ElasticSearch - 分片内部原理之动态更新索引、近实时搜索、持久化变更、段合并
文章目录
- 01. ElasticSearch 倒排索引是什么?
- 02. ElasticSearch 倒排索引为什么是不可变的?
- 03. ElasticSearch 索引文档原理?
- 04. ElasticSearch 如何动态更新索引?
- 05. ElasticSearch 文档的新增、删除、更新?
- 06. ElasticSearch 搜索为什么是近实时的?
- 07. ElasticSearch 在什么情况下使用 refresh api ?
- 08. Elasticsearch 是怎样保证更新被持久化在断电时也不丢失数据?
- 09. ElasticSearch 在什么情况下使用 flush api?
- 10. ElasticSearch 为什么需要段合并?
- 11. ElasticSearch 在什么情况下使用 optimize api?
- 12. 分片内部原理
- 1. 索引的不可变性
- 2. 动态更新索引
- 3. 近实时搜索
- 4. 持久化变更
- 5. 段合并
01. ElasticSearch 倒排索引是什么?
Elasticsearch的倒排索引是一种数据结构,它将每个单词与包含该单词的文档列表相关联。倒排索引的优势在于它可以快速地进行全文搜索和相关性评分。
倒排索引由3个主要部分组成:词项、词汇表、倒排列表。其中词项是索引中最小的存储和查询单元。词汇表是一个包含所有单词的列表,每个单词都有一个唯一的词项ID。倒排列表是一个包含每个单词的文档列表(一个单词出现在哪些文档中),每个文档都有一个唯一的文档ID。倒排列表还包含每个单词在每个文档中出现的位置和频率的信息。
当用户执行全文搜索时,Elasticsearch将查询中的每个单词与词汇表中的词项进行匹配,并检索包含这些单词的文档列表。然后,Elasticsearch使用倒排列表中的信息来计算每个文档的相关性得分,并将结果返回给用户。
ElasticSearch索引中索引了3个文档:
| 文档id | 文档内容 |
|---|---|
| 1 | 谷歌地图之父跳槽Facebook |
| 2 | 谷歌地图之父加盟Facebook |
| 3 | 谷歌地图创始人离开谷歌加盟Facebook |
倒排索引中需要记录的信息:
| 单词id | 单词 | 文档频率 | 倒排列表(文档id;单词频率;<单词在文档中的位置>) |
|---|---|---|---|
| 1 | 谷歌 | 3 | (1;1<1>),(2;1;<1>),(3;2;<5>) |
| 2 | 地图 | 3 | (1;1<2>),(2;1;<2>),(3;1;<2>) |
| 3 | 之父 | 2 | (1;1<3>),(2;1;<3>) |
| 4 | 跳槽 | 2 | (1;1<4>) |
| 5 | 3 | (1;1<5>),(2;1;<5>),(3;1;<7>) | |
| 6 | 加盟 | 2 | (2;1<4>),(3;1;<6>) |
| 7 | 创始人 | 1 | (3;1;<3>) |
| 8 | 离开 | 1 | (3;1;<4>) |
以单词谷歌为例,其单词编号为1,文档频率为3,代表有3个文档包含这个单词,对应的倒排列表为{(1;1;<1>), (2;1;<1>), (3;2;<1>)},其含义为在文档1、2、3都出现过这个单词,文档1和文档2中该单词出现的频率都为1,出现位置也都是1,即文档中第1个单词是谷歌。文档3中该单词出现的频率为2次,出现的位置为1和5,即文档3的第1个和第5个单词是谷歌。
02. ElasticSearch 倒排索引为什么是不可变的?
倒排索引被写入磁盘后是不可改变的,它永远不会修改。不变性有重要的价值:
① 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
② 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
③ 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
④ 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
03. ElasticSearch 索引文档原理?
给定一个文档集合(第一次索引文档时),此时如何建立一个索引?首先在内存里维护一个倒排索引,当内存占满后,将内存数据写入磁盘的临时文件,第二阶段对临时文件进行合并形成最终索引。
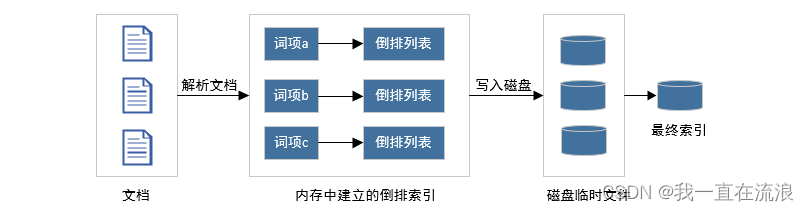
① 从磁盘读取文档,对文档内容进行解析,并在内存中建立一个倒排索引,相当于对目前处理的文档子集单独在内存中建立起了一整套倒排索引,和最终索引相比,其结构和形式是相同的,区别是这个索引只是部分文档的索引而非全部文档的索引。
② 当内存占满后,为了腾出内存空间,将整个内存中建立的倒排索引写入磁盘临时文件中,然后彻底清除所占内存,这样就空出内存来进行后续文档的处理。
③ 每一轮处理都会在磁盘产生一个对应的临时文件,当所有文档处理完成后,在磁盘中会有多个临时文件,为了产生最终的索引,需要将这些临时文件合并形成最终索引。
04. ElasticSearch 如何动态更新索引?
倒排索引一旦被写入磁盘就是不可更改的(没有写入磁盘前是可以更改的噢),如果搜索引擎需要处理的文档集合是静态集合,那么在索引建立好之后,就可以一直用建好的索引响应用户查询请求。但是,在真实环境中,搜索引擎需要处理的文档集合往往是动态集合,即在建好初始的索引后,后续不断有新文档进入系统,同时原先的文档集合内有些文档可能被删除或者内容被更改。问题是怎样在保留不变性的前提下实现倒排索引的更新呢?答案是: 用更多的索引,即增加临时索引。在动态更新索引中,有3个关键的索引结构:倒排索引、临时索引和已删除文档列表。
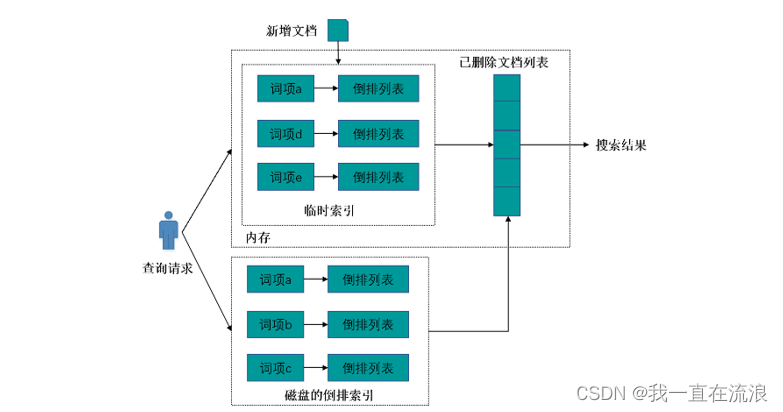
① 倒排索引就是对初始文档集合建立好的索引结构,该索引存在磁盘中,不可改变。
② 临时索引是在内存中实时建立的倒排索引,该索引存储在内存中,当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排列表末尾追加倒排列表项,随着新加入系统的文档越来越多,临时索引消耗的内存也会随之增加,一旦临时索引将指定的内存消耗光,要考虑将临时索引的内容更新到磁盘索引中,以释放内存空间来容纳后续的新进文档。
③ 已删除文档列表则用来存储已被删除的文档的相应文档ID,形成一个文档ID列表。这里需要注意的是:当一篇文档内容被更改,可以认为是旧文档先被删除,之后向系统内增加一篇新的文档,通过这种间接方式实现对内容更改的支持。
当系统发现有新文档进入时,立即将其加入临时索引中。有文档被删除时,则将其加入删除文档队列。文档被更改时,则将原先文档放入删除队列,解析更改后的文档内容,并将其加入临时索引中。通过这种方式可以满足实时性的要求。
如果用户输入查询请求,则搜索引擎同时从倒排索引和临时索引中读取用户查询单词的倒排列表,找到包含用户查询的文档集合,并对两个结果进行合并,之后利用删除文档列表进行过滤,将搜索结果中那些已经被删除的文档从结果中过滤,形成最终的搜索结果,并返回给用户。这样就能够实现动态环境下的准实时搜索功能。
注意:在内存中的临时索引是不断变化的,但是这个临时索引一旦写进磁盘,就是不可变的。
05. ElasticSearch 文档的新增、删除、更新?
在早期全文检索中为整个文档集合建立了一个很大的倒排索引,并将其写入磁盘中,如果需要让一个新的文档可被搜索,你需要重建整个索引。这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,所以对数据的更新不能过于频繁,也就不能保证时效性,因此提出了段的概念,即将一个索引文件拆分为多个文件,每个子文件叫做段,每个段都是一个被写入磁盘的倒排索引,因此段具有不变性。
Elasticsearch 基于 Lucene, 这个java库引入了按段搜索的概念。 每一段本身都是一个倒排索引, 但索引在 Lucene 中除表示所有段的集合外, 还增加了提交点的概念,提交点是一个列出了所有已知段的文件。
① 当新增一个文档时,这个文档会被添加到内存索引缓存中,随后解析文档,更新内存中维护的临时索引,文档中出现的每个单词,在其倒排列表末尾追加倒排列表项。
② 随着内存索引缓存中的的文档越来越多,临时索引消耗的内存也会随之增加,一旦临时索引将指定的内存消耗光,要考虑将临时索引的内容更新到磁盘索引中,以释放内存空间来容纳后续的新进文档。
当缓存被提交时:
(1) 一个新的段被写入磁盘。(这个段就是缓存中维护的临时倒排索引)
(2) 一个新的包含新段名字的提交点被写入磁盘。
(3) 磁盘进行同步。(所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件)
(4) 新的段被开启,让它包含的文档可见以被搜索。
(5) 内存缓存被清空,等待接收新的文档。
每一个倒排索引都会被轮流查询到,询完后再对结果进行合并。当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。 这种方式可以用相对较低的成本将新文档添加到索引。
删除和更新文档:
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。 取而代之的是,每个提交点会包含一个 .del 文件,文件中会列出这些被删除文档的段信息。
当一个文档被 “删除” 时,它实际上只是在 .del 文件中被 标记 删除。一个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。 可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
06. ElasticSearch 搜索为什么是近实时的?
新增的文档被收集到内存缓冲区,随后解析这个文档追加到临时索引的单词词典和倒排表中,随着加入的文档越来越多,最初分配的内存缓冲区被用完,就会将内存缓冲区的内容写入磁盘的段中,此时文档便可被检索了,因此一个新的文档从索引到可被搜索的时间取决于该文档多久能从内存中写入到磁盘中,当文档被写入磁盘就可被检索了。
随着按段搜索的发展,一个新的文档从索引到可被搜索的时间延迟显著降低了,新文档在几分钟之内即可被检索,但这样还是不够快。那怎样才能更快呢?可不可以把内存缓冲区大小设置的小一点,这样一个新的文档从索引到写入磁盘的时间延迟就降低了,新增的文档就能更快的被搜索到了?
原理是没错的,但是不可行!原因是磁盘在这里成为了瓶颈,当你把内存缓冲区大小设置的更小时,磁盘IO的次数就会增加,我们知道提交一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是 fsync 操作代价很大,如果每次索引一个文档都去执行一次 fsync的话会造成很大的性能问题,因此我们不能频繁的 fsync ,即无法通过提高磁盘IO次数的方式来让新增的文档更快的被用户搜索到。
那到底怎样才能更快呢?其实我们需要的是一个更轻量的方式来使一个文档可被搜索,不能让内存中维护的倒排索引直接写入磁盘中,这意味着 fsync 要从整个过程中被移除。可是文档不写入磁盘,又怎么被检索到呢?
在Elasticsearch和磁盘之间是文件系统缓存,许多人没有意识到文件系统缓存对于性能的影响,其实Linux系统默认的设置倾向于把内存尽可能的用于文缓存,所以在一台大内存机器上,往往我们可能发现没有多少剩余内存。文件系统缓存可以加速磁盘操作,使系统有更好的IO性能,代价只是把一些空闲的内存利用起来了。
在内存缓冲区中的文档会被写入一个新的段中,但是这个新段会被先写入到内存的文件系统缓存中,这一步相对于 fsync 更轻量,代价更小,当段被提交到文件系统缓存中后,新增的文档便可被检索了。
Lucene允许新段被写入和打开,使其包含的文档在未进行一次完整提交时便对搜索可见(完整提交是指将新段写入磁盘), 这种方式比进行一次提交代价 fsync 要小得多,并且在不影响性能的前提下可以被频繁地执行。
07. ElasticSearch 在什么情况下使用 refresh api ?
在Elasticsearch中,写入和打开一个新段的轻量的过程叫做refresh,即refresh是指将内存缓冲区的内容写入到文件系统缓存的一个段中,使其包含的文档便可以被搜索,默认情况下每个分片会每秒自动刷新(refresh)一次。这就是为什么我们说Elasticsearch是近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑,索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新:
// 刷新(Refresh)所有的索引
POST /_refresh
// 只刷新(Refresh) blogs 索引
POST /blogs/_refresh
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
这个问题的解决办法是执行一次手动刷新:并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率:
//每30秒刷新 my_logs 索引。
PUT /my_logs
{"settings": {"refresh_interval": "30s" }
}
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
//关闭自动刷新
PUT /my_logs/_settings
{ "refresh_interval": -1 } //每秒自动刷新
PUT /my_logs/_settings
{ "refresh_interval": "1s" }
refresh_interval 需要一个 持续时间 值, 例如 1s (1 秒) 或 2m (2 分钟)。 一个绝对值 1 表示的是 1毫秒 ,这无疑会使你的集群陷入瘫痪。
08. Elasticsearch 是怎样保证更新被持久化在断电时也不丢失数据?
为了动态更新索引,我们增加了段的概念,将新增的文档收集到内存缓冲区并维护一个倒排索引,待最初分配的内存缓冲区空间用完时,将内存缓冲区的内容写入文件系统缓存的段中(refresh),这一步相对 fsync 会更加轻量,代价更小。
但是如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。
如果将段从内存缓存刷新(refresh)到文件系统缓存而未刷新到磁盘中,那么只是让段包含的文档可被检索了,但是这个段并未提交。在动态更新索引,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。一个分片就是一个Lucene索引,一个Lucene索引包含多个段和一个包含所有段列表的提交点。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?如果在下一次完整提交之前,机器断电,那么存在文件系统缓存中的数据就没了,我们也不希望丢失掉这些数据。
Elasticsearch 增加了一个translog,或者叫事务日志,在每一次对 Elasticsearch进行操作时均进行了日志记录。通过translog ,整个流程看起来是下面这样:
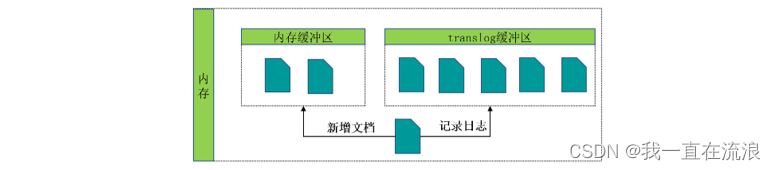
① 一个文档被索引之后,就会被添加到内存缓冲区,并在内存中写入translog 日志,后写入日志的原因是数据在建立索引时,需要经过分词等一系列复杂的操作,有可能写入失败,为了保证日志中都是成功的数据,所以后写入:
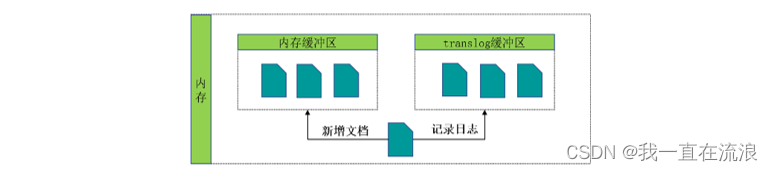
② 分片每秒被刷新(refresh)一次,刷新完成后, 缓存被清空但是事务日志不会:
(1) 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
fsync操作。
(2) 这个段被打开,使其可被搜索。
(3) 内存缓冲区被清空。
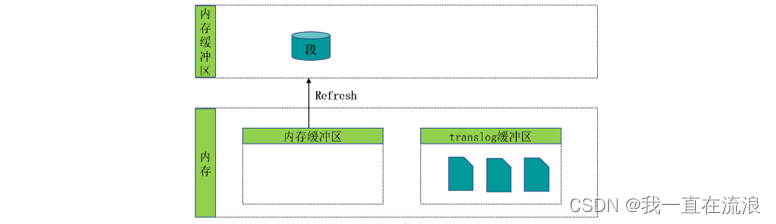
③ 这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志,事务日志不断积累文档 :
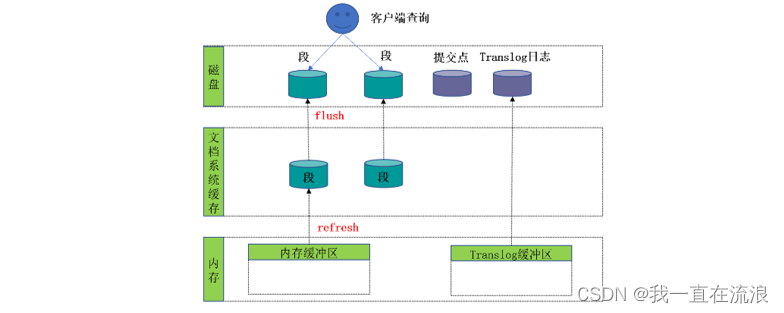
④ 在刷新(flush)之后,段被全量提交,并且事务日志被清空:
(1) 所有在内存缓冲区的文档都被写入一个新的段
(2) 缓冲区被清空
(3) 一个提交点被写入硬盘
(4) 文件系统缓存通过 fsync 被刷新(flush)
(5) 内存中的translog写入磁盘并清空老的translog日志文件
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
09. ElasticSearch 在什么情况下使用 flush api?
这个执行一个提交并且截断 translog 的行为在 ES被称作一次flush , 分片每30分钟被自动刷新flush,或者在 translog 太大的时候也会刷新。
flush API 可以被用来执行一个手工的刷新(flush):
// 刷新(flush) blogs索引。
POST /blogs/_flush // 刷新(flush)所有的索引并且并且等待所有刷新在返回前完成。
POST /_flush?wait_for_ongoing
你很少需要自己手动执行 flush 操作;通常情况下,自动刷新就足够了。这就是说,在重启节点或关闭索引之前执行 flush有益于你的索引。当 ES 尝试恢复或重新打开一个索引, 它需要重放 translog 中所有的操作,所以如果日志越短,恢复越快。
10. ElasticSearch 为什么需要段合并?
当我们往 ElasticSearch新增文档时,文档先加入内存缓冲区并更新倒排索引,然后每隔1秒将内存缓冲区的内容写入一个可被检索的新段,这个过程叫refresh。由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段,所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。启动段合并不需要你做任何事。进行索引和搜索时会自动进行。
① 两个提交了的段和一个未提交的段正在被合并到一个更大的段:
(1) 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
(2) 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
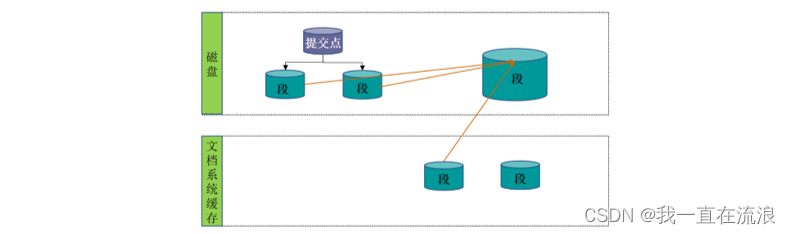
② 合并完成时的活动:
(1) 新的段被刷新(flush)到了磁盘。写入一个包含新段且排除旧的和较小的段的新提交点。
(2) 新的段被打开用来搜索。
(3) 老的段被删除。

合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。ES在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
11. ElasticSearch 在什么情况下使用 optimize api?
optimize API大可看做是强制合并 API。它会将一个分片强制合并到 max_num_segments 参数指定大小的段数目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
在特定情况下,使用 optimize API 颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。 老的索引实质上是只读的;它们也并不太可能会发生变化。在这种情况下,使用optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了;这样既可以节省资源,也可以使搜索更加快速:
POST /logstash-2014-10/_optimize?max_num_segments=1
使用 optimize API 触发段合并的操作不会受到任何资源上的限制。这可能会消耗掉你节点上全部的I/O资源, 使其没有余裕来处理搜索请求,从而有可能使集群失去响应。 如果你想要对索引执行 optimize,你需要先使用分片分配把索引移到一个安全的节点,再执行。
refresh,flush, 和optimizeAPI 都做了什么, 你什么情况下应该使用他们?
12. 分片内部原理
1. 索引的不可变性
倒排索引被写入磁盘后是不可改变的,它永远不会修改。不变性有重要的价值:
① 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
② 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
③ 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
④ 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档 可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
2. 动态更新索引
1、索引文档
下一个需要被解决的问题是怎样在保留不变性的前提下实现倒排索引的更新?答案是: 用更多的索引。
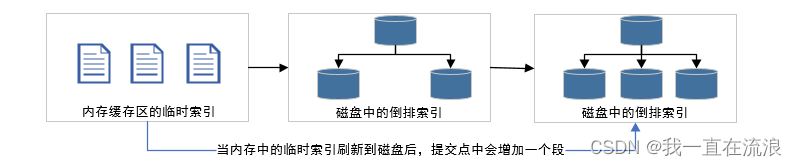
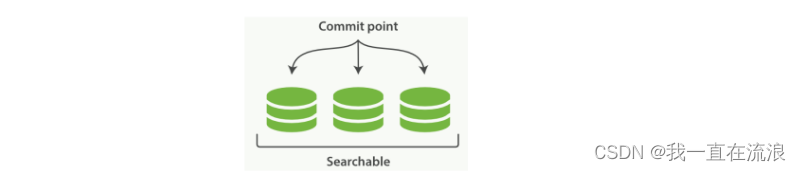
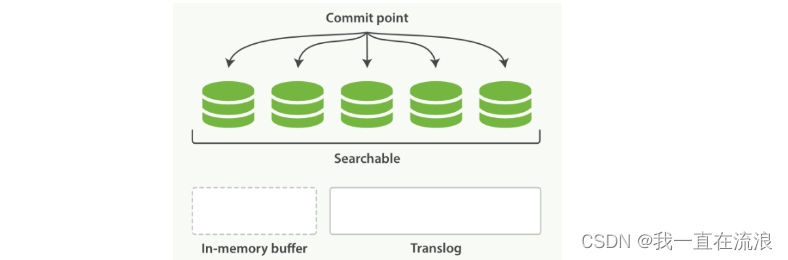
通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,查询完后再对结果进行合并。Elasticsearch 基于 Lucene, 这个 java 库引入了按段搜索的概念, 每一段本身都是一个倒排索引。 但索引在 Lucene 中除表示所有段的集合外, 还增加了提交点( 一个列出了所有已知段的文件)的概念 。如图:一个 Lucene 索引包含一个提交点和三个段:
逐段搜索会以如下流程进行工作:
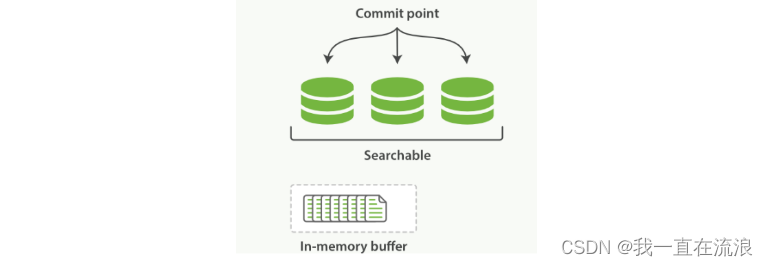
① 新文档被收集到内存索引缓存, 如图:一个在内存缓存中包含新文档的 Lucene 索引,新的文档首先被添加到内存索引缓存中,然后写入到一个基于磁盘的段。
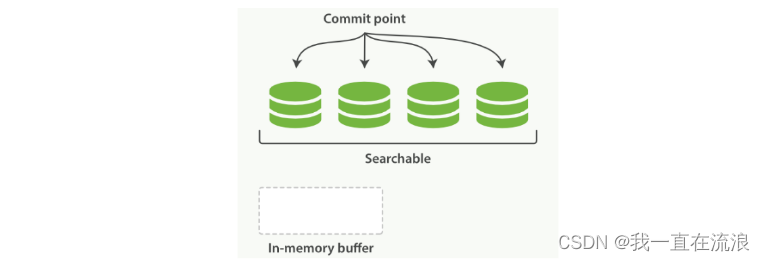
② 不时地,缓存被提交:
- 一个新的段(一个追加的倒排索引)被写入磁盘。
- 一个新的包含新段名字的提交点被写入磁盘。
- 磁盘进行同步:所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件。
③ 新的段被开启,让它包含的文档可见以被搜索。
④ 内存缓存被清空,等待接收新的文档。如图:在一次提交后,一个新的段被添加到提交点而且缓存被清空
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。 这种方式可以用相对较低的成本将新文档添加到索引。
2、删除和更新文档
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。 取而代之的是,每个提交点会包含一个 .del 文件,文件中会列出这些被删除文档的段信息。
当一个文档被 “删除” 时,它实际上只是在 .del 文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。 可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
3. 近实时搜索
随着按段搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。磁盘在这里成为了瓶颈。提交一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是 fsync 操作代价很大; 如果每次索引一个文档都去执行一次的话会造成很大的性能问题。我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着 fsync 要从整个过程中被移除。
在Elasticsearch和磁盘之间是文件系统缓存。 像之前描述的一样, 在内存索引缓冲区中的文档会被写入到一个新的段中。 但是这里新段会被先写入到文件系统缓存(这一步代价会比较低),稍后再被刷新到磁盘(这一步代价比较高)。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
在内存缓冲区中包含了新文档的 Lucene 索引:
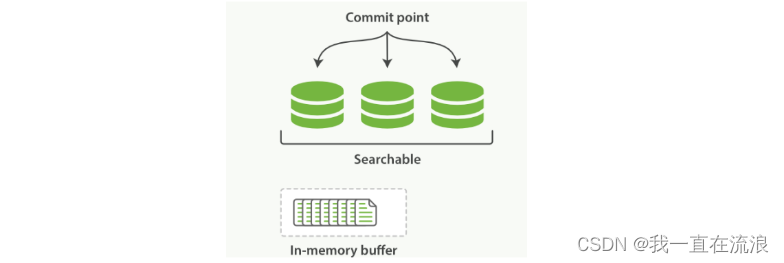
Lucene 允许新段被写入和打开,使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交:
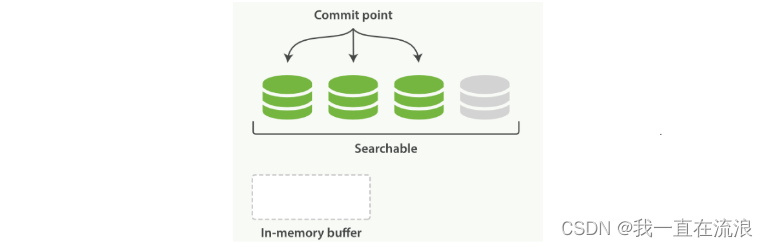
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新:
POST /_refresh # 刷新(Refresh)所有的索引。
POST /blogs/_refresh # 只刷新(Refresh) blogs 索引。
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率:
# 每30秒刷新 my_logs 索引。
PUT /my_logs
{"settings": {"refresh_interval": "30s" }
}
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
# 关闭自动刷新
PUT /my_logs/_settings
{ "refresh_interval": -1 } # 每秒自动刷新
PUT /my_logs/_settings
{ "refresh_interval": "1s" }
refresh_interval 需要一个 持续时间 值, 例如 1s (1 秒) 或 2m (2 分钟)。 一个绝对值 1 表示的是 1毫秒 ,这无疑会使你的集群陷入瘫痪。
4. 持久化变更
如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。在动态更新索引,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。通过 translog ,整个流程看起来是下面这样:
① 一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog ,如图:新的文档被添加到内存缓冲区并且被追加到了事务日志
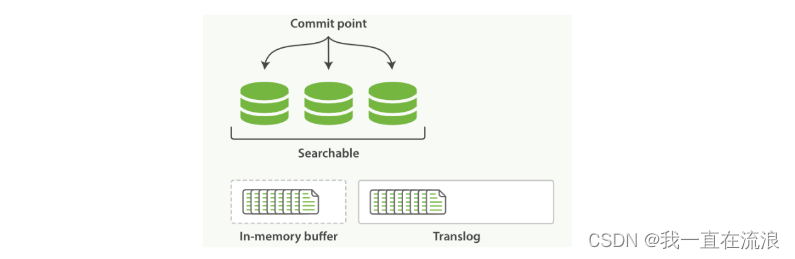
② 刷新(refresh)完成后, 缓存被清空但是事务日志不会,分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
fsync操作。 - 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
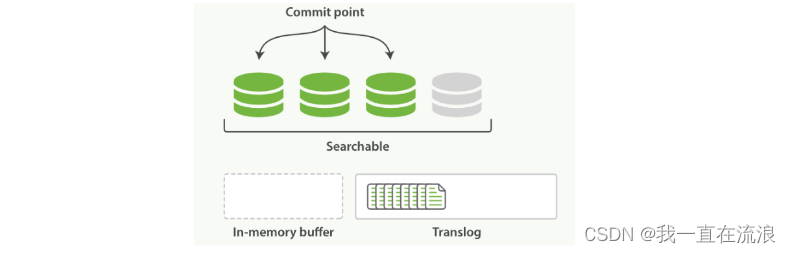
③ 这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志,如图:事务日志不断积累文档
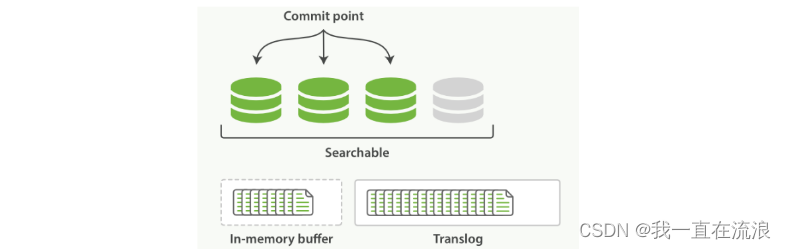
④ 每隔一段时间(translog 变得越来越大)索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行,如图:在刷新(flush)之后,段被全量提交,并且事务日志被清空:
- 所有在内存缓冲区的文档都被写入一个新的段。
- 缓冲区被清空。
- 一个提交点被写入硬盘。
- 文件系统缓存通过
fsync被刷新(flush)。 - 老的 translog 被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush 。 分片每30分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。
flush API 可以被用来执行一个手工的刷新(flush):
# 刷新(flush) blogs索引。
POST /blogs/_flush # 刷新(flush)所有的索引并且并且等待所有刷新在返回前完成。
POST /_flush?wait_for_ongoing
你很少需要自己手动执行 flush 操作;通常情况下,自动刷新就足够了。这就是说,在重启节点或关闭索引之前执行 flush 有益于你的索引。当 Elasticsearch 尝试恢复或重新打开一个索引, 它需要重放 translog 中所有的操作,所以如果日志越短,恢复越快。
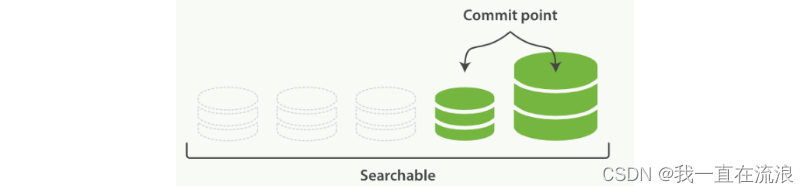
5. 段合并
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。启动段合并不需要你做任何事。进行索引和搜索时会自动进行。
① 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
② 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。如图:两个提交了的段和一个未提交的段正在被合并到一个更大的段

③ 一旦合并结束,老的段被删除:
- 新的段被刷新(flush)到了磁盘, 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。
- 老的段被删除。
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
optimize API大可看做是 强制合并 API。它会将一个分片强制合并到 max_num_segments 参数指定大小的段数目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
在特定情况下,使用 optimize API 颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。 老的索引实质上是只读的;它们也并不太可能会发生变化。在这种情况下,使用optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了;这样既可以节省资源,也可以使搜索更加快速:
POST /logstash-2014-10/_optimize?max_num_segments=1
使用 optimize API 触发段合并的操作不会受到任何资源上的限制。这可能会消耗掉你节点上全部的I/O资源, 使其没有余裕来处理搜索请求,从而有可能使集群失去响应。 如果你想要对索引执行 optimize,你需要先使用分片分配把索引移到一个安全的节点,再执行。
相关文章:
ElasticSearch - 分片内部原理之动态更新索引、近实时搜索、持久化变更、段合并
文章目录01. ElasticSearch 倒排索引是什么?02. ElasticSearch 倒排索引为什么是不可变的?03. ElasticSearch 索引文档原理?04. ElasticSearch 如何动态更新索引?05. ElasticSearch 文档的新增、删除、更新?06. Elasti…...
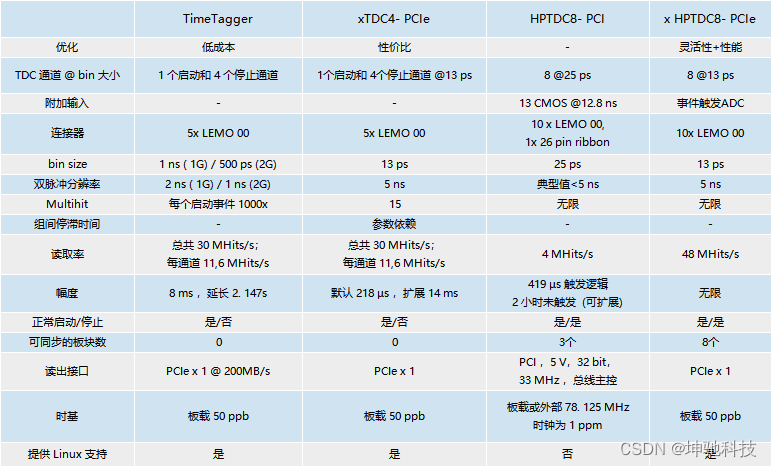
模拟数据采集卡之ADCTDC 模拟时间/数字转换器组合应用选型指南
简介 产品组合包括一系列多功能时间到数字转换器(TDC)和模数转换器(ADC)。我们的许多客户的应用场景依赖于对飞行时 间(TOF)的测量。该系列产品非常适合用于质谱系统(TOF-MS),光学相干断层扫描(OCT),荧光寿命成像显微镜(FLIM), 时间相关单光子…...
R语言编程基础
文章目录安装运算符判断函数递归安装 根据自己的操作系统,下载R语言环境后,安装,并将安装路径加入到环境变量,即可从命令行进入R环境 >rR version 4.2.2 (2022-10-31 ucrt) -- "Innocent and Trusting" Copyright …...
2023-03-15:屏幕录制并且显示视频,不要用命令。代码用go语言编写。
2023-03-15:屏幕录制并且显示视频,不要用命令。代码用go语言编写。 答案2023-03-15: 使用moonfdd/ffmpeg-go和moonfdd/sdl2-go库来实现屏幕录制并显示视频,大体流程如下: 1.使用libavdevice库中的AVInputFormat&…...
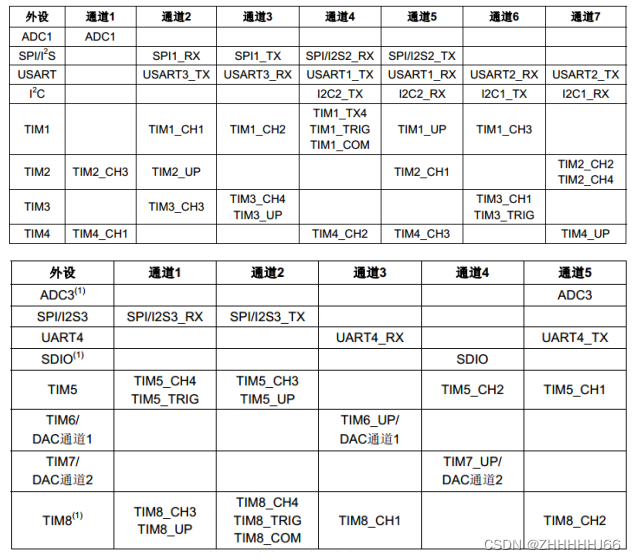
STM32外设-DMA
1. 简介 DMA(Direct Memory Access)—直接存储器存取,是单片机的一个外设,它的主要功能是用来搬数据,但是不需要占用 CPU,即在传输数据的时候, CPU 可以干其他的事情,好像是多线程一样。数据传输支持从外设…...
【面试题】面试官:如果后端给你 1w 条数据,你如何做展示?
最近一位朋友参加阿b的面试,然后面试官问了她这个问题,我问她咋写的,她一脸淡定的说:“虚拟列表。”大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面…...

第十二届蓝桥杯省赛详解
试题A:空间 1B是8位,32位二进制数占用4B空间,1MB2^10KB2^20B 那么可以存放32位二进制数的个数为256*2^20*8/3267108864 试题B:卡片 分析:因为数据只有2021,所以直接模拟即可 结果为:3181&…...

ssh创建秘钥对
1. 使用ssh-keygen 生成秘钥对 [root6zix89b87qmvuv ~]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): 按回车键或设置密钥的存储路径 Enter passphrase (empty for no passphrase): 按回车键或设置密钥的存…...
方法返回值?)
JS中sort()方法返回值?
参考 https://segmentfault.com/q/1010000043489928 精辟解释 就是说 sort() 会修改原数组项的排序,sort() 结束后会返回一个数组结果,这个结果其实就是原数组。并不是说会返回一个新的数组。 原理讲解 JS 分为栈内存和堆内存,栈内存可以…...

07从零开始学Java之如何正确的编写Java代码?
作者:孙玉昌,昵称【一一哥】,另外【壹壹哥】也是我哦CSDN博客专家、万粉博主、阿里云专家博主、掘金优质作者前言在上一篇文章中,壹哥带领大家开始编写了第一个Java案例,在我们的cmd命令窗口中输出了”Hello World“这…...

Python学习笔记14:网络编程
网络编程 几个网络模块 模块socket # 简单的服务器 import socket s socket.socket() host socket.gethostname() port 1234 s.bind((host, port))s.listen(5) while True: c, addr s.accept() print(Got connection from, addr) c.send(Thank you for connecting)c.…...

初入了解——什么是VUE
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...
)
代码规范(C++)
1.命名规范 1.目录/文件 字母、数字、下划线构成,不同单词用下划线隔开。 2.函数/接口 小驼峰命名法。 3.命名空间 字母、数字、下划线构成,不同单词用下划线隔开,但是尽量只使用一个单词。 4.结构体/类 大驼峰命名法,不包…...
)
React教程详解四(hooks、pureComponent、Context通信、错误边界、children props与render props)
前言 hooks是react16.8.0版本新增加的新特性/新语法,最大的特点是可以在开发者在函数组件中使用state以及其它React特性,下面分别对其介绍~ React.useState() state hook能让函数组件也可以拥有state状态,方便其进行state状态的…...

【Spring从成神到升仙系列 二】2023年再不会 IOC 源码,就要被淘汰了
👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙…...
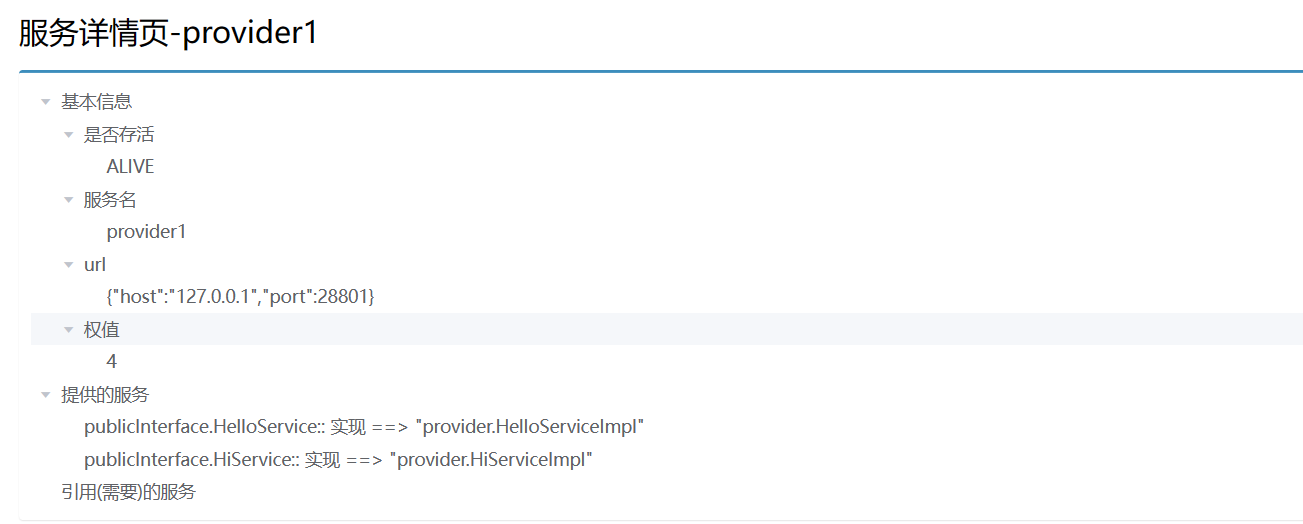
菜鸟的进阶--手写一个小型dubbo框架
1.rpc调用流程2.组件1.Redis注册中心3.编解码/序列化在本例的Netty通信中,由于每次调用rpc服务都要发送同一个类对象invoker,所以可以使用Protobuf。但是在接受方法调用结果的时候就不行了,因为我们无法提前确定对方方法返回结果的类型&#…...
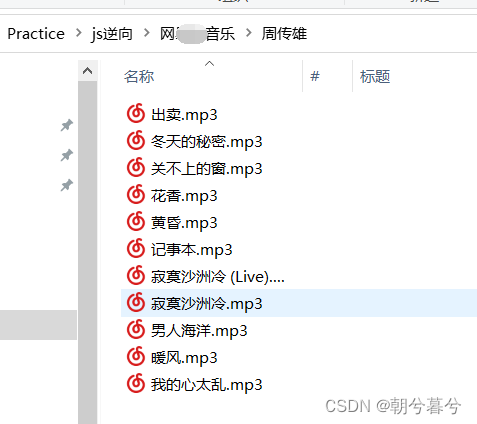
js逆向爬取某音乐网站某歌手的歌曲
js逆向爬取某音乐网站某歌手的歌曲一、分析网站1、案例介绍2、寻找列表页Ajax入口(1)页面展示图。(2)寻找部分歌曲信息Ajax的token。(3)寻找歌曲链接(4)获取歌曲名称和id信息3、寻找…...

为什么软件测试面试了几个月都没有offer,从HR角度分析
首先,我觉得你在软件测试面试的过程中,逻辑比较混乱的最大一个原因是,说明你没有形成一个一个整体的体系。 导致你说的时候很多东西都杂乱无章。 我个人认为软件测试,其实开始首先进行的是一些需求的分析工作,之后呢…...

DC-7 靶场学习
文章目录信息搜集账号密码获取修改密码反弹shell得到flag信息搜集 首先获取目标ip。 arp-scan -l nmap -sP 192.168.28.0/24得到目标ip为: 192.168.28.139先访问页面。 翻译一下。 欢迎来到 DC-7DC-7引入了一些“新”概念,但我会让你弄清楚它们是什么…...

深入理解JavaScript的事件冒泡与事件捕获
前言JavaScript中提供了很多操作DOM的API。事件冒泡和事件捕获是指浏览器中处理DOM元素上事件的两种不同方式。事件冒泡和事件捕获都是JavaScript事件模型中的一部分,可以用来处理事件。对于这个问题,在实际开发中,并不是非常重要,…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...
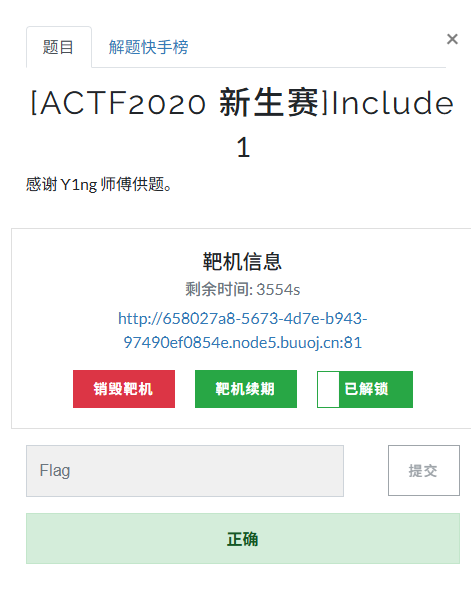
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...
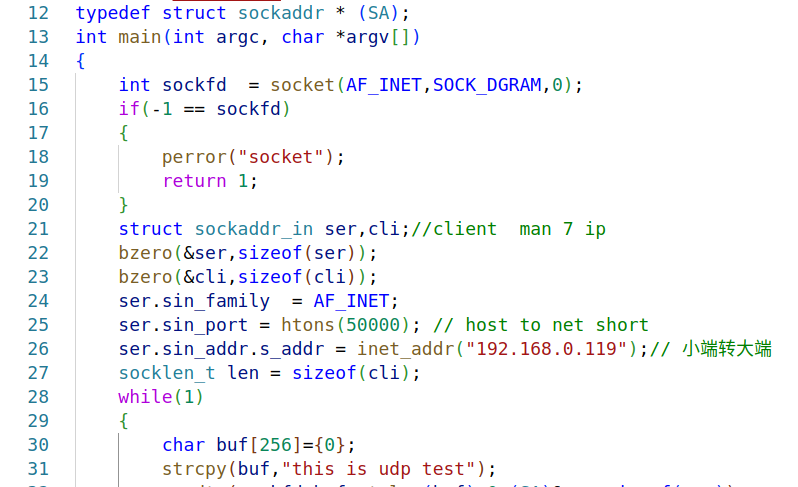
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...