PostgreSQL 中如何实现数据的增量更新和全量更新的平衡?
文章目录
- 一、增量更新与全量更新的概念
- 增量更新
- 全量更新
- 二、考虑的因素
- 1. 数据量
- 2. 数据更改的频率和规模
- 3. 数据一致性要求
- 4. 系统性能和资源利用
- 5. 业务逻辑和流程
- 三、解决方案
- (一)混合使用增量更新和全量更新
- (二)使用临时表和数据迁移
- (三)基于时间戳或版本号的增量更新
- (四)分表和分区
- (五)建立数据同步机制
- 四、示例分析
- 增量更新场景
- 全量更新场景
- 五、性能优化和注意事项
- (一)索引的使用
- (二)事务的管理
- (三)监控和日志
- (四)测试和验证
- 六、结论


在数据库管理中,数据的更新操作是常见的任务。对于大型数据集或高并发的系统,选择合适的更新策略至关重要。增量更新和全量更新是两种常见的数据更新方式,如何在 PostgreSQL 中平衡这两种更新方式以确保数据的一致性、性能和可靠性是一个值得深入探讨的问题。
一、增量更新与全量更新的概念
增量更新
增量更新是指仅对数据中发生变化的部分进行更新。通常,这涉及到识别更改的数据行,并只对这些行执行更新操作。它的优势在于更新操作的针对性强,对系统资源的消耗相对较小,尤其在处理大规模数据时,可以显著提高更新效率。
全量更新
全量更新则是将整个数据集合替换为新的数据。这种方式简单直接,但在数据量较大时,可能会导致较长的更新时间和较大的系统开销,例如占用大量的 I/O 和 CPU 资源。
二、考虑的因素
在决定如何平衡增量更新和全量更新时,需要考虑以下几个关键因素:
1. 数据量
如果数据集非常大,全量更新可能会导致长时间的锁定和性能下降,此时增量更新通常是更好的选择。相反,如果数据集较小,全量更新可能更简单和高效。
2. 数据更改的频率和规模
如果数据频繁且大量地更改,增量更新可以更准确和高效地处理这些更改。然而,如果数据的更改相对较少或者是整体性的变动,全量更新可能更易于实现。
3. 数据一致性要求
对于对数据一致性要求极高的场景,全量更新可能更能确保数据的完整性和准确性。但如果可以在一定程度上容忍短暂的数据不一致,增量更新结合适当的同步机制也可以满足要求。
4. 系统性能和资源利用
增量更新一般对系统资源的消耗较小,尤其是在并发环境中,可以减少锁定争用和提高系统的并发处理能力。全量更新可能会在短时间内占用大量资源,影响系统的可用性。
5. 业务逻辑和流程
根据具体的业务需求和流程,某些情况下增量更新更符合业务的操作方式,而在其他情况下可能全量更新更易于理解和管理。
三、解决方案
(一)混合使用增量更新和全量更新
根据数据的特点和业务需求,在不同的场景下灵活选择使用增量更新或全量更新。例如:
- 对于经常变化且变化量较小的数据表,采用增量更新。
- 对于定期进行整体性重构或数据来源完全替换的数据表,采用全量更新。
下面是一个简单的示例,假设有一个 product 表,包含 id, name, price 和 stock 列。在日常业务中,产品的价格和库存可能会频繁变化,但产品的名称相对较少更改。
-- 增量更新价格和库存
UPDATE product
SET price = 20.00, stock = 50
WHERE id = 1;-- 全量更新产品名称(假设需要重新导入所有产品名称)
TRUNCATE TABLE product; -- 先清空表
INSERT INTO product (id, name, price, stock)
VALUES (1, 'New Product Name', 20.00, 50),(2, 'Another New Name', 30.00, 60);
(二)使用临时表和数据迁移
创建临时表来处理数据的更改,然后将更改后的数据迁移到主表中。这种方法可以有效地管理数据更新的过程,并且可以在更新过程中进行数据的校验和处理。
-- 创建临时表
CREATE TEMP TABLE temp_product (id INT,name VARCHAR(255),price DECIMAL(10, 2),stock INT
);-- 向临时表中插入或更新数据
INSERT INTO temp_product (id, name, price, stock)
VALUES (1, 'New Name', 25.00, 40),(2, 'Old Name', 30.00, 50)
ON CONFLICT (id) DO UPDATESET name = EXCLUDED.name,price = EXCLUDED.price,stock = EXCLUDED.stock;-- 将临时表中的数据迁移到主表
UPDATE product
SET name = temp_product.name,price = temp_product.price,stock = temp_product.stock
FROM temp_product
WHERE product.id = temp_product.id;-- 或者使用 DELETE 和 INSERT 组合
DELETE FROM product;
INSERT INTO product
SELECT * FROM temp_product;
(三)基于时间戳或版本号的增量更新
为数据表添加一个时间戳或版本号列,用于记录数据的最后更新时间或版本。在更新数据时,根据这个时间戳或版本号来确定需要更新的行。
-- 创建表时添加时间戳列
CREATE TABLE product (id INT PRIMARY KEY,name VARCHAR(255),price DECIMAL(10, 2),stock INT,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);-- 增量更新
UPDATE product
SET price = 20.00, stock = 50
WHERE updated_at < '2023-09-15 12:00:00';
(四)分表和分区
对于大型数据表,可以根据数据的特点进行分表或分区。将经常更新的数据和相对稳定的数据分开存储,以便更灵活地选择更新策略。
例如,将近期活跃的数据存储在一个单独的表或分区中,采用增量更新;而对于历史数据,可以采用全量更新或者较少的更新频率。
-- 创建分区表
CREATE TABLE product (id INT PRIMARY KEY,name VARCHAR(255),price DECIMAL(10, 2),stock INT,creation_date DATE
) PARTITION BY RANGE (creation_date);-- 创建分区
CREATE TABLE product_current PARTITION OF productFOR VALUES FROM ('2023-09-01') TO ('2023-09-30');CREATE TABLE product_historical PARTITION OF productFOR VALUES FROM ('2023-08-31') TO ('2000-01-01');-- 对近期数据进行增量更新
UPDATE product_current
SET price = 20.00, stock = 50
WHERE id = 1;
(五)建立数据同步机制
当同时存在增量更新和全量更新时,建立数据同步机制以确保数据的一致性。这可以通过定时任务、触发器或消息队列等方式实现。
例如,使用 PostgreSQL 的 LISTEN/NOTIFY 机制在全量更新完成后通知相关的应用程序或服务进行数据同步操作。
-- 在全量更新完成后发送通知
NOTIFY update_complete;-- 在应用程序中监听通知
LISTEN update_complete;
四、示例分析
假设我们有一个电子商务网站的订单数据库,其中有 orders 表存储订单信息,包括 order_id, customer_id, order_date, total_amount 等列。随着业务的发展,订单数据不断增加,同时也需要对订单数据进行更新,例如修改订单的总价或者更新客户信息。
增量更新场景
- 当客户修改了订单中的某项商品数量,导致订单总价发生变化时,我们只需要对受影响的订单进行增量更新。
UPDATE orders
SET total_amount = 500.00
WHERE order_id = 123;
- 对于频繁发生的小范围数据更改,如客户地址的微调,也适合采用增量更新。
UPDATE orders
SET customer_address = 'New Address'
WHERE order_id = 123;
全量更新场景
- 每月进行一次数据清理和优化,将过期或无效的订单数据进行全量更新(例如标记为已删除或迁移到历史表)。
-- 标记为已删除
UPDATE orders
SET is_deleted = TRUE
WHERE order_date < '2023-08-01';-- 迁移到历史表
CREATE TABLE orders_history AS
SELECT * FROM orders
WHERE order_date < '2023-08-01';DELETE FROM orders
WHERE order_date < '2023-08-01';
- 当从外部数据源导入全新的客户信息并需要更新相关订单中的客户数据时,可能会选择全量更新。
-- 先删除原有的客户关联
DELETE FROM orders
WHERE customer_id = 101;-- 重新插入更新后的订单数据
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES (123, 101, '2023-09-15', 450.00),(124, 101, '2023-09-16', 300.00);
通过合理地判断和选择增量更新或全量更新的时机,并结合上述提到的解决方案,可以在保持数据一致性和准确性的基础上,提高数据库的性能和效率。
五、性能优化和注意事项
(一)索引的使用
无论是增量更新还是全量更新,都要确保索引的合理使用。在增量更新中,索引可以加快查找和更新相关行的速度,但过多或不合适的索引可能会影响更新的性能。对于全量更新,在更新操作之前可以考虑暂时删除不必要的索引,更新完成后再重新创建。
(二)事务的管理
对于复杂的数据更新操作,使用事务来确保数据的一致性。在事务中,可以对多个相关的更新操作进行分组,要么全部成功提交,要么全部回滚,以防止出现部分更新成功而部分失败的情况。
BEGIN;-- 一系列的更新操作
UPDATE table1...;
UPDATE table2...;COMMIT;
(三)监控和日志
建立完善的监控机制,跟踪数据更新操作的性能指标,如更新所用的时间、锁等待时长、资源使用情况等。同时,记录详细的更新日志,便于故障排查和性能优化的分析。
(四)测试和验证
在实际应用中,对于重要的数据更新操作,要在测试环境中进行充分的测试和验证,包括性能测试、数据一致性检查等,以确保在生产环境中的可靠性。
六、结论
在 PostgreSQL 中实现增量更新和全量更新的平衡需要综合考虑多个因素,包括数据量、更改频率、一致性要求、业务逻辑和系统性能等。通过灵活运用混合更新策略、使用临时表、基于时间戳或版本号进行更新、分表和分区以及建立数据同步机制等方法,并结合性能优化和注意事项,可以有效地平衡增量更新和全量更新,提高数据库的运行效率和数据管理的质量,从而更好地支持业务的发展和运行。
最终的解决方案应根据具体的应用场景和业务需求来定制,并且需要不断地进行监控和调整,以适应业务的变化和系统的发展。

🎉相关推荐
- 🍅关注博主🎗️ 带你畅游技术世界,不错过每一次成长机会!
- 📚领书:PostgreSQL 入门到精通.pdf
- 📙PostgreSQL 中文手册
- 📘PostgreSQL 技术专栏

相关文章:
PostgreSQL 中如何实现数据的增量更新和全量更新的平衡?
文章目录 一、增量更新与全量更新的概念增量更新全量更新 二、考虑的因素1. 数据量2. 数据更改的频率和规模3. 数据一致性要求4. 系统性能和资源利用5. 业务逻辑和流程 三、解决方案(一)混合使用增量更新和全量更新(二)使用临时表…...

数据结构--二叉树相关习题5(判断二叉树是否是完全二叉树 )
1.判断二叉树是否是完全二叉树 辨别: 不能使用递归或者算节点个数和高度来判断。 满二叉树可以用高度和节点来判断,因为是完整的。 但是完全二叉树前面是满的,但是最后一层是从左到右连续这种 如果仍然用这种方法的话,如下图…...

Python 轻松生成多种条形码、二维码 (Code 128、EAN-13、QR code等)
条形码和二维码是现代信息交换和数据存储的重要工具,它们将信息以图形的形式编码,便于机器识别和数据处理,被广泛应用于物流、零售、医疗、教育等各领域。 本文将介绍如何使用Python快速生成各种常见的条形码如Code 128、EAN-13,…...

Python: 分块读取文本文件
在处理大文件时,逐行或分块读取文件是很常见的需求。下面是几种常见的方法,用于在 Python 中分块读取文本文件: 1、问题背景 如何分块读取一个较大的文本文件,并提取出特定的信息? 问题描述: fopen(blank.txt,r) quot…...

服务攻防——中间件Jboss
文章目录 一、Jboss简介二、Jboss渗透2.1 JBoss 5.x/6.x 反序列化漏洞(CVE-2017-12149)2.2 JBoss JMXInvokerServlet 反序列化漏洞(CVE-2015-7501)2.3 JBossMQ JMS 反序列化漏洞(CVE-2017-7504)2.4 Adminis…...

宏碁F5-572G-59K3笔记本笔记本电脑拆机清灰教程(详解)
1. 前言 我的笔记本开机比较慢,没有固态,听说最近固态比较便宜,就想入手一个,于是拆笔记本看一下有没有可以安的装位置。(友情提示,在拆机之前记得洗手并擦干,以防静电损坏电源器件)…...

基于FPGA的LDPC编译码算法设计基础知识
基于FPGA的LDPC编译码算法设计基础知识 数字电路(数电)知识模拟电路(模电)知识1. 放大器1.1. 晶体管放大器1.2. 运算放大器1.3. 管子放大器(真空管放大器)微处理器/单片机知识其他相关知识 基于FPGA的算法设…...

国际网课平台Udemy上的亚马逊云科技AWS免费高分课程和创建、维护EC2动手实践
亚马逊云科技(AWS)是全球云行业最🔥火的云平台,在全球经济形势不好的大背景下,通过网课学习亚马逊云科技AWS基础备考亚马逊云科技AWS证书,对于找工作或者无背景转行做AWS帮助巨大。欢迎大家关注小李哥,及时了解世界最前…...

空中交通新动能!2024深圳eVTOL展动力电池展区核心内容抢先看!
空中交通新动能!2024深圳eVTOL展动力电池展区核心内容抢先看! 关键词:2024深圳eVTOL展 动力电池 高能量密度电池 高性能电池材料 作为2024深圳eVTOL展重要组成部分,2024深圳eVTOL动力电池展将于9月23-25日在深圳坪山燕子湖国际会…...

代码江湖:Python 中的进程与线程
大家好,我是阔升。今天,咱们来聊聊 Python 中的两个"老熟人"——进程和线程。这两个概念可以说是 Python 多任务编程中的"双子星",既相似又不同,让不少小伙伴们头疼不已。不过别担心,今天我们就来…...
上求解生成矩阵G)
根据H在有限域GF(2^m)上求解生成矩阵G
原理 有时间再补充。 注1:使用高斯消去法。如果Py不为单位阵,则说明进行了列置换,此时G不是系统形式。 注2:校验矩阵H必须是行满秩才存在对应的生成矩阵G,且生成矩阵G通常不唯一。 matlab实现:只做列置…...

Django 实现子模版继承父模板
背景 Django的占位符,如果不继承父模板的内容,会被子模版所覆盖,有些业务场景子模版也需要使用到父模板中的内容 可以使用Django自带的标签{% block super %}来实现此效果 base.html 最基础html,相当于第一层html,bl…...

数据安全治理:从库级权限申请到表级权限申请
背景 随着数据安全意识的提高,企业越来越重视数据治理和权限管理。传统数仓大多对库级别进行读写授权,仅对人工标记的敏感库进行表级别授权,但由于敏感等级是由人为标记,错误率较高,故期望将权限申请流程细化到表级申…...

vue3源码(六)渲染原理-runtime-core
1.依赖关系 runtime-dom 依赖于runtime-core,runtime-core 依赖于reactivity和sharedruntime-core提供跨平台的渲染方法createRenderer,用户可以自己传递节点渲染的渲染方法renderOptions,本身不关心用户使用什么APIruntime-dom提供了为浏览器而生的渲染…...

python拆分Excel数据,自动发邮箱
import pandas as pd import poplib import email from email.header import decode_header from email.parser import Parser df = pd.read_excel("年假明细表.xlsx") depts = df["部门"].unique() for dept in depts: department_df = df[df[&q…...
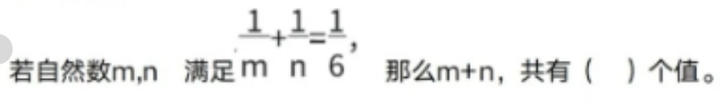
2024年福州延安中学夏季拿云杯拔尖创新人才素养测试(小高组)
1、选择题 那么,mn的值是( ) A、1243 B、1343 C、4029 D、4049 2、填空题 一副扑克牌共54张,其中1到13点各有 4张,每个数字黑色红色各两张,还有两张王牌,至少要取出( )…...
)
ES6 之 Promise 构造函数知识点总结 (四)
Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。它由社区最早提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了 Promise 对象。 Promise 对象有以下两个特点。 对象的状态不受…...

KIVY 3D Rotating Monkey Head¶
7 Python Kivy Projects (With Full Tutorials) – Pythonista Planet KIVY 3D Rotating Monkey Head kivy 3D 旋转猴子头How to display rotating monkey example in a given layout. Issue #6688 kivy/kivy GitHub 3d 模型下载链接 P99 - Download Free 3D model by …...

测试几个 ocr 对日语的识别情况
测试几个 ocr 对日语的识别情况 1. EasyOCR2. PaddleOCR3. Deepdoc(识别pdf中图片)4. Deepdoc(识别pdf中文字)5. Nvidia neva-22b6. Claude 3.5 sonnet 识别图片中的文字7. Claude 3.5 sonnet 识别 pdf 中表格8. OpenAI gpt-4o 识…...

华为机考前准备工作
很多同学在刷完真题后,就直接去考试了,会发现不是卡在了题目的难度上,而是卡在了代码数据的如何输入上。为了避免各位有志之士忽略小细节而导致的前功尽弃,博主特意总结了华为机考试题数据输入的几种情况及其源代码,仅…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...