Redis技术详解
Redis技术详解
- Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
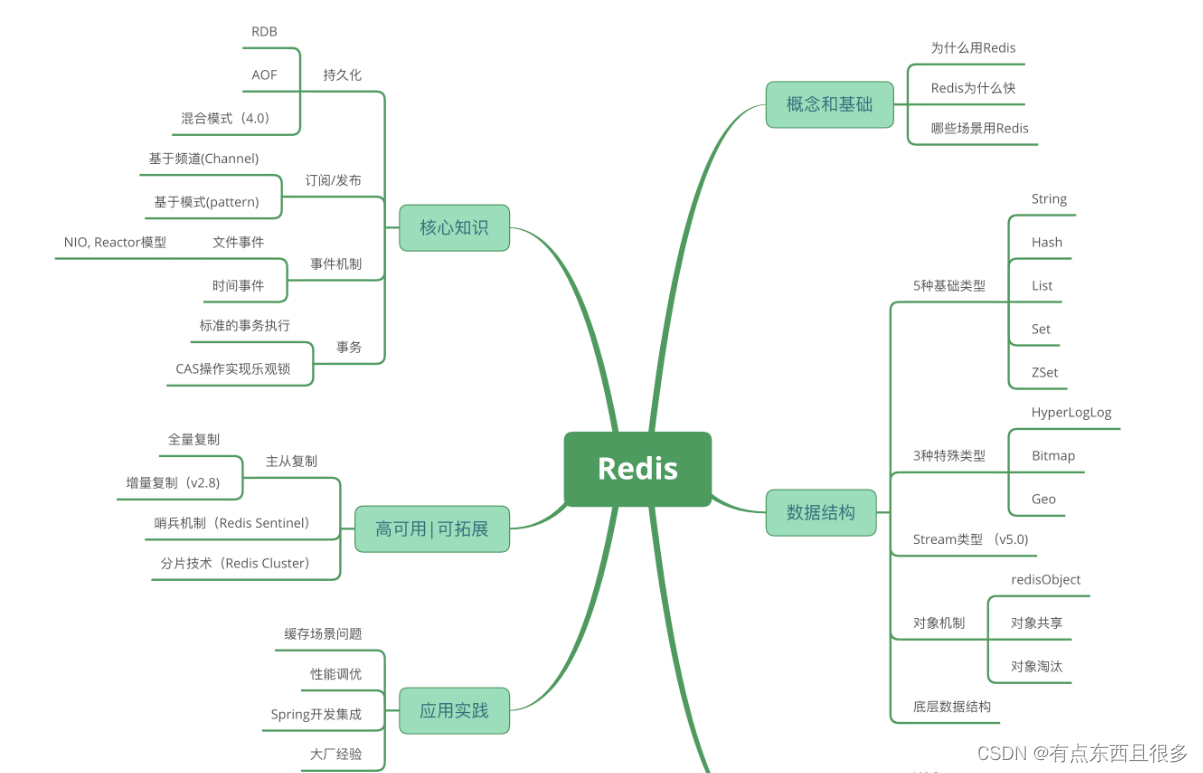
首先对redis来说,所有的key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash。
| 结构类型 | 结构存储的值 | 结构存储的值 | 使用场景 |
|---|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; | 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。例如:token |
| List | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; | 消息队列 |
| Set | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除;还包含计算交集、并集、差集等 | 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。 点赞,或点踩,收藏等,可以放到set中实现 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 | 缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 | 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行 |
1.五种常用基本数据类型
1.1 String字符串
String是redis中最基本的数据类型,一个key对应一个value。
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
- 命令执行
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> set counter 2
OK
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"1.2 List列表
Redis中的List其实就是链表(Redis用双端链表实现List)。
使用List结构,我们可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
- 使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
- 命令执行
127.0.0.1:6379> lpush mylist 1 2 ll ls mem
(integer) 5
127.0.0.1:6379> lrange mylist 0 -1
1) "mem"
2) "ls"
3) "ll"
4) "2"
5) "1"
127.0.0.1:6379> lindex mylist -1
"1"
127.0.0.1:6379> lindex mylist 10 # index不在 mylist 的区间范围内
(nil)1.3 Set集合
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
- 命令执行
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao
(integer) 3
127.0.0.1:6379> smembers myset
1) "xiaohao"
2) "hao1"
3) "hao"
127.0.0.1:6379> sismember myset hao
(integer) 1
1.4 Hash散列
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
- 命令执行
127.0.0.1:6379> hset user name1 hao
(integer) 1
127.0.0.1:6379> hset user email1 hao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
127.0.0.1:6379> hget user user
(nil)
127.0.0.1:6379> hget user name1
"hao"
127.0.0.1:6379> hset user name2 xiaohao
(integer) 1
127.0.0.1:6379> hset user email2 xiaohao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
5) "name2"
6) "xiaohao"
7) "email2"
8) "xiaohao@163.com"1.5 Zset有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
- 命令执行
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao
(integer) 2
127.0.0.1:6379> ZRANGE myscoreset 0 -1
1) "xiaohao"
2) "hao"
127.0.0.1:6379> ZSCORE myscoreset hao
"100"
2.三种特殊类型详解
Redis除了上文中5种基础数据类型,还有三种特殊的数据类型,分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置)
2.1 HyperLogLogs(基数统计)
Redis 2.8.9 版本更新了 Hyperloglog 数据结构!
- 什么是基数?
举个例子,A = {1, 2, 3, 4, 5}, B = {3, 5, 6, 7, 9};那么基数(不重复的元素)= 1, 2, 4, 6, 7, 9; (允许容错,即可以接受一定误差)
- HyperLogLogs 基数统计用来解决什么问题?
这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数等。
- 它的优势体现在哪?
一个大型的网站,每天 IP 比如有 100 万,粗算一个 IP 消耗 15 字节,那么 100 万个 IP 就是 15M。而 HyperLogLog 在 Redis 中每个键占用的内容都是 12K,理论存储近似接近 2^64 个值,不管存储的内容是什么,它一个基于基数估算的算法,只能比较准确的估算出基数,可以使用少量固定的内存去存储并识别集合中的唯一元素。而且这个估算的基数并不一定准确,是一个带有 0.81% 标准错误的近似值(对于可以接受一定容错的业务场景,比如IP数统计,UV等,是可以忽略不计的)。
- 相关命令使用
127.0.0.1:6379> pfadd key1 a b c d e f g h i # 创建第一组元素
(integer) 1
127.0.0.1:6379> pfcount key1 # 统计元素的基数数量
(integer) 9
127.0.0.1:6379> pfadd key2 c j k l m e g a # 创建第二组元素
(integer) 1
127.0.0.1:6379> pfcount key2
(integer) 8
127.0.0.1:6379> pfmerge key3 key1 key2 # 合并两组:key1 key2 -> key3 并集
OK
127.0.0.1:6379> pfcount key3
(integer) 13
2.2 Bitmap (位存储)
Bitmap 即位图数据结构,都是操作二进制位来进行记录,只有0 和 1 两个状态。
- 用来解决什么问题?
比如:统计用户信息,活跃,不活跃! 登录,未登录! 打卡,不打卡! 两个状态的,都可以使用 Bitmaps!
如果存储一年的打卡状态需要多少内存呢? 365 天 = 365 bit 1字节 = 8bit 46 个字节左右!
- 相关命令使用
使用bitmap 来记录 周一到周日的打卡! 周一:1 周二:0 周三:0 周四:1 …
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 0
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0查看某一天是否有打卡!
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 5
(integer) 0统计操作,统计 打卡的天数!
127.0.0.1:6379> bitcount sign # 统计这周的打卡记录,就可以看到是否有全勤!
(integer) 3
2.3 geospatial (地理位置)
Redis 的 Geo 在 Redis 3.2 版本就推出了! 这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人
2.3.1 geoadd
添加地理位置
127.0.0.1:6379> geoadd china:city 118.76 32.04 manjing 112.55 37.86 taiyuan 123.43 41.80 shenyang
(integer) 3
127.0.0.1:6379> geoadd china:city 144.05 22.52 shengzhen 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 3规则
两级无法直接添加,我们一般会下载城市数据(这个网址可以查询 GEO: http://www.jsons.cn/lngcode)!
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
# 当坐标位置超出上述指定范围时,该命令将会返回一个错误。
127.0.0.1:6379> geoadd china:city 39.90 116.40 beijin
(error) ERR invalid longitude,latitude pair 39.900000,116.4000002.3.2 geopos
获取指定的成员的经度和纬度
127.0.0.1:6379> geopos china:city taiyuan manjing
1) 1) "112.54999905824661255"1) "37.86000073876942196"
2) 1) "118.75999957323074341"1) "32.03999960287850968"获得当前定位, 一定是一个坐标值!
2.3.3 geodist
如果不存在, 返回空
单位如下
- m
- km
- mi 英里
- ft 英尺
127.0.0.1:6379> geodist china:city taiyuan shenyang m
"1026439.1070"
127.0.0.1:6379> geodist china:city taiyuan shenyang km
"1026.4391"
2.3.4 georadius
附近的人 ==> 获得所有附近的人的地址, 定位, 通过半径来查询
获得指定数量的人
127.0.0.1:6379> georadius china:city 110 30 1000 km 以 100,30 这个坐标为中心, 寻找半径为1000km的城市
1) "xian"
2) "hangzhou"
3) "manjing"
4) "taiyuan"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist
1) 1) "xian"2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist count 2
1) 1) "xian"2) "483.8340"3) 1) "108.96000176668167114"2) "34.25999964418929977"
2) 1) "manjing"2) "864.9816"3) 1) "118.75999957323074341"2) "32.03999960287850968"参数 key 经度 纬度 半径 单位 [显示结果的经度和纬度] [显示结果的距离] [显示的结果的数量]
2.3.5 georadiusbymember
显示与指定成员一定半径范围内的其他成员
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km
1) "manjing"
2) "taiyuan"
3) "xian"
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km withcoord withdist count 2
1) 1) "taiyuan"2) "0.0000"3) 1) "112.54999905824661255"2) "37.86000073876942196"
2) 1) "xian"2) "514.2264"3) 1) "108.96000176668167114"2) "34.25999964418929977"3.Redis持久化
- 为什么需要持久化?
Redis是个基于内存的数据库。那服务一旦宕机,内存中的数据将全部丢失。通常的解决方案是从后端数据库恢复这些数据,但后端数据库有性能瓶颈,如果是大数据量的恢复,1、会对数据库带来巨大的压力,2、数据库的性能不如Redis。导致程序响应慢。所以对Redis来说,实现数据的持久化,避免从后端数据库中恢复数据,是至关重要的。
3.1 RDB 持久化
RDB 就是 Redis DataBase 的缩写,中文名为快照/内存快照,RDB持久化是把当前进程数据生成快照保存到磁盘上的过程,由于是某一时刻的快照,那么快照中的值要早于或者等于内存中的值。
触发方式
触发rdb持久化的方式有2种,分别是手动触发和自动触发。
3.1.1 手动触发
手动触发分别对应save和bgsave命令
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
bgsave流程图如下所示
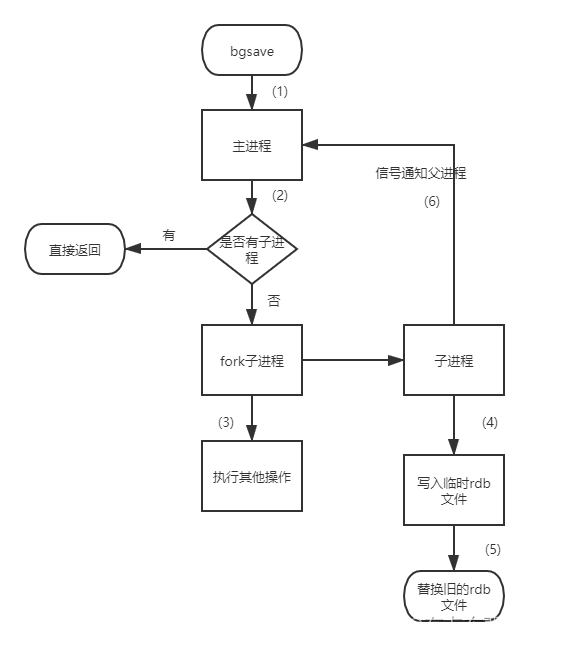
具体流程如下:
- redis客户端执行bgsave命令或者自动触发bgsave命令;
- 主进程判断当前是否已经存在正在执行的子进程,如果存在,那么主进程直接返回;
- 如果不存在正在执行的子进程,那么就fork一个新的子进程进行持久化数据,fork过程是阻塞的,fork操作完成后主进程即可执行其他操作;
- 子进程先将数据写入到临时的rdb文件中,待快照数据写入完成后再原子替换旧的rdb文件;
- 同时发送信号给主进程,通知主进程rdb持久化完成,主进程更新相关的统计信息(info Persitence下的rdb_*相关选项)。
3.1.2 自动触发
在以下4种情况时会自动触发
- redis.conf中配置
save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件; - 主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
- 执行debug reload命令重新加载redis时也会触发bgsave操作;
- 默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作;
3.1.3 redis.conf中配置RDB
快照周期:内存快照虽然可以通过技术人员手动执行SAVE或BGSAVE命令来进行,但生产环境下多数情况都会设置其周期性执行条件。
- Redis中默认的周期新设置
# 周期性执行条件的设置格式为
save <seconds> <changes># 默认的设置为:
save 900 1
save 300 10
save 60 10000# 以下设置方式为关闭RDB快照功能
save ""以上三项默认信息设置代表的意义是:
- 如果900秒内有1条Key信息发生变化,则进行快照;
- 如果300秒内有10条Key信息发生变化,则进行快照;
- 如果60秒内有10000条Key信息发生变化,则进行快照。读者可以按照这个规则,根据自己的实际请求压力进行设置调整。
- 其它相关配置
# 文件名称
dbfilename dump.rdb# 文件保存路径
dir /home/work/app/redis/data/# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes# 是否压缩
rdbcompression yes# 导入时是否检查
rdbchecksum yesdbfilename:RDB文件在磁盘上的名称。
dir:RDB文件的存储路径。默认设置为“./”,也就是Redis服务的主目录。
stop-writes-on-bgsave-error:上文提到的在快照进行过程中,主进程照样可以接受客户端的任何写操作的特性,是指在快照操作正常的情况下。如果快照操作出现异常(例如操作系统用户权限不够、磁盘空间写满等等)时,Redis就会禁止写操作。这个特性的主要目的是使运维人员在第一时间就发现Redis的运行错误,并进行解决。一些特定的场景下,您可能需要对这个特性进行配置,这时就可以调整这个参数项。该参数项默认情况下值为yes,如果要关闭这个特性,指定即使出现快照错误Redis一样允许写操作,则可以将该值更改为no。
rdbcompression:该属性将在字符串类型的数据被快照到磁盘文件时,启用LZF压缩算法。Redis官方的建议是请保持该选项设置为yes,因为“it’s almost always a win”。
rdbchecksum:从RDB快照功能的version 5 版本开始,一个64位的CRC冗余校验编码会被放置在RDB文件的末尾,以便对整个RDB文件的完整性进行验证。这个功能大概会多损失10%左右的性能,但获得了更高的数据可靠性。所以如果您的Redis服务需要追求极致的性能,就可以将这个选项设置为no。
3.1.4 RDB优缺点
- 优点
- RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景;
- Redis加载RDB文件恢复数据要远远快于AOF方式;
- 缺点
- RDB方式实时性不够,无法做到秒级的持久化;
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高;
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全;
- 版本兼容RDB文件问题;
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决
3.2 AOF 持久化
Redis是“写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
而AOF日志采用写后日志,即先写内存,后写日志。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PdE96gNe-1678194148290)(Redis%E8%AF%A6%E8%A7%A3.assets/image-20221031134702489.png)]](https://img-blog.csdnimg.cn/f3cdb400b4154a7aa74e06f8fb91a62e.png)
如何实现AOF
AOF日志记录Redis的每个写命令,步骤分为:命令追加(append)、文件写入(write)和文件同步(sync)。
- 命令追加 当AOF持久化功能打开了,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区。
- 文件写入和同步 关于何时将 aof_buf 缓冲区的内容写入AOF文件中,Redis提供了三种写回策略:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kJdQ0hLx-1678194148291)(Redis%E8%AF%A6%E8%A7%A3.assets/redis-x-aof-4.jpg)]](https://img-blog.csdnimg.cn/bafb03dd7ba64627995847659564e739.jpeg)
Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
No,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
3.2.1 redis.conf中配置AOF
默认情况下,Redis是没有开启AOF的,可以通过配置redis.conf文件来开启AOF持久化,关于AOF的配置如下:
# appendonly参数开启AOF持久化
appendonly no# AOF持久化的文件名,默认是appendonly.aof
appendfilename "appendonly.aof"# AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的
dir ./# 同步策略
# appendfsync always
appendfsync everysec
# appendfsync no# aof重写期间是否同步
no-appendfsync-on-rewrite no# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb# 加载aof出错如何处理
aof-load-truncated yes# 文件重写策略
aof-rewrite-incremental-fsync yes以下是Redis中关于AOF的主要配置信息:
appendonly:默认情况下AOF功能是关闭的,将该选项改为yes以便打开Redis的AOF功能。
appendfilename:这个参数项很好理解了,就是AOF文件的名字。
appendfsync:这个参数项是AOF功能最重要的设置项之一,主要用于设置“真正执行”操作命令向AOF文件中同步的策略。
什么叫“真正执行”呢?还记得Linux操作系统对磁盘设备的操作方式吗? 为了保证操作系统中I/O队列的操作效率,应用程序提交的I/O操作请求一般是被放置在linux Page Cache中的,然后再由Linux操作系统中的策略自行决定正在写到磁盘上的时机。而Redis中有一个fsync()函数,可以将Page Cache中待写的数据真正写入到物理设备上,而缺点是频繁调用这个fsync()函数干预操作系统的既定策略,可能导致I/O卡顿的现象频繁 。
与上节对应,appendfsync参数项可以设置三个值,分别是:always、everysec、no,默认的值为everysec。
no-appendfsync-on-rewrite:always和everysec的设置会使真正的I/O操作高频度的出现,甚至会出现长时间的卡顿情况,这个问题出现在操作系统层面上,所有靠工作在操作系统之上的Redis是没法解决的。为了尽量缓解这个情况,Redis提供了这个设置项,保证在完成fsync函数调用时,不会将这段时间内发生的命令操作放入操作系统的Page Cache(这段时间Redis还在接受客户端的各种写操作命令)。
auto-aof-rewrite-percentage:上文说到在生产环境下,技术人员不可能随时随地使用“BGREWRITEAOF”命令去重写AOF文件。所以更多时候我们需要依靠Redis中对AOF文件的自动重写策略。Redis中对触发自动重写AOF文件的操作提供了两个设置:auto-aof-rewrite-percentage表示如果当前AOF文件的大小超过了上次重写后AOF文件的百分之多少后,就再次开始重写AOF文件。例如该参数值的默认设置值为100,意思就是如果AOF文件的大小超过上次AOF文件重写后的1倍,就启动重写操作。
auto-aof-rewrite-min-size:参考auto-aof-rewrite-percentage选项的介绍,auto-aof-rewrite-min-size设置项表示启动AOF文件重写操作的AOF文件最小大小。如果AOF文件大小低于这个值,则不会触发重写操作。注意,auto-aof-rewrite-percentage和auto-aof-rewrite-min-size只是用来控制Redis中自动对AOF文件进行重写的情况,如果是技术人员手动调用“BGREWRITEAOF”命令,则不受这两个限制条件左右。
3.3 RDB和AOF混合方式(4.0版本)
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。
从持久化中恢复数据
数据的备份、持久化做完了,我们如何从这些持久化文件中恢复数据呢?如果一台服务器上有既有RDB文件,又有AOF文件,该加载谁呢?
其实想要从这些文件中恢复数据,只需要重新启动Redis即可。我们还是通过图来了解这个流程:
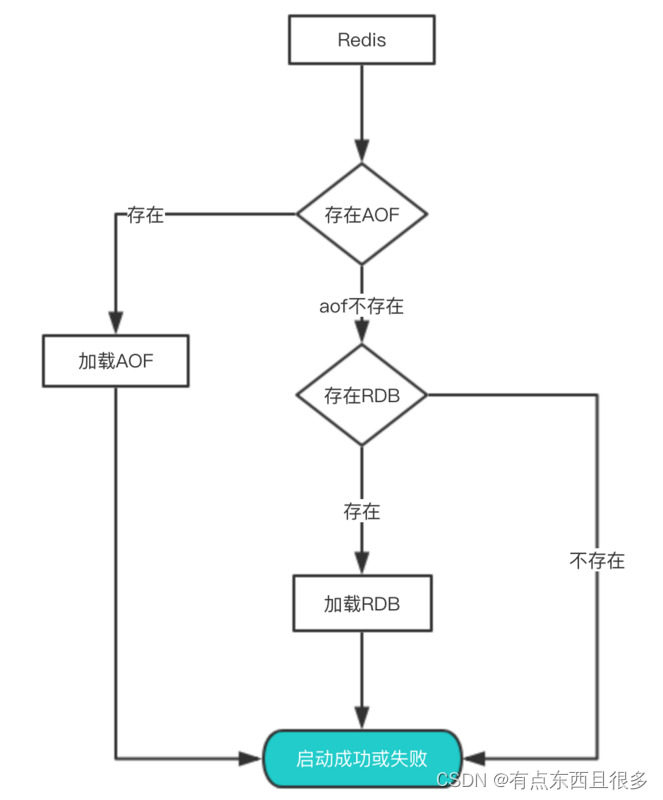
- redis重启时判断是否开启aof,如果开启了aof,那么就优先加载aof文件;
- 如果aof存在,那么就去加载aof文件,加载成功的话redis重启成功,如果aof文件加载失败,那么会打印日志表示启动失败,此时可以去修复aof文件后重新启动;
- 若aof文件不存在,那么redis就会转而去加载rdb文件,如果rdb文件不存在,redis直接启动成功;
- 如果rdb文件存在就会去加载rdb文件恢复数据,如加载失败则打印日志提示启动失败,如加载成功,那么redis重启成功,且使用rdb文件恢复数据;
那么为什么会优先加载AOF呢?因为AOF保存的数据更完整,通过上面的分析我们知道AOF基本上最多损失1s的数据。
4.redis缓存问题:一致性, 击穿, 穿透, 雪崩。
4.1 缓存穿透
- 问题来源
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
- 解决方案
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
- 布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小。
4.2 缓存击穿
- 问题来源
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
- 解决方案
1、设置热点数据永远不过期。
2、接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
3、加互斥锁
4.3 缓存雪崩
- 问题来源
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
- 解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
- 设置热点数据永远不过期。
4.4 数据库和缓存一致性
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。
方案一:队列 + 重试机制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2IdlHHUF-1678194148292)(Redis%E8%AF%A6%E8%A7%A3.assets/db-redis-cache-4.png)]](https://img-blog.csdnimg.cn/7cccc0a139164ea99bf8b862a65e91b6.png)
流程如下所示
- 更新数据库数据;
- 缓存因为种种问题删除失败
- 将需要删除的key发送至消息队列
- 自己消费消息,获得需要删除的key
- 继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案二:异步更新缓存(基于订阅binlog的同步机制)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sY4kYhcx-1678194148292)(Redis%E8%AF%A6%E8%A7%A3.assets/db-redis-cache-5.png)]](https://img-blog.csdnimg.cn/3d2278495808424ba6587e76b6871547.png)
- 技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
1)读Redis:热数据基本都在Redis
2)写MySQL: 增删改都是操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
- Redis更新
1)数据操作主要分为两大块:
- 一个是全量(将全部数据一次写入到redis)
- 一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
相关文章:
Redis技术详解
Redis技术详解 Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存&…...
解决mybatis-plus updateById方法不能set null
原因 因为 MyBatis-Plus 自带的更新方法,都有对对象空值进行判空。只有不为空的字段才会进行数据更新 所以像updateById等方法,在更新时会自动忽略为null的字段,只更新非null字段值 但在某些情况下,我们的需求就是将数据库中的值…...

Linux的mysql 数据库及开发包安装
注意:以下操作都以 root 用户进行操作 直接按照下列步骤在命令行输入即可 下载 1: sudo yum install -y mariadb 2: sudo yum install -y mariadb-server 3: sudo yum install -y mariadb-devel 接下来配置文件:在相应…...

π-Day快乐:Python可视化π
π-Day快乐:Python可视化π 今天是3.14,正好是圆周率 π\piπ 的前3位,因此数学界将这一天定为π\bold{\pi}π day。 π\piπ 可能是最著名的无理数了,人类对 π\piπ 的研究从未停止。目前人类借助计算机已经计算到 π\piπ 小数…...

【论文速递】ACM MM 2022 - 基于统一对比学习框架的新闻多媒体事件抽取
【论文速递】ACM MM 2022 - 基于统一对比学习框架的新闻多媒体事件抽取 【论文原文】:Multimedia Event Extraction From News With a Unified Contrastive Learning Framework 【作者信息】:Liu, Jian and Chen, Yufeng and Xu, Jinan 论文ÿ…...

数据库分库分表
一、为什么要分库分表 如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持…...

【C缺陷与陷阱】----语义“陷阱”
💯💯💯 本篇处理的是有关语义误解的问题:即程序员的本意是希望表示某种事物,而实际表示的却是另外一种事物。在本篇我们假定程序员对词法细节和语法细节的理解没有问题,因此着重讨论语义细节。导言…...

JavaWeb--VUE
VUE1 概述2 快速入门3 Vue 指令3.1 v-bind & v-model 指令3.2 v-on 指令3.3 条件判断指令3.4 v-for 指令4 生命周期5 案例5.1 需求5.2 查询所有功能5.3 添加功能目标 能够使用VUE中常用指令和插值表达式能够使用VUE生命周期函数 mounted 1 概述 接下来我们学习一款前端的框…...

2分钟彻底搞懂“高内聚,低耦合”
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...

网络编程UDP TCP
定义:关注底层数据的传输 区分网页编程:关注上层应用 端口号:区分软件 2个字节 0~65535表示端口号 同一协议下端口号不能冲突 8000以下称为预留端口号,建议之间设置端口号为8000以上 常见的端口号: 80:http 8080:tomcat 3306:mysql 1521:oracle InetSocketAddress:此类实现IP套…...
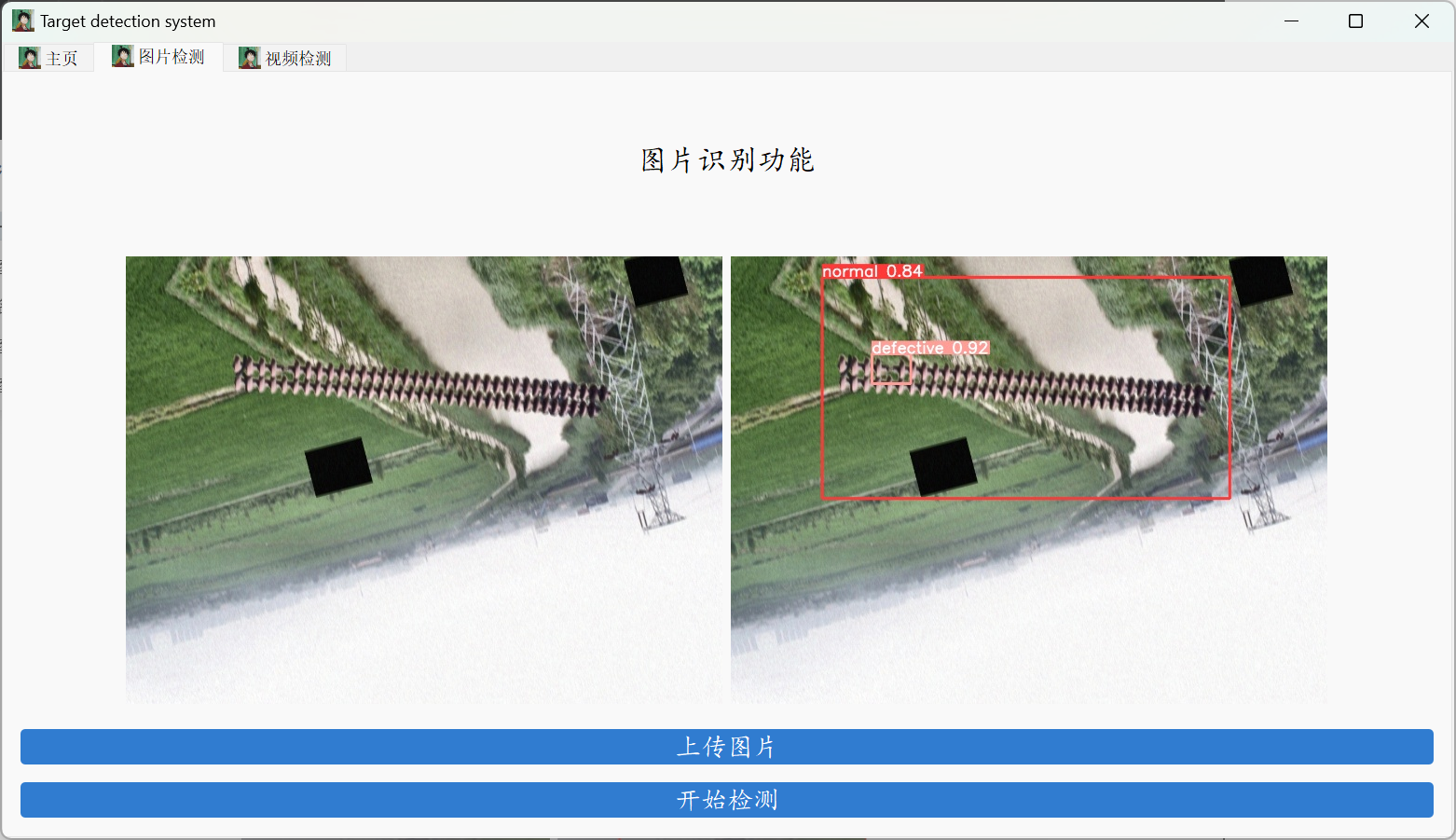
【2023-Pytorch-检测教程】手把手教你使用YOLOV5做电线绝缘子缺陷检测
随着社会和经济的持续发展,电力系统的投资与建设也日益加速。在电力系统中,输电线路作为电能传输的载体,是最为关键的环节之一。而绝缘子作为输电环节中的重要设备,在支撑固定导线,保障绝缘距离的方面有着重要作用。大…...
)
交叉编译(NDK)
文章目录前言Android-NDK使用NDK目录结构主流的Android NDK交叉编译前言 交叉编译是指在一种计算机体系结构上编译和构建应用程序,但是生成的可执行文件和库是针对另一种不同的体系结构,比如ARM、MIPS、PowerPC、x86 等。 常见的交叉编译工具集&#x…...

【数据库】MySQL 解读事务的意义及原则
目录 1.事务的概念 2.为什么要用事物 3.使用 4.事务的原则(ACID) 4.1原子性(Atomicity) 4.2一致性(Consistency) 4.3持久性(Durability) 4.4隔离性(Isolation…...
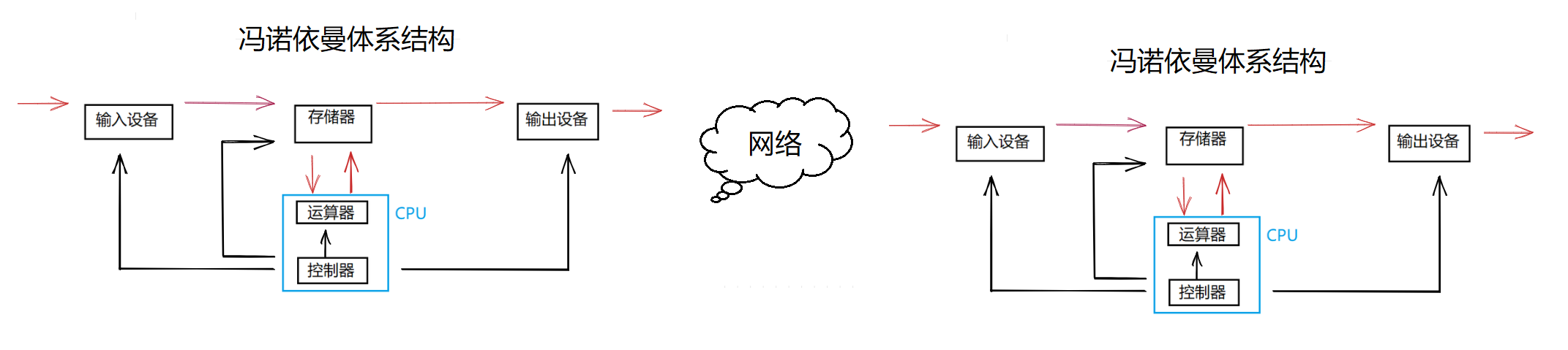
【Linux】冯诺依曼体系结构
冯诺依曼体系结构一、计算机结构体系来源二、冯诺依曼体系结构三、冯诺依曼体系结构中的数据流动一、计算机结构体系来源 研制电子计算机的想法产生于第二次世界大战期间,主要用来进行弹道计算,在"时间就是胜利"的战争年代,迫切需…...

【小白】git是什么?gitee和git和github的关系?
gitee问题一、git是什么?gitee和git和github的关系?问题二、能不能通俗易懂的说?问题一、git是什么?gitee和git和github的关系? Git是一种版本控制系统,用于管理文件的版本、记录文件的修改历史以及协同开…...

UDS 14229 -1 刷写34,36,37服务,标准加Trace讲解,没理由搞不明白
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...

【Android -- 软技能】聊聊程序员的软技能
什么是软技能? 所谓软技能,就是相对于「硬技能」而言的技能,对于程序员来说,「硬技能」就是计算机专业技术能力,软技能则是专业之外的所有技能,包括职业规划能力、处理人际关系能力、专业态度、做事的方式…...

【Java学习笔记】27.Java 抽象类
Java 抽象类 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。 抽象类除了不能实例化对象…...

Vite4 + Vue3 + vue-router4 动态路由
动态路由,基本上每一个项目都能接触到这个东西,通俗一点就是我们的菜单是根据后端接口返回的数据进行动态生成的。表面上是对菜单的一个展现处理,其实内部就是对router的一个数据处理。这样就可以根据角色权限或者一些业务上的需求࿰…...
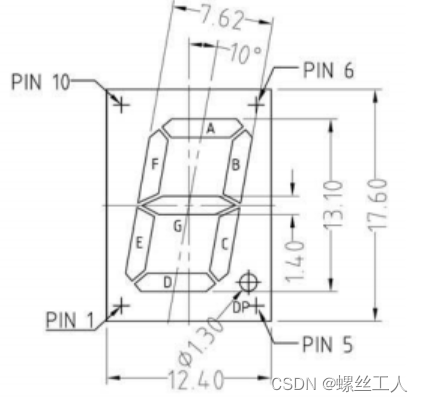
MS(mbed l432KC)-->速通9个lab详细解析[5]
Exercise5 这次实验我们将正式接触到一个相对来说有点意思并且有点牌面的传感器了----->数码管。数码管是我们生活中非常常见的一种传感器,比如计时器,秒表,以及数字显示大屏幕,其实原理都跟数码管差不多。如果是没有单片机基础的同学,突然一下接触到相对来说比较常见…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...