Python面试题-7
21. 请解释Python中的元组。
Python中的元组(Tuple)是一种内置的数据结构,它有如下特点:
- 有序性:元组中的元素是有序的,每个元素都有一个索引,索引从0开始。
- 不可变性:一旦元组被创建,就不能更改其内容,即不能添加、删除或更改其中的元素。
- 允许重复:元组允许包含重复的元素。
元组的基本用法包括元组的创建、访问元素、遍历元组等。
元组示例
以下是一个使用Python中元组的示例代码:
# 创建一个空元组
empty_tuple = ()# 创建一个包含一些元素的元组
fruits = ('apple', 'banana', 'cherry', 'apple')# 访问元组中的元素
print("First fruit:", fruits[0])
print("Second fruit:", fruits[1])# 尝试修改元组中的元素(这会导致错误)
# fruits[0] = 'orange' # 取消注释以查看错误# 遍历元组
for fruit in fruits:print(fruit)# 检查元素是否在元组中
if 'banana' in fruits:print("Banana is in the tuple.")
else:print("Banana is not in the tuple.")# 使用count方法统计元素出现的次数
apple_count = fruits.count('apple')
print("Apple count:", apple_count)# 使用index方法查找元素的位置
cherry_index = fruits.index('cherry')
print("Cherry index:", cherry_index)# 元组推导式
squared_numbers = tuple(x**2 for x in range(1, 6))
print("Squared numbers tuple:", squared_numbers)# 元组的解包
name, age = ('Alice', 30)
print("Name:", name)
print("Age:", age)
在这个示例中,我们首先创建了一个包含三个水果名称的元组fruits。我们展示了如何访问元组中的元素,以及如何遍历元组。我们还讨论了如何使用count和index方法,以及如何通过元组解包来获取元组中的数据。
需要注意的是,尽管元组的元素是不可变的,但如果元组中包含了可变元素(如列表),那么这些可变元素的内容是可以被修改的。
22. 请解释Python中的字符串。
Python中的字符串(String)是一种内置的数据类型,用于处理文本数据。字符串在Python中是不可变的,这意味着一旦一个字符串被创建,就不能更改其内容。但是,可以基于原始字符串创建新的字符串。
字符串的一些主要特点包括:
- 有序性:字符串中的字符是有序的,每个字符都有一个索引,索引从0开始。
- 不可变性:字符串一旦创建,其内容就不能被修改。
- 支持多种操作:字符串类型提供了丰富的操作方法,如拼接、切片、查找、替换等。
字符串示例
以下是一个使用Python中字符串的示例代码:
# 创建字符串
greeting = "Hello, World!"# 访问字符串中的字符
first_char = greeting[0]
print("First character:", first_char)# 字符串长度
string_length = len(greeting)
print("String length:", string_length)# 字符串拼接
name = "Alice"
greet_name = greeting + " My name is " + name + "."
print(greet_name)# 字符串格式化
age = 30
formatted_string = f"My name is {name} and I am {age} years old."
print(formatted_string)# 字符串分割
words = greeting.split()
print("Words in greeting:", words)# 字符串查找
index_world = greeting.find("World")
print("Index of 'World':", index_world)# 字符串替换
new_greeting = greeting.replace("World", "Python")
print("New greeting:", new_greeting)# 字符串大小写转换
lower_case = greeting.lower()
upper_case = greeting.upper()
print("Lower case:", lower_case)
print("Upper case:", upper_case)# 字符串去除空白
whitespace_string = " too much space "
stripped_string = whitespace_string.strip()
print("Stripped string:", stripped_string)# 字符串判断方法
is_digit = "123".isdigit()
is_alpha = "abc".isalpha()
print("Is '123' a digit?", is_digit)
print("Is 'abc' an alphabet?", is_alpha)# 字符串遍历
for char in greeting:print(char)
在这个示例中,我们展示了如何创建字符串,访问字符串中的字符,以及如何使用字符串的各种方法,如split、find、replace、lower、upper、strip等。我们还讨论了如何遍历字符串,以及如何使用判断方法如isdigit和isalpha。
23. 请解释Python中的数字类型。
Python中的数字类型主要包括整数(Integer)、浮点数(Float)、复数(Complex)。这些类型用于存储和处理数值数据。
整数(Integer)
整数是没有小数部分的数字,可以是正数、负数或零。在Python中,整数可以是任意大小,只受限于可用内存。
浮点数(Float)
浮点数是带有小数点的数字,可以表示整数和分数。在Python中,浮点数是以IEEE 754标准表示的64位双精度浮点数。
复数(Complex)
复数由实部和虚部组成,通常表示为x + yj,其中x是实部,y是虚部,j表示虚数单位。在Python中,复数用于科学计算和工程计算。
数字类型示例
以下是一个使用Python中数字类型的示例代码:
# 整数
num_int = 100 # 正整数
print("Integer:", num_int)# 浮点数
num_float = 3.14 # 浮点数
print("Float:", num_float)# 复数
num_complex = 2 + 3j # 复数
print("Complex:", num_complex)# 整数和浮点数的运算
addition = 10 + 5.5
subtraction = 10 - 5.5
multiplication = 10 * 5.5
division = 10 / 5.5
floor_division = 10 // 5.5 # 地板除法,返回整数部分
modulus = 10 % 5.5 # 取余
exponentiation = 10 ** 5.5 # 指数运算print("Addition:", addition)
print("Subtraction:", subtraction)
print("Multiplication:", multiplication)
print("Division:", division)
print("Floor Division:", floor_division)
print("Modulus:", modulus)
print("Exponentiation:", exponentiation)# 复数的运算
complex_addition = (2 + 3j) + (1 + 2j)
complex_subtraction = (2 + 3j) - (1 + 2j)
complex_multiplication = (2 + 3j) * (1 + 2j)
complex_division = (2 + 3j) / (1 + 2j)print("Complex Addition:", complex_addition)
print("Complex Subtraction:", complex_subtraction)
print("Complex Multiplication:", complex_multiplication)
print("Complex Division:", complex_division)# 类型转换
int_to_float = float(num_int)
float_to_int = int(num_float)print("Integer to Float:", int_to_float)
print("Float to Integer:", float_to_int)# 复数的实部和虚部
real_part = num_complex.real
imaginary_part = num_complex.imagprint("Real Part of Complex Number:", real_part)
print("Imaginary Part of Complex Number:", imaginary_part)# 复数的绝对值(模)
complex_abs = abs(num_complex)
print("Absolute Value of Complex Number:", complex_abs)
在这段代码中,我们展示了如何创建和使用整数、浮点数和复数。我们还演示了不同类型的数字之间的基本运算,以及如何进行类型转换。复数的运算和属性访问(如获取实部和虚部)也是在这个示例中展示的。
24. 请解释Python中的布尔类型。
布尔类型(Boolean)
布尔类型是一种数据类型,其值通常是True(真)或False(假)。在Python中,布尔类型是int的子类型,并且True和False分别对应于1和0。布尔类型主要用于表示逻辑值,如判断一个条件是否满足,或一个操作是否成功。
布尔类型示例
下面是一个Python代码示例,演示了布尔类型的使用:
# 布尔类型的定义
boolean_true = True
boolean_false = False# 打印布尔类型的值
print("Boolean True:", boolean_true)
print("Boolean False:", boolean_false)# 布尔类型的逻辑运算
# 逻辑与运算 - 两个操作数都为真时结果才为真
and_operation = boolean_true and boolean_false
print("AND Operation:", and_operation)# 逻辑或运算 - 至少一个操作数为真时结果就为真
or_operation = boolean_true or boolean_false
print("OR Operation:", or_operation)# 逻辑非运算 - 反转操作数的真假值
not_operation = not boolean_true
print("NOT Operation:", not_operation)# 布尔类型与比较运算符的结合
# 等于运算符
equal_to = 10 == 10
print("Equal To:", equal_to)# 不等于运算符
not_equal_to = 10 != 10
print("Not Equal To:", not_equal_to)# 布尔类型在控制流程中的使用
# 例如,在if语句中
if boolean_true:print("This is True.")
else:print("This is False.")# 在循环中使用布尔类型
for i in range(5):if i % 2 == 0:print(i, "is even.")else:print(i, "is odd.")# 函数返回布尔类型
def is_positive(number):return number > 0print("Is 10 positive?", is_positive(10))
print("Is -5 positive?", is_positive(-5))# 布尔类型常用于条件判断和循环控制,它们使得程序能够根据不同的输入或状态执行不同的代码块。
25. 请解释Python中的序列化和反序列化。
序列化(Serialization)
序列化是将一个对象状态转换为可以存储或传输的格式的过程。在Python中,序列化通常是指将对象转换为一个字节流,这个字节流包含了对象的所有信息,包括数据结构、属性值等。序列化后的数据可以存储到文件中、数据库中,或者通过网络传输。
反序列化(Deserialization)
反序列化是将序列化后的字节流恢复为原始对象的过程。反序列化可以将之前由序列化操作保存的数据恢复到内存中的原始对象状态。
Python中常见的序列化模块
Python提供了多个模块进行序列化和反序列化,例如:
pickle:Python标准库中的一个模块,可以序列化任何Python对象。json:用于处理JSON数据格式的模块,它支持基本数据类型,如字典、列表、字符串等。marshal:用于序列化Python对象的二进制格式。dill:一个增强型的pickle模块,它可以序列化几乎任何类型的对象。
序列化和反序列化示例
下面是一个使用pickle模块进行序列化和反序列化的Python代码示例:
import pickle# 一个简单的Python对象,例如字典
data = {'name': 'Alice','age': 25,'scores': [85, 90, 95]
}# 序列化对象
with open('data.pkl', 'wb') as file:pickle.dump(data, file)# 反序列化对象
with open('data.pkl', 'rb') as file:recovered_data = pickle.load(file)# 打印恢复后的对象
print("Recovered Data:", recovered_data)# 验证恢复的对象是否与原始对象相同
assert data == recovered_data
在这个示例中,我们首先创建了一个字典对象data,然后使用pickle.dump()函数将它序列化到一个文件中。之后,我们使用pickle.load()函数从文件中反序列化对象,并将其恢复成原始的字典形式。
请注意,不同的序列化模块可能有不同的协议和选项,因此在实际应用中,选择合适的序列化方法非常重要。例如,如果你需要序列化一个复杂的对象,或者需要考虑跨平台的兼容性,那么json或dill可能是更好的选择。
26. 请解释Python中的内存管理。
Python中的内存管理是Python解释器负责处理程序在运行时分配和释放内存的方式。Python的内存管理是自动的,这意味着开发者不需要手动释放内存,但是了解内存管理的原理对于优化Python程序的性能和避免内存泄漏是很重要的。
内存管理的基本概念
-
引用计数:Python内部使用引用计数机制来追踪对象被引用的次数。当一个对象的引用次数变为0时,内存管理器会认为这个对象不再需要,并释放其占用的内存。
-
垃圾回收:Python的垃圾回收器(garbage collector, GC)是一个后台进程,它周期性地检查并回收那些不再被引用的对象所占用的内存。
-
内存池:Python会在内存中预先分配一块较大的内存区域,称为内存池。当需要创建一个新的对象时,Python会首先尝试从内存池中分配内存,而不是每次都从操作系统请求新的内存。
内存管理示例
下面是一个简单的Python代码示例,说明引用计数是如何工作的:
import sys# 创建一个对象
a = []
b = a # 引用计数增加# 引用计数
print("Reference Count:", sys.getrefcount(a)) # 预期结果是3,因为a, b和getrefcount函数本身都有引用# 删除一个引用
b = None # b不再引用a,a的引用计数减少# 引用计数
print("Reference Count after deleting reference to a:", sys.getrefcount(a)) # 预期结果是2# 再次删除一个引用
del a # 删除最后一个引用,对象被销毁# 此时a已经不存在,无法获取其引用计数
在这个示例中,我们创建了一个列表a,并将另一个变量b指向a。这意味着a的引用计数变为2。然后我们删除了b对a的引用,这样a的引用计数就只剩下1(因为还有getrefcount函数的引用)。最后,我们使用del关键字删除了a的最后一个引用,这导致列表a被销毁,内存被释放。
垃圾回收器
尽管引用计数是一个重要的内存管理机制,但Python也使用垃圾回收器来处理更复杂的情况,例如循环引用(circular references),即两个对象互相引用对方。垃圾回收器会检测到这些情况并释放循环引用所占用的内存。
垃圾回收器的运行时机通常是不可预测的,但是可以通过调用gc.collect()函数来手动触发垃圾回收器,或者使用gc.set_threshold()来设置触发垃圾回收的阈值。
27. 请解释Python中的反射。
Python中的反射是指程序能够检查自身状态和行为的能力。在Python中,反射可以通过内置的inspect模块来实现。"反射"这个术语源于计算机科学,其中它指的是一种能够观察并修改程序运行时行为的能力。
反射的基本概念
反射主要涉及以下几个方面:
-
检查类和对象的类型:可以使用
type()函数或isinstance()函数来检查对象的类型。 -
获取对象的属性和方法:可以使用
dir()函数来获取对象的属性和方法列表。 -
动态调用对象的方法:可以使用
getattr()函数来动态地调用对象的方法。 -
创建类的实例:可以使用
__new__()方法或type()函数来动态创建类的实例。 -
修改类的定义:可以在运行时修改类的属性和方法。
反射示例
以下是一个简单的Python代码示例,演示了如何使用反射来检查对象的类型、获取其属性和方法,以及动态调用其方法:
import inspect# 定义一个类
class MyClass:def __init__(self, value):self.value = valuedef say_hello(self):return f"Hello, world! Value is {self.value}"# 创建MyClass的一个实例
my_object = MyClass(10)# 检查对象的类型
print("Type of my_object:", type(my_object)) # 输出: <class '__main__.MyClass'># 检查对象是否是某个类的实例
print("Is my_object an instance of MyClass?", isinstance(my_object, MyClass)) # 输出: True# 获取对象的属性和方法
print("Attributes and methods of my_object:", dir(my_object))# 动态调用对象的方法
method_to_call = getattr(my_object, 'say_hello')
print("Result of calling say_hello:", method_to_call()) # 输出: Hello, world! Value is 10# 创建MyClass的另一个实例,使用type()函数
another_object = type(my_object)(20)
print("Type of another_object:", type(another_object)) # 输出: <class '__main__.MyClass'>
print("Value of another_object:", another_object.value) # 输出: 20# 动态修改类的定义
MyClass.new_attribute = "New attribute value"
print("New attribute of MyClass:", MyClass.new_attribute) # 输出: New attribute value
在这个示例中,我们首先定义了一个MyClass类,并创建了该类的实例。使用反射技术,我们检查了对象的类型,获取了它的属性和方法列表,动态调用了它的方法,还创建了另一个类的实例,并修改了类的定义。
28. 请解释Python中的面向对象编程。
Python中的面向对象编程(Object-Oriented Programming,OOP)是一种编程范式,它使用“对象”来设计软件。对象是数据(属性)和操作这些数据的函数(方法)的封装。面向对象编程的核心概念包括:
-
类(Class):定义了一组属性和方法的蓝图。它是一个模板,说明了创建对象时对象应具备的标准特征和行为。
-
对象(Object):根据类的定义创建的实体。它包含了数据和行为,数据通常是通过称为属性的变量来表示的,而行为则是通过称为方法的函数来实现的。
-
封装(Encapsulation):是OOP的核心概念之一,指的是将对象的实现细节隐藏起来,仅通过一个公共的接口向外界暴露对象的行为。这可以防止外部代码无意中干扰对象内部的工作,保证了代码的安全性。
-
继承(Inheritance):允许一个类继承另一个类的特性,这意味着可以创建一个通用类,然后定义更专业化的类来继承通用类的属性和方法。
-
多态性(Polymorphism):字面意思是"多种形态",在OOP中指的是方法或实体的能力,以多种形式表现,比如,一个函数或者一个操作有多个实现方式。
面向对象编程示例
以下是一个Python中面向对象编程的简单示例:
# 定义一个基类(父类)
class Animal:def __init__(self, name):self.name = name # 属性def speak(self): # 方法raise NotImplementedError("Subclass must implement abstract method")# 定义一个派生类(子类)
class Dog(Animal):def speak(self):return f"{self.name} says Woof!"# 定义另一个派生类
class Cat(Animal):def speak(self):return f"{self.name} says Meow!"# 使用基类类型来创建对象
my_animals = [Dog('Fido'), Cat('Whiskers')]# 遍历所有动物并让它们说话
for animal in my_animals:print(animal.speak()) # 输出: Fido says Woof!# Whiskers says Meow!# 使用isinstance()检查对象类型
print("Is my_animals[0] a Dog?", isinstance(my_animals[0], Dog)) # 输出: True
print("Is my_animals[1] a Cat?", isinstance(my_animals[1], Cat)) # 输出: True# 使用issubclass()检查类继承关系
print("Is Dog a subclass of Animal?", issubclass(Dog, Animal)) # 输出: True
print("Is Cat a subclass of Animal?", issubclass(Cat, Animal)) # 输出: True
在这个例子中:
Animal是一个基类,有一个名为speak的方法,这个方法是被设计为由子类提供具体实现的。Dog和Cat是从Animal类继承而来的派生类,它们覆盖了基类的speak方法来提供具体的实现。my_animals是一个包含Dog和Cat对象的列表,尽管它们是Animal类型的对象,但我们可以通过调用speak方法来获取各自的声音。- 使用
isinstance()函数来检查对象是否是特定类的实例。 - 使用
issubclass()函数来检查一个类是否是另一个类的子类。
29. 请解释Python中的类继承。
Python中的类继承是一种机制,它允许你创建一个新类(子类)基于另一个类(父类)。子类会继承(或扩展)父类的属性和方法。类继承是面向对象编程的核心概念之一,它有助于减少重复代码并提高代码的复用性。
类继承的基本概念:
- 继承:子类自动获得了父类的所有公共方法和属性。
- 覆盖:子类可以重写父类的方法来提供新的实现。
- 扩展:子类可以添加父类没有的额外方法和属性。
- 多态:子类对象可以当作父类类型使用,这意味着你可以使用统一的接口来引用不同类型的对象。
类继承示例:
以下是一个Python中使用类继承的示例:
# 定义一个基类(父类)
class Vehicle:def __init__(self, brand, model):self.brand = brand # 品牌属性self.model = model # 型号属性def display_info(self): # 显示信息的方法print(f"This vehicle is a {self.brand} {self.model}.")# 定义一个派生类(子类)
class Car(Vehicle):def __init__(self, brand, model, num_doors):super().__init__(brand, model) # 调用父类的初始化方法self.num_doors = num_doors # 汽车特有的属性:门数量def display_info(self): # 覆盖父类的方法super().display_info() # 调用父类的方法print(f"It has {self.num_doors} doors.")# 定义另一个派生类
class Truck(Vehicle):def __init__(self, brand, model, payload_capacity):super().__init__(brand, model) # 调用父类的初始化方法self.payload_capacity = payload_capacity # 卡车特有的属性:载重能力def display_info(self): # 覆盖父类的方法super().display_info() # 调用父类的方法print(f"Its payload capacity is {self.payload_capacity} tons.")# 创建Car和Truck对象
my_car = Car('Toyota', 'Corolla', 4)
my_truck = Truck('Volvo', 'FMX', 10)# 调用display_info方法
my_car.display_info()
# 输出:
# This vehicle is a Toyota Corolla.
# It has 4 doors.my_truck.display_info()
# 输出:
# This vehicle is a Volvo FMX.
# Its payload capacity is 10 tons.# 使用isinstance()检查对象类型
print("Is my_car a Car?", isinstance(my_car, Car)) # 输出: True
print("Is my_truck a Truck?", isinstance(my_truck, Truck)) # 输出: True# 使用issubclass()检查类继承关系
print("Is Car a subclass of Vehicle?", issubclass(Car, Vehicle)) # 输出: True
print("Is Truck a subclass of Vehicle?", issubclass(Truck, Vehicle)) # 输出: True
在这个例子中:
Vehicle是一个基类,代表了交通工具的共同属性和方法。Car和Truck是从Vehicle类继承而来的派生类。它们分别添加了特有的属性(num_doors和payload_capacity)和覆盖了基类的display_info方法以显示更多的信息。- 使用
super()函数在子类中调用父类的初始化方法和其他方法。 my_car和my_truck是Car和Truck类型的对象,尽管它们都是Vehicle类的实例,但可以通过调用各自的display_info方法来显示更具体的信息。
30. 请解释Python中的多重继承。
Python支持多重继承,即一个子类可以同时继承多个父类。这种机制提供了更多的灵活性,因为它允许你组合多个类的特性。在多重继承中,可能会遇到一些复杂的情况,比如命名冲突(当多个父类有相同名称的方法或属性时),但Python通过一定的规则来解决这些问题。
多重继承的基本概念:
- MRO(方法解析顺序):Python在多重继承中使用MRO来确定调用哪个方法。它是一个继承层次结构的线性顺序,从左到右。
- 深度优先:如果在多个父类中有相同的方法,Python会按照继承列表的顺序从左到右搜索方法。
- 名字查找:如果在类中没有找到属性或方法,Python会继续在父类中查找。
多重继承示例:
以下是一个Python中使用多重继承的示例:
# 定义第一个基类
class Engine:def start(self):print("Engine started.")# 定义第二个基类
class Transmission:def shift_gear(self, gear):print(f"Gear shifted to {gear}.")# 定义一个派生类,它同时继承了Engine和Transmission
class Car(Engine, Transmission):def __init__(self, brand, model):self.brand = brandself.model = modeldef display_info(self):print(f"This car is a {self.brand} {self.model}.")# 创建Car对象
my_car = Car('Toyota', 'Corolla')# 调用Car的方法
my_car.display_info() # 输出: This car is a Toyota Corolla.
my_car.start() # 输出: Engine started.
my_car.shift_gear(1) # 输出: Gear shifted to 1.# 检查方法解析顺序
print("Method Resolution Order (MRO):", Car.__mro__)
# 输出: Method Resolution Order (MRO): (<class '__main__.Car'>, <class '__main__.Engine'>, <class '__main__.Transmission'>, <class 'object'>)
在这个例子中:
Engine和Transmission是两个独立的基类,它们分别定义了start方法和shift_gear方法。Car类继承了Engine和Transmission类,因此它同时获得了这两个类的特性。- 当创建
Car类的实例时,你可以调用start和shift_gear方法,就像这些方法是在Car类中定义的一样。 Car.__mro__属性显示了方法解析顺序,它表明了在查找方法时将考虑的类顺序。
请注意,在多重继承中,如果存在相同的方法或属性,你需要在子类中明确指出如何解决冲突。此外,过深的多重继承可能会导致复杂的层次结构,从而使得代码难以维护和理解。因此,在设计类层次结构时,应该尽量避免过多的多重继承。
31. 请解释Python中的类属性和方法。
在Python中,类属性和方法是面向对象编程的核心概念。类属性和方法是与类本身相关联的,而不是与类的某个特定实例相关联的。这意味着它们可以在不创建类的实例的情况下访问。
类属性(Class Attributes)
类属性是直接在类定义内部赋值的变量,它们对所有实例共享。类属性通常用于存储与类相关的固定数据,例如类变量、配置选项等。
类属性示例:
class Circle:# 类属性pi = 3.14159def __init__(self, radius):self.radius = radius# 计算圆的面积def area(self):return self.pi * self.radius ** 2# 访问类属性
print("Circle's pi:", Circle.pi)# 创建Circle对象
circle1 = Circle(5)
print("Area of circle1:", circle1.area())# 即使没有创建实例,也可以修改类属性
Circle.pi = 3.14
print("New Circle's pi:", Circle.pi)
在这个例子中,pi 是一个类属性,它被所有 Circle 实例共享。我们通过 Circle.pi 来访问和修改它。
类方法(Class Methods)
类方法是绑定到类而不是类的实例的方法。它们可以被调用而不需要创建类的实例。类方法通常用于执行与类状态相关的操作,例如工厂方法,或者用于修改类属性。
类方法示例:
class Person:# 类属性population = 0def __init__(self, name):self.name = name# 每创建一个人,人口数量加1Person.population += 1# 类方法@classmethoddef get_population(cls):return cls.population# 访问类方法
print("Current population:", Person.get_population())# 创建Person对象
person1 = Person("Alice")
print("Current population:", Person.get_population())# 即使没有创建实例,也可以调用类方法
print("Population through class method:", Person.get_population())
在这个例子中,get_population 是一个类方法,它返回当前的人口数量。我们使用 @classmethod 装饰器来定义类方法,并且它自动接收当前类作为第一个参数(通常命名为 cls)。
总结
类属性和方法是类的一部分,它们定义了类的行为和状态。类属性用于存储数据,而类方法用于操作数据和其他类级别的功能。它们都是通过在类定义中直接声明来创建的,并且可以通过类名直接访问,而不需要创建类的实例。
32. 请解释Python中的静态方法和类方法。
在Python中,静态方法(Static Methods)和类方法(Class Methods)都是类中定义的特殊方法,但它们在用途和行为上存在一些关键的区别。
静态方法(Static Methods)
静态方法是属于类本身的,而不是类的实例。这意味着您不需要创建类的对象来调用这个方法。静态方法通常用于执行不依赖于类实例状态的操作。它们通常用于实现一些与类相关但是与特定实例无关的功能。
静态方法在定义时使用 @staticmethod 装饰器,并且不需要接收 self 或 cls 参数。
静态方法示例:
class MathHelper:@staticmethoddef square(number):return number ** 2# 直接通过类名调用静态方法
result = MathHelper.square(4)
print("Square of 4 is:", result)
在这个例子中,我们定义了一个名为 MathHelper 的类,它有一个静态方法 square。这个方法接受一个数字并返回它的平方。我们不需要创建一个 MathHelper 的实例就能调用 square 方法。
类方法(Class Methods)
类方法与静态方法类似,但它是属于类的,而不是类的实例。类方法通常用于操作与类相关的状态,例如类变量或其他类级别的数据。类方法在定义时使用 @classmethod 装饰器,并且自动接收 cls 参数作为类本身的引用。
类方法示例:
class Person:population = 0def __init__(self, name):self.name = namePerson.population += 1@classmethoddef get_population(cls):return cls.population# 直接通过类名调用类方法
print("Current population:", Person.get_population())
在这个例子中,get_population 是一个类方法,它返回当前的 Person 类的实例数量。尽管它可以被调用而不需要创建 Person 类的实例,但它访问了类属性 population。
总结
静态方法和类方法都是类中的特殊方法,但它们的使用场景和目的有所不同:
- 静态方法用于不需要类实例的操作,通常与类的其他静态方法或类属性一起工作。
- 类方法用于需要类级别状态的操作,例如修改类属性,或者创建和返回与类相关的实例。
在设计类的时候,如果一个方法不需要访问实例属性(即不需要 self),那么它通常应该是静态的。如果一个方法需要访问类属性,但又不需要访问具体的实例,那么它应该是类方法。
33. 请解释Python中的抽象基类。
在Python中,抽象基类(Abstract Base Classes,ABC)是一种特殊的类,它不能被直接实例化。ABC旨在作为其他类的蓝图,它可以包含抽象方法(即没有具体实现的方法)和具体方法(已实现的方法)。任何继承自ABC的子类都必须实现其所有的抽象方法,除非子类也是一个ABC。
ABC模块提供了一种机制,用于标识其他类应该遵守的接口规范,从而确保子类遵循特定的方法集。
使用ABC的好处是它可以提供一个清晰的协议,使得其他开发者了解你的代码需要哪些方法,而不需要阅读整个类的方法实现。
如何定义一个抽象基类:
- 导入
abc模块。 - 创建一个继承自
abc.ABC的类。 - 在类内部,使用
@abc.abstractmethod装饰器标记抽象方法。
示例代码:
import abcclass Animal(abc.ABC):@abc.abstractmethoddef make_sound(self):"""Make some sound."""pass@abc.abstractmethoddef move(self):"""Move in some way."""passclass Dog(Animal):def make_sound(self):return "Bark"def move(self):return "Run"# 尝试实例化抽象基类会导致错误
# animal = Animal() # TypeError: Can't instantiate abstract class Animal with abstract methods make_sound, move# 实例化子类
dog = Dog()
print(dog.make_sound()) # 输出: Bark
print(dog.move()) # 输出: Run
在这个例子中:
Animal是一个抽象基类,包含两个抽象方法:make_sound和move。Dog是一个继承自Animal的子类,它实现了这两个抽象方法。- 尝试实例化抽象基类
Animal会导致一个TypeError,因为抽象类不能被直接实例化。 - 实例化
Dog子类并调用方法会正常工作,因为Dog类提供了方法的具体实现。
这个例子演示了如何使用ABC来定义一个需要子类实现特定方法的接口。这对于创建一组遵循特定协议的类非常有用,例如定义一组需要被不同类实现的数据处理方法。
34. 请解释Python中的接口。
在Python中,接口是一种特殊的类,它定义了一组方法规范,但不包含这些方法的具体实现。接口是通过协议(如抽象基类,在Python中是使用abc模块实现)来实现的,它确保实现了接口的类提供了接口所需的所有方法。
Python的接口主要是一种概念性的存在,因为Python本身不支持传统意义上的接口定义。然而,我们可以使用抽象基类来模拟接口,因为它们满足了定义接口的需求:提供一组方法规范,并且不能被直接实例化。
如何定义一个接口:
- 导入
abc模块。 - 创建一个继承自
abc.ABC的类。 - 在类内部,使用
@abc.abstractmethod装饰器标记抽象方法。
示例代码:
import abcclass JsonSerializable(abc.ABC):@abc.abstractmethoddef to_json(self):"""Serialize the object to JSON format."""passclass User(JsonSerializable):def __init__(self, name, email):self.name = nameself.email = emaildef to_json(self):return {'name': self.name, 'email': self.email}# 实例化User类
user = User("John Doe", "john@example.com")
print(user.to_json()) # 输出: {'name': 'John Doe', 'email': 'john@example.com'}
在这个例子中:
JsonSerializable是一个接口,它定义了一个抽象方法to_json,该方法用于将对象序列化为JSON格式。User类实现了JsonSerializable接口,并提供了to_json方法的具体实现。User类的实例可以调用to_json方法,因为它满足了接口的要求。
这个例子展示了如何使用抽象基类来模拟接口。这种方式可以确保所有实现了 JsonSerializable 接口的类都有一个 to_json 方法,这对于编写泛型代码和提高代码的可读性和可维护性非常有帮助。
需要注意的是,Python的动态类型系统允许我们不严格遵守接口,因此在实际的编程实践中,接口的概念可能会更加宽松和灵活。在Python中,更常见的做法是使用文档字符串或注解来明确指示函数或类的行为,而不是强制遵守接口。
35. 请解释Python中的运算符重载。
在Python中,运算符重载是一种特殊的机制,允许我们重新定义或重载内置的运算符的行为,以便用于我们自定义的对象。运算符重载可以让对象的行为看起来更像内置类型,这使得代码更简洁和易于理解。
要重载一个运算符,你需要在类中定义一个特殊的方法,这个方法的名字就是运算符的名字。例如,为了重载加法运算符(+),你会在类中定义一个名为__add__的方法。
运算符重载的基本方法:
__add__(self, other): 定义加法行为(+)。__sub__(self, other): 定义减法行为(-)。__mul__(self, other): 定义乘法行为(*)。__truediv__(self, other): 定义真除法行为(/)。__floordiv__(self, other): 定义整除法行为(//)。__mod__(self, other): 定义取模行为(%)。__pow__(self, other): 定义幂运算行为(**)。__lt__(self, other): 定义小于比较行为(<)。__le__(self, other): 定义小于等于比较行为(<=)。__eq__(self, other): 定义等于比较行为(==)。__ne__(self, other): 定义不等于比较行为(!=)。__gt__(self, other): 定义大于比较行为(>)。__ge__(self, other): 定义大于等于比较行为(>=)。
示例代码:
class Vector:def __init__(self, x, y):self.x = xself.y = ydef __add__(self, other):if isinstance(other, Vector):return Vector(self.x + other.x, self.y + other.y)else:raise TypeError("Can only add another Vector instance")def __sub__(self, other):if isinstance(other, Vector):return Vector(self.x - other.x, self.y - other.y)else:raise TypeError("Can only subtract another Vector instance")def __repr__(self):return f"Vector({self.x}, {self.y})"# 使用示例
v1 = Vector(2, 3)
v2 = Vector(1, 1)v3 = v1 + v2 # 调用 __add__ 方法
v4 = v1 - v2 # 调用 __sub__ 方法print(v3) # 输出: Vector(3, 4)
print(v4) # 输出: Vector(1, 2)
在这个例子中,我们定义了一个Vector类,它有两个坐标x和y。我们重载了加法(__add__)和减法(__sub__)运算符,以便它可以与另一个Vector实例相加或相减。重载的方法检查参数other是否也是一个Vector实例,如果是,则返回一个新的Vector实例,其坐标是两个向量坐标的和或差。
运算符重载使得我们可以使用直观的数学运算符来操作我们的自定义类型,这大大提高了代码的可读性,并让我们能够以自然的方式来表达复杂的操作。运算符重载是Python的核心特性之一,使得Python的内置类型和用户定义的类型都能表现出一致的行为。
36. 请解释Python中的鸭子类型。
在Python中,鸭子类型(Duck Typing)是一种编程风格,它强调的是"如果它走路像鸭子,叫声像鸭子,那么它就是鸭子"。这种说法来源于Donald Knuth的著名笑话,他称Python是"鸭子类型"的语言,因为它不强制对象是特定类型的,而是依赖于对象的行为。
在Python中,如果一个对象实现了特定的方法,那么它就可以被视为有效的参数传递给任何期望该方法的函数或方法。这就是所谓的"如果它看起来像鸭子,走路像鸭子,那么它就是鸭子"。
鸭子类型的一个例子:
class Duck:def quack(self):print("Quack, quack!")class Person:def quack(self):print("I'm quacking like a duck!")def make_it_quack(duck):duck.quack()# 创建两个对象,一个是Duck类型的,另一个是Person类型的
donald = Duck()
human = Person()# 调用函数,尽管它们类型不同
make_it_quack(donald) # 输出: Quack, quack!
make_it_quack(human) # 输出: I'm quacking like a duck!
在这个例子中,Duck和Person类都有一个名为quack的方法。make_it_quack函数期望它的参数对象有一个quack方法,所以无论传递的是Duck对象还是Person对象,函数都能正常工作,因为它们都有quack方法。
鸭子类型的优点:
- 增加了代码的灵活性,因为函数或方法不需要明确知道对象的类型。
- 减少了对类继承的依赖,因为不需要一个共同的基类。
- 鼓励了接口设计和多态编程,因为函数或方法可以写得更加通用,可以与任何实现了特定接口的对象一起工作。
注意事项:
虽然鸭子类型很有用,但也需要谨慎使用,因为它可能导致代码更难理解和维护,特别是当对象的行为不一致或模糊时。在一些严格的静态类型语言中,鸭子类型是不存在的,或者需要显式的接口定义。在Python中,由于其动态类型系统,鸭子类型通常被认为是一种优点,而不是缺点。
37. 请解释Python中的私有属性和方法。
在Python中,私有属性和方法是那些不应该在类的外部直接访问的属性和方法。私有成员的名称以两个下划线(__)开头。这是Python的一个约定,用来指示这些成员是私有的,并且它们不应该被直接访问,而是应该通过公共的接口(即公共的方法)来访问。
私有属性的例子:
class Account:def __init__(self, balance):# 私有属性,外部无法直接访问self.__balance = balancedef deposit(self, amount):if amount > 0:self.__balance += amountprint(f"Deposited {amount}. New balance is {self.__balance}.")else:print("Cannot deposit non-positive amount.")def get_balance(self):# 公共方法,用于获取私有属性的值return self.__balance# 创建Account对象
account = Account(100)# 尝试直接访问私有属性
# print(account.__balance) # 错误:AttributeError# 通过公共方法访问私有属性
print(account.get_balance()) # 正确:输出余额# 通过公共方法进行存款
account.deposit(50) # 正确:存款并更新余额# 再次通过公共方法访问私有属性
print(account.get_balance()) # 正确:输出新的余额
在这个例子中,Account类的__balance属性是私有的,这意味着你不能直接从类的外部访问它,例如尝试使用account.__balance将会引发一个AttributeError。相反,你应该使用公共方法get_balance来获取账户的余额,或者使用deposit方法来存款,因为它们都提供了对私有属性的安全访问。
私有方法的例子:
class Car:def __init__(self, make):self.__make = make # 私有属性def __get_make(self):# 私有方法return self.__makedef show_make(self):# 公共方法,用于调用私有方法return self.__get_make()# 创建Car对象
car = Car("Toyota")# 尝试直接调用私有方法
# print(car.__get_make()) # 错误:AttributeError# 通过公共方法调用私有方法
print(car.show_make()) # 正确:输出制造商名称
在这个例子中,Car类的__get_make方法是私有的,它只能在类的内部被调用。我们定义了一个公共方法show_make来提供对私有方法的访问。
优点:
- 封装:私有成员可以隐藏类的内部实现细节,防止外部代码随意修改对象内部状态。
- 控制:类可以通过公共方法控制对其私有成员的访问,这可以加入验证逻辑,确保对象始终保持在有效和一致的状态。
- 维护性:开发者可以自由修改类的内部实现,而不需要担心影响到依赖于这些私有成员的外部代码。
38. 请解释Python中的魔法方法。
Python中的魔法方法是一组特殊的方法,它们的名称以两个下划线(__)开头和结尾。这些方法在Python中被称为“魔法方法”,因为它们具有“魔法”般的功能,比如对象的创建和销毁、比较操作符的重载、运算符的重载等。它们通常不直接被调用,而是由Python解释器在特定情况下自动调用。
下面是一些常用的魔法方法及其用途的解释和示例:
__init__:构造函数
这个方法在对象被创建时自动调用,用于初始化对象的属性。
class Person:def __init__(self, name):self.name = nameprint(f"{self.name} has been created.")# 创建Person对象时,会自动调用__init__方法
person = Person("Alice") # 输出:Alice has been created.
__del__:析构函数
这个方法在对象被销毁时自动调用,用于释放对象占用的资源。
class Person:def __init__(self, name):self.name = nameprint(f"{self.name} has been created.")def __del__(self):print(f"{self.name} is being destroyed.")# 当Person对象不再被引用时,会自动调用__del__方法
person = Person("Bob") # 输出:Bob has been created.
del person # 输出:Bob is being destroyed.
__str__:字符串表示
这个方法用于返回一个对象的字符串表示,它通常在打印对象时被调用。
class Person:def __init__(self, name):self.name = namedef __str__(self):return f"Person object with name {self.name}"# 创建Person对象
person = Person("Charlie")# 打印对象时,会自动调用__str__方法
print(person) # 输出:Person object with name Charlie
__repr__:官方字符串表示
这个方法类似于__str__,但它返回的是一个对象的官方字符串表示,通常用于调试和开发。
class Person:def __init__(self, name):self.name = namedef __repr__(self):return f"Person(name='{self.name}')"# 创建Person对象
person = Person("Dave")# 在交互式解释器中直接输入对象时,会自动调用__repr__方法
person # 输出:Person(name='Dave')
__eq__:等于运算符
这个方法用于实现对象之间的等于比较。
class Person:def __init__(self, name):self.name = namedef __eq__(self, other):if isinstance(other, Person):return self.name == other.namereturn False# 创建两个Person对象
person1 = Person("Eve")
person2 = Person("Eve")
person3 = Person("Frank")# 比较两个对象
print(person1 == person2) # 输出:True
print(person1 == person3) # 输出:False
__lt__:小于运算符
这个方法用于实现对象之间的小于比较。
class Person:def __init__(self, age):self.age = agedef __lt__(self, other):if isinstance(other, Person):return self.age < other.agereturn False# 创建两个Person对象
person1 = Person(25)
person2 = Person(30)# 比较两个对象
print(person1 < person2) # 输出:True
还有很多其他魔法方法,如 __add__ (用于加法),__sub__ (用于减法),__len__ (用于获取长度) 等等。
使用魔法方法可以让你的对象的行为更加“魔法”般,它们在Python中扮演着至关重要的角色,使得Python代码更加简洁和强大。
39. 请解释Python中的函数式编程。
函数式编程(Functional Programming, FP)是一种编程范式,它将计算视为数学函数的评估,并避免改变状态和可变数据。在Python中,函数式编程的特点被广泛支持,并且有很多内置的函数和模块,帮助你以函数式的方式写代码。
函数式编程的核心概念包括:
-
不可变性:在函数式编程中,状态是不可变的。这意味着您创建的数据结构一旦创建,就不能被修改。任何改变将导致创建一个新的数据结构。
-
纯函数:函数必须是纯粹的,意味着给定相同的输入,总是返回相同的输出,并且没有任何可观察的副作用。纯函数使得代码更容易理解和测试。
-
高阶函数:这些函数可以接受其他函数作为参数或将函数作为结果返回。这允许一些强大的模式,如 map、filter 和 reduce。
-
函数作为一等公民:函数可以像任何其他数据类型一样被传递和操作。
Python中的函数式编程示例:
使用map函数
map函数是一个高阶函数,它将一个函数应用到输入列表的每个元素上,并返回一个新的列表,包含所有函数应用的结果。
# 定义一个函数,将每个元素乘以2
def multiply_by_two(x):return x * 2# 创建一个列表
numbers = [1, 2, 3, 4, 5]# 使用map函数将multiply_by_two函数应用到numbers列表的每个元素上
doubled_numbers = map(multiply_by_two, numbers)# 转换结果为列表并打印
print(list(doubled_numbers)) # 输出:[2, 4, 6, 8, 10]
使用filter函数
filter函数也是一个高阶函数,它构造一个新的列表,包含所有使给定函数返回True的元素。
# 定义一个函数,检查一个数字是否是偶数
def is_even(x):return x % 2 == 0# 创建一个列表
numbers = [1, 2, 3, 4, 5]# 使用filter函数筛选出numbers列表中的所有偶数
even_numbers = filter(is_even, numbers)# 转换结果为列表并打印
print(list(even_numbers)) # 输出:[2, 4]
使用reduce函数
reduce函数是Python的functools模块中的一个函数,它将一个二元函数(接受两个参数的函数)累积地应用到列表的元素上,从左到右,以便将列表减少为单个输出。
from functools import reduce# 定义一个函数,计算两个数字的乘积
def product(x, y):return x * y# 创建一个列表
numbers = [1, 2, 3, 4, 5]# 使用reduce函数计算numbers列表中所有数字的乘积
result = reduce(product, numbers)# 打印结果
print(result) # 输出:120
使用lambda函数
lambda函数是Python中的匿名函数,它们可以用在任何需要函数对象的地方。
# 使用lambda函数来代替multiply_by_two函数
doubled_numbers = map(lambda x: x * 2, numbers)# 使用lambda函数来代替is_even函数
even_numbers = filter(lambda x: x % 2 == 0, numbers)# 打印结果
print(list(doubled_numbers)) # 输出:[2, 4, 6, 8, 10]
print(list(even_numbers)) # 输出:[2, 4]
使用列表推导式
列表推导式是一种简洁且易于理解的方法来创建列表。
# 使用列表推导式来获取numbers列表中所有偶数的平方
squared_even_numbers = [x**2 for x in numbers if x % 2 == 0]# 打印结果
print(squared_even_numbers) # 输出:[4, 16]
函数式编程的使用可以使代码更加简洁、可读性和可维护性,同时也更容易进行测试和并行化处理。在Python中,由于其丰富的内置函数和模块,函数式编程成为了许多开发者喜爱的编程风格。
40. 请解释Python中的列表、元组和字典的推导式。
在Python中,列表推导式(List Comprehensions)、元组推导式(Tuple Comprehensions)和字典推导式(Dictionary Comprehensions)是一种简洁且高效的方式来创建这些数据结构。它们提供了一种在单行代码中执行循环和条件判断来生成集合的方法。
列表推导式(List Comprehensions)
列表推导式用于从一个已有的列表派生出一个新的列表。它的基本结构如下:
[expression for item in iterable if condition]
expression是当前迭代项的一个表达式,可以带有操作或函数调用。item是迭代变量。iterable是一个序列、集合或者任何可迭代对象。if condition是一个可选项,用于设置筛选条件。
列表推导式示例
例如,如果你想创建一个包含数字0到9平方的列表,你可以这样做:
squares = [x**2 for x in range(10)]
print(squares) # 输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
如果你想从一个现有的列表中找出所有偶数,并返回它们的平方,可以这样写:
original_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
squared_evens = [x**2 for x in original_numbers if x % 2 == 0]
print(squared_evens) # 输出:[4, 16, 36, 64]
元组推导式(Tuple Comprehensions)
与列表推导式类似,元组推导式用于创建元组。它的基本结构如下:
(expression for item in iterable if condition)
请注意,元组推导式会生成一个生成器对象,而不是一个元组。如果你需要一个真正的元组,你需要使用tuple()函数将生成器对象转换为元组。
元组推导式示例
squared_numbers = tuple(x**2 for x in range(10))
print(squared_numbers) # 输出:(0, 1, 4, 9, 16, 25, 36, 49, 64, 81)
字典推导式(Dictionary Comprehensions)
字典推导式用于创建字典。它的基本结构如下:
{key_expression: value_expression for item in iterable if condition}
key_expression用于生成字典的键。value_expression用于生成字典的值。item,iterable, 和if condition的含义与列表推导式相同。
字典推导式示例
如果你想使用字典推导式,从一个列表创建一个字典,其中列表中的元素作为键,它们的长度作为值,可以这样写:
words = ['apple', 'banana', 'cherry']
word_lengths = {word: len(word) for word in words}
print(word_lengths) # 输出:{'apple': 5, 'banana': 6, 'cherry': 6}
列表推导式、元组推导式和字典推导式是Python中非常有用的工具,它们可以使代码变得更加简洁,提高代码的可读性,同时也可能提升代码的执行效率。不过,需要注意的是,在推导式中使用复杂的逻辑或者嵌套太多的循环可能会使代码变得难以理解,此时可能需要考虑使用常规的循环来替代推导式。
相关文章:

Python面试题-7
21. 请解释Python中的元组。 Python中的元组(Tuple)是一种内置的数据结构,它有如下特点: 有序性:元组中的元素是有序的,每个元素都有一个索引,索引从0开始。不可变性:一旦元组被创…...

微信⼩程序的电影推荐系统-计算机毕业设计源码76756
摘 要 随着互联网的普及和移动互联网的发展,人们对于获取信息的便捷性和高效性要求越来越高。电影作为一种受众广泛喜爱的娱乐方式,电影推荐系统的出现为用户提供了更加个性化和精准的电影推荐服务。微信小程序作为一种轻量级应用形式,在用…...

理解与解读李彦宏在2024世界人工智能大会的发言:应用优先于技术
2024年7月4日,世界人工智能大会暨人工智能全球治理高级别会议在上海世博中心举行。百度创始人、董事长兼首席执行官李彦宏在产业发展主论坛上提出了一个引人深思的观点:“大家不要卷模型,要卷应用!”他强调了一个重要的观点&#…...

数字化打破传统,引领企业跨界经营与行业生态盈利
在当今数字化时代,传统的赚货差思路正面临着巨大的挑战。然而,数字化的崛起为企业提供了突破传统束缚的机会,促使其转向跨界经营,并通过行业生态经营获取利润。 首先,数字化打破了传统赚货差思路的局限性。以往&…...

【链表】- 链表相交
1. 对应力扣题目连接 链表相交 2. 实现思路 链表详情: 考虑使用双指针: 解法一: 具体代码,详见3. 实现案例代码解析: 思路:因为链表按照如图的箭头走向,走的总路程是相等的,一…...

【python 学习】快速了解python内置类型
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 文章目录 前言一、内置类型的介绍1.1 类型体系1.2 空类型和None1.3 布尔值 二、内置类型的运算2.1 布尔运算2.2 比较运算符比较…...
npm ERR! code ENOTEMPTY npm ERR! syscall rename npm ERR!
报错: npm ERR! code ENOTEMPTY npm ERR! syscall rename npm ERR! path /home/user/.local/lib/node_modules/pkg npm ERR! dest /home/user/.local/lib/node_modules/.pkg-piikcue3 npm ERR! errno -39 npm ERR! ENOTEMPTY: directory not empty, rename ‘/home/…...

智能井盖采集装置 开启井下安全新篇章
在现代城市的脉络之下,错综复杂的管网系统如同城市的血管,默默支撑着日常生活的有序进行。而管网的监测设备大多都安装在井下,如何给设备供电一直是一个难题,选用市电供电需经过多方审批,选用电池供电需要更换电池包&a…...

C# AGV小车通讯开发的方法
AGV (Automated Guided Vehicle) 小车的通讯开发通常涉及与AGV控制系统或调度系统的数据交换。在C#中实现AGV小车通讯,可以采用多种方法,具体取决于AGV的通信协议和硬件接口。以下是一些常用的开发方法: 1. 串行通讯 (Serial Communication)…...
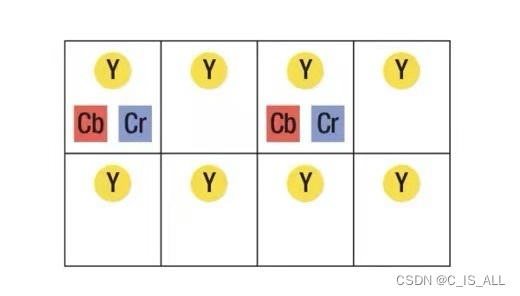
01-图像基础-颜色空间
1.RGB颜色空间 RGB是一种常用的颜色空间,比如一幅720P的图像,所对应的像素点个数是1280*720,每一个像素点由三个分量构成,分别是R,G,B。 R代表红色分量,G代表绿色分量,B代表蓝色分量,以24位色来…...

双向链表+Map实现LRU
LRU: LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。 核心思想: 基于Map实现k-v存储,双向链表中使用一个虚拟头部和虚拟尾部,虚拟头部的…...

HTML(27)——渐变
渐变是多个颜色逐渐变化的效果,一般用于设置盒子模型 线性渐变 属性:background-image : linear-gradient( 渐变方向 颜色1 终点位置, 颜色2 终点位置, ......); 取值: 渐变方向:可选 to 方位名词角度度数 终点位置:可选 百分…...
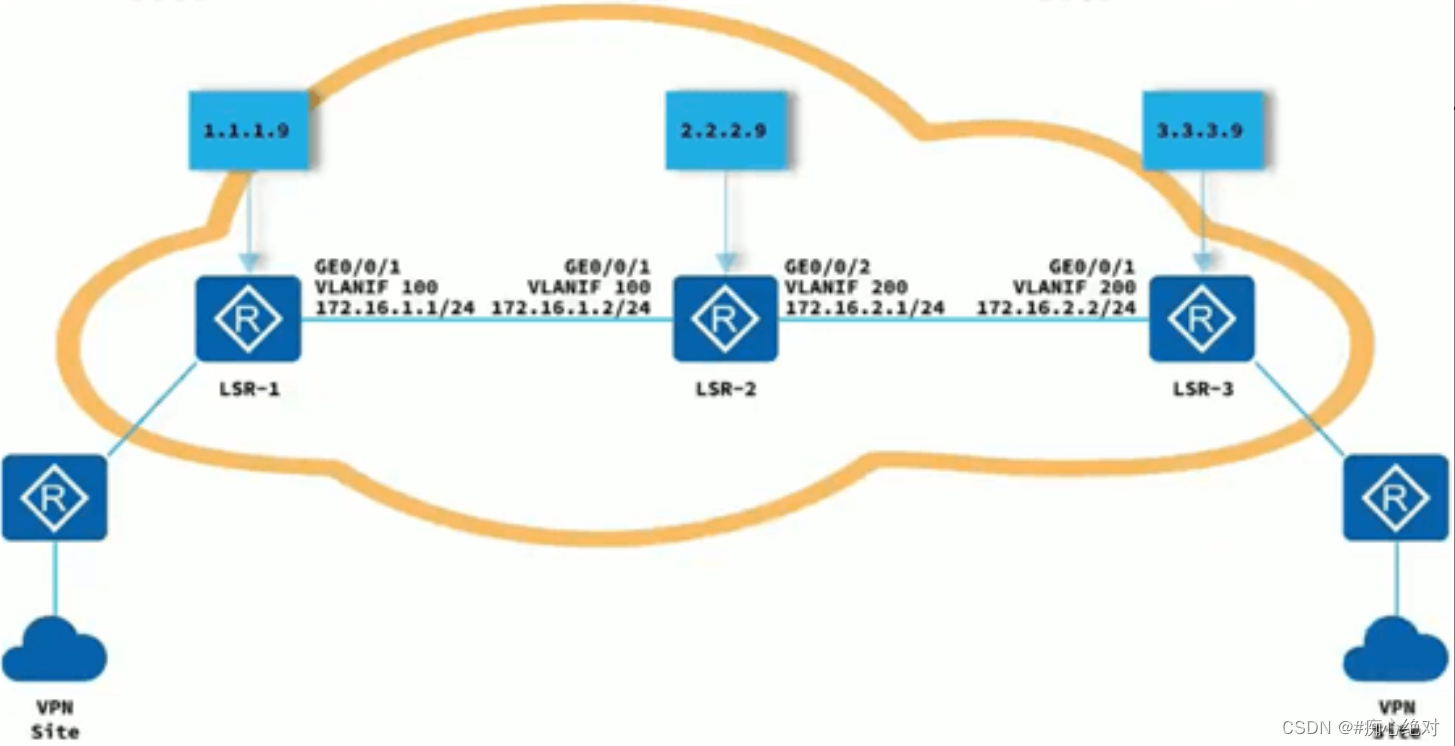
2024上半年网络工程师考试《应用技术》试题一
阅读以下说明,回答问题。 【说明】 MPLS基于(1)进行转发,进行MPLS标签交换和报文转发的网络设备称为(2),构成MPLS域(MPSDomain)。位于MPLS域边缘、连接其他网络的LSR称为(3),区域内部的LSR称为核心LSR(CoreLSR)IP报文进入MPLS网络时…...

pnpm介绍
PNPM 是一个 JavaScript 包管理器,类似于 npm 和 Yarn。它的全称是 "Performant npm",主要设计目标是优化包的安装和管理过程,以提升速度和效率。PNPM 的主要特点包括: 符号链接(Symlink)&#x…...

Linux内核的启动过程(非常详细)零基础入门到精通,收藏这一篇就够了
Linux内核的生成过程 内核的生成步骤可以概括如下: ① 先生成 vmlinux,这是一个elf可执行文件。② 然后 objcopy 成 arch/i386/boot/compressed/vmlinux.bin,去掉了原 elf 文件中一些无用的section等信息。③ gzip 后压缩为 arch/i386/boot…...

相关分析 - 肯德尔系数
肯德尔系数(Kendall’s Tau)是一种非参数统计方法,用于衡量两个变量之间的相关性。它是由统计学家莫里斯肯德尔(Maurice Kendall)在1938年提出的。肯德尔系数特别适用于有序数据,可以用来评估两个有序变量之…...

【咨询】企业数字档案馆(室)建设方案-模版范例
导读:本模版来源某国有大型医药行业集团企业数字档案馆(室)建设方案(一期300W、二期250W),本人作为方案的主要参与者,总结其中要点给大家参考。 目录 1、一级提纲总览 2、项目概述 3、总体规…...

selfClass 与 superClass 的区别
在 Objective-C 中,[self class] 和 [super class] 都用于获取对象的类信息,但它们在运行时的行为略有不同。理解它们的区别有助于更好地掌握 Objective-C 的消息传递机制和继承关系。让我们详细解释这两个调用的区别。 [self class] 当你在一个对象方…...
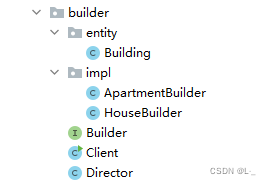
秒懂设计模式--学习笔记(6)【创建篇-建造者模式】
目录 5、建造者模式5.1 介绍5.2 建造步骤的重要性5.3 地产开发商的困惑5.4 建筑施工方5.5 工程总监5.6 项目实施5.7 建造者模式的各角色定义5.8 建造者模式 5、建造者模式 5.1 介绍 建造者模式(Builder)又称为生成器模式,主要用于对复杂对象…...
领略超越王勃的AI颂扬艺术:一睹其惊艳夸赞风采
今日,咱也用国产AI技术,文心一言3.5的文字生成与可灵的图像创作,自动生成一篇文章,提示语文章末下载。 【玄武剑颂星际墨侠】 苍穹为布,星辰织锦,世间万象,皆入我玄武剑公众号之浩瀚画卷。此号…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...