HashMap原理
初始化
从HashMap 源码中我们可以发现,HashMap的初始化有一下四种方式
//HashMap默认的初始容量大小 16,容量必须是2的幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// HashMap最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 扩容阈值,当容量超过这个阈值时触发HashMap的扩容流程
int threshold;
// 加载因子,即数组填满的程度,也可以理解为数组的利用率,我们可以通过自己指定加载因子来决定数据的扩容时机
// 因子越大利用率越高,随之hash冲突的几率也更高
// 因子越小,hash冲突的几率更小,但是浪费空间
final float loadFactor;/*** 第一种通过指定容量和加载因子创建一个空的hashMap* @param initialCapacity 初始容量* @param loadFactor 加载因子*/
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)// 指定初始容量大于最大值时重置为最大值initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;// 根据指定的初始容量计算出扩容的阈值this.threshold = tableSizeFor(initialCapacity);
}/*** 返回一个2的次幂的阈值,这里通过或运算和位运算,计算得到离指定参数最近的2的次幂数* Returns a power of two size for the given target capacity.*/
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}/*** 第二种通过指定初始容量创建,默认加载因子 0.75* @param initialCapacity 初始容量*/
public HashMap(int initialCapacity) {// 此处发现是直接调用的是第一种方法this(initialCapacity, DEFAULT_LOAD_FACTOR);
}/*** 第三种创建空对象,指定默认加载因子*/
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}/*** 第四种传入一个已有map结构数据,创建一个新的HashMap* @param m the map whose mappings are to be placed in this map*/
public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);
}// 从以上几种创建方式我们发现HashMap在初始化时并不会设置初始容量,第一种方法中的参数也只是用于计算扩容的阈值,那么HashMap是什么时候才会初始化容量值呢?我们往下看。
put流程
public V put(K key, V value) {// put流程是先计算出key的hash值,然后再调用put方法执行插入流程return putVal(hash(key), key, value, false, true);
}// 开始put流程
/**1. @param hash hash for key2. @param key the key3. @param value the value to put4. @param onlyIfAbsent if true, don't change existing value5. @param evict if false, the table is in creation mode.6. @return previous value, or null if none*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 如果数组为空或者长度为0,直接从 resize() 方法获取长度, 这里 resize() 做了哪些事情我们先不关注,继续往下看 if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)// (n - 1) & hash 计算key的下标,思考为什么要这么算?// 此处判断是否存在hash冲突,如果key所在下标为空直接创建node对象赋值tab[i] = newNode(hash, key, value, null);else {// 这里是发生了hash冲突的处理流程,p 就是冲突的NodeNode<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 如果冲突的Node hash值与插入的相等,key也相等,则直接将旧值赋值给 ee = p;else if (p instanceof TreeNode)// 如果hash不等并且key不等,并且Node已经转成红黑树结构,则使用红黑树的方式插入元素e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 如果hash不等并且key不等,并且还是链表结构,则遍历链表中的元素,for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {// 遍历链表,知道链表的最后一个元素,新建一个Node 赋值给节点的nextp.next = newNode(hash, key, value, null);// 插入后判断此时链表的长度是否超过红黑树的阈值8,数组的长度是否超过64,超过则转换成红黑树结构if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);// 跳出循环break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 如果链表上元素值与插入值相等,跳出循环break;// 如果元素不是最后节点,并且与插入元素不等,进行下一轮循环p = e;}}if (e != null) { // existing mapping for key// 通过上面的流程如果e不为空说明值已存在,拿出旧值 oldValue,并返回V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e); // 空实现return oldValue;}}// 走到这一步说明插入的值不存在,数组长度size+1++modCount;if (++size > threshold)// 判断插入元素后是否超过阈值,超过则扩容resize();afterNodeInsertion(evict); // 空实现return null;
}
分析完hashMap的put流程,下面我们做个简单总结,看看在put方法中主要做了哪些事情
- 首先判断数组是否为空,如果为空创建长度16的数组
- 通过与运算计算数组下标,如果对应下标没有元素直接创建新元素
- 如果对应小标已有元素,说明发生了hash冲突
先判断冲突的两个元素的hash值和key值是否相等,如果相等将值赋值给e变量
如果key不等,判断是否红黑树结构,如果是红黑树直接使用红黑树的方法新增元素
如果key不等并且不是红黑树结构,说明还是链表结构,直接遍历链表中的元素,如果数组长度超过阈值转换为红黑树 - 看得到的元素e是否为null,如果不为null说明元素已经存在,更新新值并返回旧值
- 如果e为null,说明没有重复元素,数组长度+1,modCount+1 最后再次判断数组长度是否超过阈值,大于则扩容
下面我们继续分析put方法中的几个重要的方法
hash - key的hash计算
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里我们思考hashMap为什么要这样计算key的hash值呢?
我们先来看看他的运算过程
1.先判断key是否为null,如果为null,赋值为0
2.如果不为null,先获取key的hashCode()值,然后将hashCode的高16位右移到低位得到新值,最后将新值异或旧值得到最终结果
这样做的目的是为了将key分布的更加均匀
resize - 扩容
/*** Initializes or doubles table size. If null, allocates in* accord with initial capacity target held in field threshold.* Otherwise, because we are using power-of-two expansion, the* elements from each bin must either stay at same index, or move* with a power of two offset in the new table.** @return the table*/
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;// 老容量int oldCap = (oldTab == null) ? 0 : oldTab.length;// 老阈值int oldThr = threshold;// 初始化新容量和阈值int newCap, newThr = 0;if (oldCap > 0) {// 如果老容量大于0,说明数组中已有元素if (oldCap >= MAXIMUM_CAPACITY) {// 如果老容量大于容量最大值直接返回,阈值也设置为Integer最大值threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)// 如果老容量没到最大值,并且*2之后小于最大值, 并且大于等于初始容量,阈值也直接*2newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in threshold// 如果老阈值大于0,新容量设置为老阈值newCap = oldThr;else { // zero initial threshold signifies using defaults// 走到这里说明容量和阈值都是0,初始化是调用resize(),就会走到这个判断,那么设置新容量为默认值16,阈值为容量16*0.75=12newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {// 新阈值等于0,新容量*加载因子得到阈值,然后判断新容量小于最大值,并且新阈值小于最大值都使用新的阈值,否则设置为最大值float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;// 创建一个新容量长度的新数组Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];// 将新数组赋值给数组table = newTab;if (oldTab != null) {// 遍历老数组中每个元素for (int j = 0; j < oldCap; ++j) {Node<K,V> e;// 遍历老数组if ((e = oldTab[j]) != null) {// 取出值然后设置为空oldTab[j] = null;if (e.next == null)// 如果元素没有链表,重新计算元素在新数组的下标并赋值newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)// 如果元素是红黑树结构,调用split方法将数放入新的数组((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order// 元素是链表,循环遍历将元素放入新数组Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}
HashMap中在初始化和扩容(链表长度大于8并且数组长度小于64)的时候都会调用resize方法,我们看看这个方法里主要做了哪些事
- 先判断老容量是否大于0,如果大于0并且大于等于最大值,设置阈值为Integer最大值,如果老容量小于最大值,并且2之后的容量也小于最大值,并且老容量大于等于默认值16,设置新阈值为老阈值2
- 如果老阈值大于0,设置新容量等于老阈值。
- 如果老容量和老阈值都不大于0,说明是新数组进度初始化,容量为16,阈值为16*0.75=12
- 如果新阈值还是0,用新容量*0.75得到一个阈值,然后判断阈值范围得到最终的新阈值
- 将得到的新阈值和新数组分别设置到HashMap的实例属性中
- 如果老数据不为空,则重新计算元素小标插入新的数组中
newNode - 创建新元素
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {return new Node<>(hash, key, value, next);
}
putTreeVal - 元素插入红黑树
/*** Tree version of putVal.*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) {// key的Class对象Class<?> kc = null;boolean searched = false;// 获取根节点TreeNode<K,V> root = (parent != null) ? root() : this;// 开始循环遍历红黑树中所有节点for (TreeNode<K,V> p = root;;) {// dir 是一个标识,1表示放在节点右边,-1表示放在节点左边// ph 当前节点的hash// pk 当前节点的keyint dir, ph; K pk;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (k != null && k.equals(pk)))// 判断当前节点的值和插入的值一样,直接返回获取的节点return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {// 当前节点的hash值相等,但是equals不等 if (!searched) {// searched 标识是否已经比较当前节点的左右子节点TreeNode<K,V> q, ch;searched = true;// 在节点的节点的左右子节点递归查找,如果找到相同的值则直接返回if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}// 走到这一步说明没有找到相同的节点,比较插入的key和当前节点的key,计算出元素是往左插入还是往右插入dir = tieBreakOrder(k, pk);}TreeNode<K,V> xp = p;// 如果计算得到的dir 小于等于0,往左插入,大于0往右插入,并且节点为空if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;// 将当前节点的下一个节点指向新节点xp.next = x;// 新节点的父节点和前节点设置为当前节点x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;// 重新平衡红黑树moveRootToFront(tab, balanceInsertion(root, x));return null;}}
}treeifyBin - 红黑树扩容
/*** Replaces all linked nodes in bin at index for given hash unless* table is too small, in which case resizes instead.*/
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)// 数组为空或者链表长度大于8,并且数组长度小于64,进行扩容resize();else if ((e = tab[index = (n - 1) & hash]) != null) {// 将链表转成红黑树TreeNode<K,V> hd = null, tl = null;do {// 将原链表中节点重新创建新的红黑树节点TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)// 头节点不为空调用该方法转红黑树hd.treeify(tab);}
}/*** Forms tree of the nodes linked from this node.* @return root of tree*/
final void treeify(Node<K,V>[] tab) {// 定义一个根节点TreeNode<K,V> root = null;// 遍历链表,this表示当前节点,next表示下一节点for (TreeNode<K,V> x = this, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;x.left = x.right = null;if (root == null) {// root为空说明是第一个节点,将父节点设置为空x.parent = null;x.red = false;root = x;}else {// 处理后续节点,获取当前节点的key,hash,这里逻辑跟往红黑树中插入元素基本一致K k = x.key;int h = x.hash;Class<?> kc = null;for (TreeNode<K,V> p = root;;) {int dir, ph;K pk = p.key;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0)xp.left = x;elsexp.right = x;root = balanceInsertion(root, x);break;}}}}// 把所有的链表节点都遍历完之后,最终构造出来的树可能经历多个平衡操作,根节点目前到底是链表的哪一个节点是不确定的// 因为我们要基于树来做查找,所以就应该把 tab[N] 得到的对象一定根节点对象,而目前只是链表的第一个节点对象,所以要做相应的处理。moveRootToFront(tab, root);
}
HashMap 在 Put 时,新链表节点是放在头部还是尾部
// 上面我们分析完HashMap的put流程,从下面这段代码可以看出1.8是采用尾插法新增元素
for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;
}
1.8如何减少hash冲突
什么是hash冲突
哈希冲突是由于hash算法被计算的数据是无限的,而计算后的结果范围是有限的,所以总会存在不同的数据计算后得到的值是一样的,那将会存在同一个位置,就会出现哈希冲突。
解决哈希冲突的方法
开放地址法:也称线性探测法,就是从发生冲突的那个位置,按照一定次序从Hash表中找到一个空闲的位置, 把发生冲突的元素存入到这个位置。而在java种ThreadLocal就用到了线性探测法,来解决Hash冲突。
链式寻址法:通过单向链表的方式来解决哈希冲突,Hashmap就是用了这个方法。(但会存在链表过长增加遍历时间)
再哈希法:key通过某个哈希函数计算得到冲突的时候,再次使用哈希函数的方法对key哈希一直运算直到不产生冲突为止 (耗时间,性能会有影响)
建立公共溢出区:就是把Hash表分为基本表和溢出表两个部分,凡是存在冲突的元素,一律放到溢出表中
HashMap在JDK1.8版本中是通过链式寻址法以及红黑树来解决Hash冲突的问题,其中红黑树是为了优化Hash表的链表过长导致时间复杂度增加的问题,当链表长度大于等于8并且Hash表的容量大于64的时候,再向链表添加元素,就会触发链表向红黑树的一个转化
get流程
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {// 数组不为空,并且数组长度大于0并且所查找的key对应下标不为空if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))// 如果key,hash相等直接返回return first;if ((e = first.next) != null) {// 查找后续链表if (first instanceof TreeNode)// 如果节点是红黑树,则以红黑树的方式查找return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {// 到这里说明是链表,遍历链表查找匹配的元素,否则直接返回空if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}
加载因子为什么是0.75
加载因子 = 填入表中的元素个数 / 散列表的长度
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;
加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容rehash操作的次数。
冲突的机会越大,说明需要查找的数据还需要通过另一个途径查找,这样查找的成本就越高。因此,必须在“冲突的机会”与“空间利用率”之间,寻找一种平衡与折衷。
负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
HashMap 的容量为什么建议是 2的幂次方?
如果不是2的幂次方的话,会导致大量的key存在同一个槽中,导致链表集中部分的槽上,影响性能
HashMap的并发问题
死循环:在链表转换成红黑数的时候无法跳出等多个地方都会出现这个问题。
put数据丢失
size计算不准:size只是用了transient关键字修饰,在各个线程中的size不会及时同步,在多个线程操作的时候,size将会被覆盖。
HashMap 在 JDK 1.8 有什么改变
结构变化:1.7是数组+链表,1.8是数组+链表+红黑树
插入方式:1.7是头插法,1.8是尾插法
拉链法导致的链表过深问题为什么不用二叉查找树代替,而选择红黑树?为什么不一直使用红黑树?
选择红黑树是为了解决二叉查找树的缺陷,二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢。而红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,引入红黑树就是为了查找数据快,解决链表查询深度的问题,我们知道红黑树属于平衡二叉树,但是为了保持“平衡”是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少,所以当长度大于8的时候,会使用红黑树,如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
相关文章:

HashMap原理
初始化 从HashMap 源码中我们可以发现,HashMap的初始化有一下四种方式 //HashMap默认的初始容量大小 16,容量必须是2的幂 static final int DEFAULT_INITIAL_CAPACITY 1 << 4; // HashMap最大容量 static final int MAXIMUM_CAPACITY 1 <&…...
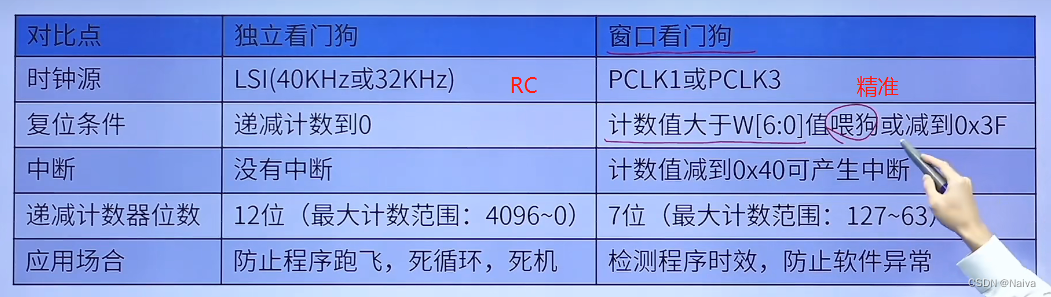
STM32入门笔记(02):独立看门狗(IWDG)和窗户看门狗(WWDG)(SPL库函数版)
1.IWDG狗简介 除了始终控制器的RCC_CSR寄存器的父为标志位和备份区域中的寄存器以外,系统复位 将复位所有寄存器至它们的复位状态。 当发生以下任一事件时,产生一个系统复位: 1.NRST引脚上的 低 电平,即 外部复位;2…...
javaSE系列之方法与数组的使用
[TOC] javaSE系列之方法与数组的使用 方法的定义 方法类似于C语言中的"函数"。 方法的种类 这里方法分为有参方法也分为无参方法, 形参和实参是两个实体(这里相当于函数的传值调用和传址调用) 1.非静态方法:普通方法/…...

常用命令总结
将常用命令汇集于此,以便在忘记的时候查询,持续更新…… Git Local changes 添加名字: git config --global user.name "<你的名字>"添加邮件: git config --globa user.email "<你的邮箱>"…...

【Linux:程序地址空间--原来操作系统也喜欢画大饼】
目录 1 代码感受 2 进程地址空间 3 扩展 1 代码感受 在正式讲程序地址空间前我们先来看一段简单的代码来分析分析: 1 #include<iostream>2 #include<unistd.h>3 using namespace std;4 5 int g_val100;6 7 int main()8 {9 pid_t idfork();10 if(i…...

Python实现简单信号滤波实战
在有些项目中需要对信号进行滤波处理,尤其是在医疗的设备中如心跳、脉搏等设备的采样后进行处理。滤波的目的就是除去某些频率的信号如噪声。常见的包括有低通滤波、高通滤波、带通滤波。 低通滤波指的是去除高于某一阈值频率的信号;高通滤波去除低于某…...

Java(110):非对称加密RSA的使用(KeyPair生成密钥)
Java(110):非对称加密RSA的使用(KeyPair生成密钥) RSA 算法是一种非对称加解密算法。服务方生成一对 RSA 密钥,即公钥 私钥,将公钥提供给调用方,调用方使用公钥对数据进行加密后,服务方根据私钥进行解密。 1、RSA生…...
整合 Mybatis 开发流程)
(Mybatis 学习【1】)整合 Mybatis 开发流程
Mybatis 整合流程 ① 添加MyBatis的依赖 ② 创建数据库表 ③ 编写pojo实体类 ④ 编写映射文件UserMapper.xml ⑤ 编写核心文件mybatis-config.xml ⑥ 编写测试类** 编写 pojo 实体类 (设计相应的数据库) Data AllArgsConstructor NoArgsConstructor public class…...

一文搞懂Kerberos
Kerberos一词来源于古希腊神话中的Cerberus——守护地狱之门的三头犬,Kerberos是为TCP/IP 网络设计的可信第三方鉴别协议,最初是在麻省理工学院(MIT)为Athena 项目而开发的。Kerberos服务起着可信仲裁者的作用,可提供安全的网络鉴别ÿ…...

Go爬虫学习笔记(三)
day3 04|敏捷之道:大型Go项目的开发流程是怎样的? 瀑布模式 流程: 市场调研需求分析产品设计研发实现集成与测试项目交付与维护 适用场景: 需求在规划和设计阶段就已经确定了,而且在项目开发周期内&…...

CASTEP参数设置(2)
虚拟试验(分子模拟) 在表征材料以及材料的相关性质时,只要是采用已有的理论加以解释 但是通常来说,需要采用已有的理论来进行设计和探索,伴随着工业软件的发展,应当选用仿真技术来缩小探索范围 传统试验V…...
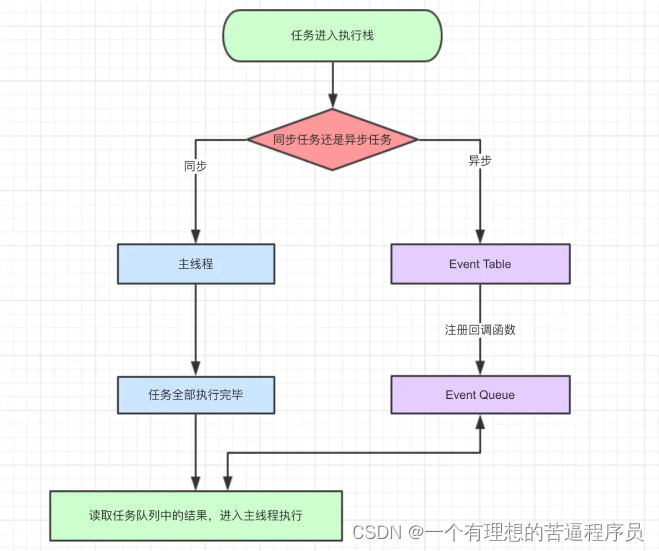
浅谈对Promise的理解以及在工作中的应用
浅谈对Promise的理解以及在工作中的应用Promise的概念背景知识JavaScript的同步和异步JavaScript事件循环回调函数进行异步操作解决方案:PromisePromise 在工作中的运用创建PromisePromise封装AJAXPromise链式操作Promise.all()Promise.race()async和await总结Promi…...
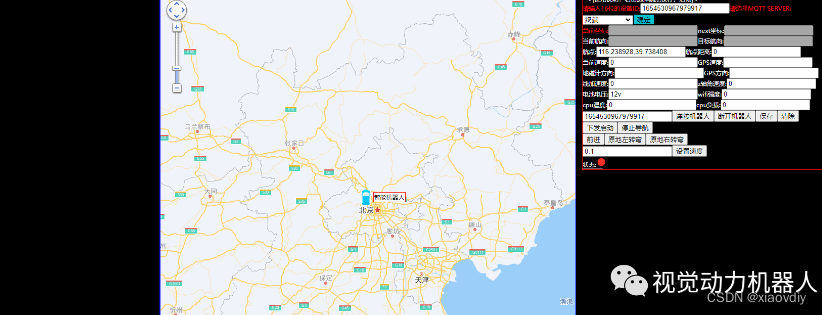
开源|快速入门和理解并模拟实现GPS户外机器人的定位与导航
户外机器人的定位导航相对于需要建图的场景来说,是比较简单容易实现的,因为可以借助第三方地图完成定位,并在第三方地图中完成路径规划和下发航点等操作,实现的难题在于如何控制机器人完成步行和转弯。 这些在不引进RTK高精度定位…...
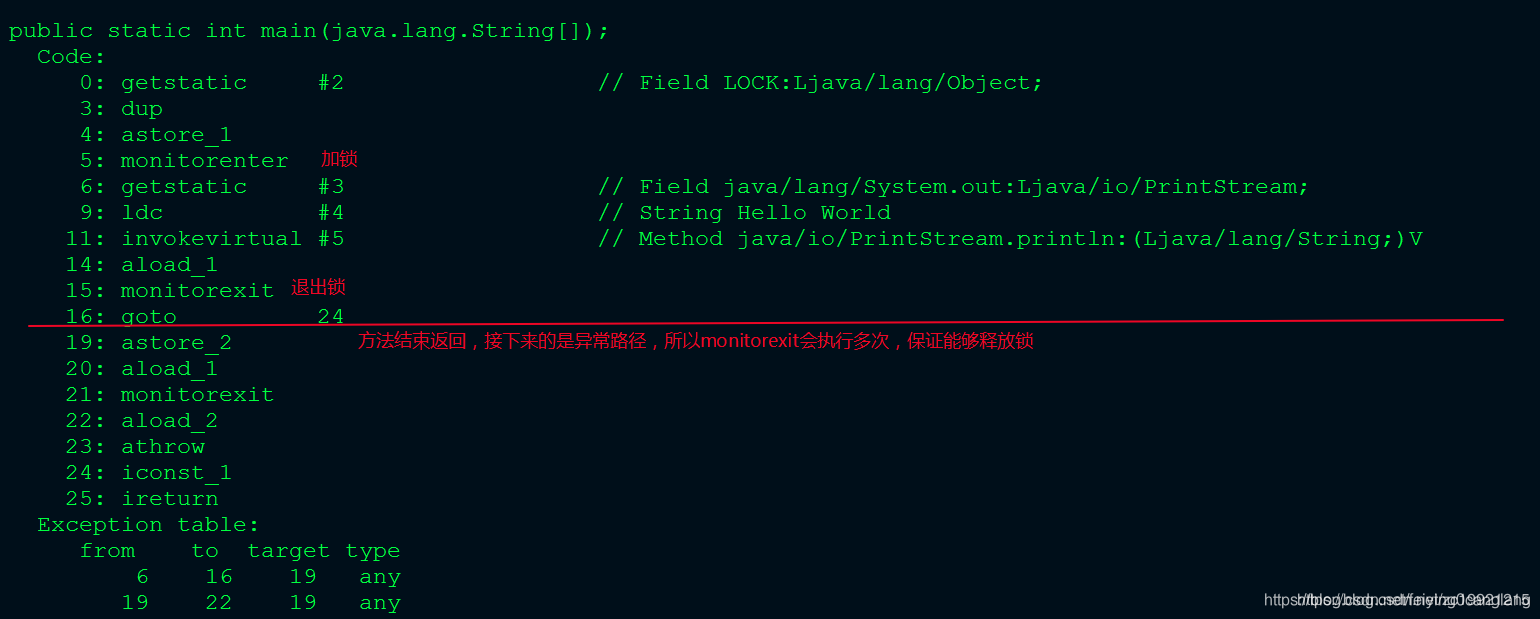
Java多线程系列--synchronized的原理
原文网址:Java多线程系列--synchronized的原理_IT利刃出鞘的博客-CSDN博客 简介 本文介绍Java的synchronized的原理。 反编译出字节码 Test.java public class Test {private static Object LOCK new Object();public static int main(String[] args) {synchro…...

QEMU启动ARM64 Linux内核
目录前言前置知识virt开发板ARM处理器家族简介安装qemu-system-aarch64安装交叉编译工具交叉编译ARM64 Linux内核交叉编译ARM64 Busybox使用busybox制作initramfs使用QEMU启动ARM64 Linux内核前言 本文介绍采用 qemu 模拟ARM-64bit开发板(针对ARM-32bit的有另一篇文…...
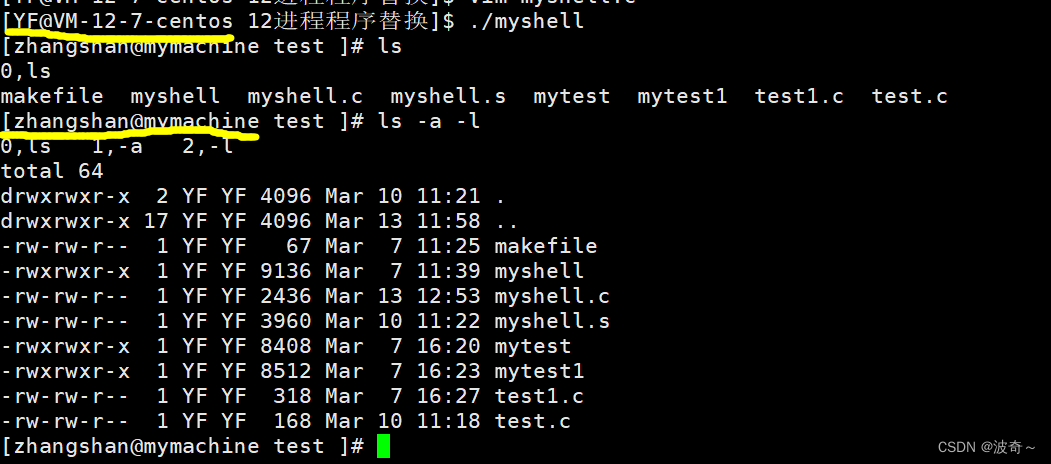
Linux->进程程序替换
目录 前言: 1 程序替换原理 2 单进程替换 3 替换函数 3.1 函数使用 4 程序去替换自己的另一个程序操作方式 5 实现自己的shell 前言: 通过我们之前对于子进程的应用,我相信大家一定是能够想到创建子进程的目的之一就是为了代劳父进程执…...
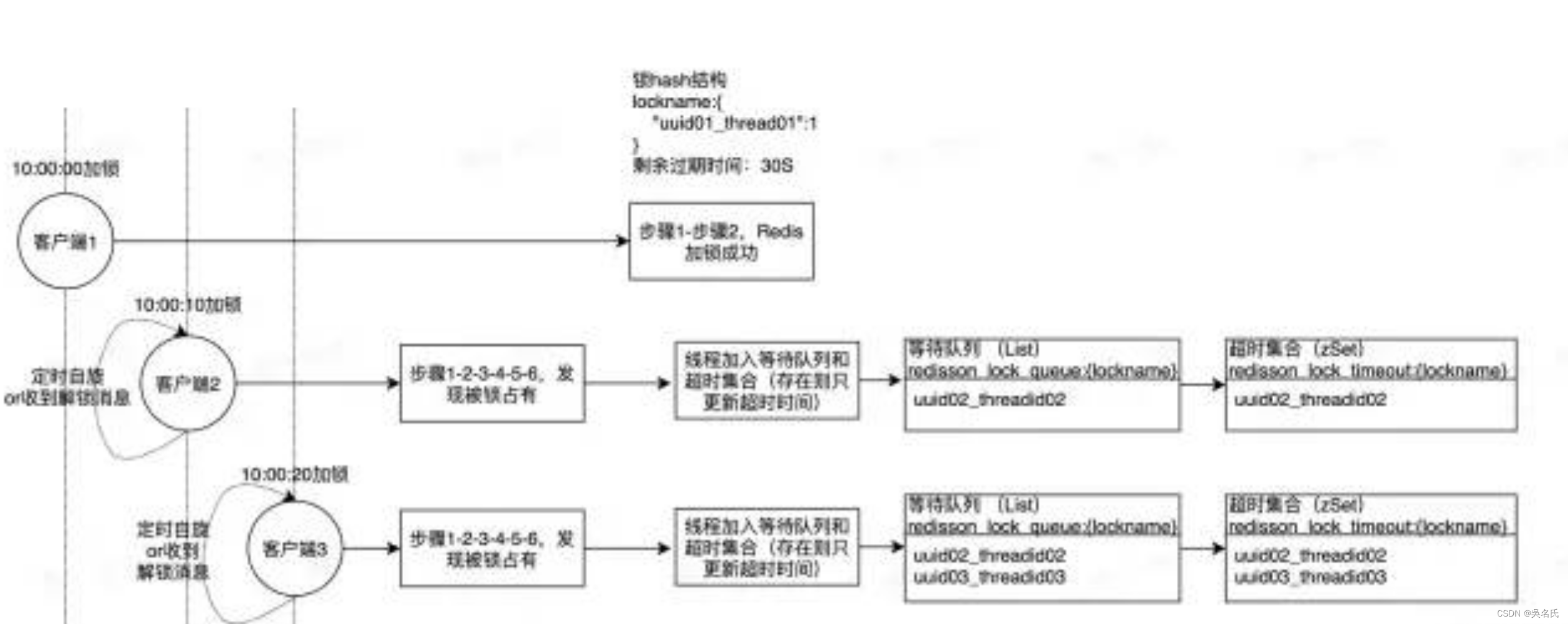
最强分布式锁工具:Redisson
1 Redisson概述1.1 什么是Redisson?Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, Sorted…...

Java9-17新特性
Java9-17新特性 一、接口的私有方法 Java8版本接口增加了两类成员: 公共的默认方法公共的静态方法 Java9版本接口又新增了一类成员: 私有的方法 为什么JDK1.9要允许接口定义私有方法呢?因为我们说接口是规范,规范时需要公开…...
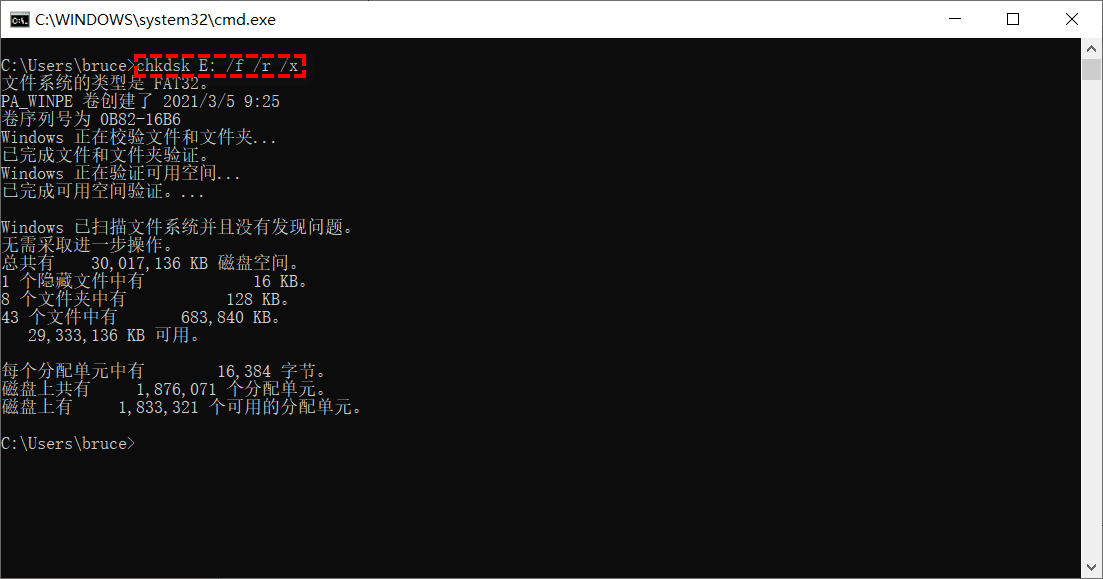
电脑开机找不到启动设备怎么办?
电脑正常开机,却提示“找不到启动设备”,这时我们该怎么办呢?本文就为大家介绍几种针对该问题的解决方法,一起来看看吧!“找不到启动设备”是什么意思?可引导设备(又称启动设备)是一…...

使用langchain打造自己的大型语言模型(LLMs)
我们知道Openai的聊天机器人可以回答用户提出的绝大多数问题,它几乎无所不知,无所不能,但是由于有机器人所学习到的是截止到2021年9月以前的知识,所以当用户询问机器人关于2021年9月以后发送的事情时,它无法给出正确的答案&#x…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...
结构化文件管理实战:实现目录自动创建与归类
手动操作容易因疲劳或疏忽导致命名错误、路径混乱等问题,进而引发后续程序异常。使用工具进行标准化操作,能有效降低出错概率。 需要快速整理大量文件的技术用户而言,这款工具提供了一种轻便高效的解决方案。程序体积仅有 156KB,…...

基于Java项目的Karate API测试
Karate 实现了可以只编写Feature 文件进行测试,但是对于熟悉Java语言的开发或是测试人员,可以通过编程方式集成 Karate 丰富的自动化和数据断言功能。 本篇快速介绍在Java Maven项目中编写和运行测试的示例。 创建Maven项目 最简单的创建项目的方式就是创建一个目录,里面…...
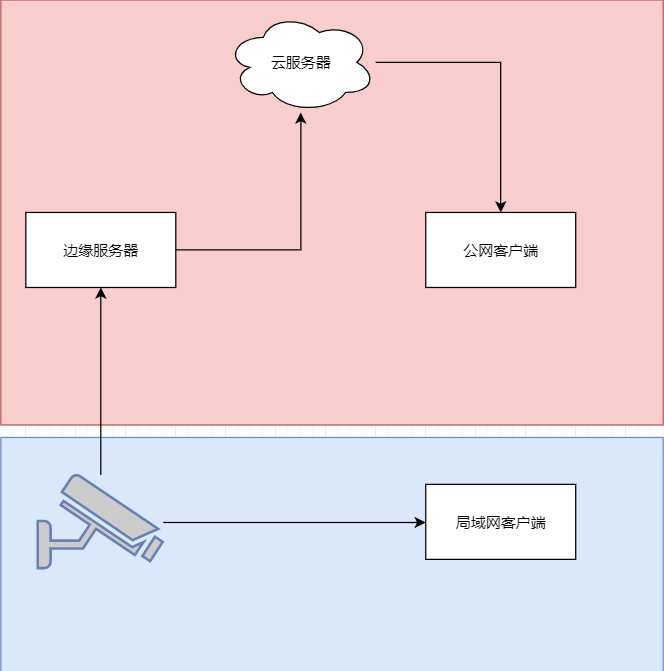
java 局域网 rtsp 取流 WebSocket 推送到前端显示 低延迟
众所周知 摄像头取流推流显示前端延迟大 传统方法是服务器取摄像头的rtsp流 然后客户端连服务器 中转多了,延迟一定不小。 假设相机没有专网 公网 1相机自带推流 直接推送到云服务器 然后客户端拉去 2相机只有rtsp ,边缘服务器拉流推送到云服务器 …...

Spring是如何实现无代理对象的循环依赖
无代理对象的循环依赖 什么是循环依赖解决方案实现方式测试验证 引入代理对象的影响创建代理对象问题分析 源码见:mini-spring 什么是循环依赖 循环依赖是指在对象创建过程中,两个或多个对象相互依赖,导致创建过程陷入死循环。以下通过一个简…...