【Hive进阶】-- Hive SQL、Spark SQL和 Hive on Spark SQL
1.Hive SQL
1.1 基本介绍
概念
Hive由Facebook开发,用于解决海量结构化日志的数据统计,于2008年贡献给 Apache 基金会。
Hive是基于Hadoop的数据仓库工具,可以将结构化数据映射为一张表,提供类似SQL语句查询功能
本质:将Hive SQL转化成MapReduce程序。
与关系型数据库的对比
项目 | Hive | 关系型数据库 |
数据存储 | HDFS | 磁盘 |
查询语言 | HQL | SQL |
处理数据规模 | 大 | 小 |
分区 | 支持 | 支持 |
扩展性 | 高 | 非常有限 |
数据写入 | 支持批量导入/单条写入 | 支持批量导入/单条写入 |
索引 | 0.7版本后添加了索引(不怎么使用) | 支持复杂索引 |
执行延迟 | 高 | 低 |
数据加载模式 | 读时模式(快) | 写时模式(慢) |
应用场景 | 海量数据查询 | 实时查询 |
PS:
读时模式: Hive 在加载数据到表中的时候不会校验.
写时模式: Mysql 数据库插入数据到表的时候会进行校验.适用场景
Hive只适合用来做海量离线的数据统计分析,也就是数据仓库。
1.2 架构
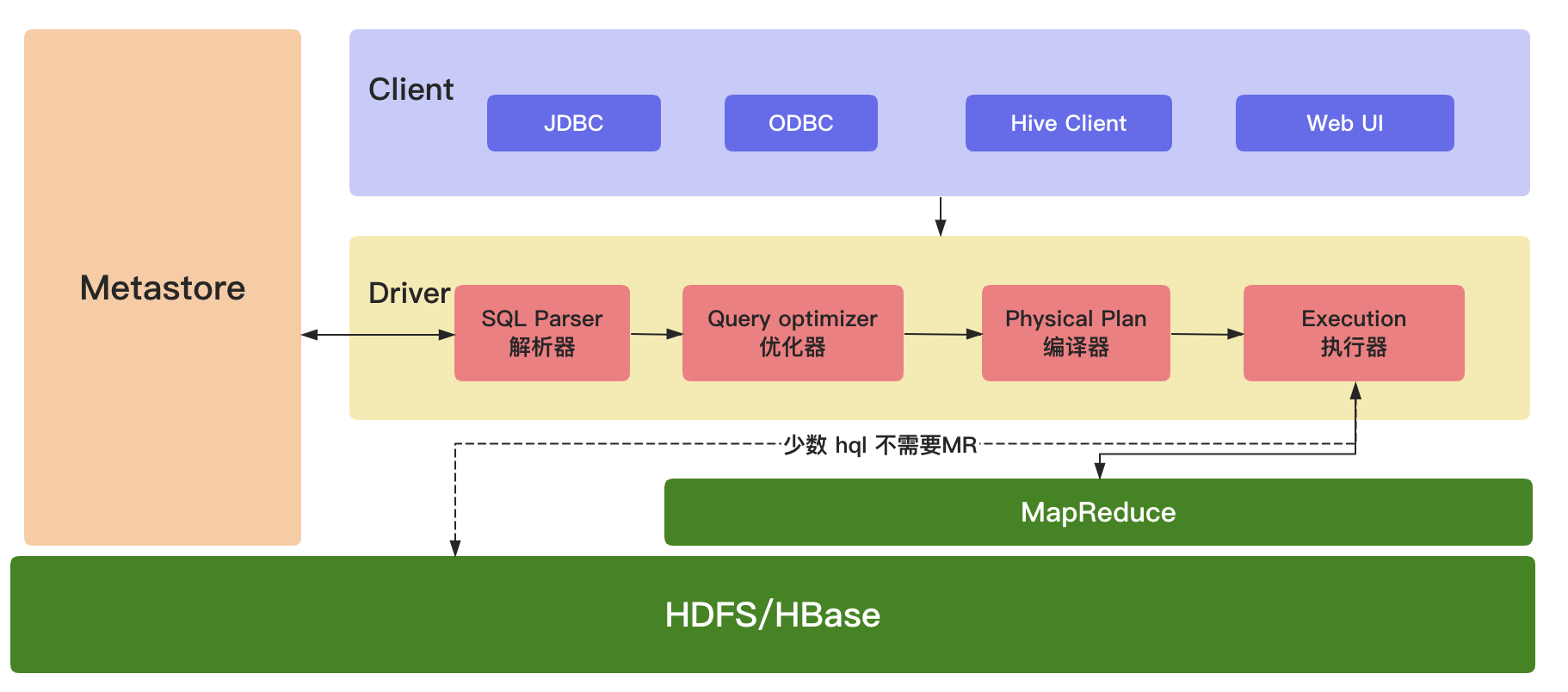
(1)Client(用户接口)
JDBC(java访问Hive);ODBC(Open Database Connectivity);Client(hive shell);WEBUI(浏览器访问Hive)
(2)元数据(MetaStore)
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段,标的类型(表是否为外部表)、表的数据所在目录。这是数据默认存储在Hive自带的derby数据库中,推荐使用MySQL数据库存储MetaStore。(3)Hadoop/HBase集群
使用 HDFS 进行存储数据,使用 MapReduce 进行计算。(4)Driver(驱动器)
解析器(SQL Parser):将SQL字符串换成抽象语法树AST,对AST进行语法分析,判断表是否存在、字段是否存在、SQL语义是否有误。
优化器(Query Optimizer):将逻辑计划进行优化。
编译器(Physical Plan):将AST编译成逻辑执行计划。
执行器(Execution):把执行计划转换成可以运行的物理计划。对于Hive来说默认就是Mapreduce任务。PS:从 hive-0.10.x开始,少数 Hql 不需要执行 MR,但是需要开启参数:
hive.fetch.task.conversion = more添参数后,简单的查询,如select,不带count,sum,group by的 SQL,都不走map/reduce,直接读取hdfs文件进行filter过滤。
2.Spark SQL
2.1 基本介绍
概念
Spark SQL主要用于结构型数据处理,它的前身为Shark,在Spark 1.3.0版本后才成长为正式版,可以彻底摆脱之前Shark必须依赖HIVE的局面。与过去的Shark相比,一方面Spark SQL提供了强大的DataFrame API,另一方面则是利用Catalyst优化器,并充分利用了Scala语言的模式匹配与quasiquotes,为Spark提供了更好的查询性能。
在Databricks工程师撰写的论文《Spark SQL: Relational Data Processing in Spark》中,给出了Spark SQL与Shark以及Impala三者间的性能对比,如下图所示:
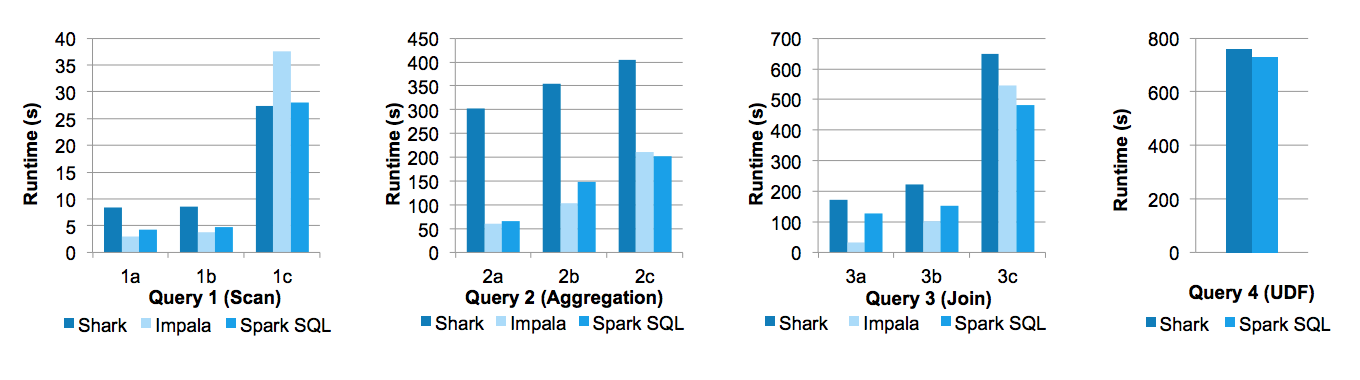
Michael Armbrust、Yin Huai等人写的博客《Deep Dive into Spark SQL’s Catalyst Optimizer》简单介绍了Catalyst的优化机制。
特点
与 Spark 集成
Spark SQL 查询与 Spark 程序集成。Spark SQL 允许我们使用 SQL 或可在 Java、Scala、Python 和 R 中使用的 DataFrame API 查询 Spark 程序中的结构化数据。要运行流式计算,开发人员只需针对 DataFrame / Dataset API 编写批处理计算, Spark 会自动增加计算量,以流式方式运行它。这种强大的设计意味着开发人员不必手动管理状态、故障或保持应用程序与批处理作业同步。相反,流式作业总是在相同数据上给出与批处理作业相同的答案。
统一数据访问
DataFrames 和 SQL 支持访问各种数据源的通用方法,如 Hive、Avro、Parquet、ORC、JSON 和 JDBC。这将连接这些来源的数据。这对于将所有现有用户容纳到 Spark SQL 中非常有帮助。
Hive兼容性
Spark SQL 对当前数据运行未经修改的 Hive 查询。它重写了 Hive 前端和元存储,允许与当前的 Hive 数据、查询和 UDF 完全兼容。
标准连接
连接是通过 JDBC 或 ODBC 进行的。JDBC和 ODBC 是商业智能工具连接的行业规范。
性能和可扩展性
Spark SQL 结合了基于成本的优化器、代码生成和列式存储,在使用 Spark 引擎计算数千个节点的同时使查询变得敏捷,提供完整的中间查询容错。Spark SQL 提供的接口为 Spark 提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL 使用这些额外信息来执行额外优化。Spark SQL 可以直接从多个来源(文件、HDFS、JSON/Parquet 文件、现有 RDD、Hive 等)读取。它确保现有 Hive 查询的快速执行。
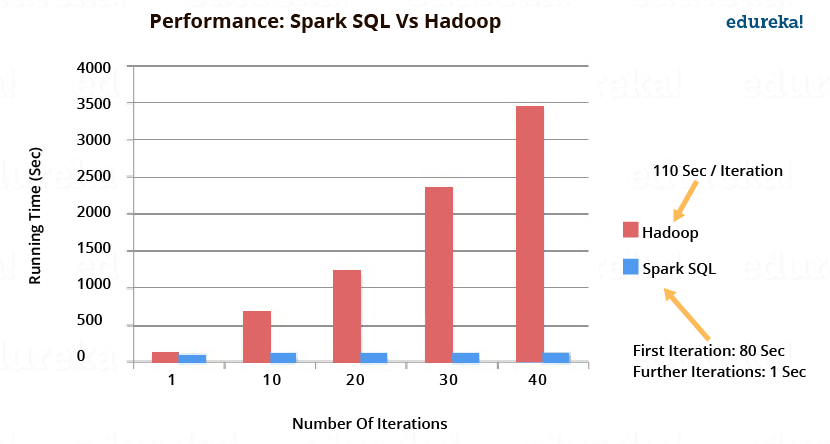
下图描述了 Spark SQL 与 Hadoop 相比的性能。Spark SQL 的执行速度比 Hadoop 快 100 倍。
适用场景
实时计算 & 离线批量计算。
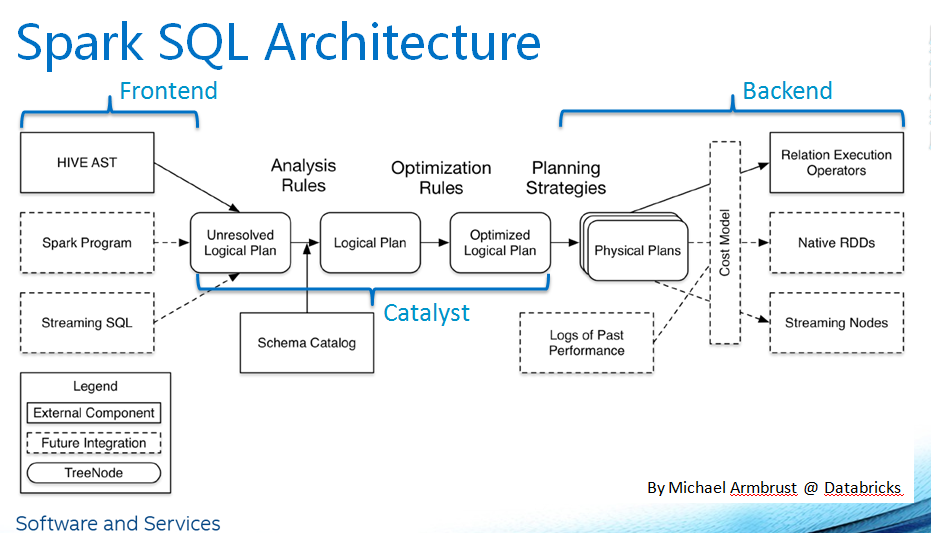
2.2 架构
3.Hive on Spark SQL
3.1基本介绍
Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。
通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。
参考:https://www.cnblogs.com/wcwen1990/p/7899530.html
3.2 架构
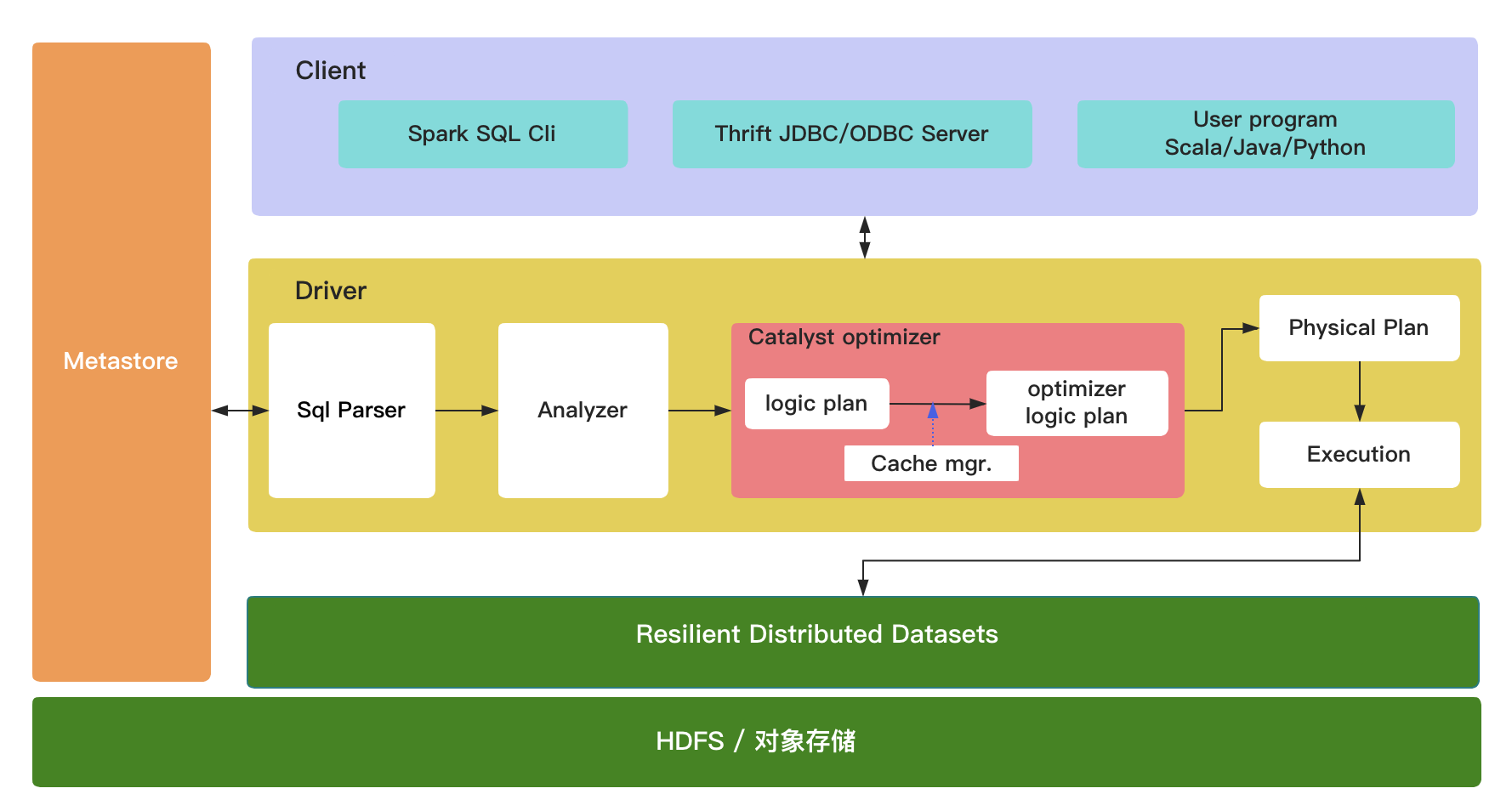
参考:http://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf
4.Hive SQL和 Spark sql 的区别
相同点
都支持ThriftServer服务,为JDBC提供解决方案
都支持静态分区、动态分区
都支持多种文件存储格式:text、parquet、orc等
都支持 UDF 函数不同点
Spark SQL 是 Spark 的一个库文件
Spark SQL 中 schema 是自动推断的
Spark SQL 支持标准 SQL 语句,也支持 HQL 语句等(即支持SQL方式开发,也支持HQL开发,还支持函数式编程(DSL)实现SQL语句)
Spark SQL 支持 Spark Datasets 和 Spark DataFrames 的操作,而 Hive SQL 仅支持 Hive 表的操作。
Spark SQL 支持使用 Spark API 和 SQL 同时进行数据处理,而 Hive SQL 仅支持 SQL 操作。
Hive中必须有元数据,一般由 MySql 管理,必须开启 metastore 服务
Hive 中在建表时必须明确使用 DDL 声明 schema相关文章:
【Hive进阶】-- Hive SQL、Spark SQL和 Hive on Spark SQL
1.Hive SQL 1.1 基本介绍概念Hive由Facebook开发,用于解决海量结构化日志的数据统计,于2008年贡献给 Apache 基金会。Hive是基于Hadoop的数据仓库工具,可以将结构化数据映射为一张表,提供类似SQL语句查询功能本质:将Hi…...

搭建自己的直播流媒体服务器SRS,以及SRS+OBS直播推拉流使用及配置
一、前言 目前,全球直播带货什么的,成为主流,那如何自己搭建一个直播服务器呢。首先需要一个流媒体服务器,搭建流媒体有很多种方式,如下: 流媒体解决方案 Live555 (C)流媒体平台框…...
Node.js-----使用express写接口
使用express写接口 文章目录使用express写接口创建基本的服务器创建API路由模块编写GET接口编写POST接口CROS跨域资源共享1.接口的跨域问题2.使用cros中间件拒绝跨域问题3.什么是cros4.cros的注意事项5.cros请求的分类JSONP接口1.回顾jsonp的概念和特点2.创建jsonp接口的注意事…...

【Linux修炼】16.共享内存
每一个不曾起舞的日子,都是对生命的辜负。 共享内存一.共享内存的原理二.共享内存你的概念2.1 接口认识2.2演示生成key的唯一性2.3 再谈key三.共享资源的查看3.1 如何查看IPC资源3.2 IPC资源的特征3.3 进程之间通过共享内存进行关联四.共享内存的特点五.共享内存的内…...

JAVA进阶 —— Stream流
目录 一、 引言 二、 Stream流概述 三、Stream流的使用步骤 1. 获取Stream流 1.1 单列集合 1.2 双列集合 1.3 数组 1.4 零散数据 2. Stream流的中间方法 3. Stream流的终结方法 四、 练习 1. 数据过滤 2. 数据操作 - 按年龄筛选 3. 数据操作 - 演员信息要求…...

Linux基础命令大全(上)
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
嵌入式 串口通信
目录 1、通信的基本概念 1.1 串行通信 1.2 并行通信 2、串行通信的特点 2.1 单工 2.2 半双工 2.3 全双工 3、串口在STM32的引脚 4、STM32的串口的接线 4.1 STM32的串口1和电脑通信的接线方式 4.2 单片机和具备串口的设备连接图 5、串口通信协议 6、串口通信…...
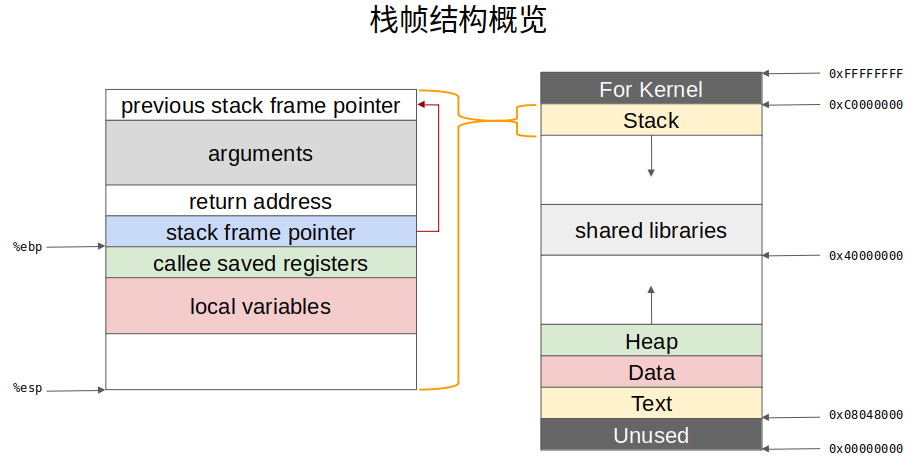
C语言函数调用栈
栈溢出(stack overflow)是最常见的二进制漏洞,在介绍栈溢出之前,我们首先需要了解函数调用栈。 函数调用栈是一块连续的用来保存函数运行状态的内存区域,调用函数(caller)和被调用函数…...

【高阶数据结构】红黑树
文章目录1. 使用场景2. 性质3. 结点定义4. 结点旋转5. 结点插入1. 使用场景 Linux进程调度CFSNginx Timer事件管理Epoll事件块的管理 2. 性质 每一个节点是红色或者黑色根节点一定是黑色每个叶子节点是黑色如果一个节点是红色,那么它的两个儿子节点都是黑色从任意…...

网络协议分析期末复习(二)
目录 12. 端口的定义及常见应用对应的端口号 13. UDP协议概述 14.UDP数据报格式及各字段意义 15. UDP-Lite协议概述 16. TCP数据报格式及各字段意义 17. TCP连接建立及协商参数的过程 18. TCP连接释放过程 19. 路由协议分类及各类的具体协议 20. 路由算法常用的度量 2…...

【C++】STL简介 及 string的使用
文章目录1. STL简介1.1 什么是STL1.2 STL的版本1.3 STL的六大组件2. string类的使用2.1 C语言中的字符串2.2 标准库中的string类2.3 string类的常用接口说明1. string类对象的常见构造2. string类对象的容量操作3. string类对象的修改操作4. resize和reserve5. 认识迭代器&…...

MySQL事务详解
🏆今日学习目标: 🍀Spring事务和MySQL事务详解 ✅创作者:林在闪闪发光 ⏰预计时间:30分钟 🎉个人主页:林在闪闪发光的个人主页 🍁林在闪闪发光的个人社区,欢迎你的加入: …...
ChatGPT背后的技术和多模态异构数据处理的未来展望——我与一位资深工程师的走心探讨
上周,我和一位从业三十余年的工程师聊到ChatGPT。 作为一名人工智能领域研究者,我也一直对对话式大型语言模型非常感兴趣,在讨论中,我向他解释这个技术时,他瞬间被其中惊人之处所吸引🙌,我们深…...

iOS-砸壳篇(两种砸壳方式)
CrackerXI砸壳呢,当时你要是使用 frida-ios-dump 也是可以的; https://github.com/AloneMonkey/frida-ios-dump frida-ios-dump: 代码中需要更改的:手机中的内网ip 密码 等 最后放到我的砸壳路径里: python dump.py -l查看应用…...

linux 基础
1.Shell 命令的格式如下:command -options [argument]command: Shell 命令名称。options: 选项,同一种命令可能有不同的选项,不同的选项其实现的功能不同。argument: Shell 命令是可以带参数的,也可以不带参…...

Java:SpringBoot给Controller添加统一路由前缀
网上的文章五花八门,不写SpringBoot的版本号,导致代码拿来主义不好使了。 本文采用的版本 SpringBoot 2.7.7 Java 1.8目录1、默认访问路径2、整个项目增加路由前缀3、通过注解方式增加路由前缀4、按照目录结构添加前缀参考文章1、默认访问路径 packag…...
Java 基于 JAVE 库 实现 视频转音频的批量转换
文章目录 Java 基于 JAVE 库 实现 视频转音频的批量转换Maven:方案一:代码优化:方案二:示例代码:代码优化:结语Java 基于 JAVE 库 实现 视频转音频的批量转换 实现视频转音频的功能需要使用到一个第三方的 Java 库,叫做 JAVE。JAVE 是一个开源的 Java 库,提供了视频和音频转换…...
Spring容器——基于XML注入
1. 容器:IOC IoC 是 Inversion of Control 的简写,译为“控制反转”,它不是一门技术,而是一种设计思想,是一个重要的面向对象编程法则,能够指导我们如何设计出松耦合、更优良的程序 Spring 通过 IoC 容器来…...

设计模式(二十一)----行为型模式之状态模式
1 概述 【例】通过按钮来控制一个电梯的状态,一个电梯有开门状态,关门状态,停止状态,运行状态。每一种状态改变,都有可能要根据其他状态来更新处理。例如,如果电梯门现在处于运行时状态,就不能…...
 亲和⼒传播算法)
一分钟理解 AP(Affinity Propagation) 亲和⼒传播算法
从来没有一个算法让我研究好几天都搞不明白,AP算法算是第一个。弄了好几天,打草纸用了几十页,反复琢磨,最后都怀疑人生了。我觉得网上那么多介绍 AP 的文章,基本上没有一篇能讲明白的。最后我都觉得 AP 的作者可能都没…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...
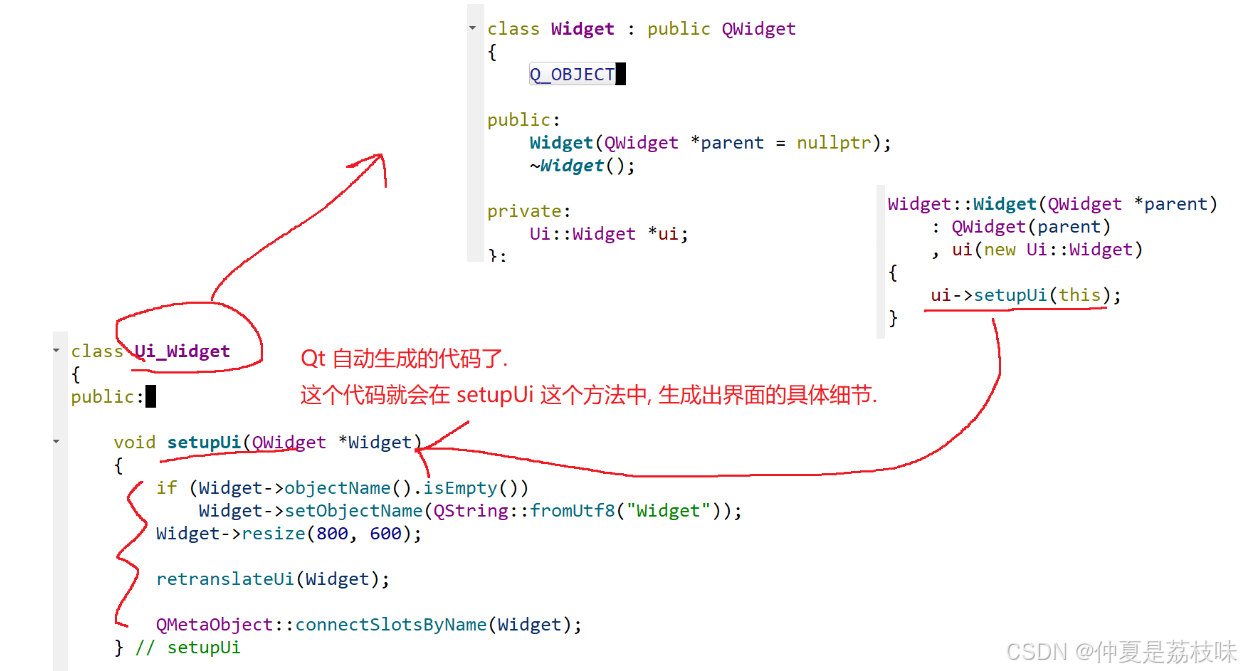
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...

如何通过git命令查看项目连接的仓库地址?
要通过 Git 命令查看项目连接的仓库地址,您可以使用以下几种方法: 1. 查看所有远程仓库地址 使用 git remote -v 命令,它会显示项目中配置的所有远程仓库及其对应的 URL: git remote -v输出示例: origin https://…...
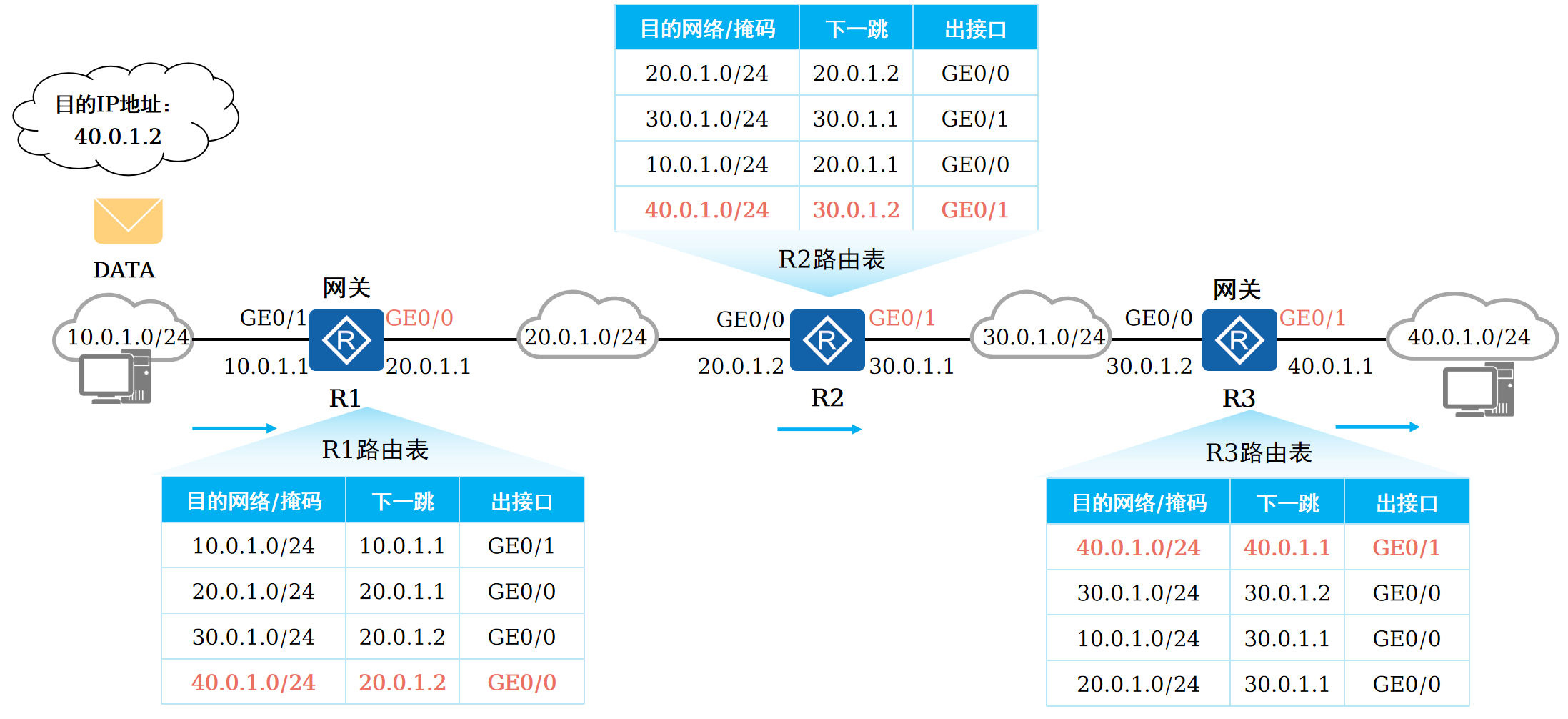
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...