数据分析之Pandas(1)
3.Pandas
文章目录
- 3.Pandas
- 3.1 Pandas基本介绍
- 3.1.1 Pandas的基本数据结构
- 3.1.1.1 Pandas库的Series类型
- 3.1.1.2 Pandas库的DataFrame类型
- DataFrame初始化
- DataFrame查看数据
- 3.1.2 Pandas读取数据及数据操作
- 行操作
- 添加一行
- 删除一行
- 列操作
- 增加一列
- 删除一列
- 通过标签选择数据
- 条件选择
- 3.1.3 数据清洗
- 缺失值处理
- 判断缺失值
- 填充缺失值
- 删除缺失值
- 异常值处理
- 3.1.4 数据保存
- 3.2 Pandas操作
- 3.2.1 数据格式转换
- 3.1.2 排序
- 单值排序
- 多个值排序
- 3.1.3基本统计分析
- 描述性统计
- 最值
- 均值和中值
- 方差和标准差
- 求和
- 相关系数、协方差
- 计数
- 数据替换
- 3.1.4 数据透视
- 基础形式
- 多个索引 index=['','']
- 指定需要统计汇总的数据 values
- 指定函数 aggfunc
- 非数值处理 fill_value
- 计算总合数据 margins=True
- 对不同值执行不同函数
- 透视表过滤
- 按照多个索引来进行汇总
3.1 Pandas基本介绍
Python Data Analysis Library或pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需要的工具。pandas提供了大量能使我们快速便捷的处理数据的函数和方法。
import pandas as pd
import numpy as np
3.1.1 Pandas的基本数据结构
pandas中有两种常用的基本结构
•Series
一维数组,与Numpy中的一维array类似,二者与Python基本的数据结构List也很相似。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series种。
•DataFrame
二维的表格型数据结构,很多功能与R种的data.frame类似。可以将DataFrame理解为Series的容器。
3.1.1.1 Pandas库的Series类型
一维Series可以用一维列表初始化
a=pd.Series([1,3,5,np.nan,6,5]) ##此处Series的S必须大写
print(a)
结果
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 5.0
dtype: float64
默认的情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的。
b=pd.Series([1,3,5,np.nan,6,5],index=['a','b','c','d','e','f'])
print(b)
结果
a 1.0
b 3.0
c 5.0
d NaN
e 6.0
f 5.0
dtype: float64
索引——数据行标签
查看索引
a.index
结果
RangeIndex(start=0, stop=6, step=1)
-----------------------------------------------
b.index
结果
Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
查看取值
a.values
结果
array([ 1., 3., 5., nan, 6., 5.])
------------------------------
a[0]
结果
1.0
切片
a[2:5]
结果
2 5.0
3 NaN
4 6.0
dtype: float64
b['b':'f':2] ## 经过多次实践发现自定义索引的确是包头包尾
结果
b 3.0
d NaN
f 5.0
dtype: float64
索引赋值
a.index.name='索引'
a
结果索引
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 5.0
dtype: float64
和Series里面赋值一样
a.index=list('abcdef')
a
结果
a 1.0
b 3.0
c 5.0
d NaN
e 6.0
f 5.0
dtype: float64
3.1.1.2 Pandas库的DataFrame类型
DataFrame初始化
DataFrame是个二维结构,这里首先构造一组时间序列,作为第一维的下标
date=pd.date_range('20230312',periods=6)
print(date)
结果
DatetimeIndex(['2023-03-12', '2023-03-13', '2023-03-14', '2023-03-15','2023-03-16', '2023-03-17'],dtype='datetime64[ns]', freq='D')
然后创建一个DataFream结构
df=pd.DataFrame(np.random.randn(6,4))
df ##默认使用0、1、2.。。作为索引index
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -1.490125 | 1.298987 | -0.543361 | 1.221980 |
| 1 | -0.849709 | 0.118608 | -0.955715 | 0.144980 |
| 2 | -0.599598 | -0.756037 | -1.795249 | -0.282495 |
| 3 | -0.332586 | 1.750622 | -1.493345 | -2.100013 |
| 4 | -0.905893 | -0.254791 | -1.476728 | -0.001651 |
| 5 | -1.121065 | -1.861881 | -0.502420 | 0.523135 |
df=pd.DataFrame(np.random.randn(6,4),index=date,columns=list('ABCD'))
df ##index参数设置行索引,columns参数设置列索引,默认情况下不指定index和columns,他们的值从0开始
| A | B | C | D | |
|---|---|---|---|---|
| 2023-03-12 | 0.443978 | -0.568280 | 0.539422 | -1.808815 |
| 2023-03-13 | -0.941946 | 1.600655 | -0.165418 | -0.143333 |
| 2023-03-14 | 0.058186 | 1.299691 | -0.722582 | -0.258170 |
| 2023-03-15 | 0.912441 | -1.347266 | -0.827097 | -1.189625 |
| 2023-03-16 | 0.427125 | 0.010411 | -0.390411 | 1.172277 |
| 2023-03-17 | -0.584286 | -0.428119 | 0.536305 | 1.327480 |
除了向DataFrame中传入二维数组,我们也可以使用字典传入数据
df1=pd.DataFrame({'A':1,'B':pd.Timestamp('20230312'),'C':pd.Series(1,index=list(range(4)),dtype=float),'D':np.array([3]*4,dtype=int),'E':pd.Categorical(['test','train','test','train']),'F':'abc'})
df1
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | 1 | 2023-03-12 | 1.0 | 3 | test | abc |
| 1 | 1 | 2023-03-12 | 1.0 | 3 | train | abc |
| 2 | 1 | 2023-03-12 | 1.0 | 3 | test | abc |
| 3 | 1 | 2023-03-12 | 1.0 | 3 | train | abc |
字典的每个key代表一列,其value可以是各种能够转化为Series的对象
与Series要求所有的类型都一致不同,DataFrame只要求每一列数据的格式相同
df1.dtypes
结果
A int64
B datetime64[ns]
C float64
D int32
E category
F object
dtype: object
DataFrame查看数据
头尾数据
head和tail方法可以分别查看最前面几行和最后面几行的数据(默认为5)
df.head()
| A | B | C | D | |
|---|---|---|---|---|
| 2023-03-12 | 0.443978 | -0.568280 | 0.539422 | -1.808815 |
| 2023-03-13 | -0.941946 | 1.600655 | -0.165418 | -0.143333 |
| 2023-03-14 | 0.058186 | 1.299691 | -0.722582 | -0.258170 |
| 2023-03-15 | 0.912441 | -1.347266 | -0.827097 | -1.189625 |
| 2023-03-16 | 0.427125 | 0.010411 | -0.390411 | 1.172277 |
df.tail(3) ##后三行
| A | B | C | D | |
|---|---|---|---|---|
| 2023-03-15 | 0.912441 | -1.347266 | -0.827097 | -1.189625 |
| 2023-03-16 | 0.427125 | 0.010411 | -0.390411 | 1.172277 |
| 2023-03-17 | -0.584286 | -0.428119 | 0.536305 | 1.327480 |
| 下标、列标、数据 | ||||
| 下标使用index属性查看 |
df.index
结果
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04','2020-01-05', '2020-01-06'],dtype='datetime64[ns]', freq='D')
列标使用columns属性查看
df.columns
结果
Index(['A', 'B', 'C', 'D'], dtype='object')
数据值使用values查看
df.values
结果
array([[ 0.44397794, -0.56828038, 0.53942245, -1.8088147 ],[-0.94194603, 1.60065473, -0.16541752, -0.14333282],[ 0.05818642, 1.2996908 , -0.72258188, -0.25816996],[ 0.91244089, -1.34726583, -0.82709665, -1.18962492],[ 0.42712501, 0.01041125, -0.39041139, 1.17227685],[-0.58428589, -0.42811927, 0.53630517, 1.32747977]])
3.1.2 Pandas读取数据及数据操作
以豆瓣的电影数据作为我们深入了解Pandas的示例
豆瓣电影数据(提取码:7tvl)
df_mv=pd.read_excel(.....) ## 括号中填写数据存放的位置
df_mv=pd.read_excel('豆瓣电影数据.xlsx') ## 直接填文件名,需要文件在当前目录下
df_mv=pd.read_excel(r'E:\数据分析与挖掘\date\豆瓣电影数据.xlsx') ## 这种情况需要在地址前加r,以便转义失效
df_mv.head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
行操作
df_mv.iloc[0]
结果
Unnamed: 0 0
名字 肖申克的救赎
投票人数 692795
类型 剧情/犯罪
产地 美国
上映时间 1994-09-10 00:00:00
时长 142
年代 1994
评分 9.6
首映地点 多伦多电影节
Name: 0, dtype: object
df_mv.iloc[0:5] ## 左闭右开
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
也可以使用 loc
df_mv.loc[0:5] ## 两边都包
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
| 5 | 5 | 泰坦尼克号 | 157074.0 | 剧情/爱情/灾难 | 美国 | 2012-04-10 00:00:00 | 194 | 2012 | 9.4 | 中国大陆 |
添加一行
dit={'名字':'复仇者联盟3','投票人数':123456,'类型':'剧情/科幻','产地':'美国','上映时间':'2017-05-04 00:00:00','时长':142,'年代':2017,'评分':8.7,'首映地点':'美国'}
s=pd.Series(dit)
s.name=38738
s
名字 复仇者联盟3
投票人数 123456
类型 剧情/科幻
产地 美国
上映时间 2017-05-04 00:00:00
时长 142
年代 2017
评分 8.7
首映地点 美国
Name: 38738, dtype: object
df_mv=df_mv.append(s)
df_mv.tail()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 38734 | 38734.0 | 1935年 | 57.0 | 喜剧/歌舞 | 美国 | 1935-03-15 00:00:00 | 98 | 1935 | 7.6 | 美国 |
| 38735 | 38735.0 | 血溅画屏 | 95.0 | 剧情/悬疑/犯罪/武侠/古装 | 中国大陆 | 1905-06-08 00:00:00 | 91 | 1986 | 7.1 | 美国 |
| 38736 | 38736.0 | 魔窟中的幻想 | 51.0 | 惊悚/恐怖/儿童 | 中国大陆 | 1905-06-08 00:00:00 | 78 | 1986 | 8.0 | 美国 |
| 38737 | 38737.0 | 列宁格勒围困之星火战役 Блокада: Фильм 2: Ленинградский ме… | 32.0 | 剧情/战争 | 苏联 | 1905-05-30 00:00:00 | 97 | 1977 | 6.6 | 美国 |
| 38738 | NaN | 复仇者联盟3 | 123456.0 | 剧情/科幻 | 美国 | 2017-05-04 00:00:00 | 142 | 2017 | 8.7 | 美国 |
删除一行
df_mv=df_mv.drop([38738])
df_mv.tail()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 38733 | 38733.0 | 神学院 S | 46.0 | Adult | 法国 | 1905-06-05 00:00:00 | 58 | 1983 | 8.6 | 美国 |
| 38734 | 38734.0 | 1935年 | 57.0 | 喜剧/歌舞 | 美国 | 1935-03-15 00:00:00 | 98 | 1935 | 7.6 | 美国 |
| 38735 | 38735.0 | 血溅画屏 | 95.0 | 剧情/悬疑/犯罪/武侠/古装 | 中国大陆 | 1905-06-08 00:00:00 | 91 | 1986 | 7.1 | 美国 |
| 38736 | 38736.0 | 魔窟中的幻想 | 51.0 | 惊悚/恐怖/儿童 | 中国大陆 | 1905-06-08 00:00:00 | 78 | 1986 | 8.0 | 美国 |
| 38737 | 38737.0 | 列宁格勒围困之星火战役 Блокада: Фильм 2: Ленинградский ме… | 32.0 | 剧情/战争 | 苏联 | 1905-05-30 00:00:00 | 97 | 1977 | 6.6 | 美国 |
列操作
df_mv.columns
Index(['Unnamed: 0', '名字', '投票人数', '类型', '产地', '上映时间', '时长', '年代', '评分','首映地点'],dtype='object')
df_mv['名字'][0:5]
0 肖申克的救赎
1 控方证人
2 美丽人生
3 阿甘正传
4 霸王别姬
Name: 名字, dtype: object
df_mv[['名字','类型']][:5]
| 名字 | 类型 | |
|---|---|---|
| 0 | 肖申克的救赎 | 剧情/犯罪 |
| 1 | 控方证人 | 剧情/悬疑/犯罪 |
| 2 | 美丽人生 | 剧情/喜剧/爱情 |
| 3 | 阿甘正传 | 剧情/爱情 |
| 4 | 霸王别姬 | 剧情/爱情/同性 |
增加一列
df_mv['序号']=range(1,len(df_mv)+1)
df_mv.head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | 序号 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 | 1 |
| 1 | 1.0 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 | 2 |
| 2 | 2.0 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 | 3 |
| 3 | 3.0 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 | 4 |
| 4 | 4.0 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 | 5 |
删除一列
df_mv=df_mv.drop('序号',axis=1) ## axis = 1 代表列方向
df_mv.head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1.0 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 2.0 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 3.0 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4.0 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
通过标签选择数据
df.loc[[index],[column]]通过标签选择数据
df_mv.loc[[1,3,4],['名字','评分']]
| 名字 | 评分 | |
|---|---|---|
| 1 | 控方证人 | 9.5 |
| 3 | 阿甘正传 | 9.4 |
| 4 | 霸王别姬 | 9.4 |
df_mv.loc[1,'名字']
'控方证人'
条件选择
选取产地为美国的所有电音
df_mv[df_mv['产地']=='中国大陆'][:5]
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 4.0 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
| 21 | 21.0 | 大闹天宫 | 74881.0 | 动画/奇幻 | 中国大陆 | 1905-05-14 00:00:00 | 114 | 1961 | 9.2 | 上集 |
| 29 | 29.0 | 穹顶之下 | 51113.0 | 纪录片 | 中国大陆 | 2015-02-28 00:00:00 | 104 | 2015 | 9.2 | 中国大陆 |
| 38 | 38.0 | 茶馆 | 10678.0 | 剧情/历史 | 中国大陆 | 1905-06-04 00:00:00 | 118 | 1982 | 9.2 | 美国 |
| 45 | 45.0 | 山水情 | 10781.0 | 动画/短片 | 中国大陆 | 1905-06-10 00:00:00 | 19 | 1988 | 9.2 | 美国 |
选取产地为美国,且评分大于9的电影
df_mv[(df_mv.产地=='美国')&(df_mv.评分>9)].head()
或者--------------------------------------------
df[(df['产地']=='美国')&(df['评分']>9)].head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1.0 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 3 | 3.0 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 5 | 5.0 | 泰坦尼克号 | 157074.0 | 剧情/爱情/灾难 | 美国 | 2012-04-10 00:00:00 | 194 | 2012 | 9.4 | 中国大陆 |
| 6 | 6.0 | 辛德勒的名单 | 306904.0 | 剧情/历史/战争 | 美国 | 1993-11-30 00:00:00 | 195 | 1993 | 9.4 | 华盛顿首映 |
选取产地为美国或中国大陆,且评分大于9的电影
df_mv[((df_mv.产地=='美国')|(df_mv.产地=='中国大陆'))&(df_mv.评分>9)].head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 1.0 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 3 | 3.0 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 4.0 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
| 5 | 5.0 | 泰坦尼克号 | 157074.0 | 剧情/爱情/灾难 | 美国 | 2012-04-10 00:00:00 | 194 | 2012 | 9.4 | 中国大陆 |
3.1.3 数据清洗
缺失值处理
dropna:根据标签中的缺失值进行过滤,删除缺失值
fillna:对缺失值进行填充
isnull:返回一个布尔值对象,判断哪些值是缺失值
notnull:isnull的否定式
判断缺失值
df_mv[df_mv['名字'].isnull()].head()
或者-------------------------------------
df[df.名字.isnull()].head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 231 | 231.0 | NaN | 144.0 | 纪录片/音乐 | 韩国 | 2011-02-02 00:00:00 | 90 | 2011 | 9.7 | 美国 |
| 361 | 361.0 | NaN | 80.0 | 短片 | 其他 | 1905-05-17 00:00:00 | 4 | 1964 | 5.7 | 美国 |
| 369 | 369.0 | NaN | 5315.0 | 剧情 | 日本 | 2004-07-10 00:00:00 | 111 | 2004 | 7.5 | 日本 |
| 372 | 372.0 | NaN | 263.0 | 短片/音乐 | 英国 | 1998-06-30 00:00:00 | 34 | 1998 | 9.2 | 美国 |
| 374 | 374.0 | NaN | 47.0 | 短片 | 其他 | 1905-05-17 00:00:00 | 3 | 1964 | 6.7 | 美国 |
填充缺失值
填充字符类
df_mv[df_mv['名字'].isnull()].head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 231 | 231.0 | NaN | 144.0 | 纪录片/音乐 | 韩国 | 2011-02-02 00:00:00 | 90 | 2011 | 9.7 | 美国 |
| 361 | 361.0 | NaN | 80.0 | 短片 | 其他 | 1905-05-17 00:00:00 | 4 | 1964 | 5.7 | 美国 |
| 369 | 369.0 | NaN | 5315.0 | 剧情 | 日本 | 2004-07-10 00:00:00 | 111 | 2004 | 7.5 | 日本 |
| 372 | 372.0 | NaN | 263.0 | 短片/音乐 | 英国 | 1998-06-30 00:00:00 | 34 | 1998 | 9.2 | 美国 |
| 374 | 374.0 | NaN | 47.0 | 短片 | 其他 | 1905-05-17 00:00:00 | 3 | 1964 | 6.7 | 美国 |
df_mv['名字'].fillna('未知电影',inplace=True)
df_mv[df_mv['名字'].isnull()].head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
填充数值类
##添加一行,用于实验。此处设置评分为空nan
dit={'名字':'复仇者联盟3','投票人数':123456,'类型':'剧情/科幻','产地':'美国','上映时间':'2017-05-04 00:00:00','时长':142,'年代':2017,'评分':np.nan,'首映地点':'美国'}
s=pd.Series(dit)
s.name=38738
df_mv=df_mv.append(s)
##判断“评分”为空的
df_mv[df_mv['评分'].isnull()].head()
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 38738 | NaN | 复仇者联盟3 | 123456.0 | 剧情/科幻 | 美国 | 2017-05-04 00:00:00 | 142 | 2017 | NaN | 美国 |
##填充评分,此处填充 均值
df_mv['评分'].fillna(np.mean(df_mv['评分']),inplace=True)
df_mv[-1:]
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 38738 | NaN | 复仇者联盟3 | 123456.0 | 剧情/科幻 | 美国 | 2017-05-04 00:00:00 | 142 | 2017 | 6.935704 | 美国 |
删除缺失值
df.dropna(参数)
subset=[‘列名’]:删除该列为空的行
how=‘all’:删除全为空值的行或列
inplace=True:覆盖之前的数据
axis=0:选择行或列(=0,删除一行;=1,删除一列),默认为0
len(df_mv)
38739
df_mv1=df_mv.dropna()
len(df_mv1)
len(df_mv) ## 值未变,因为未设置inplace=True
38735
38739
异常值处理
异常值,即在数据集中存在不合理的值,又称离群点。比如年龄为-1,笔记本电脑重量为1吨等等,都属与异常值的范围。
对于异常值,一般来说数量都会很少,在不影响整体数据分布的情况下,我们直接删除就可以了。
df_mv[(df_mv.投票人数<0)|(df_mv['投票人数']%1!=0)]
| Unnamed: 0 | 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 19777 | 19777.0 | 皇家大贼 皇家大 | -80.00 | 剧情/犯罪 | 中国香港 | 1985-05-31 00:00:00 | 60 | 1985 | 6.3 | 美国 |
| 19786 | 19786.0 | 日本的垃圾去中国大陆 にっぽんの“ゴミ” 大陆へ渡る ~中国式リサイクル錬 | -80.00 | 纪录片 | 日本 | 1905-06-26 00:00:00 | 60 | 2004 | 7.9 | 美国 |
| 19791 | 19791.0 | 女教师 女教 | 8.30 | 剧情/犯罪 | 日本 | 1977-10-29 00:00:00 | 100 | 1977 | 6.6 | 日本 |
| 19797 | 19797.0 | 女教徒 | -118.00 | 剧情 | 法国 | 1966-05-06 00:00:00 | 135 | 1966 | 7.8 | 美国 |
| 19804 | 19804.0 | 女郎漫游仙境 ドレミファ娘の血は騒 | 5.90 | 喜剧/歌舞 | 日本 | 1985-11-03 00:00:00 | 80 | 1985 | 6.7 | 日本 |
| 19820 | 19820.0 | 女仆日记 | 12.87 | 剧情 | 法国 | 2015-04-01 00:00:00 | 96 | 2015 | 5.7 | 法国 |
| 38055 | 38055.0 | 逃出亚卡拉 | 12.87 | 剧情/动作/惊悚/犯罪 | 美国 | 1979-09-20 00:00:00 | 112 | 1979 | 7.8 | 美国 |
df.drop(df[(df.投票人数<0)|(df_mv['投票人数']%1!=0)].index,inplace= True)
或者
df=df[(df.投票人数>0)|(df_mv['投票人数']%1==0)]
3.1.4 数据保存
数据处理之后,然后将数据重新保存
df_mv.to_excel('movie_data.xlsx') ## 未指定目录地址,默认存到当前目录下
3.2 Pandas操作
import pandas as pd
import numpy as np
以豆瓣电影为例
df=pd.read_excel('movie_data.xlsx')
df=df.drop('Unnamed: 0',axis=1)
df.head()
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795.0 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 控方证人 | 42995.0 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 美丽人生 | 327855.0 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 阿甘正传 | 580897.0 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 霸王别姬 | 478523.0 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
3.2.1 数据格式转换
查看格式
df['投票人数'].dtype
dtype('float64')
格式转化
df['投票人数']=df['投票人数'].astype('int')
df['投票人数'].dtype
dtype('int32')
将年代格式转化为整型
df['年代'].dtype
dtype('O')
df['年代']=df['年代'].astype('int')
------------------------------------------------------------------------
报错
---
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_21876\765820658.py in <module>
----> 1 df['年代']=df['年代'].astype('int')D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py in astype(self, dtype, copy, errors)5910 else:5911 # else, only a single dtype is given
-> 5912 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors)5913 return self._constructor(new_data).__finalize__(self, method="astype")5914 D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in astype(self, dtype, copy, errors)417 418 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T:
--> 419 return self.apply("astype", dtype=dtype, copy=copy, errors=errors)420 421 def convert(D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, align_keys, ignore_failures, **kwargs)302 applied = b.apply(f, **kwargs)303 else:
--> 304 applied = getattr(b, f)(**kwargs)305 except (TypeError, NotImplementedError):306 if not ignore_failures:D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\blocks.py in astype(self, dtype, copy, errors)578 values = self.values579
--> 580 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors)581 582 new_values = maybe_coerce_values(new_values)D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_array_safe(values, dtype, copy, errors)1290 1291 try:
-> 1292 new_values = astype_array(values, dtype, copy=copy)1293 except (ValueError, TypeError):1294 # e.g. astype_nansafe can fail on object-dtype of stringsD:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_array(values, dtype, copy)1235 1236 else:
-> 1237 values = astype_nansafe(values, dtype, copy=copy)1238 1239 # in pandas we don't store numpy str dtypes, so convert to objectD:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_nansafe(arr, dtype, copy, skipna)1152 # work around NumPy brokenness, #19871153 if np.issubdtype(dtype.type, np.integer):
-> 1154 return lib.astype_intsafe(arr, dtype)1155 1156 # if we have a datetime/timedelta array of objectsD:\ProgramData\Anaconda3\lib\site-packages\pandas\_libs\lib.pyx in pandas._libs.lib.astype_intsafe()ValueError: invalid literal for int() with base 10: '2008\u200e'
##年代中有异常值 '2008\u200e',无法正常转化
df[df.年代=='2008\u200e']
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 15205 | 狂蟒惊魂 | 544 | 恐怖 | 中国大陆 | 2008-04-08 00:00:00 | 93 | 2008 | 2.7 | 美国 |
df[df.年代=='2008\u200e']['年代'].values ## 从整行返回的结果并不能直接看出异常,所以调用valus直接查看
array(['2008\u200e'], dtype=object)
df.loc[15205,'年代']=2008
df.loc[15205]
名字 狂蟒惊魂
投票人数 544
类型 恐怖
产地 中国大陆
上映时间 2008-04-08 00:00:00
时长 93
年代 2008
评分 2.7
首映地点 美国
Name: 15205, dtype: object
df['年代']=df['年代'].astype('int')
df['年代'][:5]
0 1994
1 1957
2 1997
3 1994
4 1993
Name: 年代, dtype: int32
将时长转化为整数格式
df['时长']=df['时长'].astype('int')
---------------------------------------------------------------------------
报错
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_21876\3003640607.py in <module>
----> 1 df['时长']=df['时长'].astype('int')D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py in astype(self, dtype, copy, errors)5910 else:5911 # else, only a single dtype is given
-> 5912 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors)5913 return self._constructor(new_data).__finalize__(self, method="astype")5914 D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in astype(self, dtype, copy, errors)417 418 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T:
--> 419 return self.apply("astype", dtype=dtype, copy=copy, errors=errors)420 421 def convert(D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, align_keys, ignore_failures, **kwargs)302 applied = b.apply(f, **kwargs)303 else:
--> 304 applied = getattr(b, f)(**kwargs)305 except (TypeError, NotImplementedError):306 if not ignore_failures:D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\blocks.py in astype(self, dtype, copy, errors)578 values = self.values579
--> 580 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors)581 582 new_values = maybe_coerce_values(new_values)D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_array_safe(values, dtype, copy, errors)1290 1291 try:
-> 1292 new_values = astype_array(values, dtype, copy=copy)1293 except (ValueError, TypeError):1294 # e.g. astype_nansafe can fail on object-dtype of stringsD:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_array(values, dtype, copy)1235 1236 else:
-> 1237 values = astype_nansafe(values, dtype, copy=copy)1238 1239 # in pandas we don't store numpy str dtypes, so convert to objectD:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_nansafe(arr, dtype, copy, skipna)1152 # work around NumPy brokenness, #19871153 if np.issubdtype(dtype.type, np.integer):
-> 1154 return lib.astype_intsafe(arr, dtype)1155 1156 # if we have a datetime/timedelta array of objectsD:\ProgramData\Anaconda3\lib\site-packages\pandas\_libs\lib.pyx in pandas._libs.lib.astype_intsafe()ValueError: invalid literal for int() with base 10: '8U'
df[df.时长=='8U']
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 31644 | 一个被隔绝的世界 | 46 | 纪录片/短片 | 瑞典 | 2001-10-25 00:00:00 | 8U | 1948 | 7.8 | 美国 |
df.drop(31644,inplace=True)
df['时长']=df['时长'].astype('int')
---------------------------------------------------------------------------
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_21876\3003640607.py in <module>
----> 1 df['时长']=df['时长'].astype('int')D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py in astype(self, dtype, copy, errors)5910 else:5911 # else, only a single dtype is given
-> 5912 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors)5913 return self._constructor(new_data).__finalize__(self, method="astype")5914 D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in astype(self, dtype, copy, errors)417 418 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T:
--> 419 return self.apply("astype", dtype=dtype, copy=copy, errors=errors)420 421 def convert(D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, align_keys, ignore_failures, **kwargs)302 applied = b.apply(f, **kwargs)303 else:
--> 304 applied = getattr(b, f)(**kwargs)305 except (TypeError, NotImplementedError):306 if not ignore_failures:D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\blocks.py in astype(self, dtype, copy, errors)578 values = self.values579
--> 580 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors)581 582 new_values = maybe_coerce_values(new_values)D:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_array_safe(values, dtype, copy, errors)1290 1291 try:
-> 1292 new_values = astype_array(values, dtype, copy=copy)1293 except (ValueError, TypeError):1294 # e.g. astype_nansafe can fail on object-dtype of stringsD:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_array(values, dtype, copy)1235 1236 else:
-> 1237 values = astype_nansafe(values, dtype, copy=copy)1238 1239 # in pandas we don't store numpy str dtypes, so convert to objectD:\ProgramData\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_nansafe(arr, dtype, copy, skipna)1152 # work around NumPy brokenness, #19871153 if np.issubdtype(dtype.type, np.integer):
-> 1154 return lib.astype_intsafe(arr, dtype)1155 1156 # if we have a datetime/timedelta array of objectsD:\ProgramData\Anaconda3\lib\site-packages\pandas\_libs\lib.pyx in pandas._libs.lib.astype_intsafe()ValueError: invalid literal for int() with base 10: '12J'
df[df.时长=='12J']
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 32949 | 渔业危机 | 41 | 纪录片 | 英国 | 2009-06-19 00:00:00 | 12J | 2008 | 8.2 | USA |
df.drop(32949,inplace=True)
df['时长']=df['时长'].astype('int')
df['时长'][:5]
0 142
1 116
2 116
3 142
4 171
Name: 时长, dtype: int32
3.1.2 排序
单值排序
默认排序
df[:10] ##根据index进行排序
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 1 | 控方证人 | 42995 | 剧情/悬疑/犯罪 | 美国 | 1957-12-17 00:00:00 | 116 | 1957 | 9.5 | 美国 |
| 2 | 美丽人生 | 327855 | 剧情/喜剧/爱情 | 意大利 | 1997-12-20 00:00:00 | 116 | 1997 | 9.5 | 意大利 |
| 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 4 | 霸王别姬 | 478523 | 剧情/爱情/同性 | 中国大陆 | 1993-01-01 00:00:00 | 171 | 1993 | 9.4 | 香港 |
| 5 | 泰坦尼克号 | 157074 | 剧情/爱情/灾难 | 美国 | 2012-04-10 00:00:00 | 194 | 2012 | 9.4 | 中国大陆 |
| 6 | 辛德勒的名单 | 306904 | 剧情/历史/战争 | 美国 | 1993-11-30 00:00:00 | 195 | 1993 | 9.4 | 华盛顿首映 |
| 7 | 新世纪福音战士剧场版:Air/真心为你 新世紀エヴァンゲリオン劇場版 Ai | 24355 | 剧情/动作/科幻/动画/奇幻 | 日本 | 1997-07-19 00:00:00 | 87 | 1997 | 9.4 | 日本 |
| 8 | 银魂完结篇:直到永远的万事屋 劇場版 銀魂 完結篇 万事屋よ | 21513 | 剧情/动画 | 日本 | 2013-07-06 00:00:00 | 110 | 2013 | 9.4 | 日本 |
| 9 | 这个杀手不太冷 | 662552 | 剧情/动作/犯罪 | 法国 | 1994-09-14 00:00:00 | 133 | 1994 | 9.4 | 法国 |
按照投票人数进行排序
## 默认升序排列
df.sort_values(by='投票人数')[:5]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 19797 | 女教徒 | -118 | 剧情 | 法国 | 1966-05-06 00:00:00 | 135 | 1966 | 7.8 | 美国 |
| 19777 | 皇家大贼 皇家大 | -80 | 剧情/犯罪 | 中国香港 | 1985-05-31 00:00:00 | 60 | 1985 | 6.3 | 美国 |
| 19786 | 日本的垃圾去中国大陆 にっぽんの“ゴミ” 大陆へ渡る ~中国式リサイクル錬 | -80 | 纪录片 | 日本 | 1905-06-26 00:00:00 | 60 | 2004 | 7.9 | 美国 |
| 19804 | 女郎漫游仙境 ドレミファ娘の血は騒 | 5 | 喜剧/歌舞 | 日本 | 1985-11-03 00:00:00 | 80 | 1985 | 6.7 | 日本 |
| 19791 | 女教师 女教 | 8 | 剧情/犯罪 | 日本 | 1977-10-29 00:00:00 | 100 | 1977 | 6.6 | 日本 |
## 降序排列
df.sort_values(by='投票人数',ascending=False)[:5]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 肖申克的救赎 | 692795 | 剧情/犯罪 | 美国 | 1994-09-10 00:00:00 | 142 | 1994 | 9.6 | 多伦多电影节 |
| 9 | 这个杀手不太冷 | 662552 | 剧情/动作/犯罪 | 法国 | 1994-09-14 00:00:00 | 133 | 1994 | 9.4 | 法国 |
| 22 | 盗梦空间 | 642134 | 剧情/动作/科幻/悬疑/冒险 | 美国 | 2010-09-01 00:00:00 | 148 | 2010 | 9.2 | 中国大陆 |
| 3 | 阿甘正传 | 580897 | 剧情/爱情 | 美国 | 1994-06-23 00:00:00 | 142 | 1994 | 9.4 | 洛杉矶首映 |
| 99 | 三傻大闹宝莱坞 | 549808 | 剧情/喜剧/爱情/歌舞 | 印度 | 2011-12-08 00:00:00 | 171 | 2009 | 9.1 | 中国大陆 |
按照年代进行排序
df.sort_values(by='年代')[:5]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 14048 | 利兹大桥 | 126 | 短片 | 英国 | 1888-10 | 60 | 1888 | 7.2 | 美国 |
| 1700 | 朗德海花园场景 | 650 | 短片 | 英国 | 1888-10-14 | 60 | 1888 | 8.7 | 美国 |
| 26170 | 恶作剧 | 51 | 短片 | 美国 | 1905-03-04 00:00:00 | 60 | 1890 | 4.8 | 美国 |
| 10627 | 可怜的比埃洛 | 176 | 喜剧/爱情/动画/短片 | 法国 | 1892-10-28 | 60 | 1892 | 7.5 | 法国 |
| 14455 | 迪克森实验音膜 | 121 | 短片 | 美国 | 1905-03-08 00:00:00 | 60 | 1894 | 7.2 | 美国 |
多个值排序
先按照评分排序,再按照投票人数排序(皆为降序排序)
df.sort_values(by=['评分','投票人数'],ascending=False)[:5]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 9278 | 平安结祈 平安結 | 208 | 音乐 | 日本 | 2012-02-24 00:00:00 | 60 | 2012 | 9.9 | 美国 |
| 13882 | 武之舞 | 128 | 纪录片 | 中国大陆 | 1997-02-01 00:00:00 | 60 | 34943 | 9.9 | 美国 |
| 1110 | 未知电影 | 76 | 科幻/纪录片 | 美国 | 1905-06-23 00:00:00 | 75 | 2001 | 9.9 | 美国 |
| 23559 | 未作回答的问题:伯恩斯坦哈佛六讲 | 61 | 纪录片 | 美国 | 1905-05-29 00:00:00 | 60 | 1973 | 9.9 | 美国 |
| 35470 | 未知电影 | 46 | 纪录片/音乐 | 韩国 | 2013-10-31 00:00:00 | 90 | 2013 | 9.9 | 韩国 |
| —————————————————————————————————————————————————————————————————————————————————————— | |||||||||
| 先按照评分排序(降序),再按照投票人数排序(升序) |
df.sort_values(by=['评分','投票人数'],ascending=[False,True])[:5]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 25270 | 索科洛夫:巴黎现场 | 43 | 音乐 | 法国 | 2002-11-04 00:00:00 | 127 | 2002 | 9.9 | 美国 |
| 35465 | 未知电影 | 46 | 纪录片/音乐 | 韩国 | 2013-10-31 00:00:00 | 90 | 2013 | 9.9 | 韩国 |
| 23556 | 未作回答的问题:伯恩斯坦哈佛六讲 | 61 | 纪录片 | 美国 | 1905-05-29 00:00:00 | 60 | 1973 | 9.9 | 美国 |
| 1110 | 未知电影 | 76 | 科幻/纪录片 | 美国 | 1905-06-23 00:00:00 | 75 | 2001 | 9.9 | 美国 |
| 9278 | 平安结祈 平安結 | 208 | 音乐 | 日本 | 2012-02-24 00:00:00 | 60 | 2012 | 9.9 | 美国 |
3.1.3基本统计分析
描述性统计
dataframe.describe():对dataframe中的数值数据进行描述性统计
df.describe()
| 投票人数 | 时长 | 年代 | 评分 | |
|---|---|---|---|---|
| count | 38737.000000 | 38737.000000 | 38737.000000 | 38737.000000 |
| mean | 6189.178098 | 89.053128 | 1998.789091 | 6.935649 |
| std | 26150.607777 | 83.333528 | 253.195493 | 1.270094 |
| min | -118.000000 | 1.000000 | 1888.000000 | 2.000000 |
| 25% | 98.000000 | 60.000000 | 1990.000000 | 6.300000 |
| 50% | 341.000000 | 92.000000 | 2005.000000 | 7.100000 |
| 75% | 1741.000000 | 106.000000 | 2010.000000 | 7.800000 |
| max | 692795.000000 | 11500.000000 | 39180.000000 | 9.900000 |
通过描述性统计,可以发现一些异常值,很多异常值往往是需要我们逐步去发现的。
df[df.年代>2023]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 13882 | 武之舞 | 128 | 纪录片 | 中国大陆 | 1997-02-01 00:00:00 | 60 | 34943 | 9.9 | 美国 |
| 17115 | 妈妈回来吧-中国打工村的孩子 | 49 | 纪录片 | 日本 | 2007-04-08 00:00:00 | 109 | 39180 | 8.9 | 美国 |
df[df.时长>1000]
| 名字 | 投票人数 | 类型 | 产地 | 上映时间 | 时长 | 年代 | 评分 | 首映地点 | |
|---|---|---|---|---|---|---|---|---|---|
| 19690 | 怒海余生 | 54 | 剧情/家庭/冒险 | 美国 | 1937-09-01 00:00:00 | 11500 | 1937 | 7.9 | 美国 |
| 38730 | 喧闹村的孩子们 | 36 | 家庭 | 瑞典 | 1986-12-06 00:00:00 | 9200 | 1986 | 8.7 | 瑞典 |
df.drop(df[df.年代>2023].index,inplace=True)
df.drop(df[df.时长>1000].index,inplace=True)
df.describe()
| 投票人数 | 时长 | 年代 | 评分 | |
|---|---|---|---|---|
| count | 38730.000000 | 38730.000000 | 38730.000000 | 38730.000000 |
| mean | 6190.297005 | 88.523806 | 1996.981461 | 6.935420 |
| std | 26152.838459 | 37.946156 | 19.934657 | 1.270018 |
| min | 5.000000 | 1.000000 | 1888.000000 | 2.000000 |
| 25% | 98.000000 | 60.000000 | 1990.000000 | 6.300000 |
| 50% | 341.000000 | 92.000000 | 2005.000000 | 7.100000 |
| 75% | 1741.000000 | 106.000000 | 2010.000000 | 7.800000 |
| max | 692795.000000 | 958.000000 | 2017.000000 | 9.900000 |
##删除 行 后,重新分配 索引index
df.index=range(len(df))
最值
df['投票人数'].max()
692795
df['投票人数'].min()
5
均值和中值
df['投票人数'].mean()
6190.297004905758
df['投票人数'].median()
341.0
方差和标准差
df['评分'].var()
1.6129445680877672
df['评分'].std()
1.2700175463700363
求和
df['投票人数'].sum()
239750203
相关系数、协方差
## 相关性
df[['投票人数','评分']].corr()
| 投票人数 | 评分 | |
|---|---|---|
| 投票人数 | 1.000000 | 0.122925 |
| 评分 | 0.122925 | 1.000000 |
## 协方差
df[['投票人数','评分']].cov()
| 投票人数 | 评分 | |
|---|---|---|
| 投票人数 | 6.839710e+08 | 4082.897271 |
| 评分 | 4.082897e+03 | 1.612945 |
计数
len(df)
len(df[df.产地=='美国'])
df.count()
数据替换
len(df)
38166
## 某列的所有取值
df['产地'].unique()
array(['美国', '意大利', '中国大陆', '日本', '法国', '英国', '韩国', '中国香港', '阿根廷', '德国','印度', '其他', '加拿大', '波兰', '泰国', '澳大利亚', '西班牙', '俄罗斯', '中国台湾', '荷兰','丹麦', '比利时', 'USA', '苏联', '墨西哥', '巴西', '瑞典', '西德'], dtype=object)
len(df['产地'].unique())
28
产地中包含了一些重复数据,比如美国和USA,德国和西德,俄罗斯和苏联
我们可以通过数据替换的方法将这些相同的国家的电影数据合并一下
df['产地'].replace('USA','美国',inplace=True) ## USA->美国
df['产地'].replace(['西德','苏联'],['德国','俄罗斯'],inplace=True) ## 西德->德国,苏联->俄罗斯
len(df['产地'].unique())
25
计算每一年代电影的数量
df['年代'].value_counts()[:10] ## 已经自动排序
2012 2018
2013 1977
2008 1926
2014 1867
2010 1863
2011 1845
2009 1837
2007 1685
2015 1570
2006 1488
Name: 年代, dtype: int64
电影产出前5位的国家或地区
df['产地'].value_counts()[:5]
美国 11979
日本 5051
中国大陆 3802
中国香港 2851
法国 2816
Name: 产地, dtype: int64
df.to_excel('movie_data2.xlsx')
3.1.4 数据透视
Pandas提供了一个数据透视表功能,名为pivot_table。
使用pivot_table的一个挑战是,你需要确保你理解你的数据,并清楚的知道你通过透视表解决了什么问题,虽然pivot_table看起来知识一个简单的函数,但是它能够快速的对数据进行强大的分析。
基础形式
## 前面在未设置查看行数时,中间数据是用...代替,下面代码可设置显示长度
pd.set_option('max_columns',100) ##设置显示的最大列
pd.set_option('max_rows',500) ##设置显示的最大行
pd.pivot_table(df,index=['年代']) ## 未设置其他参数,默认均值计算
| 投票人数 | 时长 | 评分 | |
|---|---|---|---|
| 年代 | |||
| 1888 | 388.000000 | 60.000000 | 7.950000 |
| 1890 | 51.000000 | 60.000000 | 4.800000 |
| 1892 | 176.000000 | 60.000000 | 7.500000 |
| 1894 | 112.666667 | 60.000000 | 6.633333 |
| 1895 | 959.875000 | 60.000000 | 7.575000 |
| 1896 | 984.250000 | 60.000000 | 7.037500 |
| 1897 | 67.000000 | 60.000000 | 6.633333 |
| 1898 | 578.500000 | 60.000000 | 7.450000 |
| 1899 | 71.000000 | 9.500000 | 6.900000 |
| 1900 | 175.285714 | 36.714286 | 7.228571 |
| 1901 | 164.500000 | 47.250000 | 7.250000 |
| 1902 | 1934.166667 | 34.666667 | 7.483333 |
| 1903 | 295.625000 | 29.625000 | 6.968750 |
| 1904 | 195.875000 | 41.250000 | 7.212500 |
| 1905 | 332.600000 | 43.800000 | 6.820000 |
| 1906 | 189.857143 | 30.571429 | 7.342857 |
| 1907 | 213.600000 | 31.800000 | 7.020000 |
| 1908 | 258.833333 | 34.166667 | 7.150000 |
| 1909 | 58.600000 | 20.600000 | 7.560000 |
| 1910 | 105.200000 | 41.800000 | 6.940000 |
| 1911 | 240.000000 | 25.750000 | 7.375000 |
| 1912 | 152.200000 | 16.400000 | 7.920000 |
| 1913 | 66.125000 | 57.750000 | 6.862500 |
| 1914 | 104.923077 | 25.923077 | 6.473077 |
| 1915 | 314.900000 | 56.800000 | 7.260000 |
| 1916 | 613.666667 | 43.833333 | 7.758333 |
| 1917 | 124.416667 | 31.333333 | 7.075000 |
| 1918 | 357.083333 | 35.166667 | 7.200000 |
| 1919 | 179.850000 | 62.400000 | 7.490000 |
| 1920 | 636.500000 | 59.357143 | 7.492857 |
| 1921 | 729.818182 | 57.363636 | 7.750000 |
| 1922 | 767.090909 | 66.363636 | 7.804545 |
| 1923 | 426.000000 | 74.055556 | 7.883333 |
| 1924 | 371.785714 | 81.178571 | 8.053571 |
| 1925 | 1104.280000 | 84.440000 | 7.788000 |
| 1926 | 443.608696 | 80.304348 | 7.773913 |
| 1927 | 695.275862 | 87.241379 | 7.751724 |
| 1928 | 404.825000 | 71.775000 | 7.945000 |
| 1929 | 740.542857 | 69.371429 | 7.440000 |
| 1930 | 555.080000 | 74.160000 | 7.360000 |
| 1931 | 1468.666667 | 78.523810 | 7.483333 |
| 1932 | 600.081081 | 77.540541 | 7.294595 |
| 1933 | 729.720000 | 76.360000 | 7.430000 |
| 1934 | 776.490196 | 83.196078 | 7.519608 |
| 1935 | 887.695652 | 73.673913 | 7.515217 |
| 1936 | 1465.466667 | 76.266667 | 7.635000 |
| 1937 | 1580.224490 | 85.510204 | 7.575510 |
| 1938 | 552.000000 | 85.973684 | 7.736842 |
| 1939 | 5911.857143 | 97.387755 | 7.520408 |
| 1940 | 5548.743590 | 92.820513 | 7.571795 |
| 1941 | 1552.808511 | 89.127660 | 7.427660 |
| 1942 | 2607.754717 | 78.264151 | 7.554717 |
| 1943 | 742.842105 | 78.456140 | 7.615789 |
| 1944 | 1007.370370 | 81.925926 | 7.538889 |
| 1945 | 989.020408 | 86.959184 | 7.673469 |
| 1946 | 1034.457627 | 85.016949 | 7.606780 |
| 1947 | 439.400000 | 87.120000 | 7.453333 |
| 1948 | 1186.505747 | 88.206897 | 7.657471 |
| 1949 | 641.685393 | 81.988764 | 7.646067 |
| 1950 | 2235.026316 | 80.157895 | 7.655263 |
| 1951 | 956.101266 | 85.632911 | 7.636709 |
| 1952 | 1473.540230 | 81.528736 | 7.743678 |
| 1953 | 4786.113636 | 84.170455 | 7.567045 |
| 1954 | 2180.245098 | 85.549020 | 7.702941 |
| 1955 | 1983.739130 | 83.669565 | 7.580000 |
| 1956 | 1054.605442 | 76.408163 | 7.600000 |
| 1957 | 2973.579439 | 87.355140 | 7.652336 |
| 1958 | 886.196721 | 82.975410 | 7.536885 |
| 1959 | 1725.070312 | 90.070312 | 7.571875 |
| 1960 | 1446.274809 | 101.312977 | 7.569466 |
| 1961 | 3186.833333 | 98.215686 | 7.744118 |
| 1962 | 1972.118881 | 91.615385 | 7.704895 |
| 1963 | 1184.027972 | 92.020979 | 7.536364 |
| 1964 | 1107.763736 | 89.714286 | 7.523077 |
| 1965 | 1988.184049 | 90.478528 | 7.576074 |
| 1966 | 1319.525140 | 89.486034 | 7.518994 |
| 1967 | 1237.289773 | 91.590909 | 7.484659 |
| 1968 | 1096.220930 | 91.744186 | 7.317442 |
| 1969 | 593.111111 | 98.666667 | 7.370048 |
| 1970 | 676.789474 | 96.973684 | 7.291053 |
| 1971 | 1368.506849 | 96.315068 | 7.155708 |
| 1972 | 2299.096618 | 96.289855 | 7.268116 |
| 1973 | 800.103286 | 94.882629 | 7.250235 |
| 1974 | 1685.789238 | 95.318386 | 7.062332 |
| 1975 | 2222.739796 | 97.566327 | 7.071429 |
| 1976 | 1340.618026 | 95.055794 | 7.107725 |
| 1977 | 957.127273 | 98.031818 | 7.148182 |
| 1978 | 1001.820896 | 94.467662 | 7.096517 |
| 1979 | 1878.621145 | 96.000000 | 7.296035 |
| 1980 | 2407.683036 | 94.178571 | 7.186607 |
| 1981 | 1609.062044 | 93.321168 | 7.157299 |
| 1982 | 2142.729323 | 91.984962 | 7.297368 |
| 1983 | 1541.191336 | 92.169675 | 7.310108 |
| 1984 | 2667.173469 | 90.918367 | 7.375170 |
| 1985 | 1588.096573 | 93.616822 | 7.278505 |
| 1986 | 2828.506173 | 89.145062 | 7.256790 |
| 1987 | 3128.775510 | 88.938776 | 7.284548 |
| 1988 | 4800.227621 | 88.859335 | 7.265729 |
| 1989 | 2994.417303 | 88.458015 | 7.210687 |
| 1990 | 4965.587786 | 91.882952 | 7.149109 |
| 1991 | 4685.819512 | 93.370732 | 7.154634 |
| 1992 | 5486.133333 | 92.572414 | 7.223678 |
| 1993 | 8117.759637 | 95.269841 | 7.195692 |
| 1994 | 11479.255061 | 91.344130 | 7.262348 |
| 1995 | 8132.605317 | 94.441718 | 7.289366 |
| 1996 | 5095.883946 | 95.243714 | 7.258801 |
| 1997 | 8243.938547 | 94.970205 | 7.330168 |
| 1998 | 7431.790295 | 91.131716 | 7.238302 |
| 1999 | 7137.049600 | 92.457600 | 7.188000 |
| 2000 | 5907.770178 | 92.191518 | 7.134063 |
| 2001 | 8489.757246 | 90.958937 | 7.110145 |
| 2002 | 6552.593333 | 91.584444 | 7.069778 |
| 2003 | 7891.964248 | 90.558360 | 7.137750 |
| 2004 | 8587.632599 | 90.424670 | 7.031366 |
| 2005 | 6506.110847 | 92.080760 | 7.030008 |
| 2006 | 7278.260726 | 90.144554 | 6.914719 |
| 2007 | 6253.837522 | 86.628288 | 6.875102 |
| 2008 | 6750.996943 | 85.144167 | 6.910647 |
| 2009 | 8716.364662 | 86.384533 | 6.750000 |
| 2010 | 9576.387593 | 83.434252 | 6.770361 |
| 2011 | 8763.110397 | 84.125938 | 6.577010 |
| 2012 | 7082.787463 | 85.099902 | 6.458374 |
| 2013 | 7603.723138 | 84.902049 | 6.392604 |
| 2014 | 7723.302597 | 85.997880 | 6.259777 |
| 2015 | 7841.408291 | 89.863693 | 6.141960 |
| 2016 | 7176.019380 | 91.329457 | 5.868217 |
| 2017 | 123456.000000 | 142.000000 | 6.935704 |
多个索引 index=[‘’,‘’]
实际上,大多数的pivot_table参数可以通过列表获取多个值
pd.set_option('max_columns',100)
pd.set_option('max_rows',500)
pd.pivot_table(df,index=['年代','产地'])
| 投票人数 | 时长 | 评分 | ||
|---|---|---|---|---|
| 年代 | 产地 | |||
| 1888 | 英国 | 388.000000 | 60.000000 | 7.950000 |
| 1890 | 美国 | 51.000000 | 60.000000 | 4.800000 |
| 1892 | 法国 | 176.000000 | 60.000000 | 7.500000 |
| 1894 | 法国 | 148.000000 | 60.000000 | 7.000000 |
| 美国 | 95.000000 | 60.000000 | 6.450000 | |
| … | … | … | … | … |
| 2016 | 法国 | 39.000000 | 93.250000 | 7.475000 |
| 美国 | 10563.848485 | 91.984848 | 6.540909 | |
| 英国 | 14607.272727 | 85.545455 | 7.200000 | |
| 韩国 | 1739.850000 | 106.100000 | 5.730000 | |
| 2017 | 美国 | 123456.000000 | 142.000000 | 6.935704 |
1511 rows × 3 columns
指定需要统计汇总的数据 values
pd.pivot_table(df,index=['年代','产地'],values=['评分'])
| 评分 | ||
|---|---|---|
| 年代 | 产地 | |
| 1888 | 英国 | 7.950000 |
| 1890 | 美国 | 4.800000 |
| 1892 | 法国 | 7.500000 |
| 1894 | 法国 | 7.000000 |
| 美国 | 6.450000 | |
| … | … | … |
| 2016 | 法国 | 7.475000 |
| 美国 | 6.540909 | |
| 英国 | 7.200000 | |
| 韩国 | 5.730000 | |
| 2017 | 美国 | 6.935704 |
1511 rows × 1 columns
指定函数 aggfunc
pd.pivot_table(df,index=['年代','产地'],values=['投票人数'],aggfunc=np.sum)
| 投票人数 | ||
|---|---|---|
| 年代 | 产地 | |
| 1888 | 英国 | 776 |
| 1890 | 美国 | 51 |
| 1892 | 法国 | 176 |
| 1894 | 法国 | 148 |
| 美国 | 190 | |
| … | … | … |
| 2016 | 法国 | 156 |
| 美国 | 697214 | |
| 英国 | 160680 | |
| 韩国 | 34797 | |
| 2017 | 美国 | 123456 |
1511 rows × 1 columns
通过将“投票人数”和“评分”列进行对应分组,对“产地”实现数据聚合和总结
pd.pivot_table(df,index=['产地'],values=['投票人数','评分'],aggfunc=[np.sum,np.mean])
| sum | mean | |||
|---|---|---|---|---|
| 投票人数 | 评分 | 投票人数 | 评分 | |
| 产地 | ||||
| 中国台湾 | 5237466 | 4367.200000 | 8474.864078 | 7.066667 |
| 中国大陆 | 41435313 | 23058.000000 | 10898.293793 | 6.064703 |
| 中国香港 | 23285389 | 18457.700000 | 8167.446159 | 6.474114 |
| 丹麦 | 394784 | 1434.700000 | 1993.858586 | 7.245960 |
| 俄罗斯 | 3167110 | 11031.900000 | 2098.813784 | 7.310736 |
| 其他 | 3054119 | 13895.900000 | 1590.686979 | 7.237448 |
| 加拿大 | 1384765 | 4868.400000 | 1915.304288 | 6.733610 |
| 印度 | 1146271 | 2453.400000 | 3210.843137 | 6.872269 |
| 墨西哥 | 139613 | 843.400000 | 1173.218487 | 7.087395 |
| 巴西 | 357136 | 733.500000 | 3536.000000 | 7.262376 |
| 意大利 | 2502215 | 5377.300000 | 3340.740988 | 7.179306 |
| 日本 | 18000667 | 36339.300000 | 3563.782815 | 7.194476 |
| 比利时 | 170987 | 1003.300000 | 1230.122302 | 7.217986 |
| 法国 | 10213966 | 20384.700000 | 3627.118608 | 7.238885 |
| 波兰 | 159577 | 1347.000000 | 881.640884 | 7.441989 |
| 泰国 | 1564881 | 1796.100000 | 5322.724490 | 6.109184 |
| 澳大利亚 | 1415713 | 2093.400000 | 4719.043333 | 6.978000 |
| 瑞典 | 290077 | 1423.300000 | 1510.817708 | 7.413021 |
| 美国 | 101929672 | 83216.435704 | 8509.030136 | 6.946860 |
| 英国 | 13249562 | 20789.400000 | 4797.089790 | 7.526937 |
| 荷兰 | 144836 | 1114.500000 | 934.425806 | 7.190323 |
| 西班牙 | 1486733 | 3139.900000 | 3326.024609 | 7.024385 |
| 阿根廷 | 258271 | 843.700000 | 2226.474138 | 7.273276 |
| 韩国 | 8761080 | 8596.400000 | 6484.885270 | 6.362990 |
非数值处理 fill_value
非数值(NaN)难以处理,如果想移除他们,可以使用 fill_value 将其设置为0
pd.pivot_table(df,index=['产地'],aggfunc=[np.sum,np.mean],fill_value=0)
| sum | mean | |||||||
|---|---|---|---|---|---|---|---|---|
| 年代 | 投票人数 | 时长 | 评分 | 年代 | 投票人数 | 时长 | 评分 | |
| 产地 | ||||||||
| 中国台湾 | 1235388 | 5237466 | 53925 | 4367.200000 | 1999.009709 | 8474.864078 | 87.257282 | 7.066667 |
| 中国大陆 | 7621488 | 41435313 | 309608 | 23058.000000 | 2004.599684 | 10898.293793 | 81.432930 | 6.064703 |
| 中国香港 | 5676627 | 23285389 | 252431 | 18457.700000 | 1991.100316 | 8167.446159 | 88.541214 | 6.474114 |
| 丹麦 | 395820 | 394784 | 17444 | 1434.700000 | 1999.090909 | 1993.858586 | 88.101010 | 7.245960 |
| 俄罗斯 | 3006734 | 3167110 | 140761 | 11031.900000 | 1992.534129 | 2098.813784 | 93.280981 | 7.310736 |
| 其他 | 3837588 | 3054119 | 167168 | 13895.900000 | 1998.743750 | 1590.686979 | 87.066667 | 7.237448 |
| 加拿大 | 1447780 | 1384765 | 57919 | 4868.400000 | 2002.461964 | 1915.304288 | 80.109267 | 6.733610 |
| 印度 | 716133 | 1146271 | 43203 | 2453.400000 | 2005.974790 | 3210.843137 | 121.016807 | 6.872269 |
| 墨西哥 | 237145 | 139613 | 10929 | 843.400000 | 1992.815126 | 1173.218487 | 91.840336 | 7.087395 |
| 巴西 | 201987 | 357136 | 8869 | 733.500000 | 1999.871287 | 3536.000000 | 87.811881 | 7.262376 |
| 意大利 | 1487142 | 2502215 | 77902 | 5377.300000 | 1985.503338 | 3340.740988 | 104.008011 | 7.179306 |
| 日本 | 10101505 | 18000667 | 427863 | 36339.300000 | 1999.902000 | 3563.782815 | 84.708573 | 7.194476 |
| 比利时 | 277930 | 170987 | 11447 | 1003.300000 | 1999.496403 | 1230.122302 | 82.352518 | 7.217986 |
| 法国 | 5608811 | 10213966 | 253169 | 20384.700000 | 1991.765270 | 3627.118608 | 89.903764 | 7.238885 |
| 波兰 | 359652 | 159577 | 14613 | 1347.000000 | 1987.027624 | 881.640884 | 80.734807 | 7.441989 |
| 泰国 | 590684 | 1564881 | 26002 | 1796.100000 | 2009.129252 | 5322.724490 | 88.442177 | 6.109184 |
| 澳大利亚 | 600896 | 1415713 | 25549 | 2093.400000 | 2002.986667 | 4719.043333 | 85.163333 | 6.978000 |
| 瑞典 | 381491 | 290077 | 17898 | 1423.300000 | 1986.932292 | 1510.817708 | 93.218750 | 7.413021 |
| 美国 | 23892986 | 101929672 | 1070310 | 83216.435704 | 1994.572669 | 8509.030136 | 89.348861 | 6.946860 |
| 英国 | 5514959 | 13249562 | 244005 | 20789.400000 | 1996.726647 | 4797.089790 | 88.343592 | 7.526937 |
| 荷兰 | 310199 | 144836 | 11685 | 1114.500000 | 2001.283871 | 934.425806 | 75.387097 | 7.190323 |
| 西班牙 | 894710 | 1486733 | 40455 | 3139.900000 | 2001.588367 | 3326.024609 | 90.503356 | 7.024385 |
| 阿根廷 | 232468 | 258271 | 10638 | 843.700000 | 2004.034483 | 2226.474138 | 91.706897 | 7.273276 |
| 韩国 | 2712969 | 8761080 | 134734 | 8596.400000 | 2008.119171 | 6484.885270 | 99.729090 | 6.362990 |
计算总合数据 margins=True
pd.pivot_table(df,index=['产地'],aggfunc=[np.sum,np.mean],fill_value=0,margins=True)
| sum | mean | |||||||
|---|---|---|---|---|---|---|---|---|
| 年代 | 投票人数 | 时长 | 评分 | 年代 | 投票人数 | 时长 | 评分 | |
| 产地 | ||||||||
| 中国台湾 | 1235388 | 5237466 | 53925 | 4367.200000 | 1999.009709 | 8474.864078 | 87.257282 | 7.066667 |
| 中国大陆 | 7621488 | 41435313 | 309608 | 23058.000000 | 2004.599684 | 10898.293793 | 81.432930 | 6.064703 |
| 中国香港 | 5676627 | 23285389 | 252431 | 18457.700000 | 1991.100316 | 8167.446159 | 88.541214 | 6.474114 |
| 丹麦 | 395820 | 394784 | 17444 | 1434.700000 | 1999.090909 | 1993.858586 | 88.101010 | 7.245960 |
| 俄罗斯 | 3006734 | 3167110 | 140761 | 11031.900000 | 1992.534129 | 2098.813784 | 93.280981 | 7.310736 |
| 其他 | 3837588 | 3054119 | 167168 | 13895.900000 | 1998.743750 | 1590.686979 | 87.066667 | 7.237448 |
| 加拿大 | 1447780 | 1384765 | 57919 | 4868.400000 | 2002.461964 | 1915.304288 | 80.109267 | 6.733610 |
| 印度 | 716133 | 1146271 | 43203 | 2453.400000 | 2005.974790 | 3210.843137 | 121.016807 | 6.872269 |
| 墨西哥 | 237145 | 139613 | 10929 | 843.400000 | 1992.815126 | 1173.218487 | 91.840336 | 7.087395 |
| 巴西 | 201987 | 357136 | 8869 | 733.500000 | 1999.871287 | 3536.000000 | 87.811881 | 7.262376 |
| 意大利 | 1487142 | 2502215 | 77902 | 5377.300000 | 1985.503338 | 3340.740988 | 104.008011 | 7.179306 |
| 日本 | 10101505 | 18000667 | 427863 | 36339.300000 | 1999.902000 | 3563.782815 | 84.708573 | 7.194476 |
| 比利时 | 277930 | 170987 | 11447 | 1003.300000 | 1999.496403 | 1230.122302 | 82.352518 | 7.217986 |
| 法国 | 5608811 | 10213966 | 253169 | 20384.700000 | 1991.765270 | 3627.118608 | 89.903764 | 7.238885 |
| 波兰 | 359652 | 159577 | 14613 | 1347.000000 | 1987.027624 | 881.640884 | 80.734807 | 7.441989 |
| 泰国 | 590684 | 1564881 | 26002 | 1796.100000 | 2009.129252 | 5322.724490 | 88.442177 | 6.109184 |
| 澳大利亚 | 600896 | 1415713 | 25549 | 2093.400000 | 2002.986667 | 4719.043333 | 85.163333 | 6.978000 |
| 瑞典 | 381491 | 290077 | 17898 | 1423.300000 | 1986.932292 | 1510.817708 | 93.218750 | 7.413021 |
| 美国 | 23892986 | 101929672 | 1070310 | 83216.435704 | 1994.572669 | 8509.030136 | 89.348861 | 6.946860 |
| 英国 | 5514959 | 13249562 | 244005 | 20789.400000 | 1996.726647 | 4797.089790 | 88.343592 | 7.526937 |
| 荷兰 | 310199 | 144836 | 11685 | 1114.500000 | 2001.283871 | 934.425806 | 75.387097 | 7.190323 |
| 西班牙 | 894710 | 1486733 | 40455 | 3139.900000 | 2001.588367 | 3326.024609 | 90.503356 | 7.024385 |
| 阿根廷 | 232468 | 258271 | 10638 | 843.700000 | 2004.034483 | 2226.474138 | 91.706897 | 7.273276 |
| 韩国 | 2712969 | 8761080 | 134734 | 8596.400000 | 2008.119171 | 6484.885270 | 99.729090 | 6.362990 |
| All | 77337135 | 239749731 | 3428380 | 268585.635704 | 1996.982338 | 6190.764350 | 88.526868 | 6.935359 |
对不同值执行不同函数
可以向aggfunc传递一个字典。不过,这样做有一个副作用,那就是必须将标签做的更加简洁才性。
对各个产地的投票人数求和,对评分求均值
pd.pivot_table(df,index=['产地'],values=['投票人数','评分'],aggfunc={'投票人数':np.sum,'评分':np.mean},fill_value=0)
| 投票人数 | 评分 | |
|---|---|---|
| 产地 | ||
| 中国台湾 | 5237466 | 7.066667 |
| 中国大陆 | 41435313 | 6.064703 |
| 中国香港 | 23285389 | 6.474114 |
| 丹麦 | 394784 | 7.245960 |
| 俄罗斯 | 3167110 | 7.310736 |
| 其他 | 3054119 | 7.237448 |
| 加拿大 | 1384765 | 6.733610 |
| 印度 | 1146271 | 6.872269 |
| 墨西哥 | 139613 | 7.087395 |
| 巴西 | 357136 | 7.262376 |
| 意大利 | 2502215 | 7.179306 |
| 日本 | 18000667 | 7.194476 |
| 比利时 | 170987 | 7.217986 |
| 法国 | 10213966 | 7.238885 |
| 波兰 | 159577 | 7.441989 |
| 泰国 | 1564881 | 6.109184 |
| 澳大利亚 | 1415713 | 6.978000 |
| 瑞典 | 290077 | 7.413021 |
| 美国 | 101929672 | 6.946860 |
| 英国 | 13249562 | 7.526937 |
| 荷兰 | 144836 | 7.190323 |
| 西班牙 | 1486733 | 7.024385 |
| 阿根廷 | 258271 | 7.273276 |
| 韩国 | 8761080 | 6.362990 |
透视表过滤
table=pd.pivot_table(df,index=['年代'],values=['投票人数','评分'],aggfunc={'投票人数':np.sum,'评分':np.mean},fill_value=0)
type(table)
pandas.core.frame.DataFrame
table[:5]
| 投票人数 | 评分 | |
|---|---|---|
| 年代 | ||
| 1888 | 776 | 7.950000 |
| 1890 | 51 | 4.800000 |
| 1892 | 176 | 7.500000 |
| 1894 | 338 | 6.633333 |
| 1895 | 7679 | 7.575000 |
1994年被誉为电影史上伟大的一年,但是通过数据我们可以发现,1994年的平均分并不是很高。1924年的电影平均分最高。
table[table.index==1994]
| 投票人数 | 评分 | |
|---|---|---|
| 年代 | ||
| 1994 | 5670752 | 7.262348 |
table.sort_values('评分',ascending=False)[:10]
| 投票人数 | 评分 | |
|---|---|---|
| 年代 | ||
| 1924 | 10410 | 8.053571 |
| 1888 | 776 | 7.950000 |
| 1928 | 16193 | 7.945000 |
| 1912 | 761 | 7.920000 |
| 1923 | 7668 | 7.883333 |
| 1922 | 16876 | 7.804545 |
| 1925 | 27607 | 7.788000 |
| 1926 | 10203 | 7.773913 |
| 1916 | 7364 | 7.758333 |
| 1927 | 20163 | 7.751724 |
按照多个索引来进行汇总
pd.pivot_table(df,index=['产地','年代'],values=['投票人数','评分'],aggfunc={'投票人数':np.sum,'评分':np.mean},fill_value=0)
| 投票人数 | 评分 | ||
|---|---|---|---|
| 产地 | 年代 | ||
| 中国台湾 | 1963 | 121 | 6.400000 |
| 1965 | 461 | 6.800000 | |
| 1966 | 51 | 7.900000 | |
| 1967 | 4444 | 8.000000 | |
| 1968 | 178 | 7.400000 | |
| … | … | … | … |
| 韩国 | 2012 | 610829 | 6.064151 |
| 2013 | 1130983 | 6.098198 | |
| 2014 | 453152 | 5.650833 | |
| 2015 | 349808 | 5.423853 | |
| 2016 | 34797 | 5.730000 |
1511 rows × 2 columns
相关文章:
)
数据分析之Pandas(1)
3.Pandas 文章目录3.Pandas3.1 Pandas基本介绍3.1.1 Pandas的基本数据结构3.1.1.1 Pandas库的Series类型3.1.1.2 Pandas库的DataFrame类型DataFrame初始化DataFrame查看数据3.1.2 Pandas读取数据及数据操作行操作添加一行删除一行列操作增加一列删除一列通过标签选择数据条件选…...
17、江科大stm32视频学习笔记——USART串口协议和USART串口外设
目录 1、通信接口 2、 硬件电路 3、电平标准 4、串口参数及时序 5、USART简介 6、USART工作 (1)写操作 (2)读操作 (3)帧头和帧尾的添加和除由电路自动执行 (4)硬件数据控制…...

leetcode:有效地括号
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 每个右括号都…...

四等分list
Testpublic void s (){ int targ 4; List mList new ArrayList(); List<List> mEndList new ArrayList<>(); for (int i 0; i <34; i) { mList.add(“item” i); } // System.out.println(mList.toString()); if (mList.size() % targ ! 0) { for (int j …...

php连接sqlserver数据库
docker 安装sqlserver数据库sudo docker pull mcr.microsoft.com/mssql/server:2017-latestsudo docker run -e "ACCEPT_EULAY" -e "MSSQL_SA_PASSWORD<YourStrongPassw0rd>" -p 1433:1433 --name sqlserver --hostname sqlserver -d mcr.microsoft.…...

The 2019 China Collegiate Programming Contest Harbin Site F. Fixing Banners
Problem - F - Codeforces 翻译: 哈尔滨,这个名字最初是一个满语单词,意思是“晒渔网的地方”,从松花江边的一个小农村居民点发展成为中国东北最大的城市之一。1898年,随着中国东部铁路的到来,这座城市首先…...
Maven的下载和配置
一、前言 一般按要求下载jar ,但是jar 包版本不好控制。有时候就会jar版本不同导致项目运行的结果也有差异,这样在团队开发中,在多个项目开发的是,jar包还要进行拷贝,可能也会出现版本还jar损坏的情况,所以一个能统一…...

服务高并发、高性能、高可用实现方案
服务高并发、高性能、高可用实现方案 软件开发的三高指标:高并发、高性能、高可用。 高并发方面要求QPS 大于 10万;高性能方面要求请求延迟小于 100 ms;高可用方面要高于 99.99%(4个9) 一、高并发: 高并发是现在互联网分布式框架设…...
uniCloud在线升级APP配置教程
app在线升级背景实现思路流程流程背景 因用户需要添加手机h5页面来进数据操作实现思路流程 实现流程图流程 相关文档:帮助文档 https://uniapp.dcloud.net.cn/uniCloud/cf-functions.html 注册服务空间 https://unicloud.dcloud.net.cn/pages/login/login uni升级…...

idea常用的快捷键
idea常用的快捷键Alt回车 导入包,自动修正CtrlN 查找类CtrlShiftN 查找文件CtrlAltL 格式化代码CtrlAltO 优化导入的类和包AltInsert 生成代码(如get,set方法,构造函数等)CtrlE或者AltShiftC 最近更改的代码CtrlR 替换文本CtrlF 查找文本CtrlShiftSpace 自动补全代码Ctrl空格 代…...

全志V85x硬件设计大赛作品精选第一期,快来Pick你心目中的最佳方案
1、V853-智能交互摄像头开发板 该参赛作品基于全志V853开发板制作的一款类似眼镜外挂的小产品,可以对场景进行辅助识别,并通过云端交互实现物联网控制,进一步实现物联网与人机交互的融合。 开发板配置了摄像头和小屏幕接口,并外…...
博客系统(界面设计)
✏️作者:银河罐头 📋系列专栏:JavaEE 🌲“种一棵树最好的时间是十年前,其次是现在” 目录实现博客列表页预期效果导航栏页面主体左右布局左侧区域右侧区域完整代码实现博客详情页预期效果导航栏 左侧右侧完整代码实现…...

素材要VIP咋整?看python大展神通
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 再我们缺少素材的时候,我们第一反应 我们肯定会去网上寻找,但是!! 有的素材需要VIP!这可咋整呢? 看我利用python大展神通,采集某图网图片…...
[ vulnhub靶机通关篇 ] 渗透测试综合靶场 DC-1 通关详解 (附靶机搭建教程)
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

软件测试文档编写步骤
编写软件测试文档是软件测试中非常重要的一部分。以下是编写软件测试文档的一些常见步骤: 1.明确软件测试的目标和目的:在开始编写软件测试文档之前,需要明确测试的目标和目的。这包括定义测试的范围,测试的目标和测试的优先级。 …...

重新认识下网页水印
使用背景图图片 单独使用 css 实现,使用 backgroundImage,backgroundRepeat 将背景图片平铺到需要加水印的容器中即可。 如果希望实现旋转效果,可以借助伪元素,将背景样式放到伪元素中,旋转伪元素实现: &l…...
Unity脚本练习
在C# 中 class 是创建类的标志,要创建类的话得现有class上面这个的逻辑是 类的访问权限, 关键字,类名以及类继承的父类在Unity中创建一个脚本或者添加一个组件,就相当于在Unity命名空间中创建了一个可以访问的类。这些类能够直接在…...
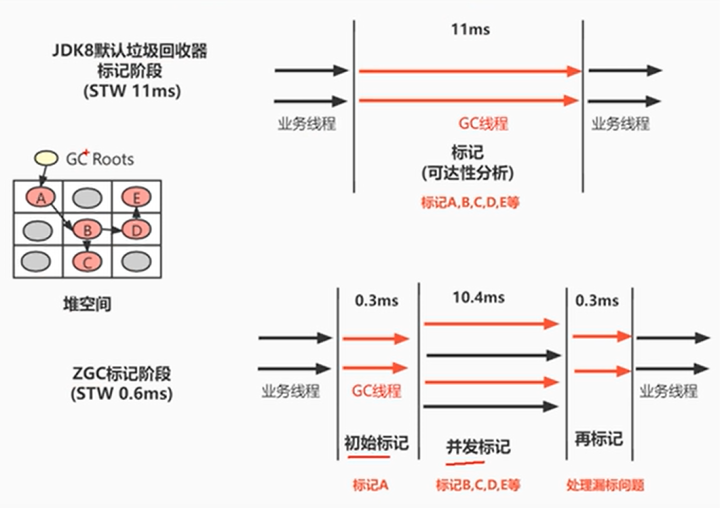
二十分钟带你了解JVM性能调优与实战进阶
ZGC 诞生原因 Java生态非常强大,但还不够,有些场景仍处于劣势,而ZGC的出现可以让Java语言抢占其他语言的某些特定领域市场。比如 谷歌主导的Android手机系统显示卡顿。证券交易市场,实时性要求非常高,目前主要是C主…...

对比应用层和内核层区别
一、所使用的空间不同: 应用层使用的空间是0-3G的用户空间。 内核层使用的是3-4G的内核空间。 二、打印信息所用函数不同: 应用层使用printf打印信息。 printf("打印信息\n"); 内核层使用printk打印信息。 …...
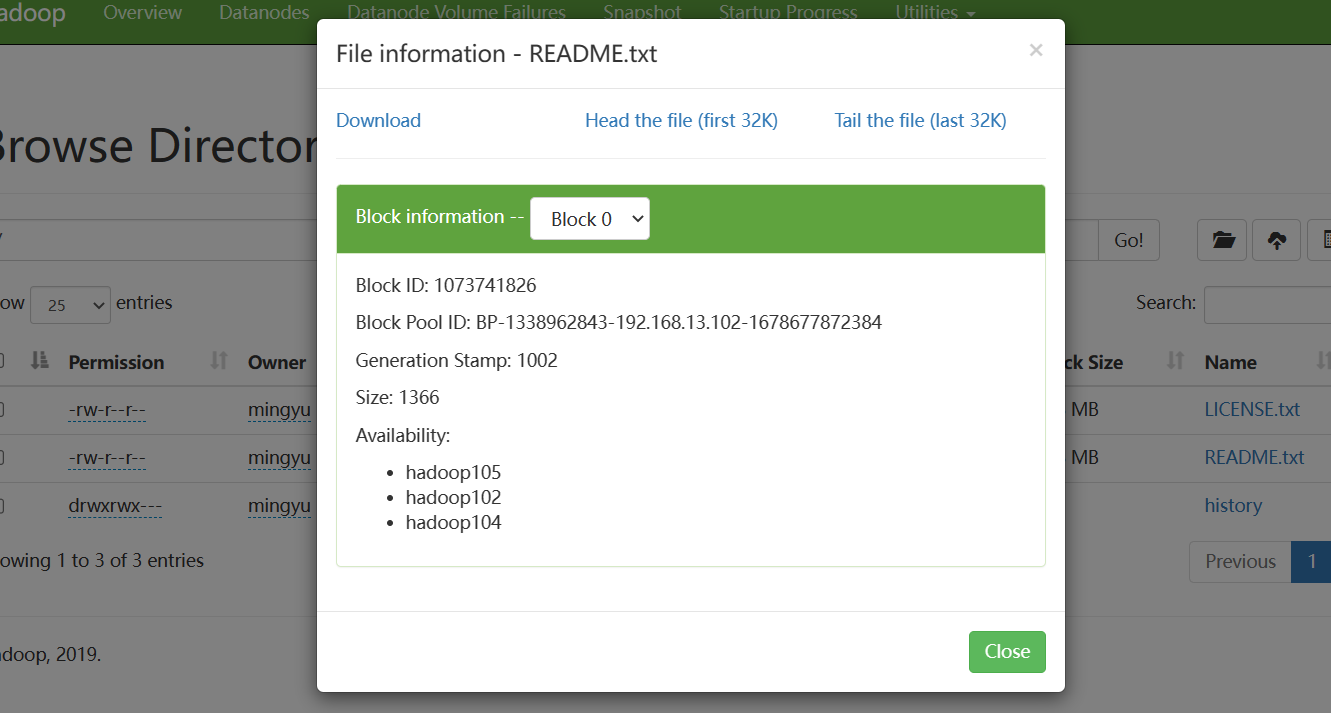
Hadoop服役新服务器
目录 0、准备一台新服务器 1、修改主机名 2、配置静态ip 3、配置xshell登录 4、关闭并禁用防火墙 5、分发hadoop和jdk文件 6、分发环境变量文件 7、source 环境变量 8、配置ssh 9、删除105节点的data、logs文件夹 10、单节点启动并关联到集群 11、验证新节点是否有效 0…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

终极鼠标连点器MouseClick:5分钟免费获取完整使用指南
终极鼠标连点器MouseClick:5分钟免费获取完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

抖音下载神器终极指南:免费批量下载视频、直播回放和音乐原声
抖音下载神器终极指南:免费批量下载视频、直播回放和音乐原声 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

如何告别城通网盘龟速下载:三步获取高速直连的终极方案
如何告别城通网盘龟速下载:三步获取高速直连的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘那令人抓狂的下载速度而苦恼吗?每次点击下载按钮后&#x…...