分布式ID生成方案
文章目录
- 前言
- 一、分布式ID需要满足的条件
- 二、分布式ID生成方式
- 基于UUID
- 数据库自增
- 数据库集群
- 数据库号段模式
- redis ID生成
- 基于雪花算法(Snowflake)模式
- 百度(uid-generator)
- 美团(Leaf)
- 滴滴(Tinyid)
前言
对于单体系统来说,主键ID可能会常用主键自动的方式进行设置,这种ID生成方法在单体项目是可行的,但是对于分布式系统,分库分表之后,就不适应了,比如订单表数据量太大了,分成了多个库,如果还采用数据库主键自增的方式,就会出现在不同库id一致的情况。
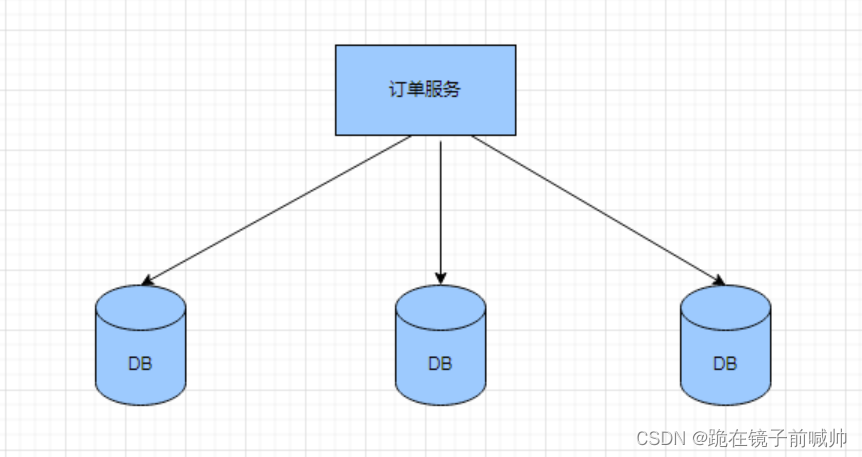
一、分布式ID需要满足的条件
① 全局唯一:必须保证ID是全局性唯一的。
② 趋势有序:业务上分页查询需求,排序需求,如果ID直接有序,则不必建立更多的索引,增加查询条件。
而且Mysql InnoDB存储引擎主键使用聚集索引,主键有序则写入性能更高。
③ 高可用:ID是一条数据的唯一标识,如果ID生成失败,则影响很大,业务执行不下去。所以好的ID方案需要有高可用。
④ 信息安全:ID虽然趋势有序,但是不可以被看出规则,免得被爬取信息。
二、分布式ID生成方式
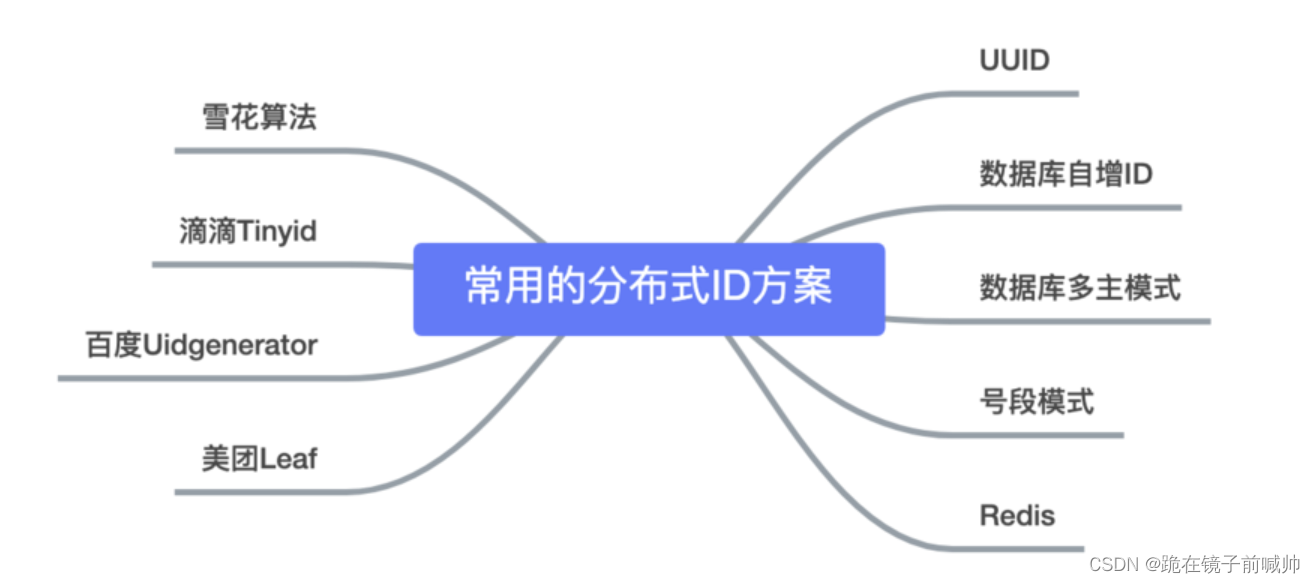
今天主要分析一下以下9种,分布式ID生成器方式以及优缺点:
- UUID
- 数据库自增ID
- 数据库多主模式
- 号段模式
- Redis
- 雪花算法(SnowFlake)
- 滴滴出品(TinyID)
- 百度 (Uidgenerator)
- 美团(Leaf)
注:主流生成ID方案都是基于数据库号段模式和雪花算法
基于UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例: 863e254b-ae34-4371-87da-204b71d46a7b。
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid);// 9c58226555c248018be2032964de2de6
优点:
- 性能非常高,本地生成的,不依赖于网络。
缺点:
- 无序。
- 不能标识出此ID的含义,不可读。
- 字符串太长且无序,作为MySQL主键,影响性能。
数据库自增
基于数据库的 auto_increment 自增ID完全可以充当分布式ID。
优点:
- 实现起来比较简单,ID 有序递增,存储消耗空间小。
缺点:
- 存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)。
- ID 没有具体业务含义。
- 安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量)。
- 每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)。
- 分库分表后,同一数据表的自增ID容易重复,无法直接使用(可以设置步长,但局限性很明显),ID没有了单调递增的特性,只能趋势递增,有些业务场景可能不符合。
数据库集群
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。
设置起始值和自增步长
MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
这样两个MySQL实例的自增ID分别就是:
1、3、5、7、9
2、4、6、8、10
水平扩展的数据库集群,有利于解决数据库单点压力的问题,同时为了ID生成特性,将自增步长按照机器数量来设置。
增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点:
- 解决DB单点问题
缺点:
- 不利于后续扩容。
- 实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
数据库号段模式
这种模式也是现在生成分布式ID的一种方法,实现思路是会从数据库获取一个号段范围,比如[1,1000],生成1到1000的自增ID加载到内存中,建表结构如:
CREATE TABLE `sequence_id_generator` (`id` int(10) NOT NULL,`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',`step` int(10) NOT NULL COMMENT '号段的长度',`version` int(20) NOT NULL COMMENT '版本号',`biz_type` int(20) NOT NULL COMMENT '业务类型',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
current_max_id 字段和 step 字段主要用于获取批量 ID,id 为: current_max_id ~ current_max_id + step 。
version 字段主要用于解决并发问题(乐观锁),biz_type 主要用于表示业务类型。
① 先插入一行数据
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`) VALUES(1, 0, 100, 0, 101);
② 通过 SELECT 获取指定业务下的批量唯一 ID
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
③ 不够用的话,更新之后重新 SELECT 即可。
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
相比于数据库主键自增的方式,数据库的号段模式对于数据库的访问次数更少,数据库压力更小。
另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
优点:
- ID 有序递增,存储消耗空间小,有比较成熟的方案,像百度Uidgenerator,美团Leaf
缺点:
- 依赖于数据库实现。
redis ID生成
Redis分布式ID实现主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis单线程的特点,可以保证ID的唯一性和有序性。
这种实现方式,如果并发请求量上来后,就需要集群,不过集群后,又要和传统数据库一样,设置分段和步长。
时间+用redis的incr自增命令(每日从1开始),代码如下:
public class RedisCounterRepository {private final DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyyMMdd");private RedisTemplate<String, Object> redisTemplate;@Autowiredpublic RedisCounterRepository(RedisTemplate<String, Object> redisTemplate) {this.redisTemplate = redisTemplate;}// 根据获取的自增数据,添加日期标识构造分布式全局唯一标识,changeNumPrefix是自己定义的随机前缀private String getNumFromRedis(String changeNumPrefix) {String dateStr = LocalDate.now().format(dateTimeFormatter);Long value = incrementNum(changeNumPrefix + dateStr);//不足4位补0,redis从1开始生成的,每天再次请0return dateStr + StringUtils.leftPad(String.valueOf(value), 4, '0');}// 从redis中获取自增数据(redis保证自增是原子操作)private long incrementNum(String key) {RedisConnectionFactory factory = redisTemplate.getConnectionFactory();if (null == factory) {log.error("Unable to connect to redis.");throw new UserException(AppStatus.INTERNAL_SERVER_ERROR);}RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, factory);long increment = redisAtomicLong.incrementAndGet();if (1 == increment) {// 如果数据是初次设置,需要设置超时时间redisAtomicLong.expire(1, TimeUnit.DAYS);}return increment;}
}
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
优点:
- 性能不错、每秒10万并发量。
- 生成的 ID 是有序递增的
缺点:
- redis 宕机后不可用,RDB重启数据丢失会重复ID。
- 自增,数据量易暴露。
基于雪花算法(Snowflake)模式
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
https://blog.csdn.net/yy139926/article/details/128468074
优点:
- 雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,生成ID的效率非常高,稳定性好,可以根据自身业务特性分配bit位,比较灵活。
缺点:
- 每台机器的时钟不同,当时钟回拨可能会发生重复ID。
- 当数据量大时,需要对ID取模分库分表,在跨毫秒时,序列号总是归0,会发生取模后分布不均衡。
如何解决时间回拨问题
时间回拨是指,当机器出现问题,时间可能回到之前,此时雪花算法生成的id可能与之前的id值相同,从而导致id重复。
- 系统抛出异常,运维来手动调整时间。
- 延迟等待,对于偶然性的时间回拨,也许是机器出现了一次小故障,频繁出现的概率并不大,所以对于这种情况没必要中断业务,可以采用阻塞线程5ms,再获取时间,对比看时间是否比上一次请求的时间大,如果大了,说明恢复正常了,则不用管;如果还小,说明真出问题了,则抛出异常,呼唤程序员处理。
- 备用机方式来解决,当前机器出现问题,迅速换一台机器,通过高可用解决。
百度(uid-generator)
略
美团(Leaf)
https://blog.csdn.net/yy139926/article/details/126740614
滴滴(Tinyid)
略
相关文章:
分布式ID生成方案
文章目录前言一、分布式ID需要满足的条件二、分布式ID生成方式基于UUID数据库自增数据库集群数据库号段模式redis ID生成基于雪花算法(Snowflake)模式百度(uid-generator)美团(Leaf)滴滴(Tinyid…...
合宙Air103|fbd数据库| fskv - 替代fdb库|LuatOS-SOC接口|官方demo|学习(16):类redis的fbd数据库及fskv库
基础资料 基于Air103开发板:🚗 Air103 - LuatOS 文档 上手:开发上手 - LuatOS 文档 探讨重点 对官方社区库接口类redis的fbd数据库及fskv库的调用及示例进行复现及分析,了解两库的基本原理及操作方法。 软件及工具版本 Luat…...

【论文精读】Deep Residual Learning for Image Recognition
1 Degradation Problem💦 深度卷积神经网络在图像分类方面取得了一系列突破。深度网络自然地将低/中/高级特征和分类器以端到端的多层方式集成在一起,特征的“层次”可以通过堆叠层数(深度)来丰富。最近的研究揭示了网络深度是至关重要的,在具…...

Lesson2:基础语法、输出输入
一、基础语法 1、行结构 一个Python程序可分为许多逻辑行,一般来说:一个语句就是一行代码,不会跨越多行。 """比如下面的Python程序,一共有3个逻辑行,每一行都通过print()输出一个结果。""…...

android 9.0去掉前置摄像头闪光灯功能
1.1概述 在9.0的系统rom定制化开发中,在系统中camera2也是非常重要的一部分功能,在很多场合会用到camera2拍照视频,等等功能, 但是在使用过程中发现系统camera2在使用的时候,在前置摄像头进行拍照的时候,会出现闪光灯的情况,对于产品来说,者就是一个大问题,所以产品要求…...

静态分析工具Cppcheck在Windows上的使用
之前在https://blog.csdn.net/fengbingchun/article/details/8887843 介绍过Cppcheck,那时还是1.x版本,现在已到2.x版本,这里再总结下。 Cppcheck是一个用于C/C代码的静态分析工具,源码地址为https://github.com/danmar/cppcheck …...

用一年时间脱胎换骨
生活习惯篇早睡早起11点30之前必须睡觉按时吃饭特别是早餐控糖,少吃甜食早起刷牙后,喝一杯温水保持身材,养成运动健身的习惯养成持续写作的习惯记录选题,金句,素材断舍离,定期整理,把不用的东西…...

全景拼接python旗舰版
前言在这个项目中,您将构建一个管道,将几幅图像拼接成一个全景图。您还将捕获一组您自己的图像来报告最终的结果。步骤1 特征检测与描述本项目的第一步是对序列中的每幅图像分别进行特征检测。回想一下我们在这个类中介绍过的一些特征探测器:…...
常见的字符串与内存操作函数)
(C语言)常见的字符串与内存操作函数
问:1. Solve the problems:我想用三种方法求字符串的长度怎么办?2. strlen处理的字符串中有什么时需要注意:什么只记为什么?当什么不起什么作用时,什么不计算在内,编译器会把什么,什…...

Linux基础笔记总结
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...

R语言学习笔记
1.R语言介绍 2.R语言安装 官网:https://www.r-project.org/ CARN → 选择China中任意镜像站点 → Download R for Windows → base(二进制版本R基础软件)→ Download R-4.2.2 for Windows (76 megabytes, 64 bit) 3.Rstudio安装 https://po…...
【软件测试】企业测试面试题9道,从自我介绍到项目考察+回答......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 1、自我介绍 您好&a…...

《Spring源码深度分析》第8章 数据库连接JDBC
目录标题前言一、数据库连接方式1.JDBC连接数据库2.Spring Jdbc连接数据库(JdbcTemplate)二、JdbcTemplate源码分析1.update/save功能的实现源码分析入口(关键)基础方法execute1.获取数据库连接池2.应用用户设定的输入参数3. 调用回调函数处理4. 资源释放Update中的回调函数2.q…...

ModuleNotFoundError的解决方案【已解决】
问题描述 有包却提示ModuleNotFoundError 在正常情况下,你使用pip或者conda检查是否有相应包的时候,显示的是有的。但是一旦运行程序就会报这个ModuleNotFoundError错误。 问题可能是程序运行环境不对。 解决方案 (1)进入正确…...
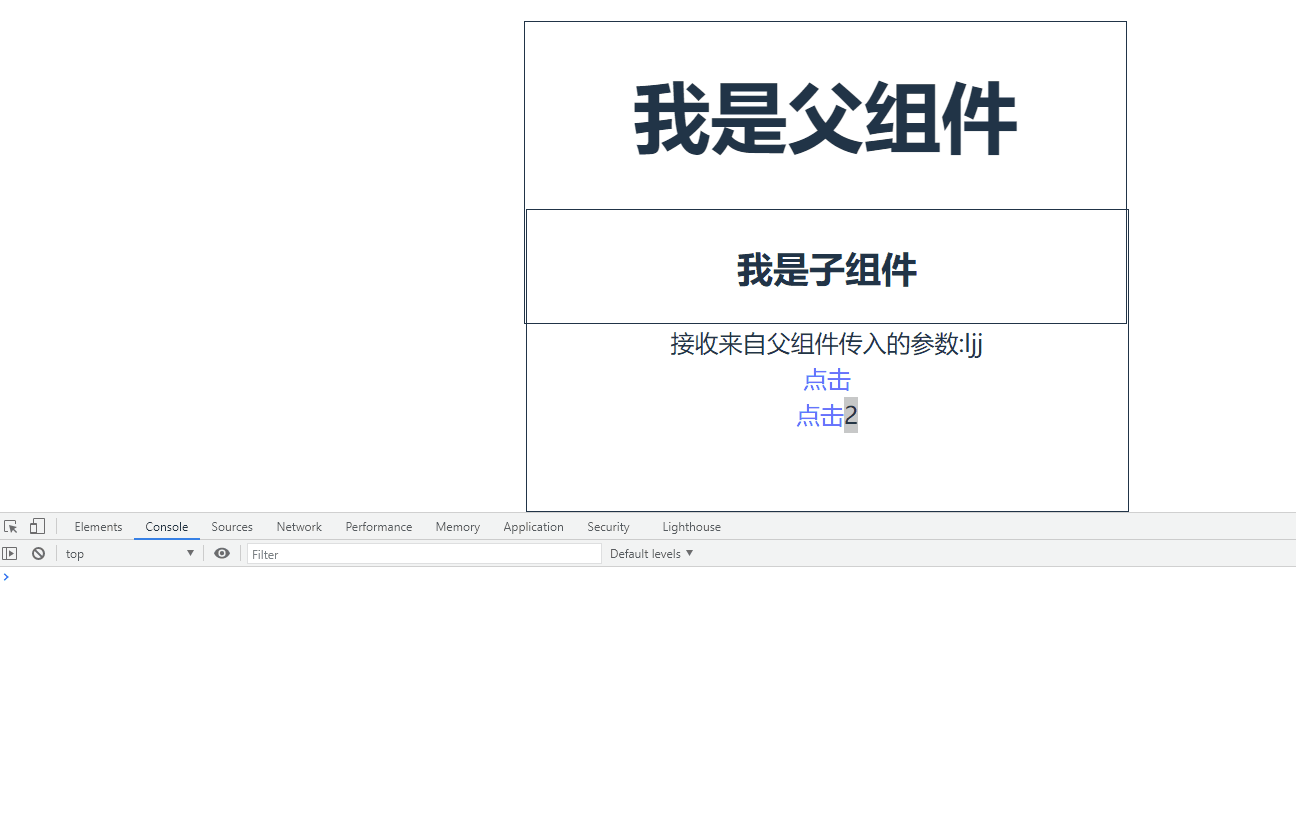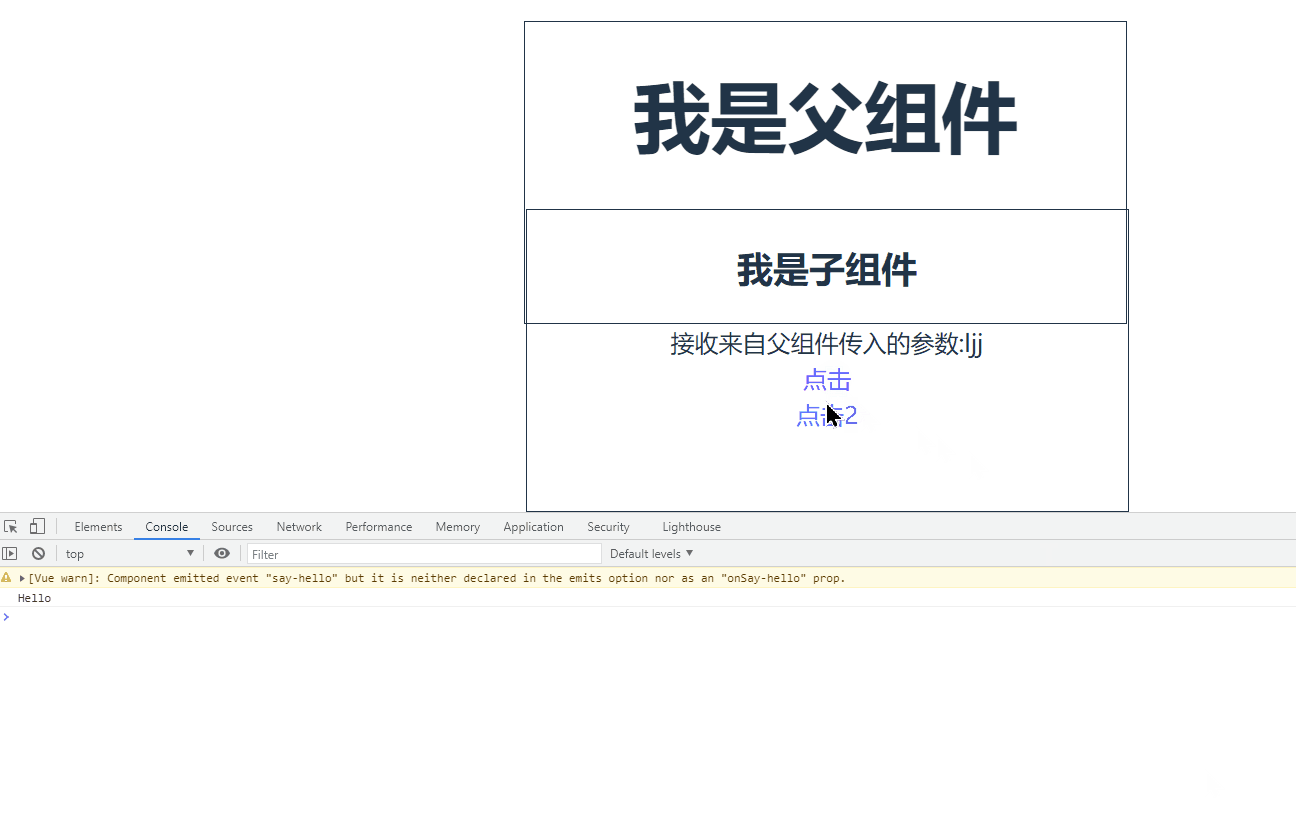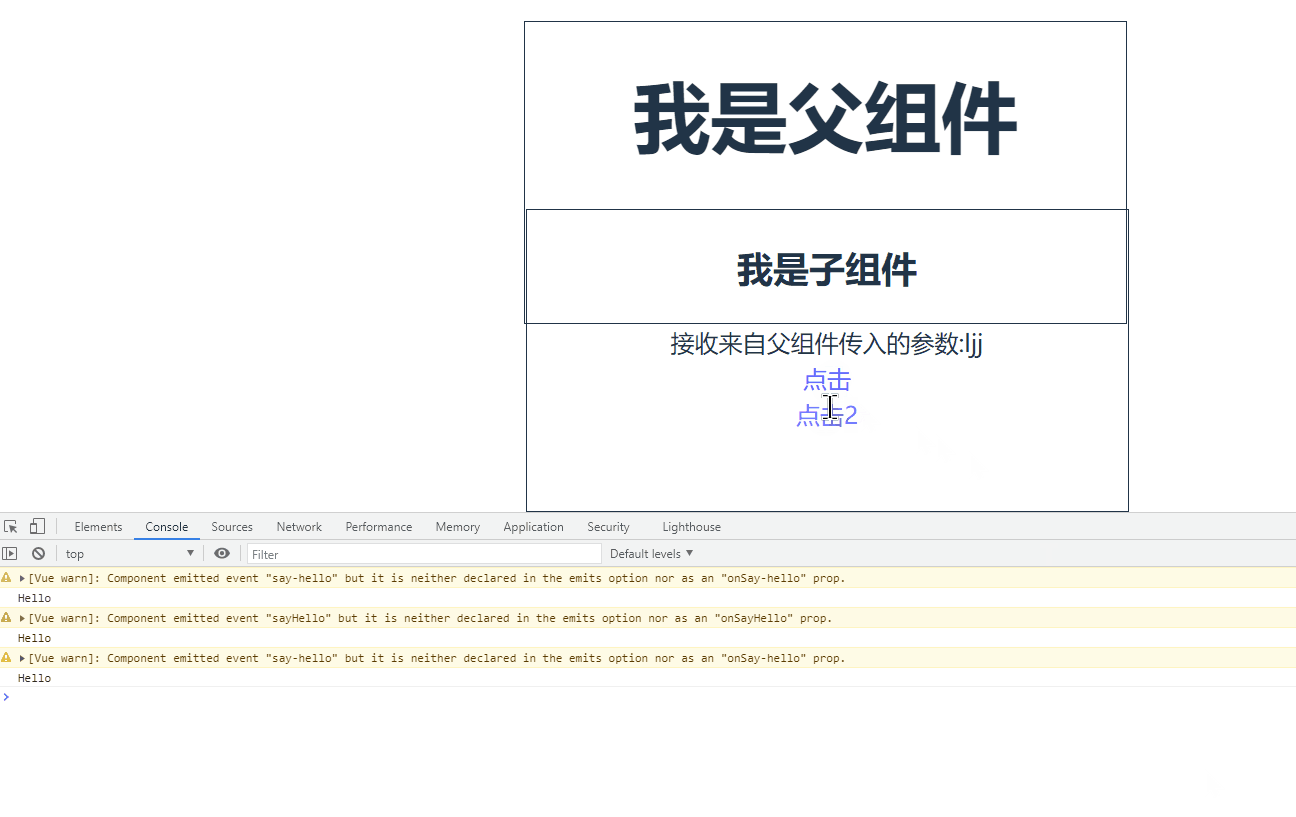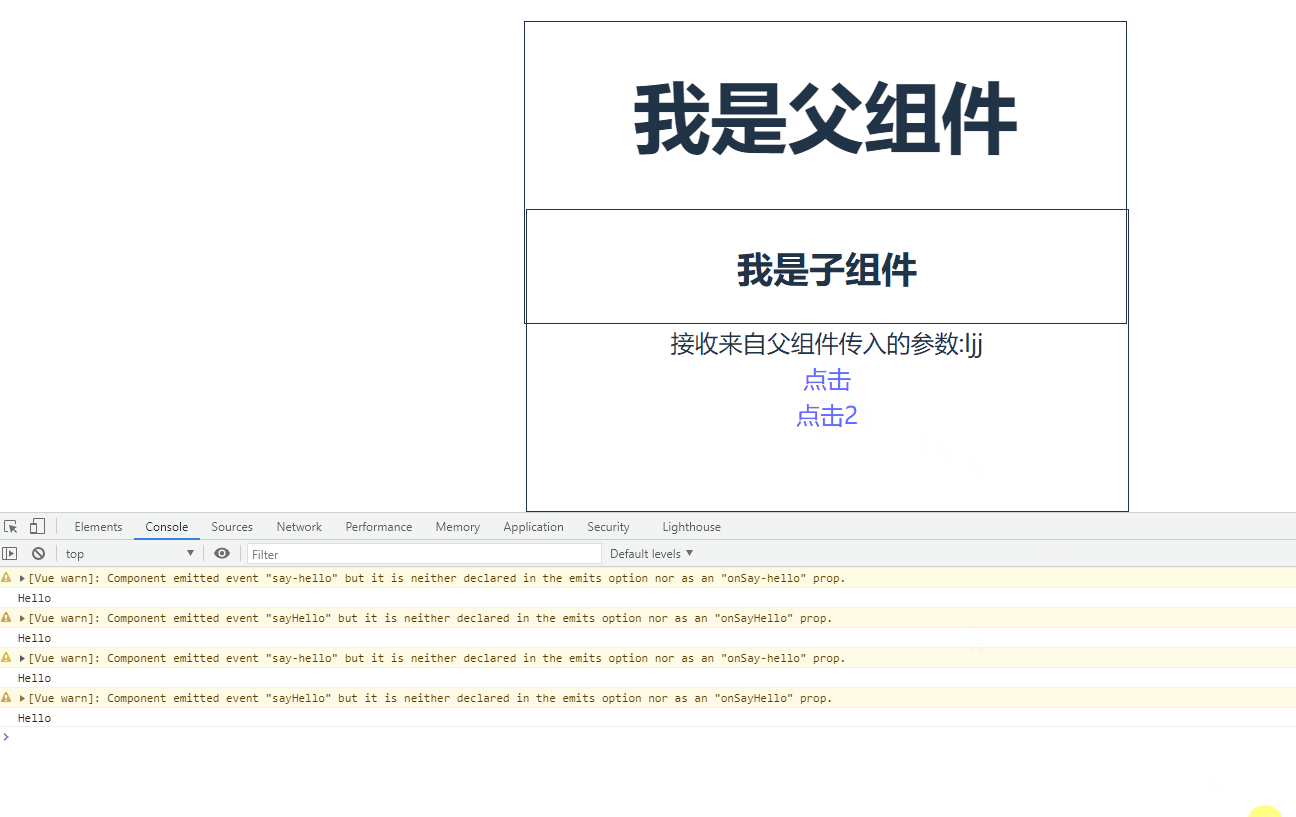
Vue驼峰与短横线分割命名中有哪些坑
目录 0.前言 驼峰和短横线分割命名注意事项 组件注册命名 父子组件数据传递时命名 父子组件函数传递 0.前言 Vue驼峰命名法指的是将变量以驼峰形式命名,例如 userName、userId 等,而短横线分隔符法则指的是用短横线分隔变量名,例如 user…...

从文件中加载数据以及异常处理
上期学习了数据的存储,这次学习数据的加载 你可以使用把openpyxl.load_workbook() 来打开一个已经存在的工作簿 >>> from openpyxl import load_workbook >>> wb load_workbook(filename empty_book.xlsx) >>> sheet_ranges wb[ran…...
【JavaSE】方法的使用
方法的使用BIT-5-方法的使用绪论1. 方法概念及使用1.1什么是方法1.2 方法定义1.3 实参和形参的关系(重要)1.4 没有返回值的方法2. 方法重载2.1 为什么需要方法重载2.2 方法重载概念3. 递归3.1 生活中的故事3.2 递归的概念3.2 递归执行过程分析3.3 递归练…...

ModelScope 垂类检测系列模型介绍
文章目录ModelScope介绍垂类模型介绍调用方式1 Demo Service2 Notebook3 本地使用* 二次开发总结ModelScope介绍 ModelScope 是阿里达摩院推出的 中文版模型即服务(MaaS, Model as a Service)共享平台。该平台在2022年的云栖大会上发布,之前…...
Linux | Linux卸载和安装MySQL(Ubuntu版)
最近又来到了Linux学习了,原因是要接触云服务器相关知识, 所以博主整理了一些关于Linux的知识, 欢迎各位朋友点赞收藏,天天开心丫,快乐写代码! Linux系列文章请戳 Linux教程专栏 目录 一、卸载MySQL 1…...
【C1】数据类型,常量变量,输入输出,运算符,if/switch/循环,/数组,指针,/结构体,文件操作,/编译预处理,gdb,makefile,线程
文章目录1.数据类型:单双引号,char(1B),int/float(32位系统,大小一样4B,但存储方式不同),double(8B),long double…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...