【计组】设计大型DMP系统--《深入浅出计算机组成原理》(十四)
目录
一、DMP:数据管理平台
二、MongoDB 真的万能吗
三、关系型数据库:不得不做的随机读写
(一)Cassandra:顺序写和随机读
1、Cassandra 的数据模型
2、Cassandra 的写操作
3、Cassandra 的读操作
(二)SSD:DBA 们的大救星
一、DMP:数据管理平台
DMP 系统的全称叫作数据管理平台(Data Management Platform),目前广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)这些领域。
DMP 系统会通过处理海量的互联网访问数据以及机器学习算法,给一个用户标注上各种各样的标签。然后,在做个性化推荐和广告投放的时候,再利用这些标签,去做实际的广告排序、推荐等工作。无论是 Google 的搜索广告、淘宝里千人千面的商品信息,还是抖音里面的信息流推荐,背后都会有一个 DMP 系统。
对于外部使用 DMP 的系统或者用户来说,可以简单地把 DMP 看成是一个键 - 值对(Key-Value)数据库。广告系统或者推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息。
这些信息中,有些是用户的人口属性信息(Demographic),比如性别、年龄;有些是非常具体的行为(Behavior),比如用户最近看过的商品是什么,用户的手机型号是什么;有一些是通过算法系统计算出来的兴趣(Interests),比如用户喜欢健身、听音乐;还有一些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。
基于此,对于这个 KV 数据库,我们的期望也很清楚,那就是:低响应时间(Low Response Time)、高可用性(High Availability)、高并发(High Concurrency)、海量数据(Big Data),付得起对应的成本(Affordable Cost)。如果用数字来衡量这些指标,那么我们的期望就会具体化成下面这样。
- 低响应时间:一般的广告系统留给整个广告投放决策的时间也就是 10ms 左右,所以对于访问 DMP 获取用户数据,预期的响应时间都在 1ms 之内。
- 高可用性:DMP 常常用在广告系统里面。DMP 系统出问题,往往就意味着整个的广告收入在不可用的时间就没了,所以对于可用性的追求可谓是没有上限的。Google 2018 年的广告收入是 1160 亿美元,折合到每一分钟的收入是 22 万美元。即使我们做到 99.99% 的可用性,也意味着每个月我们都会损失 100 万美元。
- 高并发:还是以广告系统为例,如果每天我们需要响应 100 亿次的广告请求,那么我们每秒的并发请求数就在 100 亿 / (86400) ~= 12K 次左右,所以DMP 需要支持高并发。
- 数据量:如果产品针对中国市场,那么需要有 10 亿个 Key,对应的假设每个用户有 500 个标签,标签有对应的分数。标签和分数都用一个 4 字节(Bytes)的整数来表示,那么一共需要 10 亿 x 500 x (4 + 4) Bytes = 4 TB 的数据。
- 低成本:从广告系统的角度来考虑,广告系统的收入通常用 CPM(Cost Per Mille),也就是千次曝光来统计。如果千次曝光的利润是 0.10 美元,那么每天 100 亿次的曝光就是 100 万美元的利润。这个利润听起来非常高了。但是反过来算一下,DMP 每 1000 次的请求的成本不能超过 0.10 美元。最好只有 0.01 美元,甚至更低,才能尽可能多赚到一点广告利润。
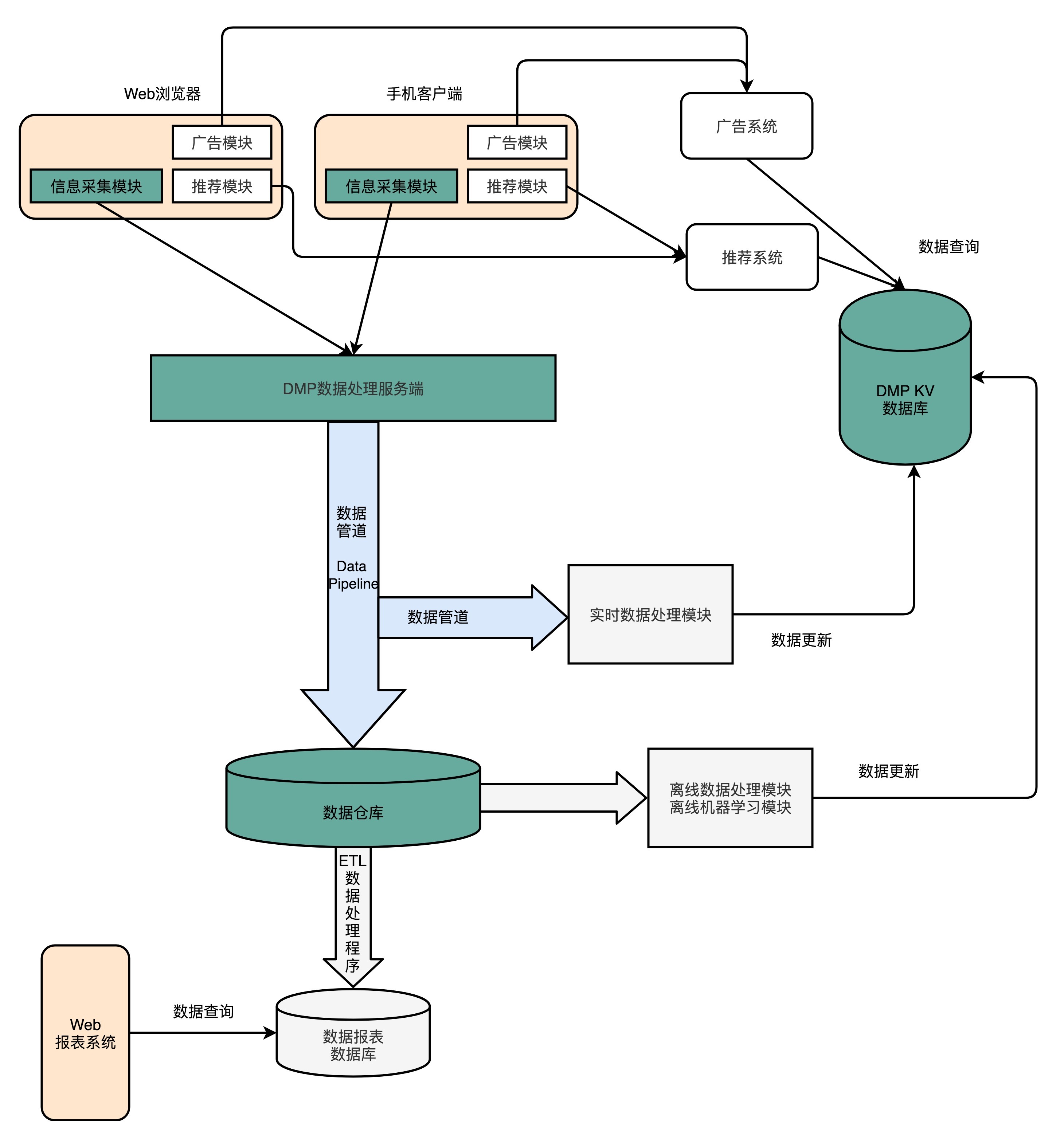
为了能够生成这个 KV 数据库,我们需要有一个在客户端或者 Web 端的数据采集模块,不断采集用户的行为,向后端的服务器发送数据。服务器端接收到数据,就要把这份数据放到一个数据管道(Data Pipeline)里面。数据管道的下游,需要实际将数据落地到数据仓库(Data Warehouse),把所有的这些数据结构化地存储起来。后续,就可以通过程序去分析这部分日志,生成报表或者或者利用数据运行各种机器学习算法。
除了数据仓库之外,还会有一个实时数据处理模块(Realtime Data Processing),也放在数据管道的下游。它同样会读取数据管道里面的数据,去进行各种实时计算,然后把需要的结果写入到 DMP 的 KV 数据库里面去。
二、MongoDB 真的万能吗
MongoDB 的设计听起来特别厉害,不需要预先数据 Schema,访问速度很快,还能够无限水平扩展。作为 KV 数据库,可以把 MongoDB 当作 DMP 里面的 KV 数据库;除此之外,MongoDB 还能水平扩展、跑 MQL,可以把它当作数据仓库来用。至于数据管道,只要我们能够不断往 MongoDB 里面,插入新的数据就好了。从运维的角度来说,只需要维护一种数据库,技术栈也变得简单了。看起来,MongoDB 这个选择真是相当完美!
然而,所有的软件系统,都有它的适用场景,想通过一种解决方案适用三个差异非常大的应用场景,显然既不合理,又不现实。接下来,我们就来仔细看一下,这个“不合理”“不现实”在什么地方。
对于数据管道来说,我们需要的是高吞吐量,它的并发量虽然和 KV 数据库差不多,但是在响应时间上,要求就没有那么严格了,1-2 秒甚至再多几秒的延时都是可以接受的。而且,和 KV 数据库不太一样,数据管道的数据读写都是顺序读写,没有大量的随机读写的需求。
数据仓库就更不一样了,数据仓库的数据读取量要比管道大得多。管道的数据读取就是当时写入的数据,一天有 10TB 日志数据,管道只会写入 10TB。下游的数据仓库存放数据和实时数据模块读取的数据,再加上个 2 倍的 10TB,也就是 20TB 也就够了。但是,数据仓库的数据分析任务要读取的数据量就大多了。一方面,我们可能要分析一周、一个月乃至一个季度的数据。这一次分析要读取的数据可不是 10TB,而是 100TB 乃至 1PB。我们一天在数据仓库上跑的分析任务也不是 1 个,而是成千上万个,所以数据的读取量是巨大的。另一方面,我们存储在数据仓库里面的数据,也不像数据管道一样,存放几个小时、最多一天的数据,而是往往要存上 3 个月甚至是 1 年的数据。所以,我们需要的是 1PB 乃至 5PB 这样的存储空间。
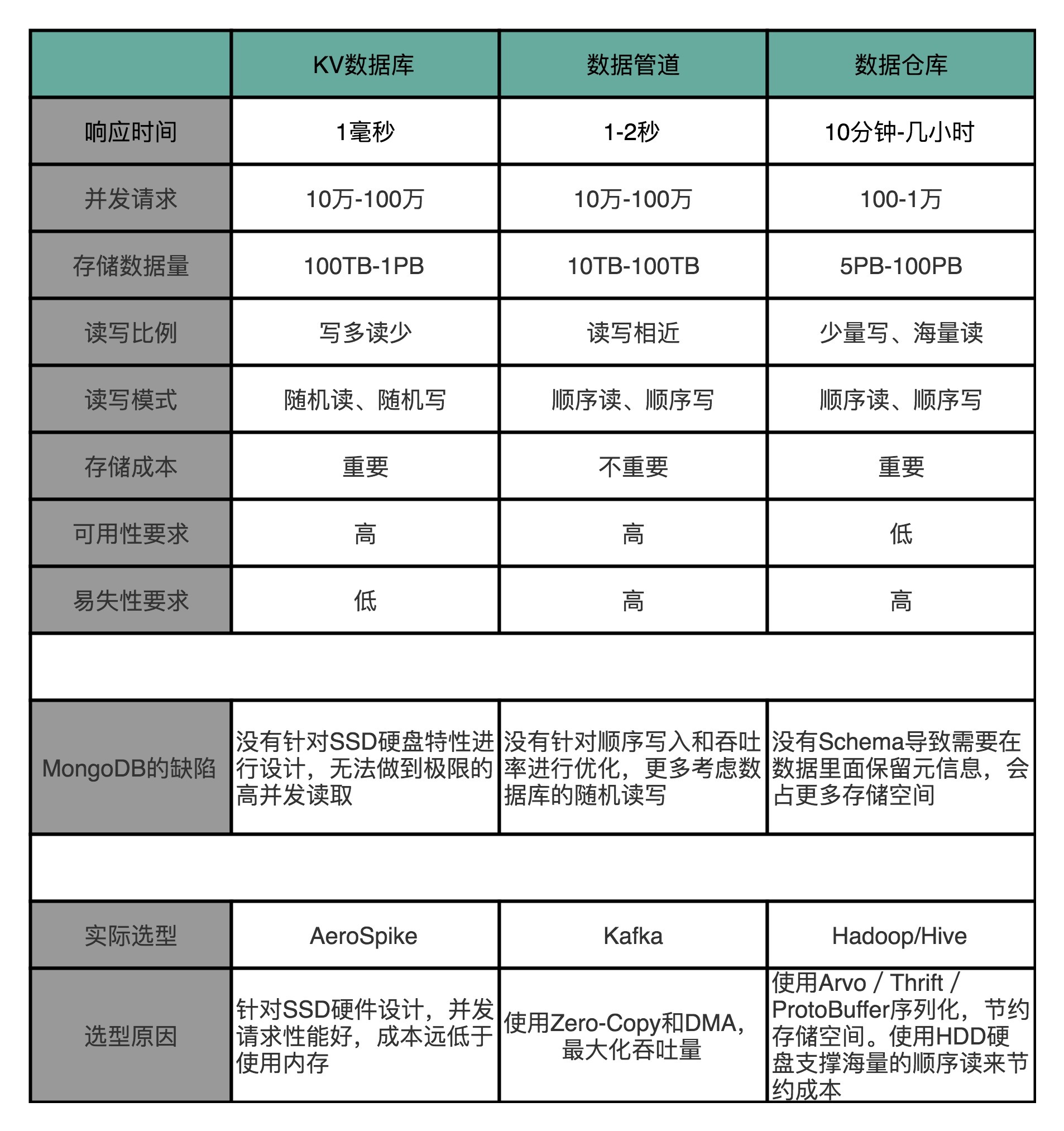
在 KV 数据库的场景下,需要支持高并发。那么 MongoDB 需要把更多的数据放在内存里面,但是这样存储成本就会特别高了。
在数据管道的场景下,需要大量的顺序读写,而 MongoDB 则是一个文档数据库系统,并没有为顺序写入和吞吐量做过优化,看起来也不太适用。
数据仓库的场景下,主要的数据读取时顺序读取,并且需要海量的存储。MongoDB 这样的文档式数据库也没有为海量的顺序读做过优化,仍然不是一个最佳的解决方案。而且文档数据库里总是会有很多冗余的字段的元数据,还会浪费更多的存储空间。
那我们该选择什么样的解决方案呢?其实并不难找。
对于 KV 数据库,最佳的选择方案自然是使用 SSD 硬盘,选择 AeroSpike 这样的 KV 数据库。高并发的随机访问并不适合 HDD 的机械硬盘,而 400TB 的数据,如果用内存的话,成本又会显得太高。
对于数据管道,最佳选择自然是 Kafka。因为我们追求的是吞吐率,采用了 Zero-Copy 和 DMA 机制的 Kafka 最大化了作为数据管道的吞吐率。而且,数据管道的读写都是顺序读写,所以也不需要对随机读写提供支持,用上 HDD 硬盘就好了。
对于数据仓库,存放的数据量更大了。2019年的应用场景下看,在硬件层面使用 HDD 硬盘成了一个必选项,否则,存储成本就会差上 10 倍。但是SSD和几年前比已经便宜了很多了,而且在PCI-E接口普及的情况下,顺序读写速度比起HDD也能拉开差距了,所以逐步我们也看到业界开始直接用SSD来部署Kafka也变得比较常见了。
这么大量的数据,在存储上我们需要定义清楚 Schema,使得每个字段都不需要额外存储元数据,能够通过 Avro/Thrift/ProtoBuffer 这样的二进制序列化的方存储下来,或者干脆直接使用 Hive 这样明确了字段定义的数据仓库产品。很明显,MongoDB 那样不限制 Schema 的数据结构,在这个情况下并不好用。
三、关系型数据库:不得不做的随机读写
DMP 的 KV 数据库主要的应用场景,是根据主键的随机查询。这个需求,实际的大型系统中,大家都会使用专门的分布式 KV 数据库来满足。
下面看一下Facebook 开源的 Cassandra 的数据存储和读写是怎么做的,这些设计是怎么解决高并发的随机读写问题的。
(一)Cassandra:顺序写和随机读
1、Cassandra 的数据模型
作为一个分布式的 KV 数据库,Cassandra 的键一般被称为 Row Key。其实就是一个 16 到 36 个字节的字符串。每一个 Row Key 对应的值其实是一个哈希表,里面可以用键值对,再存入很多需要的数据。
Cassandra 本身不像关系型数据库那样,有严格的 Schema,在数据库创建的一开始就定义好了有哪些列(Column)。但是,它设计了一个叫作列族(Column Family)的概念,我们需要把经常放在一起使用的字段,放在同一个列族里面。比如,DMP 里面的人口属性信息,我们可以把它当成是一个列族。用户的兴趣信息,可以是另外一个列族。这样,既保持了不需要严格的 Schema 这样的灵活性,也保留了可以把常常一起使用的数据存放在一起的空间局部性。
往 Cassandra 的里面读写数据,其实特别简单,就好像是在一个巨大的分布式的哈希表里面写数据。指定一个 Row Key,然后插入或者更新这个 Row Key 的数据就好了。
2、Cassandra 的写操作
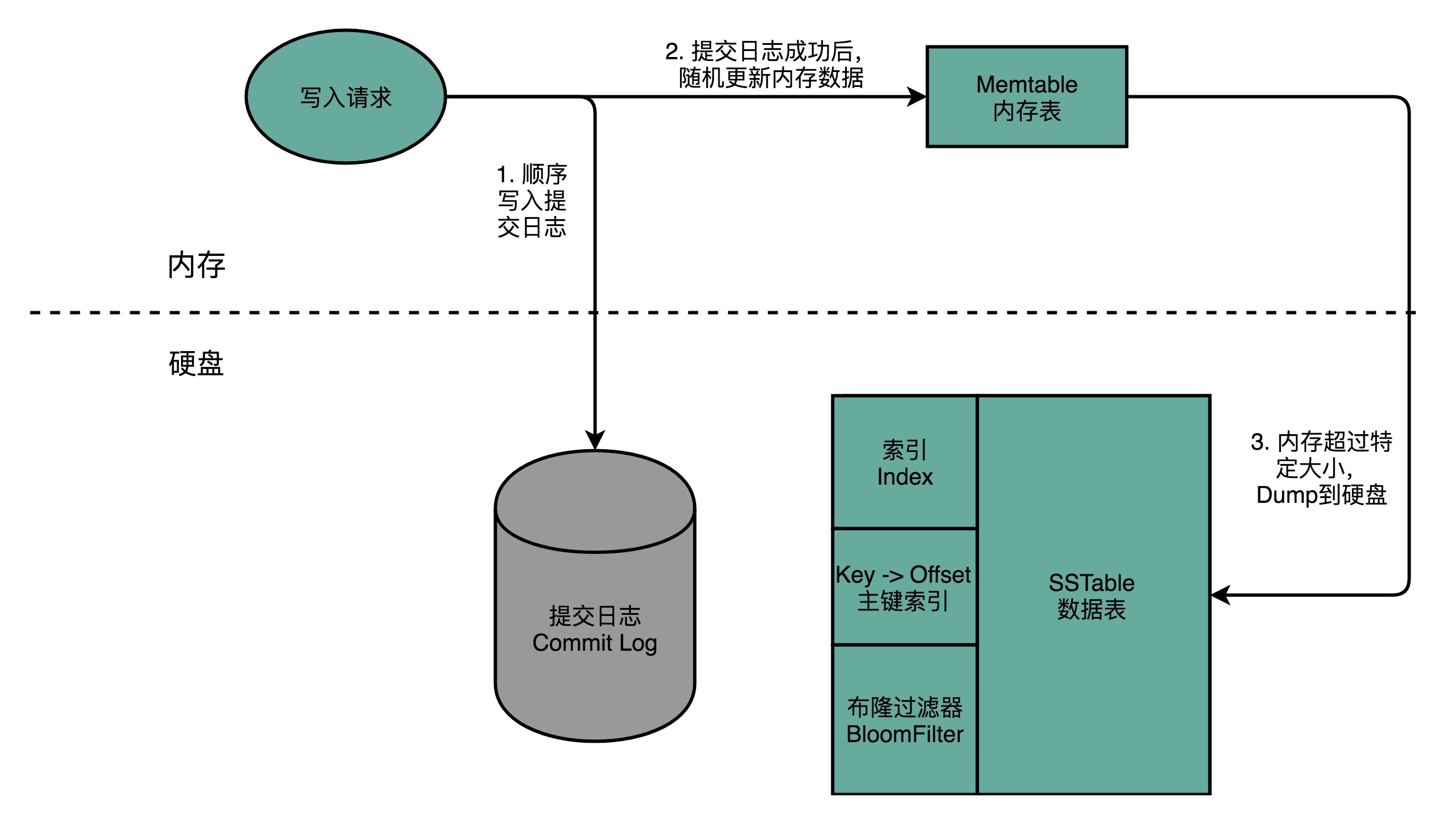
Cassandra 解决随机写入数据的解决方案,简单来说,就叫作“不随机写,只顺序写”。对于 Cassandra 数据库的写操作,通常包含两个动作。第一个是往磁盘上写入一条提交日志(Commit Log)。另一个操作,则是直接在内存的数据结构上去更新数据。后面这个往内存的数据结构里面的数据更新,只有在提交日志写成功之后才会进行。每台机器上,都有一个可靠的硬盘可以让我们去写入提交日志。写入提交日志都是顺序写(Sequential Write),而不是随机写(Random Write),最大化了写入的吞吐量。
内存的空间比较有限,一旦内存里面的数据量或者条目超过一定的限额,Cassandra 就会把内存里面的数据结构 dump 到硬盘上。这个 Dump 的操作,也是顺序写而不是随机写,所以性能也不会是一个问题。除了 Dump 的数据结构文件,Cassandra 还会根据 row key 来生成一个索引文件,方便后续基于索引来进行快速查询。
随着硬盘上的 Dump 出来的文件越来越多,Cassandra 会在后台进行文件的对比合并。在很多别的 KV 数据库系统里面,也有类似这种的合并动作,比如 AeroSpike 或者 Google 的 BigTable。这些操作我们一般称之为 Compaction。合并动作同样是顺序读取多个文件,在内存里面合并完成,再 Dump 出来一个新的文件。整个操作过程中,在硬盘层面仍然是顺序读写。
3、Cassandra 的读操作
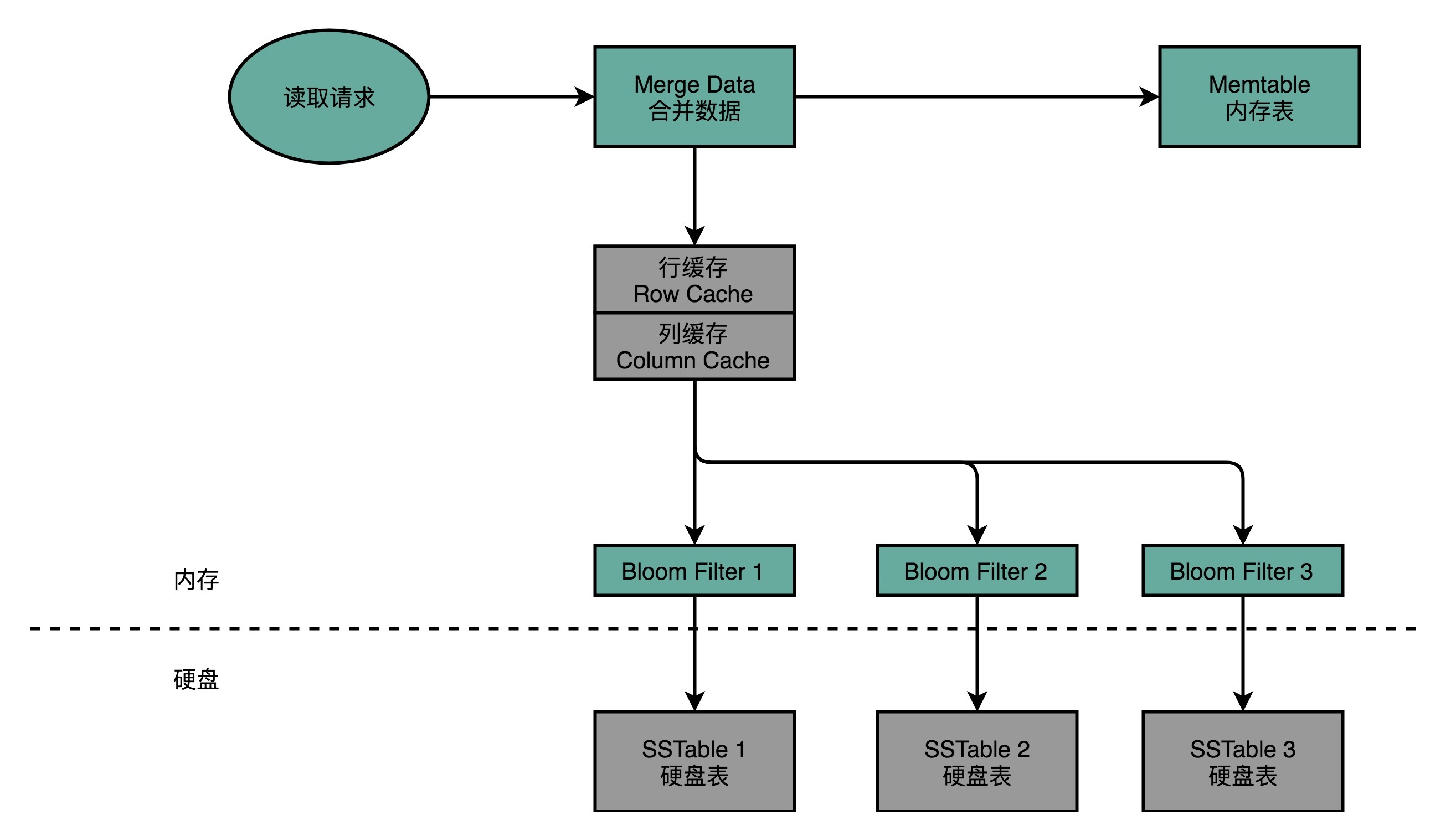
要从 Cassandra 读数据的时候,先从内存里面找,再从硬盘读,然后把两部分的数据合并成最终结果。这些硬盘上的文件,在内存里面会有对应的 Cache,只有在 Cache 里面找不到,才会去请求硬盘里面的数据。
如果不得不访问硬盘,按照时间从新的往旧的里面找,因为硬盘里面可能 Dump 了很多个不同时间点的内存数据的快照。
这也就带来另外一个问题——可能要查询很多个 Dump 文件,才能找到想要的数据。所以,Cassandra 在这一点上又做了一个优化。那就是,它会为每一个 Dump 的文件里面所有 Row Key 生成一个 BloomFilter,然后把这个 BloomFilter 放在内存里面。这样,如果想要查询的 Row Key 在数据文件里面不存在,那么 99% 以上的情况下,它会被 BloomFilter 过滤掉,而不需要访问硬盘。这样,只有当数据在内存里面没有,并且在硬盘的某个特定文件上的时候,才会触发一次对于硬盘的读请求。
(二)SSD:DBA 们的大救星
Cassandra 是 Facebook 在 2008 年开源的。那个时候,SSD 硬盘还没有那么普及。可以看到,它的读写设计充分考虑了硬件本身的特性。在写入数据进行持久化上,Cassandra 没有任何的随机写请求,无论是 Commit Log 还是 Dump,全部都是顺序写。
在数据读的请求上,最新写入的数据都会更新到内存。如果要读取这些数据,会优先从内存读到。这相当于是一个使用了 LRU 的缓存机制。只有在万般无奈的情况下,才会有对于硬盘的随机读请求。即使在这样的情况下,Cassandra 也在文件之前加了一层 BloomFilter,把本来因为 Dump 文件带来的需要多次读硬盘的问题,简化成多次内存读和一次硬盘读。
这些设计,使得 Cassandra 即使是在 HDD 硬盘上,也能有不错的访问性能。而对于数据的读,就有一些挑战了。如果数据读请求有很强的局部性,那内存就能搞定 DMP 需要的访问量。但是DMP 的数据访问分布,其实是缺少局部性的。
如果是 Facebook 那样的全球社交网络,那可能还有一定的时间局部性。毕竟不同国家的人的时区不一样。我们可以说,在印度人民的白天,把印度人民的数据加载到内存里面,美国人民的数据就放在硬盘上。到了印度人民的晚上,再把美国人民的数据换到内存里面来。如果主要业务是在国内,那这个时间局部性就没有了。大家的上网高峰时段,都是在早上上班路上、中午休息的时候以及晚上下班之后的时间,没有什么区分度。
因为缺少时间局部性,内存的缓存能够起到的作用就很小了,大部分请求最终还是要落到 HDD 硬盘的随机读上。但是,HDD 硬盘的随机读的性能太差了。如果全都放内存又太贵了。
幸运的是,从 2010 年开始,SSD 硬盘的大规模商用帮我们解决了这个问题。它的随机读的访问能力在 HDD 硬盘的百倍以上。同样的价格的 SSD 硬盘,容量则是内存的几十倍,也能够满足我们的需求,用较低的成本存下整个互联网用户信息。
不夸张地说,过去十年的“大数据”“高并发”“千人千面”,有一半的功劳应该归在让 SSD 容量不断上升、价格不断下降的硬盘产业上。
回到 Cassandra 的读写设计,你会发现,Cassandra 的写入机制完美匹配SSD 硬盘的优缺点。
在数据写入层面,Cassandra 的数据写入都是 Commit Log 的顺序写入,也就是不断地在硬盘上往后追加内容,而不是去修改现有的文件内容。一旦内存里面的数据超过一定的阈值,Cassandra 又会完整地 Dump 一个新文件到文件系统上。这同样是一个追加写入。
数据的对比和紧凑化(Compaction),同样是读取现有的多个文件,然后写一个新的文件出来。写入操作只追加不修改的特性,正好天然地符合 SSD 硬盘只能按块进行擦除写入的操作。在这样的写入模式下,Cassandra 用到的 SSD 硬盘,不需要频繁地进行后台的 Compaction,能够最大化 SSD 硬盘的使用寿命。因此,Cassandra 在 SSD 硬盘普及之后,获得了进一步快速发展。
【推荐阅读】Cassandra - A Decentralized Structured Storage System。读完这篇论文,一方面你会对分布式 KV 数据库的设计原则有所了解,了解怎么去做好数据分片、故障转移、数据复制这些机制;另一方面,你可以看到基于内存和硬盘的不同存储设备的特性,Cassandra 是怎么有针对性地设计数据读写和持久化的方式的。
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间
相关文章:
【计组】设计大型DMP系统--《深入浅出计算机组成原理》(十四)
目录 一、DMP:数据管理平台 二、MongoDB 真的万能吗 三、关系型数据库:不得不做的随机读写 (一)Cassandra:顺序写和随机读 1、Cassandra 的数据模型 2、Cassandra 的写操作 3、Cassandra 的读操作 (…...

66 使用注意力机制的seq2seq【动手学深度学习v2】
66 使用注意力机制的seq2seq【动手学深度学习v2】 深度学习学习笔记 学习视频:https://www.bilibili.com/video/BV1v44y1C7Tg/?spm_id_from…top_right_bar_window_history.content.click&vd_source75dce036dc8244310435eaf03de4e330 在机器翻译时,…...
)
NextJS(ReactSSR)
pre-render: 预渲染 1. 静态化 发生的时间:next build 1). 纯静态化 2). SSG: server static generator getStaticProps: 当渲染组件之前会运行 生成html json //该函数只可能在服务端运行 //该函数运行在组件渲染之前 //该函数只能在build期间运…...

JointBERT代码复现详解【上】
BERT for Joint Intent Classification and Slot Filling代码复现【上】 源码链接:JointBERT源码复现(含注释) 一、准备工作 源码架构 data:存放两个基准数据集;model:JointBert模型的实现;…...
进程间通信(上)
进程间通信(上)背景进程间通信目的进程间通信发展进程间通信分类管道什么是管道匿名管道实例代码简单的匿名管道实现一个父进程控制单个子进程完成指定任务父进程控制一批子进程完成任务(进程池)用fork来共享管道站在文件描述符角…...
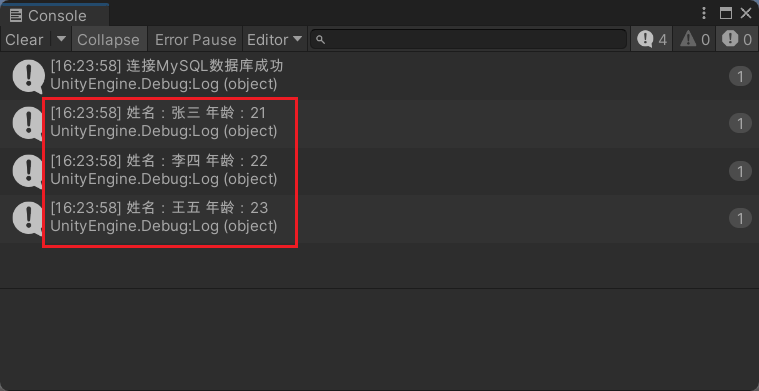
【Unity3D】Unity 3D 连接 MySQL 数据库
1.Navicat准备 test 数据库,并在test数据库下创建 user 数据表,预先插入测试数据。 2.启动 Unity Hub 新建一个项目,然后在Unity编辑器的 Project视图 中,右击新建一个 Plugins 文件夹将连接 MySQL的驱动包 导入(附加驱…...
vue通用后台管理系统
用到的js库 遇到的问题 vuex和 localStorage区别 vuex在内存中,localStorage存在本地localStorage只能存储字符串类型数据,存储对象需要JSON.stringify() 和 parse()…读取内存比读取硬盘速度要快刷新页面vuex数据丢失,localStorage不会vuex…...
IDEA设置只格式化本次迭代变更的代码
趁着上海梅雨季节,周末狠狠更新一下。平常工作在CR的时候,经常发现会有新同事出现大量代码变更行..一看原因竟是在格式化代码时把历史代码也格式化掉了这样不仅坑了自己(覆盖率问题等),也可能会影响原始代码责任到人&a…...
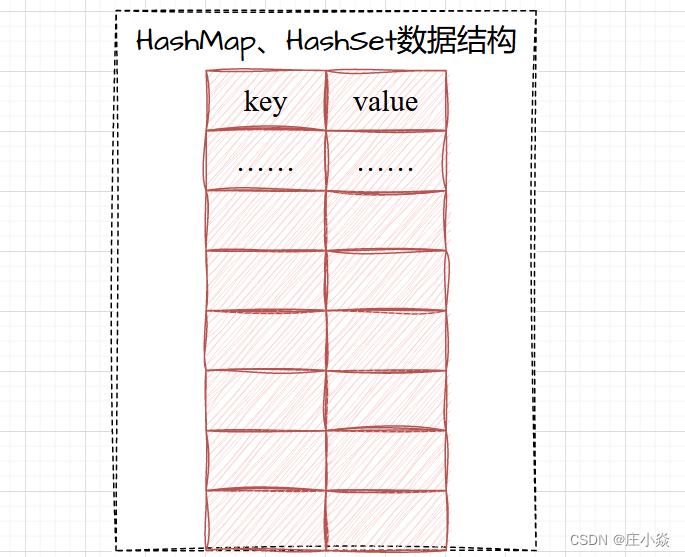
算法训练——剑指offer(Hash集合问题)
摘要 数据结构中有一个用于存储重要的数据结构,它们就是HashMap,HasSet,它典型特征就是存储key:value键值对。在查询制定的key的时候查询效率最高O(1)。Hashmap,HasSet的底层结构是如图所示。它们的区别就是是否存在重复的元素。 二、HashMa…...

Element UI框架学习篇(七)
Element UI框架学习篇(七) 1 新增员工 1.1 前台部分 1.1.1 在vue实例的data里面准备好需要的对象以及属性 addStatus:false,//判断是否弹出新增用户弹窗dailog,为true就显示depts:[],//部门信息mgrs:[],//上级领导信息jobs:[],//工作岗位信息//新增用户所需要的对象newEmp:…...
【项目实战】32G的电脑启动IDEA一个后端服务要2min!谁忍的了?
一、背景 本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置 二、问题描述 但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下…...
2022年山东省中职组“网络安全”赛项比赛任务书正式赛题
2022年山东省中职组“网络安全”赛项 比赛任务书 一、竞赛时间 总计:360分钟 竞赛阶段竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 A模块 A-1 登录安全加固 180分钟 200分 A-2 Nginx安全策略 A-3 日志监控 A-4 中间件服务加固 A-5 本地安全策略…...

RibbitMQ 入门到应用 ( 二 ) 安装
3.安装基本操作 3.1.下载安装 3.1.1.官网 下载地址 https://rabbitmq.com/download.html 与Erlang语言对应版本 https://rabbitmq.com/which-erlang.html 3.1.2.安装 Erlang 在确定了RabbitMQ版本号后,先下载安装Erlang环境 Erlang下载链接 https://packa…...

提取DataFrame中每一行的DataFrame.itertuples()方法
【小白从小学Python、C、Java】【计算机等级考试500强双证书】【Python-数据分析】提取DataFrame中的每一行DataFrame.itertuples()选择题关于以下python代码说法错误的一项是?import pandas as pddf pd.DataFrame({A:[a1,a2],B:[b1,b2]},index[i1,i2])print("【显示】d…...
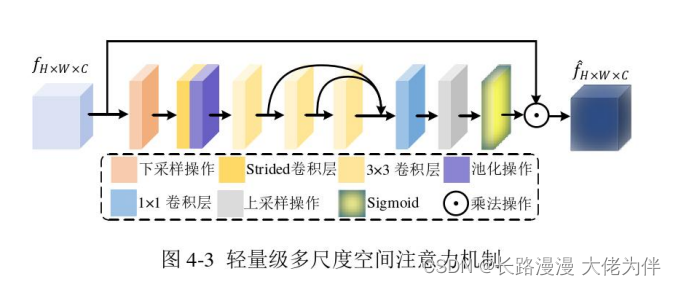
基于卷积神经网络的立体视频编码质量增强方法_余伟杰
基于卷积神经网络的立体视频编码质量增强方法_余伟杰提出的基于TSAN的合成视点质量增强方法全局信息提取流像素重组局部信息提取流多尺度空间注意力机制提出的基于RDEN的轻量级合成视点质量增强方法特征蒸馏注意力块轻量级多尺度空间注意力机制概念扭曲失真孔洞问题失真和伪影提…...
【2023unity游戏制作-mango的冒险】-3.基础动作和动画API实现
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity游戏制作 ⭐mango的基础动作动画的添加⭐ 文章目录⭐mango的基础动作动画的添加⭐…...

跨域的几种解决方案?
1-jsonp 【前端后端实现】jsonp: 利用 <script> 标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的 JSON 数据。JSONP请求一定需要对方的服务器做支持才可以。JSONP优点是简单兼容性好,可用于解决主流浏览器的跨域数据访问的问题。缺点是仅…...

2022年山东省职业院校技能大赛网络搭建与应用赛项正式赛题
2022年山东省职业院校技能大赛 网络搭建与应用赛项 第二部分 网络搭建与安全部署&服务器配置及应用 竞赛说明: 一、竞赛内容分布 竞赛共分二个模块,其中: 第一模块:网络搭建及安全部署项目 第二模块:服务…...
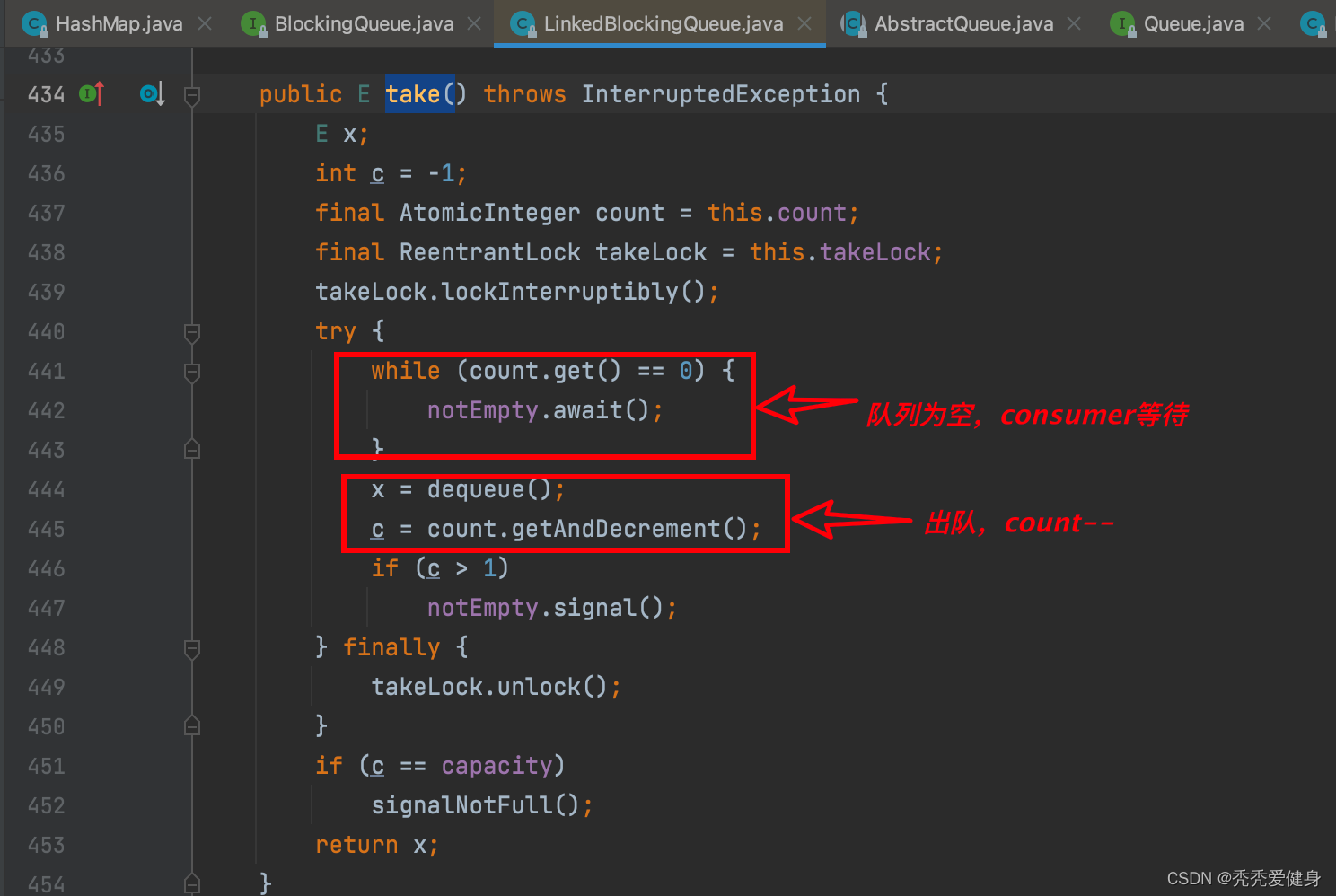
【JUC并发编程】ArrayBlockingQueue和LinkedBlockingQueue源码2分钟看完
文章目录1、BlockingQueue1)接口方法2)阻塞队列分类2、ArrayBlockingQueue1)构造函数2)put()入队3)take()出队3、LinkedBlockingQueue1)构造函数2)put()入队3)take()出队1、Blocking…...
GitHub个人资料自述与管理主题设置
目录 关于您的个人资料自述文件 先决条件 添加个人资料自述文件 删除个人资料自述文件 管理主题设置 补充:建立一个空白文件夹 关于您的个人资料自述文件 可以通过创建个人资料 README,在 GitHub.com 上与社区分享有关你自己的信息。 GitHub 在个…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...