Spark09: Spark之checkpoint
一、checkpoint概述
checkpoint,是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而且,整个任务运行的时间也特别长,比如通常要运行1~2个小时。在这种情况下,就比较适合使用checkpoint功能了。因为对于特别复杂的Spark任务,有很高的风险会出现某个要反复使用的RDD因为节点的故障导致丢失,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation算子,又要使用到该RDD时,就会发现数据丢失了,此时如果没有进行容错处理的话,那么就需要再重新计算一次数据了。所以针对这种Spark Job,如果我们担心某些关键的,在后面会反复使用的RDD,因为节点故障导致数据
丢失,那么可以针对该RDD启动checkpoint机制,实现容错和高可用
如何使用checkpoint?
(1)首先要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如HDFS;然后,对RDD调用checkpoint()方法。
(2)最后,在RDD所在的job运行结束之后,会启动一个单独的job,将checkpoint设置过的RDD的数据写入之
前设置的文件系统中。
二、RDD的checkpoint流程
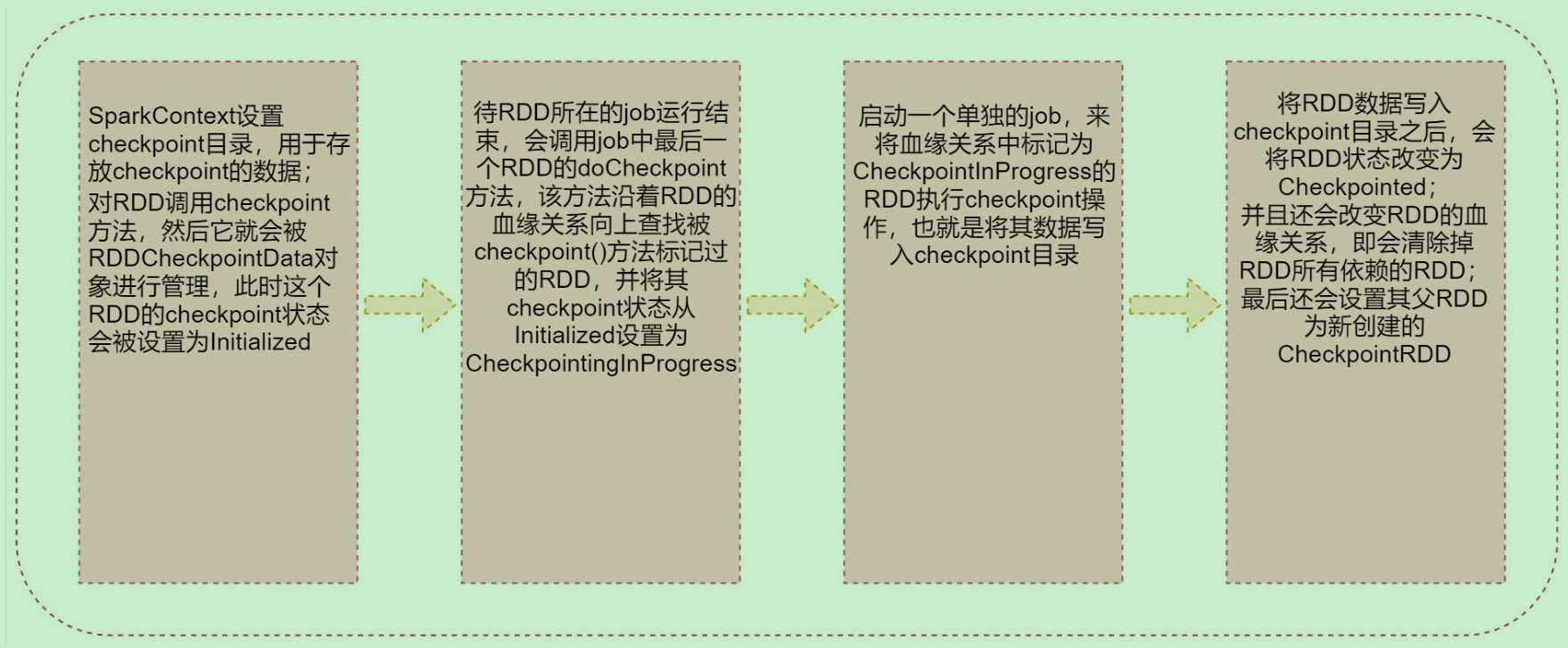
1:SparkContext设置checkpoint目录,用于存放checkpoint的数据;对RDD调用checkpoint方法,然后它就会被RDDCheckpointData对象进行管理,此时这个RDD的checkpoint状态会被设置为Initialized。
2:待RDD所在的job运行结束,会调用job中最后一个RDD的doCheckpoint方法,该方法沿着RDD的血缘关系向上查找被checkpoint()方法标记过的RDD,并将其checkpoint状态从Initialized设置为
CheckpointingInProgress
3:启动一个单独的job,来将血缘关系中标记为CheckpointInProgress的RDD执行checkpoint操作,也就是将其数据写入checkpoint目录
4:将RDD数据写入checkpoint目录之后,会将RDD状态改变为Checkpointed;并且还会改变RDD的血缘关系,即会清除掉RDD所有依赖的RDD;最后还会设置其父RDD为新创建的CheckpointRDD
三、checkpoint与持久化的区别
(1)lineage是否发生改变。
lineage(血缘关系)说的就是RDD之间的依赖关系,持久化只是将数据保存在内存中或者本地磁盘文件中,RDD的lineage(血缘关系)是不变的;Checkpoint执行之后,RDD就没有依赖的RDD了,也就是它的lineage改变了。
(2)丢失数据的可能性。
持久化的数据丢失的可能性较大,如果采用 persist 把数据存在内存中的话,虽然速度最快但是也是最不可靠的,就算放在磁盘上也不是完全可靠的,因为磁盘也会损坏。Checkpoint的数据通常是保存在高可用文件系统中(HDFS),丢失的可能性很低
建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)
为什么呢因为默认情况下,如果某个RDD没有持久化,但是设置了checkpoint,那么这个时候,本来Spark任务已经执行结束了,但是由于中间的RDD没有持久化,在进行checkpoint的时候想要将这个RDD的数据写入外部存储系统的话,就需要重新计算这个RDD的数据,再将其checkpoint到外部存储系统中。如果对需要checkpoint的rdd进行了基于磁盘的持久化,那么后面进行checkpoint操作时,就会直接从磁盘上读取rdd的数据了,就不需要重新再计算一次了,这样效率就高了。那在这能不能使用基于内存的持久化呢?当然是可以的,不过没那个必要。
四、checkpoint的使用
1. scala代码
package com.sanqian.scalaimport org.apache.spark.api.java.StorageLevels
import org.apache.spark.{SparkConf, SparkContext}object CheckPointScala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("CheckPointScala")val sc = new SparkContext(conf)if (args.length == 0) {System.exit(100)}val outoutPath = args(0)// 1.设置checkpoint目录\sc.setCheckpointDir("hdfs://bigdata01:9000/chk001")val dataRDD = sc.textFile("hdfs://bigdata01:9000/hadoop")dataRDD.persist(StorageLevels.DISK_ONLY)// 2.对RDD执行checkpoint操作dataRDD.checkpoint()dataRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(outoutPath)sc.stop()}
}
2. Java代码
package com.sanqian.java;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.Arrays;
import java.util.Iterator;public class CheckPointJava {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setAppName("CheckPointJava");JavaSparkContext sc = new JavaSparkContext(conf);if (args.length == 0){System.exit(100);}String outputPath = args[0];// 1.设置checkpoint目录sc.setCheckpointDir("hdfs://bigdata01:9000/chk001");JavaRDD<String> rdd = sc.textFile("hdfs://bigdata01:9000/hadoop");// 2.对RDD执行checkpoint操作rdd.checkpoint();rdd.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split(" ")).iterator();}}).mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<String, Integer>(word, 1);}}).reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}}).saveAsTextFile(outputPath);sc.stop();}
}
3. 打包代码
(1)将pom.xml中的spark-core的依赖设置为provided,然后编译打包
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.3</version><scope>provided</scope></dependency>(2)D:\ProgramData\IdeaProjects\db_spark>mvn clean package -DskipTests
(3)将打包的jar包上传到bigdata04的/data/soft/sparkjars目录,创建一个新的spark-submit脚本
spark-submit \
--class $1 \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 1 \
db_spark-1.0-SNAPSHOT.jar \
$2(4)提交任务:
sh lwx_run.sh com.sanqian.scala.CheckPointScala /out-chk003执行成功之后可以到 setCheckpointDir 指定的目录中查看一下,可以看到目录中会生成对应的文件保存rdd中的数据,只不过生成的文件不是普通文本文件,直接查看文件中的内容显示为乱码。
相关文章:
Spark09: Spark之checkpoint
一、checkpoint概述 checkpoint,是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而…...

《剑指offer》:数组部分
一、数组中重复的数字题目描述:在一个长度为n的数组里的所有数字都在0到n-1的范围内。 数组中某些数字是重复的,但不知道有几个数字是重复的。也不知道每个数字重复几次。请找出数组中任意一个重复的数字。 例如,如果输入长度为7的数组{2,3,1…...
基于微信小程序图书馆座位预约管理系统
开发工具:IDEA、微信小程序服务器:Tomcat9.0, jdk1.8项目构建:maven数据库:mysql5.7前端技术:vue、uniapp服务端技术:springbootmybatis本系统分微信小程序和管理后台两部分,项目采用…...
)
剑指 Offer Day1——栈与队列(简单)
本专栏将记录《剑指 Offer》的刷题,传送门:https://leetcode.cn/study-plan/lcof/。 目录剑指 Offer 09. 用两个栈实现队列剑指 Offer 30. 包含min函数的栈剑指 Offer 09. 用两个栈实现队列 原题链接:09. 用两个栈实现队列 class CQueue { pu…...
详解Python正则表达式中group与groups的用法
在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息。 group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果。而groups方法同样是re.MatchObject类中的函数&am…...

Spring面试重点(三)——AOP循环依赖
Spring面试重点 AOP 前置通知(Before):在⽬标⽅法运行之前运行;后置通知(After):在⽬标⽅法运行结束之后运行;返回通知(AfterReturning):在⽬标…...
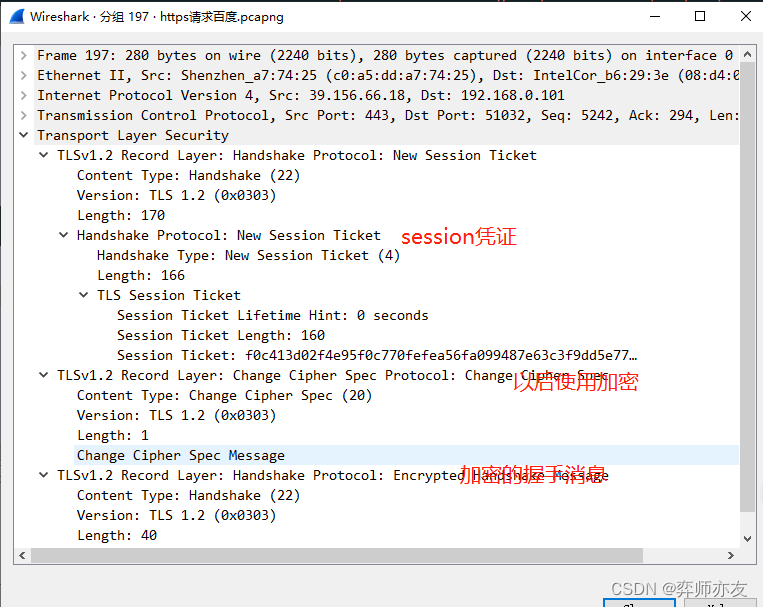
计算机网络之HTTP04ECDHE握手解析
DH算法 离散读对数问题是DH算法的数学基础 (1)计算公钥 (2)交换公钥,并计算 对方公钥^我的私钥 mod p 离散对数的交换幂运算交换律使二者算出来的值一样,都为K k就是对称加密的秘钥 2. DHE算法 E&#…...
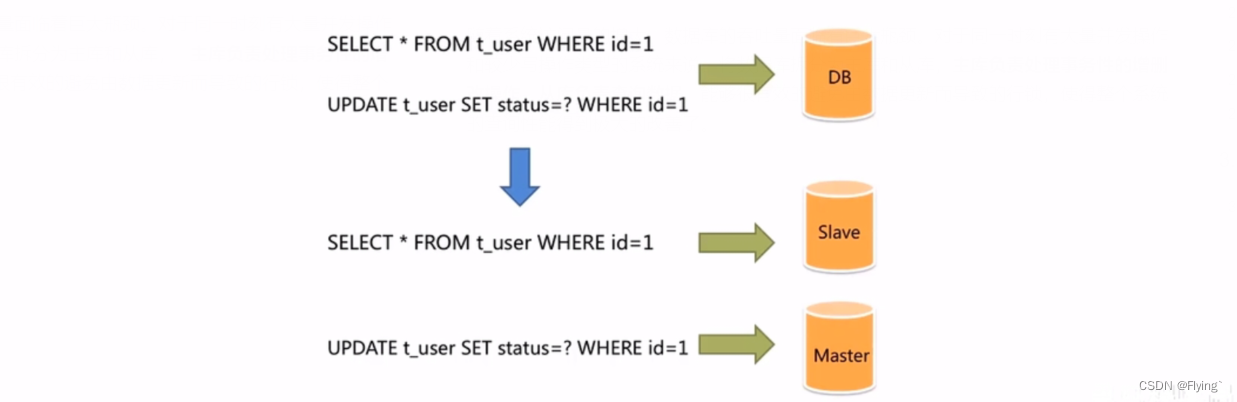
【MySQL数据库】主从复制原理和应用
主从复制和读写分离1. 主从复制的原理2. 主从复制的环境配置2.1 准备好数据库服务器2.2 配置master2.3 配置slave2.4 测试3. 主从复制的应用——读写分离3.1 读写分离的背景3.2 Sharding-JDBC介绍3.3 Sharding-JDBC使用步骤1. 主从复制的原理 MySQL主从复制是一个异步的过程&a…...
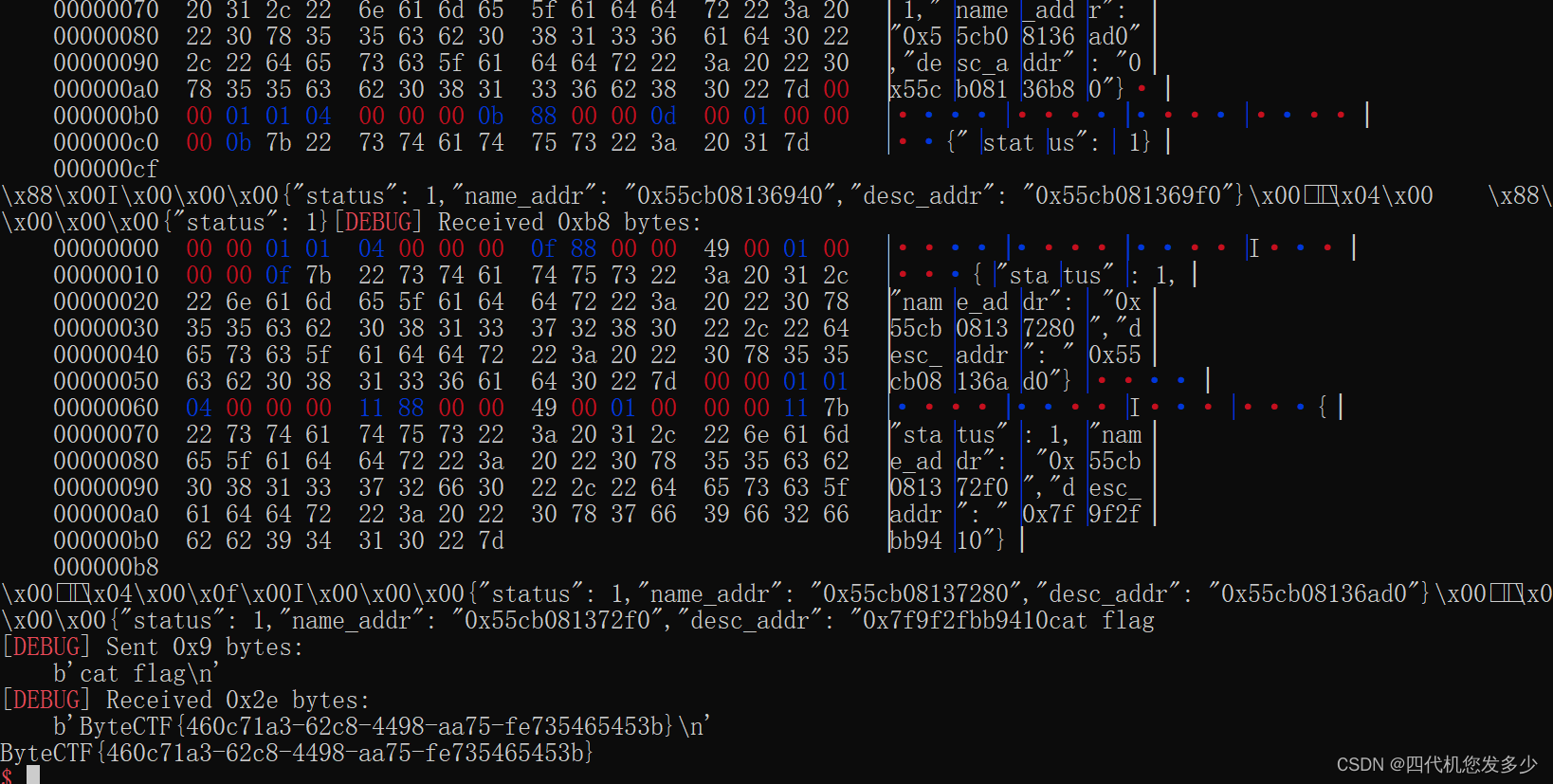
复现随记~
note(美团2022) 比较简单的越界漏洞,堆本身并没有什么漏洞,而且保护并没全开,所以逆向思维。必然是ROP类而非指针类,故我们着重注意unsigned int等无符号数前后是否不一致 int __fastcall edit(__int64 a1) {int idx; // [rsp14…...
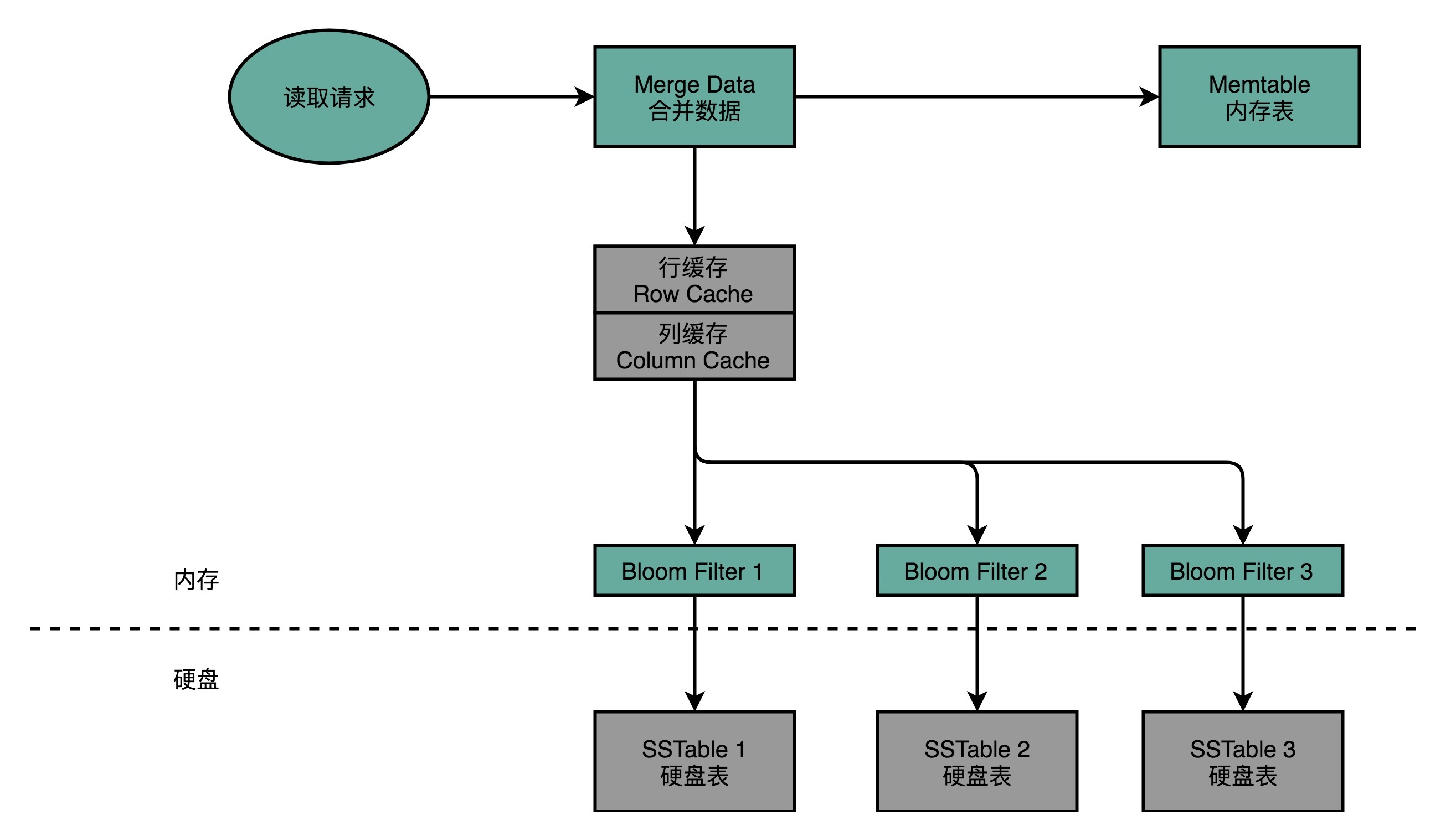
【计组】设计大型DMP系统--《深入浅出计算机组成原理》(十四)
目录 一、DMP:数据管理平台 二、MongoDB 真的万能吗 三、关系型数据库:不得不做的随机读写 (一)Cassandra:顺序写和随机读 1、Cassandra 的数据模型 2、Cassandra 的写操作 3、Cassandra 的读操作 (…...

66 使用注意力机制的seq2seq【动手学深度学习v2】
66 使用注意力机制的seq2seq【动手学深度学习v2】 深度学习学习笔记 学习视频:https://www.bilibili.com/video/BV1v44y1C7Tg/?spm_id_from…top_right_bar_window_history.content.click&vd_source75dce036dc8244310435eaf03de4e330 在机器翻译时,…...
)
NextJS(ReactSSR)
pre-render: 预渲染 1. 静态化 发生的时间:next build 1). 纯静态化 2). SSG: server static generator getStaticProps: 当渲染组件之前会运行 生成html json //该函数只可能在服务端运行 //该函数运行在组件渲染之前 //该函数只能在build期间运…...

JointBERT代码复现详解【上】
BERT for Joint Intent Classification and Slot Filling代码复现【上】 源码链接:JointBERT源码复现(含注释) 一、准备工作 源码架构 data:存放两个基准数据集;model:JointBert模型的实现;…...
进程间通信(上)
进程间通信(上)背景进程间通信目的进程间通信发展进程间通信分类管道什么是管道匿名管道实例代码简单的匿名管道实现一个父进程控制单个子进程完成指定任务父进程控制一批子进程完成任务(进程池)用fork来共享管道站在文件描述符角…...
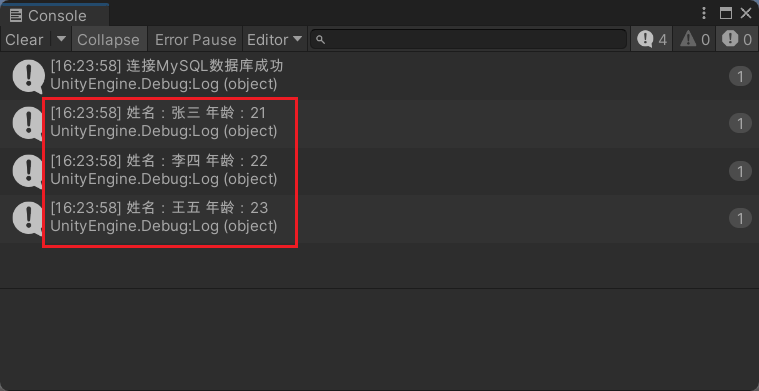
【Unity3D】Unity 3D 连接 MySQL 数据库
1.Navicat准备 test 数据库,并在test数据库下创建 user 数据表,预先插入测试数据。 2.启动 Unity Hub 新建一个项目,然后在Unity编辑器的 Project视图 中,右击新建一个 Plugins 文件夹将连接 MySQL的驱动包 导入(附加驱…...
vue通用后台管理系统
用到的js库 遇到的问题 vuex和 localStorage区别 vuex在内存中,localStorage存在本地localStorage只能存储字符串类型数据,存储对象需要JSON.stringify() 和 parse()…读取内存比读取硬盘速度要快刷新页面vuex数据丢失,localStorage不会vuex…...
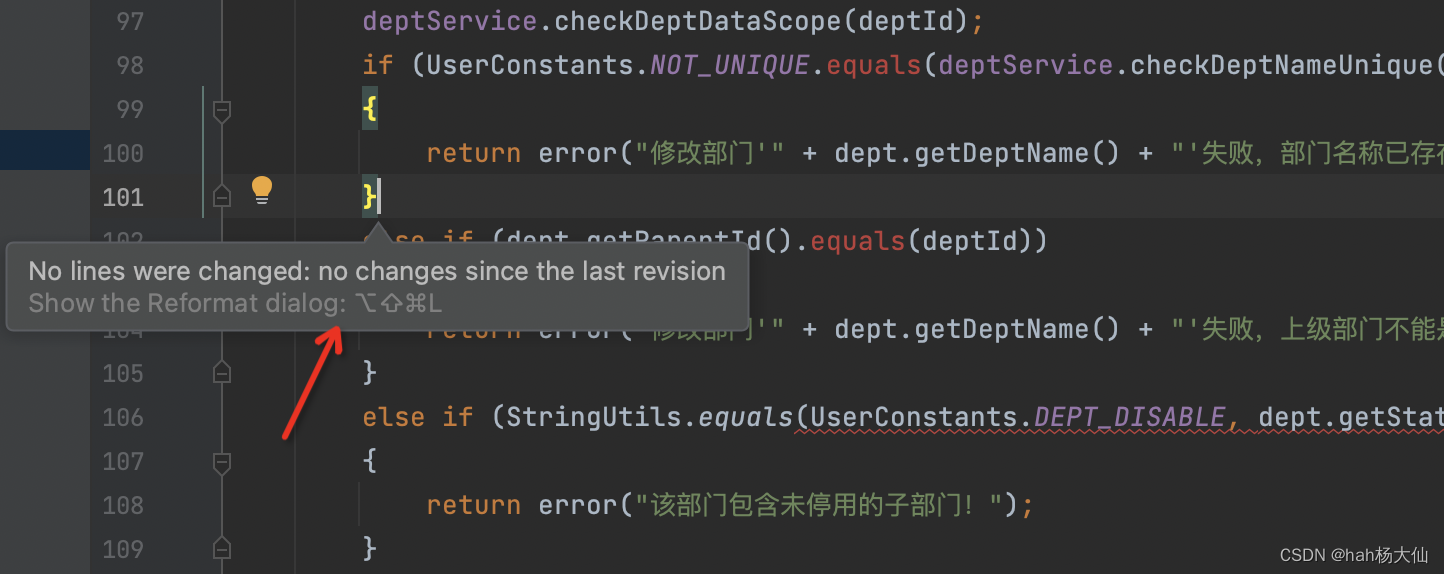
IDEA设置只格式化本次迭代变更的代码
趁着上海梅雨季节,周末狠狠更新一下。平常工作在CR的时候,经常发现会有新同事出现大量代码变更行..一看原因竟是在格式化代码时把历史代码也格式化掉了这样不仅坑了自己(覆盖率问题等),也可能会影响原始代码责任到人&a…...
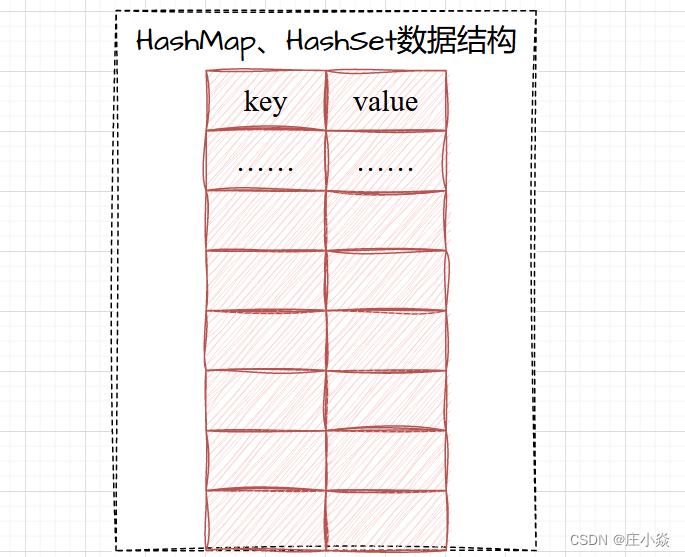
算法训练——剑指offer(Hash集合问题)
摘要 数据结构中有一个用于存储重要的数据结构,它们就是HashMap,HasSet,它典型特征就是存储key:value键值对。在查询制定的key的时候查询效率最高O(1)。Hashmap,HasSet的底层结构是如图所示。它们的区别就是是否存在重复的元素。 二、HashMa…...

Element UI框架学习篇(七)
Element UI框架学习篇(七) 1 新增员工 1.1 前台部分 1.1.1 在vue实例的data里面准备好需要的对象以及属性 addStatus:false,//判断是否弹出新增用户弹窗dailog,为true就显示depts:[],//部门信息mgrs:[],//上级领导信息jobs:[],//工作岗位信息//新增用户所需要的对象newEmp:…...
【项目实战】32G的电脑启动IDEA一个后端服务要2min!谁忍的了?
一、背景 本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置 二、问题描述 但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...
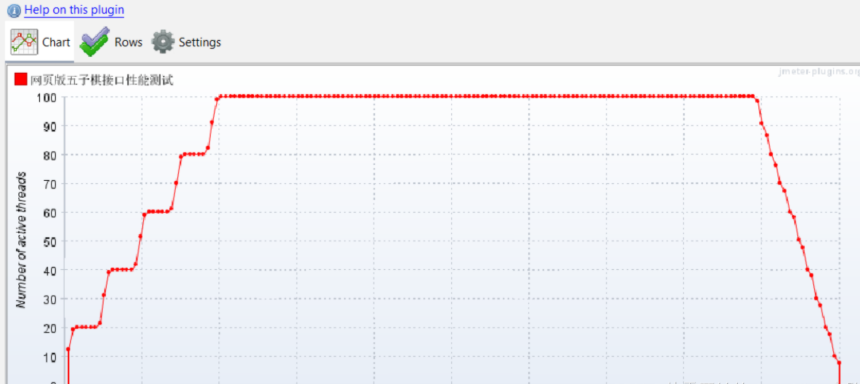
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...