如何指定多块GPU卡进行训练-数据并行
训练代码:
train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F# 假设我们有一个简单的文本数据集
class TextDataset(Dataset):def __init__(self, texts, labels, vocab):self.texts = textsself.labels = labelsself.vocab = vocabdef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]# 将文本转换为索引text_indices = [self.vocab.get(word, self.vocab['<UNK>']) for word in text.split()]return torch.tensor(text_indices, dtype=torch.long), torch.tensor(label, dtype=torch.long)# 定义一个简单的LSTM分类器
class LSTMClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):super(LSTMClassifier, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):embedded = self.embedding(x)_, (hidden, _) = self.lstm(embedded)output = self.fc(hidden[-1])return output# 构建词汇表
vocab = {'<PAD>': 0, '<UNK>': 1, 'I': 2, 'love': 3, 'this': 4, 'movie': 5, 'is': 6, 'terrible': 7}
vocab_size = len(vocab)# 示例数据
texts = ["I love this movie", "This movie is terrible"]
labels = [1, 0] # 1表示正面情感,0表示负面情感# 创建数据集和数据加载器
dataset = TextDataset(texts, labels, vocab)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True, collate_fn=lambda x: (torch.nn.utils.rnn.pad_sequence([item[0] for item in x], batch_first=True), torch.stack([item[1] for item in x])))# 实例化模型
embedding_dim = 50
hidden_dim = 50
output_dim = 2
model = LSTMClassifier(vocab_size, embedding_dim, hidden_dim, output_dim)# 使用DataParallel包装模型
model = nn.DataParallel(model)# 将模型移动到GPU
model = model.cuda()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练步骤
model.train()
for epoch in range(10): # 训练10个epochfor inputs, labels in dataloader:inputs, labels = inputs.cuda(), labels.cuda()optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item()}")print("训练完成")# 测试模型
model.eval()
test_texts = ["I love this movie", "This movie is terrible"]
test_dataset = TextDataset(test_texts, [1, 0], vocab)
test_dataloader = DataLoader(test_dataset, batch_size=2, shuffle=False, collate_fn=lambda x: (torch.nn.utils.rnn.pad_sequence([item[0] for item in x], batch_first=True), torch.stack([item[1] for item in x])))with torch.no_grad():for inputs, labels in test_dataloader:inputs, labels = inputs.cuda(), labels.cuda()outputs = model(inputs)predictions = torch.argmax(F.softmax(outputs, dim=1), dim=1)print(f"Predictions: {predictions.cpu().numpy()}, Labels: {labels.cpu().numpy()}")执行命令:
- export CUDA_VISIBLE_DEVICES=0,2
- python train.py
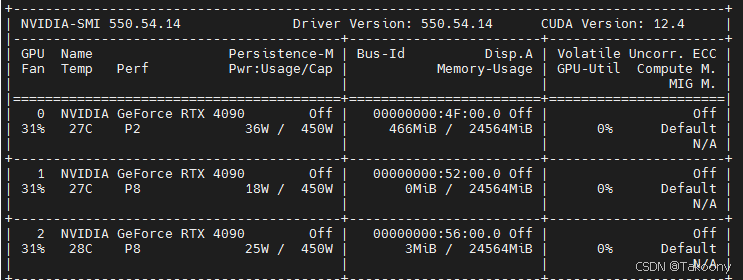
GPU监控
训练前

训练中
Epoch 1, Loss: 0.7198400497436523
Epoch 2, Loss: 0.6889444589614868
Epoch 3, Loss: 0.6591541767120361
Epoch 4, Loss: 0.630306601524353
Epoch 5, Loss: 0.6022476553916931
Epoch 6, Loss: 0.5748419761657715
Epoch 7, Loss: 0.5479871034622192
Epoch 8, Loss: 0.5216072201728821
Epoch 9, Loss: 0.4956483840942383
Epoch 10, Loss: 0.47007784247398376
训练完成
Predictions: [1 0], Labels: [1 0]
结论
export CUDA_VISIBLE_DEVICES=0,2与nn.DataParallel(model)结合的方法是正确的
为什么需要指定 CUDA_VISIBLE_DEVICES
- 在多GPU系统中,默认情况下,PyTorch 会尝试使用所有可用的GPU进行训练。
- 通过设置 CUDA_VISIBLE_DEVICES 环境变量,用于控制哪些GPU对当前进程可见,PyTorch 只会使用这些可见的GPU进行训练。
- 通过设置环境变量,你可以在不修改代码的情况下控制使用的GPU。这使得代码更加简洁和通用,不需要在代码中硬编码GPU的选择逻辑。
总的来说:通过设置 CUDA_VISIBLE_DEVICES 环境变量,你可以灵活地控制哪些GPU对当前进程可见,从而避免资源冲突、简化代码并更好地管理多GPU资源。这是使用 torch.nn.DataParallel 进行多GPU训练时的一种常见做法。
nn.DataParallel原理是什么
nn.DataParallel 是 PyTorch 中用于多 GPU 并行计算的一个模块。它的主要原理是将输入数据分割成多个子集,并将这些子集分配到不同的 GPU 上进行并行计算。具体来说,nn.DataParallel 的工作流程如下:
- 模型复制:首先,nn.DataParallel 会将模型复制到每个 GPU 上。这意味着每个 GPU 都会有一份完整的模型副本。
- 数据分割:输入数据会被分割成多个子集,每个子集会被分配到一个 GPU 上。通常,这个分割是按批次(batch)维度进行的。
- 并行计算:每个 GPU 使用其本地的模型副本对分配到的子集进行前向传播和后向传播计算。
- 梯度汇总:在所有 GPU 上完成计算后,nn.DataParallel 会将每个 GPU 计算得到的梯度汇总到主 GPU 上(通常是 GPU 0)。
- 参数更新:主 GPU 汇总梯度后,使用这些梯度更新模型参数。更新后的参数会同步到所有 GPU 上的模型副本。
相关文章:
如何指定多块GPU卡进行训练-数据并行
训练代码: train.py import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import torch.nn.functional as F# 假设我们有一个简单的文本数据集 class TextDataset(Dataset):def __init__(self, te…...

RK3568笔记三十三: helloworld 驱动测试
若该文为原创文章,转载请注明原文出处。 报着学习态度,接下来学习驱动是如何使用的,从简单的helloworld驱动学习起。 开始编写第一个驱动程序—helloworld 驱动。 一、环境 1、开发板:正点原子的ATK-DLRK3568 2、系统…...

【智能制造-14】机器视觉软件
CCD相机和COMS相机? CCD(Charge-Coupled Device)相机和CMOS(Complementary Metal-Oxide-Semiconductor)相机是两种常见的数字图像传感器技术,用于捕捉和处理图像。 CCD相机: CCD相机使用一种称为CCD的光电…...
MVC分页
public ActionResult Index(int ? page){IPagedList<EF.ACCOUNT> userPagedList;using (EF.eMISENT content new EF.eMISENT()){第几页int pageNumber page ?? 1;每页数据条数,这个可以放在配置文件中int pageSize 10;//var infoslist.C660List.OrderBy(…...

webGL可用的14种3D文件格式,但要具体问题具体分析。
hello,我威斯数据,你在网上看到的各种炫酷的3d交互效果,背后都必须有三维文件支撑,就好比你网页的时候,得有设计稿源文件一样。WebGL是一种基于OpenGL ES 2.0标准的3D图形库,可以在网页上实现硬件加速的3D图…...
HybridCLR原理中的重点总结
序言 该文章以一个新手的身份,讲一下自己学习的经过,大家更快的学习HrbirdCLR。 我之前的两个Unity项目中,都使用到了热更新功能,而热更新的技术栈都是用的HybridCLR。 第一个项目本身虽然已经集成好了热更逻辑(使用…...
昇思学习打卡-14-ResNet50迁移学习
文章目录 数据集可视化预训练模型的使用部分实现 推理 迁移学习:在一个很大的数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章学习使用的是前面学过的ResNet50,使用迁移学…...
)
软件开发面试题C#,.NET知识点(续)
1.C#中的封装是什么,以及它的重要性。 封装(Encapsulation) 是面向对象编程(OOP)的一个基本概念。它指的是将对象的状态(属性)和行为(方法)绑定在一起,并且将…...

2019年美赛题目Problem A: Game of Ecology
本题分析: 本题想要要求从实际生物角度出发,对权力游戏中龙这种虚拟生物的生态环境和生物特性进行建模,感觉属于比较开放类型的题目,重点在于参考生物的选择,龙虽然是虚拟的但是龙的生态特性可以参考目前生物圈里存在…...

沙龙回顾|MongoDB如何充当企业开发加速器?
数据不仅是企业发展转型的驱动力,也是开发者最棘手的问题。前日,MongoDB携手阿里云、NineData在杭州成功举办了“数据驱动,敏捷前行——MongoDB企业开发加速器”技术沙龙。此次活动吸引了来自各行各业的专业人员,共同探讨MongoDB的…...

云端编码:将您的技术API文档安全存储在iCloud的最佳实践
云端编码:将您的技术API文档安全存储在iCloud的最佳实践 作为一名技术专业人士,管理不断增长的API文档库是一项挑战。iCloud提供了一个无缝的解决方案,允许您在所有设备上存储、同步和访问您的个人技术API文档。本文将指导您如何在iCloud中高…...

在Spring Boot项目中集成单点登录解决方案
在Spring Boot项目中集成单点登录解决方案 大家好,我是微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在现代的企业应用中,单点登录(Single Sign-On, SSO)解决方案是确保用户…...
Java-常用API
1-Java API : 指的就是 JDK 中提供的各种功能的 Java类。 2-Scanner基本使用 Scanner: 一个简单的文本扫描程序,可以获取基本类型数据和字符串数据 构造方法: Scanner(InputStream source):创建 Scanner 对象 Sy…...

Python从Excel表中查找指定数据填入新表
#读取xls文件中的数据 import xlrd file "原表.xls" wb xlrd.open_workbook(file) #读取工作簿 ws wb.sheets()[0] #选第一个工作表 data [] for row in range(7, ws.nrows): name ws.cell(row, 1).value.strip() #科室名称 total1 ws.cell(row, 2…...
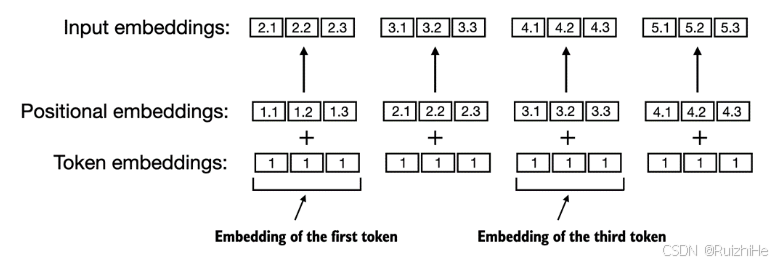
从零开始实现大语言模型(三):Token Embedding与位置编码
1. 前言 Embedding是深度学习领域一种常用的类别特征数值化方法。在自然语言处理领域,Embedding用于将对自然语言文本做tokenization后得到的tokens映射成实数域上的向量。 本文介绍Embedding的基本原理,将训练大语言模型文本数据对应的tokens转换成Em…...
视频怎么压缩变小?最佳视频压缩器
即使在云存储和廉价硬盘空间时代,大视频文件使用起来仍然不方便。无论是存储、发送到电子邮件帐户还是刻录到 DVD,拥有最好的免费压缩软件可以确保您快速缩小文件大小,而不必担心视频质量下降。继续阅读以探索一些顶级最佳 免费视频压缩器选项…...

LLM - 绝对与相对位置编码 与 RoPE 旋转位置编码 源码
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/140281680 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 Transformer 是基于 MHSA (多头自注意力),然而,MHSA 对于位置是不敏感…...

B3917 [语言月赛 202401] 小跳蛙
OK 挠~ stop here~ 好啊,现在呢,把手头的事情先放一放啊,我们来做道练习 OK? 好啊来: 小跳蛙 题目描述 有 𝑛−1 只小跳蛙在池塘中,依次被编号为 1,2,⋯ ,𝑛−1。池塘里有 &am…...

Bash ——shell
Bash作为用户与操作系统之间的接口,让用户通过命令行输入各种指令来控制和操作计算机系统。 shell的两种解释: 1.linux命令解释器 Terminal 终端 ——》shell命令 ——》 Linux kernel (内核) Linux内核的作用: 1.…...

PyTorch复现PointNet——模型训练+可视化测试显示
因为项目涉及到3D点云项目,故学习下PointNet这个用来处理点云的神经网络 论文的话,大致都看了下,网络结构有了一定的了解,本博文主要为了下载调试PointNet网络源码,训练和测试调通而已。 我是在Anaconda下创建一个新的…...

Krita平板绘画终极指南:从零开始掌握数字艺术创作
Krita平板绘画终极指南:从零开始掌握数字艺术创作 【免费下载链接】krita Krita is a free and open source cross-platform application that offers an end-to-end solution for creating digital art files from scratch built on the KDE and Qt frameworks. …...

从蓝牙到GSM:动手用MATLAB分析GMSK中BT参数如何影响你的无线连接
从蓝牙到GSM:GMSK中BT参数对无线系统设计的实战影响分析 在无线通信系统的设计中,GMSK调制技术因其出色的频谱效率和恒包络特性,成为蓝牙、GSM等主流标准的共同选择。但有趣的是,这些标准对GMSK的关键参数BT值的选择却各不相同——…...

OpenClaw怎么集成使用?OpenClaw龙虾AI本地5分钟搭建零技术教程2026年
OpenClaw怎么集成使用?OpenClaw龙虾AI本地5分钟搭建零技术教程2026年。OpenClaw怎么部署?本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含…...
,AI架构设计从入门到精通,收藏这一篇就够了!)
Prompt Cache与Agent上下文税深度解析(非常详细),AI架构设计从入门到精通,收藏这一篇就够了!
导读:本文通过Claude Code案例,解释了 AI agent 中的提示词缓存机制,实现 92% 缓存命中率,显著降低重复计算的“上下文税”,节省高达81%的成本。 核心原理在于Transformer的预填充阶段计算Key-Value向量,仅…...
)
运维系列虚拟化系列OpenStack系列【仅供参考】:配置 DHCP 服务 - 每天5分钟玩转 OpenStack(89)
配置 DHCP 服务 - 每天5分钟玩转 OpenStack(89) 配置 DHCP 服务 - 每天5分钟玩转 OpenStack(89) 配置 DHCP agent dhcp_driver interface_driver --dhcp-hostsfile --interface 配置 DHCP 服务 - 每天5分钟玩转 OpenStack(89) 前面章节我们看到 instance 在启动过程中能…...

核心常量T表生成(前16轮T_j = 0x79cc4519,后48轮T_j = 0x7a879...
算法部署设计,Sm3国密算法的硬件ip设计,纯v手写代码,图一为ip接口,图二为资源消耗,图三四为封装为axilite接口并在开发版下板测试,图五为开发版实测结果 直接联系内容包括:sm3的软件python实现代码…...

CSS 中 display 属性的值及其作用
在 CSS 中,display 属性是最核心、最常用的属性之一,它决定了元素在页面布局中的生成框类型(即元素如何渲染、如何与其他元素排列)。 以下是 display 属性的主要取值及其详细作用:1. 基础显示类型 display: block (块级…...

ControlNet-v1-1 FP16模型深度解析:SD1.5兼容性与性能优化终极指南
ControlNet-v1-1 FP16模型深度解析:SD1.5兼容性与性能优化终极指南 【免费下载链接】ControlNet-v1-1_fp16_safetensors 项目地址: https://ai.gitcode.com/hf_mirrors/comfyanonymous/ControlNet-v1-1_fp16_safetensors ControlNet-v1-1_fp16_safetensors作…...

EVA-01部署实操:Qwen2.5-VL-7B+DeepSpeed Zero-3显存优化部署
EVA-01部署实操:Qwen2.5-VL-7BDeepSpeed Zero-3显存优化部署 1. 引言:当视觉大模型穿上机甲战袍 想象一下,你有一个强大的视觉AI大脑,它能看懂图片里的每一个细节,理解复杂的场景,甚至能回答你关于图片的…...
AudioSeal Pixel Studio应用场景:法院庭审录音嵌入法官ID+案号实现司法存证
AudioSeal Pixel Studio应用场景:法院庭审录音嵌入法官ID案号实现司法存证 1. 司法存证场景的痛点与需求 在司法实践中,庭审录音作为重要的诉讼证据,其真实性和完整性至关重要。传统录音存证方式面临三大核心挑战: 身份关联性缺…...