Cacheable:根据键从缓存中取值,如果缓存存在,那么获取缓存成功之后,直接返回这个缓存的结果。如果缓存不存在,那么执行方法,并将结果放入缓存中。
@CachePut:不管之前的键对应的缓存是否存在,都执行方法,并将结果强制放入缓存
@CacheEvict:执行完方法后,会移除掉缓存中的数据。
如果要使用上面这几个注解管理缓存的话,我们就不需要配置V1版本中的那个类型为Cache的Bean了,而是需要配置spring中的CacheManager的相关参数,具体参数的配置和之前一样:
@Configuration
public class CacheManagerConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager=new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.initialCapacity(128)
.maximumSize(1024)
.expireAfterWrite(60, TimeUnit.SECONDS));
return cacheManager;
}
}然后在启动类上再添加上@EnableCaching注解,就可以在项目中基于注解来使用Caffeine的缓存支持了。下面,再次对Service层代码进行改造。
首先,还是改造查询方法,在方法上添加@Cacheable注解:
@Cacheable(value = "order",key = "#id")
//@Cacheable(cacheNames = "order",key = "#p0")
public Order getOrderById(Long id) {
String key= CacheConstant.ORDER + id;
//先查询 Redis
Object obj = redisTemplate.opsForValue().get(key);
if (Objects.nonNull(obj)){
log.info("get data from redis");
return (Order) obj;
}
// Redis没有则查询 DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(key,myOrder,120, TimeUnit.SECONDS);
return myOrder;
}
@Cacheable注解的属性多达9个,好在我们日常使用时只需要配置两个常用的就可以了。其中value和cacheNames互为别名关系,表示当前方法的结果会被缓存在哪个Cache上,应用中通过cacheName来对Cache进行隔离,每个cacheName对应一个Cache实现。value和cacheNames可以是一个数组,绑定多个Cache。
而另一个重要属性key,用来指定缓存方法的返回结果时对应的key,这个属性支持使用SpringEL表达式。通常情况下,我们可以使用下面几种方式作为key:
#参数名
#参数对象.属性名
#p参数对应下标
在上面的代码中,我们看到添加了@Cacheable注解后,在代码中只需要保留原有的业务处理逻辑和操作Redis部分的代码即可,Caffeine部分的缓存就交给spring处理了。
下面,我们再来改造一下更新方法,同样,使用@CachePut注解后移除掉手动更新Cache的操作:
@CachePut(cacheNames = "order",key = "#order.id")
public Order updateOrder(Order order) {
log.info("update order data");
orderMapper.updateById(order);
//修改 Redis
redisTemplate.opsForValue().set(CacheConstant.ORDER + order.getId(),
order, 120, TimeUnit.SECONDS);
return order;
}
注意,这里和V1版本的代码有一点区别,在之前的更新操作方法中,是没有返回值的void类型,但是这里需要修改返回值的类型,否则会缓存一个空对象到缓存中对应的key上。当下次执行查询操作时,会直接返回空对象给调用方,而不会执行方法中查询数据库或Redis的操作。
最后,删除方法的改造就很简单了,使用@CacheEvict注解,方法中只需要删除Redis中的缓存即可:
@CacheEvict(cacheNames = "order",key = "#id")
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
redisTemplate.delete(CacheConstant.ORDER + id);
}
可以看到,借助spring中的CacheManager和Cache相关的注解,对V1版本的代码经过改进后,可以把全手动操作两级缓存的强入侵代码方式,改进为本地缓存交给spring管理,Redis缓存手动修改的半入侵方式。那么,还能进一步改造,使之成为对业务代码完全无入侵的方式吗?
V3.0版本
模仿spring通过注解管理缓存的方式,我们也可以选择自定义注解,然后在切面中处理缓存,从而将对业务代码的入侵降到最低。
首先定义一个注解,用于添加在需要操作缓存的方法上:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DoubleCache {
String cacheName();
String key(); //支持springEl表达式
long l2TimeOut() default 120;
CacheType type() default CacheType.FULL;
}
我们使用cacheName + key作为缓存的真正key(仅存在一个Cache中,不做CacheName隔离),l2TimeOut为可以设置的二级缓存Redis的过期时间,type是一个枚举类型的变量,表示操作缓存的类型,枚举类型定义如下:
public enum CacheType {
FULL, //存取
PUT, //只存
DELETE //删除
}
因为要使key支持springEl表达式,所以需要写一个方法,使用表达式解析器解析参数:
public static String parse(String elString, TreeMap<String,Object> map){
elString=String.format("#{%s}",elString);
//创建表达式解析器
ExpressionParser parser = new SpelExpressionParser();
//通过evaluationContext.setVariable可以在上下文中设定变量。
EvaluationContext context = new StandardEvaluationContext();
map.entrySet().forEach(entry->
context.setVariable(entry.getKey(),entry.getValue())
);//解析表达式
Expression expression = parser.parseExpression(elString, new TemplateParserContext());
//使用Expression.getValue()获取表达式的值,这里传入了Evaluation上下文
String value = expression.getValue(context, String.class);
return value;
}
参数中的elString对应的就是注解中key的值,map是将原方法的参数封装后的结果。简单进行一下测试:
public void test() {
String elString="#order.money";
String elString2="#user";
String elString3="#p0";TreeMap<String,Object> map=new TreeMap<>();
Order order = new Order();
order.setId(111L);
order.setMoney(123D);
map.put("order",order);
map.put("user","Hydra");String val = parse(elString, map);
String val2 = parse(elString2, map);
String val3 = parse(elString3, map);System.out.println(val);
System.out.println(val2);
System.out.println(val3);
}
执行结果如下,可以看到支持按照参数名称、参数对象的属性名称读取,但是不支持按照参数下标读取,暂时留个小坑以后再处理。
123.0
Hydra
null
至于Cache相关参数的配置,我们沿用V1版本中的配置即可。准备工作做完了,下面我们定义切面,在切面中操作Cache来读写Caffeine的缓存,操作RedisTemplate读写Redis缓存。
@Slf4j @Component @Aspect
@AllArgsConstructor
public class CacheAspect {
private final Cache cache;
private final RedisTemplate redisTemplate;@Pointcut("@annotation(com.cn.dc.annotation.DoubleCache)")
public void cacheAspect() {
}@Around("cacheAspect()")
public Object doAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();//拼接解析springEl表达式的map
String[] paramNames = signature.getParameterNames();
Object[] args = point.getArgs();
TreeMap<String, Object> treeMap = new TreeMap<>();
for (int i = 0; i < paramNames.length; i++) {
treeMap.put(paramNames[i],args[i]);
}DoubleCache annotation = method.getAnnotation(DoubleCache.class);
String elResult = ElParser.parse(annotation.key(), treeMap);
String realKey = annotation.cacheName() + CacheConstant.COLON + elResult;//强制更新
if (annotation.type()== CacheType.PUT){
Object object = point.proceed();
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
cache.put(realKey, object);
return object;
}
//删除
else if (annotation.type()== CacheType.DELETE){
redisTemplate.delete(realKey);
cache.invalidate(realKey);
return point.proceed();
}//读写,查询Caffeine
Object caffeineCache = cache.getIfPresent(realKey);
if (Objects.nonNull(caffeineCache)) {
log.info("get data from caffeine");
return caffeineCache;
}//查询Redis
Object redisCache = redisTemplate.opsForValue().get(realKey);
if (Objects.nonNull(redisCache)) {
log.info("get data from redis");
cache.put(realKey, redisCache);
return redisCache;
}log.info("get data from database");
Object object = point.proceed();
if (Objects.nonNull(object)){
//写入Redis
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
//写入Caffeine
cache.put(realKey, object);
}
return object;
}
}
切面中主要做了下面几件工作:
通过方法的参数,解析注解中key的springEl表达式,组装真正缓存的key
根据操作缓存的类型,分别处理存取、只存、删除缓存操作
删除和强制更新缓存的操作,都需要执行原方法,并进行相应的缓存删除或更新操作
存取操作前,先检查缓存中是否有数据,如果有则直接返回,没有则执行原方法,并将结果存入缓存
修改Service层代码,代码中只保留原有业务代码,再添加上我们自定义的注解就可以了:
@DoubleCache(cacheName = "order", key = "#id",
type = CacheType.FULL)
public Order getOrderById(Long id) {
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return myOrder;
}@DoubleCache(cacheName = "order",key = "#order.id",
type = CacheType.PUT)
public Order updateOrder(Order order) {
orderMapper.updateById(order);
return order;
}@DoubleCache(cacheName = "order",key = "#id",
type = CacheType.DELETE)
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
到这里,基于切面操作缓存的改造就完成了,Service的代码也瞬间清爽了很多,让我们可以继续专注于业务逻辑处理,而不用费心去操作两级缓存了。
总结
本文按照对业务入侵的递减程度,依次介绍了三种管理两级缓存的方法。至于在项目中是否需要使用二级缓存,需要考虑自身业务情况,如果Redis这种远程缓存已经能够满足你的业务需求,那么就没有必要再使用本地缓存了。毕竟实际使用起来远没有那么简单,本文中只是介绍了最基础的使用,实际中的并发问题、事务的回滚问题都需要考虑,还需要思考什么数据适合放在一级缓存、什么数据适合放在二级缓存等等的其他问题。
160;
相关文章:
Redis+Caffeine多级(二级)缓存,让访问速度纵享丝滑
目录多级缓存的引入多级缓存的优势CaffeineRedis实现多级缓存V1.0版本V2.0版本V3.0版本多级缓存的引入 在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中࿰…...
C#和.net框架之第一弹
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录C# 简介一、微软平台的编程二、使用VS创建第一个c#程序1、第一步2、第二步3、第三步4、第四步5、第五步C# 简介 C# 是一个现代的、通用的、面向对象的编程语言&…...
)
C++---背包模型---潜水员(每日一道算法2023.3.12)
注意事项: 本题是"动态规划—01背包"和"背包模型—二维费用的背包问题"的扩展题,优化思路不多赘述,dp思路会稍有不同,下面详细讲解。 题目: 潜水员为了潜水要使用特殊的装备。 他有一个带2种气体…...

C++类的成员变量和成员函数详解
类可以看做是一种数据类型,它类似于普通的数据类型,但是又有别于普通的数据类型。类这种数据类型是一个包含成员变量和成员函数的集合。 类的成员变量和普通变量一样,也有数据类型和名称,占用固定长度的内存。但是,在定义类的时候不能对成员变量赋值,因为类只是一种数据类…...
(模拟)(位运算)116. 飞行员兄弟)
(枚举)(模拟)(位运算)116. 飞行员兄弟
目录 题目链接 一些话 切入点 流程 套路 ac代码 题目链接 116. 飞行员兄弟 - AcWing题库 我草,又~在~水~字~数~啦!我草,又~在~水~字~数~啦…...
详解Array.prototype.shift.call(arguments)
经常看到如下代码: function foo() {let k Array.prototype.shift.call(arguments);console.log(k) } foo(11,22) //11 Array.prototype.shift.call(arguments)的作用是: 取 arguments 中的第一个参数 一、为啥要这么写,不直接使用argume…...
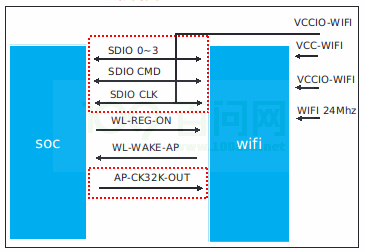
Tina_Linux_Wi-Fi_开发指南
Tina Linux Wi-Fi 开发指南 1 前言 1.1 文档简介 介绍Allwinner 平台上Wi-Fi 驱动移植,介绍Tina Wi-Fi 管理框架,包括Station,Ap 以及Wi-Fi 常见问题。 1.2 目标读者 适用Tina 平台的广大客户和对Tina Wi-Fi 感兴趣的同事。 1.3 适用范…...
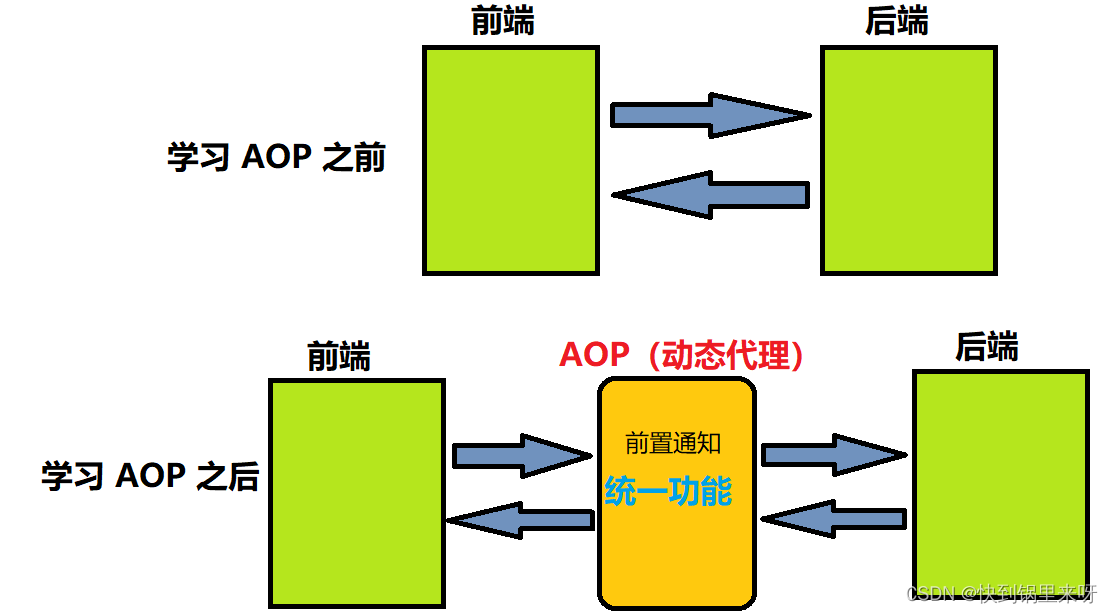
Spring AOP(AOP概念、组成、Spring AOP实现及实现原理)
文章目录1. Spring AOP 是什么2. 为什么要用 AOP3. 怎么学 Spring AOP4. AOP 组成5. Spring AOP 实现5.1 添加 Spring AOP 框架支持5.2 定义切面和切点5.3 实现通知方法5.4 使⽤ AOP 统计 UserController 每个⽅法的执⾏时间 StopWatch5.4 切点表达式说明 AspectJ6. Spring AOP…...
8.条件渲染指令
目录 1 v-if v-show 2 v-if v-else-if v-else 1 v-if v-show v-if与v-show都可以控制DOM的显示与隐藏 由于flag是布尔值,所以这里可以直接写 v-if"flag" 当flag为true的时候,v-if与v-show控制的div都会被显示出来 当flag为false的时候&a…...
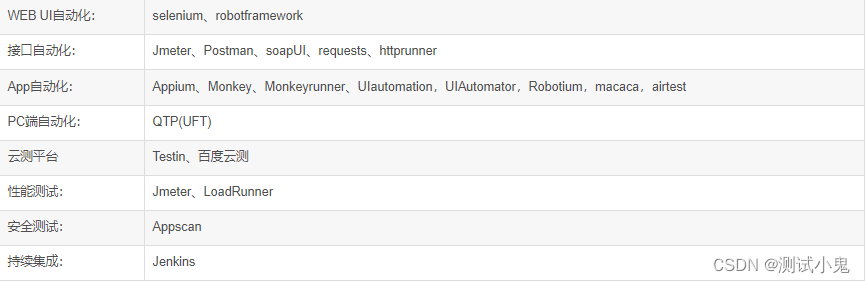
2023年全网最全最细最流行的自动化测试工具有哪些?你都知道吗!
下面就是我个人整理的一些比较常用的自动化测试工具,并且还有视频版本的详细介绍,同时在线学习人数超过1000人! B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)一:前言 随着测试工程师技能和…...

网络安全——数据链路层安全协议
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.数据链路层安全协议简介 1.数据链路安全性 二.局域网数据链路层协议 1.…...
编译原理基础概念
一、什么是编译程序编译程序是一种程序,能够将某一种高级语言编写的源程序改造成另一种低级语言编写的目标程序,他们在逻辑上等价、完成相同的工作二、编译阶段1、当目标程序是机器语言时,编译阶段:(1)编译…...
蔬菜视觉分拣机器人的设计与实现(RoboWork参赛方案)
蔬菜视觉分拣机器人的设计与实现 文章目录蔬菜视觉分拣机器人的设计与实现1. 技术栈背景2. 整体设计3. 机械结构3.1 整体结构3.2 底座结构3.3 小臂结构3.4 大臂结构3.5 负载组件结构3.6 末端执行器结构4. 硬件部分4.1 视觉系统4.1.1 光源4.1.2 海康工业相机4.2 传送带系统4.2.1…...
【LVGL移植】STM32F1基于STM32CubeMX配置硬件SPI驱动1.8寸TFT ST7735S跑LVGL图形demo
【LVGL移植】STM32F1基于STM32CubeMX配置硬件SPI驱动1.8寸TFT ST7735S屏幕跑LVGL图形demo🎬运行LVGL 按键组件demo ✨基于STM32CubeMX配置工程是因为方便移植,只要是STM32芯片,拿到我的这个工程源码就可以根据自己的stm32芯片,自…...
写给20、21级学生的话
写给20、21级学生的话前言一、关于招聘变招生,你怎么看?二、对于即将实习/已经实习的学生,你有什么建议?1.学习方面2.提升方面三、思想成年真的很重要前言 最近,有一些同学遇到的实习问题,我统一回复下&…...
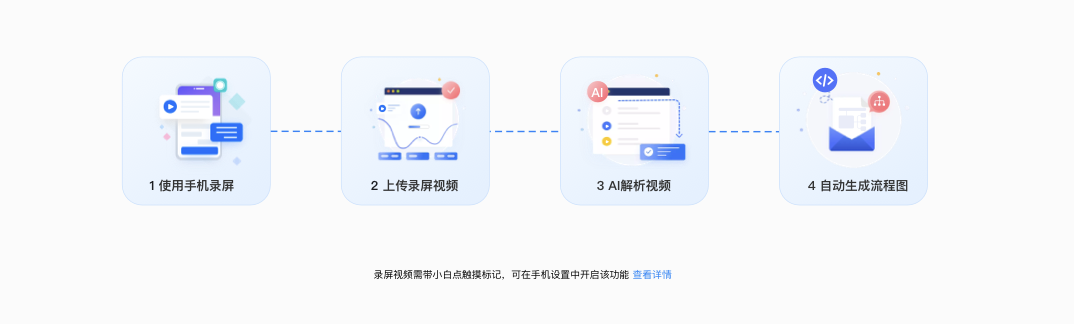
功能测试用例多次录制后,我丢掉了selenium,选择龙测AI-TestOps云平台
目录一、如何使用龙测AI-TestOps云平台1、进入龙测AI-TestOps云平台2、新建项目3、新建流程图4、创建任务5、查看任务状态6、查看报告、图片7、下载流程图、测试报告、excel用例二、龙测AI-TestOps云平台AI功能介绍1、NLP2、视频AI转流程图三、总结功能测试用例多次录制后&…...

【C++知识点】C++20 常用新特性总结
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

数据库体系结构概念--集中式数据库、分布式数据库
数据库模式 前言: 平时我们接触的‘数据库’一般指的是DBMS,数据库管理系统,DBMS是软件如:mysql、oracle、dm等等都是集中式数据库,但它们不能代表整个数据库,只是通过这些软件来管理相应的数据内容&#…...
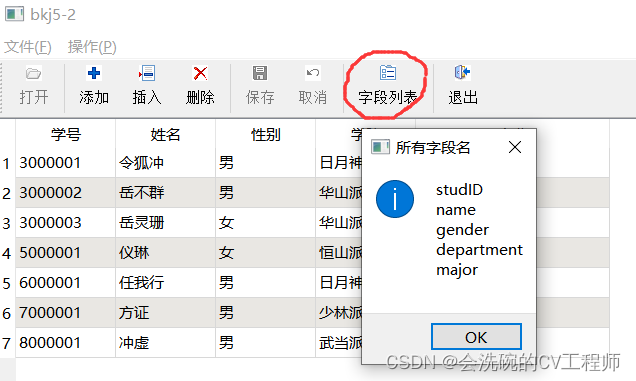
PyQt5数据库开发2 5.2 QSqlRelationalTableModel
目录 一、Qt窗体设计 1. 新建Qt项目 2. 添加组件 3. 添加资源 4. 添加Action 5. 添加工具栏 6. 添加菜单项 7. 添加退出功能 二、SQL Server下建表插数据 1. 建立表 2. 插入数据 3. 单表数据 4. 联合查询 三、代码实现 1. 新建项目目录 2. 编译窗体文件和资…...

树莓派——智能家居第一步
辛辛苦苦配了成功让树莓派开始工作了,开始搞智能家居!大体思路:基于工厂模式,分模块来实现上图分为三部分:主控、外设、控制主控我采用的是树莓派的4b4G版本,外设包括四个区域的灯(我的和上图有…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...